
Сегодня мы хотим поделиться опытом решения задачи детекции дефектов на снимках промышленных объектов методами современного компьютерного зрения.
Наш рассказ будет состоять из нескольких частей:
- “Постановка задачи и Данные”, в которой мы будем смотреть на ржавые отопительные котлы и лопнувшие трубы, наслаждаться разметкой и аугментацией данных, а также будем вращать и шатать трубы чтобы сделать данные разнообразнее;
- “Выбор архитектуры”, в которой мы
сядем на два стулапопытаемся выбрать между скоростью и точностью; - “Фреймворки для обучения”, в которой мы будем погружаться в Darknet и заглянем в MMLab и покажем как сделать итоговое решение воспроизводимым и удобным для тестов.
Всем кому интересно взглянуть на пайплайн решения задачи из области машинного зрения и любителям ржавчины и трещин (не показывайте эту заметку сантехникам) просим под кат.
Заметка от партнера IT-центра МАИ и организатора магистерской программы “VR/AR & AI” — компании PHYGITALISM.
Описание задачи
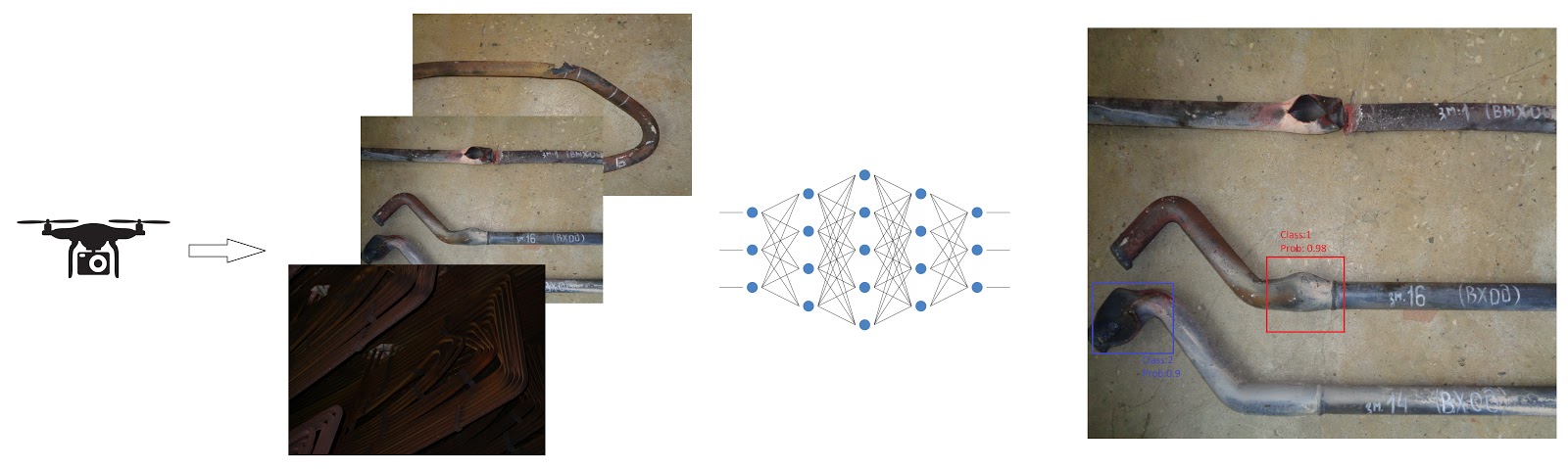
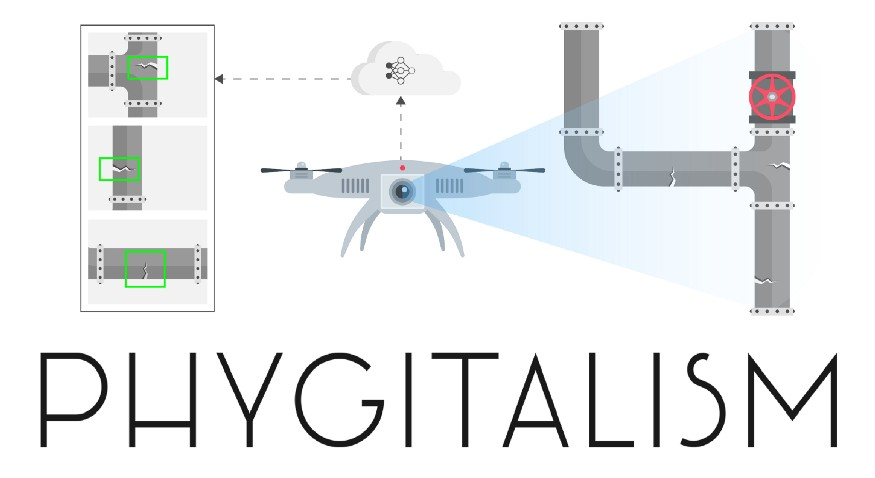
Рис 1. Схематичное изображение рассматриваемого проекта.
Машинное обучение (machine learning / ML) в общем и компьютерное зрение (computer vision / CV) в частности находят сегодня все больше применений в решение задач из промышленной области (пример). Начиная от задач нахождения бракованных деталей на конвейере и заканчивая управлением беспилотным транспортом — везде используются глубокие архитектуры, позволяющие детектировать многочисленные объекты разных категорий, предсказывать пространственное расположение объектов друг относительно друга и многое другое.
Сегодня мы рассмотрим кейс (проект Defects detector CV) по созданию прототипа программного обеспечения (ПО), которое использует нейронные сети, для того, чтобы на фото или видеопотоке детектировать объекты заданных категорий. В качестве предметной области, в данном проекте, выступила дефектоскопия промышленных труб.

Рис 2.Схематичное изображение парового котла, аналогичного тому, что рассматривался в проекте.
Кратко опишем предметную постановку задачи:
В системах теплового обогрева городов и промышленных предприятий используются специальные паровые котлы (см. пример на рис. 2), внутренность которых пронизана многочисленными трубами, которые в процессе эксплуатации могут получать различные повреждения (разного рода трещины, разрывы, деформации, коррозию и многое другое). Для того, чтобы своевременно устранять повреждения и поддерживать работоспособность котлов, периодически их работа останавливается, из них выкачиваются все жидкости, вскрывается проход во внутреннее пространство котла, которое представляет из себя ряд связанных пространственных отсеков без освещения, способных вместить внутрь себя трехэтажный дом. После производят очистку поверхности труб, выстраивают промышленные леса, чтобы у специалистов по дефектоскопии была возможность получить прямой доступ к трубам, которые они будут осматривать и проверять с помощью специальной аппаратуры. После того как все дефекты обнаружены, производится замена или ремонт поврежденных участков, после чего необходимо разобрать леса, законсервировать котел и снова его запустить.
Зачастую, большую часть времени отнимает сбор и демонтаж промышленных лесов и визуальный осмотр труб специалистами. Для того, чтобы сократить время на выполнение этих этапов было предложено использовать пилотируемый дрон с системой освещения, фото и видеосъемки, который смог бы быстро облететь внутреннее пространство котла (в том числе, небольшие размеры дрона позволяют попасть во внутрь труднодоступных узких шахт, куда человеку сложно проникнуть), собрать данные для обработки, и с помощью алгоритмов компьютерного зрения, выделить все обнаруженные дефекты.
