
В этой статье вы узнаете, как МТС решает задачи по хранению и обработке больших данных. Как архитектура платформы Big Data совместно с инфраструктурой помогает их решать более эффективно. А когда наоборот — инфраструктура выступает существенным ограничителем, влияющим на архитектуру платформы.
Меня зовут Сергей Косый komgbu, я работаю руководителем центра компетенций архитектуры в центре Big Data МТС. Я и многие мои коллеги очень любим две вещи: большие данные и велосипеды. На велосипедах предпочитаем ездить, а не изобретать их.

Итак, наша задача при построении платформы Big Data – найти компромисс: чтобы слон (большие данные) не раздавил велосипед (инфраструктуру), а велосипед был быстрым, надежным, и слону было удобно на нем ездить.
Летом наша компания проводила на Хабре опрос про применение технологий в российских IT. В копилку «больших данных» существенный вклад опрос не внес, но, тем не менее, осенью подвели его итоги.
Одним из вопросов был «Используются ли в вашей компании технологии Big Data?»
Посмотрим, как распределились ответы.
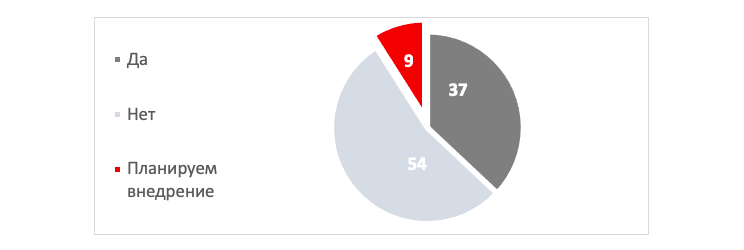
Используются ли в вашей компании технологии Big Data?
37% респондентов ответили что они уже сейчас используют технологии Big Data — возможно, если бы вы ответили так же, то можно перейти на другую статью. Оставшимся 63% материал вполне может пригодиться.
Второй вопрос, на который хочу обратить внимание: «Какие «подводные камни» наиболее ощутимы при внедрении технологий Big Data?». Ответы вполне ожидаемы.
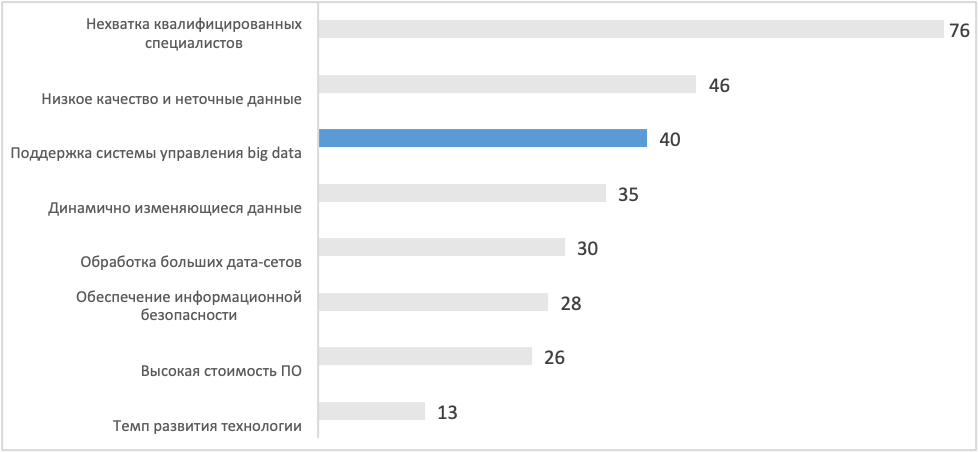
«Подводные камни» при внедрении технологий Big Data
1 позиция: Квалифицированных специалистов, владеющих нужным стеком технологий, действительно мало. Мы идем по пути развития компетенций своих сотрудников, в том числе новых.
2, 4, 5 позиции: Низкое качество данных, динамично меняющиеся данные, обработка больших наборов данных – это базовые задачи, которые приходится решать в повседневной работе. Я бы сказал, что работа с Big Data предполагает необходимость решения этих вопросов, т.е. это не «подводные камни», а что ни на есть явные, заранее известные проблемы.
3 позиция: Поддержка системы управления Big Data, к которому я отношу в т.ч. проблемы построения инфраструктуры платформы. Про этот вопрос и пойдет речь далее.
История МТС показывает, что «Большие данные» в компании были даже тогда, когда не существовало какого-то устоявшегося термина. Как это возможно? Как-то так:

Big Data образца 1993г.
Компания МТС основана в октябре 1993 года. Данные уже тогда перестали помещаться на один носитель (дискета 5,25” объемом 360КБ, если память меня не подводит) и не могли быть обработаны одновременно. Приходилось искать решения для возможности обработать объемы в десятки мегабайт. Чем не Big Data?
По мере роста количества данных, над которыми нужно было проводить аналитику, в ландшафте МТС появлялись:
— В 2003 году SAS, который до сих пор выполняет свой функционал. При этом объем хранимых и обрабатываемых данных составляет десятки и сотни гигабайт.
— В 2014 году MPP Teradata с возможностью хранить и обрабатывать уже десятки терабайт.
— В 2016 году назрела необходимость работать с сотнями терабайт, петабайтами и понимание, что для решения этой задачи нужна новая платформа.
Мы на тот момент выбрали платформу HDP от Hortonworks (ныне Cloudera). Какие задачи предполагалось решать и какие требования к платформе предъявлялись?
Работа любого хорошего архитектора начинается конечно же с требований (наша работа по выбору платформы – не исключение).
Рассмотрим для начала некоторые архитектурно-значимые функциональные требования к платформе:
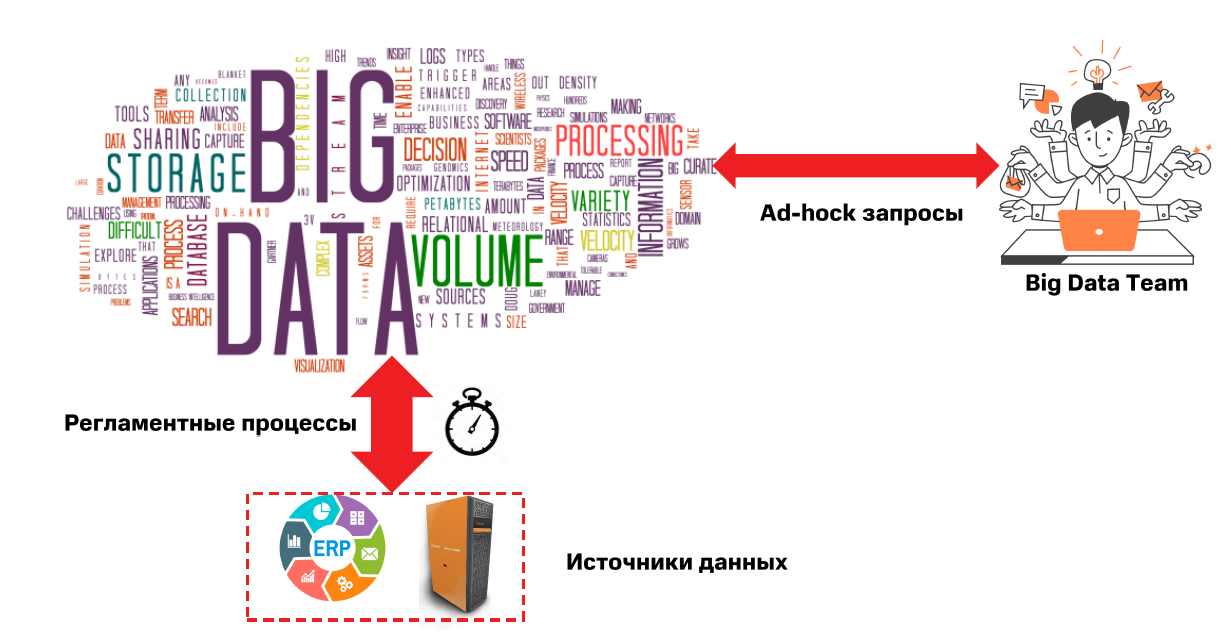
Функциональные требования к платформе Big Data 2016 года
1) Big Data начинается с источников данных. В 2016 году состав источников был примерно такой: ERP системы, данные (готовые витрины) в MPP системе.
Для многих аналитических задач, проверки гипотез, задач Data Science требуются данные на достаточно отдаленные моменты времени в прошлом. Во многих корпоративных системах нет возможности хранить историю в удобном для пользователей виде. Также рано или поздно заканчиваются ресурсы быстрой, но дорогой MPP, и куда-то нужно деть «холодные данные».
2) Регламентные ETL/ELT процессы. Преимущественно пакетная обработка и загрузка данных в кластер, запуск процессов по расписанию.
3) Пользователи. Информационные системы имеют свойство работать отлично, когда у них нет данных, регламентных процессов и пользователей. В нашей команде было около 30 человек: аналитики, разработчики, специалисты по Data Science.
И более подробно остановимся на архитектурных требованиях (так же как и Нил Форд я не люблю термин «нефункциональные требования» из-за частицы «не»: приходилось ли вам читать технические задания, в одном предложении которых раз 15 написана частица «не»?).
Рассмотрим 8 наиболее существенных требований для платформы обработки и хранения больших данных.
Требование №1. Высокая доступность
Посмотрим, чем обусловлено данное требование. Желание иметь информационную систему в состоянии «up and running» 24х7 похвально, но если ей пользуются офисные работники в одном часовом поясе при графике с 9 до 18 без дополнительных длительных ночных процессов, оно вряд ли оправдано.

• на кластере должны выполняться сотни ETL/ELT процессов (преимущественно ночью, но не исключая и запуски в дневное время)
• более 30 пользователей в рабочее время (но не исключая и вечернее – продолжительные процессы и возможность запускать задачи из дома никто не отменял)
• доступность 95% система все-таки аналитическая, можно устроить и down-time на обслуживание, тюнинг. К тому же, все начиналось с этапа RnD.
• время сборки витрин до 48 часов (главное, чтобы такой процесс не попал в «регламентное окно» на кластере)
• целевое время готовности витрин T-7 (начиналось с того, что принятие решений на данных с таким лагом – вполне допустимо)
Требование №2. Надежность
Вы точно захотите, чтобы платформа Big Data была надежна, не меньше, чем Швейцарский банк.
Зачем это нужно? — Давайте смотреть.

• на источниках, как правило, невозможно хранить исторические данные на большую глубину, это не их задача. Такие данные должны быть на платформе Big Data и, собственно, только тут они и будут доступны. В случае потери вы останетесь без исторических данных.
• если вы хотите начать собирать данные и сразу их использовать, получать от них некий профит, это скорее всего не получится. Для задач Data Science часто требуются исторические данные. Историю нужно еще накопить. В 2016 суммарно эти данные не превышали 1ПБ.
• классические реляционные СУБД давно решили проблему надежности: бэкап -> внешний носитель -> восстановление. Смотрим, что получается у нас с Big Data: 1 ПБ –> внешний носитель на 1ПБ –> восстановление 1ПБ. Да, кластер еще как ни как – распределенная система. Сделать бэкап такого объема и потом восстановиться из него – задача очень нетривиальная.
Требование №3. Отказоустойчивость
В современном мире очень технологичное производство. Качество компонентов, из которых собираются сервера, неизменно растет. Но теорию вероятностей никто не отменял — неприятности случаются. Часто даже не по вине техники.

• когда в вашем кластере сотни серверов с тысячами шпиндельных дисков. Кластер спокойно должен пережить потерю диска, сервера и при достаточном объеме кластера – даже целой стойки. И хотелось бы без заметной деградации в производительности.
• ошибки в прикладных задачах, запущенных на кластере, тоже могут случаться. Это не повод делать перезагрузку кластера.
Требование №4. Горизонтальная масштабируемость
Любимое требование архитекторов, которым в эру Docker + Kubernetes никого уже не удивишь. Надо 2 экземпляра приложения? – Поднимаем и работаем!

