
В данной статье я бы хотел познакомить читателей с одним из проектов Apache Software Foundation сообщества — NlpCraft. NlpCraft — библиотека с открытым исходным кодом, предназначенная для интеграции языкового интерфейса в пользовательские приложения.
Цель проекта — тотальное упрощение доступа к возможностям NLP (Natural Language Processing) разработчикам приложений. Основная идея системы — это уловить баланс между простотой вхождения в NLP проблематику и поддержкой широкого диапазона возможностей промышленной библиотеки. Задача проекта бескомпромиссна — простота без упрощения.
На момент версии 0.7.1 проект находится в стадии инкубации Apache сообщества и доступен по адресу https://nlpcraft.apache.org.
Ограничения — текущая версия 0.7.1 поддерживает только английский язык.
Договоримся о некоторых терминах и понятиях, используемых в дальнейшем изложении.
На примере системы управления умным домом, рассмотрим последовательность работы с NlpCraft. Разрабатываемая нами система управления должна понимать такие команды как “Включи свет во всем доме” или “Погаси лампы на кухне”. Обратите внимание на то, что NlpCraft не занимается распознаванием речи и принимает в качестве аргумента уже готовый текст.
Мы должны:
Для разработки примера нам потребуется три сущности — два признака действия, ”включить” и ”выключить”, и место действия.
Теперь мы должны спроектировать модель, то есть определить механизм нахождения этих элементов в тексте. По умолчанию, для нестандартных сущностей NlpCraft использует механизм поиска по списку синонимов. Для того чтобы задача составления списка синонимов была максимально простой и удобной, NlpCraft предоставляет набор инструментов, включающий в себя макросы и Synonym DSL.
Ниже приведена статическая конфигурация lightswitch_model.yaml, включающая в себя определение трех наших сущностей и одного интента.
Вкратце о содержимом:
Несмотря на всю свою простоту, данный тип моделирования — мощное и гибкое средство.
Обратите внимание, что если необходимо, специфичный для модели NER компонент может быть запрограммирован пользователем NlpCraft любым другим способом, с использованием нейросетей или иных подходов и алгоритмов. Пример — потребность в недетерминированном, зависящем от времени суток алгоритме распознавания сущностей и т.д.
Как происходит матчинг:
Приведенный ниже пример функции интента “ls” написан на Java, но это может быть любой другой Java совместимый язык программирования.
Что происходит в теле функции:
Полученных данных достаточно для обращения к API управляемой нами системы.
В данной статье мы не будем приводить детальный пример интеграции с каким-либо конкретным API. Также за рамками примера останутся управление контекстом беседы, учет диалога, работа с кратковременной памятью системы, возможности настройки механизма intent matching, вопросы интеграции со стандартными провайдерами NER, утилиты по расширению списка синонимов и т.д. и т.п.
Ближайшие и наиболее известные “аналоги“ Amazon Alexa и Google DialogFlow имеют целый ряд существенных отличий от данной системы. С одной стороны они в чем-то проще в использовании, так как для своих начальных примеров не требуют даже IDE. C другой стороны их возможности весьма ограничены и во многом они гораздо менее гибкие.
С помощью нескольких строчек кода мы смогли запрограммировать простой, но вполне рабочий прототип системы управления светом в умном доме, понимающий множество команд в различных форматах. Теперь вы с легкостью можете расширить возможности модели. Например, дополнить список синонимов сущностей или добавить какую-то новую, необходимую для дополнительного функционала, такую как “яркость света” и т.д. Изменения займут считанные минуты и не потребуют дополнительного обучения модели.
Надеюсь, что благодаря данной заметке, вы смогли получить первое, пусть и поверхностное представление о системе Apache NlpCraft.
Цель проекта — тотальное упрощение доступа к возможностям NLP (Natural Language Processing) разработчикам приложений. Основная идея системы — это уловить баланс между простотой вхождения в NLP проблематику и поддержкой широкого диапазона возможностей промышленной библиотеки. Задача проекта бескомпромиссна — простота без упрощения.
На момент версии 0.7.1 проект находится в стадии инкубации Apache сообщества и доступен по адресу https://nlpcraft.apache.org.
Ключевые особенности системы
- Семантическое моделирование. Простой встроенный механизм распознавания элементов моделей в тексте запросов, не требующий машинного обучения.
