
Роман-эпопею Льва Николаевича Толстого «Война и мир» я так и не прочитал до сих — в школе было не интересно из-за «словоблудия» автора, а с возрастом как-то нет времени взяться за такой объемный труд.
Однако решил, что изучить стоит…

Я не вычищал от сторонних слов и знаков (латинских номер частей, номеров сносок и части комментариев), что на фоне почти 400 тысяч слов текста романа, погрешность даже в тысячу слов не даст неверных данных, но я решил минимальную подготовку текста все-таки совершить.
Как человеку, работающему постоянно с числами, мне стали интересны следующие вопросы:
Узнав от жены, что Лев Николаевич еще тот графоман, решил узнать, каких длинных слов выдумал для романа Толстой.
Итак, ТОП-3 длинных слов.
Первое место (27 букв и дефис) поделили слова сверхъестественно-прекрасное, сверхъестественно-утонченное и непреодолимо-обворожительным:
… Как хороший метрдотель подает как нечто сверхъестественно-прекрасное тот кусок говядины, который есть не захочется, если увидать его в грязной кухне, так в нынешний вечер Анна Павловна сервировала своим гостям сначала виконта, потом аббата, как что-то сверхъестественно-утонченное…
… Француз бывает самоуверен потому, что он почитает себя лично, как умом, так и телом, непреодолимо-обворожительным как для мужчин, так и для женщин. Англичанин самоуверен на том основании, что он есть гражданин благоустроеннейшего в мире государства, и потому, как англичанин, знает всегда, что ему делать нужно, и знает, что все, что он делает как англичанин, несомненно хорошо. Итальянец самоуверен потому, что он взволнован и забывает легко и себя и других...
Второе место (25 букв и дефис) заняло слово однообразно-разнообразными:
… Гусары не оглядывались, но при каждом звуке пролетающего ядра, будто по команде, весь эскадрон со своими однообразно-разнообразными лицами, сдерживая дыханье, пока летело ядро, приподнимался на стременах и снова опускался…
Третье место (24 буквы) заняло слово высокопревосходительство, данное слово в отличие от предыдущих встречается восемь раз, как обращение к фельдмаршалу Михаилу Илларионовичу Кутузову.
Предварительно список был очищен от слов из одной и двух букв, чтобы из циклов сравнений убрать предлоги и короткие местоимения. После первой итерации оказалось, что в ТОП-10 не попадает ни одного существительного из трех букв (меч, зло, тыл и т.п.), и я последовательно подчистил список от трехбуквенных слов, и даже, после дальнейших опытов, — от четырехбуквенных слов.
В списке наиболее часто употребляемых слов оказалось не так уж и много существительных, поэтому пришлось из списка слов романа для дальнейшей оценки убрать слова «только», «когда»,
«чтобы», «теперь», «этого», «которые», «который», «потому», «опять», «вдруг», «очень», «ничего», «своей».
В итоге ТОП-10 популярных слов:
1. сказал — 1411
2. князь — 952
3. время — 544
4. Андрей — 500
5. говорил — 464
6. княжна — 435
7. сказала — 424
8. человек — 391
9. Наташа — 376
10. людей — 372
Так как поиск велся без учета форм слов, для «князь» пришлось отыскать все формы слова. После уточнения данных КНЯЗЬ занял первое место в ТОПе с 1435 упоминаниями в романе, против глагола СКАЗАЛ.
Как видно из списка глаголы СКАЗАЛ(1411) и ГОВОРИЛ(464) в романе встречаются чаще, чем глаголы СКАЗАЛА(424), что говорит о том, что в романе мужчины в 4,5 раза говорят больше, чем женщины (тут слышны обвинения в сексизме в адрес Льва Николаевича), да и КНЯЖНА (435) появляется намного реже КНЯЗЯ.
Так же стало интересно, какое отношение у общества было к Наталье Ильиничне Ростовой aka Наташа Ростова. На протяжении романа она так и осталась Наташей, несмотря на то, что к концу романа Наталья Ростова стала женой Пьера Безухова. Во всех формах Наташа встречается в тексте 591 раз, при этом формы имени Наталья и Натали встречаются всего 9 раз.
Не смотря на название, «война» в романе встречается во всех формах только 278 раз.
Я разбил весь роман на участки по 10 тыс. слов и решил проследить упоминания слов «князь», «Наташа» и «война» по ходу романа.
