
Когда Facebook «лежит», люди думают, что это из-за хакеров или DDoS-атак, но это не так. Все «падения» за последние несколько лет были вызваны внутренними изменениями или поломками. Чтобы учить новых сотрудников не ломать Facebook на примерах, всем большим инцидентам дают имена, например, «Call the Cops» или «CAPSLOCK». Первый так назвали из-за того, что когда однажды соцсеть упала, в полицию Лос-Анджелеса звонили пользователи и просили его починить, а шериф в отчаянии в Твиттере просил не беспокоить их по этому поводу. Во время второго инцидента на кэш-машинах опустился и не поднялся сетевой интерфейс, и все машины перезапускали руками.
Элина Лобанова работает в Facebook последние 4 года в команде Web Foundation. Участники команды зовутся продакшн-инженерами и следят за надежностью и производительностью всего бэкенда, тушат Facebook, когда он горит, пишут мониторинг и автоматизацию, чтобы облегчить жизнь себе и другим.

В статье, основанной на докладе Элины на HighLoad++ 2019, расскажем, как продакшн-инженеры следят за бэкендом Facebook, какие инструменты используют, из-за чего возникают крупные сбои и как с ними справиться.
Меня зовут Элина, почти 5 лет назад меня позвали в Facebook обычным разработчиком, где я впервые столкнулась с по-настоящему высоконагруженными системами — такому в институтах не учат. Компания нанимает не в команду, а в офис, поэтому я приехала в Лондон, выбрала команду, которая следит за работой facebook.com и оказалась среди продакшн-инженеров.
Для начала расскажу, что мы делаем и почему называемся Production Engineers, а не SRE как у Google, например.
Стандартная модель, которая до сих пор используется во многих компаниях это «разработчики — тестировщики — эксплуатация». Часто они разделены: сидят на разных этажах, иногда даже в разных странах, и между собой не общаются.
В 2009 году в Facebook уже были SRE. В Google SRE начались раньше, они знают, как достичь DevOps, и прописали это в своей книге «Site Reliability Engineering».

В Facebook образца 2009 года ничего подобного не было. Мы назывались SRE, но выполняли ту же работу, что Ops в остальном мире: ручной труд, никакой автоматизации, деплой всех сервисов руками, мониторинг кое-как, oncall за всё, набор shell-скриптов.
Это все не масштабировалось, потому что количество пользователей в то время увеличивалось в 3 раза за год, и количество сервисов росло соответственно. В 2010 году волевым решением Ops разбили на две группы.
Первая группа — SRO, где «O» — это «operations», занялась развитием, автоматизацией и мониторингом сайта.
Вторая группа — AppOps, они были интегрированы в команды, каждая под большие сервисы. AppOps уже близко к идее DevOps.
Разделение на некоторое время всех спасло.
В 2012 AppOps просто переименовали в продакшн-инженеров. Кроме названия ничего не поменялось, но так стало комфортнее. Как яхту назовете, так она и поплывет, а плавать как Ops мы не хотели.
SRO все еще существовали, Facebook рос, и следить за всеми сервисами сразу было тяжело. Человеку, который был oncall, даже нельзя было сходить в туалет: он просил кого-то его подменить, потому что горело постоянно.
В один момент начальство всех перевело в oncall. «Всех» значит, что и разработчиков тоже: пишешь свой код, вот ты за этот код и отвечай!
В самые важные команды для помощи уже были встроены продакшн-инженеры, а остальным не повезло. Начали с больших команд и за пару лет перевели в oncall всех во всем Facebook. Среди разработчиков были большие волнения: кто-то уволился, кто-то писал плохие посты. Но все улеглось, и в 2014 году SRO закрыли, потому что они стали не нужны. Так мы живем по сей день.
У слова «SRE» в компании дурная слава, но мы похожи на SRE в Google. Есть и отличия.
Это самое важное. Как мы это делаем? Как все: без черной магии, на своем, домашнем. Но дьявол, как обычно, в деталях, о них и расскажу.
Начнем с низов. TOP в Linux знают все, а мы используем ATOP, где «A» это «advanced» — монитор производительности системы. Основная польза от ATOP в том, что он хранит историю: можно его сконфигурировать, чтобы он сохранял снапшоты на диск. У нас ATOP работает на всех машинах раз в 5 секунд.
Вот пример сервера, на котором работает PHP бэкенд для facebook.com. Мы написали свою виртуальную машину для исполнения PHP кода, она называется HHVM (HipHop Virtual Machine). По экспортируемым метрикам мы обнаружили, что несколько машин в течении одной минуты не обрабатывали практически ни одного запроса. Давайте разберемся почему, откроем ATOP за 30 секунд до зависания.

Видно, что с процессором проблемы, мы слишком много его нагружаем. С памятью тоже беда, в кэше осталось всего 1,5 Гбайта, а через 5 секунд всего 800 Мбайт.

Еще через 5 секунд CPU освобождается, ничего не исполняется. ATOP говорит посмотреть на нижнюю строчку, мы пишем на диск, но что? Оказывается, мы пишем swap.

Кто это делает? Процессы, у которых из памяти отобрали 0,5 Гбайт и положили в swap. На их место пришли два подозрительных Python-процесса, которые потом можно посмотреть как командную строку.

Багам и большим инцидентам мы даем имена. С ATOP связан один забавный баг, который назвали Malloc HTTP. Мы дебажили его как раз с помощью ATOP и strace.
Мы везде используем Thrift как RPC. В ранних версиях его парсера был восхитительный баг, который работал так: приходило сообщение, в котором первые 4 байта — это размер данных, затем сами данные, а первые байты добавляем в следующее сообщение.
Но как-то раз одна из программ вместо того, чтобы ходить в сервис Thrift, пошла в HTTP, и получила ответ «HTTP Bad Request»:
После взяла HTTP и аллоцировала с помощью malloc HTTP количество байт.
Ничего страшного, у нас же есть overcommit, выделим еще памяти! Мы аллоцировали malloc'ом, а пока мы туда не пишем и не читаем, реальную память нам не дадут.
Но не тут-то было! Если захотим сделать форк, форк вернет ошибку — не хватает памяти.
Но почему, память же есть? Разбираясь в мануалах, обнаружили, что все очень просто: текущая конфигурация overcommit такая, что это магическая эвристика, и ядро само решает, когда много, а когда нет:
Для работающего процесса это нормально, можно malloc’ом выбрать себе до Тбайта, а для нового процесса — нет. А часть мониторинга у нас была завязана на то, что главный процесс форкал маленькие скрипты по сбору данных. В итоге у нас сломалась часть мониторинга, потому что форкаться мы больше не могли.
FB303 — наша базовая система мониторинга. Её назвали в честь стандартного басового синтезатора 1982 года выпуска.

Принцип простой, поэтому и работает до сих пор: каждый сервис имплементирует интерфейс Thrift getCounters.
На самом деле он его не имплементирует, потому что библиотеки уже написаны, в коде все делают
В итоге каждый сервис экспортирует counters на порту, который он регистрирует в Service Discovery. Ниже пример машины, которая генерирует новостную ленту и экспортирует порядка 5,5 тысяч пар (строка, число): память, продакшн, все, что угодно.

На каждой машине работает бинарный процесс, который ходит по всем сервисам вокруг, собирает эти counters и кладет их в хранилище.
Так выглядит GUI хранилища.

Очень похоже на Prometheus и Grafana, но это не так. Первая запись FB303 в GitHub была в 2009, а Prometheus — в 2012. Это объяснение всех «самоделок» Facebook: мы их делали, когда еще ничего нормального в Open Source не было.
Например, есть поиск по именам каунтеров.
Сами графики выглядят примерно так.

