

Озера данных (data lakes) фактически стали стандартом для предприятий и корпораций, которые стараются использовать всю имеющуюся у них информацию. Компоненты с открытым исходным кодом часто являются привлекательным вариантом при разработке озер данных значительного размера. Мы рассмотрим общие архитектурные паттерны необходимые для создания озера данных для облачных или гибридных решений, а также обратим внимание на ряд критически важных деталей которые не стоит упускать при внедрения ключевых компонентов.
Проектирование потока данных
Типичный логический поток озера данных включает следующие функциональные блоки:
- Источники данных;
- Получение данных;
- Узел хранения;
- Обработка и обогащение данных;
- Анализ данных.
В этом контексте источники данных, как правило, представляют собой потоки или коллекции сырых событийных данных (например, логи, клики, телеметрия интернета вещей, транзакции).
Ключевой особенностью таких источников является то, что необработанные данные хранятся в их оригинальном виде. Шум в этих данных обычно состоит из дублированных или неполных записей с избыточными или ошибочными полями.
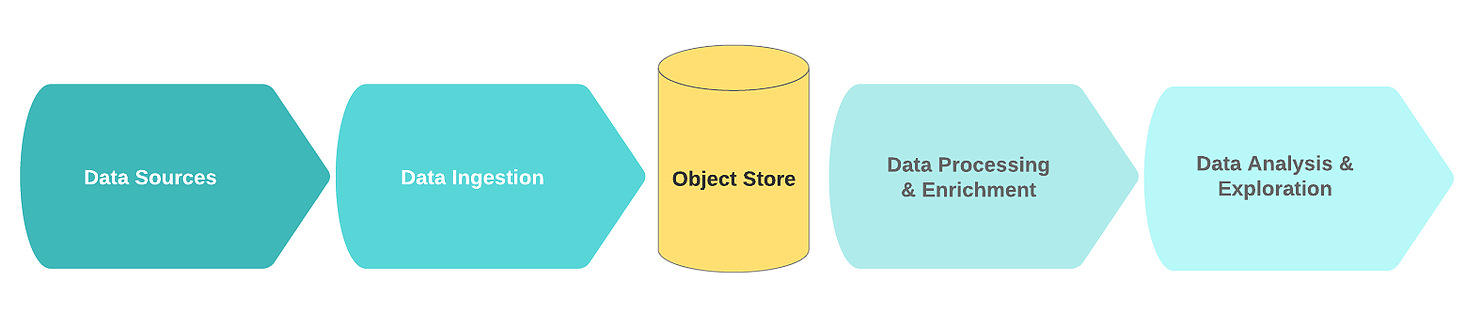
На этапе приёма сырые данные приходят из одного или нескольких источников данных. Механизм приёма чаще всего реализуется в виде одной или нескольких очередей сообщений с простым компонентом, направленным на первичную очистку и сохранение данных. Для того, чтобы построить эффективное, масштабируемое и целостное озеро данных, рекомендуется различать простую очистку данных и более сложные задачи обогащения данных. Одно из проверенных правил заключается в том, что задачи очистки требуют данных из одного источника в пределах скользящего окна.
Скрытый текст
Под обогащением данных подразумеваем насыщение данных дополнительной информацией из других источников (это могут быть какие-то справочники, информациях из сторонних сервисов и т.п.). Обогащение данных распространённый процесс, когда следует учесть все возможные аспекты для проведения дальнейшего анализа.
Как пример, удаление дублей, которое ограничено только сравнением ключей от событий, полученных в течение 60 секунд друг от друга из одного и того же источника, будет типичной задачей очистки. С другой стороны, задача слияния данных из нескольких источников данных в течение относительно длительного промежутка времени (например, за последние 24 часа), скорее соответствует фазе обогащения.
Как пример, удаление дублей, которое ограничено только сравнением ключей от событий, полученных в течение 60 секунд друг от друга из одного и того же источника, будет типичной задачей очистки. С другой стороны, задача слияния данных из нескольких источников данных в течение относительно длительного промежутка времени (например, за последние 24 часа), скорее соответствует фазе обогащения.
После того, как данные приняты и очищены, они сохраняются в распределенной файловой системе (для повышения отказоустойчивости). Часто данные записываются в табличном формате. Когда новая информация записывается в узел хранения, каталог данных, содержащий схему и метаданные, может обновляться с помощью автономного краулера. Запуск краулера обычно запускается событийно, например при поступлении нового объекта в хранилище. Хранилища обычно интегрированы со своими каталогами. Они выгружают базовую схему для того, чтобы к данным можно было обращаться.
