
Большинство разработчиков, когда-либо сталкивавшихся с NLP задачами, рано или поздно задумывались над проблемой, обозначенной в заголовке статьи. Решений подобного рода создавалось достаточное количество, каждое со своими особенностями, плюсами и минусами. Первое, с которым мы с коллегами встретились лет 10 назад, и ссылку на которое я не смог сейчас даже найти, было оформлено в виде абсолютно нечитаемой диссертации. Мы честно, шаг за шагом пытались прорваться сквозь ее страницы, но отчаялись и утратили интерес к данной тематике на несколько лет. Но, рано или поздно к этой проблеме возвращаешься. И в целом в индустрии интерес к данному вопросу уже не один раз разогревался и остывал, а в последние годы он снова на подъеме.

Что должна уметь такая система:
То есть на первом шаге нужно разобрать запрос, точно так же как и при работе со всеми другими NLP системами, а далее, или сгенерировать SQL на лету, или найти какой-то наиболее подходящий интент, в функции которого прописан заранее подготовленный параметризованный SQL запрос. На первый взгляд первый вариант выглядит куда как более впечатляющим. Поговорим о нем чуть детальнее.
Особенность таких систем — в них по сути зарегистрирован всего один интент, срабатывающий на все подряд, имеющее хоть какое-то отношение к модели, с некой супер-функцией, формирующей SQL на все типы запросов. SQL может быть создан на основе каких-либо правил, алгоритмически или с участием нейросетей.
На первый взгляд задача преобразования разобранного предложения в SQL — проблема чисто алгоритмическая, то есть без проблем решаемая. Кажется, что у нас есть все, что нужно для конвертации одной строгой модели в другую: распознанные сущности, ссылки, co-references и т.д. Но, к сожалению, нюансы и неоднозначности как и всегда все усложняют, а в данном случае делают стопроцентно универсальный подход почти нерабочим. Модели неидеальны (см. примеры выше и далее по ходу статьи), сущности пересекаются, как по именам так и по смыслу, рост сложности при росте количества сущностей и усложнении базы становится нелинейным.
Использование нейросетей для подобных систем — бурно развивающееся направление. В рамках данной статьи ограничусь ссылками и краткими выводами.
Советую прочесть небольшой цикл статей: 1, 2, 3, 4, 5, в них совсем немного теории, рассказ о том как проводится обучение и тестирование на качество, краткий обзор решений. Дополнительно здесь — подробнее о SparkNLP. Здесь — о решении Photon от SalesForce. По ссылке еще один представитель open source сообщества — Allennlp. Здесь — данные по качеству систем, то есть показатели тестов. Здесь — данные по использованию NLP библиотек и в частности подобных решений в enterprise.
За данным направлением большое будущее, но снова с оговорками — пока не для всех типов моделей. Если при работе с моделью не требуется получение совершенно строгих цифр и гарантированно точного, повторяемого, предсказуемого результата (например, требуется определить тренд, сравнить показатели, выявить зависимость и т.д.) — все хорошо. Но недетерминированность и вероятностный характер ответов накладывают ограничения на использование подобного подхода для целого ряда систем.
Зачастую компании, предоставляющие сервисы подобного рода, демонстрируют прекрасные результаты на отлично сделанных видео и далее предлагают связаться с ними для детальной беседы. Но есть и доступные в сети онлайн демо. Особенно удобно экспериментировать с Photon, так как в данном случае схема базы сразу перед глазами. Второе демо, которое я видел в свободном доступе — от Allennlp. Разбор некоторых запросов удивляет своей изощренностью, некоторые варианты чуть менее удачны. Общее впечатление смешанное, попробуйте поиграть с этими демо, если есть интерес, и составить свое мнение.
В целом получается достаточно интересная ситуация. Системы автоматического перевода текстовых неструктурированных запросов в SQL, основанные на нейронных сетях, становятся все лучше и лучше, качество прохождения тестовых наборов все выше и выше, но все равно их значение не превышает в лучшем случае 70% (spider dataset — порядка 69% на сегодняшний день). Можно ли считать этот результат хорошим? С точки зрения развития подобных систем — да, безусловно, результаты впечатляют, но использовать их уже сегодня в реальных системах без доработки возможно далеко не для всех видов задач.