• не хочется «упираться» в ресурсы одного сервера. Хочется получать линейный рост производительности и места для хранения данных при добавлении новых узлов в кластер (без его остановки). Чем плохи высокопроизводительные сервера, например, построенные на архитектуре mainframe? Дорого, сложно, долго… В общем, пока вы его введете в эксплуатацию, есть риск начать все делать с начала.
• хочется иметь возможность расширять кластер неоднородными узлами: вряд ли вам одобрят проект закупки 30ПБ кластера на перспективу 7 лет, учитывая, что в первый год эксплуатации вы будете использовать всего 1 ПБ. 7 лет – довольно большой срок в ИТ. Даже через 3 года может случиться, что серверов, которые вы кажется совсем недавно заказывали у вендора – больше нет. Зато есть другие, более производительные, с лучшими компонентами и как правило, более дешевыми. Применение «магии» в виде ре-балансировки кластера должно позволить решить эту проблему.
Требование №5. Высокая производительность
Хранить большие объемы данных – это прекрасно. Куда более важно быть способными их обработать за приемлемое время.

• обработка датасетов размером десятки ТБ должно занимать часы, а не дни. Иначе пользователи платформы выпьют весь кофе, съедят все печенки и выкурят все сигареты. В лучшем случае – проедут несколько сотен километров на «шоссере» пока будет готов результат. А дальше, как говорится, «ride, eat, sleep — repeat».
Требование №6. Мультиарендность
Ничего так не напрягает человека, особенно человека, который что-то помнит о 80-90 годах прошлого века, как очередь (даже если именно очередь лежит в основе менеджера ресурсов кластера).

• нужна возможность распределять ресурсы кластера между различными командами, регламентными процессами, ad-hock запросами и т.д. Каждый захочет свой, хоть и не большой, но изолированный кусочек кластера.
Требование №7. Безопасность
Безопасность важна как нигде более в вашем ландшафте. Почему? Потому что в кластере будут данные практически из всех информационных систем компании. Да, маскированные. Да, обезличенные. Но от этого не менее ценные. Вы же не захотите прочитать про утечку данных в вашей компании на Хабре? Вот и мы тоже не хотим.

• потребуется обеспечение ролевой модели доступа к данным: не всем должны быть доступны все области данных в кластере
• интеграция с корпоративным Active Directory
• интеграция с SIEM: также должна решаться задача аудита и обнаружения несанкционированного доступа
• выполнение прочих требований информационной безопасности
Требование №8. Низкая стоимость хранения
Если горизонтальная масштабируемость – любимое требование архитектора, то низкая стоимость хранения или владения – любимое требование менеджера. На данных можно и нужно зарабатывать. При том, что расходы на Big Data тоже не маленькие.

