
Многим знакома гипотеза зарождения человечества в Африке. В рамках этой гипотезы предполагается, что все современное неафриканское население Земли в значительной степени происходит от популяций Homo sapiens, покинувших Африку. Первым эту теорию предложил Чарльз Дарвин, основываясь на том, что человек очень близок к таким обезьянам, как гориллы и шимпанзе, которые обитают в Африке. И если в основных моментах этой гипотезы ученые уже пришли к консенсусу, то многие детали остаются дискуссионными: был ли один выход из Африки или несколько, когда это происходило, какой длительности были эти волны и так далее.
В идеале, для ответа на эти вопросы подошел бы сравнительный анализ геномов людей, проживавших в разные периоды истории — это позволило бы установить взаимосвязи между человеческими популяциями, населяющими разные территории в разные промежутки времени. Такие геномы можно выделить, например, из археологических останков, но, к сожалению, количество и качество таких геномов довольно ограничено. С другой стороны, оказывается, что часть ответа заключена в геномах современных людей. Как именно по таким геномным данным можно восстановить детали популяционной истории, мы и расскажем в этой статье.
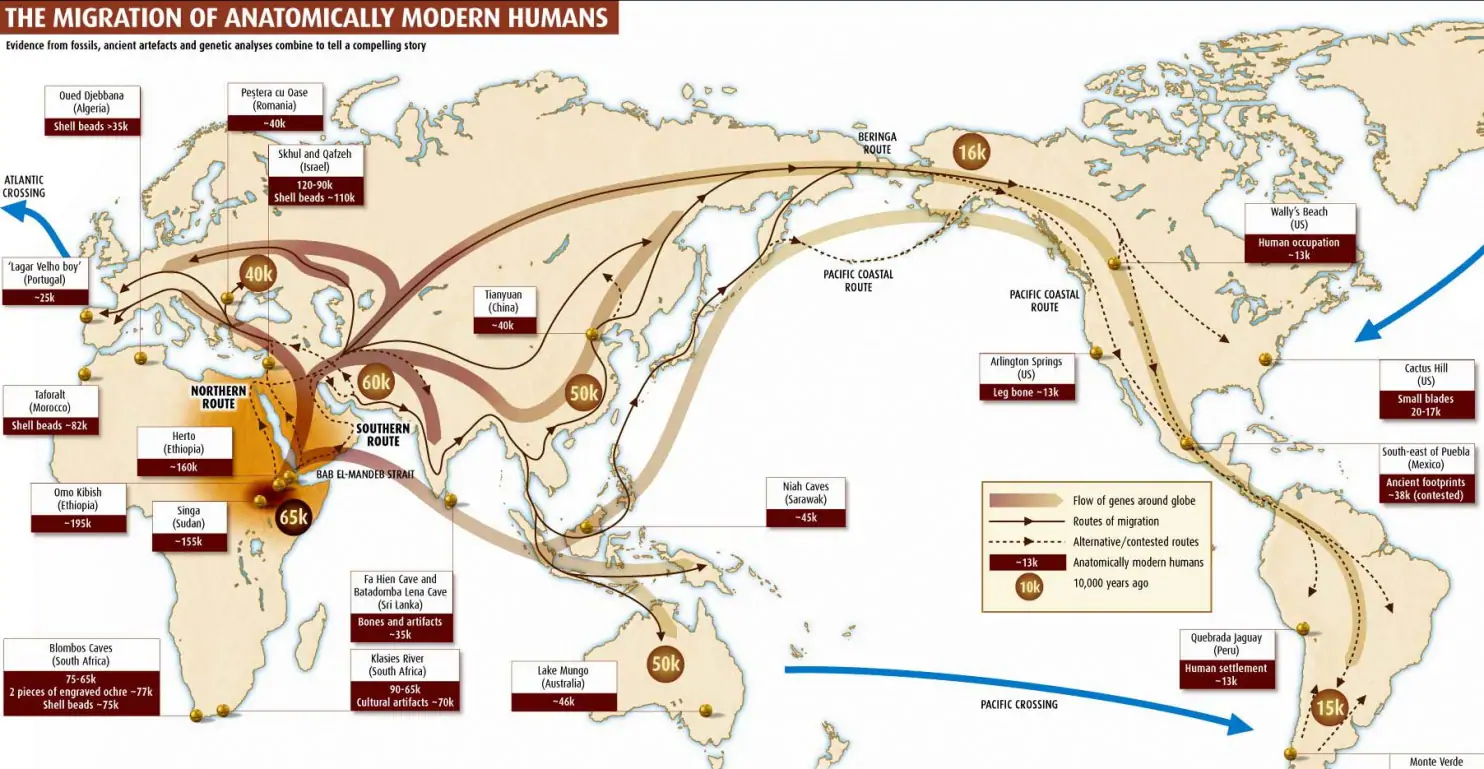
Источник картинки
В целом, вопросами влияния движущих сил эволюции на геномы занимается популяционная генетика. Ее ключевыми сущностями являются особь, популяция и вид. Особью, как несложно догадаться, считается отдельный организм. Видом называется группа особей с общими признаками, дающая плодовитое потомство.
Плодовитость потомства важна, так как, например, можно скрестить осла и лошадь — получится мул, но он стерилен, а значит по этому определению осел и лошадь — это разные виды. Популяцией же называют группу особей одного вида, живущую на отдельной территории, частично или полностью изолированную от других таких же групп.
Определение видов совсем не простая задача. Давным-давно это делали по фенотипическим, то есть видимым, признакам, однако при исследовании геномов в такой классификации были найдены ошибки. Известным примером являются археи: изначально их причисляли по строению к прокариотам, но анализ генов показал их сильное отличие от прокариотов и эукариотов, и ученые выделили их в отдельный домен классификации. Определение популяций тоже вызывает жаркие споры.
Например, существует два подвида исчезающей газели Dama gazelle: mhorr и addra. Эти подвиды отличаются фенотипически, поэтому их выделяют в отдельные популяции. Однако анализ геномов показывает, что на самом деле это одна популяция.
Являются ли газели addra (слева) и mhorr (справа) представителями одной популяции? На первый взгляд кажется, что нет, но на самом деле может и являются. Во всяком случае, наш анализ показал такую возможность.
Источник картинки
История развития популяций и видов называется демографической историей. События этой истории включают в себя разделение популяций, миграции и изменение численности. При этом важно не просто число особей, а число особей, которые размножаются, — так называемая эффективная численность. Общее количество особей в популяции при этом может быть гораздо больше и сильно меняться с течением времени, поэтому в эволюции эффективная численность гораздо важнее общей.