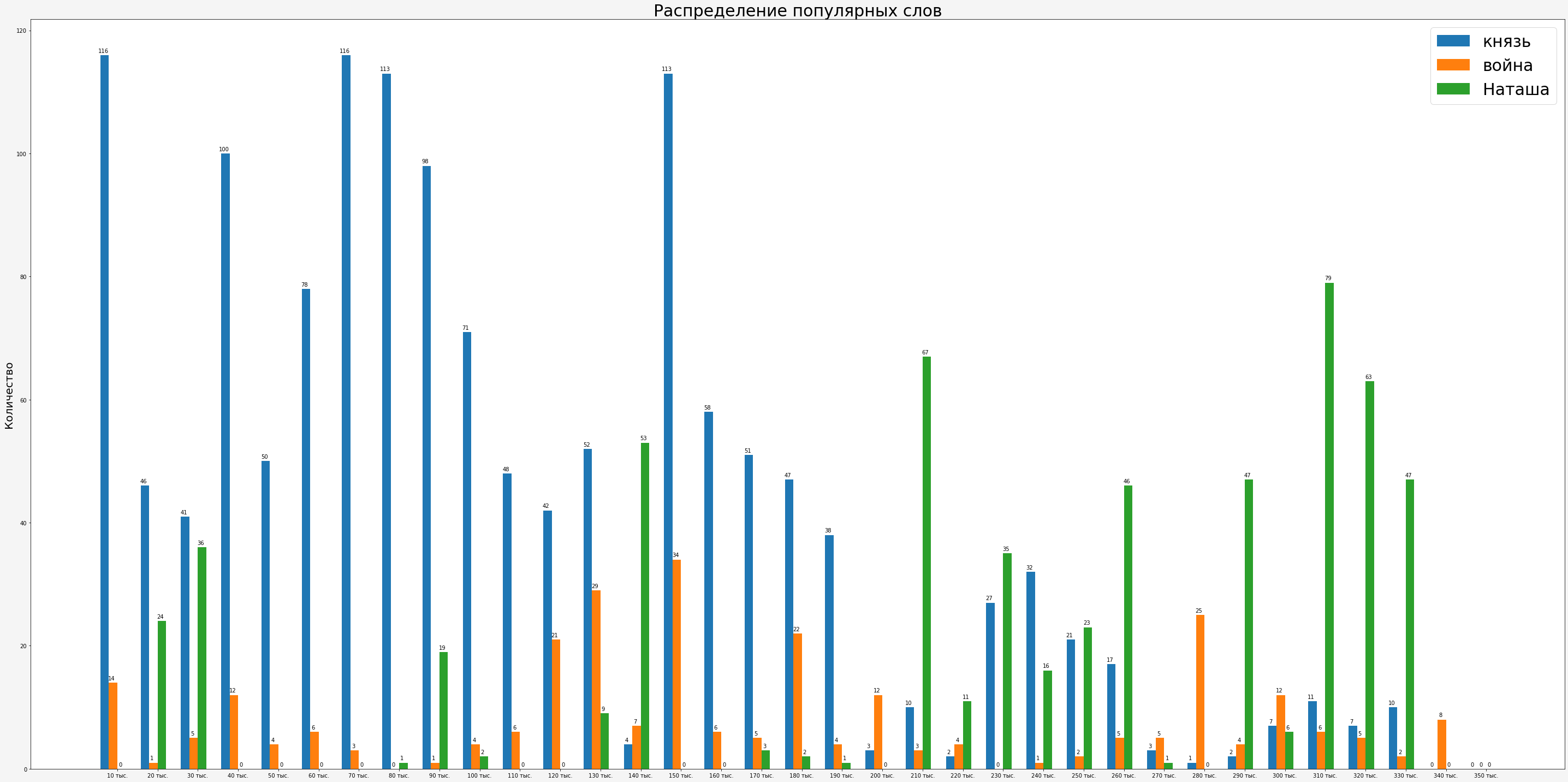
По гистограмме видно, что про князей после всплеска описания войны к концу романа говорят меньше, а все больше вспоминают про Наташу.
Хорошо видна обратная корреляция в распределении зависимости упоминания слов «война» и «Наташа» — чем меньше войны, тем больше Наташи.
