
Что самое сложное в проектной работе? Пожалуй, свести к общему знаменателю ожидания от процесса и результата у заказчика и исполнителя. Когда мы начинали внедрять безопасную разработку в группе GK-приложений (кассового ПО) крупного ритейлера, то на входе имели вагон времени и задачи снижения уязвимостей в коде. А вот что и как нам пришлось решать на практике, мы вам расскажем под катом.
Кстати, это уже третий пост, в котором мы делимся своим опытом выстраивания процесса безопасной разработки для крупного ритейлера. Если пропустили, можете прочитать первые две части: о безопасной разработке порталов и мобильных приложений и о безопасной разработке в группе приложений SAP.

С этого скоупа мы начинали, когда пришли к заказчику. Согласно стартовому плану проекта, у нас были довольно вольготные сроки его реализации. Мы очень радовались, наивно думая, что сможем вести несколько проектов одновременно. В итоге мы почти все время уделяли именно кассовому ПО, потому что все оказалось гораздо сложнее. В целом, это стало самым сложным направлением интеграции, поскольку здесь требовалась наиболее серьезная автоматизация процесса.
Во-первых, мы столкнулись с мощной бюрократической машиной. Каждое действие требовало постоянных согласований, внесения в них правок, отчётов, их исправлений, запросов, ожиданий ответов и получений уточнений, которые меняли подходы и требовали серьёзных трудозатрат. А во-вторых, – с тем, что у представителей заказчика не было ни желания, ни времени нам помогать.
GK – это по сути фреймворк, на основе которого можно создавать свою кастомизацию кассового ПО. Заказчик несколько лет назад выкупил у GK некоторую часть исходного кода этого софта для создания собственной версии, соответственно, это направление представляло собой очень большую группу разработки. Большая часть ПО написана на языке Java (90% проектов). Встречались и некоторые проекты, написанные на C++ с использованием довольно древних библиотек, поскольку аппаратное обеспечение было заточено под этот стек технологий. Для Windows – под Windows Server 2008 и под набор библиотек для Visual Studio, для которых данная версия ОС была последней совместимой.
В группе имелись свои жесткие процессы разработки, свои релизные циклы. Процесс ветвления был похож на Gitflow с основной веткой разработки и feature-ветками под разнообразные задачи. Однако feature-ветки могли быть в статусе разработки месяцами (часто готовые к merge, но заброшенные) и вливались прямо перед релизом, в который они по плану должны были войти.
Помимо внедрения в CI/CD мы еще внедрялись и в Jira, для чего нам пришлось создать отдельную сущность для классификации задач «уязвимость». Этот вид задачи позволял заводить уязвимости внутри Jira в соответствии с процессом разработки и работы с таск-трекером.
Направление GK имело длинный процесс разработки, когда создается feature на какой-либо функционал, а потом эта feature-ветка может жить очень долго отдельно от основной ветки разработки. Ее могут верифицировать, но не могут влить в master или development почти вплоть до самого релиза ввиду технических сложностей регрессионного тестирования и т.п.
Когда мы пришли в группу GK внедрять Solar appScreener, мы были удивлены огромным количеством кода в проектах этого направления и предложили стандартный вариант сканирования основной ветки разработки. Разработчики сказали, что они тоже хотят получать информацию об уязвимостях и тоже хотят пользоваться анализатором, но не так, как офицеры безопасности. Им нужна была автоматизация проверки на уязвимости: единая точка входа в виде GitLab, где можно видеть все изменения. Чтобы на сканирование автоматически запускался код не только основной ветки разработки, но и всех побочных веток. При этом нужен был автоматизированный запуск из Jira и по просьбе заказчика полуавтоматизированный – из Jenkins и GitLab.
