
Хорошая спецификация к API помогает клиентам его использовать. Несколько месяцев назад на большом Pytup разработчик Яндекса Александр Брязгин bryazginnn выступил с докладом о том, что собой представляет спецификация REST API на примере OpenAPI + Swagger и зачем нужна такая связка. Из конспекта можно узнать, как мы прикручивали автоматическую генерацию спецификации в уже готовом сервисе, какие библиотеки нам пригодились и какой есть тулинг вокруг спецификации OpenAPI.
— Всем привет, меня зовут Александр. Я хотел бы поговорить с вами про спецификации.

Если конкретно, я бы хотел затронуть несколько тем. Во-первых — что такое спецификации на примере спецификаций REST API. Далее — как мы в нашем сервисе прикручивали генерацию спецификации. И в конце, на сладенькое — какие есть инструменты, тулинг, чтобы использовать результаты нашей генерации спецификаций, на примере такой спецификации, как OpenAPI и Swagger UI.
Что такое спецификации и что я под этим подразумеваю в своем докладе?

В первую очередь это Interface Description Language, язык описания интерфейсов, какое-то описание, которое соответствует определенному формату. Его можно парсить автоматически, потому что у него строгий формат и такая специфика, что оно не зависит от самого языка, на котором реализован интерфейс. То есть, допустим, у вас есть веб-сервер на Python, для Interface Description Language это не имеет значения.
Языков описания спецификаций достаточно много. Это спецификации для REST, RPC, GraphQL и т. д. Сегодня мы остановимся подробнее на спецификации REST.
Давайте будем говорить о спецификациях на примере OpenAPI.
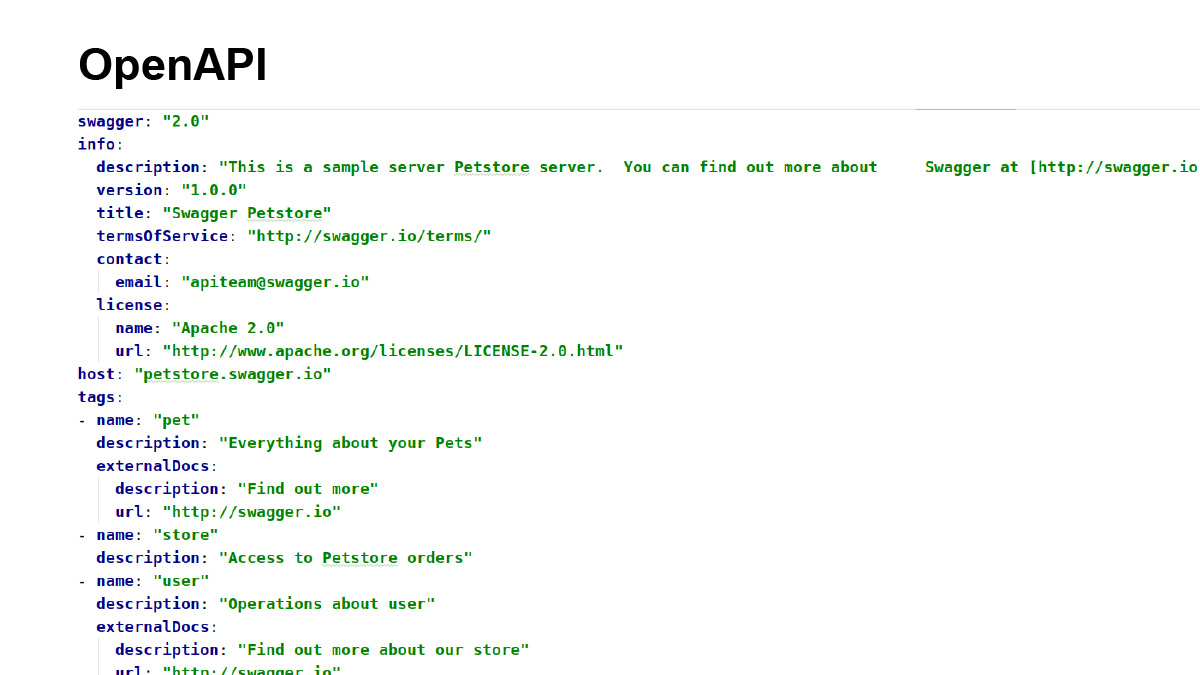
Сначала поймем, что такое OpenAPI. Это как раз таки language для описания спецификаций. Сам по себе он представляет собой файл — в формате YAML, JSON или XML, кому что больше нравится — с описанием интерфейса, ручек-endpoints и схем.
Когда мы говорим про OpenAPI, нельзя не сказать про Swagger.

Swagger — это, по сути, UI для OpenAPI, который позволяет вам красиво визуализировать вашу спецификацию.

В Swagger, как и в OpenAPI, есть описание endpoints, которые есть в вашей спецификации.

Есть описание авторизации в вашем API.

Есть описание моделей или же схем, с которыми вы манипулируете в вашем API — допустим, принимаете на вход или отдаете на выход.

Есть описание примеров и ожидаемых запросов и ответов вашего API.

И дополнительно в своем Swagger, благодаря тому, что это UI и он запущен у вас в браузере, вы можете в реалтайме выполнять запросы к вашему API прямо здесь и сейчас.

Ссылка со слайда
С этим всем можно поиграться на тестовом стенде, подготовленном командой Swagger. Это petstore.swagger.io. Там есть пример спецификации, поднят Swagger. Вы можете сходить в реальный бэкенд и пощупать. Рекомендую.

Итак, мы говорим: OpenAPI, Swagger, спецификация. Но зачем все это нужно человеку, который пишет, допустим, бэкенд?
В первую очередь, спецификации часто используются на этапе проектирования нашего API. То есть нормальные люди, придя к задаче написания бэкенда, начинают с того, что описывают, что же они хотят реализовать. То есть они начинают проектировать свой API, список endpoints, которые они хотят реализовать, список схем, с которыми будут манипулировать, параметров и т. д. В этом случае спецификации и инструменты вокруг спецификаций очень удобны.
Помимо этого есть популярный кейс. Ради чего мы затаскивали спецификацию к нам в сервис? Это документирование. Наличие спецификаций дает вам такую хорошую возможность описывать ваш API и делиться этой информацией с кем-то: или с фронтендерами в вашей команде, или с внешними клиентами, которые хотят с вами интегрироваться.
Также благодаря тому, что спецификация написана в определенном строгом формате, ее можно автоматически процессить, то есть заниматься интроспекцией API. И поверх можно навертеть очень много инструментария, который позволяет облегчить вам жизнь. Конкретнее и подробнее расскажу чуть попозже.
Мы определились, зачем нам все это нужно. Давайте расскажу, как мы в нашем сервисе прикручивали генерацию спецификаций. Сначала немного контекста.

Когда мы пришли к мысли, что давайте запилим спецификацию, мы пошли не по нормальному пути, когда мы сначала написали проект, в смысле прототип со спецификацией. Мы уже подняли какой-то бэкенд, он у нас уже летел, и мы захотели расшарить спецификацию как способ документирования.
И наш бэкенд внезапно был на Python. В качестве фреймворка мы использовали Falcon, в качестве инструмента сериализации и десериализации данных — marshmallow, в качестве инструмента валидации — webargs.
На примере простейшей вырезки из petstore, о котором я говорил раньше, представим, как бы мог выглядеть наш сервис на этапе, когда мы захотели генерировать спецификацию.
В нашем сервисе упрощенно была бы пара схем: тип нашего домашнего животного, то есть категория, и, собственно, сами животные.

То есть мы бы описали несколько схем на Marshmallow. Дальше мы подготовили бы несколько ручек для того, чтобы, допустим, регистрировать и получать наших любимчиков.

И, собственно, описали бы сам application, которым подняли бы endpoint по созданию и получению pets.

Вот так это выглядело бы вместе. Достаточно простой сервис.
Давайте подумаем, какие у нас есть варианты формирования OpenAPI-конфига. Самый простой и наивный вариант, как я говорил ранее, — это просто файлик. Почему бы нам этот файлик не составить руками? Мы знаем, какие у нас есть данные на входе, у нас есть endpoints. Кажется очевидным, просто берем и пишем.

Но, во-первых, мы программисты. Мы не любим ничего делать руками. Мы хотим, чтобы нечто стандартное генерировалось за нас. Во-вторых, если бы мы поддерживали все руками, нам непременно бы пришлось поддерживать изменения API, а также файлик, который лежит где-то в другом месте. Как и любой сервис, наш продукт изменчив, и спецификация тоже.
Поэтому мы пришли к тому, что хотим генерировать OpenAPI-конфиг. С учетом нашего стека технологий мы нашли такую библиотеку, как apispec. Apispec — библиотека от производителей, то есть авторов Marshmallow и Webargs. Они вместе составляют большую экосистему.
Давайте посмотрим, как можно воспользоваться apispec на нашем стеке, чтобы научить его генерировать для нас спецификацию.

У нас был ресурс и определенный хендлер на метод get этого ресурса. У него есть какое-то тело.

