
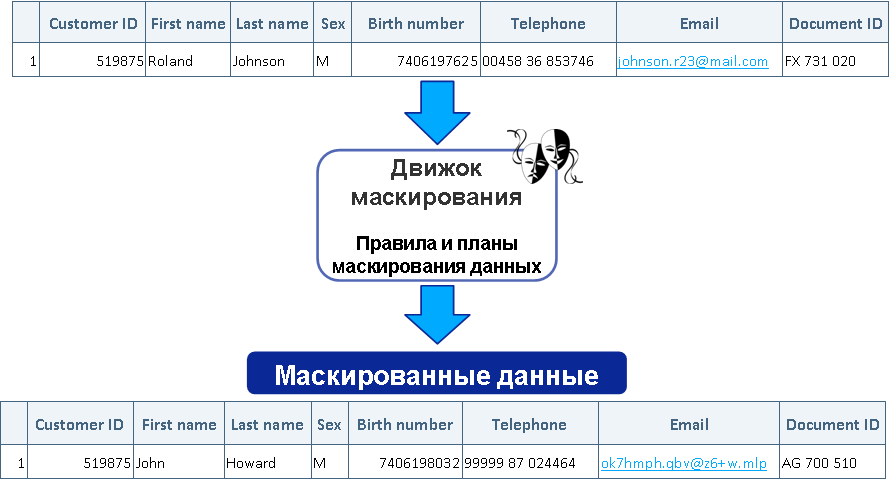
В банке есть проблема: нужно давать доступ к базе данных разработчикам и тестировщикам. Есть куча клиентских данных, которые по PCI DSS требованиям Центробанка и законам о персональных данных вообще нельзя использовать для раскрытия на отделы разработки и тестирования.
Казалось бы, достаточно просто поменять всё на какие-нибудь несимметричные хеши, и всё будет хорошо.
Так вот, не будет.
Дело в том, что база данных банка — это множество связанных между собой таблиц. Где-то они связаны по ФИО и номеру счёта клиента. Где-то по его уникальному идентификатору. Где-то (тут начинается боль) через хранимую процедуру, которая вычисляет сквозной идентификатор на основе этой и соседней таблицы. И так далее.
Обычная ситуация, что разработчик первой версии системы уже десять лет как умер или уехал, а системы ядра, запущенные в старом гипервизоре внутри нового гипервизора (чтобы обеспечить совместимость) ещё в проде.
То есть прежде чем всё это обезличить, сначала надо разобраться в базе данных.
Кто делает обезличивание и зачем?
Обезличиванием или маскированием занимаются потому, что есть законы и стандарты. Да, гораздо лучше тестировать на «снапшоте прода», но за такой залёт регуляторы могут и отозвать лицензию. То есть прикрыть бизнес как таковой.
Любое обезличивание — это достаточно дорогая и неповоротливая прослойка между продуктивными системами и тестированием с разработкой.
Цель проектов по обезличиванию (маскированию) практически всегда — подготовить данные для тестирования, максимально похожие на реальные, хранящиеся в продуктивных базах. То есть если данные содержат ошибки — вместо email забит телефон, вместо кириллицы в фамилии латиница и т. п., то и замаскированные данные должны быть такого же качества, но изменёнными до неузнаваемости. Вторая цель — уменьшение объёма баз данных, которые используются в тестировании и разработке. Полный объём оставляют только под нагрузочное тестирование, а под остальные задачи обычно делается некий срез данных по заранее определённым правилам — усечение БД. Третья цель — получить связанные между собой данные в разных замаскированных и усечённых базах. Имеется в виду, что данные в разных системах, в разное время, должны быть обезличены единообразно.
По вычислительной сложности обезличивание — это примерно как несколько архивирований базы данных на предельной компрессии. Алгоритм примерно похож. Разница в том, что алгоритмы архивирования оттачивались годами и дошли до почти максимального КПД. А алгоритмы обезличивания пишут так, чтобы они хотя бы работали на текущей базе и были достаточно универсальными. И софт после обезличивания вообще заработал. То есть отличный результат — перемолоть 40 ТБ за ночь. Бывает так, что заказчику дешевле загонять в обезличивание базу раз в полгода на неделю на слабеньком сервере — тоже подход.