Как может помочь проект Apache NlpCraft при построении и организации подобного рода систем? Если по первой части задачи (разбор текстового запроса) вопросов не возникает, все как обычно, то для второй части (формирование SQL запросов, основанных на NLP данных), NlpCraft не предоставляет стопроцентно законченного решения, а лишь инструментарий, помогающий в самостоятельном решении данной проблемы.
С чего начать? Если мы хотим по максимуму автоматизировать процесс разработки, нам помогут метаданные схемы базы и сами данные. Перечислим какую информацию мы можем извлечь из базы и для простоты ограничимся таблицами, не будем пытаться анализировать триггеры, stored procedures и т.д.
Таким образом, если вами получены метаданные, то вы уже много знаете о сущностях модели. Так, например, в неком идеальном мире вы почти все знаете о таблице представленной ниже:
В реальности все будет не так уж и радужно, имена будут сокращены и нечитаемы, типы данных зачастую окажутся совершенно неожиданными, а денормализованные поля и впопыхах добавленные таблицы типа 1:0 будут разбросаны там и тут. В итоге, если быть реалистами, большинство существующих какое-то продолжительное время в продакшене БД, можно будет разве что с большим трудом использовать для распознания сущностей без какой-то предварительной подготовки. Это касается любых систем, а основанных на нейросетях, возможно, даже в большей степени, чем прочих.
В данной ситуации можно посоветовать дать NLP модулю доступ к несколько облагороженной схеме — заранее подготовленному набору views, с правильными названиями полей, необходимым и достаточным набором таблиц и столбцов, тут же можно учесть вопросы security и т.д.
Основная и очень простая мысль — все пользовательские запросы покрыть практически невозможно. Если пользователь поставит перед собой цель обмануть систему и захочет задать вопрос, который собьет ее с толку, он без труда это сделает. Задача разработчика — соблюсти баланс между возможностями разрабатываемой системы и сложностью ее реализации. Отсюда тоже очень простой совет — не пытайтесь поддержать один универсальный интент, отвечающий на все вопросы, с одним универсальным методом, формирующим SQL для всех этих вариантов. Попробуйте отказаться от стопроцентной универсальности, это сделает проект немного менее ярким, но более реализуемым.
При таких объемах работы и достаточных ресурсах, время, требующееся для решения подобной задачи, измеряется днями, и на выходе вы имеете 80% покрытия потребностей пользователя, причем с достаточно высоким качеством исполнения. Далее вернитесь к первому пункту и добавьте еще интентов.
Зачем стоит поддерживать несколько интентов, проще всего пояснить на примере. Почти всегда пользователей интересует какое-то количество весьма нестандартных отчетов, что-то вроде “сравни мне то-то и то-то для такого-то периода, но не входящее в такой-то период и при этом ...”. Ни одна система не сможет сразу сформировать SQL для подобного запроса, вам придется или как-то обучать ее, или выделять и отдельно программировать подобные случаи. Умение отвечать на ограниченный круг замысловатых запросов очень важно для ваших пользователей. Снова ищите баланс, не факт, что вообще хватит ресурсов удовлетворить все подобные запросы, но полностью игнорировать такие пожелания значит сузить функционал системы до неприемлемого уровня. Если вы найдете правильное соотношение, ваша система будет требовать конечного времени на разработку и не являться просто забавной игрушкой на несколько дней, вызывающей впоследствии скорее раздражение, а не приносящей пользу. Очень важный момент — добавлять интенты для хитрых запросов, можно не сразу, а в процессе работы, один за одним. MVP мы имеем сразу всего с одним универсальным интентом.
Apache NlpCraft предлагает инструментарий для упрощения процедуры работы с базой данных.
Порядок работы:
Ниже для наглядности фрагмент кода:
Здесь представлен фрагмент функции интента по умолчанию, реагирующего на любой определенный в запросе элемент базы и срабатывающего если в процессе матчинга не было найдено ни одного более строгого совпадения. В нем продемонстрировано использование API SQL elements extractor, задействованного при построении SQL запросов, а также работа с SQL builder примера.
