
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.

Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.
1. URL идентифицирует ресурс — некоторую разделяемую сущность. Файл — ресурс. Ручка, которая что-то ищет — ресурс. Вызов метода — не ресурс. Если вы хотите шарахнуть из пушки по Луне, то вот так делать не надо:
GET /?method=шарахнуть&to=ЛунаЗаведите ресурс «шарахалка», и тогда у вас всё будет логично:
POST /шарахалка/?to=Луна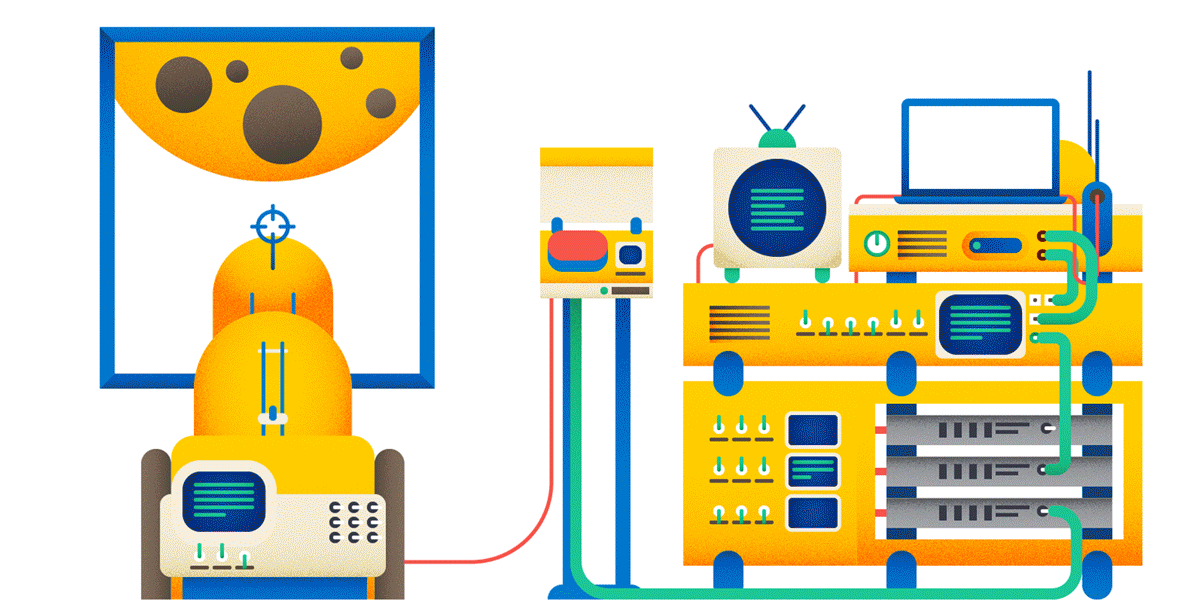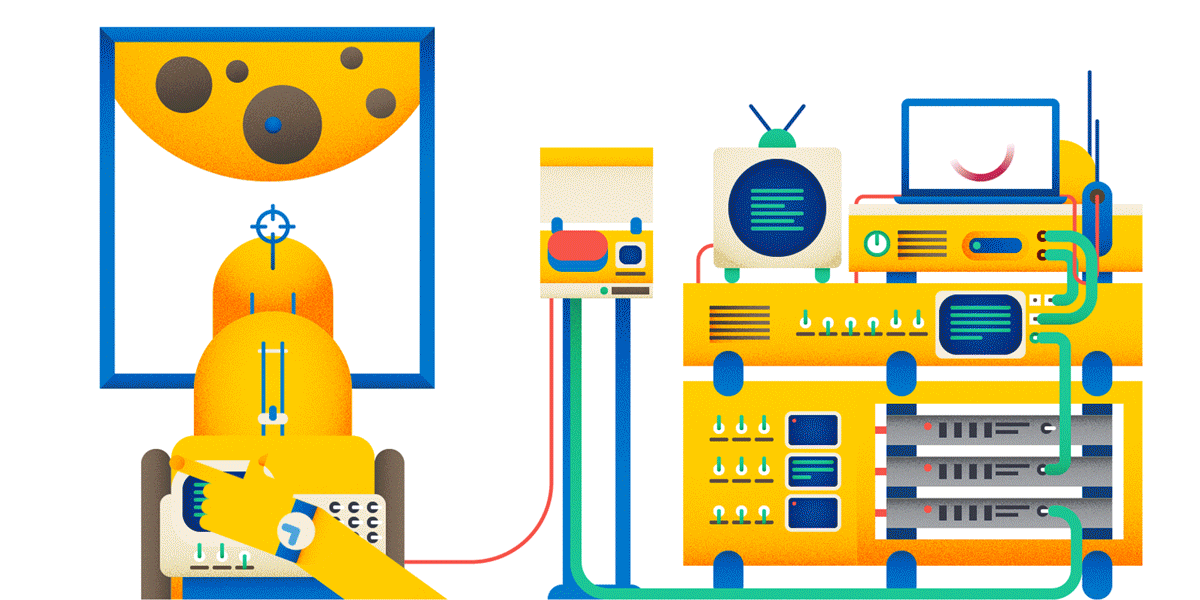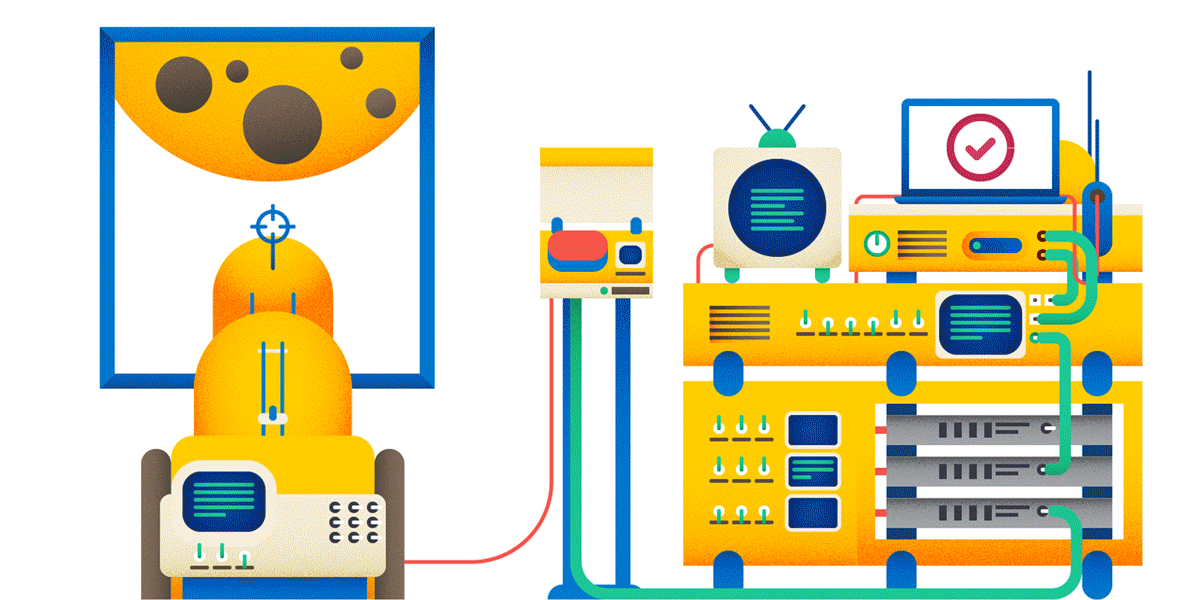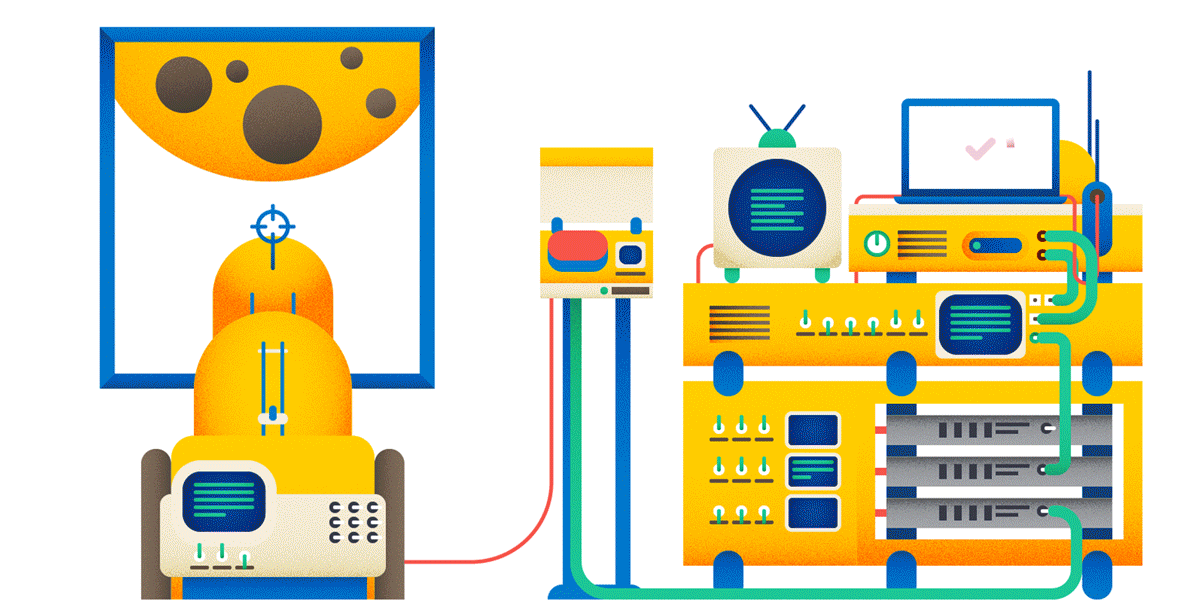
Почему POST, а не GET? Читай ниже.
2. URL состоит из схемы (протокола), хоста, пути (path), запроса (query) и фрагмента. Путь используется для организации иерархических ресурсов, запрос — для неиерархических ресурсов и для параметров операции. Фрагмент идентифицирует подчинённый ресурс, не имеющий прямого URL.
Scheme Host Path Query Fragment v v v v v http://nyashnye-kotiki.xxx/breeds/maine-coon/?deliver_to=Moscow#photo
Если на вашем сайте «Няшные котики» есть каталог по породам, то его вполне логично организовать в виде частей path, поскольку каждый котик принадлежит ровно к одной породе. А вот доставлять одного котика можно в несколько городов, поэтому фильтр «с доставкой в город N» следует организовать через query.
3. Обращение по HTTP состоит из применения метода (глагола) к URL. Результатом такого применения должно быть — сюрприз-сюрприз! — то, что в глаголе написано. То есть GET возвращает представление ресурса, DELETE удаляет и т.п.
4. Методы GET, HEAD, OPTIONS — безопасные. Предполагается, что вызов этих методов состояния ресурса не изменяет. Поэтому многие сетевые агенты — такие, например, как префетчер ссылок в браузере или мессенджере — считают себя вправе по таким ссылкам ходить без явного волеизъявления пользователя. ИЧСХ, никаких стандартов не нарушают.
5. По умолчанию методы GET и HEAD кэшируются, OPTIONS, POST, PUT, PATCH, DELETE — нет. Поэтому если вы шарахнули по Луне методом POST, вы можете быть (почти) уверены, что этот запрос выполнится. Если вы шарахаете методом GET, какой-нибудь промежуточный прокси может ВНЕЗАПНО отдать вам ответ из кэша, и шарах в реальности не произойдёт.
6. Операции GET, PUT, DELETE симметричны. PUT кладёт нечто по URL-у (создавая новый ресурс или перезаписывая старый), GET по этому URL-у возвращает представление того, что положил PUT, DELETE удаляет ресурс.
Метод HEAD синонимичен по семантике методу GET, но не возвращает тело ответа, а только его заголовки (метаинформацию о ресурсе).
7. POST используется в том случае, если у вас нет URL, к которому вы хотите применить операцию. Например, если пользователь пишет новое сообщение в тредик на форуме, он может сам вычислить его id и сделать:
PUT /threads/php-rulezz/messages/100500Если клиенту генерировать id не разрешено, ему придётся делать POST на ресурс уровнем выше по иерархии:
POST /threads/php-rulezz/messagesИ этот ресурс сам создаст новое сообщение.
Обратите внимание, если вы по ошибке или вследствие сетевых проблем повторите POST запрос — создастся второе сообщение в треде, идентичное первому. PUT вы можете делать хоть 100500 раз, результат не изменится. Это свойство называется идемпотентностью.
Ладно создание постов на форуме. Вот если вы делаете тяжёлую и дорогую операцию по пользовательскому запросу — очень рекомендуется выполнять для этого идемпотентный запрос. А то может получиться как на картинке:

