
А/Б-тестирование — это способ измерить эффективность нового функционала путем сравнения. Вы создаете новый заголовок, кнопку или изображение и показываете их только части аудитории сайта. В течение нескольких недель собираете статистику об использовании нового функционала и на основании этого принимаете решение об открытии новой фичи для 100% пользователей.
Senior Frontend Developer ЦИАН Иван Бабков, который разрабатывал приложения для регистрации доменов, интернет-банкинга и поиска по жилой недвижимости в своем докладе на конференции FrontendConf рассказал об инфраструктуре компании для работы с А/Б-экспериментами, проблемах и путях их решения.

Предположим, есть две кнопки, и вы хотите понять, на какую будут кликать больше: на красную или на синюю. Вы добавляете отправку аналитики на каждую из этих кнопок, ждете какое-то время, пока накопятся данные и решаете что-то. Например, узнаете, что красная кнопка в этом случае лучше, и оставляете на сайте только ее.
В ЦИАН A/B тестирование – больше, чем просто сравнение. Это целый процесс, который начинается с того, что стейкхолдер и аналитики продумывают дизайн эксперимента. Не тот дизайн, к которому мы привыкли, не дизайн нарисованный, а дизайн, позволяющий понять, сколько будет групп в эксперименте, сколько вариантов наших кнопок, сколько придется ждать результаты проведения A/B эксперимента и т.д.
Для того, чтобы больше погрузиться в этот процесс, предположим, что у вас есть красивый сайт, на который приходит 100% ваших пользователей.
Вверху на сайте меню с текстом: «Покупайте наши товары со скидкой 10%». Кликаем на него и получаем больше информации о том, что это за акция.
Все было хорошо ровно до того момента, пока в компании не предположили, что, во-первых, люди не замечают этот блок; во-вторых, в ЦИАН много акций, и размещать их на главной странице сайта больше не хотят.
Изменили дизайн. Получили макет с тремя блоками акций. На них сделан акцент и, вроде бы, этот вариант лучше предыдущего.
Но хорошо бы основывать решение на аналитике. Поэтому нужно сделать следующее: взять 100% пользователей и разделить их на две группы по 50%. Первой показать старый вариант интерфейса, второй — новый.
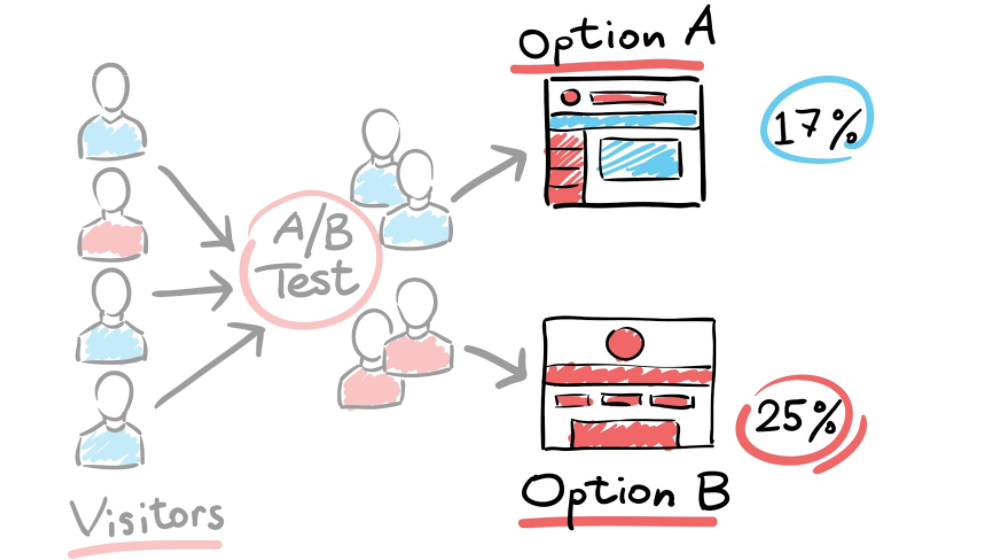
Спустя какое-то время, когда накоплены данные, которые отправлялись с разных вариантов интерфейса, можно сделать вывод, что конверсия в клики по первому варианту интерфейса 17%, по второму – 25%. Логично, что на сайте предпочли оставить второй вариант. Это поможет в дальнейшем улучшить user experience.
Последний шаг, который необходимо сделать: пустить все 100% пользователей на новый вариант интерфейса.
Чтобы погрузиться глубже, приведу пример того, разрабатывали отдельно взятый A/B эксперимент в компании с самого начала и до момента его завершения (полной выкатки на бой).
В какой-то момент продакт-менеджер ЦИАН совместно с дизайнером и аналитиком создали задачу следующего вида:

На сайте есть страница, где люди вбивают фильтры, поисковый запрос и видят релевантную выдачу по жилым комплексам. Это обычная поисковая страница: сверху фильтры, снизу выдача.
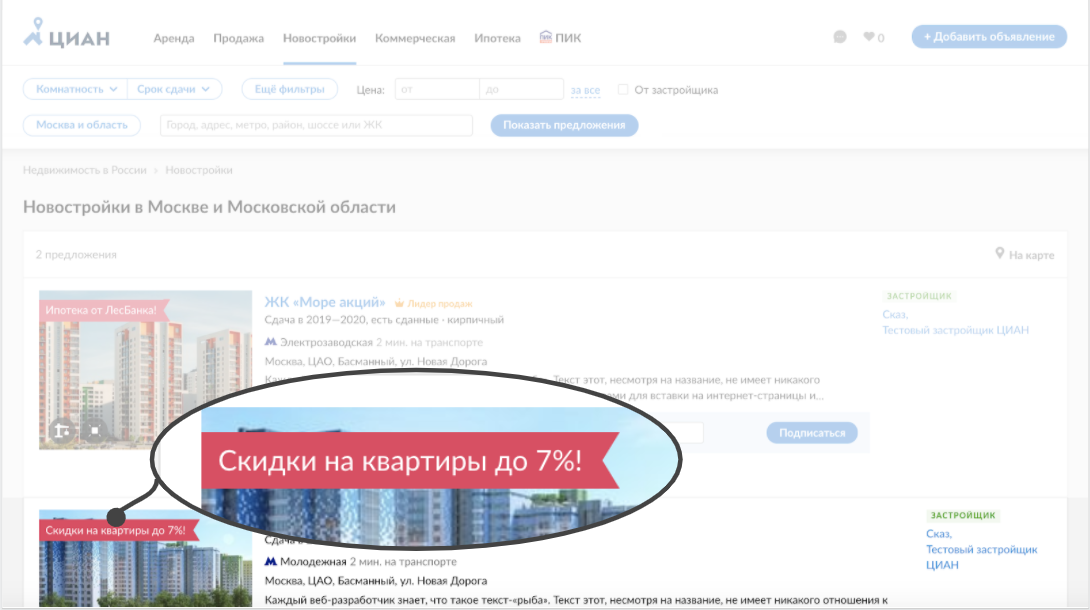
На этой странице в некоторых карточках жилого комплекса есть блоки, где написано, например: «Скидки на квартиры до 7%». По клику на ссылку пользователь видит больше информации об акции.
Дизайнер рисует два варианта макета:
А. Старый вариант, где есть один блок акций.
В. Новый вариант с тремя блоками акций, между которыми можно переключаться.
Первое, что необходимо сделать: перенести описание эксперимента в код. В ЦИАН есть админка, позволяющая добавлять и редактировать новые эксперименты:
В ней нужно заполнить форму следующего содержания:
При нажатии кнопки «СГЕНЕРИРОВАТЬ», вся информация попадает в базу данных, откуда бэкенд может ее запрашивать.
Далее можно запросить c бэкенда только что сгенерированную информацию по актуальным для пользователя экспериментам из бэкендового микросервиса.
Для этого нужно сделать вопрос, который выглядит следующим образом:

