
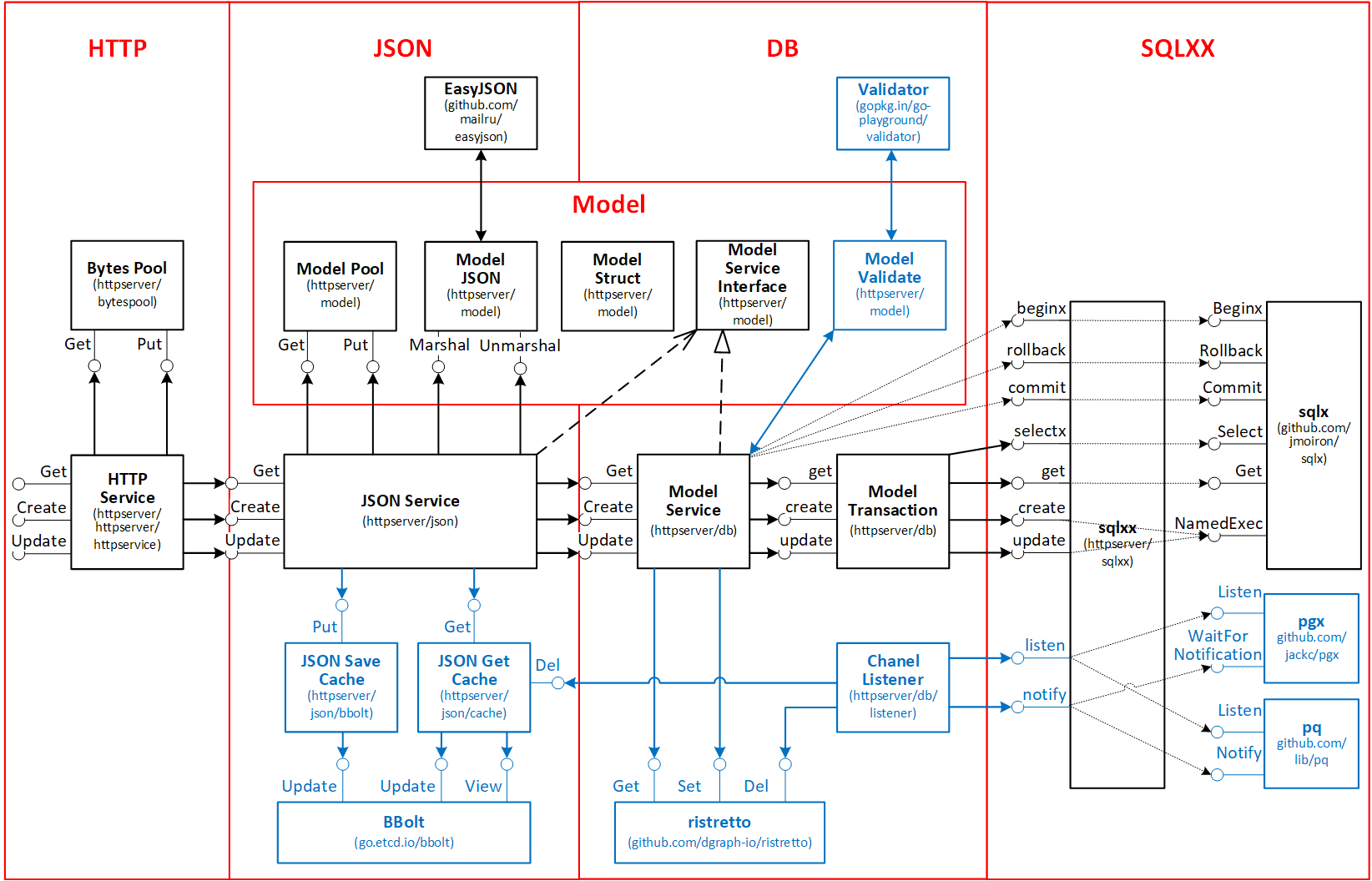
Представленный ниже шаблон сервера на Golang был подготовлен для передачи знаний внутри нашей команды. Основная цель шаблона, кроме обучения — это снизить время на прототипирование небольших серверных задач на Go.
Первая часть шаблона была посвящена HTTP серверу:
- настройка HTTP сервера через командную строку и конфигурационный файл
- настройка параметров TLS HTTP сервера
- настройка роутера и регистрация HTTP и prof-обработчиков
- настройка логирования HTTP трафика, логирования ошибок в HTTP
- HTTP Basic и MS AD аутентификация, JSON Web Token
- запуск сервера с ожиданием возврата в канал ошибок
- использование контекста для корректной остановки сервера и связанных сервисов
- настройка кастомной обработки ошибок и кастомного логирования
- сборка кода с внедрением версии, даты сборки и commit
Вторая часть шаблона посвящена прототипированию REST API.
Ссылка на репозиторий проекта осталась прежней.
В ходе тестирования шаблона на стенде были получены следующие результаты.
{kind=link}
{kind=link}
- в режиме прямого чтения из PostgreSQL — до 16 000 [get/sec], сoncurrency 1024, медиана 60 [ms]. Кажды Get запрашивает данные из двух таблиц общим размером 360 000 000 строк. Размер JSON 1800 байт.
- в режиме кэширования эту цифру можно поднять до 100 000 — 120 000 [get/sec], сoncurrency 1024, медиана 2 [ms]. Transfer rate в пределах 200-250 [MB/sec]
- на вставку в PostgreSQL — около 10 000 [insert/sec].
Содержание статьи
- Описание архитектурного подхода
- Модель данных
- Структура модели данных, интерфейс обработки
- Валидация модели данных
- Пул объектов модели
- Marshal / Unmarshal модели в JSON
- Слой SQLXX
- Обработка ошибок и паник
- Параметры БД
- Работа с SQL
- Слой DB
- Изоляцию от слоя драйвера БД
- Реализация интерфейсов модели данных
- Кэширование данных в памяти
- Слой JSON
- Marshal / Unmarshal JSON
- Unmarshal JSON
- Работа с интерфейсными методами модели данных
- Кэширование JSON
- Слой HTTP
- Работа с буферным пулом
- Обработчик GET, POST, PUT
- Регистрация обработчиков
- Тестирование производительности
- Тестовый стенд
- Результаты тестирования
1. Описание архитектурного подхода
Шаблон представлен в виде нескольких изолированных слоев.
- Слой модели данных Model отвечает за:
- определение структуры модели данных
- определение интерфейсных методов работы с моделью данных
- валидацию модели данных
- оптимизированные методы для Marshal / Unmarshal JSON модели
- работу с пулом объектов модели
- обработку бизнес-логики
- Служебный слой работы с реляционной БД SQLXX отвечает за:
- изоляцию от слоя драйвера БД
- реализацию специфичных особенностей работы с БД
- обработку ошибок и паник
- работа с SQL
- Слой реализации в реляционной БД DB отвечает за:
- подключение к БД, изоляция от слоя SQL
- реализацию интерфейсов модели данных
- управление транзакциями
- кэширование объектов в памяти
- Слой обработки JSON JSON отвечает за:
- работу с интерфейсными методами модели данных
- Marshal / Unmarshal JSON
- кэширование JSON
- Слой HTTP обработчиков HTTP отвечает за:
- логирование входящего HTTP запроса
- проверка на допустимость HTTP метода
- выполнение аутентификации (basic, MS AD, ...)
- проверка валидности token
- считывание тела (body) входящего запроса
- считывание заголовка (header) входящего запроса
- управление буферным пулом для ответов
- передача запроса на обработку и формирование ответа
- установка HSTS Strict-Transport-Security
- установка Content-Type для исходящего ответа (response)
- логирование исходящего HTTP ответа
- запись заголовка (header) исходящего ответа
- запись тела исходящего ответа
- обработка и логирование ошибок
- обработка defer recovery для восстановления после panic
Наличие нескольких слоев позволяет адаптировать шаблон с класического REST API под другие варианты архитектуры: FaaS, очередь, gRPC.
2 Модель данных Model
2.1. Структура модели данных, интерфейс обработки
2.1.1 Пример формализованной модели данных
Для целей демонстрации, в шаблон включены два объекта "Department" и "Employee". Реализация этих объектов сделана в реляционной БД.
На уровне модели данных определяются теги для работы с БД, формирования JOSN и правила валиации.
Имена структур для модели данных выбираются на основании уникальных кратких имен сущностей (бизнес-объектов).
