
Привет, Хабр!
Мы продолжаем серию статей про модерацию контента на площадках Центра Развития Финансовых Технологий Россельхозбанка. В прошлой статье мы рассказывали, как решали задачу модерации текста для одной из площадок экосистемы для фермеров “Свое Фермерство”. Почитать немного о самой площадке и о том какой результат мы получили можно здесь.
Если коротко, то нами использовался ансамбль из наивного классификатора (фильтр по словарю) и BERT’a. Тексты, прошедшие фильтр по словарю, пропускались на вход в BERT, где они также проходили проверку.
А мы, совместно с Лабораторией МФТИ, продолжаем улучшать нашу площадку, поставив перед собой более сложную задачу премодерации графической информации. Эта задача оказалась сложнее предыдущей, так как при обработке естественного языка можно обойтись и без применения нейросетевых моделей. С изображениями все сложнее — большинство задач решается с помощью нейронных сетей и подбором их правильной архитектуры. Но и с этой задачей, как нам кажется, мы неплохо справились! А что у нас из этого получилось, читайте далее.

Итак, поехали! Давайте сразу определимся, что из себя должен представлять инструмент модерации изображений. По аналогии с инструментом модерации текста это должен быть некоторого рода “черный ящик”. Подавая ему на вход изображение, загружаемое продавцами товаров на площадку, мы бы хотели понимать, насколько данное изображение приемлемо для публикации на площадке. Таким образом, получаем задачу: определить подходит ли изображение для публикации на сайте или нет.
Задача премодерации изображений является распространенной, но решение зачастую отличается в зависимости от площадок. Так, изображения внутренних органов могут быть приемлемыми для медицинских форумов, но не подходить для соцсетей. Или, к примеру, изображения разделанных тушек животных допустимо на сайте, где их продают, но вряд ли понравится детям, которые заходят в интернет, чтобы посмотреть Смешариков. Что касается нашей площадки, то для нее были бы приемлемыми изображения сельскохозяйственных товаров (овощи/фрукты, корма для животных, удобрения и т.д). С другой стороны, очевидно, что тематика нашего маркетплейса не подразумевает наличие изображений с различным непотребным или оскорбляющим кого-то контентом.
Для начала мы решили ознакомиться с уже известными решениями задачи и попробовать адаптировать их под нашу площадку. Как правило, многие задачи модерации графического контента сводятся к решению задач класса NSFW, для которых существует датасет в открытом доступе.
Для решения задач NSFW, как правило, используются классификаторы на базе ResNet, которые показывают качество accuracy > 93%.
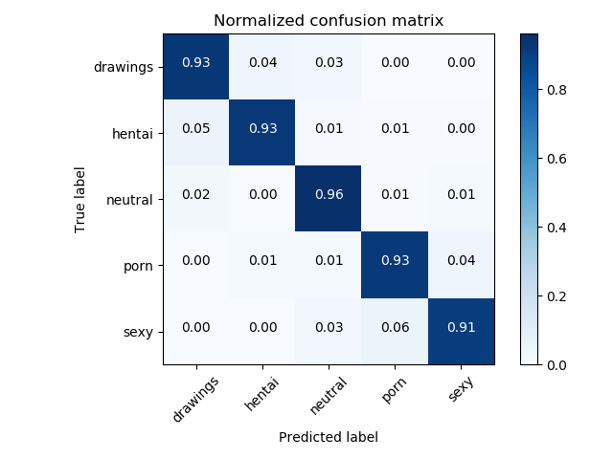
Матрица ошибок исходного NSFW классификатора
Хорошо, допустим у нас есть хорошая модель и уже готовый датасет для NSFW, но будет ли этого достаточно для определения приемлемости изображения для площадки? Оказалось, что нет. Обсудив такой первоначальный подход с моделью NSFW с владельцами нашей площадки, мы поняли, что необходимо определять немного больше категорий, а именно:
То есть, нам все же пришлось составлять свой датасет и думать какие еще модели могли бы быть полезны.