Далее данные попадают в специальную область, предназначенную для «золотых данных». С этого момента данные готовы для обогащения другими процессами.
Скрытый текст
Данные называют золотыми, потому что они остаются сырыми и полуструктурированными, и это основной источник знаний о бизнесе.
В процессе обогащения данные дополнительно изменяются и очищаются в соответствии с бизнес-логикой. В результате они сохраняются в структурированном формате в хранилище данных или в базе данных, которое используется для быстрого получения информации, аналитики или обучающей модели.
Наконец, использование данных — аналитика и исследования. Именно здесь извлечённая информация преобразуется в бизнес-идеи при помощи визуализации, дашбордов и отчётов. Также эти данные — источник для прогнозирования с помощью машинного обучения, результат которого помогает принимать лучшие решения.
Компоненты платформы
Облачная инфраструктура озёр данных требует надёжного, а в случае гибридных облачных систем ещё и унифицированного уровня абстракции, который поможет развёртывать, координировать и запускать вычислительные задачи без ограничений в API провайдеров.
Kubernetes — отличный инструмент для такой работы. Он позволяет эффективно развёртывать, организовывать и запускать различные сервисы и вычислительные задачи озера данных надёжным и выгодным способом. Он предлагает унифицированный API, который будет работать и локально и в каком-либо публичном или приватном облаке.
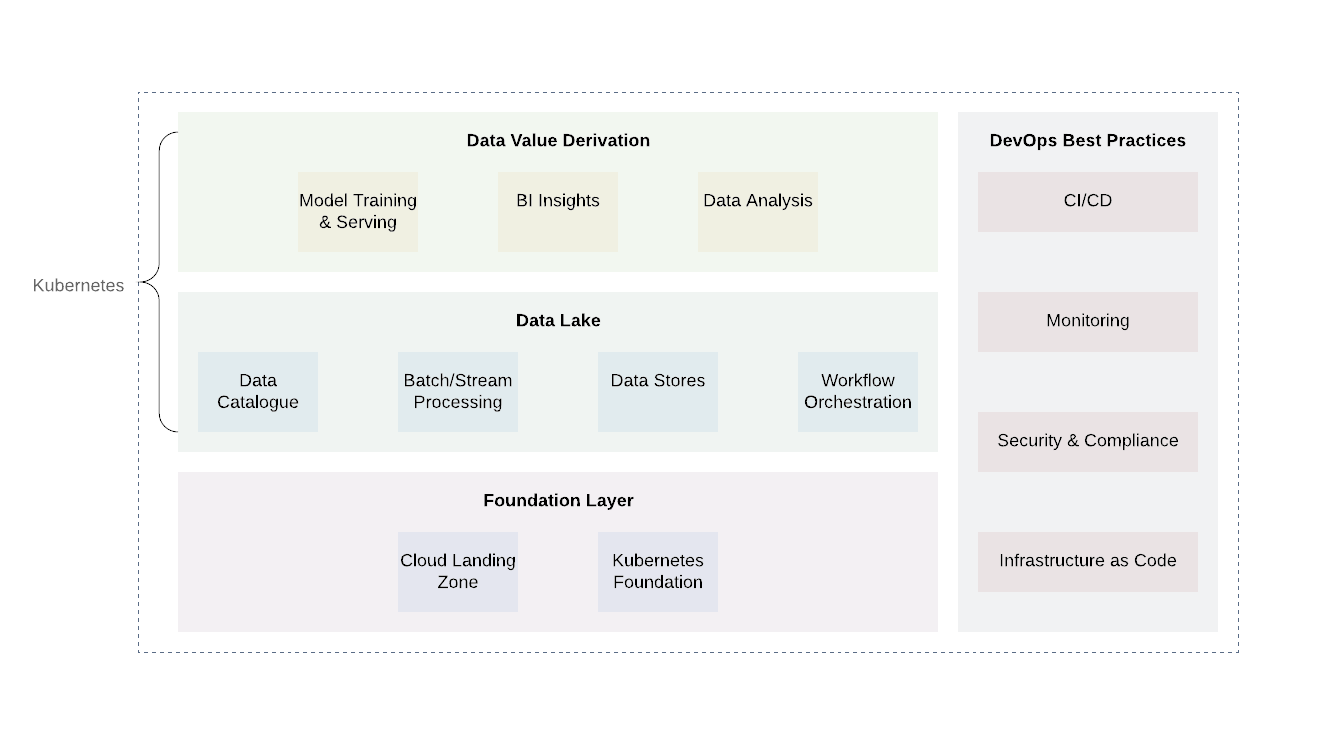
Платформу можно условно разделить на несколько слоёв. Базовый слой — это то место, где мы развертываем Kubernetes или его эквивалент. Базовый слой также можно использовать для обработки вычислительных задач вне компетенций озера данных. При использовании облачных провайдеров, перспективно было бы использовать уже наработанные практики облачных поставщиков (ведение журнала и аудит, проектирование минимального доступа, сканирование уязвимостей и отчетность, сетевая архитектура, архитектура IAM и т.д.) Это позволит достичь необходимого уровня безопасности и соответствия другим требованиям.