Чтобы научить apispec, дать ему понять, что же мы делаем в нашей ручке, мы что-то дописываем в docstring. Мы дописываем туда описание, понятное человеку. В нашем случае это пример ответов: иногда бывает, наша ручка отвечает двухсоткой, и в теле нашего ответа есть JSON со схемой, моделью данных Pet.


На примере post-запроса мы описываем: помимо того, что есть ответ 201, в котором мы возвращаем Pet, есть еще ожидаемое тело запроса, который к нам приходит. И внутри этого запроса мы ожидаем JSON, и ожидаем, что этот JSON будет в формате Pet.

Мы добавили docstrings, дальше нам нужно научиться генерить спецификацию. Для этого мы пишем какой-то скриптик, красную кнопочку, и учим apispec генерировать для нас спецификацию. Мы декларируем объект apispec, у которого описываем какие-то метаданные нашего сервиса, и дальше просто пишем файл, сгенерированную спецификацию в формате YAML.
Давайте посмотрим, что для нашего огромного приложения сгенерировалось в этом файлике.

В первую очередь в этом файлике будет описание версии, в котором сгенерировалась спецификация. Это важно для того, чтобы все, кто будут интерпретировать эту спецификацию, понимали, в каком формате надо интерпретировать. От версии к версии спецификации меняются.
Дальше есть описание нашего сервиса. Это title, версия, возможно, будет какой-то description, если вы этого хотите, и дальше список серверов, на которые можно сходить, подергать ручки, увидеть и пощупать наш бэкенд.

Помимо этого там прорастают сами схемы данных, которыми мы манипулируем, с описанием типов, с описанием примеров заполнения этих данных и каких-то правил. Возможно, это какие-то крайние значения, возможно, обязательность параметров. Вот здесь вы видите список обязательных атрибутов.

Помимо схем туда прорастает описание самих endpoints. В данном случае прорастает описание по каждому методу.

По методу get у нас прорастает описание того, что мы делаем на метод get.

И на post проросло ровно то описание, которое мы положили в docstrings соответствующего endpoint. То есть мы уже получили какой-то файл.
Что нам теперь с ним делать? В чем польза? В первую очередь вы как владельцы бэкенда уже можете всем потенциальным клиентам, которые будут ходить в ваши ручки, отдавать эту спецификацию. И это поможет ребятам проинтегрироваться. То есть тот файлик, который мы сгенерировали, не заставляет вам выколоть глаза. Он достаточно читабельный. Его можно посмотреть глазами и как-то распарсить.
Но это тоже сложно. Давайте посмотрим, какие есть другие инструменты, чтобы упростить себе жизнь и какой есть тулинг вокруг сгенерированной спецификации.
И тут мы приходим к следующему этапу, где мы будем говорить о том, какой есть полезный инструментарий вокруг спецификаций на примере OpenAPI.
Ссылка со слайда
Первый инструмент, про который я хотел бы сказать, это Swagger-UI. Здесь и далее я буду приводить ссылочки или на веб-ресурс, в котором можно потыкать соответствующий инструмент, в данном случае это SwaggerHub, или на команду запуска соответствующего документа с помощью Docker.
Мы все очень любим Docker. Docker помогает вам не ставить на локале JavaScript или какую-нибудь Java. Просто берете, запускаете одной командой, и у вас все работает.
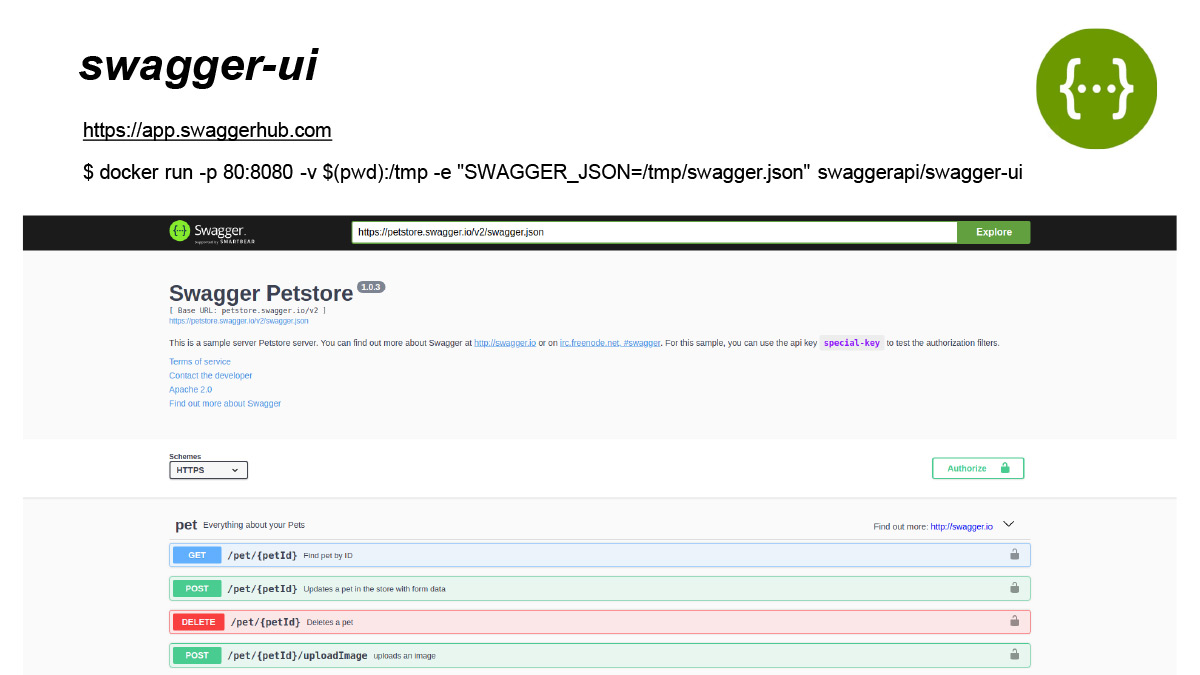
Так вот, Swagger-UI — это, по сути, утилита, которая позволяет вам красиво отобразить вашу спецификацию. Как я ранее говорил, это запущенные на локале с помощью Docker, возможно, Swagger.
Вы можете на локале посмотреть или расшарить, запустив на своем железе, спецификацию в Swagger. И дальше отправлять всех ваших потенциальных пользователей на эту спецификацию. Она уже намного более понятная, красивая. Прямо в ней можно делать выполнение запросов.
Ссылка со слайда
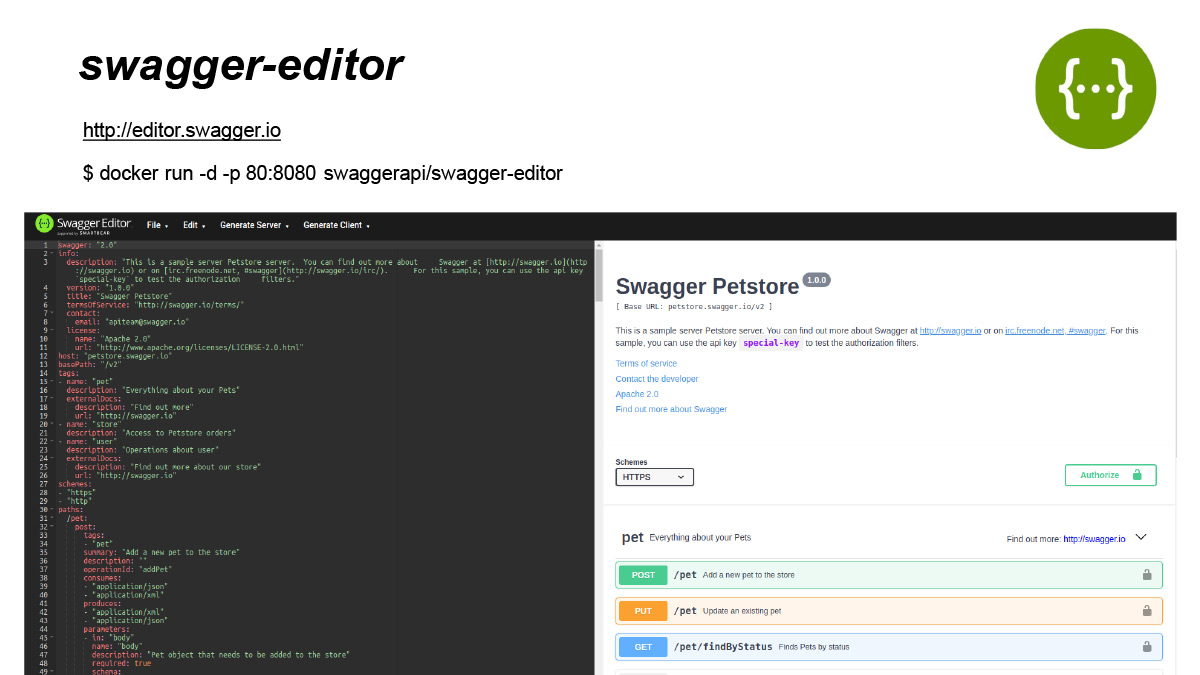
Помимо Swagger-UI есть удобный инструмент Swagger-editor. Можно использовать его в вебе, можно поднять на локале или на любой машинке. Он позволяет вам в реалтайме изменять спецификацию и видеть ее отображение прямо тут. То есть это очень удобный инструмент на этапе, допустим, проектирования API, когда у вас не генерируется спецификация, а вы хотите как-то подшаманить или описать ваш бэкенд, не имея ни реального, ни генерируемого бэкенда позади,.
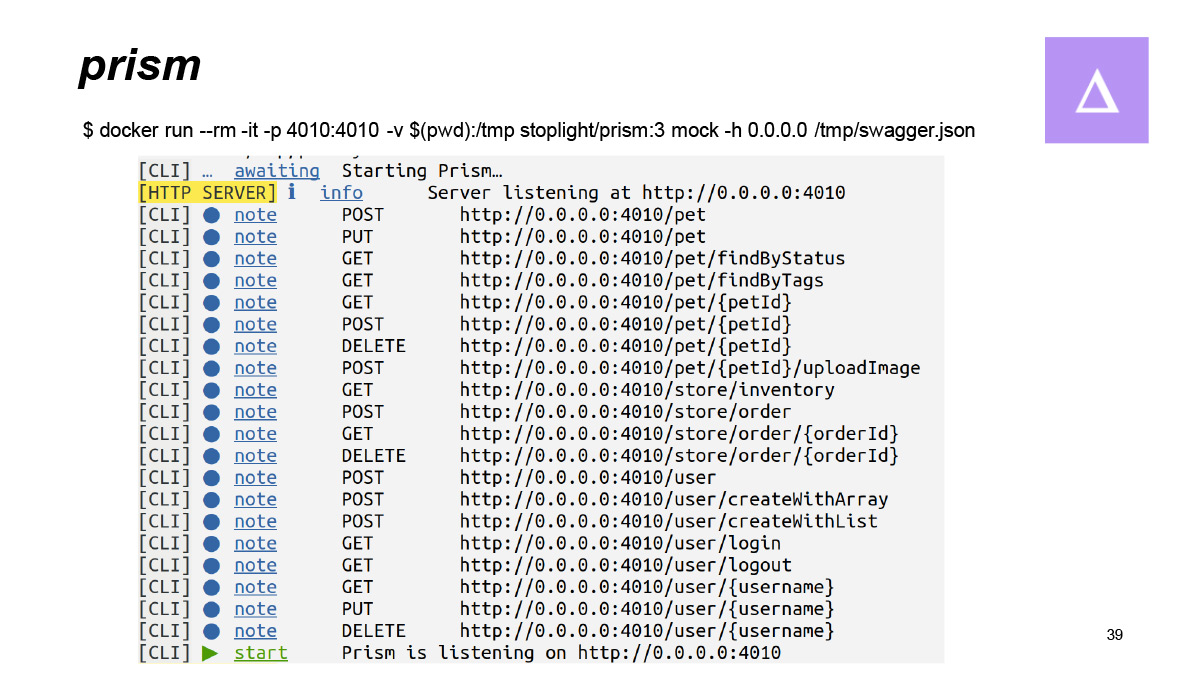
Дальше есть замечательный инструмент Prism. На нем я бы хотел остановиться поподробнее. Prism — это утилита от Spotlight. Он позволяет вам, имея спецификацию, поднять mock-server, который будет работать согласно той спецификации, которую вы ему скормили.
То есть в данном случае мы видим запуск Prism поверх спецификации, которую я стащил как раз из-под сваггеровского store. Мы видим, что Prism нашел все endpoints, которые указаны в спецификации, и сказал, что честно их замокал.
Давайте попробуем пощупать, что Prism умеет делать.

