
Привет, меня зовут Дарья, и я Frontend-разработчик юнита Гео в Авито. Хочу поделиться опытом того, как мы сделали на вебе новый поиск по карте, заменив кластеры более удобным решением и сняв ограничение на количество отображаемых объектов.
В статье я расскажу, какая перед нами стояла задача и как мы справлялись с проблемами в процессе реализации.

Чем нас не устраивал старый поиск по карте
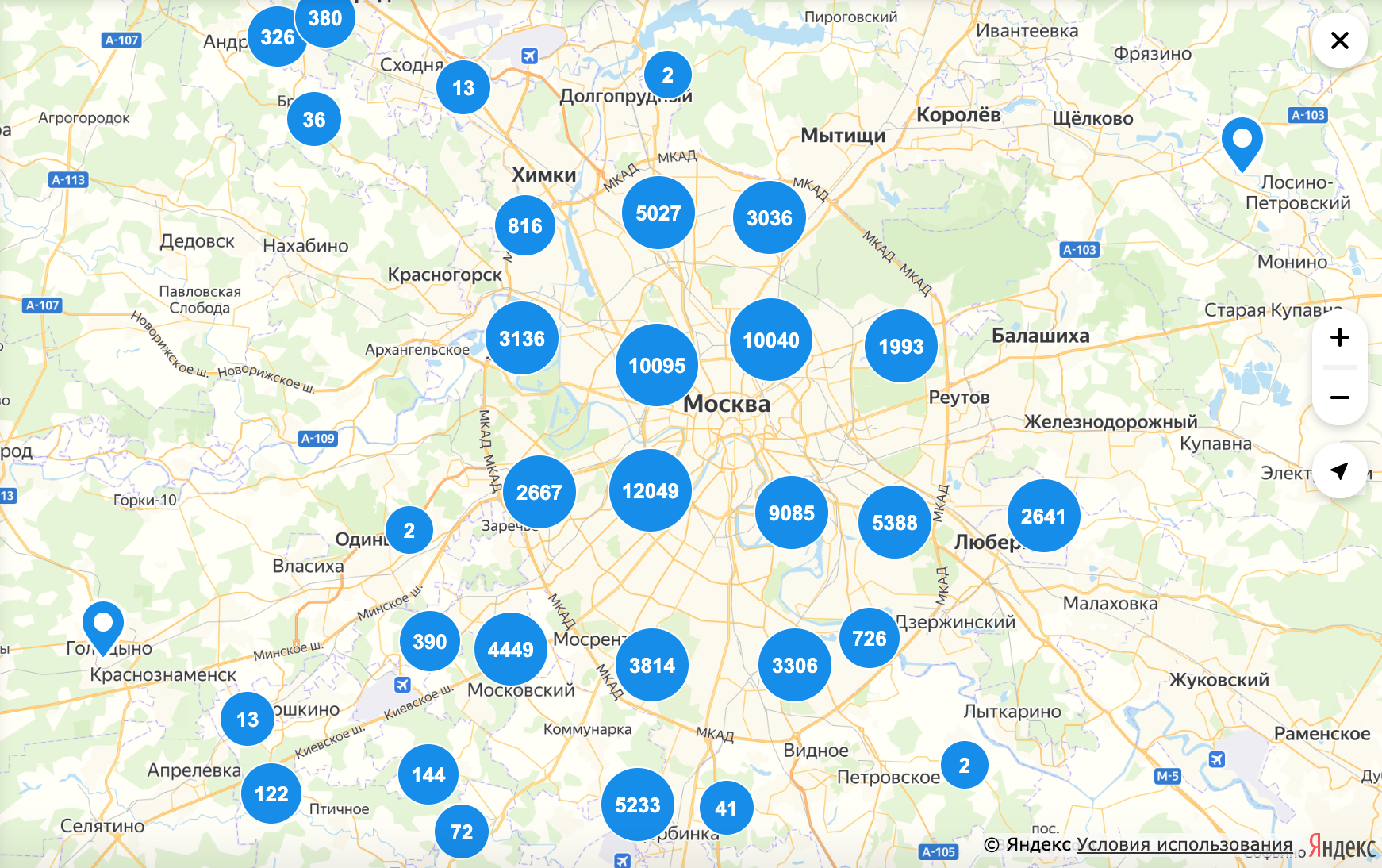
Раньше в поиске на карте объявления отображались кластерами, а при приближении или на небольшой выборке — пинами. Кластеры — это когда близкие объекты на карте собраны в одну большую группу, обозначенную кружком с цифрой. Пин — это объект с объявлениями в доме.
Решение с кластерами было неудобным по нескольким причинам. Во-первых, пользователям нужно было сделать от трёх до семи кликов по ним, прежде чем появлялась возможность кликнуть на конкретный пин и посмотреть объявления из него в списке слева. Во-вторых, кластеры плохо считывались — нужно было сравнивать цифры внутри них или сопоставлять визуально размеры кластеров. В итоге пользователю приходилось прилагать много усилий для того, чтобы найти интересующие его объявления.
