
Всем привет! Ранее мы выкладывали статью про наше распознавание речи, сегодня мы хотим рассказать вам о нашем опыте по созданию синтеза речи на русском языке, а также поделиться ссылками на репозитории и датасеты для свободного использования в любых целях.

Если вам интересна история о том, как мы разработали собственный сервис синтеза речи и каких результатов нам удалось достигнуть, то добро пожаловать под кат.
Введение в задачу синтеза
Про существующие технологии реализации синтеза подробно рассказывать не будем, благо на хабре уже есть хорошая статья от блога компании Тинькофф на эту тему, упомянем лишь то, что существуют два основных подхода:
Фонема — минимальная смыслоразличительная единица языка. Простыми словами, является для устной речи тем же, чем буквы для письменной. В фонему может входить множество аллофнов. Фонема может быть отражением как одной буквы, так и их сочетания.
Аллофон — вариация фонемы в зависимости от окружения. В отличие от фонемы, является не абстрактным понятием, а конкретным речевым звуком. Например, фонема <а> имеет следующие аллофоны: (а) — в слове пат, (а·) — в слове мать, (•а) — в слове пятый и т.д.
Дифон — сегмент речи между серединами соседних фонем. В отличие от аллофона, границы которого совпадают с границами гласных или согласных звуков, дифон представляет собой такой звуковой элемент, начало которого находится примерно посередине одного гласного или согласного звука, а конец – примерно посередине следующего.
Полуфон — сегемент речи, у которого одна из границ совпадает с границей аллофона, а другая – с границей дифона.
- Конкатенативный синтез (unit selection) – заранее готовится база дифонов и полуфонов, которые потом склеиваются между собой. Недавнно на хабре как раз вышла статья о самом известном подобном синтезаторе на русском языке;
- Параметрический – вычисление на основе текста набора акустических признаков, по которым генерируется аудио сигнал. Естественно, что самым популярным представителем параметрического метода являются нейронные сети.
Итак, для создания нашего синтеза было решено использовать параметрический подход, а значит, перед нами встал вопрос, какую архитектуру использовать. После непродолжительных поисков выбор был сделан в пользу Tacotron 2 по ряду причин:
- Популярная архитектура, хорошо справляющаяся со своей задачей. Её рекомендацией являлись, как минимум, её использование банком Тинькофф для своего чат-бота Олега (см. статью выше), а также неявные намёки на её использование у Яндекса.
- Конечно же ещё одной немаловажной причиной стало то, что NVIDIA любезно предоставила свою реализацию Tacotron 2 (репозиторий) с её же вокодером Waveglow (статья, репозиторий), и всё это на pytorch (мы симпатизируем ему больше, чем tensorflow и keras).
Начало экспериментов
Так как сперва нашей задачей было обучение синтеза для русского языка, и собственным набором данных мы ещё не обзавелись, естественно, что для начала работы мы взяли единственный (на тот момент) приемлемый датасет для обучения синтеза на русском языке – RUSLAN (прим. автора: есть подозрение, что это не имя диктора, а акроним от RUSsian LANguage).
Какие проблемы сразу же бросаются в глаза (в уши) при синтезе после обучения на оригинальном датасете с помощью кода NVIDIA:
- Проскакивает случайная простановка ударений даже в тех словах, где ударение единственно возможное
Многие члены моей семьи любили ходить в зоопарк и наблюдать за тем, как едят слоны.
Также попадается озвучка графем, а не фонем («синтез» вместо «синтэз»)
Синтез речи – это увлекательно
- Нестабильность механизма внимания (который занимается, грубо говоря, выявлением соответствия символов входного текста и фреймов мел-спектрограммы), особенно на длинных входных текстах. Такая нестабильность, а другими словами, разрыв линии внимания, как на картинке:
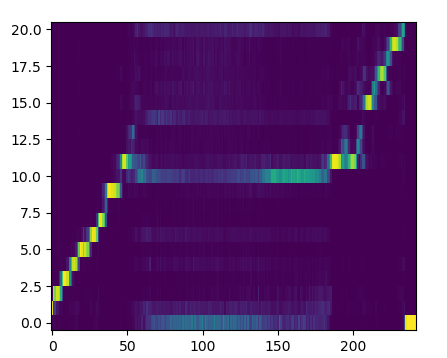
приводит к появлению различных артефактов в речи
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
- Нестабильность срабатывания гейт слоя, генерирующего сигнал об окончании генерации
В чащах юга жил бы цитрус? Да, но фальшивый экземпляр!