- Java API, дающий возможность разрабатывать модели на любом Java совместимом языке — Java, Scala, Kotlin, Groovy и т.д.
- Подход Model-as-a-Code, позволяющий создавать и редактировать модели с помощью привычных разработчикам инструментов.
- Возможность взаимодействия со всеми видами устройств, имеющих API — чатботами, голосовым ассистентами, устройствами умного дома и т.д., а также использования любых пользовательских источников данных, от баз данных до SaaS систем, закрытых или открытых.
- Продвинутый набор NLP инструментов, включающий систему работы с кратковременной памятью, шаблонами диалоговов и т.д.
- Интеграция со множеством провайдеров NER компонентов (Apache OpenNlp, Stanford NLP, Google Natural Language API, Spacy)
Ограничения — текущая версия 0.7.1 поддерживает только английский язык.
Договоримся о некоторых терминах и понятиях, используемых в дальнейшем изложении.
Терминология
- Named Entity — именованная сущность. Простыми словами, это объект или понятие распознаваемое в тексте. Полное определение — здесь. Сущности могут быть универсальными, таким как даты, страны и города, или специфичными для конкретной модели.
- NER (Named Entity Recognition) компоненты – программные компоненты, отвечающие за распознавание сущностей в тексте.
- Intent, далее интенты. Интент — это сочетание функции и правила, по которому функция должна быть вызвана. Правило — это чаще всего шаблон, состоящий из набора ожидаемых именованных сущностей в тексте запроса.
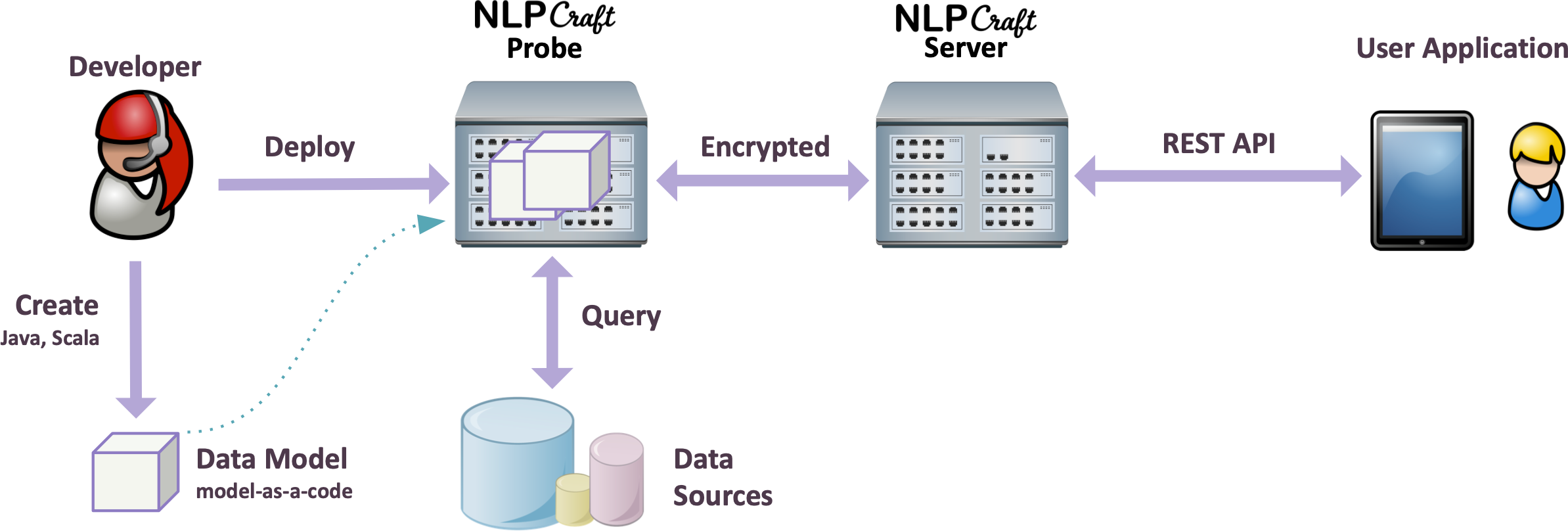
Компоненты системы
- Data model
Содержит конфигурацию NER компонентов, интентов с соответствующими функциями и т.д. В большинстве случаев процесс конфигурации сводится к созданию и поддержке простого Json или Yaml файла.
