
Меня зовут Виктор Ягофаров, и я занимаюсь развитием Kubernetes-платформы в компании ДомКлик в должности технического руководителя разработки в команде Ops (эксплуатация). Я хотел бы рассказать об устройстве наших процессов Dev <-> Ops, об особенностях эксплуатации одного из самых больших k8s-кластеров в России, а также о DevOps/SRE-практиках, которые применяет наша команда.

В команде Ops на данный момент работает 15 человек. Трое из них отвечают за офис, двое работают в другом часовом поясе и доступны, в том числе, и ночью. Таким образом, всегда кто-то из Ops находится у монитора и готов среагировать на инцидент любой сложности. Ночных дежурств у нас нет, что сохраняет нашу психику и даёт возможность всем высыпаться и проводить досуг не только за компьютером.
Компетенции у всех разные: сетевики, DBA, специалисты по стеку ELK, Kubernetes-админы/разработчики, специалисты по мониторингу, виртуализации, железу и т.д. Объединяет всех одно — каждый может заменить в какой-то степени любого из нас: например, ввести новые ноды в кластер k8s, обновить PostgreSQL, написать pipeline CI/CD + Ansible, автоматизировать что-нибудь на Python/Bash/Go, подключить железку в ЦОД. Сильные компетенции в какой-либо области не мешают сменить направление деятельности и начать прокачиваться в какой-нибудь другой области. Например, я устраивался в компанию как специалист по PostgreSQL, а сейчас моя главная зона ответственности — кластеры Kubernetes. В команде любой рост только приветствуется и очень развито чувство плеча.
Кстати, мы хантим. Требования к кандидатам довольно стандартные. Лично для меня важно, чтобы человек вписывался в коллектив, был неконфликтным, но также умел отстаивать свою точку зрения, желал развиваться и не боялся делать что-то новое, предлагал свои идеи. Также, обязательны навыки программирования на скриптовых языках, знание основ Linux и английского языка. Английский нужен просто для того, чтобы человек в случае факапа мог загуглить решение проблемы за 10 секунд, а не за 10 минут. Со специалистами с глубоким знанием Linux сейчас очень сложно: смешно, но два кандидата из трех не могут ответить на вопрос «Что такое Load Average? Из чего он складывается?», а вопрос «Как собрать core dump из сишной программы» считают чем-то из мира сверхлюдей… или динозавров. С этим приходится мириться, так как обычно у людей сильно развиты другие компетенции, а «линуксу» мы научим. Ответ на вопрос «зачем это всё нужно знать DevOps-инженеру в современном мире облаков» придётся оставить за рамками статьи, но если тремя словами: всё это нужно.
Немалую роль в автоматизации играет команда Tools. Их основная задача — создание удобных графических и CLI-инструментов для разработчиков. Например, наша внутренняя разработка Confer позволяет буквально несколькими кликами мыши выкатить приложение в Kubernetes, настроить ему ресурсы, ключи из vault и т.д. Раньше был Jenkins + Helm 2, но пришлось разработать собственный инструмент, чтобы исключить копи-пасту и привнести единообразие в жизненный цикл ПО.
Команда Ops не пишет пайплайны за разработчиков, но может проконсультировать по любым вопросам в их написании (у кое-кого еще остался Helm 3).
Что касается DevOps, то мы видим его таким:
Команды Dev пишут код, выкатывают его через Confer в dev -> qa/stage -> prod. Ответственность за то, чтобы код не тормозил и не сыпал ошибками, лежит на командах Dev и Ops. В дневное время реагировать на инцидент со своим приложением должен, в первую очередь, дежурный от команды Ops, а в вечернее и ночное время дежурный админ (Ops) должен разбудить дежурного разработчика, если он точно знает, что проблема не в инфраструктуре. Все метрики и алерты в мониторинге появляются автоматически или полуавтоматически.
Зона ответственности Ops начинается с момента выкатки приложения в прод, но и ответственность Dev на этом не заканчивается — мы делаем одно дело и находимся в одной лодке.
Разработчики консультируют админов, если нужна помощь в написании админского микросервиса (например, Go backend + HTML5), а админы консультируют разработчиков по любым инфраструктурным вопросам, или вопросам, связанным с k8s.