В первую очередь, мы находим ручку, пробуем ее дернуть и внезапно видим, что Prism говорит нам: sorry, 401 ошибка. Мы идем в спецификацию и видим, что на самом деле эта ручка спрятана за авторизацией. Там явно описана секция секьюрити. В ней мы видим, что способ авторизации — OAuth, и понимаем: на самом деле Prism ожидал от нас какие-то авторизационные данные.

Давайте попробуем ему передать авторизационные данные согласно тому формату, который он ждет. Понятно, что токен здесь какой-то воздушный, для Prism неважно, какой он по сути. Ему важен именно формат. То есть, если он ждет именно OAuth, он ждет авторизационные данные в определенном формате.
Мы дергаем с Authorization и видим уже 400-ю ошибку. Смотрим, что же у нас в спецификации. В спецификации мы видим, что мы не передали некоторые обязательные атрибуты. Давайте их передадим.

Волшебный атрибут status. Он, на самом деле, дан согласно спецификации ENUM. Если бы мы передали статус, не входящий в этот ENUM, то получили бы четырехсоточку.
Здесь мы передали валидный статус и видим, что бэкенд ответил уже вполне валидным xml с данными. Данные в этом xml сейчас отдаются всего лишь сгенерированные из example, указанные в спецификации. То есть в спецификации для каждого поля есть такая секция, как example, где вы можете указать пример данных, которые могут вернуться. Здесь Prism просто вернул их.

Но помимо того, что вы можете дернуть ручку и ожидать, что будет честная двухсоточка, есть возможность сказать Prism — верни мне определенный код ответа. Обычно в спецификации мы описываем различное поведение нашей ручки, и при валидных данных они не всегда отвечают двухсотками. Они могут посмотреть, допустим, на наличие айдишников в базе, посмотреть, что такого айдишника не существует.
Для этого случая мы декларируем определенный код, допустим, 400-й или 422-й, кому как угодно. То есть при валидном входе не всегда есть валидный выход. Поэтому в спецификации мы описываем различные варианты ответов. И мы можем явно при дергании ручки сказать Prism: в этот раз я жду, что ты мне ответишь, допустим, 404-й ошибкой. Допустим, это кейс, когда я дергаю ручку с айдишником, но такого айдишника нет.