Выглядело это так:
Что мы решили изменить
Мы исследовали описанные выше проблемы, обращая внимание на то, как их решают конкуренты, и увидели, что многие ушли от кластеров в пользу отдельных точек. Точки хорошо подсвечивают, в каком месте карты объявлений больше — там выше плотность точек.
Мы пришли к выводу, что нам подойдёт решение с точками вместо кластеров. Пины же останутся на ближних уровнях зума и наборе фильтров, которые дают небольшую выдачу, когда реально нарисовать все объявления в области и не закрыть ими всю карту.
Поскольку мы решили рисовать пины или точки в зависимости от плотности объектов на экране и полноты выборки, нам понадобилась формула, которая бы говорила, когда рисовать какой тип объектов. Переменные этой формулы — размер карты и размер пина в пикселях. Константы в ней подбирали на основе наших ощущений того, какая плотность пинов кажется нам уместной, и здесь всё индивидуально. Мы выбрали вариант, при котором каждый девятый элемент сетки со сторонами, равными диаметру пина, может быть занят. Получилось так:
Если количество найденных объявлений меньше этого лимита, то показываем пины, а иначе точки.
Мы хотели сделать консистентное поведение для всех объектов на карте, чтобы пользователю было удобно пользоваться поиском. Поэтому нужно было применить для точек те же требования, которыми обладают пины. В итоге получился такой список:
- точки должны быть кликабельными на всех уровнях зума (сокращаем трудозатраты пользователя);
- точки должны реагировать на наведение (подсказываем пользователю, что они кликабельны);
- точки должны становиться просмотренными, если по ним кликали, и сохранять просмотренность на длительное время (чтобы пользователю было легче ориентироваться на карте).
Приведу примеры целевого состояния поиска по карте для разных случаев:

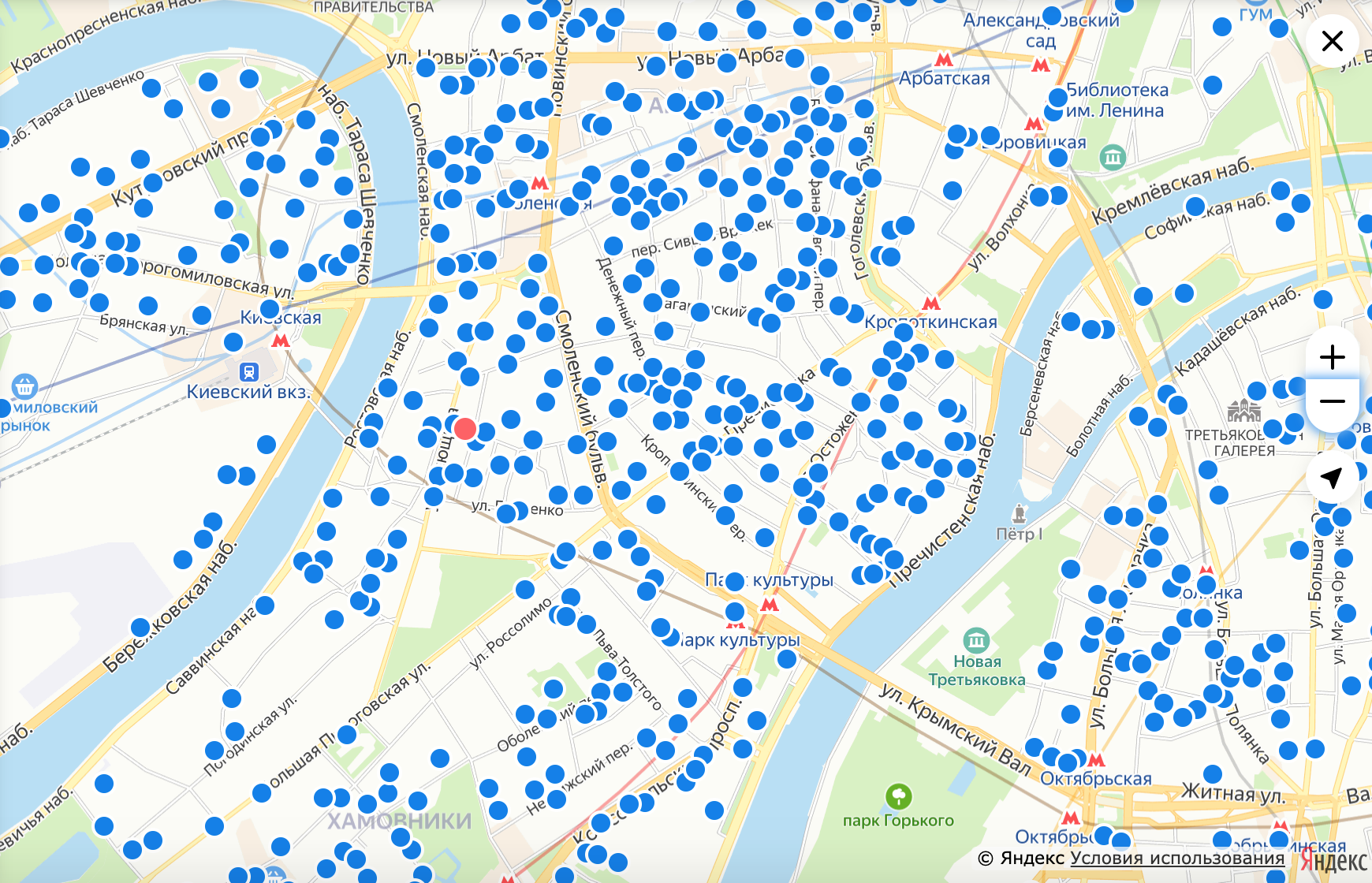
Много объявлений без фильтров — показываем точки. Голубой цвет точек обозначает просмотренность, красный — ховер
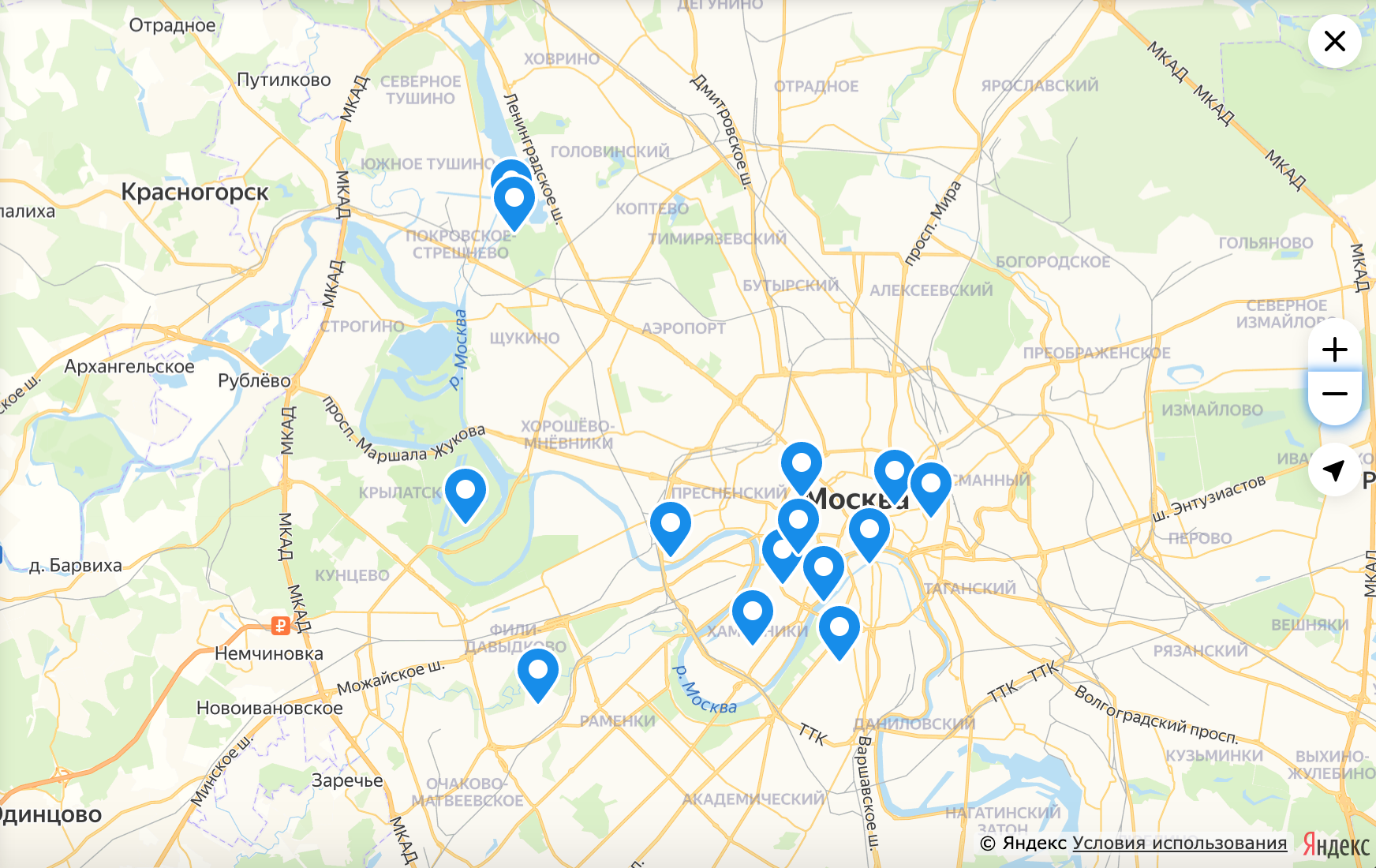
Выбраны фильтры, которые дают небольшую выдачу — показываем пины
Приблизились на уровень, когда виды дома, и можем отобразить все объявления — показываем пины
Далее я перечислю вопросы, с которыми мы столкнулись в процессе реализации, и расскажу, как их решали.
