
Привет, Хабр! Представляю вашему вниманию перевод статьи «4 Engineers, 7000 Servers, And One Global Pandemic» автора Adib Daw.
Если этот заголовок не вызвал легкую дрожь в позвоночнике, вам следует перейти к следующему абзацу или перейти на нашу страницу, посвященную карьере в компании — мы хотели бы поговорить.
Мы команда из 4 пингвинов, которые любят писать код и работать с оборудованием. В свободное время мы отвечаем за развёртывание, обслуживание и эксплуатацию парка из более 7000 физических серверов под управлением Linux, распределенных по 3 разным дата-центрам на территории США.
Нам также довелось заниматься этим на расстоянии 10 000 км от объектов, не выходя из нашего собственного кабинета, который расположен в нескольких минутах езды от пляжа на Средиземном море.
Хотя для стартапа имеет смысл начать с размещения своей инфраструктуры в облаке из-за относительно небольших первоначальных инвестиций, мы в Outbrain решили использовать свои собственные сервера. Мы сделали так по той причине, что расходы на инфраструктуру облаков намного превышают затраты на эксплуатацию нашего собственного оборудования, размещённого в дата-центрах после развития до определённого уровня. К тому же, свой сервер обеспечивает высочайшую степень контроля и возможностей по устранению неисправностей.
По мере того, как мы развиваемся, проблемы всегда находятся рядом. Причём они обычно приходят группами. Управление жизненным циклом сервера требует постоянного самосовершенствования, чтобы иметь возможность нормально работать в условиях быстрого увеличения количества серверов. Программные методы управления серверными группами в центрах обработки данных очень быстро становятся громоздкими. Обнаружение, устранение неисправностей и устранение сбоев при обеспечении норм, прописанных в договоре об качестве обслуживания превращается в манипулирование чрезвычайно разнообразными аппаратными массивами, различными нагрузками, сроками обновления и другими приятными вещами, о которых никто не хочет заботиться.
Чтобы решить многие из этих проблем, мы разбили жизненный цикл сервера в Outbrain на его основные компоненты и назвали их доменами. Например, один домен охватывает потребность в оборудовании, другой — логистику, связанную с жизненным циклом запасов, а третий — связь с персоналом на месте. Есть еще один, касающийся аппаратной наблюдаемости, но мы не будем расписывать все-все моменты. Нашей целью являлось изучение и определение доменов, чтобы их можно было абстрагировать с помощью кода. Как только рабочая абстракция разработана, она переводится в ручной процесс, который развертывается, тестируется и дорабатывается. Наконец, домен настроен для интеграции с другими доменами через API, формируя целостную, динамичную и постоянно развивающуюся систему жизненного цикла оборудования, которая может быть развернута, тестируема и наблюдаема. Как и все наши другие производственные системы.
Принятие такого подхода позволило нам правильно решать многие проблемы — путём создания инструментов и средств автоматизации.
Хотя email и электронные таблицы были приемлемым способом удовлетворения спроса в первые дни, это нельзя было назвать удачным решением, особенно когда количество серверов и объём входящих запросов достигли определённого уровня. Чтобы лучше организовать и расставить приоритеты входящих запросов в условиях быстрого расширения, нам пришлось использовать систему тикетов, которая могла предложить:
Поскольку мы используем Джиру для управления нашими спринтами и внутренними задачами, то решили создать ещё один проект, который помог бы нашим клиентам отправлять заявки и отслеживать их результаты. Использование Джиры для входящих запросов и для управления внутренними задачами позволила нам создать единую Канбан-доску, которая позволила нам взглянуть на все процессы в целом. Наши внутренние «клиенты» видели только заявки на оборудование, не вникая в менее значимые детали дополнительных задач (таких как улучшение инструментов, исправление ошибок).