Если подытожить, то какие в целом есть фичи, помимо тех, о которых я уже сказал? Опять же, это mock server, который вы можете поднять. Он будет отвечать согласно спецификации, валидировать запросы на авторизацию. Также он будет валидировать на те данные, которые вы ему отправили.
Помимо валидации запроса, он будет генерировать ответы. В простейшем случае, как я сказал, он генерирует ответы по example. Есть второй вариант — когда вы просите его явно: генерируй, пожалуйста, динамические ответы. Динамическая стратегия означает, что он, в зависимости от типа, допустим, int, будет генерировать какие-нибудь тысячи, миллиарды или еще что-нибудь. Или для строки странный и непонятный хэш.
Также, когда я рассказал на первом прогоне, что можно генерировать данные, мы задались вопросом: было бы прикольно, если бы Prism интегрировался c faker. Те, кто пользовался питоновским faker, наверное, знают, насколько он клевый, когда вы хотите замокать какие-то данные или эмулировать данные в базе.
Так вот, Prism написан на JavaScript. В JavaScript тоже есть Faker.js, и у Prism есть автоматическая интеграция с faker. Вы можете в своей спецификации явно указать типы faker-данных, которые ваша ручка будет отдавать. То есть OpenAPI поддерживает систему плагинов, которая позволяет расширять вашу спецификацию так, что OpenAPI и самому парсеру это не важно. Но если есть плагины, которые парсят вашу спецификацию, они могут пользоваться какими-то дополнительными полями.
Так вот, Prism предлагает вам использовать дополнительное плагин-поле X-faker. Очень удобно.
Здесь под звездочкой я указал, что в OpenAPI можно описывать callbacks. Это схема взаимодействия, когда вы регистрируете callback на определенную ручку и ждете, что после этого вам придет определенный callback на зарегистрированный вами url. Так вот, Prism и это умеет мокать.
Из интересного: Prism можно поднять не только в режиме mock, но и в режиме Proxy. Вы просто ставите эту Proxy перед своим реальным бэкендом, и все запросы, которые идут через Prism и возвращаются обратно, Prism будет валидировать на соответствие спецификации.
Если какие-то данные — допустим, вход или выход, request или response — будут расходиться, он будет писать это в логе. Он делает это достаточно прозрачно, это никак на реальном поведении не сказывается. И вообще, в документации написано, что это можно спокойно поднимать в продакшене. Честно говоря, сам не пробовал. Наверняка существует какой-то overhead, но про него пока сказать не могу. Вы можете пощупать, попробовать и рассказать.
Дальше можно через то, что я уже сказал, форсировать определенные запросы. То есть к mock server прийти и сказать: я хочу определенный example или тип ответа. Про тип ответа мы уже поговорили. Также в OpenAPI-спецификации есть возможность указать несколько вариантов ответов и их явно именовать.
Так вот, можно прийти и сказать Prism: в этот раз я хочу определенный example, в следующий раз я хочу другой example.
Ссылка со слайда
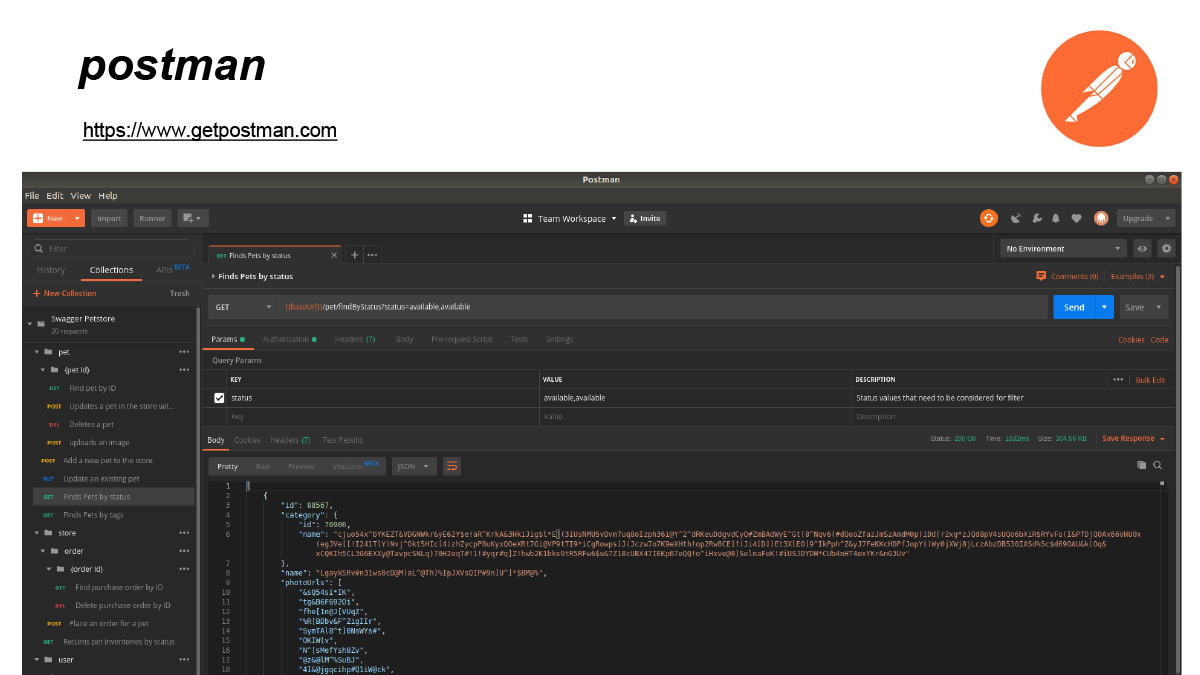
Про Prism поговорили. Теперь про Postman. Я его очень люблю. Так вот, у Postman есть из коробки интеграция с OpenAPI. Вы можете буквально двумя нажатиями кнопочек заимпортировать OpenAPI-спецификацию. И он создаст коллекцию запросов по вашей спецификации.
При этом он заранее предподготовит все query параметры, все body-параметры, весь environment и авторизацию. Вам останется только добить данные какими-то реальными айдишниками или еще чем-то, авторизационными токенами. Очень удобно.
Переходим от Postman дальше. Мы поговорили про Prism, у него есть функциональность — валидация запросов. На самом деле, есть отдельная утилита, которая позволяет вам нещадно поддосить ваш реально запущенный бэкенд и проверить, реально ли он работает согласно спецификации.
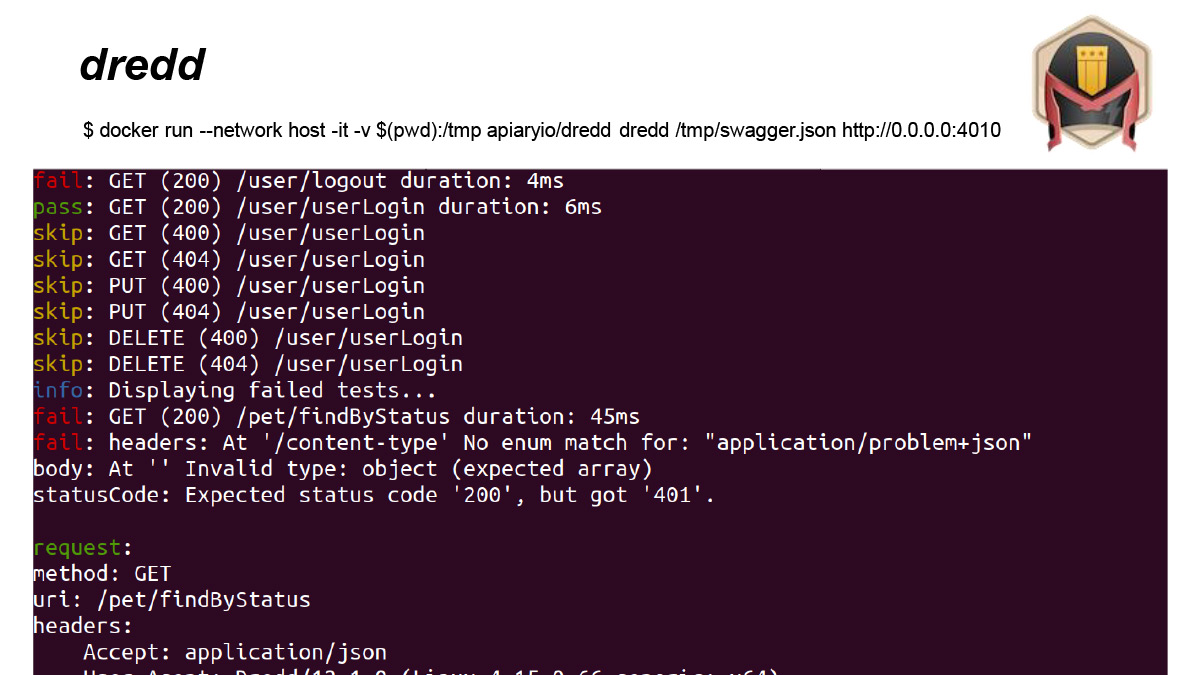
Dredd парсит спецификацию. Берет, дергает все ручки и смотрит, что же ему вернулось. В целом, к dredd можно относиться как к инфраструктуре по написанию тестов, потому что все его запросы можно дополнить своими хуками. То есть из коробки можно запустить dredd просто as is, как я запустил его вот здесь.
А можно запустить dredd, передав ему набор хуков, которые, на самом деле, работают в идеологии обычного теста. Там есть что-то, что поднимается на все множество тестов, есть хуки, которые запускаются перед тестом, после теста, вся инфраструктура.

Ссылка со слайда
Дальше хочу поподробнее поговорить про такой инструмент от самого Swagger, как Swagger-codegen. На самом деле это немного напоминает швейцарский нож. Начну с того, какие мысли были у ребят, когда они писали этот инструмент.
Обычно, когда кому-то нужно проинтегрироваться с бэкендом, вы в бизнес-логике редко описываете прямо здесь, на определенном этапе, http-запрос. Чаще всего вы инкапсулируете работу с определенным бэкендом в какой-то сущности, в клиенте.
Так вот, ребята пришли к мысли, что, имея спецификацию, мы достаточно понятно можем описать и предсказать, как выглядел бы клиент к этому бэкенду. И ребята сделали генератор клиентов.

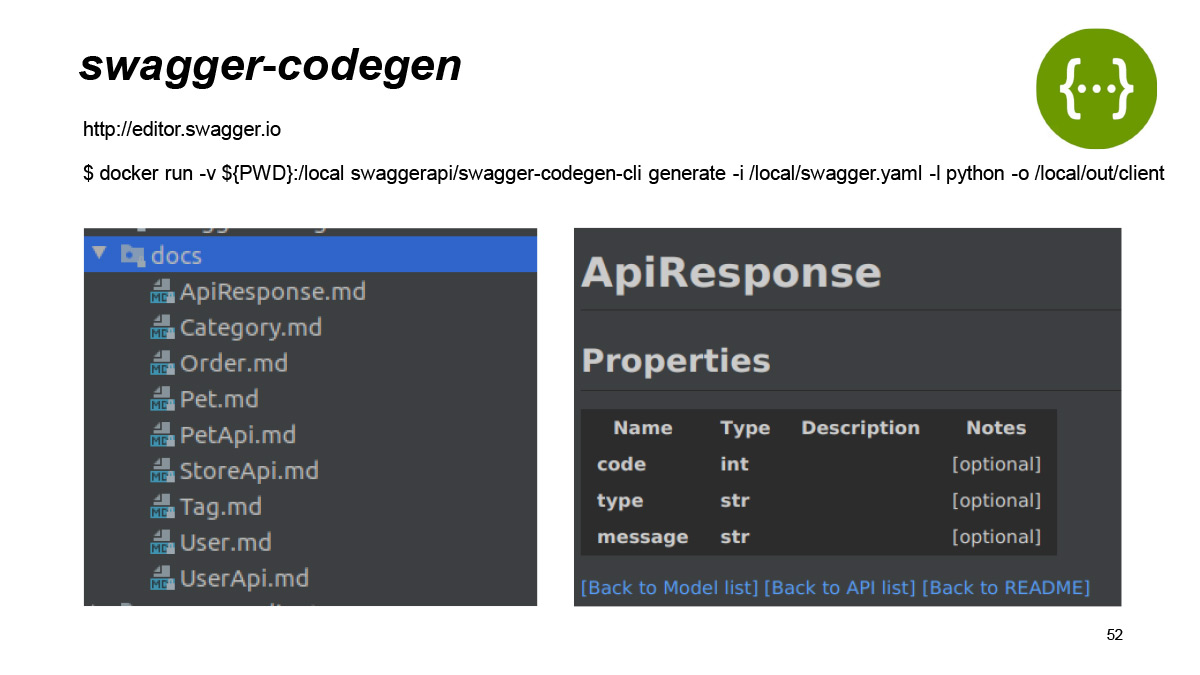
Давайте попробуем запустить генерацию клиента по спецификации petstore. Мы увидим, что этот генератор сгенерировал сам Swagger-клиент, в котором есть сам Python-клиент. Тут в строке запуска можно явно увидеть, что я генерирую клиент на Python. На самом деле он поддерживает огромное количество языков. Что тут есть из важного? Фронтендерам понравится, что есть JavaScript, хипстерам понравится, что есть Go. Все, что вы хотите.
Так вот, помимо клиента на Python, он сгенерировал парочку волшебных папочек docs и test. О них мы потом поговорим чуть подробнее. И очень много сахара, чтобы вы могли обернуть этот клиент в уже готовую библиотеку. Тут есть gitignore, тут есть CI-файлики, допустим, для Travis, есть сахар для git. Есть requirements, setup.py и tox.ini. То есть все то, что поможет вам просто взять, закоммитить и отправить этот клиент уже в виде библиотеки, которую можно переиспользовать.
Давайте подробнее посмотрим, что же он нагенерировал в клиенте.