Как нарисовали на карте несколько тысяч точек
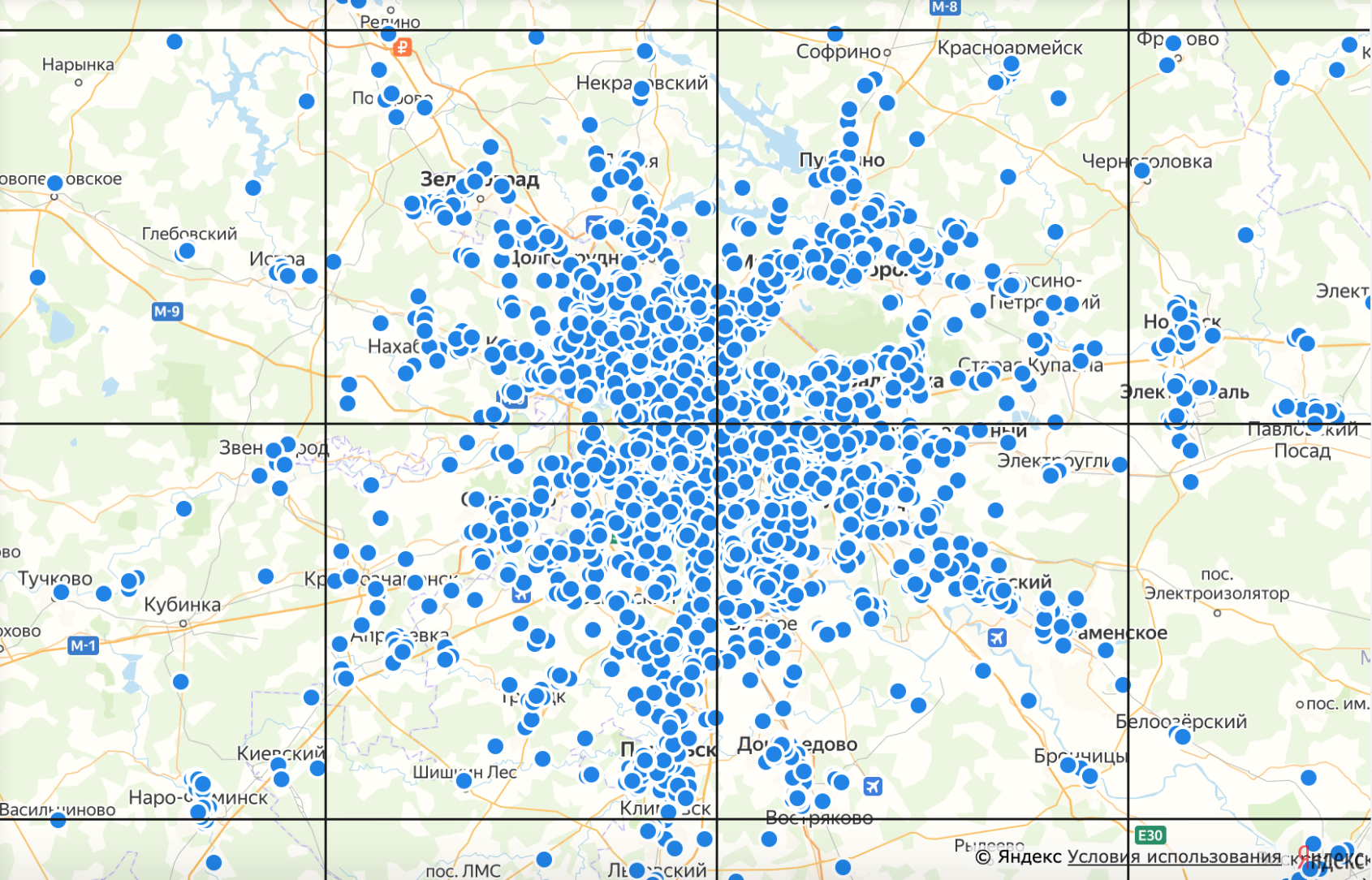
Когда у нас были кластеры и пины, мы рисовали на карте меньше 1000 объектов. В случае с точками нужно уметь рисовать много объектов, чтобы подсвечивать пользователям, где объявлений больше. Например, так:
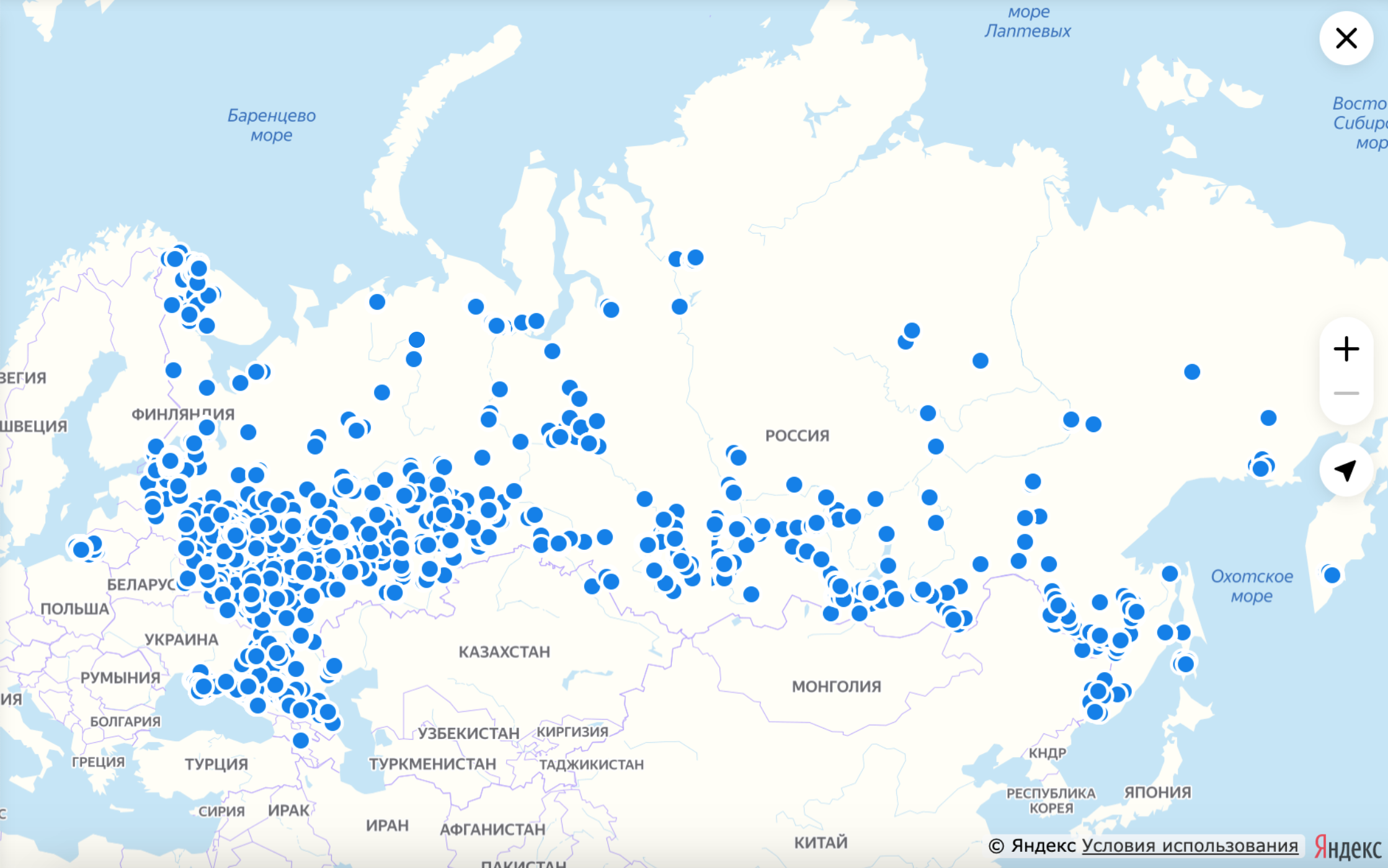
Поиск двухкомнатных квартир по всей России
Мы используем Яндекс-карты, API которых предоставляет разные способы отрисовки объектов. Например, кластеры мы рисовали через инструмент ObjectManager, и он отлично подходит для случаев, когда количество объектов на карте не превышает 1000. Если попробовать нарисовать с его помощью, например, 3000 объектов, карта начинает подтормаживать при взаимодействии с ней.
Мы понимали, что может появиться необходимость отрисовать несколько тысяч объектов без вреда для производительности. Поэтому посмотрели в сторону ещё одного API Яндекс-карт — картиночного слоя, для которого используется класс Layer.
Основной принцип этого API заключается в том, что вся карта делится на тайлы (изображения в png или svg формате) фиксированного размера, которые маркируются через номера X, Y и зум Z. Эти тайлы накладываются поверх самой карты, и в итоге каждая область представляется каким-то количеством изображений в зависимости от размера области и разрешения экрана. Собственно, API берёт на себя всю фронтовую часть, запрашивая нужные тайлы при взаимодействии с картой (изменении уровня зума и сдвиге), а бэкенд-часть нужно писать самостоятельно.

Разбиение на тайлы. Для наглядности их границы выделены черными линиями. Каждый квадрат — отдельное изображение
Этот механизм подходит для решения нашей задачи, ведь мы можем отрисовать на бэкенде любое количество точек и отдать на фронт готовые изображения. При этом количество изображений не будет зависеть от данных.