// Dept represent object "Department"
type Dept struct {
Deptno int `db:"deptno" json:"deptNumber" validate:"required"`
Dname string `db:"dname" json:"deptName" validate:"required"`
Loc null.String `db:"loc" json:"deptLocation,nullempty"`
Emps []*Emp `json:"emps,omitempty"`
}
// Emp represent object "Employee"
type Emp struct {
Empno int `db:"empno" json:"empNo" validate:"required"`
Ename null.String `db:"ename" json:"empName,nullempty"`
Job null.String `db:"job" json:"job,nullempty"`
Mgr null.Int `db:"mgr" json:"mgr,omitempty"`
Hiredate null.String `db:"hiredate" json:"hiredate,nullempty"`
Sal null.Int `db:"sal" json:"sal,nullempty" validate:"gte=0"`
Comm null.Int `db:"comm" json:"comm,nullempty" validate:"gte=0"`
Deptno null.Int `db:"deptno" json:"deptNumber,nullempty"`
}Все методы работы с моделью сгруппированы в несколько интерфейсов.
Это позволяет изолировать выше лежащие слои обработки от слоя хранения модели в конкретной реализации (можно относительно легко переключиться с одной БД на другую).
Количество интерфейсов, обычно, соответствует количеству бизнес-сущностей (объектов, которые могут существовать и обрабатываться независимо). Объекты с типом отношений "композиция" нет смысла разносить по различным интерфейсам.
Так как пример в шаблоне ориентирован на REST API над реляционной БД, то и методы в него включены соответствующие: Get, Create, Update.
Все методы первым параметром принимают context.Context — это позволяет реализовать "отмену запросов".
Передача параметров осуществляется через указатели, причем при реализации интерфейсов, по возможности, не должны создаваться новые объекты, необходимо использовать те объекты, которые были переданы. Такой подход позволяет эффективно использовать механизм sync.Pool.
// DeptService represent basic interface for Dept
type DeptService interface {
GetDept(ctx context.Context, out *Dept) (bool, error)
GetDeptsPK(ctx context.Context, out *DeptPKs) error
CreateDept(ctx context.Context, in *Dept, out *Dept) error
UpdateDept(ctx context.Context, in *Dept, out *Dept) (bool, error)
}
// EmpService represent basic interface for Emp
type EmpService interface {
GetEmp(ctx context.Context, out *Emp) (bool, error)
GetEmpsByDept(ctx context.Context, in *Dept, out *EmpSlice) error
CreateEmp(ctx context.Context, in *Emp, out *Emp) error
UpdateEmp(ctx context.Context, in *Emp, out *Emp) (bool, error)
}2.1.2 Пример модели данных для работы с очередью
Пример модели для работы с очередью IBM MQ.
// Request represent a type for request
type Request struct {
QObject string // идентификатор очереди
QueueName string // имя очереди для обработки
QueueOptions int32 // MQOO_OUTPUT, MQOO_BROWSE, MQOO_INPUT_AS_Q_DEF
QueueWaitInterval int // период ожидания сообщения в очереди seconds
MsgIdHex string // идентификатор сообщения в Hex формате
CorrelIdHex string // идентификатор коррелирующего сообщения в Hex формате
MesFormat string // MQFMT_NONE, MQFMT_STRING
MesSyncpoint int32 // MQPMO_NO_SYNCPOINT, MQPMO_SYNCPOINT
MesOptions int32 //
BrowseOptions int32 // MQGMO_BROWSE_FIRST, MQGMO_BROWSE_NEXT, ...
Bufsize int // размер сообщения
Buf []byte `json:"-"` // буфер для обработки
}
// Response represent a type for response
type Response struct {
QObject string // идентификатор очереди
QueueName string // имя очереди для обработки
MsgId []byte // идентификатор сообщения в byte формате
MsgIdHex string // идентификатор сообщения в Hex формате
CorrelId []byte // идентификатор коррелирующего сообщения в byte формате
CorrelIdHex string // идентификатор коррелирующего сообщения в Hex формате
PutDate string // дата помещения сообщения в очередь
PutTime string // время помещения сообщения в очередь
DataLen int // размер сообщения
ErrCode string // код ошибки
ErrMes string // сообщение о ошибки
ErrTrace string // трайс места возникновения ошибки
CauseErrCode string // оригинальный код ошибки - причины
CauseErrMes string // оригинальный текст ошибки - причины
Buf []byte // буфер с возвратом
}Пример методов модели для работы с очередью IBM MQ.
// QueueService represent basic service for queue
type QueueService interface {
OpenQueue(ctx context.Context, req *Request, resp *Response) error
CloseQueue(ctx context.Context, req *Request, resp *Response) error
BrowseMessage(ctx context.Context, req *Request, resp *Response) error
BrowseFirstMessage(ctx context.Context, req *Request, resp *Response) error
BrowseNextMessage(ctx context.Context, req *Request, resp *Response) error
BrowseUnderMessage(ctx context.Context, req *Request, resp *Response) error
GetMessage(ctx context.Context, req *Request, resp *Response) error
DeleteUnderMessage(ctx context.Context, req *Request, resp *Response) error
PutMessage(ctx context.Context, req *Request, resp *Response) error
RegisterCallback(ctx context.Context, req *Request, resp *Response) error
DeregisterCallback(ctx context.Context, req *Request, resp *Response) error
}2.2. Валидация модели данных
Я привык классифицировать проверки, по принадлежности проверяемых атрибутов:
- Один атрибут — проверки, которые можно сделать с одним отдельным атрибутом. Например, "зарплата" > 0, "имя" not null.
- Несколько атрибутов одного простого объекта — например, "дата окончания" >= "дата начала"
- Несколько атрибутов одного составного объекта (композиция) — например, "дата плановой поставки строки ордера" >= "даты оформления ордера"
- Атрибуты разных объектов одной сущности — например, проверка уникальности (PK, UK), проверка дат последовательных событий.
- Атрибуты разных объектов разных сущностей — например, проверка внешних ключей (FK), сравнение количества заказанных и отгруженных товарных позиций.
- Атрибуты одного объекта при обновлении — например, сравнение новых и старых значений одной и той же простой или составной сущности.
Проверки 1, 2 и 3 уровней могут быть выполнены на основании входных данных. Проверки 4, 5, 6 уровней, обычно, требуют извлечения данных из системы хранения.
Подход к выполнению проверок сильно зависит от специфики приложения и организации хранения данных.
В случае если данные хранятся в жестко структурированных нормализованных реляционных таблицах, то может быть, например, использован следующих подход.
- Вставка и чтение данных напрямую в реляционные таблицы запрещена.
- На процедурном языке БД создаются слой "табличного API". Набор пакетов, который выполняет все DML операции. Все проверки, сообщения об ошибках выполняется в слое табличного API. Например, для БД Oracle есть продукты, которые полностью автоматизируют генерацию табличного API.
- Над таблицами создается слой представлений (View API), обычно, размещенных в отдельной схеме БД.
- Для представлений создается Instead of Trigger для обработки DML операций с использованием табличного API.
Еще один подход, который отлично работает с реляционным БД — использование промежуточных интерфейсных таблиц для DML операций. Данные сначала помещаются в интерфейсную таблицу (в БД Oracle есть возможность создавать временные сессионные таблицы). Потом запускается процедура из табличного API, которая выполняет проверки и переносит данные в основные таблицы.
Этот подход особенно хорошо подходит для массовой загрузки данных.
Если хранение данных нереляционное, то проще реализовать валидацию 1, 2 и 3 уровней через проверку JSON схемы.
В качестве примера в 3 части шаблона будут включены проверки 1, 2 и 3 уровней на основе библиотеки gopkg.in/go-playground/validator.
Проверки 4 уровня в шаблоне реализованы в части контроля уникальности по натуральным и суррогатным ключам (PK, UK).
Для проверок 5 и 6 уровня в шаблоне предусмотрены места для встраивания.
2.3. Пул объектов модели
Приведенная в шаблоне схема построения REST API (JSON->Model->DB) не требует длительного хранения объектов (структур). Объекты создаются, считываются из БД, парсятся в JSON и выбрасываются. При большом количестве запросов к API, это приводит к существенной нагрузке на сборщик мусора (GC). Это проявляется как периодическое резкое падение производительности (до завершения работы GC).
Один вариантов снижения нагрузки на GC — использование стандартного sync.Pool. Принцип использования очень простой. Когда объект не нужен — кладем его в sync.Pool.
Вместо того, чтобы создавать новый объект — обращаемся к sync.Pool, если там уже есть свободный объект, то получите на него указатель, если нет, то будет создан новый объект.