Тут мы сталкиваемся с частой проблемой машинного обучения: нехваткой данных. Она обусловлена тем, что наша площадка создана не так давно, и на ней нет негативных примеров, то есть размеченных, как неприемлемые. Для её решения нам на помощь приходит метод few-shot learning. Суть этого метода в том, что мы можем дообучить, например, ResNet на небольших, собранных нами датасетах, и получить точность выше, чем если бы делали классификатор с нуля и только с использованием нашего небольшого датасета.
Ниже представлена общая схема нашего решения, начиная от входного изображения и заканчивая результатом детектирования различных категорий, в случае подачи на вход изображения яблока.

Общая схема решения
Рассмотрим каждую часть схемы подробнее.
Мы ожидаем, что на наш сайт будут загружать товары с текстом на упаковках и, соответственно, возникает задача детектирования надписей и выявления их значения.
Первым этапом мы с помощью библиотеки OpenCV Text Detection находили надписи на упаковках.
OpenCV Text Detection — это инструмент оптического распознавания символов (OCR) для Python. То есть он распознает и «прочитает» текст, встроенный в изображения.

Пример работы EAST детектора
Пример детектирования надписей вы можете видеть на фото. Для выявления bounding box мы использовали модель EAST, но здесь читатель может почувствовать подвох, так как данная модель обучена на распознавание английских текстов, а на наших изображениях тексты на русском языке. Именно поэтому далее используется модель бинарной классификации (граффити/ не граффити) на базе ResNet, доученная до нужного качества на наших данных. Мы взяли ResNet-18, так как эта модель лучше всего показала себя при подборе архитектуры.
В нашей задаче мы бы хотели отличать фото, где надписи являются надписями на упаковках товаров от граффити. Поэтому решили разделить все фото с текстом на два класса: граффити и не граффити
Полученная точность модели составила 95% на заранее отложенной выборке:
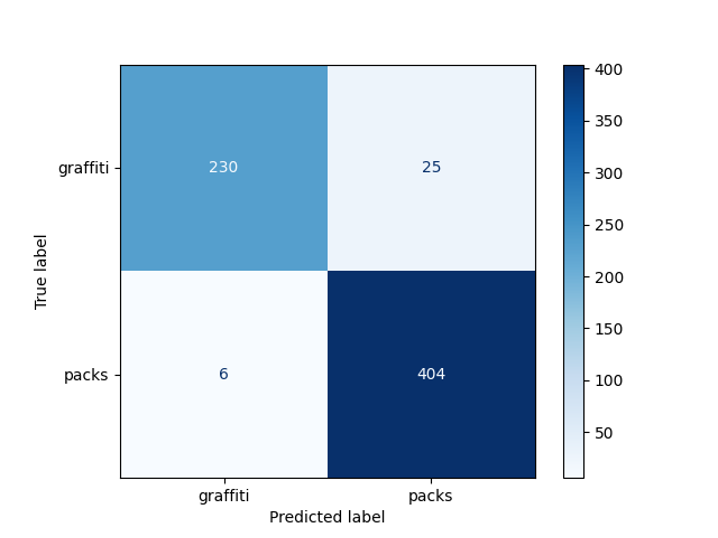
Матрица ошибок детектора граффити
Неплохо! Теперь мы умеем вычленять текст на фото и с хорошей вероятностью понимать подходит ли оно для публикации. Но что делать, если текст на фото отсутствует?
Если на картинке мы не обнаруживаем текст это не значит, что она неприемлема, поэтому дальше мы хотим оценить насколько контент на изображении соответствует тематике сайта.
На этом этапе задача состоит в том, чтобы отнести изображение к одной из категорий:
При этом важно, чтобы модель возвращала не только категорию, но и степень уверенности в ней алгоритмов.
Для классификации использовали модель на базе NSFW. Она обучена так, что разделяет фото на 7 классов и только один из них мы ожидаем увидеть на сайте. Таким образом, мы оставляем только нейтральные фото.
