

Первое что нужно сделать при разработке поисковых, диалоговых и прочих систем, основанных на natural language processing — это научиться разбирать тексты пользовательских запросов и находить в них сущности рабочей модели. Задача нахождения стандартных сущностей (geo, date, money и т.д.) в целом уже решена, остается лишь выбрать подходящий NER компонент и воспользоваться его функционалом. Если же вам нужно найти элемент, характерный для вашей конкретной модели или вы нуждаетесь в улучшенном качестве поиска стандартного элемента, придется создать свой собственный NER компонент или обучить какой-то уже существующий под свои цели.
Если вы работаете с системами вроде Alexa или Google Dialogflow — процесс обучения сводится к созданию простейшей конфигурации. Для каждой сущности модели вы должны создать список синонимов. Далее в дело вступают нейронные сети. Это быстро, просто, очень удобно, все заработает сразу. Из минусов — отсутствует контроль за настройками нейронных сетей, а также одна общая для данных систем проблема — вероятностный характер поиска. Все эти минусы могут быть совершенно не важны для вашей модели, особенно если в ней ищется одна-две принципиально отличающиеся друг от друга сущности. Но если элементов модели достаточно много, а особенно если они в чем-то пересекаются, проблема становится более значимой.
Если вы проектируете собственную систему, обучаете и настраиваете поисковые компоненты, например от Apache OpenNlp, Stanford NLP, Google Language API, Spacy или Apache NlpCraft для поиска собственных элементов, забот, разумеется, несколько больше, но и контроль над такой системой заметно выше.
Ниже поговорим о том, как нейронные сети используются при поиске сущностей в проекте Apache NlpCraft. Для начала вкратце опишем все возможности поиска в системе.
Поиск пользовательских сущностей в Apache NlpCraft
При построении систем на базе Apache NlpCraft вы можете использовать следующие возможности по поиску собственных элементов:
- Встроенные компоненты поиска, основанные на конфигурации синонимов элементов. Пример описания элементов моделей, основанных на синонимах, Synonym DSL т.д. приведены в ознакомительной статье о проекте.
- Использование любого из вышеупомянутых внешних компонентов, интеграция с ними уже предусмотрена, вы просто подключаете их в конфигурации.
- Применение составных сущностей. Суть — в возможности построения новых NER компонентов на основе уже существующих. Подробнее — тут.
- Самый низкоуровневый вариант — программирование и подключение в систему своего собственного парсера. Данная задача сводится к имплементации интерфейса и добавлении его в систему через IoC. На входе реализуемого компонента есть все для написания логики поиска сущностей в запросе: сам запрос и его NLP представление, модель и все уже найденные в тексте запроса другими компонентами сущности. Эта имплементация — место для подключения нейросетей, использования собственных алгоритмов, интеграции с любыми внешними системами и т.д., то есть точка полного контроля над поиском.
Первый подход, работающий на основе настройки синонимов, не требующий ни программирования, ни текстовых корпусов для обучения модели, является самым простым, универсальным и быстрым для разработки.
Ниже представлен фрагмент конфигурации модели “умный дом” (подробнее о макросах и synonym DSL можно прочесть по ссылке).
macros:
- name: "<ACTION>"
macro: "{turn|switch|dial|control|let|set|get|put}"
- name: "<ENTIRE_OPT>"
macro: "{entire|full|whole|total|*}"
- name: "<LIGHT>"
macro: "{all|*} {it|them|light|illumination|lamp|lamplight}"
...
- id: "ls:on"
description: "Light switch ON action."
synonyms:
- "<ACTION> {on|up|*} <LIGHT> {on|up|*}"
- "<LIGHT> {on|up}"
Элемент “ls:on” описан очень компактно, при этом данное описание содержит в себе более 3000 синонимов. Вот их малая часть: “set lamp“, “light on“, “control lamp“, “put them“, “switch it all“… Синонимы конфигурируются в весьма сжатом виде, при этом вполне читаемы.
Несколько замечаний:
- Разумеется, при работе с поиском по синонимам учитываются начальные формы слов (леммы, стеммы), стоп-слова текста запроса, конфигурируется поддержка прерывистости многословных синонимов и т.д. и т.п.