Для реализации пула объектов достаточно объявить переменную sync.Pool и реализовать несколько методов:
- создания нового объекта
- извлечения объекта из пула — после извлечения необходимо выполнить очистку
- помещение объекта в пул
- очистка объекта — необходима для установления всех атрибутов в дефолтные значения
Ниже пример для пула объектов Dept
// deptsPool represent depts pooling
var deptsPool = sync.Pool{
New: func() interface{} { return new(Dept) },
}
// GetDept allocates a new struct or grabs a cached one
func GetDept() *Dept {
p := deptsPool.Get().(*Dept)
p.Reset()
return p
}
// PutDept return struct to cache
func PutDept(p *Dept, isCascad bool) {
if p != nil {
PutEmpSlice(p.Emps, isCascad)
p.Emps = nil
deptsPool.Put(p)
}
}
// Reset reset all fields in structure - use for sync.Pool
func (p *Dept) Reset() {
p.Deptno = 0
p.Dname = ""
p.Loc.String = ""
p.Loc.Valid = false
if p.Emps != nil {
EmpSlice(p.Emps).Reset()
}
p.Emps = nil
}
При реализации пула срезов указателей нужно не забывать обнулять все значения среза
//EmpSlice represent slice of Emps
type EmpSlice []*Emp
// PutEmpSlice return struct to cache
func PutEmpSlice(p EmpSlice) {
if p != nil {
for i := range p {
p[i] = nil // что бы не осталось подвисших ссылок
}
p = p[:0] // сброс указателя среза
empSlicePool.Put(p)
}
}Замеры показали, что при интенсивной нагрузке, на 1000000 Get запросов, было создано не более 500 новых объектов. Все остальные брались из пула.
Нужно иметь в виду, что обслуживание sync.Pool требует затрат CPU, поэтому для небольших и редко используемых структур использование sync.Pool избыточно.
Структуры dept и emp из примера шаблона очень компактные и точно не стоят того, чтобы делать ради них отдельный пул.
2.4. Marshal / Unmarshal модели в JSON
Стандартный пакет encoding/json не славится высокой производительностью.
В качестве альтернативы рассматривал две библиотеки:
На страницах авторов есть сравнения. Производительность в целом сопоставимая.
Из отличительных особенностей:
- github.com/francoispqt/gojay
- Отлично работает с NULL значениями из БД.
- Не использует sync.Pool для буферов при encode. Если в буфере заканчивается место, от создается новый в 2 раза больше, в него копируются данные, а старый буфер выбрасывается. Начальный размер буфера не настраивается — равен 512 байт.
- Не умеет использовать внешний буфер для передачи результатов encode JSON.
- github.com/mailru/easyjson
- Не умеет работать с NULL значениями из БД
- Имеет сложную структуру из нескольких внутренних sync.Pool. Размер буферов варьируется от 512 до 32768 байт (параметры настраиваются). Алгоритм encode JSON максимально оптимизирован для сокращения нагрузки на сборщик мусора.
- Позволяет использовать внешний буфер для передачи результатов encode JSON
В текущем шаблоне используется github.com/mailru/easyjson.
После определения структур модели данных, нужно указать рядом с каждой структурой, которую нужно кодировать/декодировать в JSON комментарий для генератора.
//easyjson:json
type Dept struct {
Deptno int `db:"deptno" json:"deptNumber" validate:"required"`
Dname string `db:"dname" json:"deptName" validate:"required"`
Loc null.String `db:"loc" json:"deptLocation,nullempty"`
Emps []*Emp `json:"emps,omitempty"`
}Для того, чтобы easyjson корректно обрабатывал NULL поля из БД, используется библиотека gopkg.in/guregu/null.v4. Поля структуры, которые могут быть NULL в БД определяются с использованием этой библиотеки, например, "Loc null.String" вместо привычных "Loc sql.NullString".
Собственно генератор запускается командой.
easyjson model.goИспользование Marshal / Unmarshal описано в разделе, посвященном JSON.
3. Слой SQLXX
Служебный слой работы с БД SQLXX в шаблоне отвечает за:
- Обработку ошибок и паник на уровне драйвера БД
- Изоляцию от слоя драйвера БД
- Реализацию специфичных особенностей работы с БД, например, работа с Listen/notify для различных драйверов PostgreSQL (jackc/pgx/stdlib и lib/pq)
Если вы используете привязку к особенностям конкретной БД, то этот уровень абстракции вам вряд ли нужен.
Я его включил в шаблон, в основном, для обработки ошибок и паник и изоляции работы с SQL от следующих слоев.
В пакете шаблона httpserver/sqlxx обернуты некоторые типы и методы из пакета jmoiron/sqlx.
// DB is a wrapper around sqlx.DB
type DB struct {
*sqlx.DB
cfg *Config
sqlStms SQLStms // SQL команды
}
// Tx is an sqlx wrapper around sqlx.Tx
type Tx struct {
*sqlx.Tx
}Такая обертка позволит, при необходимости, с меньшими затратами переключиться с пакета jmoiron/sqlx, например, на пакет jackc/pgx.
3.1. Обработка ошибок и паник
Пакет jmoiron/sqlx напичкан паниками, поэтому в шаблоне обернуты все ключевые методы: Beginx, Rollback, Commit, Select, Get, Exec.
Возврат ошибки после обработки паники осуществляется через именованную переменную.
Первичное логирование ошибок происходит в месте возникновения в режиме INFO без trace. В этот момент, обычно, не известно, является ли это ошибкой, или она будет успешно обработана на уровне выше.
func Commit(reqID uint64, tx *Tx) (myerr error) {
// функция восстановления после паники
defer func() {
r := recover()
if r != nil {
msg := "PostgreSQL recover from panic: commit transaction: reqID"
switch t := r.(type) {
case string:
myerr = myerror.New("4008", msg, reqID, t).PrintfInfo()
case error:
myerr = myerror.WithCause("4006", msg, t, reqID).PrintfInfo()
default:
myerr = myerror.New("4006", msg, reqID).PrintfInfo()
}
}
}()
// Проверяем определен ли контекст транзакции
if tx == nil {
return myerror.New("4004", "Transaction is not defined: reqID", reqID).PrintfInfo()
}
if err := tx.Commit(); err != nil {
return myerror.WithCause("4008", "Error commit the transaction: reqID", err, reqID).PrintfInfo()
}
return nil
}Все параметры на этом слое передаются через interface{}, поэтому нужно проверять, не только что интерфейс не пустой, но и что указатель, который в нем передается также не пустой.
func Select(reqID uint64, tx *Tx, sqlStm *SQLStm, dest interface{}, args ...interface{}) (myerr error) {
if dest != nil && !reflect.ValueOf(dest).IsNil() {
// ...
}
return myerror.New("4400", "Incorrect call - nil dest interface{} pointer: reqID", reqID).PrintfInfo()
}Операция reflect.ValueOf(in).IsNil() может привести к панике, поэтому во всех методах этого слоя предусмотрена обработка паники и возврат ошибки через именованную переменную.
3.2. Параметры БД
На этом же слое определяются основные настройки БД и параметры подключения. Конфигурация считывается из общего конфиг файла.
// Config конфигурационные настройки БД
type Config struct {
ConnectString string // строка подключения к БД
Host string // host БД
Port string // порт листенера БД
Dbname string // имя БД
SslMode string // режим SSL
User string // пользователь для подключения к БД
Pass string // пароль пользователя
ConnMaxLifetime int // время жизни подключения в миллисекундах
MaxOpenConns int // максимальное количество открытых подключений
MaxIdleConns int // максимальное количество простаивающих подключений
DriverName string // имя драйвера "postgres" | "pgx" | "godror"
}
3.3. Работа с SQL
Слой SQLXX работает с предварительно подготовленными именованными SQL командами и interface{}.
Он не имеет представления ни о модели данных, ни о параметрах SQL команд.
В слое SQLXX для хранения SQL предусмотрены отдельная структура и хэш таблица. Можно хранить SQL и во внешнем файле, но большого преимущества я не вижу, а риск ошибок возрастает (любое изменение SQL требует перетестирования).
// SQLStm represent SQL text and sqlx.Stmt
type SQLStm struct {
Text string // текст SQL команды
Stmt *sqlx.Stmt // подготовленная SQL команда
IsPrepare bool // признак, нужно ли предварительно готовить SQL команду
}
// SQLStms represent SQLStm map
type SQLStms map[string]*SQLStm4. Слой DB
Слой реализации DB в шаблоне отвечает за:
- Изоляцию от слоя драйвера БД
- Реализацию интерфейсов модели данных в реляционной БД
- Управление транзакциями
- Кэширование объектов в памяти
4.1. Подключение к БД, работа с SQL
Хорошая практика, иметь в реляционной БД для каждой таблицы (бизнес-сущности) следующие ключи:
- суррогатный первичный ключ (PK) — генерируется автоматически в БД или в отдельном методе API. Это может быть последовательность или GUID, последний даже предпочтительней, так как BTree индексы получаются более сбалансированными.