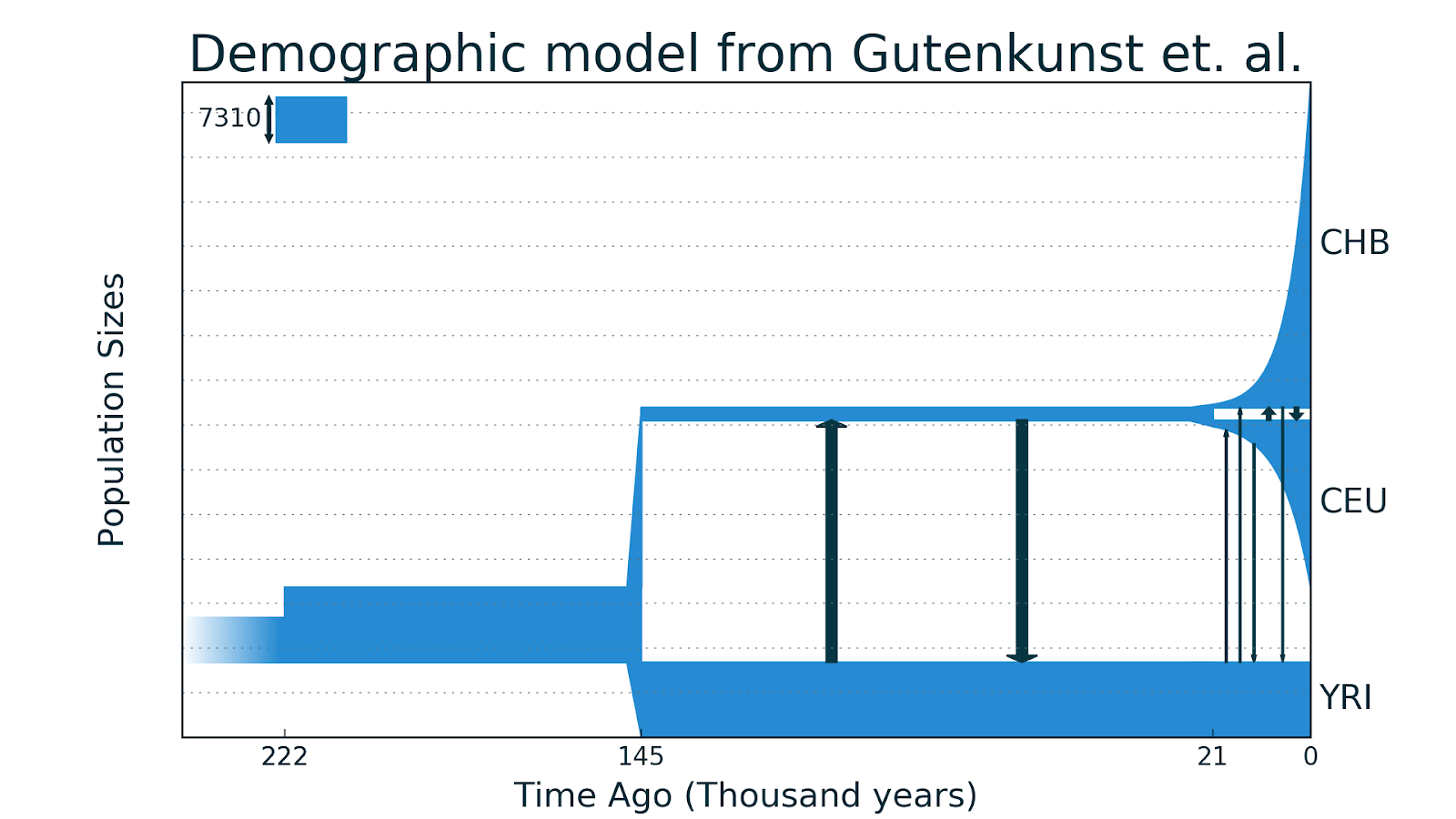
Обычно демографическая история — это словесное описание развития популяций и видов, однако ее можно изобразить графически. Например, вот так может выглядеть история Африканской и Европейской популяций, предложенная в статье Gutenkunst et al. 2009 года.
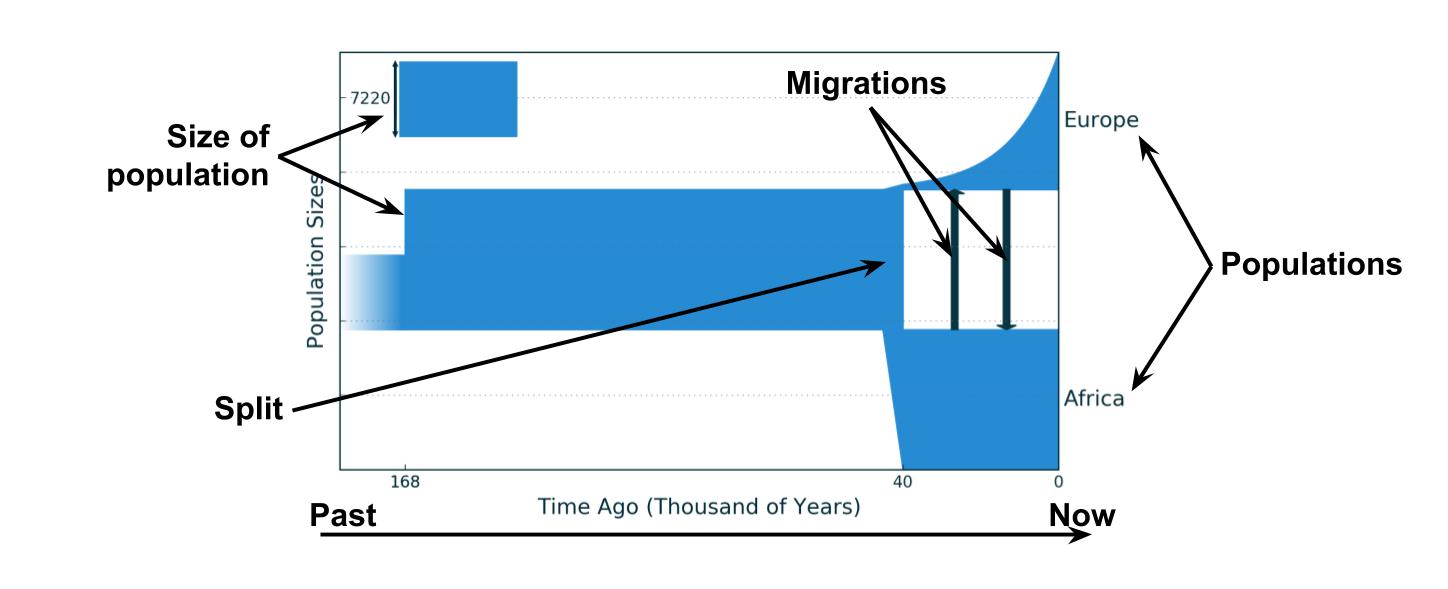
Более чем 168 тысяч лет назад была общая африканская популяция предков численностью 7 200 человек, 168 тысяч лет назад численность резко возросла до 13 500 человек, а затем оставалась постоянной. 40 тысяч лет назад от африканской популяции отделилась популяция европейская, ее численность сначала была небольшой — примерно 500 человек, но она экспоненциально росла до 13 тысяч человек к настоящему времени. После разделения между популяциями также происходила небольшая симметричная миграция.
Если вам кажется, что европейцев сейчас живет не 13 тысяч, то вы правы. Во-первых, это эффективная численность, которая всегда ниже обычной, во-вторых недавно людей было не так много как сейчас и этот рост еще не сильно выразился в геномных данных, да и у метода есть своя погрешность.
Приведем несколько примеров так называемых простейших демографических историй, из которых можно составлять более сложные истории:
Демографические истории, полученные из генетических данных, играют важную роль: во-первых, они дополняют археологические сведения об исторических событиях, которые не оставили письменных свидетельств, например о темпах и времени основных континентальных миграций людей. Также демографические истории способствуют увеличению информации об эволюционных силах и их влиянии на геномы, например, предоставляют данные о регионах, которые подверглись недавнему отбору. И наконец, они могут быть основой для последующих исследований популяций и медицинских генетических исследований.
Использование полных геномов вычислительно трудная задача, поэтому исследуемые данные часто упрощают. Одним из представлений генетической информации является аллель-частотный спектр — распределение частот аллелей в популяциях. Для его построения берут данные геномов особей или их часть, считают частоту приобретенных аллелей и строят гистограмму.