- Часть сгенерированных синонимов не будет иметь практического смысла, это вполне ожидаемая плата за компактность записи. Если использование памяти станет узким местом (тут речь должна идти о миллионах и более вариантов синонимов на сущность), стоит задуматься об оптимизации. Вы получите все необходимые warnings при старте системы.
Итак вы полностью управляете процессом поиска ваших элементов в тексте запросов, этот процесс является детерминированным, то есть в итоге отлаживаемым, контролируемым, и имеет возможности для последовательного улучшения. Теперь вам нужно лишь аккуратно составить достаточный список синонимов. Здесь вступает в игру человеческий фактор. На этапе старта проекта можно ограничиться лишь несколькими основными синонимами на элемент, достаточно добавить буквально одно-два слова, все будет работать, но в итоге конечно хочется поддержать максимально полный список синонимов для обеспечения наиболее качественного процесса распознавания.
Что может подсказать нам недостающие синонимы в конфигурации, ведь от ее полноты напрямую будет зависеть качество нашей системы?
Расширение списка синонимов
Первое очевидное направление — это в ручном режиме отслеживать логи и анализировать неотвеченные вопросы.
Второе — посмотреть в словаре синонимов, что может быть достаточно полезно для очевидных случаев. Один их самых известных словарей — wordnet.

Работа в ручном режиме может принести определенную пользу, но процесс поиска и конфигурирования дополнительных синонимов элементов здесь явно не стоит автоматизировать.
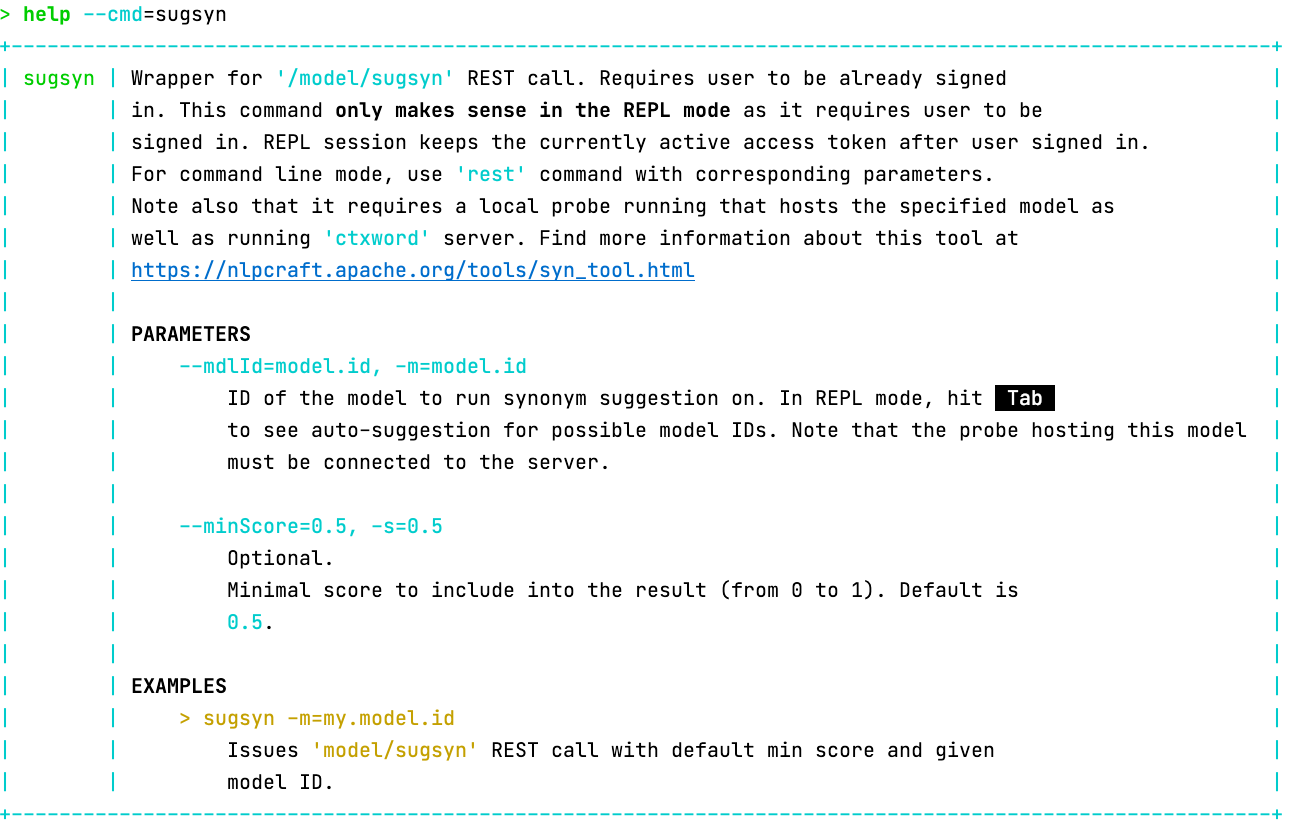
Помимо этого, разработчики Apache NlpCraft добавили в проект инструмент sugsyn, предлагающий, в процессе использования, дополнительные синонимы для элементов модели.
