
На Хабре вы можете найти множество статей применения данной архитектуры. Этой теме уже более 10 лет и, казалось бы, о чем же здесь еще говорить? Но я бы хотел не просто еще раз вспомнить об микросервисах, а рассказать о применении данной архитектуры именно в разрезе потоковой обработки Big Data. Попытаться объяснить, чем отличается модель потоковой обработки от классической трехуровневой. На реальном примере сравнить применение микросервисов и монолита.
Для начала вспомним, что такое микросервисы и монолиты.
Микросервисы — паттерн проектирования программного обеспечения с помощью набора небольших независимых и легко изменяемых сервисов. Основная цель — это сокращение времени вывода на рынок новых продуктов или функционала (Time to market или TTM). Достигается эта цель за счет разделения сервисов исходя из бизнес-контекста.
Монолит – это паттерн проектирования программного обеспечения, где все компоненты объединены в одну единицу развертывания.
Далее я хочу прояснить, что имею в виду под понятием «потоковой обработки Big Data». В нашей компании «МТС ИТ» в Центре Big Data под потоковой обработкой данных понимается именно обработка потока данных в режиме реального времени. Это может быть построение аналитических отчетов, например, статистика по загруженности станций метрополитена или отгрузка данных при наступлении каких-либо событий (триггеры), например, вход абонентов в определенную геозону.
Под Big Data подразумевается огромная нагрузка – несколько миллионов событий в секунду. Таким образом, можно прийти к следующему определению: системы потоковой обработки Big Data — это высоконагруженные системы, используемые для построения real-time аналитики.
В чем главное отличие такой архитектурной модели, скажем, от классической трехуровневой?
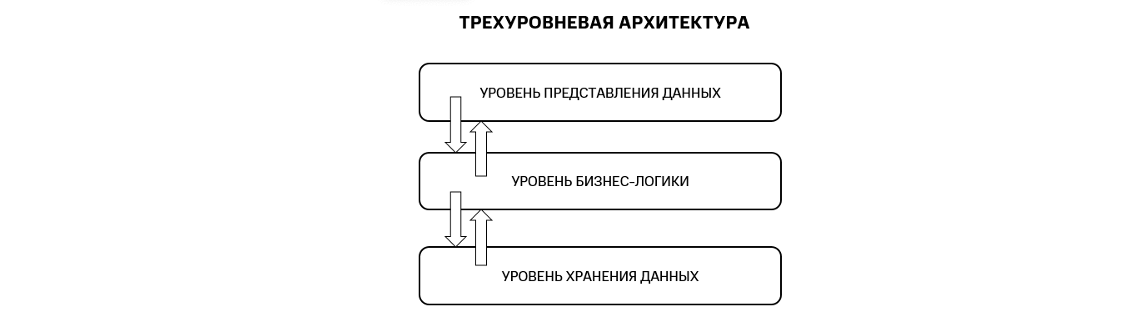
Рисунок 1. Трехуровневая архитектура
В трехуровневой архитектуре данные не только предоставляются пользователям, но также могут быть ими изменены или удалены. Это, в свою очередь, приводит к необходимости хранить данные в строгой согласованности. Пользователь будет очень разочарован, если зачислит себе через мобильное приложение средства на карту, а потом в магазине получит сообщение, что на его счету недостаточно средств. Это пример того, как данные могут быть в несогласованном состоянии. Согласованность данных достигается через транзакции.
Организовать транзакции в распределенной системе, которая неизбежно получается при применении микросервисной архитектуры, непростая задача. Самый простой вариант — вынести всю транзакционность, если это возможно, в один сервис. Но есть вероятность, что в него будут добавлять все больше бизнес логики, а это нарушает концепцию микросервисов, и со временем этот сервис будет напоминать монолит.
Другой способ – это использовать механизма двухфазного коммита. Из-за сетевого взаимодействия между сервисами он подвержен сбоям, причем, вероятность сбоя возрастает с добавление новых сервисов, участвующих в распределенной транзакции.
