
Канарейка — маленькая птица, которая постоянно поет. Эти птички чувствительны к метану и угарному газу. Даже от небольшой концентрации лишних газов в воздухе они теряют сознание или умирают. Золотоискатели и шахтеры брали птичек на добычу: пока канарейки поют, можно работать, если замолчали — в шахте газ и пора уходить. Шахтеры жертвовали маленькой птичкой, чтобы выбираться из шахт живыми.

Подобная практика нашла себя и в IT. Например, в стандартной задаче деплоя новой версии сервиса или приложения на продакшн с тестированием перед этим. Тестовое окружение может быть слишком дорогим, автоматизированные тесты не покрывают все, что хотелось бы, а не тестировать и жертвовать качеством рискованно. Как раз в таких случаях помогает подход Canary Deployment, когда немного настоящего продакшн-трафика пускается на новую версию. Подход помогает безопасно проверить новую версию на продакшн, жертвуя малым ради большой цели. Подробнее, как работает подход, чем полезен и как его реализовать, расскажет Андрей Маркелов (Andrey_V_Markelov), на примере реализации в компании Infobip.
Андрей Маркелов — ведущий инженер-программист в Infobip, уже 11 лет занимается разработкой приложений на Java в области финансов и телекоммуникаций. Разрабатывает Open Source продукты, активно участвует в Atlassian Community и пишет плагины для продуктов Atlassian. Евангелист Prometheus, Docker и Redis.
Это глобальная телекоммуникационная платформа, которая позволяет банкам, ретейлу, интернет-магазинам и транспортным компаниям отправлять сообщения своим клиентам с помощью SMS, push, писем и голосовых сообщений. В таком бизнесе важна стабильность и надежность, чтобы клиенты вовремя получали сообщения.
IT-инфраструктура Infobip в цифрах:
Бизнес растет, а с ним количество релизов. Мы проводим по 60 релизов в день, потому что клиенты хотят больше возможностей и мощностей. Но это сложно — сервисов много, а команд мало. Приходится быстро писать код, который должен работать в продакшн без ошибок.
Типичный релиз у нас проходит так. Например, есть сервисы A, B, C, D и E, каждый из них разрабатывается отдельной командой.
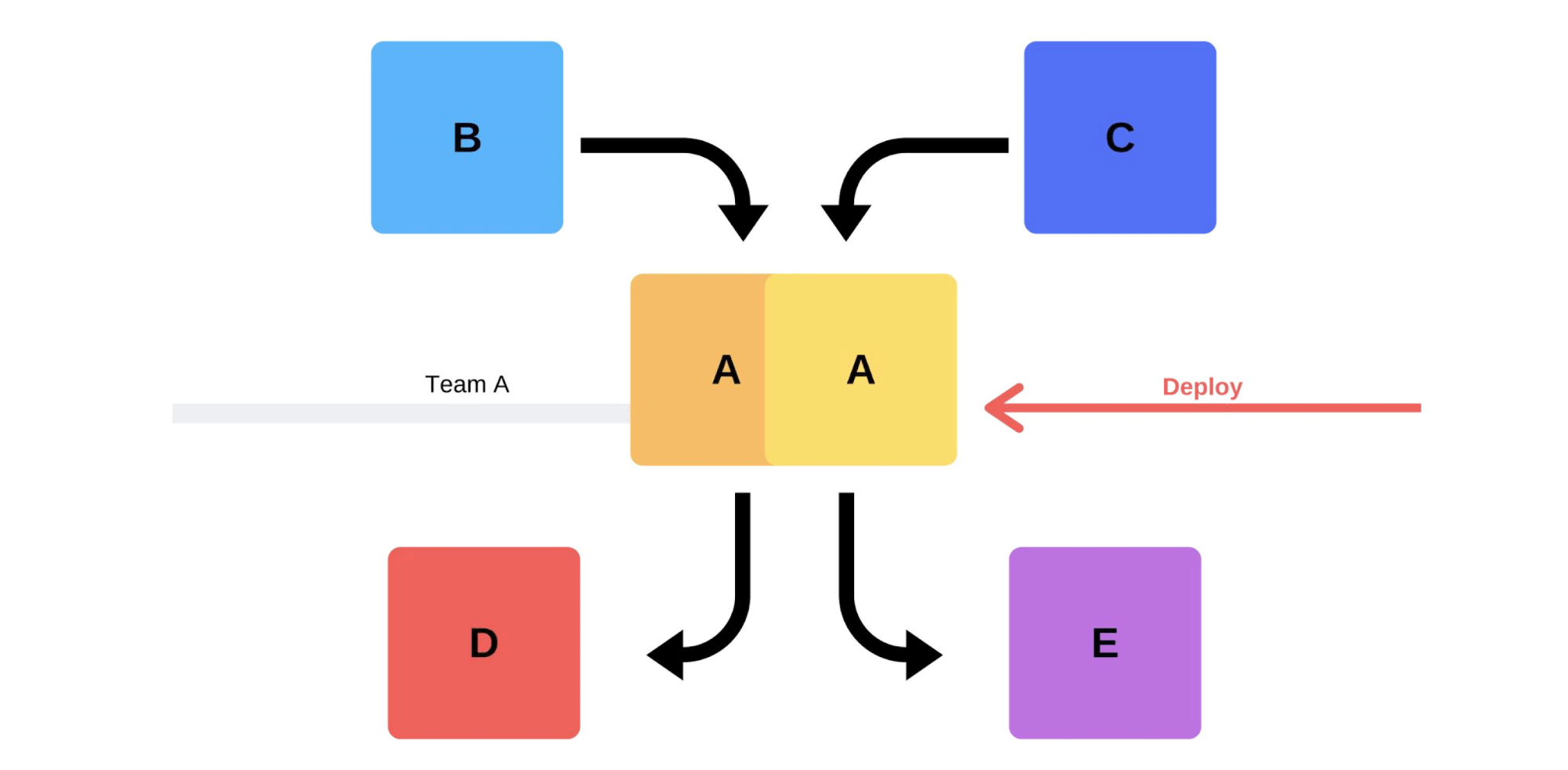
В какой-то момент команда сервиса А решает задеплоить новую версию, но команды сервисов B, C, D и E об этом не знают. Вариантов, как поступит команда сервиса А, два.
Проведет инкрементальный релиз: сначала заменит одну версию, а потом вторую.

Но есть второй вариант: команда найдет дополнительные мощности и машины, задеплоит новую версию, а потом переключит роутер, и версия начнет работать на продакшн.

В любом варианте после деплоя почти всегда возникают проблемы, даже если версия протестирована. Тестировать можно руками, можно автоматизированно, можно не тестировать — проблемы возникнут в любом случае. Самый простой и правильный способ их решить — откатиться назад на работающую версию. Уже потом можно разбираться с ущербом, с причинами и исправлять их.