- Data probe
Приложение контейнер для моделей. Обеспечивает требуемую приватность доступа к пользовательским данным, возможность подключения необходимых плагинов, быстрого рестарта для отладки моделей и т.д. В системе может быть несколько Data Probe, каждый Data Probe может поддерживать несколько моделей.
- REST server
Предоставляет REST API для пользовательских приложений
Пример использования NlpCraft
На примере системы управления умным домом, рассмотрим последовательность работы с NlpCraft. Разрабатываемая нами система управления должна понимать такие команды как “Включи свет во всем доме” или “Погаси лампы на кухне”. Обратите внимание на то, что NlpCraft не занимается распознаванием речи и принимает в качестве аргумента уже готовый текст.
Мы должны:
- Определить какие именованные сущности потребуются нам в работе и как нам обнаружить их тексте.
- Составить интенты для различных наборов сущностей, то есть разных типов команд.
Для разработки примера нам потребуется три сущности — два признака действия, ”включить” и ”выключить”, и место действия.
Теперь мы должны спроектировать модель, то есть определить механизм нахождения этих элементов в тексте. По умолчанию, для нестандартных сущностей NlpCraft использует механизм поиска по списку синонимов. Для того чтобы задача составления списка синонимов была максимально простой и удобной, NlpCraft предоставляет набор инструментов, включающий в себя макросы и Synonym DSL.
Ниже приведена статическая конфигурация lightswitch_model.yaml, включающая в себя определение трех наших сущностей и одного интента.
id: "nlpcraft.lightswitch.ex"
name: "Light Switch Example Model"
version: "1.0"
description: "NLI-powered light switch example model."
macros:
- name: "<ACTION>"
macro: "{turn|switch|dial|control|let|set|get|put}"
- name: "<ENTIRE_OPT>"
macro: "{entire|full|whole|total|*}"
- name: "<LIGHT>"
macro: "{all|*} {it|them|light|illumination|lamp|lamplight}"
enabledBuiltInTokens: [] # This example doesn't use any built-in tokens.
elements:
- id: "ls:loc"
description: "Location of lights."
synonyms:
- "<ENTIRE_OPT> {upstairs|downstairs|*} {kitchen|library|closet|garage|office|playroom|{dinning|laundry|play} room}"
- "<ENTIRE_OPT> {upstairs|downstairs|*} {master|kid|children|child|guest|*} {bedroom|bathroom|washroom|storage} {closet|*}"
- "<ENTIRE_OPT> {house|home|building|{1st|first} floor|{2nd|second} floor}"
- id: "ls:on"
groups:
- "act"
description: "Light switch ON action."
synonyms:
- "<ACTION> {on|up|*} <LIGHT> {on|up|*}"
- "<LIGHT> {on|up}"
- id: "ls:off"
groups:
- "act"
description: "Light switch OFF action."
synonyms:
- "<ACTION> <LIGHT> {off|out}"
- "{<ACTION>|shut|kill|stop|eliminate} {off|out} <LIGHT>"
- "no <LIGHT>"
intents:
- "intent=ls term(act)={groups @@ 'act'} term(loc)={id == 'ls:loc'}*"
Вкратце о содержимом:
- В модели задан один элемент, определяющий локацию “ls:loc”, и два элемента признака действия: “ls:on” и “ls:off”, объединенных в группу “act” для удобства использования в интентах.
- Использование макросов и Synonym DSL позволяет определять необходимое и сколько угодно большое количество синонимов с помощью нескольких строк конфигурационного файла. Так, например, элемент “ls:on” определяется словами и словосочетаниями “turn”, “turn it”, “turn all it” и т.д., а “ls:loc” — “light”, “entire light”, “entire light upstairs” и т.д. Приведенная в примере конфигурация описывает более чем 7700 уникальных синонимов.
- Поиск по синонимам в тексте производится с учетом начальных форм слов (леммы и стеммы), наличия стоп-слов, возможных перестановок слов в словосочетаниях и т.д.
- В модели определен один интент с именем “ls”. Условие срабатывания интента — запрос должен содержать одну сущность группы “act” и может содержать несколько сущностей типа “ls:loc”. Полный синтаксис Intents DSL можно найти по ссылке.