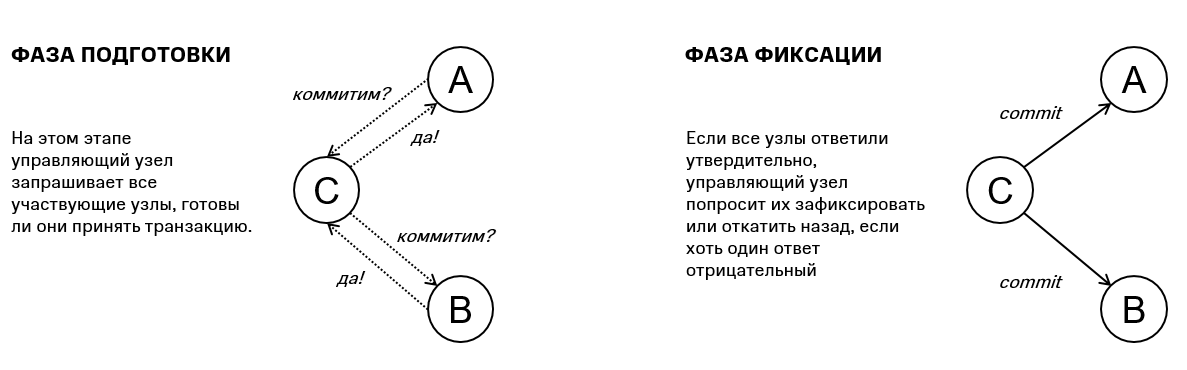
Рисунок 2. Двухфазный коммит
Еще один способ – применить паттерн Сага. Используя этот паттерн, мы уходим от распределенных транзакций, но существенно повышаем сложность реализации и увеличиваем время на разработку.
В модели потоковой обработки полученные данные не модифицируются пользователями, а это значит, что нам достаточно согласованности данных в конечном счете и нет необходимости вводить транзакции в нашу систему, которые сильно усложняют разработку распределенных систем.
Рассмотрим применение микросервисной архитектуры на примере небольшой части геоплатформы МТС, которая отвечает за потоковую обработку данных.
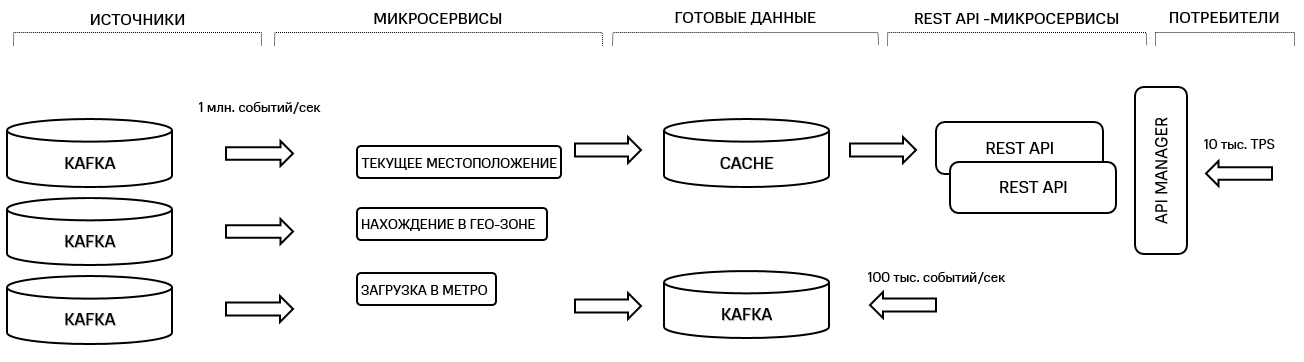
Рисунок 3. Микросервисная архитектура геоплатформы
Есть источник данных, в данном случае — это Kafka кластер. Далее идет набор сервисов, каждый из которых реализует отдельный бизнес-кейс. Например, сервис определения текущего местоположения клиента, сервис мониторинга входа клиентов в заданную геозону или определение загруженности станций метрополитена в реальном времени. Затем эти данные могут запрашивать по требованию, например, через API, которые также разделены на сервисы по бизнес-кейсам, или читать из очереди сообщений, например, Kafka.