Картинка из внутренней группы, в которой мы постим красивые графики.
Важное отличие нашего стека мониторинга от Prometheus и Grafana в том, что мы храним данные вечно. Наш мониторинг пересэмплирует данные, и через 2 недели у нас будет одна точка на каждые 5 минут, а через год на каждый час. Поэтому они могут столько храниться. Автоматически это нигде не конфигурируется.
Но если говорить об особенностях мониторинга Facebook, то я бы описала это одним английским словом «observability».
Есть «black box», есть «white box», а у нас стеклянный прозрачный «box». Это значит, что когда мы пишем код, то пишем в логи все, что можно, а не выборочно. Сэмплинг везде настроен хорошо, поэтому бэкенд для хранилища, counters и всего остального живет нормально.
При этом мы можем строить наши дашборды уже на имеющихся counters. В случае изучения данных дашборды — это не конечная точка с 10 графами, а начальная, от которой идем в наш UI и находим там все, что можно.
Это апогей идеи «observability». Это наш ELK стэк. Принцип тот же: пишем в JSON без определенной схемы, потом запрашиваем в виде таблицы, time series данных или еще 10 вариантов визуализаций.
В Scuba логируется порядка сотен гигабайт в секунду. Запрашивается все очень быстро, потому что это не Elasticsearch, и все в памяти на мощных машинах. Да, на это тратятся деньги, но как же это прекрасно!
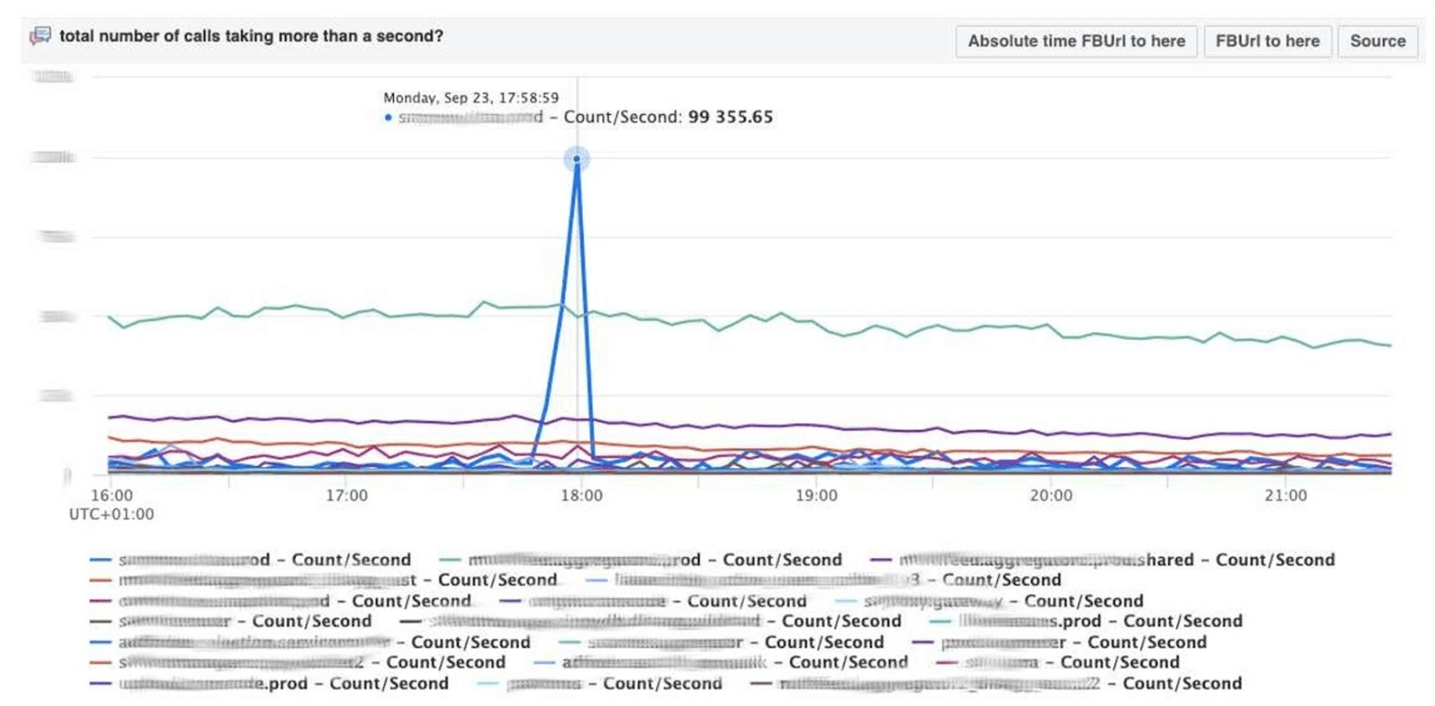
Для примера ниже Scuba UI, в нем открыта одна из самых популярных таблиц, в которую пишут логи все клиенты всех сервисов Thrift.
На графике видно, что в сервисе под конец что-то пошло не так. Чтобы узнать задержку, идем в список каунтеров, выбираем задержку, агрегацию, нажимаем «Dive».
Ответ приходит за 2 секунды.
Видно, что в тот момент что-то случилось и задержка значительно увеличилась. Чтобы изучить подробнее, можно группировать по разным параметрам.
Таких таблиц сотни.
Scuba также выступает бэкендом для нашего основного инструмента дебага PHP. Код PHP пишут тысячи инженеров, и надо как-то спасать глобальный репозиторий от плохих вещей.
Как все работает? PHP на каждый лог пишет еще и stack trace. Scuba (наш Elasticsearch) просто не может вместить stack trace от всех логов со всех машин. Перед тем, как положить лог в Scuba, мы преобразуем stack trace в хэш, семплируем по хешам и сохраняем только их. Сами stack traces отправляем в Memcached. Потом уже во внутреннем инструменте можно вытащить конкретный stack trace из Memcached достаточно быстро.

Визуализация с группировкой по хэшам от логов и stack traces.
Отладку кода производим по методу pattern matching: открываем Scuba, смотрим, как выглядит график ошибки.
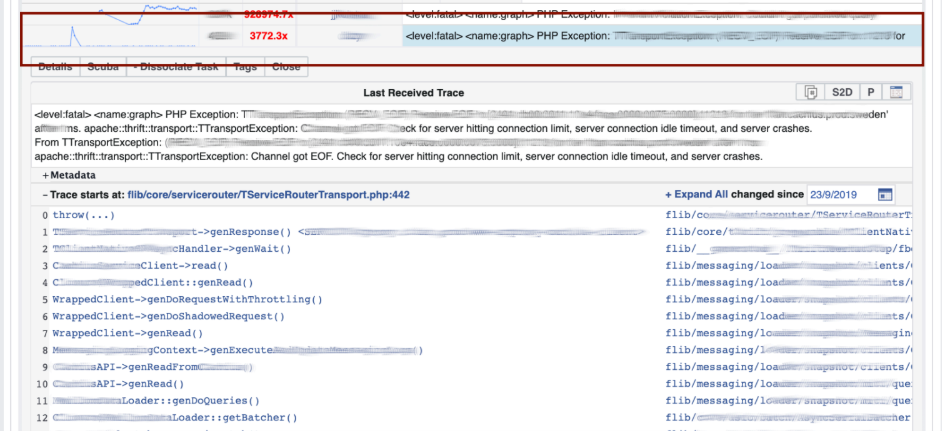
Идем в LogView, там ошибки уже сгруппированы по stack traces.