- Все предыдущие моменты касались движка синтеза (так мы называем Tacotron 2 у себя), а что касается самого датасета, то там можно отметить плохие условия записи диктора – слышите это эхо?
Разберём, как мы боролись с каждым из этих пунктов.
Работы по улучшению
Случайная простановка ударений и озвучка графем
Понятное дело, что для устранения этих недостатков надо правильным образом подготовить текст и обучать модель уже на нём, используя какой-то nlp-препроцессор. Начнём с того, как готовились данные.
Данные
Вот тут-то нам и пригодился наш отдел разметчиков: чтобы проставить ударения, над текстом трудились 5 разметчиков в течение двух недель. Результат – полностью размеченный ударениями датасет Руслан (ссылку см. ниже), который мы предоставляем сообществу для экспериментов. Но это касается только обучения, а что с инференсом? Тут всё просто: мы нашли словарь ударений (сначала аналог CMU dict для русского языка, а потом полную акцентуированную парадигму по А.А. Зализняку). Дальше нужно было подготовить код для использования этого словаря, и вуаля — получаем контроль ударений для нашей системы синтеза.
Что касается более естественного озвучивания с помощью фонем, то мы рассматривали два репозитория для решения этой задачи: RusPhonetizer и russian_g2p. В итоге, первый не завёлся, второй оказался слишком медленным (0.24 секунды на предложение из 100 символов), а тут ещё и CMU словарь содержит не только ударения, но и фонетические записи слов, так что решили использовать его. Честно сказать, из-за отсутствия чёткого понимания, какие же всё-таки фонемы нужны, работа с этим словарём вылилась в обычную транслитерацию текста с периодически встречающейся редуцированной "о". Сейчас мы экспериментируем с фонетизатором на основе фонем из russian_g2p.
NLP-препроцессор
Для работы со словарями и конвертацией текста в фонемный вид пакет text из оригинального репозитория такотрона уже не подходил, так что был заведён отдельный репозиторий для преподготовки текста. Опуская все подробности его разработки, резюмируем, каким функционалом он обладает на сегодняшний день:
- единый пайплайн обработки, принимающий на вход отдельные модули, производящие свои собственные операции над текстом;
- два готовых модуля для работы со словарями (ударник и фонетизатор);
- методы модулей для разбиения текста на различные составляющие;
- потенциал расширения арсенала модулей предобработчиков для русского и других языков.
Документация к репозиторию пока что находится в разработке.
Примеры
Контроль ударений:
Мн+огие чл+ены мо+ей семь+и люб+или ход+ить в зооп+арк и наблюд+ать за тем, как ед+ят слон+ы.
Тв+орог или твор+ог, к+озлы или козл+ы, з+амок или зам+ок.
Фонемы вместо графем:
Пример контроля фонем придётся показать на другом дикторе — Наталье — часть датасета которой вместе с весами (обычными, не фонемными) мы также выкладываем в открытый доступ (см. ссылку ниже).
Заодно приведём ещё пару синтезированных на open source модели примеров:
Съешь же ещё этих мягких французских булок да выпей чаю.
Широкая электрификация южных губерний даст мощный толчок подъёму сельского хозяйства.
В чащах юга жил бы цитрус? Да, но фальш+ивый экземпляр!
Нестабильность механизма внимания
Решение этой проблемы потребовало изучения статей по теме и имплементацию методик, представленных в них. Вот что мы нашли:
- Diagonal guided attention (DGA) – здесь идея простая: так как в синтезе, в отличие от машинного перевода, соответствие выходов энкодера и декодера последовательное, то есть система воспроизводит звуки по мере их появления в тексте, то давайте штрафовать матрицу внимания тем больше, чем больше она отступает от диагонального вида. Можно, конечно, возразить, «а что если звук тянется и на линии внимания появляется полка», но мы решили не рассматривать подобные экстремальные случаи. В качестве бонуса получаем ускорение процесса схождения матрицы внимания;
- Pre-alignment guided attention – в этой статье изложен более сложный подход: требуется с помощью стороннего инструмента (например, Montreal-Forced-Aligner) получить временные метки каждой фонемы на аудиозаписи и составить из них матрицу внимания, которая будет являться для системы целевой;
- Maximizing Mutual Information for Tacotron – авторы статьи утверждают, что подобные артефакты в матрице внимания возникают из-за недостаточной связи декодера с текстом. Для укрепления этой связи вводится модуль примитивного предсказания текста из итоговой мел-спектрограммы (эдакая asr в миниатюре) и расчёт ошибки с помощью CTC. Также ускоряет сходимость матрицы внимания.