Над базовым уровнем есть два дополнительных — само озеро данных и уровень вывода значений. Эти два уровня отвечают за основу бизнес-логики, а также за процессы обработки данных. Несмотря на то, что существует множество технологий для этих двух уровней, Kubernetes снова окажется хорошим вариантом из-за его гибкости для поддержки различных вычислительных задач.
Уровень озера данных включает в себя все необходимые сервисы для приёма (Kafka, Kafka Connect), фильтрации, обогащения и переработки (Flink и Spark), управления рабочим процессом (Airflow). Помимо этого, он включает хранилища данных и распределённые файловые системы (HDFS), а также базы данных RDBMS и NoSQL.
Самый верхний уровень — получение значений данных. По сути, это уровень потребления. Он включает в себя такие компоненты, как инструменты визуализации для понимания бизнес-аналитики, инструменты для исследования данных (Jupyter Notebooks). Другим важным процессом, который происходит на этом уровне, является машинное обучение с использованием обучающей выборки из озера данных.
Важно отметить, что неотъемлемой частью каждого озера данных является внедрение распространённых практик DevOps: инфраструктура как код, наблюдаемость, аудит и безопасность. Они играют важную роль в решении повседневных задач и должны применяться на каждом отдельном уровне, чтобы обеспечивать стандартизацию, безопасность и быть удобными в использовании.
Скрытый текст
При выборе решений с открытым исходным кодом на любом из этапов проектирования облака данных, хорошим показателем является — распространённое применение этого решения в индустрии, подробная документация и поддержка opensource-сообществом.
Взаимодействие компонентов платформы
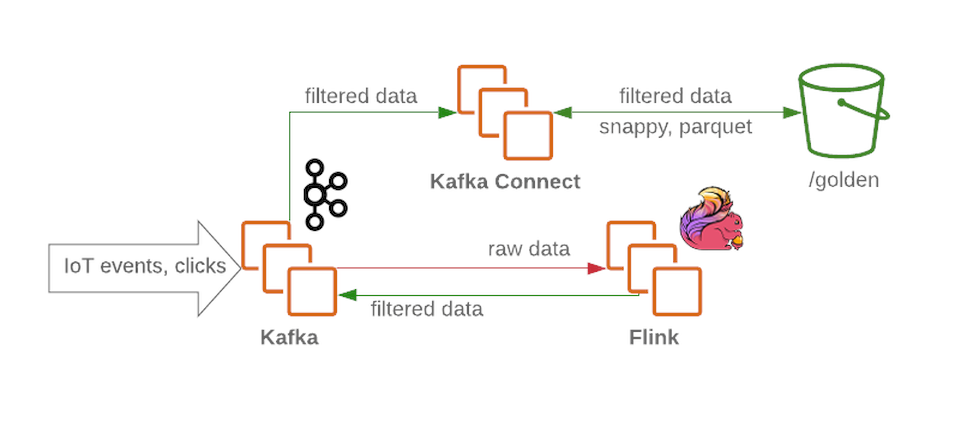
Кластер Kafka будет получать неотфильтрованные и необработанные сообщения и будет функционировать как узел приёма в озере данных. Kafka обеспечивает высокую пропускную способность сообщений надёжным способом. Кластер обычно содержит несколько разделов для сырых данных, обработанных (для потоковой обработки) и недоставленных или искажённых данных.