Компонент sugsyn работает стандартным образом через REST API, взаимодействуя с дополнительным сервером, поставляемым в бинарных релизах — ContextWordServer.
Описание ContextWordServer
ContextWordServer позволяет искать синонимы к слову в заданном контексте. В качестве запроса пользователь передает предложение с помеченным словом, к которому нужно подобрать синонимы, а сервер, используя выбранную модель, возвращает список наиболее подходящих слов заменителей.
Изначально в качестве базовой модели был использован word2vec (skip-gram модель), позволяющий строить векторные представления слов (или эмбеддинги). Идея заключалась в том, чтобы посчитать эмбеддинги слов и основываясь на полученном векторном пространстве отобрать слова, находящиеся ближе всего к целевому.
В целом данный подход работал удовлетворительно, но контекст слов учитывался недостаточно хорошо, даже при больших значениях N для n-граммов. Тогда было предложено использование Bert для решения задачи masked language modeling (поиск наиболее подходящих слов, которые можно подставить вместо маски в предложение). В предложении, которое передавал пользователь, маскировалось целевое слово, и выдача Bert являлась ответом. Недостатком использования одного лишь Bert также было получение не совсем удовлетворительного списка слов, подходящих по контексту использования, но не являющихся близкими синонимами заданного.
Решением этой проблемы стало комбинирование двух методов. Теперь, выдача Bert отфильтровывается, выкидывая слова с векторным расстоянием до целевого слова выше определенного порога.
Далее, по результатам экспериментов, word2vec был заменен на fasttext (логический наследник word2vec), показывающий лучшие результаты. Была использована готовая модель, предобученная на статьях из Wikipedia, а модель Bert была заменена на улучшенную модель — Roberta, смотри ссылку на предобученную модель.
Итоговый алгоритм не требует использования именно fasttext или Roberta в качестве составных частей. Обе подсистемы могут быть заменены альтернативными, способными решить схожие задачи. Кроме того, для лучшего результата предобученной модели могут быть fine-tuned, либо обучены с нуля.
Описание инструмента sugsyn
Работа с sugsyn, удобней всего осуществляется через CLI. Требуется скачать последнюю версию бинарного релиза, использование NlpCraft через maven central в данном случае будет недостаточно.
Общий принцип работы sugsyn достаточно прост. Он собирает примеры использования всех интентов запрашиваемой модели и объединяет их со всеми сконфигурированными синонимами каждого элемента модели. Созданные гибридные предложения посылаются на ContextWordServer, который возвращает рекомендации по использованию дополнительных слов в запрашиваемом контексте. Обратите внимание, для обучения нейронной сети требуются подготовленные и размеченные данные, но для работы sugsyn тоже требуются подготовленные данные — примеры использования, выигрыш в том, что данных для sugsyn нужно совсем немного, кроме того мы используем уже имеющиеся примеры из тестов системы.
Пример. Пусть некий элемент какой-то модели сконфигурирован с помощью двух синонимов: “ping“ и “buzz“ (сокращенный вариант модели, взятой из примера с будильником), и пусть единственный интент модели содержит два примера: «Ping me in 3 minutes» и «In an hour and 15mins, buzz me». Тогда sugsyn пошлет на ContextWordServer 4 запроса:
- text=”ping me in 3 minutes”, index=0
- text=”buzz me in 3 minutes”, index=0
- text=”in an hour and 15mins, ping me”, index=6
- text=”in an hour and 15mins, buzz me”, index=6
Это означает следующее — для каждого предложения (поле “text“) предложи мне какие-нибудь дополнительные подходящие слова, кроме уже имеющихся слов в позиции “index“. ContextWordServer вернет несколько вариантов, отсортированных по итоговому весу (комбинации результатов обеих моделей, влияние каждой модели может быть сконфигурировано), далее отсортированных по повторяемости.