Как заменяются данные?
Каждый тип данных меняется в соответствии с правилами, которые могут использоваться в коде. Например, если мы заменим ФИО на случайный хеш со спецсимволами и цифрами, то первая же проверка корректности данных сразу выдаст ошибку в реальном тестировании.
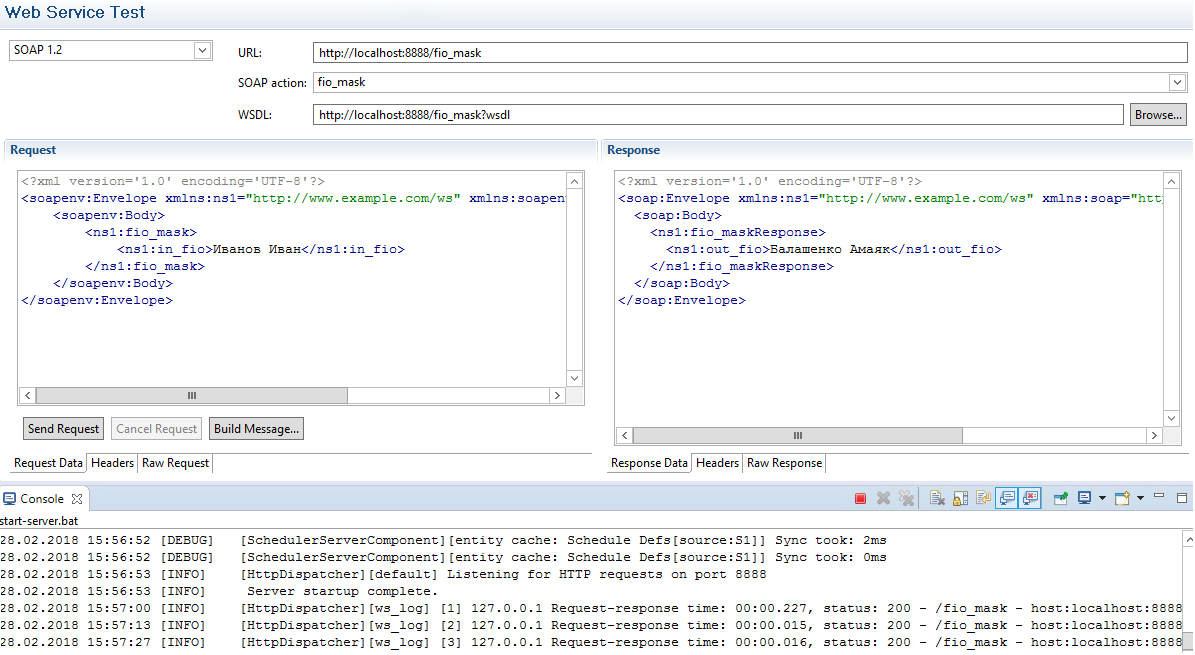
Поэтому сначала система обезличивания должна определить, что за тип данных хранится в поле. В зависимости от вендора используются разные подходы от ручной разметки до попыток дискаверинга базы и автоопределения, что же там хранится. У нас есть практика внедрения всех основных решений на рынке. Разберём один из вариантов, когда есть визард, который пытается найти данные и «угадать», что там за тип данных хранится.

Естественно, для работы с этим софтом нужен допуск к реальным данным (обычно это копия недавнего бекапа БД). По банковскому опыту мы сначала два месяца подписываем тонну бумаг, а потом приезжаем в банк, нас раздевают, обыскивают и одевают, потом мы идём в отдельное обшитое клеткой Фарадея помещение, в котором стоят двое безопасников и тепло дышат нам в затылок.
