
Тестирование как универсальный принцип
Уже почти четверь века празднуем миллениум, а тестирование ещё только входит в нашу жизнь… Сложно убедить начинающих разработчиков использовать эту потрясающую технику в своей работе… Да чего уж там говорить о разработчиках, простым смертным и то не всегда доступно понимание того, что тестирование — основа устойчивых систем! Как сложно бывает убедить продавщицу в том, что протестировать новый продукт — не значит съесть его! Даже бывалые охранники явно работают по старинке — пытаются догнать и отобрать тестируемое. И не докажешь им, что если уж сам Господь Бог не гнушается использовать TDD в своей работе (вспомним Великий Потоп), то нам как говорится сам бог велел…
Количество разводов растёт — почему? Да всё потому же! TDD! Сначала тестируй — потом женись! Нет, доверчивые мужички в расхристанных тулупах, падкие на эксплуатирующую секс рекламу, выкатывают молодую жену прямо в продакшн…
Ну мы то с вами из другого теста, сначала тестирование — потом всё остальное!
Я тестировщика узнаю по походке…
И вот когда я начал писать очередную базу данных code first то задумался, а почему бы не сделать автоматическое тестирование своего DAL слоя прямо на встроенных в VisualStudio тестах?
И у меня получилось! Прозрачно для EntityFramework, без всякой ловкости рук под одеялом и мошенничества с fake-объектами. Кому интересно — расчехляем VS, одеваемся как тестировщики и вперёд! (я всегда одеваюсь как тестировщик)

Всем лежать, это тестирование!
ObjectLink link = this.ObjectLinks.ToList().Where(x => x.SpotCode.ToLowerInvariant() == code.ToLowerInvariant()).SingleOrDefault();Этот код не был покрыт тестами, потому что не успел — нужно было срочно запустить новый функционал, связанный с маркетингом. Всё работало при проверке вручную, и я уже было расслабился… но Билл Гейтс подкрался незаметно…
Стояла поэтичная питерская осень, снег с дождём нежно полосовал лицо, грязь весело стекала со штанин и сквозь растёкшуюся косметику улыбались незнакомые девчёнки, обливаясь проезжающими мимо грузовиками… я уже направился за пальцем, чтобы поковырять в носу, как вдруг коварно, без объявления войны, перед самым рассветом Microsoft порезала колючую проволоку и выпустила обновление core 3.0. Хостер обновился, я тоже обновился, чего в старом ходить — я что, хуже хостера? всё проверил вроде и выкатил апдейт… а следом выкатил глаза! новый функционал не работал! казалось бы, я же тестировал это раньше — что могло случиться?
А случилось вот что: старина Билли решил выпилить из LINQ ToLowerInvariant… теперь его нужно вызывать заранее и вставлять уже готовое значение… если бы код был покрыт тестами, я бы это заметил сразу при тестировании. Хорошо что я сам всё заметил, не пришлось материться перед заказчиком, тестировщику ведь краснеть стыдно… пришлось решать проблему и делать новый deploy.
приборы и материалы:
Microsoft VisualStudio 2019
asp.net Core 3.1 (у меня поставилась вместе со студией, если что можно доставить через меню проекта install other frameworks)
SQL Server Express (идёт вместе со студией)
Git Extension to visual studio (идёт в комплекте)
Обычно в юнит-тестах каждый тест должен быть изолированным, и состояние между ними не сохраняется. Так что у нас фактически получатся интеграционные тесты, но использовать мы будем для этого MSTest. В милицию надеюсь нас за это не заберут.
В нескольких изданиях встречал использование Mock-объектов для тестирования базы данных.
Идея на первый взгляд хорошая, пока не начнутся сложные взаимодействия между таблицами.
Тогда настройка mock будет занимать больше чем само тестирование. А по сути это — Control+С — Control+V! мы все constraints базы данных, которые уже прописали в EF, базе данных, DataAnnotations или FluentAPI дублируем в mock-слое. А копирование — это вроде как нарушение паттерна… аяяй, гражданин, нарушаем… нехорошо!
А если сложная настройка mock, и мы там например ошиблись в ограничениях, получается что — тест на mock пройдёт, а на реальной базе будет ошибка?
Меня это всё заинтересовало, и я решил потестировать новый подход.
Идея пришла как всегда из ТРИЗ: идеальная система это та система, которая отсутствует, но её функции выполняются. И я подумал, что нужно задействовать в тестах саму базу данных.
И у меня вроде получилось. Этим и хочу поделиться, надеюсь кому-то поможет.
Минусы mock:
- много предварительных настроек которым тоже не помешали бы тесты
- тесты становятся грязными, много лишнего кода
- сложно тестировать migrations
- ведут себя хорошо только под присмотром, на реальной базе могут выдавать неведомые ошибки
- при изменении структуры базы нужно постоянно лезть в mock и изменять там всё тоже
Плюсы тестирования на реальной базе:
- программа ведёт себя точно так же как и на боевом сервере
- тесты проще, можно строить их друг за другом так же как заполняются данные в базе
- мы сами можем регулировать чистоту базы нумеруя тесты (в MSTest они выполняются по алфавиту)
- видно время, за которое выполняется тест (на реальном сервере оно будет отличаться, но виден хотя бы порядок — в 10 раз дольше, в 2 раза, и предварительно уже можно оценить как работает программа, эффективно или нет)
- можно тестить хранимые процедуры
В данном подходе есть определённые сложности, с которыми я копался несколько дней, но мы их успешно решим, и да пребудет с вами мой каменный бэкенд!
Поехали!
Создаём новый проект ASP.Net Core 3.1 Web Application (Model-View-Controller), Authentication меняем на Individual User Accounts (Store user accounts in-app) и нажимаем создать
С этого момента я буду сохранять снимки проекта в git, можно скачать его и загружать каждую ветку для того чтобы с ней поэкспериментировать
github.com/3263927/Habr_1
Snapshot: Snapshot_0_ProjectCreated
В этом месте я создал репозиторий, поэтому сейчас нужно будет планировать работу, чтобы создавать новые ветки. В дальнейшем, по ключевому слову Snapshot можно будет найти контрольные точки восстановления если что-то пойдёт не так.
Я создам новую ветку (Branch) в репозитории прямо из VisualStudio, и назову её для краткости «Сестра Таланта» (шутка, Snap_1_DataBases).
цель: создать работающее подключение и базы.
Начинаем создавать наши базы.
Сразу скажу, базы у нас будет 3 — одна тестовая (на локальной машине), другая production (на удалённом сервере, рабочая) и ещё одна локальная рабочая (для проверки работоспособности сайта в конфигурации DEBUG).
Логика такая:
- если мы хотим запустить сайт на локальной машине и посмотреть как он работает, то у нас будет работать Habr1_Local
- если мы выложим код в production то будет работать Habr1_Production
- когда наша инфраструктура тестирования будет запускать тестирование, то она должна находить базу Habr1_Test и запускать её
При этом у нас есть одно противоречие — конфигураций всего две, Debug и Release. Это пока проблема, но потом она решится.
Итак, создаём минимально работающую программу — для начала просто проверим, работает ли у нас хотя бы одна база. Создадим её… руками самого Visual Studio!
Открываем файл appsettings.json
Там есть такие строки:
"ConnectionStrings": {
"DefaultConnection": "Server=(localdb)\\mssqllocaldb;Database=aspnet-WebApp-[какие-то цифры, у всех разные];Trusted_Connection=True;MultipleActiveResultSets=true"
},Туда надо будет вписать правильные названия строк соединения, название сервера, и название базы данных. Сразу скажу, в production используются другие соединения, но нам сейчас это не нужно. У нас задача — создать две базы (local и test, production сделаем просто для примера — она будет использоваться в release конфигурации. Потом её можно будет заменить на рабочую удалённую базу).
Зачем это нужно?
Конфигурации Visual Studio позволяют менять какие-то настройки переключением конфигурации на панели visual studio:
В общем случае среда разработки просто декларирует DEBUG константу, которую можно потом откуда угодно из кода прочитать и понять, в какой конфигурации мы сейчас находимся, какая активная.
Удалённый отладчик не всегда доступен, например на colocation хостингах. Мы можем запустить наш asp.net сервер локально, а к базе подключиться к удалённой, и сможем увидеть все ошибки которые были в продакшн. Вот в release конфигурации мы это и будем делать, а конфигурация debug будет работать с нашей локальной базой. А test конфигурацию не будем делать, по причинам безопасности — чтобы случайно не стереть никакие данные, забыв переключить конфигурацию
Итак, начинаем менять строку подключения.
Имя сервера — его можно посмотреть на вкладке view -> SQL server object explorer
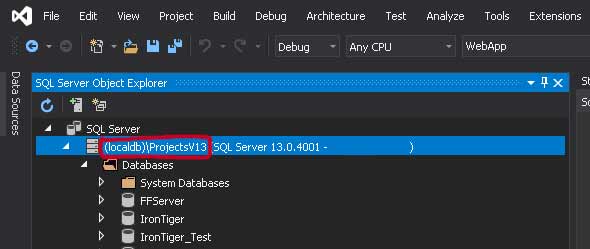
(Имя моего компьютера я предусмотрительно сотру, а то вы меня вычислите по IP и что-нибудь набьёте).
Итак, у меня это (localdb)\ProjectsV13. не знаю почему, мой SQL при установке так назвал.
Это значит что наша строка подключения становится
"DefaultConnection": "Server=(localdb)\\ProjectsV13;Database=Habr1_Local;
Trusted_Connection=True;MultipleActiveResultSets=true"У вас может быть по-другому, но только ProjectV13. Остальное надо оставить так.
DefaultConnection меняем на Habr1_Local
Получается так:
"ConnectionStrings": {
"Habr1_Local": "Server=(localdb)\\ProjectsV13;Database=Habr1_Local;Trusted_Connection=True;MultipleActiveResultSets=true"
},Теперь нужно перейти в файл Startup.cs и заменить там DefaultConnection на Habr1_Local:
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));превращается в
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("Habr1_Local")));
Запускаем наш проект в конфигурации Debug, открывается браузер, мы видим первую страницу, нажимаем кнопочку Login, вводим туда любой валидный email (он не будет посылать вам письма, просто валидирует формат) и нажимаем Login — и видим вот такой экран:
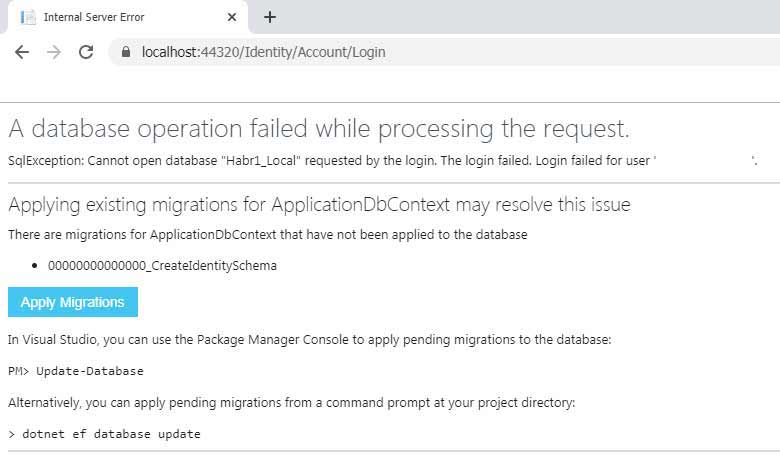
Нажимаем Apply Migration, ждём когда появится подтверждение справа от синей кнопки что миграция прошла и нужно обновить страницу, обновляем, нажимаем подвердить повторную отправку данных и получаем экран о том что Login Failed:
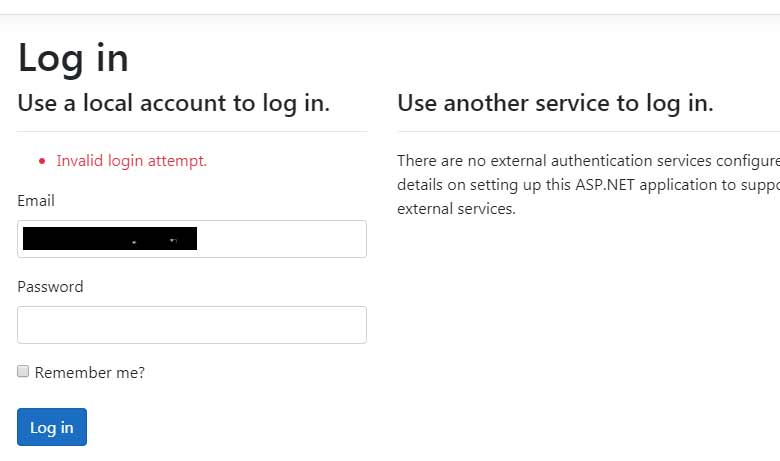
Если виден такой экран, значит всё ок — раз запрос прошёл и возвратил invalid login attempt, значит ошибки базы данных не было, а просто она не нашла такого пользователя.