Результат такой модели — 97% (в терминах accuracy)

Матрица ошибок NSFW детектора
Но даже после того, как мы научились фильтровать NSFW, задачу еще нельзя считать решенной. Например, фото человека не попадает ни в категорию с NSFW, ни в категорию фото с текстом, но и на сайте мы подобные изображения не хотели бы видеть. Тогда мы добавили в нашу архитектуру еще и модель детекции человека — Single Shot Detector (далее SSD).
Выделение людей или каких-либо других заранее известных объектов также является популярной задачей с широкой областью применения. Мы использовали готовую модель nvidia_ssd из pytorch.

Пример работы алгоритма SSD
Результаты работы модели ниже (accuracy — 96%):

Матрица ошибок детектора человека
Мы оценивали качество работы нашего инструмента метриками weighted F1, Precision, Recall. Результаты представлены в таблице:
А вот еще несколько наглядных примеров его работы:
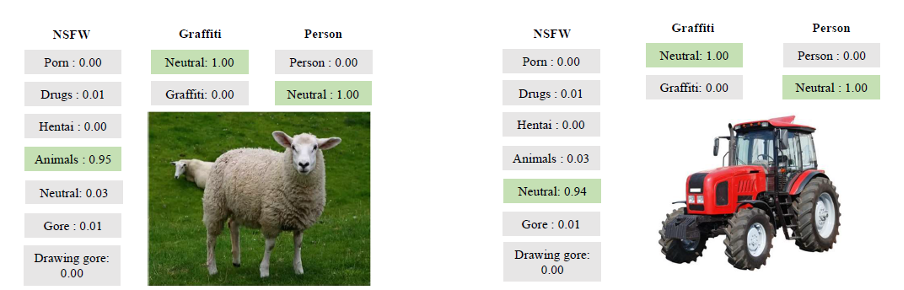
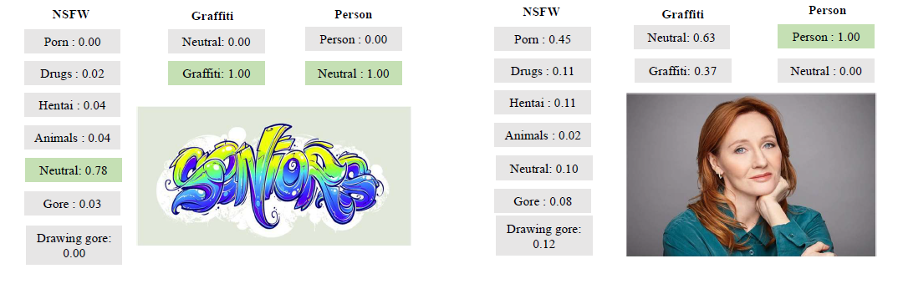
Примеры работы инструмента
В процессе решения мы пользовались целым “зоопарком” моделей, которые часто используются для задач компьютерного зрения. Мы научились “читать” текст с фото, находить людей, различать непозволительный контент.
Напоследок, хочется отметить, что рассмотренная задача полезна с точки зрения получения опыта и применения модифицированных классических моделей. Вот некоторые полученные нами инсайты:
Благодарю за внимание и до встречи в следующей статье!
Мы продолжаем серию статей про модерацию контента на площадках Центра Развития Финансовых Технологий Россельхозбанка. В прошлой статье мы рассказывали, как решали задачу модерации текста для одной из площадок экосистемы для фермеров “Свое Фермерство”. Почитать немного о самой площадке и о том какой результат мы получили можно здесь.
Если коротко, то нами использовался ансамбль из наивного классификатора (фильтр по словарю) и BERT’a. Тексты, прошедшие фильтр по словарю, пропускались на вход в BERT, где они также проходили проверку.
А мы, совместно с Лабораторией МФТИ, продолжаем улучшать нашу площадку, поставив перед собой более сложную задачу премодерации графической информации. Эта задача оказалась сложнее предыдущей, так как при обработке естественного языка можно обойтись и без применения нейросетевых моделей. С изображениями все сложнее — большинство задач решается с помощью нейронных сетей и подбором их правильной архитектуры. Но и с этой задачей, как нам кажется, мы неплохо справились! А что у нас из этого получилось, читайте далее.