Из Memcached подгружается stack trace, а уже по нему можно найти diff (коммит в PHP репозиторий), который запостили примерно в это же время, и откатить его. У нас откатывать и коммитить может кто угодно, никаких разрешений для этого не нужно.
Тему мониторинга закончу дашбордами. Их у нас мало — всего два на три показателя. Сам дашборд довольно необычный. Про него хотелось бы рассказать подробнее. Ниже стандартный дашборд с набором графиков.
К сожалению, с ним не все так просто. Дело в том, что фиолетовая линия на одном графе — это тот же самый сервис, которому на другом графике соответствует голубая линия, а еще один график может быть за один день, а другой за месяц.
Мы используем свой дашборд, сделанный на основе Cubism — Open Source JS-библиотеки. Ее написали в Square и выпустили под лицензией Apache. У них есть встроенная поддержка Graphite и Cube. Но ее легко расширить, что мы и сделали.
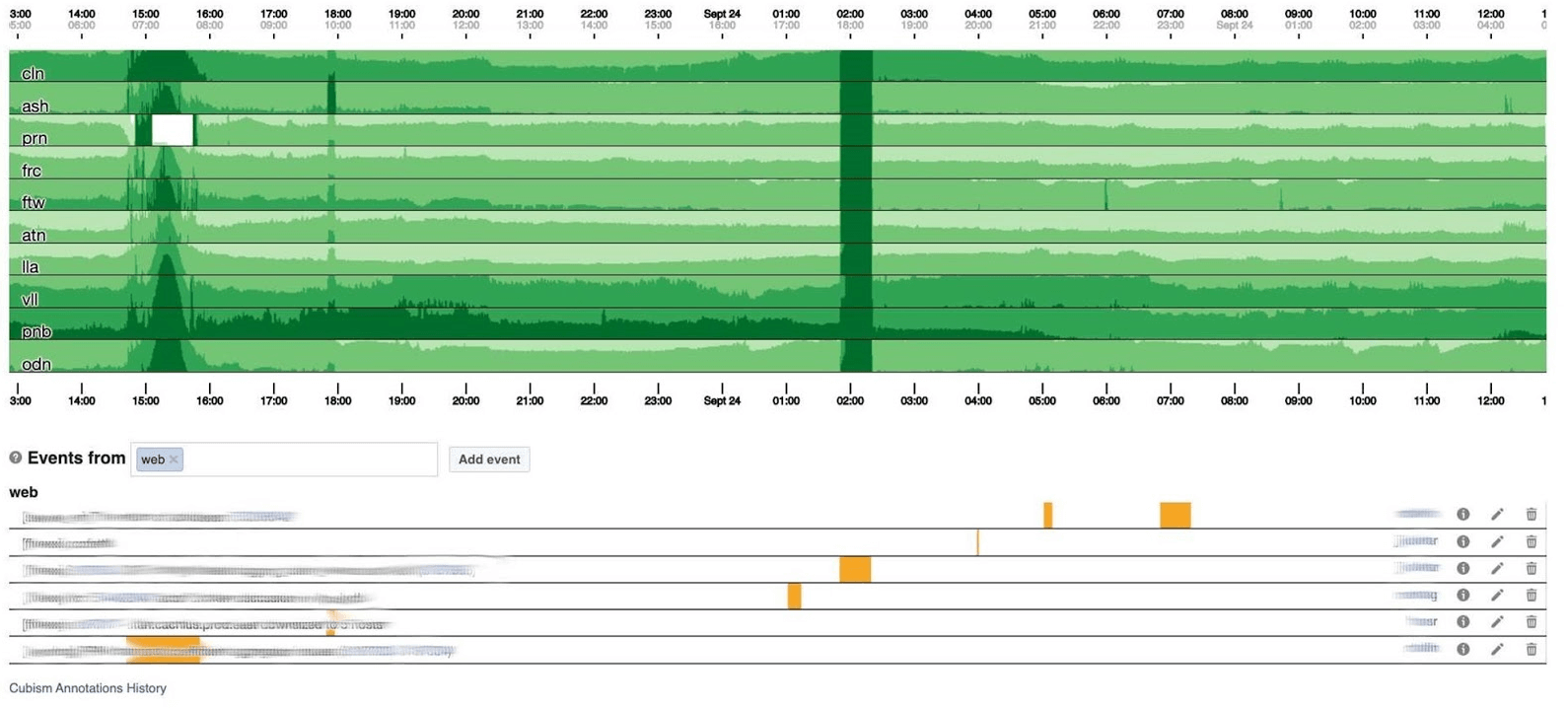
На дашборде ниже представлен один день по одному пикселю на минуту. Каждая линия это регион: дата-центры, которые находятся рядом. Они отображают количество логов, которые бэкенд Facebook пишет в байтах в секунду. Внизу аннотации для команд в Америке, чтобы они видели, что мы уже исправили из случившегося днем. На этой картинке легко искать корреляцию.
Ниже — количество ошибок 500. То, что слева, для пользователей не имело никакого значения, а темно-зеленая полоса в центре явно им не понравилась.
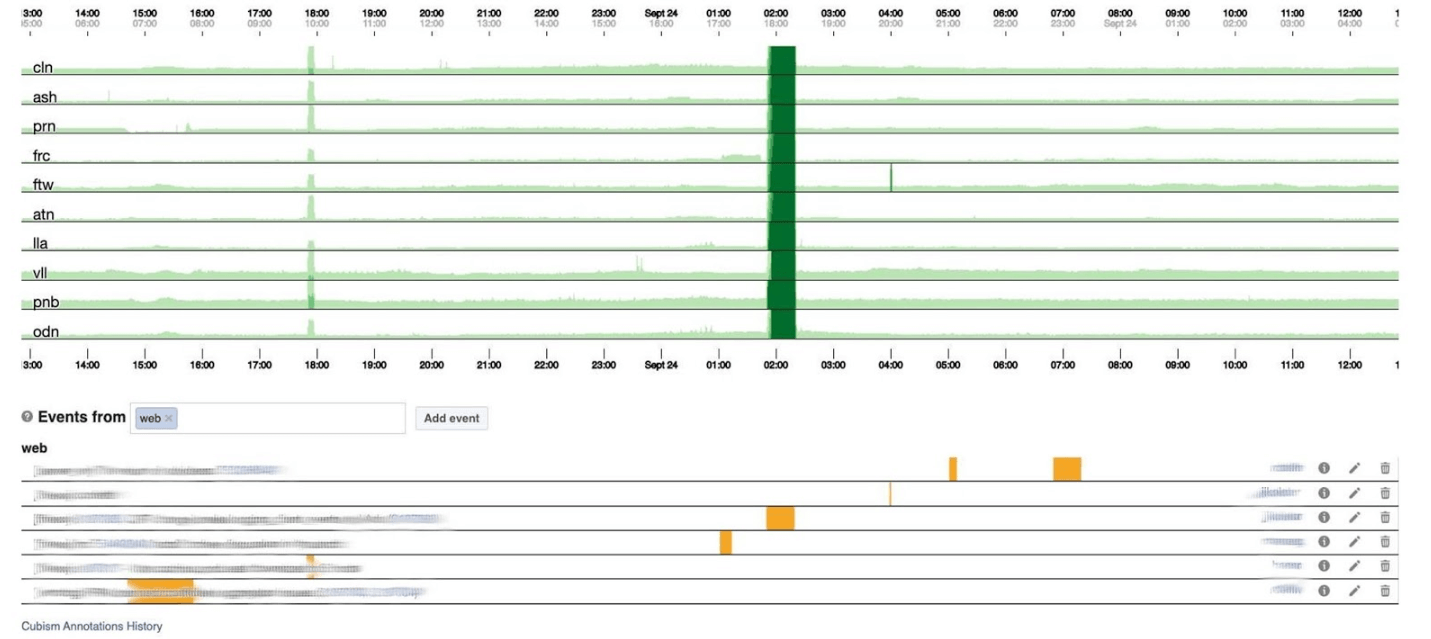
Дальше 99-й перцентиль latency. В то же время, что и на графике выше, видно, что latency просела. Чтобы вернуть ошибку, много времени тратить не нужно.

На графике высотой 120 пикселей все видно. Но много таких на один дашборд не поместить, поэтому сожмем до 30.

К сожалению, тогда получается какой-то удав. Вернемся обратно и посмотрим, что с этим делает Cubism. Он разбивает график на 4 части: чем выше, тем темнее, а потом схлопывает.

Теперь у нас тот же график, что и раньше, но при этом все хорошо видно: чем темнее зеленый цвет, тем хуже. Теперь гораздо понятней, что происходит.
Слева видно волну, как она поднималась, а в центре, где темно-зеленое, все очень плохо.
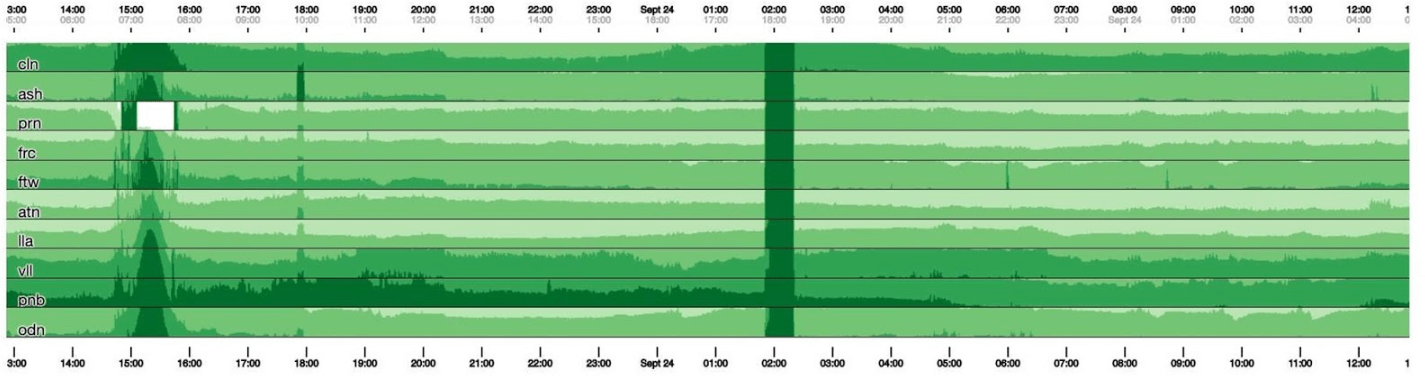
Cubism — это только начало. Он нужен для визуализации, чтобы понять, все сейчас плохо или нет. Для каждой таблицы существуют дашборды уже с развернутыми графиками.

Сам по себе мониторинг помогает понять состояние системы и отреагировать, если она сломалась. В Facebook каждый сотрудник oncall, и чинить обязаны уметь все. Если горит ярко, то включаются все, но особенно продакшн-инженеры с опытом системного администратора, потому что они знают, как решить проблему быстро.
Иногда инциденты случаются, и Facebook лежит. Обычно люди думают, что Facebook лежит, потому что произошел DDoS или напали хакеры, но за 5 лет ни разу такого не было. Причиной всегда были наши инженеры. Они не специально: системы очень сложные и сломаться может там, где не ждешь.
Всем большим инцидентам мы даем имена, чтобы было удобно о них упоминать и рассказывать новичкам, дабы не повторять ошибок в будущем. Чемпион по самому забавному имени — инцидент «Call the Cops». Люди звонили в полицию Лос-Анджелеса и просили починить Facebook, потому что он лежал. Шерифу Лос-Анджелеса это настолько надоело, что он написал в Твиттере: «Пожалуйста, не звоните нам! Мы за это не отвечаем!»