Приобретенные аллели — это те, которые отличаются от аллели в референсе. Референс может быть получен другими методами и являться общепризнанным геномом общего предка, но если он неизвестен, референсными аллелями обычно считают мажорные, то есть те, которые чаще встречаются. Учитывают также только биаллельные локусы, то есть позиции в геноме, где наблюдается только два вида аллелей (референсная и приобретенная). У человека все вариабельные локусы биаллельны, как и у многих млекопитающих, но не для всех живых организмов это правда.
Рассмотрим простейший пример построения аллель-частотного спектра:
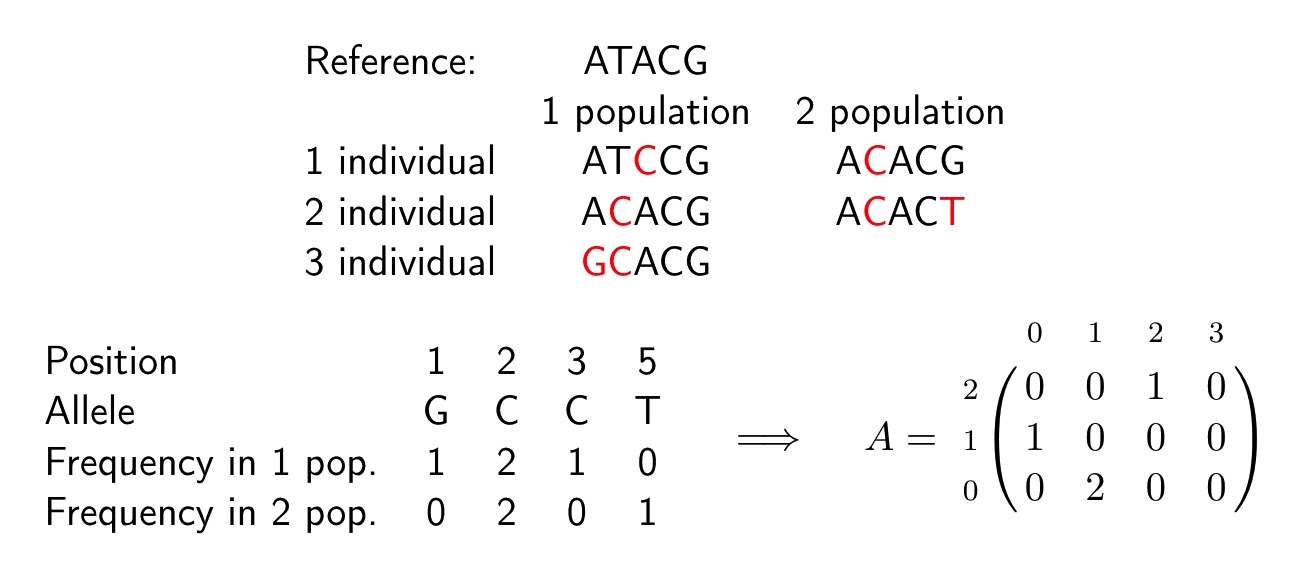
У нас известен референс (ATACG) и геномы трех особей в популяции 1 и двух в популяции 2. Красным выделены отличные от референса буквы — приобретенные аллели. Считаем частоту каждой приобретенной аллели: идем по позициям и считаем в скольких особях каждой из популяций встретилась эта аллель. На первой позиции у нас приобретенная аллель G, она встречается у одной особи в популяции 1 (третья особь) и не представлена в популяции 2. На позиции 2 приобретенная аллель C встречается у двух особей в популяции 1 и у двух в популяции 2.
И так далее, считаем для каждой позиции. Если на позиции нет приобретенной аллели, в данном примере это позиция 4, мы ее просто пропускаем. Затем по этой таблице строим гистограмму: в матрице А элемент на позиции (i, j) равен числу позиций на которых частоты приобретенных аллелей равны j в популяции 1 и i в популяции 2. В нашем примере А[1, 0] = 1 — пятая позиция, на которой аллель не представлена в популяции 1 и встречается всего у одной особи в популяции 2. A[0, 1] = 2 — это позиции 1 и 3. Таким образом, полученная матрица А является аллель-частотным спектром, построенным по геномным данным двух популяций.
Общая схема вывода демографической истории по аллель-частотному спектру
Самым популярным методом восстановления демографических историй по геномным данным, а именно по аллель-частотному спектру, является программа dadi (Gutenkunst et al., 2009). Она позволяет пользователю написать свою демографическую историю как функцию, а затем сравнить ее с геномными данными по значению правдоподобия.
Для этого по геномным данным строится аллель-частотный спектр, а по заданной демографической истории пакет составляет и численно решает уравнение диффузии, после чего получает математическое ожидание аллель-частотного спектра. Значение правдоподобия является результатом вычисления вероятности наблюдать спектр наших геномных данных при заданном математическом ожидании. Вывод демографической истории заключается в поиске параметров, дающих максимальное значение правдоподобия на генетических данных.
В целом это все выглядит так:

Теория, которая лежит в основе dadi, была создана еще в XX веке одним из самых влиятельных ученых Мотоо Кимурой. С тех пор она получила широкое распространение и развитие. Она включает множество математических моделей для описания сил эволюции. Эта математика очень увлекательна и элегантна, однако в данной статье мы не будем на ней останавливаться. Если читателям будет интересно, мы добавим дополнительную статью по этой теме.
В идеале хотелось бы найти наиболее подходящую демографическую модель, то есть дающую наибольшее значение правдоподобия. Данная задача является задачей оптимизации. И тут начинается главная часть нашего исследования. Программные решения, позволяющие вычислить ожидаемый аллель-частотный спектр предоставляют локальные оптимизации, которые работают хорошо, только если заданная начальная точка будет недалеко от оптимума.
Для поиска глобального оптимума алгоритмы локального поиска использовать можно, например, запустить из разных точек много раз, но бывают и более эффективные алгоритмы глобального поиска.
Существует множество алгоритмов глобальной оптимизации, некоторые из которых используют даже идеи эволюции. Один из таких алгоритмов — генетический алгоритм, который симулирует эволюционный процесс какой-то «популяции» в течении времени с целью найти наиболее приспособленную «особь», а именно с наибольшим значением целевой функции.
Таким образом рассматривается совокупность «особей» с «генетической информацией», которые могут давать потомство, на которое в свою очередь действуют силы естественного отбора, то есть выживают сильнейшие, наиболее приспособленные. При размножении происходит передача генетического материала от родителей к детям, а также мутации.
Как много знакомых понятий в совсем ином свете, не правда ли? Если мы вернемся к нашим демографическим историям, то генетической информацией будет являться сама демографическая история и ее параметры, мутацией — изменение значений параметров, скрещиванием — обмен параметрами между родителями, а приспособленностью — правдоподобие, которое определяет, насколько демографическая история соответствует аллель-частотному спектру.
Нам было интересно применить данный алгоритм для поиска оптимальных демографических историй. Мы разработали и реализовали его в программном обеспечении GADMA (Genetic Algorithm for Demographic Model Analysis).
Общая схема генетического алгоритма выглядит следующим образом. Алгоритм итеративно формирует новое поколение из старого, выбирая пару особей с лучшим правдоподобием, несколько особей мутированных и скрещенных, а также создает совершенно новых. Для особей в новом поколении вычисляется значение правдоподобия и, если нашлась модель с лучшим значением, то обновляется результат. Когда алгоритм не может в течение определенного количества итераций улучшить результат, он останавливается.
Мутация демографической истории происходит путем изменения значений нескольких параметров. Скрещивание двух особей — это произвольный выбор параметров от двух родителей.