В клиенте он сгенерировал, помимо каких-то вспомогательных файликов, две очень важные директории api и models. В models у нас лежат те модели данных, которыми мы манипулируем. Каждая модель из себя представляет просто питоновский класс, который унаследован от object с __init__, который принимает всевозможные параметры этой схемы, и геттерами и сеттерами, которые меняют состояние объекта.

Помимо модели там также появились такие сущности, как PetApi — это как раз клиентские обертки над группой endpoints, которые OpenAPI группирует или по тегам, или по endpoints.
И в этом клиенте есть все ручки, которые вы можете подергать, передав реальные данные. Тогда они улетят на какой-то бэкенд.

Что в этом из сгенерированного клиента реализовано? Из интересного — контрактный подход. Давайте поподробнее про него расскажу.
Контрактный подход к программированию говорит о том, что когда вы реализуете взаимодействие между клиентом и сервером, вы на самом деле всегда закладываетесь на определенные правила, на контракты, будь то данные, которые клиент отдает серверу, или данные, которые сервер отдает клиенту.
Так вот, контрактный подход рекомендует вам каждый раз в реалтайме проверять ваши данные и ваше взаимодействие на соответствие контракту. Если этот контракт представляет собой схему данных, которые мы передаем, и не соответствует нашим ожиданиям, не удовлетворен, то нужно об этом сказать, показать ошибку прямо здесь и сейчас. Не ходить в реальный бэкенд, не ждать какую-нибудь четырехсоточку, а прямо сейчас сказать.
Или другой случай: мы сходили в бэкенд, получили какие-то данные, но они не соответствуют тому, что мы ждали. Допустим, какие-то поля, которые мы ожидали видеть заполненными, пришли пустыми. Мы скажем об этом здесь и сейчас, а не когда по стеку вызовов уйдем куда-то в лес и не узнаем, почему у нас что-то отвалилось.
Так вот, Swagger-codegen генерирует клиенты и модели согласно контрактному подходу. Он позволяет в реалтайме сказать: да, я хочу, чтобы клиент в режиме выполнения проверял все данные на соответствие контрактам. И если контракт не удовлетворен, он тут же об этом скажет.
Мы сгенерировали какой-то питонячий клиент с контрактным подходом, но помимо этого Swagger-codegen сгенерировал для нас stubs документации. На самом деле они достаточно простые, но их все можно докручивать по каждой модели.

Еще Swagger-codegen сгенерировал какие-то stubs тестов. Все для того, чтобы вы могли минимальными усилиями докрутить сгенерированный код и запустить его с тестами, с Continuous Integration, в виде библиотеки с гитом, со всеми прибамбасами.

Пройдемся еще раз вкратце. Мы посмотрели всего лишь один кейс — способ генерации клиентов к API. Из важного } контрактный подход. Очень хочется сказать: когда я сгенерировал клиента к реальному petstore по их спецификации и реально ходил в их бэкенд, то внезапно этот контрактный подход отловил невалидные данные, которые возвращал сам petstore.
Я сначала подумал — они немного странные. Сами сгенерировали спецификацию, а бэкенд у них работает неправильно. Но мне кажется, они сделали это специально, чтобы мы увидели мощь контрактного подхода. Данных было не так много, и они явно были сгенерированы.
Также в генерации клиентов и в другой генерации можно использовать свои шаблоны. То есть если вы любите генерировать клиента в определенном формате, вы можете сохранить и подготовить свой шаблон и генерировать клиентов так, как вы хотите. Если вы ходите и генерируете интеграции каждый день, вам, возможно, это очень понравится.
Также можно конфигурировать таких клиентов и писать импорт своих моделей, а не тех, которые сгенерировал Swagger-codegen.
Помимо генерации клиентов к API, можно скормить генератору спецификацию и сгенерировать stubs самого сервера. Это очень странно. То есть вы генерируете какой-то бэкенд, который якобы работает согласно спецификации. Понятно, что там никакой бизнес-логики нет. Но возможно, это будет удобно в качестве какого-то scaffolding, то есть подготовки черновика, с которым уже можно что-то делать. Я не использовал, но рекомендую глянуть — возможно, вы найдете для себя что-то полезное.
Помимо всего прочего, он позволяет вам генерировать документацию в формате HTML и Confluence, если кто-то пользуется. Примеры, которые я хотел показать для OpenAPI, тоже на этом закончились.

Все перечисленные инструменты доступны по двум ссылкам внизу на слайде: openapi.tools и github.com/APIs-guru/awesome-openapi3
Хочу показать группы тулинга вокруг OpenAPI-спецификации. На самом деле инструментов очень много. Это просто группы, то есть типы инструментария, который вы можете использовать.
Из важного здесь есть конвертор из одной спецификации в другую. То есть вы можете из OpenAPI-спецификации генерировать API Blueprint или то, что вы любите, и наоборот. Есть библиотека для mock, для документирования. То есть все, о чем я рассказал, будет отражено в этих группах.
Есть ссылочка, по которой вы тоже можете пройти. Обязательно походите, посмотрите.

Ссылка со слайда
Помимо инструментов вокруг OpenAPI, есть инструментарий вокруг Swagger. Есть SwaggerHub и Swagger Inspector. Они выделены синеньким, потому что это веб-инструментарий. Вы можете прямо перейти туда и as a service воспользоваться SwaggerHub и Swagger Inspector, которые на самом деле являются суперпозицией следующих библиотек: Swagger-editor, Swagger-codegen, Swagger-UI. Все то, что мы только что обсудили.
Все библиотеки желтые, они в опенсорсе, как мы видели. Есть на GitHub, есть в виде Docker. Используйте.
Что мы сегодня обсудили? Спецификацию REST API на примере OpenAPI и Swagger. Я хочу акцентировать внимание, что OpenAPI — всего лишь один из способов описания спецификации. Их много. Из интересных посмотрите еще API Blueprint. Возможно, кому-то еще что-то приглянется.

Также мы посмотрели Swagger. По сути это, как мы уже говорили, всего лишь красивый UI вокруг спецификации, который позволяет вам глянуть и поисследовать ее в удобном виде. На самом деле этих инструментов тоже много, начиная от популярного ReDoc и Sphinx, а заканчивая, по сути, Markdown. То есть вы можете из OpenAPI генерировать Markdown, и он будет красиво отображаться во всех GitHub, GitLab — везде, где захотите.
Также мы посмотрели пример на нашем стеке технологий, как мы сейчас генерируем спецификацию. Но как вы заметили, это достаточно сложно и неудобно, потому что мы, по сути, дублируем бизнес-логику и docstrings.

Ссылки со слайда: FastAPI, SAFRS, rororo
Из интересного я советую глянуть на FastAPI. Про это подробнее вам сегодня расскажет Стёпа. FastAPI помогает вам генерировать спецификацию из коробки. Вы там можете вообще ни о чем не задумываться. Просто пишете код и получаете готовую спецификацию.
Есть еще два фреймворка: SAFRS и rororo. Названия, конечно, волшебные. Они работают немного по другой модели, не заставляют вас не задумываться о спецификации и получать ее просто как побочный эффект. Наоборот, у вас есть спецификация, которая рулит хендлерами. Это, грубо говоря, specification driven development. У них не так много звездочек, как у FastAPI, но мне кажется, они заслуживают внимания, гляньте обязательно.

