
В современном мире Kubernetes-облаков, так или иначе, приходится сталкиваться с ошибками в программном обеспечении, которые допустил не ты и не твой коллега, но решать их придется тебе. Данная статья, возможно, поможет новичку в мире Golang и Kubernetes понять некоторые способы отладки своего и чужого софта.

Меня зовут Виктор Ягофаров, я занимаюсь развитием Kubernetes-облака в компании ДомКлик, и сегодня хочу рассказать о том как мы решили проблему с одним из ключевых компонентов нашего production k8s (Kubernetes) кластера.
В нашем боевом кластере (на момент написания статьи):
Несколько месяцев назад наши pod'ы начали испытывать проблему с разрешением DNS-имён. Дело в том, что DNS работает, в основном, по UDP, а в ядре Linux есть некоторые проблемы с conntrack и UDP. DNAT при обращении на сервисные адреса k8s Service только усугубляет проблему с conntrack races. Стоит добавить, что в нашем кластере на момент проблемы было около 40k RPS в сторону DNS-серверов, CoreDNS.

Было принято решение использовать специально созданный сообществом локальный кэширующий DNS-сервер NodeLocal DNS (nodelocaldns) на каждой worker-ноде кластера, который всё еще находится в beta и призван решить все проблемы. Если вкратце: избавляемся от UDP при коннекте к кластерному DNS, убираем NAT, добавляем дополнительный слой кэширования.
В первую итерацию внедрения nodelocaldns мы использовали версию 1.15.4 (не путать с версией куба), которая шла в комплекте с «kubernetes-инсталлятором» Kubespray – речь идёт о нашем форке форка от компании Southbridge.
Почти сразу же после внедрения начались проблемы: текла память, и происходил рестарт подов по memory limits (OOM-Kill). На момент рестарта такого пода терялся весь трафик на хосте, так как во всех подах /etc/resolv.conf указывал именно на IP-адрес nodelocaldns.
Эта ситуация решительно всех не устраивала, и наша команда OPS предприняла ряд мер, чтобы ее устранить.
Так как я сам являюсь новичком в Golang, мне было очень интересно пройти весь этот путь и познакомиться с отладкой приложений на этом замечательном языке программирования.
Итак, поехали!
На dev кластер была выкачена версия 1.15.7, которая уже считается beta, а не alpha как 1.15.4, но на деве нет такого трафика в DNS (40k RPS). Печально.
По ходу дела мы отвязали nodelocaldns от Kubespray и написали специальный Helm chart для более удобной выкатки. Заодно написали playbook для Kubespray, который позволяет менять настройки kubelet, не переваривая весь стейт кластера по часу; причем, делать это можно точечно (проверяя сначала на небольшом количестве нод).
Далее, мы выкатили версию nodelocaldns 1.15.7 на прод. Ситуация, увы, повторилась. Память текла.
В официальном репозитории nodelocaldns была версия с тэгом 1.15.8, но я почему-то не смог сделать docker pull на эту версию и посчитал, что раз еще не собрали официальный Docker-образ – значит версию эту использовать не стоит. Это важный момент, и мы к нему еще вернемся.
Я долго не мог понять, как вообще собрать свою версию nodelocaldns в принципе, так как Makefile из репы валился с непонятными ошибками изнутри докер-образа, а я не очень понимал, как хитро собрать Go-проект с govendor, разложенным странным образом по директориям сразу для нескольких разных вариантов DNS-серверов. Всё дело в том, что Go я начинал изучать, когда уже появилось нормальное версионирование зависимостей «из коробки».
С проблемой мне очень помог справиться Павел Селиванов pauljamm, за что ему огромное спасибо. Удалось собрать свою версию.
Далее мы прикрутили профайлер pprof, протестировали сборку на деве и выкатили в прод.
Коллега из команды Chat очень помог разобраться с профилированием так, чтобы можно было удобно цепляться через URL CLI утилитой pprof и изучать память и треды процесса с помощью интерактивных меню в браузере, за что ему тоже огромное спасибо.
На первый взгляд, исходя из вывода профайлера, у процесса было всё хорошо — бОльшая часть памяти выделялась на стеке и, вроде бы, использовалась Go-рутинами постоянно.
Но в какой-то момент стало понятно, что у «плохих» подов nodelocaldns было активно слишком много тредов по сравнению со «здоровыми» экземплярами. И треды никуда не девались, а продолжали висеть в памяти. В этот момент подтвердилась догадка Павла Селиванова о том, что «текут треды».

