
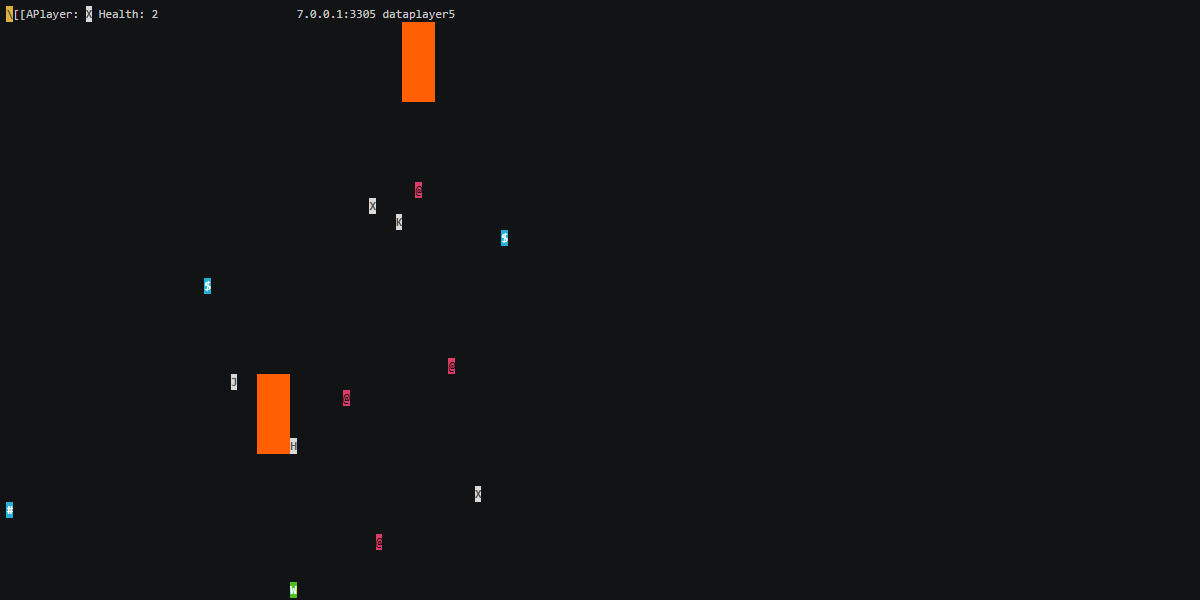
В качестве примера мастер-мастер кластера Tarantool я предлагаю сделать небольшую текстовую мультиплеер-игру, где каждый участник стремится набрать большее число очков.
Каждый игрок будет некоторым узлом, который меняет данные в игровом мире. Эти данные реплицируются между узлами. Таким образом, репликация Tarantool будет являться своего рода транспортом для игрового процесса.
Но что будет, если два игрока одновременно создадут или поменяют какой-то объект в мире и создадут соответствующие транзакции? Если этого не предусмотреть, то, или данные на разных узлах «разъедутся», и у каждого игрока сложится своя картина мира, или репликация «сломается», и, как следствие, игровой процесс остановится. Есть разные способы решения таких конфликтов. Я выбрал схему данных и распределил операции над данными по узлам так, чтобы конфликтов в кластере не возникало. Чуть позже я объясню это подробнее.
Игра будет с ascii-графикой, и такое отображение репликации позволяет сразу видеть картину происходящего на каждом инстансе, не требуя дополнительных запросов к данным.
Кроме этого, перезапуская узлы, можно будет визуально проследить процесс запуска базы, загрузки данных, подключения репликации.
Геймплей
Игра чем-то похожа на bomberman. Игровое поле 80x40. Каждый игрок управляет своим персонажем. Игроки должны собирать фрукты, которые добавляют жизней. Порции жизней можно потратить на создание бомб. Бомбы взрываются и небольшой волной забирают жизни тех, кто оказался рядом.
Как запустить
Установить Tarantool 2-ой версии по инструкции.
