
Всем привет! Я бэкэнд-разработчик, пишу микросервисы на Java + Spring. Работаю в одной из команд разработки внутренних продуктов в компании Тинькофф.

У нас в команде часто встает вопрос оптимизации запросов в СУБД. Всегда хочется еще чуть-чуть быстрее, но не всегда можно обойтись продуманно выстроенными индексами — приходится искать какие-то обходные пути. Во время одного из таких скитаний по сети в поисках разумных оптимизаций при работе с БД я нашел бесконечно полезный блог Маркуса Винанда, автора книги SQL Performance Explained. Это тот самый редкий вид блогов, в котором можно читать все статьи подряд.
Хочу перевести для вас небольшую статью Маркуса. Ее можно назвать в какой-то степени манифестом, который стремится привлечь внимание к старой, но до сих пор актуальной проблеме производительности операции offset по стандарту SQL.
В некоторых местах я буду дополнять автора пояснениями и замечаниями. Все такие места я буду обозначать как «прим.» для большей ясности
Небольшое введение
Думаю, многие знают, насколько проблемной и тормозной оказывается работа с постраничными селектами через offset. А знаете ли вы, что ее можно довольно просто заменить на более производительную конструкцию?
Итак, ключевое слово offset указывает базе пропустить первые n записей в запросе. Однако база все еще должна прочитать эти первые n записей с диска, причем в заданном порядке (прим.: применить сортировку, если она задана), и только после этого будет возможно вернуть записи начиная с n+1 и далее. Самое интересное, что проблема не в конкретной реализации в СУБД, но в изначальном определении по стандарту:
...the rows are first sorted according to the <order by clause> and then limited by dropping the number of rows specified in the <result offset clause> from the beginning…
-SQL:2016, Part 2, 4.15.3 Derived tables (прим.: cейчас самый используемый стандарт)
Ключевой пункт здесь в том, что offset принимает единственный параметр — количество записей, которые нужно пропустить, и все. Следуя такому определению СУБД может только достать все записи, а затем отбросить ненужные. Очевидно, что такое определение offset’а заставляет проделывать лишнюю работу. И тут даже не важно, SQL это или NoSQL.
Еще немного боли
Проблемы offset на этом не заканчиваются, и вот почему. Если между чтением двух страниц данных с диска другая операция вставит новую запись, что произойдет в этом случае?
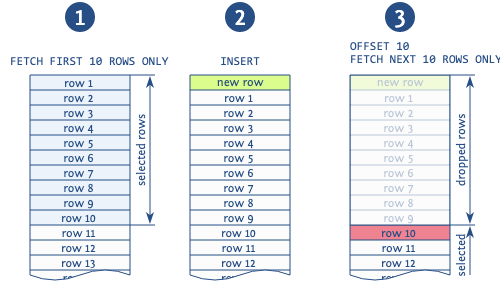
Когда используется offset для пропуска записей с предыдущих страниц, в ситуации добавления новой записи между операциями чтения разных страниц, вероятнее всего, вы получите дубликаты (прим.: такое возможно, когда мы читаем постранично с использованием конструкции order by, тогда в середину нашей выдачи может попасть новая запись).
Рисунок наглядно изображает такую ситуацию. База читает первые 10 записей, после этого вставляется новая запись, которая смещает все прочитанные записи на 1. Затем база берет новую страницу из 10 следующих записей и начинает не с 11-й, как должна, а с 10-й, дублируя эту запись. Есть и другие аномалии, связанные с использованием этого выражения, но эта — самая распространенная.
Как мы уже выяснили, это не проблемы конкретной СУБД или их реализаций. Проблема — в определении пагинации по стандарту SQL. Мы говорим СУБД, какую страницу нужно достать или как много записей пропустить. База просто не в состоянии оптимизировать такой запрос, так как для этого слишком мало информации.
Стоит также уточнить, что это проблема не конкретного ключевого слова, а скорее семантики запроса. Есть еще несколько идентичных по проблемности синтаксисов:
- Ключевое слово offset, как говорилось ранее.
- Конструкция из двух ключевых слов limit [offset] (хотя сам по себе limit не так уж и плох).
- Фильтрация по нижним границам, построенная на нумерации строк (например, row_number(), rownum и т. д.).
Все эти выражения просто говорят, сколько строк нужно пропустить, никакой дополнительной информации или контекста.
Далее в этой статье ключевое слово offset используется как обобщение всех этих вариантов.