Стало интересно, почему это происходит (текут треды), и начался следующий этап изучения процесса nodelocaldns.
Статический анализатор кода staticcheck показал, что есть некие проблемы как раз на этапе создания тредов в библиотеке, которая используется в nodelocaldns (её инклудит CoreDNS, который инклудится nodelocaldns'ом). Как я понял, в некоторых местах передаются не указатели на структуру, а копия их значений.
Было решено сделать coredump «плохого» процесса с помощью утилиты gcore и посмотреть что там внутри.
Потыкав в coredump с помощью gdb-подобного инструмента dlv я осознал его мощь, но понял, что причину искать таким образом буду очень долго. Поэтому, я загрузил coredump в IDE Goland и проанализировал состояние памяти процесса.
Было очень интересно изучать структуры программы, видя код, который их создаёт. Минут за 10 стало понятно, что множество go-рутин создают некую структуру для TCP- соединений, помечает их как false и никогда не удаляет (помним про 40k RPS?).

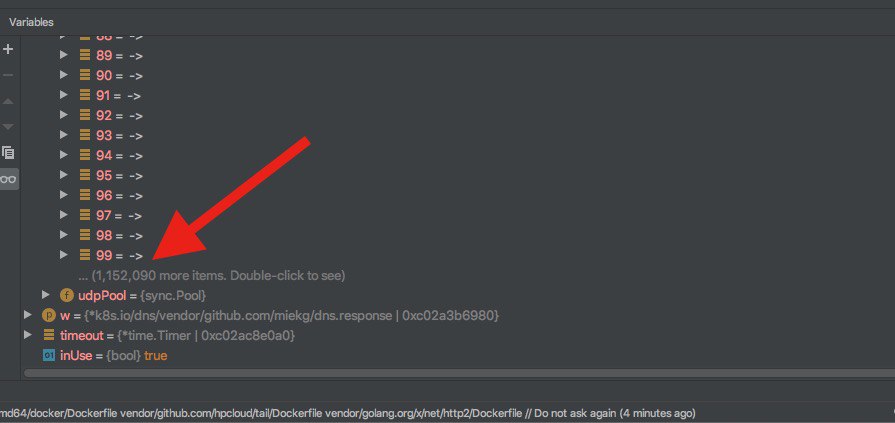
На скриншотах виден и проблемный участок кода и структура, которая не очищалась при закрытии UDP-сессии.
Также, из coredump по IP-адресам в этих структурах стал известен виновник такого количества RPS (спасибо, что помогли найти узкое место в нашем кластере :).
Во время борьбы с этой проблемой я обнаружил с помощью коллег из сообщества Kubernetes, что официальный Docker-образ nodelocaldns 1.15.8 всё же существует (а у меня на самом деле кривые руки и я как-то неправильно сделал docker pull, либо WIFI шалил в момент pull'а).
В данной версии сильно «апнуты» версии библиотек, которые он использует: конкретно «виновница» «апнулась» примерно аж на 20 версий вверх!
Мало того, в новой версии уже есть поддержка профилирования через pprof и включается через Configmap, ничего пересобирать не нужно.
Была выкачена новая версия сначала в dev, а потом в прод.
Ииии… Победа!
Процесс стал возвращать свою память в систему и проблемы прекратились.
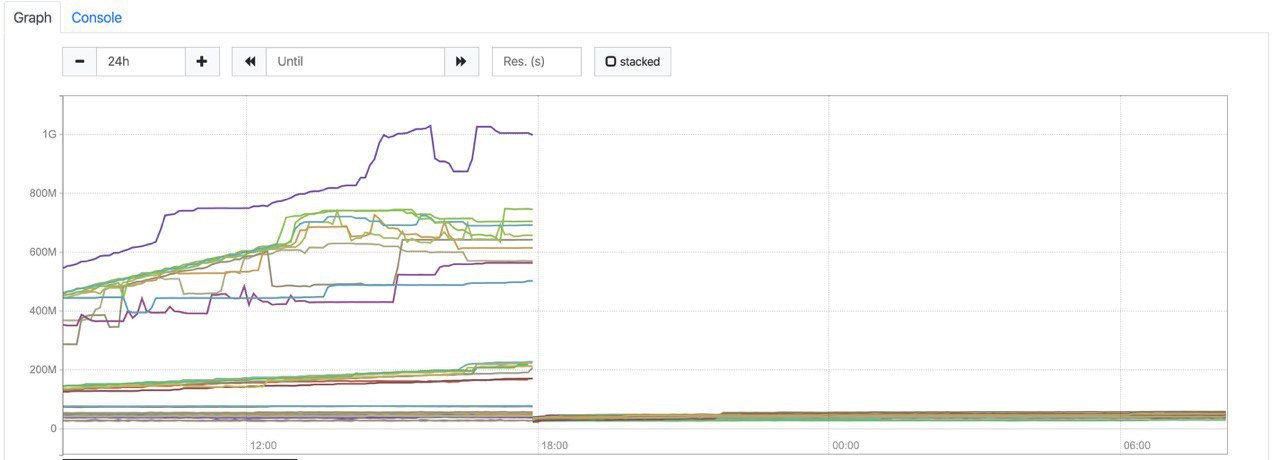
На графике ниже можно видеть картину: «DNS курильщика vs. DNS здорового человека».