Что еще раз хочется подчеркнуть, Apache NlpCraft не предоставляет готовый tool для перевода разобранного текстового запроса в SQL, эта задача находится вне рамок проекта, по крайней мере в текущей версии. Код построителя запросов доступен в примерах, а не в API, он имеет существенные ограничения, но он и состоит при этом всего из 500 строк кода с комментариями, или около 300 без них. При этом, несмотря на всю свою простоту и даже ограниченность, даже эта простейшая имплементация способна сформировать нужные SQL для весьма существенного количества самых разнообразных типов пользовательских запросов. В настоящей версии мы предлагаем нашим пользователям, заинтересованным в построении подобных систем, использовать данный пример в качестве шаблона и развивать его под свои потребности. Да, это задача не на один вечер, но вы получите результат несопоставимо более высокого качества, чем при использовании в лоб универсальных решений.
Повторюсь, что в функции интента по умолчанию вы можете как просто доработать примеры из example (по отзывам его функциональности вполне может хватить), так и задействовать решения с нейронными сетями.
Построить систему обращения к базе данных задача не из простых, но Apache NlpCraft уже взял на себя немалую часть рутинной работы, и во многом благодаря этому, разработка системы достойного качества займет измеримое время и ресурсы. Будет ли Apache NlpCraft community развивать направление автоматизации перевода текстовых запросов в SQL и расширять этот простой SQL пример до полноценного API — покажет время и запросы пользователей, формирующие план и направление развития проекта.
Системы преобразования текстовых запросов в SQL
Что должна уметь такая система:
- Найти в тексте сущности, соответствующие сущностям базы данных: таблицы, колонки, иногда значения.
- Связать таблицы, сформировать фильтры.
- Определить набор возвращаемых данных, то есть составить select list.
- Определить порядок выборки и количество строк.
- Выявить, помимо относительно очевидных, некие абсолютно неявные зависимости или фильтры, непрозрачные ни для кого, кроме дизайнеров схемы базы (смотри условие по полю bonus_type на картинке выше)
- Разрешить неоднозначности при выборе сущностей. “Дай мне данные по Иванову” — следует запросить информацию по контрагенту или сотруднику с такой фамилией? “Данные по сотрудникам за февраль” — ограничить выборку по дате найма или по дате продаж? и т.д.
То есть на первом шаге нужно разобрать запрос, точно так же как и при работе со всеми другими NLP системами, а далее, или сгенерировать SQL на лету, или найти какой-то наиболее подходящий интент, в функции которого прописан заранее подготовленный параметризованный SQL запрос. На первый взгляд первый вариант выглядит куда как более впечатляющим. Поговорим о нем чуть детальнее.
Особенность таких систем — в них по сути зарегистрирован всего один интент, срабатывающий на все подряд, имеющее хоть какое-то отношение к модели, с некой супер-функцией, формирующей SQL на все типы запросов. SQL может быть создан на основе каких-либо правил, алгоритмически или с участием нейросетей.
Алгоритмы и правила
На первый взгляд задача преобразования разобранного предложения в SQL — проблема чисто алгоритмическая, то есть без проблем решаемая. Кажется, что у нас есть все, что нужно для конвертации одной строгой модели в другую: распознанные сущности, ссылки, co-references и т.д. Но, к сожалению, нюансы и неоднозначности как и всегда все усложняют, а в данном случае делают стопроцентно универсальный подход почти нерабочим. Модели неидеальны (см. примеры выше и далее по ходу статьи), сущности пересекаются, как по именам так и по смыслу, рост сложности при росте количества сущностей и усложнении базы становится нелинейным.
Нейросети
Использование нейросетей для подобных систем — бурно развивающееся направление. В рамках данной статьи ограничусь ссылками и краткими выводами.
Советую прочесть небольшой цикл статей: 1, 2, 3, 4, 5, в них совсем немного теории, рассказ о том как проводится обучение и тестирование на качество, краткий обзор решений. Дополнительно здесь — подробнее о SparkNLP. Здесь — о решении Photon от SalesForce. По ссылке еще один представитель open source сообщества — Allennlp. Здесь — данные по качеству систем, то есть показатели тестов. Здесь — данные по использованию NLP библиотек и в частности подобных решений в enterprise.