Чтобы реализовать бэкенд, мы взяли формулы для приведения координат точек к системе тайлов в проекции Меркатора:
func (*Tile) Deg2num(t *Tile) (x int, y int) {
x = int(math.Floor((t.Long + 180.0) / 360.0 * (math.Exp2(float64(t.Z)))))
y = int(math.Floor((1.0 - math.Log(math.Tan(t.Lat*math.Pi/180.0)+1.0/math.Cos(t.Lat*math.Pi/180.0))/math.Pi) / 2.0 * (math.Exp2(float64(t.Z)))))
return
}
func (*Tile) Num2deg(t *Tile) (lat float64, long float64) {
n := math.Pi - 2.0*math.Pi*float64(t.Y)/math.Exp2(float64(t.Z))
lat = 180.0 / math.Pi * math.Atan(0.5*(math.Exp(n)-math.Exp(-n)))
long = float64(t.X)/math.Exp2(float64(t.Z))*360.0 - 180.0
return lat, long
}
Приведённый код написан на Go, формулы для других языков в проекции Меркатора можно найти по ссылке.
Нарисовав svg по данным, мы получили подобные изображения тайлов:

Поскольку нам необходимо учитывать разные фильтры в поиске по карте, мы добавили значения выбранных фильтров в GET-запросы за тайлами. Реализация на фронте свелась к нескольким строкам кода:
const createTilesUrl = (tileNumber, tileZoom) => {
// params - выбранные фильтры в формате строки параметров, которые можно передать в GET-запрос
return `/web/1/map/tiles?${params}&z=${tileZoom}&x=${tileNumber[0]}&y=${tileNumber[1]}`;
};
const tilesLayer = new window.ymaps.Layer(createTilesUrl, { tileTransparent: true });
ymap.layers.add(tilesLayer);
В итоге карта с тайлами, подготовленными на бэкенде и отрисованными через Layer, выглядит так:
Как оптимизировали бэкенд
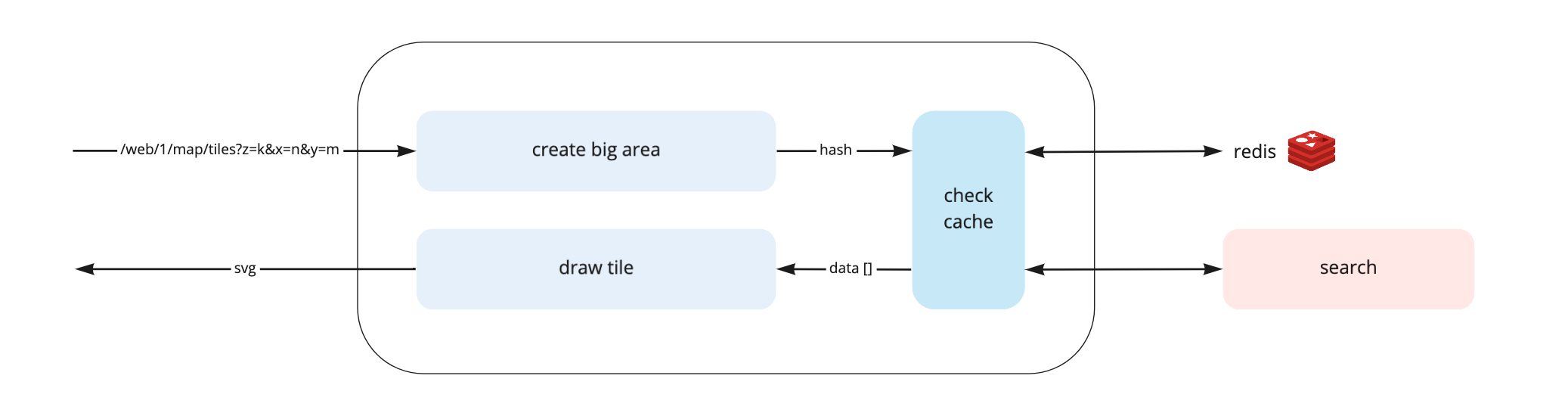
Используя механизм тайлов, мы будем присылать на каждую область примерно 15-30 запросов от одного пользователя, и при максимальном трафике на карте нагрузка на сервис будет достигать 5000 rps. При этом наш сервис только формирует изображения для карты на основании запросов с фронта, а данные для объектов собирает сервис поиска. Очевидно, в сервис поиска не нужно ходить на каждый запрос.
Решая проблему сетевых походов в другой сервис, мы придумали запрашивать данные для области в несколько раз больше, чем реально отображаемая область. Будем называть её большой областью. При этом для разных уровней зума мы установили разный коэффициент. Например, для уровня, когда отображается вся Россия, это 4, а максимальное значение равно 25.
На изображении ниже разными цветами выделены разные большие области. При запросе определённой области на карте, данные для неё могут формироваться из нескольких больших областей.