Канбан-доска в Джире
В качестве бонуса тот факт, что очереди и приоритеты теперь были видны всем, позволял понять, «где в очереди» находится конкретный запрос и что предшествовало ему. Это позволяло владельцам менять приоритеты в своих собственных запросах без необходимости связываться с нами. Перетащил – и всех делов. Это также позволило нам мониторить и оценивать наши SLA в соответствии с типами запросов на основе показателей, сгенерированных в Джире.
Попробуйте представить сложность управления оборудованием, используемым в каждой серверной стойке. Что ещё хуже, многие железки (RAM, ROM) могут перемещаться со склада в серверную и обратно. А ещё они выходят из строя или списываются и заменяются, возвращаются поставщику для замены/ремонта. Всё это нужно сообщать сотрудникам колокейшн-службы, занимающихся физическим обслуживанием оборудования. Для решения этих проблем мы создали внутренний инструмент под названием Floppy. Его задача в:
Склад, в свою очередь, визуализируется с помощью Grafana, которую мы используем для построения графиков всех наших показателей. Таким образом, мы используем один и тот же инструмент для визуализации склада и для других производственных нужд.
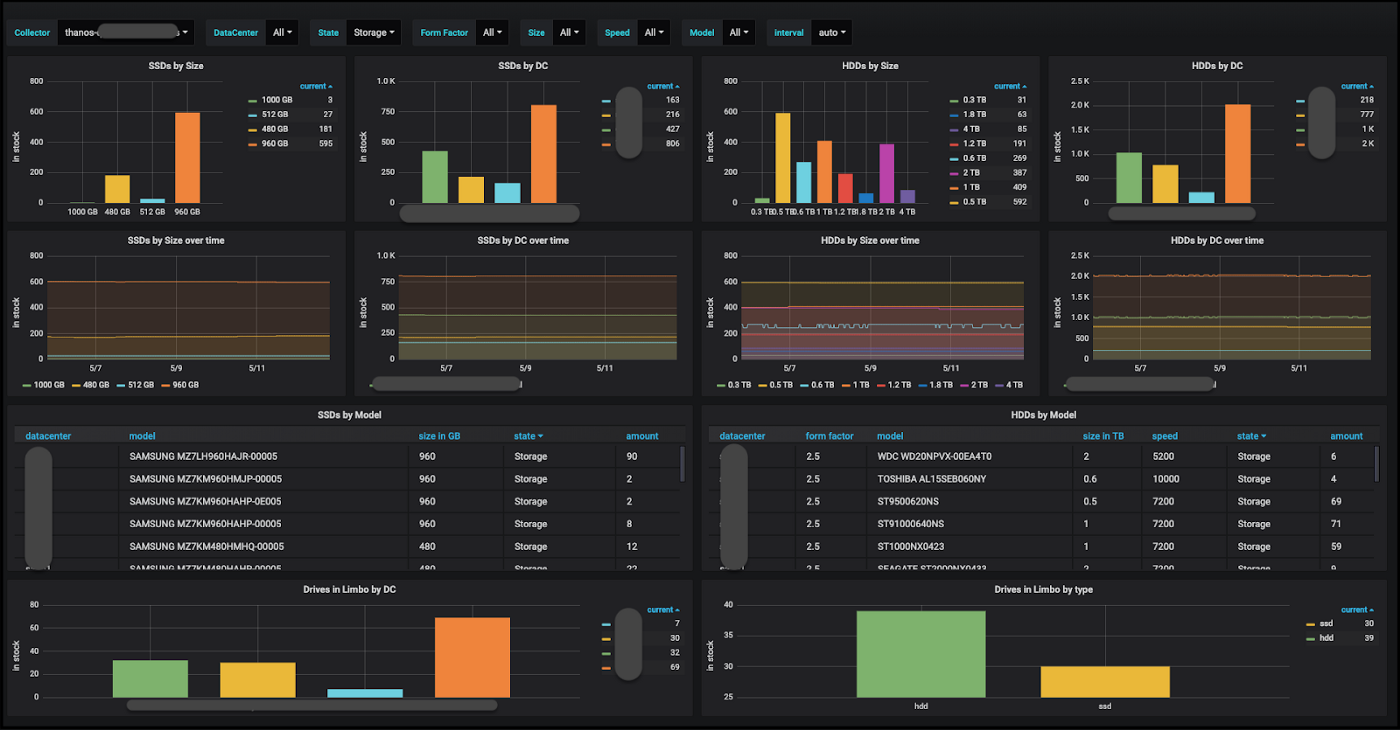 Панель управлением оборудованием на складе в Grafana
Панель управлением оборудованием на складе в Grafana
Для серверных устройств, которые находятся на гарантии, мы используем другой инструмент, который мы назвали Dispatcher. Он:
После того, как наша претензия принимается (как правило, это происходит в течение рабочего дня), запасная часть отправляется в соответствующий ЦОД и принимается персоналом.