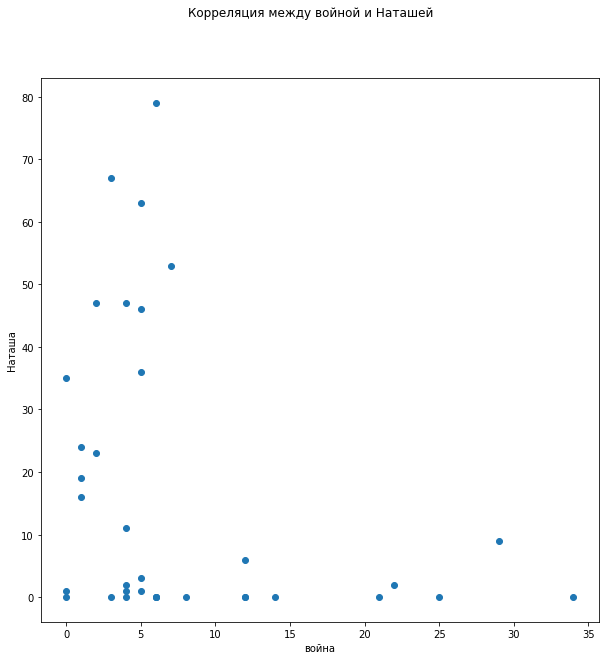
Также четко просматривается обратная корреляция в распределении зависимости упоминания слов «князь» и «Наташа».

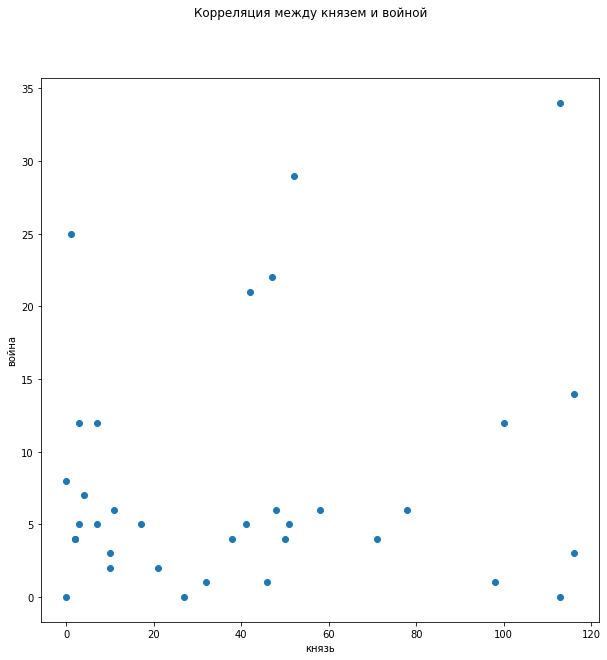
В распределении зависимости упоминания слов «князь» и «война» не просматривается четкой корреляции, хотя видно, что когда про войну мало говорят, то и про князей не вспоминают, однако это не объясняет большое число упоминаний «князей» в отсутствие «войны».
Необходимо отследить корреляцию по ходу развития повествования.
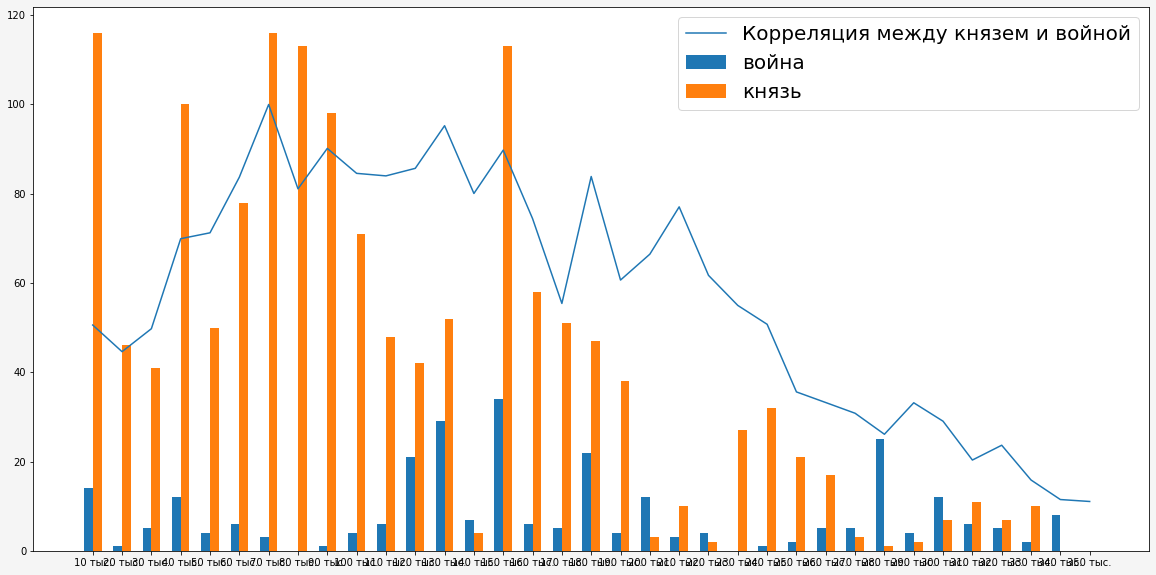
Как видно из графика, высокая корреляция присутствует только в середине романа, когда в романе идет война, в иных местах романа корреляция низкая, на основании чего можно сделать вывод, что употребление «князя» и «войны» не имеет постоянной корреляции по ходу романа.