Итак, что мы хотим?
Проблемы нам не нужны. Если клиенты обнаружат их быстрее нас, это ударит по репутации. Поэтому мы должны находить проблемы быстрее клиентов. Работая на опережение, мы минимизируем ущерб.
В то же время, мы хотим ускорить деплой, чтобы это происходило быстро, легко, само собой и без напряжения со стороны команды. Инженеров, DevOps-инженеров и программистов надо беречь — релиз новой версии это стресс. Команда это не расходный материал, мы стремимся рационально использовать человеческие ресурсы.
Клиентский трафик непредсказуем. Невозможно предсказать, когда клиентский трафик будет минимальным. Мы не знаем, где и когда клиенты начнут свои кампании — может, сегодня ночью в Индии, а завтра в Гонконге. С учетом большой разницы во времени, деплой даже в 2 часа ночи не гарантирует, что клиенты не пострадают.
Проблемы провайдеров. Мессенджеры и провайдеры — наши партнеры. Иногда у них бывают сбои, которые вызывают ошибки во время деплоя новых версий.
Распределенные команды. Команды, которые разрабатывают клиентскую часть и бэкенд, находятся в разных часовых поясах. Из-за этого они часто не могут договориться между собой.
Дата-центры нельзя повторить на стейдже. В одном дата-центре 200 стоек — повторить это в песочнице даже приблизительно не получится.
Даунтаймынедопустимы! У нас есть допустимый уровень доступности (Error Budget), когда мы работаем 99,99% времени, например, а оставшиеся проценты это «право на ошибку». Достичь 100% надежности невозможно, но важно постоянно следить за падениями и простоями.
Писать код без багов. Когда я был молодым разработчиком, ко мне подходили менеджеры с просьбой провести релиз без багов, но это не всегда возможно.
Писать тесты. Тесты работают, но иногда совсем не так, как хочет бизнес. Зарабатывать деньги — это не задача тестов.
Тестировать на стейдже. За 3,5 года моей работы в Infobip я ни разу не видел, чтобы состояние стейджа хотя бы частично совпадало с продакшн.

Мы даже пытались развить эту идею: сначала у нас был стейдж, потом препродакшн, а потом препродакшн препродакшна. Но и это не помогло — они не совпадали даже по мощности. Со стейджем мы можем гарантировать базовую функциональность, но не знаем, как она будет работать при нагрузках.
Релиз делает тот, кто разрабатывал. Это хорошая практика: даже если кто-то меняет название комментария, сразу добавляет в продакшн. Это помогает развивать ответственность и не забывать о внесенных изменениях.
Дополнительные сложности тоже есть. Для разработчика это стресс — тратить много времени, чтобы все проверить вручную.
Согласованные релизы. Этот вариант обычно предлагает менеджмент: «Давайте договоримся, что каждый день будете тестировать и добавлять новые версии». Это не работает: всегда есть команда, которая ждет все остальных или наоборот.
Еще один способ решить наши проблемы с деплоем. Рассмотрим, как работают smoke-тесты на предыдущем примере, когда команда A хочет задеплоить новую версию.
Сначала команда деплоит один инстанс на продакшн. Сообщениями в инстанс от моков имитируется реальный трафик, чтобы он совпадал с нормальным ежедневным трафиком. Если все хорошо, команда переключает новую версию на пользовательский трафик.
Второй вариант — деплоить с дополнительным железом. Команда тестирует его на продакшн, потом переключает, и все работает.

Недостатки smoke-тестов:
Единственный бонус здесь — можно проверить производительность.
Из-за недостатков smoke-тестов мы начали использовать canary-релизы.
Практика, подобная тому, как шахтеры использовали канареек для индикации уровня газов, нашла себя и в IT. Мы пускаем немного настоящего продакшн-трафика на новую версию, при этом стараемся уложиться в Service Level Agreement (SLA). SLA — это наше «право на ошибку», которое мы можем использовать раз в год (или за какой-то другой промежуток времени). Если все будет хорошо, добавим больше трафика. Если нет — вернем предыдущие версии.

Как мы реализовали canary-релизы? Например, группа клиентов отправляет сообщения через наш сервис.
Деплой проходит так: убираем один узел из-под балансировщика (1), меняем версию (2) и отдельно пускаем немного трафика (3).

В целом, в группе будут счастливы все, даже если один пользователь будет недоволен. Если все хорошо — меняем все версии.

Покажу схематично, как это выглядит для микросервисов в большинстве случаев.
Есть Service Discovery и еще два сервиса: S1N1 и S2. Первый сервис (S1N1) оповещает Service Discovery, когда стартует, а Service Discovery его запоминает. Второй сервис с двумя узлами (S2N1 и S2N2) тоже оповещает Service Discovery при старте.
Второй сервис для первого работает как сервер. Первый запрашивает у Service Discovery информацию о своих серверах, а когда получает — ищет и проверяет их («health check»). Когда проверит, то отправит им сообщения.
Когда кто-то хочет задеплоить новую версию второго сервиса, он сообщает Service Discovery, что вторая нода будет canary-нодой: на нее будет отправляться меньше трафика, потому что сейчас пройдет деплой. Убираем canary-ноду из-под балансировщика и первый сервис не отправляет в нее трафик.
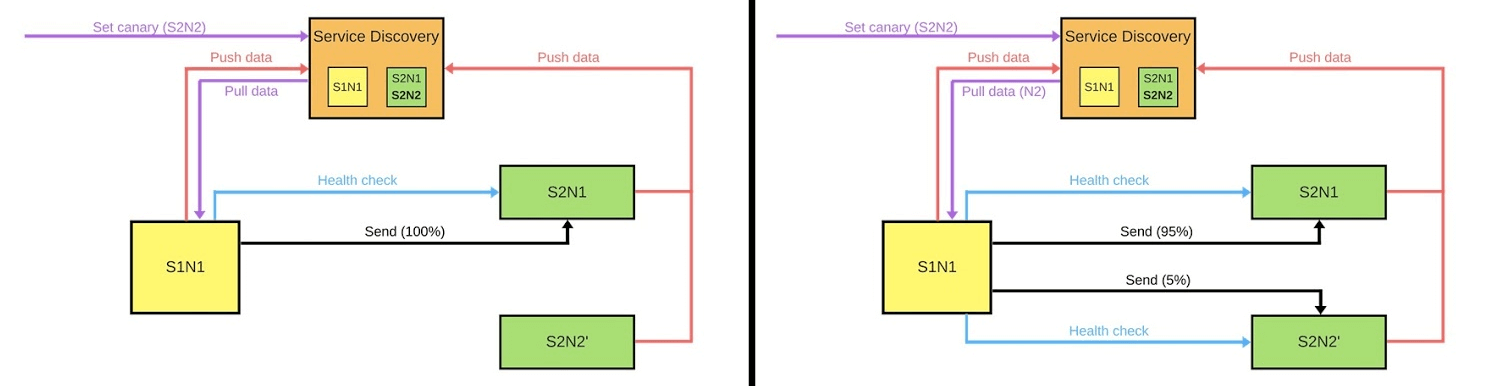
Меняем версию и Service Discovery знает, что вторая нода теперь canary — можно давать ей меньше нагрузки (5%). Если все хорошо, меняем версию, возвращаем нагрузки и работаем дальше.