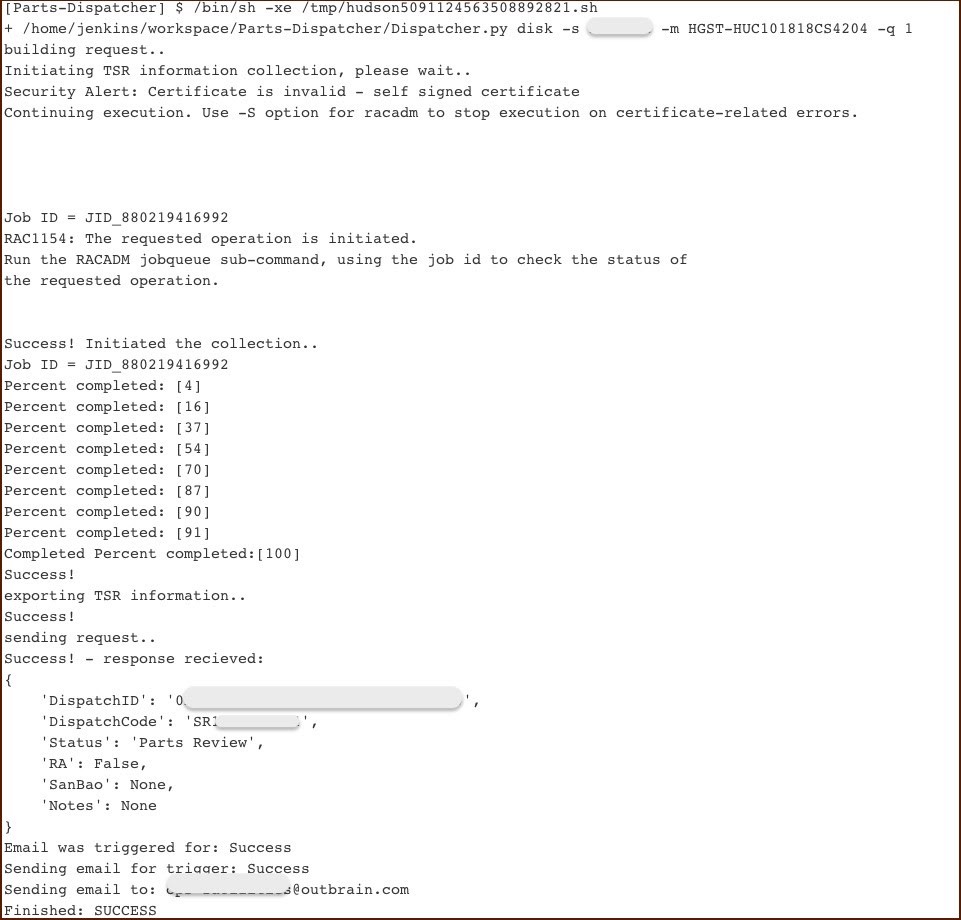
Вывод консоли Jenkins
Чтобы успевать за быстрым ростом бизнеса, требующего всё большей ёмкости, нам пришлось адаптировать под себя методы работы с техническими специалистами локальных центров обработки данных. Если сначала увеличение масштаба означало покупку новых серверов, то после проекта консолидации (основанного на переход в Кубернетес) это стало чем-то совершенно другим. Наше развитие из «добавления стоек» превратилось в «перепрофилирование серверов».