— стоимость хранения должна быть существенно ниже классических аналитических хранилищ данных от известных и уважаемых вендоров. Любому менеджеру не интересна прибыль ради данных, интересен обратный сценарий.
С требованиями более-менее разобрались. Теперь нужно разобраться, что нам может помочь в их реализации.
Возьмем наши требования и для наглядности поместим их в матрицу влияния архитектуры и инфраструктуры.
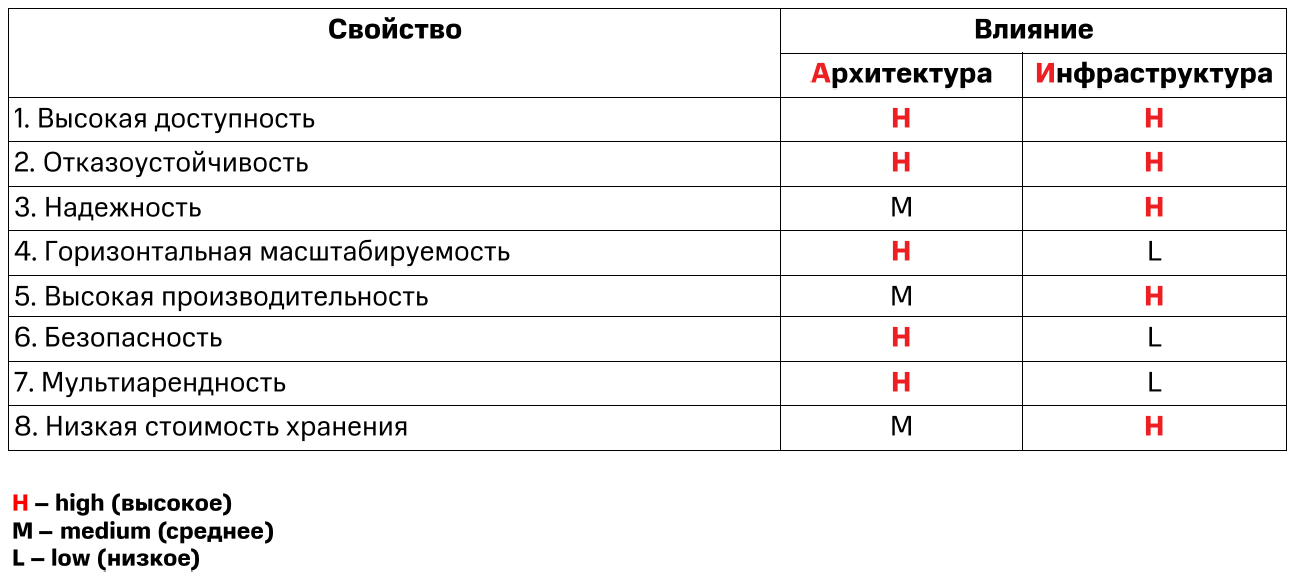
Матрица влияния на выполнение требований
Глядя на матрицу, кажется, что все в порядке: многие требования зависят от выбранной архитектуры платформы Big Data, многие требования зависят от инфраструктуры, на которой платформа будет развернута. Напомню, одно из главных заявленных преимуществ платформы Hadoop является «commodity hardware», а, судя по матрице, так и не скажешь.
Посмотрим, что нам дает архитектура Hadoop на примере референсной архитектуры размещения кластера в ЦОД от Cloudera.
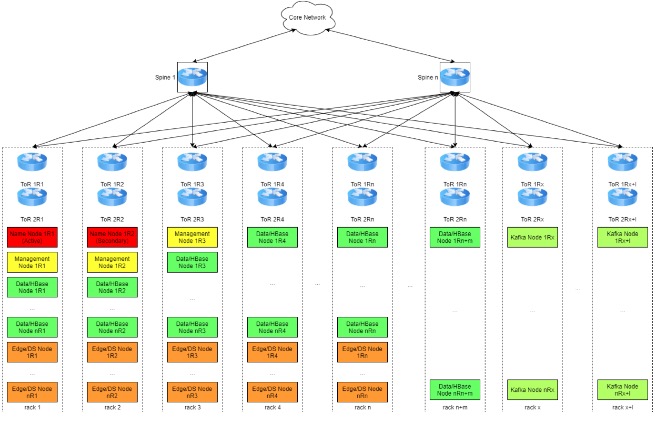
Архитектура разворачивания узлов кластера Hadoop в ЦОД
В кластере присутствуют узлы различного назначения:
Name Node – это «Master» узел кластера, наиболее критичный узел и, по совместительству, единая точка отказа, хранит всю мета-информацию о файловой системе кластера и поддерживает ее работоспособность. Нет Name Node – кластер превращается в груду бесполезного железа. На нем, наверное, можно будет майнить криптовалюты, но для этого есть более эффективные решения. Уменьшить риски, связанные с его потерей, поможет Standby Name Node. Естественно, располагаться они должны в разных стойках и быть подключены к разным коммутаторам.
Management Node – это узлы, позволяющие работать базовым сервисам кластера также в отказоустойчивом режиме. Таких узлов может быть достаточно много, отказ одного из них не повлияет сильно на работу кластера.
Data/HBase Node – это узлы, на которых уже непосредственно хранятся и обрабатываются данные. Это самый многочисленный тип узлов кластера. Они равномерно «размазываются» по стойкам и генерируют высокий трафик (особенно в процессах репликации).
Edge/DS Node – строго говоря, не члены кластера. Эти узлы нужны для загрузки данных в кластер / выгрузки из кластера, а также для обработки данных в случаях, когда параллельная обработка на кластере невозможна. В ряде случаев эти узлы содержат GPU для выполнения задач обучения моделей Data Science, на них разворачивается ETL/ELT инструментарий, сервера приложений, мониторинга, проверки качества и т.д. На этих узлах работают и пользователи.
Kafka Node – узлы распределенного брокера сообщений Kafka, используются в задачах потоковой обработки с архитектурой Pub/Sub. Узлы также равномерно «размазываются» по стойкам.
Кроме того, в каждой стойке есть дублированные ToR-коммутаторы, а каждый узел кластера по 2x10Gb интерфейсам соединен с обоими коммутаторами. В свою очередь, ToR коммутаторы соединяются с коммутаторами уровня Spine и наиболее интенсивный траффик, как видно из схемы, перемещается по направлению «Восток-Запад», т.е. не покидает пределы ЦОД-а. На уровне выше находятся коммутаторы ядра сети.
Такая архитектура помогает нам выполнить требования:
• Высокая доступность
• Отказоустойчивость
• Надежность
• Горизонтальное масштабируемость
• Высокая производительность
Посмотрим, какой вклад в выполнение требований может сделать инфраструктура.

Типовые спецификации стоек и узлов кластера Hadoop 2016-2017гг
Подобная конфигурация положительно влияет на выполнение требований:
• Высокая доступность
• Отказоустойчивость
• Надежность
• Горизонтальное масштабируемость
• Высокая производительность
• Низкая стоимость хранения
Кажется, все у нас работает замечательно, платформа Big Data готова: данные хранятся, ETL процессы работают, пользователи тоже и практически ничего не меняется. Или меняется…
Посмотрим, что случилось с требованиями к платформе спустя всего 3-4 года.

Функциональные требования к платформе Big Data 2019 года
• расширился круг источников данных: добавился трафик служебных событий с мобильных устройств (control plane). Появились внешние данные из интернета (в том числе от внешних провайдеров);
• добавилась обработка потоковых данных, в сценариях обработки событий по триггерам и аналитики в online и в offline;
• с пользователями, кажется, ничего не произошло, разве что их стало около 300 вместо 30, «выросли» вместе с данными.
Все это повлияло и на архитектурные требования:
• высокая доступность – на кластере выполняются более 1000 задач, многие из которых практически в режиме 24х7. Увеличилось кратно количество пользователей платформы и соответственно уровень энтропии в ad-hock аналитике. Целевое время готовности витрин данных T-1 – лаг в неделю – теперь моветон. Целевая доступность кластера не хуже 99%.
• Надежность – с появлением источников потоковых данных появилась необходимость их непрерывной обработки. «Простой» обработчиков ведет к полной или частичной потере данных. Требуется накапливать историю в 10 ПБ и более
Если посмотреть на исходные требования, мы все это закладывали при выборе платформы Big Data как в архитектуру, так и в инфраструктуру: добавляем новые узлы в кластер и проблем нет!?
Если бы все так и было, мы были бы счастливы, сэкономили себе много времени, усилий и не пришлось бы писать эту статью. Кое-что пошло не так, как предполагалось.

Существенные ограничения инфраструктуры на платформу Big Data
Оказалось, что ЦОД, в котором была развернута наша платформа, тоже не бесконечен. Мы перестали выполнять требование по возможности горизонтального масштабирования. Инфраструктура при этом в нашей матрице влияла на это требования меньше всего!
Какие варианты остаются, когда заканчиваются места в стойках?
• масштабироваться вертикально: никто не отменял такой вариант. Но тут есть проблемы:
— Куда деть «старые» компоненты серверов при том что срок их эксплуатации 5-7 лет, а прошло всего 3 года (продать на ebay?).
— Компоненты нелинейно растут в цене (посмотрите на прайс планки 64ГБ RAM и 128ГБ RAM) также потребуется поменять процессоры (есть ограничения по поддерживаемому объему RAM) и т.д.
— Закупки, поставка, монтаж, настройка и передача в эксплуатацию занимают у нас до 6 месяцев – это довольно долго.
• искать другой ЦОД
Мы выбрали второй вариант. Хорошо, что у МТС площадок много и среди них есть даже свободные и подходящие под наши требования.