- натуральный уникальный ключ (UK), например, "Номер отдела". Натуральный UK используется для проверки существования объекта при его создании и обновлении.
- при построении внешних ключей (FK) используются только неизменяемые суррогатные PK. В некоторых решениях не создают физических внешних ключей (FK), вместо этого поддерживается логические FK на уровне табличного API в БД. Нужно не забывать создавать индексы на все логические и физические FK.
В примерах таблиц dept и emp, которые включены в шаблон, первичный ключ совпадает с натуральным — в промышленных решениях так делать не рекомендуется.
При инициализации сервиса DB создается и наполняется хэш таблица с SQL командами.
Вся дальнейшая работа с SQL идет только по ключам хэш таблицы: "GetDept", "GetDeptUK", "DeptExists" и т.д. Это сделано намеренно, чтобы снизить риск ошибок в SQL.
Для каждого объекта в модели, создается несколько SQL запросов:
- извлечение всех полей по суррогатному PK, например, "GetDept"
- извлечение всех полей по натуральному UK, например, "GetDeptUK"
- проверка существования объекта по суррогатному PK или натуральному UK, например, "DeptExists"
Если объект собирается из нескольких таблиц БД, то лучше сделать отдельный слой View API. Заниматься отладкой SQL запросов на уровне REST API очень дорогостоящее занятие. Лучше перенести это на уровень БД.
service.SQLStms = map[string]*sql.SQLStm{
"GetDept": &sql.SQLStm{"SELECT deptno, dname, loc FROM dept WHERE deptno = $1", nil, true},
"GetDeptUK": &sql.SQLStm{"SELECT deptno, dname, loc FROM dept WHERE deptno = $1", nil, true},
"DeptExists": &sql.SQLStm{"SELECT 1 FROM dept WHERE deptno = $1", nil, true},
"GetDepts": &sql.SQLStm{"SELECT deptno, dname, loc FROM dept", nil, true},
"GetDeptsPK": &sql.SQLStm{"SELECT deptno FROM dept", nil, true},
"CreateDept": &sql.SQLStm{"INSERT INTO dept (deptno, dname, loc) VALUES (:deptno, :dname, :loc)", nil, false},
"UpdateDept": &sql.SQLStm{"UPDATE dept SET dname = :dname, loc = :loc WHERE deptno = :deptno", nil, false},
"EmpExists": &sql.SQLStm{"SELECT 1 FROM emp WHERE empno = $1", nil, true},
"GetEmp": &sql.SQLStm{"SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp WHERE empno = $1", nil, true},
"GetEmpUK": &sql.SQLStm{"SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp WHERE empno = $1", nil, true},
"GetEmpsByDept": &sql.SQLStm{"SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp WHERE deptno = $1", nil, true},
"GetEmpsPKByDept": &sql.SQLStm{"SELECT empno FROM emp WHERE deptno = $1", nil, true},
"CreateEmp": &sql.SQLStm{"INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno) VALUES (:empno, :ename, :job, :mgr, :hiredate, :sal, :comm, :deptno)", nil, false},
"UpdateEmp": &sql.SQLStm{"UPDATE emp SET empno = :empno, ename = :ename, job = :job, mgr = :mgr, hiredate = :hiredate, sal = :sal, comm = :comm, deptno = :deptno WHERE empno = :empno", nil, false},
}После создания подключения, SQL запросы предварительно "парсятся".
4.2. Реализация интерфейсов модели данных
Реализация интерфейсов модели данных разделена на два слоя:
- внутренний слой работает в транзакционном режиме.
- внешний слой нужен для управления транзакциями и соответствия формальному интерфейсу модели.
4.2.1 Шаблон Get методов
Шаблон внутреннего слоя для Get метода крайне простой. Для простоты, часть проверок и обработка ошибок в тексте статьи убрана.
func (s *Service) getDept(ctx context.Context, tx *mysql.Tx, out *model.Dept) (exists bool, myerr error) {
// Запросим основной объект
if exists, myerr = s.db.Get(reqID, tx, "GetDept", out, out.Deptno); myerr != nil {
return false, myerr
}
// Запросим вложенные объекты
if exists {
outEmps := model.GetEmpSlice() // Извлечем из pool срез для вложенных объектов
if myerr = s.getEmpsByDept(ctx, tx, out, &outEmps); myerr != nil {
return false, myerr
}
out.Emps = outEmps // Встроим срез в основной объект
}
return exists, nil
}Внешний слой для Get метода еще проще.
func (s *Service) GetDept(ctx context.Context, out *model.Dept) (exists bool, myerr error) {
return s.getDept(ctx, nil, out)
}4.2.2 Шаблон Create методов
Шаблон внутреннего слоя для Create метода включает шаги:
- Извлечение из пула модели объекта newDept, в которые будут считываться промежуточные результаты создания model.GetDept(). Если структуры компактные, то дешевле размещать их в стеке в виде локальных переменных.
- Проверка существует ли уже такая строка в БД. При создании объекта лучше делать проверку по натуральному уникальному ключу UK (в примере первичный ключ Dept совпадает с натуральным).
- в вызове Get(reqID, tx, "DeptExists", &foo, in.Deptno), последний параметр — это столбцы UK. Они передается как args ...interface{}, поэтому можно передать любое количество атрибутов.
- если объект существует, то при попытке создания — происходит ошибка. Неявное обновление существующих объектов не приветствуется.
- Собственно вставка и получение значение суррогатного PK
- добавлена проверка на количество обработанных строк. Больше для подстраховки, если SQL написан не верно и случайно создаст / обновит более 1 строки. Шаблон подразумевает, что объекты на этом слое обрабатываются по одному.
- если в БД есть табличное API, триггера, которые меняют / дополняют данные или автоматическое формирование суррогатного PK, то после создания, объект запрашивается из БД Get(reqID, tx, "GetDeptUK", newDept, in.Deptno) по натуральному UK.
- Обработка вложенных подобъектов
- проходим циклом по всем объектам, устанавливаем значение внешнего ключа FK newEmp.Deptno = null.Int{sql.NullInt64{int64(newDept.Deptno), true}} и вызываем соответствующий внутренний метод подобъекта createEmp(ctx, tx, newEmp, nil).
- Шаблон подразумевает, что подобъекты так же обрабатываются по одному.
- Последний блок — это запрос реальных созданных данных из БД по суррогатному PK
- используется для тестирования — на слое JSON можно сравнивать отправленные и считанные из БД данные.
- так же удобно в ходе разработки видеть в теле HTTP ответа реально сохраненные в БД данные.
- для промышленной эксплуатации лучше отключить, для этого передать nil в последний параметр out.
func (s *Service) createDept(ctx context.Context, tx *mysql.Tx, in *model.Dept, out *model.Dept) (myerr error) {
newDept := model.GetDept() // Извлечем из pool структуру для нового экземпляра в БД
defer model.PutDept(newDept, true) // Вернем структуру в pool
{ // Проверим, существует ли строка по натуральному уникальному ключу UK
var foo int
exists, myerr := s.db.Get(reqID, tx, "DeptExists", &foo, in.Deptno)
if myerr != nil {
return myerr
}
if exists {
return myerror.New("4004", "Error create - row already exists: reqID, Deptno", reqID, in.Deptno).PrintfInfo()
}
} // Проверим, существует ли строка по натуральному уникальному ключу UK
{ // Выполняем вставку и получим значение суррогатного PK
rows, myerr := s.db.Exec(reqID, tx, "CreateDept", in)
if myerr != nil {
return myerr
}
// проверим количество обработанных строк
if rows != 1 {
return myerror.New("4004", "Error create: reqID, Deptno, rows", reqID, in.Deptno, rows).PrintfInfo()
}
// считаем созданный объект - в БД могли быть триггера, которые меняли данные
// запрос делаем по UK, так как суррогатный PK мы еще не знаем
exists, myerr := s.db.Get(reqID, tx, "GetDeptUK", newDept, in.Deptno)
if myerr != nil {
return myerr
}
if !exists {
return myerror.New("4004", "Row does not exists after creating: reqID, Deptno", reqID, in.Deptno).PrintfInfo()
}
} // Выполняем вставку и получим значение суррогатного PK
{ // Обработаем вложенные объекты в рамках текущей транзакции
if in.Emps != nil {
for _, newEmp := range in.Emps {
// Копируем суррогатный PK во внешний ключ вложенного объекта
newEmp.Deptno = null.Int{sql.NullInt64{int64(newDept.Deptno), true}}
// создаем вложенные объекты
if myerr = s.createEmp(ctx, tx, newEmp, nil); myerr != nil {
return myerr
}
}
}
} // Обработаем вложенные объекты в рамках текущей транзакции
// считаем обновленный объект из БД
if out != nil {
out.Deptno = newDept.Deptno // столбцы первичного ключа PK
exists, myerr := s.getDept(ctx, tx, out)
if myerr != nil {
return myerr
}
// Проверка для отладки табличного API
if !exists {
return myerror.New("4004", "Row does not exists after updating: reqID, PK", reqID, in.Deptno).PrintfInfo()
}
}
return nil
}Внешний слой для Create метода включает шаги:
- создание транзакции
- вызов внутреннего слоя
- rollback или commit транзакции
func (s *Service) CreateDept(ctx context.Context, in *model.Dept, out *model.Dept) (myerr error) {
var tx *mysql.Tx
reqID := myctx.FromContextRequestID(ctx) // RequestID передается через context
// Начинаем новую транзакцию
if tx, myerr = s.db.Beginx(reqID); myerr != nil {
return myerr
}
// Создаем объект в рамках транзакции
if myerr = s.createDept(ctx, tx, in, out); myerr != nil {
_ = s.db.Rollback(reqID, tx)
return myerr
}
// завершаем транзакцию
return s.db.Commit(reqID, tx)
}4.2.3 Шаблон Update методов
Шаблон внутреннего слоя для Update метода включает шаги:
- Извлечение из пула модели объектов oldDept и newDept, в которые будут считываться старые и новые значения объектов из БД.