Рассмотрим плюсы использования данной архитектуры:
Конечно, есть и минусы:
С другой стороны, можно было бы не делить бизнес-кейс по разным сервисам и сделать все в одном монолите, вот так:
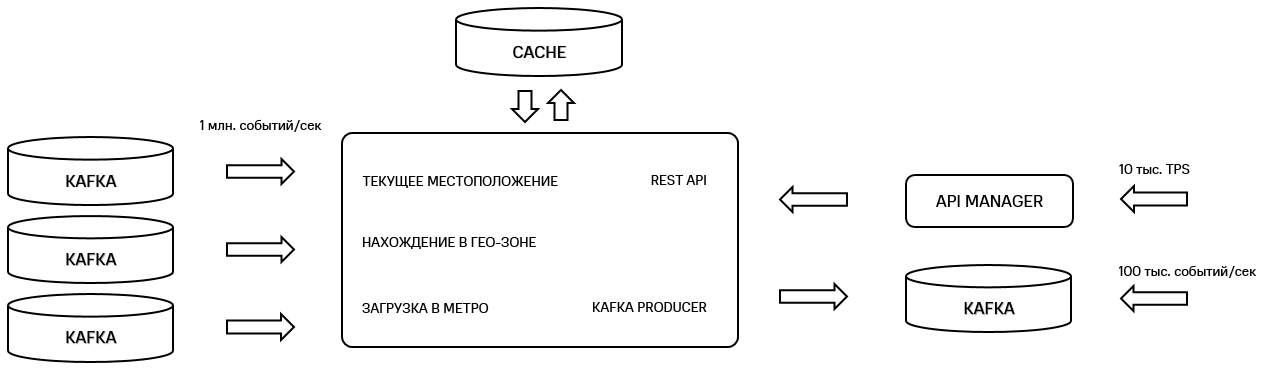
Рисунок 4. Монолитная архитектура геоплатформы
Преимущества, которые мы получим:
Но есть и недостатки, перечислим их:
В итоге минусов у монолита получилось больше, чем у микросервисов. Многие из вас, наверное, сейчас думают, что большинство минусов надуманы. Ведь никто не пишет так код, это плохой стиль программирования и т.п. И в этих рассуждениях есть доля правды, ведь все знают о GRASP паттернах и принципах SOLID. Если им следовать, действительно, можно написать модульный монолит, в котором каждый модуль будет иметь низкую связанность и высокое зацепление. Таким образом, мы избавимся от всех выше перечисленных минусов монолита.
Я тоже согласен с этим утверждением, сам работал с большими монолитами, которые были отлично спроектированы. Но такое бывает не всегда, так как код модульного монолита сложно писать, а самое главное, очень сложно поддерживать модульность. Особенно тогда, когда монолит становится все больше и сложнее. У разработчиков всегда появляется соблазн немного «допилить» и переиспользовать существующий функционал. Это можно контролировать на код ревью. Проблемы могут наступить, когда уходят ключевые специалисты из команды.
На моей практике был такой случай, когда с большого модульного монолита почти одновременно ушли лид команды и ведущий разработчик. Они много лет писали данный монолит и заботились о том, чтобы он оставался модульным. Им быстро нашли замену, но разобраться в большой кодовой базе было непросто. Под давлением бизнеса, испытательного срока и простого желания себя проявить они начали писать код «как поняли», и модульный монолит достаточно быстро скатился до обычного монолита. К нему вернулись все те минусы, о которых я писал выше. И это привело к стагнации проекта. Мораль истории такова: уход ключевого специалиста чаще всего приводит к смерти модульного монолита.
Даже если вы работаете с потоковой обработкой данных, не стоит все бросать и переписывать на микросервисы. Микросервисная архитектура — не панацея. Решая одни проблемы, получаем другие.
Давайте подведем итоги. В каких условиях нам стоит задуматься над применение той или иной архитектуры? И еще раз хочу заметить, что все рекомендации, плюсы и минусы касаются только систем потоковой обработки данных.
Когда следует подумать над применением микросервисной архитектуры:
Когда не следует применять:
Автор: Андрей Ефремов, руководитель центра Java МТС ИТ
Об архитектурных паттернах
Для начала вспомним, что такое микросервисы и монолиты.
Микросервисы — паттерн проектирования программного обеспечения с помощью набора небольших независимых и легко изменяемых сервисов. Основная цель — это сокращение времени вывода на рынок новых продуктов или функционала (Time to market или TTM). Достигается эта цель за счет разделения сервисов исходя из бизнес-контекста.
Монолит – это паттерн проектирования программного обеспечения, где все компоненты объединены в одну единицу развертывания.
Об архитектурных моделях
Далее я хочу прояснить, что имею в виду под понятием «потоковой обработки Big Data». В нашей компании «МТС ИТ» в Центре Big Data под потоковой обработкой данных понимается именно обработка потока данных в режиме реального времени. Это может быть построение аналитических отчетов, например, статистика по загруженности станций метрополитена или отгрузка данных при наступлении каких-либо событий (триггеры), например, вход абонентов в определенную геозону.