В итоге мы решили, что самым простым способом анализа ветки (в особенности для «долгих» feature-веток) будет запуск сканирования таким образом, чтобы задача в Jira при ее полном завершении (финальном push-е) переводилась в статус in review. После чего она попадала к специалисту, который может принять изменения и дать добро на старт сканирования кода на уязвимости. Иначе анализ кода по каждому push-у разработчика в репозитории создал бы адскую нагрузку и на людей, и на технику. Разработчики комитили код в репозитории не реже раза в пять минут, и при этом проекты порой содержали по 3,5 млн строк кода, одно сканирование которого, соответственно, длилось 6-8 часов. Такое никакими ресурсами не покроешь.
Теперь немного о том, какой набор технологий использовался в проекте. GitLab – в качестве системы контроля версий, Jenkins – в качестве CI/CD-системы, Nexus – в качестве хранилища артефактов и Jira в качестве системы отслеживания задач. При этом сами разработчики взаимодействовали только с Jira и с GitLab, тогда как с Jenkins – инженеры, а с Solar appScreener – безопасники. Вся информация об уязвимостях в коде присутствовала в GitLab и Jira.
Поэтому пришлось организовать процесс сканирования следующим образом: в Jira задача переводилась в in review через Jenkins, так как была необходима сборка. Имелся целый стек из Jenkins-плагинов и скриптов, которые получали веб-хук из Jira. То есть помимо вида задачи «уязвимость» нам пришлось создавать в Jira еще и веб-хуки, которые при изменении проекта в GK отправлялись в Jenkins и требовали дополнительных шагов по настройке и серьёзной доработке двусторонней интеграции. Процесс был таким: когда в GK обновлялась какая-либо задача, Jira проверяла, соответствует ли эта задача тем, которые должны отправляться в Jenkins, а именно — является ли это задачей разработки. И только после этого веб-хук уходил в Jenkins, который парсил веб-хук и на основе тела запроса понимал, какому репозиторию в GitLab и какой группе работ (job-ов) нужно запускаться.
Разработчики GK выставили ряд требований при заведении задач в Jira, и мы старались их использовать по полной, чтобы получить максимальное количество информации. Благодаря этому мы смогли правильно матчить репозитории в GitLab и ветку, которую мы должны были стянуть из конкретного репозитория для ее запуска на анализ. В требованиях мы жестко прописали, что ветка в GitLab обязательно должна содержать в названии номер задачи в Jira. В принципе, это best practice, который используется повсеместно – в самой задаче должны быть метки, маркирующие, к какой части приложения/системы относится проблема.
На основе веб-хука, в котором содержалось название проекта, метки, поля с компонентами, а также ключ самой задачи и т.п., происходило автоматическое определение необходимости запуска всех задач. Часть проектов получала ответ всех значений «удовлетворительно» и после этого отправлялась на сканирование. А именно: поступал запрос в GitLab, проверялось наличие в нем данной ветки разработки, и при подтверждении система запускала сканирование новой части кода этой ветки в Solar appScreener.

Кадр из мультфильма «Вовка в тридевятом царстве»
Поскольку уязвимостей в GK-проектах было десятки тысяч, разработчики не хотели видеть их все. Меж тем в коде содержались порой критичные уязвимости: вставленные в код пароли, отраженные межсайтовые скриптинги, SQL-инъекции и т.п.
Разработчики планировали исправлять уязвимости в бэклоге, а прежде всего хотели видеть изменения: то есть появившиеся в новом коде уязвимости по сравнению с кодом предыдущей версии.
Однако реализованные в нашем продукте механизмы не подразумевают инкрементальный анализ для Java: анализируется байт-код, и невозможно проверить только измененные файлы, потому что теряется связность кода. Изменился один файл, использующий несколько библиотек или других пакетов, которые принадлежат тому же исходному коду, – тогда и вся информация об уязвимости теряется. Поэтому мы сразу обозначили заказчику, что в данном случае возможен анализ исходного кода только целиком, и предложили следующую схему.