Взять исходники игры:
$ git clone https://github.com/filonenko-mikhail/mmgame.git
$ cd mmgame- Запустить координатора геймплея:
- В аргументе адрес, на котором запустится координатор.
$ reset && clear $ tarantool ./foodmaker.lua 127.0.0.1:3301
- В аргументе адрес, на котором запустится координатор.
- Запустить первого игрока в отдельном терминале:
- Первый аргумент — адрес координатора;
- Второй — адрес, на котором запустить игрока;
- Третий — рабочая директория.
$ reset && clear $ tarantool ./player.lua 127.0.0.1:3301 127.0.0.1:3302 ./player1data
- Стрелками можно управлять черной буквой на сером фоне и собирать символы на синем фоне. Первая строку вверху экрана отображает:
- Анимацию, что репликация с координатором работает;
- Персонажа игрока и его жизни.
- Игрок 2 в другом отдельном терминале:
$ reset
$ tarantool ./player.lua 127.0.0.1:3301 127.0.0.1:3303 ./player2data- Пробелом устанавливаем бомбы — красный символ на черном фоне.
Troubleshooting
Если что-то случилось во время запуска, я подготовил небольшой список ситуаций и решений.
Эти рекомендации применимы только к этой игре, в случае проблемных ситуаций на проде, я, конечно же, рекомендую более детальное исследование ситуации.
Консоль сломалась так, что ничего не видно
reset<Enter> не глядя
ER_REPLICASET_UUID_MISMATCH: Replica set UUID mismatch: expected 4f8d5028-3f4e-4f8f-a237-bb3db620813f, got 03982784-c023-4661-afe1-96752d90df86
- Кластер создавался непоследовательно, и в итоге скорее всего кластеров получилось несколько, и реплика не может найти себе место
- Удалить снапы и логи и перезапустить
ER_UNKNOWN_REPLICA: Replica 904c70b2-be5a-4e5f-afd0-daa0be66f729 is not registered with replica set d4f37bc6-3a71-43a2-8ca5-65e2bcc0bfda
- Кластер пересоздавался, а реплика пытается присоединиться со старыми настройками
- Удалить снапы и логи и перезапустить
Если у вас ошибка не такая как из списка, или вы делаете что-то ещё и возникают вопросы, то у нас есть русскоязычный чат в телеграме.
Как это выглядит
Игровой «спейс»
Все объекты игры будут содержаться в одном спейсе (таблице), который будет реплицироваться между узлами.
Вот как она будет выглядеть:
| ID | Icon | X | Y | Type | Health |
|---|---|---|---|---|---|
| uuid | symbol | int | int | string | int |
Первичным ключом будет является поле ID. Для каждого объекта в том числе персонажей это поле будет уникальным.
Icon содержит текстовый спрайт объекта.
X, Y содержит текущие координаты объекта.
Type тип объекта:
- игрок;
- фрукты;
- бомба;
- огонь после бомбы;
- поезд;
- бесконечный прогрессбар.
Health жизни объекта:
- для игрока это жизни;
- для других объектов это энергетическая ценность.
Все действия над объектами будут производится с помощью обновления соответствующих полей.
Индексация
Индексов на спейсе будет несколько:
- первичный ключ, конечно же:
{ID}; - позиция объекта для вычисления столкновений:
{x, y, type}; - тип объекта для быстрого подсчета и итерации по разным объектам:
{type}; - жизни для наблюдения статистики:
{health}.
Бесконфликтность транзакций и консистентность данных
Конфликт транзакций возникает в случае, когда два узла тарантула вставляют новые данные по одному и тому же уникальному ключу. В этому случае репликация останавливается.
Для таких случаев тарантул позволяет написать некоторую логику, которая в случае конфликтов будет выбирать из двух транзакций одну, а другую отбрасывать.
Но в рамках моей задачи, мне показалось это избыточным, и я распределил создание объектов так, что любой узел создавая игровые объекты генерировал для них уникальный для всего кластера ключ. Я воспользовался генерацией uuid.