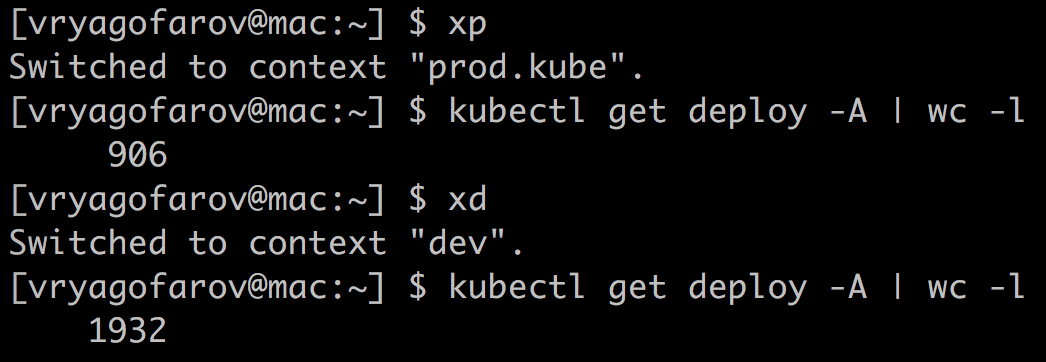
Кстати, у нас вообще нет монолита, только микросервисы. Их количество пока что колеблется между 900 и 1000 в prod k8s-кластере, если измерять по количеству deployments. Количество подов колеблется между 1700 и 2000. Подов в prod-кластере сейчас около 2000.
Точные числа назвать не могу, так как мы следим за ненужными микросервисами и выпиливаем их в полуавтоматическом режиме. Следить за ненужными сущностями в k8s нам помогает useless-operator, что здорово экономит ресурсы и деньги.
Краеугольным камнем в эксплуатации большого кластера становится грамотно выстроенный и информативный мониторинг. Мы пока не нашли универсального решения, которое покрыло бы 100 % всех «хотелок» по мониторингу, поэтому периодически клепаем разные кастомные решения в этой среде.
Еще одним полезным инструментом для нас стал list-ingress. Мы написали его после того, как несколько раз столкнулись с ситуацией, когда одна команда перекрывает своими путями Ingress другой команды, из-за чего возникали ошибки 50x. Сейчас перед деплоем на прод разработчики проверяют, что никого не заденут, а для моей команды это хороший инструмент для первичной диагностики проблем с Ingress'ами. Забавно, что сначала его написали для админов и выглядел он довольно «топорно», но после того, как инструмент полюбился dev-командам, он сильно преобразился и стал выглядеть не как «админ сделал веб-морду для админов». Скоро мы откажемся от этого инструмента и подобные ситуации будут валидироваться еще до выкатки пайплайна.
Прежде чем приступить к примерам, стоит объяснить, как у нас работает выделение ресурсов для микросервисов.
Чтобы понимать, какие команды и в каких количествах используют свои ресурсы (процессор, память, локальный SSD), мы выделяем на каждую команду свой namespace в «Кубе» и ограничиваем его максимальные возможности по процессору, памяти и диску, предварительно обговорив нужды команд. Соответственно, одна команда, в общем случае, не заблокирует для деплоя весь кластер, выделив себе тысячи ядер и терабайты памяти. Доступы в namespace выдаются через AD (мы используем RBAC). Namespace'ы и их лимиты добавляются через пул-реквест в GIT-репозиторий, а далее через Ansible-пайплайн всё автоматически раскатывается.
Пример выделения ресурсов на команду:
В «Кубе» Request — это количество гарантированно зарезервированных ресурсов под pod (один или более докер-контейнеров) в кластере. Limit — это негарантированный максимум. Часто можно увидеть на графиках, как какая-то команда выставила себе слишком много реквестов для всех своих приложений и не может задеплоить приложение в «Куб», так как под их namespace все request'ы уже «потрачены».
Правильный выход из такой ситуации: смотреть реальное потребление ресурсов и сравнивать с запрошенным количеством (Request).