Разумеется, использование идемпотентного PUT порождает свои проблемы — в частности, как разрешать конфликты. Придётся больше программировать, зато результат будет более надёжным и безопасным.
8. PUT может использоваться как для создания новых ресурсов, так и для обновления старых. Однако в случае использования PUT для перезаписи предполагается, что в теле запроса передаётся закодированный ресурс целиком. Если же вы хотите модифицировать ресурс, т.е. изменить его внутреннее представление без полной перезаписи, то для этого был придуман метод PATCH. Этот метод некэшируемый, небезопасный и неидемпотентный.
9. Коды ответа нужны в первую очередь для того, чтобы клиент мог понять, что ему делать дальше. 3хх говорит, что для успешного выполнения запроса нужно выполнить дополнительное действие. 4хх говорит, что клиент, составляя запрос, сделал что-то неправильно и, обычно, о том, что умолять бесполезно — повторное выполнение запроса всё равно выкинет ошибку. В 4хх крайне рекомендуется включать информацию о том, что конкретно клиент сделал не так. 5хх говорит о том, что клиент всё сделал правильно — проблема на стороне сервера.
Обычно при успешном выполнении операции сервер отвечает на GET — 200, на PUT — 201 Created (если ресурс создан) или 200 (ресурс обновлён), на DELETE — 204 (операция успешна, возвращать нечего), на POST — 200 или 201 (во втором случае в заголовке, обычно Location, указывается URL созданного ресурса).
10. Работая с HTTP-статусами, не наступите на популярные грабли:
- статус 401 Unauthorized обязан сопровождаться заголовком WWW-Authenticate и, таким образом, применим только тогда, когда клиент аутентифицируется посредством HTTP-аутентификации; во всех остальных случаях следует использовать 403 Forbidden;
- статусы 3xx — это не только редиректы; они показывают, что клиент должен выполнить дополнительное действие, иначе запрос не может считаться успешным; например, по статусу 304 Not Modified клиент должен взять актуальную версию ресурса из кэша;
- статус 404, как ни странно, один из немногих 4xx статусов, которые клиент имеет право повторять — он означает, что ресурса сейчас нет, но вполне возможно, что он появится; вообще 404 — статус неопределённости, который используется, если сервер не хочет раскрывать механику ошибки; для того, чтобы индицировать клиенту, что без дополнительных действий с его стороны ресурс не появится, следует использовать 410 Gone (ресурс был удалён) либо общий статус 400.
11. Существует особый подкласс URL-ов, которые кодируют в себе и ресурс, и действие над ним. В англоязычной литературе их принято называть Capability URLs. Классический пример такого URL — ссылки на восстановление паролей, а также всевозможные «секретные» прямые ссылки на всяческие ресурсы.
12. Поскольку основная опасность при работе с Capability URL — возможность их утечки, следует максимально закрыть возможности случайно такой URL найти или перехватить:
- для генерации секретных частей URL должен использоваться сильный генератор случайных строк (например, UUID 4), исключающий возможности найти Capability URL перебором; разумеется, URL не должен генерироваться детерминированным способом типа md5(username) и такие URL нельзя пропускать через сокращатели ссылок;
- Capability URLs должны работать только по HTTPS;
- страницы, доступные через Capability URL, должны быть закрыты wildcard-ом от индексации роботами.
13. Должны быть предусмотрены меры минимизации возможного ущерба:
пользователь, создавший Capability URL (например, расшаривший документ), должен иметь возможность сделать обратную операцию, т.е. отозвать URL;
Capability URLs должны протухать со временем; чем опаснее предоставляемый доступ, тем короче должен быть срок жизни URL.
14. Наконец, сами «секретные» страницы должны быть защищены от сливания данных сторонним агентам:
- на них не должно быть никаких third-party скриптов и картинок, желательно — на уровне CSP;
- на них не должно быть ссылок на third-party сайты; если они необходимы, то нужно скрывать referrer, например, через rel=«noreferrer»;
- вообще желательно через Referrer Policy настроить скрытие referrer-а;
- желательно сразу после захода пользователя через History API менять URL в адресной строке браузера, чтобы его нельзя было подсмотреть через плечо;
- если ссылка предполагает какое-то действие (например, смену пароля), то на секретной странице должна быть форма (кнопка, скрипт), которую требуется отослать, чтобы действие осуществить, причём эта форма должно быть подписана CSRF-токеном (иначе префетчер браузера / почтового клиента / мессенджера сможет восстановить пароль за юзера).
15. Всё описанное выше существует в стандартах исключительно в форме рекомендации, и принудить кого-либо к строгому исполнению этих рекомендаций нельзя. Я уже не первый раз рассказываю про всю эту тривию, и часто слышу в ответ «да плевать я на всё это хотел, придумали какой-то ненужной ерунды; как у меня работали все сервисы только на GET, так и дальше будут, мучайтесь со своими PUT-ами и DELETE-ми сами».
Разумеется, вы вольны писать свой сервис сами. Но имейте, пожалуйста, в виду, что между вашим сервером и вашим клиентом, даже если они стоят физически рядышком в одном ДЦ, есть огромное множество других сетевых агентов — браузеров, прокси, роутеров, имплементаций HTTP-протокола в разных языках программирования и разных ОС, DPI-оборудование провайдеров и так далее. Все эти агенты плюс-минус имплементируют протокол HTTP с оглядкой на RFC.
Если вдруг клиентский браузер запрефетчит GET-ссылку и шарахнет по Луне — это будет ваша вина, бесполезно писать производителю. Если у вас деньги переводятся GET-запросом, а имплементация HTTP протокола в вашем языке программирования, не дождавшись ответа от соседнего роутера, решит повторить запрос и проведёт транзакцию дважды — это будет опять ваша вина.
Но даже не это главное. Допустим, ваши HTTP-пакеты гуляют в строго контролируемой среде. Как вы собираетесь объяснять другим разработчикам, какие рекомендации вы нарушили и почему? Как ваш коллега должен понять, что вот этот GET-запрос повторять нельзя, а статус 400 вовсе не означает клиентскую ошибку? Отступая от рекомендаций, вы, фактически, каждый раз создаёте какой-то свой диалект HTTP с собственной семантикой. Не забудьте его хотя бы задокументировать ;)
Список литературы:
- www.rfc-editor.org/rfc/rfc2616.txt
- tools.ietf.org/html/rfc5789
- www.w3.org/TR/webarch
- w3ctag.github.io/capability-urls
(В разработке последнего документа ваш покорный слуга принимал определённое участие.)
Комментарии (111)