Что хотим?
Итак, поехали! Давайте сразу определимся, что из себя должен представлять инструмент модерации изображений. По аналогии с инструментом модерации текста это должен быть некоторого рода “черный ящик”. Подавая ему на вход изображение, загружаемое продавцами товаров на площадку, мы бы хотели понимать, насколько данное изображение приемлемо для публикации на площадке. Таким образом, получаем задачу: определить подходит ли изображение для публикации на сайте или нет.
Задача премодерации изображений является распространенной, но решение зачастую отличается в зависимости от площадок. Так, изображения внутренних органов могут быть приемлемыми для медицинских форумов, но не подходить для соцсетей. Или, к примеру, изображения разделанных тушек животных допустимо на сайте, где их продают, но вряд ли понравится детям, которые заходят в интернет, чтобы посмотреть Смешариков. Что касается нашей площадки, то для нее были бы приемлемыми изображения сельскохозяйственных товаров (овощи/фрукты, корма для животных, удобрения и т.д). С другой стороны, очевидно, что тематика нашего маркетплейса не подразумевает наличие изображений с различным непотребным или оскорбляющим кого-то контентом.
Для начала мы решили ознакомиться с уже известными решениями задачи и попробовать адаптировать их под нашу площадку. Как правило, многие задачи модерации графического контента сводятся к решению задач класса NSFW, для которых существует датасет в открытом доступе.
Для решения задач NSFW, как правило, используются классификаторы на базе ResNet, которые показывают качество accuracy > 93%.
Матрица ошибок исходного NSFW классификатора
Хорошо, допустим у нас есть хорошая модель и уже готовый датасет для NSFW, но будет ли этого достаточно для определения приемлемости изображения для площадки? Оказалось, что нет. Обсудив такой первоначальный подход с моделью NSFW с владельцами нашей площадки, мы поняли, что необходимо определять немного больше категорий, а именно:
- людей (изображения с людьми мы не хотим видеть, так как они не соответствуют целям платформы)
- животных (нельзя пропускать мертвых животных, а, к примеру, от спящих их отличить весьма проблематично. Поэтому такие фото мы хотим отправлять дальше на ручную модерацию)
- а также корректно работать с надписями на изображениях (различные неприемлемые надписи нам также ни к чему)
То есть, нам все же пришлось составлять свой датасет и думать какие еще модели могли бы быть полезны.
Тут мы сталкиваемся с частой проблемой машинного обучения: нехваткой данных. Она обусловлена тем, что наша площадка создана не так давно, и на ней нет негативных примеров, то есть размеченных, как неприемлемые. Для её решения нам на помощь приходит метод few-shot learning. Суть этого метода в том, что мы можем дообучить, например, ResNet на небольших, собранных нами датасетах, и получить точность выше, чем если бы делали классификатор с нуля и только с использованием нашего небольшого датасета.
Как делали?
Ниже представлена общая схема нашего решения, начиная от входного изображения и заканчивая результатом детектирования различных категорий, в случае подачи на вход изображения яблока.
Общая схема решения
Рассмотрим каждую часть схемы подробнее.
1 этап: Graffiti detector
Мы ожидаем, что на наш сайт будут загружать товары с текстом на упаковках и, соответственно, возникает задача детектирования надписей и выявления их значения.
Первым этапом мы с помощью библиотеки OpenCV Text Detection находили надписи на упаковках.
OpenCV Text Detection — это инструмент оптического распознавания символов (OCR) для Python. То есть он распознает и «прочитает» текст, встроенный в изображения.
Пример работы EAST детектора
Пример детектирования надписей вы можете видеть на фото. Для выявления bounding box мы использовали модель EAST, но здесь читатель может почувствовать подвох, так как данная модель обучена на распознавание английских текстов, а на наших изображениях тексты на русском языке. Именно поэтому далее используется модель бинарной классификации (граффити/ не граффити) на базе ResNet, доученная до нужного качества на наших данных. Мы взяли ResNet-18, так как эта модель лучше всего показала себя при подборе архитектуры.