Использование нового подхода потребовало и новых инструментов, позволяющих с большим комфортом взаимодействовать с персоналом центров обработки данных. От этих инструментов требовалась:
Нам пришлось исключить себя из цепочки и построить работу так, чтобы техники могли напрямую работать серверным оборудованием. Без нашего вмешательства и без регулярного поднятия всех этих вопросов, касающихся рабочей нагрузки, рабочего времени, наличия оборудования и пр.
Чтобы добиться этого, мы установили iPad в каждом дата-центре. После подключения к серверу произойдет следующее:
Помимо этого, мы также подготовили бота Slack, который бы помогал техническому специалисту. Благодаря широкому набору возможностей (мы постоянно расширяли функционал) бот сделал их работу проще, а нам здорово облегчил жизнь. Так мы оптимизировали большую часть процесса перепрофилирования и обслуживания серверов, исключив себя из рабочего процесса.

iPad в одном из наших центров обработки данных
Надёжное масштабирование инфраструктуры нашего центра обработки данных требует хорошей видимости каждого компонента, например:
Наши решения позволяют нам принимать решения о том, как, где и когда приобретать оборудование, иногда даже до того, как в нём реально возникнет потребность. Также путем определения уровня нагрузок на разное оборудование мы смогли добиться улучшения распределения ресурсов. В частности, энергопотребления. Теперь мы можем принимать обоснованные решения относительно размещения сервера до того, как он будет установлен в стойку и подключен к источнику питания, а также на протяжении всего цикла эксплуатации и вплоть до его возможного списания.
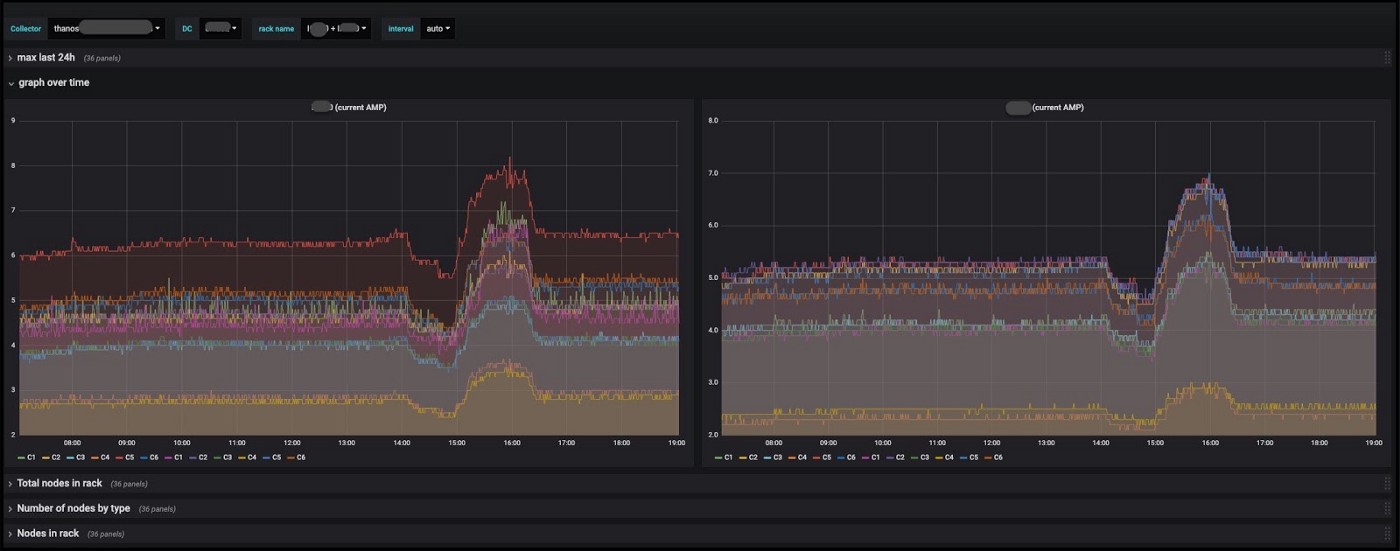
Панель энергопотребления в Grafana
Наша команда создаёт технологии, которые расширяют возможности медиакомпаний и издательств в сети, помогают посетителям находить релевантный контент, продукты и услуги, которые могут быть им интересны. Наша инфраструктура предназначена для обслуживания трафика, генерируемого при выходе каких-то ажиотажных новостей.
