

Меня всегда занимали отказы систем и странности их поведения, в особенности когда те работают в нормальных для себя условиях. Недавно я видел один из слайдов презентации Йена Гудфелло, показавшийся мне очень смешным. Случайный визуальный шум скормили обученной нейросети, и она распознала его как один из известных ей объектов. Тут сразу появляется много вопросов. Будут ли видеть один и тот же объект разные обученные нейросети? Каков максимальный уровень уверенности нейросети в том, что этот случайный шум действительно является распознанным ею объектом? И что на самом деле «видит» там нейросеть?
Из моего любопытства по этому поводу и родилась данная запись. К счастью, подобные эксперименты очень легко проводить при помощи PyTorch. Для визуализации того, почему нейросеть классифицирует объекты определённым образом, я использую платформу интерпретируемости модели Captum. Код можно скачать с Github.
Важность вопросов
Вы можете спросить, почему эти вопросы важны. Во многих случаях разработчики строят модели не с нуля. Они выбирают платформы и предварительно обученные сети из зоопарка моделей в качестве отправных точек. Это экономит время – не нужно собирать данные и проводить первоначальное обучение нейросети. Однако это также означает, что в неожиданных местах могут возникнуть неожиданные проблемы. В зависимости от того, как используют эту модель, в процессе могут возникнуть проблемы с безопасностью.
Предварительно обученные модели
С предварительно обученными моделями легко начать работать, и им можно быстро отправить данные на классификацию. В таком случае вам не надо определять модели и обучать их – всё это сделано уже до вас, и они готовы к использованию сразу после развёртывания. Предварительно обученные модели из библиотеки Torchvision обучены на наборе изображений из базы Imagenet, разбитых на 1000 категорий. Важно помнить, что это обучение предполагало определение единственного объекта на картинке, а не разбор сложных изображений, содержащих различные объекты. Во втором случае тоже можно получать интересные результаты, однако это уже совершенно другая тема. Скачать предварительно обученные модели из библиотеки Torchvision очень легко. Нужно просто импортировать выбранную модель, установив параметр pretrained в True. Я также включил оценочный режим в модели, поскольку во время тестов не предполагается вести обучение.
Сначала у меня идёт сточка кода, выбирающая использование cuda или cpu, в зависимости от того, есть ли в наличии GPU. Для таких простых тестов GPU не обязателен, однако поскольку он у меня есть, я его использую.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Со списком предварительно обученных моделей из Torchvision можно ознакомиться по ссылке. Я не хотел использовать все предварительно обученные нейросети, это уже чересчур. Я выбрал пять следующих:
- vgg16
- resnet18
- alexnet
- densenet
- inception
Какой-то особой методологией для выбора нейросетей я не пользовался. Например, Vgg16 и Inception часто используются в разных примерах, кроме того, все эти сети разные.
Создаём изображения с шумом
Нам понадобится способ автоматической генерации изображений, содержащих шум, которые можно скармливать нейросети. Для этого я использовал комбинацию библиотек Numpy и PIL, и написал небольшую функцию, возвращающую заполненное случайным шумом изображение.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
В итоге получается что-то вроде следующего:

Преобразование изображений
После этого нам нужно преобразовать наши изображения в тензор и нормализовать их. Следующий код можно использовать не только на случайном шуме, но и на любом изображении, которое мы захотим скормить предварительно обученным нейросетям (поэтому в коде и используются значения Resize и CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageПолучаем предсказания
Подготовив преобразованные изображения, легко получить предсказания от развёрнутой модели. В данном случае предполагается, что функция xform_image возвращает image_xform. В коде, который я использовал для тестирования, я разделил работу между двумя этими функциями, однако здесь для простоты восприятия я составил их вместе. Нам, по сути, нужно скормить преобразованное изображение сети, запустить функцию softmax, использовать функцию topk для получения оценки и идентификатор предсказанной метки для наилучшего результата.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
Результаты
Ну вот, теперь мы представляем, как генерировать содержащие шум изображения и скармливать их предварительно обученной сети. Так какие получаются результаты? Для этого теста я решил сгенерировать 1000 изображений с шумом, прогнал их через 5 выбранных предварительно обученных сетей и запихнул в датафрейм Pandas для быстрого анализа. Результаты оказались интересными и немного неожиданными.
| vgg16 | resnet18 | alexnet | densenet | inception | |
|---|---|---|---|---|---|
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | 0.226978 | 0.328249 | 0.147289 | 0.409413 | 0.020204 |
| std | 0.067972 | 0.071808 | 0.038628 | 0.148315 | 0.016490 |
| min | 0.074922 | 0.127953 | 0.061019 | 0.139161 | 0.005963 |
| 25% | 0.178240 | 0.278830 | 0.120568 | 0.291042 | 0.011641 |
| 50% | 0.223623 | 0.324111 | 0.143090 | 0.387705 | 0.015880 |
| 75% | 0.270547 | 0.373325 | 0.171139 | 0.511357 | 0.022519 |
| max | 0.438011 | 0.580559 | 0.328568 | 0.868025 | 0.198698 |
Как видите, некоторые из нейросетей решили, что этот шум на самом деле изображает что-то конкретное с довольно высоким уровнем уверенности. У resnet18 и densenet максимальные значения достигли 50%. Это всё хорошо, однако что именно эти сети «видят» в шуме? Интересно, что разные сети «находили» там разные объекты.
Vgg16:
стола 978
медуза 14
коралловый риф 7
пончо 1
Resnet18:
медуза 1000
Alexnet:
пончо 942
тряпка для посуды 58
Densenet:
сетка рабица 893
оконная сетка 37
кольчуга 33
дверной коврик 20
черепичная крыша 16
электрокамин 1
Inception:
переключатель 155
сорока 123
пазл 102
подушка 85
джинсовая ткань 83
американский зяблик 81
скворечник 69
соты 32
пончо 26
картон 25
мышеловка 24
саронг 18
кукуруза 16
кольчуга 16
вакуум 12
оконная сетка 12
кардиган 11
американская цапля 9
брокколи 9
кошелек 8
песочница 7
щурок 5
эскимо 5
посудомоечная машина 5
рыба-молот 5
сетка рабица 4
пасека 4
гвоздь 4
бочка 4
мусорка 3
трикотаж 3
нагрудник 3
малая голубая цапля 3
таракан 3
конверт 2
скат 2
занавеска для душа 2
фартук 2
морская звезда 2
мини юбка 1
варежка 1
итальянская гончая 1
спичка 1
цемент 1
громкоговоритель 1
ведро 1
ухо 1
обувной магазин 1
носовой платок 1
лоток 1
трость 1
толстовка 1
тарелка 1
сороконожка 1
кимоно 1Каждая из сетей увидела что-то своё. Resnet18 была на 100% уверена, что это медуза, а у Inception наоборот, уверенности в предсказаниях было очень мало, хотя при этом она увидела гораздо больше объектов, чем любая другая сеть.
Просто для интереса я решил посмотреть, какую подпись поставит Microsoft под изображением шума, которое я привёл ближе к началу данной записи. Для теста я решил пойти наипростейшим путём, и использовал PowerPoint из Office 365. Результат получился интересным, поскольку в отличие от моделей, работающих с imagenet, которые пытаются распознать единственный объект, PowerPoint пытается распознать несколько объектов, чтобы создать точное описание изображения.
На изображении представлены слон, люди, большой, мяч.
Результат меня не разочаровал. С моей точки зрения, изображение шума было распознано как цирк.
Перспективы
Это приводит нас к другому вопросу – что такого видит нейросеть, что заставляет её думать, будто шум – это объект? В поисках ответа мы можем использовать инструмент для интерпретирования модели, который позволит нам примерно понять, что «видит» сеть. Captum – это платформа интерпретации моделей для PyTorch. Тут я не делал ничего особенного, а просто использовал код из обучающих материалов с их веб-сайта. Я только добавил параметр internal_batch_size со значением 50, поскольку без него на моём GPU очень быстро кончалась память.
Для визуализаций я использовал две градиентных атрибуции [gradient based attributions] и заграждающую атрибуцию [occlusion based attribution]. С помощью этих визуализаций мы пытаемся понять, что было важным для классификатора, и, следовательно, «увидеть» то, что видит сеть. Также я использовал свою предварительно обученную модель resnet, однако вы можете изменить код и использовать любые другие предварительно обученные модели.
Перед тем, как перейти к шуму я взял изображение ромашки в качестве демонстрации процесса визуализации, поскольку её признаки легко распознать.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)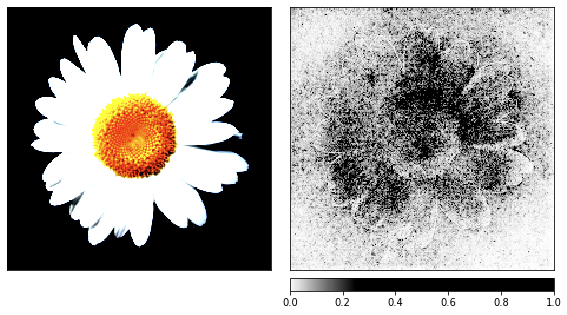
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Визуализация шума
Мы сгенерировали предыдущие изображения на основе ромашки, и теперь пора посмотреть, как всё работает со случайным шумом.
Я использую предварительно обученную сеть resnet18, и с данным изображением она на 40% уверена, что видит медузу. Код повторять не буду, код для визуализации такой же, как и тот, что приведён выше.