Несмотря на всю свою простоту, данный тип моделирования — мощное и гибкое средство.
- Списки синонимов просто и быстро расширяются, легко тестируются и поддерживаются. А известная проблема многозначности слов не является существенной для специализированных моделей.
- Модели не требуется обучение и размеченные корпусы текстов, которые непросто найти или создать для конкретной предметной области.
- Данный NER компонент пытается захватить как можно большее количество слов. Чем меньше нераспознанных слов в запросе — тем тверже уверенность в том, что запрос был разобран и интерпретирован верно.
- Важный момент – поведение системы становится полностью предсказуемым, а не вероятностным, в отличие от систем основанных на NER компонентах, базирующихся на нейронных сетях.
Обратите внимание, что если необходимо, специфичный для модели NER компонент может быть запрограммирован пользователем NlpCraft любым другим способом, с использованием нейросетей или иных подходов и алгоритмов. Пример — потребность в недетерминированном, зависящем от времени суток алгоритме распознавания сущностей и т.д.
Как происходит матчинг:
- Текст пользовательского запроса разбивается на составляющие (слова, токены),
- слова приводятся в базовую форму (леммы и стеммы), для них находятся части речи и другая низкоуровневая информация.
- Далее, на основе токенов и их сочетаний, в тексте запроса ищутся именованные сущности.
- Найденные сущности сопоставляются с шаблонами всех заданных в модели интентов, и если подходящий интент находится, вызывается соответствующая ему функция.
Приведенный ниже пример функции интента “ls” написан на Java, но это может быть любой другой Java совместимый язык программирования.
public class LightSwitchModel extends NCModelFileAdapter {
public LightSwitchModel() throws NCException {
super("lightswitch_model.yaml");
}
@NCIntentRef("ls")
NCResult onMatch(
@NCIntentTerm("act") NCToken actTok,
@NCIntentTerm("loc") List<NCToken> locToks
) {
String status = actTok.getId().equals("ls:on") ? "on" : "off";
String locations =
locToks.isEmpty() ?
"entire house" :
locToks.stream().
map(p -> p.meta("nlpcraft:nlp:origtext").toString()).
collect(Collectors.joining(", "));
// Add HomeKit, Arduino or other integration here.
// By default - just return a descriptive action string.
return NCResult.text(
String.format("Lights are [%s] in [%s].", status, locations)
);
}
}
Что происходит в теле функции:
- Статическая конфигурация, определенная нами выше с помощью файла lightswitch_model.yaml, считывается при использовании адаптера NCModelFileAdapter.
- В качестве входных аргументов функция получает набор данных из сущностей, соответствующих шаблону своего интента.
- По элементу группы “act” определяется конкретное действие, которое необходимо выполнить.
- Из списка “ls:loc” извлекается информация о конкретном месте или местах, где действие должно быть произведено.
Полученных данных достаточно для обращения к API управляемой нами системы.
В данной статье мы не будем приводить детальный пример интеграции с каким-либо конкретным API. Также за рамками примера останутся управление контекстом беседы, учет диалога, работа с кратковременной памятью системы, возможности настройки механизма intent matching, вопросы интеграции со стандартными провайдерами NER, утилиты по расширению списка синонимов и т.д. и т.п.
Схожие системы
Ближайшие и наиболее известные “аналоги“ Amazon Alexa и Google DialogFlow имеют целый ряд существенных отличий от данной системы. С одной стороны они в чем-то проще в использовании, так как для своих начальных примеров не требуют даже IDE. C другой стороны их возможности весьма ограничены и во многом они гораздо менее гибкие.
Заключение
С помощью нескольких строчек кода мы смогли запрограммировать простой, но вполне рабочий прототип системы управления светом в умном доме, понимающий множество команд в различных форматах. Теперь вы с легкостью можете расширить возможности модели. Например, дополнить список синонимов сущностей или добавить какую-то новую, необходимую для дополнительного функционала, такую как “яркость света” и т.д. Изменения займут считанные минуты и не потребуют дополнительного обучения модели.
Надеюсь, что благодаря данной заметке, вы смогли получить первое, пусть и поверхностное представление о системе Apache NlpCraft.
sshikov
А другие языки вообще планируются?
sergeykamov Автор
Да, архитектура проекта позволяет расширить список поддерживаемых языков, но список приоритетных и сроки разработки еще не определены.