Вариант ответа – это список, в котором есть объекты с именем эксперимента и A/B группа, в которую попадает пользователь в этом отдельном эксперименте.
Нужно внести полученную с бэкенда информацию об эксперименте в Redux store и проверить в компонентах, какой вариант интерфейса в коде нужно отрисовывать в A/B группе.
В проекте есть всего две директории:

В компоненте GKCard отрисовывается PromoLabel.
Первое, что нужно сделать перед тем, как приступить к работе с кодом и добавлять новые файлы и директории — изолировать новый код эксперимента, чтобы потом легко было его удалять и рефакторить. Для этого необходимо создать дополнительную директорию прямо в контейнере, в котором будет происходить эксперимент:
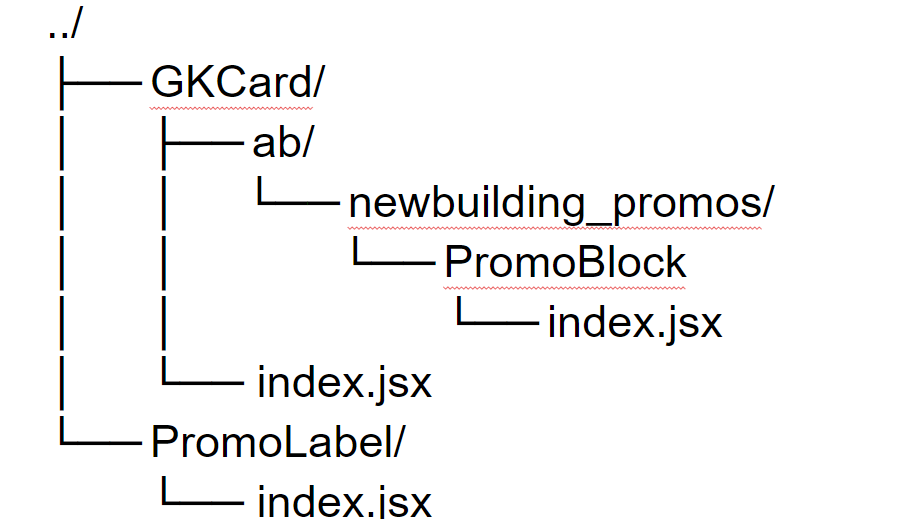
Добавляем директорию ab, в нее — директорию с названием эксперимента (в нашем примере: newbuilding_promos), а туда — все файлы.
В компоненте жилого комплекса добавляем всего несколько строк:

В connect берем список всех экспериментов, ищем в них эксперимент под именем newbuilding_promos, проверяем, есть ли такой эксперимент, и в этом объекте находим поле A/B групп, которое получили с бэкенда.

Если его значение 1, то отрисовываем новый вариант акции. Если нет, то старый:

То есть пользователь попадает в группу 1, если он получает новый вариант интерфейса.
Когда момент выбора отрисовки разных блоков закончен, нужно добавить аналитику, чтобы собрать данные. Добавляем метод в наш новый блок, который будет отравлять аналитику.

Для отправки в примере использована библиотека ReactGA, но можно использовать множество других библиотек в NPM. В ЦИАН используют библиотеку собственной разработки, дублируя туда отправку:


Мы зарелизили задачу, все хорошо. Спустя две недели приходит новая.
Важный момент: аналитики провели статистические тесты, подтвердили правильность полученных результатов.

В задаче были данные, что 13% пользователей кликают на блок акций в старом варианте, 21% — в новом. Стейкхолдер вместе с аналитиками попросили Ивана раскатать вариант В на 100% пользователей. Это повысит конверсию в клике: пользователи видят эти акции, все хорошо.
Чтобы сделать это, нужно воспользоваться админкой:
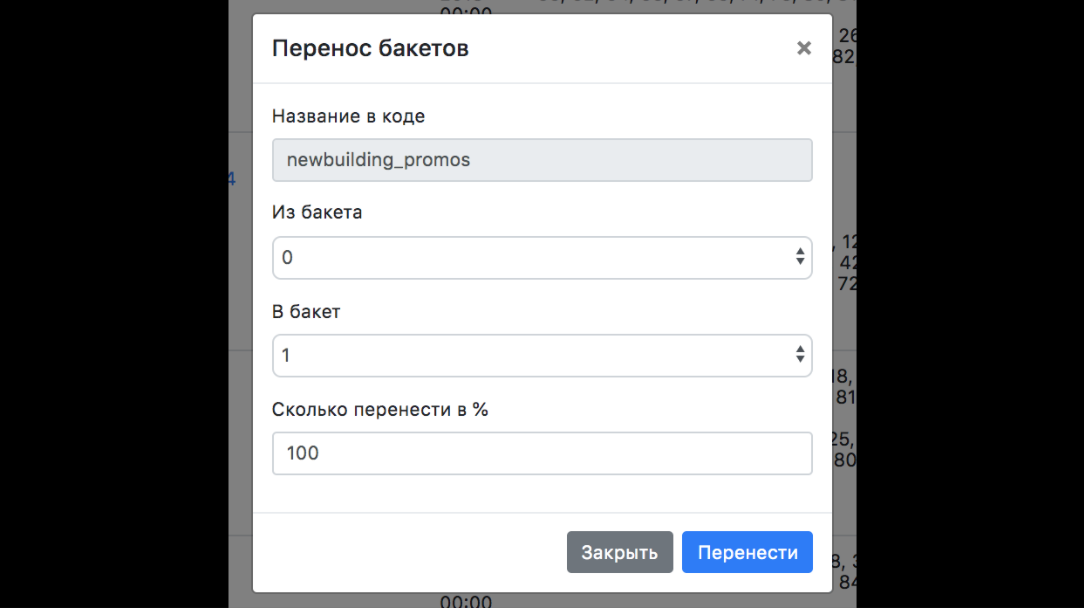
Нужно перекинуть пользователей в БД в группу В. Теперь пользователи с ID от 0 до 99 увидят второй вариант интерфейса. Первый вариант не увидит никто.