Жизнь без OFFSET
А теперь представим, каким был бы наш мир без всех этих проблем. Оказывается, жизнь без offset не так уж и сложна: селектом можно выбирать только те строки, что мы еще не видели (прим.: то есть те, которых не было на прошлой странице), с помощью условия в where.
В этом случае мы отталкиваемся от того факта, что селекты исполняются над упорядоченным множеством (старый добрый order by). Поскольку имеем упорядоченное множество, можем использовать довольно простой фильтр, чтобы доставать только те данные, которые находятся за последней записью предыдущей страницы:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYВот и весь принцип такого подхода. Конечно, при сортировке по многим столбцам все становится веселее, но идея все та же. Важно заметить, что эта конструкция применима на многих NoSQL-решениях.
Такой подход называется seek method или keyset pagination. Он решает проблему с плавающим результатом (прим.: ситуация с записью между чтениями страниц, описанная ранее) и, конечно, что мы все любим, работает быстрее и стабильнее, чем классический offset. Стабильность заключается в том, что время обработки запроса не увеличивается пропорционально номеру запрашиваемой таблицы (прим.: если хочется подробнее узнать про работу разных подходов к пагинации, можно полистать презентацию автора. Там же можно найти сравнительные бенчмарки по разным методам).
Один из слайдов рассказывает о том, что пагинация по ключам, конечно же, не всемогущая — она имеет свои ограничения. Наиболее значимое — у нее нет возможности читать случайные страницы (прим.: непоследовательно). Однако в эпоху бесконечного скроллинга (прим.: на фронтэнде) это не такая уж и проблема. Указание номера страницы для щелчка — в любом случае плохое решение при разработке UI (прим.: мнение автора статьи).
А что с инструментами?
Пагинация на ключах часто не подходит из-за отсутствия инструментальной поддержки данного метода. Большинство из инструментов разработки, в том числе различные фреймворки, не дают выбора, каким именно способом будет выполняться пагинация.
Ситуацию усугубляет то, что описанный метод требует сквозной поддержки в используемых технологиях — начиная от СУБД и заканчивая исполнением AJAX-запроса в браузере при бесконечном скроллинге. Вместо того чтобы указывать только номер страницы, теперь придется указывать набор ключей для всех страниц сразу.
Однако количество фреймворков, поддерживающих пагинацию на ключах, постепенно растет. Вот что есть на данный момент:
- jOOQ для Java;
- order_query для Ruby;
- chunkator и Django Infinite Scroll Pagination для Django;
- SQL Alchemy sqlakeyset для Python;
- blaze-persistence — criteria API для реализаций JPA;
- DBIx::Class::Wrapper для Perl;
- Massive.js, мапер для Node.js Keyset Documentation.
(Прим.: некоторые ссылки были убраны ввиду того, что на момент перевода некоторые библиотеки не обновлялись с 2017—2018 года. Если интересно, можно заглянуть в первоисточник.)
Как раз на этом моменте и нужна ваша помощь. Если вы разрабатываете или поддерживаете фреймворк, который хоть как-то использует пагинацию, то я прошу, я призываю, я молю вас сделать нативную поддержку для пагинации на ключах. Если есть вопросы или вам нужна помощь, буду раду помочь (форум, Twitter, форма для обращений) (прим.: по моему опыту общения с Маркусом могу сказать, что он действительно относится с энтузиазмом к распространению этой темы).
Если же вы пользуетесь готовыми решениями, которые, как вы думаете, достойны иметь поддержку пагинации по ключам, — создайте реквест или даже предложите готовое решение, если это возможно. Можно также указать в ссылке данную статью.
Заключение
Причина, почему такой простой и полезный подход, как пагинация по ключам, мало распространен, не в том, что это сложно в технической реализации или требует каких-то больших усилий. Главная причина в том, что многие привыкли видеть и работать с offset — такой подход диктуется самим стандартом.
Как следствие, немногие задумываются о смене подхода к пагинации, а из-за этого и инструментальная поддержка со стороны фреймворков и библиотек развивается слабо. Поэтому, если вам близка идея и цель безофсетной пагинации, — помогите распространить ее!
Источник: https://use-the-index-luke.com/no-offset
Автор: Markus Winand










UncleAndy
Как-то я раньше не рассматривал этот вопрос комплексно. Использую пажинацию по ключам в проекте по факту и давно уже подумываю про оптимизацию. Думаю, в ближайшее время попробую сделать библиотеку для golang с поддержкой этого вида пажинации.