

Рассказываем о нейросети, которая применяет глубокое обучение и обучение с подкреплением, чтобы играть в Змейку. Код на Github, разбор ошибок, демонстрации иры искусственного интеллекта и эксперименты над ним вы найдете под катом.
С тех пор, как я посмотрела документальный фильм Netflix об AlphaGo, я была очарована обучением с подкреплением. Такое обучение сравнимо с человеческим: вы видите что-то, делаете что-то и у ваших действий есть последствия. Хорошие или не очень. Вы учитесь на последствиях и корректируете действия. У обучения с подкреплением множество приложений: автономное вождение, робототехника, торговля, игры. Если обучение с подкреплением вам знакомо, пропустите следующие два раздела.
Обучение с подкреплением
Принцип простой. Агент учится через взаимодействие со средой. Он выбирает действие и получает отклик от среды в виде состояний (или наблюдений) и наград. Этот цикл продолжается постоянно или до состояния прерывания. Затем наступает новый эпизод. Схематично это выглядит так:

Цель агента — получить максимум наград за эпизод. Вначале обучения агент исследует среду: пробует разные действия в одном и том же состоянии. С течением обучения агент исследует всё меньше. Вместо этого он, основываясь на собственном опыте, выбирает действие, приносящее наибольшую награду.
Глубокое обучение с подкреплением
Глубокое обучение использует нейронные сети, чтобы из входных данных получать выходные. Всего один скрытый слой — и глубокое обучение может приближать любую функцию. Как это работает? Нейронная сеть — это слои с узлами. Первый слой — это слой входных данных. Скрытый второй слой преобразует данные с помощью весов и функции активации. Последний слой — это слой прогноза.

Как следует из названия, глубокое обучение с подкреплением — это комбинация глубокого обучения и обучения с подкреплением. Агент учится прогнозировать лучшее действие для данного состояния, используя состояния как входные данные, значения для действий как выходные данные и награды для настройки весов в правильном направлении. Давайте напишем Змейку с применением глубокого обучения с подкреплением.

Определяем действия, награды и состояния
Чтобы подготовить игру для агента, формализуем проблему. Определить действия просто. Агент может выбирать направление: вверх, вправо, вниз или влево. Награды и состояние пространства немного сложнее. Есть много решений и одно будет работать лучше, а другое хуже. Одно из них опишу ниже и давайте попробуем его.
Если Змейка подбирает яблоко, ее награда 10 баллов. Если Змейка умирает, отнимаем от награды 100 баллов. Чтобы помочь агенту, добавляем 1 балл, когда Змейка проходит близко к яблоку и отнимаем один балл, когда Змейка удаляется от яблока.
У состояния много вариантов. Можно взять координаты Змейки и яблока или направления к яблоку. Важно добавить расположение препятствий, то есть стен и тела Змейки, чтобы агент учился выживать. Ниже резюме действий, состояний и наград. Позже мы увидим, как корректировка состояния влияет на производительность.

Создаем среду и агента
Добавляя методы в программу Змейки, мы создаём среду обучения с подкреплением. Методы будут такими:
reset(self), step(self, action) и get_state(self). Кроме того, нужно рассчитывать награду на каждом шаге агента. Посмотрите на run_game(self).Агент работает с сетью Deep Q, чтобы найти лучшие действия. Параметры модели ниже:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Если интересно посмотреть на код, вы найдёте его на GitHub.
Агент играет в Змейку
А теперь — ключевой вопрос! Научится ли агент играть? Понаблюдаем, как он взаимодействует со средой. Ниже первые игры. Агент ничего не понимает:

Первое яблоко! Но по-прежнему выглядит так, будто нейросеть не знает, что делает.

Находит первое яблоко… и чуть позже ударяется о стену. Начало четырнадцатой игры:

Агент учится: его путь к яблоку не самый короткий, но он находит яблоко. Ниже тридцатая игра:

После всего 30 игр Змейка избегает столкновений с самой собой и находит быстрый путь к яблоку.
Поиграем с пространством
Может быть, возможно изменить пространство состояний и достичь похожей или лучшей производительности. Ниже возможные варианты.
- Без направлений: не сообщать агенту направления, в которых движется Змейка.
- Состояние с координатами: замени положение яблока (вверх, вправо, вниз и / или влево) координатами яблока (x, y) и змеи (x, y). Значения координат находятся на шкале от 0 до 1.
- Состояние «направление 0 или 1».
- Состояние «только стены»: сообщает только о том, есть ли стена. Но не о том, где находится тело: внизу, наверху, справа или слева.

