
Всем привет! Меня зовут Дмитрий, я релиз-инженер в команде CI/CD Speed Авито. Вот уже несколько лет мы с коллегами отвечаем за всё, что связано с релизами наших мобильных приложений и не только. В прошлый раз я рассказывал о нашей системе релизов мобильных приложений на основе контракта. Сегодня речь пойдет о том, как мы автоматизировали сбор информации из Firebase о новых фатальных ошибках в мобильных приложениях.

Проблематика
В процессе написания программ неизбежно возникают ошибки. Некоторые из них могут быть фатальными и приводить к крашу приложения. Для сбора, анализа и исправления таких ошибок используются специальные системы мониторинга.
Раньше, как и многие на рынке мобильных приложений, мы использовали Fabric, для которого vadimsmal и YourDestiny написали очень удобный клиент Fabricio. На базе этого клиента у нас была создана система мониторинга, которая заводила Jira-задачи на новые фатальные ошибки, искала ответственных по Git-Blame и сообщала об ошибках в cпециальный слак-канал.
Но компания Google решила прекратить развитие проекта Fabric, объявила дату закрытия и предложила всем желающим мигрировать на их платформу Firebase, что мы благополучно и сделали.
Система автоматического мониторинга крашей перестала работать, и нам пришлось возвращаться к постоянному ручному мониторингу. При первичном изучении документации выяснилось, что у Firebase нет публичного API для получения необходимой информации, и придётся искать обходные пути.
Получаем данные
Google Cloud Functions
Первая проблема для организации автоматического мониторинга, которую нужно было решить — как оперативно получать информацию о новых сбоях в работе приложения.
Исследование документации Firebase привело нас к Google Cloud Functions или же облачным функциям. Это serverless FaaS от Google, который позволяет запускать ваш код в облачной инфраструктуре Google. У Firebase-Crashlytics есть встроенная интеграция с облачными функциями (на момент написания статьи данная функциональность помечена как deprecated). Вы можете написать call-back на один из трёх crashlytics-ивентов и дальше обрабатывать его как вашей душе угодно. Особенно нас интересуют два ивента — “onNew”(новое событие crashlytics) и “onVelocityAlert” (резкий рост события crashlytics).

В голове сразу же родилась схема. Настраиваем интеграцию Firebase-Google Cloud Functions, шлём оттуда все новые краши сразу в свой сервис, и там уже обрабатываем. Берём пример из документации, вносим несколько доработок и получаем следующий код на JS который загружаем в Google Cloud:
const functions = require('firebase-functions');
const rp = require('request-promise');
function sendEvent(event) {
return rp({
method: 'POST',
uri: functions.config().crashlytics.crash_collector_url,
body: event,
json: true,
});
}
exports.NewIssueEvent = functions.crashlytics.issue().onNew(async (issue) => {
await processEvent(issue, 'NewIssueEvent')
});
exports.RegressedEvent = functions.crashlytics.issue().onRegressed(async (issue) => {await processEvent(issue, 'RegressedEvent')});
exports.VelocityAlertEvent = functions.crashlytics.issue().onVelocityAlert(async (issue) => {await processEvent(issue, 'VelocityAlertEvent')});
const processEvent = async (event, type) =>{
if (isActualEvent(event)) {
await sendEvent(event);
console.log(`Posted ${type} ${event.issueId} successfully to crash collector`);
}
else{
console.log(`It's old event or not Avito. Do nothing`);
}
}
const isActualEvent = (event) =>{
const {appInfo} = event;
const {appName, latestAppVersion} = appInfo;
const version = latestAppVersion && parseFloat(latestAppVersion.split(' ')[0]);
console.log(`Event appName: ${appName} version: ${version}`);
return appName === 'Avito' && version > 60.0
}
Тут мы добавили небольшое изящное архитектурное решение, чтобы не получать события, не относящиеся к Авито, или же события совсем старых версий приложения.