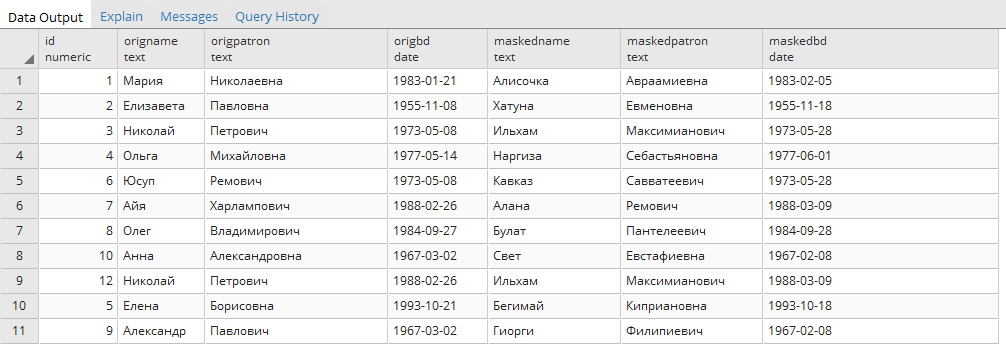
Итак, предположим, после всего этого мы видим таблицу, в которой есть поле «ФИО». Визард уже за нас его разметил как ФИО, и нам остаётся только подтвердить и выбрать тип обезличивания. Визард предлагает случайную замену на славянские имена (есть базы для разных регионов). Мы соглашаемся и получаем замены вроде Иван Иванов Петренко — Иосиф Альбертович Чингачгук. Если это важно, сохраняется пол, если нет — замены идут по всей базе имён.
Примеры замен:
Джеймс К. Максвелл -> Альберт ЭйнштейнСледующее поле — дата в юникстайме. Визард это тоже определил, а нам надо выбрать функцию обезличивания. Обычно даты используются для контроля последовательности событий, и ситуации, когда клиент сначала сделал перевод в банке, а потом открыл счёт, никому особо не нужны на тестировании. Поэтому мы задаём небольшую дельту — по умолчанию в пределах 30 дней. Ошибки всё равно будут, но если это критично, можно настроить более сложные правила, дописав свой скрипт в обработку обезличивания.
Макс Планк -> Чарльз Дарвин
Галилео Галилей -> Майкл Фарадей
Исаак Ньютон -> Никола Тесла
Мария Кюри -> Барбара Мак-Клинток
Адрес должен валидироваться, поэтому используется база российских адресов. Номер карточки должен соответствовать реальным номерам и валидироваться по ним. Иногда бывает задача «сделать все Визы случайными Мастеркардами» — это тоже выполнимо в пару кликов.
Под капотом визарда находится профилирование. Профилирование — это поиск данных в БД по заранее заданным правилам (атрибутам, доменам). Фактически мы читаем каждую ячейку базы данных заказчика, применяем к каждой ячейке набор регулярных выражений, сравниваем значения в этой ячейке со словарями и т. д. В результате чего имеем набор сработавших правил на столбцах таблиц базы данных. Профилирование мы можем настраивать, можем читать не все таблицы в БД, можем брать только определённое количество строк из таблицы или определённый процент строк.
Что происходит внутри?