Vanger13
27.08.2015 19:14+9Тема для холиваров на каждый день :)
По-сути на http хорошо ложится более-менее стандартный CRUD, вопросы начинаются с более сложными вещами.
Как вы обычно делаете (отображаете в HTTP API) query сущностей? А есть query возвращает данные по нескольким сущностям сразу? POST или GET для query? Odata, свой DSL или jquery format для параметров запроса? :)
Вы предлагаете «query» задавать как параметр запроса к сущности (../etntity/?query) т.е. в самом URL path глаголов быть не должно? Нам, вот, часто нужны глаголы и засовываем мы их именно в path (entity/copy, entity/prefetch, entity/lock). От части это связно с выбранной библиотекой HTTP: так удобнее писать роутеры — они биндятся на конкрутный path, а вот разделять по query param пришлось бы внутри каждого роута, что неудобно. Как и на чем вы пишете роутинг? И насколько разнообразны потребители вашего API в плане платформ\языков? У нас service'ы на scala, апотребители C#, C++, python, javascript и typescript и у каждого свои претензии что «что-то» делать недобно (например дописывать ID в середину path). :)
И в общем, в каких случаях вы позволяете себе отойти от следования рекомендациям по формированию пары method + URL?
forgotten
27.08.2015 19:30+8> Тема для холиваров на каждый день :)
Не совсем.
Про REST-архитектуру действительно можно много холиварить, но пост-то не про неё, а про то, что нужно понимать смысл используемых сущностей — чем PUT отличается от POST, 400 от 500, ресурс от вызова метода. Здесь, в общем, разногласий быть не может: нравится тебе эта архитектура или нет, но Сеть работает именно так.
> Как вы обычно делаете (отображаете в HTTP API) query сущностей? А есть query возвращает данные по нескольким сущностям сразу? POST или GET для query? Odata, свой DSL или jquery format для параметров запроса? :)
> Вы предлагаете «query» задавать как параметр запроса к сущности (../etntity/?query) т.е. в самом URL path глаголов быть не должно? Нам, вот, часто нужны глаголы и засовываем мы их именно в path (entity/copy, entity/prefetch, entity/lock).
Вообще, в парадигме REST ответ на каждый из ваших запросов такой: создавайте специальный ресурс для каждого специфического требования.
Нужна мультиплексация? Значит, сделайте ресурс multiplexer.
Хотите избежать глагола в path? Сделайте ресурс: не GET /entity/prefetch, а GET /prefetcher/entity. И биндинги писать проще станет.
И так везде, где стандартной номенклатуры вам не хватает.
Я не могу дать универсальной рекомендации типа «всегда кладите query в query». Нужно смотреть на семантику конкретной операции и укладывать в HTTP-термины.
> И в общем, в каких случаях вы позволяете себе отойти от следования рекомендациям по формированию пары method + URL?
В целом, я вовсе не являюсь фанатом REST-архитектуры, многие вещи в неё ложатся плохо. Я категорически против смешения французского с нижегородским: если отходить от рекомендаций RFC — то полностью. Скажем, переходить на JSON-RPC или, прости господи, SOAP.
В реальности же постоянно наблюдаются адские кадавры, в которых перемешано всё, что можно.
Encircled
28.08.2015 13:59+1Немного обидно за SOAP, за что вы его так? :) Свои задачи он решает достаточно хорошо

