
Обратился заказчик, с проблемой, что его сборщик не может справиться с защитой "incapsula".
В двух словах, вместо кода страницы возвращается javascript код, при выполнении которого, идет запрос на сервера инкапсулы, проверяются какие-то параметры браузера и в случае если браузер признан валидным, отдается страница и некоторые cookie.
Подробное описание есть на сайте разработчика (www.imperva.com)
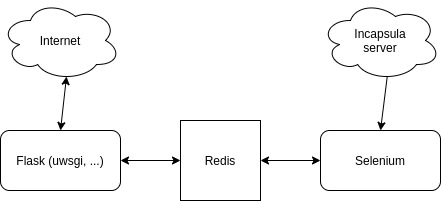
Добавление обработчика javascript, так же как и другие решения, предлагаемые гуглом(например поднять свои сервера), показалось слишком сложными\долгими. Selenium же, как оказалось, прекрасно обходит, данную защиту, но так как данных много и собирать в один поток, (или даже переключаясь между вкладками) не хотелось, а запускать несколько браузеров не хватало ресурсов было решено написать proxy сервер.
Так как нагрузка менялась, в зависимости от времени суток и других условий, было решено сделать масштабируемую веб часть через комбинацию Nginx + uwsgi + flask. Запускать на каждый, воркер, версию Selenium показалось слишком затратным, поэтому вынести Selenium было решено в отдельный сервис, со связью между блоками через Redis. Чтобы максимально упростить реализацию, запросы выполняются синхронно.
Структура проекта
uwsgi.ini – файл с конфигурацией. Существует куча статей по настройке, поэтому я опущу этот этап. На всякий случай в конце статьи оставлю ссылку по настройке (
Микросервис selenium:
Файл gecko/Sel.py
Класс с sellenium модулем. Реализована инициализация, запуск selenium без гуи, и авторизация на сайте (проект изначально писался под конкретный сайт). Также в цикле обновляется главная страница для получения обновленных cookie и в случае появления сообщения в очереди Redis. Cookie выгружаются и хранятся в общем словаре, в redis. Получение cookie от селениума вынесены в callback функции.
Микросервис API:
Файлы в папке src
Во фласке реализован только базовый функционал, слушающий 1 url:
@app.route('/', methods=['GET', 'POST'])Сервер ожидает запрос, с параметром url с urlом, который необходимо получать, и с телом запроса в случае post запроса.
Например:
http://127.0.0.1:5000/?url=https://www.example.com/vehicledetails/34313441?RowNumber=0& Запрос без изменений и модификаций передается дальше, что впрочем, не мешает редактировать его, в случае необходимости.
В файле request.py реализована следующая логика.
Инициализация параметров для библиотеки requests, такие как хедеры.
Инициализация подключения к Redis, а также Post, Get запросы c помощью библиотеки reqests.
При получении сообщения, происходит обновление cookie, полученных от Selenium сервиса.
Надо понимать, что это лишь заготовка. Такие вопросы как https, настройка сервера, дополнительная обработка ошибок, авторизация и т.д я намеренно оставил за пределами статьи. Дополнительная кастомизация и доработка работы с ресурсом, также остается на стороне пользователя.
Pro-dev-pm
Так, а где собственно обход из заголовка, увидел только улучшение (усложнение) архитектуры самого парсера. Или там все элементарно оказалось и задача превратилась из обхода защиты в ускорение парсинга?
karon Автор
Сам обход берет на себя селениум. Получив js код от сервера, он его спокойно выполняет, обращается к серверам защиты, доказывает, что он браузер и получает валидные куки. А валидных кук достаточно, чтобы сборщик, для системы, выглядел как обычный пользователь.
Чего собственно и требовалось добиться.