Вот к примеру нужно изменить состояние базы данных на какое-то определённое — для этого можно создать снимок базы данных, или для каждого состояния создать несколько снимков, и эти снимки включать/выключать как программно так и специальными командами.
Или когда разрабатываешь на локальной машине что-то, а потом нужно новое состояние базы синхронизировать на сервере с локальным, обновить production сервер до состояния своей локальной базы, и сделать это автоматически — тоже можно применить migration. Это собственно вот эта синяя кнопочка. База знает, что состояние её отлично от состояния кода и пытается синхронизировать эти состояния. Для этого в базе создаётся специальная таблица с закодированным состоянием структуры базы.
К сожалению, этот инструмент усложняется тем что для него нет визуального интерфейса, и нужно работать с ним из командной строки. Migrations удобно использовать, когда нужно передавать состояния через Git — просто создавая такие снимки базы данных в виде C# файлов. Но у этого инструмента есть одна опасность — если его неправильно настроить, он может потереть данные в базе, поэтому пользоваться им стоит с осторожностью.
Проверяем наличие базы — Visual Studio должна была её создать
Если базы нет, значит что-то пошло не так — или не установлен SQL сервер, или что-то ещё, в общем как в анекдоте про то, как если бы программисты были врачами: «доктор, у меня нога болит… — ну не знаю, у меня такая же нога и ничего не болит!»
В этом месте я делаю ещё две строки подключения, appsettings.json приобретает такой вид:
"ConnectionStrings": {
"Habr1_Local": "Server=(localdb)\\ProjectsV13;Database=Habr1_Local;Trusted_Connection=True;MultipleActiveResultSets=true",
"Habr1_Test": "Server=(localdb)\\ProjectsV13;Database=Habr1_Test;Trusted_Connection=True;MultipleActiveResultSets=true",
"Habr1_Production": "Server=(localdb)\\ProjectsV13;Database=Habr1_Production;Trusted_Connection=True;MultipleActiveResultSets=true"
},
Делаю commit и кладу в репозиторий следующий снимок:
Snapshot: Snap_1_DataBases
Создаю новую ветку, Snap_2_Configurations
цель: создать работающие конфигурации
При переключении конфигураций мы можем считать из любого места программы какая конфигурация текущая (на самом деле не из любого, из View не получится — нужно делать специальную функцию, но для этого проекта это не важно):
#if DEBUG
конфигурация DEBUG
#else
конфигурация RELEASE (не DEBUG во всяком случае)
#endifОткрываем файл Startup.cs и приводим метод ConfigureServices к такому виду:
public void ConfigureServices(IServiceCollection services)
{
String ConnStr = "";
#if DEBUG
ConnStr = "Habr1_Local";
#else
ConnStr = "Habr1_Production";
#endif
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(
Configuration.GetConnectionString(ConnStr)));
services.AddDefaultIdentity<IdentityUser>(options => options.SignIn.RequireConfirmedAccount = true)
.AddEntityFrameworkStores<ApplicationDbContext>();
services.AddControllersWithViews();
services.AddRazorPages();
}
Как видно, мы заменили Habr1_Local на переменную, и теперь в зависимости от конфигурации connectionstring будет или Habr1_Local или Habr1_Production
Теперь можно запустить проект и проверить, как создаются базы в зависимости от конфигурации
Выбираем DEBUG на панели, запускакаем, логинимся, применяем migration, проверяем что база создалась (Habr1_Local)
Останавливаем проект, выбираем Release конфигурацию, запускаем, логинимся, применяем migration, проверяем что база создалась — у нас 2 базы.
Готово!
Snapshot: Snap_3_HabrDB
Цель: создание отдельного проекта базы данных, который потом можно будет использовать в разных проектах
Зачем отдельный проект?
У отдельных проектов есть ряд преимуществ:
- Их можно использовать в других проектах
- Они не перекомпилируются если в них нет изменений, а значит общее время компиляции сокращается
- Отдельные проекты легче тестировать
Итак, правой кнопочкой на решение — add -> new solution folder, назвать его DB.
Потом правой на созданную папку — add new project -> .net standard, назвать HabrDB.
У меня почему-то он создаётся как .net standard 2.0, нужно изменить на 2.1
(при создании он предлагает физический путь, пусть лежит в папке DB и физически тоже).
У меня вот так выглядит:
Итак, у нас есть какой-то ApplicationDBContext в проекте, а мы создали ещё один свой? Не будут ли конфликтовать друг с другом? Сейчас мы их подружим. У нас будет два разных контекста к одной и той же базе данных, которые не будут пересекаться через Entity Framework. Мы раздадим им разные schema name: один останется dbo по-умолчанию, а другой будет «habr».
Если связывать такие контексты через корень композиции, то их можно рециркулировать в других проектах практически прозрачно. (Например, контекст склада и контекст сотрудников)
И ещё один архитектурный момент, иногда надо добавить какие-то свои свойства к пользователю, это не относится напрямую к теме статьи, но мы это сделаем просто чтобы знать как это делать. Помимо этого, мы сможем создавать и удалять контексты независимо друг от друга. Хорошая идея в том, чтобы отделить таблицу безопасности с персональными данными и зашифровать её на уровне базы данных (в этом проекте мы не будем этого делать, но в целом это иногда это требуется, в том числе по законодательству).
Да и тестировать так проще, можно не создавать все таблицы сразу, а только те которые нужны для теста заданного контекста.
Создаю новый снимок проекта — этап 4.
Цели этого этапа такие:
- сменить стандартного пользователя на расширенного
- сменить пользователя в файле Srartup.cs
- сменить пользователя в файле LoginPartial и ViewImports
- создать новый Migration для автоматического создания базы в новом формате
Итак, переносим класс ApplicationDBContext из проекта WebApp в HabrDB.
Он не переносится, просто копируется. Удаляем его из WebApp, открываем его из проекта HabrDB и меняем ему namespace на HabrDB, появляется куча ошибок.
Да, в этом проекте нет нужных пакетов, сейчас мы их доставим.
Через nuget в проекте HabrDB нужно установить Microsoft.AspNetCore.Identity.EntityFrameworkCore.
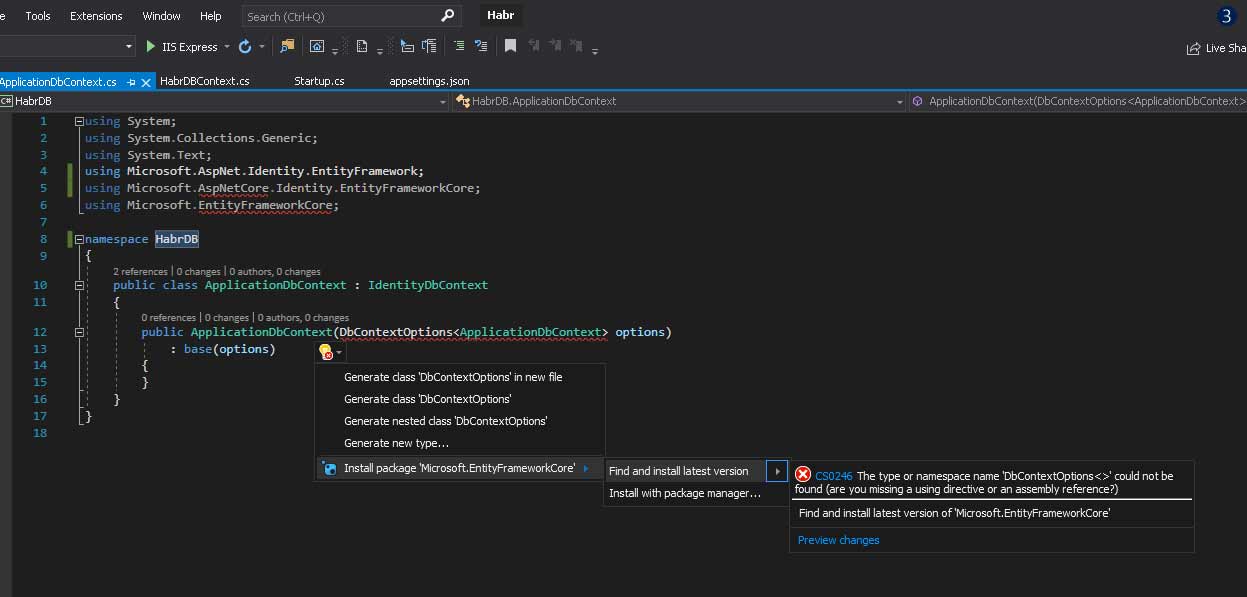
Кликаем на лампочку и она нам предлагает установить из последних
Конечный файл SecurityDBContext (его надо тоже переименовать) приобретает такой вид:
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.AspNetCore.Identity.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore;
namespace HabrDB
{
public class SecurityDBContext : IdentityDbContext
{
public SecurityDBContext(DbContextOptions<SecurityDBContext> options)
: base(options)
{
}
}
}После сборки
После этого у меня в проекте на references из WebApp появились жёлтые треугольнички, которые говорят о том что какие-то ссылки работают неправильно. Я очистил проект (build -> clean solution), закрыл проект, из папки проекта удалил все Debug, Release, Obj и Bin директории, после этого открыл проект заново, он какое-то время поискал нужные ссылки в интернете и подгрузил их, и треугольнички исчезли — значит всё ок.
Теперь удаляем папку Data из проекта WebApp, удаляем в окне SQL Server Object Explorer наши базы (Habr1_Local и Habr1_Production) и запускаем проект. Пробуем залогиниться — и теперь вместо предложения применить migration выдаёт ошибку.
Всё правильно, мы удалили папку Data где были все migrations и теперь фреймворк не знает что делать. Но это же было так круто?! Зачем?! Затем что мы сейчас будем расширять класс пользователя.