Envek
28.08.2015 14:24+1Его просто почти никто не умеет правильно готовить. Когда появляется задача «синтегрироваться с вон теми ребятами, у них SOAP», то в 9 случаях из 10 не получится просто взять клиентскую SOAP-библиотеку и синтегрироваться. Обязательно что-то сделано… не так (вон, ниже привели пример про fault). И нужно наворачивать слои костылей. В общем, SOAP очень хорошо ассоциируется с болью и страданием.
Впрочем, если быть справедливыми, HTTP REST тоже мало кто умеет правильно готовить (с теми же вытекающими последствиями). Собственно, поэтому, видимо, и написали этот капитана пост.Encircled
28.08.2015 14:32Логично, что при интеграции, если кто-то не соблюдает спецификацию, то вероятно где-то будет боль :)

Flammar
04.09.2015 18:40Его просто почти никто не умеет правильно готовить.
Похоже, не неумеют, а ленятся. И это, в виду повсеместности, говорит уже не о людях, а о протоколе, в частности, об удобстве его использования. Вот я это у вас прочитал, и тут же возникла ассоциация с программированием на Java без IDE: раз для правильности и красивости нужно вручную набивать «многабукаф», то никто не захочет делать это дотошно и правильно, а предпочтут как-то «срезать углы» и делать менее трудозатратно.

force
27.08.2015 19:36+3Такой вопрос: у нас есть метод, возвращающий текущее время (как пример). Логично, что он должен быть GET'ом, но при этом кешировать его явно не надо, ибо глупо. Решение в явном запрете кеширования со стороны сервера, или есть что-то умнее с учётом кеширования шарахалок по луне?
forgotten
27.08.2015 19:51В общем-то, можно придумать много решений, зависит от того, насколько важно всегда получать значение в обход кэша.
Вполне валидно в этой ситуации использовать POST, например, т.к. это метод с максимально широкой семантикой.
Можно обязать клиента приписывать к запросу время по его собственным часам и/или просто рандомное значение, тоже никто не запрещает.
На практике заголовков запрета кэширования от сервера обычно достаточно.force
27.08.2015 23:04+1POST — несемантично, рандомное значение — костыль. Но концепцию понял, волшебства тут нет :)
force
29.08.2015 12:01+1Извините, я не специально, но только сейчас заметил, что у вас кешируется время на yandex.ru/internet :)
Скриншот

artem_dev
27.08.2015 21:52Мы как-то для подобных случаев (у нас не должны были кешироваться динамические картинки) просто добавляли к таким URL параметр со случайным значением который ни на что не влиял.

Alexeyslav
28.08.2015 00:11+1Но тем не менее они все равно будут кешироваться забивая кеш бесполезными копиями…
т.е. перенесли проблему с больной головы на здоровую.
Doomsday_nxt
28.08.2015 07:35+3Ну если добавить еще заголовки запрета кэширования, то тот кто будет кэшировать (браузер, прокси и пр.) — ССЗБ.

tonymadbrain
28.08.2015 11:52Еще есть вариант с сохранением результата запроса на сервере или кодирование его в урле для последующей отдачи уже по другому ресурсу. К примеру:
1 запрос> POST /current_timestamp/
< 201 created
< Location: /timestamp/1440751720/force
28.08.2015 12:08+6А это уже бредом попахивает. Конечно, семантичненько вышло, но накручивание могучей логики ради красоты семантики это уж слишком.

Evengard
27.08.2015 20:19Прокси-сервера не очень охотно поддерживают что-то кроме get и post, особенно какие-нибудь корпоративные всеограничивающие.
forgotten
27.08.2015 20:20+3Я таких давно уже не видел. В любом случае, специально для таких ситуаций придуман X-HTTP-Method.
habrahabr.ru/company/yandex/blog/265569/#comment_8552479
dem0n3d
27.08.2015 20:24+410 пункт насилует логику. В заголовке написано что все что дальше — заблуждения. Т.е. в итоге получается что:
* 401 Unauthorized не обязан сопровождаться заголовком WWW-Authenticate (хотя выделение болдом намекает на обратное);
* статусы 3xx — это только редиректы;
* статус 404 клиент не имеет права повторять (кстати предложение сформулировано вообще неправильно: клиент имеет право повторять запрос а не статус).
mtp
27.08.2015 20:53-15Где-то минимум трети написанного — субъективщина. Начиная с первого пункта и далее. Чем вам не нравится метод в запросе? Почему не /Луна/?who=шарахалка?
Якорь ещё зачем-то фрагментом обозвали. И про сортировку по породам — тоже спорный вопрос, многие интернет-магазины уже отошли от этой концепции нулевых и ссылаются на один и тот же монитор и как /monitors/HP/model, и как /HP/monitors/lcd/model, фильтры и теги вместо жесткой каталогизированной структуры.
torkve
27.08.2015 21:01+13en.wikipedia.org/wiki/Fragment_identifier
tools.ietf.org/html/rfc3986#section-3.5
В RFC нет ни одного упоминания слова anchor.