За данным направлением большое будущее, но снова с оговорками — пока не для всех типов моделей. Если при работе с моделью не требуется получение совершенно строгих цифр и гарантированно точного, повторяемого, предсказуемого результата (например, требуется определить тренд, сравнить показатели, выявить зависимость и т.д.) — все хорошо. Но недетерминированность и вероятностный характер ответов накладывают ограничения на использование подобного подхода для целого ряда систем.
Примеры работы с системами, основанными на нейросетях
Зачастую компании, предоставляющие сервисы подобного рода, демонстрируют прекрасные результаты на отлично сделанных видео и далее предлагают связаться с ними для детальной беседы. Но есть и доступные в сети онлайн демо. Особенно удобно экспериментировать с Photon, так как в данном случае схема базы сразу перед глазами. Второе демо, которое я видел в свободном доступе — от Allennlp. Разбор некоторых запросов удивляет своей изощренностью, некоторые варианты чуть менее удачны. Общее впечатление смешанное, попробуйте поиграть с этими демо, если есть интерес, и составить свое мнение.
В целом получается достаточно интересная ситуация. Системы автоматического перевода текстовых неструктурированных запросов в SQL, основанные на нейронных сетях, становятся все лучше и лучше, качество прохождения тестовых наборов все выше и выше, но все равно их значение не превышает в лучшем случае 70% (spider dataset — порядка 69% на сегодняшний день). Можно ли считать этот результат хорошим? С точки зрения развития подобных систем — да, безусловно, результаты впечатляют, но использовать их уже сегодня в реальных системах без доработки возможно далеко не для всех видов задач.
Инструменты Apache NlpCraft
Как может помочь проект Apache NlpCraft при построении и организации подобного рода систем? Если по первой части задачи (разбор текстового запроса) вопросов не возникает, все как обычно, то для второй части (формирование SQL запросов, основанных на NLP данных), NlpCraft не предоставляет стопроцентно законченного решения, а лишь инструментарий, помогающий в самостоятельном решении данной проблемы.
С чего начать? Если мы хотим по максимуму автоматизировать процесс разработки, нам помогут метаданные схемы базы и сами данные. Перечислим какую информацию мы можем извлечь из базы и для простоты ограничимся таблицами, не будем пытаться анализировать триггеры, stored procedures и т.д.
- Имена таблиц и имена колонок — самая важная информация. Эти имена по сути определяют сущности нашей модели, мы можем искать их в тексте запроса напрямую или через синонимы.
- Признак обязательности (null / not null) поможет правильно составить запросы с фильтром (where clause).
- Отношения между сущностями, определяющиеся через объявленные foreign keys и уникальные индексы, выявляют связи типа 1:1, 1:0, 1:n, n:m. Информация необходимая для построения корректных joins.
- Типы данных столбцов могут помочь в создании правильных фильтров. Так, например, условия сравнения могут применяться для числовых столбцов и гораздо реже используются для строковых и т.д. Также по типам данных могут быть сделаны выводы, стоит ли включать эти данные в select list.
- Анализ самих данных. Простор для творчества безграничен. Если в каком-то столбце на все множество записей приходится лишь ограниченный повторяющийся набор значений — можно предположить, что тип данных рассматриваемого столбца — enumeration, это может пригодиться для построения запросов. И это только один пример.
- Наличие индексов. Указывает на то, что по данным индексированным полям предполагается делать соединения между таблицами или осуществлять фильтрацию. Это знание очевидно пригодится в процессе формирования все тех же фильтров.
- Primary and unique keys — информация об уникальности записей, помимо многого другого, поможет составить подзапросы, возвращающие гарантированное количество строк.
- Комментарии для таблиц и столбцов (имеющиеся, например, в Oracle) — очевидная дополнительная информация к именам.
- Check constraints — знание ограничений может помочь в построении все тех же фильтров по данным столбцам.
Таким образом, если вами получены метаданные, то вы уже много знаете о сущностях модели. Так, например, в неком идеальном мире вы почти все знаете о таблице представленной ниже:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
В реальности все будет не так уж и радужно, имена будут сокращены и нечитаемы, типы данных зачастую окажутся совершенно неожиданными, а денормализованные поля и впопыхах добавленные таблицы типа 1:0 будут разбросаны там и тут. В итоге, если быть реалистами, большинство существующих какое-то продолжительное время в продакшене БД, можно будет разве что с большим трудом использовать для распознания сущностей без какой-то предварительной подготовки. Это касается любых систем, а основанных на нейросетях, возможно, даже в большей степени, чем прочих.