Но в текущей реализации нам не хватает данных. В Firebase-Crashlytics есть fatal события (собственно фатальные ошибки-краши) и non-fatal (остальные события которые по той или иной причине логируются в crashlytics). Все летящие к нам ивенты на событие “onNew” не имеют признака фатальности, к тому же нам хотелось как-то фильтровать события по количеству затронутых пользователей и частоте возникновения, но этой информации в событиях нет.
BigQuery
Google позволяет экспортировать данные из Firebase в BigQuery. BigQuery — облачное хранилище, предоставляющее удобную платформу для хранения и обработки данных. На момент исследования в середине 2019 года был доступен только один тип синхронизации c Firebase — Batch Table.
Нужно отметить ключевые особенности данного типа синхронизации:
- Синхронизация происходит раз в сутки, при этом нет гарантии, когда она будет завершена.
- Нельзя настроить тип экспортируемых событий — экспортируется и fatal и non-fatal.
- Чем дольше живёт таблица, тем больше в ней данных (ваш кэп) и тем дороже стоят услуги хранения.
Дорабатываем изначальную схему:

После получения ивента в нашем сервисе идём в BigQuery и получаем недостающую информацию: признак фатальности, число задетых пользователей и так далее. При этом запросы к BigQuery отправляем не на каждый новый ивент, а периодически. Для нас оптимальная частота запросов — раз в день после 17:00, так как за это время выгрузка данных из Firebase-Crashlytics в BigQuery успевала завершиться, и можно было получить информацию по всем необработанным ивентам простым запросом:
SELECT issue_id, is_fatal, COUNT(*) as crashes_counter,
COUNT(DISTINCT installation_uuid) AS affected_users
FROM `android.firebase_crashlytics.{table}`
WHERE issue_id in ( {issues_id_string} )
GROUP BY issue_id, is_fatal
LIMIT 1000Внимательный читатель может заметить, что тут образовывается временной лаг между фактическим появлением краша и получением нами информации о нём. Чтобы не пропускать редкие, но действительно важные краши, которые резко растут и задевают сразу много пользователей, у нас по-прежнему оставалось событие “onVelocityAlert” в Google Cloud Function. По документации это событие вызывается исключительно на фатальные ошибки в работе приложения, если ошибка привела к сбою N сеансов пользователей за последний час. По факту же “onVelocityAlert” не работало, мы зарепортили это в Google, нас внесли во внутренний трекер, и на этом всё.
Слак
Нас вполне устраивал временной лаг при получении «обычных» фатальных ошибок, но совсем не хотелось пропустить пожар. В поисках возможности получения VelocityAlert мы пришли к интеграции Firebase-Crashlytics и слака. В консоли Firebase вы можете достаточно просто и быстро настроить отправку событий в определённый слак-канал, в том числе событий VelocityAlert. Это было почти то, что мы искали. Интеграция позволяла оперативно получать информацию о том, что всё плохо, но при этом нельзя было фильтровать события по версии. В итоге канал больше напоминал свалку.
Тогда мы решили использовать канал с сырыми VelocityAlert как источник данных для сервиса. Слушать этот канал, подтягивать из него новые сообщения с VelocityAlert и уже на уровне сервиса фильтровать.
Новая схема выглядела так:

Обрабатываем данные
С источником данных вроде определились. Теперь нужно эти данные обрабатывать.
Напомню, что наша старая система на Fabric делала с данными о крашах:
- Искала ответственного по Git-Blame.
- Создавала задачу на исправление.
- Оповещала о новом событии в специальный слак-канал.
Первое от чего мы решили отказаться — это автоматическое создание задачи и поиск ответственного по Git-Blame. По опыту, автоматически созданные задачи отправлялись на кладбище Jira, и к ним редко кто возвращался, а поиск по Git-Blame иногда давал сбой, что ещё больше повышало шансы забыть задачу. А вот оповещения в слак мы решили развивать, этот канал коммуникации показал себя наиболее эффективным.