Добавляем новый файл в проект HabrDB:
ApplicationUser.cs
Наследуем его от IdentityUser
using Microsoft.AspNetCore.Identity;
using System;
using System.Collections.Generic;
using System.Text;
namespace HabrDB
{
public class ApplicationUser:IdentityUser
{
public String NickName { get; set; }
public DateTime BirthDate { get; set; }
public String PassportNumber { get; set; }
}
}В файл SecurityDBContext в заголовок класса добавляем:
public class SecurityDBContext : IdentityDbContext<ApplicationUser>Это нужно чтобы EntityFramework знал что теперь при создании базы нужно использовать расширенную модель пользователя из класса AppllicationUser вместо стандартной.
Метод ConfigureServices в файле Startup.cs приобретает вид:
public void ConfigureServices(IServiceCollection services)
{
String ConnStr = "";
#if DEBUG
ConnStr = "Habr1_Local";
#else
ConnStr = "Habr1_Production";
#endif
services.AddDbContext<SecurityDBContext>(options =>
options.UseSqlServer(
Configuration.GetConnectionString(ConnStr)));
services.AddDefaultIdentity<ApplicationUser>(options => options.SignIn.RequireConfirmedAccount = true)
.AddEntityFrameworkStores<SecurityDBContext>();
services.AddControllersWithViews();
services.AddRazorPages();
}(Заменяем IdentityUser на ApplicationUser)
В файле _ViewImports.cshtml добавляем строку
using HabrDB
Теперь все виды будут видеть наш проект с базой и не нужно будет в начале видов писать using HabrDB.
В файле _LoginPartial.cshtml меняем все IdentityUser на ApplicationUser.
using Microsoft.AspNetCore.Identity
inject SignInManager SignInManager
inject UserManager UserManager
На всякий случай компилируем проект, чтобы знать что у нас нет ошибок и мы нигде ничего не забыли заменить.
Теперь делаем миграцию.
Надо открыть Package Manager Console, выбрать проект DB/HabrDB и написать ему
add-migration initialВот что у меня получилось:
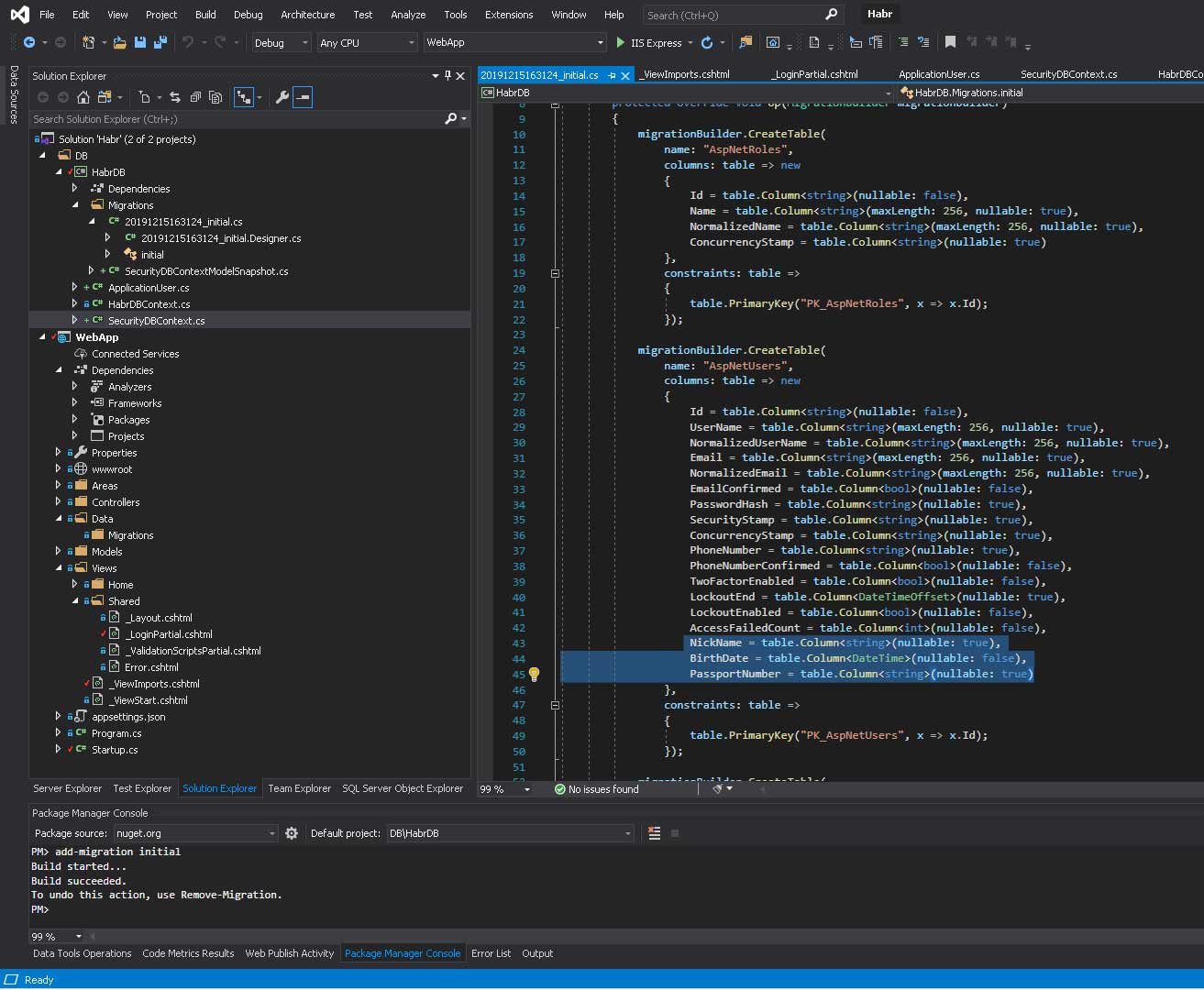
В проекте HabrDB появилась папочка Migrations и в ней файлики которые позволят нам создать нашу базу автоматически, но теперь уже с нашими дополнительными полями — NickName, BirthDate, PassportNumber.
Попробуем как это работает — давайте запустим и попробуем залогиниться (не зарегистрироваться, там придётся сложные пароли вводить):
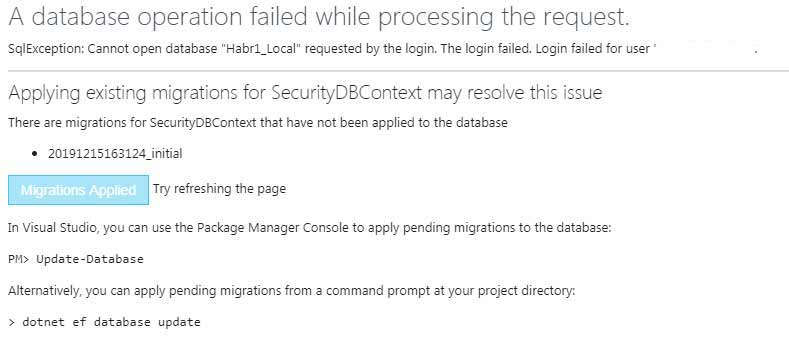
Мне предложили сделать миграцию и я согласился — вот наша база:
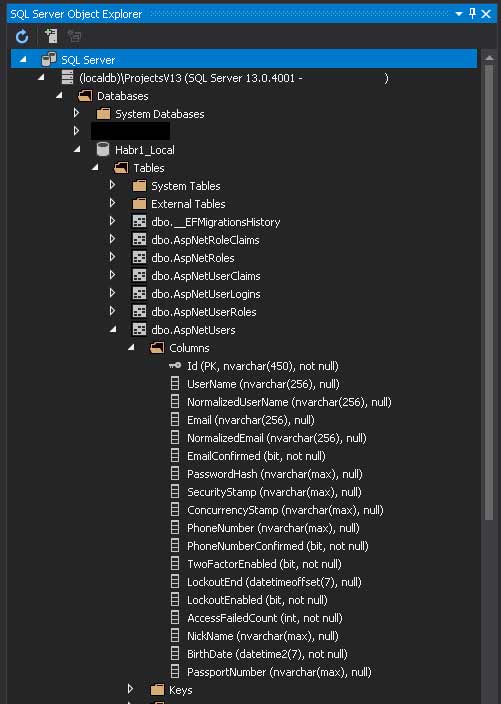
C этим этапом всё
Snapshot: Snap_4_Security готов
Создаём пятый снимок.
Цели:
- заставить работать тестовый connection string
- создать проект тестирования базы данных
- заставить тестовый проект создавать базу и тестировать что-нибудь полезное
Кликаем правой на папочке DB, создаём новый проект — MSTest .net core.
Переименовываем единственный файл в этом проекте в DBTest и размышляем…
Дальше будет сложно.
Проблема
Как нам создать такой контекст, который будет гарантированно связываться с тестовой базой данных, то есть использовать ConnectionString мало того что из другого проекта (WebApp), но и как-то увязываться с Release/Debug конфигурациями?.. Может создать новую конфигурацию, Test например?
Нет, это потенциальная потеря данных — как-нибудь мы забудем что забыли переключиться с тестовой конфигурации, нажмём кнопочку Run All Tests — а там удаление всей базы… нет, такой вариант не подходит…
Значит будем явно создавать тестовый контекст!
Открываем файл HabrDBContext и меняем его содержимое на:
using System;
using System.IO;
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Configuration;
namespace HabrDB
{
public class HabrDBContext:DbContext
{
public String ConnectionString = "";
public IConfigurationRoot Configuration { get; set; }
public HabrDBContext CreateTestContext()
{
DirectoryInfo info = new DirectoryInfo(Directory.GetCurrentDirectory());
DirectoryInfo temp = info.Parent.Parent.Parent.Parent;
String CurDir = Path.Combine(temp.ToString(), "WebApp");
String ConnStr = "Habr1_Test";
Configuration = new ConfigurationBuilder().SetBasePath(CurDir).AddJsonFile("appsettings.json").Build();
var builder = new DbContextOptionsBuilder<HabrDBContext>();
var connectionString = Configuration.GetConnectionString(ConnStr);
builder.UseSqlServer(connectionString);
ConnectionString = connectionString;
return this;
}
}
}Через Nuget добавляем к базе данных следующие библиотеки:
Microsoft.AspNetCore.Identity.EntityFrameworkCore
Microsoft.EntityFrameworkCore
Microsoft.EntityFrameworkCore.SqlServer
Microsoft.Extensions.Configuration.FileExtensions
Microsoft.Extensions.Configuration.JsonМетод CreateTestContext просто принудительно может возвращать только Connection String с именем Habr1_Test. Взять его нужно в другом проекте. Чтобы не подключать проект через reference потому что нам нужна только одна настройка, мы просим builder создать опции исходя из заданного connectionString, для этого добираемся по цепочке директорий из директории где скомпилирован тестовый проект наверх до корневой директории проекта, собираем из частей путь к проекту WebApp, просим добавить для нас конфигурационный файл appsettings.json где хранятся наши настройки, и скомпилировать его в конфигурацию. Дальше из этой конфигурации берём connectionString и запоминаем её (это нам понадобится в дальнейшем).
В крупных проектах можно вынести настройки в отдельный проект со строками, DLL или объект доступа к данным настроек с кешированием. Нам пока достаточно будет более простого подхода.
Почему так?
Можно положить тестовый ConnectionString прямо в тестовый проект и инициализировать им базу, можно в базе создать тестовый ConnectionString. Но тогда будет одна неприятная вещь: все строки подключения будут храниться в разных местах. А я по себе знаю что голова у меня дырявая и я могу забыть что-нибудь изменить, когда например изменится название базы данных или сервера, и чтобы у меня все строки подключения были в одном месте я делаю так. Теперь, изменив конфигурационный файл appsettings.json можно управлять всеми подключениями.