Sild
27.08.2015 21:25+7Не стоит брать за основу своих доводов некорректно написанные ядра интернет-магазинов. За разные запросы, возвращающие одинаковые сущности, можно и с поисковой выдачи улететь.
forgotten
27.08.2015 21:51+11> Где-то минимум трети написанного — субъективщина.
К рекомендациям RFC и IETF можно много претензий предъявлять, но уж точно не в плане субъективности.
> Почему не /Луна/?who=шарахалка?
Потому что ресурс — то, над чем выполняется действие. Стреляя из пушки, вы выполняете действие над пушкой, а не над Луной. К тому же, вряд ли у вас есть ресурс «Луна».
> Якорь ещё зачем-то фрагментом обозвали.
Это не я, это Тим Бёрнерс-Ли
tools.ietf.org/html/rfc3986#section-3.5
> И про сортировку по породам — тоже спорный вопрос, многие интернет-магазины уже отошли от этой концепции нулевых и ссылаются на один и тот же монитор и как /monitors/HP/model, и как /HP/monitors/lcd/model
Тем самым нарушая самый базовый принцип архитектуры Web из возможных.
Although there are benefits (such as naming flexibility) to URI aliases, there are also costs. URI aliases are harmful when they divide the Web of related resources. [...] Good practice: Avoiding URI aliases. A URI owner SHOULD NOT associate arbitrarily different URIs with the same resource.
www.w3.org/TR/webarch/#uri-aliases
Nashev
02.09.2015 08:48Теги/фильтры из путей кыш! Тип товара и производителя — тоже, ибо бывают комбинированные типы товара, бывает мультибрендовые товары, и если в пути есть бренд или тип товара, такие товары в него честно не положить. Так?
То есть, GET shop.example.com/catalog/article наше всё, а теги — идут в характеристики товара, и в URL им не место?forgotten
02.09.2015 09:04+1Зависит от конретной стуктуры каталога.
Общий вариант — отдельная страница товара типа /goods/{name}, и отдельный поисковый ресурс типа /search?tag=lcd, который умеет фильтровать по признакам (ну или несколько таких ручек под каждый тип фильтра).
musuk
27.08.2015 20:59+3А если переделать фразу с Get на Post:
«да плевать я на всё это хотел, придумали какой-то ненужной ерунды; как у меня работали все сервисы только на POST, так и дальше будут, мучайтесь со своими PUT-ами и DELETE-ми сами».
То что в ней не так?forgotten
27.08.2015 21:53+7Да практически всё.
— Нет кэширования.
— В условиях плохого соединения запросы повторять нельзя.
— При нажатии Back или Refresh браузер будет показывать сообщение «Подтвердите повторную отправку формы».
И так далее.musuk
28.08.2015 11:30Если я делаю REST API для SPA или для мобильного приложения, то мне как раз не нужно кеширование.
Надеяться, что кто-то повторит мой запрос тоже как-то странно, для этого я делаю отдельный обработчик, хотя, тут, может и стоит заиспользовать GET.
Ну а проблема Back или Refresh для REST API не актуальна.
На счёт Get/Post понятно, но зачем усложнять REST API всякими PUT и DELETE, если достаточно POST и GET.forgotten
28.08.2015 11:34Вот как раз мобильное приложение — это то место, где *необходимо* использовать идемпотентные методы, поскольку мобильная сеть крайне ненадёжна, и любой запрос может отвалиться по таймауту (и при этом успешно выполниться на сервере).
Ну и как-то странно отказывать от кэширования в мобильном о_Оmusuk
28.08.2015 12:55Зачем в мобильном REST API использовать PUT, DELETE, CREATE и т.п. если можно обойтись POST и GET?
В чём реальный профит?
lair
28.08.2015 13:06Приблизительно в том же, в чем вообще профит от хорошей архитектуры — проще, понятнее, расширяемее.
musuk
28.08.2015 13:22+1«Хорошая архитектура» — слишком абстрактное понятие. Я предпочитаю конкретные вещи. Вроде того, что ответили выше про то, что GET-кешируемый и повторяемый. Ок, это может помочь достучаться до сервера. Хотя логику кеширования и обработки таймаутов и ошибок всё равно нужно писать на клиенте.
Вот, например, я реализовал публичный REST API, и мне надо чтобы клиенты могли им просто воспользоваться по простой доке и не трогали меня. По мне, так лучше предложить им 1 или 2 типа запроса, чем 5.
Как-то предложить людям постить JSON запрос на /FunctionName проще, чем заставлять их выставлять X-Header, тип запроса, а данные либо пихать в query, либо в body и прочее.
Kлиенты же потом прийдут мозг выносить: «почему мой запрос не проходит» из-за этой расширяемости архитектуры.lair
28.08.2015 13:37+1Вроде того, что ответили выше про то, что GET-кешируемый и повторяемый.
PUT тоже (может быть) повторяемый. И это очень удобно, когда вам надо создавать объект по нестабильному соединению.
Хотя логику кеширования и обработки таймаутов и ошибок всё равно нужно писать на клиенте.
Дело в том, что если вы используете стандартные средства, то можно найти стандартный же клиент, который будет их поддерживать, и тем самым упростить свою жизнь.
По мне, так лучше предложить им 1 или 2 типа запроса, чем 5.
Эти «типы запросов» потом где-то выражать. У вас есть выразительное средство, но вы им не пользуетесь.
Вот, например, я реализовал публичный REST API, [...] Как-то предложить людям постить JSON запрос на /FunctionName проще
Просто это больше не REST, вот и все.
Есть такая штука — семантика. Вот вы ее нарушаете. Человеку, который привык к нормальным REST API будет сложно понять, что у вас происходит, и как этим пользоваться. Это как в SOAP вместо fault возвращать обычный ответ с кодом ошибки.
Flammar
04.09.2015 18:57мне надо чтобы клиенты могли им просто воспользоваться по простой доке и не трогали меня
Как-то год работал с CMS, оптимизированной по такому принципу — было жутко неудобно и медленно.
Flammar
04.09.2015 18:46Кстати, меня как-то на одном собеседовании спрашивали, зачем нужен GET, когда есть POST, который по идее должен делать всё то же самое. Сошлись на том, что из-за кэширования.

tenbits
27.08.2015 22:11+1Вот меня уже давно мучает вопрос по custom http codes. При ошибках нам всегда нужно приложению отдавать конкретный номер ошибки, сейчас отдаем более подходящий стандартный http статус, а в теле ответа уже код конкретной ошибки. Боюсь за неадекватное поведение разных прокси у клиентов. Но такое дублирование разных кодов, сначала в заголовках, а потом в теле мне не совсем нравится. Есть у кого-то идеи по этому поводу или даже опыт работы с пользовательскими статусами?
forgotten
27.08.2015 22:18+6Чтобы ответить на ваш вопрос, требуется конкретика. Почему вас не устраивает стандартная номенклатура http-кодов?
Если у вашего ресурса есть какая-то своя внутренняя номенклатура ошибок, то никто не мешает отвечать статусом 400 или 500 (в зависимости от того, клиентская ли ошибка) и отдавать в теле ответе, скажем, JSON с описанием произошедшей ошибки (в т.ч. внутренним кодом). Однако в такой ситуации я бы рекомендовал работать по RPC-протоколам, т.е. использовать HTTP как транспорт и отвечать строго 200.tenbits
27.08.2015 23:22Не хотел приводить конкретный пример, что бы не обсуждать частный случай. Но представьте, у нас есть игра, и некий ресурс, который возвращает актуальный статус игры: Фаза1, 2… 10. Хотелось бы, например, возвращать коды 251, 252… 260 соответственно. Тогда даже простым HEAD запросом можно уже знать состояние. Или другая ситуация с ошибкой валидации запроса: 471 — неверный параметр «А», 472 — конфликт значения «Б», и т.д.
никто не мешает отвечать статусом 400 или 500 (в зависимости от того, клиентская ли ошибка) и отдавать в теле ответе, скажем, JSON
Мы так и делаем сейчас, другого варианта пока нет. Но повторюсь, что конкретный статус непосредственно в заголовках мне кажется лучше, ведь а) можно HEAD запросом уже получить состояние и б) не нужно повторяться (один код в заголовках, и другой код в теле).
Но к сожалению на данный момент нет общепринятого промежутка для пользовательских статусов, например45X-49X;55X-59X;7XX-9XX;, или другой способ: конкретный номер через точку:400.ХХХ.

