
 В этом посте я расскажу об инструменте для быстрого поиска строк в базе данных и навигации по ним. Если вы работаете в поддержке и вам приходится выполнять много запросов к базам данных, если вы устали писать SELECT'ы, прошу под кат.
В этом посте я расскажу об инструменте для быстрого поиска строк в базе данных и навигации по ним. Если вы работаете в поддержке и вам приходится выполнять много запросов к базам данных, если вы устали писать SELECT'ы, прошу под кат.Мотивация
Некоторое время назад я помогал поддерживать большую учетную систему. В ходе работы требовалось искать информацию по базе данных. Типичный сценарий: звонит пользователь с проблемой по заявке N1. Для диагностики нужно просмотреть некоторые данные по этой заявке в базе. Выполняем запрос:
SQL SELECT * FROM ORDER WHERE ID = 'N1'С заявкой связан агрегат, поэтому выполняем следующий запрос для получения информации по агрегату:
SQL SELECT * FROM DEVICE WHERE ORDER_ID = 'N1'Затем ищем все заявки, связанные с агрегатом:
SQL SELECT * FROM ORDERS WHERE DEVICEID = '92375'И так далее. После выполнения N запросов рано или поздно найдем проблему в данных и примем меры. Недостатки такого подхода очевидны:
- Вручную писать запросы медленно и неудобно. Особенно если структура базы данных сложная и таблиц много. Так можно и до туннельного синдрома доработаться.
- Когда нужно найти связанную строчку по Unique constraint или Foreign Key, приходится писать новый запрос.
- Обычно инструменты для работы с базами данных отображают данные в виде таблиц. Когда колонок в таблице много, таблицу приходится прокручивать горизонтально, либо выбирать колонки в запросе. Опять же, требуется ручная работа.
Идея
Сначала нужно упростить поиск. Это действие должно выполняться с помощью минимального количества кликов. Просто вводим искомую строку в текстовое поле, и нажимаем Enter. Обычно первичные ключи индексируются, поэтому можно искать значение сразу по всем колонкам, которые включены в Primary Keys или Unique Constraints.
Затем нужно решить задачу навигации. Как быстро перейти к связанной записи по Foreign Key? Можно представить базу данных как файловую систему: вообразим, что строчка базы данных это директория, связанная строчка по Foreign Key — симлинк, а поле, не являющееся Foreign Key это простой файл. Я не собираюсь писать драйвер файловой системы, это просто аналогия. Так строчки базы данных можно представить в виде иерархической структуры, которую можно отобразить с помощью компонента TreeTable.
Также в компонент TreeTable можно добавить колонку, в которой будет отображаться некоторое осмысленное значение для заданной строки. Это значение можно получить, сконкатенировав значения полей строки базы данных. Например, для строки заявки можно составить выражение:
ORDER_NAME + ', ' + ORDER_STATUS + ', ' + ORDER_CUSTOMERБлижайшая аналогия: метод toString() в java.
Реализация
Программирование заняло много месяцев. Сначала я пытался использовать C++ и Qt, но это оказалось трудно: в мире C++ нет чего-то похожего на jdbc-драйверы, да и сам язык существенно сложнее. Поэтому приложение написано на Java.
