

Не далее, как в прошлую пятницу у меня было интервью в одной компании в Palo Alto на позицию Data Scientist и этот многочасовой марафон из технических и не очень вопросов должен был начаться с моей презентации о каком-нибудь проекте, в котором я занимался анализом данных. Продолжительность — 20-30 минут.
Data Science — это необъятная область, которая включает в себя много всего. Поэтому, с одной стороны, есть из чего выбрать, но, с другой стороны, надо было подобрать проект, который будет правильно воcпринят публикой, то есть так, чтобы слушатели поняли поставленную задачу, поняли логику решения и при этом могли проникнуться тем, как подход, который я использовал может быть связан с тем, чем они каждый день занимаются на работе.
За несколько месяцев до этого в эту же компанию пытался устроиться мой знакомый индус. Он им рассказывал про одну из своих задач, над которой работал в аспирантуре. И, навскидку, это выглядело хорошо: с одной стороны, это связано с тем, чем он занимается последние несколько лет в университете, то есть он может объяснять детали и нюансы на глубоком уровне, а с другой стороны, результаты его работы были опубликованы в рецензируемом журнале, то есть это вклад в мировую копилку знаний. Но на практике это сработало совсем по-другому. Во-первых, чтобы объяснить, что ты хочешь сделать и почему, надо кучу времени, а у него на всё про всё 20 минут. А во-вторых, его рассказ про то, как какой-то граф при каких-то параметрах разделяется на кластеры, и как это всё похоже на фазовый переход в физике, вызвал законный вопрос: «А зачем это надо нам?». Я не хотел такого же результата, так что я не стал рассказывать про: «Non linear regression as a way to get insight into the region affected by a sign problem in Quantum Monte Carlo simulations in fermionic Hubbard model.»
Я решил рассказать про одно из соревнований на kaggle.com, в котором я участвовал.
Выбор пал на задачу, в которой надо было предсказать продажи товаров, которые чувствительны к погодным условиям в зависимости от даты и этих самых погодных условий. Соревнование проходило с 1 апреля по 25 мая 2015 года. В отличие от обычных соревнований, в которых призёры получают большие и не очень деньги и где разрешается делиться кодом и, что важнее, идеями, в этом соревновании приз был прост: job recruiter посмотрит на твоё резюме. И так как рекрутер хочет оценить твою модель, то делиться кодом и идеями было запрещено.
Задача:
- 45 гипермаркетов в 20 различных местах на карте мира (географические координаты нам неизвестны)
- 111 товаров, продажи которых теоретически могут зависеть от погоды, типа зонтиков или молока (товары анонимизированы. То есть мы не пытаемся предсказать, сколько галош было продано в данный день. Мы пытаемся предсказать, сколько было продано товара, скажем, с индексом 31)
- Данные с 1 января 2012 по 30 сентября 2014 года
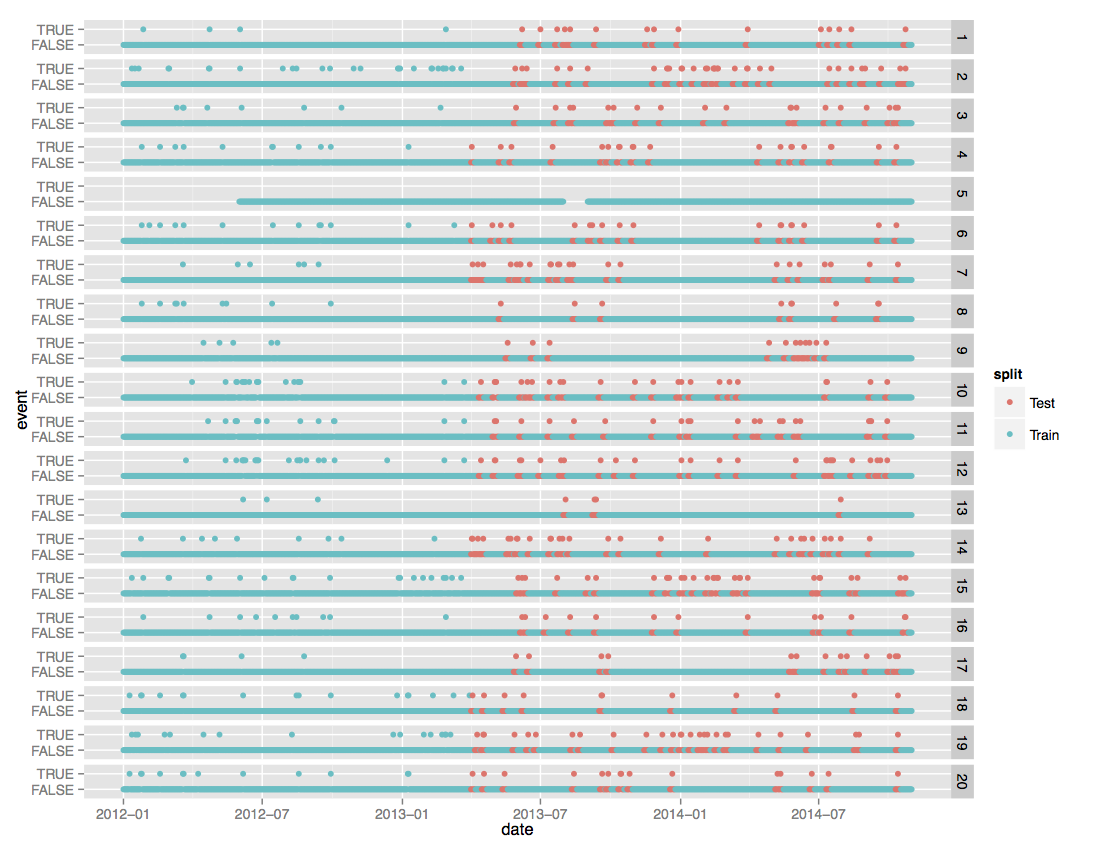
На этой не очень понятной картинке, которая позаимствована со страницы с описанием данных для данного соревнования, изображено:
- Колонка с цифрами справа — метеорологические станции.