Как и для остальных проектов компании, мы выстроили для GK соответствие проекта в GitLab проекту в Solar appScreener, а дополнительно провели корреляцию с веткой разработки. Чтобы разработчикам и офицерам ИБ было проще искать, мы создали файл с реестром названия группы репозиториев, конкретного проекта из этой группы и ветки в Solar appScreener.
Кроме того, разработчики хотели видеть комментарии с изменениями сразу в GitLab, и вот как мы это сделали.
Сначала мы сканировали основную ветку разработки для каждого репозитория, от которой шла ветка с изменениями. Поскольку разработчики хотели видеть комментарии с изменениями сразу в GitLab, мы договорились, что если ветка переведена в статус in review, это значит, что уже есть соответствующий merge request на ее вливание. Система проверяла, что merge request был действительно открыт, и если это подтверждалось, то Solar appScreener анализировал основную ветку разработки. Затем он сканировал ветку с изменениями, строил diff, выгружал его, получал только новые уязвимости, брал из них критичные (наш инструмент позволяет настраивать уровни критичности) и преобразовывал их описание в формат текстовых сообщений со ссылкой на данное вхождение в конкретном проекте в Solar appScreener (см.скриншот ниже). Эти сообщения отправлялись в GitLab в виде дискуссии от имени технической учетной записи. В merge request вместе с измененным кодом можно было увидеть непосредственно строку срабатывания. Её сопровождал адресованный конкретному разработчику комментарий в GitLab типа «вот здесь содержится уязвимость, пожалуйста, поправьте или закройте ее».
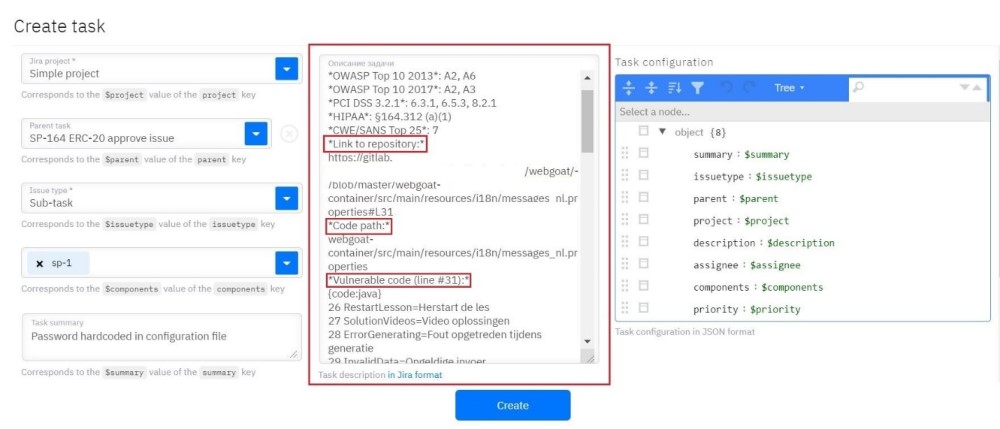
Таким образом, между этими двумя сканированиями мы выявляли изменения, которые привнес разработчик. Если количество уязвимостей увеличивалось, это обязательно отражалось в комментариях отчёта. Такая схема была очень удобна для всех участников, потому что в GitLab сразу же появлялись неразрешенные дискуссии, а это значит, что merge request влить нельзя. И ответственный за approve merge request’а видел, что разработчик допустил уязвимости, и их нужно закрыть.
Чтобы просматривать уязвимости через Solar appScreener, разработчикам нужны были права. Поэтому помимо всей интеграции с системами разработки и со всеми тремя скоупами мы еще интегрировались и с сервисами Active Directory. Для нас некоторую сложность представляло то, что у заказчика был чудовищно большой AD с миллионом вложенных групп, что потребовало множества оптимизаций. То есть помимо внедрения CI/CD нам приходилось в процессе решать много сопутствующих задач настройки, адаптации и оптимизации (см. скриншот ниже).

Что касается интеграции с Active Directory, разработчики GK не хотели настраивать параметры доступа в ряд проектов Solar appScreener непосредственно в AD, потому что они не были владельцами этого ресурса. В компании процесс выдачи прав доступа выглядел следующим образом: если разработке нужно было внести нового человека в группу, приходилось писать заявку в техподдержку. Там определяли, кому именно отправлять данный запрос, кто отвечает за выдачу подобных прав, действительно ли можно выдать этому человеку права, авторизованы они или нет и т.п.
Это трудоемкий процесс, которым разработчики не управляли, в отличие от GitLab.Поэтому они попросили организовать интеграцию с AD следующим образом. Они разрешают видеть уязвимости не только техвладельцам системы и офицерам безопасности, как это было сделано для других направлений, но и сделать матчинг прав в GitLab. То есть если человек имеет права разработчика и выше (maintainer, владелец репозитория), то он может просматривать соответствующие проекты в Solar appScreener, которые относятся к этому репозиторию. Когда в Solar appScreener создавался новый проект, система запрашивала имена всех, кто состоит в GitLab в данном репозитории с уровнем доступа выше разработчика. Список выгружался, поступало обращение в анализатор кода, который в свою очередь отправлял запрос в AD с добавлением списка отобранных людей. Все, кто состоял в данном репозитории в GitLab, получали автоматические права через свои AD-учетки на доступ к проекту в Solar appScreener. В конце всей цепочки генерился pdf-файл с отчетом по уязвимостям из анализатора кода. В отчете содержался diff, который рассылался списку пользователей проектов GK на электронную почту.
Реализованная интеграция с кассовым ПО GK – это пример весьма масштабного проекта внедрения и автоматизации в компании процесса безопасной разработки, который был выстроен не только вокруг службы информационной безопасности, но и вокруг разработчиков. Причем в этой группе проектов так же, как и в других группах, параллельно шли сканирования основной ветки разработки: офицеры безопасности тоже заводили задачи в Jira и их верифицировали. Уязвимости заносились в бэклог и позже исправлялись.
Разработчики получили для себя удобный инструмент, встроенный в привычную среду и workflow. Так как они выбрали для себя порог из топ критических уязвимостей, которые довольно редко возникают, их нагрузка несильно возросла после внедрения. В итоге довольны оказались все участники проекта: и те, кто стремился повысить безопасность кода, и те, кому приходилось исправлять уязвимости.
Если у вас есть собственный опыт реализации практик безопасной разработки, пожалуйста, поделитесь им в комментариях!
Напомним: это третья часть цикла статей о построении процесса безопасной разработки в крупном ритейлере. В следующем посте будем подводить итоги работы над этим масштабным проектом: поговорим о том, чему мы научились в процессе, и какое развитие получил наш инструмент благодаря такому опыту.
Автор: Иван Старосельский, руководитель отдела эксплуатации и автоматизации информационных систем
Кстати, это уже третий пост, в котором мы делимся своим опытом выстраивания процесса безопасной разработки для крупного ритейлера. Если пропустили, можете прочитать первые две части: о безопасной разработке порталов и мобильных приложений и о безопасной разработке в группе приложений SAP.
О проекте
С этого скоупа мы начинали, когда пришли к заказчику. Согласно стартовому плану проекта, у нас были довольно вольготные сроки его реализации. Мы очень радовались, наивно думая, что сможем вести несколько проектов одновременно. В итоге мы почти все время уделяли именно кассовому ПО, потому что все оказалось гораздо сложнее. В целом, это стало самым сложным направлением интеграции, поскольку здесь требовалась наиболее серьезная автоматизация процесса.
Во-первых, мы столкнулись с мощной бюрократической машиной. Каждое действие требовало постоянных согласований, внесения в них правок, отчётов, их исправлений, запросов, ожиданий ответов и получений уточнений, которые меняли подходы и требовали серьёзных трудозатрат. А во-вторых, – с тем, что у представителей заказчика не было ни желания, ни времени нам помогать.
