
Любое ПО содержит уязвимости, причем они появляются на разных этапах его жизненного цикла. Полностью избавиться от уязвимостей в коде достаточно сложно, но можно, как минимум, сократить их количество. Для этого используются средства SAST, DAST и IAST – статический, динамический и интерактивный методы анализа соответственно. Эти средства можно гибко интегрировать в процесс разработки, тем самым повысив качество собственного кода. Дела обстоят сложнее со сторонним программным обеспечением, так как исправлять уязвимости в заимствованных библиотеках/фреймворках сложно и трудозатратно. Библиотеки могут быть без исходного кода, в компании может отсутствовать специалист, который готов такие исправления вносить. Да и в целом стоит задуматься о целесообразности исправлений, поскольку библиотека все-таки должна обновляться и поддерживаться командой, которая ее выпускает. Но что делать, если эта команда ленится, а использовать библиотеку надо, чтобы приложение работало? Тут пригодятся средства анализа состава программного обеспечения – SCA. Разберемся, какие SCA-инструменты существуют, как они помогают устранять уязвимости в заимствованных частях кода, и почему их имеет смысл использовать вместе с SAST.

Что представляет собой SCA как процесс? На вход подается исходный код приложения или в некоторых случаях исполняемый, после чего SCA определяет, какие сторонние библиотеки используются в приложении. В дальнейшем эта информация применяется для определения уязвимостей в приложении, а также может пригодиться для проверки лицензионной чистоты библиотеки. Есть различные способы определения используемых библиотек/фреймворков:
Источники информации будут варьироваться в зависимости от рисков, которые анализируются с помощью SCA. Их можно поделить на три типа:
В нашем случае речь идет о рисках безопасности, для работы с которыми в качестве источников информации используются базы данных уязвимостей. Ниже приведу пару примеров таких баз:
После загрузки проекта, например, git репозитория, происходит анализ его компонентов. Следует отметить, что для каждого языка программирования могут быть свои требования для проведения анализа. Например, для Java нужно, чтобы проект корректно собирался базовыми командами средства Maven, или же можно передать на анализ уже собранный проект. В первую очередь оценивается безопасность проекта, после чего следует оценка лицензионной чистоты, то есть насколько правомерно используется та или иная сторонняя библиотека. В качестве примера рассмотрим результаты анализа, проведенного с помощью продукта компании WhiteSource, так как представленный им отчёт и его визуализация наиболее наглядно демонстрируют возможности SCA-инструментов.

Этот продукт работает по 3-му способу определения используемых библиотек/фреймворков – определение по хеш-сумме: хеш-сумма библиотеки сопоставляется с различными хеш-суммами из базы данных вендора. Как можно увидеть на скриншотах выше, действительно, SCA средство может найти проблемные библиотеки и подсказать, что же с ними делать. Зачастую достаточно их просто пропатчить до безопасной версии. Но так ли все просто на самом деле?

Есть несколько нюансов:
Это достаточно частые случаи, с которыми необходимо работать. Кроме того, могут появляться проблемы со сборкой какого-то из компонентов системы или корректной настройки SCA-инструмента для получения полных результатов. Но подобные сложности уже не связаны с технологией анализа сторонних компонентов в целом, а скорее с решением конкретного вендора.
Для борьбы с нюансами хорошо подходят средства статического анализа: с их помощью можно проанализировать, например, .jar файл, которого нет в базе, и устранить уязвимости на уровне исходного кода. А если есть исходный код разрабатываемой компоненты, то задача становится еще проще.
Рассмотрим более подробно варианты использования инструментов SAST для решения подобных проблем.
Самый простой вариант, когда исходный код библиотеки есть. В таком случае для анализа кода на уязвимости достаточно лишь загрузить его в статический анализатор в виде архива с кодом.