- У каждой метеорологической станции два ряда: нижний — все даты, верхний — даты с нестандартными погодными условиями: шторм, сильный ветер, сильный дождь или град, и т.д.
- Синие точки — train set, для которого известны и погода, и продажи. Красные — test set. Погодные условия известны, а вот продажи нет.
Данные представлены в четырёх csv файлах:
- train.csv — продажи каждого из 111 товаров в каждом из 45 магазинов в каждый день из train set
- test.csv — даты, в которые надо предсказать продажи в каждом из 45 магазинов для каждого из 111 товаров
- key.csv — какие метеорологические станции расположены рядом с какими магазинами
- weather.csv — погодные условия для каждого из дней в интервале с 1 января 2012 по 30 сентября 2012 для каждой из 20 погодных станций
Метеорологические станции предоставляют следующие данные (В скобках процент пропущенных значений.):
- Максимальная температура [градусы Фаренгейта] (4.4%)
- Минимальная температура [градусы Фаренгейта] (4.4%)
- Средняя температура [градусы Фаренгейта] (7.4%)
- Отклонение от ожидаемой температуры [градусы Фаренгейта] (56.1%)
- Точка росы [градусы Фаренгейта] (3.2%)
- Температура по влажному термометру [градусы Фаренгейта] (6.1%)
- Время восхода (47%)
- Время заката (47%)
- Суммарное описание типа дождь, туман, торнадо (53.8%)
- Осадки в виде снега [дюймы] (35.2%)
- Осадки в виде дождя [дюймы] (4.1%)
- Атмосферное давление на станции [дюймы ртутного столба] (4.5%)
- Атмосферное давление на уровне моря [дюймы ртутного столба] (8.4%)
- Скорость ветра [мили в час] (2.8%)
- Направление ветра [градусы] (2.8%)
- Средняя скорость ветра [мили в час] (4.2%)
Очевидные проблемы с данными:
- Мы не знаем географических координат магазинов. И это плохо. Дождь или солнце — это важно, но скорее всего Аляска и Сан Франциско покажут разную динамику продаж.
- Названия товаров анонимизированы. Мы не знаем, товар с ID=35 — это молоко, виски или ватные штаны.
- Организаторы соревнования решили усугубить предыдущий пункт и английским по белому написали, что нет никаких гарантий, что ID=35 в одном магазине будет означать то же, что и в другом.
- Метеорологические станции меряют не всё и не всегда. Погодные данные достаточно дырявые. И вопрос как эти пробелы заполнять надо будет как-то решать.
Для меня главное в любой задаче в машинном обучении, над которой я работаю — это «вопроc». В том смысле, что надо понимать вопрос, чтобы найти ответ. Это кажется тавтологией, но у меня есть примеры и в научной деятельности, и в сторонних проектах вроде кагла, когда люди пытались найти ответ не на тот вопрос, который был задан, а на какой-то ими самими придуманный, и ничем хорошим это не заканчивалось.
Второе по важности — это метрика. Мне не нравится как звучит: «Моя модель точнее твоей». Гораздо приятнее будет звучать похожее по смыслу, но чуть более точное:«Моя модель точнее твоей, если мы применим данную метрику для оценки.»
Нам надо предсказать, сколько товаров будет продано, то есть эта регрессионная задача. Стандартную регрессионную метрику среднеквадратичного отклонения использовать можно, но нелогично. Проблема в том, что алгоритм, который будет пытаться предсказать сколько пар резиновых сапог будет продано, может предсказать отрицательные значения. И тогда встанет вопрос, что с этими отрицательными значениями делать? Обнулять? Брать абсолютное значение? Муторно это. Можно сделать лучше. Давайте сделаем монотонное преобразование того, что надо предсказать, так, чтобы преобразованные значения могли принимать любые вещественные, в том числе и отрицательные, значения. Предскажем их, а потом произведём обратное преобразование на интервал неотрицательных вещественных чисел.
Об этом можно думать так, как если бы наша функция ошибки была определена вот таким образом:
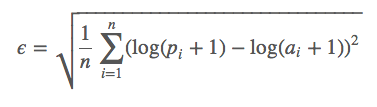
Где:
- a — реальное значение
- p — наше предсказание
- натуральный логарифм от сдвинутого на 1 аргумента — это монотонное отображение с неотрицательной вещественной оси на всю ось, с очевидным обратным преобразованием.
Но, что ещё важнее — в данном соревновании точность нашего предсказания оценивается именно этой метрикой. И использовать я буду именно её: что хотят организаторы, то я им и выдам.
Нулевая итерация или базовая модель.
При работе над различными задачами хорошо себя показал такой подход: как только ты начал работать над задачей — создаёшь «корявый» скрипт, который делает предсказание на нашем test set. Корявый потому, что создаётся по-тупому, без размышлений, не глядя на данные. И не строя никаких распределений. Идёя в том, что мне нужна нижняя оценка точности модели, которую я могу предложить. Как только у меня есть такой «корявый» скрипт, я могу проверять какие-то новые идеи, создавать новые признаки, настраивать параметры модели. Оценку точности я обычно провожу двумя способами:
- Результат оценки предсказания на test set, который нам показывает Public Leaderboard на kaggle.
- hold out set, если train set большой и равномерный, или 5 fold cross validation если train set маленький или неравномерный
Первый хорош тем, что не занимает много времени. Сделал предсказание, отправил на сайт — получил результат. Плох тем, что число попыток в день ограничено. В данном соревновании это 5. Ещё он хорош тем, что показывает относительную точность модели. Ошибка 0.1 — это много или мало? Если у многих на Public Leaderboard ошибка их предсказания меньше, то это много.
Второй хорош тем, что можно оценивать различные модели, сколько угодно раз.
Проблема в том, что модель оцененная, одной и той же метрикой может дать различную точность в этих двух подходах:
Несоответствия могут быть вызваны тем, что:
- данные в train и test набраны из разных распределений
- очень маленький train или test
- хитрая метрика не позволяет сделать человеческий cross validation
На практике достаточно, чтобы улучшение точности модели по cross validation соответствовало улучшению результатов на Public Leaderboard, точное численное соответствие не обязательно.