Flink принимает сообщение из узла c необработанными данных от Kafka, фильтрует данные и делает, при необходимости, предварительное обогащение. Затем данные передаются обратно в Kafka (в отдельный раздел для отфильтрованных и обогащенных данных). В случае сбоя, или при изменении бизнес-логики, эти сообщения можно будет вызвать повторно, т.к. что они сохраняются в Kafka. Это распространенное решение для в потоковых процессов. Между тем, Flink записывает все неправильно сформированные сообщения в другой раздел для дальнейшего анализа.
Используя Kafka Connect получаем возможность сохранять данные в требуемые бекенды хранилищ данных (вроде золотой зоны в HDFS). Kafka Connect легко масштабируется и поможет быстро увеличить количество параллельных процессов, увеличив пропускную способность при большой загрузке:
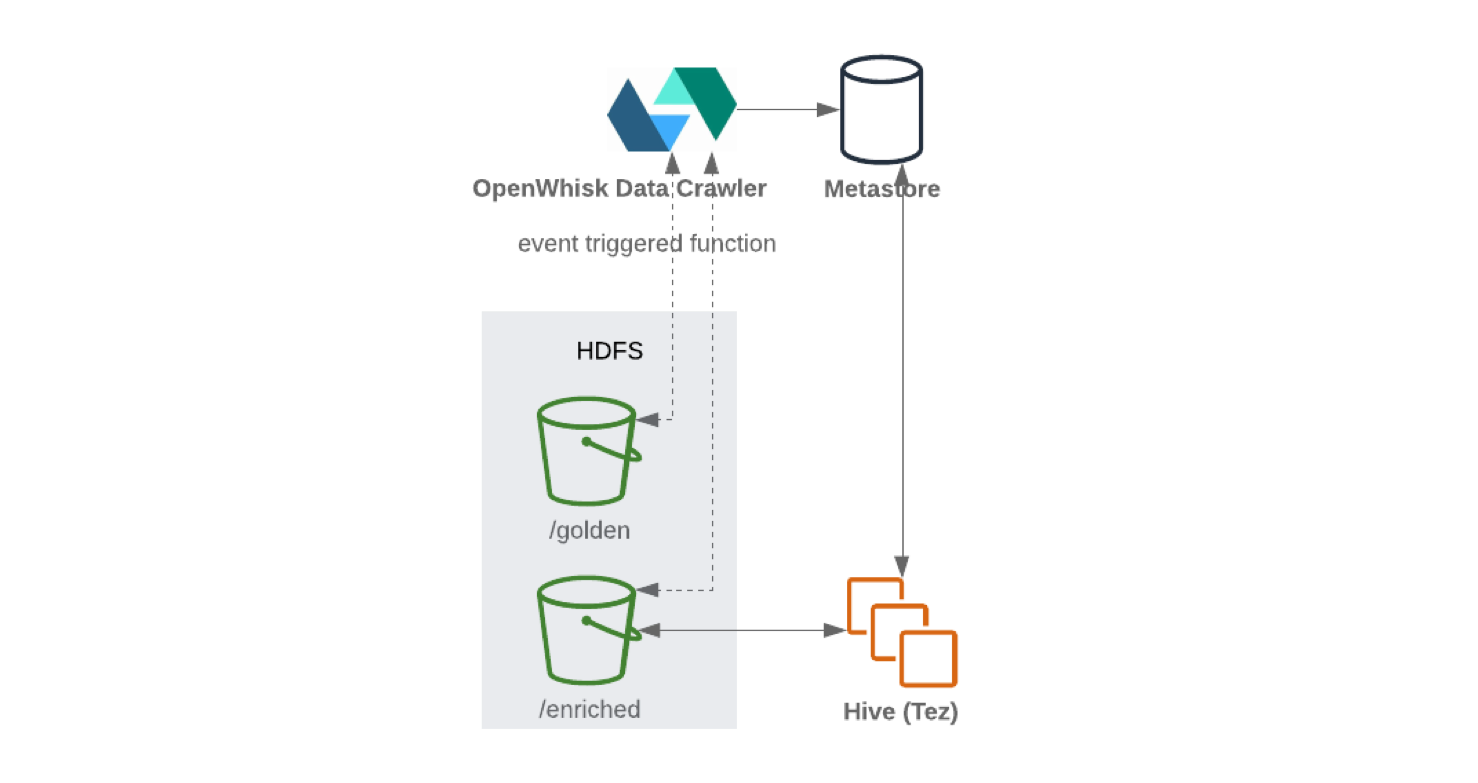
При записи из Kafka Connect в HDFS рекомендуется выполнять разбиение контента для эффективности обращения с данными (чем меньше данных для сканирования тем меньше запросов и ответов). После того, как данные были записаны в HDFS, serverless функциональность (вроде OpenWhisk или Knative) будет периодически обновлять хранилище метаданных и параметров схемы. В результате, к обновленной схеме становится возможно обращаться через SQL-подобный интерфейс (например, Hive или Presto).