Мой любимый инцидент, в котором я участвовала, получил название «CAPSLOCK». Он интересен тем, что показывает, что случиться может все, что угодно. А случилось вот что. Это обычныйIP-адрес:
Facebook использует Сhef, чтобы настраивать ОС. Service Inventory хранит в своей БД конфигурацию хоста, а Chef получает от сервиса файл с конфигурацией. Однажды сервис поменял себе версию, стал читать IP-адреса из БД сразу в формате MySQL и подкладывать их в файлик. Новый адрес теперь написан заглавными:
Сhef смотрит в новый файл и видит, что «поменялся» IP-адрес, потому что сравнивает не в бинарном виде, а строкой. IP-адрес «новый», а это значит, что надо опустить интерфейс и поднять интерфейс. На всех миллионах машин за 15 минут интерфейс опустился и поднялся.
Казалось бы, ничего страшного — capacity уменьшилась, пока сеть лежала на некоторых машинах. Но неожиданно открылся баг в сетевом драйвере наших кастомных сетевых карт: при старте они требовали 0,5 Гбайта последовательной физической памяти. На кэш-машинах эти 0,5 Гбайта пропадали, пока мы опускали и поднимали интерфейс. Поэтому на кэш-машинах сетевой интерфейс опустился и не поднялся, а без кэшей ничего не работает. Мы сидели и перезапускали эти машины руками. Было весело.
Когда Facebook «горит» требуется организовать работу «пожарной команды», а главное — понять, где горит, потому что в огромной компании «пахнуть горелым» может в одном месте, а проблема будет в другом. В этом нам помогает UI-инструмент, который называется Incident Manager Portal. Его написали продакшн-инженеры, и он открыт для всех. Как только что-то случается, мы заводим там инцидент: название, начало, описание.
У нас есть специально обученный человек — Incident Manager On-Call (IMOC). Это не постоянная должность, менеджеры регулярно меняются. В случае больших пожаров IMOC организовывает и координирует людей на починку, но при этом не обязан чинить сам. Как только создается инцидент с высоким уровнем опасности, IMOC получает СМС и начинает помогать все организовывать. В большой системе без таких людей не обойтись.
Facebook лежит не так часто. Большую часть времени мы не тушим пожары и не перезапускаем кэш-машины, а правим баги заранее, и, если можно, для всех сразу.
Однажды мы нашли и поправили «проблему очереди». Количество запросов увеличивается на 50%, а ошибок на 100%, потому что никто throttling не имплементирует заранее, особенно в небольших сервисах.
Мы разобрались на примере нескольких сервисов и примерно определили модель поведения.
Красным выделен клиентский таймаут.
А клиент повторяет снова! Получается, что все запросы, которые мы исполняем, выбрасываются в мусорку и уже никому не нужны.
Как эту проблему решить для всех и сразу? Ввести ограничение на время ожидание в очереди. Если запрос стоит в очереди больше чем положено — выбрасываем и не обрабатываем на сервере, не тратим на него CPU. У нас получается честная игра: выбрасываем все, что не можем обработать, а все, что смогли — обработали.
Ограничение позволило при увеличении нагрузки на 50% выше максимальной, все еще обрабатывать 66% запросов и получать только 33% ошибок. Разработчики фреймворка для Dispatch реализовали это на стороне сервера, а мы, продакшн-инженеры, нежно задеплоили 100 мс таймаут в очереди на всех. Так все сервисы сразу получили дешевый базовый throttling.
Идеология SRE говорит, что если у вас большой флот машин, куча сервисов, и руками ничего не сделать, то надо автоматизировать. Поэтому половину времени мы пишем код и строим инструменты.
Последнее, что мы делаем — разговариваем с людьми, опрашиваем их. Нам кажется, что это очень важно.
Один из полезных опросов — о надежности. Об уже работающих сервисах мы спрашиваем в ключе цитаты из нашего опросника:
Опросы только для средних сервисов, крупные сами разбираются. Мы даем опросник, в котором спрашиваем базовые вещи об архитектуре, SLO, тестировании, например.
В опроснике нет никакого кодинга, он стандартизирован и меняется каждый полгода. Это документ на две страницы, который мы помогаем заполнить за 2-3 недели. А потом мы устраиваем двухчасовой митинг и находим решения многих болей. Этот простой инструмент хорошо работает у нас, может помочь и вам.
Элина Лобанова работает в Facebook последние 4 года в команде Web Foundation. Участники команды зовутся продакшн-инженерами и следят за надежностью и производительностью всего бэкенда, тушат Facebook, когда он горит, пишут мониторинг и автоматизацию, чтобы облегчить жизнь себе и другим.
В статье, основанной на докладе Элины на HighLoad++ 2019, расскажем, как продакшн-инженеры следят за бэкендом Facebook, какие инструменты используют, из-за чего возникают крупные сбои и как с ними справиться.
Меня зовут Элина, почти 5 лет назад меня позвали в Facebook обычным разработчиком, где я впервые столкнулась с по-настоящему высоконагруженными системами — такому в институтах не учат. Компания нанимает не в команду, а в офис, поэтому я приехала в Лондон, выбрала команду, которая следит за работой facebook.com и оказалась среди продакшн-инженеров.
Production Engineers