Так вот. Первым делом я написал скрипт, который:
- Перегоняет время рассвета/заката из часов и минут в число минут с полуночи.
- Суммарное описание погодных условий в dummy variables.
- Вместо всех пропущенных значений -1.
- Соединяем соответствующие train.csv/test.csv, key.csv и weather.csv
- Полчившийся train set — 4,617,600 объектов.
- Получившийся test set — 526,917 объектов.
Теперь надо скормить эти данные какому-нибудь алгоритму и сделать предсказание. Существует море различных регрессионных алгоритмов, каждый со своими плюсами и минусами, то есть есть из чего выбрать. Мой выбор в данном случае для базовой модели — Random Forest Regressor. Логика этого выбора в том, что:
- Random Forest обладает всеми преимуществами алгоритмов из семейства Decision Tree. Например, теоретически он безразличен к тому, численная или категорийная переменная.
- Достаточно шустро работает. Если мне не изменяет память — сложность O(n log(n)), где n — число объектов. Это хуже, чем метод стохастического градиентного спуска с его линейной сложностью, но лучше, чем метод опорных векторов с нелинейным ядром, в котором O(n^3).
- Оценивает важность признаков, что важно для интерпретации модели.
- Безразличен к мультиколлинеарности и коррелированности данных.
Предсказание => 0.49506
Итерация 1.
Обычно во всех online классах очень много обсуждают какие графики строить, чтобы попытаться понять, что вообще происходит. И это идея правильная. Но! В данном случае есть проблема. 45 магазинов, 111 товаров, причём нет гарантии, что одно и то же ID в разных магазинах соответствует одному и тому же товару. То есть получается, что надо исследовать, а затем предсказать 45*111 = 4995 различных пар (магазин, товар). Для каждой пары погодные условия могут работать по разному. Правильная, простая, но неочевидная идея — построить для каждой пары (магазин, товар) heatmap, на котором отобразить, сколько единиц товара было продано за всё время:

- Во вертикали — индекс товара.
- По горизонтали — интекс магазина.
- Яркость точек — Log(сколько единиц товара, проданного за всё время).
И что мы видим? Картинка достаточно бледная. То есть не исключено, что какие-то товары в каких-то магазинах впринципе не продавались. Я это связываю с географическим расположением магазинов. (Кто будет покупать пуховый спальник на Гаваях?). А давайте исключим из нашего train и test те товары, которые в данном магазине никогда и не продавались.
- train с 4617600 сокращается до 236038
- test с 526917 сокращается до 26168
то есть размер данных сократился почти в 20 раз. И как следствие:
- Мы убрали часть шума из данных. Как следствие, алгоритму будет проще тренироваться и предсказывать, то есть должна увеличиться точность модели.
- Модель тренируется гораздо быстрее, то есть проверять новые идеи стало гораздо проще.
- Теперь мы тренируем на уменьшенном train (236038 объектов), предсказываем на уменьшенном test(26168 объектов), но так как кагл хочет предсказание с размером (526917 объектов) то остаток забиваем нулями. Логика в том, что если какой-то товар никогда не был продан в данном магазине, то либо он так никогда и не будет продан, либо он будет продан, но мы этого не сможем предсказать в любом случае.
Предсказание -> 0.14240. Ошибка уменьшилась в три раза.
Итерация 2.
Урезание размеров train/test сработало замечательно. Можно ли усугубить? Оказывается, что можно. После предыдущей итерации у меня получилось всего 255 ненулевых пар (магазин, товар), а это уже обозримо. Я просмотрел на графики для каждой пары и обнаружилось, что какие-то товары не продавались не из-за плохих/хороших погодных условий, а просто потому, что их не было в наличии. Например, вот такая картинка для товара 93, в магазине 12:
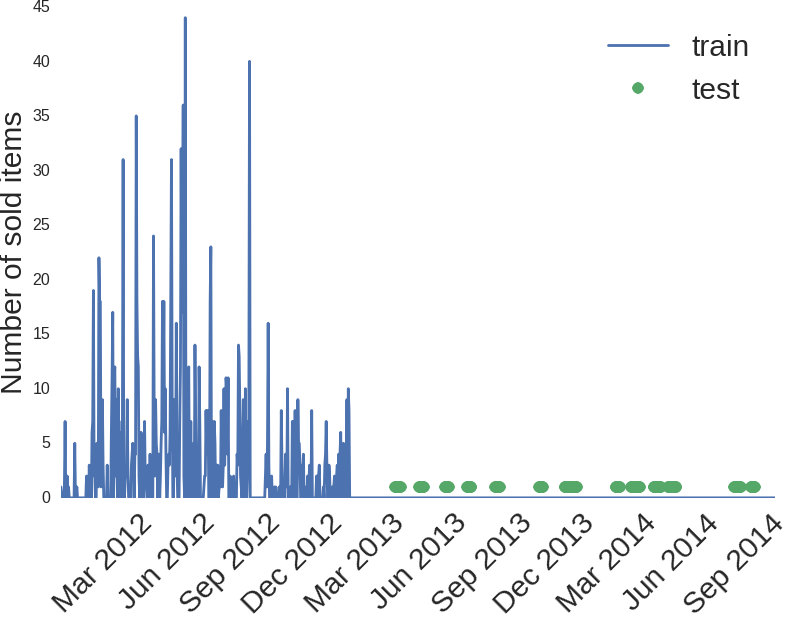
Я не знаю, что это за товар, но есть подозрение, что его продажи закончились в конце 2012 года. Можно попробовать удалить эти товары из train и в test всем им поставить 0, как наше предсказание.
- train уменьшается до 191000 объектов
- test уменьшается до 21272 объектов
Предсказание -> 0.12918
Итерация 3.