Под Big Data подразумевается огромная нагрузка – несколько миллионов событий в секунду. Таким образом, можно прийти к следующему определению: системы потоковой обработки Big Data — это высоконагруженные системы, используемые для построения real-time аналитики.
В чем главное отличие такой архитектурной модели, скажем, от классической трехуровневой?
Рисунок 1. Трехуровневая архитектура
В трехуровневой архитектуре данные не только предоставляются пользователям, но также могут быть ими изменены или удалены. Это, в свою очередь, приводит к необходимости хранить данные в строгой согласованности. Пользователь будет очень разочарован, если зачислит себе через мобильное приложение средства на карту, а потом в магазине получит сообщение, что на его счету недостаточно средств. Это пример того, как данные могут быть в несогласованном состоянии. Согласованность данных достигается через транзакции.
Организовать транзакции в распределенной системе, которая неизбежно получается при применении микросервисной архитектуры, непростая задача. Самый простой вариант — вынести всю транзакционность, если это возможно, в один сервис. Но есть вероятность, что в него будут добавлять все больше бизнес логики, а это нарушает концепцию микросервисов, и со временем этот сервис будет напоминать монолит.
Другой способ – это использовать механизма двухфазного коммита. Из-за сетевого взаимодействия между сервисами он подвержен сбоям, причем, вероятность сбоя возрастает с добавление новых сервисов, участвующих в распределенной транзакции.
Рисунок 2. Двухфазный коммит
Еще один способ – применить паттерн Сага. Используя этот паттерн, мы уходим от распределенных транзакций, но существенно повышаем сложность реализации и увеличиваем время на разработку.
В модели потоковой обработки полученные данные не модифицируются пользователями, а это значит, что нам достаточно согласованности данных в конечном счете и нет необходимости вводить транзакции в нашу систему, которые сильно усложняют разработку распределенных систем.
О примере реализации
Рассмотрим применение микросервисной архитектуры на примере небольшой части геоплатформы МТС, которая отвечает за потоковую обработку данных.
Рисунок 3. Микросервисная архитектура геоплатформы
Есть источник данных, в данном случае — это Kafka кластер. Далее идет набор сервисов, каждый из которых реализует отдельный бизнес-кейс. Например, сервис определения текущего местоположения клиента, сервис мониторинга входа клиентов в заданную геозону или определение загруженности станций метрополитена в реальном времени. Затем эти данные могут запрашивать по требованию, например, через API, которые также разделены на сервисы по бизнес-кейсам, или читать из очереди сообщений, например, Kafka.
Рассмотрим плюсы использования данной архитектуры:
- Независимое развертывание и обновление сервисов. Можно быстро выпустить новую бизнес-фичу или целый сервис в промышленную эксплуатацию, не опасаясь сломать работу других сервисов (сокращение TТM). Это особенно актуально при обработке больших данных. Большой объем поступающих данных и их разнообразие приводит к образованию большого числа новых бизнес-кейсов и частым изменениям в существующих.
- Эффективное горизонтальное масштабирование. Какие-то сервисы более нагружены и требовательны к ресурсам, какие-то — менее. Зная эту информацию, мы можем индивидуально масштабировать каждый сервис, что более эффективно, чем масштабирование сервиса в составе монолита.
- Сервисы могут быть реализованы с использованием различных языков программирования, фреймворков и т.д. Опять очень актуально именно в Big Data, где из-за большого числа бизнес-кейсов над одной платформой одновременно работают много разных команд. Еще один значимый плюс — возможность опробовать «в бою» новую технологию или фреймворк на отдельно взятом сервисе.
- Низкий порог входа для новых разработчиков. Разобраться в маленькой кодовой базе не составляет большого труда. Даже если сервис написан давно и качество кода оставляет желать лучшего — это тоже не проблема. Как правило, сервис можно переписать с «нуля» за несколько спринтов.
- Масштабирование команды. Если сразу понятен бизнес-контекст, т.е. как разделить систему на микросервисы, то, при наличии ресурсов, можно распараллелить разработку, существенно снизить общее время на реализацию платформы.
Конечно, есть и минусы:
- Распределенная система. Систему, состоящую из десятка сервисов, становится сложно проектировать и разрабатывать. Требуется высокая квалификация архитекторов и разработчиков.