Попробуем теперь сделать что-то полезное с базой, например создадим что-нибудь.
В проекте HabrDB я создал папку DBClasses, там будут только классы таблиц базы данных. Работаем через code first, если я представляю что делаю то обычно мне так удобней.
Создадим такую таблицу:
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using System.Text;
namespace HabrDB.DBClasses
{
[Table("Phones", Schema ="Habr")]
public class Phone
{
[Key]
public int Id { get; set; }
public String Model { get; set; }
public DateTime DayZero { get; set; }
}
}Для красоты, пусть мой класс называется «телефон» а таблица в базе во множественном числе — «телефоны». Поэтому я в атрибуте Table указываю как назвать мою таблицу и в каком namespace она должна быть в базе (в SQL это называется Schema).
Теперь ещё вопрос эстетики: вот у нас будет куча разных инфраструктурных методов в классе базы данных, а потом ещё разные таблицы и всё это в одну кучу — можно сделать partial классы.
Добавим слово partial после слова class в файле HabrDBContext.cs — вот так:
public partial class HabrDBContext:DbContextСоздадим копию файла HabrDBContext.cs — проосто CTRL+С — CTRL+V на файле, создастся его копия, меняем у исходного файла имя на HabrDBContext_Infrastructure.cs, у нового на HabrDBContext_Data.cs
В новом пишем:
using HabrDB.DBClasses;
using Microsoft.EntityFrameworkCore;
namespace HabrDB
{
public partial class HabrDBContext:DbContext
{
public DbSet<Phone> Phones { get; set; }
}
}Вот теперь красиво — с данными работаем в одном месте, с инфраструктурой в другом. Файлы разные, а класс один и тот же — среда его сама соберёт из нескольких в один при сборке проекта.
Ну, попробуем!
Заменим код в нашем единственном тестовом классе на:
using HabrDB;
using HabrDB.DBClasses;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using System;
using System.Collections.Generic;
using System.Linq;
namespace DBTest
{
[TestClass]
public class DBTest
{
[TestMethod]
public void TestMethod1()
{
String PhoneName = "Nokia";
DateTime now = DateTime.Now;
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();
List<Phone> Phones = db.Phones.ToList();
Assert.AreEqual(0, Phones.Count);
Phone ph = new Phone();
ph.Model = PhoneName;
ph.DayZero = now;
db.Phones.Add(ph);
db.SaveChanges();
Phone ph1 = db.Phones.Single();
Assert.AreEqual(PhoneName, ph1.Model);
Assert.AreEqual(now, ph1.DayZero);
}
}
}
Нажимаем кнопочку play на вкладке Test Explorer (или Test -> Run All Tests) и…
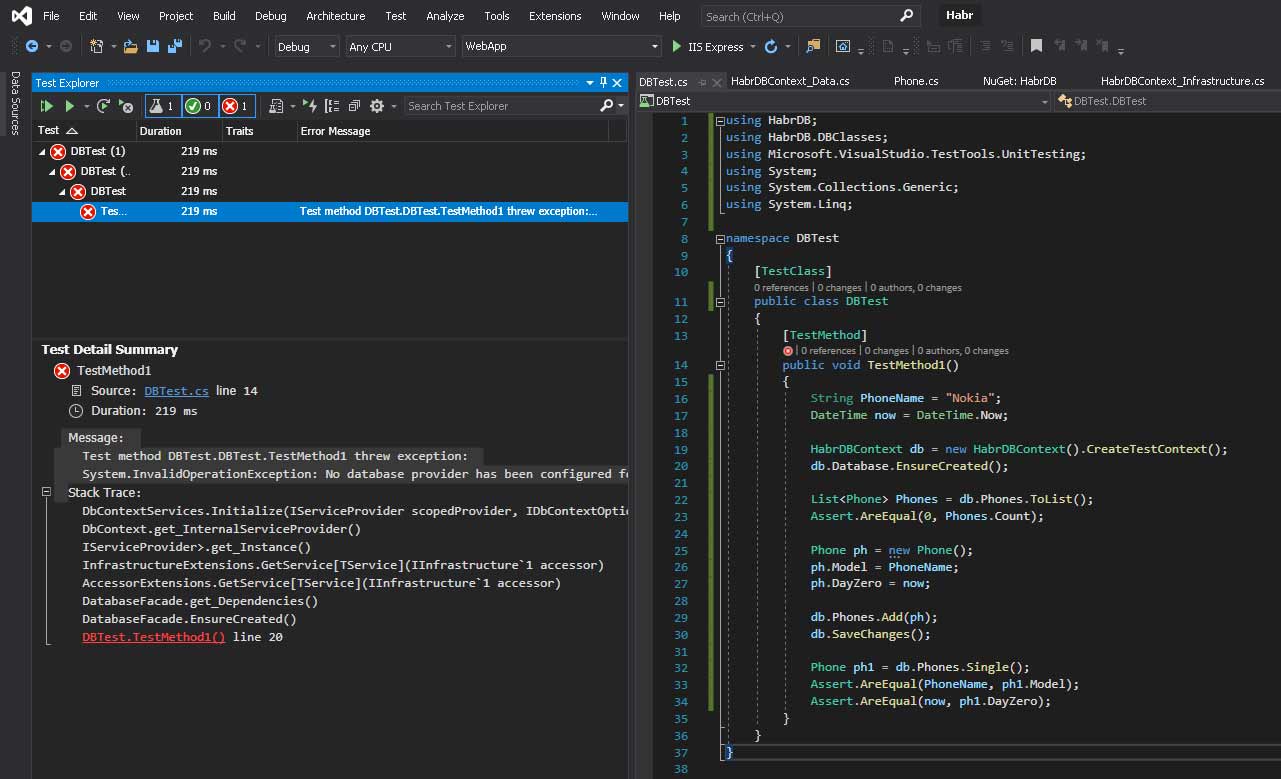
Ошибка! вот те на.
Читаем что нам пишут:
Message:
Test method DBTest.DBTest.TestMethod1 threw exception:
System.InvalidOperationException: No database provider has been configured for this DbContext. A provider can be configured by overriding the DbContext.OnConfiguring method or by using AddDbContext on the application service provider. If AddDbContext is used, then also ensure that your DbContext type accepts a DbContextOptions<TContext> object in its constructor and passes it to the base constructor for DbContext.Какая-то лабуда на английском…
Ладно, будем действовать наугад!
Не запилить ли нам такую функцию в файл HabrDBContext_Infrastructure.cs? Попробуем!
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
String ConnStr = "";
if (Configuration == null)
{
#if DEBUG
ConnStr = "Habr1_Local";
#else
ConnStr= "Habr1_Production";
#endif
Configuration = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json").Build();
ConnectionString = Configuration.GetConnectionString(ConnStr);
}
optionsBuilder.UseSqlServer(ConnectionString);
}Запускаем…
Вот повезло!!!
Создалась новая база и в ней — наша таблица!
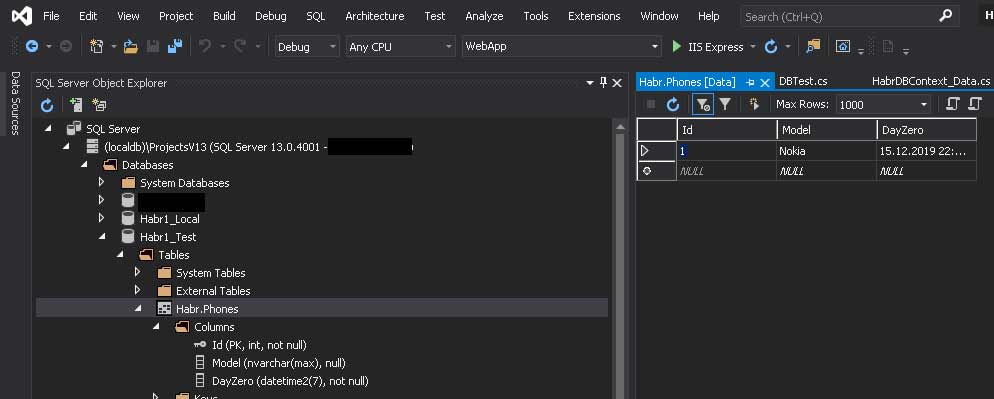
Зачем так?
Если поставить пару breakpoints на функции OnConfiguring и CreateTestContext то будет видно, что сначала вызывается метод CreateTestContext, и сохраняет в объекте ConnectionString строку подключения. Всё казалось бы ОК. Но потом кто-то пытается вызвать OnConfiguring… кто же это? Посмотрим call stack — да это же строка db.Database.EnsureCreated() из теста! дело в том, что базы как таковой у нас ещё нет — создаёт её метод EnsureCreated. Но этот метод уже не принимает параметров, и контекст надо как-то сохранить между вызовами конструктора и EnsureCreated. Помимо этого, когда мы будем этот контекст применять из самого проекта (не в тестировании, а на сайте например) то всякие middlware, DI, и прочие заковыристые механизмы будут тоже пытаться его вызывать, так что заранее всё предусмотрим — кто бы ни вызывал нашу базу, если он захочет вызвать OnConfiguring — у него будет такая возможность. Мы всё предусмотрели.
Запустим тест ещё раз — и …
Опять ошибка?
База уже есть, данные есть… что не так?
База это персистентный объект который остаётся, даже если мы перезапускаем наш проект… и теперь начинается по-настоящему самое сложное. Как удалить эти все таблицы? Как удалить данные, сбросить все индексы?
Snapshot: Snap_5_ContextCrafting готов
Для начала напишем DAL — Data Access Layer.
Создадим копию файла HabrDBContext_Data.cs, назовём её HabrDBContext_DAL.cs
в ней напишем:
using HabrDB.DBClasses;
using Microsoft.EntityFrameworkCore;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace HabrDB
{
public partial class HabrDBContext:DbContext
{
public async Task<int> AddPhone(Phone ph)
{
this.Phones.Add(ph);
int res = await this.SaveChangesAsync();
return res;
}
public async Task<List<Phone>> GetAllPhones()
{
List<Phone> phones = await this.Phones.ToListAsync();
return phones;
}
}
}
Это — обёртка над нашими данными. Мне бы не хотелось, если я что-то изменю в интерфейсах обращения к базе, иметь дело с поиском по всему проекту где я это вызывал. Поэтому сделаем слой абстракции — Data Access Layer. Он будет посредником между базой и MVC механизмами сайта или других механизмов. И — совпадение? — у нас сразу появляются объекты тестирования! Ещё одна причина использовать тесты — они провоцируют на решения с низкой связностью.
Изменим код функции в тестах — и за одно изменим её название. Теперь мы знаем что тестируем!
Добавление телефона!
Репозиторий делать не будем, для демонстрационного проекта это избыточное решение.
По нормальному можно всё соединить через DI в startup.cs, но для демонстрационного опять же проекта это слишком запутанно, поэтому оставим так
Новый код функции тестирования:
[TestMethod]
public void AddPhone_Test()
{
String PhoneName = "Nokia";
DateTime now = DateTime.Now;
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();
List<Phone> Phones = db.GetAllPhones().Result;
Assert.AreEqual(0, Phones.Count);
Phone ph = new Phone();
ph.Model = PhoneName;
ph.DayZero = now;
db.AddPhone(ph);
Phone ph1 = db.Phones.Single();
Assert.AreEqual(PhoneName, ph1.Model);
Assert.AreEqual(now, ph1.DayZero);
}
Удалим из тестовой базы строку с телефоном, и запустим тест повторно — он должен сработать.