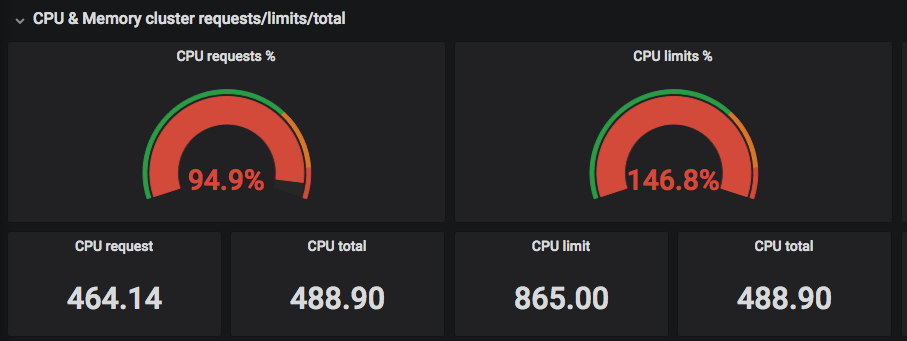
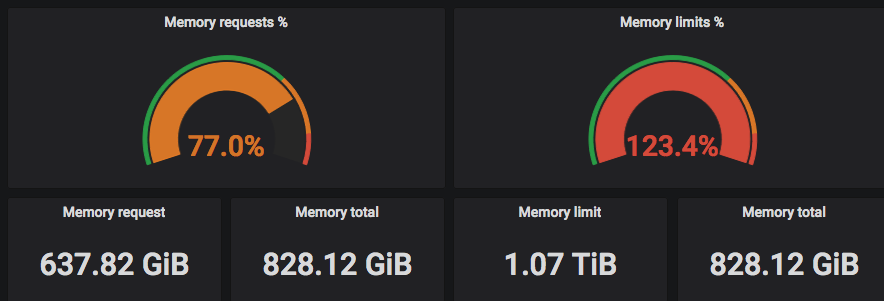
На скриншотах выше видно, что «запрошенные» (Requested) CPU подбираются к реальному количеству потоков, а Limits могут превышать реальное количество потоков центральных процессоров =)
Теперь подробно разберём какой-нибудь namespace (я выбрал namespace kube-system — системный namespace для компонентов самого «Куба») и посмотрим соотношение реально использованного процессорного времени и памяти к запрошенному:
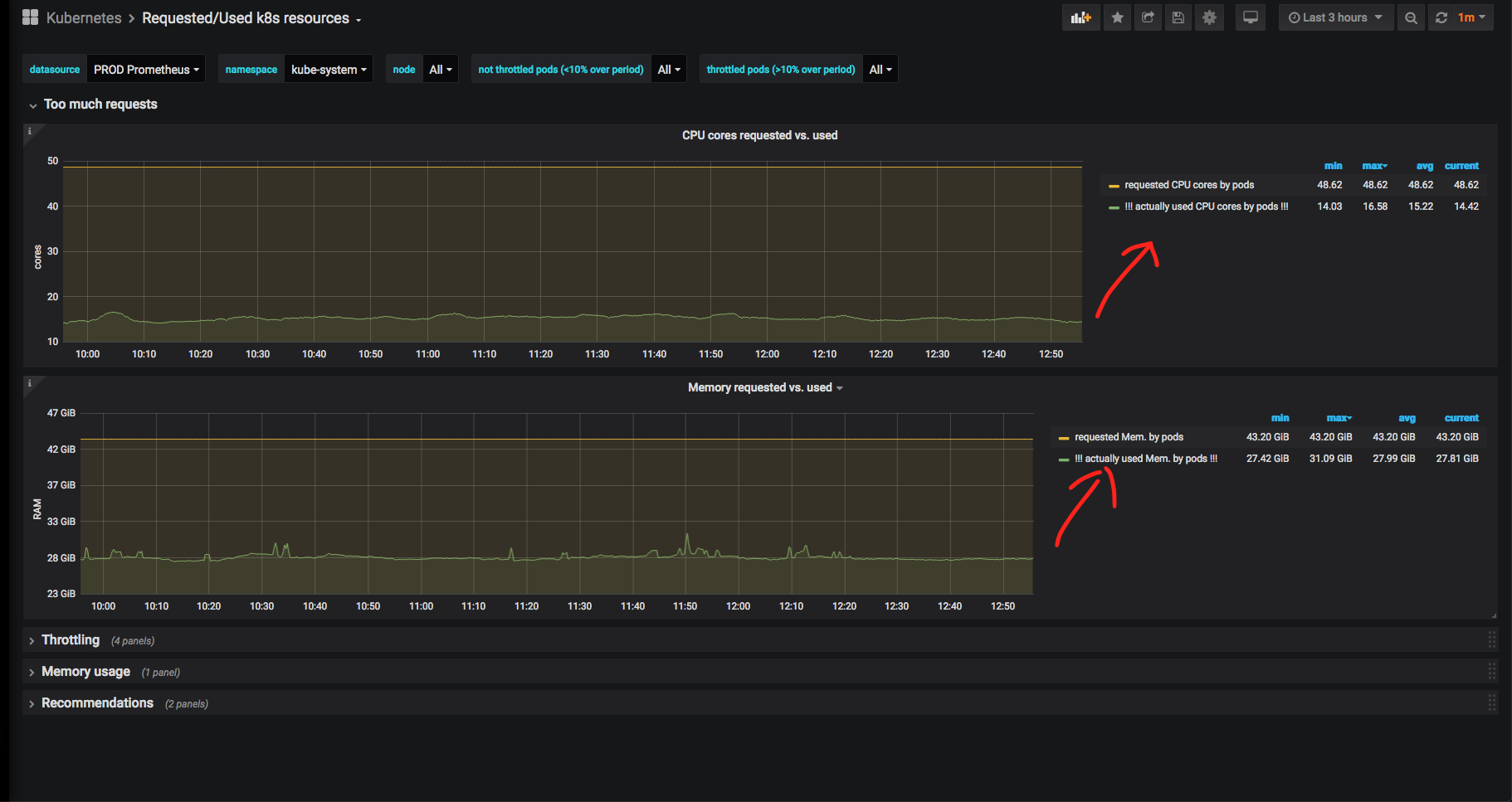
Очевидно, что памяти и ЦПУ зарезервировано под системные службы намного больше, чем используется реально. В случае с kube-system это оправдано: бывало, что nginx ingress controller или nodelocaldns в пике упирались в CPU и отъедали очень много RAM, поэтому здесь такой запас оправдан. К тому же, мы не можем полагаться на графики за последние 3 часа: желательно видеть исторические метрики за большой период времени.