Ответ по большой области от сервиса поиска мы складываем в Redis с хэш-ключом, содержащим в себе фильтры, диапазон тайлов и зум. Для каждого запроса бэкенд проверяет, есть ли в кэше данные для этих фильтров и тайлов, и если есть, они отдаются из кэша. Если соответствий не нашлось, то для этих тайлов строится новая большая область и выполняется запрос в поиск по ней.
Большая область геостационарна, то есть она строится всегда одинаково, независимо от того, на какой тайл пришёлся первый запрос. Это избавляет от накладок больших областей, чем обеспечивает консистентность данных и уменьшает размер кэша.
Время жизни разных запросов в Redis отличается. Для широких и популярных запросов, например, по всей России без фильтров, оно больше, чем для запросов с узкими фильтрами. Кроме долгого кэша в Redis есть быстрый кэш непопулярных запросов в in-memory. Он позволяет уменьшить нагрузку на сеть и освободить место в Redis.
Поскольку наш сервис горизонтально масштабирован и поднят на нескольких десятках подов, важно, чтобы параллельные запросы от одного пользователя попали на один под. Тогда мы можем взять эти данные из in-memory cache пода, и не хранить одну и ту же большую область на разных подах. Этот механизм называется стики-сессиями. На схеме его можно представить так:

Сейчас среднее время ответа запроса тайла на 99 перцентиле составляет ~140 ms. То есть 99% измеряемых запросов выполняются за это или меньшее время. Для сравнения: в реализации через кластеры запрос выполнялся ~230 ms на том же перцентиле.
Работу пода упрощённо можно представить следующим образом: на вход поступает запрос за тайлом, строится большая область, проверяется кэш. Если в кэше есть данные, по ним рисуется svg. Если данных для этой большой области нет, происходит запрос в сервис поиска.
Итак, мы решили проблему с отрисовкой большого числа объектов на карте. Осталось разобраться с интерактивностью.
Кликабельность, ховер и просмотренность точек
Кликабельность. Самой критичной для нас была кликабельность, поэтому мы начали с неё. В рамках ресёрча мы сделали простое решение — отправку запроса с координатами на бэк, бэк проверял, есть ли в кэше объявления по этим координатам с радиусом 50 метров. Если объявление находилось, рисовался пин. Если в кэше не было данных по области, в которой находились координаты, то есть истекло время хранения кэша, бэк запрашивал данные из сервиса поиска. Это решение оказалось нестабильным — иногда пин рисовался в том месте, где не было точки как объекта на карте. Так происходило потому, что кэш на бэке протухал, и появлялись новые объявления — данные расходились с тем, что есть на карте.
Мы поняли, что стабильнее будет реализовать кликабельность на фронте. Помимо запросов за тайлами, у нас всегда отправлялся один запрос за пинами. Пины мы рисуем на фронте, и фронт ничего не знает про то, рисовать в данный момент времени пины или точки. Запросы за пинами и тайлами уходят всегда — на каждый сдвиг или изменение уровня зума. Чтобы не усложнять и рисовать всё быстрее, тайлы для непустых выдач всегда возвращаются с точками. Если нужно рисовать пины, они рисуются поверх точек, перекрывая их. Поэтому всё, что нам оставалось для кликабельности точек, — добавить в ответ запроса за пинами объект точек, который будет содержать координаты, id и количество объявлений в этой точке. Этих данных достаточно для того, чтобы нарисовать по клику на точку пин.

Ховер. Идея присылать данные на фронт отлично решала также проблему ховера — мы могли подписаться на событие движения мыши по карте и проверять, попадают ли координаты курсора в радиус какой-то из точек, что нам прислал бэкенд. Если совпадения найдены, рисуется красная точка на карте. По нашему опыту даже для 10 тысяч через forEach точек это выглядит нормально.
Просмотренность. Просмотренность пинов на карте уже была реализована на клиенте. Мы хранили в localStorage стек из 1000 id объявлений. Ids вытеснялись более свежими, которые были просмотрены позже других. Бэкенд ничего не знал про просмотренные объявления, отдавал одинаковые данные всем пользователям, а клиент делал пин просмотренным на основании данных из localStorage.
Для простоты мы поддержали это решение, распространив его на точки. Разница между точками и пинами в том, что пины — это физические объекты карты, а точки — нет. Поэтому на этапе обогащения данных нам приходится рисовать просмотренные точки как объекты карты.
Поскольку запросы за тайлами и запрос за пинами и точками независимые, иногда мы можем видеть небольшой лаг в окрашивании точек в бледно-голубой. Тайлы обычно приходят раньше ответа запроса по точкам/пинам, и соответветственно, сначала мы увидим все синие точки, а потом нарисуем просмотренные точки как объекты. Сейчас для нас это не выглядит критичным моментом.
В целевом состоянии мы планируем перевести хранение просмотренных объявлений на бэкенд и обогащать данные на этапе рисования svg и формирования ответа запроса за пинами. Тогда тайлы будут рисоваться сразу с бледно-голубыми точками.