В данной ситуации можно посоветовать дать NLP модулю доступ к несколько облагороженной схеме — заранее подготовленному набору views, с правильными названиями полей, необходимым и достаточным набором таблиц и столбцов, тут же можно учесть вопросы security и т.д.
Приступаем к проектированию
Основная и очень простая мысль — все пользовательские запросы покрыть практически невозможно. Если пользователь поставит перед собой цель обмануть систему и захочет задать вопрос, который собьет ее с толку, он без труда это сделает. Задача разработчика — соблюсти баланс между возможностями разрабатываемой системы и сложностью ее реализации. Отсюда тоже очень простой совет — не пытайтесь поддержать один универсальный интент, отвечающий на все вопросы, с одним универсальным методом, формирующим SQL для всех этих вариантов. Попробуйте отказаться от стопроцентной универсальности, это сделает проект немного менее ярким, но более реализуемым.
- Опросите пользователей и выпишите 30-40 наиболее стандартных типов вопросов.
- Выявите запрашиваемые сущности, определите их соответствие сущностям базы данных, таблицам, столбцам и т.д.
- Объедините группы запросов в интенты. Пусть интенту соответствует один параметризованный SQL, тогда для выбранных на первом этапе вопросов вы получите максимум 20-30 интентов. При этом оставьте один общий интент, по умолчанию. Вы можете сами формировать для него SQL или воспользоваться одной из ML библиотек text2Sql, о которых мы говорили выше.
- Далее задача легко параллелится. С одной стороны — описываете элементы через синонимы, для начала с помощью минимального набора, пусть даже одного слова, этот список может быть расширен позднее. С другой стороны — отлаживаете параметризованные SQL запросы. C третьей — формируете интенты и пишите тесты на сам факт их срабатывания, на первом этапе можно даже без выполнения реальных запросов.
При таких объемах работы и достаточных ресурсах, время, требующееся для решения подобной задачи, измеряется днями, и на выходе вы имеете 80% покрытия потребностей пользователя, причем с достаточно высоким качеством исполнения. Далее вернитесь к первому пункту и добавьте еще интентов.
Зачем стоит поддерживать несколько интентов, проще всего пояснить на примере. Почти всегда пользователей интересует какое-то количество весьма нестандартных отчетов, что-то вроде “сравни мне то-то и то-то для такого-то периода, но не входящее в такой-то период и при этом ...”. Ни одна система не сможет сразу сформировать SQL для подобного запроса, вам придется или как-то обучать ее, или выделять и отдельно программировать подобные случаи. Умение отвечать на ограниченный круг замысловатых запросов очень важно для ваших пользователей. Снова ищите баланс, не факт, что вообще хватит ресурсов удовлетворить все подобные запросы, но полностью игнорировать такие пожелания значит сузить функционал системы до неприемлемого уровня. Если вы найдете правильное соотношение, ваша система будет требовать конечного времени на разработку и не являться просто забавной игрушкой на несколько дней, вызывающей впоследствии скорее раздражение, а не приносящей пользу. Очень важный момент — добавлять интенты для хитрых запросов, можно не сразу, а в процессе работы, один за одним. MVP мы имеем сразу всего с одним универсальным интентом.
Инструментарий и API
Apache NlpCraft предлагает инструментарий для упрощения процедуры работы с базой данных.
Порядок работы:
- Сгенерируйте шаблон модели по jdbc url базы данных. Как я уже упоминал выше, иногда лучше подготовить набор views с более “правильной“ репрезентацией данных и предоставить доступ к этому набору. Генерация шаблона проще всего производится с помощью утилиты CLI. Запускаем утилиту, указываем в качестве параметров схему базы, jdbc driver, список используемых и игнорируемых таблиц и другие параметры, подробнее в документации.
- В результате работы утилиты получаем модель в виде JSON или YAML файла, описывающую таблицы, столбцы, связи между таблицами, простейшие синонимы и т.д., то есть все, что можно извлечь из данных и метаданных схемы базы.