Ниже графики производительности разных состояний:
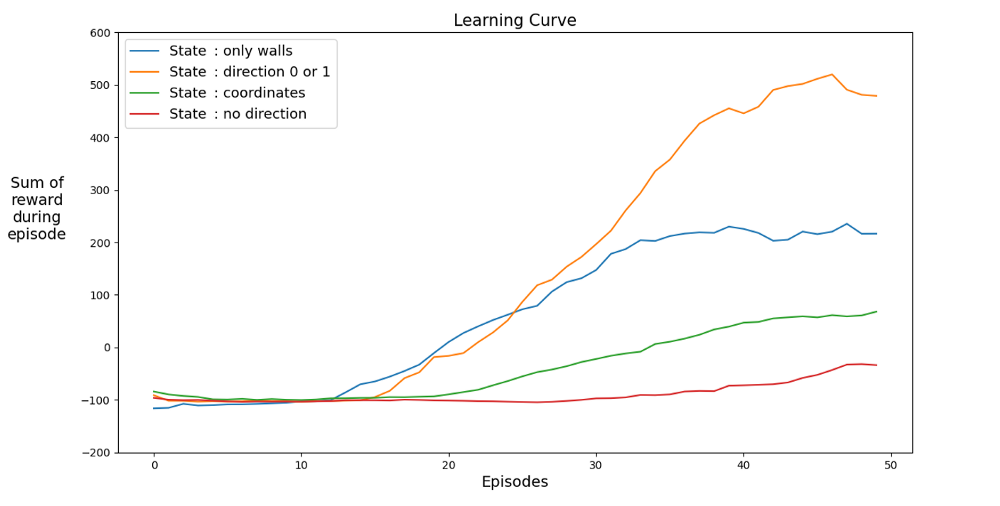
Найдем пространство, ускоряющее обучение. График показывает средние достижения последних 12 игр с разными состояниями.
Понятно, что когда пространство состояний имеет направления, агент учится быстро, достигая наилучших результатов. Но пространство с координатами лучше. Может быть, можно достичь лучших результатов, дольше тренируя сеть. Причиной медленного обучения может быть число возможных состояний: 20?*2?*4 = 1,024,000. Поле 20 на 20, 64 варианта для препятствий и 4 варианта текущего направления. Для исходного пространства вариантов 3?*2?*4 = 576. Это более чем в 1700 раз меньше, чем 1,024,000 и, конечно, влияет на обучение.
Поиграем с наградами
Есть ли лучшая внутренняя логика награждения? Напоминаю, Змейка награждается так:

Первая ошибка. Хождение по кругу
Что, если изменить -1 на +1? Это может замедлить обучение, но в конце концов Змейка не умирает. И это очень важно для игры. Агент быстро учится избегать смерти.

На одном временном отрезке агент получает один балл за выживание.
Вторая ошибка. Удар о стену
Изменим количество баллов за прохождение около яблока на -1. Награду за само яблоко установим в 100 баллов. Что произойдет? Агент получает штраф за каждое движение, поэтому двигается к яблоку максимально быстро. Так может случиться, но есть и другой вариант.

ИИ проходит по ближайшей стене, чтобы минимизировать потери.
Опыт
Нужно только 30 игр. Секрет искусственного интеллекта — опыт предыдущих игр, который учитывается, чтобы нейросеть училась быстрее. На каждом обычном шаге выполняется ряд шагов переигрывания (параметр
batch_size). Это так хорошо работает потому, что для данной пары действия и состояния разница в награде и следующем состоянии небольшая.Ошибка №3. Нет опыта
Опыт действительно так важен? Давайте уберём его. И возьмём награду за яблоко в 100 баллов. Ниже агент без опыта, сыгравший 2500 игр.

Хотя агент сыграл 2500 (!) игр, в змейку он не играет. Игра быстро заканчивается. Иначе 10 000 игр заняли бы дни. После 3000 игру у нас только 3 яблока. После 10 000 игр яблок по-прежнему 3. Это удача или результат обучения?
Действительно, опыт очень помогает. Хотя бы опыт, учитывающий награды и тип пространства. Как много нужно переигрываний на шаг? Ответ может удивить. Чтобы ответить на этот вопрос, поиграем с параметром batch_size. В исходном эксперименте он установлен в 500. Обзор результатов с разным опытом:

200 игр с разным опытом: 1 игра (опыта нет), 2 и 4. Среднее за 20 игр.
Даже с опытом в 2 игры агент уже учится играть. В графе вы видите влияние
batch_size, та же производительность достигается на 100 игр, если вместо 2 используется 4. Решение в статье дает результат. Агент учится играть в Змейку и достигает хороших результатов, собирая от 40 до 60 яблок за 50 игр.Внимательный читатель может сказать: максимум яблок в змейке — 399. Почему ИИ не выигрывает? Разница между 60 и 399, в сущности, небольшая. И это верно. И здесь есть проблема: Змейка не избегает столкновений при замыкании на себя.
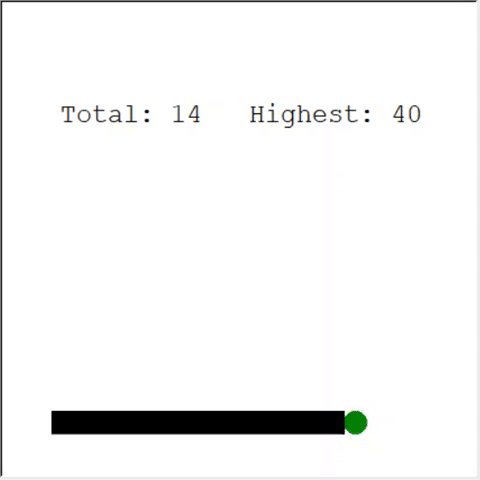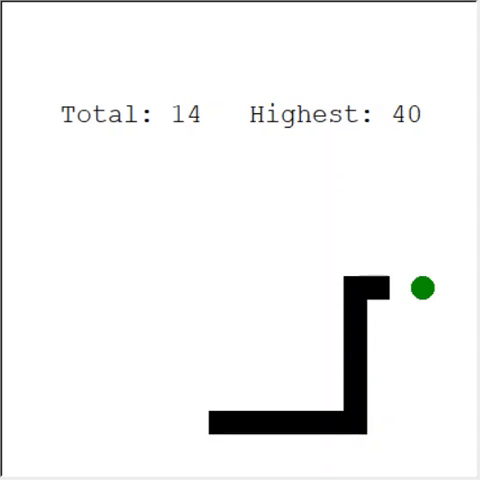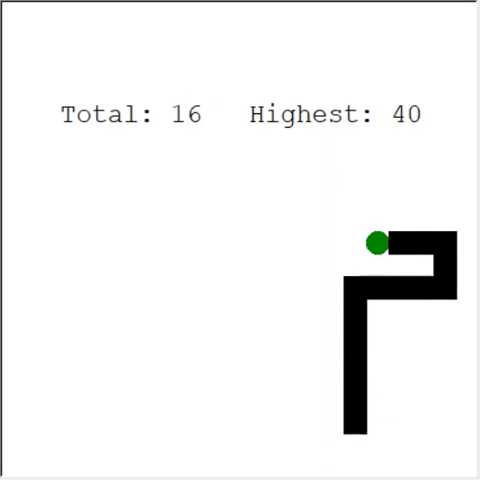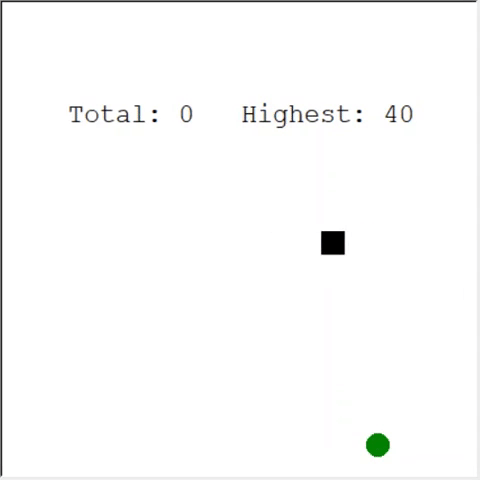
Интересный способ решить проблему — использовать CNN для поля игры. Так ИИ может увидеть всю игру, а не только ближайшие препятствия. Он сможет распознавать места, которые нужно обойти, чтобы победить.
Библиография
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Курс «Математика и Machine Learning для Data Science» (20 недель)
- Продвинутый курс «Machine Learning Pro + Deep Learning» (20 недель)
- Обучение профессии Data Science с нуля (12 месяцев)
Eще курсы
- Профессия Веб-разработчик (8 месяцев)
- Онлайн-буткемп по Data Analytics (5 недель)
- Курс по аналитике данных (6 месяцев)
- Профессия аналитика с любым стартовым уровнем (18 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
- Курс по DevOps (12 месяцев)
- Профессия Java-разработчик с нуля (18 месяцев)
- Курс по JavaScript (12 месяцев)
- Профессия UX-дизайнер с нуля (9 месяцев)
- Профессия Web-дизайнер (7 месяцев)



ganqqwerty
Вот так, оказывается это были яблоки!