- Сетевые взаимодействия. Сервисы общаются между собой по сети, а сетевые соединения ненадежны и подвержены отказам.
- Сложность эксплуатации. Распределенную систему становится сложно разворачивать и поддерживать. Требуется высокая квалификация службы devops и служб поддержки.
С другой стороны, можно было бы не делить бизнес-кейс по разным сервисам и сделать все в одном монолите, вот так:
Рисунок 4. Монолитная архитектура геоплатформы
Преимущества, которые мы получим:
- «Быстрый старт». Безусловно, платформу в виде монолита можно реализовать быстрее.
- Нет сетевого взаимодействия между модулями монолита. Не надо писать много кода по обработке исключительных ситуаций, возникающих из-за проблем на сети. Это сильно упрощает и ускоряет разработку.
Но есть и недостатки, перечислим их:
- Уменьшение надежности. Одна небольшая доработка одного из модулей теоретически может «положить» всю платформу, на которой у нас работает несколько разных кейсов для разных заказчиков.
- Сильная связанность. Одни модули начинают использовать в своей реализации методы других модулей, как следствие, чтобы доработать один модуль — нужно изменять несколько. Это сильно усложняет разработку и тестирование. Время вывода нового, даже незначительно функционала, существенно возрастает.
- Большой порог входя для новых разработчиков. Нужны месяцы, чтобы разработчик смог разобраться в большой кодовой базе. Да и мало кто любит работать с большим количеством legacy кода.
- Сложно внедрять новые технологии. Если в монолите вы начали использовать какой-то фреймворк или технологию, то в последствии заменить его на другой будет очень трудно.
В итоге минусов у монолита получилось больше, чем у микросервисов. Многие из вас, наверное, сейчас думают, что большинство минусов надуманы. Ведь никто не пишет так код, это плохой стиль программирования и т.п. И в этих рассуждениях есть доля правды, ведь все знают о GRASP паттернах и принципах SOLID. Если им следовать, действительно, можно написать модульный монолит, в котором каждый модуль будет иметь низкую связанность и высокое зацепление. Таким образом, мы избавимся от всех выше перечисленных минусов монолита.
Я тоже согласен с этим утверждением, сам работал с большими монолитами, которые были отлично спроектированы. Но такое бывает не всегда, так как код модульного монолита сложно писать, а самое главное, очень сложно поддерживать модульность. Особенно тогда, когда монолит становится все больше и сложнее. У разработчиков всегда появляется соблазн немного «допилить» и переиспользовать существующий функционал. Это можно контролировать на код ревью. Проблемы могут наступить, когда уходят ключевые специалисты из команды.
На моей практике был такой случай, когда с большого модульного монолита почти одновременно ушли лид команды и ведущий разработчик. Они много лет писали данный монолит и заботились о том, чтобы он оставался модульным. Им быстро нашли замену, но разобраться в большой кодовой базе было непросто. Под давлением бизнеса, испытательного срока и простого желания себя проявить они начали писать код «как поняли», и модульный монолит достаточно быстро скатился до обычного монолита. К нему вернулись все те минусы, о которых я писал выше. И это привело к стагнации проекта. Мораль истории такова: уход ключевого специалиста чаще всего приводит к смерти модульного монолита.
О выводах
Даже если вы работаете с потоковой обработкой данных, не стоит все бросать и переписывать на микросервисы. Микросервисная архитектура — не панацея. Решая одни проблемы, получаем другие.
Давайте подведем итоги. В каких условиях нам стоит задуматься над применение той или иной архитектуры? И еще раз хочу заметить, что все рекомендации, плюсы и минусы касаются только систем потоковой обработки данных.
Когда следует подумать над применением микросервисной архитектуры:
- большая команда разработчиков, или команд несколько;
- команда специалистов высокой квалификации;
- хорошо описан бизнес-контекст, на начальном этапе есть понимание как разбить систему на сервисы;
- часто меняются требования бизнеса и нужен быстрый вывод на рынок данных изменений.
Когда не следует применять:
- плохо описан бизнес-контекст, нет понимания, как разделить функционал на сервисы;
- мало времени на реализацию — если очень сжатые сроки на реализацию, лучше всегда начинать с монолита;
- маленькая команда — ей понадобится гораздо больше времени на реализацию системы через микросервисы, лучше начинать с монолита.
Автор: Андрей Ефремов, руководитель центра Java МТС ИТ
devopg
кафка микросервисы — неплохо