Вывод здесь простой: перепроверяй что делаешь по несколько раз и не гнушайся помощью сообщества. В итоге, мы потратили на проблему на несколько дней времени больше, чем могли бы, зато получили отказоустойчивую работу DNS в контейнерах. Спасибо, что дочитали до этого момента :)
Полезные ссылки:
1. www.freecodecamp.org/news/how-i-investigated-memory-leaks-in-go-using-pprof-on-a-large-codebase-4bec4325e192
2. habr.com/ru/company/roistat/blog/413175
3. rakyll.org
Меня зовут Виктор Ягофаров, я занимаюсь развитием Kubernetes-облака в компании ДомКлик, и сегодня хочу рассказать о том как мы решили проблему с одним из ключевых компонентов нашего production k8s (Kubernetes) кластера.
В нашем боевом кластере (на момент написания статьи):
- запущено 1890 pod'ов и 577 сервисов (количество реальных микросервисов тоже в районе этой цифры)
- Ingress-контроллеры обслуживают около 6k RPS и примерно столько же идёт мимо Ingress сразу в hostPort.
Проблема
Несколько месяцев назад наши pod'ы начали испытывать проблему с разрешением DNS-имён. Дело в том, что DNS работает, в основном, по UDP, а в ядре Linux есть некоторые проблемы с conntrack и UDP. DNAT при обращении на сервисные адреса k8s Service только усугубляет проблему с conntrack races. Стоит добавить, что в нашем кластере на момент проблемы было около 40k RPS в сторону DNS-серверов, CoreDNS.
Было принято решение использовать специально созданный сообществом локальный кэширующий DNS-сервер NodeLocal DNS (nodelocaldns) на каждой worker-ноде кластера, который всё еще находится в beta и призван решить все проблемы. Если вкратце: избавляемся от UDP при коннекте к кластерному DNS, убираем NAT, добавляем дополнительный слой кэширования.
В первую итерацию внедрения nodelocaldns мы использовали версию 1.15.4 (не путать с версией куба), которая шла в комплекте с «kubernetes-инсталлятором» Kubespray – речь идёт о нашем форке форка от компании Southbridge.
Почти сразу же после внедрения начались проблемы: текла память, и происходил рестарт подов по memory limits (OOM-Kill). На момент рестарта такого пода терялся весь трафик на хосте, так как во всех подах /etc/resolv.conf указывал именно на IP-адрес nodelocaldns.
Эта ситуация решительно всех не устраивала, и наша команда OPS предприняла ряд мер, чтобы ее устранить.
Так как я сам являюсь новичком в Golang, мне было очень интересно пройти весь этот путь и познакомиться с отладкой приложений на этом замечательном языке программирования.
Ищем решение
Итак, поехали!
На dev кластер была выкачена версия 1.15.7, которая уже считается beta, а не alpha как 1.15.4, но на деве нет такого трафика в DNS (40k RPS). Печально.
По ходу дела мы отвязали nodelocaldns от Kubespray и написали специальный Helm chart для более удобной выкатки. Заодно написали playbook для Kubespray, который позволяет менять настройки kubelet, не переваривая весь стейт кластера по часу; причем, делать это можно точечно (проверяя сначала на небольшом количестве нод).
Далее, мы выкатили версию nodelocaldns 1.15.7 на прод. Ситуация, увы, повторилась. Память текла.