Чтобы все это реализовать, нам нужны:

Это первое, о чем мы должны задуматься. Есть две стратегии балансировки.
Простейший вариант, когда одна нода всегда canary. Эта нода всегда получает меньше трафика и мы начинаем деплой с нее. В случае проблем мы сравним ее работу до деплоя и во время него. Например, если ошибок стало в 2 раза больше, значит и ущерб вырос в 2 раза.
Canary-нода задается в процессе деплоя. Когда деплой закончится и мы снимем с нее статус canary-ноды, баланс трафика восстановится. С меньшим количеством машин мы получим честное распределение.
Краеугольный камень canary-релизов. Мы должны точно понимать, зачем мы это делаем и какие метрики хотим собирать.
Примеры метрик, которые мы собираем с наших сервисов.
Примеры метрик в большинстве популярных систем мониторинга.
Counter. Это некоторая возрастающая величина, например, количество ошибок. Эту метрику просто интерполировать и изучать график: вчера было 2 ошибки, а сегодня 500, значит, что-то пошло не так.
Количество ошибок в минуту или в секунду, это важнейший показатель, который можно вычислить используя Counter. Эти данные дают четкое представление о работе системы на дистанции. Рассмотрим на примере графика количества ошибок в секунду для двух версий продакшн-системы.

В первой версии было мало ошибок, возможно, не работал аудит. Во второй версии все намного хуже. Можно точно сказать, что есть проблемы, поэтому мы должны откатить эту версию.
Gauge. Метрики похожи на Counter, но мы записываем значения, которые могут как увеличиваться, так и уменьшаться. Например, время выполнения запросов или размер очереди.
На графике пример времени отклика (latency). По графику видно, что версии похожи, с ними можно работать. Но если приглядеться, то заметно, как меняется величина. Если время выполнения запросов увеличивается при добавлении пользователей, то сразу понятно, что есть проблемы — раньше такого не было.

Summary. Один из важнейших показателей для бизнеса — перцентили. Метрика показывает, что в 95% случаев наша система работает так, как мы хотим. Мы можем смириться, если где-то проблемы, потому что понимаем общую тенденцию, насколько все хорошо или плохо.
ELK Stack. Реализовать canary можно, используя Elasticsearch — записываем в него ошибки, когда происходят события. Простейшим вызовом API можно получить количество ошибок в любой момент времени и сравнить с прошлыми отрезками:
Prometheus. Хорошо себя проявил в Infobip. Он позволяет реализовать многомерные метрики, потому что используются лейблы.
Мы можем использовать
Есть несколько стратегий анализа версий.
Смотреть метрики только canary-ноды. Один из простейших вариантов: задеплоили новую версию и изучаем только работу. Но если инженер в это время начнет изучать логи, постоянно нервно перезагружая страницы, то это решение ничем не отличается от остальных.
Canary-нода сравнивается с любой другой нодой. Это сравнение с другими инстансами, которые работают на полном трафике. Например, если с маленьким трафиком дела обстоят хуже, или не лучше, чем на реальных инстансах, то что-то не так.
Canary-нода сравнивается с собой в прошлом. Ноды, выделенные для canary, можно сравнивать с историческими данными. Например, если неделю назад все было хорошо, то можем ориентироваться на эти данные, чтобы понять текущую ситуацию.
Мы хотим освободить инженеров от ручного сравнения, поэтому важно реализовать автоматизацию. Процесс деплоя (deployment pipeline) обычно выглядит так:

На этом этапе мы реализуем автоматическое сравнение. Как оно может выглядеть и почему лучше, чем проверка после деплоя, рассмотрим на примере из Jenkins.
Это pipeline к Groovy.
Здесь в цикле задаем, что будем сравнивать новую ноду в течение часа. Если canary процесс еще не закончился процесс — вызываем функцию. Она сообщает, что все хорошо или нет:
Если все хорошо —
Описание метрики. Посмотрим, как может выглядеть функция
Допустим, мы сравниваем количество ошибок и хотим узнать количество ошибок в секунду за последние 5 минут.
У нас есть два значения: базовое и canary-ноды. Значение у canary-ноды — текущее. Базовое —
Зачем это все нужно?
Человек не может проверить сотни и тысячи метрик, тем более сделать это быстро. Автоматическое сравнение помогает проверить все метрики и быстро оповещает о проблемах. Время оповещения критично: если что-то случилось за последние 2 секунды, то ущерб будет не такой большой, как если бы это произошло 15 минут назад. Пока кто-то заметит проблему, напишет в поддержку, а поддержка нам, чтобы откатить, можно потерять клиентов.
Если процесс прошел и все хорошо, мы деплоим все остальные ноды автоматически. В это время инженеры не делают ничего. Только когда они запускают canary, решают, какие метрики взять, сколько по времени делать сравнение, какую стратегию использовать.

Если возникли проблемы — автоматически откатываем canary-ноду, работаем на прошлых версиях и исправляем ошибки, которые нашли. По метрикам их легко найти и увидеть ущерб от новой версии.
Реализовать это, конечно, непросто. Прежде всего нужна общая система мониторинга. У инженеров свои метрики, у поддержки и аналитиков — другие, у бизнеса третьи. Общая система — это общий язык, на котором разговаривают бизнес и разработка.
Нужно проверить на практике стабильность метрик. Проверка помогает понять, какой минимальный набор метрик нужен, чтобы обеспечить качество.
Как этого достичь? Использовать canary-сервис не в момент деплоя. Добавляем на старой версии некий сервис, который в любой момент времени сможет взять любую выделенную ноду, уменьшить трафик без деплоя. После сравниваем: изучаем ошибки и ищем ту грань, когда мы достигаем качества.
Минимизировали процент ущерба от багов. Большинство ошибок деплоя происходит из-за несогласованности каких-то данных или приоритета. Таких ошибок стало намного меньше, потому что мы можем решить проблему в первые секунды.