Ниже речь пойдет о поиске и тестировании подходящих для рассматриваемой задачи глубоких архитектур машинного обучения и встраивание их в прототип программного обеспечения для анализа накапливаемых фото и видеоматериалов.
Мы постараемся осветить все основные этапы при разработке проекта, связанного с машинным
- обучением;
- сбор данных;
- разметка данных;
- дополнение данных (аугментация);
- обучение модели;
- оценка качества работы модели;
- подготовка к внедрению.
В первую очередь поговорим о самом главном с точки зрения машинного обучения объекте — о данных. Откуда их взять, в каком формате хранить обрабатывать, как из меньшего количества данных получить больше информации и пр.
Набор данных

Рис. 3 Пример объекта обучающей выборки — фото, сделанное при осмотре внутренности остановленного котла.
Данные в нашей задачи представлены классическим для CV образом — в виде цветных RGB снимков. На каждом снимки может как присутствовать сразу несколько дефектов, так и не присутствовать вовсе.
Ниже постараемся ответить на следующие основные вопросы о данных, которые возникают почти во всех проектах, связанных с компьютерным зрением:
- Как разметить сырые данные?
- Как разделить обучающую выборку на тестовую и обучающую?
- В каком формате хранить разметку и как структурировать датасет?
- Как имея выборку скромного размера, тем не менее добиваться приличного качества обучения?
- В какой форме нужно делать предсказания?
- Как оценивать качества новых предсказаний?
Виды задач распознавания образов на изображениях

Рис.4 Пример разметки для задачи детекции объектов на изображениях из датасета MS COCO. Иллюстрация из репозитория detectron2.
Сложность задачи в области компьютерного зрения отчасти определяется формой предсказания. Отметим сразу, что задача распознавания образов на изображения логически подразделяется на две подзадачи:
- выделения области интереса;
- классификация объекта в области интереса.
В зависимости от формы области интереса, задачи детекции делят на детектирование в виде ограничивающих прямоугольников (bounding boxes), в виде многоугольников, в виде битовых масок, в виде точек интереса и пр.
В нашей задаче были выбраны ограничивающие прямоугольники, но эксперименты с многоугольными областями также проводились.
Помимо формы предсказания, также необходимо было определить формат датасета (способ организации данных и аннотаций). Формат датасета обычно определяется группами исследователей и разработчиков, которые создают значимые датасеты или архитектуры. В нашем случае, датасеты рассматривались в форматах MS COCO и YOLO.
Подробнее про задачи детекции объектов на изображениях и основные подходы при конструировании архитектур глубокого обучения для решения этой задачи можно прочитать здесь.
Про устройство формата MS COCO и формы предсказаний можно узнать здесь.
Разметка данных
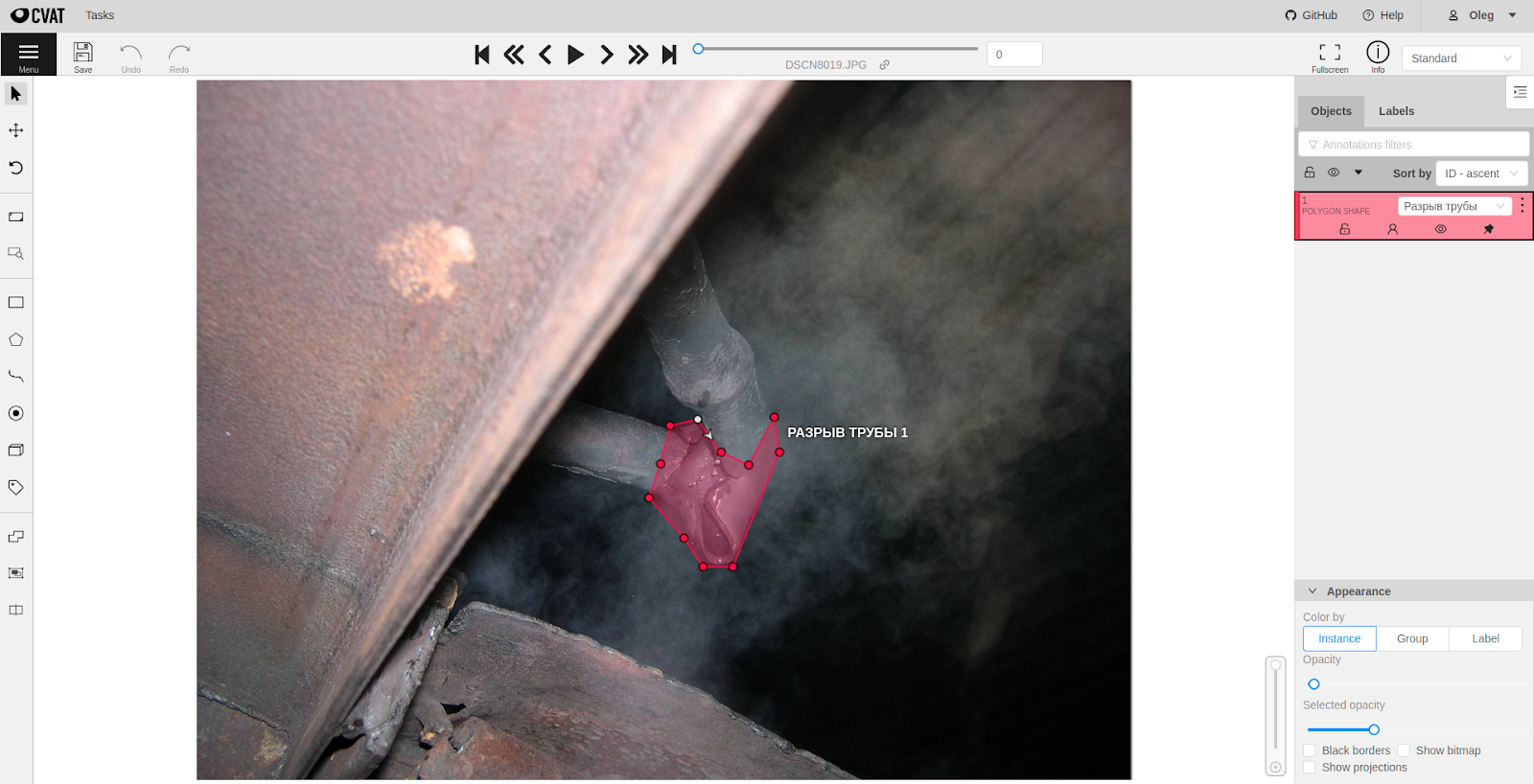
Рис. 5 Демонстрация работы CVAT для разметки дефекта трубы в виде полигональной маски.
Для того, чтобы разметить сырые данные существует несколько основных способов. Во-первых, можно воспользоваться услугами сервисов облачной распределенной разметки данных, вроде Amazon Mechanical Turk или Яндекс.Толока, во-вторых, если данные приходят не из реального мира, а генерируются искусственно, то разметку можно генерировать вместе с данными, ну и самым доступным способом является использование специализированного ПО для разметки данных.
В нашей задаче, мы воспользовались вторым и третьим способами. Про наш генератор синтетических данных мы расскажем отдельно во второй части. В качестве ПО для разметки мы выбрали Intel CVAT (заметка про инструмент на Хабре), который был развернут на сервере заказчика.
Некоторые альтернативные инструменты разметки:
Усиление обобщающей способности
В случае, когда данных для обучения мало и необходимо добиться хорошей обобщающей способности от алгоритма, обычно прибегают к разного рода “трюкам” — манипуляциям с данными.

Рис. 5.1 Изображение из сообщества “Memes on Machine Learning for Young Ladies”. Там же можно увидеть пример того как не нужно делать аугментации.
Такие трюки могут быть связаны как с процессом обучения (использование беггинга или дропаута), так и с процессом подготовки данных (аугментация данных). При решении нашей задачи, чтобы расширить исходный датасет небольшого размера, мы прибегли к аугментации данных — различные преобразования исходных данных, такие как добавление шума к изображению, различные повороты и растяжения, обесцвечивание и многое другое. Для обеих архитектур были подготовлены одинаковые датасеты с аугментированными изображениями, хотя стоит отметить, что у обоих фреймворков есть встроенные возможности автоматической аугментации в процессе обучения (заложено в возможностях фреймворков).
Подробнее про примеры аугментации данных в задачах компьютерного зрения можно прочитать здесь и здесь.
Метрики качества
Для того, чтобы измерять качество работы алгоритма после процесса обучения на тестовой выборке в задачах детекции объектов на изображениях традиционно используют метрику mean average precision (mAP), рассчитанную для каждого класса по отдельности и усредненную для всех классов. Значение этой метрики рассчитываются при разных уровнях характеристики Intersection over Union (IoU). Здесь мы не будем подробно останавливаться на разъяснении устройства этих функций, всем заинтересованным предлагаем пройти по ссылкам ниже на статьи и заметки, которые помогут освоится в данном вопросе, но все же поясним некоторые основные моменты оценки качества работы алгоритмов в нашей задаче.
Для оценки результатов были выбраны следующие метрики:
- mAP (mean average precision) — среднее значение точности по всем классам (поскольку у термина могут быть разные трактовки, рекомендуем ознакомится с различными вариантами здесь).
- AP (средняя точность) — средняя точность по каждому отдельному классу.
- Precision Recall кривая.
- Число случаев когда дефект был обнаружен и он на самом деле был (TP).
- Число случаев когда дефект был обнаружен, но его не было на самом деле (FP) т. е. ложное срабатывание.
Расчет метрик производился следующим образом. Так как целевым объектом для оценки был ограничивающий прямоугольник (bounding box), то интерес для оценки представляет три свойства:
- Насколько модель уверена в предсказании. Чем выше уверенность, тем более надёжным будет результат. В идеале все правильные предсказания должны быть с высокой степенью уверенности.
- Правильно ли предсказан класс объекта.
- Насколько предсказанный ограничивающий прямоугольник совпадает с правильным.
Под правильным подразумевается тот ограничивающий прямоугольник, который был в разметке. Здесь появляется вопрос о важности качественной разметки для обучения нейронных сетей.
Рассмотрим пример вычисления метрик на основе примера из рис. ниже. Для этого определяется величина IoU, которая равна отношению площади пересечения прямоугольников (серый прямоугольник) к площади их объединения. Она принимает значения в отрезке [0;1]. Можно выбрать определённый порог и считать, что при превышении этого порога прямоугольники совпадают.

Определение TP:
Если IoU больше определенного порога и метки классов совпадают, то предсказание считается правильным.
Определение FP:
Если IoU меньше определенного порога и метки классов совпадают, то предсказание считается ложным.
На основании этих показателей рассчитывается точность и полнота. Если кратко, то точность показывает насколько хорошо модель предсказывает дефекты определенного класса из тех которые были обнаружены вообще. Чем больше значение, тем меньше ошибок совершается. Значение в отрезке от [0;1].
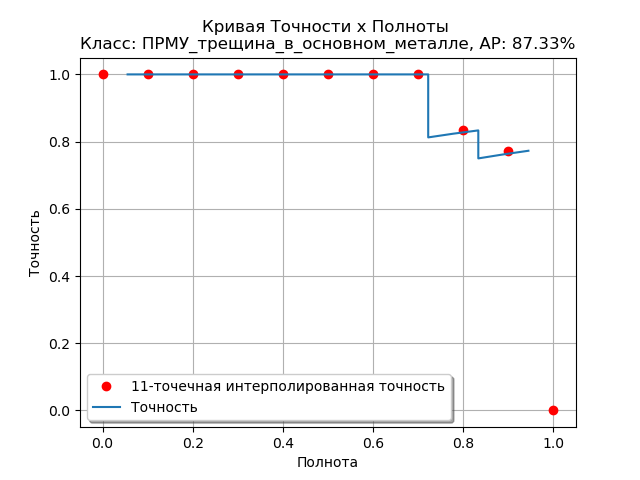
Рис. 6 Пример рассчитанной Precision-Recall кривой для одного из классов дефектов для архитектуры DetectoRS.
Полнота показывает способность модели найти все дефекты определенного класса. Чем выше значение тем больше будет обнаруживаться дефектов, но не все могут быть точно предсказаны Эти величины взаимосвязаны. Как правило, чем больше точность, тем меньше полнота и наоборот. Т. к. предсказания зависят от некоторого порога принятия решения, то строят графики точности-полноты при разных значениях порога принятия решения для его оптимального определения и оценки возможностей модели.

Рис. 7 Сравнение технических метрик для выбранных архитектур для процесса обучения.
Подробную статью про метрики качества и функции ошибок в задачах компьютерного зрения можно найти здесь. Про метрики в задачах машинного обучения в целом смотрите эту замечательную заметку на хабре.
Заметку с примерами и объяснениями всей терминологии про метрики качества в CV можно посмотреть здесь.
Помимо метрик качества задачи детекции, на практике также важны технические метрики реализации, такие как скорость работы сети и место в памяти, которое сеть занимает, также важным фактором может стать время, необходимое для обучения.
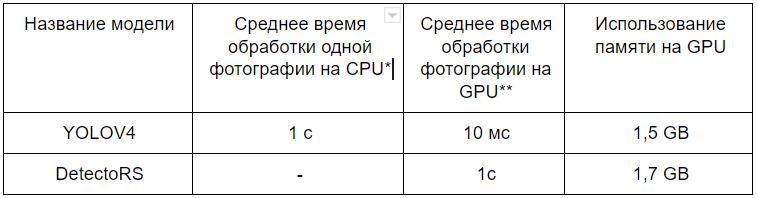
*Рис. 8 Сравнение технических метрик для выбранных архитектур для процесса использования.* тестирование проводилось на видеокарте RTX 2080 Ti, тестирование проводилось на CPU AMD Ryzen 7 2700X Eight-Core Processor.*
Деление данных на обучающую и тестовую выборку
Для тестирования алгоритмов и оценки качества их работы часто нужно поделить данные на несколько частей. Одна часть используется при обучении, а другая для проверки обобщающей способности и подсчета метрик. Обычно это не представляет проблемы, но в нашем случае ситуация сложнее, т. к. каждое изображение (объект) может содержать несколько классов и в разном количестве. Изображение атомарно и мы не можем его как-то разделить логически, чтобы число примеров каждого класса поделилось в нужном соотношении. Тут стоит заметить, что фактически можно разделить изображение на множество отдельных частей, в которых есть только один класс, но это приведёт к уничтожению изначальной структуры изображений.
Рассмотрим пример, изображенный на рис. 9 — случай, когда каждый объект принадлежит одному классу:
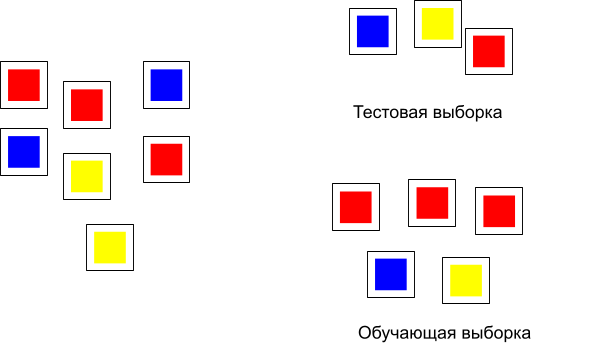
Рис. 9 Деление данных на тестовую и обучающую выборку.
Особой проблемы здесь нет и разделение на две выборке можно сделать достаточно просто. В нашем же случае картина с распределением объектов и классов будет такая:
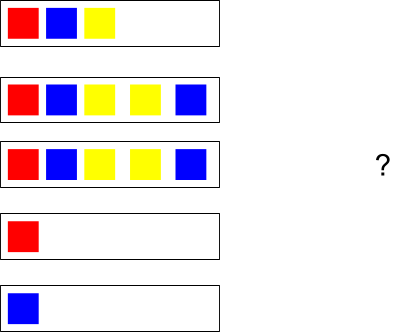
Рис. 10 Каждый объект может содержать иметь несколько классов.
Для решения проблемы разделения такого вида данных на подвыборки была использована библиотека scikit-multilearn и метод iterative_train_test_split. На вход подавалась матрица из нулей и единиц. Каждая строка обозначала изображение. Единицы стояли в столбцах с номерами соответствующими номерам классов. Если применить функцию к объектам на рис. выше, то получится следующее разделение:
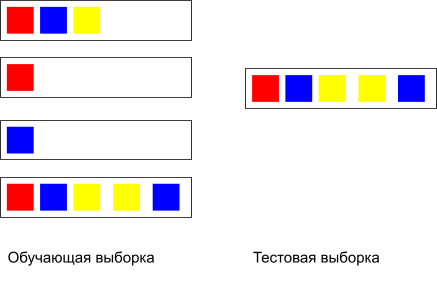
Рис. 11 Результат разделения на тестовую и обучающую выборку.
Конечно, здесь не учитывается количество повторений классов в рамках одного изображения (объекта), поэтому деление может быть несбалансированным.
Выбор архитектуры
На основе результатов анализа известных архитектур собранных на paperwithcode (на момент 3 квартала 2020 года) для детектирования дефектов были выбраны две архитектуры:
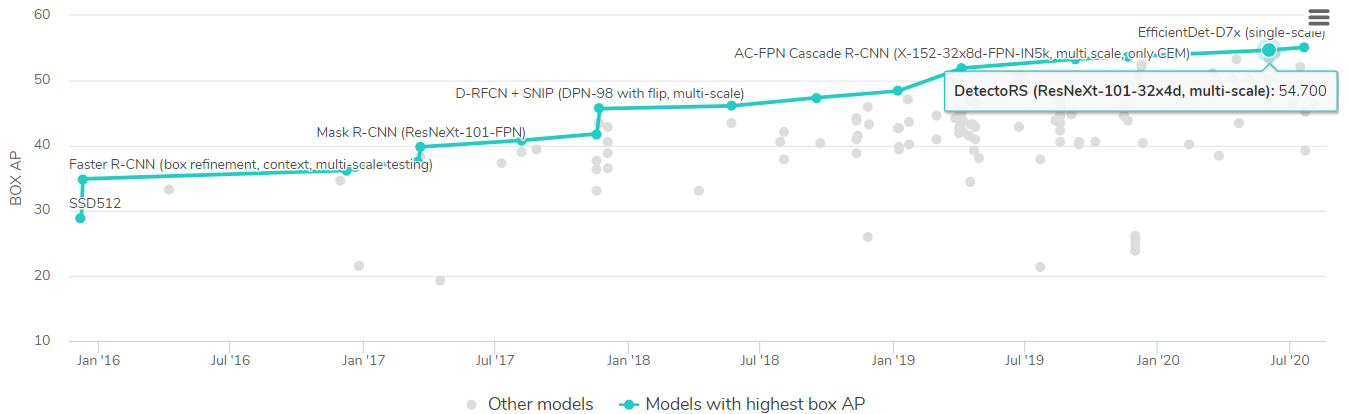
Рис. 12 Сравнение архитектур на бенчмарке MS COCO object detection с сайта papesrwithcode (3 квартал 2020 года).
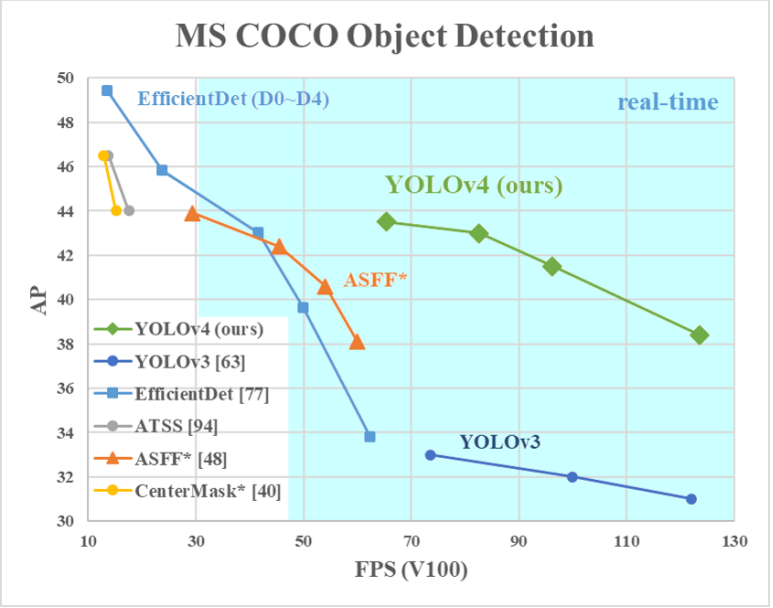
Рис.13 Сравнение архитектур на бенчмарке MS COCO, полученное авторами архитектуры YOLOv4.
YOLOv4 попала в этот список из-за своей скорости работы. Мы хотели посмотреть на результаты разных моделей и выбрать итоговый вариант в зависимости от требований. Потенциально могла быть потребность в обработке видео и для этого случая планировалось использовать YOLOv4. Более точная, но медленная работа ожидалась от DetectoRS.
Больше информации о том, как конструируются современные глубокие архитектуры для задач детекции объектов на изображениях можно прочитать в этой статье или в этой заметке.
DetectoRS
Данная архитектура базируется на использовании специального типа сверток (Switchable Atrouse Convolution / SAC) и в верхнем уровне устроена в виде рекурсивной пирамиды (Recursive Feature Pyramid / RFP), объединяющий локальные и глобальные признаки.
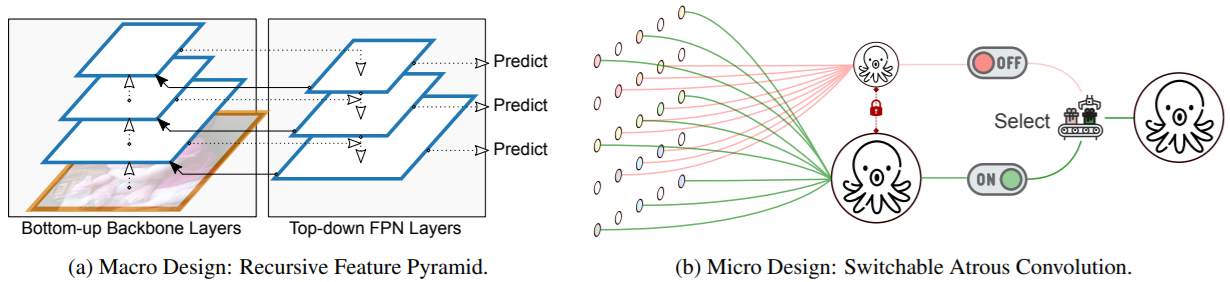
Рис. 14 Основные нововведения, используемые авторами архитектуры DetectoRS: (a) — рекурсивная пирамида признаковых описаний, используемая для объединения глобальных признаков на изображении; (b) — переключательные свертки типа “atrouse” для работы с локальными признаками.
Реализация данной модели присутствует внутри фреймворка MMDetection.
Об устройстве архитектуры можно прочитать здесь.
YOLOv4
Эта модель делает свои предсказания на основе анализа изображения, разбивая его на квадратную сетку как на рис. ниже:
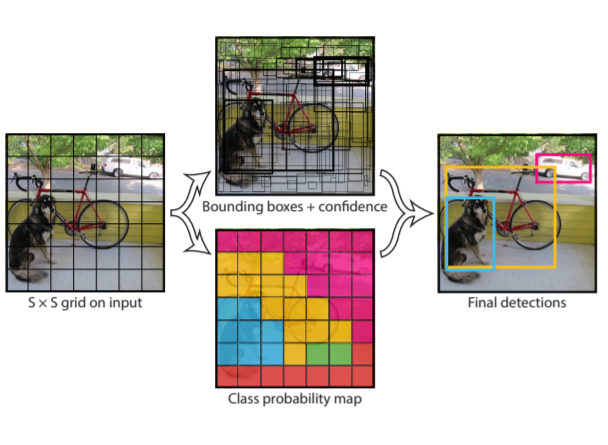
Рис. 15 Принцип работы из оригинальной статьи про YOLO.
Видео с объяснением работы можно найти здесь.
YOLOv4 это дальнейшее улучшение (четвертая версия) оригинальной архитектуры как с точки зрения устройства так и процесса обучения. В данной статье про YOLOv4 исследуются как различные техники аугментации изображений влияют на конечный результат.
Фреймворки для обучения моделей в задачах CV
Для того, чтобы экспериментировать с различными архитектурами, выстраивать процессы загрузки изображений, аугментации данных, расчета метрик, визуализации результатов и решение других сопутствующих задач, исследователи создают собственные фреймворки, включающие весь функционал.
Для разработки под Python, двумя наиболее популярными фреймворками являются MMdetection (open source) и Detectron2 (Facebook research). Для разработки под C, существует фреймворк Darknet (open source). Подробнее про то, как использовать данные фреймворки можно прочитать в заметках один, два, три.
MMDetection
Поскольку архитектура DetectoRS имела единственную реализацию на момент работы над проектом и эта реализация была написана на фреймворке MMDetection, имплементация архитектуры была основана на использовании данного фреймворка.
Устройство фреймворка
Для того, чтобы организовать процесс обучения сети с помощью данного фреймворка, необходимо:
- подготовить веса при тренированной модели в формате
.pthили прописать самостоятельно инициализацию новых весов; - написать конфигурационный файл в виде Python скрипта со всеми настройками для сети и описание хода обучения, валидации и пр.;
- выбрать способ логирования процесса обучения (доступна запись в текстовый файл и логирование с помощью tensorboard);
- организовать данные в файловой системе согласно выбранному типу разметки (доступны MS COCO, Pascal VOC и поддерживается возможность внедрение пользовательских форматов);
- написать основный скрипт, собирающий воедино все перечисленные выше составные части.
После тестов локально на компьютере, на котором была установлена и развернута среда для работы с MMDetection, аналогично YOLOv4, сборка была перенесена внутрь NVidia Docker контейнера.
Основная сложность при работе с данным фреймворком, как нам показалась, заключается в аккуратном прописывании конфигурационного файла. Примеры конфигурационных файлов и туториал по их составлению можно найти на странице проекта с документацией.
# Обучения на 9 классах без масок
model = dict(
type='CascadeRCNN',
pretrained='torchvision://resnet50',
backbone=dict(
type='DetectoRS_ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
conv_cfg=dict(type='ConvAWS'),
sac=dict(type='SAC', use_deform=True),
stage_with_sac=(False, True, True, True),
output_img=True),
neck=dict(
type='RFP',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5,
rfp_steps=2,
aspp_out_channels=64,
aspp_dilations=(1, 3, 6, 1),
rfp_backbone=dict(
rfp_inplanes=256,
type='DetectoRS_ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
conv_cfg=dict(type='ConvAWS'),
sac=dict(type='SAC', use_deform=True),
stage_with_sac=(False, True, True, True),
pretrained='torchvision://resnet50',
style='pytorch')),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(
type='SmoothL1Loss', beta=0.1111111111111111, loss_weight=1.0)),
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=9,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=9,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.05, 0.05, 0.1, 0.1]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
loss_weight=1.0)),
dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=9,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.033, 0.033, 0.067, 0.067]),
reg_class_agnostic=True,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
],
train_cfg=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.7,
min_pos_iou=0.7,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
],
test_cfg=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5),
max_per_img=100)))
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=2000,
max_num=2000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=[
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.6,
neg_iou_thr=0.6,
min_pos_iou=0.6,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False),
dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.7,
min_pos_iou=0.7,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)
])
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=1000,
nms_post=1000,
max_num=1000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100))
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
classes = ('ПРМУ_поперечная трещина на изгибе', 'ПРМУ_выход трубы из ряда',
'ПРМУ_Крип', 'ПРМУ_свищи', 'ПРМУ_разрыв трубы',
'ПРМУ_поперечная трещина в околошовной зоне',
'ПРМУ_трещина в основном металле', 'ПРМУ_продольные трещины',
'ПРМУ_Цвета побежалости')
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1280, 720), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1280, 720),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=1,
train=dict(
type='CocoDataset',
classes=('ПРМУ_поперечная трещина на изгибе',
'ПРМУ_выход трубы из ряда', 'ПРМУ_Крип', 'ПРМУ_свищи',
'ПРМУ_разрыв трубы',
'ПРМУ_поперечная трещина в околошовной зоне',
'ПРМУ_трещина в основном металле', 'ПРМУ_продольные трещины',
'ПРМУ_Цвета побежалости'),
ann_file='data/coco/annotations/instances_train.json',
img_prefix='data/coco/train/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1280, 720), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
val=dict(
type='CocoDataset',
classes=('ПРМУ_поперечная трещина на изгибе',
'ПРМУ_выход трубы из ряда', 'ПРМУ_Крип', 'ПРМУ_свищи',
'ПРМУ_разрыв трубы',
'ПРМУ_поперечная трещина в околошовной зоне',
'ПРМУ_трещина в основном металле', 'ПРМУ_продольные трещины',
'ПРМУ_Цвета побежалости'),
ann_file='data/coco/annotations/instances_val.json',
img_prefix='data/coco/val/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1280, 720),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
classes=('ПРМУ_поперечная трещина на изгибе',
'ПРМУ_выход трубы из ряда', 'ПРМУ_Крип', 'ПРМУ_свищи',
'ПРМУ_разрыв трубы',
'ПРМУ_поперечная трещина в околошовной зоне',
'ПРМУ_трещина в основном металле', 'ПРМУ_продольные трещины',
'ПРМУ_Цвета побежалости'),
ann_file='data/coco/annotations/instances_val.json',
img_prefix='data/coco/val/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1280, 720),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric='bbox')
optimizer = dict(type='SGD', lr=0.0001, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None, type='OptimizerHook')
lr_config = dict(
policy='step',
warmup=None,
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11],
type='StepLrUpdaterHook')
total_epochs = 12
checkpoint_config = dict(interval=-1, type='CheckpointHook')
log_config = dict(
interval=10,
hooks=[dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = './checkpoints/detectors_cascade_rcnn_r50_1x_coco-32a10ba0.pth'
resume_from = None
workflow = [('train', 1)]
work_dir = './logs'
seed = 0
gpu_ids = range(0, 1)Обучение модели
Обучение модели занимало порядка 2 часов на RTX 2080 Ti. Прогресс можно было отслеживать с помощью запущенного tensorboard. Ниже приведены графики эволюции метрик и функции ошибки в процессе обучения на реальных данных.
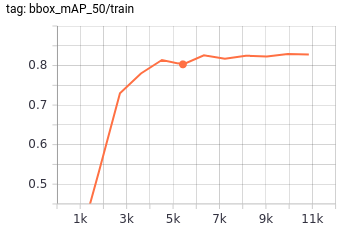
Рис. 16 Зависимость mAP от числа итераций обучения для архитектуры DetectoRS для датасета дефектов труб по 9 классам на валидационном датасете.

Рис. 17 Зависимость функции потерь (multiclass cross entropy) от числа итераций обучения для архитектуры DetectoRS для датасета дефектов труб по 9 классам.
Подготовка модели для использования
После того, как сеть была обучена, ее конфигурационный файл и веса, были помещены внутрь отдельного NVidia Docker контейнера вместе с самим фреймворком и необходимыми зависимостями, для того, чтобы использовать готовую архитектуру внутри прототипа ПО для детекции дефектов.
Стоит отметить, что, несмотря на то, что данная архитектура обучается в несколько раз быстрее чем YOLOv4, она занимает в 2 раза больше памяти (500 MB для DetectoRS против 250 MB для YOLOv4 для хранения весов модели) и работает на порядок медленнее (1 с. для DetectoRS против 10 мс. для YOLOv4).
Малое время обучения DetectoRS отчасти объясняется тем, что веса базовых слоев сети (backbone и neck) были взяты из претренированной на ImageNet датасете аналогичной архитектуры и в процессе обучения не изменялись. Такой прием называется transfer learning. Про него вы можете подробнее прочитать в этой заметке.
Darknet
Оригинальная реализация YOLOV4 написана на C c использованием CUDA C. Было принято решение использовать оригинальную реализацию модели, хотя обычно доминируют эксперименты на Python. Это накладывало свои ограничения и риски, связанные с необходимость разбираться в коде на C, в случае каких-то проблем или переделки частей под свои нужды. Подробной документации с примерами не было, поэтому пришлось в некоторых местах смотреть исходный код на C.
Для успешного запуска нужно было решить несколько проблем:
- Собрать проект.
- Понять что необходимо для обучения модели.
- Обучить модель.
- Подготовить код для использования.
Сборка проекта
Первая сборка проекта происходила на Windows. Для сборки использовался CMake, поэтому особых проблем с этим не возникло. Единственная проблема была с компиляцией динамической библиотеки для обёртки на Python. Пришлось редактировать файл с проектом для Visual Studio, чтобы включить поддержку CUDA. Динамическая библиотека была нужна т. к. это позволяло использовать код на Python для запуска модели.
После было принято решение перенести сборку внутрь Docker контейнера. Для того чтобы оставить возможность использовать видеокарту был установлен NVIDIA Container Toolkit. Это позволяет достаточно просто организовать перенос проекта на другую машину при необходимости, а также упрощает дальнейшее использование. Благодаря наличию различных образов nvidia/cuda на Docker Hub, можно достаточно просто менять конфигурации. Например, переключение между различными версиями CUDA или cuDNN.
Необходимые файлы для обучения
Для обучения модели нужно было подготовить данные и дополнительные файлы как было описано в самом начале, а также правильно настроить конфигурационный файл. В репозитории предлагается взять за основу образец, который представляет из себя текстовый файл и поменять в нужных местах значения параметров. В основном всё зависит от числа классов. Т. к. у нас число классов могло варьироваться, то постоянно так делать было нецелесообразно. Конфигурационный файл был шаблонизирован с помощью выражений jinja2. Код на Python позволял генерировать нужные конфигурационные файлы в зависимости от входных параметров.
Обучение модели
Обучение модели производилось в контейнере NVIDIA Docker. Занимало порядка 12 часов на RTX 2080 Ti. Прогресс можно было отслеживать периодически копируя график функции потерь из контейнера на хост, где запущен контейнер. Красным показано значение mAP на тестовой выборке.
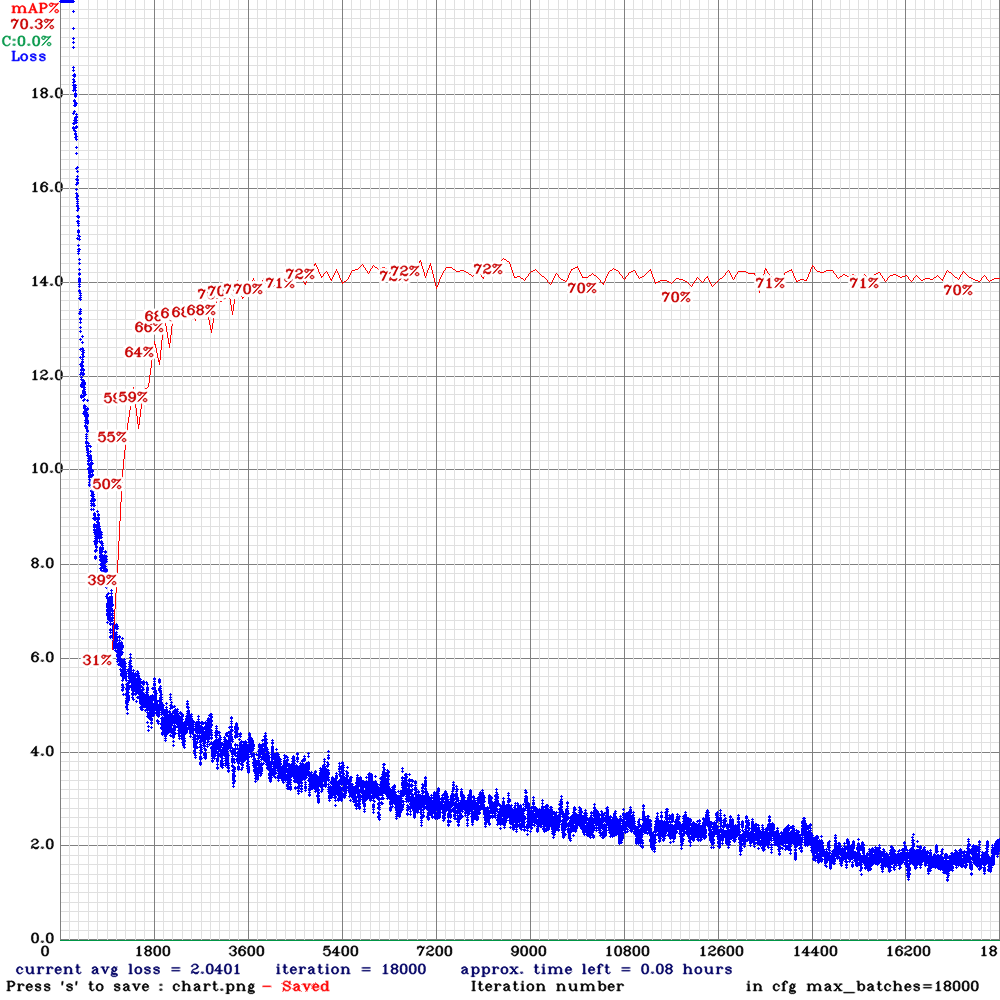
Рис. 18 График обучения YOLOv4.
Подготовка модели для использования
После обучения модели была необходимость в ее использовании для визуализации результатов. От кода на Python пришлось отказаться т. к. были проблемы с неожиданным завершением программы. Некоторые части кода пришлось дописать на языке С под собственные нужды.
Результаты
После всех экспериментов были выявлены следующие зависимости:
- Обучение на смеси данных (реальные + искусственные) приводит к небольшому ухудшению обобщающей способности (это связано с тем, что в данной итерации генератора синтетических данных присутствуют недостаточно разнообразные данные и однотипное освещение);
- После недолгого подбора гиперпараметров для архитектуры DetectoRS удалось добиться показателя , а для архитектуры YOLOv4 ;
- Некоторые типы дефектов, такие как разного рода трещины или выход труб из ряда, детектируются лучше чем иные типы дефектов, такие как вздутие труб. Это можно объяснить не только дисбалансом и малым количеством примеров, но и тем, что для определения некоторых типов дефектов, нужно больше пространственной информации (аналогично этому, в реальной детекции дефектов, некоторые дефекты определяются на глаз, а некоторые требуют специальных измерительных приборов). Потенциально, использование помимо RGB каналов с камеры также еще и канала глубины (RGB-D) могло бы помочь с детектированием этих сложных пространственных дефектов: в этом случае мы смогли бы прибегнуть к методам и алгоритмама 3D ML.
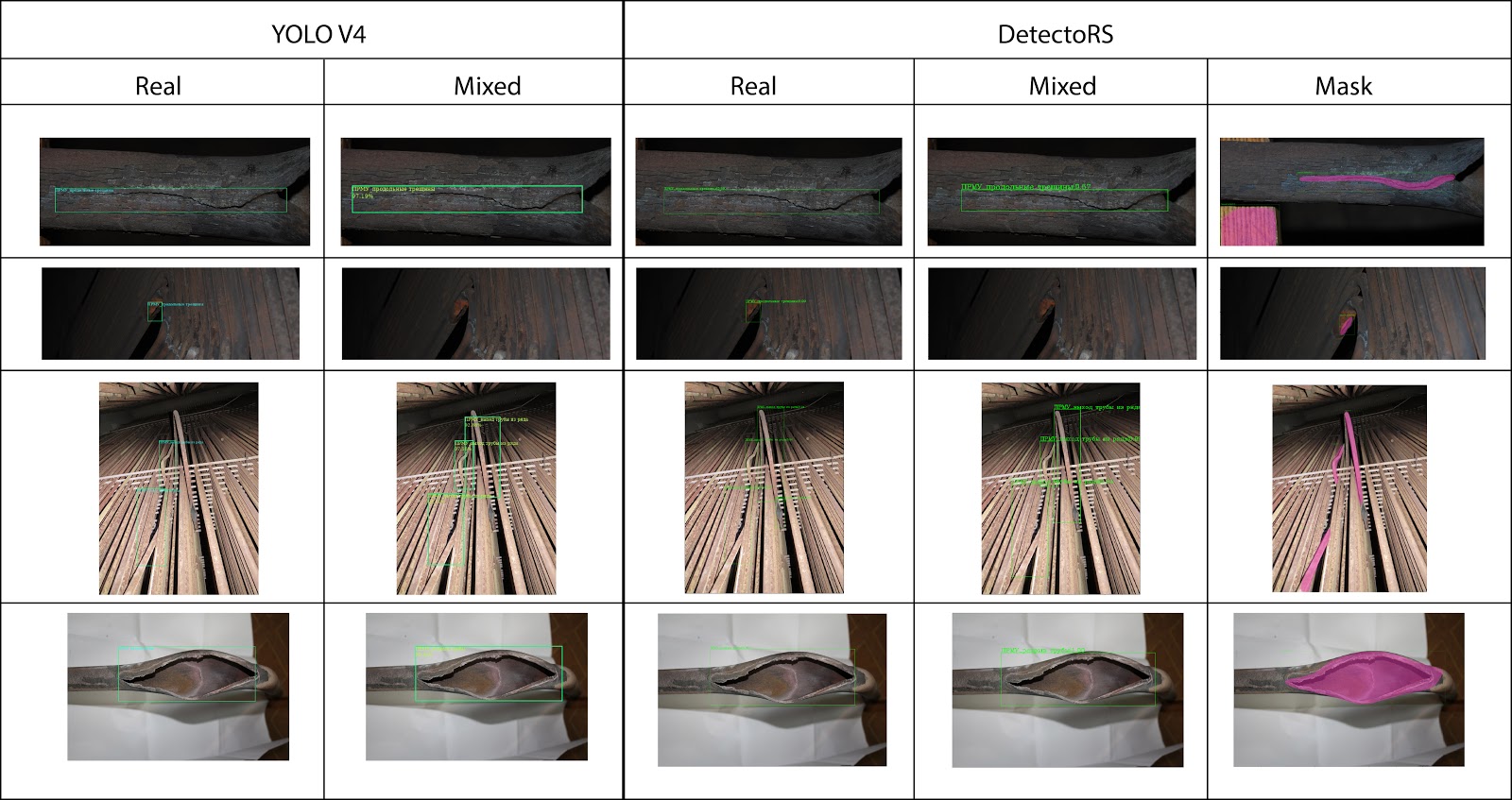
Рис. 19 Сравнение работы архитектур, обученных на разных датасетах: Real — только реальные изображение, Mixed — обучении на смеси реальных и синтетических изображений, Mask — обучения на реальных изображениях, с многоугольной разметкой областей.

Рис. 20 Пример некорректной детекции модели DetectoRS, обученной на синтетических данных — отсутствие посторонних предметов в синтетическом датасете приводит к определению куска деревянной балки как трещины.

Рис. 21 Пример детекции дефектов в виде многоугольных масок модели DetectoRS, обученной на датасете реальных изображений с соответствующей разметкой.

Рис. 22 Пример детекции дефектов в виде прямоугольников для одного и того же изображения с помощью разных архитектур.
Финальное решение с интерфейсом
В итоге, был получен работающий прототип ПО с интерфейсом, который можно было бы просто использовать как со стороны пользователя так и для разработчиков. Так как проекты на основе ML часто требуют вычислительных мощностей видеокарт NVIDIA для своей работы, то было принято решение сделать клиент-серверное приложение. При необходимости всё можно развернуть на одном компьютере. Если же есть в наличии свободный сервер с видеокартой, то основную логику можно перенести туда, оставив возможность любым пользователям использовать сервис даже на слабом по вычислительным возможностям компьютере.
Для архитектуры ПО была выбрана следующая схема:
Финальное решение с интерфейсом
В итоге, был получен работающий прототип ПО с интерфейсом, который можно было бы просто использовать как со стороны пользователя так и для разработчиков. Так как проекты на основе ML часто требуют вычислительных мощностей видеокарт NVIDIA для своей работы, то было принято решение сделать клиент-серверное приложение. При необходимости всё можно развернуть на одном компьютере. Если же есть в наличии свободный сервер с видеокартой, то основную логику можно перенести туда, оставив возможность любым пользователям использовать сервис даже на слабом по вычислительным возможностям компьютере.
Для архитектуры ПО была выбрана следующая схема:

Рис. 23 Схема архитектуры прототипа ПО для детектирования дефектов на изображениях.
Все модели для детектирования дефектов работают внутри NVIDIA Docker. Остальные части, кроме Web-интерфейса внутри обычных контейнеров Docker. Логика работы следующая:
- Пользователь загружает изображение и выбирает нужную модель вместе с порогом принятия решения.
- Изображение отправляется на сервер. Оно сохраняется на диске и сообщение с заданием на обработку попадает в RabbitMQ, в соответствующую очередь.
- Модель берёт сообщение с заданием из очереди, когда готова выполнить предсказание. Выполняет предсказание и сохраняет необходимые файлы на диск. Отправляет сообщение в RabbitMQ о готовности результат.
- Когда результат готов он отображается в web-интерфейсе.
RabbitMQ занимается логикой по распределению и хранению сообщений во время работы. Из-за того что сервер, в общем случае, выполняет запросы быстрее, чем ML сервис, то естественным образом возникает очередь сообщений на обработку. Например, несколько пользователей могут загрузить изображения одновременно, но из-за нехватки ресурсов может быть запущена только одна модель каждого типа для обнаружения дефектов.
RabbitMQ также позволяет изолировать систему друг от друга и начать разработку независимо. При разработке сервера не надо дожидаться реализации ML моделей и наоборот. Каждая система общается только с RabbitMQ. В случае падения какого-то сервиса сообщение не потеряется, если соответствующим образом настроить RabbitMQ.
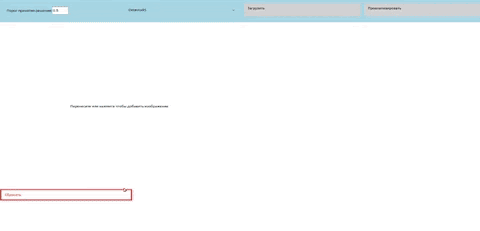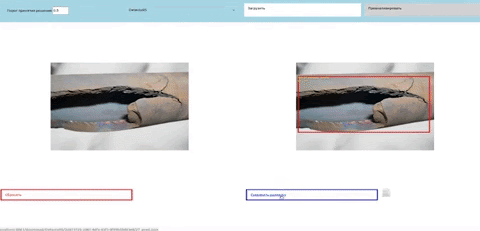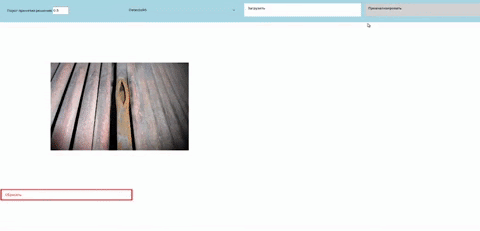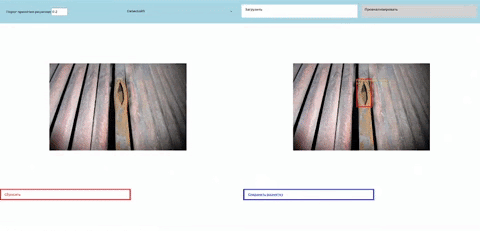
Рис. 24 Демонстрация работы созданного прототипа ПО для детекции дефектов на трубах.
В заключении, отметим, что при разработке ПО, в котором используются модели машинного обучения, требуется очень много обмениваться данными и целыми пайплайнами эксперементов с членами команды. Для того, чтобы это было удобно делать мы пользовались на протяжении всего проекта системой DVC. Примеры использования этой системы контроля данных и моделей машинного обучения можно посмотреть в этой статье на хабре.
Основные источники
- Qiao, S., Chen, L.C. and Yuille, A., 2020. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. arXiv preprint arXiv:2006.02334.
- Bochkovskiy, A., Wang, C.Y. and Liao, H.Y.M., 2020. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv preprint arXiv:2004.10934.
- Tan, M., Pang, R. and Le, Q.V., 2020. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10781-10790).
- Zhao, Z.Q., Zheng, P., Xu, S.T. and Wu, X., 2019. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems, 30(11), pp.3212-3232.
- Szeliski, R., 2010. Computer vision: algorithms and applications. Springer Science & Business Media.
- Nixon, M. and Aguado, A., 2019. Feature extraction and image processing for computer vision. Academic press.
- Jiang, X. ed., 2019. Deep Learning in Object Detection and Recognition. Springer.
- Pardo, A. and Kittler, J. eds., 2015. Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 20th Iberoamerican Congress, CIARP 2015, Montevideo, Uruguay, November 9-12, 2015, Proceedings (Vol. 9423). Springer.