Пример описания для одной и таблиц и одного из ее столбцов схемы примера:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column." - Полученная модель — это шаблон, полученный на основании анализа данных и метаданных, он сформирован для экономии вашего времени. Теперь его нужно внимательно изучить, расширить и возможно исправить. Дополнить список синонимов, уточнить, если потребуется, значения по умолчанию, сортировку, указанные межтабличные связи, таблицы дополнений и т.д. Вся документация приведена на сайте.
- На основании обогащенной модели разработчик может воспользоваться компактным API, существенно облегчающим построение SQL запросов в функции интентов — смотри детальный пример.
Ниже для наглядности фрагмент кода:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// Все прочие операции по построению SQL запроса из найденных
// сущностей.
}
Здесь представлен фрагмент функции интента по умолчанию, реагирующего на любой определенный в запросе элемент базы и срабатывающего если в процессе матчинга не было найдено ни одного более строгого совпадения. В нем продемонстрировано использование API SQL elements extractor, задействованного при построении SQL запросов, а также работа с SQL builder примера.
Что еще раз хочется подчеркнуть, Apache NlpCraft не предоставляет готовый tool для перевода разобранного текстового запроса в SQL, эта задача находится вне рамок проекта, по крайней мере в текущей версии. Код построителя запросов доступен в примерах, а не в API, он имеет существенные ограничения, но он и состоит при этом всего из 500 строк кода с комментариями, или около 300 без них. При этом, несмотря на всю свою простоту и даже ограниченность, даже эта простейшая имплементация способна сформировать нужные SQL для весьма существенного количества самых разнообразных типов пользовательских запросов. В настоящей версии мы предлагаем нашим пользователям, заинтересованным в построении подобных систем, использовать данный пример в качестве шаблона и развивать его под свои потребности. Да, это задача не на один вечер, но вы получите результат несопоставимо более высокого качества, чем при использовании в лоб универсальных решений.
Повторюсь, что в функции интента по умолчанию вы можете как просто доработать примеры из example (по отзывам его функциональности вполне может хватить), так и задействовать решения с нейронными сетями.
Заключение
Построить систему обращения к базе данных задача не из простых, но Apache NlpCraft уже взял на себя немалую часть рутинной работы, и во многом благодаря этому, разработка системы достойного качества займет измеримое время и ресурсы. Будет ли Apache NlpCraft community развивать направление автоматизации перевода текстовых запросов в SQL и расширять этот простой SQL пример до полноценного API — покажет время и запросы пользователей, формирующие план и направление развития проекта.


mr_tron
SQL специально создавали чтобы на нём могли писать не программисты.
Он и так очень похож на естественный язык.
При этом он позволяет чётко описать что именно хочет автор запроса. Без каких-либо разночтений. А эти нейросеточки только будут генерировать ошибки в данных, которых и без того полно в окружающем нас мире.
sergeykamov Автор
Все так, но все же SQL, понимание реляционных баз и т.д. — не самая простая задача для бизнес пользователей.
mikhailian
Лубочные бизнес-пользователи только и делают, что линкуют между собой десятки Excel файлов. Проблем с пониманием никаких не видят.
aradzinski
99.99% of business users have no knowledge of SQL (let alone of serious SQL level). So, natural language interface, if one exists, is a real advantage for this massive class of users.
mr_tron
Это безусловно, но вообще нейросеточки всегда будут давать ошибки. Просто потому что запросы делает человек без понимания структуры данных, например связей между сущностями. И эти ошибки будут скрыты от пользователя. И они потянутся в отчёты. А потом выяснится, что кто-то потерял миллионы просто потому что нейросеточка неправильно поняла как преобразовать желания человека в запрос реальных данных.