В официальном репозитории nodelocaldns была версия с тэгом 1.15.8, но я почему-то не смог сделать docker pull на эту версию и посчитал, что раз еще не собрали официальный Docker-образ – значит версию эту использовать не стоит. Это важный момент, и мы к нему еще вернемся.
Отладка: этап 1
Я долго не мог понять, как вообще собрать свою версию nodelocaldns в принципе, так как Makefile из репы валился с непонятными ошибками изнутри докер-образа, а я не очень понимал, как хитро собрать Go-проект с govendor, разложенным странным образом по директориям сразу для нескольких разных вариантов DNS-серверов. Всё дело в том, что Go я начинал изучать, когда уже появилось нормальное версионирование зависимостей «из коробки».
С проблемой мне очень помог справиться Павел Селиванов pauljamm, за что ему огромное спасибо. Удалось собрать свою версию.
Далее мы прикрутили профайлер pprof, протестировали сборку на деве и выкатили в прод.
Коллега из команды Chat очень помог разобраться с профилированием так, чтобы можно было удобно цепляться через URL CLI утилитой pprof и изучать память и треды процесса с помощью интерактивных меню в браузере, за что ему тоже огромное спасибо.
На первый взгляд, исходя из вывода профайлера, у процесса было всё хорошо — бОльшая часть памяти выделялась на стеке и, вроде бы, использовалась Go-рутинами постоянно.
Но в какой-то момент стало понятно, что у «плохих» подов nodelocaldns было активно слишком много тредов по сравнению со «здоровыми» экземплярами. И треды никуда не девались, а продолжали висеть в памяти. В этот момент подтвердилась догадка Павла Селиванова о том, что «текут треды».
Отладка: этап 2
Стало интересно, почему это происходит (текут треды), и начался следующий этап изучения процесса nodelocaldns.
Статический анализатор кода staticcheck показал, что есть некие проблемы как раз на этапе создания тредов в библиотеке, которая используется в nodelocaldns (её инклудит CoreDNS, который инклудится nodelocaldns'ом). Как я понял, в некоторых местах передаются не указатели на структуру, а копия их значений.
Было решено сделать coredump «плохого» процесса с помощью утилиты gcore и посмотреть что там внутри.
Потыкав в coredump с помощью gdb-подобного инструмента dlv я осознал его мощь, но понял, что причину искать таким образом буду очень долго. Поэтому, я загрузил coredump в IDE Goland и проанализировал состояние памяти процесса.
Отладка: этап 3
Было очень интересно изучать структуры программы, видя код, который их создаёт. Минут за 10 стало понятно, что множество go-рутин создают некую структуру для TCP- соединений, помечает их как false и никогда не удаляет (помним про 40k RPS?).
На скриншотах виден и проблемный участок кода и структура, которая не очищалась при закрытии UDP-сессии.
Также, из coredump по IP-адресам в этих структурах стал известен виновник такого количества RPS (спасибо, что помогли найти узкое место в нашем кластере :).
Решение
Во время борьбы с этой проблемой я обнаружил с помощью коллег из сообщества Kubernetes, что официальный Docker-образ nodelocaldns 1.15.8 всё же существует (а у меня на самом деле кривые руки и я как-то неправильно сделал docker pull, либо WIFI шалил в момент pull'а).
В данной версии сильно «апнуты» версии библиотек, которые он использует: конкретно «виновница» «апнулась» примерно аж на 20 версий вверх!
Мало того, в новой версии уже есть поддержка профилирования через pprof и включается через Configmap, ничего пересобирать не нужно.
Была выкачена новая версия сначала в dev, а потом в прод.
Ииии… Победа!
Процесс стал возвращать свою память в систему и проблемы прекратились.
На графике ниже можно видеть картину: «DNS курильщика vs. DNS здорового человека».
Выводы
Вывод здесь простой: перепроверяй что делаешь по несколько раз и не гнушайся помощью сообщества. В итоге, мы потратили на проблему на несколько дней времени больше, чем могли бы, зато получили отказоустойчивую работу DNS в контейнерах. Спасибо, что дочитали до этого момента :)
Полезные ссылки:
1. www.freecodecamp.org/news/how-i-investigated-memory-leaks-in-go-using-pprof-on-a-large-codebase-4bec4325e192
2. habr.com/ru/company/roistat/blog/413175
3. rakyll.org




drWhy
Подпись под КДПВ: «Учись, сынок, а то всю жизнь ключи подавать будешь».
Спасибо за пример благополучного разрешения проблемы за счёт настойчивости и глубокого погружения.