

Эта статья о том, как извлечь максимум пользы из статической системы типов при дизайне вашего кода. Статья пытается быть language agnostic (получается не всегда), примеры на Java и взяты из жизни. Хотя академические языки вроде Idris позволяют делать больше полезных трюков со статической типизацией, а полный вывод типов существенно сокращает размер церемоний, на работе мы пишем на языках другого типа, а хорошие знания хочется уметь применять на практике, так как это сделает нашу жизнь лучше уже сегодня.
Краткий пересказ сюжета статьи
В этой достаточно длинной статье я пытаюсь, набрасывая примеры удачных дизайнерских решений, дать вам прочувствовать идею дизайнить код с оглядкой на статическую типизацию таким образом, чтобы он получался более гибким, быстрым, надёжным и понятным.
Это именно идея, а не какая-то конкретная методология или принцип (хотя отдельные принципы есть внутри, как примеры). В каждой новой ситуации вам придется самому размышлять как сделать лучше, но важно что бы вы вообще задумались, что удачное решение существует и стоит потратить время на его поиск.
Дизайн важен, т.к. текст программы это больше, чем набор инструкций. Это проявляется в двух сюжетах.
Для начала в статически типизированном языке ваш код не только будет производить вычисления над данными в рантайме, но и произведёт верифицируемые вычисления над типами в момент компиляции. Этому механизму можно сесть на шею и написать код, который верифицирует высокоуровневые свойства программы.
Помимо этого есть языковые конструкции, которые вообще не существуют как конкретный набор инструкций вне своего контекста: макросы, дженерики (в большинстве реализаций, кроме, кстати, Java) или код с полным выводом типов.
То есть во время дизайна вам стоит взглянуть на те свойства вашей программы, которые есть у её текста, но которых нет у тех инструкций, которые в конце концов будут исполнены.
План у нас следующий:
Сперва рассмотрим минусы статической типизации перед динамической: обозначим проблемы, которые хочется решить.
Потом я коротко уточню, какие свойства программ важны лично мне, чтобы вам было ясно, почему я решаю проблемы именно таким образом.
Затем мы подробно поговорим об основных видах полиморфизма. Полиморфизм в широком смысле — это основной инструмент, с помощью которого мы будем решать проблемы. Глубокое понимание полиморфного кода — ядро всей статьи.
Наконец, мы рассмотрим ряд примеров решения описанных проблем.
Пара слов о том, как абстрагирование уменьшает связанность и где это уместно.
Замечание о важности баланса: как не написать случайно DSL, следуя принципам из статьи.
Вместо заключения я скажу почему такого рода идеи вообще приходят людям в голову.
Почему статическую типизацию можно не любить
Прежде чем хвалить статическую типизацию, стоит понять какие с ней возникают проблемы и почему.
Неполнота
Начнем с того, что какой бы мощной ваша система типов не была, всегда найдутся корректные программы, которые будут ею отвергнуты. С этим хорошо знакомы разработчики на Rust (читайте статьи о non lexical lifetimes: раз, два, три, четыре), но проблема касается любой статической системы типов. Это прямое следствие теоремы Гёделя о неполноте (ещё по теме советую прочитать книгу "ГЭБ: эта бесконечная гирлянда"). Она, грубо говоря, гласит что в любой достаточно сложной формальной системе либо есть теоремы, которые верны, но их верность нельзя доказать в рамках самой системы, либо можно доказать теоремы, которые не верны.
Статическая система типов валидирует код, фактически она доказывает теоремы о том, что код корректен в узком смысле, т.е. в нем нет некоторого класса ошибок исполнения.
Допустим, вы решаете некоторую задачу: программа корректно решает её, если всегда возвращает верные ответы, и не корректно, если не всегда. Тогда множество всех возможных программ относительно данной задачи разбивается на следующие множества:
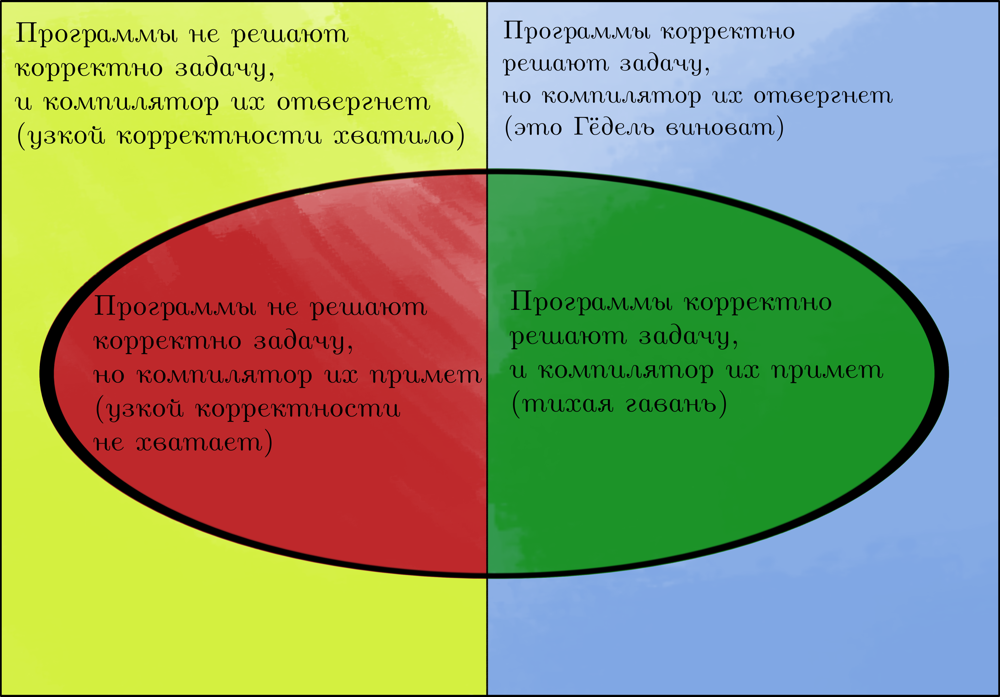
В разных системах типов классы ошибок, от которых защищает компилятор, разные: например, безопасная часть языка Rust гарантирует, что в коде нет гонок данных, но возможности большинства систем намного скромнее и ограничиваются проверкой существования функций с соответствующими сигнатурами.