Для начала расскажу, что мы делаем и почему называемся Production Engineers, а не SRE как у Google, например.
2009. SRE
Стандартная модель, которая до сих пор используется во многих компаниях это «разработчики — тестировщики — эксплуатация». Часто они разделены: сидят на разных этажах, иногда даже в разных странах, и между собой не общаются.
В 2009 году в Facebook уже были SRE. В Google SRE начались раньше, они знают, как достичь DevOps, и прописали это в своей книге «Site Reliability Engineering».
В Facebook образца 2009 года ничего подобного не было. Мы назывались SRE, но выполняли ту же работу, что Ops в остальном мире: ручной труд, никакой автоматизации, деплой всех сервисов руками, мониторинг кое-как, oncall за всё, набор shell-скриптов.
2010. SRO и AppOps
Это все не масштабировалось, потому что количество пользователей в то время увеличивалось в 3 раза за год, и количество сервисов росло соответственно. В 2010 году волевым решением Ops разбили на две группы.
Первая группа — SRO, где «O» — это «operations», занялась развитием, автоматизацией и мониторингом сайта.
Вторая группа — AppOps, они были интегрированы в команды, каждая под большие сервисы. AppOps уже близко к идее DevOps.
Разделение на некоторое время всех спасло.
2012. Production Engineers
В 2012 AppOps просто переименовали в продакшн-инженеров. Кроме названия ничего не поменялось, но так стало комфортнее. Как яхту назовете, так она и поплывет, а плавать как Ops мы не хотели.
SRO все еще существовали, Facebook рос, и следить за всеми сервисами сразу было тяжело. Человеку, который был oncall, даже нельзя было сходить в туалет: он просил кого-то его подменить, потому что горело постоянно.
2014. Закрытие SRO
В один момент начальство всех перевело в oncall. «Всех» значит, что и разработчиков тоже: пишешь свой код, вот ты за этот код и отвечай!
В самые важные команды для помощи уже были встроены продакшн-инженеры, а остальным не повезло. Начали с больших команд и за пару лет перевели в oncall всех во всем Facebook. Среди разработчиков были большие волнения: кто-то уволился, кто-то писал плохие посты. Но все улеглось, и в 2014 году SRO закрыли, потому что они стали не нужны. Так мы живем по сей день.
У слова «SRE» в компании дурная слава, но мы похожи на SRE в Google. Есть и отличия.
- Мы всегда встроены в команды. У нас нет SRE-поиска в целом как в Google, он есть для каждого сервиса поиска в отдельности.
- Нас нет в продуктах, только в инфраструктуре продакт справляется сам.
- Мы oncall вместе с разработчиками.
- У нас чуть больше опыта в системах и сетях, поэтому мы фокусируемся на мониторинге и тушим сервисы, когда они ярко горят. Мы заранее исправляем ошибки, которые могли бы привести к падениям, и влияем на архитектуру новых сервисов с самого начала, чтобы они потом бесперебойно работали в продакшне.
Мониторинг
Это самое важное. Как мы это делаем? Как все: без черной магии, на своем, домашнем. Но дьявол, как обычно, в деталях, о них и расскажу.
ATOP
Начнем с низов. TOP в Linux знают все, а мы используем ATOP, где «A» это «advanced» — монитор производительности системы. Основная польза от ATOP в том, что он хранит историю: можно его сконфигурировать, чтобы он сохранял снапшоты на диск. У нас ATOP работает на всех машинах раз в 5 секунд.
Вот пример сервера, на котором работает PHP бэкенд для facebook.com. Мы написали свою виртуальную машину для исполнения PHP кода, она называется HHVM (HipHop Virtual Machine). По экспортируемым метрикам мы обнаружили, что несколько машин в течении одной минуты не обрабатывали практически ни одного запроса. Давайте разберемся почему, откроем ATOP за 30 секунд до зависания.
Видно, что с процессором проблемы, мы слишком много его нагружаем. С памятью тоже беда, в кэше осталось всего 1,5 Гбайта, а через 5 секунд всего 800 Мбайт.
Еще через 5 секунд CPU освобождается, ничего не исполняется. ATOP говорит посмотреть на нижнюю строчку, мы пишем на диск, но что? Оказывается, мы пишем swap.
Кто это делает? Процессы, у которых из памяти отобрали 0,5 Гбайт и положили в swap. На их место пришли два подозрительных Python-процесса, которые потом можно посмотреть как командную строку.
ATOP прекрасен, мы его используем постоянно.Если у вас его нет — настоятельно рекомендую использовать. Не бойтесь за диск, ATOP ест всего по 200-300 Мбайт за день раз в 5 секунд.
Malloc HTTP
Багам и большим инцидентам мы даем имена. С ATOP связан один забавный баг, который назвали Malloc HTTP. Мы дебажили его как раз с помощью ATOP и strace.
Мы везде используем Thrift как RPC. В ранних версиях его парсера был восхитительный баг, который работал так: приходило сообщение, в котором первые 4 байта — это размер данных, затем сами данные, а первые байты добавляем в следующее сообщение.
Но как-то раз одна из программ вместо того, чтобы ходить в сервис Thrift, пошла в HTTP, и получила ответ «HTTP Bad Request»:
HTTP/1.1 400.После взяла HTTP и аллоцировала с помощью malloc HTTP количество байт.
Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450Ничего страшного, у нас же есть overcommit, выделим еще памяти! Мы аллоцировали malloc'ом, а пока мы туда не пишем и не читаем, реальную память нам не дадут.