Оптимизировали работу команд. У новичков есть «право на ошибку»: они могут деплоить в продакшн без страха ошибиться, появляется дополнительная инициатива, стимул работать. Если они что-то сломают, то это будет не критично, а ошибившегося не уволят.
Автоматизировали деплой. Это уже не ручной процесс, как раньше, а настоящий автоматизированный. Но он проходит дольше.
Выделили важные метрики. Вся компания, начиная от бизнеса и инженеров, понимает, что действительно важно в нашем продукте, какие метрики, например, отток и приток пользователей. Мы контролируем процесс: тестируем метрики, вводим новые, смотрим, как работают старые, чтобы строить систему, которая будет зарабатывать деньги производительнее.
У нас много классных практик и систем, которые нам помогают. Несмотря на это, мы стремимся быть профессионалами и делать свою работу качественно, вне зависимости от того, есть у нас система, которая нам поможет, или нет.
Подобная практика нашла себя и в IT. Например, в стандартной задаче деплоя новой версии сервиса или приложения на продакшн с тестированием перед этим. Тестовое окружение может быть слишком дорогим, автоматизированные тесты не покрывают все, что хотелось бы, а не тестировать и жертвовать качеством рискованно. Как раз в таких случаях помогает подход Canary Deployment, когда немного настоящего продакшн-трафика пускается на новую версию. Подход помогает безопасно проверить новую версию на продакшн, жертвуя малым ради большой цели. Подробнее, как работает подход, чем полезен и как его реализовать, расскажет Андрей Маркелов (Andrey_V_Markelov), на примере реализации в компании Infobip.
Андрей Маркелов — ведущий инженер-программист в Infobip, уже 11 лет занимается разработкой приложений на Java в области финансов и телекоммуникаций. Разрабатывает Open Source продукты, активно участвует в Atlassian Community и пишет плагины для продуктов Atlassian. Евангелист Prometheus, Docker и Redis.
О компании Infobip
Это глобальная телекоммуникационная платформа, которая позволяет банкам, ретейлу, интернет-магазинам и транспортным компаниям отправлять сообщения своим клиентам с помощью SMS, push, писем и голосовых сообщений. В таком бизнесе важна стабильность и надежность, чтобы клиенты вовремя получали сообщения.
IT-инфраструктура Infobip в цифрах:
- 15 дата-центров по всему миру;
- 500 уникальных сервисов в эксплуатации;
- 2500 экземпляров сервисов, что намного больше, чем команд;
- 4,5 Tбайт месячного трафика;
- 4,5 миллиарда телефонных номеров;
Бизнес растет, а с ним количество релизов. Мы проводим по 60 релизов в день, потому что клиенты хотят больше возможностей и мощностей. Но это сложно — сервисов много, а команд мало. Приходится быстро писать код, который должен работать в продакшн без ошибок.
Релизы
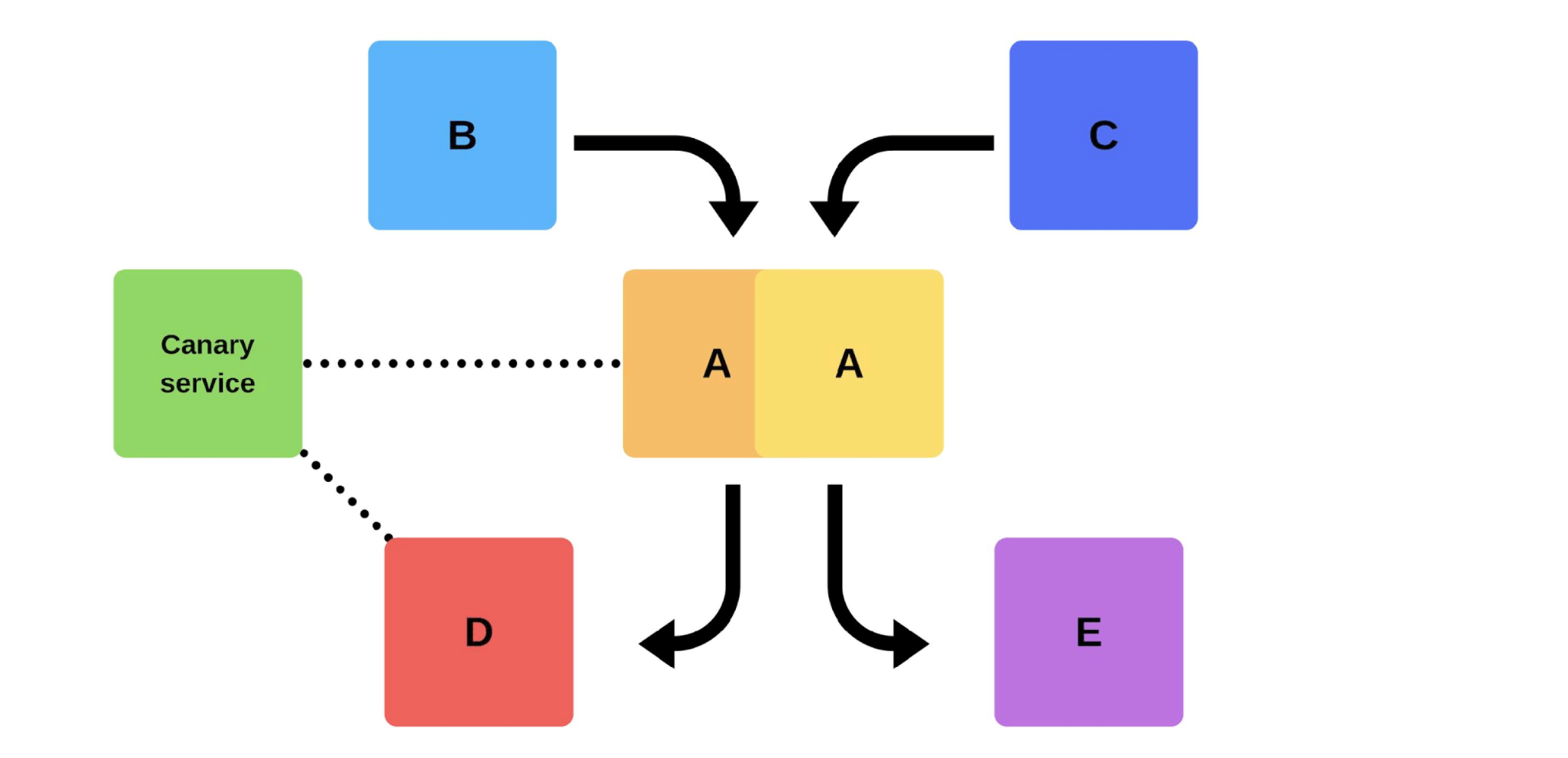
Типичный релиз у нас проходит так. Например, есть сервисы A, B, C, D и E, каждый из них разрабатывается отдельной командой.