После проведённых экспериментов можем сказать, что первый вариант определённо выигрывает по соотношению (положительный эффект/затраченные усилия). В качестве доказательства приведём запись, синтезированную моделью, обученной с DGA, из текста длиной 560 символов (без учёта токенов ударения) без его разбиения:
Все смешалось в доме Облонских. Жена узнала, что муж был в связи с бывшею в их доме француженкою-гувернанткой, и объявила мужу, что не может жить с ним в одном доме. Положение это продолжалось уже третий день и мучительно чувствовалось и самими супругами, и всеми членами семь+и, и домочадцами. Все члены семь+и и домочадцы чувствовали, что нет смысла в их сожительстве и что на каждом постоялом дворе случайно сошедшиеся люди более связаны между собой, чем они, члены семь+и и домочадцы Облонских. Жена не выходила из своих комнат, мужа третий день не было дома.
Как видите, на протяжении всей записи движок уверенно держал своё внимание: фраза не "разваливается", не возникает артефактов и мычания.
Нестабильность срабатывания гейт слоя
Напомним, что гейт слой отвечает за остановку генерации, и если он не сработает, то декодер будет продолжать генерировать фреймы, пока не достигнет лимита по шагам декодинга. Это выливается в продолжительное мычание в конце предложения, что забавно, но мешает презентовать свой синтез заказчикам.
Эта проблема решается несколькими небольшими уловками:
- Символ EOS вводится для каждого предложения, даже если у него в конце уже проставлен знак препинания из набора [“.”, “!”, “?”];
- В конце каждой аудиозаписи добавляется небольшой участок тишины;
- При расчёте функции потерь для гейт слоя нужно увеличить вес его положительных выходов, чтобы они играли бОльшую роль.
Все вышеперечисленные ухищрения присутствуют в нашем репозитории движка, который мы выложили в открытый доступ (об этом ниже).
Некачественный датасет
Нам повезло, что в команде есть человек, увлекающийся музыкой, так что для облагораживания датасетов, в частности Руслана, мы вручную подбирали параметры различных фильтров и обрабатывали ими аудиодорожки в Logic Pro X. Ниже можете прослушать примеры оригинального и прошедшего обработку Руслана:
Также стоит отметить, что в датасете немного почищена пунктуация, так как движок реагирует на неё весьма чувствительно.
Дополнительные эксперименты
После решения всех насущных вопросов встала задача улучшить и разнообразить звучание, придать ему изюминки. Любой знакомый с темой скажет «Ок, посмотрите в сторону GST и VAE [ссылка раз, ссылка два]», и мы посмотрели.
Введение в пайплайн GST, на субъективный слух автора, не давало каких-то особых запоминающихся изменений, пока мы не попробовали подход, описанный в Text predicted GST – предлагается модели самой подбирать комбинацию стилистических токенов, чтобы добиться лучшего звучания для текущего текста. Для демонстрации работы этого модуля приведём аудио, полученные моделью, которая обучалась на датасете реплик персонажей из популярных зарубежных сериалов (актриса озвучки Екатерина). Уточним, что датасет изначально не предназначался для синтеза.
В общем, как и в жизни: главное найти подход к человеку.
Что касается использования вариационных автоэнкодеров, то эксперименты пока продолжаются, и похвастаться на данный момент нечем, так как столкнулись с определёнными проблемами. Если интересны технические детали — прошу под спойлер.
Проблема posterior collapse (KL loss vanishing), характерная для вариационных моделей в сочетании с авторегрессионным декодером.
В начале обучения, декодер может отставать от вариацинного энкодера и научиться игнорировать неосмысленные латентные переменные, что приводит к почти нулевой ошибке KL для VAE (расстояние Кульбака–Лейблера). Апостериорная оценка латентной переменной p(z|x) ослабевает и становится неотличимой от априорного Гауссовского шума p(z) ~ N(0, 1). Как следствие, вариационный энкодер не моделирует значимые свойства аудио и модель не предоставляет контроль над стилем и эмоцями речи.
Для борьбы с posterior collapse были опробованы уменьшение веса ошибки KL с его монотонным увеличение в процессе обучения, а также неучёт ошибки в начале обучения, равносильный игнорированию вариационных свойств модели и обучению стандартного автоэнкодера. Оба способа, в теории, позволяют декодеру сначала научиться синтезу речи и замедляют обучение вариационного автоэнкодера, повышая общую стабильность модели.