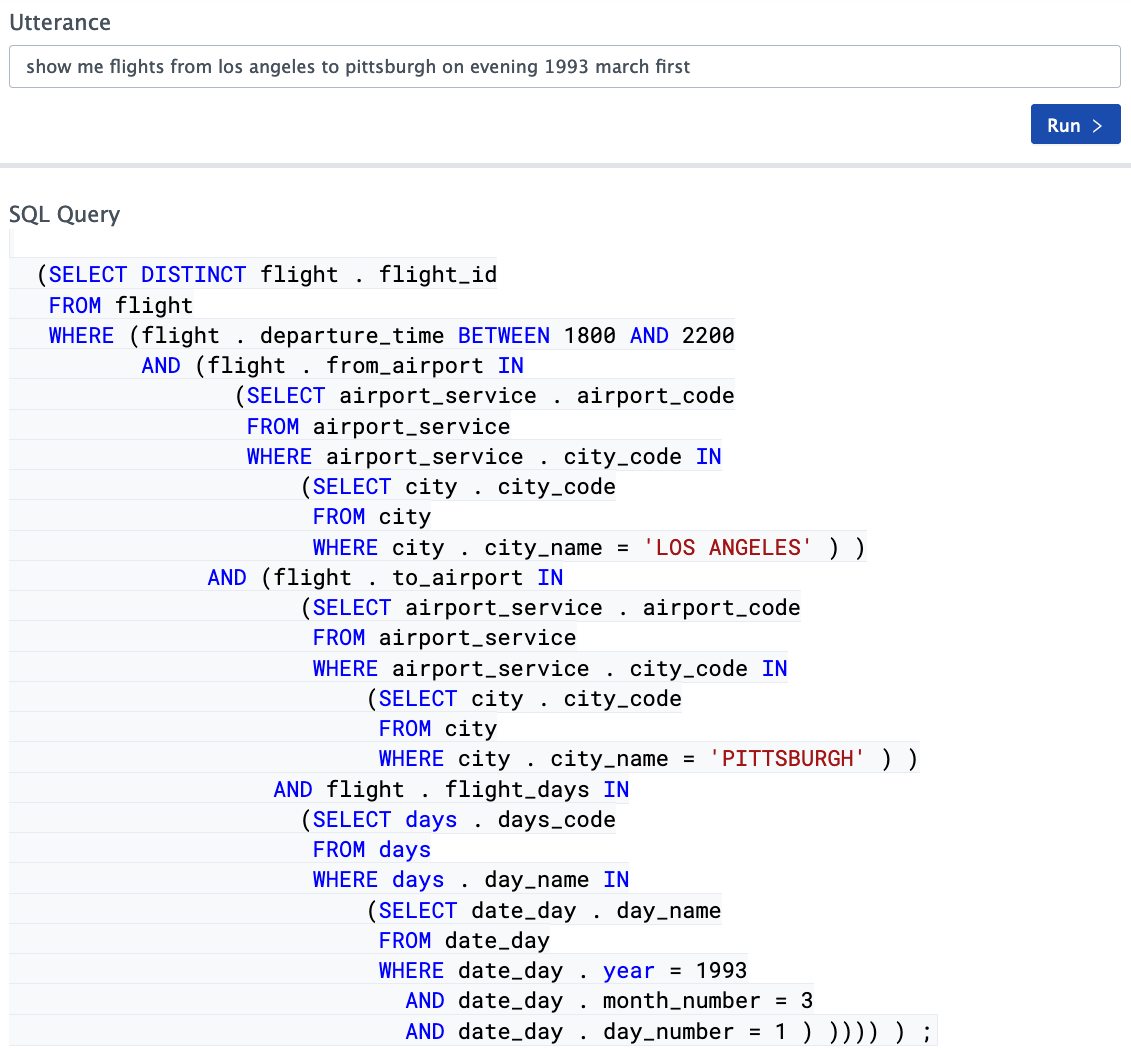
Научить человека sql чтоб он смог написать запрос как в примере про аэропорты реально не сложно. Там реально сплошные select from where in and <=
Я показал такое жене и она через 15 минут уже писала простенькие аналитические запросы в базу. Всякие эти бизнес-аналитики такой ад в экселе творят, который за гранью моего понимаю. Освоить sql не сильно сложнее особенно в редакторе нормальном типа datagrip.
aradzinski
One of the unique sides of Apache NLPCraft is the fact that it is not using neural networks in its intent matching — but rather a fully deterministic algorithm. It also requires that the models would be created by engineers and not by users or even data scientists.
This approach, obviously, has pros and cons…