
Анализ тональности текста (или сентимент-анализ) – одна из задач, с которыми работают специалисты Data Science. С помощью такого анализа можно изучить массив сообщений и иных данных и определить, как они эмоционально окрашены – позитивно, негативно или нейтрально.
Рассмотрим, как это работает – проанализируем ряд статей на основании датасета Linis Crowd. Предлагаем определить, какие модели наиболее перспективны, например, для разработки всевозможных сервисов мониторинга. В качестве предметной области выберем статьи технического характера (например, на Хабре), что может быть полезно для реализации автоматического сбора мнений.

Тональность – выявление в текстах эмоционально окрашенной лексики, а также эмоциональной оценки мнений, высказанных авторами.
Для оценки тональности, в первую очередь, нужно “перевести” сообщение с естественного языка на компьютерный. Для этого есть различные способы, которые уже давно подробно описаны в научной литературе (посмотреть отдельные примеры можно в конце этой статьи). Один из наиболее простых методов – определить лексическую тональность слов, составляющих сообщение, без учета контекста.
Для одного из внутренних проектов исследовательского характера мы разобрали, с помощью каких инструментов можно решить задачу по сентимент-анализу. Делимся этапами анализа и полученными результатами, которые могут быть полезны для тех специалистов, которые сейчас находятся на первых этапах знакомства с этой областью знаний.
Что мы делали
Задача: определить тональность текстов технического характера на Хабре. Ожидаемый результат – оценка тональности с точностью около 70-80%, как правило, наблюдаемой при анализе естественного языка.
Для решения этой задачи зачастую используют следующие основные алгоритмы:
Статистический метод. Для его использования необходимы заранее размеченные по тональности коллекции (корпуса) текстов. Они служат для обучения модели, с помощью которой и происходит определение тональности текста или фразы.
Метод, основанный на словарях и правилах. Для этого нужно заранее составить словари позитивных и негативных слов и выражений. Этот метод может использовать как списки шаблонов, так и правила соединения тональной лексики внутри предложения, основанные на грамматическом и синтаксическом разборе.
В нашем случае мы выбрали статистический метод, основанный на модели машинного обучения с учителем. Его преимущество – возможность масштабировать задачу в рамках небольшого обучаемого корпуса данных. Нам нужно было добиться того, чтобы пользователь мог добавить в IT-систему ссылку на новость, а система определила бы эмоциональную окраску сообщения. Для этого мы составили классификацию:
-1 – текст с отрицательной окраской
0 – нейтральный;
1 – положительный текст;
При этом для выполнения анализа нужно было решить 2 дополнительные задачи:
Подбор русскоязычного датасета с размеченной тональностью для обучения системы. В ходе исследования мы убедились, что таких датасетов не очень много, и после их оценки приняли решение использовать корпус Linis Crowd.
Создать алгоритм для автоматической подготовки датасета, чтобы дать на обучение модели сформулированные тексты в рамках заданной предметной области. Для этого был использован скрипт на python, который подбирает нужный текст из корпуса текстов по имеющимся ключевым словам на техническую тематику.
Что мы использовали
Поскольку в рамках исследовательской задачи у нас не было жестких требований к полученному веб-приложению, мы выбрали легковесный фреймворк Flask, который позволяет быстро разработать веб-приложение без лишнего функционала.
Библиотека nltk для исключения стоп-слов русского языка. На ее основе мы создали свой словарь с исключением слов, не влияющих на тональность.
Для векторизации текста и удобной работы с моделями машинного обучения мы использовали открытую библиотеку Fasttext. Она является модификацией привычного всем в мире эмбединга Word2Vec и хорошо подходит для морфологически богатых языков, в том числе русского языка, рассматриваемого в задаче. Полученные из векторов тексты мы отправляли в модель и после этого выполняли расчет тональности. Для этого мы выбираем первые 500 слов, которые прошли обработку с исключением.
Принцип работы Fasttext поясняют следующие примеры (источник):
Модели анализа
Для классификации текстов по тональности мы использовали следующие модели – наиболее простые и высокоскоростные, что было предпочтительно для нашего исследования.
1) Наивный байесовский классификатор
Основан на алгоритме с байесовского классификатора, где для классифицируемого объекта вычисляются функции правдоподобия каждого из классов, по которым, в свою очередь, определяют апостериорные вероятности классов. Объект относится к тому классу, для которого апостериорная вероятность максимальна. Для работы модели вводится допущение о независимых признаках.
Параметры, которые мы применили:
alpha = 0.3; fitprior = True; classprior = None
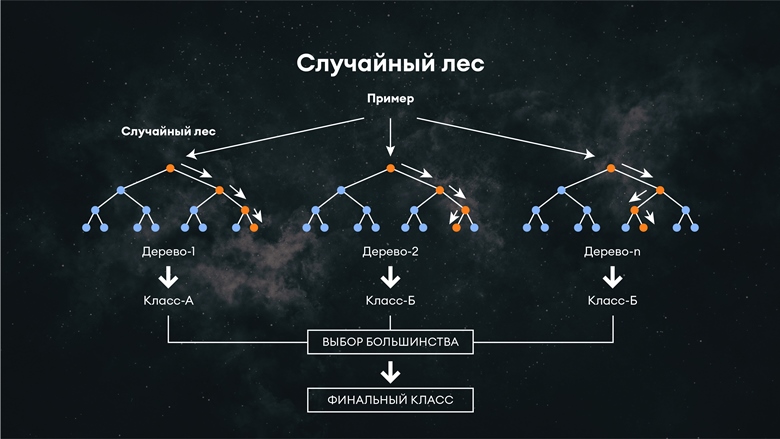
2) Случайный лес
Данный алгоритм является модификацией применения решающих деревьев, где для задач классификации решение выносится согласно выбору большинства деревьев.
Схема работы:
Выбирается подвыборка обучающего корпуса размера samplesize, при этом она может быть с возвращением. Далее строится дерево, и здесь для каждого дерева нужна своя подвыборка.
Для построения каждого расщепления в дереве просматриваем max_features случайных признаков (для каждого нового расщепления — свои случайные признаки).
Выбираем наилучшие признак и расщепление по нему (по заранее заданному критерию). Дерево строится, как правило, до исчерпания выборки (пока в листьях не останутся представители только одного класса). При этом в современных реализациях есть параметры, которые ограничивают высоту дерева, число объектов в листьях и число объектов в подвыборке, при котором проводится расщепление.
Подробнее с работой алгоритма можно познакомиться в источнике.
Параметры, которые мы применили:
nestimators = 200; maxdepth = 3; random_state = 0
3) Рекуррентная нейронная сеть
Вид нейронных сетей, где связи между элементами образуют направленную последовательность.
Архитектура сети включает слой Embedding, который преобразует данные в 64-мерный вектор, слой LSTM (128 узлов) и слой Dense (10 узлов).
Датасет
Для реализации обучения с учителем мы взяли открытый датасет Linis Crowd, который содержит 29 тысяч размеченных текстов – наиболее крупный датасет для неформальных текстов на русском языке. Для обучения модели были использованы размеченные тексты с разделением на заданные по задачам исследования классы.
В нашем исследовании датасет был ограничен в рамках предметной области путем выборки текстов из корпуса по ключевым словам.
Время обработки
По результатом тестов выяснилось, что решение моделей по определению тональности слабо влияет на время выполнение запроса. Основную нагрузку вносит использование fasttext для эмбеддинга входящего текста, занимающее в районе 5 - 10 секунд с использованием вычислений на CPU. При работе с GPU показатели стали в диапазоне 0.7 – 1.
Показатели точности
Для тестирования мы разделили модели со следующим соотношением:
Обучающая выборка – 60%.
Валидационная проверка – 20%
Тестирование – 20% с балансировкой датасета.
Как отмечено ранее, в начале исследования мы рассчитывали на оценку тональности с точностью на уровне 70-80%.
Выводы
По итогам исследования мы получили следующие оценки точности:
Наивный байесовский классификатор (88,32%)
Случайный лес (78,91%)
Рекуррентная нейронная сеть. RNN (83,26%)
Таким образом, наиболее перспективные результаты – 88,32% – показал наивный байесовский классификатор. Получение показателей выше, чем 80%, можно считать успешным при работе с естественными языками.
Спасибо за внимание! Надеемся, что описанный пример был для вас полезен.
А если вы хотите больше узнать о сентимент-анализе, рекомендуем несколько статей по теме:
QtRoS
Попробуйте SVM, метод опорных векторов. На таких задачах он не слишком быстро учится, но как правило обходит NB по скору.
SSul Автор
Спасибо, присмотримся к этому методу)