Может показаться, что корректные программы, отбракованные системой типов, не встречаются на практике. Но это не так. Возможность делать тайп касты ровно по тому и добавлена в языки, чтобы позволить обойти именно эту проблему. Но, в полном согласии с теоремой, система типов становится противоречивой.
Вот маленький пример на Java:
Optional<? extends CharSequence> x = getContent();
/*
Не компилируется с ошибкой:
incompatible types: java.lang.String cannot be converted to
capture#1 of ? extends java.lang.CharSequenc
*/
CharSequence y = x.orElse("");
// А с кастом компилируется и прекрасно работает:
// CharSequence y = ( (Optional<CharSequence>) x).orElse("");Мы обсудим дженерики чуть позже, поэтому этот код может быть пока не до конца понятен. Главное, что этот код корректен, но компилятор не может этого доказать.
Сперва давайте убедимся в корректности, а о проблемах компилятора я расскажу позже, в разделе про вариантность.
В x лежит Optional — реализация монады maybe в Java, а в Rust и Scala оно ещё называется Option. В C# такого нет, поэтому для простоты скажу, что внутри просто лежит nullable ссылка на объект, а сам Optional предоставляет безопасные методы для работы с ним. В частности метод Optional.orElse возвращает либо этот внутренний объект, если он не равен null, либо переданный в аргумент объект.
Синтаксис ? extends CharSequence значит, что внутри лежит объект, реализующий интерфейс CharSequence. В Java "" имеет тип String, который реализует CharSequence.
Очевидно, что какой бы CharSequence не был в x его можно присвоить в y, но конечно же и "" тоже можно присвоить. Поэтому программа корректна и кастовать здесь можно. Однако система типов Java не может этого доказать.
В прошлом проекте это мешало, т.к. у нас были свои CharSequence указывающие на оффхиповые строки, ведь довольно много методов могут работать с CharSequence напрямую. А во время миграции возникают Optional объекты. Когда же они встречаются вместе, всем становится немного грустно.
Церемонии
Другой проблемой является наличие церемоний. Так называют действия, которые необходимо совершить прежде, чем получить желаемое. Если мы посмотрим на статическую типизацию в языке C, то может возникнуть впечатление, что система типов там нужна скорее для того, чтобы программист помог компилятору собрать программу, а не для того, чтобы компилятор помог программисту обнаружить ошибки.
Механизм вывода типов решает эту проблему, но в мейнстримных языках вроде C++ и особенно в Java вывод типов ограничен и церемоний там в избытке: мы тратим существенную часть времени, чтобы объяснить компилятору, как компилировать программу. Дела обстоят еще хуже, когда разработчики привыкают к вербозному стилю настолько, что им сложно писать иначе, даже когда соответствующий инструментарий в языке наконец появляется.
Справедливости ради вывод типов плохо дружит с перегрузками и неявным приведением типов.
Логические ошибки

Статическая система типов в мейстримных языках проверяет корректность в узком смысле и защищает от небольшого числа ошибок, в духе деления строки на число. Логика вашей программы неизвестна никому, кроме вас, и поэтому компилятор не может её проверить. И сторонники динамической типизации говорят, что бенефиты корректности от статической типизации слишком малы, чтобы платить за это церемониями и борьбой с компилятором.
Однако, и тут мы подбираемся к теме статьи, статическую типизацию можно использовать для защиты и от логических ошибок, просто это требует некоторого мастерства. В статье я буду описывать, как снизить стоимость и повысить полезность статической системы типов, но, конечно, использовать её или нет— личное дело каждого.
Мои субъективные ценности

В процессе написания статьи я понял, что мне не обойтись без некоторой существенной предпосылки о моем внутреннем понимании: что есть "хороший код"? Подобные вопросы по определению не объективны — другие люди могут желать другого, поэтому мне необходимо явно проговорить то, во что верю я.