К тому же, так как мы часто слышали вопрос «А можно ли управлять скоростью и высотой тона речи?», мы добавили небольшой инструментарий для проведения этих операций на сгенерированных записях.
SOVA
В тексте неоднократно упоминалось, что мы выложили в открытый доступ часть своих наработок по синтезу. Вот их список:
- sova-tts-engine – движок на базе Tacotron 2 от NVIDIA. Всё вышеперечисленное, за исключением text predicted GST и VAE, было опубликовано в этом репозитории, плюс проведён избирательный рефакторинг кода;
- sova-tts-tps – тот самый nlp-препроцессор;
- sova-tts-vocoder – практически не изменённый вокодер от NVIDIA, но всё-таки с отличиями;
- sova-tts-binding – пакет для связывания nlp-препроцессора, движка и вокодера в единый инференс-пайплайн. Реализован с прицелом на добавление новых движков и вокодеров;
- sova-tts – упакованный в докер стенд синтеза с простеньким GUI интерфейсом;
- Почищенный датасет и веса Руслана (This work, "SOVA Dataset (TTS RUSLAN)", is a derivative of "RUSLAN: Russian Spoken Language Corpus For Speech Synthesis" by Lenar Gabdrakhmanov, Rustem Garaev, Evgenii Razinkov, used under CC BY-NC-SA 4.0. "SOVA Dataset (TTS RUSLAN)" is licensed under CC BY-NC-SA 4.0 by Virtual Assistant, LLC)
- Датасет и веса Наталии ("SOVA Dataset (TTS Natasha)" is licensed under CC BY 4.0 by Virtual Assistant, LLC)
Наш SOVA TTS (весь код + модель и датасет Наталии) вы можете свободно использовать для коммерческих задач бесплатно.
Планы
Планы у нас грандиозные, а именно:
- Полноценный нормализатор текста для раскрытия чисел, аббревиатур и сокращений;
- Модуль для решения неоднозначностей в ударениях и словах с буквой «ё»;
- Добавление поддержки ssml;
- Дальнейшие эксперименты с VAE, получение контроля над отдельными словами и фонемами;
- Подготовка эмоционального синтеза, по возможности с контролем уровня эмоции;
- Мультидикторный синтез на одной модели;
- Новые голоса;
- Клонирование голоса;
- Возможный переход на более современные архитектуры типа Flowtron или FastSpeech2;
- Эксперименты с вокодерами: дообучение Waveglow, обучение LPCNet, тестирование MelGAN;
- Оптимизация архитектуры для работы в реальном времени на CPU.
На текущий момент мы продолжаем двигаться в сторону улучшения качества синтеза речи. Если то, что мы делаем, вам интересно – пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Все наши наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Синтез речи: SOVA TTS
Спасибо за внимание, впереди еще много интересного!
TiesP
Неплохо, такими темпами аудиокниги скоро будут не нужны)
Интересно, насколько правильно (в плане ударений) ваша «Наталия» прочитает текст Лигурии (как тестовый, без разметки… сомневаюсь что все слова встречались при обучении)
лигурийский регулировщик регулировал в Лигурии,
но тридцать три корабля лавировали, лавировали, да так и не вылавировали,
а потом протокол про протокол протоколом запротоколировал,
как интервьюером интервьюируемый лигурийский регулировщик речисто,
да не чисто рапортовал, да не дорапортовал дорапортовывал
да так зарапортовался про размокропогодившуюся погоду
что, дабы инцидент не стал претендентом на судебный прецедент,
лигурийский регулировщик
акклиматизировался в неконституционном Константинополе,
где хохлатые хохотушки хохотом хохотали и кричали турке,
который начерно обкурен трубкой: не кури, турка, трубку,
купи лучше кипу пик, лучше пик кипу купи,
а то придет бомбардир из Бранденбурга — бомбами забомбардирует за то,
что некто чернорылый у него полдвора рылом изрыл, вырыл и подрыл;
но на самом деле турка не был в деле,
да и Клара к крале в то время кралась к ларю,
пока Карл у Клары кораллы крал, за что Клара у Карла украла кларнет,
а потом на дворе деготниковой вдовы Варвары
два этих вора дрова воровали;
но грех — не смех — не уложить в орех: о Кларе с Карлом
во мраке все раки шумели в драке, — вот и не до бомбардира ворам было,
и не до деготниковой вдовы, и не до деготниковых детей;
зато рассердившаяся вдова убрала в сарай дрова: раз дрова, два дрова,