Когда остался единственный вариант, можно спокойно удалить эксперимент: указать, что он не активен через админку в базе данных:

В ЦИАН хранят не только актуальные, но и уже завершенные эксперименты. Никогда не знаешь, когда может понадобиться информация о них.
Теперь нужно перенести файлы из этой директории на нужный уровень вложенности проекта (в нашем случае рядом со старым блоком акций) и удалить старый блок:
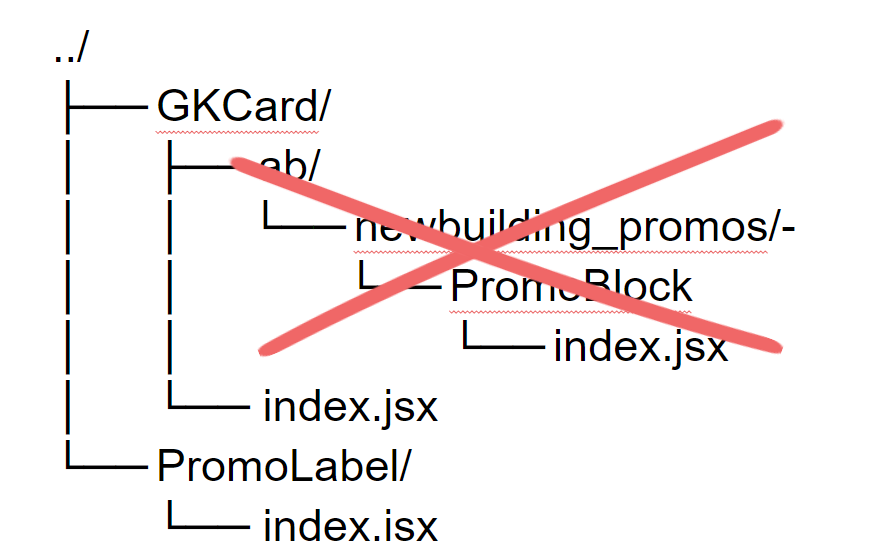
Все! Следы эксперимента остались лишь в git log и в БД.
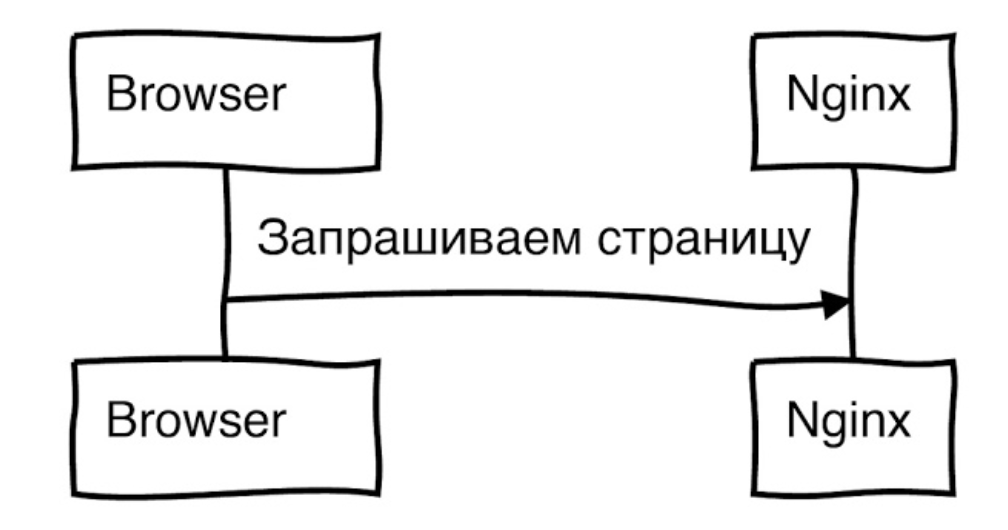
Есть запрос. Он пришел из браузера на наш внешний Nginx:
На Nginx мы запускаем скрипт, который генерирует ID от 0 до 99. Есть функция примерно следующего вида:

Функция возвращает число от 0 до 99. Она принимает строчку в виде уникального идентификатора пользователя. В нашем примере это будет:
uid = ‘abfd-4843’
Эта строчка передается функции md5 для генерации хэша:

Хэш получается шестнадцатеричный:
hash = ‘FD029AAD2251AD74F8223B4F4A80B6EA’
Мы преобразуем его в десятичное число и делим на 100:

parseInt(hash, 16)=3.363082047354731e+38
Остатком от этого деления будет число от 0 до 99. В нашем примере — 68:
parseInt(hash, 16) % 100 = 68
График, который иллюстрирует равномерность распределения сгенерированных ID на 10 млн уникальных идентификаторов пользователя:

Видно, что есть небольшие пики и падения. Они обусловлены рандомизацией ID, и не являются для нас проблемой.
Мы запрашиваем страницу с ID, который только что сгенерировали, и передаем его как HTTP заголовок:
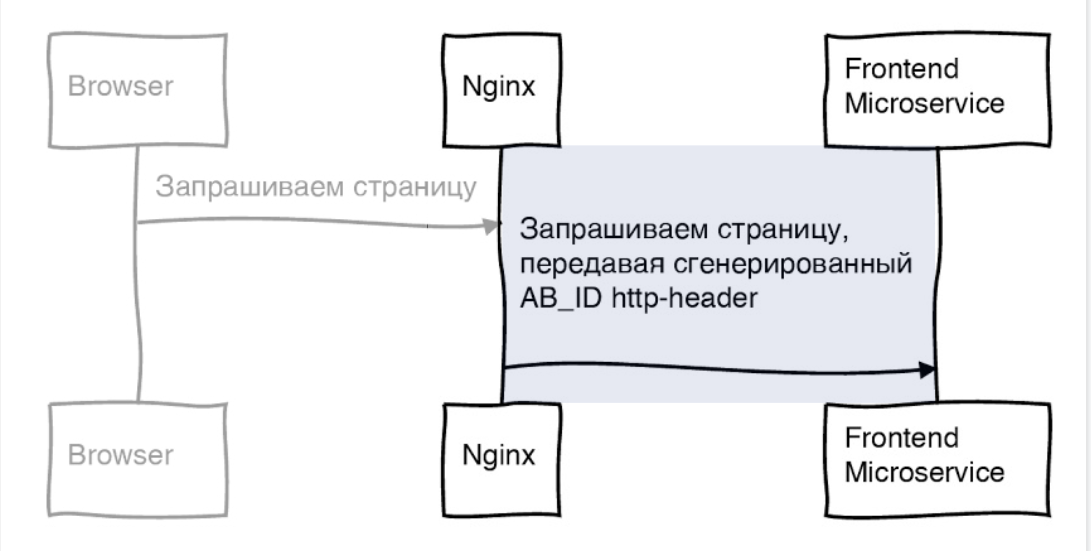
Эти данные попадают на фронтовый микросервис (в вашем случае это может быть монолитное приложение). Приложение должно понять, какой блок интерфейса отрисовывать. Для этого запрашивает бэкенд. В частности, информацию об экспериментах, которую мы храним.

Запрос выглядит примерно так:
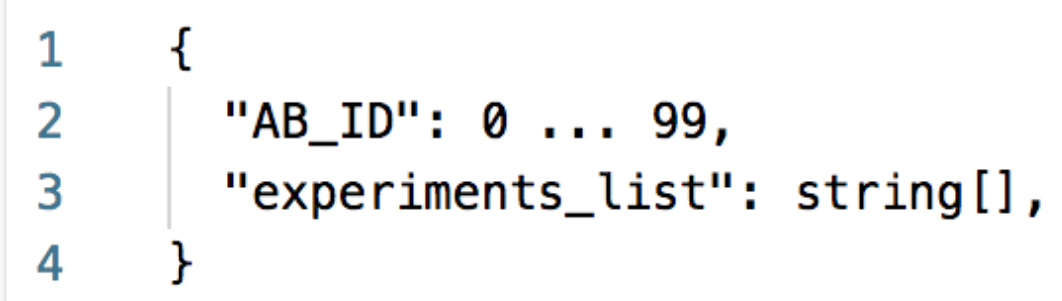
Мы передаем ID, только что нами сгенерированный на Nginx, и список экспериментов (их имен, которые фронтенд хочет получить от бэкенда). Бэкенд должен запросить этот список из БД, что он и делает:
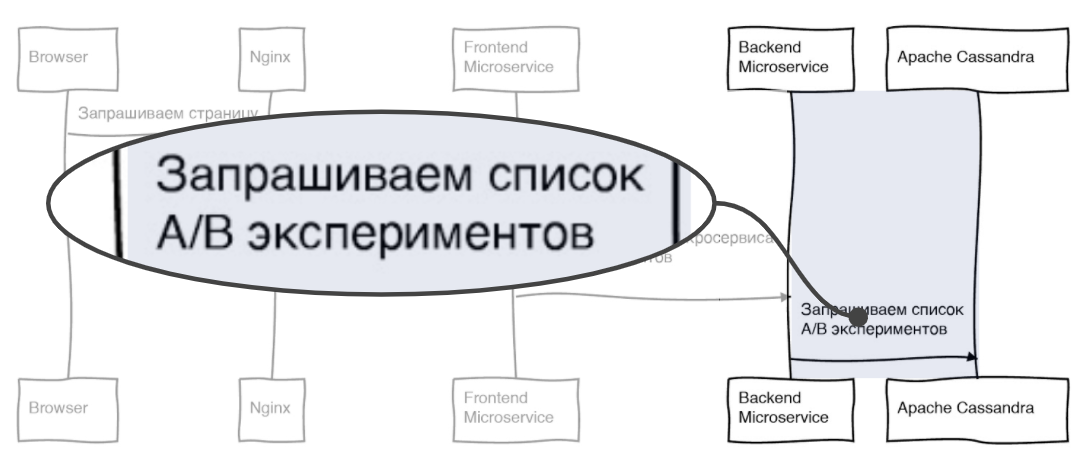
Мы получили информацию из БД и должны вернуть приложение в наш фронтовый микросервис.

Но тут есть важный момент: мы должны вернуть не все эксперименты, а только часть.
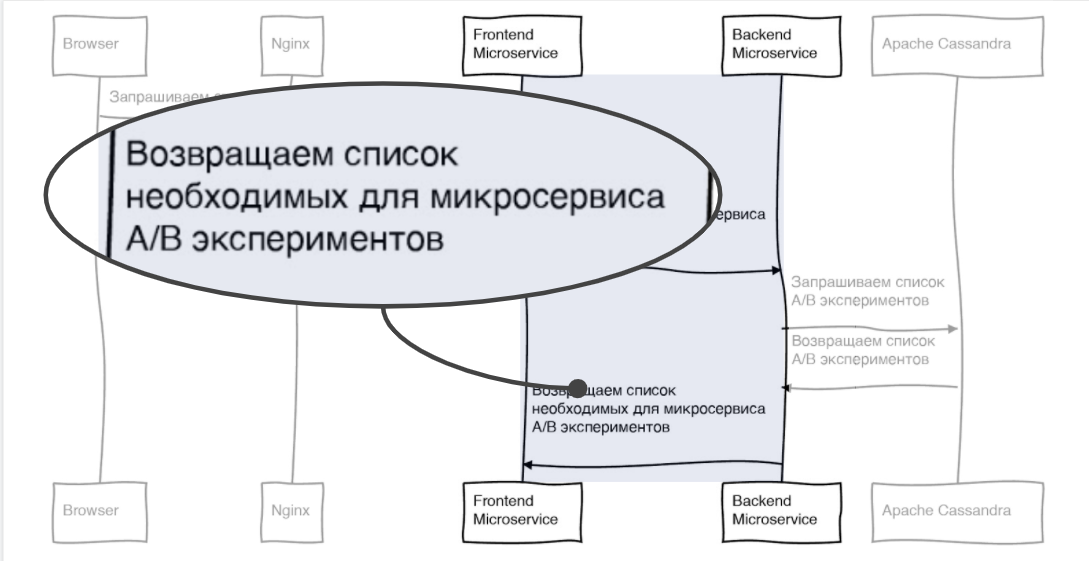
Поэтому мы формируем ответ для фронтового микросервиса. Берем список всех экспериментов, убираем неактивные и те, которые не нужны для фронтового микросервиса. И определяем, в какой группе находится пользователь.
Это мы делаем следующим образом: берем сгенерированный ID (например, 50) и информацию, которую храним в БД.