Теперь представим, что свойство одного игрового объекта меняется на двух узлах одновременно. Первый узел назначит свойство в значение X, второй узел — в значение Y. Во время репликации первый узел получит транзакцию со значением Y и применит её у себя, а второй узел — со значением X, и тоже применит её у себя. В результате данные «разъедутся». Чтобы такого не происходило, я воспользовался аддитивными операциями. В этом случае, в какой бы последовательности не применялись транзакции, результат окажется одинаковым.
Например:
- Некорретный вариант, присвоить десять жизней игроку.
- Корректный, добавить некоторое число к жизням чтобы получилось десять.
Или, другими словами, операция присваивания значения неаддитивна, а операции сложения и вычитания аддитивны.
Топология
В топологии игры будет один узел-координатор, ответственный за геймплей, и некоторое количество узлов игроков. Максимальное количество активных реплик может достигать 32, это ограничение репликации Tarantool. Узлы, которые работают только на чтение, называются анонимными репликами, и их может быть сколько угодно.
Репликасет в Tarantool — это группа серверов, которые реплицируют данные между собой. У каждого узла есть свой уникальный идентификатор instance uuid. И одновременно с этим у узлов репликасета есть одинаковое для всех поле replicaset uuid.
Чтобы все эти идентификаторы узлов правильно сошлись, создавать репликасет лучше последовательно.
Я предлагаю сначала запустить координатор, который выполнит все первоначальные настройки, и затем к нему подключать игроков. Их можно будет подключать как одновременно, так и последовательно.
Вот как это будет выглядеть:
- Запускается
foodmaker(координатор) и создаетcluster uuid.

- Далее к нему подключается игрок, который настраивает свою репликацию. Стрелкой показан поток данных репликации.

- После успешного подключения игрок настраивает репликацию в обратную сторону.

- После подключения нескольких игроков получится топология «звезда».

Топология full-mesh также возможна, но потребует дополнительных действий. Если вы хотите её построить, то можете на координаторе мониторить топологию и рассылать всем игрокам изменения, и игроки будут у себя настраивать репликацию на других игроков.
Программирование на Tarantool
Tarantool, с одной стороны, это база данных с возможностью репликации, а с другой — полноценный сервер приложений.
Для создания приложений в Tarantool используется язык Lua с JIT-компиляцией.
Сама база данных также конфигурируется с помощью Lua.
Таким образом вы можете управлять базой данных изнутри с помощью Lua-скриптов. И если вам понравилась такая идея, то в реальных проектах я рекомендую пользоваться готовым решением для оркестрации кластера – Tarantool Cartridge.Конфигурирование координатора
Основное конфигурирование базы данных происходит с помощью функции box.cfg. На координаторе функция должна будет сделать первоначальную настройку репликасета.
Для настройки репликации используются параметры:
replicationreplication_connect_quorumreplication_connect_timeout
В случае координатора я точно знаю, что кворум не нужен, так как это самые первый инстанс, который логически не нуждается в остальных. Соответственно, параметры примут значения:
box.cfg{
listen=server,
replication_connect_quorum=0,
replication_connect_timeout=0.1,
work_dir=wrkdir,
log="file:foodmaker.log",
}Конфигурирование игрока
Конфигурирование игрока заключается в том, чтобы прежде всего подключиться к координатору с репликацией, а затем настроить обратную репликацию с игрока на координатор.
box.cfg{
listen=localserver,
replication={ remoteserver },
replication_connect_timeout=60,
replication_connect_quorum=1,
work_dir=wrkdir,
log="file:player.log"
}Подключение репликации от координатора к игроку
Координатор, с одной стороны, знает о том, кто к нему подключен по репликации, но, с другой стороны, не знает, как ему самому подключиться к новому игроку.
Я решил это следующим образом:
Координатор создает функцию
add_player.
Игрок удаленно вызывает эту функцию на координаторе со своим адресом.