Но не тут-то было! Если захотим сделать форк, форк вернет ошибку — не хватает памяти.
malloc("HTTP")
pid = fork(); // errno = ENOMEMНо почему, память же есть? Разбираясь в мануалах, обнаружили, что все очень просто: текущая конфигурация overcommit такая, что это магическая эвристика, и ядро само решает, когда много, а когда нет:
malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0Для работающего процесса это нормально, можно malloc’ом выбрать себе до Тбайта, а для нового процесса — нет. А часть мониторинга у нас была завязана на то, что главный процесс форкал маленькие скрипты по сбору данных. В итоге у нас сломалась часть мониторинга, потому что форкаться мы больше не могли.
FB303
FB303 — наша базовая система мониторинга. Её назвали в честь стандартного басового синтезатора 1982 года выпуска.
Принцип простой, поэтому и работает до сих пор: каждый сервис имплементирует интерфейс Thrift getCounters.
Service FacebookService {
map<string, i64> getCounters()
}На самом деле он его не имплементирует, потому что библиотеки уже написаны, в коде все делают
increment или set.incrementCounter(string& key);
setCounter(string& key, int64_t value);В итоге каждый сервис экспортирует counters на порту, который он регистрирует в Service Discovery. Ниже пример машины, которая генерирует новостную ленту и экспортирует порядка 5,5 тысяч пар (строка, число): память, продакшн, все, что угодно.
На каждой машине работает бинарный процесс, который ходит по всем сервисам вокруг, собирает эти counters и кладет их в хранилище.
Так выглядит GUI хранилища.
Очень похоже на Prometheus и Grafana, но это не так. Первая запись FB303 в GitHub была в 2009, а Prometheus — в 2012. Это объяснение всех «самоделок» Facebook: мы их делали, когда еще ничего нормального в Open Source не было.
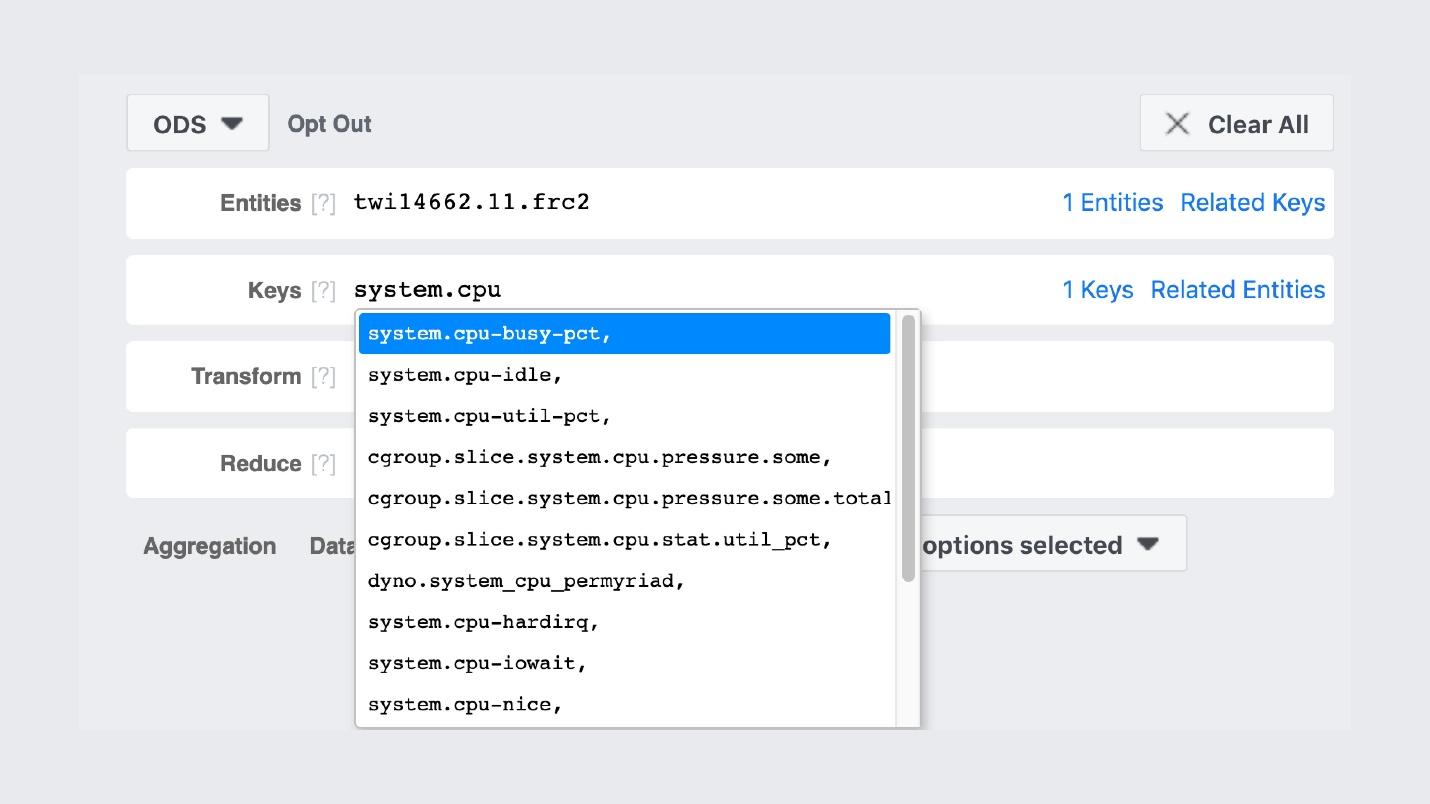
Например, есть поиск по именам каунтеров.
Сами графики выглядят примерно так.
Картинка из внутренней группы, в которой мы постим красивые графики.
Важное отличие нашего стека мониторинга от Prometheus и Grafana в том, что мы храним данные вечно. Наш мониторинг пересэмплирует данные, и через 2 недели у нас будет одна точка на каждые 5 минут, а через год на каждый час. Поэтому они могут столько храниться. Автоматически это нигде не конфигурируется.
Но если говорить об особенностях мониторинга Facebook, то я бы описала это одним английским словом «observability».
Observability
Есть «black box», есть «white box», а у нас стеклянный прозрачный «box». Это значит, что когда мы пишем код, то пишем в логи все, что можно, а не выборочно. Сэмплинг везде настроен хорошо, поэтому бэкенд для хранилища, counters и всего остального живет нормально.
При этом мы можем строить наши дашборды уже на имеющихся counters. В случае изучения данных дашборды — это не конечная точка с 10 графами, а начальная, от которой идем в наш UI и находим там все, что можно.
Scuba
Это апогей идеи «observability». Это наш ELK стэк. Принцип тот же: пишем в JSON без определенной схемы, потом запрашиваем в виде таблицы, time series данных или еще 10 вариантов визуализаций.
В Scuba логируется порядка сотен гигабайт в секунду. Запрашивается все очень быстро, потому что это не Elasticsearch, и все в памяти на мощных машинах. Да, на это тратятся деньги, но как же это прекрасно!
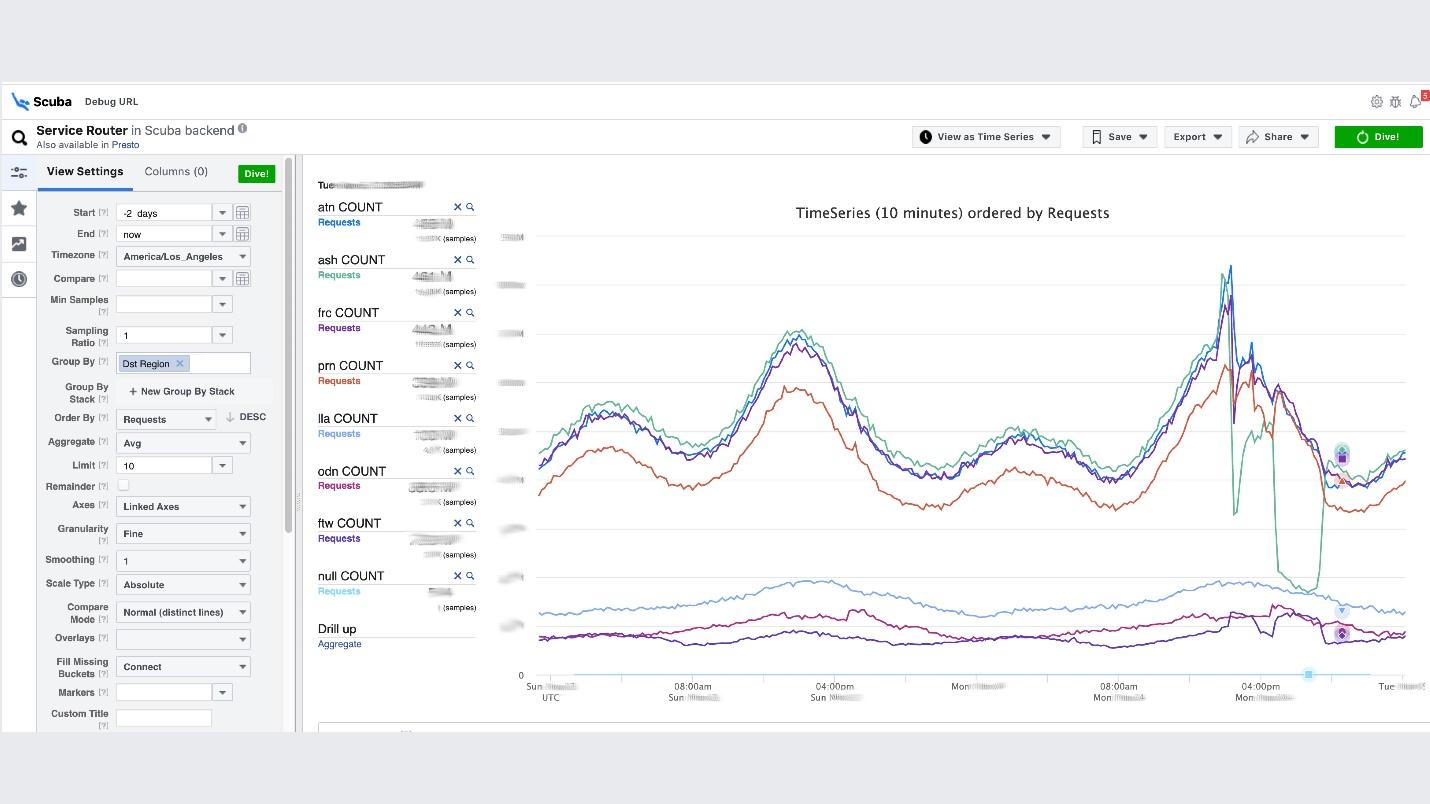
Для примера ниже Scuba UI, в нем открыта одна из самых популярных таблиц, в которую пишут логи все клиенты всех сервисов Thrift.
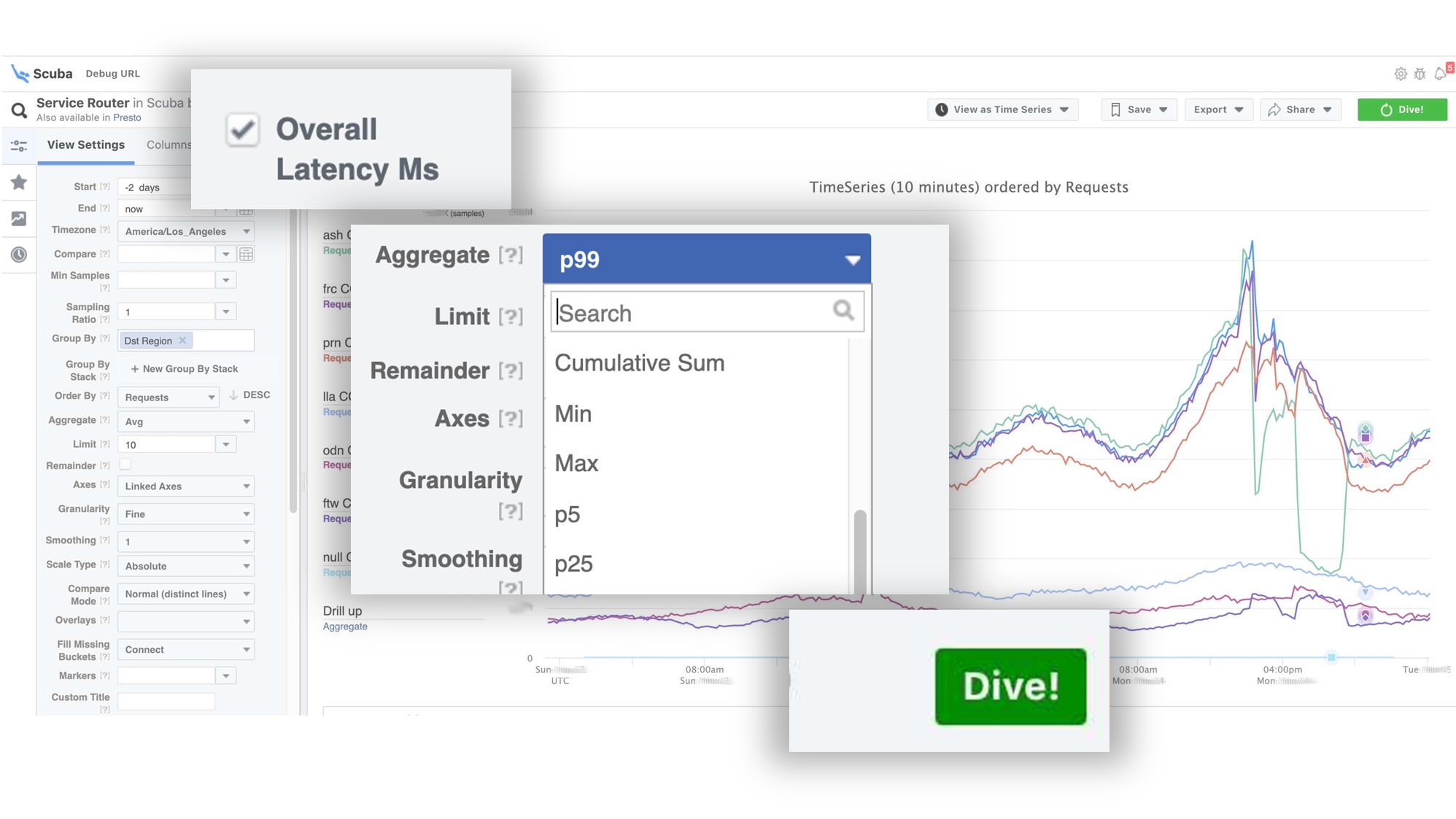
На графике видно, что в сервисе под конец что-то пошло не так. Чтобы узнать задержку, идем в список каунтеров, выбираем задержку, агрегацию, нажимаем «Dive».
Ответ приходит за 2 секунды.
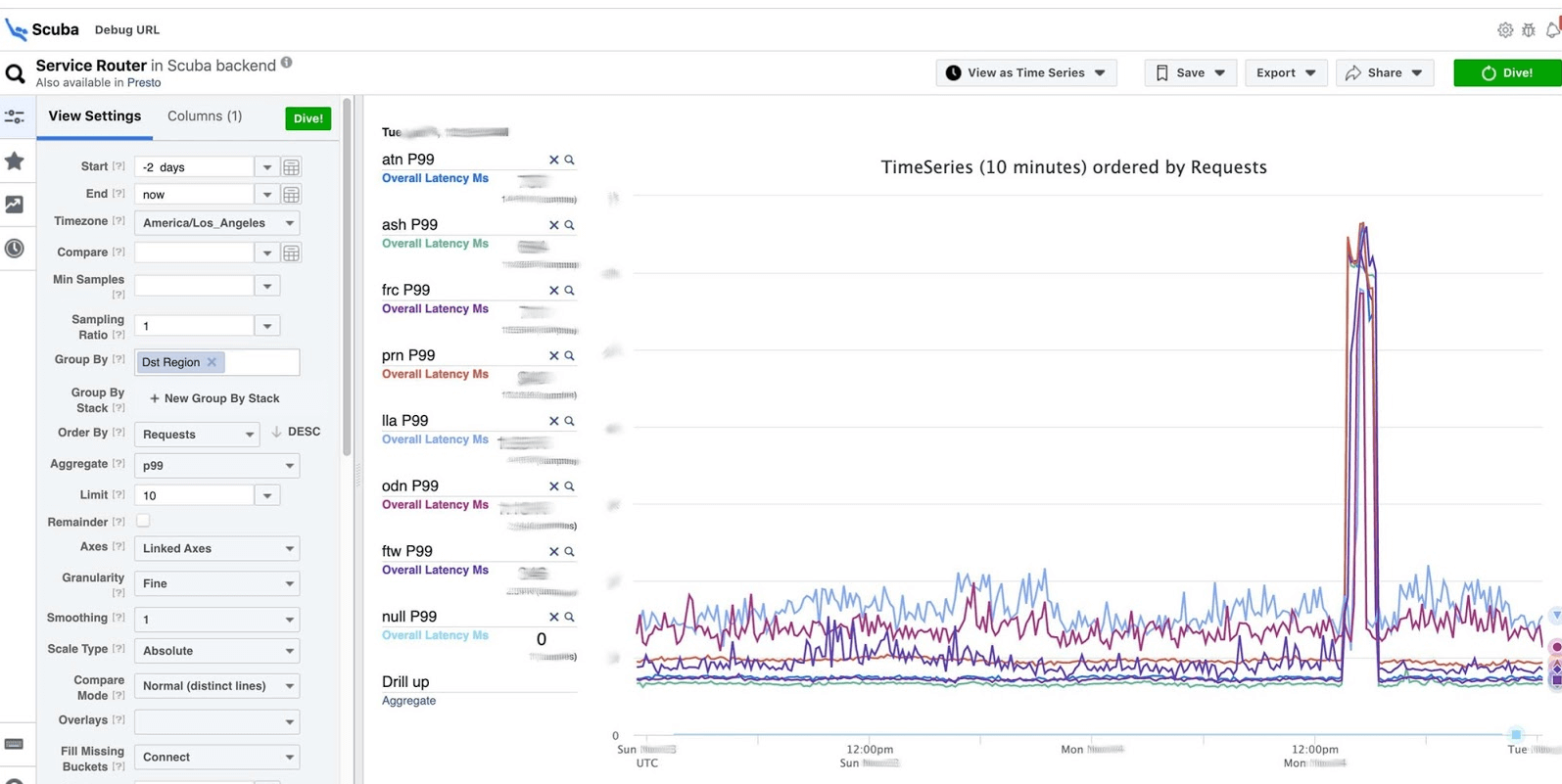
Видно, что в тот момент что-то случилось и задержка значительно увеличилась. Чтобы изучить подробнее, можно группировать по разным параметрам.
Таких таблиц сотни.
- Таблица, в которой видно версии бинарных файлов, пакетов, сколько памяти съедено на всех миллионах машин. На каждом хосте раз в час делается PS и отправляется в Scuba.
- В другие таблицы отправляется весь dmesg, все дампы памяти. Perf мы запускаем раз в 10 минут на каждой машине, поэтому знаем, какие stack traces у нас работают на ядре и что может загружать глобальный CPU.
Дебаг PHP
Scuba также выступает бэкендом для нашего основного инструмента дебага PHP. Код PHP пишут тысячи инженеров, и надо как-то спасать глобальный репозиторий от плохих вещей.
Как все работает? PHP на каждый лог пишет еще и stack trace. Scuba (наш Elasticsearch) просто не может вместить stack trace от всех логов со всех машин. Перед тем, как положить лог в Scuba, мы преобразуем stack trace в хэш, семплируем по хешам и сохраняем только их. Сами stack traces отправляем в Memcached. Потом уже во внутреннем инструменте можно вытащить конкретный stack trace из Memcached достаточно быстро.
Визуализация с группировкой по хэшам от логов и stack traces.
Отладку кода производим по методу pattern matching: открываем Scuba, смотрим, как выглядит график ошибки.
Идем в LogView, там ошибки уже сгруппированы по stack traces.