В какой-то момент команда сервиса А решает задеплоить новую версию, но команды сервисов B, C, D и E об этом не знают. Вариантов, как поступит команда сервиса А, два.
Проведет инкрементальный релиз: сначала заменит одну версию, а потом вторую.
Но есть второй вариант: команда найдет дополнительные мощности и машины, задеплоит новую версию, а потом переключит роутер, и версия начнет работать на продакшн.
В любом варианте после деплоя почти всегда возникают проблемы, даже если версия протестирована. Тестировать можно руками, можно автоматизированно, можно не тестировать — проблемы возникнут в любом случае. Самый простой и правильный способ их решить — откатиться назад на работающую версию. Уже потом можно разбираться с ущербом, с причинами и исправлять их.
Итак, что мы хотим?
Проблемы нам не нужны. Если клиенты обнаружат их быстрее нас, это ударит по репутации. Поэтому мы должны находить проблемы быстрее клиентов. Работая на опережение, мы минимизируем ущерб.
В то же время, мы хотим ускорить деплой, чтобы это происходило быстро, легко, само собой и без напряжения со стороны команды. Инженеров, DevOps-инженеров и программистов надо беречь — релиз новой версии это стресс. Команда это не расходный материал, мы стремимся рационально использовать человеческие ресурсы.
Проблемы деплоя
Клиентский трафик непредсказуем. Невозможно предсказать, когда клиентский трафик будет минимальным. Мы не знаем, где и когда клиенты начнут свои кампании — может, сегодня ночью в Индии, а завтра в Гонконге. С учетом большой разницы во времени, деплой даже в 2 часа ночи не гарантирует, что клиенты не пострадают.
Проблемы провайдеров. Мессенджеры и провайдеры — наши партнеры. Иногда у них бывают сбои, которые вызывают ошибки во время деплоя новых версий.
Распределенные команды. Команды, которые разрабатывают клиентскую часть и бэкенд, находятся в разных часовых поясах. Из-за этого они часто не могут договориться между собой.
Дата-центры нельзя повторить на стейдже. В одном дата-центре 200 стоек — повторить это в песочнице даже приблизительно не получится.
Даунтаймынедопустимы! У нас есть допустимый уровень доступности (Error Budget), когда мы работаем 99,99% времени, например, а оставшиеся проценты это «право на ошибку». Достичь 100% надежности невозможно, но важно постоянно следить за падениями и простоями.
Классические варианты решения
Писать код без багов. Когда я был молодым разработчиком, ко мне подходили менеджеры с просьбой провести релиз без багов, но это не всегда возможно.
Писать тесты. Тесты работают, но иногда совсем не так, как хочет бизнес. Зарабатывать деньги — это не задача тестов.
Тестировать на стейдже. За 3,5 года моей работы в Infobip я ни разу не видел, чтобы состояние стейджа хотя бы частично совпадало с продакшн.
Мы даже пытались развить эту идею: сначала у нас был стейдж, потом препродакшн, а потом препродакшн препродакшна. Но и это не помогло — они не совпадали даже по мощности. Со стейджем мы можем гарантировать базовую функциональность, но не знаем, как она будет работать при нагрузках.
Релиз делает тот, кто разрабатывал. Это хорошая практика: даже если кто-то меняет название комментария, сразу добавляет в продакшн. Это помогает развивать ответственность и не забывать о внесенных изменениях.
Дополнительные сложности тоже есть. Для разработчика это стресс — тратить много времени, чтобы все проверить вручную.
Согласованные релизы. Этот вариант обычно предлагает менеджмент: «Давайте договоримся, что каждый день будете тестировать и добавлять новые версии». Это не работает: всегда есть команда, которая ждет все остальных или наоборот.
Smoke-тесты
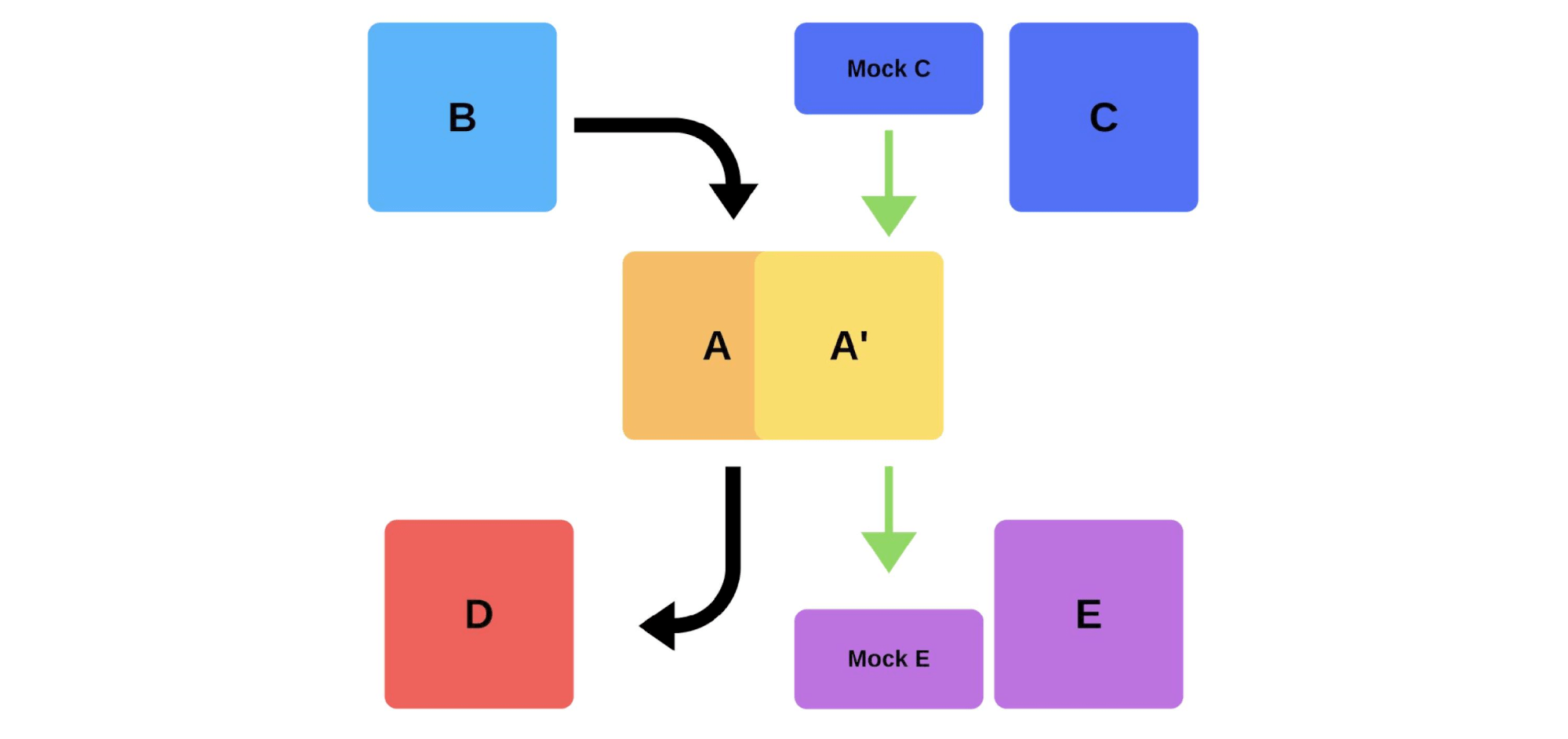
Еще один способ решить наши проблемы с деплоем. Рассмотрим, как работают smoke-тесты на предыдущем примере, когда команда A хочет задеплоить новую версию.