Активное освещение в СМИ событий, связанных с COVID-19, в сочетании с приростом трафика означало, что нам необходимо было срочно научиться справляться с такими нагрузками. К тому же, всё это нужно было сделать в условиях глобального кризиса, когда цепочки поставок были нарушены, а большая часть персонала находилась дома.
Но, как мы уже говорили, наша модель уже предполагает, что:
Таким образом, глобальные ограничения, помешавшие многим компаниям получить физический доступ к своим центрам обработки данных, оказали на нас мало влияния А что касается запчастей и серверов — да, мы старались обеспечить стабильную работу оборудования. Но делалось с целью предотвратить возможные казусы, когда внезапно выясняется, что какой-то «железки» нет в наличии. Мы обеспечивали наполнение наших резервов, не ставя целью удовлетворение текущего спроса.
Как итог, я хотел бы сказать, что наш подход к работе в сфере ЦОДов доказывает, что можно применить принципы хорошего проектирования кода к процессам физического управления центром обработки данных. И, возможно, вам это покажется интересным.
Оригинал: тыц
Если этот заголовок не вызвал легкую дрожь в позвоночнике, вам следует перейти к следующему абзацу или перейти на нашу страницу, посвященную карьере в компании — мы хотели бы поговорить.
Кто мы
Мы команда из 4 пингвинов, которые любят писать код и работать с оборудованием. В свободное время мы отвечаем за развёртывание, обслуживание и эксплуатацию парка из более 7000 физических серверов под управлением Linux, распределенных по 3 разным дата-центрам на территории США.
Нам также довелось заниматься этим на расстоянии 10 000 км от объектов, не выходя из нашего собственного кабинета, который расположен в нескольких минутах езды от пляжа на Средиземном море.
Проблемы масштаба
Хотя для стартапа имеет смысл начать с размещения своей инфраструктуры в облаке из-за относительно небольших первоначальных инвестиций, мы в Outbrain решили использовать свои собственные сервера. Мы сделали так по той причине, что расходы на инфраструктуру облаков намного превышают затраты на эксплуатацию нашего собственного оборудования, размещённого в дата-центрах после развития до определённого уровня. К тому же, свой сервер обеспечивает высочайшую степень контроля и возможностей по устранению неисправностей.
По мере того, как мы развиваемся, проблемы всегда находятся рядом. Причём они обычно приходят группами. Управление жизненным циклом сервера требует постоянного самосовершенствования, чтобы иметь возможность нормально работать в условиях быстрого увеличения количества серверов. Программные методы управления серверными группами в центрах обработки данных очень быстро становятся громоздкими. Обнаружение, устранение неисправностей и устранение сбоев при обеспечении норм, прописанных в договоре об качестве обслуживания превращается в манипулирование чрезвычайно разнообразными аппаратными массивами, различными нагрузками, сроками обновления и другими приятными вещами, о которых никто не хочет заботиться.
Освойте свои Домены
Чтобы решить многие из этих проблем, мы разбили жизненный цикл сервера в Outbrain на его основные компоненты и назвали их доменами. Например, один домен охватывает потребность в оборудовании, другой — логистику, связанную с жизненным циклом запасов, а третий — связь с персоналом на месте. Есть еще один, касающийся аппаратной наблюдаемости, но мы не будем расписывать все-все моменты. Нашей целью являлось изучение и определение доменов, чтобы их можно было абстрагировать с помощью кода. Как только рабочая абстракция разработана, она переводится в ручной процесс, который развертывается, тестируется и дорабатывается. Наконец, домен настроен для интеграции с другими доменами через API, формируя целостную, динамичную и постоянно развивающуюся систему жизненного цикла оборудования, которая может быть развернута, тестируема и наблюдаема. Как и все наши другие производственные системы.