Обработку решили реализовать на базе сервиса мобильных релизов Nupokati. Он собирает информацию по новым крашам, раз в день по крону запрашивает дополнительные данные из BigQuery, фильтрует краши по фатальности и частоте возникновения — нас не интересуют единичные сбои — и отправляет daily report в слак по актуальной версии приложения.

Пример daily report
Сразу в треде к этому репорту находятся ответственные, и создаются соответствующие задачи. Опять же по опыту, задачи, которые заведены ответственным разработчиком самостоятельно, гораздо чаще закрываются с исправлением краша.
Помимо daily report мы отлавливаем VelocityAlert для актуальной версии и тут же репортим о пожаре в слак-канал и ответственному за конкретный релиз инженеру. В треде определяется, насколько взрыв фатален, и что с ним делать.

Google Cloud Functions всё
Около года мы успешно эксплуатировали новую систему автоматического сбора и алертинга фатальных ошибок в мобильных приложениях. Уже практически забыли, как заходить в Firebase и смотреть краши. Как вдруг было объявлено, что интеграция Firebase-crashlytics и Google Cloud Functions deprecated и её работа будет приостановлена 1 октября 2020 года. Нужно было оперативно дорабатывать решение и отказываться от облачных функций. При этом хотелось обойтись минимальными изменениями в работающей системе.
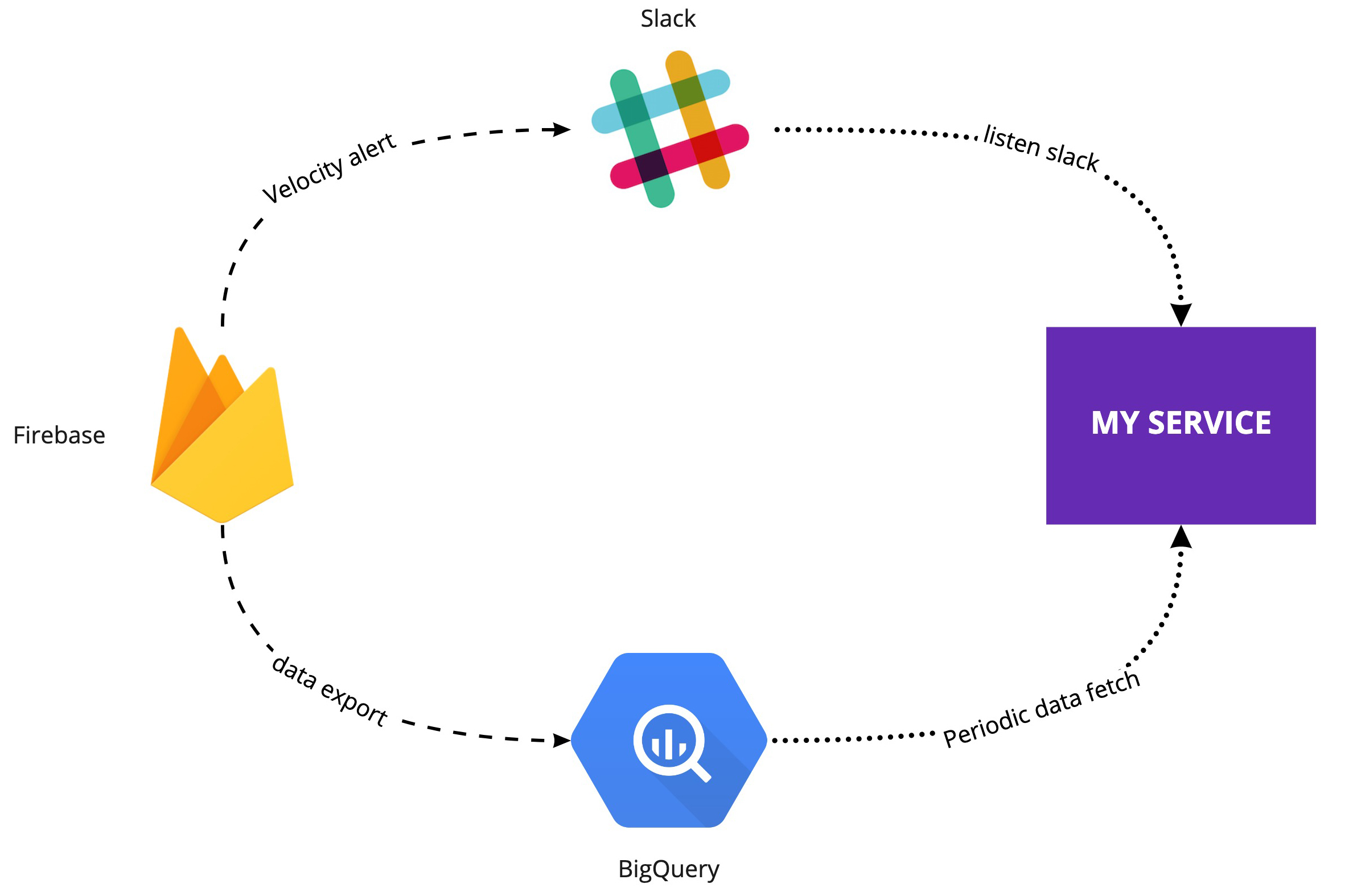
Так мы просто убрали Cloud Functions и доработали запрос на получения данных из BigQuery. Вся остальная система осталась прежней: daily report, velocityAlerts, фильтры по количеству задетых пользователей и слак-каналы. Новый запрос получает сразу все уникальные краши по нужной версии и отправляет их в поток обработки.
SELECT
issue_id,
issue_title,
is_fatal,
COUNT(issue_id) as crashes_counter,
ARRAY_AGG (distinct application.display_version) AS versions,
COUNT(DISTINCT installation_uuid) AS affected_users