И напоследок мы обсудили, какие вообще есть полезности вокруг спецификации на примере OpenAPI и Swagger. По всем пунктам я выношу ссылочки, посмотрите обязательно, там очень много интересного:
— OpenAPI / Swagger
swagger.io/docs/specification/about
— Пример на falcon + marshmallow + apispec
github.com/marshmallow-code/apispec
github.com/tiangolo/fastapi
— Плюшки OpenAPI / Swagger
openapi.tools
swagger.io/tools swagger.io/tools/open-source/open-source-integrations github.com/APIs-guru/awesome-openapi3
Какой у меня вообще был посыл доклада? Ребята, писать спецификации — это не какая-то бюрократия. И это не так сложно, как может показаться на первый взгляд, а достаточно просто и дает много полезных инструментариев, открывает вам большие возможности.
Пишите спецификации. Рекомендую. Спасибо большое.
Весь код и ссылки доступны в презентации.
— Всем привет, меня зовут Александр. Я хотел бы поговорить с вами про спецификации.
Если конкретно, я бы хотел затронуть несколько тем. Во-первых — что такое спецификации на примере спецификаций REST API. Далее — как мы в нашем сервисе прикручивали генерацию спецификации. И в конце, на сладенькое — какие есть инструменты, тулинг, чтобы использовать результаты нашей генерации спецификаций, на примере такой спецификации, как OpenAPI и Swagger UI.
Спецификация REST API
Что такое спецификации и что я под этим подразумеваю в своем докладе?
В первую очередь это Interface Description Language, язык описания интерфейсов, какое-то описание, которое соответствует определенному формату. Его можно парсить автоматически, потому что у него строгий формат и такая специфика, что оно не зависит от самого языка, на котором реализован интерфейс. То есть, допустим, у вас есть веб-сервер на Python, для Interface Description Language это не имеет значения.
Языков описания спецификаций достаточно много. Это спецификации для REST, RPC, GraphQL и т. д. Сегодня мы остановимся подробнее на спецификации REST.
OpenAPI
Давайте будем говорить о спецификациях на примере OpenAPI.
Сначала поймем, что такое OpenAPI. Это как раз таки language для описания спецификаций. Сам по себе он представляет собой файл — в формате YAML, JSON или XML, кому что больше нравится — с описанием интерфейса, ручек-endpoints и схем.
Swagger
Когда мы говорим про OpenAPI, нельзя не сказать про Swagger.
Swagger — это, по сути, UI для OpenAPI, который позволяет вам красиво визуализировать вашу спецификацию.
В Swagger, как и в OpenAPI, есть описание endpoints, которые есть в вашей спецификации.
Есть описание авторизации в вашем API.
Есть описание моделей или же схем, с которыми вы манипулируете в вашем API — допустим, принимаете на вход или отдаете на выход.
Есть описание примеров и ожидаемых запросов и ответов вашего API.
И дополнительно в своем Swagger, благодаря тому, что это UI и он запущен у вас в браузере, вы можете в реалтайме выполнять запросы к вашему API прямо здесь и сейчас.
Ссылка со слайда
С этим всем можно поиграться на тестовом стенде, подготовленном командой Swagger. Это petstore.swagger.io. Там есть пример спецификации, поднят Swagger. Вы можете сходить в реальный бэкенд и пощупать. Рекомендую.
Итак, мы говорим: OpenAPI, Swagger, спецификация. Но зачем все это нужно человеку, который пишет, допустим, бэкенд?
В первую очередь, спецификации часто используются на этапе проектирования нашего API. То есть нормальные люди, придя к задаче написания бэкенда, начинают с того, что описывают, что же они хотят реализовать. То есть они начинают проектировать свой API, список endpoints, которые они хотят реализовать, список схем, с которыми будут манипулировать, параметров и т. д. В этом случае спецификации и инструменты вокруг спецификаций очень удобны.
Помимо этого есть популярный кейс. Ради чего мы затаскивали спецификацию к нам в сервис? Это документирование. Наличие спецификаций дает вам такую хорошую возможность описывать ваш API и делиться этой информацией с кем-то: или с фронтендерами в вашей команде, или с внешними клиентами, которые хотят с вами интегрироваться.
Также благодаря тому, что спецификация написана в определенном строгом формате, ее можно автоматически процессить, то есть заниматься интроспекцией API. И поверх можно навертеть очень много инструментария, который позволяет облегчить вам жизнь. Конкретнее и подробнее расскажу чуть попозже.
Как мы готовим OpenAPI
Мы определились, зачем нам все это нужно. Давайте расскажу, как мы в нашем сервисе прикручивали генерацию спецификаций. Сначала немного контекста.
Когда мы пришли к мысли, что давайте запилим спецификацию, мы пошли не по нормальному пути, когда мы сначала написали проект, в смысле прототип со спецификацией. Мы уже подняли какой-то бэкенд, он у нас уже летел, и мы захотели расшарить спецификацию как способ документирования.
И наш бэкенд внезапно был на Python. В качестве фреймворка мы использовали Falcon, в качестве инструмента сериализации и десериализации данных — marshmallow, в качестве инструмента валидации — webargs.
На примере простейшей вырезки из petstore, о котором я говорил раньше, представим, как бы мог выглядеть наш сервис на этапе, когда мы захотели генерировать спецификацию.
В нашем сервисе упрощенно была бы пара схем: тип нашего домашнего животного, то есть категория, и, собственно, сами животные.
То есть мы бы описали несколько схем на Marshmallow. Дальше мы подготовили бы несколько ручек для того, чтобы, допустим, регистрировать и получать наших любимчиков.
И, собственно, описали бы сам application, которым подняли бы endpoint по созданию и получению pets.
Вот так это выглядело бы вместе. Достаточно простой сервис.
Давайте подумаем, какие у нас есть варианты формирования OpenAPI-конфига. Самый простой и наивный вариант, как я говорил ранее, — это просто файлик. Почему бы нам этот файлик не составить руками? Мы знаем, какие у нас есть данные на входе, у нас есть endpoints. Кажется очевидным, просто берем и пишем.
Но, во-первых, мы программисты. Мы не любим ничего делать руками. Мы хотим, чтобы нечто стандартное генерировалось за нас. Во-вторых, если бы мы поддерживали все руками, нам непременно бы пришлось поддерживать изменения API, а также файлик, который лежит где-то в другом месте. Как и любой сервис, наш продукт изменчив, и спецификация тоже.
Поэтому мы пришли к тому, что хотим генерировать OpenAPI-конфиг. С учетом нашего стека технологий мы нашли такую библиотеку, как apispec. Apispec — библиотека от производителей, то есть авторов Marshmallow и Webargs. Они вместе составляют большую экосистему.
Давайте посмотрим, как можно воспользоваться apispec на нашем стеке, чтобы научить его генерировать для нас спецификацию.
У нас был ресурс и определенный хендлер на метод get этого ресурса. У него есть какое-то тело.
Чтобы научить apispec, дать ему понять, что же мы делаем в нашей ручке, мы что-то дописываем в docstring. Мы дописываем туда описание, понятное человеку. В нашем случае это пример ответов: иногда бывает, наша ручка отвечает двухсоткой, и в теле нашего ответа есть JSON со схемой, моделью данных Pet.
На примере post-запроса мы описываем: помимо того, что есть ответ 201, в котором мы возвращаем Pet, есть еще ожидаемое тело запроса, который к нам приходит. И внутри этого запроса мы ожидаем JSON, и ожидаем, что этот JSON будет в формате Pet.
Мы добавили docstrings, дальше нам нужно научиться генерить спецификацию. Для этого мы пишем какой-то скриптик, красную кнопочку, и учим apispec генерировать для нас спецификацию. Мы декларируем объект apispec, у которого описываем какие-то метаданные нашего сервиса, и дальше просто пишем файл, сгенерированную спецификацию в формате YAML.
Давайте посмотрим, что для нашего огромного приложения сгенерировалось в этом файлике.
В первую очередь в этом файлике будет описание версии, в котором сгенерировалась спецификация. Это важно для того, чтобы все, кто будут интерпретировать эту спецификацию, понимали, в каком формате надо интерпретировать. От версии к версии спецификации меняются.
Дальше есть описание нашего сервиса. Это title, версия, возможно, будет какой-то description, если вы этого хотите, и дальше список серверов, на которые можно сходить, подергать ручки, увидеть и пощупать наш бэкенд.
Помимо этого там прорастают сами схемы данных, которыми мы манипулируем, с описанием типов, с описанием примеров заполнения этих данных и каких-то правил. Возможно, это какие-то крайние значения, возможно, обязательность параметров. Вот здесь вы видите список обязательных атрибутов.
Помимо схем туда прорастает описание самих endpoints. В данном случае прорастает описание по каждому методу.
По методу get у нас прорастает описание того, что мы делаем на метод get.
И на post проросло ровно то описание, которое мы положили в docstrings соответствующего endpoint. То есть мы уже получили какой-то файл.
Что нам теперь с ним делать? В чем польза? В первую очередь вы как владельцы бэкенда уже можете всем потенциальным клиентам, которые будут ходить в ваши ручки, отдавать эту спецификацию. И это поможет ребятам проинтегрироваться. То есть тот файлик, который мы сгенерировали, не заставляет вам выколоть глаза. Он достаточно читабельный. Его можно посмотреть глазами и как-то распарсить.