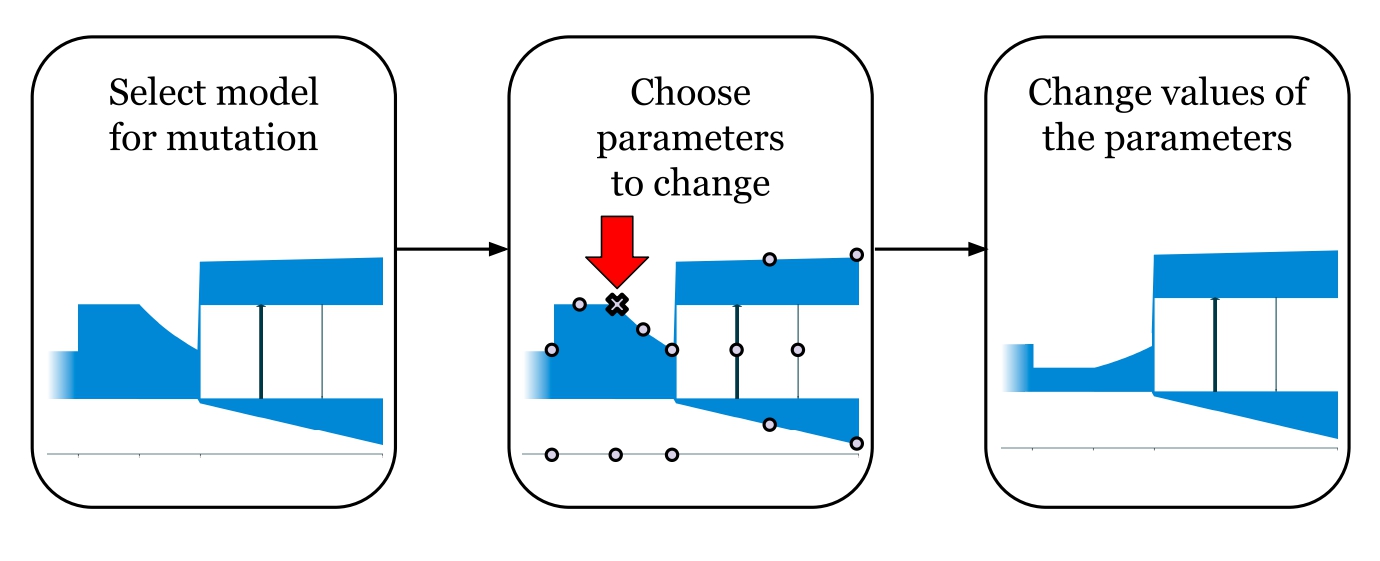
Диаграмма, показывающая как происходит “мутация” демографической истории: у модели выбирается несколько параметров и изменяется их значения. На данном изображении показано уменьшение значения одного параметра — размера предковой популяции в конце второго периода времени.

Диаграмма, показывающая как происходит “скрещивание” двух демографических историй: для каждого параметра происходит случайный выбор родителя от которого будет передано его значение.
GADMA избавляет от необходимости задавать демографическую историю подробно. Алгоритм просит пользователя задать только степень детализации, а именно число интервалов времени, для каждого из которых берется определенное число параметров. Более того, GADMA умеет подбирать динамику изменения численности популяций для каждого интервала: внезапное изменение, линейное или экспоненциальное.
Например, модель, которая была изображена самой первой (для двух популяций Africa и Europe), имеет три интервала времени, у каждого из которых три параметра: время, численность в конце интервала и динамика изменения численности. Также всегда есть первый интервал, он длится с момента существования популяций (бесконечно) и имеет один параметр — размер популяции. При этом в GADMA осталась возможность поиска параметров для заданной пользователем модели.
Более подробное описание метода приведено в статье Noskova E, Ulyantsev V., Koepfli K-P., O’Brien S.J., Dobrynin P. «Genetic Algorithm for Automatic Inferring the Joint Demographic History of Multiple Populations from Allele Frequency Spectrum». GigaScience, 2020 / 10.1093/gigascience/giaa005
После реализации алгоритма осталось провалидировать его на реальных данных. Существовало несколько работ, в которых были получены демографические истории, и нам было необходимо узнать, сможет ли наша программа на тех же данных найти что-то лучше, чем то, что было найдено до этого?
Мы взяли историю выхода людей из Африки. Она построена для трех популяций людей:
Данный выбор популяций является традиционным для исследований современных людей в популяционной генетике: данные для жителей США используют из-за проблем с доступом к данным жителей Евросоюза, а народы Йоруба и Хань являются наиболее яркими и изученными представителями своих популяций. Все три популяции имеют кодовые международные названия: YRI, CEU и CHB соответственно, эти обозначения используются и на наших картинках демографических историй.
Ранее была получена следующая демографическая история: когда-то давно была общая предковая африканская популяция постоянного размера 7 тысяч особей, численность которой около 222 тысяч лет назад выросла до 13 тысяч особей; 145 тысяч лет назад от этой популяции (ее размер остался тем же) отделилась евроазиатская популяция (это и есть момент выхода людей из Африки) размером 2 тысячи особей, которая 21 тысячу лет назад разделилась на популяции Европы и Азии, численность которых экспоненциально росла.
Логарифм правдоподобия такой модели был равен -6316. Мы взяли тот же аллель-частотный спектр и демографическую модель и подобрали параметры. И тут мы обнаружили, что это не оптимум: мы нашли модель с логарифмом правдоподобия равным -6314! Но к сожалению, время выхода людей из Африки было 400 тысяч лет назад в полученной демографической истории. Это не согласуется с современными представлениями: хотя недавно и нашли останки людей в Европе возрастом около 210 тысяч лет, нет подтверждений более ранней миграции. Тогда мы ограничили время разделения 150 тысячами лет и попробовали еще раз подобрать параметры. Полученная история имела параметры очень близкие к параметрам из работы, но логарифм правдоподобия опять был немного лучше. Ура, наш алгоритм работает!
Но мы не остановились на этом и решили увеличить число параметров: во-первых, а что если внезапные изменения численности на самом деле не внезапные, а экспоненциальные — не экспоненциальные? Во-вторых, пусть миграции не будут симметричными, а численность африканской популяции меняется чаще, например и в момент разделений. В целом, мы попросили GADMA подобрать нам модель так, чтобы у нее было два интервала времени перед первым разделением, один между первым и вторым разделениями и один после второго.
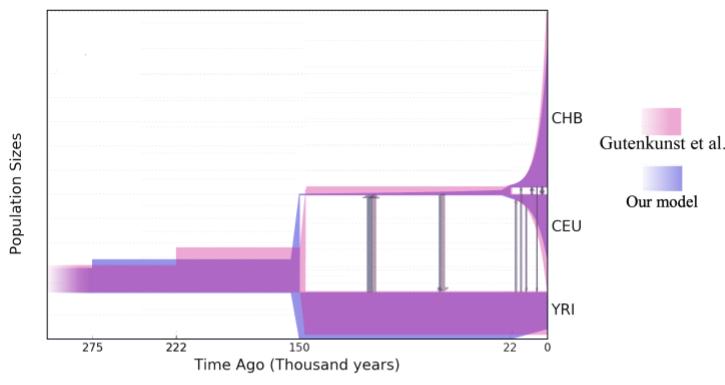
Мы оставили ограничение на время выхода из Африки, так как и для этой модели оно смещалось сильно в прошлое. Полученная модель имела самое большое значение логарифма правдоподобия, а именно -6288. Кроме этого, мы посчитали другую метрику для сравнения моделей с разным числом параметров, а именно Composite Likelihood Akaike Information Criterion и он показал, что модель с бОльшим числом параметров лучше подходит к данным. При сравнении параметров историй последняя показала несимметричные миграции, экспоненциальный рост евроазиатской популяции и более ранний скачок роста предковой популяции. Вот картинка сравнения двух историй:
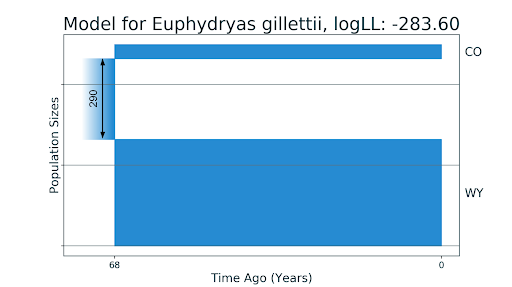
Мы также задались вопросом: а насколько верны текущие результаты статей про виды и популяции, об истории которых ничего неизвестно? Мы рассмотрели статью McCoy et al. (2013) про бабочек E. gillettii. Эти бабочки обитают в дикой природе в штате Вайоминг, в 1977 году исследователи поместили несколько особей на поля рядом со своей лабораторией в штате Колорадо. И спустя 33 года после этого в 2010 году отсеквенировали РНК восьми особей из каждой популяции. Авторы исследования также построили демографические истории бабочек без миграций, основываясь на том, что, благодаря такому искусственному созданию популяции в штате Колорадо, достоверно известно их отсутствие.