Если он не сработает, значит у вас всё-таки другая нога. У меня всё зелёненькое:
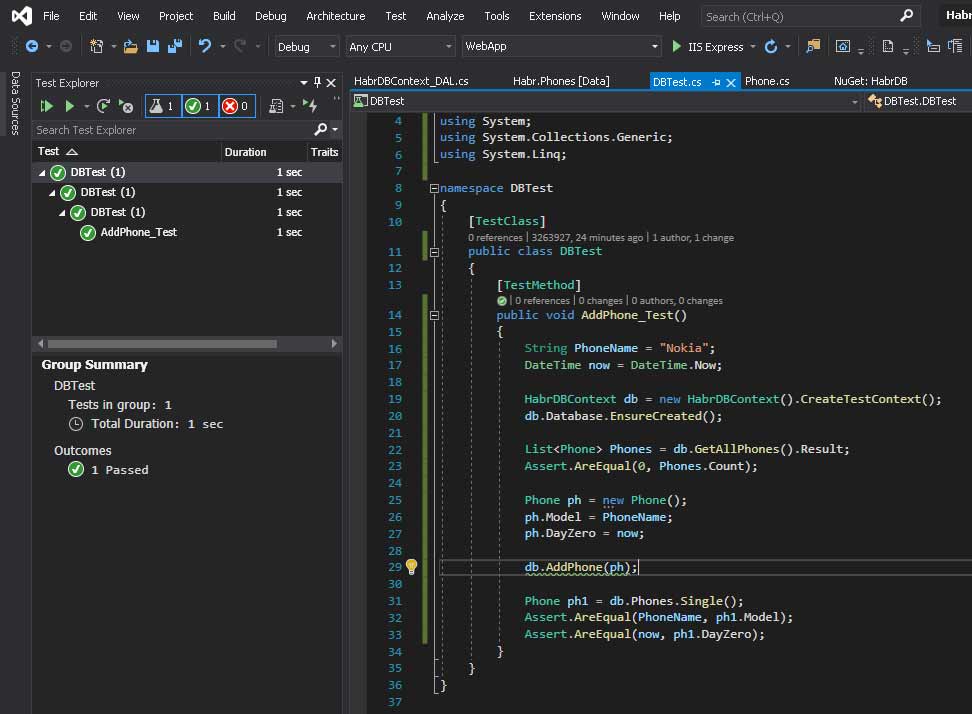
Что такое db.GetAllPhones().Result? Дело в том, что наши фукции DAL асинхронные. Но сам метод тестирования обычный, и поэтому в нём нельзя вызвать await. Попробуем удалить данные, сделать метод асинхронным и посмотреть что будет.
Наша функция стала async Task — иначе тест вобще не запустится, и везде где вызов асинхронных методов — перед ними нужен await
[TestMethod]
public async Task AddPhone_Test()
{
String PhoneName = "Nokia";
DateTime now = DateTime.Now;
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();
List<Phone> Phones = await db.GetAllPhones();
Assert.AreEqual(0, Phones.Count);
Phone ph = new Phone();
ph.Model = PhoneName;
ph.DayZero = now;
await db.AddPhone(ph);
Phone ph1 = db.Phones.Single();
Assert.AreEqual(PhoneName, ph1.Model);
Assert.AreEqual(now, ph1.DayZero);
}
Важно, чтобы все тестовые функции, в которых есть асинхронные вызовы возвращали Task а не void — иначе тесты или не запустятся или не будут ждать возврата асинхронных данных и пойдут дальше и будет ошибка.
Так, более менее работает.
Snapshot: Snap_6_Dal
А что, так данные и удалять вручную? Конечно нет!
Нам нужна функция удаления таблиц из базы…
Круто было бы задействовать db.Database.EnsureDeleted… и действительно можно!
Но лучше не нужно… дело в том что в этом проекте у нас базы не связаны с паролями. А если база связана с паролем, то создать её нужно будет отдельно — через SQL Management Studio, а при удалении из db.Database.EnsureDeleted она удалится вместе со всеми паролями, доступами, правами пользователей, и когда фреймворк попытается её создать в следующий раз, то к базе просто не будет доступа, придётся настраивать всё заново.
Это первое.
Второе заключается в том, что лучше не делать лишней работы, и так тесты базы данных будут проходить дольше чем обычных функций, не связанных с внешними механизмами, и лучше оптимизировать время работы тестов всеми возможными способами.
И третье: возможно, за один тест нам понадобится несколько раз удалить какую-то таблицу или несколько и создать заново, при этом оставив другие таблицы нетронутыми.
Попробуем вызвать функцию db.Database.EnsureDeleted, нажать скобочку и посмотреть, что она принимает, и есть ли у неё перегрузки…

Да, не густо…
ну ладно, напишем свою.
Сразу добавим к решению новый проект, (в самом solution) на решении правой кнопкой, add -> .net standard C#, и назовём его Extensions. Проверим чтобы он был 2.1 версии.
Дальше нужно переименовать единственный файл в проекте Extensions в DBContextExtensions.cs и поместить туда следующий код:
using Microsoft.EntityFrameworkCore;
using System;
using System.Linq;
using Microsoft.EntityFrameworkCore.Infrastructure;
namespace Extensions
{
public static class DBContextExtensions
{
public static int EnsureDeleted<TEntity>(this DatabaseFacade db, DbSet<TEntity> set) where TEntity : class
{
TableDescription Table = GetTableName(set);
int res = 0;
try
{
res = db.ExecuteSqlRaw($"DROP TABLE [{Table.Schema}].[{Table.TableName}];");
}
catch (Exception)
{
}
return res;
}
public static TableDescription GetTableName<T>(this DbSet<T> dbSet) where T : class
{
var dbContext = dbSet.GetDbContext();
var model = dbContext.Model;
var entityTypes = model.GetEntityTypes();
var entityType = entityTypes.First(t => t.ClrType == typeof(T));
var tableNameAnnotation = entityType.GetAnnotation("Relational:TableName");
var tableSchemaAnnotation = entityType.GetAnnotation("Relational:Schema");
var tableName = tableNameAnnotation.Value.ToString();
var schemaName = tableSchemaAnnotation.Value.ToString();
return new TableDescription { Schema = schemaName, TableName = tableName };
}
public static DbContext GetDbContext<T>(this DbSet<T> dbSet) where T : class
{
var infrastructure = dbSet as IInfrastructure<IServiceProvider>;
var serviceProvider = infrastructure.Instance;
var currentDbContext = serviceProvider.GetService(typeof(ICurrentDbContext)) as ICurrentDbContext;
return currentDbContext.Context;
}
}
public class TableDescription
{
public String Schema { get; set; }
public String TableName { get; set; }
}
}
Из Nuget добавить Microsoft.EntityFrameworkCore
И ещё один пакет — Microsoft.EntityFrameworkCore.Relational
Extensions — очень удобный механизм. С помощью него можно добавить к объекту класса дополнительную функциональность, что мы и сделали — ключевое слово this перед типом первого параметра
public static int EnsureDeleted<TEntity>(this DatabaseFacade db, DbSet<TEntity> set) where TEntity : classуказывает на расширяемый тип. Это значит, что после того, как мы это написали, у объекта класса DatabaseFacade появится новый метод — EnsureDeleted с параметром, который и будет этой нашей функцией которую мы только что написали! where TEntity: class в конце означает что TEntity имеет constraint — ограничение на использование, и если мы попытаемся обобщить его не классом, а чем-то другим то будет ошибка времени компиляции.
Предвижу ваш закономерный вопрос — зачем это?
Затем что функции GetTableName, которая вызывается из EnsureDeleted, нужно это ограничение.
А зачем ей это ограничение?
Затем что функции GetDbContext, которая вызывается из GetTableName, тоже нужно это ограничение…
А ей зачем это ограничение???!!! спросите вы на повышенных тонах и будете правы…
DbSet, который мы пытаемся расширить методом GetDbContext в строке
Public static DbContext GetDbContext<T>(this DbSet<T> dbSet) where T : class, требует чтобы T был ссылочным типом, а class как раз один из них…
Так вот, все эти сложности — для одной маленькой, но очень полезной особенности — не передавать в качестве параметра в метод EnsureDeleted строковых значений. Потому что у меня плохая память. Я хочу чтобы мне DBContext подсказал какие таблицы у него есть, и из этого датасета он уже вычисляет контекст, приводит его к текущему контексту через сервис провайдер, потом из этого контекста берёт модель, из неё типы, потом среди этих типов ищет тот у кого тип такой же как у датасета (это уже в GetTableName), потом через аннотации берёт название таблицы и схемы, передаёт это уже в EnsureDeleted и там — вот блин! опять нет функции типа removetable или чего-то типа того, приходится из строк конструировать какие-то SQL сырники… ну хорошо хоть как-то получилось!
А exception в функции EnsureDeleted для того, чтобы можно было не задумываться о порядке удаления таблиц, если вдруг там будут какие-то связанные данные, просто после удаления связанных таблиц попробовать удалить таблицу ещё раз и не заморачиваться.
Добавляем в тесты метод (в конец)
[TestMethod]
public void DeleteTable_Test()
{
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureDeleted(db.Phones);
}Запускаем, проверяем, выдыхаем…
Запускаем ещё раз — должно работать.
Теперь каждый раз при запуске тестов будут создаваться нужные таблицы, а потом удаляться.
Snapshot: Snap_7_Extensions
к новым
Но есть одна проблема — объект HabrDBContext у нас не персистентный (создаётся в каждом тестовом методе). (Ну да, кагбэ идея модульных тестов в том, чтобы они были изолированными. А мы это пытаемся нарушить! Хорошо что милиция не видит...)
То есть в каждом тестовом методе контекст создаётся заново, и мы не можем расшарить этот объект между функциями, чтобы он был общим для всех и создавался один раз для всех тестов. Не можем? Ну и ладно, будем в каждой фукнции писать.
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();а последним методом вызывать
HabrDBContext db = new HabrDBContext().CreateTestContext();
db.Database.EnsureDeleted(db.Phones);и ещё какие-нибудь таблицы…
Не очень красиво, поэтому подумаем как можно решить этот вопрос… раз мы одеваемся как тестировщики, нужно соответствовать имиджу — поищем решение!
Есть такая занимательная особенность у классов — статические члены.
Это как если представить чертёж и объект, созданный по этому чертежу, то выходит что статический член это такой член который присущ не объекту, созданному по чертежу, а самому этому чертежу.
Вот это уже интересно…
Сейчас попробуем!
Наш тестовый класс называется DBTest, создадим ему статический объект — db
using HabrDB;
using HabrDB.DBClasses;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Extensions;
namespace DBTest
{
[TestClass]
public class DBTest
{
public static HabrDBContext db;
[TestMethod]
public void AA0_init()
{
db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();
}
[TestMethod]
public async Task AddPhone_Test()
{
String PhoneName = "Nokia";
DateTime now = DateTime.Now;
List<Phone> Phones = await db.GetAllPhones();
Assert.AreEqual(0, Phones.Count);
Phone ph = new Phone();
ph.Model = PhoneName;
ph.DayZero = now;
await db.AddPhone(ph);
Phone ph1 = db.Phones.Single();
Assert.AreEqual(PhoneName, ph1.Model);
Assert.AreEqual(now, ph1.DayZero);
}
[TestMethod]
public void DeleteTable_Test()
{
db.Database.EnsureDeleted(db.Phones);
}
}
}
Работает!