GK
GK – это по сути фреймворк, на основе которого можно создавать свою кастомизацию кассового ПО. Заказчик несколько лет назад выкупил у GK некоторую часть исходного кода этого софта для создания собственной версии, соответственно, это направление представляло собой очень большую группу разработки. Большая часть ПО написана на языке Java (90% проектов). Встречались и некоторые проекты, написанные на C++ с использованием довольно древних библиотек, поскольку аппаратное обеспечение было заточено под этот стек технологий. Для Windows – под Windows Server 2008 и под набор библиотек для Visual Studio, для которых данная версия ОС была последней совместимой.
В группе имелись свои жесткие процессы разработки, свои релизные циклы. Процесс ветвления был похож на Gitflow с основной веткой разработки и feature-ветками под разнообразные задачи. Однако feature-ветки могли быть в статусе разработки месяцами (часто готовые к merge, но заброшенные) и вливались прямо перед релизом, в который они по плану должны были войти.
Помимо внедрения в CI/CD мы еще внедрялись и в Jira, для чего нам пришлось создать отдельную сущность для классификации задач «уязвимость». Этот вид задачи позволял заводить уязвимости внутри Jira в соответствии с процессом разработки и работы с таск-трекером.
Направление GK имело длинный процесс разработки, когда создается feature на какой-либо функционал, а потом эта feature-ветка может жить очень долго отдельно от основной ветки разработки. Ее могут верифицировать, но не могут влить в master или development почти вплоть до самого релиза ввиду технических сложностей регрессионного тестирования и т.п.
Решение для интеграции
Когда мы пришли в группу GK внедрять Solar appScreener, мы были удивлены огромным количеством кода в проектах этого направления и предложили стандартный вариант сканирования основной ветки разработки. Разработчики сказали, что они тоже хотят получать информацию об уязвимостях и тоже хотят пользоваться анализатором, но не так, как офицеры безопасности. Им нужна была автоматизация проверки на уязвимости: единая точка входа в виде GitLab, где можно видеть все изменения. Чтобы на сканирование автоматически запускался код не только основной ветки разработки, но и всех побочных веток. При этом нужен был автоматизированный запуск из Jira и по просьбе заказчика полуавтоматизированный – из Jenkins и GitLab.
В итоге мы решили, что самым простым способом анализа ветки (в особенности для «долгих» feature-веток) будет запуск сканирования таким образом, чтобы задача в Jira при ее полном завершении (финальном push-е) переводилась в статус in review. После чего она попадала к специалисту, который может принять изменения и дать добро на старт сканирования кода на уязвимости. Иначе анализ кода по каждому push-у разработчика в репозитории создал бы адскую нагрузку и на людей, и на технику. Разработчики комитили код в репозитории не реже раза в пять минут, и при этом проекты порой содержали по 3,5 млн строк кода, одно сканирование которого, соответственно, длилось 6-8 часов. Такое никакими ресурсами не покроешь.
Стек технологий
Теперь немного о том, какой набор технологий использовался в проекте. GitLab – в качестве системы контроля версий, Jenkins – в качестве CI/CD-системы, Nexus – в качестве хранилища артефактов и Jira в качестве системы отслеживания задач. При этом сами разработчики взаимодействовали только с Jira и с GitLab, тогда как с Jenkins – инженеры, а с Solar appScreener – безопасники. Вся информация об уязвимостях в коде присутствовала в GitLab и Jira.
Поэтому пришлось организовать процесс сканирования следующим образом: в Jira задача переводилась в in review через Jenkins, так как была необходима сборка. Имелся целый стек из Jenkins-плагинов и скриптов, которые получали веб-хук из Jira. То есть помимо вида задачи «уязвимость» нам пришлось создавать в Jira еще и веб-хуки, которые при изменении проекта в GK отправлялись в Jenkins и требовали дополнительных шагов по настройке и серьёзной доработке двусторонней интеграции. Процесс был таким: когда в GK обновлялась какая-либо задача, Jira проверяла, соответствует ли эта задача тем, которые должны отправляться в Jenkins, а именно — является ли это задачей разработки. И только после этого веб-хук уходил в Jenkins, который парсил веб-хук и на основе тела запроса понимал, какому репозиторию в GitLab и какой группе работ (job-ов) нужно запускаться.