Типовые спецификации стоек и узлов кластера Hadoop 2019 г. в ЦОД-е «Б»
В новых узлах мы увеличили количество ядер и памяти, равно как и количество и объем дисков. Также у нас изменился характер использования кластера пользователями: ранее преимущественно нагрузка ложилась на движок TEZ, сейчас практически все пользователи пишут задачи с использованием Spark. Под его кэш в спецификации были включены NVMe диски.
И все же еще есть большой вопрос над красной стрелкой между двумя ЦОД. Что же у нас опять не так?
Не так у нас то, что ЦОД-ов теперь два, а это означает:
• Необходимость репликации больших объемов данных – как пользователям, так и регламентным процессам могут требоваться данные, находящиеся в разных кластерах одновременно
• Дублирование данных – теперь часть данных есть на обоих кластерах, что снижает автоматически TCO в 2 раза
• Нагрузка на сетевую инфраструктуру – схема трафика «Восток-Запад» больше не работает. На каждой площадке сотни узлов, трафик усиливается в направлении «Север-Юг»
• Другие ИС в коммунальных каналах – Big Data большая, но и «маленьких» обижать нельзя, те же ERP системы не должны страдать от копирования таблиц между кластерами
• Негативное влияние на SLA по сборке витрин – дополнительные шаги в регламентных процессах
• Усложнение оркестрации процессов
• Усложнение архитектуры платформы
Все эти проблемы и способы их решения заслуживают отдельной статьи.
Кроме того, в ближайшее время мы будем пилотировать добавление к кластеру узлов в роли Compute Node. С ростом количества пользователей возросла роль вычислительных ресурсов в кластере. Хочется управлять вычислительными ресурсами и ресурсами хранения кластера независимо. А еще попробуем в 2 раза снизить TCO — включить механизм Erasure Coding, который судя по совместным тестам Cloudera и Intel, дает еще и увеличение скорости записи файлов.
Итак, если у вас действительно «большие данные», то объем данных, количество источников, количество пользователей и количество продуктов, построенных на этих технологиях, будут увеличиваться примерно в 10 раз каждые 3 года. Это потребует новых стоек, запаса по питанию и охлаждению, сетевой инфраструктуры.
Даже если в начале пути кейсов по обработке потоковых данных нет или их не много – скоро они точно появятся и потребуют дополнительных ресурсов: Volume, Velocity, Variety способны очень быстро «догнать» возможности инфраструктуры.
Спланируйте рост на 5-7 лет — «время жизни» сервера исходя из показателя x10 за 3 года.
Учитывайте инфраструктуру ЦОД-а, в котором будете размещать сервера для платформы. Менять ее будет крайне сложно или даже невозможно.

Чтобы стать лидером в отрасли, технологии Big Data вам смогут помочь. Для этого совсем необязательно быть телеком-компанией №1 в России.
Планируйте велосипед-инфраструктуру уже сейчас. Стройте кластера, собирайте и обрабатывайте данные, находите в них новые инсайты и делитесь как успехами, так и неудачами с сообществом.
Если хочется попробовать свои силы в Big Data, но по каким-то причинам нет возможности – приходите к нам! it-mts-job.ru/invite
Меня зовут Сергей Косый komgbu, я работаю руководителем центра компетенций архитектуры в центре Big Data МТС. Я и многие мои коллеги очень любим две вещи: большие данные и велосипеды. На велосипедах предпочитаем ездить, а не изобретать их.
Итак, наша задача при построении платформы Big Data – найти компромисс: чтобы слон (большие данные) не раздавил велосипед (инфраструктуру), а велосипед был быстрым, надежным, и слону было удобно на нем ездить.
«Боли» при построении платформы Big Data
Летом наша компания проводила на Хабре опрос про применение технологий в российских IT. В копилку «больших данных» существенный вклад опрос не внес, но, тем не менее, осенью подвели его итоги.
Одним из вопросов был «Используются ли в вашей компании технологии Big Data?»
Посмотрим, как распределились ответы.
Используются ли в вашей компании технологии Big Data?
37% респондентов ответили что они уже сейчас используют технологии Big Data — возможно, если бы вы ответили так же, то можно перейти на другую статью. Оставшимся 63% материал вполне может пригодиться.
Второй вопрос, на который хочу обратить внимание: «Какие «подводные камни» наиболее ощутимы при внедрении технологий Big Data?». Ответы вполне ожидаемы.
«Подводные камни» при внедрении технологий Big Data
1 позиция: Квалифицированных специалистов, владеющих нужным стеком технологий, действительно мало. Мы идем по пути развития компетенций своих сотрудников, в том числе новых.
2, 4, 5 позиции: Низкое качество данных, динамично меняющиеся данные, обработка больших наборов данных – это базовые задачи, которые приходится решать в повседневной работе. Я бы сказал, что работа с Big Data предполагает необходимость решения этих вопросов, т.е. это не «подводные камни», а что ни на есть явные, заранее известные проблемы.
3 позиция: Поддержка системы управления Big Data, к которому я отношу в т.ч. проблемы построения инфраструктуры платформы. Про этот вопрос и пойдет речь далее.
Big Data или не Big Data?
История МТС показывает, что «Большие данные» в компании были даже тогда, когда не существовало какого-то устоявшегося термина. Как это возможно? Как-то так:
Big Data образца 1993г.
Компания МТС основана в октябре 1993 года. Данные уже тогда перестали помещаться на один носитель (дискета 5,25” объемом 360КБ, если память меня не подводит) и не могли быть обработаны одновременно. Приходилось искать решения для возможности обработать объемы в десятки мегабайт. Чем не Big Data?
По мере роста количества данных, над которыми нужно было проводить аналитику, в ландшафте МТС появлялись:
— В 2003 году SAS, который до сих пор выполняет свой функционал. При этом объем хранимых и обрабатываемых данных составляет десятки и сотни гигабайт.
— В 2014 году MPP Teradata с возможностью хранить и обрабатывать уже десятки терабайт.
— В 2016 году назрела необходимость работать с сотнями терабайт, петабайтами и понимание, что для решения этой задачи нужна новая платформа.
Мы на тот момент выбрали платформу HDP от Hortonworks (ныне Cloudera). Какие задачи предполагалось решать и какие требования к платформе предъявлялись?
Функциональные и архитектурные (нефункциональные) требования к платформе Big Data
Работа любого хорошего архитектора начинается конечно же с требований (наша работа по выбору платформы – не исключение).
Рассмотрим для начала некоторые архитектурно-значимые функциональные требования к платформе:
Функциональные требования к платформе Big Data 2016 года
1) Big Data начинается с источников данных. В 2016 году состав источников был примерно такой: ERP системы, данные (готовые витрины) в MPP системе.
Для многих аналитических задач, проверки гипотез, задач Data Science требуются данные на достаточно отдаленные моменты времени в прошлом. Во многих корпоративных системах нет возможности хранить историю в удобном для пользователей виде. Также рано или поздно заканчиваются ресурсы быстрой, но дорогой MPP, и куда-то нужно деть «холодные данные».
2) Регламентные ETL/ELT процессы. Преимущественно пакетная обработка и загрузка данных в кластер, запуск процессов по расписанию.
3) Пользователи. Информационные системы имеют свойство работать отлично, когда у них нет данных, регламентных процессов и пользователей. В нашей команде было около 30 человек: аналитики, разработчики, специалисты по Data Science.
И более подробно остановимся на архитектурных требованиях (так же как и Нил Форд я не люблю термин «нефункциональные требования» из-за частицы «не»: приходилось ли вам читать технические задания, в одном предложении которых раз 15 написана частица «не»?).
Рассмотрим 8 наиболее существенных требований для платформы обработки и хранения больших данных.
Требование №1. Высокая доступность
Посмотрим, чем обусловлено данное требование. Желание иметь информационную систему в состоянии «up and running» 24х7 похвально, но если ей пользуются офисные работники в одном часовом поясе при графике с 9 до 18 без дополнительных длительных ночных процессов, оно вряд ли оправдано.
• на кластере должны выполняться сотни ETL/ELT процессов (преимущественно ночью, но не исключая и запуски в дневное время)
• более 30 пользователей в рабочее время (но не исключая и вечернее – продолжительные процессы и возможность запускать задачи из дома никто не отменял)
• доступность 95% система все-таки аналитическая, можно устроить и down-time на обслуживание, тюнинг. К тому же, все начиналось с этапа RnD.
• время сборки витрин до 48 часов (главное, чтобы такой процесс не попал в «регламентное окно» на кластере)
• целевое время готовности витрин T-7 (начиналось с того, что принятие решений на данных с таким лагом – вполне допустимо)
Требование №2. Надежность
Вы точно захотите, чтобы платформа Big Data была надежна, не меньше, чем Швейцарский банк.
Зачем это нужно? — Давайте смотреть.
• на источниках, как правило, невозможно хранить исторические данные на большую глубину, это не их задача. Такие данные должны быть на платформе Big Data и, собственно, только тут они и будут доступны. В случае потери вы останетесь без исторических данных.
• если вы хотите начать собирать данные и сразу их использовать, получать от них некий профит, это скорее всего не получится. Для задач Data Science часто требуются исторические данные. Историю нужно еще накопить. В 2016 суммарно эти данные не превышали 1ПБ.
• классические реляционные СУБД давно решили проблему надежности: бэкап -> внешний носитель -> восстановление. Смотрим, что получается у нас с Big Data: 1 ПБ –> внешний носитель на 1ПБ –> восстановление 1ПБ. Да, кластер еще как ни как – распределенная система. Сделать бэкап такого объема и потом восстановиться из него – задача очень нетривиальная.
Требование №3. Отказоустойчивость
В современном мире очень технологичное производство. Качество компонентов, из которых собираются сервера, неизменно растет. Но теорию вероятностей никто не отменял — неприятности случаются. Часто даже не по вине техники.
• когда в вашем кластере сотни серверов с тысячами шпиндельных дисков. Кластер спокойно должен пережить потерю диска, сервера и при достаточном объеме кластера – даже целой стойки. И хотелось бы без заметной деградации в производительности.
• ошибки в прикладных задачах, запущенных на кластере, тоже могут случаться. Это не повод делать перезагрузку кластера.
Требование №4. Горизонтальная масштабируемость
Любимое требование архитекторов, которым в эру Docker + Kubernetes никого уже не удивишь. Надо 2 экземпляра приложения? – Поднимаем и работаем!
• не хочется «упираться» в ресурсы одного сервера. Хочется получать линейный рост производительности и места для хранения данных при добавлении новых узлов в кластер (без его остановки). Чем плохи высокопроизводительные сервера, например, построенные на архитектуре mainframe? Дорого, сложно, долго… В общем, пока вы его введете в эксплуатацию, есть риск начать все делать с начала.
• хочется иметь возможность расширять кластер неоднородными узлами: вряд ли вам одобрят проект закупки 30ПБ кластера на перспективу 7 лет, учитывая, что в первый год эксплуатации вы будете использовать всего 1 ПБ. 7 лет – довольно большой срок в ИТ. Даже через 3 года может случиться, что серверов, которые вы кажется совсем недавно заказывали у вендора – больше нет. Зато есть другие, более производительные, с лучшими компонентами и как правило, более дешевыми. Применение «магии» в виде ре-балансировки кластера должно позволить решить эту проблему.
Требование №5. Высокая производительность
Хранить большие объемы данных – это прекрасно. Куда более важно быть способными их обработать за приемлемое время.
• обработка датасетов размером десятки ТБ должно занимать часы, а не дни. Иначе пользователи платформы выпьют весь кофе, съедят все печенки и выкурят все сигареты. В лучшем случае – проедут несколько сотен километров на «шоссере» пока будет готов результат. А дальше, как говорится, «ride, eat, sleep — repeat».
Требование №6. Мультиарендность
Ничего так не напрягает человека, особенно человека, который что-то помнит о 80-90 годах прошлого века, как очередь (даже если именно очередь лежит в основе менеджера ресурсов кластера).
• нужна возможность распределять ресурсы кластера между различными командами, регламентными процессами, ad-hock запросами и т.д. Каждый захочет свой, хоть и не большой, но изолированный кусочек кластера.
Требование №7. Безопасность
Безопасность важна как нигде более в вашем ландшафте. Почему? Потому что в кластере будут данные практически из всех информационных систем компании. Да, маскированные. Да, обезличенные. Но от этого не менее ценные. Вы же не захотите прочитать про утечку данных в вашей компании на Хабре? Вот и мы тоже не хотим.
• потребуется обеспечение ролевой модели доступа к данным: не всем должны быть доступны все области данных в кластере
• интеграция с корпоративным Active Directory
• интеграция с SIEM: также должна решаться задача аудита и обнаружения несанкционированного доступа
• выполнение прочих требований информационной безопасности
Требование №8. Низкая стоимость хранения
Если горизонтальная масштабируемость – любимое требование архитектора, то низкая стоимость хранения или владения – любимое требование менеджера. На данных можно и нужно зарабатывать. При том, что расходы на Big Data тоже не маленькие.
— стоимость хранения должна быть существенно ниже классических аналитических хранилищ данных от известных и уважаемых вендоров. Любому менеджеру не интересна прибыль ради данных, интересен обратный сценарий.
Архитектура W инфраструктура платформы Big Data
С требованиями более-менее разобрались. Теперь нужно разобраться, что нам может помочь в их реализации.
Возьмем наши требования и для наглядности поместим их в матрицу влияния архитектуры и инфраструктуры.
Матрица влияния на выполнение требований
Глядя на матрицу, кажется, что все в порядке: многие требования зависят от выбранной архитектуры платформы Big Data, многие требования зависят от инфраструктуры, на которой платформа будет развернута. Напомню, одно из главных заявленных преимуществ платформы Hadoop является «commodity hardware», а, судя по матрице, так и не скажешь.
Посмотрим, что нам дает архитектура Hadoop на примере референсной архитектуры размещения кластера в ЦОД от Cloudera.
Архитектура разворачивания узлов кластера Hadoop в ЦОД
В кластере присутствуют узлы различного назначения:
Name Node – это «Master» узел кластера, наиболее критичный узел и, по совместительству, единая точка отказа, хранит всю мета-информацию о файловой системе кластера и поддерживает ее работоспособность. Нет Name Node – кластер превращается в груду бесполезного железа. На нем, наверное, можно будет майнить криптовалюты, но для этого есть более эффективные решения. Уменьшить риски, связанные с его потерей, поможет Standby Name Node. Естественно, располагаться они должны в разных стойках и быть подключены к разным коммутаторам.
Management Node – это узлы, позволяющие работать базовым сервисам кластера также в отказоустойчивом режиме. Таких узлов может быть достаточно много, отказ одного из них не повлияет сильно на работу кластера.
Data/HBase Node – это узлы, на которых уже непосредственно хранятся и обрабатываются данные. Это самый многочисленный тип узлов кластера. Они равномерно «размазываются» по стойкам и генерируют высокий трафик (особенно в процессах репликации).
Edge/DS Node – строго говоря, не члены кластера. Эти узлы нужны для загрузки данных в кластер / выгрузки из кластера, а также для обработки данных в случаях, когда параллельная обработка на кластере невозможна. В ряде случаев эти узлы содержат GPU для выполнения задач обучения моделей Data Science, на них разворачивается ETL/ELT инструментарий, сервера приложений, мониторинга, проверки качества и т.д. На этих узлах работают и пользователи.
Kafka Node – узлы распределенного брокера сообщений Kafka, используются в задачах потоковой обработки с архитектурой Pub/Sub. Узлы также равномерно «размазываются» по стойкам.
Кроме того, в каждой стойке есть дублированные ToR-коммутаторы, а каждый узел кластера по 2x10Gb интерфейсам соединен с обоими коммутаторами. В свою очередь, ToR коммутаторы соединяются с коммутаторами уровня Spine и наиболее интенсивный траффик, как видно из схемы, перемещается по направлению «Восток-Запад», т.е. не покидает пределы ЦОД-а. На уровне выше находятся коммутаторы ядра сети.
Такая архитектура помогает нам выполнить требования:
• Высокая доступность
• Отказоустойчивость
• Надежность
• Горизонтальное масштабируемость
• Высокая производительность
Посмотрим, какой вклад в выполнение требований может сделать инфраструктура.
Типовые спецификации стоек и узлов кластера Hadoop 2016-2017гг
Подобная конфигурация положительно влияет на выполнение требований:
• Высокая доступность
• Отказоустойчивость
• Надежность
• Горизонтальное масштабируемость
• Высокая производительность
• Низкая стоимость хранения
Кажется, все у нас работает замечательно, платформа Big Data готова: данные хранятся, ETL процессы работают, пользователи тоже и практически ничего не меняется. Или меняется…
Посмотрим, что случилось с требованиями к платформе спустя всего 3-4 года.
Функциональные требования к платформе Big Data 2019 года
• расширился круг источников данных: добавился трафик служебных событий с мобильных устройств (control plane). Появились внешние данные из интернета (в том числе от внешних провайдеров);
• добавилась обработка потоковых данных, в сценариях обработки событий по триггерам и аналитики в online и в offline;
• с пользователями, кажется, ничего не произошло, разве что их стало около 300 вместо 30, «выросли» вместе с данными.
Все это повлияло и на архитектурные требования:
• высокая доступность – на кластере выполняются более 1000 задач, многие из которых практически в режиме 24х7. Увеличилось кратно количество пользователей платформы и соответственно уровень энтропии в ad-hock аналитике. Целевое время готовности витрин данных T-1 – лаг в неделю – теперь моветон. Целевая доступность кластера не хуже 99%.
• Надежность – с появлением источников потоковых данных появилась необходимость их непрерывной обработки. «Простой» обработчиков ведет к полной или частичной потере данных. Требуется накапливать историю в 10 ПБ и более
Если посмотреть на исходные требования, мы все это закладывали при выборе платформы Big Data как в архитектуру, так и в инфраструктуру: добавляем новые узлы в кластер и проблем нет!?
Архитектура VS инфраструктура платформы Big Data
Если бы все так и было, мы были бы счастливы, сэкономили себе много времени, усилий и не пришлось бы писать эту статью. Кое-что пошло не так, как предполагалось.
Существенные ограничения инфраструктуры на платформу Big Data
Оказалось, что ЦОД, в котором была развернута наша платформа, тоже не бесконечен. Мы перестали выполнять требование по возможности горизонтального масштабирования. Инфраструктура при этом в нашей матрице влияла на это требования меньше всего!
Какие варианты остаются, когда заканчиваются места в стойках?
• масштабироваться вертикально: никто не отменял такой вариант. Но тут есть проблемы:
— Куда деть «старые» компоненты серверов при том что срок их эксплуатации 5-7 лет, а прошло всего 3 года (продать на ebay?).
— Компоненты нелинейно растут в цене (посмотрите на прайс планки 64ГБ RAM и 128ГБ RAM) также потребуется поменять процессоры (есть ограничения по поддерживаемому объему RAM) и т.д.
— Закупки, поставка, монтаж, настройка и передача в эксплуатацию занимают у нас до 6 месяцев – это довольно долго.
• искать другой ЦОД
Мы выбрали второй вариант. Хорошо, что у МТС площадок много и среди них есть даже свободные и подходящие под наши требования.
Типовые спецификации стоек и узлов кластера Hadoop 2019 г. в ЦОД-е «Б»
В новых узлах мы увеличили количество ядер и памяти, равно как и количество и объем дисков. Также у нас изменился характер использования кластера пользователями: ранее преимущественно нагрузка ложилась на движок TEZ, сейчас практически все пользователи пишут задачи с использованием Spark. Под его кэш в спецификации были включены NVMe диски.
И все же еще есть большой вопрос над красной стрелкой между двумя ЦОД. Что же у нас опять не так?
Не так у нас то, что ЦОД-ов теперь два, а это означает:
• Необходимость репликации больших объемов данных – как пользователям, так и регламентным процессам могут требоваться данные, находящиеся в разных кластерах одновременно
• Дублирование данных – теперь часть данных есть на обоих кластерах, что снижает автоматически TCO в 2 раза
• Нагрузка на сетевую инфраструктуру – схема трафика «Восток-Запад» больше не работает. На каждой площадке сотни узлов, трафик усиливается в направлении «Север-Юг»
• Другие ИС в коммунальных каналах – Big Data большая, но и «маленьких» обижать нельзя, те же ERP системы не должны страдать от копирования таблиц между кластерами
• Негативное влияние на SLA по сборке витрин – дополнительные шаги в регламентных процессах
• Усложнение оркестрации процессов
• Усложнение архитектуры платформы
Все эти проблемы и способы их решения заслуживают отдельной статьи.
Кроме того, в ближайшее время мы будем пилотировать добавление к кластеру узлов в роли Compute Node. С ростом количества пользователей возросла роль вычислительных ресурсов в кластере. Хочется управлять вычислительными ресурсами и ресурсами хранения кластера независимо. А еще попробуем в 2 раза снизить TCO — включить механизм Erasure Coding, который судя по совместным тестам Cloudera и Intel, дает еще и увеличение скорости записи файлов.
Инфраструктура Big Data это и инфраструктура ЦОД
Итак, если у вас действительно «большие данные», то объем данных, количество источников, количество пользователей и количество продуктов, построенных на этих технологиях, будут увеличиваться примерно в 10 раз каждые 3 года. Это потребует новых стоек, запаса по питанию и охлаждению, сетевой инфраструктуры.
Даже если в начале пути кейсов по обработке потоковых данных нет или их не много – скоро они точно появятся и потребуют дополнительных ресурсов: Volume, Velocity, Variety способны очень быстро «догнать» возможности инфраструктуры.
Спланируйте рост на 5-7 лет — «время жизни» сервера исходя из показателя x10 за 3 года.
Учитывайте инфраструктуру ЦОД-а, в котором будете размещать сервера для платформы. Менять ее будет крайне сложно или даже невозможно.
Чтобы стать лидером в отрасли, технологии Big Data вам смогут помочь. Для этого совсем необязательно быть телеком-компанией №1 в России.
Планируйте велосипед-инфраструктуру уже сейчас. Стройте кластера, собирайте и обрабатывайте данные, находите в них новые инсайты и делитесь как успехами, так и неудачами с сообществом.
Если хочется попробовать свои силы в Big Data, но по каким-то причинам нет возможности – приходите к нам! it-mts-job.ru/invite


PTM
Я очень прошу прощения, что не по теме, но всё же.
Вот вы рассуждаете Big data и прочее, но я как пользователем с печалью обнаружил 2 вещи: что на ваших якобы таривах с бесплатными ресурсами- некоторые ресурсы не такие и бесплатные, второе: что поддержка отвечает стандартными фразами и шаг влево от стандартных фраз-она не компетентна, ну и третье… а не буду, хватит уже двух.
Так что big data это хорошо, но как она будет обрабатывать то, что содержит ошибку на уровне входных данных?
например рассмотрите: у вас на тарифе X трафик от Apple Music должен учитываться как бесплатный с соответствующей припиской, а он учитывается как «мобильный трафик 2-3-4 G». а теперь вопрос сколько абонентов пользовались Apple music по бесплатному и сколько за это платили и сколько они потратили gb…
Да вы сможете получить какую-то цифру, но будет ли она достоверной? и как это верифицировать?
Shaman_RSHU
К сожалению, уже можно принять за аксиому, что у компаний с таким большим количеством клиентов основная цель BigData — это получение ещё большей прибыли. А вопросы клиентов — это не приоритетные задачи.