Среди прочей информации (название эксперимента, время его начала, насколько эксперимент актуален, идет ли он сейчас, номер задачи) есть два важных элемента. Это списки, которые были сгенерированы при создании. Они содержат числа от 0 до 99. Числа уникальны, то есть в первом и втором списке не может быть числа 0.
Почему их два? Потому что при создании эксперимента мы создавали две A/B группы.
Берем наше число (в примере AB_ID = 50) и ищем в каждом из списков. Находим во втором:
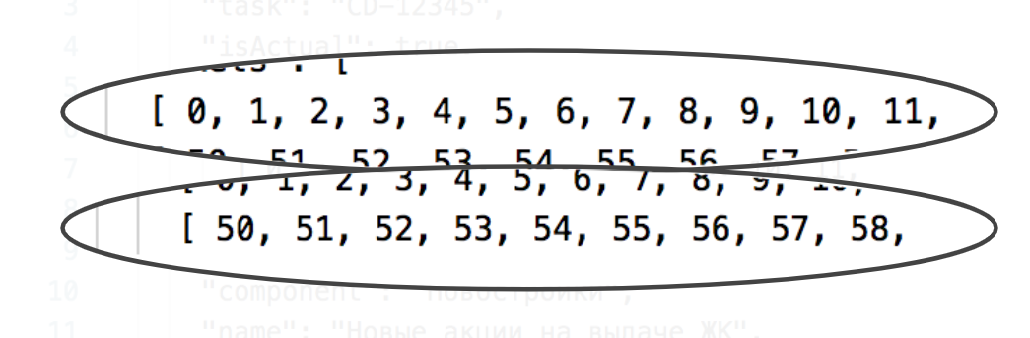
Это говорит нам о том, что пользователь с ID = 50 попадает во вторую A/B группу и увидит второй вариант интерфейса.
Но одновременно у нас идет множество экспериментов:

В одном из них пользователь может попасть в третью группу, в другом во вторую, в третьем — в первую.

Естественно, для того, чтобы облегчить работу фронтового приложения, мы должны сгенерировать ответ таким образом, чтобы передать, в какой группе находится пользователь по отношению к каждому эксперименту, что мы и делаем, генерируя ответ.
Ответ выглядит следующим образом:

Это список, в котором есть объекты следующего содержания: имя эксперимента и A/B группа, в которую попадает пользователь.
Теперь фронтовое приложение имеет все данные, чтобы понять, в какой группе находится пользователь. Нужно отрисовать необходимый блок, передать его на клиент, и вместе с ним отослать список информации об экспериментах. Чтобы, если это необходимо, продолжить эксперимент на клиенте (допустим, отправку данных в систему аналитики).
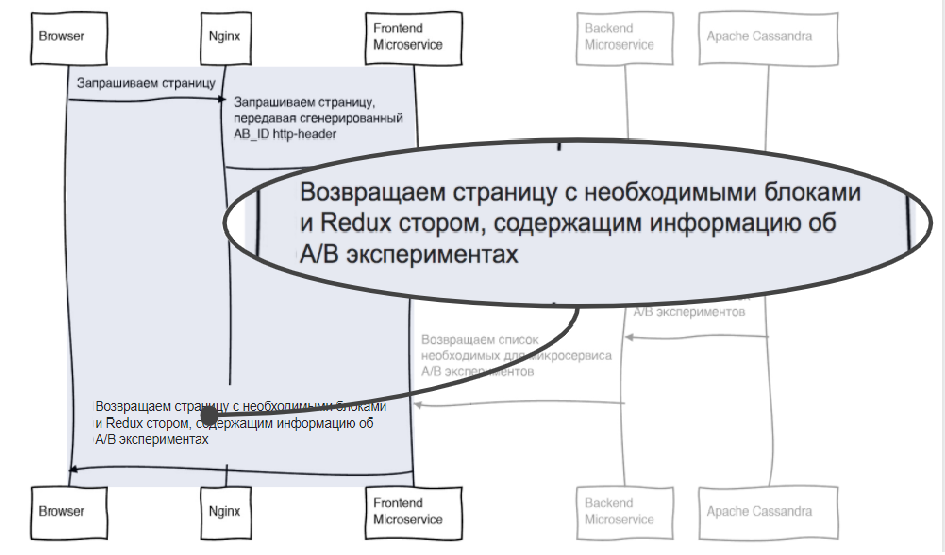
Теперь у нас есть два варианта интерфейса, на которые приходят две разные группы пользователей:

Озвученный подход к проведению A/B экспериментов не единственный. Можно проводить их не только в приложениях сервера рендерингом, но и исключительно на клиенте. Например, делать это на бэкенде, подмешивая дополнительные результаты в поисковую выдачу только для определенной группы пользователей. И даже на Nginx (но мы так не поступаем, так как считаем его неподходящим инструментом для бизнес-логики).
Понятие A/B тестирования отчасти пришло к нам из медицины. Есть понимание, что в каждом эксперименте должна быть контрольная группа.
В ЦИАН ею является нулевая группа. То есть пользователи при делении попадают, допустим, в две группы, и нулевая всегда избавлена от интерфейсов.
Чтобы автотесты или ручное тестирование, когда тестировщик проверяет задачу, могли попасть в определенную группу, передаем с фронта HTTP заголовок с ID.
Это ID от 0 до 99. Nginx настроен таким образом, что он игнорирует генерацию нового идентификатора и принимает тот, который пришел с клиента, пробрасывая его дальше. Соответственно, все дальнейшие предложения видят ID, которые мы передали с клиента.
Когда Nginx проигнорировал генерацию нового ID, он передает запрос на фронтовый микросервис.
Система ЦИАН не идеальна. И есть некоторые моменты, которые Иван планирует улучшить:
Но уже сегодня A/B эксперименты приносят свои плоды.
ЦИАН – это крупнейший сервис по поиску недвижимости в России и один из самых больших в мире. Компания входит в мировой ТОП-10 крупнейших сайтов по недвижимости по версии Similar Web.
В подобных условиях каждое – продуктовое или архитектурное – решение должно быть продуманным и обоснованным, и постоянное проведение A/B экспериментов помогает этого достичь.
С момента представления доклада, инфраструктура A/B-тестирования ЦИАН шагнула вперед и претерпела значительные изменения. И сегодня в компании используются новые инструменты, о которых мы надеемся услышать на грядущей конференции.
Senior Frontend Developer ЦИАН Иван Бабков, который разрабатывал приложения для регистрации доменов, интернет-банкинга и поиска по жилой недвижимости в своем докладе на конференции FrontendConf рассказал об инфраструктуре компании для работы с А/Б-экспериментами, проблемах и путях их решения.
Что такое A/B тестирование
Предположим, есть две кнопки, и вы хотите понять, на какую будут кликать больше: на красную или на синюю. Вы добавляете отправку аналитики на каждую из этих кнопок, ждете какое-то время, пока накопятся данные и решаете что-то. Например, узнаете, что красная кнопка в этом случае лучше, и оставляете на сайте только ее.
В ЦИАН A/B тестирование – больше, чем просто сравнение. Это целый процесс, который начинается с того, что стейкхолдер и аналитики продумывают дизайн эксперимента. Не тот дизайн, к которому мы привыкли, не дизайн нарисованный, а дизайн, позволяющий понять, сколько будет групп в эксперименте, сколько вариантов наших кнопок, сколько придется ждать результаты проведения A/B эксперимента и т.д.
Для того, чтобы больше погрузиться в этот процесс, предположим, что у вас есть красивый сайт, на который приходит 100% ваших пользователей.
Вверху на сайте меню с текстом: «Покупайте наши товары со скидкой 10%». Кликаем на него и получаем больше информации о том, что это за акция.
Все было хорошо ровно до того момента, пока в компании не предположили, что, во-первых, люди не замечают этот блок; во-вторых, в ЦИАН много акций, и размещать их на главной странице сайта больше не хотят.
Изменили дизайн. Получили макет с тремя блоками акций. На них сделан акцент и, вроде бы, этот вариант лучше предыдущего.
Но хорошо бы основывать решение на аналитике. Поэтому нужно сделать следующее: взять 100% пользователей и разделить их на две группы по 50%. Первой показать старый вариант интерфейса, второй — новый.
Спустя какое-то время, когда накоплены данные, которые отправлялись с разных вариантов интерфейса, можно сделать вывод, что конверсия в клики по первому варианту интерфейса 17%, по второму – 25%. Логично, что на сайте предпочли оставить второй вариант. Это поможет в дальнейшем улучшить user experience.
Последний шаг, который необходимо сделать: пустить все 100% пользователей на новый вариант интерфейса.
Пример разработки frontend A/B эксперимента в ЦИАН
Чтобы погрузиться глубже, приведу пример того, разрабатывали отдельно взятый A/B эксперимент в компании с самого начала и до момента его завершения (полной выкатки на бой).
В какой-то момент продакт-менеджер ЦИАН совместно с дизайнером и аналитиком создали задачу следующего вида:
На сайте есть страница, где люди вбивают фильтры, поисковый запрос и видят релевантную выдачу по жилым комплексам. Это обычная поисковая страница: сверху фильтры, снизу выдача.
На этой странице в некоторых карточках жилого комплекса есть блоки, где написано, например: «Скидки на квартиры до 7%». По клику на ссылку пользователь видит больше информации об акции.
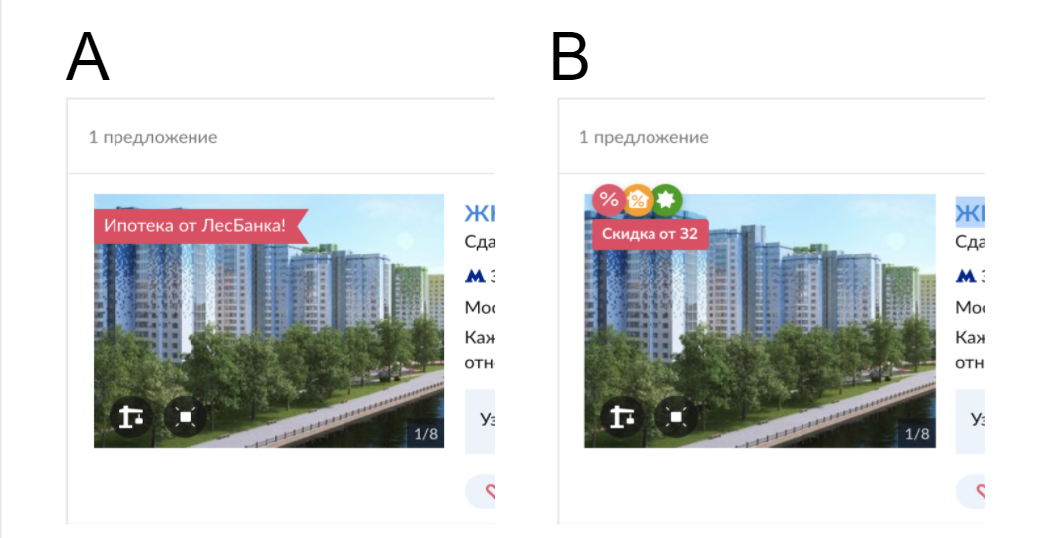
Дизайнер рисует два варианта макета:
А. Старый вариант, где есть один блок акций.
В. Новый вариант с тремя блоками акций, между которыми можно переключаться.