Разработчики GK выставили ряд требований при заведении задач в Jira, и мы старались их использовать по полной, чтобы получить максимальное количество информации. Благодаря этому мы смогли правильно матчить репозитории в GitLab и ветку, которую мы должны были стянуть из конкретного репозитория для ее запуска на анализ. В требованиях мы жестко прописали, что ветка в GitLab обязательно должна содержать в названии номер задачи в Jira. В принципе, это best practice, который используется повсеместно – в самой задаче должны быть метки, маркирующие, к какой части приложения/системы относится проблема.
На основе веб-хука, в котором содержалось название проекта, метки, поля с компонентами, а также ключ самой задачи и т.п., происходило автоматическое определение необходимости запуска всех задач. Часть проектов получала ответ всех значений «удовлетворительно» и после этого отправлялась на сканирование. А именно: поступал запрос в GitLab, проверялось наличие в нем данной ветки разработки, и при подтверждении система запускала сканирование новой части кода этой ветки в Solar appScreener.
Учитываем пожелания
Кадр из мультфильма «Вовка в тридевятом царстве»
Поскольку уязвимостей в GK-проектах было десятки тысяч, разработчики не хотели видеть их все. Меж тем в коде содержались порой критичные уязвимости: вставленные в код пароли, отраженные межсайтовые скриптинги, SQL-инъекции и т.п.
Разработчики планировали исправлять уязвимости в бэклоге, а прежде всего хотели видеть изменения: то есть появившиеся в новом коде уязвимости по сравнению с кодом предыдущей версии.
Однако реализованные в нашем продукте механизмы не подразумевают инкрементальный анализ для Java: анализируется байт-код, и невозможно проверить только измененные файлы, потому что теряется связность кода. Изменился один файл, использующий несколько библиотек или других пакетов, которые принадлежат тому же исходному коду, – тогда и вся информация об уязвимости теряется. Поэтому мы сразу обозначили заказчику, что в данном случае возможен анализ исходного кода только целиком, и предложили следующую схему.
Как и для остальных проектов компании, мы выстроили для GK соответствие проекта в GitLab проекту в Solar appScreener, а дополнительно провели корреляцию с веткой разработки. Чтобы разработчикам и офицерам ИБ было проще искать, мы создали файл с реестром названия группы репозиториев, конкретного проекта из этой группы и ветки в Solar appScreener.
Кроме того, разработчики хотели видеть комментарии с изменениями сразу в GitLab, и вот как мы это сделали.
Интеграция с GitLab
Сначала мы сканировали основную ветку разработки для каждого репозитория, от которой шла ветка с изменениями. Поскольку разработчики хотели видеть комментарии с изменениями сразу в GitLab, мы договорились, что если ветка переведена в статус in review, это значит, что уже есть соответствующий merge request на ее вливание. Система проверяла, что merge request был действительно открыт, и если это подтверждалось, то Solar appScreener анализировал основную ветку разработки. Затем он сканировал ветку с изменениями, строил diff, выгружал его, получал только новые уязвимости, брал из них критичные (наш инструмент позволяет настраивать уровни критичности) и преобразовывал их описание в формат текстовых сообщений со ссылкой на данное вхождение в конкретном проекте в Solar appScreener (см.скриншот ниже). Эти сообщения отправлялись в GitLab в виде дискуссии от имени технической учетной записи. В merge request вместе с измененным кодом можно было увидеть непосредственно строку срабатывания. Её сопровождал адресованный конкретному разработчику комментарий в GitLab типа «вот здесь содержится уязвимость, пожалуйста, поправьте или закройте ее».