Использование инструмента sugsyn
Приступим к работе
- Запускам ContextWordServer, то есть сервер с готовыми, предобученными моделями.
> cd ~/apache/incubator-nlpcraft/nlpcraft/src/main/python/ctxword
> ./bin/start_server.sh
Обратите внимание на то, что ContextWordServer должен быть предварительно проинсталирован и для успешной работы ему требуется python версий 3.6 — 3.8. См. “install_dependencies.sh“ для linux и mac или мануал по установке для windows. Имейте в виду, что процесс инсталляции влечет за собой скачивание файлов моделей существенных размеров, будьте внимательны.
- Запускаем CLI, стартуем в нем server и probe с подготовленной моделью, подробности см. в разделе Quick Start. Для начальных экспериментов можно подготовить свою собственную модель или воспользоваться уже имеющимися в поставке примерами.
- Используем команду sugsyn, с одним обязательным параметром — идентификатором модели, которая должна быть уже запущена в probe. Второй, необязательный параметр — значение минимального коэффициента достоверности результата, поговорим о нем ниже.
Все описанное выше расписано шаг за шагом в мануале по ссылке.
Получение результатов для разных моделей
Начнем с примера по прогнозу погоды. Элемент “wt:phen“ сконфигурирован с помощью множества синонимов среди которых «rain», «storm», «sun», «sunshine», «cloud», «dry» и т.д., а элемент “wt:fcast” с помощью «future», «forecast», «prognosis», «prediction» и т.д.
Вот часть ответа sugsyn на запрос со значением коэффициента minScore = 0.
> sugsyn --mdlId=nlpcraft.weather.ex --minScore=0
"wt:phen": [
{ "score": 1.00000, "synonym": "flooding" },
...
{ "score": 0.55013, "synonym": "freezing" },
...
{ "score": 0.09613, "synonym": "stop"},
{ "score": 0.09520, "synonym": "crash" },
{ "score": 0.09207, "synonym": "radar" },
...
"wt:fcast": [
{ "score": 1.00000, "synonym": "outlook" },
{ "score": 0.69549, "synonym": "news" },
{ "score": 0.68009, "synonym": "trend" },
...
{ "score": 0.04898, "synonym": "where" },
{ "score": 0.04848, "synonym": "classification" },
{ "score": 0.04826, "synonym": "the" },
...
Как мы видим из полученного ответа, чем больше значение коэффициента — тем выше ценность предложенных синонимов для элементов модели. Можно сказать, что интересные для использования синонимы здесь начинаются со значения коэффициента равного 0.5. Коэффициент достоверности результата — интегральный показатель, учитывающий коэффициенты выдачи моделей и частоту, с которой системой предлагается синоним в разных контекстах.
Посмотрим, что будет предложено в качестве дополнительных синонимов для элементов примера “умный дом”. Для “ls:loc”, описывающего расположение элементов освещения (синонимы: «kitchen», «library», «closet» и т.д.), предложенные варианты с высокими значениями коэффициента, большим чем 0.5, тоже выглядят заслуживающими внимания:
"lc:loc": [
{ "score": 1.00000, "synonym": "apartment" },
{ "score": 0.96921, "synonym": "bed" },
{ "score": 0.93816, "synonym": "area" },
{ "score": 0.91766, "synonym": "hall" },
...
{ "score": 0.53512, "synonym": "attic" },
{ "score": 0.51609, "synonym": "restroom" },
{ "score": 0.51055, "synonym": "street" },
{ "score": 0.48782, "synonym": "lounge" },
...
Но около коэффициента 0.5 для нашей модели уже попадается откровенный мусор — ”street”.
Для элемента “x:alarm” модели будильник, с синонимами: ”ping”, ”buzz”, ”wake”, ”call”, ”hit” и т.д. имеем следующий результат:
"x:alarm": [
{ "score": 1.00000, "synonym": "ask" },
{ "score": 0.94770, "synonym": "join" },
{ "score": 0.73308, "synonym": "remember" },
...