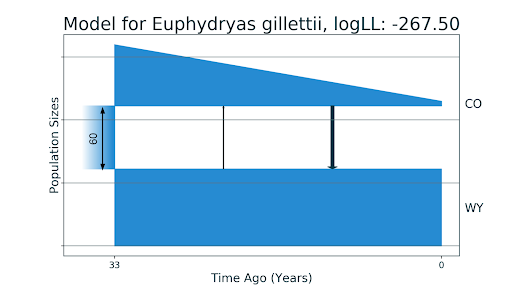
Мы взяли тот же аллель-частотный спектр и получили новую демографическую историю. Для начала мы подобрали параметры для точно такой же модели, получили почти такие же значения, но с более хорошим правдоподобием. После этого мы подобрали расширенную историю: мы не только разрешили миграции между популяциями, но и еще подбирали функцию изменения численности: константная численность, линейное или экспоненциальное изменение.
В модели из статьи рассматривалась только константная численность. Предсказанная демографическая история показала, что популяция бабочек из штата имела линейный рост численности после разделения, и близкие к нулю миграции. Стоит отметить, что dadi известен свойством преувеличения значений миграций, поэтому можно считать маленькие величины как равные нулю. Добавление параметров сказалось позитивно на качестве модели — время разделения популяций оказалось равным 33 годам, как и есть в действительности.
??????????(a)?????????????????????(b)
Модели для двух популяций бабочек E. gillettii: CO — из штата Колорадо, WY — из штата Вайоминг. На первом изображении (a) — модель без миграций, полученная до этого в статье McCoy et al., 2013. На втором изображении (b) — полученная нами модель с миграциями близкими к нулю, линейным падением численности популяции из Колорадо и временем разделения, равным реальным 33 годам.
Мы рассказали о методах, которые позволяют кое-что узнать об истории развития видов и популяций. Демографические истории отвечают на множество вопросов: как менялась численность популяций, когда происходило разделение и какие были темпы миграций. Но в то же время это всего лишь один из множества способов анализа генетической информации, которые вместе дают возможность узнавать историю эволюции современного человека и животных.
Генетический алгоритм, который мы применили для поиска демографических историй, дает широкое поле для дальнейших усовершенствований. Например, можно добавить дополнительные данные, кроме аллель-частотного спектра, и использовать другие методы поиска. Существуют данные гаплотипов — участков, которые передаются детям от родителей целиком, а также гистограмма длин между снипами.
Автор статьи: Екатерина Носкова, исследователь лаборатории проблем оптимизации в программной инженерии в JetBrains Research.
В идеале, для ответа на эти вопросы подошел бы сравнительный анализ геномов людей, проживавших в разные периоды истории — это позволило бы установить взаимосвязи между человеческими популяциями, населяющими разные территории в разные промежутки времени. Такие геномы можно выделить, например, из археологических останков, но, к сожалению, количество и качество таких геномов довольно ограничено. С другой стороны, оказывается, что часть ответа заключена в геномах современных людей. Как именно по таким геномным данным можно восстановить детали популяционной истории, мы и расскажем в этой статье.
Карта мира, показывающая передвижение людей Homo Sapiens. Показано всего лишь одно из множества представлений того как это могло происходить. На карте выделена область северо-востока Африки — примерное место, где жили наши предки перед переселением. На карте линии показывают основные миграции, а время событий отмечено в кругах. Так 65 тысяч лет назад люди через Аравийский полуостров попали в Евразию и разделились: одна группа пошла в Европу, другая — в Азию. А через Берингов пролив люди заселили Америку около 16 тысяч лет назад.
Источник картинки
В целом, вопросами влияния движущих сил эволюции на геномы занимается популяционная генетика. Ее ключевыми сущностями являются особь, популяция и вид. Особью, как несложно догадаться, считается отдельный организм. Видом называется группа особей с общими признаками, дающая плодовитое потомство.
Плодовитость потомства важна, так как, например, можно скрестить осла и лошадь — получится мул, но он стерилен, а значит по этому определению осел и лошадь — это разные виды. Популяцией же называют группу особей одного вида, живущую на отдельной территории, частично или полностью изолированную от других таких же групп.
Определение видов совсем не простая задача. Давным-давно это делали по фенотипическим, то есть видимым, признакам, однако при исследовании геномов в такой классификации были найдены ошибки. Известным примером являются археи: изначально их причисляли по строению к прокариотам, но анализ генов показал их сильное отличие от прокариотов и эукариотов, и ученые выделили их в отдельный домен классификации. Определение популяций тоже вызывает жаркие споры.
Например, существует два подвида исчезающей газели Dama gazelle: mhorr и addra. Эти подвиды отличаются фенотипически, поэтому их выделяют в отдельные популяции. Однако анализ геномов показывает, что на самом деле это одна популяция.
 Dama gazelle addra |
 Dama gazelle mhorr |
Источник картинки
История развития популяций и видов называется демографической историей. События этой истории включают в себя разделение популяций, миграции и изменение численности. При этом важно не просто число особей, а число особей, которые размножаются, — так называемая эффективная численность. Общее количество особей в популяции при этом может быть гораздо больше и сильно меняться с течением времени, поэтому в эволюции эффективная численность гораздо важнее общей.
Обычно демографическая история — это словесное описание развития популяций и видов, однако ее можно изобразить графически. Например, вот так может выглядеть история Африканской и Европейской популяций, предложенная в статье Gutenkunst et al. 2009 года.
Более чем 168 тысяч лет назад была общая африканская популяция предков численностью 7 200 человек, 168 тысяч лет назад численность резко возросла до 13 500 человек, а затем оставалась постоянной. 40 тысяч лет назад от африканской популяции отделилась популяция европейская, ее численность сначала была небольшой — примерно 500 человек, но она экспоненциально росла до 13 тысяч человек к настоящему времени. После разделения между популяциями также происходила небольшая симметричная миграция.
Если вам кажется, что европейцев сейчас живет не 13 тысяч, то вы правы. Во-первых, это эффективная численность, которая всегда ниже обычной, во-вторых недавно людей было не так много как сейчас и этот рост еще не сильно выразился в геномных данных, да и у метода есть своя погрешность.
Приведем несколько примеров так называемых простейших демографических историй, из которых можно составлять более сложные истории:
- Изоляция. Очень давно была одна общая популяция размера , которая времени назад разделилась на две субпопуляции размером и . При этом никаких миграций между ними не было, то есть была изоляция. Подставьте какие-нибудь численные значения и получится реальная демографическая история.