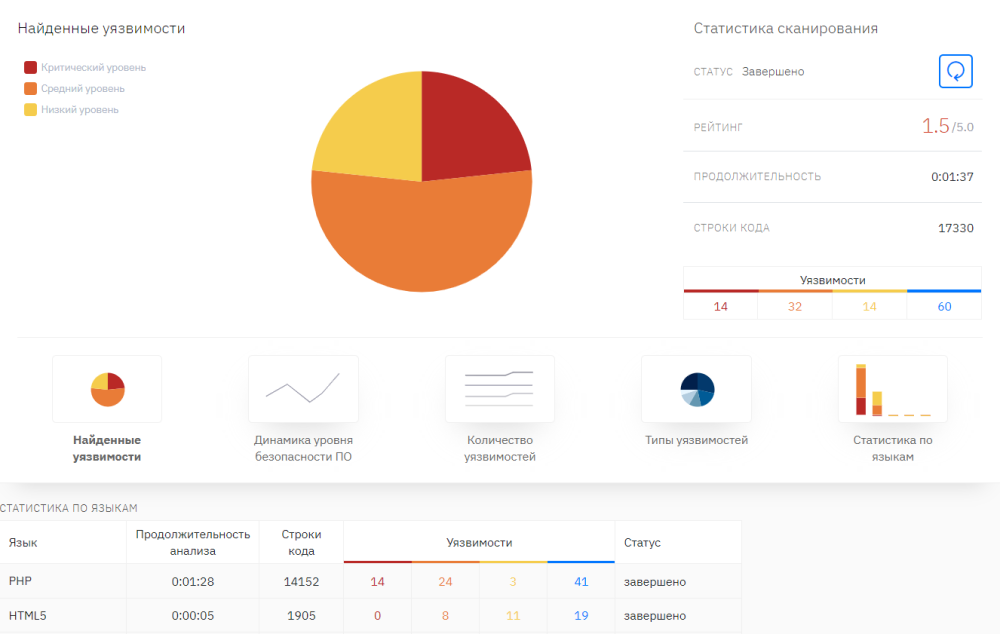
Хорошо, получили результаты работы статического анализатора, что делать дальше? В идеальной ситуации нужно смотреть на все уязвимости и оценивать их реальную критичность в контексте вашего приложения, так как статический анализатор может не до конца понимать логику вашего приложения.
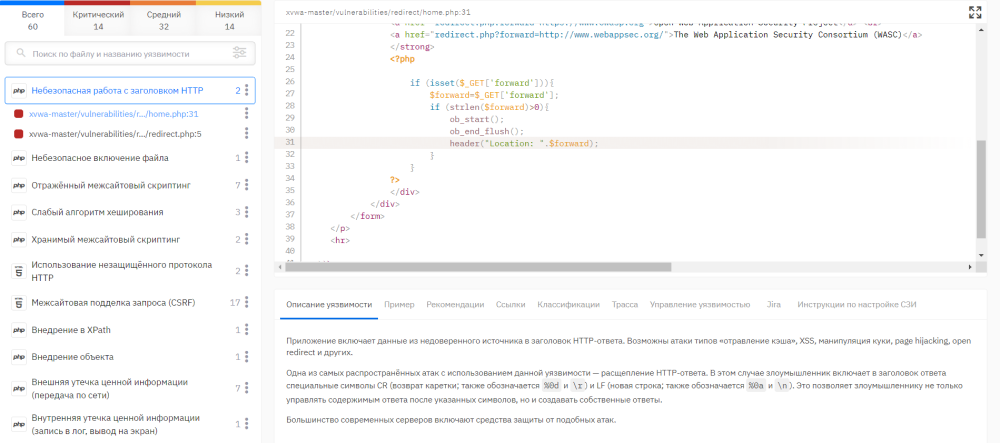
Но если быть реалистами, то переписывать чужую библиотеку, тратя на это много ресурсов (которых и так нет), не хочется. В таком случае рекомендуем постараться закрыть хотя бы критичные уязвимости. Статический анализатор явно показывает, где именно в коде содержится уязвимость, и выдает ее детальное описание с рекомендациями по устранению, что значительно упрощает подобную работу.