Но это тоже сложно. Давайте посмотрим, какие есть другие инструменты, чтобы упростить себе жизнь и какой есть тулинг вокруг сгенерированной спецификации.
Плюшки
И тут мы приходим к следующему этапу, где мы будем говорить о том, какой есть полезный инструментарий вокруг спецификаций на примере OpenAPI.
Ссылка со слайда
Первый инструмент, про который я хотел бы сказать, это Swagger-UI. Здесь и далее я буду приводить ссылочки или на веб-ресурс, в котором можно потыкать соответствующий инструмент, в данном случае это SwaggerHub, или на команду запуска соответствующего документа с помощью Docker.
Мы все очень любим Docker. Docker помогает вам не ставить на локале JavaScript или какую-нибудь Java. Просто берете, запускаете одной командой, и у вас все работает.
Так вот, Swagger-UI — это, по сути, утилита, которая позволяет вам красиво отобразить вашу спецификацию. Как я ранее говорил, это запущенные на локале с помощью Docker, возможно, Swagger.
Вы можете на локале посмотреть или расшарить, запустив на своем железе, спецификацию в Swagger. И дальше отправлять всех ваших потенциальных пользователей на эту спецификацию. Она уже намного более понятная, красивая. Прямо в ней можно делать выполнение запросов.
Ссылка со слайда
Помимо Swagger-UI есть удобный инструмент Swagger-editor. Можно использовать его в вебе, можно поднять на локале или на любой машинке. Он позволяет вам в реалтайме изменять спецификацию и видеть ее отображение прямо тут. То есть это очень удобный инструмент на этапе, допустим, проектирования API, когда у вас не генерируется спецификация, а вы хотите как-то подшаманить или описать ваш бэкенд, не имея ни реального, ни генерируемого бэкенда позади,.
Дальше есть замечательный инструмент Prism. На нем я бы хотел остановиться поподробнее. Prism — это утилита от Spotlight. Он позволяет вам, имея спецификацию, поднять mock-server, который будет работать согласно той спецификации, которую вы ему скормили.
То есть в данном случае мы видим запуск Prism поверх спецификации, которую я стащил как раз из-под сваггеровского store. Мы видим, что Prism нашел все endpoints, которые указаны в спецификации, и сказал, что честно их замокал.
Давайте попробуем пощупать, что Prism умеет делать.
В первую очередь, мы находим ручку, пробуем ее дернуть и внезапно видим, что Prism говорит нам: sorry, 401 ошибка. Мы идем в спецификацию и видим, что на самом деле эта ручка спрятана за авторизацией. Там явно описана секция секьюрити. В ней мы видим, что способ авторизации — OAuth, и понимаем: на самом деле Prism ожидал от нас какие-то авторизационные данные.
Давайте попробуем ему передать авторизационные данные согласно тому формату, который он ждет. Понятно, что токен здесь какой-то воздушный, для Prism неважно, какой он по сути. Ему важен именно формат. То есть, если он ждет именно OAuth, он ждет авторизационные данные в определенном формате.
Мы дергаем с Authorization и видим уже 400-ю ошибку. Смотрим, что же у нас в спецификации. В спецификации мы видим, что мы не передали некоторые обязательные атрибуты. Давайте их передадим.
Волшебный атрибут status. Он, на самом деле, дан согласно спецификации ENUM. Если бы мы передали статус, не входящий в этот ENUM, то получили бы четырехсоточку.
Здесь мы передали валидный статус и видим, что бэкенд ответил уже вполне валидным xml с данными. Данные в этом xml сейчас отдаются всего лишь сгенерированные из example, указанные в спецификации. То есть в спецификации для каждого поля есть такая секция, как example, где вы можете указать пример данных, которые могут вернуться. Здесь Prism просто вернул их.
Но помимо того, что вы можете дернуть ручку и ожидать, что будет честная двухсоточка, есть возможность сказать Prism — верни мне определенный код ответа. Обычно в спецификации мы описываем различное поведение нашей ручки, и при валидных данных они не всегда отвечают двухсотками. Они могут посмотреть, допустим, на наличие айдишников в базе, посмотреть, что такого айдишника не существует.
Для этого случая мы декларируем определенный код, допустим, 400-й или 422-й, кому как угодно. То есть при валидном входе не всегда есть валидный выход. Поэтому в спецификации мы описываем различные варианты ответов. И мы можем явно при дергании ручки сказать Prism: в этот раз я жду, что ты мне ответишь, допустим, 404-й ошибкой. Допустим, это кейс, когда я дергаю ручку с айдишником, но такого айдишника нет.
Если подытожить, то какие в целом есть фичи, помимо тех, о которых я уже сказал? Опять же, это mock server, который вы можете поднять. Он будет отвечать согласно спецификации, валидировать запросы на авторизацию. Также он будет валидировать на те данные, которые вы ему отправили.
Помимо валидации запроса, он будет генерировать ответы. В простейшем случае, как я сказал, он генерирует ответы по example. Есть второй вариант — когда вы просите его явно: генерируй, пожалуйста, динамические ответы. Динамическая стратегия означает, что он, в зависимости от типа, допустим, int, будет генерировать какие-нибудь тысячи, миллиарды или еще что-нибудь. Или для строки странный и непонятный хэш.
Также, когда я рассказал на первом прогоне, что можно генерировать данные, мы задались вопросом: было бы прикольно, если бы Prism интегрировался c faker. Те, кто пользовался питоновским faker, наверное, знают, насколько он клевый, когда вы хотите замокать какие-то данные или эмулировать данные в базе.
Так вот, Prism написан на JavaScript. В JavaScript тоже есть Faker.js, и у Prism есть автоматическая интеграция с faker. Вы можете в своей спецификации явно указать типы faker-данных, которые ваша ручка будет отдавать. То есть OpenAPI поддерживает систему плагинов, которая позволяет расширять вашу спецификацию так, что OpenAPI и самому парсеру это не важно. Но если есть плагины, которые парсят вашу спецификацию, они могут пользоваться какими-то дополнительными полями.
Так вот, Prism предлагает вам использовать дополнительное плагин-поле X-faker. Очень удобно.
Здесь под звездочкой я указал, что в OpenAPI можно описывать callbacks. Это схема взаимодействия, когда вы регистрируете callback на определенную ручку и ждете, что после этого вам придет определенный callback на зарегистрированный вами url. Так вот, Prism и это умеет мокать.
Из интересного: Prism можно поднять не только в режиме mock, но и в режиме Proxy. Вы просто ставите эту Proxy перед своим реальным бэкендом, и все запросы, которые идут через Prism и возвращаются обратно, Prism будет валидировать на соответствие спецификации.
Если какие-то данные — допустим, вход или выход, request или response — будут расходиться, он будет писать это в логе. Он делает это достаточно прозрачно, это никак на реальном поведении не сказывается. И вообще, в документации написано, что это можно спокойно поднимать в продакшене. Честно говоря, сам не пробовал. Наверняка существует какой-то overhead, но про него пока сказать не могу. Вы можете пощупать, попробовать и рассказать.
Дальше можно через то, что я уже сказал, форсировать определенные запросы. То есть к mock server прийти и сказать: я хочу определенный example или тип ответа. Про тип ответа мы уже поговорили. Также в OpenAPI-спецификации есть возможность указать несколько вариантов ответов и их явно именовать.
Так вот, можно прийти и сказать Prism: в этот раз я хочу определенный example, в следующий раз я хочу другой example.
Ссылка со слайда
Про Prism поговорили. Теперь про Postman. Я его очень люблю. Так вот, у Postman есть из коробки интеграция с OpenAPI. Вы можете буквально двумя нажатиями кнопочек заимпортировать OpenAPI-спецификацию. И он создаст коллекцию запросов по вашей спецификации.
При этом он заранее предподготовит все query параметры, все body-параметры, весь environment и авторизацию. Вам останется только добить данные какими-то реальными айдишниками или еще чем-то, авторизационными токенами. Очень удобно.
Переходим от Postman дальше. Мы поговорили про Prism, у него есть функциональность — валидация запросов. На самом деле, есть отдельная утилита, которая позволяет вам нещадно поддосить ваш реально запущенный бэкенд и проверить, реально ли он работает согласно спецификации.
Dredd парсит спецификацию. Берет, дергает все ручки и смотрит, что же ему вернулось. В целом, к dredd можно относиться как к инфраструктуре по написанию тестов, потому что все его запросы можно дополнить своими хуками. То есть из коробки можно запустить dredd просто as is, как я запустил его вот здесь.
А можно запустить dredd, передав ему набор хуков, которые, на самом деле, работают в идеологии обычного теста. Там есть что-то, что поднимается на все множество тестов, есть хуки, которые запускаются перед тестом, после теста, вся инфраструктура.
Ссылка со слайда
Дальше хочу поподробнее поговорить про такой инструмент от самого Swagger, как Swagger-codegen. На самом деле это немного напоминает швейцарский нож. Начну с того, какие мысли были у ребят, когда они писали этот инструмент.
Обычно, когда кому-то нужно проинтегрироваться с бэкендом, вы в бизнес-логике редко описываете прямо здесь, на определенном этапе, http-запрос. Чаще всего вы инкапсулируете работу с определенным бэкендом в какой-то сущности, в клиенте.