В случае перезагрузки координатора игрок перенастраивает репликацию, когда тот вернется.
Функция на координаторе выглядит так:
function add_player(server) if box.session.peer() == nil then return false end local server = uri.parse(server) local replica = uri.parse(box.session.peer()) replica.service = server.service replica.login = conf.user replica.password = conf.password replica = uri.format(replica, {include_password=true}) local replication = box.cfg.replication or {} local found = false for _, it in ipairs(replication) do if it == replica then found = true break end end if not found then table.insert(replication, replica) box.cfg({replication={}}) box.cfg({replication=replication}) end return true end
Игрок сохраняет соединение в глобальном неймспейсе, чтобы его не остановил сборщик мусора.
_G.conn = netbox.connect(remoteserver, {wait_connected=false, reconnect_after=2}) conn:on_connect(function(client) fiber.new(function () local rc, res = pcall(client.call, client, 'add_player', {localserver}) if not rc then log.info(res) end end) end)
Схема данных
Схема данных задается на координаторе сразу после конфигурирования базы данных. Она может создаваться только на одном узле, остальные получают её по репликации.
В процессе разработки я постоянно перезапускал и дорабатывал детали на уже инициализированной базе. Чтобы повторное применение схемы данных не вызывало ошибки, я пользовался флагом if_not_exists=true. Он позволяет игнорировать DDL-команды, когда спейсы, индексы и другие объекты уже существуют.
Data Definition Language
Краткий обзор DDL-операций, которые я использую:
- Создание спейса.
box.schema.space.create(<name>, options) - Формирование структуры спейса.
box.space.<name>:format( {{name=<field_name>, type=<field_type>}, ..., }) - Создание индекса.
box.space.<name>:create_index(<index_name>, { parts={{field=<field_name> type=<field_type>}, ..., }, unique=false|true, }) - Создания пользователя.
box.schema.user.create(<name>, {password=<pass>}) - Предоставление прав.
box.schema.user.grant(<name>, ....) - Создание функции для удаленного вызова.
box.schema.func.create(<name>)
Ожидание схемы данных
Часть логики приложения может быть запущена до инициализации базы данных. В этом случае я использую цикл, ожидающий появления таблицы в БД.
while true do
if type(box.cfg) ~= 'function'
and box.space[conf.space_name] ~= nil
and not box.info.ro then
break
end
fiber.sleep(0.1)
endТриггеры в Tarantool
Триггеры в Tarantool являются частью сервера приложений и не сохраняются в базе данных.
Чтобы создать триггер, я:
- Создаю функцию на lua, которая обрабатывает логику.
- При запуске приложения устанавливаю функцию на нужные спейсы в качестве триггера.
Инициализация базы данных — процесс из нескольких стадий, поэтому установка триггера, на первый взгляд, может показаться сложной. На второй взгляд — скорее всего, тоже :)
Итак, чтобы установить триггер в спейс, предлагается такая схема:
- Установить триггер в инициализацию системной схемы базы данных.
box.ctl.on_schema_init(<CALLBACK>) - В триггере инициализации схемы установить триггер на реестр спейсов.
box.ctl_on_schema_init(function() box.space._space:on_replace(<CALLBACK 2>) end) - В триггере реестра спейсов обнаружить искомый пользовательский спейс и создать триггер завершения транзакции.
box.ctl.on_schema_init(function() box.space._space:on_replace(function(old, space) if not old and sp and sp.name == <USER SPACE NAME> then box.on_commit(<CALLBACK 3>) end end) end) - И вот, наконец, у меня в руках игла Кощея
^W^W— то место, где я устанавливаю пользовательский триггер в пользовательский спейс.
box.ctl.on_schema_init(function() box.space._space:on_replace(function(old, sp) if not old and sp and sp.name == <USER SPACE NAME> then box.on_commit(function() box.space[sp.name]:on_replace(<USER TRIGGER>) end) end end) end)
Логика
Часть логики запускается на координаторе, часть — на узлах игроков.