Была разработана система «рекомендаций». Например, здесь можно увидеть, каким ресурсам лучше бы поднять «лимиты» (верхняя разрешенная планка), чтобы не происходило «троттлинга» (throttling): момента, когда под уже потратил CPU или память за отведенный ему квант времени и находится в ожидании, пока его «разморозят»:
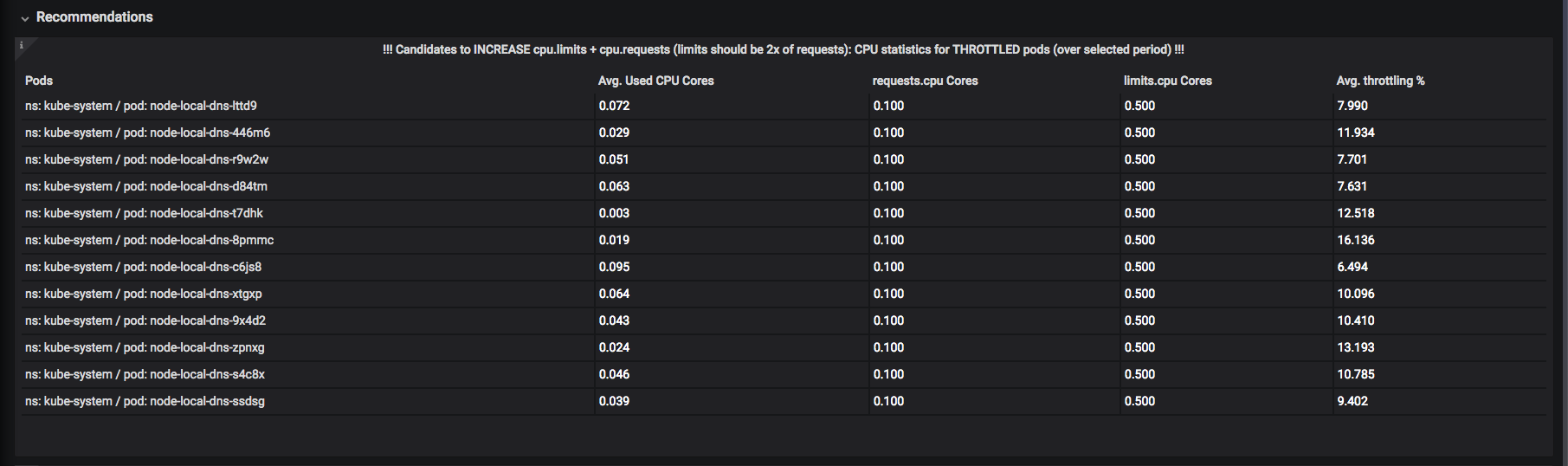
А вот поды, которым следовало бы умерить аппетиты:

Про троттлинг + мониторинг ресурсов можно написать не одну статью, поэтому задавайте вопросы в комментариях. В нескольких словах могу сказать, что задача автоматизации подобных метрик весьма непростая и требует много времени и эквилибристики с «оконными» функциями и «CTE» Prometheus / VictoriaMetrics (эти термины взяты в кавычки, так как в PromQL почти что нет ничего подобного, и приходится городить страшные запросы на несколько экранов текста и заниматься их оптимизацией).