Рассмотрим также вариант посложнее, когда есть, например, .jar файл, для которого SCA-средство не смогло найти никакой информации. На самом деле, это достаточно частый случай, когда какая-то из компонент не идентифицируется – такое происходит в 6ти из 10ти сканирований. Как в таком случае убедиться в безопасности использования заимствованной компоненты?
SCA явно показывает, что за файл не удалось проверить – тогда это можно сделать с помощью статического анализатора.
Для специалиста, занимающегося анализом байт-кода, важно отображать уязвимости и НДВ на исходный код. Для этого на завершающем этапе статического бинарного анализа запускается процесс декомпиляции байт-кода в исходный. То есть уязвимости можно демонстрировать на декомпилированном коде. Сразу возникает вопрос – достаточно ли декомпилированного кода для того, чтобы понять и локализовать уязвимость?
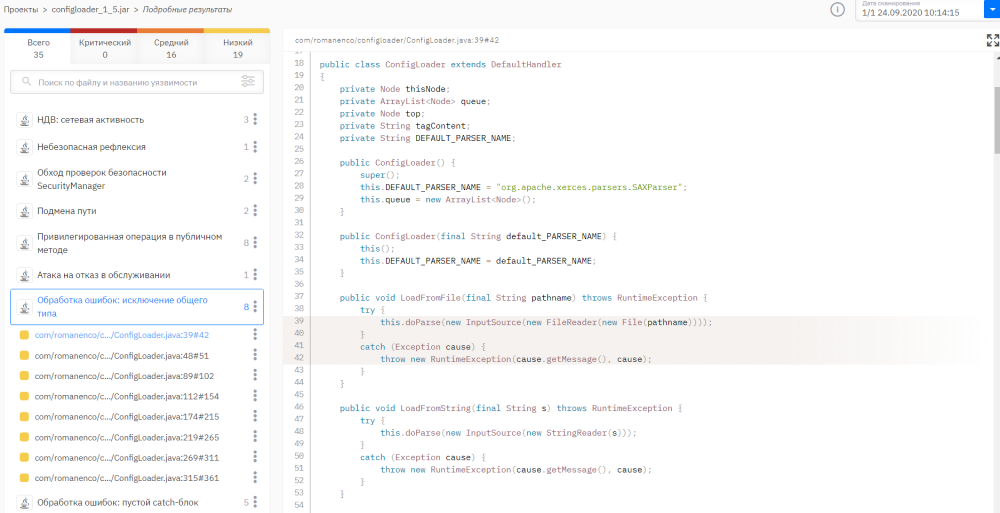
Качество декомпиляции для байт-кода велико. Практически всегда можно разобраться, в чем уязвимость, об этом мы писали более подробно в одной из наших предыдущих статей. После этого повторяется та же последовательность действий, что и после анализа исходного кода.
У данных подходов помимо плюсов есть и свои недостатки. При статическом анализе существует вероятность получить ложные срабатывания (когда выявленная уязвимость не является реальной). Или в процессе декомпиляции, например, даже если мы декомпилируем байт-код JVM, часть информации может восстанавливаться некорректно, поэтому сам анализ происходит на представлении, близком к бинарному коду. Соответственно, встает вопрос: как, находя уязвимости в бинарном коде, локализовать их в исходнике?
Но все эти вопросы, на самом деле, решаемы: для фильтрации ложных срабатываний также существуют специальные модули и фильтры. Решение задачи для байт-кода JVM мы описывали в статье о поиске уязвимостей в байт-коде Java.
Помимо этого, еще одной альтернативой может быть ручное ревью, так как в некоторых эвристических результатах SCA-инструмент может быть не до конца уверен. В подобном случае привлекается эксперт, который оценивает изменения, сделанные в библиотеке, и предлагает рекомендации по исправлению, учитывая последнюю версию оригинальной библиотеки. Подход достаточно трудоемкий, так как вручную разобраться с этим будет в ряде случаев нетривиальной задачей, а также может оказаться затратным, если привлечен эксперт от сторонней организации. Однако при наличии бюджета это вариант может дать хороший результат.
