

Есть множество подходов к созданию кода приложений, направленных на то, чтобы сложность проекта не росла со временем. Например, объектно-ориентированный подход и множество прилагаемых паттернов, позволяют если не удерживать сложность проекта на одном уровне, то хотя бы держать ее под контролем в ходе разработки, и делать код доступным для нового программиста в команде.
Как можно управлять сложностью проекта по разработке ETL-трансформаций на Spark?
Тут все не так просто.
Как это выглядит в жизни? Заказчик предлагает создать приложение, собирающее витрину. Вроде бы надо выполнить через Spark SQL код и сохранить результат. В ходе разработки выясняется, что для сборки этой витрины требуется 20 источников данных, из которых 15 похожи, остальные нет. Эти источники надо объединить. Далее выясняется, что для половины из них надо писать собственные процедуры сборки, очистки, нормализации.
И простая витрина после детального описания начинает выглядеть примерно так:
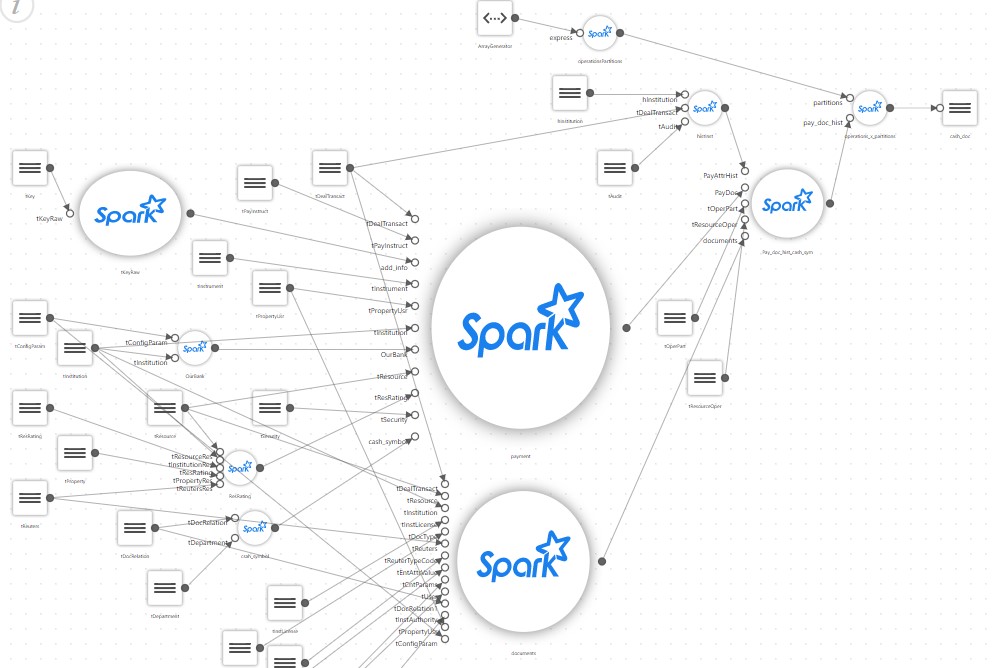
В результате простой проект, который должен был всего лишь запустить на Spark скрипт SQL собирающий витрину, обрастает собственным конфигуратором, блоком чтения большого числа настроечных файлов, собственным ответвлением маппинга, трансляторами каких-нибудь специальных правил и т.д.
К середине проекта оказывается, что получившийся код способен поддерживать только автор. Да и тот основное время проводит в задумчивости. А заказчик тем временем просит собрать еще пару витрин и опять на основе сотни источников. При этом, надо помнить, что Spark вообще не очень подходит для создания собственных фреймворков.
Например, Spark предназначен, чтобы код выглядел как-то так (псевдокод):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)Вместо этого приходится делать что-то такое:
var Source1 = readSourceProps(“source1”)
var sql = readSQL(“destTable”)
writeSparkData(source1, sql)То есть выносить блоки кода в отдельные процедуры и пытаться писать что-то свое, универсальное, что может быть кастомизировано настройками.