- Считывание из БД старого значения объекта по первичному ключу PK.
- если объект не существует — то ошибка. Неявное создание объектов не приветствуется.
- Выполнение проверок и действий на основании старых и новых значений атрибутов
- например, проверить все подобъекты в БД и во входной структуре. Если в обновляемом объекте присутствуют не все подобъекты, то удалить из БД неактуальные.
- если обновляется натуральный UK, то выполнить дополнительную проверку на существование объекта с новыми значениями UK.
- Собственно обновление основного объекта
- добавлена проверка на количество обработанных строк. Больше для подстраховки, если SQL написан не верно и случайно обновит более 1 строки.
- если в БД есть табличное API, триггера, которые меняют / дополняют данные, то после обновления, объект запрашивается из БД по суррогатному PК Get(reqID, tx, "GetDept", newDept, in.Deptno).
- Обработка вложенных подобъектов
- проходим циклом по всем подобъектов, устанавливаем значение внешнего ключа FK и вызываем соответствующий внутренний метод подобъекта updateEmp(ctx, tx, inEmp, nil).
- если подобъект не существует, то создаем его
- Последний блок — это запрос реальных обновленных данных из БД по суррогатному PK
func (s *Service) updateDept(ctx context.Context, tx *mysql.Tx, in *model.Dept, out *model.Dept) (exists bool, myerr error) {
oldDept := model.GetDept() // Извлечем из pool структуру для старого экземпляра в БД
defer model.PutDept(oldDept, true) // Вернем структуру в pool
newDept := model.GetDept() // Извлечем из pool структуру для нового экземпляра в БД
defer model.PutDept(newDept, true) // Вернем структуру в pool
{ // Считаем состояние объекта до обновления и проверим его существование
oldDept.Deptno = in.Deptno // столбцы первичного ключа PK
if exists, myerr = s.getDept(ctx, tx, oldDept); myerr != nil {
return false, myerr
}
if !exists {
mylog.PrintfDebugMsg("Row does not exists: reqID, PK", reqID, in.Deptno)
return false, nil
}
} // Считаем состояние объекта до обновления и проверим его существование
{ // выполняем проверки / действия на основании старых и новых значений атрибутов
// Проверить изменение UK
// для Dept PK и UK совпадают - эта проверка только для примера
if oldDept.Deptno != in.Deptno {
var foo int
exists, myerr := s.db.Get(reqID, tx, "DeptExists", &foo, in.Deptno)
if myerr != nil {
return false, myerr
}
if exists {
return false, myerror.New("4004", "Error update - row with UK already exists: reqID, Deptno", reqID, in.Deptno).PrintfInfo()
}
}
} // выполняем проверки / действия на основании старых и новых значений атрибутов
{ // Выполняем обновление
rows, myerr := s.db.Exec(reqID, tx, "UpdateDept", in)
if myerr != nil {
return false, myerr
}
// проверим количество обработанных строк
if rows != 1 {
return false, myerror.New("4004", "Error update: reqID, Deptno, rows", reqID, in.Deptno, rows).PrintfInfo()
}
// считаем объект - запрос делаем по суррогатному PK
exists, myerr := s.db.Get(reqID, tx, "GetDept", newDept, in.Deptno)
if myerr != nil {
return false, myerr
}
if !exists {
return false, myerror.New("4004", "Row does not exists after creating: reqID, PK", reqID, in.Deptno).PrintfInfo()
}
} // Выполняем обновление
{ // Обработаем вложенные объекты в рамках текущей транзакции
if in.Emps != nil {
for _, inEmp := range in.Emps {
// Копируем суррогатный PK во внешний ключ вложенного объекта
inEmp.Deptno = null.Int{sql.NullInt64{int64(in.Deptno), true}}
// обновляем вложенные объекты
if exists, myerr = s.updateEmp(ctx, tx, inEmp, nil); myerr != nil {
return false, myerr
}
// Если одного из вложенных объектов не существует - то создать его
if !exists {
if myerr = s.createEmp(ctx, tx, inEmp, nil); myerr != nil {
return false, myerr
}
}
}
}
} // Обработаем вложенные объекты в рамках текущей транзакции
// считаем обновленный объект из БД
if out != nil {
out.Deptno = in.Deptno // столбцы первичного ключа PK
if exists, myerr = s.getDept(ctx, tx, out); myerr != nil {
return false, myerr
}
// Проверка для отладки табличного API
if !exists {
return false, myerror.New("4004", "Row does not exists after updating: reqID, PK", reqID, in.Deptno).PrintfInfo()
}
}
return true, nil
}Внешний слой для Update метода включает шаги:
- создание транзакции
- вызов внутреннего слоя
- rollback или commit транзакции
- если при обновлении не нашли объекта, то exists = false
func (s *Service) UpdateDept(ctx context.Context, in *model.Dept, out *model.Dept) (exists bool, myerr error) {
var tx *mysql.Tx
reqID := myctx.FromContextRequestID(ctx) // RequestID передается через context
// Начинаем новую транзакцию
if tx, myerr = s.db.Beginx(reqID); myerr != nil {
return false, myerr
}
// Создаем объект в рамках транзакции
if exists, myerr = s.updateDept(ctx, tx, in, out); myerr != nil {
_ = s.db.Rollback(reqID, tx)
return false, myerr
}
// Если объект или один из вложенных подобъектов не был найден при обновлении, то откат
if !exists {
_ = s.db.Rollback(reqID, tx)
return false, nil
}
// завершаем транзакцию
if myerr = s.db.Commit(reqID, tx); myerr != nil {
return false, myerr
}
return exists, nil
}4.3 Кэширование данных в памяти
Кэширование в памяти имеет смысл применять, если решение преимущественно ориентировано на чтение данных из БД и текущую производительность БД не получается улучшить более простыми и дешевыми способами.
К основному недостатку кэширования в памяти можно отнести необходимость отслеживания изменений и менять данные в кэше. В случае, если у вас один backend узел, то отслеживать изменения достаточно легко. Но если предполагается распределенное / кластерное решение, то придется придумывать дополнительные механизмы.
В 3 части шаблона будут описано кэширование в памяти на основе библиотеки dgraph-io/ristretto. Отслеживания изменений будет осуществляться через БД PostgreSQL используя механизм listen/notify.
5. Слой JSON
Слой JSON в шаблоне отвечает за:
- Работу с интерфейсными методами модели данных
- Marshal / Unmarshal JSON
- Кэширование JSON
JSON слой работает только с интерфейсом модели данных. Он полностью отвязан от конкретной реализации модели в какой-либо БД (реляционной или нет).
Точно также слой JSON отвязан от специфики HTTP. Он не работает запросами и ответами, заголовками и телом. Он оперирует толь моделью данных и буферами []byte, которые содержат JSON.
5.1. Marshal JSON
Для encode в JSON используется возможность пакета github.com/mailru/easyjson передавать результат через внешний буфер.