Запуск логики происходит либо в отдельном файбере, либо из триггера.
Файберы — легковесные потоки исполнения (сопрограмма, зеленый тред, корутина, горутина). Они используют кооперативную многозадачность. То есть, в один момент времени запущен только один файбер. Когда он выполнил свою логику, то должен явно отдать управление через fiber.sleep(N) или fiber.yield(), либо вызвав некоторую io-операцию.
Вся логика выполняется с помощью изменения данных в спейсе.
Data Modification Language
Вставка данных
-- вставка
box.space.Name.insert({id, sprite, x, y, type, health})
-- вставка или полная перезапись
box.space.Name.put({id, sprite, x, y, type, health})Обновление данных
box.space.Name.update({primary key}, {{operation, field, value}})Удаление
box.space.Name.delete({primary key})Игрок
Узел игрока при первом запуске создаёт своего персонажа. ID персонажа применяется из значения instance uuid.
Далее узел игрока слушает события клавиатуры и меняет позицию персонажа.
Чтобы события от клавиатуры приходили как есть, я использую функции tcgetattr и tcsetattr через LuaJIT FFI.
Для создания транзакции с несколькими действиями я пользуюсь паттерном.
box.begin()
local rc, res, err = pcall(function()
...
box.space[conf.space_name]:put(bomb)
box.space[conf.space_name]:update(player['id'],
{{'-', conf.health_field, conf.bomb_energy}})
end)
if not rc then
log.info(res)
box.rollback()
else
box.commit()
endДля обработки событий клавиатуры запущен отдельный файбер.
Рендерер
Рендерер отображает любые графически значимые изменения в текстовую консоль. Он запускается из триггера как на узлах игроков, так и на координаторе. На узлах игроков рендерер также отображает информацию о жизнях.
Генератор продуктов
Генератор продуктов запускается на координаторе и раз в N секунд создает объект.
Генератор продуктов работает в отдельном файбере.
Анимация поезда
Чтобы быстро увидеть, идет ли репликация от координатора к игроку, необходим цикл, который создает анимацию поезда и бесконечного индикатора прогресса. Цикл запускается на координаторе в отдельном файбере.
Обработка столкновений
Обработка столкновений состоит из двух частей: «детектора» и «обработчика».
«Детектор» запускается из триггера в случае, когда произошли значимые для этого изменения. Например, позиция игрока поменялась, сгенерировался новый фрукт и т.п.
«Детектор» через межфайберный канал отправляет «обработчику» информацию о столкнувшихся объектах.
«Обработчик» запускается на координаторе в отдельном файбере, в цикле читает сообщения из канала, и, в зависмости от столкновений объектов, меняет значения в полях с жизнями.
Жизненный цикл бомб
На координаторе запущен файбер, который раз в секунду прокручивает жизненный цикл бомбы.
- Отнимает от существования единицу.
- При достижении 0 удаляет бомбу и создаёт ударную волну.
Этот файбер таким же образом следит за ударной волной.
Ветер
Чтобы игровой процесс чуть больше мотивировал двигаться, на координаторе запущен файбер, который сдувает всех игроков в правый нижний угол.
Таблица игроков
Я предлагаю самый простой путь для создания таблицы игроков, а именно — сделать анонимную реплику. Она будет подключена к координатору и станет в триггере отображать список игроков с сортировкой начиная с лидеров.
Для подключения анонимной реплики предназначен параметр replication_anon.
box.cfg{listen=localserver,
replication={ remoteserver },
replication_connect_timeout=60,
replication_connect_quorum=1,
read_only=true,
replication_anon=true,
work_dir=wrkdir}В заключение
Вот так с помощью нехитрых приспособлений буханку хлеба можно превратить в троллейбус
Таким приложением я хочу:
- Подчеркнуть, как просто создать топологию «мастер-мастер» в Tarantool.
- Визуализировать процесс репликации.
- Показать, что происходит в моменты перезапуска реплик.
- Напомнить, что терминал содержит в себе много интересного.