Принятие такого подхода позволило нам правильно решать многие проблемы — путём создания инструментов и средств автоматизации.
Домен потребностей
Хотя email и электронные таблицы были приемлемым способом удовлетворения спроса в первые дни, это нельзя было назвать удачным решением, особенно когда количество серверов и объём входящих запросов достигли определённого уровня. Чтобы лучше организовать и расставить приоритеты входящих запросов в условиях быстрого расширения, нам пришлось использовать систему тикетов, которая могла предложить:
- Возможность настройки представления только соответствующих полей (простой)
- Открытые API (расширяемый)
- Известный нашей команде (понятный)
- Интегрированность с нашими существующими рабочими процессами (унифицированный)
Поскольку мы используем Джиру для управления нашими спринтами и внутренними задачами, то решили создать ещё один проект, который помог бы нашим клиентам отправлять заявки и отслеживать их результаты. Использование Джиры для входящих запросов и для управления внутренними задачами позволила нам создать единую Канбан-доску, которая позволила нам взглянуть на все процессы в целом. Наши внутренние «клиенты» видели только заявки на оборудование, не вникая в менее значимые детали дополнительных задач (таких как улучшение инструментов, исправление ошибок).
Канбан-доска в Джире
В качестве бонуса тот факт, что очереди и приоритеты теперь были видны всем, позволял понять, «где в очереди» находится конкретный запрос и что предшествовало ему. Это позволяло владельцам менять приоритеты в своих собственных запросах без необходимости связываться с нами. Перетащил – и всех делов. Это также позволило нам мониторить и оценивать наши SLA в соответствии с типами запросов на основе показателей, сгенерированных в Джире.
Домен жизненного цикла оборудования
Попробуйте представить сложность управления оборудованием, используемым в каждой серверной стойке. Что ещё хуже, многие железки (RAM, ROM) могут перемещаться со склада в серверную и обратно. А ещё они выходят из строя или списываются и заменяются, возвращаются поставщику для замены/ремонта. Всё это нужно сообщать сотрудникам колокейшн-службы, занимающихся физическим обслуживанием оборудования. Для решения этих проблем мы создали внутренний инструмент под названием Floppy. Его задача в:
- Управлении связью с персоналом на местах, агрегация всей информации;
- Обновлении данных «склада» после каждой выполненной и проверенной работы по обслуживанию оборудования.
Склад, в свою очередь, визуализируется с помощью Grafana, которую мы используем для построения графиков всех наших показателей. Таким образом, мы используем один и тот же инструмент для визуализации склада и для других производственных нужд.
Панель управлением оборудованием на складе в GrafanaДля серверных устройств, которые находятся на гарантии, мы используем другой инструмент, который мы назвали Dispatcher. Он:
- Собирает логи системы;
- Формирует отчёты в нужном вендору формате;
- Заводит заявку у вендора через API;
- Получает и хранит идентификатор заявки для дальнейшего отслеживания её хода.
После того, как наша претензия принимается (как правило, это происходит в течение рабочего дня), запасная часть отправляется в соответствующий ЦОД и принимается персоналом.
Вывод консоли Jenkins
Домен связи
Чтобы успевать за быстрым ростом бизнеса, требующего всё большей ёмкости, нам пришлось адаптировать под себя методы работы с техническими специалистами локальных центров обработки данных. Если сначала увеличение масштаба означало покупку новых серверов, то после проекта консолидации (основанного на переход в Кубернетес) это стало чем-то совершенно другим. Наше развитие из «добавления стоек» превратилось в «перепрофилирование серверов».
Использование нового подхода потребовало и новых инструментов, позволяющих с большим комфортом взаимодействовать с персоналом центров обработки данных. От этих инструментов требовалась:
- Простота;
- Автономность;
- Эффективность;
- Надёжность.