Например, так выглядит encode в JSON для объекта Dept:
- внешний буфер для копирования создается на слое HTTP и передается в слой JSON отдельным параметром buf []byte
- если емкости внешнего буфера будет достаточно, то метод w.Buffer.BuildBytes(buf) использует его, иначе будет выделен новый буфер
- работа с буферным пулом будет описана в разделе про слой HTTP
func deptMarshal(reqID uint64, v *model.Dept, buf []byte) (outBuf []byte, myerr error) {
w := jwriter.Writer{} // подготовим EasyJSON Writer
v.MarshalEasyJSON(&w) // сформируем JSON во внутренний буфер EasyJSON Writer
if w.Error != nil {
return nil, myerror.WithCause("6001", "Error Marshal: reqID", w.Error, reqID).PrintfInfo(1)
}
// Скопируем из внутреннего буфера EasyJSON Writer во внешний буфер
return w.Buffer.BuildBytes(buf), nil
}5.2. Unmarshal JSON
Decode из JSON еще проще:
if err := vIn.UnmarshalJSON(inBuf); err != nil {
return 0, nil, myerror.WithCause("6001", "Error Unmarshal: reqID, buf", err, reqID, string(inBuf)).PrintfInfo()
}Есть только одна хитрость. После генерации методов для mailru/easyjson необходимо руками поправить методы отвечающие за decode в местах, где выделяется память для вложенных подобъектов и срезов. Вместо явных операций make и new, нужно указать "правильные" методы для работы с пулом объектов модели.
Например:
- заменить out.Emps = make([]*Emp, 0, 8) на out.Emps = []*Emp(GetEmpSlice())
- заменить v1 = new(Emp) на v1 = GetEmp()
5.3. Работа с интерфейсными методами модели данных
5.3.1. Сценарий Get
Сценарий Get крайне простой:
- входные параметры: id — сурогатный PK, для запроса данных, buf — внешний буфер для передачи сформированного JSON
- выходные параметры: outBuf результирующий буфер с JSON (может не совпадать с buf)
- слой JSON отвечает за правильное использование пула объектов модели. Он запрашивает корневые объекты vOut := model.GetDept() (например Dept — корневой объект, а Emp — это подобъект) по завершению отправляет их в пул defer model.PutDept(vOut, true). последний параметр указывает нужно ли отправлять в пул и все подобъекты.
func (s *Service) GetDept(ctx context.Context, id int, buf []byte) (outBuf []byte, myerr error) {
vOut := model.GetDept() // Извлечем из pool новую структуру
defer model.PutDept(vOut, true) // возвращаем в pool структуру со всеми вложенными объектами
vOut.Deptno = id // PK для запроса передается в структуре
// вызываем сервис обработки
exists, myerr := s.deptService.GetDept(ctx, vOut)
if myerr != nil {
return nil, myerr
}
// сформируем json
if exists {
return deptMarshal(reqID, vOut, buf)
}
return nil, nil // возврат пустого буфера - признак, что объекта не найдено
}5.3.2. Сценарий Create
Сценарий Create немногим сложнее:
- к выходным параметрам добавляется inBuf — входной буфер с JSON
- к выходным параметрам добавляется id — суррогатный PK созданного объекта
func (s *Service) CreateDept(ctx context.Context, inBuf []byte, buf []byte) (id int, outBuf []byte, myerr error) {
vIn := model.GetDept() // Извлечем из pool новую структуру
defer model.PutDept(vIn, true) // возвращаем в pool структуру
vOut := model.GetDept() // Извлечем из pool новую структуру
defer model.PutDept(vOut, true) // возвращаем в pool структуру
// Парсим JSON в структуру
if err := vIn.UnmarshalJSON(inBuf); err != nil {
return 0, nil, myerror.WithCause("6001", "Error Unmarshal: reqID, buf", err, reqID, string(inBuf)).PrintfInfo()
}
// вызываем сервис обработки
if myerr = s.deptService.CreateDept(ctx, vIn, vOut); myerr != nil {
return 0, nil, myerr
}
// сформируем json
if outBuf, myerr = deptMarshal(reqID, vOut, buf); myerr != nil {
return 0, nil, myerr
}
return vOut.Deptno, outBuf, myerr
}5.3.3. Сценарий Update
Сценарий Update:
- к входным параметрам добавляется id — суррогатный PK обновляемого объекта.
- пустой outBuf трактуется как NO_DATA_FOUND
func (s *Service) UpdateDept(ctx context.Context, id int, inBuf []byte, buf []byte) (outBuf []byte, myerr error) {
vIn := model.GetDept() // Извлечем из pool новую структуру
defer model.PutDept(vIn, true) // возвращаем в pool структуру
vOut := model.GetDept() // Извлечем из pool новую структуру
defer model.PutDept(vOut, true) // возвращаем в pool структуру
// Парсим JSON в структуру
if err := vIn.UnmarshalJSON(inBuf); err != nil {
return nil, myerror.WithCause("6001", "Error Unmarshal: reqID, buf", err, reqID, string(inBuf)).PrintfInfo()
}
// проверим ID объекта
if id != vIn.Deptno {
return nil, myerror.New("6001", "Resource ID does not corespond to JSON: resource.id, json.Deptno", id, vIn.Deptno).PrintfInfo()
}
// вызываем сервис обработки
exists, myerr := s.deptService.UpdateDept(ctx, vIn, vOut)
if myerr != nil {
return nil, myerr
}
// сформируем json
if exists {
return deptMarshal(reqID, vOut, buf)
}
return nil, nil // возврат пустого буфера - признак, что объекта не найдено
}5.4. Кэширование JSON
Кэширование в памяти имеет несколько недостатков:
- это собственно расход памяти
- необходимость каждый раз выполнять encode в JSON
- падение производительности с ростом размера кэша.
В 3 части шаблона будут описано кэширование JSON в go.etcd.io/bbolt. Отслеживания изменений будет осуществляться так же через БД PostgreSQL используя механизм listen/notify.
6. Слой HTTP
Слой HTTP в шаблоне отвечает за:
- Логирование входящего HTTP запроса
- Проверка на допустимость HTTP метода
- Выполнение аутентификации (basic, MS AD, ...)
- Проверка валидности token (при необходимости)
- Считывание тела (body) входящего запроса
- Считывание заголовка (header) входящего запроса
- Управление буферным пулом для ответов
- Передача запроса на обработку и формирование ответа
- Установка HSTS Strict-Transport-Security
- Установка Content-Type для исходящего ответа (response)
- Логирование исходящего HTTP ответа
- Запись заголовка (header) исходящего ответа
- Запись тела исходящего ответа
- Обработка и логирование ошибок
- Обработка defer recovery для восстановления после panic
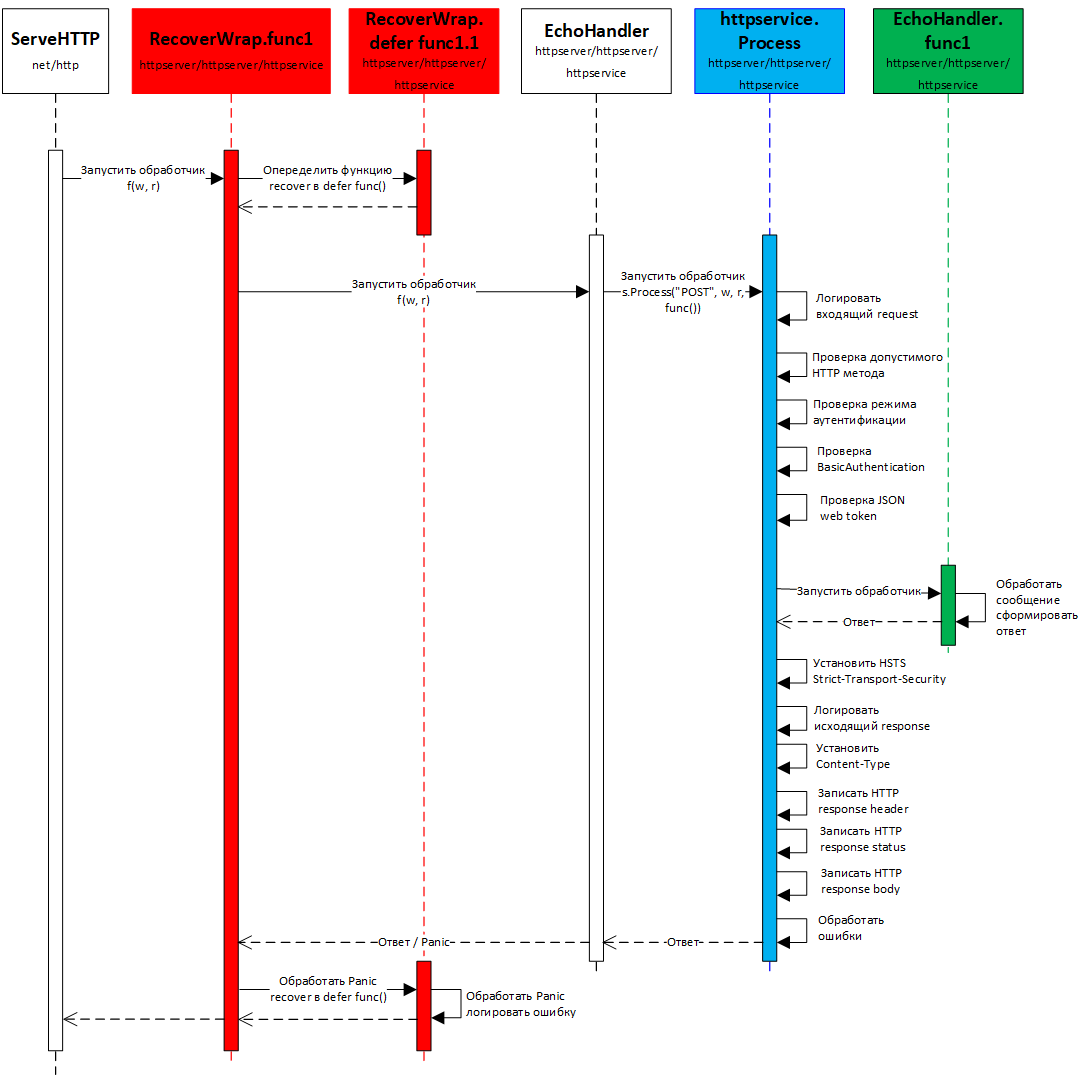
Большая часть этих операций отлично типизируется. Подходы к типизации написания HTTP обработчиков были описаны в моей статье Упрощаем написание HTTP обработчиков на Golang.