Однако решил, что изучить стоит…
Подготовка
Я не вычищал от сторонних слов и знаков (латинских номер частей, номеров сносок и части комментариев), что на фоне почти 400 тысяч слов текста романа, погрешность даже в тысячу слов не даст неверных данных, но я решил минимальную подготовку текста все-таки совершить.
Часть программы подготовки файла
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
#filename = input(«Введите путь к файлу: „)
filename = # полный путь к файлу
file = open(filename, 'r')
text = file.read()
text = text.replace(“\n», " ")
text =text.replace(']','').replace('[','').replace('\"','').replace(",", "").replace(".", "").replace("?", "").replace("!", "").replace(")", "").replace("(", "")
text =text.lower()
words_untill = text.split() # отдельно сохранил роман по словам до всех изменений
…
import matplotlib.pyplot as plt
import numpy as np
#filename = input(«Введите путь к файлу: „)
filename = # полный путь к файлу
file = open(filename, 'r')
text = file.read()
text = text.replace(“\n», " ")
text =text.replace(']','').replace('[','').replace('\"','').replace(",", "").replace(".", "").replace("?", "").replace("!", "").replace(")", "").replace("(", "")
text =text.lower()
words_untill = text.split() # отдельно сохранил роман по словам до всех изменений
…
Как человеку, работающему постоянно с числами, мне стали интересны следующие вопросы:
1. Самое длинное слово в романе
Узнав от жены, что Лев Николаевич еще тот графоман, решил узнать, каких длинных слов выдумал для романа Толстой.
Итак, ТОП-3 длинных слов.
Первое место (27 букв и дефис) поделили слова сверхъестественно-прекрасное, сверхъестественно-утонченное и непреодолимо-обворожительным:
… Как хороший метрдотель подает как нечто сверхъестественно-прекрасное тот кусок говядины, который есть не захочется, если увидать его в грязной кухне, так в нынешний вечер Анна Павловна сервировала своим гостям сначала виконта, потом аббата, как что-то сверхъестественно-утонченное…
… Француз бывает самоуверен потому, что он почитает себя лично, как умом, так и телом, непреодолимо-обворожительным как для мужчин, так и для женщин. Англичанин самоуверен на том основании, что он есть гражданин благоустроеннейшего в мире государства, и потому, как англичанин, знает всегда, что ему делать нужно, и знает, что все, что он делает как англичанин, несомненно хорошо. Итальянец самоуверен потому, что он взволнован и забывает легко и себя и других...
Второе место (25 букв и дефис) заняло слово однообразно-разнообразными:
… Гусары не оглядывались, но при каждом звуке пролетающего ядра, будто по команде, весь эскадрон со своими однообразно-разнообразными лицами, сдерживая дыханье, пока летело ядро, приподнимался на стременах и снова опускался…
Третье место (24 буквы) заняло слово высокопревосходительство, данное слово в отличие от предыдущих встречается восемь раз, как обращение к фельдмаршалу Михаилу Илларионовичу Кутузову.