В итоге, у разработчиков есть инструменты для мониторинга своих namespaces в «Кубе», и они способны сами выбирать, где и в какое время у каких приложений можно «подрезать» ресурсы, а каким подам можно на всю ночь отдать весь CPU.
В компании, как сейчас модно, мы придерживаемся DevOps- и SRE-практик. Когда в компании 1000 микросервисов, около 350 разработчиков и 15 админов на всю инфраструктуру, приходится «быть модным»: за всеми этими «базвордами» скрывается острая необходимость в автоматизации всего и вся, а админы не должны быть бутылочным горлышком в процессах.
Как Ops, мы предоставляем различные метрики и дашборды для разработчиков, связанные со скоростью ответа сервисов и их ошибками.
Мы используем такие методологии, как: RED, USE и Golden Signals, комбинируя их вместе. Стараемся минимизировать количество дашбордов так, чтобы с одного взгляда было понятно, какой сервис сейчас деградирует (например, коды ответов в секунду, время ответа по 99-перцентилю), и так далее. Как только становятся нужны какие-то новые метрики для общих дашбордов, мы тут же их рисуем и добавляем.
Я не рисовал графики уже месяц. Наверное, это хороший знак: значит большинство «хотелок» уже реализованы. Бывало, что за неделю я хотя бы раз в день рисовал какой-нибудь новый график.


Получившийся результат ценен тем, что теперь разрабы довольно редко ходят к админам с вопросами «где посмотреть какую-то метрику».
Внедрение Service Mesh не за горами и должно сильно облегчить всем жизнь, коллеги из Tools уже близки к внедрению абстрактного «Istio здорового человека»: жизненный цикл каждого HTTP(s)-запроса будет виден в мониторинге, и всегда можно будет понять «на каком этапе всё сломалось» при межсервисном (и не только) взаимодействии. Подписывайтесь на новости хаба компании ДомКлик. =)
Исторически сложилось так, что мы используем патченную версию Kubespray — Ansible-роль для разворачивания, расширения и обновления Kubernetes. В какой-то момент из основной ветки была выпилена поддержка non-kubeadm инсталляций, а процесс перехода на kubeadm предложен не был. В итоге, компания Southbridge сделала свой форк (с поддержкой kubeadm и быстрым фиксом критических проблем).
Процесс обновления всех кластеров k8s выглядит так:
В будущем есть планы заменить Kubespray на что-нибудь более быстрое и перейти на kubeadm.
Всего у нас три «Куба»: Stress, Dev и Prod. Планируем запустить еще один (hot standby) Prod-«Куб» во втором ЦОДе. Stress и Dev живут в «виртуалках» (oVirt для Stress и VMWare cloud для Dev). Prod-«Куб» живёт на «голом железе» (bare metal): это одинаковые ноды с 32 CPU threads, 64-128 Гб памяти и 300 Гб SSD RAID 10 — всего их 50 штук. Три «тонкие» ноды выделены под «мастера» Prod-«Куба»: 16 Гб памяти, 12 CPU threads.
Для прода предпочитаем использовать «голое железо» и избегаем лишних прослоек вроде OpenStack: нам не нужны «шумные соседи» и CPU steal time. Да и сложность администрирования возрастает примерно вдвое в случае in-house OpenStack.
Для CI/CD «Кубовых» и других инфраструктурных компонентов используем отдельный GIT-сервер, Helm 3 (перешли довольно болезненно с Helm 2, но очень рады опции atomic), Jenkins, Ansible и Docker. Любим feature-бранчи и деплой в разные среды из одного репозитория.

Вот так, в общих чертах, в компании ДомКлик выглядит процесс DevOps со стороны инженера эксплуатации. Статья получилась менее технической, чем я ожидал: поэтому, следите за новостями ДомКлик на Хабре: будут более «хардкорные» статьи о Kubernetes и не только.