{ "score": 0.51398, "synonym": "stop" },
{ "score": 0.51369, "synonym": "kill" },
{ "score": 0.50011, "synonym": "send" },
...
То есть для элементов данной модели, с понижением коэффициента качество предложенных синонимов снижается заметно быстрее.
Для элемента “x:time” модели “текущее время“ (1, 2), с синонимами типа ”what time”, ”clock”, ”date time”, ”date and time” и т.д. имеем следующий результат:
"x:time": [
{ "score": 1.00000, "synonym": "night" },
{ "score": 0.92325, "synonym": "year" },
{ "score": 0.58671, "synonym": "place" },
{ "score": 0.55458, "synonym": "month" },
{ "score": 0.54937, "synonym": "events" },
{ "score": 0.54466, "synonym": "pictures"},
...
Качество предложенных синонимов оказалось неудовлетворительным даже при высоких коэффициентах.
Оценка результатов
Перечислим факторы, от которых зависит качество синонимов, предлагаемых sugsyn для поиска в тексте элементов модели:
- Количество синонимов, определенных пользователем в конфигурации элементов.
- Количество и качество примеров запросов к интентам. Под “качеством“ понимается естественность и распространенность добавленных примеров. Спросите гугл «который час», и число полученных результатов будет “примерно 2 630 000“. Спросите — «час который», результатов будет “примерно 136 000“. Текст первого запроса более качественный, и для примера он подойдет лучше.
- Самое главное и непредсказуемое — качество зависит от типа самого элемента и типа его модели.
Иными словами, даже при прочих равных условиях, таких как достаточное количество заранее сконфигурированных синонимов и примеров использования, для некоторых видов сущностей нейронная сеть предложит более качественный набор синонимов, а для некоторых менее качественный, и это зависит от природы самих сущностей и моделей. То есть для достижения сопоставимого уровня качества поиска, выбирая из списка предлагаемых к использованию синонимов, для разных элементов и разных моделей мы должны использовать разные значения минимального коэффициента достоверности предлагаемых вариантов. В целом это вполне объяснимо, так как даже одни и те же слова в разных смысловых контекстах могут быть заменены несколько разными наборами слов заменителей. Предобученная модель, используемая по умолчанию с ContectWordServer может быть адаптирована для одних типов сущностей лучше чем для других, однако перенастройка модели может и не улучшить итоговый результат. Так как Apache NlpCraft — это opensource решение, вы всегда можете изменить все настройки модели, как параметры, так и саму модель с учетом специфики вашей предметной области. К примеру, для специфичной, изолированной области, имеет смысл обучить модель bert с нуля, поскольку данных об этой области в “стандартной” модели может оказаться недостаточно.
При работе с sugsyn, помимо идентификатора модели, вы можете использовать всего один параметр — minScore, просто ограничивая размер выборки синонимов, отсортированных в порядке снижения их качества. Подобное упрощение используется для облегчения работы специалистов, ответственных за расширение списка синонимов элементов настраиваемой модели. Обилие конфигурационных параметров, свойственное работе с нейронными сетями в данном случае способно лишь запутать пользователей системы.
Заключение
Если вы полностью делегируете задачу поиска ваших сущностей нейронным сетям, то для разных элементов и разных типов моделей вы будете получать результаты, заметно отличающиеся качеством распознавания. При этом вы даже не сможете оценить эту разницу, особенно если вы не контролируете настройки сети. Но и самостоятельная конфигурация для установки желаемого порога срабатывания, не будет являться простой задачей. Причиной, как правило, является недостаток достаточного количества данных, необходимых для корректного обучения и тестирования сети. Используя предлагаемый Apache NlpCraft механизм поиска сущностей через набор синонимов и инструмент, предлагающий варианты обогащения данного списка, вы можете самостоятельно контролировать степень достоверности синонимов вашей модели и выбрать из предлагаемых сетью только одобренные вами подходящие варианты. Фактически вы получаете возможность заглянуть в черный ящик и достать из него лишь то, что вам нужно.
aradzinski
Next versions of NLPCraft will perform this in a more automated/regular way. Ideally, it shouldn't be a «up to the user» tool.