Нам пришлось исключить себя из цепочки и построить работу так, чтобы техники могли напрямую работать серверным оборудованием. Без нашего вмешательства и без регулярного поднятия всех этих вопросов, касающихся рабочей нагрузки, рабочего времени, наличия оборудования и пр.
Чтобы добиться этого, мы установили iPad в каждом дата-центре. После подключения к серверу произойдет следующее:
- Устройство подтверждает, что этот сервер действительно требует проведения каких-то работ;
- Приложения, запущенные на сервере, закрываются (при необходимости);
- Набор рабочих инструкций публикуется на канале Slack с объяснением необходимых шагов;
- По завершению работы устройство проверяет корректность конечного состояния сервера;
- При необходимости перезапускает приложения.
Помимо этого, мы также подготовили бота Slack, который бы помогал техническому специалисту. Благодаря широкому набору возможностей (мы постоянно расширяли функционал) бот сделал их работу проще, а нам здорово облегчил жизнь. Так мы оптимизировали большую часть процесса перепрофилирования и обслуживания серверов, исключив себя из рабочего процесса.
iPad в одном из наших центров обработки данных
Домен аппаратного обеспечения
Надёжное масштабирование инфраструктуры нашего центра обработки данных требует хорошей видимости каждого компонента, например:
- Обнаружение сбоя в железе
- Состояния сервера (активный, размещаемый, зомби и т.д.)
- Потребляемая мощность
- Версию прошивки
- Аналитика по всему этому хозяйству
Наши решения позволяют нам принимать решения о том, как, где и когда приобретать оборудование, иногда даже до того, как в нём реально возникнет потребность. Также путем определения уровня нагрузок на разное оборудование мы смогли добиться улучшения распределения ресурсов. В частности, энергопотребления. Теперь мы можем принимать обоснованные решения относительно размещения сервера до того, как он будет установлен в стойку и подключен к источнику питания, а также на протяжении всего цикла эксплуатации и вплоть до его возможного списания.
Панель энергопотребления в Grafana
И тут появился COVID-19…
Наша команда создаёт технологии, которые расширяют возможности медиакомпаний и издательств в сети, помогают посетителям находить релевантный контент, продукты и услуги, которые могут быть им интересны. Наша инфраструктура предназначена для обслуживания трафика, генерируемого при выходе каких-то ажиотажных новостей.
Активное освещение в СМИ событий, связанных с COVID-19, в сочетании с приростом трафика означало, что нам необходимо было срочно научиться справляться с такими нагрузками. К тому же, всё это нужно было сделать в условиях глобального кризиса, когда цепочки поставок были нарушены, а большая часть персонала находилась дома.
Но, как мы уже говорили, наша модель уже предполагает, что:
- Оборудование в наших центрах обработки данных, по большей части, физически недоступно для нас;
- Мы выполняем почти всю физическую работу удалённо;
- Работа выполняется асинхронно, автономно и в большом объёме;
- Мы удовлетворяем спрос на оборудование методом «сборки из деталей» вместо покупки нового оборудования;
- У нас есть склад, который позволяет создавать что-то новое, а не просто выполнять текущий ремонт.
Таким образом, глобальные ограничения, помешавшие многим компаниям получить физический доступ к своим центрам обработки данных, оказали на нас мало влияния А что касается запчастей и серверов — да, мы старались обеспечить стабильную работу оборудования. Но делалось с целью предотвратить возможные казусы, когда внезапно выясняется, что какой-то «железки» нет в наличии. Мы обеспечивали наполнение наших резервов, не ставя целью удовлетворение текущего спроса.
Как итог, я хотел бы сказать, что наш подход к работе в сфере ЦОДов доказывает, что можно применить принципы хорошего проектирования кода к процессам физического управления центром обработки данных. И, возможно, вам это покажется интересным.
Оригинал: тыц
beho1der
Сплошная вода и никаких технических подробностей!