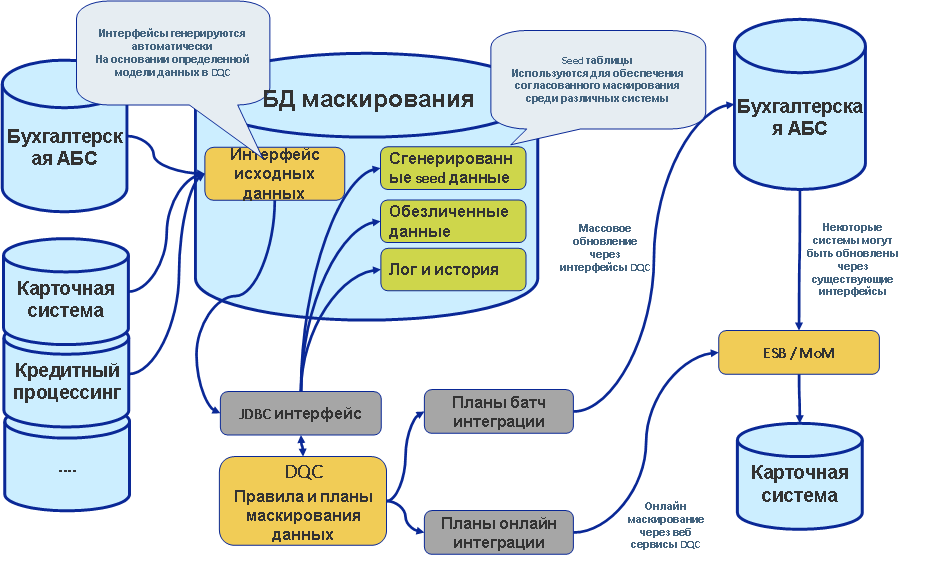
К каждой записи в базе применяются правила обезличивания, которые мы выбрали. При этом на время работы процесса создаются временные таблицы, куда записываются замены. Каждая последующая запись в БД прогоняется по этим таблицам соответствия замен, и если там есть соответствие — заменяется так же, как раньше. Всё на деле чуть сложнее в зависимости от ваших скриптов и правил сопоставления паттернов (может быть неточная замена, например для родов или замен дат, хранимых в разном формате), но общая идея такова.
Если есть размеченные соответствия «имя кириллицей — имя латиницей», то они должны быть явно обозначены на этапе разработки, и тогда в таблице замен они будут соответствовать друг другу. То есть имя кириллицей будет обезличено, а потом эта обезличенная запись будет сконвертирована в латиницу, например. В этом моменте мы отходим от подхода «не улучшать качество данных в системе», но это один из компромиссов на которые приходится идти ради какой-никакой, но производительности системы. Практика показывает, что если нагрузочное, функциональное тестирование в своей работе не замечает компромисса, то ничего не было. И тут всплывает важный момент, что обезличивание в целом это не шифрование. Если у вас пару ярдов записей в таблице, а в десятке из них ИНН не изменился, то что? То ничего, этот десяток записей не найти.
После окончания процесса таблицы перекодировки остаются в защищённой базе сервера обезличивания. База нарезается (усекается) и передается в тестирование без таблиц перекодировки, таким образом, для тестировщика обезличивание становится необратимым.
Полная обезличенная база передаётся тестировщикам для нагрузочного тестирования.
Это значит, что во время работы с БД таблица перекодировки «пухнет» (точный объём зависит от выбора замен и их типа), но рабочая база остаётся исходного размера.
Как примерно выглядит процесс в интерфейсе оператора?
Общий вид IDE на примере одного из вендоров:
Дебаггер:

Запуск трансформации из IDE:
Настройка выражения для поиска чувствительных данных в профилировщике:

Страница с набором правил для профилировщика:

Результат работы профилировщика, веб-страница с поиском по данным:
Все ли данные в базе маскируются?
Нет. Обычно список данных под обезличивание регулируется законами и стандартами сферы, плюс у заказчика есть пожелания по конкретным полям, про которые не должен знать никто.
Логика в том, что если мы замаскировали ФИО пациента в больнице, можно маскировать или не маскировать диагноз — всё равно никто не узнает, от кого он. У нас был случай, когда примечания к операции в банке просто маскировали случайными буквами. Там были заметки уровня: «В кредите отказано, так как клиент пришёл пьяным, его вырвало на стойку». С точки зрения отладки это просто строка символов. Ну вот пусть ей и остаётся.
Пример стратегий:

Динамическая seed-таблица это таблица перекодировки в которую складываем уже случившиеся перекодировки. Хеш может быть сильно разный и в случае того же ИНН, чаще генерируется новый случайный ИНН с сохранением первых символов, с контрольными цифрами.
Можно ли менять данные средствами самой СУБД?
Да. При обезличивании данных есть два основных подхода — изменять данные в БД средствами самой БД либо организовать ETL-процесс и менять данные посредством стороннего софта.