alekciy
27.08.2015 23:31+5Наверное что-то не уловил, но почему не использовать X-Status?
tenbits
27.08.2015 23:49Да, это действительно отличный вариант! Не хочу писать это слово, «но» это уже из области пользовательских заголовков. А работа лишь с http статусом была бы предпочтительнее.
torkve
28.08.2015 00:10+7Почему? Ведь HTTP-статус — это «транспортная» часть, статус доступа. А Вы хотите отдавать логическую часть приложения, смешать два уровня.
tenbits
28.08.2015 02:37Согласен, так оно и есть. Но на данный момент, мне кажется, это вовсе не два изолированных уровня, особенно в контексте API ресурсов, ведь за частую, как раз приложение решает или это Bad Request, или Conflict, или что-то там ещё. Выходит эти уровни уже давно смешаны. Поэтому пора бы уже сделать окончательное смешивание.
forgotten
28.08.2015 08:35+6torkve совершенно прав, так делать ни в коем случае не надо.
HTTP статусы должны индицировать статус самого обращения по HTTP. Если HTTP — просто транспорт до некоторого программного endpoint-а, то номенклатура HTTP-статусов должна описывать строго транспортную часть. 200 — запрос дошел и обработан endpoint-ом (независимо от успешности и состояния такой обработки), 4xx — запрос сформирован неправильно и до endpoint-а не дошёл, 500 — ошибка сети или веб-сервера (т.е. обработчика HTTP-запросов, не самого endpoint-а).tenbits
28.08.2015 13:34Неужели никто никогда не меняет напрямую, или косвенно статус код ответа в самом приложении? Если «нет», то тут вы меня удивите, а если «да», то речи о разделении транспорта и приложения уже быть не может. Или мы как-то друг друга не верно понимаем? Или ещё пример: Если endpoint по фазе луны определил что запрос не верный, неужели статус не измените на 400?
forgotten
28.08.2015 14:10> Неужели никто никогда не меняет напрямую, или косвенно статус код ответа в самом приложении?
Ммм, это как?
> Если endpoint по фазе луны определил что запрос не верный, неужели статус не измените на 400?
Нет.
HTTP статусы — для ошибок уровня протокола HTTP.
Вас же не удивляет, что TCP не знает про ошибки HTTP, и статус его пакетов «ок», даже если в них передаётся закодированная 500-ая ошибка HTTP? Так и в вашем случае. HTTP отработал валидно — статус 200.tenbits
28.08.2015 14:39> Неужели никто никогда не меняет напрямую, или косвенно статус код ответа в самом приложении?
Ммм, это как?
Response.StatusCode = HttpStatusCode.BadRequest; // или через exception throw new HttpBadRequest(message); // или ещё другими 100500 способами.
> Если endpoint по фазе луны определил что запрос не верный, неужели статус не измените на 400?
Интересно, как же по вашему в этом случае приложение должно получить и отреагировать на ошибку (если мы говори о RESTful запросах и json формате)? lair упоминает о адекватном использовании существующих статусов. И действительно, все так делают, вы наверное первый от кого я слышу, что нельзя в приложении менять статус на 400, например.
Нет.
lair, «адекватно-не-адекватно» это в любом случае «использование» в целях приложения, и я к тому и веду, что раз мы уже используем статусы, то чисто из мышления программиста у меня возник вопрос, ведь это абсолютно не DRY менять http-status, и ещё! дополнительно! передавать конкретный статус или в кастомном заголовке, или же где-то в теле ответа. И клиент тоже соответственно должен реагировать на http статус, a потом ещё на конкретный статус ответа.forgotten
28.08.2015 14:45Здесь какое-то недопонимание.
Если у вас REST-приложение, оно *обязано* отвечать HTTP-статусами, соответствующими типу ошибки.
Если у вас не-REST (JSON-RPC, SOAP, whatever) приложение, то good practice — отвечать не-200 статусами только в случае проблем самого HTTP-протокола (сетевые ошибки, веб-сервер упал). Все ошибки внутреннего состояния сервиса кодируются в соответствующий (JSON, XML) формат и возвращаются с HTTP-статусом 200.soniq
28.08.2015 18:00Читал-читал ваш диалог, и окончательно запутался с REST и кодами ответа.
При запросе, например, профиля пользователя по id возможны варианты:
1. Пользователь найден, статус ответа 200, в теле ответа профиль в формате xml. Семантика xml описывается в доке на API.
2. Пользователь удален, статус 410, тело ответа пустое
3. Такой пользователь никогда не был зарегистрирован, статус 404, тело ответа пустое
4. Этот профиль запрашивающему смотреть нельзя, ответ 403
5. Пользователь в отпуске, отвечаем 303 и id заместителя
По-моему, это ерунда какая-то?lair
28.08.2015 18:06Если вы про REST, то никакой особой ерунды (разве что последнее вызывает у меня сомнения — во-первых, должен быть не ID, а Location, а во-вторых, что важнее, я не уверен, что семантика 303 совпадает с семантикой «замещения»).
soniq
28.08.2015 22:21Ерунда тут в том, что таким подходом можно описать только работу с чем-то, очень похожим на файловую систему: ссылки, каталоги, права доступа, вот это все, а содержимое файлов — просто блоб. Можно, конечно, притвориться, что наши сервисы (как профили пользователей в моем примере) — это такие хитрые ресурсы, но тогда от REST в такой схеме ничего не остается.
lair
29.08.2015 00:41+1Зачем притворяться? Профили — и правда ресурсы, а то, что вы называете «файловой системой» — всего лишь иерархически организованные ресурсы с перекрестными ссылками. И это вполне понятное человеку структурирование домена.
Кстати, почему же содержимое — просто блоб? Нет, отнюдь, это гипермедиа.
lair
28.08.2015 14:45ведь это абсолютно не DRY менять http-status, и ещё! дополнительно! передавать конкретный статус или в кастомном заголовке, или же где-то в теле ответа.
Почему же? Это типичная ситуация статуса и сабстатуса. Один клиент будет разбирать тело, другой — нет, но оба они получат ошибочный статус верхнего уровня и не будут считать сообщение успешным.
lair
28.08.2015 14:18Вообще, это вы странное сейчас описываете. Так (разделяя транспорт и бизнес) действительно делали в SOAP, а вот в REST так не делают. REST признает HTTP-протокол и использует его статусы для описания своего состояния.
Это не повод, конечно, заводить собственные статусы, но вот адекватно использовать существующие — например, 500 при любой серверной ошибке, которую мы согласились разглашать, или 400 в случае ошибки валидации, или 409, если изменилось состояние объекта для модификации — вполне разумно и адекватно.forgotten
28.08.2015 14:25Не очень понимаю, о чём вы. REST — это как раз предложенная идеологами HTTP архитектура веб-приложений, полностью на HTTP основанная. Разумеется, REST-сервис должен полностью и строго следовать описанным в стандарте принципам.
Я пишу ровно о том, что правильно или делать приложение в REST-парадигме, полностью следуя семантике HTTP; или делать приложение в другой архитектуре, например, SOAP или JSON-RPC, но тогда ни в коем случае не нужно смешивать статусы высокоуровневых операций с низкоуровневыми. HTTP 500 и HTTP 200 передаются через TCP совершенно одинаково, никто не пытается HTTP-статусы спустить на уровень TCP. Так же и ваше приложение поверх HTTP не должно использовать HTTP-статусы для индицирования своего высокоуровневого состояния.lair
28.08.2015 14:27Окей, признаю, не отследил момент, когда вы предложили отказаться от REST и перейти на RPC-over-HTTP. В этом случае, действительно, вы правы (другое дело, что я не могу найти достаточно мотивирующих факторов для такого перехода, но это тема другого обсуждения).
alekciy
28.08.2015 15:17Поскольку REST признает HTTP-протокол и использует его состояние, то он не исключает использование и собственных заголовков, ведь HTTP не запрещает этого делать (ну кроме префикса X- который записали в старевший).
Конечно приложение должно максимально использовать существующие статусы, но если логика приложения требует своих, то ни что не мешает их добавить. Просто отражать они должны нужные состояние приложения, а не соединения.
alekciy
28.08.2015 15:27Вопрос с подковыркой. Где в приведенных примерах 3хх?
Я к тому, что endpoint как именно конечно точка htpp взаимодействия может и сам отвечать статусами.forgotten
28.08.2015 15:333xx в этой ситуации возможен, кажется, только в случае переезда endpoint-а за другой URL
alekciy
28.08.2015 15:39На вскидку 304. Веб сервер без участия endpoint не знает, можно ли так ответить (мы же говорим про приложение, т.е. запросы динамические и это не статика в ФС в которую веб сервер может сходить и сам).
forgotten
28.08.2015 15:53Как правильно должно выглядеть такое взаимодействие:
клиент: POST /resource/
{ «method»: «getNyashnyKotikNextPhoto», «ifModifiedSince»: <таймстэмп> }
сервер: 200 OK
в теле либо { «notModified»: true }, либо фотка няшного котика
Неправильно:
клиент: GET /resource/?method=getNyashnyKotikNextPhoto
If-Modified-Since: <таймстэмп>
Сервер: 200 OK или 304 Not Modified
Почему так неправильно: потому что ручка resource обладает внутренней семантикой, неизвестной протоколу HTTP. В данном примере — сервер не только отдаёт/не отдаёт картинку, но и смещает внутренний указатель (getNextPhoto).
Соответственно, возможны практически любые спецэффекты. Например, где-то прокси может закэшировать ответ, и фоточки котиков не будут листаться.
Я специально подобрал такой пример, конечно. Но, если у вашей ручки нет внутренней семантики, не ложащейся в HTTP — значит, можно строго по HTTP и работать. А если она есть, то на подобные грабли вы обязательно и наступите.
milast
28.08.2015 12:50+1Мне так не ясен один вопрос. Если HTTP имеет методы GET, POST, PUT, DELETE и другие, почему же в самом HTML в теге FORM могут присутствовать только два метода: GET и POST?
forgotten
28.08.2015 14:07+6Вероятно, потому, что HTTP и HTML — разные вещи, и их даже разрабатывают три разные организации.
Nashev
02.09.2015 10:00Вот кстати да, из html все эти навороты http не доступны фактически, то есть они нужны лишь небольшому подмножеству ваятелей собственных клиент-серверных API, не имеющих отношения у браузеру, но почему-то желающих пользоваться именно http и ничем сверх него. Странные это люди, кажись…
forgotten
02.09.2015 10:14+3Говорят, XML HTTP Request бывает в браузерах. А в некоторых даже таки Fetch.