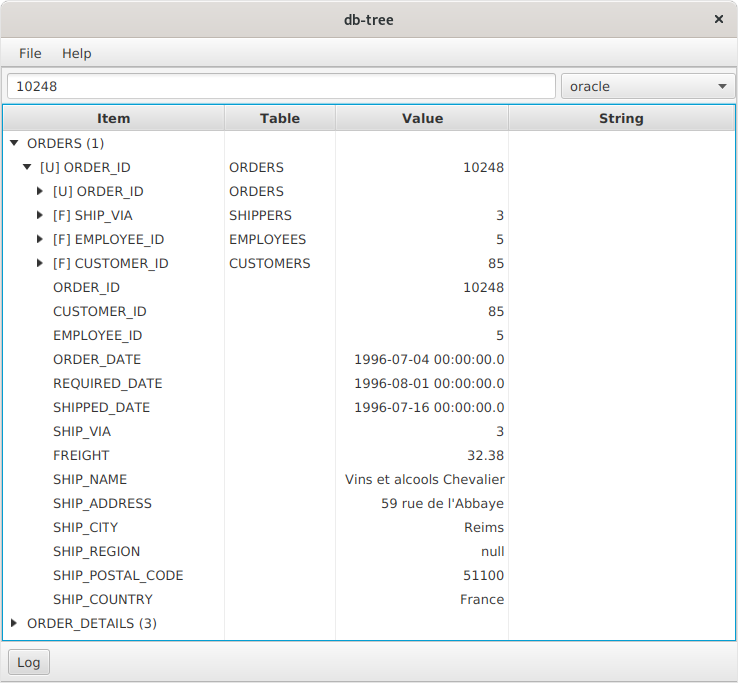
На скриншоте мы видим поле для поиска, комбобокс для переключения текущего соединения и компонент TreeTable, в котором отображаются иерархические данные.
Поиск
В текстовое поле можно ввести строку и нажать Enter. Поиск сейчас работает только по колонкам строковых и числовых типов: VARCHAR, NUMBER, и т. д. Типы даты и времени пока не поддерживаются. По умолчанию инструмент ищет значения в колонках, которые включены в Primary Key. В настройках можно отметить галочками прочие поля, которые будут использованы при поиске.
Навигация по ключам
Узлы, помеченные меткой [F], это Foreign Key. В колонке Table мы видим имя таблицы, на которую этот ключ ссылается. Раскрыв узел мы перейдем к связанной строчке. Составные Foreign Key также поддерживаются.
Узлы, помеченные меткой [U], это Unique Constraint или Primary Key. Раскрыв узел можно перейти к связанным строчкам. Посмотрите на скриншот:
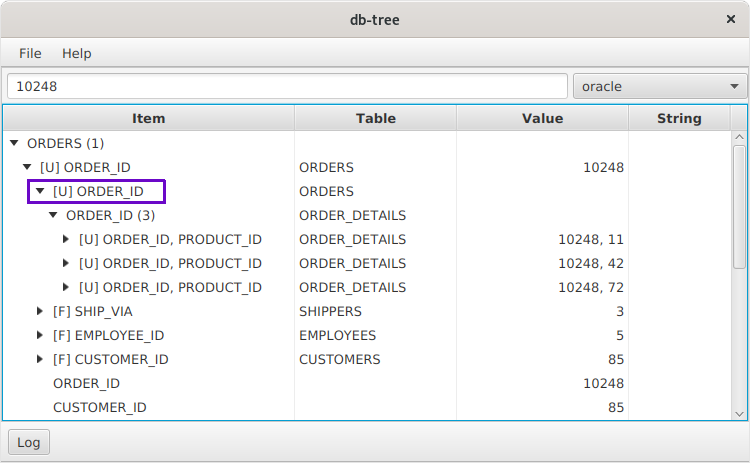
Мы ввели в строку поиска значение 10248 и нашли строчку в таблице ORDERS. Раскрыли узел [U] ORDER_ID и нашли 3 строчки в таблице ORDER_DETAILS. Затем можно раскрыть каждый узел и перейти к строчкам таблицы ORDER_DETAILS.