Название соревнований предполагает предсказание на основе погодных данных, но, как обычно, они лукавят. Задача, которую мы пытаемся решить, звучит по-другому:
«У вас есть train, у вас есть test, крутитесь, как хотите, но сделайти наиболее точное при данной метрике предсказание.»
А в чём разница? Разница в том, что у нас есть не только погодные данные, но и дата. А дата — это источник очень мощных признаков.
- Данные за три года => годовая периодичность => новые признаки год и число дней с нового года
- Люди получают зарплату раз в месяц. Не исключено, что есть месячная периодичность в покупках. => новый признак месяц
- То, как люди совершают покупки может быть связано с днём недели. Дождь — это, конечно, да, но вечер пятницы — это вечер пятницы => новый признак день недели.
Предсказание -> 0.10649 (кстати мы уже в топ 25%)
А что насчёт погоды?
Оказывается, что погода не очень-то и важна. Я честно пытался добавить ей веса. Пытался заполнять пропущенные значения различными способами, как то средние значение по признаку, по разным хитрым подгруппам, пытался предсказывать пропущенные значения используя различные алгоритмы машинного обучения. Слегка помогло, но на уровне погрешности.
Следующий этап — линейная регрессия.
Не смотря на кажущуюся простоту алгоритма, и кучу проблем, которыми данный алгоритм обладает, есть и у него существенные преимущества, которые делают его одним из моих любимых регрессионных алгоритмов.
- Категорийные признаки, такие как день недели, месяц, год, номер магазина, индекс товара перегоняются в dummy variables
- Масштабирование, чтобы увеличисть скорость сходимости и интепретируемость результатов.
- Подкрутка параметров L1 и L2 регуляризации.
Предсказание -> 0.12770
Это хуже, чем Random Forest, но не так чтобы очень сильно.
Спрашивается, зачем мне вообще линейная регрессия на нелинейных данных? Есть на то причина. И причина эта — оценка важности признаков.
Я использую три различных подхода для этой оценки.
Первый — это то, что выдаёт RandomForest после того, как мы его натренировали:

Что мы видим на этой картинке? То, что тип продаваемого товара, а также номер магазина — это важно. А остальное важно гораздо меньше. Но это мы могли сказать, даже и не глядя на данные. Давайте уберём тип товара и номер магазина:
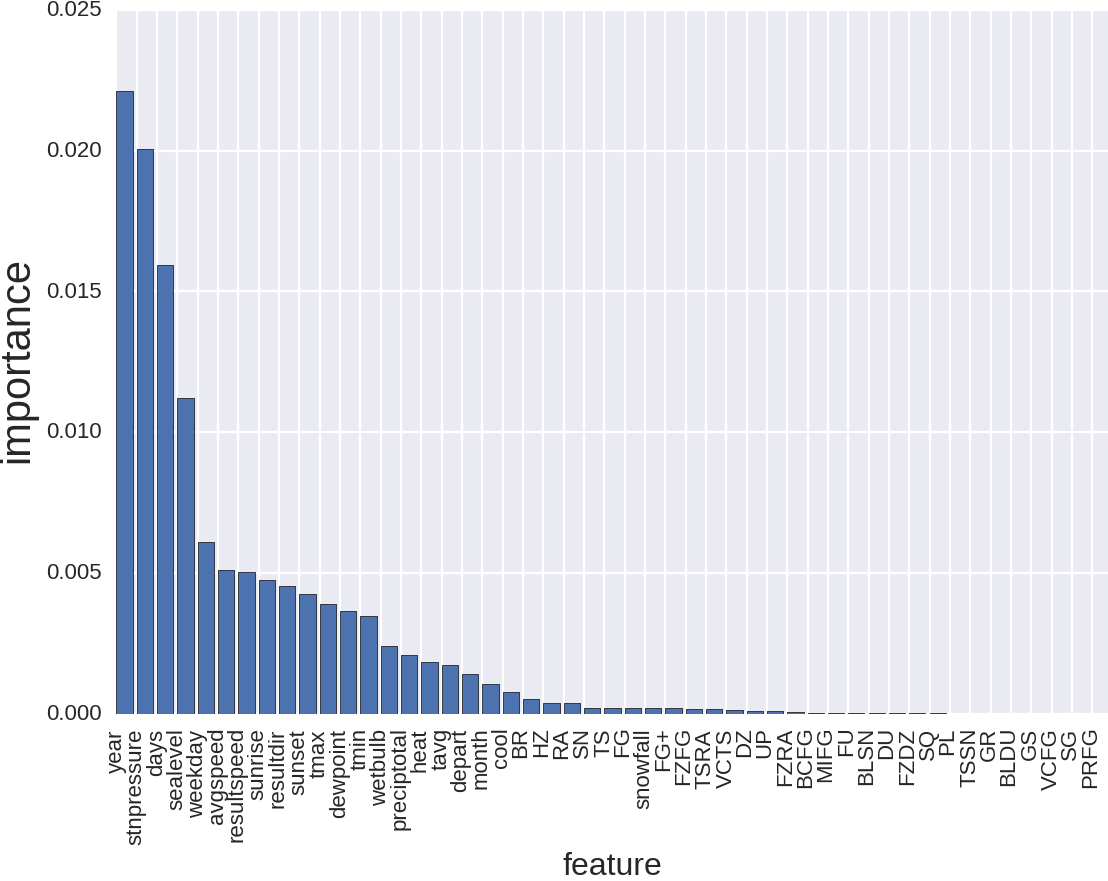
И что тут? Год — возможно это логично, но это мне неочевидно. Давление — это, мне кстати, было понятно, а вот людям которым я это вещал, было не очень. Всё-таки в Питере частая смена погода, которая сопровождается сменой атмосферного давления, и про то, как это меняет настроение и самочуствие, в особенности у пожилых людей, я был в курсе. Людям, живущим в Калифорнии, с её стабильным климатом это было неочевидно. Что дальше? Число дней с начала года — тоже логично. Отсекает, в какой сезон мы пытаемся предсказать продажи. И погода, как ни крути, с сезоном может быть и связана. Далее день недели — тоже понятно. И т.д.