Резюмируя, хотелось бы отметить: SCA-средства отчасти помогут избежать головной боли со сторонними и собственными библиотеками, но их рекомендуется использоваться в комбинации с инструментами статического анализа для действительно качественного устранения уязвимостей в приложениях. Более того, эти решения должны постоянно участвовать в разработке, для этого их стоит внедрить в процесс безопасной разработки. Это позволит проводить проверки на различных этапах жизненного цикла программного обеспечения (об этом мы писали в нашей серии статей про внедрение SAST для обеспечения безопасной разработки). Таким образом можно получить максимальную пользу от подобных инструментов.
Автор: Антон Прокофьев, ведущий аналитик Solar appScreener
Что представляет собой SCA как процесс? На вход подается исходный код приложения или в некоторых случаях исполняемый, после чего SCA определяет, какие сторонние библиотеки используются в приложении. В дальнейшем эта информация применяется для определения уязвимостей в приложении, а также может пригодиться для проверки лицензионной чистоты библиотеки. Есть различные способы определения используемых библиотек/фреймворков:
- Если на вход подается исходный код, то самый верный способ – посмотреть на конфигурационные файлы, так как в большинстве случаев система сборки может показать все зависимости без самой сборки. Например, на mvn dependency:tree, в которых прописаны зависимости, – нужно составить список таких файлов. Также необходимые зависимости могут создаваться путем компиляции нужных файлов, например, для Java такие файлы будут добавляться путем сборки исходного кода (см. примеры файлов):
- Java/Scala/Kotlin — pom.xml, build.gradle, build.sbt + Manifest
- C# — *.csproj
- PHP — composer.json
- JavaScript — package.json (Node.js)
- Ruby — Gemfile, Gemfile.lock
- Можно определять по названиям пакетов/файлов.
- По хешам файлов можно понять, какие библиотеки и какой версии используются.
- Также можно применять специальные средства, например, OWASP dependency check, для последующей обработки полученных результатов. Например, для самостоятельного поиска уязвимостей в компонентах, которые определились подобными средствами.