Команда Ops
В команде Ops на данный момент работает 15 человек. Трое из них отвечают за офис, двое работают в другом часовом поясе и доступны, в том числе, и ночью. Таким образом, всегда кто-то из Ops находится у монитора и готов среагировать на инцидент любой сложности. Ночных дежурств у нас нет, что сохраняет нашу психику и даёт возможность всем высыпаться и проводить досуг не только за компьютером.
Компетенции у всех разные: сетевики, DBA, специалисты по стеку ELK, Kubernetes-админы/разработчики, специалисты по мониторингу, виртуализации, железу и т.д. Объединяет всех одно — каждый может заменить в какой-то степени любого из нас: например, ввести новые ноды в кластер k8s, обновить PostgreSQL, написать pipeline CI/CD + Ansible, автоматизировать что-нибудь на Python/Bash/Go, подключить железку в ЦОД. Сильные компетенции в какой-либо области не мешают сменить направление деятельности и начать прокачиваться в какой-нибудь другой области. Например, я устраивался в компанию как специалист по PostgreSQL, а сейчас моя главная зона ответственности — кластеры Kubernetes. В команде любой рост только приветствуется и очень развито чувство плеча.
Кстати, мы хантим. Требования к кандидатам довольно стандартные. Лично для меня важно, чтобы человек вписывался в коллектив, был неконфликтным, но также умел отстаивать свою точку зрения, желал развиваться и не боялся делать что-то новое, предлагал свои идеи. Также, обязательны навыки программирования на скриптовых языках, знание основ Linux и английского языка. Английский нужен просто для того, чтобы человек в случае факапа мог загуглить решение проблемы за 10 секунд, а не за 10 минут. Со специалистами с глубоким знанием Linux сейчас очень сложно: смешно, но два кандидата из трех не могут ответить на вопрос «Что такое Load Average? Из чего он складывается?», а вопрос «Как собрать core dump из сишной программы» считают чем-то из мира сверхлюдей… или динозавров. С этим приходится мириться, так как обычно у людей сильно развиты другие компетенции, а «линуксу» мы научим. Ответ на вопрос «зачем это всё нужно знать DevOps-инженеру в современном мире облаков» придётся оставить за рамками статьи, но если тремя словами: всё это нужно.
Команда Tools
Немалую роль в автоматизации играет команда Tools. Их основная задача — создание удобных графических и CLI-инструментов для разработчиков. Например, наша внутренняя разработка Confer позволяет буквально несколькими кликами мыши выкатить приложение в Kubernetes, настроить ему ресурсы, ключи из vault и т.д. Раньше был Jenkins + Helm 2, но пришлось разработать собственный инструмент, чтобы исключить копи-пасту и привнести единообразие в жизненный цикл ПО.
Команда Ops не пишет пайплайны за разработчиков, но может проконсультировать по любым вопросам в их написании (у кое-кого еще остался Helm 3).
DevOps
Что касается DevOps, то мы видим его таким:
Команды Dev пишут код, выкатывают его через Confer в dev -> qa/stage -> prod. Ответственность за то, чтобы код не тормозил и не сыпал ошибками, лежит на командах Dev и Ops. В дневное время реагировать на инцидент со своим приложением должен, в первую очередь, дежурный от команды Ops, а в вечернее и ночное время дежурный админ (Ops) должен разбудить дежурного разработчика, если он точно знает, что проблема не в инфраструктуре. Все метрики и алерты в мониторинге появляются автоматически или полуавтоматически.
Зона ответственности Ops начинается с момента выкатки приложения в прод, но и ответственность Dev на этом не заканчивается — мы делаем одно дело и находимся в одной лодке.
Разработчики консультируют админов, если нужна помощь в написании админского микросервиса (например, Go backend + HTML5), а админы консультируют разработчиков по любым инфраструктурным вопросам, или вопросам, связанным с k8s.
Кстати, у нас вообще нет монолита, только микросервисы. Их количество пока что колеблется между 900 и 1000 в prod k8s-кластере, если измерять по количеству deployments. Количество подов колеблется между 1700 и 2000. Подов в prod-кластере сейчас около 2000.
Точные числа назвать не могу, так как мы следим за ненужными микросервисами и выпиливаем их в полуавтоматическом режиме. Следить за ненужными сущностями в k8s нам помогает useless-operator, что здорово экономит ресурсы и деньги.
Управление ресурсами
Мониторинг
Краеугольным камнем в эксплуатации большого кластера становится грамотно выстроенный и информативный мониторинг. Мы пока не нашли универсального решения, которое покрыло бы 100 % всех «хотелок» по мониторингу, поэтому периодически клепаем разные кастомные решения в этой среде.