Spoofi
28.08.2015 14:29Отличная статья, спасибо кэпу :)
Но у меня есть вопрос: где посмотреть реальный пример, где все эти методы реализованы и правила соблюдаются?
Мне вот, например, не доводилось использовать такой API :)Envek
28.08.2015 14:38У GitHub'а весьма недурной API, я думаю, что там выдержаны как минимум почти все пожелания из этого поста (кроме Capability URL, но они не к API относятся, а к веб-интерфейсу): developer.github.com/v3
forgotten
28.08.2015 14:47+2REST API Диска, например, почти полностью по стандарту.
tech.yandex.ru/disk/poligon/#!//v1/disk/resources
maxvoloshin
01.09.2015 08:51+1Было бы круто чтобы API Яндекс.Директ и Яндекс.Маркет также можно было показать в пример к этой статье :)
Diokuz
28.08.2015 19:33Последний абзац можно отнести к любым стандартам и соглашениям — они для того и есть, чтоб все понимали друг друга.
foxkeys
01.09.2015 11:45+2сильный генератор случайных строк (например, UUID)
Это вы так пошутили? UUID не является криптографически стойким рандомом, от слова «вообще»
Теорию, почему так — читайте в вики. А чтобы убедиться на практике — сделайте:
SELECT CONCAT(UUID(), '|', UUID())
И получите что-то вроде:
f24bdc1a-5082-11e5-b94b-001d92633d17
f24bdc47-5082-11e5-b94b-001d92633d17
А повторный вызов минут через пять даст:
2a3b5871-5083-11e5-b94b-001d92633d17
2a3b589e-5083-11e5-b94b-001d92633d17
Более того, имея один UUID() с нужного хоста и примерное время прошедшее с момента генерации «искомого» — диапазон значений «искомого» можно определить очень легко, т.к. функция обратима.
Для тех, кто не понял, практическая реализация атаки:
- Делаем восстановление пароля «на себя» — запоминаем время запроса
- Делаем восстановление пароля на «цель» — запоминаем время
- Вычисляем примерное значение для цели по разности времени между запросами
- Брутфорсим по значению п.3 +- #ffff
Резюме: НИКОГДА не используйте uuid как секретную строку!
Ну, и раз сказал «как не надо» — в качестве дополнения, простой способ получить нормальный криптостойкий секрет на ПХП (с переводом в шестнадцатеричную строку)
bin2hex( openssl_random_pseudo_bytes( 16 ) )lair
01.09.2015 11:54получите что-то вроде:
f24bdc1a-5082-11e5-b94b-001d92633d17
f24bdc47-5082-11e5-b94b-001d92633d17
Это конкретно ваша реализация GUID так себя ведет. Сравните:
CE46945F-61F2-4D52-96F1-5F57D99EC519 31FB8849-CC81-460B-B873-58CEA0E7443E 04298C79-8B33-4C44-8314-CA6A7F27ED4D 813F0486-3C04-45D9-8D63-B5131DC75708
(это четыре последовательных вызова генерации GUID на Windows, конкретно —newid()в MS SQL)
Функция, конечно, все равно не годится для сильной криптографии, но вот реально предсказать ее значения за разумное время вам будет непросто. А ведь еще может быть не один хост.foxkeys
01.09.2015 12:03+3К сожалению, вы не правы. Значения только выглядят рандомными, но таковыми не являются.
Хотя реализация GUID в Windows проприетарна, тем не менее, есть исследования показывающие ее уязвимость.
Сама по себе природа UUID такова, что генерируемые значения не будут иметь криптографически-нормального распределения, т.к. uuid должен обеспечивать уникальность, а не случайность.
А это совершенно разные вещи!lair
01.09.2015 12:08Не прав в чем? Я сказал, что они случайные? Я сказал, что они имеют распределение, неотличимые от случайного?
Я всего лишь сказал, что предсказать значения этой функции за разумное время непросто. Да, несомненно, атаковать ее проще, чем криптографически сильную, но дальше вопрос баланса (как обычно).
(BTW, вполне возможно генерить криптографически сильные (122 бита из 128) GUID-ы, удовлетворяющие четвертой версии стандарта)foxkeys
01.09.2015 12:16+3Вы написали:
Функция, конечно, все равно не годится для сильной криптографии, но вот реально предсказать ее значения за разумное время вам будет непросто.
Однако, приведенная по ссылке работа четко показывает, что это просто. Более того, там даже есть готовые инструменты для этого.
Для тех, кому неохота вникать в статью целиком, приведу несколько ключевых моментов:
Сейчас мы уже знаем, из какого теста сделан Uuid-генератор и с уверенностью можем сказать — испытания на backward security он не выдерживает. Полное обновление состояния у него возникает спустя 4·106 байт выхода (8 экземпляров RC4 * 500 000 байт), поэтому злоумышленник, сумевший заполучить «слепок» всех регистров и S-блоков UuidCreate в определённый момент времени, способен предугадать до 250 000 будущих Uuid-значений. Более того, источником энтропии генератора выступает ГПСЧ Windows в лице SystemFunction036, что, с учётом предсказуемости последнего [8], увеличивает длину скомпрометированного потока данных до запредельных 256·106 байт!
Вы спросите, зачем потребовалось вместо источников энтропии ОС использовать суррогат, получаемый из ГПСЧ Windows? Начну издалека. Во-первых, никто в здравом уме на стойкость UuidCreate больших надежд не возлагал (а те, кто возлагал, просто обязаны дочитать эту статью до конца). Сами демиурги вполне внятно обозначили свою позицию в RFC4122[1]: «Do not assume that UUIDs are hard to guess; they should not be used as security capabilities (identifiers whose mere possession grants access), for example. A predictable random number source will exacerbate the situation». Так что перед разработчиками никогда не стояло цели создать безопасный Uuid-генератор. К сожалению, планету Земля все ещё топчут гоблины (не только топчут, но и карты экспресс-оплаты штампуют!), которые к подобным предостережениям относятся без должного трепета.
Как видите, даже в стандарте, четко сказано — что uuid нельзя использовать как «секрет» — так как ее значения «угадываемые»
Я вот прямо даже не знаю, что еще можно добавить, если уж разработчики стандарта однозначно пишут, что "should not be used as security capabilities (identifiers whose mere possession grants access)"…lair
01.09.2015 12:25Однако, приведенная по ссылке работа четко показывает, что это просто.
… в определенных условиях. В частности, вы должны хотя бы предполагать, сколько именно гуидов было создано между вашим и атакующим.
Впрочем, это не так критично. Для «честных» capability urls действительно лучше использовать криптографически сильные GUID.foxkeys
01.09.2015 12:32+1Сколько — можно предполагать с очень высокой точностью. Посмотрите пример атаки-же… Вы сами формируете оба запроса, «эталонный» и «хакерский».
Время между ними — минимально и контролируемо. Если атакуемая система не какой-нить фейсбук, с его миллионами запросов в секунду — то с большой долей вероятности, речь идет максимум о десятках. Более того, несколько запросов «на себя» позволят еще и вычислить примерный «темп» генерации.
Не забывайте, главная-то проблема в том, что вы в любой момент можете «попросить» генератор дать новое значение. И, таким образом, исследовать поведение генератора.lair
01.09.2015 12:34Вы сами формируете оба запроса, «эталонный» и «хакерский».
Вот только (а) вы на сервере не единственный пользователь (б) генератор гуидов — если люди не заморачивались с безопасностью — один на всю систему, а это значит, что он используется в каждой операции, а не только в атакуемой
Envek
01.09.2015 12:49А ещё (ц) вы должны знать, какая реализация используется. Мы вот используем gen_random_uuid() из модуля pgcrypto для PostgreSQL. Хоть в исходниках там и используются псевдослучайные числа (не иначе, как для производительности), но для целей генерации Capability URLs этого должно быть более, чем достаточно.
forgotten
01.09.2015 12:12Речь идёт о UUID версии 4. Исправил в тексте, спасибо.
foxkeys
01.09.2015 12:27Как-бы формально вы правы.
Но я боюсь, большинство не поймет / не обратит внимания на разницу. Тем более, что UUID 4 просто недоступен в большинстве популярных окружений. Поправьте меня, если это не так.
А еще лучше — приведите примеры практической реализации. Думаю, это будет полезно всем, так как тема на самом деле «больная». Ну очень уж часто я встречаю генерацию «секретов» с использованием uuid, к сожалению…
step307
01.09.2015 12:06+1У меня вот другой взгляд на шараханье по Луне. Из REST и соответственно HTTP мы знаем, что кошерно выполнять операции CRUD над ресурсами. Когда мы выполняем
POST /шарахалка/?to=Луна
можно подумать что мы то ли изменяем состояние шарахалки то ли создаем новую шарахалку.
Я бы делал либо так
POST /шарахалка/выстрелы/?to=Луна
ну или может еще так
POST /луна/ущерб?weapon=шарахалка
Т.е. всегда фокусироваться на том, что мы создаем или меняем, и использовать это в качестве ресурса а не инструмент или фабрику, с помощью которых это делается.