Второй способ — это абсолютная величина коэффициентов, которую выдаёт линейная регрессия на отмасштабированных данных. Чем больше коэффициент — тем большее влияние он имеет.
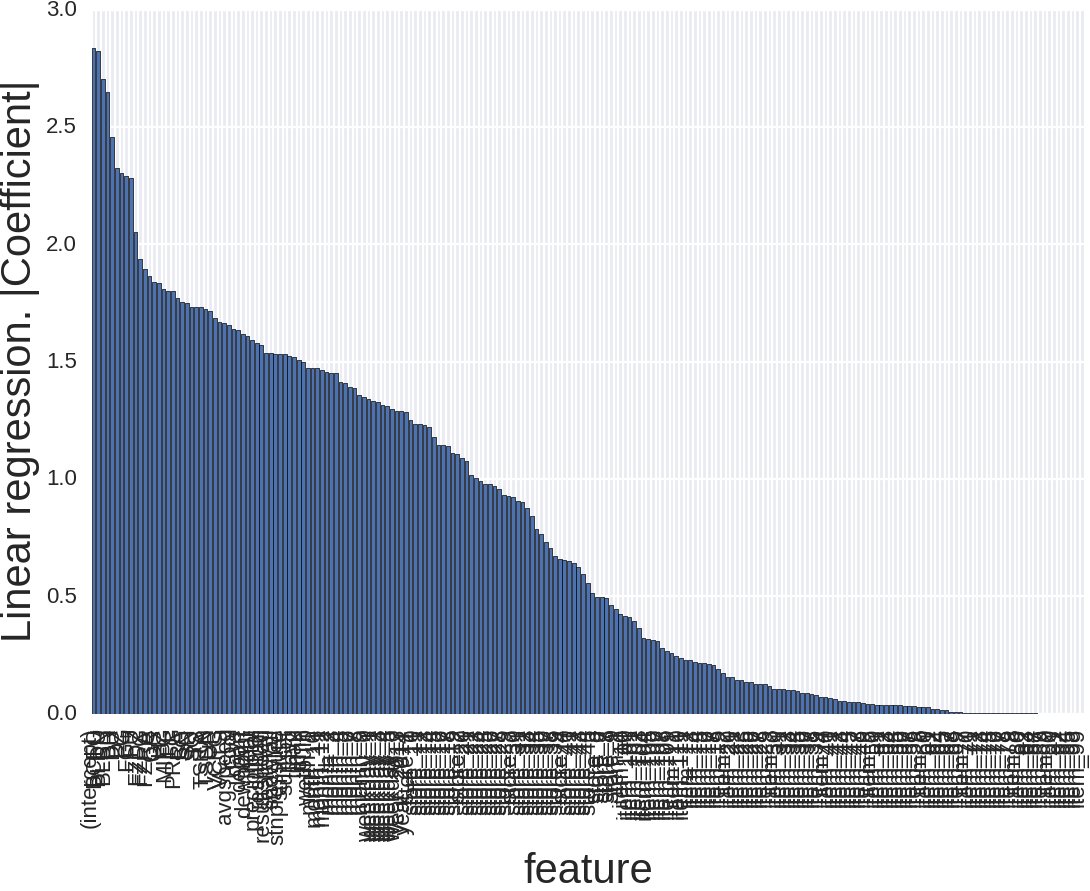
Картинка выглядит вот так и тут мало что понятно. Причина того, что признаков так много, в том, что, например, тип товара для RandomForest — это один признак, а тут их аж 111, то же и с номером магазина, месяцем и днём недели. Давайте уберём тип товара и номер магазина.
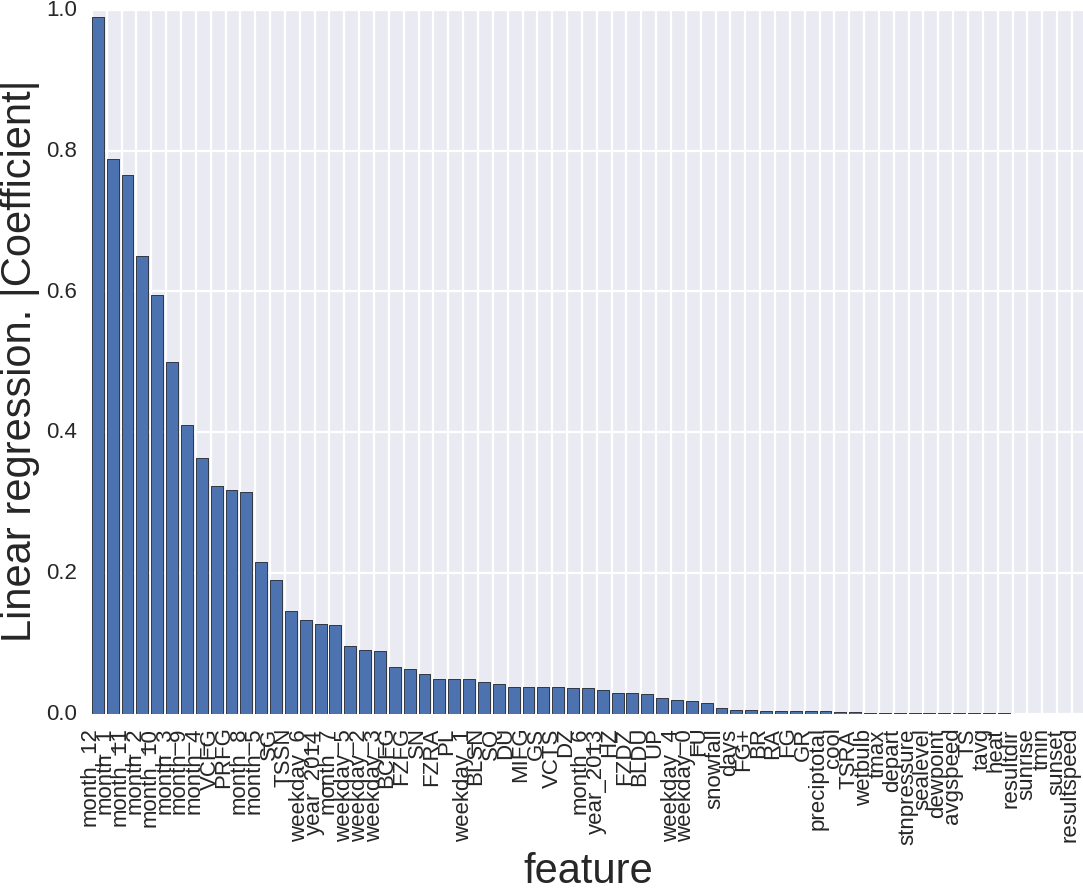
Так лучше. Что тут происходит? Месяц — это важно, причём особенно, если это декабрь, январь или ноябрь. Вроде тоже логично. Зима. Погода. И, что немаловажно, праздники. Тут и новый год, и день благодарения, и рождество.
Третий метод — метод грубой силы, выкидывать признаки по одному и смотреть, как это повлияет на точность предсказания. Самый надёжный, но, самый муторный.
С нахождением признаков и их интерпретацией вроде закончили, теперь численные методы. Тут всё прямолинейно. Пробуем разные алгоритмы, находим оптимальные параметры вручную или используя GridSearch. Комбинируем. Предсказываем.
- Линейная регрессия (0.12770)
- Random Forest (0.10649)
- Gradient Boosting (0.09736)
Я особо изобретать не стал. Взял взвешенное среднее от этих предсказаний. Веса вычислил, предсказывая этими алгоритмами на holdout set, который откусил от train set.
Получилось что-то вроде 0.85% Gradient Boosting, 10% Random Forest, 5% Linear regression.
Результат 0.09532 (15 место, топ 3%)

На этом графике best known result — это первое место на Private LeaderBoard.
Что не сработало:
- kNN — простой алгоритм, но часто хорошо показывает себя как часть ансамбля. Я не смог выжать из него меньше (0.3)
- Нейронные сети — при правильном подходе даже на таких разношёрстных данных показывают достойный результат, и что важно, часто замечательно показывают себя в ансамлях. Тут у меня прямоты рук не хватило, что-то где-то я перемудрил.
- Я пытался строить отдельные модели для каждой погодной станции, товара и магазина, но данных становится совсем мало, так что точность предсказания падает.
- Была предпринята попытка анализа временных рядов и выделения тренда, и периодичных компонент, но это точность предсказания также не увеличило.
Итого:
- Хитроумные алгоритмы — это важно, и сейчас существуют алгоритмы, которые прямо из коробки выдают очень точные результаты. (Например, меня порадовала конволюционная нейронная сеть из 28 слоёв, которая сама вычленяет выжные признаки из изображений.)
- Подготовка данных и создание грамотных признаков — это часто (но не всегда) гораздо важнее, чем сложные модели.
- Часто гениальные идеи не работают.
- Иногда совершенно глупые и бесперспективные идеи работают замечательно.
- Люди — это такие существа, которые любят находиться в зоне комфорта и следовать своему проверенному временем графику, который основывается на календаре, а не на сиюминутном импульсе, вызванном погодными условиями.
- Я пытался выжать как можно больше из этих данных, но если бы мы знали цену товаров, или их названия, или географическое положение магазинов, решение было бы другим.
- Я не пробовал добавлять погоду до и после дня, для которого надо делать предсказание. Также я не пробовал создавать отдельный признаку для описания праздников. Не исключено, что это бы помогло.
- На все про всё я потратил неделю, время от времени отрываясь от дописывания диссертации и запуская очередную итерацию. Возможно, точность предсказания можно было бы увеличить, если бы я потратил больше времени, хотя с другой стороны, раз я этого не сделал за неделю, значит так тому и быть. На kaggle.com куча интересных соревнований, и зацикливаться на каком-то одном не очень правильно с точки зрения эффективности получения знаний.
- Всем, кто не пробовал участвовать в соревнованиях на kaggle.com — рекомендую. Оно интересно и познавательно.
UPDATE:
В комментариях был задан очень правильный вопрос про оверфиттинг, и я решил добавить текст с описанием того, как оценивается точность вашей модели на kaggle.com.
Часто при прохождении интервью меня спрашивают, откуда у меня опыт в машинном обучении. Раньше я отвечал, что теоретическая подготовка из online классов, чтения книжек, научных статей и форумов соответствуеющей тематики. А практическая из попыток применения машинного обучения в физике конденсированных сред и опыте участия в соревнованиях на кагле. Причём, по факту с точки зрения знаний, kaggle дал мне гораздо больше. Как минимум потому, что там я работал с более чем 20 различными задачами, и у каждой свои нюансы и заморочки. Например:
- Otto Group Product Classification Challenge — Данные были подготовлены так, что ни у кого толком не получилось никакого создания признаков. Акцент в данном соревновании был на численные методы. Алгоритмы, параметры моделей, ансамбли. В данном соревновании я разобрался с алгоритмами: Gradient Boosting, познакомился с Neural Networks, научился делать простые ансамбли. Начал активно использовать scikit-learn, graphlab, xgboost.
- Search Results Relevance — Тут Natural Language Processing со всеми соотвествующими теоретическими и практическими заморочками. Теоретическая база и практический опыт использования SVM, bag of words, word2vec, glove, nltk.
- Avito Context Ad Clicks — Встал вопрос масштабируемости. 300 миллионов объектов с кучей признаков. И тут у меня пошёл Apache Spark, проявилась вся мощь и недостатки логистической регрессии. (До FFM у меня, к сожалению, руки не дошли)
- Diabetic Retinopathy Detection — Обработка изображений, извлечение признаков из изображений, нейронные сети, преимущества и недостатки использования GPU. Опыт работы с Theano и ImageMagic.
и так далее, ещё 15 различных проблем. Очень важно, что над этими задачами одновременно работали тысячи людей с различными знаниями и опытом, делясь идеями и кодом. Море знаний. На мой взгляд, это очень эффективное обучение, особенно если параллельно знакомиться с соответствующей теорией. Каждое соревнование чему то учит, причём на практике. Например, у нас на факульте, многие слышали про PCA, и эти многие верят, что это волшебная палочка, которую можно использовать практически вслепую, чтобы уменьшить число признаков. А по факту PCA — это очень мощная техника, если правильно его использовать. И очень мощно стреляет в ногу, если неправильно. Но пока не попробовал его на различных типах данных, толком этого не чувствуешь.
И, по свойственной мне наивности, я предполагал, что те, кто про кагл слышал, так его и воспринимает. Оказалось что нет. Общаясь со знакомыми Data Scientist'ами, а также слегка обсуждая мой опыт на кагле на различных, интервью я осознал, что народ не в курсе, как вообще происходит оценка точности модели на этих соревнованиях и, общее мнение о каглерах — оверфиттеры, и этот опыт участия в соревнованиях — скорее негатив, чем позитив.
Так вот, попытаюсь объяснить, как оно и что:
Большинство (но не все), задач, которые предлагаются желающим — это обучение с учителем. То есть у нас есть train set, есть test set. И надо сделать предсказание на test. Точность модели оценивается по тому, как правильно мы предсказали test. И это звучит плохо. В том смысле, что опытные Data Scientist'ы тут же увидят проблему. Делая кучу предсказаний на test мы агрессивно оверфитим. И та модель, которая точно работает на test может отвратительно работать на новых данных. И вот именно так большинство из тех кто про Кагл слышал, но не пробовал, об этом процессе и думает. Но! На самом деле всё не так.
Идея в том, что test set раздёляется на две части: Public и Private. Обычно в пропорции 30% на Public, и 70% на Private. Вы, делаете предсказание на всём test set, но, пока соревнование не окончится, вы можете увидеть точность вашего предсказания только на Public. А после окончания соревнований вам становится доступна точность на Private, и вот эта Private и является итоговой точностью вашей модели.
Пример о соревновании, которое я в этом тексте описывал.
Соревнование заканчивается 25 мая. => До 17:00, PST вам доступна ошибка предсказания на 30% test set, то есть Public part. В моём случае это было 0.09486 и 10 место на Public Leaderboard. В пять вечера PST соревнование заканчивается. И становится доступным предсказание на оставшихся 70% (Private).
У меня это 0.09532 и 15 место. То есть я слегка оверфитил.
Итоговая точность вашей модели на Private, оценивается по двум выбранным вами предсказаниям. Как правило, я выбираю одно из них — то, которое даёт наименьшую ошибку на Public Leaderboard, а второе то, которе даёт наименьшую ошибку на Cross Validation, вычесденную по train set.
Обычно я работаю в таком режиме: если ошибка на локальном cross validation уменьшилась => отсылаю предсказание на кагл. То есть сильного оверфита не происходит. Параметры модели также выбираются исходя из величины ошибки на cross validation. Например, веса, с которыми я усреднял Linear Regression, Random Forest и Gradient Boosting определялись по куску данных, которые я откусил от train и для тренировки модели не использовал, как не использовал и test set.
Как правильно подметил Owen, в одной из своих презентаций, правильная оценка точности модели гораздо важнее, чем сложность модели. Поэтому, когда я создаю свой наивный скрипт (нулевая итерация), упомянутый выше, то делаю упор не на анализ данных и точность модели, а на то, чтобы cross validation ошибка на train set соответствовала ошибке на Public Leaderboard.
Это не всегда просто, а часто и просто невозможно.
Примеры:
- Facebook Recruiting IV: Human or Robot? — тут у меня что-то не срасталось. Причём, народ на форуме обсуждал, как делать это по-человечески, то есть я не один такой. Я как раз с рецензентами на тему диссертации воевал, поэтому тут я просто оверфитил Public Leaderboard, но аккуратно. Моё место на Private на 91 место выше, чем на Public. Скорее всего потому, что остальные оверфитили более агрессивно. Но вообще это пример соревнования, когда Public и Private из немного разных распределений.
- Restaurant Revenue Prediction — это вообще ахтунг. train set — 137 объектов, включая outliers. test set — 10000. Тут просто в силу маленького размера train, ничего кроме как оверфитить Public Leaderboard и не придумаешь. Как следствие, сильная разница между Private и Public. Но это, в принципе, была самая бестолковая задача среди тех, над которыми я работал.
- ECML/PKDD 15: Taxi Trajectory Prediction (I) и ECML/PKDD 15: Taxi Trip Time Prediction (II) — в этих двух соревнованиях, во-первых, структура задачи такая хитрая, что надо сильно думать, как правильно оценивать точность, используя локальный cross validation. Ну и размеры train/test тоже добавляют. Миллионы объектов в train и около тысячи в test.
- ICDM 2015: Drawbridge Cross-Device Connections — это semi-supervised learning и с этой задачей я мозг себе уже сломал. Вроде придумал, как локально оценивать точность модели. Но тут мне надо много думать и читать. Это соревнование заканчивается через 12 дней. Как говорят в Одессе: «Будем посмотреть». Может что-нибудь и изобрету.
Мораль — я попытался пояснить, что люди, которые участвовуют в соренованиях на kaggle.com — это разная публика. Поначалу большинство занимается подгонкой параметров, базируясь на результатах Public Leaderboard, а потом воет на форуме, что «мир жесток, все вокруг виноваты», когда их итоговое место на Private гораздо ниже ожидаемого. Но, как правило, после первого такого прокола, открываются чакры и публика подходит к вопросу оценки точности модели очень трепетно, с понимаением того, где нужен KFold, где StarifiedKFold, а где достаточно hold out set, сколько фолдов надо брать, как интерпретировать результаты, и вообще где какие грабли сущуствуют, и когда на них можно наступать, а когда не стоит.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (15)

efremovaleksey
13.08.2015 12:31+1В своё время я решал похожую задачу прогнозирования объема выручки магазина, в котором работал.