- Zabbix. Старый добрый мониторинг, который предназначен, в первую очередь, для отслеживания общего состояния инфраструктуры. Он говорит нам, когда нода умирает по процу, памяти, дискам, сети и так далее. Ничего сверхъестественного, но также у нас есть отдельный DaemonSet из агентов, с помощью которых, например, мы мониторим состояние DNS в кластере: ищем тупящие поды coredns, проверяем доступность внешних хостов. Казалось бы, зачем ради этого заморачиваться, но на больших объемах трафика этот компонент является серьезной точкой отказа. Ранее я уже описывал, как боролся с производительностью DNS в кластере.
- Prometheus Operator. Набор различных экспортеров даёт большой обзор всех компонентов кластера. Далее визуализируем всё это на больших дашбордах в Grafana, а для оповещений используем alertmanager.
Еще одним полезным инструментом для нас стал list-ingress. Мы написали его после того, как несколько раз столкнулись с ситуацией, когда одна команда перекрывает своими путями Ingress другой команды, из-за чего возникали ошибки 50x. Сейчас перед деплоем на прод разработчики проверяют, что никого не заденут, а для моей команды это хороший инструмент для первичной диагностики проблем с Ingress'ами. Забавно, что сначала его написали для админов и выглядел он довольно «топорно», но после того, как инструмент полюбился dev-командам, он сильно преобразился и стал выглядеть не как «админ сделал веб-морду для админов». Скоро мы откажемся от этого инструмента и подобные ситуации будут валидироваться еще до выкатки пайплайна.
Ресурсы команд в «Кубе»
Прежде чем приступить к примерам, стоит объяснить, как у нас работает выделение ресурсов для микросервисов.
Чтобы понимать, какие команды и в каких количествах используют свои ресурсы (процессор, память, локальный SSD), мы выделяем на каждую команду свой namespace в «Кубе» и ограничиваем его максимальные возможности по процессору, памяти и диску, предварительно обговорив нужды команд. Соответственно, одна команда, в общем случае, не заблокирует для деплоя весь кластер, выделив себе тысячи ядер и терабайты памяти. Доступы в namespace выдаются через AD (мы используем RBAC). Namespace'ы и их лимиты добавляются через пул-реквест в GIT-репозиторий, а далее через Ansible-пайплайн всё автоматически раскатывается.
Пример выделения ресурсов на команду:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
Реквесты и лимиты
В «Кубе» Request — это количество гарантированно зарезервированных ресурсов под pod (один или более докер-контейнеров) в кластере. Limit — это негарантированный максимум. Часто можно увидеть на графиках, как какая-то команда выставила себе слишком много реквестов для всех своих приложений и не может задеплоить приложение в «Куб», так как под их namespace все request'ы уже «потрачены».
Правильный выход из такой ситуации: смотреть реальное потребление ресурсов и сравнивать с запрошенным количеством (Request).
На скриншотах выше видно, что «запрошенные» (Requested) CPU подбираются к реальному количеству потоков, а Limits могут превышать реальное количество потоков центральных процессоров =)
Теперь подробно разберём какой-нибудь namespace (я выбрал namespace kube-system — системный namespace для компонентов самого «Куба») и посмотрим соотношение реально использованного процессорного времени и памяти к запрошенному:
Очевидно, что памяти и ЦПУ зарезервировано под системные службы намного больше, чем используется реально. В случае с kube-system это оправдано: бывало, что nginx ingress controller или nodelocaldns в пике упирались в CPU и отъедали очень много RAM, поэтому здесь такой запас оправдан. К тому же, мы не можем полагаться на графики за последние 3 часа: желательно видеть исторические метрики за большой период времени.
Была разработана система «рекомендаций». Например, здесь можно увидеть, каким ресурсам лучше бы поднять «лимиты» (верхняя разрешенная планка), чтобы не происходило «троттлинга» (throttling): момента, когда под уже потратил CPU или память за отведенный ему квант времени и находится в ожидании, пока его «разморозят»:
А вот поды, которым следовало бы умерить аппетиты:
Про троттлинг + мониторинг ресурсов можно написать не одну статью, поэтому задавайте вопросы в комментариях. В нескольких словах могу сказать, что задача автоматизации подобных метрик весьма непростая и требует много времени и эквилибристики с «оконными» функциями и «CTE» Prometheus / VictoriaMetrics (эти термины взяты в кавычки, так как в PromQL почти что нет ничего подобного, и приходится городить страшные запросы на несколько экранов текста и заниматься их оптимизацией).