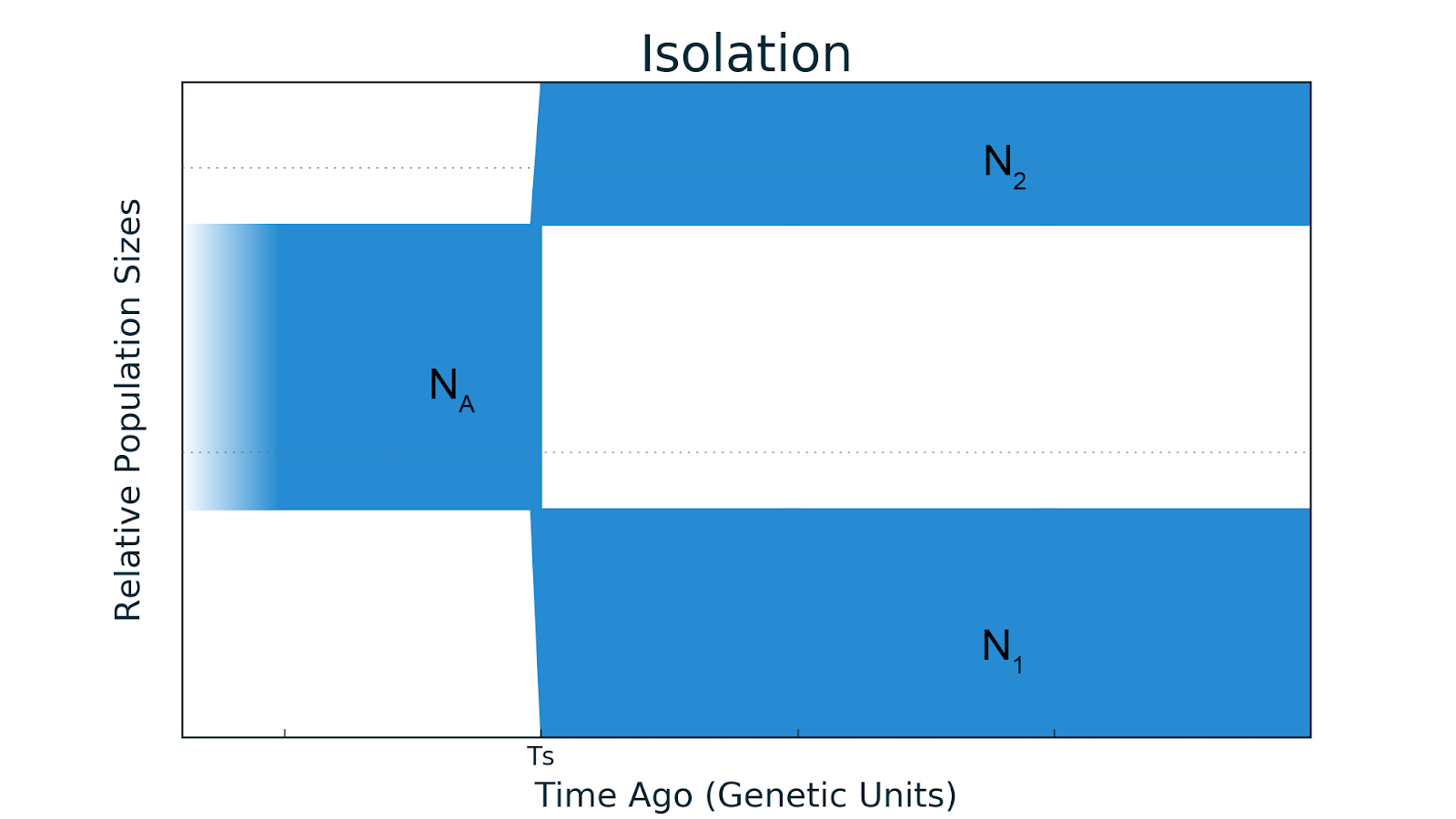
Описанная схема часто является случаем так называемого аллопатрического видообразования, когда виды формируются за счет появления географического барьера, который разделяет вид/популяцию на две группы, и каждая из них начинает развиваться независимо. Примеров такого видообразования очень много. Самый известный — дарвиновские или галапагосские вьюрки, которые были впервые описаны Чарльзом Дарвином. Анализ их геномов показал, что они являются потомками одного континентального вида, представители которого попали на Галапагосы миллионы лет назад и дали начало 4 различным линиям.
??????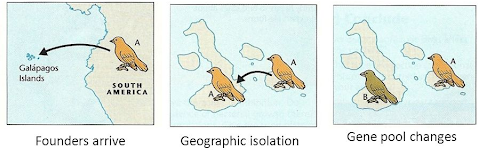
Источник картинки
- Изоляция после миграции. Примерно такая же история как и изоляция, однако включает в себя миграции в течении какого-то времени после разделения. Такие события уже не обязательно говорят о медленно появляющемся географическом барьере, хотя это один из возможных вариантов развития событий. Вероятен сценарий, когда произошло не просто разделение популяций, а уже видообразование, и два новых вида больше не могут скрещиваться между собой, а следовательно нет и мигрантов.

- Второй контакт. Иногда географический барьер, разделивший популяции исчезает: они встречаются вновь и начинается миграция.
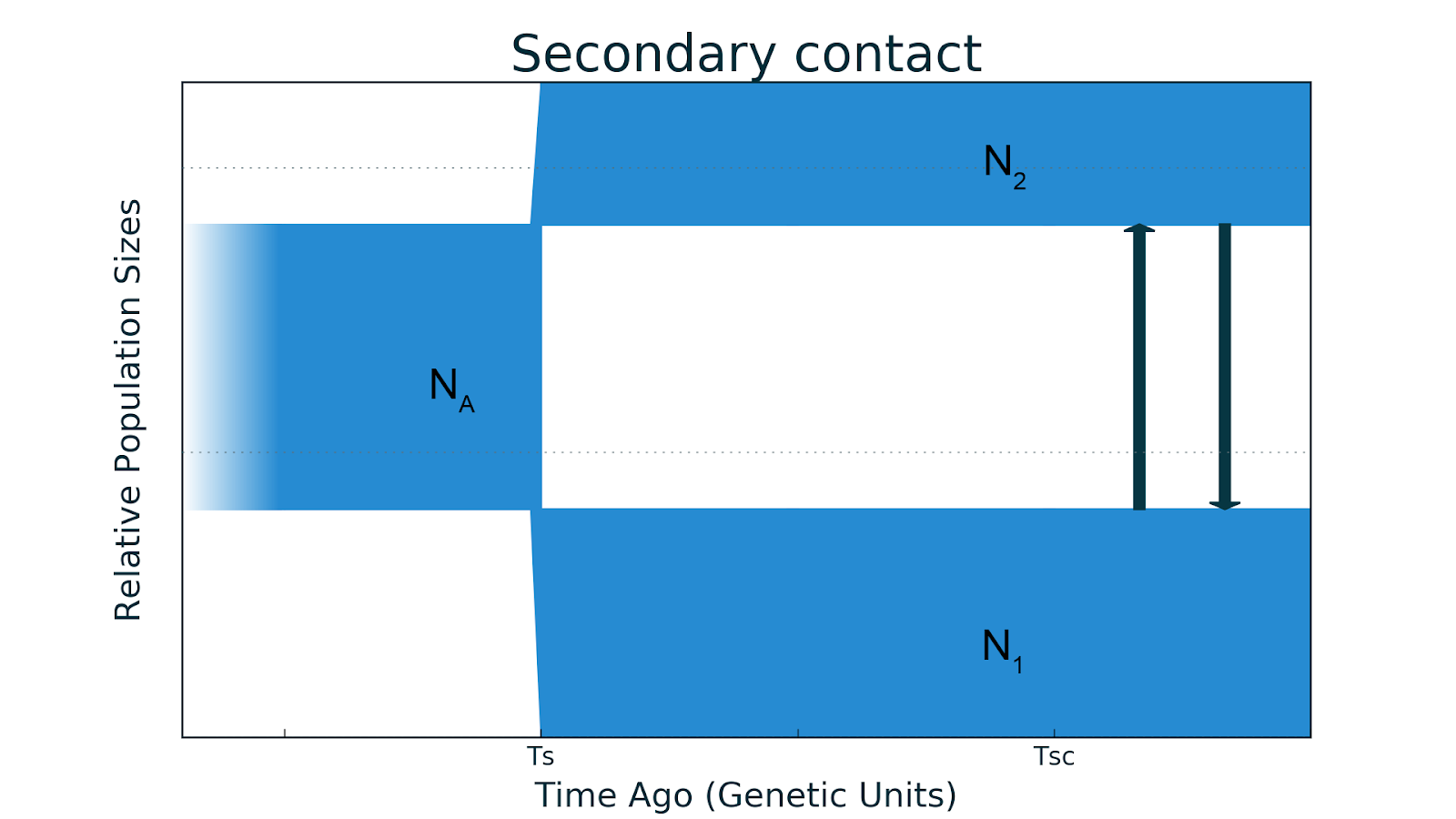
Примером такого развития являются два подвида золотого шилоклювого дятла из Северной Америки. Западный с желтым валом (Colaptes auratus) и восточный с красным валом (Colaptes cafer) подвиды были изолированы, а потом образовали гибридную зону — территорию, на которой два подвида скрещиваются и образуют гибриды.

Демографические истории, полученные из генетических данных, играют важную роль: во-первых, они дополняют археологические сведения об исторических событиях, которые не оставили письменных свидетельств, например о темпах и времени основных континентальных миграций людей. Также демографические истории способствуют увеличению информации об эволюционных силах и их влиянии на геномы, например, предоставляют данные о регионах, которые подверглись недавнему отбору. И наконец, они могут быть основой для последующих исследований популяций и медицинских генетических исследований.
Аллель-частотный спектр
Использование полных геномов вычислительно трудная задача, поэтому исследуемые данные часто упрощают. Одним из представлений генетической информации является аллель-частотный спектр — распределение частот аллелей в популяциях. Для его построения берут данные геномов особей или их часть, считают частоту приобретенных аллелей и строят гистограмму.
Приобретенные аллели — это те, которые отличаются от аллели в референсе. Референс может быть получен другими методами и являться общепризнанным геномом общего предка, но если он неизвестен, референсными аллелями обычно считают мажорные, то есть те, которые чаще встречаются. Учитывают также только биаллельные локусы, то есть позиции в геноме, где наблюдается только два вида аллелей (референсная и приобретенная). У человека все вариабельные локусы биаллельны, как и у многих млекопитающих, но не для всех живых организмов это правда.
Рассмотрим простейший пример построения аллель-частотного спектра:
У нас известен референс (ATACG) и геномы трех особей в популяции 1 и двух в популяции 2. Красным выделены отличные от референса буквы — приобретенные аллели. Считаем частоту каждой приобретенной аллели: идем по позициям и считаем в скольких особях каждой из популяций встретилась эта аллель. На первой позиции у нас приобретенная аллель G, она встречается у одной особи в популяции 1 (третья особь) и не представлена в популяции 2. На позиции 2 приобретенная аллель C встречается у двух особей в популяции 1 и у двух в популяции 2.
И так далее, считаем для каждой позиции. Если на позиции нет приобретенной аллели, в данном примере это позиция 4, мы ее просто пропускаем. Затем по этой таблице строим гистограмму: в матрице А элемент на позиции (i, j) равен числу позиций на которых частоты приобретенных аллелей равны j в популяции 1 и i в популяции 2. В нашем примере А[1, 0] = 1 — пятая позиция, на которой аллель не представлена в популяции 1 и встречается всего у одной особи в популяции 2. A[0, 1] = 2 — это позиции 1 и 3. Таким образом, полученная матрица А является аллель-частотным спектром, построенным по геномным данным двух популяций.
Общая схема вывода демографической истории по аллель-частотному спектру
Самым популярным методом восстановления демографических историй по геномным данным, а именно по аллель-частотному спектру, является программа dadi (Gutenkunst et al., 2009). Она позволяет пользователю написать свою демографическую историю как функцию, а затем сравнить ее с геномными данными по значению правдоподобия.
Для этого по геномным данным строится аллель-частотный спектр, а по заданной демографической истории пакет составляет и численно решает уравнение диффузии, после чего получает математическое ожидание аллель-частотного спектра. Значение правдоподобия является результатом вычисления вероятности наблюдать спектр наших геномных данных при заданном математическом ожидании. Вывод демографической истории заключается в поиске параметров, дающих максимальное значение правдоподобия на генетических данных.
В целом это все выглядит так:
Теория, которая лежит в основе dadi, была создана еще в XX веке одним из самых влиятельных ученых Мотоо Кимурой. С тех пор она получила широкое распространение и развитие. Она включает множество математических моделей для описания сил эволюции. Эта математика очень увлекательна и элегантна, однако в данной статье мы не будем на ней останавливаться. Если читателям будет интересно, мы добавим дополнительную статью по этой теме.
Оптимизация
В идеале хотелось бы найти наиболее подходящую демографическую модель, то есть дающую наибольшее значение правдоподобия. Данная задача является задачей оптимизации. И тут начинается главная часть нашего исследования. Программные решения, позволяющие вычислить ожидаемый аллель-частотный спектр предоставляют локальные оптимизации, которые работают хорошо, только если заданная начальная точка будет недалеко от оптимума.
Для поиска глобального оптимума алгоритмы локального поиска использовать можно, например, запустить из разных точек много раз, но бывают и более эффективные алгоритмы глобального поиска.
Генетический алгоритм
Существует множество алгоритмов глобальной оптимизации, некоторые из которых используют даже идеи эволюции. Один из таких алгоритмов — генетический алгоритм, который симулирует эволюционный процесс какой-то «популяции» в течении времени с целью найти наиболее приспособленную «особь», а именно с наибольшим значением целевой функции.
Таким образом рассматривается совокупность «особей» с «генетической информацией», которые могут давать потомство, на которое в свою очередь действуют силы естественного отбора, то есть выживают сильнейшие, наиболее приспособленные. При размножении происходит передача генетического материала от родителей к детям, а также мутации.
Как много знакомых понятий в совсем ином свете, не правда ли? Если мы вернемся к нашим демографическим историям, то генетической информацией будет являться сама демографическая история и ее параметры, мутацией — изменение значений параметров, скрещиванием — обмен параметрами между родителями, а приспособленностью — правдоподобие, которое определяет, насколько демографическая история соответствует аллель-частотному спектру.
Нам было интересно применить данный алгоритм для поиска оптимальных демографических историй. Мы разработали и реализовали его в программном обеспечении GADMA (Genetic Algorithm for Demographic Model Analysis).
Общая схема генетического алгоритма выглядит следующим образом. Алгоритм итеративно формирует новое поколение из старого, выбирая пару особей с лучшим правдоподобием, несколько особей мутированных и скрещенных, а также создает совершенно новых. Для особей в новом поколении вычисляется значение правдоподобия и, если нашлась модель с лучшим значением, то обновляется результат. Когда алгоритм не может в течение определенного количества итераций улучшить результат, он останавливается.
Мутация демографической истории происходит путем изменения значений нескольких параметров. Скрещивание двух особей — это произвольный выбор параметров от двух родителей.
Диаграмма, показывающая как происходит “мутация” демографической истории: у модели выбирается несколько параметров и изменяется их значения. На данном изображении показано уменьшение значения одного параметра — размера предковой популяции в конце второго периода времени.
Диаграмма, показывающая как происходит “скрещивание” двух демографических историй: для каждого параметра происходит случайный выбор родителя от которого будет передано его значение.
GADMA избавляет от необходимости задавать демографическую историю подробно. Алгоритм просит пользователя задать только степень детализации, а именно число интервалов времени, для каждого из которых берется определенное число параметров. Более того, GADMA умеет подбирать динамику изменения численности популяций для каждого интервала: внезапное изменение, линейное или экспоненциальное.
Например, модель, которая была изображена самой первой (для двух популяций Africa и Europe), имеет три интервала времени, у каждого из которых три параметра: время, численность в конце интервала и динамика изменения численности. Также всегда есть первый интервал, он длится с момента существования популяций (бесконечно) и имеет один параметр — размер популяции. При этом в GADMA осталась возможность поиска параметров для заданной пользователем модели.
Более подробное описание метода приведено в статье Noskova E, Ulyantsev V., Koepfli K-P., O’Brien S.J., Dobrynin P. «Genetic Algorithm for Automatic Inferring the Joint Demographic History of Multiple Populations from Allele Frequency Spectrum». GigaScience, 2020 / 10.1093/gigascience/giaa005
Выход людей из Африки
После реализации алгоритма осталось провалидировать его на реальных данных. Существовало несколько работ, в которых были получены демографические истории, и нам было необходимо узнать, сможет ли наша программа на тех же данных найти что-то лучше, чем то, что было найдено до этого?
Мы взяли историю выхода людей из Африки. Она построена для трех популяций людей:
- Народа Йоруба из Нигерии (назовем ее африканской популяцией);
- Жителей штата Юта, имеющих предков в Европе (европейская популяция);
- Представителей народа Хань из Пекина (азиатская популяция).
Данный выбор популяций является традиционным для исследований современных людей в популяционной генетике: данные для жителей США используют из-за проблем с доступом к данным жителей Евросоюза, а народы Йоруба и Хань являются наиболее яркими и изученными представителями своих популяций. Все три популяции имеют кодовые международные названия: YRI, CEU и CHB соответственно, эти обозначения используются и на наших картинках демографических историй.
Ранее была получена следующая демографическая история: когда-то давно была общая предковая африканская популяция постоянного размера 7 тысяч особей, численность которой около 222 тысяч лет назад выросла до 13 тысяч особей; 145 тысяч лет назад от этой популяции (ее размер остался тем же) отделилась евроазиатская популяция (это и есть момент выхода людей из Африки) размером 2 тысячи особей, которая 21 тысячу лет назад разделилась на популяции Европы и Азии, численность которых экспоненциально росла.
Логарифм правдоподобия такой модели был равен -6316. Мы взяли тот же аллель-частотный спектр и демографическую модель и подобрали параметры. И тут мы обнаружили, что это не оптимум: мы нашли модель с логарифмом правдоподобия равным -6314! Но к сожалению, время выхода людей из Африки было 400 тысяч лет назад в полученной демографической истории. Это не согласуется с современными представлениями: хотя недавно и нашли останки людей в Европе возрастом около 210 тысяч лет, нет подтверждений более ранней миграции. Тогда мы ограничили время разделения 150 тысячами лет и попробовали еще раз подобрать параметры. Полученная история имела параметры очень близкие к параметрам из работы, но логарифм правдоподобия опять был немного лучше. Ура, наш алгоритм работает!
Но мы не остановились на этом и решили увеличить число параметров: во-первых, а что если внезапные изменения численности на самом деле не внезапные, а экспоненциальные — не экспоненциальные? Во-вторых, пусть миграции не будут симметричными, а численность африканской популяции меняется чаще, например и в момент разделений. В целом, мы попросили GADMA подобрать нам модель так, чтобы у нее было два интервала времени перед первым разделением, один между первым и вторым разделениями и один после второго.
Мы оставили ограничение на время выхода из Африки, так как и для этой модели оно смещалось сильно в прошлое. Полученная модель имела самое большое значение логарифма правдоподобия, а именно -6288. Кроме этого, мы посчитали другую метрику для сравнения моделей с разным числом параметров, а именно Composite Likelihood Akaike Information Criterion и он показал, что модель с бОльшим числом параметров лучше подходит к данным. При сравнении параметров историй последняя показала несимметричные миграции, экспоненциальный рост евроазиатской популяции и более ранний скачок роста предковой популяции. Вот картинка сравнения двух историй:
Демографическая модель бабочек
Мы также задались вопросом: а насколько верны текущие результаты статей про виды и популяции, об истории которых ничего неизвестно? Мы рассмотрели статью McCoy et al. (2013) про бабочек E. gillettii. Эти бабочки обитают в дикой природе в штате Вайоминг, в 1977 году исследователи поместили несколько особей на поля рядом со своей лабораторией в штате Колорадо. И спустя 33 года после этого в 2010 году отсеквенировали РНК восьми особей из каждой популяции. Авторы исследования также построили демографические истории бабочек без миграций, основываясь на том, что, благодаря такому искусственному созданию популяции в штате Колорадо, достоверно известно их отсутствие.
Мы взяли тот же аллель-частотный спектр и получили новую демографическую историю. Для начала мы подобрали параметры для точно такой же модели, получили почти такие же значения, но с более хорошим правдоподобием. После этого мы подобрали расширенную историю: мы не только разрешили миграции между популяциями, но и еще подбирали функцию изменения численности: константная численность, линейное или экспоненциальное изменение.
В модели из статьи рассматривалась только константная численность. Предсказанная демографическая история показала, что популяция бабочек из штата имела линейный рост численности после разделения, и близкие к нулю миграции. Стоит отметить, что dadi известен свойством преувеличения значений миграций, поэтому можно считать маленькие величины как равные нулю. Добавление параметров сказалось позитивно на качестве модели — время разделения популяций оказалось равным 33 годам, как и есть в действительности.
??????????(a)?????????????????????(b)
Модели для двух популяций бабочек E. gillettii: CO — из штата Колорадо, WY — из штата Вайоминг. На первом изображении (a) — модель без миграций, полученная до этого в статье McCoy et al., 2013. На втором изображении (b) — полученная нами модель с миграциями близкими к нулю, линейным падением численности популяции из Колорадо и временем разделения, равным реальным 33 годам.
Заключение
Мы рассказали о методах, которые позволяют кое-что узнать об истории развития видов и популяций. Демографические истории отвечают на множество вопросов: как менялась численность популяций, когда происходило разделение и какие были темпы миграций. Но в то же время это всего лишь один из множества способов анализа генетической информации, которые вместе дают возможность узнавать историю эволюции современного человека и животных.
Генетический алгоритм, который мы применили для поиска демографических историй, дает широкое поле для дальнейших усовершенствований. Например, можно добавить дополнительные данные, кроме аллель-частотного спектра, и использовать другие методы поиска. Существуют данные гаплотипов — участков, которые передаются детям от родителей целиком, а также гистограмма длин между снипами.
Автор статьи: Екатерина Носкова, исследователь лаборатории проблем оптимизации в программной инженерии в JetBrains Research.
Exchan-ge
Показанная карта хорошо согласуется и с другими источниками, так что, вероятно, она весьма близка к истине.