Ключевой плюс первого подхода — данные не надо никуда из базы выносить, нет затрат на сеть, используются быстрые и оптимизированные средства БД. Ключевой минус — отдельная разработка под каждую систему, отсутствие общих таблиц перекодировки для разных систем. Таблицы перекодировки нужны для воспроизводимости обезличивания, дальнейшей интеграции данных между системами.
Ключевой плюс второго подхода — неважно, какая у вас БД, система, файл это или какой-то веб-интерфейс, — один раз реализовав какое-то правило, вы можете использовать его везде. Ключевой минус — надо читать данные из базы, обрабатывать их отдельным приложением, записывать в базу обратно.
Практика показывает, что если у заказчика есть набор из нескольких систем, которые требуют дальнейшей интеграции, то реализуемым за конечную стоимость в деньгах, а также за приемлемые сроки разработки может быть только второй подход.
То есть сделать можем всё, что угодно, но в банковском секторе очень хорошо зарекомендовал себя именно ETL-подход.
А почему данные просто не портят вручную?
Один раз так можно сделать. Кто-то просидит три дня, обезличит кучу данных и подготовит базу данных на 500-1000 записей. Сложность в том, что процесс надо повторять регулярно (с каждым изменением структуры БД и появлением новых полей и таблиц) и на больших объёмах (для разных видов тестирования). Обычный запрос — обезличить первые 10-50 ГБ базы так, чтобы этот объём пришёлся на каждую таблицу равномерно.
Что делать, если в базе хранятся сканы документов?
Если документ можно свести к XML и конвертировать обратно (это, например, документы офиса), — можно провести и обезличивание в них. Но иногда бывают бинарники вроде сканов паспортов в PDF/JPG/TIFF/BMP. В этом случае общепринятая практика — нагенерить сторонним скриптом похожих документов и подменять реальные на образцы из базы нагенерённых случайным образом. Сложнее всего с фотографиями, но есть сервисы вроде этого, которые примерно похожим образом решают вопрос.
Кто за что отвечает?
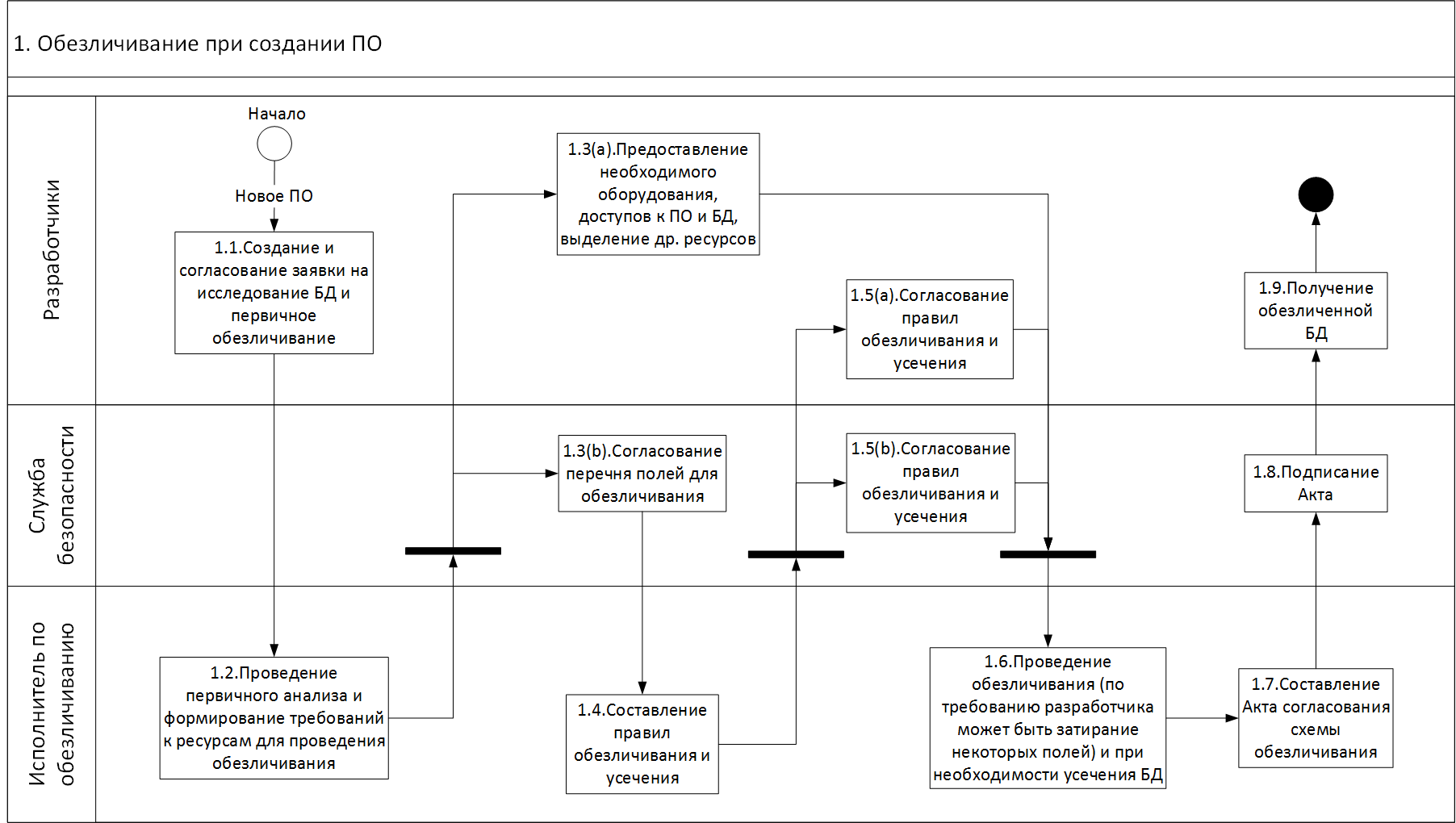
При обновлении после изменения ПО или «вдогонку» процессы попроще.
А что, если на тестах что-то пойдёт не так?