В итоге, у разработчиков есть инструменты для мониторинга своих namespaces в «Кубе», и они способны сами выбирать, где и в какое время у каких приложений можно «подрезать» ресурсы, а каким подам можно на всю ночь отдать весь CPU.
Методологии
В компании, как сейчас модно, мы придерживаемся DevOps- и SRE-практик. Когда в компании 1000 микросервисов, около 350 разработчиков и 15 админов на всю инфраструктуру, приходится «быть модным»: за всеми этими «базвордами» скрывается острая необходимость в автоматизации всего и вся, а админы не должны быть бутылочным горлышком в процессах.
Как Ops, мы предоставляем различные метрики и дашборды для разработчиков, связанные со скоростью ответа сервисов и их ошибками.
Мы используем такие методологии, как: RED, USE и Golden Signals, комбинируя их вместе. Стараемся минимизировать количество дашбордов так, чтобы с одного взгляда было понятно, какой сервис сейчас деградирует (например, коды ответов в секунду, время ответа по 99-перцентилю), и так далее. Как только становятся нужны какие-то новые метрики для общих дашбордов, мы тут же их рисуем и добавляем.
Я не рисовал графики уже месяц. Наверное, это хороший знак: значит большинство «хотелок» уже реализованы. Бывало, что за неделю я хотя бы раз в день рисовал какой-нибудь новый график.
Получившийся результат ценен тем, что теперь разрабы довольно редко ходят к админам с вопросами «где посмотреть какую-то метрику».
Внедрение Service Mesh не за горами и должно сильно облегчить всем жизнь, коллеги из Tools уже близки к внедрению абстрактного «Istio здорового человека»: жизненный цикл каждого HTTP(s)-запроса будет виден в мониторинге, и всегда можно будет понять «на каком этапе всё сломалось» при межсервисном (и не только) взаимодействии. Подписывайтесь на новости хаба компании ДомКлик. =)
Поддержка инфраструктуры Kubernetes
Исторически сложилось так, что мы используем патченную версию Kubespray — Ansible-роль для разворачивания, расширения и обновления Kubernetes. В какой-то момент из основной ветки была выпилена поддержка non-kubeadm инсталляций, а процесс перехода на kubeadm предложен не был. В итоге, компания Southbridge сделала свой форк (с поддержкой kubeadm и быстрым фиксом критических проблем).
Процесс обновления всех кластеров k8s выглядит так:
- Берем Kubespray от Southbridge, сверяем с нашей веткой, мерджим.
- Выкатываем обновление в Stress-«Куб».
- Выкатываем обновление по одной ноде (в Ansible это «serial: 1») в Dev-«Куб».
- Обновляем Prod в субботу вечером по одной ноде.
В будущем есть планы заменить Kubespray на что-нибудь более быстрое и перейти на kubeadm.
Всего у нас три «Куба»: Stress, Dev и Prod. Планируем запустить еще один (hot standby) Prod-«Куб» во втором ЦОДе. Stress и Dev живут в «виртуалках» (oVirt для Stress и VMWare cloud для Dev). Prod-«Куб» живёт на «голом железе» (bare metal): это одинаковые ноды с 32 CPU threads, 64-128 Гб памяти и 300 Гб SSD RAID 10 — всего их 50 штук. Три «тонкие» ноды выделены под «мастера» Prod-«Куба»: 16 Гб памяти, 12 CPU threads.
Для прода предпочитаем использовать «голое железо» и избегаем лишних прослоек вроде OpenStack: нам не нужны «шумные соседи» и CPU steal time. Да и сложность администрирования возрастает примерно вдвое в случае in-house OpenStack.
Для CI/CD «Кубовых» и других инфраструктурных компонентов используем отдельный GIT-сервер, Helm 3 (перешли довольно болезненно с Helm 2, но очень рады опции atomic), Jenkins, Ansible и Docker. Любим feature-бранчи и деплой в разные среды из одного репозитория.
Заключение
Вот так, в общих чертах, в компании ДомКлик выглядит процесс DevOps со стороны инженера эксплуатации. Статья получилась менее технической, чем я ожидал: поэтому, следите за новостями ДомКлик на Хабре: будут более «хардкорные» статьи о Kubernetes и не только.








Nastradamus Автор
Ответ на вопрос моей мамы «чем я занимаюсь на работе» =)