Сначала команда деплоит один инстанс на продакшн. Сообщениями в инстанс от моков имитируется реальный трафик, чтобы он совпадал с нормальным ежедневным трафиком. Если все хорошо, команда переключает новую версию на пользовательский трафик.
Второй вариант — деплоить с дополнительным железом. Команда тестирует его на продакшн, потом переключает, и все работает.
Недостатки smoke-тестов:
- Тестам нельзя доверять. Где взять тот же трафик, что и на продакшн? Можно использовать вчерашний или недельной давности, но он не всегда совпадает с текущим.
- Сложно поддерживать. Придется поддерживать тестовые аккаунты, постоянно их сбрасывать перед каждым деплоем, когда в хранилище отправляются активные записи. Это сложнее, чем писать тест в своей песочнице.
Единственный бонус здесь — можно проверить производительность.
Canary-релизы
Из-за недостатков smoke-тестов мы начали использовать canary-релизы.
Практика, подобная тому, как шахтеры использовали канареек для индикации уровня газов, нашла себя и в IT. Мы пускаем немного настоящего продакшн-трафика на новую версию, при этом стараемся уложиться в Service Level Agreement (SLA). SLA — это наше «право на ошибку», которое мы можем использовать раз в год (или за какой-то другой промежуток времени). Если все будет хорошо, добавим больше трафика. Если нет — вернем предыдущие версии.
Реализация и нюансы
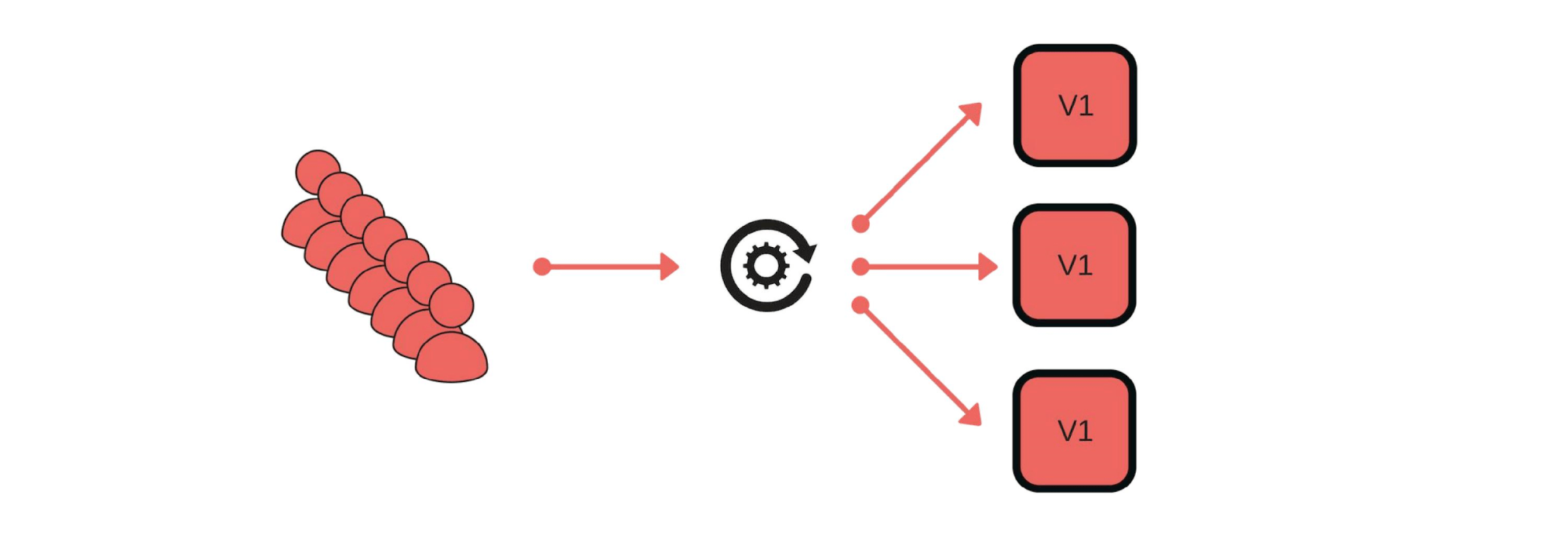
Как мы реализовали canary-релизы? Например, группа клиентов отправляет сообщения через наш сервис.
Деплой проходит так: убираем один узел из-под балансировщика (1), меняем версию (2) и отдельно пускаем немного трафика (3).
В целом, в группе будут счастливы все, даже если один пользователь будет недоволен. Если все хорошо — меняем все версии.
Покажу схематично, как это выглядит для микросервисов в большинстве случаев.