Но что-то тупо нумеровать так методы.
Есть решение!
Специальные тестовые атрибуты!
Создадим в тестовом проекте новый класс с названием DBTestBase, и унаследуем от него наш класс DBTest.
Из DBTest нужно убрать всё, кроме:
using HabrDB;
using HabrDB.DBClasses;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Extensions;
namespace DBTest
{
[TestClass]
public class DBTest:DBTestBase
{
[TestMethod]
public async Task AddPhone_Test()
{
String PhoneName = "Nokia";
DateTime now = DateTime.Now;
List<Phone> Phones = await db.GetAllPhones();
Assert.AreEqual(0, Phones.Count);
Phone ph = new Phone();
ph.Model = PhoneName;
ph.DayZero = now;
await db.AddPhone(ph);
Phone ph1 = db.Phones.Single();
Assert.AreEqual(PhoneName, ph1.Model);
Assert.AreEqual(now, ph1.DayZero);
}
[ClassCleanup]
public static void DeleteTable()
{
db.Database.EnsureDeleted(db.Phones);
}
}
}
Содержимое класса DBTestBase:
using HabrDB;
using Microsoft.VisualStudio.TestTools.UnitTesting;
namespace DBTest
{
[TestClass]
public class DBTestBase
{
public static HabrDBContext db{ get; set; }
/// <summary>
/// Executes once before the test run. (Optional)
/// </summary>
/// <param name="context"></param>
[AssemblyInitialize]
public static void AssemblyInit(TestContext context)
{
db = new HabrDBContext().CreateTestContext();
db.Database.EnsureCreated();
}
/// <summary>
/// Executes before this class creation
/// </summary>
/// <param name="context"></param>
[ClassInitialize]
public static void TestFixtureSetup(TestContext context)
{
}
/// <summary>
/// Executes Before each test
/// </summary>
[TestInitialize]
public void Setup()
{
}
/// <summary>
/// Executes once after the test run
/// </summary>
[AssemblyCleanup]
public static void AssemblyCleanup()
{
}
/// <summary>
/// Runs once after all tests in this class are executed.
/// Not guaranteed that it executes instantly after all tests from the class.
/// </summary>
[ClassCleanup]
public static void TestFixtureTearDown()
{
}
/// <summary>
/// Executes after each test
/// </summary>
[TestCleanup]
public void TearDown()
{
//db.Database.EnsureDeleted();//don`t call! delete database instead of tables!
}
}
}Теперь всё понятно! Наша база создаётся как статическая часть класса DBTestBase, и таким образом доступна всем классам, унаследованным от неё. Это значит, что создаётся база только один раз — при запуске тестов.
Добавляем [ClassCleanup] атрибут к любому методу любого класса — и получаем «cleaner» теста — такая функция которая сделает что-то после выполнения всех тестов этого класса.
Например, удалит все таблицы, которые были созданы в этом тесте, не трогая саму базу.
Поскольку все эти специальные функции исключены из метрик, то мы можем видеть чистое время за которое работают наши функции — добавляем стопицот левых объектов и видим резкий рост времени работы функции выборки — значит что-то не так с нашими DAL функциями, причём если тестировать одну функцию в одном тестовом методе то сразу будет понятно где проблема.
Ещё из функций можно создавать плейлисты.
Это нужно для того, чтобы например вызвать функцию подготовки данных (чисто для тестирования).
Потом функцию DAL обновления этих данных, потом ещё одну функцию DAL, которая например что-то считает, или выводит из этих данных отчёт, а потом эти данные удалить.
Таким образом мы можем имитировать какие-то действия пользователя из реальных бизнес-процессов.
Главное запомнить, что за рамками этих тестовых атрибутов тесты вызываются в алфавитном порядке.
Поэтому если нужна какая-то статичная последовательность, то так и надо называть:
T1_AddPhone_Test,
T2_RemovePhone_Test,
и т.д.…
Ну вот, теперь можно не волноваться за нашу базу — всё будет оттестировано по полной!
А сейчас давно пора спать! У меня там ещё девчёнка не тестированная…
Удачного тестирования! Всем пока!
git repository проекта: https://github.com/3263927/Habr_1
Пишите в комментариях, если эта тема интересна то запилю пост про тестирование Identity, Roles, Claims, 3D аутентификацию и написание своего TypeFilterAttribute (потому что стандартный кеширует и если вы удалили человека из роли он будет всё равно иметь эту роль пока не выйдет замуж. А ЗАМУЖ НЕ ВЫЙДЕТ ПОКА НЕ БУДЕТ ПРОТЕСТИРОВАН! :/)

Комментарии (40)

AlexZyl
21.12.2019 23:56+1Статья очень тяжело читается.
Начиная с цели этой статьи: почему именно MSTest? Потому что есть драйвер в VS? Так и для xUnit есть, и более того, MS уже давно его адаптировал в своих проектах.
Зачем в статье затрагивается Identity и MVC? Если цель показать просто тестирование DbContext вместе с миграциями, то и обычного консольного приложения хватило бы. Здесь же это добавляет информационного шума на полстатьи.
И третье: возможно, за один тест нам понадобится несколько раз удалить какую-то таблицу или несколько и создать заново, при этом оставив другие таблицы нетронутыми.
Если вам для тестов приходится удалять таблицу, то вы делаете что-то не так.
var tableNameAnnotation = entityType.GetAnnotation("Relational:TableName"); var tableSchemaAnnotation = entityType.GetAnnotation("Relational:Schema");
В 95% случаев используется Fluent api, и этот код работать не будет.
3263927 Автор
22.12.2019 01:19в больших проектах у меня есть ещё перегруженная функция EnsureDeleted(String,String) которая в этих случаях удаляет таблицу просто по имени и схеме, напрямую
иногда бывают проекты где таблицы создаются по нескольку штук для отдельного пользователя или подсистемы, ничего в этом нет необычного. есть задача — есть решение
Identity и MVC я затронул потому что если мы пишем просто базу данных для простого проекта то у неё нет таких архитектурных сложностей при которых нужен устойчивый проект с автоматическим тестированием в долгосрочной перспективе, это как раз для сложных случаев. тут архитектурные вопросы — часть общей проблемы
MSTest можно заменить любым другим тестом — это ничего не изменит, всё равно нужно будет контролируемо иметь тестовый контекст, возможность лёгкого применения миграций, добавления/удаления таблиц. MSTest просто потому что я с ним работаю обычно
обратите внимание на тип статьи — tutorial, это для тех кто возможно вобще не знает что такое тестирование. хабр же не только для самых опытных
а насчёт FluentAPI поясните пожалуйста, почему не будет работать?
Dartal2
22.12.2019 00:05this.ObjectLinks.ToList().Where(...).SingleOrDefault()
Загружаем ВСЕ записи из таблицы, когда нам нужна только одна.
А если их там тысячи или миллионы?3263927 Автор
22.12.2019 01:20о! это косяк, спасибо!
посмотрел в рабочем проекте, там уже всё нормально. наверное это артефакты того времени когда я только пытался решить эту проблему, взял наугад из каких-то промежуточных коммитов в качестве примера

nzeemin
22.12.2019 00:16До того как начали лабать код не увидел толкового объяснения, что же мы такое делаем. В статье какая-то сборная солянка между способом построения слоя доступа к данным и собственно его тестированием. Почему сделано именно так как сделано — непонятно. Какие проблемы мы решили таким подходом — тоже неясно. Шутки сомнительного свойства.
alexeystarchikov
22.12.2019 12:11Согласен с автором на счет тестирования БД. Да, это будут уже совсем не unit-тесты, а интеграционные. Но, как правильно было замечено, попытка замокать приводит к копипасту кода EF. Кстати, нельзя просто так замокать DbContext или DbSet. Отсюда вытекают фразы «так есть же шаблон UnitOfWork + Repository». Опять начинаются «танцы с бубном», чтобы обернуть EF в шаблон репозиторий, в то время как сам EF уже реализует UnitOfWork+Repo.
Второе. Когда ж, закончиться этот ужас с #if DEBUG. Ну специально для этого в .Net Core при работе с файлами конфигураций добавили поддержка имени окружения. Не зря же пустом проекте можно найти appsettings.json и appsettings.development.json
Почему не рассматривается вариант с проектом интеграционных тестов в Core? В своей практике я всегда его использовал для работы unit-тестов, связанных с БД. Нужна минимальная «обвязка». К тому же, в некоторых случаях необходимо работать с in-memory database. В случае статического метода, класс контекста начинает «обрастать» новыми метода, в зависимости от сценариев использования, что никак не добавляет читабельности коду. Даже class helpers проблему не решат, а только спрячут ее3263927 Автор
22.12.2019 15:11Когда ж, закончиться этот ужас с #if DEBUG.
он уже закончился когда ввели имя окружения, но оно не работает тогда когда нет окружения — это в другом проекте есть окружение, в тестовом его нет и оно там не нужно.
а главное, #if DEBUG визуально показывает вам какие строчки выполнятся сейчас, в текущей конфигурации, это удобно чтобы их не перепутать
Почему не рассматривается вариант с проектом интеграционных тестов в Core?
это не совсем понял — у меня же всё в core 3.1? или вы что-то другое имеете в виду?alexeystarchikov
22.12.2019 16:02docs.microsoft.com/en-us/aspnet/core/test/integration-tests?view=aspnetcore-3.1
Вот и будет у вас окружение
TimurNes
22.12.2019 12:54Как то очень сумбурно.
Если вы хотите автоматизировать тестирование БД, то тестировать нужно конкретно те методы, которые DAL предоставляет другим слоям. Причем порядок вызова тестов не должен иметь никакого значения. В каком порядке методы DAL будут вызывать другие слои — ни DAL, ни тесты совершенно не должно волновать. Если нужно вытащить юзера по емейлу — вот вам метод, а разбираться, возвращена ли Entity (если есть) или null (если нет юзера с таким емейлом) — это задача не DAL, а того слоя, который вызвал метод. И юнит тесты с моками с этим прекрасно справляются. Плюс, для тестирования DAL тащить SQL Server Express совершенно необязательно, когда есть SQLite, а в dotnet core давным давно появился InMemory провайдер специально для тестов.
Если вам нужна персистентность DAL в юнит тестах — у меня для вас плохие новости.
Юнит тесты вообще не должны зависеть от любого другого слоя, моки именно для этого и существуют.
Моки — не уродливы, не раздувают код, и, тем более, не являются дублированием кода или копи-пастой. Они имитируют зависимости так, как это нужно для конкретного теста. Если DAL может выдать разную реакцию на вызов его метода — пишем несколько тестов.
Мало того, если у вас успешность прохождения тестов зависит от порядка их вызова — это вообще ужас-ужас.
Интеграционные же тесты лучше проводить не на машинах девелоперов (хотя это не запрещено), а, например, дерганьем реальных апи в специально подготовленном для этого окружении с реальной БД, настройками, связями сервисов, DI и т.д.
А так получается раздутый юнит тест, натянутый на глобус и названный интеграционнным
qw1
22.12.2019 13:29+1Очень интересно. Я нашёл вот такой пример: docs.microsoft.com/en-us/ef/core/miscellaneous/testing/in-memory
И сразу возник вопрос: в примере сервисы проектируются так, что DbContext является зависимостью, похоже её можно инжектить через DI. Но у нас, ради производительности, сервисы проектируются так, что один созданный экземпляр со всеми зависимостями можно использовать многократно, и даже параллельно — у сервисов нет состояния, результат зависит только от параметров. Здесь же придётся создавать на каждый запрос свой DbContext и зависимые от него сервисы. Вопрос в том, хорошая ли это практика.