При этом сложность проекта остается на одном уровне, конечно же, но только для автора проекта, и только короткое время. Любой приглашенный программист будет долго осваиваться, и главное, что не получится к проекту привлекать людей, знающих только SQL.
А это печально, так как Spark сам по себе прекрасно позволяет разрабатывать ETL-приложения тем, кто знает только SQL.
И в ходе развития проекта получилось так, что из простой вещи сделали сложную.
А теперь представьте реальный проект, где таких витрин, как на картинке, десятки, а то и сотни, и используют они разные технологии, например, часть могут быть основаны на парсинге XML данных, а часть на потоковых данных.
Очень хочется как-то удержать сложность проекта на приемлемом уровне. Как же это сделать?
Решением может стать использование инструмента и подхода low-code, когда за тебя решает среда разработки, которая берет на себя всю сложность, предлагая какой-нибудь удобный подход, как, например, описано в этой статье.
В статье описываются подходы и преимущества применения инструмента для решения такого рода проблем. В частности, «Неофлекс» предлагает собственное решение Neoflex Datagram, который с успехом применяется у разных заказчиков.
Но не всегда можно такое приложение использовать.
Что же делать?
В таком случае мы используем подход, который условно называется Orc – Object Spark, или Orka, кому как нравится.
Исходные данные такие:
Есть заказчик, который предоставляет рабочее место, где есть стандартный набор инструментов, а именно: Hue для разработки Python или Scala-кода, Hue редакторы для отладки SQL через Hive или Impala, а также Oozie workflow Editor. Этого немного, но вполне достаточно для решения задач. Добавить что-то к среде нельзя, никакие новые инструменты поставить невозможно, в силу разных причин.
Так как же разрабатывать ETL-приложения, которые, как обычно, перерастут в большой проект, в котором будут участвовать сотни таблиц источников данных и десятки целевых витрин, и при этом не утонуть в сложности, и не написать лишнего?
Для решения проблемы используется ряд положений. Они не являются собственным изобретением, а целиком основаны на архитектуре самого Spark.
- Все сложные объединения, вычисления и трансформации делаются через Spark SQL. Spark SQL оптимизатор улучшается с каждой версией и работает очень хорошо. Поэтому отдаем всю работу по вычислению Spark SQL оптимизатору. То есть наш код опирается на цепочку SQL, где шаг 1 готовит данные, шаг 2 джойнит, шаг 3 вычисляет и так далее.
- Все промежуточные вычисления сохраняются как временные таблицы в каталоге Spark, в результате чего они становятся доступны в Spark SQL. Любой промежуточный источник данных (DataFrame) можно сохранять в текущей сессии и дальше обращаться к нему через Spark SQL.
- Поскольку Spark приложение выполняется как Directed Acicled Graph, то есть выполнение идет сверху вниз без всяких циклов, то любой датасет, сохраненный как временная таблица, допустим, на шаге 2, доступен на любом этапе после шага 2.
- Все операции в Spark это lazy, то есть данные подгружаются только тогда, когда они нужны, поэтому регистрация датасетов как временных таблиц на производительность не влияет.
В результате всё приложение можно сделать очень простым.
Достаточно сделать файл конфигурации, в котором определить одноуровневый список источников данных. Этот последовательный список источников данных и есть object, описывающий логику всего приложения.
Каждый источник данных содержит ссылку на SQL. В SQL для текущего источника можно использовать источник, отсутствующий в Hive, но описанный в файле конфигурации выше текущего.
Например, источник 2, если переложить его в код на Spark, выглядит примерно так (псевдокод):
var df = spark.sql(“select * from t1”);
df.saveAsTempTable(“source2”);А источник 3 уже может выглядеть так:
var df = spark.sql(“select count(*) from source2”)
df.saveAsTempTable(“source3”);То есть источник 3 видит все, что было вычислено до него.
А для тех источников, что являются целевыми витринами, надо указать параметры сохранения этой целевой витрины.
В результате примерно так выглядит файл конфигурации приложения:
[{name: “source1”, sql: “select * from t1”},
{name: “source2”, sql: “select count(*) from source1”},
...
{name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]А код приложения выглядит примерно так:
List = readCfg(...)
For each source in List:
df = spark.sql(source.sql).saveAsTempTable(source.name)
If(source.target == true) {
df.write(“format”, source.format).save(source.path)
}Это, собственно, и всё приложение. Больше ничего не требуется, кроме одного момента.
А как это все отлаживать?
Ведь сам код в данном случае очень простой, что там отлаживать, а вот логику того, что делается, неплохо бы проверить. Отладка очень простая — надо пройти все приложения до проверяемого источника. Для этого в Oozie workflow надо добавить параметр, который позволяет остановить приложение на требуемом источнике данных, распечатав в лог его схему и содержимое.
Мы назвали этот подход Object Spark, в том смысле, что вся логика приложения отвязана от Spark кода и сохранена в одном, довольно простом файле конфигурации, который и является объектом-описанием приложения.
Код остается простым, и после его создания можно разрабатывать даже сложные витрины, привлекая программистов всего лишь знающих SQL.
Процесс разработки получается очень простой. В начале привлекается опытный Spark программист, создающий универсальный код, а потом правится файл конфигурации приложения путем добавления туда новых источников.
Что дает такой подход:
- Можно привлекать к разработке SQL-программистов;
- С учетом параметра в Oozie отлаживать такое приложение становится легко и просто. Это отладка любого промежуточного шага. Приложение отработает все до нужного источника, вычислит его и остановится;
- По мере добавления требований заказчика код самого приложения меняется мало (ну конечно… ну ладно), а вот все его требования, вся логика сборки витрин, остаются не в коде, а в файле конфигурации, который управляет работой приложения. Этот файл и есть объектное описание сборки витрины, тот самый Object Spark;
- Такой подход обладает всей гибкостью доступной в языке программирования, что исключено при использовании инструмента. В случае необходимости простой и универсальный код можно дописывать. Например, можно добавить поддержку стриминга, вызова моделей, поддержку парсинга XML или JSON, вложенного в поля таблиц-источников. При том, что такое приложение может быть быстро написано с нуля в зависимости от требований заказчика;
- Главное следствие такого подхода. По мере усложнения проекта вся логика сборки витрин не размазывается по коду приложения, откуда ее довольно трудно извлечь, а сохраняется в файле конфигурации, отдельно от кода, где доступна для анализа.
akryukov
Странное какое-то решение. Изначально у вас было одно приложение и вас хоть как-то проверял компилятор, а в итоге вы все вынесли в конфигурацию и никакой компилятор вас уже не спасет.
Почему вы решили все эти трансформации держать в одной джобе? Казалось бы уже напрашивается разделение на части: одна принимает данные из источников и готовит полуфабрикат, а другая часть из полуфабриката делает итоговую витрину.
Когда появляется такая внутренняя сложность, то уже хочется писать какие-нибудь тесты. Если бы у вас эта трансформация состояла из маленьких деталей, то каждую деталь можно будет покрыть интеграционными тестами. Соответственно и запускать можно будет ровно то, что требуется.
sshikov
Соглашусь. Весь мой опыт спарка активно сопротивляется такому подходу. У нас в приложении есть еще и SQL запросы, не к Hive, а к обычным источникам, Oracle и другим, и там нет особых вариантов выбора (ORM и т.п. не годятся), а вот для доступа к источникам в Hive мы как раз наоборот, выбросили практически весь HQL, осталось только то, до чего руки не доходят. Т.е. вместо запросов (которые как было замечено, фиг протестируешь), у нас везде Spark Dataset API, и мы в принципе довольны. Ну, не как слоны, но близко к тому.
Хотя надо заметить, ничего похожего на описанный случай построения витрины из 20 источников у нас нет, поэтому не могу полностью исключить, что наш опыт тут неприменим.
Ну т.е. у нас даже был опыт, когда мы прикрутили парсер HQL, который строит AST дерево для запроса, применяли его, и пытались тесты писать, на генерацию запроса (который у нас был динамический). Плюнули, и работаем на API.
neoflex Автор
Все правильно. Об этом и сказано в самом начале. Только разбиение проекта на части, и покрытие их тестами означает превращение в полноценный проект. Именно это и превратит простой проект в сложный.
И в результате резко возрастают требования к команде.
Но в этом нет необходимости.
По сути рост сложности спарк проекта, это всего лишь добавление новых датасетов.
Да и что тут покрывать тестами? Есть такой датасет или нет?
Поэтому если идти указанным в самом начале путем, тем, про который вы говорите, это усложнение, которого можно избежать.
akryukov
Ну нет же. Он у вас уже сложный, независимо от того, есть там тесты или нет. Сложность возникает не потому, что мы тесты написали, а из требований: количества сущностей и связей между ними.
Вы ведь и сами заметили эту сложность. Вот только мне не понятно, почему вы считаете, что перенос сложности в json-конфиг уменьшает ее? Я думаю от этой сложности уже никуда не деться.
Тестами можно покрыть атрибутный состав датасетов и результаты промежуточных действий.
neoflex Автор
Справедливый вопрос. Может показаться, что мы, не зная ничего о разработке, выдумали свое решение и радуемся. Это не совсем так. Дело в том, что spark-ETL проекты делаются немного не так, как обычные приложения. В обычном случае вы пишете код, при появлении сложностей или повторяющихся кусков применяете паттерны, покрываете это все тестами. Проект усложняется, но его ведет либо одна команда, либо новые люди набираются подходящего уровня и обучаются в проекте.
А разработка на ETL процессов на spark выглядит несколько иначе. Сначала заказчики хотят витрину. По ходу добавляются еще пожелания, витрин становится больше. И вот тут важный момент — резко растет объем проекта. Что делается в этом случае? Обычно, применяются подходы, усложняющие код, как при разработке обычных приложений.
То есть команда проекта должна усложнить код.
Но людей, способных разрабатывать spark на подходящем уровне крайне мало, а набрать новых нереально, так как это очень дорого и долго. Что получается? Надо на проекте постоянно держать команду spark разработчиков высокого класса. А где они?
А людей, знающих SQL, и имеющих начальные знания и разработке много.
Вот и хочется быть уверенным, что можно осилить проект где обрабатывается не пять источников, как предполагалось сначала, а пятьсот. А это можно сделать, если код проекта остается простым, при этом обеспечивая и увеличение объема проекта, и возможность отладки.
akryukov
Вы все правильно говорите, но эти тезисы не отвечают на вопрос: зачем прятать сложность в json конфигурацию? Хотите чтобы все писалось на SQL — да флаг вам в руки. Но почему этот SQL нужно писать в какой-то левый файлик и городить какие-то параметры запуска для oozie?
Можно ведь сделать отдельные спарк-приложения и тем же oozie настроить их последовательный запуск. Не изобретая велосипед с json-конфигом.
Зачем вам вообще спарк, если вы SQL пишете? Опять же oozie поддерживает запуск Hive скриптов, где чистый SQL без всякой обвязки.
neoflex Автор
Не прятать, а выносить из кода во внешний файл, чтобы код не усложнялся с усложнением проекта. Это всего лишь развитие идеи параметризации проекта. Во внешний файл выносим не список источников, а чуть больше.
Oozie запускает Spark Action в отдельных сессиях. Тогда промежуточные данные придется сохранять на диск. Во-первых, это место. Во-вторых, тогда весь смысл spark оптимизации теряется.
Hive пока работает на map-reduce и на схожих задачах на порядке медленней spark.
akryukov
Понял. Вы хотите все это запустить в одной spark-сессии. Но если вы храните все в памяти, то у вас при сбое все промежуточные расчеты пропадут и надо будет заново все считать.
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties#ConfigurationProperties-QueryandDDLExecution
SET hive.execution.engine=spark;Стало доступно примерно в 2017 году.
У нас Hive работает на Tez и производительность весьма неплоха. Один фрагмент на Hive-Tez мы пробовали переписать на спарк ради оптимизаций, но серьезного выигрыша не получили.
sshikov
На самом деле, я бы согласился с такой идеей. Но, не в такой реализации. Ну т.е. у вас есть API для работы с датасетами, и вот над ним бы я попробовал бы построить DSL на скале, который бы описывал, где эти датасеты берутся, и куда дальше передаются. И что с ними делается. И на выходе попробовать построить из датасетов, а не запросов (которые есть текст, и о структуре которых вы почти не знаете) уже граф приложения.
sshikov
>Можно ведь сделать отдельные спарк-приложения и тем же oozie настроить их последовательный запуск.
Не, ну так тоже плохо. Мы так пробовали. Если вы внутри одного спарка — у вас какая-никакая проверка, в том числе и статическая. Если вы вылезли в узи — все, конец проверкам, все что вы знаете — это наличие файлов в HDFS. Ну т.е. тут уже заморочки другого вида возникают, потому что возможностей узи по планирования исполнения задач сильно не хватает. И хочется чего-то такого… экзотического, скажем, вот этот процесс запустить когда закончатся вон тот и вон тот, но при этом дождаться загрузки кластера ниже N% (или скажем наступления дня/ночи).
akryukov
Странно. Спарк ведь не черные ящики выдает в результате своей работы. А орки или паркеты поддерживают типизацию схемы. Ну и еще есть метаданные в пропертях hive-таблицы и где там еще спарк их сохраняет.
Проверки схемы на мой взгляд лучше вынести на этап интеграционного тестирования.
Накладные ресурсы на поднятие спарк-сессии ничтожны по сравнению с общим временем выполнения. А если это не так, то кажется не тот молоток используется.
Ну и я в целом плохо понимаю как можно оркестрировать множество джобов в рамках одного приложения, без внешнего инструмента. Что если там только один кусок завис или упал?
sshikov
Ну, во-первых, какое такое тестирование, если схемы меняются каждый запуск? У нас так (по крайней мере, мы к этому должны быть готовы, потому что схемы вообще не наши, а внешние).
Ну и потом, самое главное чего вы не знаете — это как раз факта, что какой-то кусок завершился. Ну там, упрощенно — мы как-то пытались заменить spark.jdbc на Sqoop, потому что там достаточно навороченная оптимизация по поводу распараллеливания запросов на несколько потоков. Пришли к простому выводу — что мы знаем про процесс Sqoop, кроме того, что он завершился? Практически ничего. Что мы видим в HDFS? А фиг его знает. Ну т.е. если в одном приложении я скажем словил исключение — то в случае отдельных приложений и оркестратора с этим уже сложно. Сильно сложнее. Это не значит, что мы узи не применяем, это лишь значит, что на его уровень выходить обычно невыгодно, не удобно, негибко.
akryukov
У нас интеграции более строгие. Все что не проходит первоначальную валидацию, возвращается источнику в виде ошибки.
А вот факт завершения куска мы знаем. т.к. oozie джоба создает приложение, которое видно в yarn. Ну а там есть и логи и занимаемые ресурсы в процессе работы и т.п.
В самом oozie можно как success path построить, так и error path.
Скуп раньше был, но выкинули, как раз чтобы заливка сотни табличек из РСУБД в hive была в одной спарк сессии. Очень сэкономили на накладных расходах. Но там у нас логики нет. Просто читаем все данные и все эти данные пишем.
sshikov
>У нас интеграции более строгие. Все что не проходит первоначальную валидацию, возвращается источнику в виде ошибки.
А у вас их сколько, просто для понимания? Если бы мы так делали, у нас бы их возможно было в 10 раз меньше. Ну просто потому, что та сторона свободна в выборе решений, и нам от них нужно не многое, и мы им эту свободу даем.
>А вот факт завершения куска мы знаем.
Знаем. Но опять же — только в рамках одного узи задания, не двух и не трех. Т.е. мы должны интегрироваться через узи в виде одного потока — а это намного менее приятно, чем писать на скале, увы. Ну и потом — попробуйте сделать так, чтобы часть узи приложения стартовала, когда закончатся несколько других? Это же только fork для этого есть, а он ужасно негибкий, пока все его ветки не завершились, следующий кусок не стартует (а иногда хочется — потому что ресурсы-то уже освободились).
Ну и скажем, я вот уже пару лет не могу понять, могу ли я гарантированно вернуть из sub-workflow что-то типа key-value пар, которые узи называет data? Ну или даже хотя бы сообщение об ошибке, для простоты.
При этом в своем приложении я есттественно хозяин-барин — хочу исключения кидаю, хочу в функциональном стиле, возвращают результаты в виде Option[Dataset[Row]], ну или там Try[Dataset[Row]], т.е. кусок, который может не вернуть результат или упасть. Т.е. по сути — модуль моего приложения, это скорее некая трансформация над Dataset, которая может быть описана на API, ну и протестирована. А трансформации — это понятно JOIN, UNION, ну и некоторые другие посложнее.
akryukov
На днях внедрили №132. Если у вас тысяча интеграций, то наверное строгий подход действительно не подойдет.
Расскажите как вы это же сделаете на спарке. Особенно ту часть, которая про запуск при "ресурсы то уже освободились".
Пишете на диск, читаете. Ну или не на диск, а в какую-нибудь СУБД. Зачем сами данные через oozie таскать то? Можно попробовать наколдовать что-нибудь через stdout.
Сообщение об ошибке в результатах запуска тоже не понятно зачем нужно. Можно в лог написать. Если в каком-нибудь UI показывать, то тоже надо в специальное место писать. Не будет же UI лезть в oozie за ошибками. А какой-нибудь hue и в логи и в stdout сам лезет за стектрейсами.
Впрочем я про оркестрацию джобов на scala тоже думал, но у нас очень разнородный проект. Есть куски на hive есть куски на спарке и нет ресурсов и необходимости все переводить на однообразные рельсы.
sshikov
Не, на самом деле 132 — это сопоставимо. У нас тоже где-то штук сто их. Тут скорее разница в том что мы (наш хадуп) — платформа для аналитики. А они — те с кем мы интегрируемся, они например карточный процессинг. Или CRM. У них пользователи работают, а у нас просто создается копия с историей из их данных.
Главное тут то, что они важнее. И нам даже если интеграция нужна, ставить им какие-то требования не всегда разумно. Поэтому жесткая интеграция в такой ситуации — это будет скорее всего медленно. Ну т.е. мы можем попросить — но та сторона обычно имеет право мягко отказаться в форме «ну мы это сделаем… через годик» :)
>Расскажите как вы это же сделаете на спарке.
На спарке вряд ли я буду прямо такое писать. Это скорее были мечты об оркестраторе, который мог бы легко проверить загрузку по API ярна. Узи наверное сможет — но скорее гипотетически.
Но с другой стороны, вот у нас есть источник данных — внешний оракл, например. И есть там схема и скажем 1000 таблиц. И мы просто вынуждены оптимизировать сразу две вещи — нагрузку на наш кластер, и нагрузку на источник, потому что оракл тот — он обычно куда менее мощный, чем хадуп, у него редко когда 1/100 от наших ядер в наличии (хотя бывает что их и много — но тогда они обычно загружены по уши). И я подозреваю, что мне все же придется писать это на спарке, как ни крути. Чтобы и jdbc не больше чем в N потоков, которые оракл позволит, и в тоже время, чтобы 1000 таблиц постоянно в эти N потоков работали, а не так как в узи через форки получается — пока последний поток форка не завершился, весь форк тоже.
>Зачем сами данные через oozie таскать то
Ну, затем что узи умеет их анализировать в своем EL. Т.е. на эти данные можно навесить условия как на ${data[имя action][key]}. А больше пожалуй и никак — разве что написать функцию в узи (так можно, но я даже не пытался — мороки полно) которая прочитает файл, и возьмет значение там.
>Можно попробовать наколдовать что-нибудь через stdout.
Ну вот в том-то и дело, что узи — это почти как unix shell и его пайпы — весь обмен через файлы (я понимаю, отчего так — они же пытались интегрировать в себя и shell action тоже). А хочется передавать структурированную информацию. И писать все в файлы это конечно возможно — но иногда очень неудобно.
>Сообщение об ошибке в результатах запуска тоже не понятно зачем нужно. Можно в лог написать.
Ну вот это мне как раз очевидно. У нас поддержка работает примерно так — вот Hue, вот потоки узи. Вот этот красный, какого фига? Идем и смотрим на него, что там упало, какая таблица? Все что можно увидеть в узи — это сообщение об ошибке, и эти самые Data, т.е. key-value. Data — это наши метрики, скажем, а сообщение об ошибке — ну это понятно что. Ну т.е. когда это все видно в одном месте — это удобно. А когда это в логах — то разбор полетов уже медленнее на порядок-другой.
sshikov
Уф. Вообще получается, что можно спокойно садиться и писать еще одну статью про то, как устроены хадуп/спарк приложения в нашей окрестности :)
akryukov
Действительно. Пока сам по себе варишься, то и не понятно в чем вообще могут быть отличия и на что есть смысл обращать внимание.
sshikov
А у вас датасеты никогда не меняются что-ли? В смысле, ни набор колонок, ни типы данных, ничего такого? Я почему спрашиваю — вы по сути строите приложение из набора статических запросов. При этом соответствие набора колонок на выходе одного запроса и на входе другого никто не проверяет — ну или такого вы не показали.
При этом у меня скажем типовая картинка — я хочу сделать union, или там except. При этом чтобы это сделать — нужно согласовать схемы двух датасетов. Ну и статические запросы сами по себе ну никак не позволяют это провернуть.
neoflex Автор
Да, схемы на выходе из одного и входе в другой датасет мы не проверяем, такая проблема есть. Но отсутствие проверки схем основано на том, что в spark вообще поддерживается 'select * from table1'. По крайней мере в нашем случае эта проблема не сильно портит картину. Как раз для валидации запросов и есть в нашем подходе отладка — возможность прогнать задачу до нужного датасета. Но вообще вопрос поставлен верно. Если на основе описанного нами подхода делать серьезный инструмент, то валидацию схем туда надо бы прикрутить. Но как раз необходимости серьезного инструмента мы и хотели избежать.
sshikov
Ну я не думаю, что это прям серьезная проблема, сделать именно валидацию. У схемы датасета есть просто .diff(другая схема), его правда только в лог хорошо писать — ну или я не знаю, каков API у него, т.е. что можно из этого diff программно достать. Но если схемы плоские — то .schema.fields это просто массив колонок, сравнить два набора — вообще ничего сложного, задачка на пять строк.
У меня обычная повседневная задача предполагает манипулирование набором колонок датасета, и это не так уж и сложно — пока вы остаетесь в рамках Dataset API. А вот если приходится выйти за его рамки, т.е. грубо говоря, написать что-то типа groupByKey, а потом mapGroups — т.е. применить к датасету функции — вот тут начинается достаточно мозголомная возня по согласованию схем на входе и на выходе.
Ну т.е. пока вы укладываетесь условно, в JOIN/UNION/filter и т.п. операции из набора SQL — то я думаю сваять аналог вашего приложения как DSL внутри Spark Shell было бы не так и сложно. Т.е. прочитать тот же json, и построить некий датасет, который в нем описан — ну так, идеологически выглядит как задачка на недельку. Хотя я известный оптимист в своих оценках :)