Источники информации для SCA
Источники информации будут варьироваться в зависимости от рисков, которые анализируются с помощью SCA. Их можно поделить на три типа:
- риски безопасности (Security Risk), то есть поиск уязвимостей в сторонних компонентах;
- риски использования устаревшего программного обеспечения (Obsolescence Risk);
- лицензионные риски (License Risk), то есть правомерность использования сторонних компонентов из-за лицензионной политики.
В нашем случае речь идет о рисках безопасности, для работы с которыми в качестве источников информации используются базы данных уязвимостей. Ниже приведу пару примеров таких баз:
- CVE – основной источник информации об уязвимостях в конкретных версиях продукта, самая полная из бесплатных баз данных с уязвимостями, остальные на нее опираются (см. скриншот):
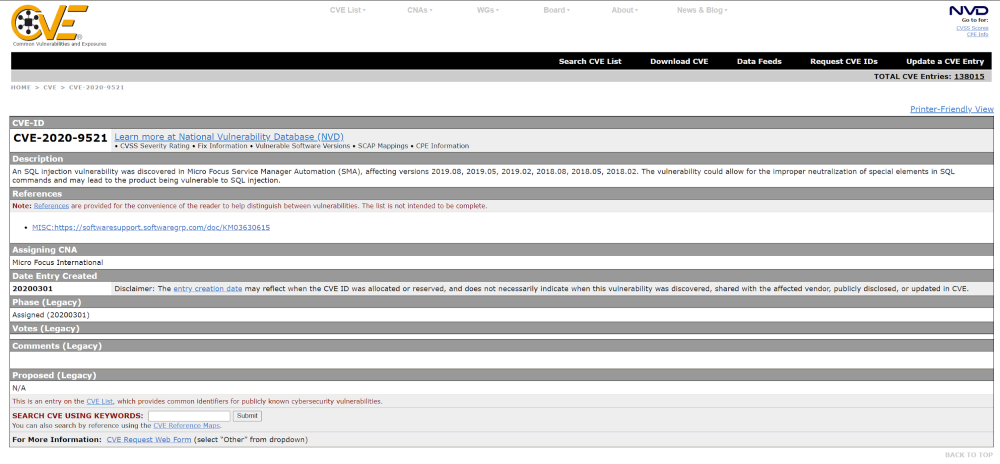
- NVD – национальная база данных уязвимостей США, основана на CVE, для многих уязвимостей указана оценка CVSS (Common Vulnerability Scoring System) версии 3.0 и 2.0, что может быть полезно для понимания критичности вхождения. Пример:
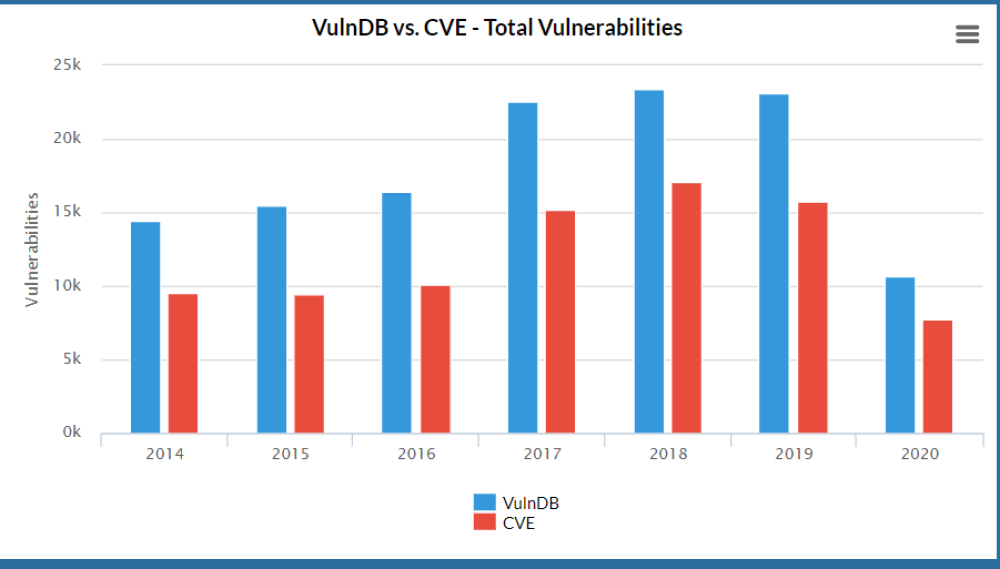
- VulnDB – платная база данных, которая содержит более полную информацию по уязвимостям, чем CVE.
Пример работы SCA-инструмента
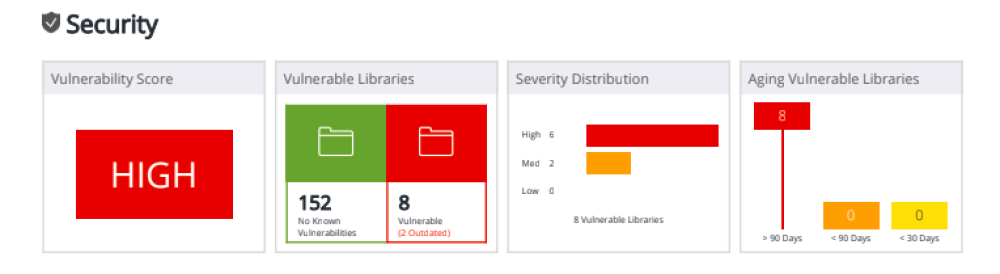
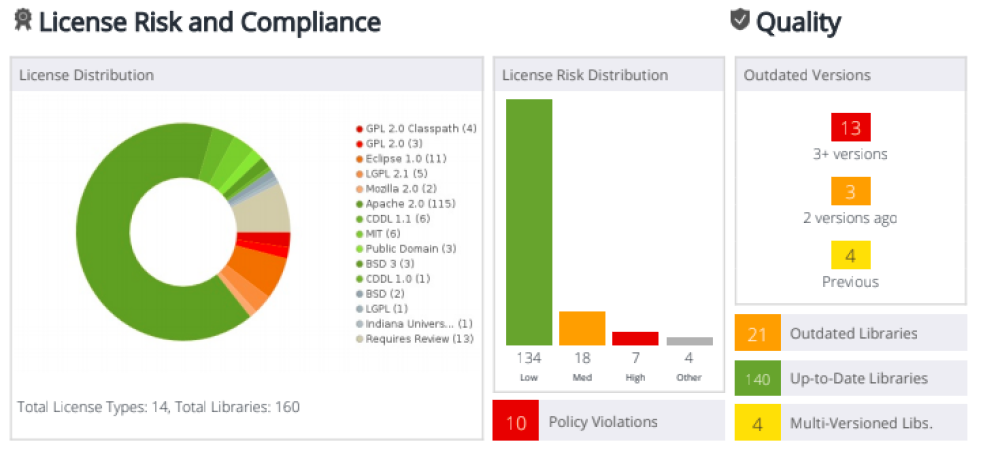
После загрузки проекта, например, git репозитория, происходит анализ его компонентов. Следует отметить, что для каждого языка программирования могут быть свои требования для проведения анализа. Например, для Java нужно, чтобы проект корректно собирался базовыми командами средства Maven, или же можно передать на анализ уже собранный проект. В первую очередь оценивается безопасность проекта, после чего следует оценка лицензионной чистоты, то есть насколько правомерно используется та или иная сторонняя библиотека. В качестве примера рассмотрим результаты анализа, проведенного с помощью продукта компании WhiteSource, так как представленный им отчёт и его визуализация наиболее наглядно демонстрируют возможности SCA-инструментов.