Просмотренный пин выделен бледно-голубым
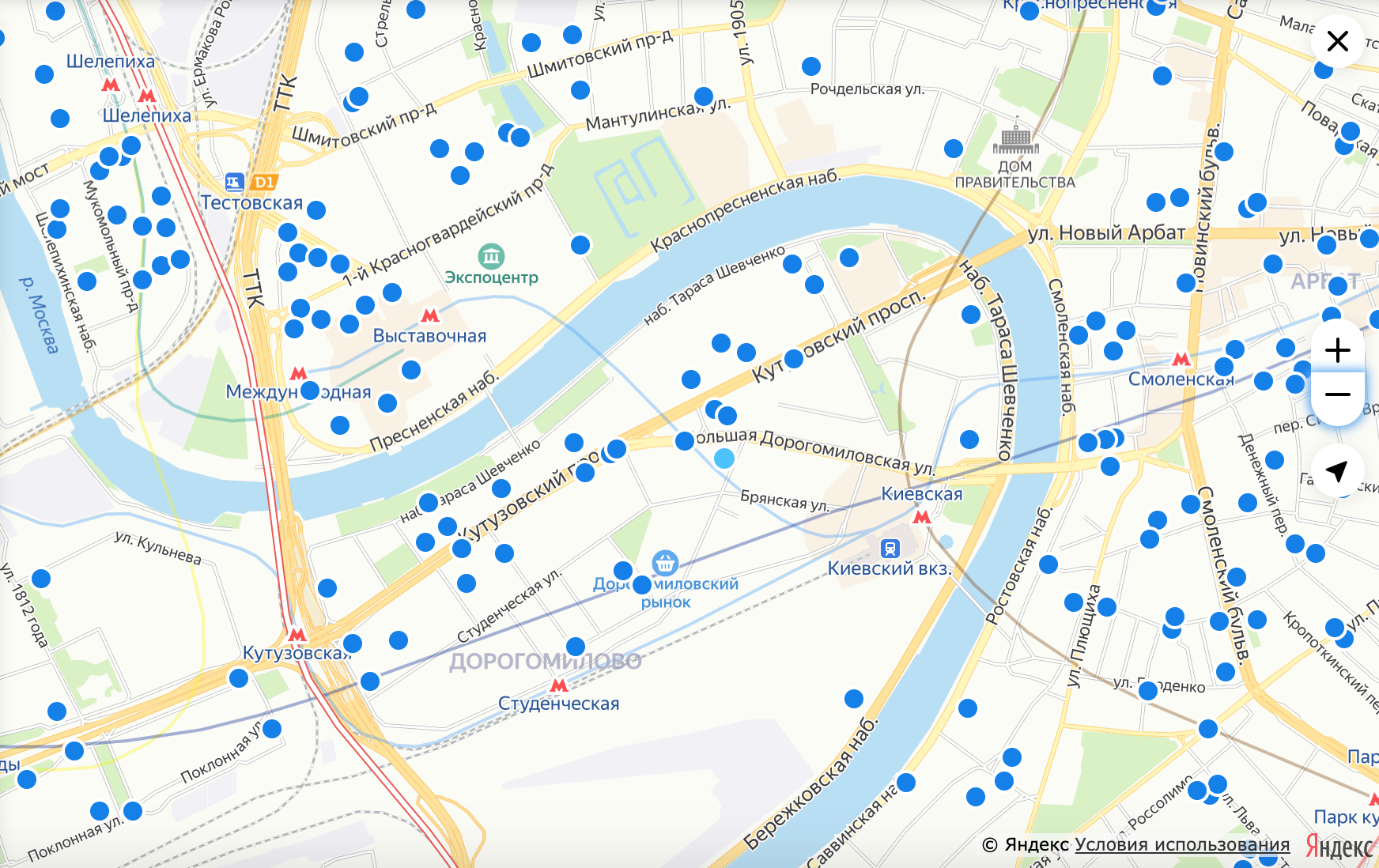
Просмотренная точка выделена бледно-голубым
Заключение
Качественные и количественные исследования показали, что решение с точками вместо кластеров облегчило поиск по карте для пользователей — выросло использование карты и сократились трудозатраты до совершения контакта.






andreyverbin
Титаническая работа, сколько человеко-часов на это ушло? Полезно было бы это знать прежде чем браться повторять ваш путь.
dssaenko Автор
Спасибо за вопрос. Точных чисел у меня, к сожалению, нет. Могу сказать так — путь от идеи до раскатки фичи занял около полугода, работала над задачей одна команда (но мы работали не только над этой фичей, конечно, у нас были и другие затратные задачи). Одна команда — все функции в количестве 1 человека.
Стоит отметить, что достаточно много времени занимали ресерчи и прототипы: мы смотрели, подойдет ли нам решение через тайлы, писали прототип на NodeJS, писали и переделывали кликабельность и ховер. Ну, и еще большой кусок ушел на оптимизацию бэкенда. Кроме того, мы делали не только веб-реализацию, но и мобилки.