Из Memcached подгружается stack trace, а уже по нему можно найти diff (коммит в PHP репозиторий), который запостили примерно в это же время, и откатить его. У нас откатывать и коммитить может кто угодно, никаких разрешений для этого не нужно.
Дашборды
Тему мониторинга закончу дашбордами. Их у нас мало — всего два на три показателя. Сам дашборд довольно необычный. Про него хотелось бы рассказать подробнее. Ниже стандартный дашборд с набором графиков.
К сожалению, с ним не все так просто. Дело в том, что фиолетовая линия на одном графе — это тот же самый сервис, которому на другом графике соответствует голубая линия, а еще один график может быть за один день, а другой за месяц.
Мы используем свой дашборд, сделанный на основе Cubism — Open Source JS-библиотеки. Ее написали в Square и выпустили под лицензией Apache. У них есть встроенная поддержка Graphite и Cube. Но ее легко расширить, что мы и сделали.
На дашборде ниже представлен один день по одному пикселю на минуту. Каждая линия это регион: дата-центры, которые находятся рядом. Они отображают количество логов, которые бэкенд Facebook пишет в байтах в секунду. Внизу аннотации для команд в Америке, чтобы они видели, что мы уже исправили из случившегося днем. На этой картинке легко искать корреляцию.
Ниже — количество ошибок 500. То, что слева, для пользователей не имело никакого значения, а темно-зеленая полоса в центре явно им не понравилась.
Дальше 99-й перцентиль latency. В то же время, что и на графике выше, видно, что latency просела. Чтобы вернуть ошибку, много времени тратить не нужно.
Как это работает
На графике высотой 120 пикселей все видно. Но много таких на один дашборд не поместить, поэтому сожмем до 30.
К сожалению, тогда получается какой-то удав. Вернемся обратно и посмотрим, что с этим делает Cubism. Он разбивает график на 4 части: чем выше, тем темнее, а потом схлопывает.
Теперь у нас тот же график, что и раньше, но при этом все хорошо видно: чем темнее зеленый цвет, тем хуже. Теперь гораздо понятней, что происходит.
Слева видно волну, как она поднималась, а в центре, где темно-зеленое, все очень плохо.
Cubism — это только начало. Он нужен для визуализации, чтобы понять, все сейчас плохо или нет. Для каждой таблицы существуют дашборды уже с развернутыми графиками.
Сам по себе мониторинг помогает понять состояние системы и отреагировать, если она сломалась. В Facebook каждый сотрудник oncall, и чинить обязаны уметь все. Если горит ярко, то включаются все, но особенно продакшн-инженеры с опытом системного администратора, потому что они знают, как решить проблему быстро.
Когда Facebook лежал
Иногда инциденты случаются, и Facebook лежит. Обычно люди думают, что Facebook лежит, потому что произошел DDoS или напали хакеры, но за 5 лет ни разу такого не было. Причиной всегда были наши инженеры. Они не специально: системы очень сложные и сломаться может там, где не ждешь.
Всем большим инцидентам мы даем имена, чтобы было удобно о них упоминать и рассказывать новичкам, дабы не повторять ошибок в будущем. Чемпион по самому забавному имени — инцидент «Call the Cops». Люди звонили в полицию Лос-Анджелеса и просили починить Facebook, потому что он лежал. Шерифу Лос-Анджелеса это настолько надоело, что он написал в Твиттере: «Пожалуйста, не звоните нам! Мы за это не отвечаем!»
Мой любимый инцидент, в котором я участвовала, получил название «CAPSLOCK». Он интересен тем, что показывает, что случиться может все, что угодно. А случилось вот что. Это обычныйIP-адрес:
fd3b:5679:92eb:9ce4::1.Facebook использует Сhef, чтобы настраивать ОС. Service Inventory хранит в своей БД конфигурацию хоста, а Chef получает от сервиса файл с конфигурацией. Однажды сервис поменял себе версию, стал читать IP-адреса из БД сразу в формате MySQL и подкладывать их в файлик. Новый адрес теперь написан заглавными:
FD3B:5679:92EB:9CE4::1.Сhef смотрит в новый файл и видит, что «поменялся» IP-адрес, потому что сравнивает не в бинарном виде, а строкой. IP-адрес «новый», а это значит, что надо опустить интерфейс и поднять интерфейс. На всех миллионах машин за 15 минут интерфейс опустился и поднялся.
Казалось бы, ничего страшного — capacity уменьшилась, пока сеть лежала на некоторых машинах. Но неожиданно открылся баг в сетевом драйвере наших кастомных сетевых карт: при старте они требовали 0,5 Гбайта последовательной физической памяти. На кэш-машинах эти 0,5 Гбайта пропадали, пока мы опускали и поднимали интерфейс. Поэтому на кэш-машинах сетевой интерфейс опустился и не поднялся, а без кэшей ничего не работает. Мы сидели и перезапускали эти машины руками. Было весело.
Incident Manager Portal
Когда Facebook «горит» требуется организовать работу «пожарной команды», а главное — понять, где горит, потому что в огромной компании «пахнуть горелым» может в одном месте, а проблема будет в другом. В этом нам помогает UI-инструмент, который называется Incident Manager Portal. Его написали продакшн-инженеры, и он открыт для всех. Как только что-то случается, мы заводим там инцидент: название, начало, описание.