Колонка String
Значения первичных ключей часто неинформативны. На предыдущем скриншоте мы видим значения ORDER_ID=10248,PRODUCT_ID=11. Эти числа ни о чем нам не говорят. Чтобы их как-то очеловечить, можно составить выражение:
'Product: ' + PRODUCT_ID.PRODUCT_NAME + ', Price: ' + UNIT_PRICEи ввести его в ячейку колонки String:
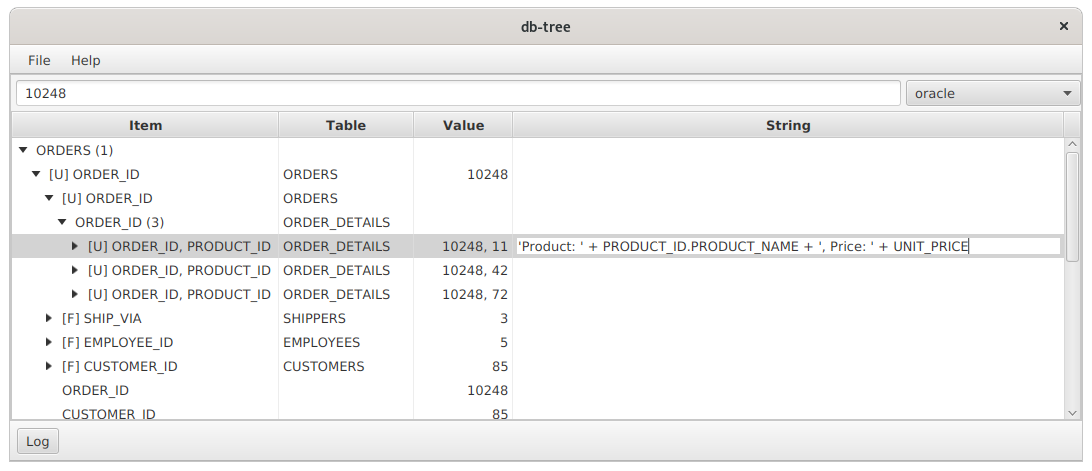
Нажимаем Enter и видим более осмысленные значения:

Технические подробности
Приложение написано на Java, интерфейс на JavaFX. Можно заметить, что в TreeTable используются строки "[U]" и "[F]" вместо иконок, это сделано по причине этого досадного бага: JDK-8190331. Пароли к базам данных хранятся в защищенном хранилище с помощью библиотеки java-keyring. Для сборки инсталляторов используется OpenJDK 13 и early-access build jpackage. Команды сборки можно посмотреть здесь.
Сейчас поддерживаются базы данных Oracle, MariaDB и PostgreSQL.
Ссылки
Страничка проекта на github: db-tree-fx
Если вы нашли ошибку, или нужно что-нибудь добавить, смело заводите issue или пишите прямо на почту: db.tree.app@gmail.com.
Пакеты для установки
Rpm для GNU/Linux: db-tree-0.0.2-1.x86_64.rpm
Deb для GNU/Linux: db-tree_0.0.2-1_amd64.deb
Подписанный dmg для macOS: db-tree-0.0.2.dmg
Подписанный msi для Windows: db-tree-0.0.2.msi
Последний релиз можно найти на github
Комментарии (4)

somebody4
04.12.2019 09:44Если база служит для хранения данных доступных с веб сайта, то имеет смысл сделать возможность внешних коммункаций.
Так же как вы «очеловечиваете» значение, можно его «оинтернетить», т.е. сгенерировать правильную ссылку для доступа к странице конкретного продукта, заказа и т.п.
И точно также в обратную сторону. Можно сделать расширение для браузера, при навигации по сайту, можно из URL или контента страницы получаться идентификаторы и автоматически синхронизовать то что показывает ваш db-tree с тем на какой странице находишься. Мы такой режим у себя делали, очень много времени экономит и ощущение как от магии. Перешёл на страницу и сразу видешь все данные из базы, которые имеют отношение к данной странице, без дополнительных усилий.
Fregl
Не совсем понятен мотив написания тулзы. Почему не использовать join?
vzhilin Автор
Проблема с join в том, что их нужно набирать руками. Если база сложная, в ней много таблиц и связей, это сильно замедляет работу. Мотив в том, чтобы свести ручную работу к минимуму: сtrl-v, enter, пара кликов и нужные данные получены.
bugdesigner
Для того, чтобы постоянно не писать join-ы можно сделать некое количество view для частых применений, и select делать уже к ним.