Идея, заложенная в предлагаемый подход, достаточно простая:
- на верхнем уровне необходимо внедрить defer функцию для восстановления после паники. На UML диаграмме — это анонимная функция RecoverWrap.func1, показана красным цветом.
- весь типовой код необходимо вынести в отдельный типовой обработчик process. Этот обработчик встраивается в наш HTTP handler. На UML диаграмме process — показан синим цветом.
- собственно код функциональной обработки запроса и формирования ответа вынесен в анонимную функцию в нашем HTTP handler. На UML диаграмме это функция EchoHandler.func1 — показана зеленым цветом.
Количество типовых обработчиков зависит от специфики приложения. В шаблоне включен один такой обработчик process, который включает большинство типовых задач для работы с REST API.
Далее будет описаны только отличия от ранее опубликованной статьи и код собственно функциональной обработки (на схеме зеленым цветом).
6.1. Работа с буферным пулом
После формирования JSON, []byte записывается в http.ResponseWriter и выбрасывается. В последствии он убирается сборщиком мусора GC. Есть два подхода как снизить нагрузку на GC в этой ситуации.
- сразу формировать и писать JSON потоком в http.ResponseWriter
- использовать буферный пул для передачи сформированного JSON и записи в http.ResponseWriter
В шаблоне используется второй подход.
Методы для работы с буферным пулом аналогичны для любого пула, построенного с использование стандартного sync.Pool:
- создания нового объекта
- извлечения объекта из пула
- помещение объекта в пул
В конфигурационный файл добавлены параметры настройки буферного пула:
[HTTP_POOL]
UseBufPool = true // признак использования буферного пула
BufPooledSize = 512 // минимальный размер буфера, выделяемого или сохраняемого в пуле
BufPooledMaxSize = 32768 // максимальный размер буфера сохраняемого в пулеВыделение буфера из пула осуществляется в типовом process перед вызовом функционального обработчика.
var buf []byte
if s.cfg.UseBufPool && s.bytesPool != nil {
buf = s.bytesPool.GetBuf()
}Если выделенный буфер будет недостаточного размера, то он не будет использован, и при encode в JSON будет создан новый буфер.
Это нормальная ситуация, результирующий буфер с JSON проверяется на максимальный размер и отправляется в буферный пул.
Постепенно в буферном пуле наберутся []byte подходящего размера.
if responseBuf != nil && s.cfg.UseBufPool && s.bytesPool != nil {
// Если новый буфер подходит по размерам для хранения в pool
if cap(responseBuf) >= s.cfg.BufPooledSize && cap(responseBuf) <= s.cfg.BufPooledMaxSize {
defer s.bytesPool.PutBuf(responseBuf)
}
}Понять вернулся ли нам тот же самый буфер или был создан новый, можно сравнением указателей. Метод Pointer() возвращает указатель на первый элемент в []byte.
if reflect.ValueOf(buf).Pointer() != reflect.ValueOf(responseBuf).Pointer() {
// ...
}6.2. Обработчик GET
Так как вся типовая обработка вынесена в process, то собственно в обработчике остаются задачи:
- считывание из URL запроса ID запрашиваемого ресурса — в нашем случае это PK объекта
- вызов методов слоя JSON для формирования ответа jsonService.GetDept(ctx, id, buf), в последнем параметре buf передается буфер из пула для копирования результата.
- формирование заголовка ответа. Чтобы проще разбираться в логах, везде передается информацию о уникальном номере запроса header["RequestID"]
func (s *Service) GetDeptHandler(w http.ResponseWriter, r *http.Request) {
// Запускаем типовой process, возврат ошибки игнорируем
_ = s.process("GET", w, r, func(ctx context.Context, requestBuf []byte, buf []byte) ([]byte, Header, int, error) {
reqID := myctx.FromContextRequestID(ctx) // RequestID передается через context
// Считаем PK из URL запроса и проверим на число
vars := mux.Vars(r)
idStr := vars["id"]
id, err := strconv.Atoi(idStr)
if err != nil {
return nil, nil, http.StatusBadRequest, myerror.WithCause("8001", "Failed to process parameter 'id' invalid number: reqID, id", err, reqID, idStr).PrintfInfo()
}
// вызываем JSON сервис, передаем ему буфер для копирования
responseBuf, err := s.jsonService.GetDept(ctx, id, buf)
if err != nil {
return nil, nil, http.StatusInternalServerError, err
}
// Если данные не найдены
if responseBuf == nil {
return nil, nil, http.StatusNotFound, nil
}
// формируем ответ
header := Header{}
header["Content-Type"] = "application/json; charset=utf-8"
header["Errcode"] = "0"
header["RequestID"] = fmt.Sprintf("%v", reqID)
return responseBuf, header, http.StatusOK, nil
})
}6.3. Обработчик POST
POST обработчик еще проще:
- в заголовке ответа возвращается ID созданного ресурса — PK объекта
func (s *Service) CreateDeptHandler(w http.ResponseWriter, r *http.Request) {
// Запускаем типовой process, возврат ошибки игнорируем
_ = s.process("POST", w, r, func(ctx context.Context, requestBuf []byte, buf []byte) ([]byte, Header, int, error) {
reqID := myctx.FromContextRequestID(ctx) // RequestID передается через context
mylog.PrintfDebugMsg("START: reqID", reqID)
// вызываем JSON сервис
id, responseBuf, err := s.jsonService.CreateDept(ctx, requestBuf, buf)
if err != nil {
return nil, nil, http.StatusInternalServerError, err
}
// формируем ответ
header := Header{}
header["Content-Type"] = "application/json; charset=utf-8"
header["Errcode"] = "0"
header["Id"] = fmt.Sprintf("%v", id)
header["RequestID"] = fmt.Sprintf("%v", reqID)
return responseBuf, header, http.StatusOK, nil
})
}6.4. Обработчик PUT
PUT обработчик немногим сложнее:
func (s *Service) UpdateDeptHandler(w http.ResponseWriter, r *http.Request) {
// Запускаем типовой process, возврат ошибки игнорируем
_ = s.process("PUT", w, r, func(ctx context.Context, requestBuf []byte, buf []byte) ([]byte, Header, int, error) {
reqID := myctx.FromContextRequestID(ctx) // RequestID передается через context
mylog.PrintfDebugMsg("START: reqID", reqID)
// Считаем параметры и проверим на число
vars := mux.Vars(r)
idStr := vars["id"]
id, err := strconv.Atoi(idStr)
if err != nil {
return nil, nil, http.StatusBadRequest, myerror.WithCause("8001", "Failed to process parameter 'id' invalid number: reqID, id", err, reqID, idStr).PrintfInfo()
}
// вызываем JSON сервис
responseBuf, err := s.jsonService.UpdateDept(ctx, id, requestBuf, buf)
if err != nil {
return nil, nil, http.StatusInternalServerError, err
}
// Если данные не найдены
if responseBuf == nil {
return nil, nil, http.StatusNotFound, nil
}
// формируем ответ
header := Header{}
header["Content-Type"] = "application/json; charset=utf-8"
header["Errcode"] = "0"
header["RequestID"] = fmt.Sprintf("%v", reqID)
return responseBuf, header, http.StatusOK, nil
})
}
6.5. Регистрация обработчиков
Для упрощения регистрации новых обработчиков, в httpserver/httpservice создана простая хэш таблица Handlers.