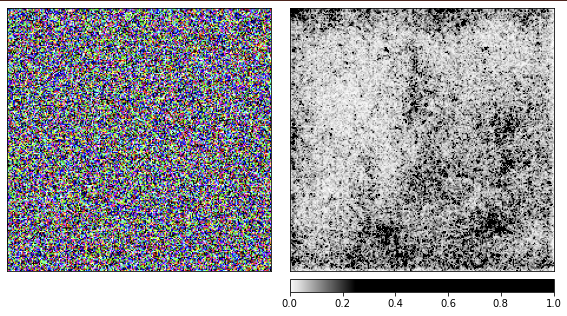

Из визуализаций видно, что нам, людям, так и не удастся понять, почему сеть видит тут медузу. Некоторые области изображения отмечены, как более важные, однако они совсем не такие определённые, как мы видели в примере с ромашкой. В отличие от ромашки, медузы аморфные и отличаются уровнем прозрачности.
Возможно, вам интересно, как будет выглядеть визуализация обработки реального изображения медузы? Мой код выложен на Github, и с его помощью на этот вопрос будет легко получить ответ.
Заключение
На основе этой записи легко видеть, насколько просто можно обмануть нейросети, скармливая им неожиданные входные данные. К их чести скажем, что работу свою они сделали и выдали наилучший результат из тех, на что способны. Также из результатов работы можно увидеть, что в таких случаях недостаточно просто отфильтровать варианты с малой уверенностью, поскольку у некоторых вариантов уверенность была довольно высокой. Нам нужно внимательно следить за ситуациями, в которых системы, работающие в реальных условиях, так легко идут в отказ. Нас не должно заставать врасплох попадание на вход системе неожиданных данных – а именно этим уже довольно долгое время занимаются специалисты по безопасности.


lxsmkv
Просто ассоциативные способности человека еще не настолько продвинуты, чтобы распознать в россыпи разноцветных точек «слона, людей, и большой мяч» ;)
WarMonSlim
Помню в детстве развлекался тем, что смотрел на шум помех телевизора, пока не начинал там видеть всякие образы :)