Так вот, ребята пришли к мысли, что, имея спецификацию, мы достаточно понятно можем описать и предсказать, как выглядел бы клиент к этому бэкенду. И ребята сделали генератор клиентов.
Давайте попробуем запустить генерацию клиента по спецификации petstore. Мы увидим, что этот генератор сгенерировал сам Swagger-клиент, в котором есть сам Python-клиент. Тут в строке запуска можно явно увидеть, что я генерирую клиент на Python. На самом деле он поддерживает огромное количество языков. Что тут есть из важного? Фронтендерам понравится, что есть JavaScript, хипстерам понравится, что есть Go. Все, что вы хотите.
Так вот, помимо клиента на Python, он сгенерировал парочку волшебных папочек docs и test. О них мы потом поговорим чуть подробнее. И очень много сахара, чтобы вы могли обернуть этот клиент в уже готовую библиотеку. Тут есть gitignore, тут есть CI-файлики, допустим, для Travis, есть сахар для git. Есть requirements, setup.py и tox.ini. То есть все то, что поможет вам просто взять, закоммитить и отправить этот клиент уже в виде библиотеки, которую можно переиспользовать.
Давайте подробнее посмотрим, что же он нагенерировал в клиенте.
В клиенте он сгенерировал, помимо каких-то вспомогательных файликов, две очень важные директории api и models. В models у нас лежат те модели данных, которыми мы манипулируем. Каждая модель из себя представляет просто питоновский класс, который унаследован от object с __init__, который принимает всевозможные параметры этой схемы, и геттерами и сеттерами, которые меняют состояние объекта.
Помимо модели там также появились такие сущности, как PetApi — это как раз клиентские обертки над группой endpoints, которые OpenAPI группирует или по тегам, или по endpoints.
И в этом клиенте есть все ручки, которые вы можете подергать, передав реальные данные. Тогда они улетят на какой-то бэкенд.
Что в этом из сгенерированного клиента реализовано? Из интересного — контрактный подход. Давайте поподробнее про него расскажу.
Контрактный подход к программированию говорит о том, что когда вы реализуете взаимодействие между клиентом и сервером, вы на самом деле всегда закладываетесь на определенные правила, на контракты, будь то данные, которые клиент отдает серверу, или данные, которые сервер отдает клиенту.
Так вот, контрактный подход рекомендует вам каждый раз в реалтайме проверять ваши данные и ваше взаимодействие на соответствие контракту. Если этот контракт представляет собой схему данных, которые мы передаем, и не соответствует нашим ожиданиям, не удовлетворен, то нужно об этом сказать, показать ошибку прямо здесь и сейчас. Не ходить в реальный бэкенд, не ждать какую-нибудь четырехсоточку, а прямо сейчас сказать.
Или другой случай: мы сходили в бэкенд, получили какие-то данные, но они не соответствуют тому, что мы ждали. Допустим, какие-то поля, которые мы ожидали видеть заполненными, пришли пустыми. Мы скажем об этом здесь и сейчас, а не когда по стеку вызовов уйдем куда-то в лес и не узнаем, почему у нас что-то отвалилось.
Так вот, Swagger-codegen генерирует клиенты и модели согласно контрактному подходу. Он позволяет в реалтайме сказать: да, я хочу, чтобы клиент в режиме выполнения проверял все данные на соответствие контрактам. И если контракт не удовлетворен, он тут же об этом скажет.
Мы сгенерировали какой-то питонячий клиент с контрактным подходом, но помимо этого Swagger-codegen сгенерировал для нас stubs документации. На самом деле они достаточно простые, но их все можно докручивать по каждой модели.
Еще Swagger-codegen сгенерировал какие-то stubs тестов. Все для того, чтобы вы могли минимальными усилиями докрутить сгенерированный код и запустить его с тестами, с Continuous Integration, в виде библиотеки с гитом, со всеми прибамбасами.
Пройдемся еще раз вкратце. Мы посмотрели всего лишь один кейс — способ генерации клиентов к API. Из важного } контрактный подход. Очень хочется сказать: когда я сгенерировал клиента к реальному petstore по их спецификации и реально ходил в их бэкенд, то внезапно этот контрактный подход отловил невалидные данные, которые возвращал сам petstore.
Я сначала подумал — они немного странные. Сами сгенерировали спецификацию, а бэкенд у них работает неправильно. Но мне кажется, они сделали это специально, чтобы мы увидели мощь контрактного подхода. Данных было не так много, и они явно были сгенерированы.
Также в генерации клиентов и в другой генерации можно использовать свои шаблоны. То есть если вы любите генерировать клиента в определенном формате, вы можете сохранить и подготовить свой шаблон и генерировать клиентов так, как вы хотите. Если вы ходите и генерируете интеграции каждый день, вам, возможно, это очень понравится.
Также можно конфигурировать таких клиентов и писать импорт своих моделей, а не тех, которые сгенерировал Swagger-codegen.
Помимо генерации клиентов к API, можно скормить генератору спецификацию и сгенерировать stubs самого сервера. Это очень странно. То есть вы генерируете какой-то бэкенд, который якобы работает согласно спецификации. Понятно, что там никакой бизнес-логики нет. Но возможно, это будет удобно в качестве какого-то scaffolding, то есть подготовки черновика, с которым уже можно что-то делать. Я не использовал, но рекомендую глянуть — возможно, вы найдете для себя что-то полезное.
Помимо всего прочего, он позволяет вам генерировать документацию в формате HTML и Confluence, если кто-то пользуется. Примеры, которые я хотел показать для OpenAPI, тоже на этом закончились.
Все перечисленные инструменты доступны по двум ссылкам внизу на слайде: openapi.tools и github.com/APIs-guru/awesome-openapi3
Хочу показать группы тулинга вокруг OpenAPI-спецификации. На самом деле инструментов очень много. Это просто группы, то есть типы инструментария, который вы можете использовать.
Из важного здесь есть конвертор из одной спецификации в другую. То есть вы можете из OpenAPI-спецификации генерировать API Blueprint или то, что вы любите, и наоборот. Есть библиотека для mock, для документирования. То есть все, о чем я рассказал, будет отражено в этих группах.
Есть ссылочка, по которой вы тоже можете пройти. Обязательно походите, посмотрите.
Ссылка со слайда
Помимо инструментов вокруг OpenAPI, есть инструментарий вокруг Swagger. Есть SwaggerHub и Swagger Inspector. Они выделены синеньким, потому что это веб-инструментарий. Вы можете прямо перейти туда и as a service воспользоваться SwaggerHub и Swagger Inspector, которые на самом деле являются суперпозицией следующих библиотек: Swagger-editor, Swagger-codegen, Swagger-UI. Все то, что мы только что обсудили.
Все библиотеки желтые, они в опенсорсе, как мы видели. Есть на GitHub, есть в виде Docker. Используйте.
Заключение
Что мы сегодня обсудили? Спецификацию REST API на примере OpenAPI и Swagger. Я хочу акцентировать внимание, что OpenAPI — всего лишь один из способов описания спецификации. Их много. Из интересных посмотрите еще API Blueprint. Возможно, кому-то еще что-то приглянется.
Также мы посмотрели Swagger. По сути это, как мы уже говорили, всего лишь красивый UI вокруг спецификации, который позволяет вам глянуть и поисследовать ее в удобном виде. На самом деле этих инструментов тоже много, начиная от популярного ReDoc и Sphinx, а заканчивая, по сути, Markdown. То есть вы можете из OpenAPI генерировать Markdown, и он будет красиво отображаться во всех GitHub, GitLab — везде, где захотите.
Также мы посмотрели пример на нашем стеке технологий, как мы сейчас генерируем спецификацию. Но как вы заметили, это достаточно сложно и неудобно, потому что мы, по сути, дублируем бизнес-логику и docstrings.
Ссылки со слайда: FastAPI, SAFRS, rororo
Из интересного я советую глянуть на FastAPI. Про это подробнее вам сегодня расскажет Стёпа. FastAPI помогает вам генерировать спецификацию из коробки. Вы там можете вообще ни о чем не задумываться. Просто пишете код и получаете готовую спецификацию.
Есть еще два фреймворка: SAFRS и rororo. Названия, конечно, волшебные. Они работают немного по другой модели, не заставляют вас не задумываться о спецификации и получать ее просто как побочный эффект. Наоборот, у вас есть спецификация, которая рулит хендлерами. Это, грубо говоря, specification driven development. У них не так много звездочек, как у FastAPI, но мне кажется, они заслуживают внимания, гляньте обязательно.
И напоследок мы обсудили, какие вообще есть полезности вокруг спецификации на примере OpenAPI и Swagger. По всем пунктам я выношу ссылочки, посмотрите обязательно, там очень много интересного:
— OpenAPI / Swagger
swagger.io/docs/specification/about
— Пример на falcon + marshmallow + apispec
github.com/marshmallow-code/apispec
github.com/tiangolo/fastapi
— Плюшки OpenAPI / Swagger
openapi.tools
swagger.io/tools swagger.io/tools/open-source/open-source-integrations github.com/APIs-guru/awesome-openapi3
Какой у меня вообще был посыл доклада? Ребята, писать спецификации — это не какая-то бюрократия. И это не так сложно, как может показаться на первый взгляд, а достаточно просто и дает много полезных инструментариев, открывает вам большие возможности.
Пишите спецификации. Рекомендую. Спасибо большое.
Весь код и ссылки доступны в презентации.