TimurNes
22.12.2019 13:52+1Не совсем так
DbContext желательно передавать как зависимость, причем отдельный экземпляр желательно создавать на каждый LifetimeScope, говоря терминами IoC контейнеров. А еще лучше брать из пула подключений, но этим всем обычно занимается asp net core и разработчик не забивает себе этим голову. Причин несколько, главная из которых — нельзя шарить один контекст на несколько, скажем, api запросов, потому что контекст один, а реальное состояние могло поменяться. Плюс EntityFramework Core не допускает параллельного выполнения запросов в рамках одного DbContext (читай — подключения к БД).
Нужно понимать, что репозиторий (как паттерн), хоть программно и является обычным сервисом, но все таки имеет свои особенности, связанные именно с тем, что под капотом у него есть конкретное состояние и взаимодействие с «внешним миром» (БД), который может изменится в любой момент времени, вплоть до недоступности.
Исходя из этого, Persistence, как слой архитектуры, зачастую выносится отдельно и является подвидом инфраструктурного слоя.
По этому DbContext обычно создается на весь LifetimeScope.
К примеру, в рамках WebApi — это http запрос. Создается один DbContext, который инжектируется во все (требующие DbContext) зависимости этого запроса и используется на столько запросов к БД, сколько нужно. После завершения http запроса DbContext закрывается или передается обратно в пул.
А юнит тестах с InMemory провайдером — на каждый тест создается новый, чистый DbContext, который уже в тесте конфигурируется под потребности теста. Это очень быстро и вполне нормальноqw1
22.12.2019 14:29Понятно, .net развивается. Уже можно отдать фреймворку asp.net создание и сервисов, и DbContext-ов, при этом можно добиться переиспользования как сервисов, так и контекстов между запросами.
Возможно, в следующих проектах надо будет присмотреться к такой практике. А сейчас переписать всё так, чтобы DbContext-ы не создавались сервисами, а передавались как зависимость, малореально.3263927 Автор
22.12.2019 15:07у меня написано именно так чтобы не надо было ничего переписывать — просто добавьте ещё один контекст через
services.AddDbContext<ваш_контекст>(options => options.UseSqlServer(Configuration.GetConnectionString(ConnStr)));
в Startup.cs и передавайте его куда хотите как завимость — у него для этого есть OnConfiguring, в статье на этом специально внимание заостреноqw1
22.12.2019 17:00В проекте на гитхабе не увидел ни одного сервиса, HomeController — пустой.
Возможно, в вашем рабочем проекте это и так, но по статье не скажешь.
Также меня сильно озадачили тесты. Их внешняя зависимость — класс HabrDBContext. То есть, вы тестируете не сервис, а DbContext? То есть, вы почему-то думаете, что код типаdb.Phones.Add(new Phone { ... });может работать не так, как написан? Или вы выполняете роль DBA и тестируете миграции?
upd. Ага, тут вся бизнес-логика лежит в HabrDBContext. Ну, не стоит так делать, наверное — тянет на нарушение SRP ))3263927 Автор
22.12.2019 18:36да, это тестирование только DAL. функций DBContext.
нарушение SRP это философский вопрос — метод контроллера «GetUserAndAllConnectionData» нарушает SRP если внутри себя вызывает GetUser, GetUserData, GetUserLogins и прочие связанные вещи? наверное нарушает, но так же и надо — ведь этот метод должен возвращать полную модель. DAL точно так же можно разделить на слои, где в одном будут простейшие функции, дальше из них будет уже собираться более сложные (тут есть вопросы к производительности, возможно лучше сделать одну большую функцию чем 2 маленькие потому что база реже будет дёргаться)
То есть, вы почему-то думаете, что код типа db.Phones.Add(new Phone {… }); может работать не так, как написан?
да, это основная цель такого метода тестирования.
исходя из практики, я не видел ни одного проекта, в котором бы не было постоянных изменений модели данных базы. заказчик постоянно что-то просит, вносит какие-то новые предложения, требования, это всё требует изменения модели базы, изменения самих данных, чтобы они соответствовали новым требованиям, плюс данные должны оставаться консистентными и прочие требования. и вот я выяснил, что простейший метод, который работал вчера, например AddApparat, где запись из трёх полей, вдруг может перестать работать, потому что раньше аппарат был уникальным для места где он находится, а потом оказалось что их там может быть два одинаковых, но их нужно отличать, потому что на них нужно повесить оборудование которое отличается на каждом из них… и таких примеров — куча. и вот я для себя проработал такую стратегию тестирования, при которой я не лезу в mock вобще — у меня его нет, потому что там очень легко ошибиться при такой скорости изменений. и получается что тестировать контроллеры тоже не нужно — тут я доверяю Microsoft, если у них написано что return View(моя модель) то это будет работать. а вот как в моей модели данные появятся, если функции DAL которая их формирует, передать что-то отличное, от того что было раньше (а это возвращает другая DAL функция в 90% случаев) то вот что тогда будет?
вот та система которую я предлагаю и позволяет ответить на этот вопрос — что будет с остальными частями базы данных, если мы изменим эту таблицу и сделаем это вот так и так.
бывают такие изменения, которые EF не может отследить, потому что например constraint какой-то сменился в новой модели, и при компиляции ошибок не будет. а SQL выдаст исключение
3263927 Автор
22.12.2019 14:55в основном проекте так и есть. а в тестовом не получится, потому что данные для тестирования нужно сначала положить в базу, потом вызвать тестовый метод, потом удалить данные, потом вызвать другой тестовый метод. и база должна шариться между этими методами, потому что иначе её придётся избыточно создавать в каждом. это не unit тесты, об этом достаточно ясно сказано в статье. это интеграционный тест для которого мне лично удобнее использовать встроенную систему тестирования.
тут для внедрения зависимостей всё есть, но инжектирование придётся настраивать в самих тестах, а по сути это будет имитация инжектирования ради самого процесса — контекст то один, и конфигурируется он в самом тесте. ещё обратите внимание, InMemory имеет ограничения, от которых я как раз и пытаюсь избавитьсяTimurNes
22.12.2019 14:59инжектирование придётся настраивать в самих тестах, а по сути это будет имитация инжектирования ради самого процесса — контекст то один, и конфигурируется он в самом тесте
Именно это и есть самый настоящий юнит тест, в котором зависимости настроены на поведение, тестируемое в конкретном кейсе. Несколько вариаций поведения зависимостей (сущность найдена или не найдена) — пишем еще юнит тесты с измененной логикой зависимостей3263927 Автор
22.12.2019 15:42я использую механизм MSTest но там нигде не сказано что я могу его использовать только как unit тест. это по факту интеграционное тестирование, и в статье об этом написано. базу данных не целесообразно тестировать в юнит-форме, потму что подготовка данных — это одна функция, а использование их — другая. и мне удобно видеть за какое время выполняется каждый отдельный тест, проще говоря отдельно положить, отдельно взять — так сразу ясно какой метод отнимает много времени. и если у вас пару тысяч тестов то класть лишнее будет слишком много времени отнимать. поэтому я уже наученный практическим опытом, решил немного отойти от догм и канонов «юнит» подхода и сделать просто удобно — чтобы всё работало быстро, как надо, без дополнительной работы и сразу давало знать об ошибках
TimurNes
22.12.2019 15:50Использовать MsTest для интеграционного тестирования с привлечением реальной СУБД конечно можно, но напоминает троллейбус из буханки хлеба.
базу данных не целесообразно тестировать в юнит-форме, потму что подготовка данных — это одна функция, а использование их — другая
Это отлично вписывается в паттерн AAA (Arrange-Act-Assert) для юнит тестов, где подготовка данных — arrange, использование — act, и, наконец, проверка валидности запроса — assert3263927 Автор
22.12.2019 15:59да, только arrange происходит в специальном методе который исключён из метрики, там надо сделать [ClassInitialize] атрибут
3263927 Автор
22.12.2019 15:00многократно он используется только в тестировании, во всех остальных случаях идёт как обычная зависимость — внедряйте его сколько хотите как сервис, у меня это в моих проектах именно так работает. не хотелось бы DI вставлять туда, где я его не планирую использовать — в тестировании он не нужен. но сделать это можно, создав провайдер сервисов и засунув туда, но потом придётся его оттуда вытаскивать, а смысл это делать если я его планирую использовать в тестах только напрямую?
DI я делаю в тестах для тестирования Identity, но там смысл имитировать поведение служб именно в интеграционной схеме (при проверке ролей)
а в той статье которую вы привели описаны ограничения которые я как раз пытаюсь обойти
3263927 Автор
22.12.2019 14:48так у меня конкретно те методы которые надо и тестируются. просто проблема данных в том, что они связаны изначально, а тесты не должны быть. как вы предлагаете решить эти противоречия без mock? у которых на самом деле те же самые проблемы?
про InMemory: у них есть ограничения, в той же самое статье, которую приводит qw1, написано предупреждение, что многое не работает. и зачем мне об этом думать если цель статьи была чтобы работало всё абсолютно точно так же как на реальной базе?
про DI — специально сделал проект где в Setup.exe даются все DI в рекомендованном Microsoft стиле. просто в одном из последних проектов я столкнулся с стакой базой, в которой логику, написанную на EF нужно было анализировать вдвоём по паре часов, чтобы просто понять что будет если изменить вот эту вот одну строку. это для сложных проектов, в которых логика базы данных с многими зависимостями таблиц и данных друг от друга. а как вы гарантируете что написали mock правильно?TimurNes
22.12.2019 15:24Эти вопросы у вас возникают потому, что вы «из контроллера» пытаетесь «смотреть на логику» в DAL.
Вот в этом и кроется ошибка.
Контроллеру должно быть совершенно фиолетово, насколько сложен реальный запрос и сколько задействуется таблиц в методе _repository.GetSomeEntity(...). Пишется простейший мок вида:
var repositoryMock = new Mock<IRepository>(); repositoryMock .Setup(e => e.GetSomeEntity(...)) .Returns(someEntity);
и забывается вся сложная логика из множества таблиц, связей и т.д на десятки строк в DAL.
Если в контроллере вызывается несколько методов репозитория — создаем несколько настроек на этот мок.
Если логика контроллера зависит от результатов вызова репозитория — пишем несколько юнит тестов.
Кто сказал что будет легко? Юнит тесты должны покрывать все возможные сценарии тестируемого метода, включая ошибки, разные результаты вызовов репозиторя, в том числе и цепочки вызовов. И при этом очень важно, чтоб они были изолированы друг от друга и не зависели от неких внешних БД, последовательности вызова тестов и т.д. Если делать только один тест на ожидаемый сценарий — то лучше вообще ничего не делать.
А вот для таких сложных и запутанных DAL методов, как вы привели в примере (пара часов и сложные зависимости таблиц) и пишутся отдельные юнит тесты, тестирующие конкретно эти методы, со своей настройкой подключения, заполнением таблиц, всеми возможными состояниями и т.д. Если в них что то нужно будет поменять — то изменятся только юнит тесты, покрывающие DAL. Все остальные потребители (контроллеры) остануться неизменными, потому что им все равно, что там происходит в DAL — им нужна SomeEntity, которая в тестах получается настройкой мока.