Если вам хотелось бы рассмотреть более практичное приложение на Tarantool, то есть отличная статья от codesign про создание очереди.


maxim_ge
Можно сразу вопрос — если ставить таким образом на сервера, где по 16 vCPU, будут ли они все задействованы?
Мы как-то экспериментировали, и загружался только один из vCPU.
michael-filonenko Автор
Да, тарантул условно говоря однопоточный. Запросы обрабатываются в файберах (корутинах), которые поочередно запускаются на одном железном треде.
Почему «условно говоря» — потому что внтури тарантула есть еще два служебных железных треда для io операций.
Таким образом мы рекомендуем на каждые полтора ядра запускать один тарантул.
Чтобы расшардить данные на все эти инстансы, у нас есть фреймворк бакетного шардирования — https://github.com/tarantool/vshard
andreyverbin
А как синхронная репликация дружит с однопоточностью и с транзакциями?
kritikanstvo
Разве у Тарантула синхронная репликация?
С однопоточностью и транзакциями идея в том, что Tarantool изначально очень быстрая СУБД in-memory и транзакция отрабатывает моментально, освобождая СУБД для следующего запроса. Плюс там еще бизнес-логика внутри СУБД живет, что позволяет транзакциям еще быстрее отрабатывать.
По утверждению разработчиков — именно один поток и позволяет проводить операции настолько быстро, что позволяет обойтись без блокировок, которыми вынуждены пользоваться другие СУБД.
andreyverbin
Без синхронной репликации наступает печалька с возможной потерей данных. Тут я об этом беседую с людьми из тарантула — habr.com/ru/company/rebrainme/blog/521556/#comment_22146644
Там все было примерно так
1. Запись в WAL асинхронная, транзакция может закомититься, а данные на диск не приедут. Это делает тарантул таким быстрым на запись по сравнению с тем же PG. Синхронная запись в WAL возможна и даст надежность, но это больно для однопоточной архитектуры и все будет очень медленно.
2. Мне отвечают — реплицируйте и будем вам счастье. Нормальный и известный подход — вместо записи в WAL пишем в N реплик и надеемся, что они не упадут вместе с мастером.
3. Я выясняю, что мастер данные не пушит в реплики, а реплика их забирает с мастера раз в какое-то время — это называется асинхронная репликация. Возникает вопрос — сервер упадет, реплика данные не забрала — будет печалька.
4. Мне советуют использовать синхронную репликацию, которую завезли в какой-то версии тарантула.
5. Я прошу объяснить как это будет работать в однопоточной архитектуре. Но ответа не получаю.
Поэтому буду ходить по тредам с тарантулом и спрашивать :) Вот такой я тролль.
kritikanstvo
Разве асинхронная?
В свое время разработчики Тарантула как раз хвастали, что успевают данные записывать на диск.
Скорость записи на современные диски — довольно велика. А с учетом того, что Тарантул пишет не полностью данные, а только изменения — может быть и быстрее сетевых запросов на изменение данных.
andreyverbin
Да, асинхронная, можете в исходник посмотреть. Тарантул пишет с помощью write в файл без O_DIRECT или O_SYNC, а значит данные лягут в буфер ОС, а на диск отправятся когда-то потом. Есть опция это поведение отключить, но это убьёт скорость.
Вы можете удивиться, но без буферизации на десктоп SSD можно получить 2-3 Мб/с, на серверном 20-30 Мб/с. Но дело даже не в этом — если писать WAL «честно», то скорость на вставку/обновление будет не выше чем у того-же PG. Возможно разница и будет, но не принципиальная.
Изменения пишут все известные мне БД, это не то чтобы фишка тарантула.
kritikanstvo
При переполненном диске, когда TRIM отключен и удаление не успевает до записи? Зачем на сервере в таком режиме эксплуатировать диск?
А в нормальном режиме эксплуатации даже при отключенном кэше записи даже на десктопе — цифры на порядок выше, чем те, что привели вы. Как бы даже не на 2 порядка.
andreyverbin
Чувствую скепсис, попробую развеять.