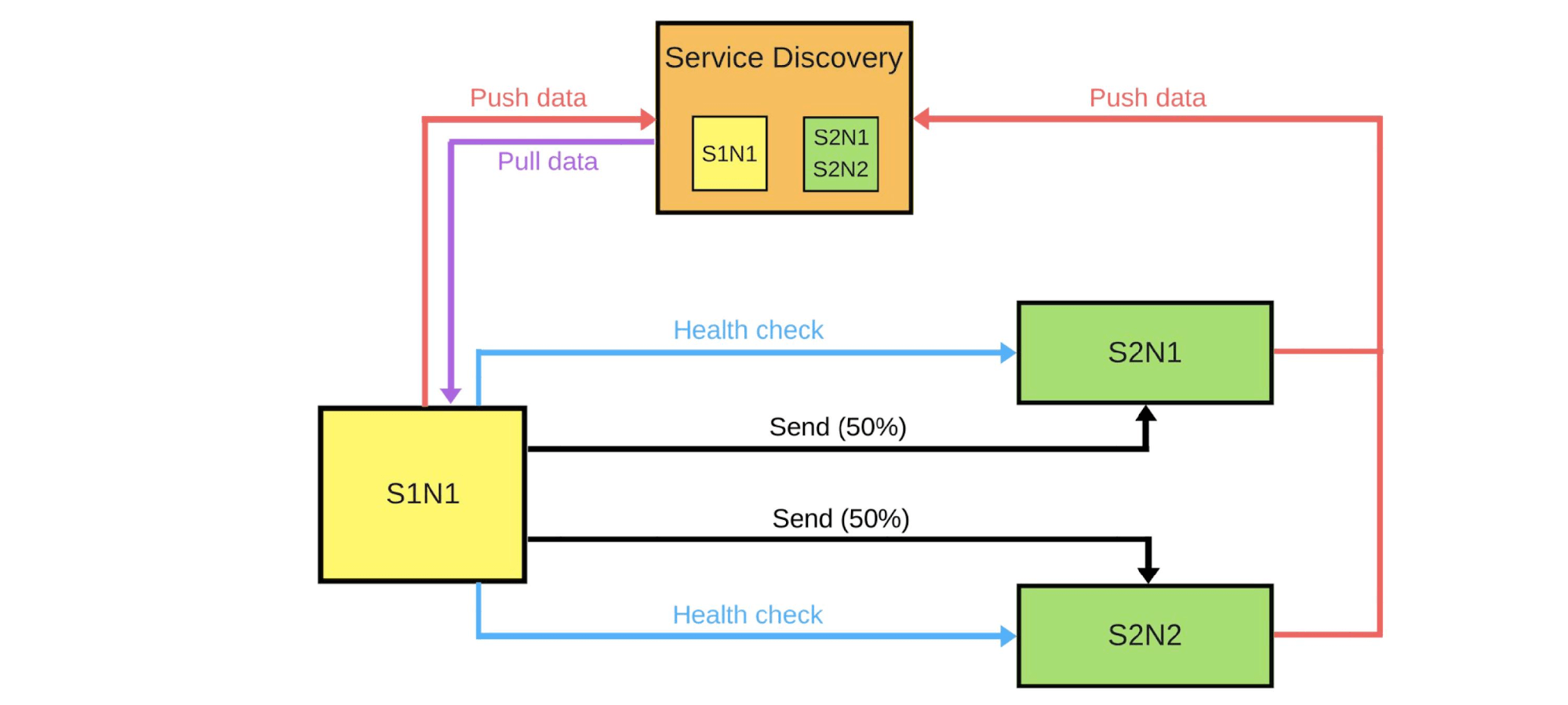
Есть Service Discovery и еще два сервиса: S1N1 и S2. Первый сервис (S1N1) оповещает Service Discovery, когда стартует, а Service Discovery его запоминает. Второй сервис с двумя узлами (S2N1 и S2N2) тоже оповещает Service Discovery при старте.
Второй сервис для первого работает как сервер. Первый запрашивает у Service Discovery информацию о своих серверах, а когда получает — ищет и проверяет их («health check»). Когда проверит, то отправит им сообщения.
Когда кто-то хочет задеплоить новую версию второго сервиса, он сообщает Service Discovery, что вторая нода будет canary-нодой: на нее будет отправляться меньше трафика, потому что сейчас пройдет деплой. Убираем canary-ноду из-под балансировщика и первый сервис не отправляет в нее трафик.
Меняем версию и Service Discovery знает, что вторая нода теперь canary — можно давать ей меньше нагрузки (5%). Если все хорошо, меняем версию, возвращаем нагрузки и работаем дальше.
Чтобы все это реализовать, нам нужны:
- балансировка;
- мониторинг, так как важно знать, что ожидает каждый пользователь, и как детально работают наши сервисы;
- анализ версий, чтобы понимать, насколько хорошо новая версия будет работать в продакшн;
- автоматизация — пишем последовательность развертывания (deployment pipeline).
Балансировка
Это первое, о чем мы должны задуматься. Есть две стратегии балансировки.
Простейший вариант, когда одна нода всегда canary. Эта нода всегда получает меньше трафика и мы начинаем деплой с нее. В случае проблем мы сравним ее работу до деплоя и во время него. Например, если ошибок стало в 2 раза больше, значит и ущерб вырос в 2 раза.
Canary-нода задается в процессе деплоя. Когда деплой закончится и мы снимем с нее статус canary-ноды, баланс трафика восстановится. С меньшим количеством машин мы получим честное распределение.
Мониторинг
Краеугольный камень canary-релизов. Мы должны точно понимать, зачем мы это делаем и какие метрики хотим собирать.
Примеры метрик, которые мы собираем с наших сервисов.
- Количество ошибок, которые пишутся в логи. Это очевидный показатель того, что все работает как надо. В целом, это хорошая метрика.
- Время выполнения запросов (latency). Эту метрику мониторят все, потому что все хотят работать быстро.
- Размер очереди (throughput).
- Количество успешных ответов в секунду.
- Время выполнения 95% всех запросов.
- Бизнес-метрики: сколько денег бизнес зарабатывает за определенное время или отток пользователей. Эти метрики для нашей новой версии могут быть важнее, чем те, что добавляют инженеры.
Примеры метрик в большинстве популярных систем мониторинга.
Counter. Это некоторая возрастающая величина, например, количество ошибок. Эту метрику просто интерполировать и изучать график: вчера было 2 ошибки, а сегодня 500, значит, что-то пошло не так.
Количество ошибок в минуту или в секунду, это важнейший показатель, который можно вычислить используя Counter. Эти данные дают четкое представление о работе системы на дистанции. Рассмотрим на примере графика количества ошибок в секунду для двух версий продакшн-системы.
В первой версии было мало ошибок, возможно, не работал аудит. Во второй версии все намного хуже. Можно точно сказать, что есть проблемы, поэтому мы должны откатить эту версию.
Gauge. Метрики похожи на Counter, но мы записываем значения, которые могут как увеличиваться, так и уменьшаться. Например, время выполнения запросов или размер очереди.
На графике пример времени отклика (latency). По графику видно, что версии похожи, с ними можно работать. Но если приглядеться, то заметно, как меняется величина. Если время выполнения запросов увеличивается при добавлении пользователей, то сразу понятно, что есть проблемы — раньше такого не было.
Summary. Один из важнейших показателей для бизнеса — перцентили. Метрика показывает, что в 95% случаев наша система работает так, как мы хотим. Мы можем смириться, если где-то проблемы, потому что понимаем общую тенденцию, насколько все хорошо или плохо.
Инструменты
ELK Stack. Реализовать canary можно, используя Elasticsearch — записываем в него ошибки, когда происходят события. Простейшим вызовом API можно получить количество ошибок в любой момент времени и сравнить с прошлыми отрезками:
GET /applg/_cunt?q=level:errr.Prometheus. Хорошо себя проявил в Infobip. Он позволяет реализовать многомерные метрики, потому что используются лейблы.