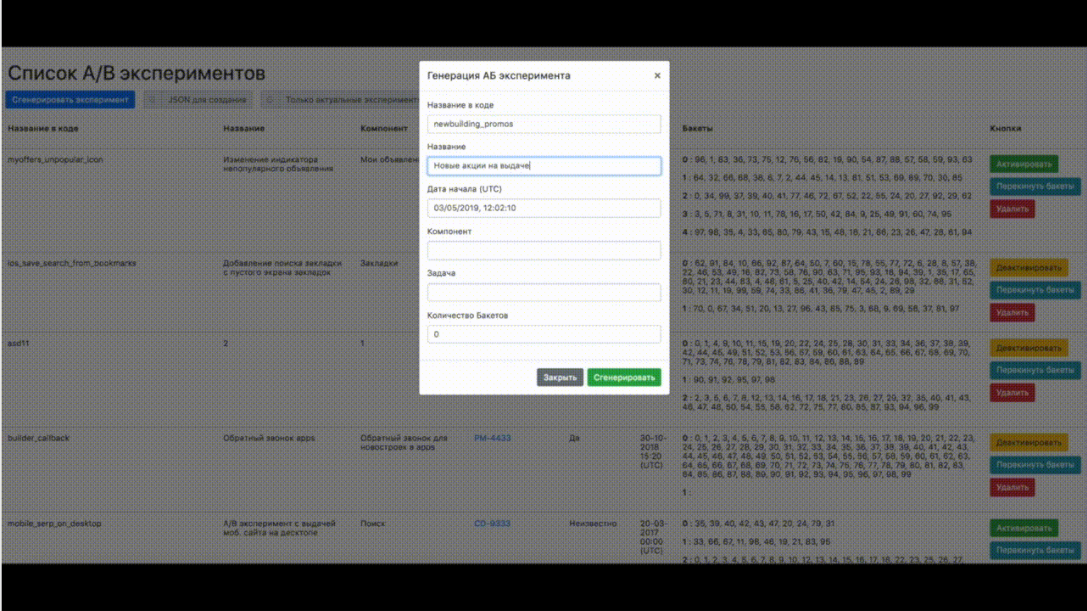
Первое, что необходимо сделать: перенести описание эксперимента в код. В ЦИАН есть админка, позволяющая добавлять и редактировать новые эксперименты:
В ней нужно заполнить форму следующего содержания:
- Название эксперимента;
- Время, когда он начнется;
- Количество A/B групп;
- Процентное соотношение в A/B группах.
При нажатии кнопки «СГЕНЕРИРОВАТЬ», вся информация попадает в базу данных, откуда бэкенд может ее запрашивать.
Далее можно запросить c бэкенда только что сгенерированную информацию по актуальным для пользователя экспериментам из бэкендового микросервиса.
Для этого нужно сделать вопрос, который выглядит следующим образом:
Вариант ответа – это список, в котором есть объекты с именем эксперимента и A/B группа, в которую попадает пользователь в этом отдельном эксперименте.
Нужно внести полученную с бэкенда информацию об эксперименте в Redux store и проверить в компонентах, какой вариант интерфейса в коде нужно отрисовывать в A/B группе.
В проекте есть всего две директории:
- GKCard – это директория, в которой лежит компонент жилого комплекса, который вы видели на скриншоте;
- PromoLabel – компонент акции (в примере: скидка на квартиры до 7%).
В компоненте GKCard отрисовывается PromoLabel.
Первое, что нужно сделать перед тем, как приступить к работе с кодом и добавлять новые файлы и директории — изолировать новый код эксперимента, чтобы потом легко было его удалять и рефакторить. Для этого необходимо создать дополнительную директорию прямо в контейнере, в котором будет происходить эксперимент:
Добавляем директорию ab, в нее — директорию с названием эксперимента (в нашем примере: newbuilding_promos), а туда — все файлы.
В компоненте жилого комплекса добавляем всего несколько строк:
- connect, чтобы получать данные из store;
- PromoLabel с новой версткой, где будет 3 акции;
- Флаг isABEnabled для того, чтобы отрисовывать либо старый, либо новый вариант акции.
В connect берем список всех экспериментов, ищем в них эксперимент под именем newbuilding_promos, проверяем, есть ли такой эксперимент, и в этом объекте находим поле A/B групп, которое получили с бэкенда.
Если его значение 1, то отрисовываем новый вариант акции. Если нет, то старый:
То есть пользователь попадает в группу 1, если он получает новый вариант интерфейса.
Когда момент выбора отрисовки разных блоков закончен, нужно добавить аналитику, чтобы собрать данные. Добавляем метод в наш новый блок, который будет отравлять аналитику.
Для отправки в примере использована библиотека ReactGA, но можно использовать множество других библиотек в NPM. В ЦИАН используют библиотеку собственной разработки, дублируя туда отправку:
Мы зарелизили задачу, все хорошо. Спустя две недели приходит новая.
Важный момент: аналитики провели статистические тесты, подтвердили правильность полученных результатов.
В задаче были данные, что 13% пользователей кликают на блок акций в старом варианте, 21% — в новом. Стейкхолдер вместе с аналитиками попросили Ивана раскатать вариант В на 100% пользователей. Это повысит конверсию в клике: пользователи видят эти акции, все хорошо.
Чтобы сделать это, нужно воспользоваться админкой:
Нужно перекинуть пользователей в БД в группу В. Теперь пользователи с ID от 0 до 99 увидят второй вариант интерфейса. Первый вариант не увидит никто.
Когда остался единственный вариант, можно спокойно удалить эксперимент: указать, что он не активен через админку в базе данных:
В ЦИАН хранят не только актуальные, но и уже завершенные эксперименты. Никогда не знаешь, когда может понадобиться информация о них.
Теперь нужно перенести файлы из этой директории на нужный уровень вложенности проекта (в нашем случае рядом со старым блоком акций) и удалить старый блок:
Все! Следы эксперимента остались лишь в git log и в БД.
Немного про инфраструктуру
Есть запрос. Он пришел из браузера на наш внешний Nginx:
На Nginx мы запускаем скрипт, который генерирует ID от 0 до 99. Есть функция примерно следующего вида:
Функция возвращает число от 0 до 99. Она принимает строчку в виде уникального идентификатора пользователя. В нашем примере это будет:
uid = ‘abfd-4843’
Эта строчка передается функции md5 для генерации хэша:
Хэш получается шестнадцатеричный:
hash = ‘FD029AAD2251AD74F8223B4F4A80B6EA’
Мы преобразуем его в десятичное число и делим на 100:
parseInt(hash, 16)=3.363082047354731e+38
Остатком от этого деления будет число от 0 до 99. В нашем примере — 68:
parseInt(hash, 16) % 100 = 68
График, который иллюстрирует равномерность распределения сгенерированных ID на 10 млн уникальных идентификаторов пользователя:
Видно, что есть небольшие пики и падения. Они обусловлены рандомизацией ID, и не являются для нас проблемой.
Мы запрашиваем страницу с ID, который только что сгенерировали, и передаем его как HTTP заголовок:
Эти данные попадают на фронтовый микросервис (в вашем случае это может быть монолитное приложение). Приложение должно понять, какой блок интерфейса отрисовывать. Для этого запрашивает бэкенд. В частности, информацию об экспериментах, которую мы храним.