Этот продукт работает по 3-му способу определения используемых библиотек/фреймворков – определение по хеш-сумме: хеш-сумма библиотеки сопоставляется с различными хеш-суммами из базы данных вендора. Как можно увидеть на скриншотах выше, действительно, SCA средство может найти проблемные библиотеки и подсказать, что же с ними делать. Зачастую достаточно их просто пропатчить до безопасной версии. Но так ли все просто на самом деле?
Есть несколько нюансов:
- У вас может эксплуатироваться разрабатываемая или модифицированная компонента (библиотека/фреймворк), которой, попросту нет в базе данных вендора, а проверять ее нужно. Например, .jar библиотека, без которой не работает какой-то модуль вашего веб-приложения.
- Также вы можете использовать узкоспециализированную версию библиотеки, которую невозможно обновить до безопасной без ущерба для работы вашего приложения.
- Или же применяется библиотека на каком-то специализированном языке программирования, например, Solidity, для которого просто нет записи в базе данных вендора, как и поддержки анализа подобных библиотек в целом.
- Может возникнуть проблема с полнотой базы данных SCA-инструмента для вашего типа проектов. В основном вендоры этих систем используют свои собственные базы поиска библиотек, поэтому для вашего стэка проектов подобных библиотек в базе вендора может и не найтись.
Это достаточно частые случаи, с которыми необходимо работать. Кроме того, могут появляться проблемы со сборкой какого-то из компонентов системы или корректной настройки SCA-инструмента для получения полных результатов. Но подобные сложности уже не связаны с технологией анализа сторонних компонентов в целом, а скорее с решением конкретного вендора.
Что же делать с нюансами?
Для борьбы с нюансами хорошо подходят средства статического анализа: с их помощью можно проанализировать, например, .jar файл, которого нет в базе, и устранить уязвимости на уровне исходного кода. А если есть исходный код разрабатываемой компоненты, то задача становится еще проще.
Рассмотрим более подробно варианты использования инструментов SAST для решения подобных проблем.