Мы можем использовать
level, instance, service, комбинировать их в одной системе. C помощью offset можно посмотреть, например, значение величины неделю назад всего одной командой GET /api/v1/query?query={query}, где {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)Анализ версий
Есть несколько стратегий анализа версий.
Смотреть метрики только canary-ноды. Один из простейших вариантов: задеплоили новую версию и изучаем только работу. Но если инженер в это время начнет изучать логи, постоянно нервно перезагружая страницы, то это решение ничем не отличается от остальных.
Canary-нода сравнивается с любой другой нодой. Это сравнение с другими инстансами, которые работают на полном трафике. Например, если с маленьким трафиком дела обстоят хуже, или не лучше, чем на реальных инстансах, то что-то не так.
Canary-нода сравнивается с собой в прошлом. Ноды, выделенные для canary, можно сравнивать с историческими данными. Например, если неделю назад все было хорошо, то можем ориентироваться на эти данные, чтобы понять текущую ситуацию.
Автоматизация
Мы хотим освободить инженеров от ручного сравнения, поэтому важно реализовать автоматизацию. Процесс деплоя (deployment pipeline) обычно выглядит так:
- стартуем;
- убираем ноду из-под балансера;
- ставим canary-ноду;
- включаем балансер уже с ограниченным количеством трафика;
- сравниваем.
На этом этапе мы реализуем автоматическое сравнение. Как оно может выглядеть и почему лучше, чем проверка после деплоя, рассмотрим на примере из Jenkins.
Это pipeline к Groovy.
while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}Здесь в цикле задаем, что будем сравнивать новую ноду в течение часа. Если canary процесс еще не закончился процесс — вызываем функцию. Она сообщает, что все хорошо или нет:
def isOk = compare(srv, canary, time, base, offset, metrics). Если все хорошо —
sleep DEFAULT SLEEP, например, на секунду, и продолжаем. Если нет, выходим — деплой не удался.Описание метрики. Посмотрим, как может выглядеть функция
compare на примере DSL.metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)Допустим, мы сравниваем количество ошибок и хотим узнать количество ошибок в секунду за последние 5 минут.
У нас есть два значения: базовое и canary-ноды. Значение у canary-ноды — текущее. Базовое —
baseValue — это значение любой другой не canary-ноды. Сравниваем значения между собой по формуле, которую ставим исходя из своего опыта и наблюдений. Если значение canaryValue плохое, то деплой не удался, и мы откатываемся.Зачем это все нужно?
Человек не может проверить сотни и тысячи метрик, тем более сделать это быстро. Автоматическое сравнение помогает проверить все метрики и быстро оповещает о проблемах. Время оповещения критично: если что-то случилось за последние 2 секунды, то ущерб будет не такой большой, как если бы это произошло 15 минут назад. Пока кто-то заметит проблему, напишет в поддержку, а поддержка нам, чтобы откатить, можно потерять клиентов.
Если процесс прошел и все хорошо, мы деплоим все остальные ноды автоматически. В это время инженеры не делают ничего. Только когда они запускают canary, решают, какие метрики взять, сколько по времени делать сравнение, какую стратегию использовать.
Если возникли проблемы — автоматически откатываем canary-ноду, работаем на прошлых версиях и исправляем ошибки, которые нашли. По метрикам их легко найти и увидеть ущерб от новой версии.
Препятствия
Реализовать это, конечно, непросто. Прежде всего нужна общая система мониторинга. У инженеров свои метрики, у поддержки и аналитиков — другие, у бизнеса третьи. Общая система — это общий язык, на котором разговаривают бизнес и разработка.
Нужно проверить на практике стабильность метрик. Проверка помогает понять, какой минимальный набор метрик нужен, чтобы обеспечить качество.
Как этого достичь? Использовать canary-сервис не в момент деплоя. Добавляем на старой версии некий сервис, который в любой момент времени сможет взять любую выделенную ноду, уменьшить трафик без деплоя. После сравниваем: изучаем ошибки и ищем ту грань, когда мы достигаем качества.
Какую пользу мы получили от canary-релизов
Минимизировали процент ущерба от багов. Большинство ошибок деплоя происходит из-за несогласованности каких-то данных или приоритета. Таких ошибок стало намного меньше, потому что мы можем решить проблему в первые секунды.
Оптимизировали работу команд. У новичков есть «право на ошибку»: они могут деплоить в продакшн без страха ошибиться, появляется дополнительная инициатива, стимул работать. Если они что-то сломают, то это будет не критично, а ошибившегося не уволят.
Автоматизировали деплой. Это уже не ручной процесс, как раньше, а настоящий автоматизированный. Но он проходит дольше.
Выделили важные метрики. Вся компания, начиная от бизнеса и инженеров, понимает, что действительно важно в нашем продукте, какие метрики, например, отток и приток пользователей. Мы контролируем процесс: тестируем метрики, вводим новые, смотрим, как работают старые, чтобы строить систему, которая будет зарабатывать деньги производительнее.
У нас много классных практик и систем, которые нам помогают. Несмотря на это, мы стремимся быть профессионалами и делать свою работу качественно, вне зависимости от того, есть у нас система, которая нам поможет, или нет.
Инженерные подходы и практики — основной фокус конференции TechLead Conf. Если вы достигли успехов на пути к техническому совершенству и готовы рассказать, что вам в этом помогло, — подавайте заявку на доклад.
Мы планируем провести TechLead Conf 8 июня. Мы понимаем, что сейчас трудно принимать решения об участии в конференции. Но в то же время считаем, что карантин не повод останавливать профессиональное общение и развитие. Поэтому мы в любом случае найдем способ обсудить задачи техлида и подходы к их решению — если понадобится, уйдём в онлайн и развернем нетворкинг там!
softaria
Это должно работать для микросервисов. Интересно, можно ли применить подобный подход, когда речь идет о компоненте, который может менять схему данных? На первый взгляд — нет.
druss
Если нужен 99.99% uptime все равно не получится вносить ломающие обратную совместимость изменения в схему. Скорее всего нужно делать обратно совместимые изменения схемы, что бы и старый и новый сервис могли с ней работать одновременно. Потом в следующем релизе удалять не нужное.
softaria
Так можно. Но тут ломаетя сама идея проверки изменений на небольшом количестве пользователей. Если ошибка как-раз в изменении схемы, то от нее пострадают все.
druss
Тогда нужно делать шардирование базы и канаречный деплой схемы в один из шардов
softaria
Ага. И озаботиться, чтобы именно с этим шардом всегда работал один и только один инстанс application server… Сложности, сложности :)