Часть программы по поиску самого длинного слова
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
…
words = text.split() #сделал копию романа, из которой в дальнейшем буду вырезать все не нужное, для сокращения циклов
words = sorted(words, key = len, reverse=True) #отсортированный по длине слов
…
for i in range(3): #отсортированный по длине слов
print(words[i].ljust(30), len(words[i])) #вывод топ-3 самых длинных слов с указанием их длины
…
import matplotlib.pyplot as plt
import numpy as np
…
words = text.split() #сделал копию романа, из которой в дальнейшем буду вырезать все не нужное, для сокращения циклов
words = sorted(words, key = len, reverse=True) #отсортированный по длине слов
…
for i in range(3): #отсортированный по длине слов
print(words[i].ljust(30), len(words[i])) #вывод топ-3 самых длинных слов с указанием их длины
…
2. Самое часто употребляемое слово
Предварительно список был очищен от слов из одной и двух букв, чтобы из циклов сравнений убрать предлоги и короткие местоимения. После первой итерации оказалось, что в ТОП-10 не попадает ни одного существительного из трех букв (меч, зло, тыл и т.п.), и я последовательно подчистил список от трехбуквенных слов, и даже, после дальнейших опытов, — от четырехбуквенных слов.
Часть программы по очистке от коротких слов
…
words2 =[]#список cлов, длиннее четырех букв
for i in range(len(words)):#запись всех слов длиннее четырех букв в новый список
if len(words[i])>4:
words2.append(words[i])
else: break #до этого у нас словарь был отсортирован по длине, поэтому, как только четырехбуквенные слова закончатся, дальше нет смысла циклу работать
…
words2 =[]#список cлов, длиннее четырех букв
for i in range(len(words)):#запись всех слов длиннее четырех букв в новый список
if len(words[i])>4:
words2.append(words[i])
else: break #до этого у нас словарь был отсортирован по длине, поэтому, как только четырехбуквенные слова закончатся, дальше нет смысла циклу работать
…
В списке наиболее часто употребляемых слов оказалось не так уж и много существительных, поэтому пришлось из списка слов романа для дальнейшей оценки убрать слова «только», «когда»,
«чтобы», «теперь», «этого», «которые», «который», «потому», «опять», «вдруг», «очень», «ничего», «своей».
Часть программы по поиску самых популярных слов
…
words_counts = Counter(words2)
n = []
pop_word = []
for word, count in words_counts.most_common(10):#вывод топ-10 самых популярных слов
n.append(count)
pop_word.append(word)
print(word.ljust(20), count)
…
words_counts = Counter(words2)
n = []
pop_word = []
for word, count in words_counts.most_common(10):#вывод топ-10 самых популярных слов
n.append(count)
pop_word.append(word)
print(word.ljust(20), count)
…
В итоге ТОП-10 популярных слов:
1. сказал — 1411
2. князь — 952
3. время — 544
4. Андрей — 500
5. говорил — 464
6. княжна — 435
7. сказала — 424
8. человек — 391
9. Наташа — 376
10. людей — 372
Так как поиск велся без учета форм слов, для «князь» пришлось отыскать все формы слова. После уточнения данных КНЯЗЬ занял первое место в ТОПе с 1435 упоминаниями в романе, против глагола СКАЗАЛ.
Поиск всех форм слова КНЯЗЬ
…
n4 = []
form_n4 = []
for i in range(len(words_untill)):
if «княз» in words_untill[i]:
n4.append(1)
form_n4.append(words_untill[i])
else: n4.append(0)
print(«Формы слова КНЯЗЬ — » + str(len(form_n4)))
…
n4 = []
form_n4 = []
for i in range(len(words_untill)):
if «княз» in words_untill[i]:
n4.append(1)
form_n4.append(words_untill[i])
else: n4.append(0)
print(«Формы слова КНЯЗЬ — » + str(len(form_n4)))
…
Как видно из списка глаголы СКАЗАЛ(1411) и ГОВОРИЛ(464) в романе встречаются чаще, чем глаголы СКАЗАЛА(424), что говорит о том, что в романе мужчины в 4,5 раза говорят больше, чем женщины (тут слышны обвинения в сексизме в адрес Льва Николаевича), да и КНЯЖНА (435) появляется намного реже КНЯЗЯ.
Так же стало интересно, какое отношение у общества было к Наталье Ильиничне Ростовой aka Наташа Ростова. На протяжении романа она так и осталась Наташей, несмотря на то, что к концу романа Наталья Ростова стала женой Пьера Безухова. Во всех формах Наташа встречается в тексте 591 раз, при этом формы имени Наталья и Натали встречаются всего 9 раз.