В нашей задаче мы бы хотели отличать фото, где надписи являются надписями на упаковках товаров от граффити. Поэтому решили разделить все фото с текстом на два класса: граффити и не граффити
Полученная точность модели составила 95% на заранее отложенной выборке:
Матрица ошибок детектора граффити
Неплохо! Теперь мы умеем вычленять текст на фото и с хорошей вероятностью понимать подходит ли оно для публикации. Но что делать, если текст на фото отсутствует?
2 этап: NSFW detector
Если на картинке мы не обнаруживаем текст это не значит, что она неприемлема, поэтому дальше мы хотим оценить насколько контент на изображении соответствует тематике сайта.
На этом этапе задача состоит в том, чтобы отнести изображение к одной из категорий:
- наркотики (drugs)
- порно (porn)
- животные (animals)
- фото, способные вызвать отторжение (в том числе и рисунки) (gore/drawing_gore)
- хентай (hentai)
- нейтральные изображения (neutral)
При этом важно, чтобы модель возвращала не только категорию, но и степень уверенности в ней алгоритмов.
Для классификации использовали модель на базе NSFW. Она обучена так, что разделяет фото на 7 классов и только один из них мы ожидаем увидеть на сайте. Таким образом, мы оставляем только нейтральные фото.
Результат такой модели — 97% (в терминах accuracy)
Матрица ошибок NSFW детектора
3 этап: Person detector
Но даже после того, как мы научились фильтровать NSFW, задачу еще нельзя считать решенной. Например, фото человека не попадает ни в категорию с NSFW, ни в категорию фото с текстом, но и на сайте мы подобные изображения не хотели бы видеть. Тогда мы добавили в нашу архитектуру еще и модель детекции человека — Single Shot Detector (далее SSD).
Выделение людей или каких-либо других заранее известных объектов также является популярной задачей с широкой областью применения. Мы использовали готовую модель nvidia_ssd из pytorch.
Пример работы алгоритма SSD
Результаты работы модели ниже (accuracy — 96%):
Матрица ошибок детектора человека
Результаты
Мы оценивали качество работы нашего инструмента метриками weighted F1, Precision, Recall. Результаты представлены в таблице:
| Метрика | Полученная точность |
| Weighted F1 | 0.96 |
| Weighted Precision | 0.96 |
| Weighted Recall | 0.96 |
А вот еще несколько наглядных примеров его работы:
Примеры работы инструмента
Заключение
В процессе решения мы пользовались целым “зоопарком” моделей, которые часто используются для задач компьютерного зрения. Мы научились “читать” текст с фото, находить людей, различать непозволительный контент.
Напоследок, хочется отметить, что рассмотренная задача полезна с точки зрения получения опыта и применения модифицированных классических моделей. Вот некоторые полученные нами инсайты:
- Можно обходить проблему нехватки данных с помощью метода few-shot learning: большие модели можно доучить до необходимой точности на собственных данных
- Не нужно стесняться добавлять ручную модерацию: чтобы отличить мертвое животное от спящего необходимы очень сложные модели, которые вряд ли оправдают потраченное на них время
- Хорошей практикой является использование качественных моделей, обученных на больших датасетах, которые помогут закрыть хотя бы часть потребностей
- Решать задачи с изображениями становится в разы проще, если удается вычленить из них текст, а значит примерно понимать к какой категории оно относится. Это довольно удобно для сайтов различных магазинов, так как по тексту и фону упаковки, как правило, можно быстро понять является ли товар допустимым или нет
- Несмотря на то, что задача модерации изображений довольно популярная, ее решение, как и в случае с текстами, может отличаться от площадки к площадке, так как каждая из них рассчитана на разную аудиторию. В нашем случае, к примеру, мы, дополнительно к неприемлемому контенту, детектировали еще животных и людей
Благодарю за внимание и до встречи в следующей статье!
Dydjayz
В целом, ничего нового и интересного не изложено, но спасибо, что довольно понятно все написано