

Photo by Victor Rodriguez on Unsplash
Часто мы получаем от клиентов (включая даже крупных) сообщения, в которых сквозит общий мотив: «У %provider_name% нам не хватало 192 ядер, а у вас и 120 достаточно. Почему так?». Причем в последнее время из-за пандемии таких запросов стало больше. То ли потому что клиенты вышли в онлайн и почувствовали нехватку ресурсов из-за ажиотажного спроса и у других клиентов тоже, то ли потому что некоторые провайдеры из-за все того же высокого спроса на услуги стали плотнее «упаковывать» в облаке заказчиков.
Вот эта переподписка, которая обострилась, судя по всему, из-за Covid-19, сейчас волнует очень многих облачных пользователей. Поэтому мы постараемся ответить на наиболее распространенные вопросы и рассказать про инструмент, который позволит проверить наличие переподписки у вашего провайдера.
Может показаться, что эта тема уже не раз поднималась на Хабре и за его пределами, а статья будет полезной только совсем зеленым новичкам. Но мы не писали бы этот материал, если бы предполагаемый уровень осведомленности клиентов об этом явлении совпадал с реальным.
Что такое переподписка
Здесь все достаточно просто. К примеру, заказываете вы у провайдера определенные мощности — ядра CPU, оперативную память, дисковое пространство. При этом вы не планируете постоянно использовать его на все 100%, следовательно, утилизация мощностей будет очень невелика. Провайдер — тоже человек. Ему хочется зарабатывать, а значит, важно повышать утилизацию оборудования. Поэтому на свой страх и риск некоторые провайдеры перепродают выделенные для вас мощности другим клиентам из расчета, что ваши пиковые моменты никогда не произойдут в одно и то же время. А если и произойдут, то без какого-то сильного ущерба для бизнеса. Иными словами, может оказаться, что вы рассчитываете на конкретные мощности, проводите тесты и живете в уверенности, что в условную Черную пятницу приложение выстоит. А по факту информация от провайдера не соответствует действительности. Что в итоге? Падение, нервы, выяснение отношений?
Не все так однозначно.
Провайдеры: взгляд изнутри
Бесконечно можно делать три вещи: обновлять ленту инстаграма, скучать по офису на карантине и сравнивать облачных провайдеров.
Допустим, можно зайти с позиции цены. Каждый провайдер обозначает стоимость одного vCPU. Но что собой представляет этот vCPU, как его сопоставить с реальной производительностью? Проблема актуальна и для компаний, «живущих» у единственного провайдера, и для тех, кто арендует мощности сразу у нескольких. В последнем случае у этой задачки появляется дополнительная «звездочка»: нужно сопоставить тарифы разных провайдеров и привести их к единой сетке. У кого-то цены пониже, у кого-то — процессоры помощнее.
Почему сложно сравнивать провайдеров? Во-первых, разные провайдеры по-разному распределяют ресурсы. Используют разное «железо» — например, те же процессоры могут значительно отличаться. Конечно, надо сверить модель процессоров — насколько они «свежие». Однако, главное — у всех разная переподписка. Она многократно усложняет расчеты: чтобы понять, сколько именно денег вы платите за конкретные мощности, требуется провести несколько замеров — о них и поговорим.
Зная реальные цифры, уже можно сравнивать.
В ИТ-среде, особенно у клиентов, которые непосредственно в технической нише не работают, бытует мнение, что переподписка — это чистое, рафинированное зло. На самом деле, это не так. Практически все клиенты, закупая мощности, закладывают некоторую их часть на компенсацию возможной переподписки. Если посмотреть на ситуацию со стороны провайдера, выходит, что средняя утилизация даже у очень крупных компаний (торговая сеть, банк) составляет буквально 5-7%. Это ничтожно мало. Как провайдеру бороться с такой низкой утилизацией?
Самое первое, что приходит на ум — hyper-threading. Режим многопоточности включен абсолютно у всех провайдеров. В некотором смысле, он уже является переподпиской. Кто-то на этом останавливается, кто-то идет дальше. Здесь все зависит от целевого сегмента провайдера. Заказчики enterprise-уровня тщательно следят за показателями, умеют мониторить загрузку процессоров. Мыслят они приблизительно так: «на своем сервере хочется иметь загрузку ЦП на уровне 15-20%. В облаке можно не скромничать и выжимать все 40-50%». И действительно нагружают. Переподписывать в такой ситуации — как минимум некультурно. В некоторых случаях имеет смысл разве что перебалансировать нагрузку. Перенести сильно нагруженную машину на хост к менее загруженной, чтобы физический сервер был сбалансирован.