FROM `android.firebase_crashlytics.{table}`
WHERE is_fatal=true
GROUP BY issue_title, issue_id, is_fatal
HAVING ARRAY_LENGTH(versions)=1 AND "{version}" in UNNEST(versions)
ORDER BY crashes_counter DESCИтоги
Система автоматической сборки крашей позволила нам снизить ручной труд и человеческий фактор. Больше не нужно заходить в консоль Firebase и следить за крашами. Мы смогли построить процесс по исправлению фатальных ошибок на базе предоставляемых ей данных и улучшить качество наших мобильных приложений. При этом в текущей реализации с получением данных из BigQuery напрямую мы можем легко расширять и дорабатывать её, если понадобится.
Несколько советов тем, кто захочет повторить наш путь:
- Использование BigQuery платное, но есть песочница, в которой можно поэкспериментировать.
- Оптимизируйте запросы к BigQuery. Процессинг данных не бесплатный, он в прямом смысле имеет денежное выражение согласно тарифам.
- Для оптимизации затрат на хранение данных в BigQuery уменьшайте время жизни таблиц, это есть в настройках. Для нас оптимальным отказался период жизни таблицы в пять дней.
- Уже после создания нашей системы появился BigQuery streaming. На нём можно собрать аналогичную систему или даже лучше.
- Внимательней читайте документацию к Google Cloud Platform. Это очень мощная платформа с множеством инструментов и возможностей.
Blyabtroi
Сколько в месяц стоит для вас такая интеграция?
JasperJhons Автор
Около 100$/месяц.
Но тут нужно учитывать 2 фактора:
1. Время жизни наших таблиц 5 дней.
2. Так сложилось, что на одной из платфом в crashlytics логируются дополнительные данные не являющиеся крашами. И в пике (на пятый день) таблица весит более 5ТБ, что несомненно прибавляет к стоимости интеграции.(
Ваша итоговая стоимость может отличаться как в плюс, так и в минус. Тут очень много пространства для фантазии и оптимизации.