Самый простой вариант, когда исходный код библиотеки есть. В таком случае для анализа кода на уязвимости достаточно лишь загрузить его в статический анализатор в виде архива с кодом.
Хорошо, получили результаты работы статического анализатора, что делать дальше? В идеальной ситуации нужно смотреть на все уязвимости и оценивать их реальную критичность в контексте вашего приложения, так как статический анализатор может не до конца понимать логику вашего приложения.
Но если быть реалистами, то переписывать чужую библиотеку, тратя на это много ресурсов (которых и так нет), не хочется. В таком случае рекомендуем постараться закрыть хотя бы критичные уязвимости. Статический анализатор явно показывает, где именно в коде содержится уязвимость, и выдает ее детальное описание с рекомендациями по устранению, что значительно упрощает подобную работу.
Рассмотрим также вариант посложнее, когда есть, например, .jar файл, для которого SCA-средство не смогло найти никакой информации. На самом деле, это достаточно частый случай, когда какая-то из компонент не идентифицируется – такое происходит в 6ти из 10ти сканирований. Как в таком случае убедиться в безопасности использования заимствованной компоненты?
SCA явно показывает, что за файл не удалось проверить – тогда это можно сделать с помощью статического анализатора.
Для специалиста, занимающегося анализом байт-кода, важно отображать уязвимости и НДВ на исходный код. Для этого на завершающем этапе статического бинарного анализа запускается процесс декомпиляции байт-кода в исходный. То есть уязвимости можно демонстрировать на декомпилированном коде. Сразу возникает вопрос – достаточно ли декомпилированного кода для того, чтобы понять и локализовать уязвимость?
Качество декомпиляции для байт-кода велико. Практически всегда можно разобраться, в чем уязвимость, об этом мы писали более подробно в одной из наших предыдущих статей. После этого повторяется та же последовательность действий, что и после анализа исходного кода.
У данных подходов помимо плюсов есть и свои недостатки. При статическом анализе существует вероятность получить ложные срабатывания (когда выявленная уязвимость не является реальной). Или в процессе декомпиляции, например, даже если мы декомпилируем байт-код JVM, часть информации может восстанавливаться некорректно, поэтому сам анализ происходит на представлении, близком к бинарному коду. Соответственно, встает вопрос: как, находя уязвимости в бинарном коде, локализовать их в исходнике?
Но все эти вопросы, на самом деле, решаемы: для фильтрации ложных срабатываний также существуют специальные модули и фильтры. Решение задачи для байт-кода JVM мы описывали в статье о поиске уязвимостей в байт-коде Java.
Помимо этого, еще одной альтернативой может быть ручное ревью, так как в некоторых эвристических результатах SCA-инструмент может быть не до конца уверен. В подобном случае привлекается эксперт, который оценивает изменения, сделанные в библиотеке, и предлагает рекомендации по исправлению, учитывая последнюю версию оригинальной библиотеки. Подход достаточно трудоемкий, так как вручную разобраться с этим будет в ряде случаев нетривиальной задачей, а также может оказаться затратным, если привлечен эксперт от сторонней организации. Однако при наличии бюджета это вариант может дать хороший результат.
Резюмируя, хотелось бы отметить: SCA-средства отчасти помогут избежать головной боли со сторонними и собственными библиотеками, но их рекомендуется использоваться в комбинации с инструментами статического анализа для действительно качественного устранения уязвимостей в приложениях. Более того, эти решения должны постоянно участвовать в разработке, для этого их стоит внедрить в процесс безопасной разработки. Это позволит проводить проверки на различных этапах жизненного цикла программного обеспечения (об этом мы писали в нашей серии статей про внедрение SAST для обеспечения безопасной разработки). Таким образом можно получить максимальную пользу от подобных инструментов.
Автор: Антон Прокофьев, ведущий аналитик Solar appScreener

Andrey2008
И я как раз сегодня опубликовал статью на тему проверки сторонних библиотек :)
Проверка коллекции header-only C++ библиотек (awesome-hpp).