три дрова — не вместились все дрова,
и два дровосека, два дровокола-дроворуба
для расчувствовавшейся Варвары
выдворили дрова вширь двора обратно на дровяной двор,
где цапля чахла, цапля сохла, цапля сдохла;
цыпленок же цапли цепко цеплялся за цепь;
молодец против овец, а против молодца сам овца,
которой носит Сеня сено в сани,
потом везет Сеньку Соньку с Санькой на санках:
санки скок, Сеньку — в бок, Соньку — в лоб, все — в сугроб,
а Сашка только шапкой шишки сшиб,
затем по шоссе Саша пошел, Саша на шоссе саше нашел;
Сонька же — Сашкина подружка шла по шоссе и сосала сушку,
да притом у Соньки-вертушки во рту еще и три ватрушки —
аккурат в медовик, но ей не до медовика —
Сонька и с ватрушками во рту
пономаря перепономарит, — перевыпономарит:
жужжит, как жужелица, жужжит, да кружится:
была у Фрола — Фролу на Лавра наврала,
пойдет к Лавру на Фрола Лавру наврет,
что — вахмистр с вахмистршей, ротмистр с ротмистршей,
что у ужа — ужата, а у ежа — ежата,
а у него высокопоставленный гость унес трость,
и вскоре опять пять ребят съели пять опят с полчетвертью четверика
чечевицы без червоточины,
и тысячу шестьсот шестьдесят шесть пирогов с творогом
из сыворотки из-под простокваши,
о всем о том около кола колокола звоном раззванивали,
да так, что даже Константин — зальцбуржский бесперспективняк
из-под бронетранспортера констатировал:
как все колокола не переколоколовать, не перевыколоколовать,
так и всех скороговорок не перескороговорить, не перевыскороговорить;
но попытка — не пытка
Sdima1357
Я это даже про себя прочитать не смог, не то что вслух :). Но это не интересный кейз, для реального применения. А вот аудио книги… Всё-таки без понимания контекста, для озвучки аудио книг, по сравнению с с хорошим диктором, наверное ещё очень далеко…
TiesP
Ну да, видимо, в ближайшие несколько лет у Клюквина хлеб не отнимут) Но прогресс ощущается. Мне кажется, что движок из статьи даже лучше движка для русского языка от google в android
miolini
deepzen.io
Dekakhrone Автор
Я так понимаю, что интересен вариант, который был бы озвучен безо всякой помощи со стороны nlp-препроцессора, который бы расставил ударения по словарю. Если так, то вот open source озвучка без ударений:
TiesP
Спасибо, интересно)… да, здесь есть ошибки ударений (первые что услышал «вылавировали», ...«Константинополе», «хохотом»… )
Вообще, интересен полный финальный вариант. Сомнительно же, что в словаре есть все слова с ударениями… Просто, по идее, хорошая модель должна и незнакомые слова правильно озвучивать, верно?
kryvichh
В общем случае в незнакомом слове ударение может быть где угодно. Хотя можно строить предположения и выявлять самые вероятные позиции ударений, главного и (если есть) второстепенного. Это можно делать по однокоренным словам, уже имеющимся в словаре, по семантике (напр. в английских фамилиях ударение обычно на первом слоге, во французских — на последнем, в польских — на предпоследнем), и т.п.
TiesP
Ну да, всё верно. Хорошая модель на основе изученных данных выделяет основные паттерны, которые может применить к новым данным, которые она не видела при обучении. Особенно нейронные сети… а именно они, насколько я понял, и используются в решении.
Dekakhrone Автор
Да, в сети, вообще говоря, мелькает информация, что если скормить такотрону достаточно большой датасет, то он выучит всю необходимую информацию, чтобы синтезировать грамотную речь без использования nlp-препроцессора, однако размер датасета должен исчисляться сотнями часов надиктованной речи.
pvsur
Что-то не завелась шарманка:
sur@hnt56:~/sova-tts$ sudo docker-compose up -d sova-tts
Creating network "sova-tts_default" with the default driver
Creating sova-tts ... done
sur@hnt56:~/sova-tts$ curl --request POST 'http://localhost:8899/tts/' --form 'voice=all' --form 'text="Добрый день!"'
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
404 Not Found
Not Found
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
Dekakhrone Автор
Пардон, обновили имя запроса, а в документации поправить забыли.