Если целевая аудитория компании — частные лица, ситуация меняется. Допустим, Васе Доу (или Джону Пупкину) понадобилась виртуальная машина. Он хочет разместить на ней сайт «мистервася.рф». Потенциальное количество его уникальных посетителей — 3 с половиной человека в год. То есть сайт должен работать стабильно, но нагрузка у него будет очень скромная. Исходя из этих требований, Вася-Джон не захочет платить за сайт много денег. А крупному провайдеру будет нерентабельно отдавать виртуальную машину за сумму, комфортную для нашего героя. Компания, специализирующаяся на небольших клиентах, с радостью предоставит ему ВМ. Не потому что у нее процессоры намного дешевле или стойки хуже. Дело в переподписке. Enterprise-провайдер на одном физическом хосте может разместить 25-30 виртуальных машин, а компания поменьше —120-130. Чем менее требовательна к ресурсам целевая аудитория, тем большую переподписку можно себе позволить. И тем дешевле будет обходится каждая виртуальная машина для всех действующих лиц.
На самом деле, величина переподписки в чистом виде заказчику не интересна. Для него важно, сколько ресурсов он получит, нагружая систему. Так зачем же, если все устраивает, измерять переподписку своего провайдера?
Объективных причин всего две. Первая — если вы чувствуете, что переплачиваете за мощности. Вторая — если тормозит то, что тормозить не должно. В обоих случаях действительно имеет смысл замерять переподписку у нескольких провайдеров и переехать туда, где она ниже. Причем настолько ниже, чтобы решить все возникшие проблемы за те же или меньшие деньги.
Инструменты измерения переподписки
Приведенная ниже инструкция написана максимально простым языком, чтобы даже неспециалист мог запустить приведенные ниже скрипты и верно расшифровать результаты.
Итак, поехали.
Нам понадобится две виртуальные машины CentOS 7.x по 1 vCPU, так как мы тестируем производительность одного ядра.
Предварительно скачаем сам скрипт тестирования:
@vm1:
curl https://storage.cloud.croc.ru/cloud-tests/perf.sh > perf.sh; chmod +x perf.sh
@vm2:
curl https://storage.cloud.croc.ru/cloud-tests/iperf.sh > iperf.sh; bash iperf.sh@VM1 — на данной ВМ будем запускать все необходимые нам тесты
@VM2 — потребуется нам для тестирования сетевой подсистемы, поэтому установим сюда только необходимые нам утилиты
C помощью утилиты NBench замеряется скорость выполнения различных математических операций. Соответственно, чем она выше, тем лучше.
Запускаем тест на производительность CPU:
@vm1
./perf.sh cpuПосле первого шага будут созданы следующие файлы:
./testresults/cpuinfo.txt — в него будет помещена информация о физическом процессоре, которую можно будет расшифровать на сайте вендора. Если эта информация не идет в разрез с информацией от провайдера, все в порядке.
./testresults/cpu_bench.txt — результаты теста производительности процессора утилитой NBench
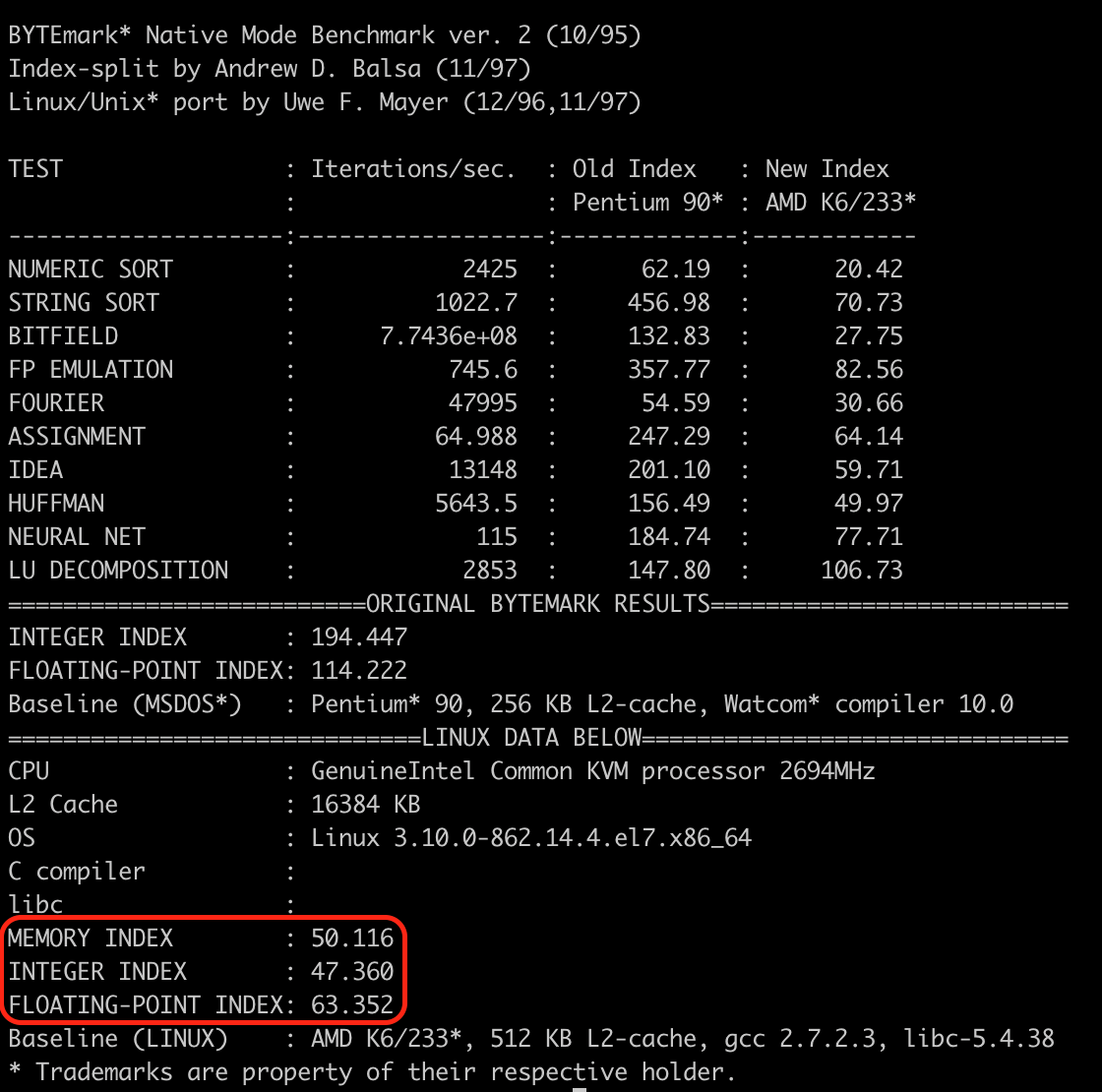
Тут нас интересует сумма этих трех значений. Чем она больше, тем лучше производительность
./testresults/steal.log — ежесекундные результаты замера параметра steal time
./testresults/average-steal.log — среднее значение steal time
Steal time — это процент времени, в течение которого виртуальный процессор (vCPU) ожидает физический CPU, пока гипервизор обслуживает другой vCPU.
В случае когда виртуальная машина совместно использует ресурсы с другими экземплярами на одном хосте в виртуализированной среде, этот параметр определяет потерю времени за счет ожидания выполнения задач других виртуальных машин.
Steal time измеряется в процентах и указывает на то, что процессам внутри ВМ не хватает процессорного времени. Этот показатель напрямую влияет на производительность ваших приложений и по-хорошему должен быть равен нулю. Однако здесь есть нюанс: если провайдер пользуется ПО от VMware, виртуальная машина может показывать ноль из-за того, что гипервизор не «отдает» ей актуальные данные. Так что, если steal time отсутствует, а ВМ очевидно притормаживает, имеет смысл потребовать объяснений у провайдера. Возможна переподписка,
Далее обратимся к дискам. Помимо очевидного — IOPS и Bandwidth, нас будет интересовать показатель времени отклика. Он отражает время, которое проходит с момента обращения к диску до того, как он начнет передавать данные. В нормальной ситуации должно проходить <5мс.
@vm1
./perf.sh disk
Тестирование диска проводится при помощи утилиты fio. Эта утилита симулирует желаемую нагрузку операциями ввода\вывода. Существует несколько основных задаваемых параметров, о которых ниже:
1. I/O type (тип ввода\вывода)
Определяет основной алгоритм проверки. Последовательное или случайное чтение\запись или, возможно, даже смешанный режим. Буферизированный ввод-вывод или прямой (raw).
2.Block size (размер блока)
Очевидно, определяет размер блока (ов), используемого в тестах. Это может быть единственное значение или диапазон.
3. I/O size (размер ввода/вывода)
Определяет количество данных, используемых в тесте.
I/O engine (движок)
Определяет использование технологий, таких как: Memory mapping, splice, async I/O, SG.
I/O depth (глубина)
При использовании операций асинхронного ввода/вывода определяет количество потоков, которые используются в тесте.
После данного шага будут создан следующий файл:
./testresults/fio-results.txt — данные о производительности дисков (input/output). Разумеется, чем быстрее, тем лучше, но стоит учесть, что если во время тестирования на ВМ проводились операции чтения/записи, эти показатели могут быть хуже, чем реальные.
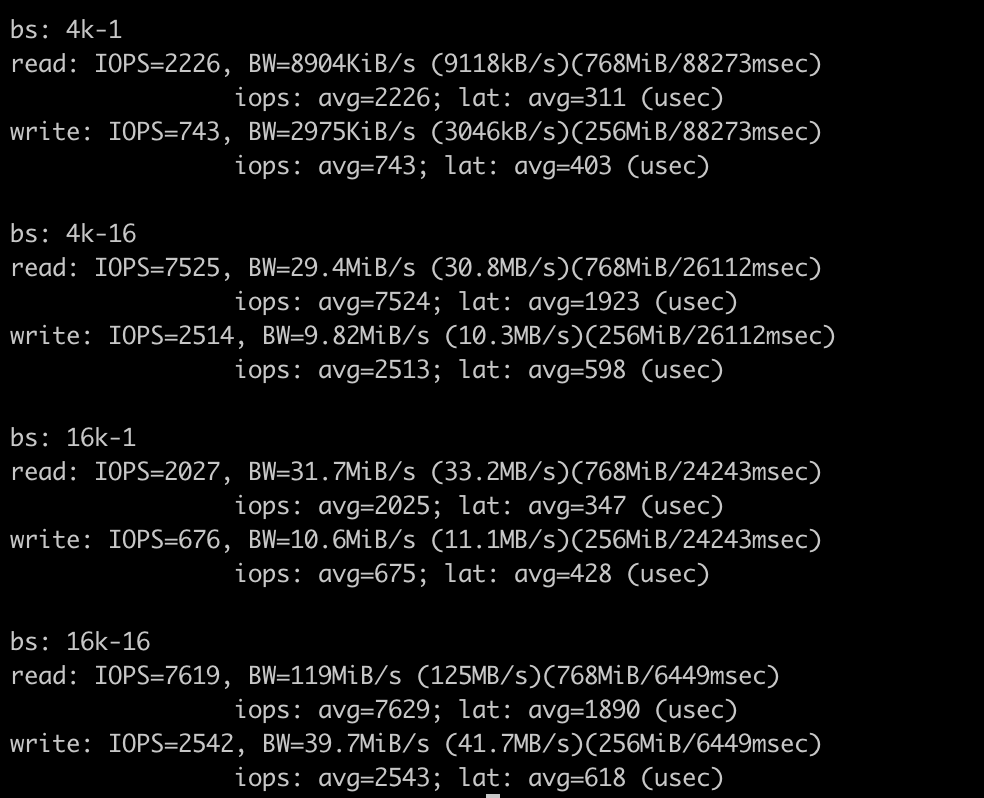
Если по результатам этого теста какие-то параметры оказались хуже, чем вы ожидали, не спешите огорчаться. Есть автомобили гоночные, а есть грузовые. Болид Формулы легко обгонит тяжелую фуру, но при этом не сможет везти многотонный груз. Так что при оценке результатов исходите из своих задач и цифр, прописанных в SLA с провайдером.
Далее мы замеряем скорость обмена данными между виртуальными машинами. Здесь все точно так же, как и в случае с дисками: чем быстрее, тем лучше. Чтобы понять, насколько ваши параметры близки к нормальным, обратитесь к SLA. Оптимальные результаты выглядят следующим образом:
Скорость между BM (замеряем пропускную способность сети (gbit/sec)):
@vm1:
iperf3 -s -p 5201
@vm2:
iperf3 -c <vm1_ip> -p 5201 -t 300 -V

Тут необходимо обратить внимание на следующие показатели:
Bandwidth — средняя скорость передачи данных за интервал времени. Чем выше этот показатель, тем больше пропускная способность сети
Retr — количество повторно отправленных TCP-сегментов. Чем ниже этот показатель, тем лучше. В идеале он должен равняться нулю.
Разумеется, по итогам этих тестов вы не сможете со 100% гарантией утверждать, что переподписки у вашего провайдера нет совсем или что она «душит» ваше приложение. По-настоящему важно не то, что происходит на бэкграунде провайдера, а то, как фактически ведут себя ваши приложения в его инфраструктуре. Если вас все устраивает, запускать тесты и тратить уйму времени на сопоставление результатов будет странно. Если что-то не так — замеряйте, ищите причины и разговаривайте с провайдером.





DikSoft
Спасибо, толково расписано, такой себе SPEC Cloud® IaaS «на коленке» получился. )
Подскажите, с каким минимальным сайзингом машинку-пробник есть смысл делать?
SZinkevich Автор
?1 vcpu – 2 gb ram