avesus
01.09.2015 12:28forgotten давно хочется почитать то же самое, но с учётом современных реалий — HTTPS. А то все про долбаное «старьё» в виде ответа на GET кеширующим прокси пишут и пишут всё. Хочется вычеркнуть из поста 80%, не относящееся к HTTPS. Кстати, тема для отдельного поста…
forgotten
01.09.2015 12:33+2Во-первых, HTTPS исключает кэширование на стороне промежуточных сетевых агентов. Но вот конечный клиент и имеющиеся на его стороне агенты, будь то браузеры/месенджеры/иные приложения (и плагины/аддоны к ним!) или используемый разработчиком фреймворк, имеют прямой доступ к данным, и все указанные спецэффекты пронаблюдать довольно тривиально.
Во-вторых, про 80% вы, кхм, несколько преувеличиваете. Неидемпотетные методы останутся таковыми независимо от секьюрности протокола.lair
01.09.2015 12:36Но вот конечный клиент и имеющиеся на его стороне агенты,
Аналогично и на стороне поставщика данных: HTTPS может начинаться с внешней границы, на которой стоит простая железка с большим кэшом.forgotten
01.09.2015 12:37Да, и это тоже правда. Далеко не все гоняют трафик внутри ДЦ по HTTPS, часто внутренние прокси по HTTP работают.
avesus
01.09.2015 12:45Пожалуй, с 80% я перегибаю, но вот если речь идёт о том, что вы можете контролировать (nginx и другие reverse-proxy) и параметры кеширования в браузере — то всё-таки отличия существенные. Если у тебя https и куки солёные, ответ от своего сервера получишь всегда, независимо от метода.

mahoro
01.09.2015 17:34-2Самое удивительное в этой статье то, что в блоге Яндекса кто-то использует матюки для большей доходчивости :)
Но придраться не к чему — на то он и Капитан, чтобы использовать армейскую лексику (хотя бы чуть-чуть).













NiPh
Лаконично и понятно, спасибо за статью. Довольно часто приходится сталкиваться с мифом/немифом о том, что вообще не стоит использовать операции отличные от GET/POST/PUT/DELETE, мол не по стандарту это, с отсылкой как раз к промежуточным узлам которые могу отказаться не в курсе, и программистам на принимающей стороне, которые тоже могут быть не готовы, а в некоторых случаях — и вовсе не иметь инструментов для обработки таких запросов. В итоге вся логика которая в статье выкидывается на PATCH, например, запихивается в хитрый PUT. И так далее. В принципе, вся статья как бы намекает на ваше отношение к этому, но тем не менее — выскажитесь пожалуйста )
forgotten
В 2015 году промежуточных узлов, не умеющих PUT/PATCH/DELETE, кажется, не осталось. Я, по крайней мере, не сталкивался.
В любом случае, есть стандартный механизм обхода таких ограничений: использовать GET/POST (первый в случае не изменяющих состояние ресурса операций, второй — для изменяющих), а нужный реально метод передавать заголовком X-HTTP-Method.
avesus
В 2015 году большинство сервисов пишутся на HTTPS.