Обычно так и случается. Во-первых, тестировщики после первого прогона обезличивания точнее формулируют требования к базе. Мы можем поменять правила обезличивания или отбраковывать записи вроде «вот тут действия должны идти в хронологическом порядке, а не в хаотичном». Во-вторых, в зависимости от внедрения мы или поддерживаем обезличивание по мере изменения базы, либо оставляем всю документацию, описания структуры БД и типов обработки, передаём весь код обработки (правила в xml/sql) и обучаем специалистов у заказчика.
Как посмотреть демо?
Самый простой способ — написать мне на почту PSemenov@technoserv.com.






trolley813
Интересно, а зачем маскировать дату рождения? Ведь она не только не уникальна, но даже не «почти уникальна» (как ФИО, например — в России каждый день рождается почти по 5000 человек, а при Союзе было еще больше). Имея только дату рождения, вряд ли можно сделать какие-то выводы о клиенте, если остальные данные преобразованы до неузнаваемости (разве что о возрасте, но ведь в статье говорится о сдвиге даты с сохранением возраста). Собственно,
Почему такая логика неприменима к дате рождения?
myprettyusername Автор
Потому что дата рождения — часть базовых предопределённых наборов, составляющих персональные данные. Она в сочетании с другими данными с высокой вероятностью даёт ПД. Да, по логике она редко сама по себе деперсонализирует. Вот наш старый пост про то, как работают ПД.
hippohood
Все-таки дата рождения это самый надёжный случайный хэш для человека. Особенно для относительно небольших выборок в несколько сотен человек. Когда звоню в больницу, школу и тд для быстрого поиска они спрашивают дату рождения пациента студента (пол они знают их контекста) — второго вопроса почти никогда не следует, сразу называют правильную фамилию.
Можно подумать что у банка клиентов десятки тысяч, но, мне кажется, в тестовой БД все равно останутся неизменные параметры — например, год открытия счета, пол, город — которые разобьют всю выборку на группы в несколько десятков /сотен человек. Дата рождения в такой группе почти наверняка деанонимизирует
trolley813
В статье написано, что адрес-таки меняется целиком, включая регион и город.