Результат получился довольно интересным. В первую очередь на объемах продаж сказывались недельные / месячные / годовые циклы, праздничные дни. Если же, учитывая их влияние, пытаться построить зависимость от погодных условий, то самым значимым оказался фактор изменения температуры, но не её абсолютная величина.
И действительно, вспомните себя, к примеру, осенью. Когда холодает градусов на 5-10, вам день-два зябко, не хочется выходить из дома, а потом вы привыкаете. И неважно, холодает с 0 до -5 или с -15 до -20 градусов.
Использование «истории» погоды — обязательно для данной задачи.

homm
13.08.2015 15:46-2Простите, у вас иллюстрация к посту неверная. Батарея зонтиков не спасет от дождя — струи воды будут стекать сильными потоками с нижних зонтов на плечи и одежду тех, кто стоит рядом с ними.

{kind=link}

Alexey_mosc
14.08.2015 16:24Про отбор информативных признаков, вы перечислили: веса линейной функции и важность, сгенерированная случайным лесом. Упомянули «Третий метод — метод грубой силы, выкидывать признаки по одному и смотреть, как это повлияет на точность предсказания. Самый надёжный, но, самый муторный.»
Недостатком всех трех перечисленных подходов является их суб-оптимальность. И причина проста: делается анализ важности одного из признаков, когда в реальности мы можем легко получить ситуацию, когда, например, 2 признака будут очень слабо влиять на зависимую переменную, а в комбинации давать скачкообразный рост важности. Ситуация становится еще интереснее, если попробовать представить, сколько всего взаимодействий между всеми признаками и всеми их подгруппами могут давать разное значение важности.
При этом еще отмечу, что важность признаков, сгенерированная, например, случайным лесом не трактуема в том смысле, что не ясно, температура, например, повышаясь увеливает продажи или понижаясь. Но это вроде и не требуется здесь.
Я отбираю признаки по информационному критерию: скорректированная взаимная информация между подпространством признаков и зависимой переменной. Почитайте, может, пригодится. Этот метод, в частности, анализирует взаимодействия в группе предикторов, но может и отдельные переменные посмотреть в процессе обучения.
ternaus
14.08.2015 20:07+2Я обеими руками за почитать и научиться чему-то новому и правильному. Ссылкой не поделитесь на статью/книжку/пример?
Alexey_mosc
17.08.2015 15:02Ок, про взаимную информацию легко найти материалы, вики та же. А про скорректированную взаимную информацию посоветую эту публикацию: Analytical estimates of limited sampling biases in different information measures by S. Panzeri et al.
Взаимная информация как мера связанности, будучи посчитанной без коррекции на ограниченную длину выборки, это путь в ошибки.
Фитнесс функции я пишу сам, тут уж только опыт поможет.
Базовые функции есть в пакетах для R, например. infotheo, например.
Alexey_mosc
17.08.2015 15:13научиться чему-то новому и правильному
И я, кстати, не говорю, что вы делаете неправильно. Просто каждому методу свое назначение. Если задача содержит только линейные зависимости, простые коэффициенты лин.функции могут быть полезны. Однако, там все равно остается проблема анализа каждого признака в отдельности. Но если есть уверенность, что признаки информативны только в отдельности, то метод идеально подходит. Но в реальном мире это встречается редко.
J_K
17.08.2015 04:35+2То ли не вижу, то ли вы не написали, но удалось ли получить работу?
ternaus
25.08.2015 23:17На данный момент — я как тот кот, которого пытался отравить Шрёдингер.
Мутная какая-то контора в том смысле, что тянут и кормят отговорками вроде:
«I am so sorry it is taking a little longer I will know more by Monday. » И в понедельник тишина.
Я написал письмо, с напоминанием о том, что я существую. И получаю:
"The team was supposed to debrief yesterday and I am still waiting for an answer. Let me check again."
И опять тишина.
Видимо, не судьба. Буду подавать в другие компании.J_K
26.08.2015 19:46Ой, у меня подобная ситуация была… тоже пришлось напоминать о себе несколько раз, но в конце концов надоело — если бы хотели меня, то сами бы написали. Это также говорит о том, что у них либо бардак в компании, либо они не очень уважают людей, в любом случае лучше держаться от подобных контор подальше…
Удачи!ternaus
26.08.2015 21:55У меня сложилось такое же впечатление. В этом отношении мне гугл понравился. После технического интервью позвонили и сказали, что не смотря на впечатляющие технические навыки они предпочли более сильного кандидата. И несмотря на то, что с ними не срослось и что они просто пытались сделать пилюлю отказа чуть менее горькой, общее впечатление от взаимодействия с их рекрутером и представителями их Data Science team было очень положительное. Чувствовалось, что к тебе относятся как к человеку. А тут такое неуважение к моему времени, причём со стороны достаточно большого стартапа. Я даже имя компании скажу вслух, чтобы те, кто будут пытаться к ним устроиться — это Pivotal. Индус, про которого я упоминал в начале поста, в своё время оказался в похожей ситуации так он написал им, что при таком отношении к кандидатам, работать в такой компании он не хочет.
Кстати, если кто-то увидит этот комментарий и кто работает в какой-нибудь компании в San Francisco Bay Area или New York и у них есть свободная вакансия на позицию Data Scientist'a, я буду премного благодарен, если вы перешлёте моё резюме вашему Job Recruiter'у.
ServPonomarev
А причём тут выделение признаков из изображений?
Спасибо за статью, хорошая. И показывает порочную практику каггля — настраивать свои системы через обратную связь каггля — загружая прогоны и подгоняя параметры. В боевых условиях этот подход не работает.
SKolotienko
Насколько я знаю, предварительный leaderboard считается не на всей тестовой выборке, а только на её части. А финальное тестирование уже проходит на всей тестовой выборке. И во время финального тестирования можно ожидать что все позиции изменятся и те, кто сделал грамотную модель, не переобучившись на результате предварительного leaderboard, должны занять позиции выше. Поэтому, конечно, надо всегда держать в голове, что переобучение — зло :)
ternaus