Все быстро пока вы можете загрузить pipeline диска. И все очень медленно как только вы пишите по 100 байт и каждый раз ждёте подтверждения записи. Второй режим характерен для БД, которая пишет в WAL результаты небольших транзакций. Аналогичная штука с сетью происходит. Вот тут можете посмотреть результаты теста дисков — https://m.habr.com/ru/company/selectel/blog/521168/ аналогичных тестов навалом в сети. В тесте по ссылке десктоп как раз даёт 3 Мб/с на запись.
maxim_ge
Это влияет на скорость если у БД только одно соединение с одним клиентом. Когда есть поток запросов, можно в WAL писать относительно большими пачками (batching).
kritikanstvo
Безусловно.
Но Tarantool однопоточный (это принципиальное решение разработчиков, так по их мнению получается существенно быстрее) и с пачками клиентов там всё непросто.
Хочется надеяться, что разрабатывая систему под highload разработчики всё это учли. Но как именно учли?
Если их решение — это шардинг на 100 000 экземпляров Тарантула запросов 100 000 пользователей, но при этом каждый экземпляр из за однопоточности обрабатывает только 1 запрос при этом — тогда такое решение очень нишевым получается.
maxim_ge
Непросто, если на одно клиентское соединение приходится один CPU. Но это какая-то экзотика, а "в среднем" не должно быть проблем с собиранием пачек для записи в WAL.
andreyverbin
Не совсем так. После того как клиент получил сообщение о завершении транзакции должно быть одно из двух — либо его данные записаны на диск, либо его данные подтверждены N репликами. Поэтому если писать в WAL пачками, то нужно будет и ответы о завершении транзакции тоже отдавать пачками, после того как данные попали в WAL. Это может негативно скажется на транзакциях которые были вначале пачки, они будут ждать завершения других транзакций. Чем больше вы делаете размер пачки тем лучше для диска, но тем дольше ждет тот, кто оказался вначале пачки.
maxim_ge
Естественно, мы размениваем latency на throughput. Конкретные пропорции этого размена сильно зависят от конфигурации теста, на каком-то этапе производительность растет быстро (если собираемые в пачки запросы невелики по размеру), а задержка практически не меняется.
kritikanstvo
В реальности в подобных системах есть 2 параметра:
Размер буфера, по достижению которого производится сброс на диск.
И таймаут, по достижению которого производится сброс на диск даже если в буфере всего лишь одна транзакция.
kritikanstvo
Там вы еще вот что интересное пишете:
Есть еще разрушение файловой системы, которое зеркально отразиться на всех зеркалирующих дисках RAID.
Нет, RAID недостаточно…
msiomkin
Все правильно. А еще есть такой сюрприз: диск сказал операционке OK, но в реальности это сообщение оказалось несколько преувеличено…
https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration
michael-filonenko Автор
Если мы переходим к разговору о синхронной репликации, то сейчас состоялся релиз
Tarantool, в котором реализована эта синхронная репликация наряду сmvcc. Или если быть точнее — с помощью.https://github.com/tarantool/tarantool/releases/tag/2.6.1
andreyverbin
Вопрос немного не об этом. Будет ли тарантул ждать пока данные уйдут на синхронную реплику прежде чем начинать следующую транзакцию? Если ждёт, то как это сказывается на производительности. Если не ждёт, то есть ли вероятность потерять данные или даже разломаться кластер если мастер упал?
michael-filonenko Автор
Да. Производительность будет зависеть от настроек
replication_synchro_quorum,replication_synchro_timeoutи железа.kritikanstvo
Тарантул принципиально однопоточный.
Разработчики говорят, что за счет того, что они даже не заморачивались блокировками внутри, то работает быстрее, чем на несколько потоков, мол проверяли.
А, говорят, если нужно задействовать все ядра — просто запускайте несколько Тарантулов. И делайте шардинг или еще как делите между ними данные.