Запомните, логика DAL ни в коем случае не должна проникать в другие слои, в том числе и в тестах.
InMemory — это как пример очень быстрой конфигурации, работающий практически из коробки. Есть еще отличный SQLite. Хотите реальную БД — создавайте полноценное окружние с СУБД, эквивалентной боевой и там настраивайте полноценные интеграционные тесты.3263927 Автор
22.12.2019 15:48вот! золотые слова!
только проникновения слоёв там не было — эти все сложности были в самом DAL слое, потому что очень сложная логика самих данных — куча связанных таблиц, и от выбора пользователя в одном месте зависит поиск данных в другом, и в итоге это всё собирается в гигантскую структуру данных, которую надо проверить не просто на «есть там такие данные или нет», а на то, что выбор пользователя правильно повлиял на дальнейшие действия системы. и написать mock для этого — я просто посчитал время, которое я на это потрачу, а потом прикинул чего будет стоить одна ошибка в написании mock, и понял что надо использовать другой подход — вот как раз тот, который использован в этой статьеTimurNes
22.12.2019 16:00Я вам вот что пытаюсь донести:
- Если у вас сложная логика в методе из DAL — то создайте тестовое окружение конкретно для тестов этого метода, хотя бы даже так, как вы написали в статье. Не перекладывайте настройку окружения на тест контроллера, который использует этот метод. Что, если этот метод будут дергать несколько контроллеров? на каждый будете копипастить настройку?
- Если у вас сложная логика в методе из контроллера — то здесь нужно использовать только моки. Если вы всунете реальную БД в тест контроллера — то вот тут то и произойдет проникновение слоя DAL в тест и появится прямая зависимость теста от некоего внешнего состояния. А потом новый сотрудник что то изменит, и все-все тесты упали — будете очень долго разгребать, что и почему. А глядя на настроенные моки — все сразу станет понятно, какой тест упал и на каких настройках.
Я уже писал, что тесты должны быть произведены на все сценарии. Если все настолько сложно и запутано — сколько вы делаете таких интеграционных тестов? Один с успешным сценарием? А ведь надо проверить все сценарии, будете для этого создавать множество заполнений таблиц? Поверьте, с моками все гораздо проще
3263927 Автор
22.12.2019 16:12у меня нет контроллера, только DAL.
особенность моего подхода в том, что:
1. он позволяет создать персистентный объект базы данных один на все тесты
2. использовать результат прохождения одного теста в других (это удобно, потому что иначе один и тот же код просто будет выполняться много раз, зачем это?
3. сценарии проверяются в конкретном тесте
мы добровольно отказываемся от изоляции тестов чтобы получить дополнительные преимущества — последовательности использования методов (в самом деле, чтобы проверить выборку товара его нужно сначала положить — вот в таком порядке и тестируем:
тест 1 — положить товар в базу;
тест 2 — взять товар из базы.
если делать как вы предлагаете, то нужно будет делать так:
тест 1 — положить товар в базу;
удалить товар из базы
тест 2 — положить товар в базу
взять товар из базы
и так далее — в итоге вам придётся делать по 10-20 однотипных действий, которые уже прошли в предыдущих тестах, только для того чтобы назвать это «юнит» тестами. смысл? не проще ли учесть то что уже сделано до того и использовать это?TimurNes
22.12.2019 16:53Вы нарушаете одно из правил тестов — они должны быть независимы друг от друга.
Ок, если у вас в DAL 2 метода — «Добавить товар» и «Получить товар», то это 2 совершенно независимых метода, на которые пишуться совершенно разные и независимые тесты.
Первый тест — на метод «Добавить товар». Проверяется только то, что тавар добавился. Все.
Вторая группа тестов — на «Получить товар». Тут количество тестов зависит только от количества сценариев этого метода.
Тесты из этой группы не должны зависеть от предыдущего выполнения метода «Добавить товар». Да, вам придется ручками в каждом тесте настаивать заполненность таблиц (почему бы это просто не вынести в отдельным метод и вызывать в каждом тесте в начале). И протестировать вам придется несколько ситуаций, одна из которых — есть ли товар в таблице. Товара нет — другой тест.
Метод «Получить товар» не должен опираться на то, был ли до этого где-то в бизнес логике вызван метод «Добавить товар». Это самостоятельная единица. Тестируйте бизнес-логику на то, что должно быть перед чем вызвано, отдельно.
Вы делаете критическую ошибку в том, что понадеялись на особенность фреймворка, который выполняет тесты «по алфавиту». Прийдет на проект синьер и совершенно обоснованно выкинет MsTest в помойку и прикрутит современный xUnit — а вот тут то и все упадет. Потому что тесты должны быть независимы друг от друга, поймите это. И настраиваться должны все по отдельности. А еще может прийти джун, даст новом тесту «неправильное» имя, из-за чего рухнет вся ваша цепочка вызовов. А еще есть всякие умные утилиты типа NCrunch, которые запускают только изменившиеся тесты, и в вашем случае они упадут даже будучи корректными, потому что перед ними не был вызван другой тест. Перезапускать весь проект каждый раз?
Юнит тесты — далеко не самая простая штука, и, зачастую, времени на их написание уходит порядочно. В том числе и выполнять однотипную настройку. По этому аргумент — много времени уходит на настройку, по этому давайте переиспользуем существующие тесты — не аргумент. Вы можете общий код вынести в общие методы, но переиспользовать результат других тестов, а тем более, использовать некое внешнее состояние — это табу.
Кстати, если вы просто тестируете метод из DAL — это классический юнит тест. То, что вы прикрутили туда реальную СУБД и состояние — не позволяет назвать этот тест интеграционным.
Интеграционный тест — это когда некий бизнес-процесс из конечного множества действий тестируется с начала и до конца в реальных условиях. Вызов метода DAL — не бизнес-процесс, сколько бы там сложных запросов и связей ни было.
3263927 Автор
22.12.2019 18:46я строю тесты последовательно, и сразу вижу какой упал — если он упал, то в нём и проблема.
контроллеров там нет вобще, это только тестирование DAL изолированно
прямая зависимость теста от состояния — это преимущество, а не недостаток.
потому что реальная база тоже зависит от состояния — например, как вы добавите права несуществующему пользователю? или как осуществить продажу, если нет контрагента? это же тоже всё надо учесть, поэтому вызываем функции по очереди и становится понятна иерархия вызовов, что должно быть к тому моменту как оно будет использоваться
я согласен с вами в том что да, это не совсем привычное использование тестов, но они понятны и сразу виден способ взаимодействия между различными механизмами.
вам уже не нужно заходить на какую-то страницу, смотреть что будет если пользователь введёт те или иные данные — просто добавьте в метод тестирования добавления этих данных и посмотрите что будет, и добавьте новый сценарий
и это не замена полному интеграционному тестированию, это именно тест на консистентность базы данных при необходимости быстрых изменений
при этой методике в одном тестовом методе я делаю все сценарииTimurNes
22.12.2019 19:04+1я строю тесты последовательно, и сразу вижу какой упал — если он упал
А потом нужно модифицировать логику, и вы полдня будете искать, между какими тестами нужно вставить новый тест. Так нельзя.
прямая зависимость теста от состояния — это преимущество, а не недостаток.
Это недостаток, а не преймущество. Окружение теста должно настраиваться в самом тесте, а не «где-то там». Только так видна полная картина теста и что именно он тестирует.
как вы добавите права несуществующему пользователю?
Это бизнес-логика, и ей не место в DAL
как осуществить продажу, если нет контрагента?
Это бизнес-логика, и ей не место в DAL
вызываем функции по очереди и становится понятна иерархия вызовов
И это тоже бизнес-логика, которой не место в DAL.
смотреть что будет если пользователь введёт те или иные данные
валидация данных — это вообще Presentation Layer, а проверка бизнес-требований — это задача для слоя бизнес-логики
тест на консистентность базы данных
Вас вообще это не должно волновать. В случае RDB и правильной схемы консистентность вам гарантируется. А если приложение падает из-за того, что в какой то момент не был найден контрагент — то это явный баг в бизнес-логике. Тесты консистентности БД тут не помогут.
В общем, вы запихнули кучу логики в DAL, которой там не должно быть в принципе, пытаетесь это как то проверить и городите костыли. В целом, хоть какое то тестирование — это хорошо, но вы натягиваете свои тесты на явный архитектурный просчет.
Задача DAL проста — обеспечить персистентность данных. Это не место для логики.
jetcar
22.12.2019 21:47Моки зачастую зло, тесты с ними не говорят о работоспособности приложения ну вообще, они говорят лишь о тестируемом куске. Моки можно использовать если интеграция компонентов сделана идеально или есть функциональные тесты.
3263927 Автор
23.12.2019 04:44я так понял по отзывам что это очень индивидуальный момент, какие технологии тестирования подходят для какой ситуации. если база сложная — один подход, если часто меняется — другой, это зависит ещё и от того стиля в котором вы пишете.
вот TimurNes в своей статье про DDD вобще другой стиль работы использует, хотя там тоже можно использовать то что я предлагаю. не вижу противоречия. попробую завтра написать пример, может я как-то не так выразился...TimurNes
23.12.2019 16:26В своем проекте, в котором я стараюсь использовать DDD и Clean Architecture на полную катушку, и с опыта которого я написал статью про ValueObjects в EF Core, слой Persistence выполняет строго отведенную ему роль — обеспечивает персистентность сущностей. Другими словами — сохраняет и загружает требуемые обьекты/коллекции.
Никакой бизнес-логики, манипуляций данными и т.д. там нет — все это в отдельном слое.
Если я хочу, условно, сделать заказ, то бизнес логика сначала загружает контрагента через var partner = _partners.WithId(id), если не найден — кидает специальное исключение, потом формирует заказ примерно как var order = new Order(partner), потом сохраняет его _orders.Add(order).
В итоге репозитории — обычно простые, как угол дома, потому что методы выполняют строго отведенную им задачу.
Бизнес-логика в RequestHandler'ах точно так же наглядна и понятна.
И то, и то просто и понятно тестируется — бизнес-логика мокает методы репозиториев и других зависимостей, а сами репозитории тестируются уже с помощью InMemory провайдера. Если бы мне были критичны ограничения InMemory — я бы использовал SQLite
Это буква S из аббревиатуры SOLID — Single responsibility. Не должен репозиторий что то там проверять и вычислять — не его это задача.3263927 Автор
23.12.2019 16:35ну да, я заметил что у нас немного разные архитектурные подходы.
у меня DAL делится на 2 слоя — один это простейшие функции доступа к данным, другой слой, который эти функции вызывает уже — это более сложная бизнес-логика, которую я убираю из контроллеров. таким способом я могу потом этот класс отдать инженеру баз данных на оптимизацию, и он может без проблем какие-то сложные вызовы переписать на хранимые процедуры. это развязывает его от серверного программиста и от дизайнера, потому что он должен только своим слоем заниматься — тем что в функцию приходит и то что из неё уходит

TaF
22.12.2019 14:53С юмором у автора все в порядке.
Для серьезных же тестов использовать MS Visual Studio??
Особенно, 2019, которая еще только в стадии «допиливания»?
Ну это скорее от безысходности и отсутствия нормальных инструментов для тестирования.3263927 Автор
22.12.2019 14:54спасибо! приведите пожалуйста пример нормального инструмента, который лучше подходит для этой задачи чем встроенные тесты
chuikoffru
Так я не понял, как вы все таки предлагаете решить проблему разводов?
3263927 Автор
через тестирование!