У нас есть специально обученный человек — Incident Manager On-Call (IMOC). Это не постоянная должность, менеджеры регулярно меняются. В случае больших пожаров IMOC организовывает и координирует людей на починку, но при этом не обязан чинить сам. Как только создается инцидент с высоким уровнем опасности, IMOC получает СМС и начинает помогать все организовывать. В большой системе без таких людей не обойтись.
Профилактика
Facebook лежит не так часто. Большую часть времени мы не тушим пожары и не перезапускаем кэш-машины, а правим баги заранее, и, если можно, для всех сразу.
Однажды мы нашли и поправили «проблему очереди». Количество запросов увеличивается на 50%, а ошибок на 100%, потому что никто throttling не имплементирует заранее, особенно в небольших сервисах.
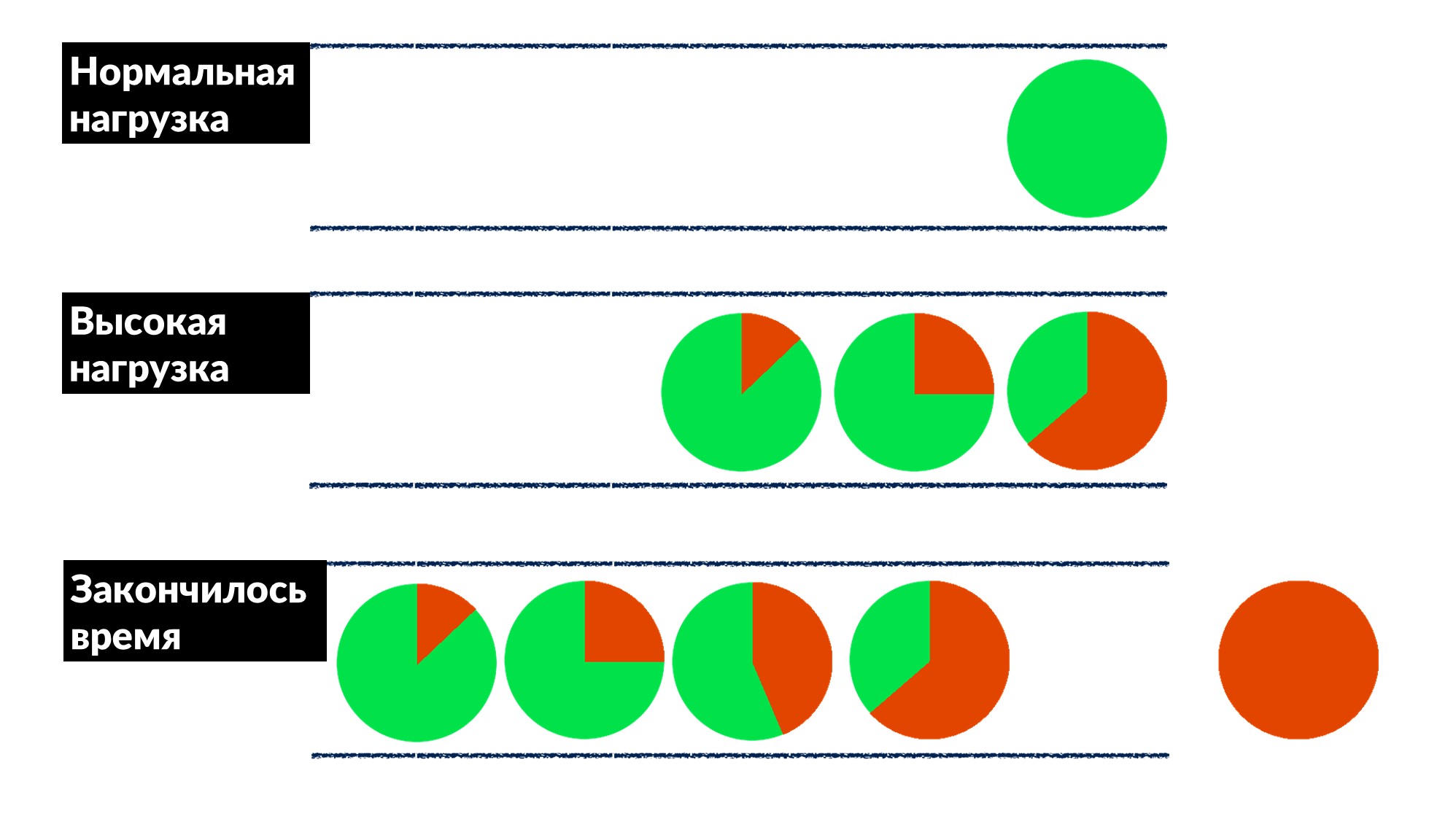
Мы разобрались на примере нескольких сервисов и примерно определили модель поведения.
- При нормальной нагрузке запрос приходит, обрабатывается и возвращается клиенту.
- При высокой нагрузке запросы ждут в очереди, потому что все потоки для обработки запросов заняты. Задержка увеличивается, но пока все нормально.
- Очередь растет, нагрузка увеличивается. В какой-то момент у всего, что исполняет сервер на клиенте заканчивается время ожидания ответа, и клиент вываливается с ошибкой. В этот момент результат работы сервера можно просто выбросить.
Красным выделен клиентский таймаут.
А клиент повторяет снова! Получается, что все запросы, которые мы исполняем, выбрасываются в мусорку и уже никому не нужны.
Как эту проблему решить для всех и сразу? Ввести ограничение на время ожидание в очереди. Если запрос стоит в очереди больше чем положено — выбрасываем и не обрабатываем на сервере, не тратим на него CPU. У нас получается честная игра: выбрасываем все, что не можем обработать, а все, что смогли — обработали.
Ограничение позволило при увеличении нагрузки на 50% выше максимальной, все еще обрабатывать 66% запросов и получать только 33% ошибок. Разработчики фреймворка для Dispatch реализовали это на стороне сервера, а мы, продакшн-инженеры, нежно задеплоили 100 мс таймаут в очереди на всех. Так все сервисы сразу получили дешевый базовый throttling.
Инструменты
Идеология SRE говорит, что если у вас большой флот машин, куча сервисов, и руками ничего не сделать, то надо автоматизировать. Поэтому половину времени мы пишем код и строим инструменты.
- Интегрировали Cubism в систему.
- FBAR — это «рабочая лошадка», которая приходит и чинит, поэтому у на никто не беспокоится из-за одной сломанной машины. Это основная задача FBAR, но сейчас у него задач еще больше.
- Coredumper, который мы написали с двумя коллегами. Он мониторит coredump’ы на всех машинах и скидывает их в одно место вместе со stack traces со всей информацией о хосте: где лежит, как найти, какой размер. Но главное, stack traces достаются бесплатно, без запуска GDB с помощью BPF программ.
Опросы
Последнее, что мы делаем — разговариваем с людьми, опрашиваем их. Нам кажется, что это очень важно.
Один из полезных опросов — о надежности. Об уже работающих сервисах мы спрашиваем в ключе цитаты из нашего опросника:
«The primary responsibility of system software must be to continue running. Providing service should be seen as a beneficial side-effect of continued operation»Это значит, что основная обязанность системы — продолжать работать, а то, что она предоставляет какой-то сервис, это дополнительный бонус.
Опросы только для средних сервисов, крупные сами разбираются. Мы даем опросник, в котором спрашиваем базовые вещи об архитектуре, SLO, тестировании, например.
- «Что будет, если ваша система получит 10% нагрузки?». Когда люди думают: «А действительно, что?» — появляются озарения, и многие даже правят свои системы. Раньше они об этом не думали, а после вопроса есть повод.
- «Кто первый обычно замечает проблемы с вашим сервисом — вы или ваши пользователи?» Разработчики начинают вспоминать, когда такое было и: «…Может быть, надо алёртов добавить».
- «Какая у вас самая большая боль oncall?» Для разработчиков это непривычно, особенно для новых. Они тут же говорят: «У нас много алёртов! Давайте их почистим и уберем те, которые не по делу».
- «Как часты у вас релизы?» Сначала вспоминают, что проводят релиз руками, а потом, что есть свой кастомный деплой.
В опроснике нет никакого кодинга, он стандартизирован и меняется каждый полгода. Это документ на две страницы, который мы помогаем заполнить за 2-3 недели. А потом мы устраиваем двухчасовой митинг и находим решения многих болей. Этот простой инструмент хорошо работает у нас, может помочь и вам.
6-7 апреля разработчики высоконагруженных систем снова собираются вместе на Saint HighLoad++, чтобы перенимать опыт лидеров индустрии и профессионалов в прикладных областях. До конца недели еще можно подать доклад и оказаться в очень хорошей компании спикеров или успеть сэкономить на билете (традиционно, чем ближе конференция, тем дороже).
Подписывайтесь на нашу рассылку с полезными подборками докладов и на telegram-канал с новостями. Увидимся в Питере!


serghd
то есть вы используете atop (а не htop, например), в первую очередь, из-за хранения истории?