Для последующего data-flows и управления ETL-процессом можно использовать Apache Airflow. Он позволяет пользователям запускать многоступенчатые pipline обработки данных с использованием Python и объектов типа Directed Acyclic Graph (DAG). Пользователь может задавать зависимости, программировать сложные процессы и отслеживать выполнение задач через графический интерфейс. Apache Airflow также может служить для обработки всех внешних данных. Например, для получения данных через внешний API и сохранения их в постоянном хранилище.
Spark под управлением Apache Airflow через специальный плагин, может периодически обогащать сырые отфильтрованные данные в соответствии с бизнес-задачами, и подготавливать данные для исследования специалистами по данным, и бизнес-аналитикам. Специалисты по данным могут использовать JupyterHub для управления несколькими Jupyter Notebook. Поэтому стоит воспользоваться Spark для настройки многопользовательских интерфейсов для работы с данными, их сбором и анализом.

Для машинного обучения можно воспользоваться фреймворками, вроде Kubeflow, используя возможность масштабируемости Kubernetes. Получившиеся модели обучения могут быть возвращены в систему.
Если сложить паззл воедино, мы получим что-то вроде этого:

Операционное совершенство
Мы уже говорили, что принципы DevOps и DevSecOps являются важными компонентами любого озера данных и никогда не должны упускаться из виду. С большой властью приходит большая ответственность, особенно когда все структурированные и неструктурированные данные о вашем бизнесе находятся в одном месте.
Основные принципы будут следующими:
- Ограничить доступ пользователей;
- Ведение мониторинга;
- Шифрование данных;
- Serverless-решения;
- Использование процессов CI/CD.
Принципы DevOps и DevSecOps являются важными компонентами любого озера данных и никогда не должны упускаться из виду. С большой властью приходит большая ответственность, особенно когда все структурированные и неструктурированные данные о вашем бизнесе находятся в одном месте.
Один из рекомендуемых методов — разрешить доступ только для определённых сервисов, распределив соответствующие права, и запретить прямой доступ пользователей, чтобы пользователи не смогли изменить данные (это касается и команды). Также для защиты данных важен полный мониторинг при помощи фиксации действий в журнал.
Шифрование данных — ещё один механизм для защиты данных. Шифрование хранимых данных может производиться при помощи системы управления ключами (KMS). Это зашифрует вашу систему хранения и текущее состояние. В свою очередь, шифрование при передаче может производиться при помощи сертификатов для всех интерфейсов и эндпоинтов сервисов вроде Kafka и ElasticSearch.
А в случае систем поиска, которые могут не соответствуют политике безопасности, лучше отдавать предпочтение serverless-решениям. Необходимо также отказаться от ручных деплоев, ситуативных изменений в любом компоненте озера данных; каждое изменение должно приходить из системы контроля версий и проходить серию CI-тестов перед развертыванием на продуктовое озеро данных (smoke-тестирование, регрессия, и т. д.).
Эпилог
Мы рассмотрели основные принципы проектирования архитектуры озера данных с открытым исходным кодом. Как часто бывает, выбор подхода не всегда очевиден и может быть продиктован разными требованиями бизнеса, бюджета и времени. Но использование облачных технологий для создания озёр данных, вне зависимости от того, это гибридное или полностью облачное решение, является развивающейся тенденцией в отрасли. Это происходит благодаря огромному количеству преимуществ, предлагаемых таким подходом. Он обладает большим уровнем гибкости и не ограничивает развитие. Важно понимать, что гибкая модель работы несёт заметную экономическую выгоду, позволяя комбинировать, масштабировать и совершенствовать применяемые процессы.

azzas
Я дико извиняюсь за вопрос не по теме, но что на первой фотке? Титульной фотке, так сказать.
podivilov
Это из фильма «Чужой».
CoolJuice Автор
Да, это фильм Чужой. Если быть точным, то это панель управления корабля Ностромо, из этого фильма.