3. Где в романе была война?
Не смотря на название, «война» в романе встречается во всех формах только 278 раз.
Поиск всех форм слова ВОЙНА
…
n3 = []
form_n3 = []
for i in range(len(words_untill)):
if «войн» in words_untill[i] and «конвойн» not in words_untill[i]:# слова типа «конвойный» надо исключить из списка
n3.append(1)
form_n3.append(words_untill[i])
else: n3.append(0)
print(form_n3)
print(«Формы слова ВОЙНА — » + str(len(form_n3)))
…
n3 = []
form_n3 = []
for i in range(len(words_untill)):
if «войн» in words_untill[i] and «конвойн» not in words_untill[i]:# слова типа «конвойный» надо исключить из списка
n3.append(1)
form_n3.append(words_untill[i])
else: n3.append(0)
print(form_n3)
print(«Формы слова ВОЙНА — » + str(len(form_n3)))
…
Я разбил весь роман на участки по 10 тыс. слов и решил проследить упоминания слов «князь», «Наташа» и «война» по ходу романа.
Разбиение романа по 10 тыс. слов
…
как вы ранее могли заметить все упоминания слов записаны как двоичные векторы по длине романа: «0» — не совпадают слова, «1» — совпадают.
…
m1=[]
m2=[]
m3 =[]
m4 = []
while i <= len(n1):
m1.append(sum(n1[i: i+10000]))# «сказал»
m2.append(sum(n4[i: i+10000]))# с учетом форм слова «князь»
m3.append(sum(n3[i: i+10000]))# с учетом форм слова «война»
m4.append(sum(nata1[i: i+10000]))# с учетом форм слова «Наташа»
i=i+10000
…
как вы ранее могли заметить все упоминания слов записаны как двоичные векторы по длине романа: «0» — не совпадают слова, «1» — совпадают.
…
m1=[]
m2=[]
m3 =[]
m4 = []
while i <= len(n1):
m1.append(sum(n1[i: i+10000]))# «сказал»
m2.append(sum(n4[i: i+10000]))# с учетом форм слова «князь»
m3.append(sum(n3[i: i+10000]))# с учетом форм слова «война»
m4.append(sum(nata1[i: i+10000]))# с учетом форм слова «Наташа»
i=i+10000
…
По гистограмме видно, что про князей после всплеска описания войны к концу романа говорят меньше, а все больше вспоминают про Наташу.
Хорошо видна обратная корреляция в распределении зависимости упоминания слов «война» и «Наташа» — чем меньше войны, тем больше Наташи.
Также четко просматривается обратная корреляция в распределении зависимости упоминания слов «князь» и «Наташа».
В распределении зависимости упоминания слов «князь» и «война» не просматривается четкой корреляции, хотя видно, что когда про войну мало говорят, то и про князей не вспоминают, однако это не объясняет большое число упоминаний «князей» в отсутствие «войны».
Необходимо отследить корреляцию по ходу развития повествования.
Как видно из графика, высокая корреляция присутствует только в середине романа, когда в романе идет война, в иных местах романа корреляция низкая, на основании чего можно сделать вывод, что употребление «князя» и «войны» не имеет постоянной корреляции по ходу романа.
Выводы
- Классику надо читать!!!
- Если вы хотите прочитать про войну, а не про любовь, то читайте первую часть первого тома и третий том.
- Если вы хотите прочитать про то, как жили князья в мирное время, то подойдет прекрасно второй том.
- Если вам интересна любовь в отсутствие войны, то стоит почитать четвертый том.




empenoso
Интересно. А как-то можно определять эмоциональную окраску текста? Позитивный/негативный?
9_pm
Вообще да, но чаще всего модели натренированы на каких-нибудь отзывах о продуктах/фильмах/программах и могут показывать весьма странные результаты на художественном тексте.
empenoso
А практически как это осуществить?
9_pm
Слова для гугления — «sentiment analysis» можно python добавить. Тут, например, несколько статей было про это. Есть куча готовых библиотек в открытом доступе. Для русского языка тоже. Правда, когда смотрел (года полтора назад), качество свободных моделей для русского языка сильно отличалось от качества свободных моделей для английского. Но всё развивается — может, сейчас уже всё лучше.