Request body
Запрос выглядит примерно так:
Мы передаем ID, только что нами сгенерированный на Nginx, и список экспериментов (их имен, которые фронтенд хочет получить от бэкенда). Бэкенд должен запросить этот список из БД, что он и делает:
Мы получили информацию из БД и должны вернуть приложение в наш фронтовый микросервис.
Но тут есть важный момент: мы должны вернуть не все эксперименты, а только часть.
Поэтому мы формируем ответ для фронтового микросервиса. Берем список всех экспериментов, убираем неактивные и те, которые не нужны для фронтового микросервиса. И определяем, в какой группе находится пользователь.
Это мы делаем следующим образом: берем сгенерированный ID (например, 50) и информацию, которую храним в БД.
Среди прочей информации (название эксперимента, время его начала, насколько эксперимент актуален, идет ли он сейчас, номер задачи) есть два важных элемента. Это списки, которые были сгенерированы при создании. Они содержат числа от 0 до 99. Числа уникальны, то есть в первом и втором списке не может быть числа 0.
Почему их два? Потому что при создании эксперимента мы создавали две A/B группы.
Берем наше число (в примере AB_ID = 50) и ищем в каждом из списков. Находим во втором:
Это говорит нам о том, что пользователь с ID = 50 попадает во вторую A/B группу и увидит второй вариант интерфейса.
Но одновременно у нас идет множество экспериментов:
В одном из них пользователь может попасть в третью группу, в другом во вторую, в третьем — в первую.
Естественно, для того, чтобы облегчить работу фронтового приложения, мы должны сгенерировать ответ таким образом, чтобы передать, в какой группе находится пользователь по отношению к каждому эксперименту, что мы и делаем, генерируя ответ.
Ответ выглядит следующим образом:
Это список, в котором есть объекты следующего содержания: имя эксперимента и A/B группа, в которую попадает пользователь.
Теперь фронтовое приложение имеет все данные, чтобы понять, в какой группе находится пользователь. Нужно отрисовать необходимый блок, передать его на клиент, и вместе с ним отослать список информации об экспериментах. Чтобы, если это необходимо, продолжить эксперимент на клиенте (допустим, отправку данных в систему аналитики).
Теперь у нас есть два варианта интерфейса, на которые приходят две разные группы пользователей:
Озвученный подход к проведению A/B экспериментов не единственный. Можно проводить их не только в приложениях сервера рендерингом, но и исключительно на клиенте. Например, делать это на бэкенде, подмешивая дополнительные результаты в поисковую выдачу только для определенной группы пользователей. И даже на Nginx (но мы так не поступаем, так как считаем его неподходящим инструментом для бизнес-логики).
Как принудительно попасть в определенную A/B группу?
Понятие A/B тестирования отчасти пришло к нам из медицины. Есть понимание, что в каждом эксперименте должна быть контрольная группа.
В ЦИАН ею является нулевая группа. То есть пользователи при делении попадают, допустим, в две группы, и нулевая всегда избавлена от интерфейсов.
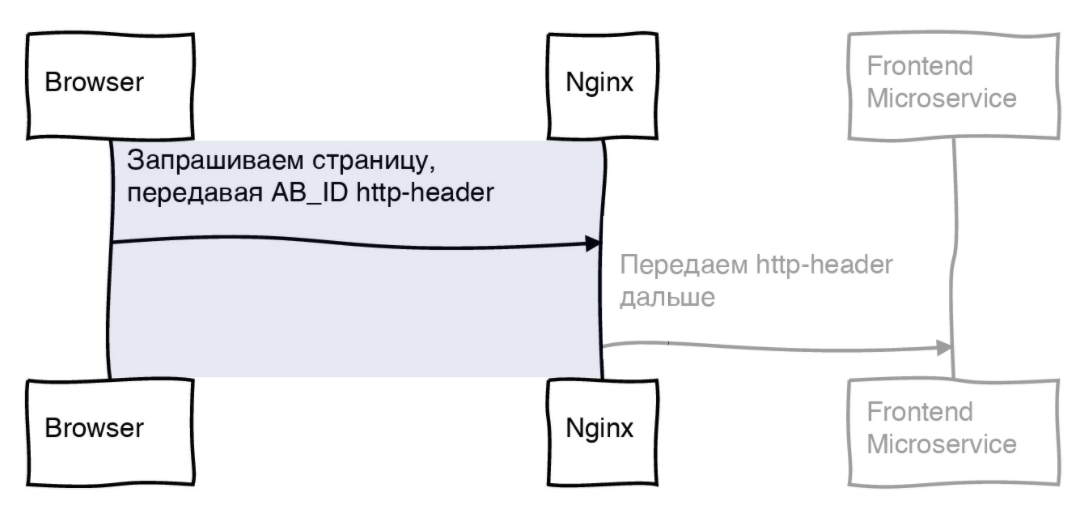
Чтобы автотесты или ручное тестирование, когда тестировщик проверяет задачу, могли попасть в определенную группу, передаем с фронта HTTP заголовок с ID.
Это ID от 0 до 99. Nginx настроен таким образом, что он игнорирует генерацию нового идентификатора и принимает тот, который пришел с клиента, пробрасывая его дальше. Соответственно, все дальнейшие предложения видят ID, которые мы передали с клиента.
Когда Nginx проигнорировал генерацию нового ID, он передает запрос на фронтовый микросервис.
Планы
Система ЦИАН не идеальна. И есть некоторые моменты, которые Иван планирует улучшить:
- Таргетировать эксперименты по определенным параметрам (пол, геопозиция, дата регистрации и т.п.).
В компании хотят научиться проводить эксперименты, например, для 17% пользователей из Петербурга, которые зарегистрировались у нас не ранее года назад. - Добавить возможность таргетировать по дополнительным параметрам в админку, чтобы не делать этого руками.
- Разрабатывать больше экспериментов.
Но уже сегодня A/B эксперименты приносят свои плоды.
ЦИАН – это крупнейший сервис по поиску недвижимости в России и один из самых больших в мире. Компания входит в мировой ТОП-10 крупнейших сайтов по недвижимости по версии Similar Web.
В подобных условиях каждое – продуктовое или архитектурное – решение должно быть продуманным и обоснованным, и постоянное проведение A/B экспериментов помогает этого достичь.
С момента представления доклада, инфраструктура A/B-тестирования ЦИАН шагнула вперед и претерпела значительные изменения. И сегодня в компании используются новые инструменты, о которых мы надеемся услышать на грядущей конференции.
FrontendConf 2021 пройдет 29 и 30 апреля. Но билеты на нее по самой выгодной цене вы можете приобрести уже сегодня.
slavik83sunday
Спасибо большое за такой четкий и подробный разбор) я хоть сам и не бекендер, но интересно было посмотреть что в коде происходит.