Таким образом, между этими двумя сканированиями мы выявляли изменения, которые привнес разработчик. Если количество уязвимостей увеличивалось, это обязательно отражалось в комментариях отчёта. Такая схема была очень удобна для всех участников, потому что в GitLab сразу же появлялись неразрешенные дискуссии, а это значит, что merge request влить нельзя. И ответственный за approve merge request’а видел, что разработчик допустил уязвимости, и их нужно закрыть.
Интеграция с Active Directory
Чтобы просматривать уязвимости через Solar appScreener, разработчикам нужны были права. Поэтому помимо всей интеграции с системами разработки и со всеми тремя скоупами мы еще интегрировались и с сервисами Active Directory. Для нас некоторую сложность представляло то, что у заказчика был чудовищно большой AD с миллионом вложенных групп, что потребовало множества оптимизаций. То есть помимо внедрения CI/CD нам приходилось в процессе решать много сопутствующих задач настройки, адаптации и оптимизации (см. скриншот ниже).
Что касается интеграции с Active Directory, разработчики GK не хотели настраивать параметры доступа в ряд проектов Solar appScreener непосредственно в AD, потому что они не были владельцами этого ресурса. В компании процесс выдачи прав доступа выглядел следующим образом: если разработке нужно было внести нового человека в группу, приходилось писать заявку в техподдержку. Там определяли, кому именно отправлять данный запрос, кто отвечает за выдачу подобных прав, действительно ли можно выдать этому человеку права, авторизованы они или нет и т.п.
Это трудоемкий процесс, которым разработчики не управляли, в отличие от GitLab.Поэтому они попросили организовать интеграцию с AD следующим образом. Они разрешают видеть уязвимости не только техвладельцам системы и офицерам безопасности, как это было сделано для других направлений, но и сделать матчинг прав в GitLab. То есть если человек имеет права разработчика и выше (maintainer, владелец репозитория), то он может просматривать соответствующие проекты в Solar appScreener, которые относятся к этому репозиторию. Когда в Solar appScreener создавался новый проект, система запрашивала имена всех, кто состоит в GitLab в данном репозитории с уровнем доступа выше разработчика. Список выгружался, поступало обращение в анализатор кода, который в свою очередь отправлял запрос в AD с добавлением списка отобранных людей. Все, кто состоял в данном репозитории в GitLab, получали автоматические права через свои AD-учетки на доступ к проекту в Solar appScreener. В конце всей цепочки генерился pdf-файл с отчетом по уязвимостям из анализатора кода. В отчете содержался diff, который рассылался списку пользователей проектов GK на электронную почту.
Резюме
Реализованная интеграция с кассовым ПО GK – это пример весьма масштабного проекта внедрения и автоматизации в компании процесса безопасной разработки, который был выстроен не только вокруг службы информационной безопасности, но и вокруг разработчиков. Причем в этой группе проектов так же, как и в других группах, параллельно шли сканирования основной ветки разработки: офицеры безопасности тоже заводили задачи в Jira и их верифицировали. Уязвимости заносились в бэклог и позже исправлялись.
Разработчики получили для себя удобный инструмент, встроенный в привычную среду и workflow. Так как они выбрали для себя порог из топ критических уязвимостей, которые довольно редко возникают, их нагрузка несильно возросла после внедрения. В итоге довольны оказались все участники проекта: и те, кто стремился повысить безопасность кода, и те, кому приходилось исправлять уязвимости.
Если у вас есть собственный опыт реализации практик безопасной разработки, пожалуйста, поделитесь им в комментариях!
Напомним: это третья часть цикла статей о построении процесса безопасной разработки в крупном ритейлере. В следующем посте будем подводить итоги работы над этим масштабным проектом: поговорим о том, чему мы научились в процессе, и какое развитие получил наш инструмент благодаря такому опыту.
Автор: Иван Старосельский, руководитель отдела эксплуатации и автоматизации информационных систем
ajijiadduh
о, gravity defied