Попробуйте исправленный вариант:
pvsur
Ага, отлично, вариант с CPU заработал.
Прикольно, но для коммерческого применения пока не юзабельно, большие проблемы с ударениями.
«лигурийского регулировщика » за раз полностью озвучить не получилось, ноут думал минут 30, выжрал всю память но не смог… ну или может скорее мне надоело ждать.
Но первые два предложения звучат неестественно как-то, ну и ударения…
Вот звонил недавно бот МТС-вский, там у них качество как-то на уровень выше, даже не сразу сообразил, что бот, и к речи придраться там нельзя было… И ударения, и паузы все естественные были.
За работу зачет. Вполне возможно, что ваш коммерческий вариант более умен, чем опенсорсный, это ваше право. Молодцы!
Dekakhrone Автор
Всё так, есть проблемы с произношением (ударения и ё), но они, в основном, связаны с неоднозначностью их простановки, то есть если подготовить решение по их устранению (на правилах или, опять же, на нейронках) и прикрутить к sova tts, то получится уже так:
vazir
час+а если поставить, то получается идеально, иначе ставит на первое (ч+аса) у обоих спикеров. На моем ноуте 6.703с для версии с GPU и Наташей и 7с для Руслана
Общее впечатление у меня — ОФИГЕННО. :)
ramovich
Пытался поставить под Ubuntu версию с Докером — после долгих мучений все запустилось и… зависло намертво без всяких ошибок. Может у меня руки не из того места растут, не спорю. Сколько ОЗУ нужно для работы TTS примерно? Под Windows завести возможно?
Dekakhrone Автор
ОЗУ требуется около 3 ГБ что для gpu, что для cpu версий докера. Под Windows, если честно, пока не тестировали, но как только сделаем это — отпишемся.
А вообще по поводу таких вещей открывайте issue на гитхаб, пожалуйста, всё-таки комментарии не предназначены для решения таких вопросов. Попробуем там разобраться, в чём проблема.
DrAndyHunter
На реддите пишут, что tacotron 2 уже устаревшая и вышедшая из употребления архитектура.
zbot
soundcloud.com/mrironfox/liguriyskiy-regulirovshchik-reguliroval-v-ligurii
TiesP
А у вас что за движок tts? Интересно, что у всех движков разные ошибки в ударениях)… я сравнил ещё с типовым tts на android от гугл. У него тоже несколько ошибок, причем странная ошибка в имени Варвара и более понятные ошибки в незвестных словах «дровокола… дроворуба». Ещё выделяется в движке у гугл, что в таких коротких словах как «во», «до» не меняет гласную от «о» ближе к «а» и за счет этого звучит не очень естественно.
zbot
это IVONA Tatiana — harposoftware.com/en/russian/167-tatyana-russian-voice.html
польская разработка покупал за 35 евро года 4 назад для озвучивания аудиокниг, из ошибок самая досаждающая ПОРОГ — ПРОРОГ
snakers4
Для полноты повествования нужно осветить ряд вещей, о которых авторы вероятно немного постеснялись высказаться для "красивой истории":
Зачем выкладывать чужой код, но не в виде форка, а виде отдельного репо с минимальными изменениями — честно говоря не совсем понятно;
Скорость конструкции Такотрон + WaveGlow примерно в 100 — 1000 ниже (понятное дело на CPU) чем коммерчески рентабельно, да и вообще ради синтеза ставить GPU довольно непонятная для "бизнеса" затея;
"Естественность" у оригинальных английских реализаций понятно на уровень выше, но английский как ни странно фонетически сложнее, но "секретный" соус естественно никто не раскрывает. Имеет место неограниченный доступ к compute и черри-пикинг со стороны Нвидии (они очень любят показывать примеры WaveGlow на оригинальной спектрограмме, а комбинацию с Tacotron засунуть в низ страницы);
Также смотря на описанные планы:
Не могу сказать про полноценность, но мы выкладывали уже такое https://github.com/snakers4/russian_stt_text_normalization
В остальном авторов явно еще ждет много разочарований, т.к. там указан целый ряд пунктов, качественное решение которых — это тема для серьезных исследований, а не просто пункт в чеклисте.
Dekakhrone Автор
Отнюдь, я старался писать статью не как "красивую историю", а как историю разработки и проведённых экспериментов. Не возражаю, что какие-то моменты я мог не упомянуть, но это прозошло не из-за злого умысла. Теперь по пунктам: