

Мы рады сообщить о выходе общедоступной предварительной версии образа виртуальной машины (ВМ) на базе CentOS 7, оптимизированного для высокопроизводительных вычислений (HPC). Прежде всего, он рассчитан на сильносвязанные рабочие нагрузки Message Passing Interface (MPI). В этой статье подробно рассказано о специальных образе ВМ для высокопроизводительных вычислений и его преимуществах. Чтобы сразу перейти к созданию экземпляров на основе этого образа, прочитайте документацию и краткое руководство.
В 2020 году мы рассказывали о ряде функций и настроек для оптимизации работы интерфейса MPI на платформе Google Cloud. Они позволяют сократить задержку при обмене сообщениями до нескольких микросекунд и обеспечивают доставку небольших сообщений MPI за 10 микросекунд и меньше. Оптимизация MPI улучшает масштабирование приложений и увеличивает количество задач, которые могут выполняться на платформе Google Cloud. Однако чтобы создать образ ВМ с учетом этих приемов, необходимы глубокие знания о системах и платформе Google Cloud. Поэтому логичнее начать работу с образом изначально рассчитанным и подготовленным для высокопроизводительных вычислений. С его помощью можно легко развернуть экземпляр ВМ, настроенный для оптимальной производительности процессора и сети, в Google Cloud. Образ ВМ для высокопроизводительных вычислений доступен в Google Cloud Marketplace без дополнительной платы.
Преимущества образа ВМ для высокопроизводительных вычислений по сравнению с обычными образами ВМ
Выбирая образ ВМ для высокопроизводительных вычислений, вы получаете готовую конфигурацию и регулярное обслуживание, а также следующие преимущества при выполнении высокопроизводительных вычислений на платформе Google Cloud:
-
Удобное создание виртуальных машин, адаптированных под сильносвязанные рабочие нагрузки. Легко создайте ВМ для высокопроизводительных вычислений и регулярно обновляйте ее конфигурацию с учетом последних настроек.
-
Оптимизация сетей для сильносвязанных систем. Сократите задержку при передаче небольших сообщений и ускорьте работу приложений, для которых важна двухточечная или коллективная коммуникация.
-
Более эффективные вычисления. Повысьте производительность на отдельных узлах, уменьшив количество колебаний в системе.
-
Стабильная и воспроизводимая работа нескольких узлов. Применяйте настройки, эффективность которых была многократно проверена на различных задачах из области высокопроизводительных вычислений.
Образ ВМ для высокопроизводительных вычислений легко заменяет стандартный образ на базе CentOS 7.
Реальный пример: масштабирование программы для решения уравнений SDPB с помощью CloudyCluster и образа ВМ для высокопроизводительных вычислений
Уолтер Лондри из Caltech Particle Theory Group разрабатывает исследовательское ПО в рамках международного проекта Bootstrap Collaboration. В проекте используется полуопределенная программа для решения уравнений (SDPB). С ее помощью исследуются теории квантового поля применительно к широкому спектру проблем теоретической физики, таких как расширение ранней Вселенной, сверхпроводники, квантовый эффект Холла и фазовые переходы.
Чтобы расширить вычислительные возможности проекта, Лондри решил масштабировать программу SDPB на платформе Google Cloud. Используя среду CloudyCluster компании Omnibond и образ ВМ для высокопроизводительных вычислений, он сумел вывести проект на уровни производительности и масштабирования, сопоставимые с локальным кластером в Йельском университете на базе компьютеров с процессорами Intel Xeon Gold 6240 и технологией Infiniband FDR.
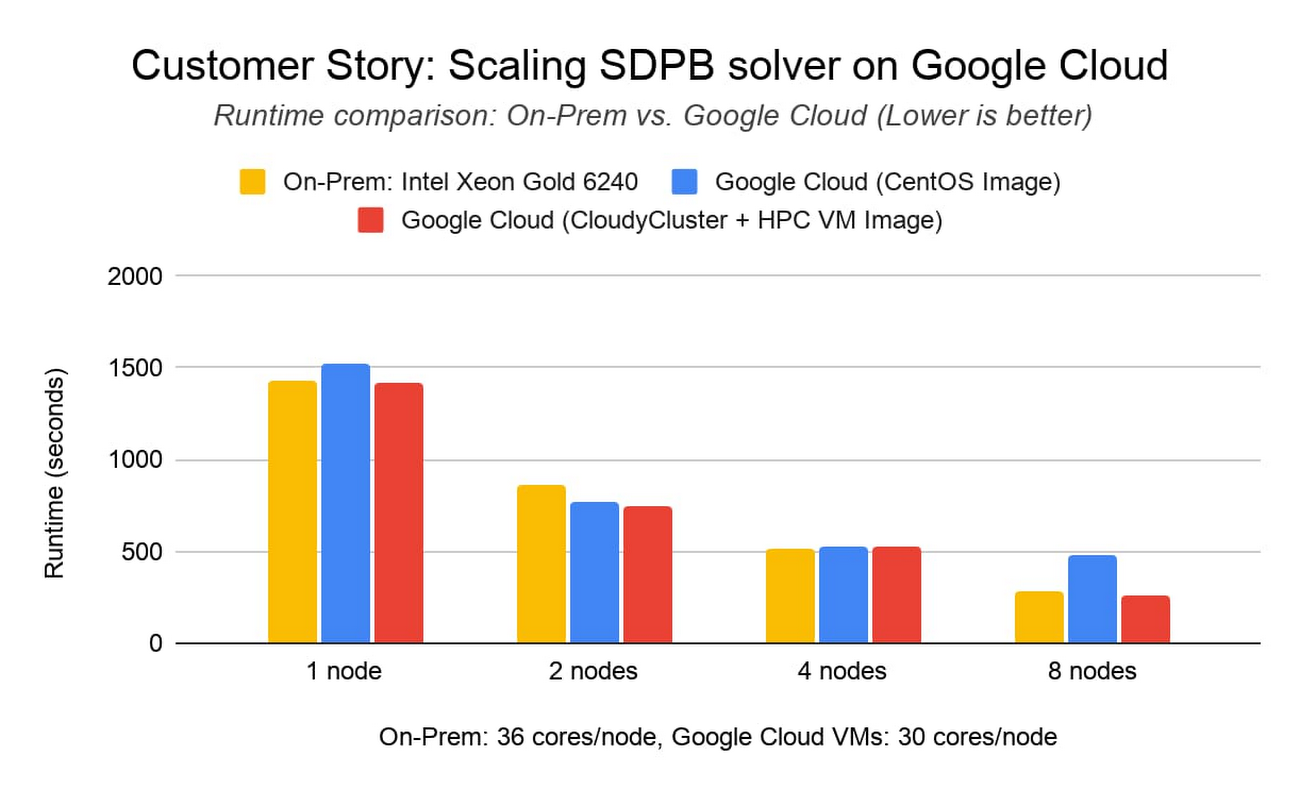
В экземпляре C2-Standard-60 для Google Cloud используются масштабируемые процессоры Intel Xeon второго поколения. Экземпляры C2 поддерживают правила размещения, которые уменьшают задержки связи между узлами, поэтому они отлично подходят для сильносвязанных рабочих нагрузок MPI. Решение CloudyCluster изначально содержит образ ВМ для высокопроизводительных вычислений и правила размещения для семейства C2, поэтому исследователям не нужно выполнять никаких лишних действий. Тесты показали, что в Google Cloud можно масштабировать рабочие нагрузки с низкой задержкой на множестве экземпляров.
Если вы хотите убедиться в этом сами, в Google Cloud Marketplace доступна обновленная версия среды CloudyCluster от Omnibond с образом ВМ для высокопроизводительных вычислений. Эта версия также включает в себя приложение Open OnDemand, которое распространяет Суперкомпьютерный центр штата Огайо и финансирует NSF. С его помощью системные администраторы могут легко предоставлять веб-доступ к ресурсам для высокопроизводительных вычислений.
Возможности образа ВМ для высокопроизводительных вычислений
Настройки и оптимизация. В текущей версии образа ВМ для высокопроизводительных вычислений основное внимание уделено настройкам для сильносвязанных рабочих нагрузок и применены следующие решения для повышения производительности MPI:
-
Отказ от гиперпотоковой обработки Intel Hyper-Threading. По умолчанию в образе ВМ для высокопроизводительных вычислений технология гиперпотоковой обработки Intel Hyper-Threading отключена. Это позволяет точнее оценивать текущую производительность и ускорять выполнение некоторых задач.
-
Коллективные настройки для MPI. Производительность приложения MPI во многом зависит от выбранных коллективных алгоритмов MPI. Образ ВМ для высокопроизводительных вычислений содержит рекомендуемые коллективные алгоритмы MPI от Intel, которые применяются в основных операциях MPI.
-
Увеличенные параметры tcp_*mem. Экземпляры C2 поддерживают пропускную способность до 32 Гбит/с и больший объем памяти TCP по сравнению со стандартными машинами на базе Linux.
-
Поддержка обработчика busy polling. Обработчик busy polling уменьшает задержку в приемном тракте сети, так как позволяет выполнить опрос очереди приема сетевого устройства на уровне сокета, не прерывая соединение с сетью.
-
Увеличенный лимит ресурсов. Стандартные ограничения системных ресурсов для пользователей, например по числу открытых файлов (дескрипторов) или запущенных процессов, как правило, не применяются для задач высокопроизводительных вычислений, если каждому пользователю выделен свой вычислительный узел в кластере.
-
Отключение брандмауэров Linux и технологии SELinux. Механизм SELinux и брандмауэр, которые по умолчанию включены для образов CentOS Linux в Google Cloud, не используются в образе ВМ для высокопроизводительных вычислений. Это позволяет повысить производительность MPI.
-
Отключение утилиты CPUIdle. Виртуальные машины семейства C2 поддерживают состояние простоя ЦП и могут переходить в режим пониженного энергопотребления. Отключив утилиту CPUIdle, можно вывести время задержки на стабильно низкий уровень.
Эффективность этих настроек зависит от конкретного приложения. Рекомендуем проверить их на практике, чтобы найти самую мощную и экономичную конфигурацию.
Сравнительный анализ эффективности образов
Мы сравнили производительность образа ВМ для высокопроизводительных вычислений и стандартного образа CentOS 7, используя тесты Intel MPI Benchmarks и тесты реальных приложений для анализа методом конечных элементов (ANSYS LS-DYNA), гидродинамического моделирования (ANSYS Fluent) и моделирования погоды (WRF).
В этом разделе для сравнения были взяты следующие версии образа ВМ для высокопроизводительных вычислений и образа CentOS:
-
Образ ВМ для высокопроизводительных вычислений: hpc-centos-7-v20210119 (применены настройки --nomitigation и mpitune, как рекомендовано в документации)
-
Образ CentOS: centos-7-v20200811
Тест Ping-Pong из набора Intel MPI Benchmark (IMB) – используется для измерения задержки при передаче сообщения фиксированного размера между двумя рангами через пару виртуальных машин. Выяснилось, что при использовании образа ВМ для высокопроизводительных вычислений время задержки в среднем на 50 % меньше по сравнению со стандартным образом CentOS 7.
Тестовая конфигурация:
- 2 ВМ C2-standard-60 с правилами компактного размещения
-
Библиотека MPI: Intel MPI Library 2018 (обновление 4)
-
Командa запуска: mpirun -genv I_MPI_PIN=1 -genv I_MPI_PIN_PROCESSOR_LIST=0 -hostfile <hostfile> -np 2 -ppn 1 IMB-MPI1 Pingpong -iter 50000
Результаты

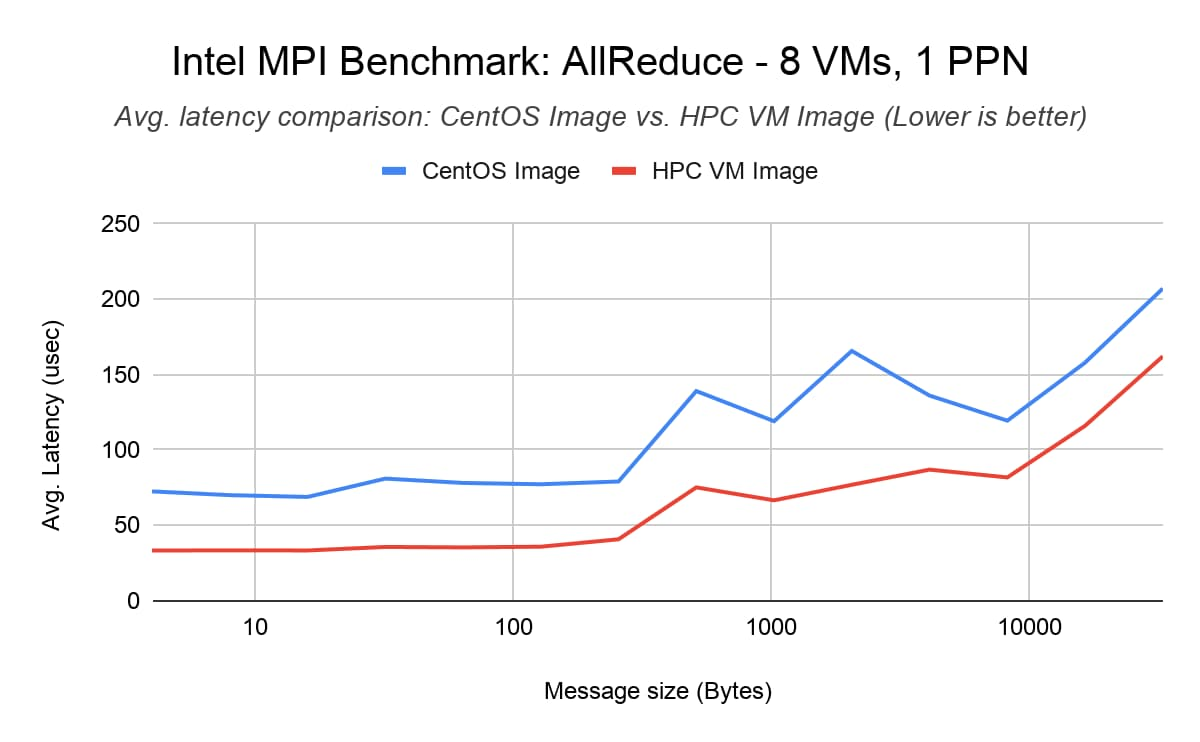
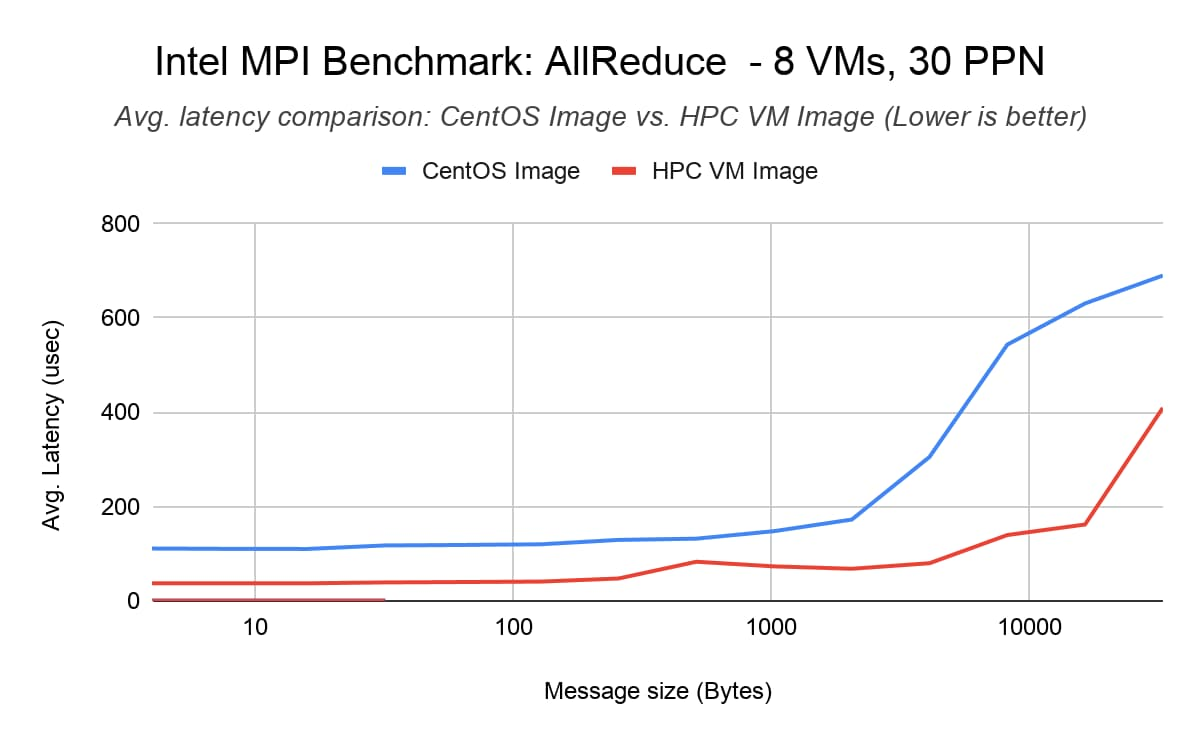
Тест AllReduce из набора Intel MPI Benchmark (IMB) – используется для измерения коллективной задержки при передаче данных между несколькими рангами через ВМ. Он сокращает вектор фиксированной длины с помощью операции MPI_SUM. Показаны результаты для одного PPN (процесса на узел), где есть 1 ранг MPI на узел и 30 потоков на ранг, а также результаты для 30 PPN, когда имеется 30 рангов MPI на узел и 1 поток на ранг. Выяснилось, что по сравнению со стандартным образом CentOS 7 образ ВМ для высокопроизводительных вычислений уменьшает задержку AllReduce для 240 рангов MPI в 8 узлах (30 процессов в каждом узле) вплоть до 40 %.
Тестовая конфигурация:
- 8 ВМ C2-standard-60 с правилами компактного размещения
-
Библиотека MPI: Intel MPI Library 2018 (обновление 4)
-
Командa запуска: mpirun -tune -genv I_MPI_PIN=1 -genv I_MPI_FABRICS ‘shm:tcp’ -hostfile <hostfile> -np <#vm*ppn> -ppn <ppn> IMB-MPI1 AllReduce -iter 50000 -npmin <#vm*ppn>
Результаты
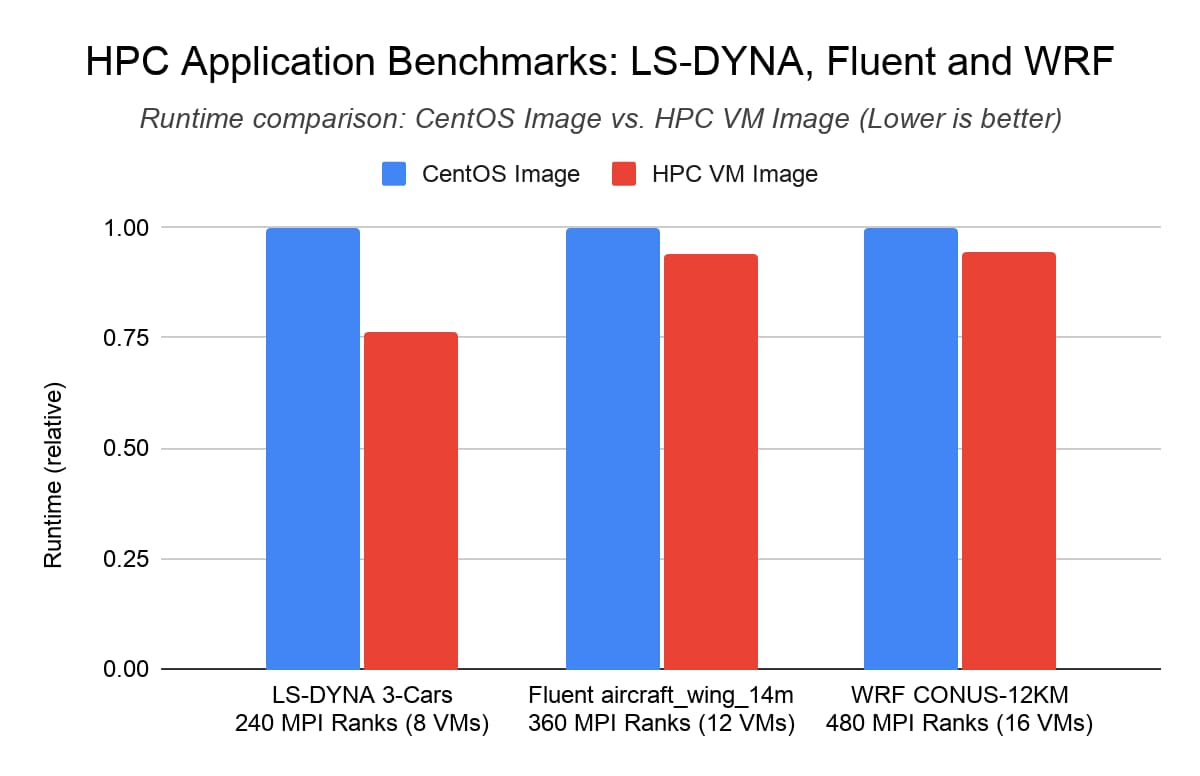
Тесты приложения высокопроизводительных вычислений: LS-DYNA, Fluent и WRF. При использовании образа ВМ для высокопроизводительных вычислений на уровне приложения был отмечен рост производительности вплоть до 25 % по сравнению с симуляцией столкновения “3 автомобилей” в рамках анализа ANSYS LS-DYNA (было задействовано 240 рангов MPI в 8 экземплярах C2 на базе процессоров Intel Xeon). В рамках анализа ANSYS Fluent и WRF образ ВМ для высокопроизводительных вычислений обеспечивал рост производительности на 6 % по сравнению со стандартным образом CentOS.
Тестовая конфигурация:
-
ANSYS LS-DYNA (модель “3 автомобиля”): 8 ВМ C2-standard-60 с правилами компактного размещения, используется двоичный код LS-DYNA MPP, скомпилированный при помощи AVX-2
-
ANSYS Fluent (модель “aircraft_wing_14m”): 12 ВМ C2-standard-60 с правилами компактного размещения
-
WRF V3 Parallel Benchmark (12 KM CONUS): 16 ВМ C2-standard-60 с правилами компактного размещения
-
Библиотека MPI: Intel MPI Library 2018 (обновление 4)
Результаты
Что дальше? Поддержка SchedMD Slurm и дополнительные дистрибутивы Linux
Мы будем расширять список партнерских решений, в которых образ ВМ для высокопроизводительных вычислений будет использоваться по умолчанию. Начиная со следующего месяца все клиенты, работающие с сервисом Slurm, смогут запускать кластеры, в которых образ ВМ для высокопроизводительных вычислений используется по умолчанию (ознакомительная версия доступна здесь).
Хорошие новости для тех, кому требуется корпоративная версия Linux для высокопроизводительных вычислений! Компания SUSE совместно с Google разрабатывает образ ВМ для высокопроизводительных вычислений SUSE Enterprise, оптимизированный для Google Cloud. Если вы хотите получить дополнительную информацию или запросить другие интеграции и дистрибутивы Linux, свяжитесь с нами.
Начните работу сегодня!
Ознакомительная версия образа ВМ для высокопроизводительных вычислений уже доступна для всех пользователей в Google Cloud Marketplace . О том, как создавать экземпляры с помощью образа ВМ для высокопроизводительных вычислений, рассказано в документации и кратком руководстве. Также напоминаем что при первой регистрации в Google Cloud: вам доступны бонусы на сумму 300 долларов США и более 20 бесплатных продуктов доступны всегда. Попробовать GCP можно по специальной ссылке.
Отдельная благодарность за помощь в подготовке материала коллегам Цзю Сяо Лью, Таннера Лава, Ян Цзяня, Хун Бо Лу и Паллави Фен.