// Handler represent HTTP handler
type Handler struct {
Path string
HundlerFunc func(http.ResponseWriter, *http.Request)
Method string
}
// Handlers represent HTTP handlers map
type Handlers map[string]HandlerНаполнение хэш таблицы происходит в методе httpservice.New. Если обработчик нужно обернуть для обработки паники, то используется service.recoverWrap().
service.Handlers = map[string]Handler{
// Типовые обработчики
"EchoHandler": Handler{"/echo", service.recoverWrap(service.EchoHandler), "POST"},
"SinginHandler": Handler{"/signin", service.recoverWrap(service.SinginHandler), "POST"},
"JWTRefreshHandler": Handler{"/refresh", service.recoverWrap(service.JWTRefreshHandler), "POST"},
"HTTPLogHandler": Handler{"/httplog", service.recoverWrap(service.HTTPLogHandler), "POST"},
"HTTPErrorLogHandler": Handler{"/httperrlog", service.recoverWrap(service.HTTPErrorLogHandler), "POST"},
"LogLevelHandler": Handler{"/loglevel", service.recoverWrap(service.LogLevelHandler), "POST"},
// JSON обработчики
"CreateDeptHandler": Handler{"/depts", service.recoverWrap(service.CreateDeptHandler), "POST"},
"GetDeptHandler": Handler{"/depts/{id:[0-9]+}", service.recoverWrap(service.GetDeptHandler), "GET"},
"UpdateDeptHandler": Handler{"/depts/{id:[0-9]+}", service.recoverWrap(service.UpdateDeptHandler), "PUT"},
}7. Тестирование производительности
7.1. Тестовый стенд
Тестовый стенд был собран в облаке Oracle на 3-х идентичных серверах:
- конфигурации VM.DenseIO2.8 — 8 Core Intel (16 virtual core), 120 Memory (GB), Oracle Linux 7.7
- использовались локальные NVMe диски — 6.4 TB NVMe SSD Storage (1 drives) min 250k IOPS (4k block)
- локальная сеть между серверами — 8.2 Network Bandwidth (Gbps)
- БД — PostgreSQL 12. Оптимизация настроек БД не производилась.
- тестирование велось через ApacheBench:
- concurrency level от 4 до 16384
- от 10 000 до 1 000 000 запросов случайными образом.
- в фоне запускалось от 2 до 8 экземпляров ApacheBench (один процесс ApacheBench не может нагрузить более 1 виртуального процессора)

7.2. Результаты тестирования GET с разными видами кэширования
- Размер JSON — 1800 байт. Один мастер объект Dept и 10 вложенных объектов Emp.
- Размер таблицы Dept — 33 000 000, таблицы Emp — 330 000 000 строк.
Тестировались следующие сценарии:
- GET без кэширования с прямым доступом к PostgreSQL
- GET с кэшированием JSON из BBolt (размер 74 Гбайт)
- GET с кэшированием в памяти (стандартный map)
Исходные результаты тестирования доступны в репозитории.
Таблица с агрегированными данными доступна по ссылке
График зависимости Requests per second от Concurrency.
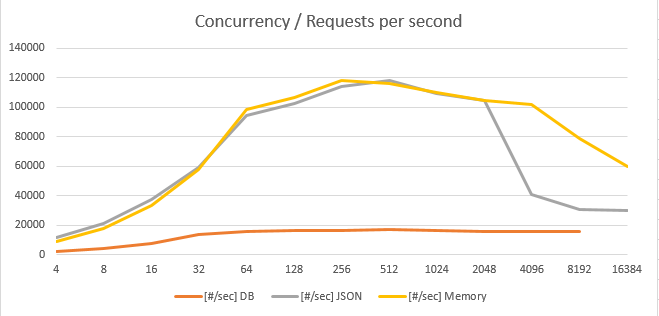
График зависимости Time per req. [ms] от Concurrency (логарифмическая шкала).

График зависимости 99% percentile [ms] от Concurrency.

График зависимости 99% percentile [ms] от Concurrency (логарифмическая шкала).

Так выглядит загрузка backend сервера при 100 000 [#/sec] и кэшировании данных в BBolt (Concurrency 128). Средняя задержка ввода / вывода на NVMe диск 0,02 [ms] (500 000 IOPS).

asmm
Это очень плохо и самое ужасное это работа с БД.
Каждый запрос в БД это упрощённо
* отправка запроса по протоколу БД
* парсинг запроса, синтаксический разбор
* поиск запроса в кэше запросов
* если нет, то составление плана запроса
* выделение ресурсов на выполнение запроса
* поиск данных в буферном кэше
* чтение отсутствующих с диска
* отправка запроса по протоколу БД
+ Постгре версионник значит на транзакцию идёт снапшот и чем быстрее завершим её, тем меньше ресурсов потребуется при конкурентной работе
На примере: createDept
C Go не работал, поэтому буду писать на псевдо языке и с PostrgeSQL тоже мало работал, поэтому могут быть синтаксические ошибки, но общий смысл будет понятен
т.е. сначала выполнится запрос «SELECT 1 FROM dept WHERE deptno = $1»
если он не вернёт данные, то вставим
INSERT INTO dept (deptno, dname, loc) VALUES (:deptno, :dname, :loc)
проверим кол-во строк, а потом запросим по уникальности вставленный IDшник
сделаем лучше
идём дальше
т.е. в цикле начинаем выполнять createEmp, который не описан, но я так понимаю тоже предполагается что там выполняются все этапы: проверка, вставка, повторное извлечение. Если у нас 10 дочерних записей, то будет выполнено 30 запросов, хотя раз у нас есть json, просто в тексте, то его легко скормить Постгресу, он ещё оч круто оптимизирован на работу с JSON'ом
Запрос будт что-то вида:
т.е. суммарно заменили 30 запросов к БД 1м запросом, ещё на ходу и JSON распарсили, и кучу всяких не нужных структур из кода можно выкинуть и памяти тонну освободить…
ну и в конце у Вас идёт getDept который двумя запросами возвращает мастера и детеил
ну тут опять можно соптимизить, получить всё одним запросом, да ещё и сразу в готовом JSON'е который тут же и вернуть без всякого дополнительного оверхэда
Дак о чём это я… Я простейшими модификациями, базовым SQL-ем сократил кол-во кода, уменьшил кол-во запросов с условных ~35 до 4х, ну и работать это будет раз в 10-50 быстрее. Это ещё без всяких специфичных для постгреса оптимизаций, хотя он вроде всё это умеет:
строка->JSON->multi_table_insert + returning array->select->agregate_JSON
и всё это в одном запросе! но это уже тонкий тюнинг
В общем напишите 1 такой сервис, выкиньте весь тот оверхэд с типами, надстройками, моделями, убедитесь что всё это будет работать в десятки раз быстрее на более простом железе.
Вот кста хорошая лекция о Постгре, тут немного про другое, про то как хорошо они заточили работу с JSON, но опять же на более простом железе показывают лучшую производительность
www.youtube.com/watch?v=SNzOZKvFZ68
Далее про кэширование, тут я не на 100% уверен, но тоже видится, что команда постгреса над которым работают десятки и сотни человек и не один десяток лет, наверняка лучше справились с этой задачей. Не надо изобретать велосипед, лучше настроить и потюнить инструмент, который специально для этого предназначен
romapres2010 Автор
Спасибо, что очень внимательно прочитали статью. Ваш отзыв очень полезен.
Вы правильно заметили, что это не универсальная библиотека — это шаблон, который нужно адаптировать под конкретную реализацию.
Если ваше решение работает только с PostgreSQL и вам не нужна реализация проверок на слое backend, то в шаблоне нужно правильно реализовать слой DB.
Используйте максимально все возможности PostgreSQL. Библиотека jackc/pgx отлично поддерживает массовую вставку из срезов.
Очень может быть, что вам и Go не нужен — используйте стандартные возможности PostgreSQL.