Итак: Я бы хотел описывать функции как абстрактные преобразования над любыми сущностями, для которых, такое преобразование имеет смысл. Но вместе с тем, мне хочется увернуться от проблем, которые за этим последуют: во-первых, на этапе компиляции обнаружить все некорректные с логической точки зрения варианты использования, во-вторых, запретить явно опасные для производительности использования, и в-третьих, иметь возможность легко понять, почему что-то пошло не так. Другими словами, я хочу одновременно получить корректный, гибкий, производительный и понятный код.
Полиморфизм
Трюки, о которых я хочу рассказать, будут использовать множество возможностей языка, главные из которых — разные виды полиморфизма, поэтому прежде, чем продолжить я хочу убедиться, что мы на одной волне.

Что отличает систему типов в C от системы типов в Java? Почему я сказал, что в C вы помогаете компилятору больше, чем он вам? Все дело в полиморфизме. В C нельзя описать функцию, работающую с разными типами, одинаковым образом. Например, нельзя описать функцию сортировки, где проверялась бы совместимость массива и компаратора. То есть общая функция сортировки, конечно, существует, работать же как-то надо:
void qsort (
void* base,
size_t num,
size_t size,
int (*comparator)(const void*, const void*)
);Но никакой проверки соответствия типов сортируемого массива и компоратора здесь нет. Код же самого компоратора будет кастовать указатели void* к нужному типу.
Насколько я понял, подобные функции не называют полиморфными примерно по той же причине, почему утиную типизацию не считают видом полиморфизма. Однако, неявное приведение типов это тоже ad-hoc полиморфизм, поэтому нельзя говорить, что в C совсем нет полиморфизма (более того, в новых стандартах есть полиморфные макросы). Люди по-всякому выкручиваются и пишут об этом статьи.
В Java же есть ещё 3 вида полиморфизма. Два универсальных: параметрический (с помощью дженериков) и включений (через наследование), а так же один ad-hoc: через перегрузку функций.
Я настоятельно советую прочитать большую обзорную статью о полиморфизме, которую я во многом дальше пересказываю.
Перегрузка функций
Перегрузка функций — неоднозначная фича. Её минус в том, что не очевидно какой на самом деле код будет вызван. Более того, в перегруженных функциях нередко возникает дублирование кода, что в свою очередь приводит к багам: когда одну из реализаций забывают поправить. Скажем, в Rust перегрузок функций нет, а другие виды полиморфизма есть.
Если оба класса, для которых вы хотели бы воспользоваться перегрузкой, написаны вами, тогда надо выделить общий интерфейс и перегрузка уйдет.
В Rust есть трейты и они позволяют вам сделать тот же трюк, даже когда классы чужие: т.к. трейт (аналог интерфейса) можно реализовать для любой структуры.
Но в Java такого механизма нет, поэтому, уверен, каждый из вас писал такой код:
class Builder {
void addNames(String... names) {addNames(List.of(names))}
void addNames(Iterable<String> names) {/*...*/}
}Лично я пришел к выводу, что это нормально, если классы не доступны для модификации и выделения интерфейса. Так что мой совет: воспринимайте перегрузку функций, как небольшой костылек, которым вы можете подпереть вашу систему типов, когда она не справляется.
Главное следить, чтобы случайно не возникло перегрузки в большом классе из-за конфликта имен. Если функции делают разное, они должны называться по-разному, иначе рефакторинг превратится в боль.
Не забудьте так же проверить поломку механизма вывода типов: даже если в языке нет вывода типов, как отдельной фичи, он всё равно есть ограниченный, если в языке есть дженерики или лямбды.
Вот скажем пример, как не надо делать:
// Метод run принимает функцию из String в T и возвращает T для пустой строки.
<T> T run(Function<String, T> x) {
return x.apply("");
}
// Метод run принимает функцию из String в ничего,
// вызывает её с пустой строкой и тоже ничего не возвращает.
void run(Consumer<String> x) {
run(y-> {
x.accept(y);
return null;
});
}
void doWork() {
run(x-> System.out.println(x)); // Не компилируется.
run((String x)-> System.out.println(x)); // А это компилируется кстати.
}Если вы не понимаете этот пример — это нормально: я сам до конца его не понимаю. При компиляции Java сообщает, что оба метода run(Function) и run(Consumer) подходят, и она не может выбрать какой вызов сгенерировать, хотя на самом деле это не так: если стереть метод run(Consumer), тогда программа продолжит некомпилироваться, т.к. в переданной лямбде нет возвращаемого значения, и конечно, она не подходит в run(Function). Но самое удивительное, что программа начинает компилироваться, если подсказать ей тип аргумента, хотя уж в нём-то, казалось бы, нет никакого сомнения.
Уверен, в других языках тоже бывают аналогичные ситуации, когда вывод типов отваливается.
Полиморфизм включений
Полиморфизмом включений называют такое поведение, когда описывая код для каких-то типов, он так же работает и для всех подтипов. Если грубо и в терминах ООП, то тип — это класс, а подтип — его потомок. Но вообще, это немного не одно и тоже, я подсвечу разницу, когда мы затронем дженерики.
Обычно полиморфизм включений реализуется с помощью динамической диспетчеризации — виртуальных вызовов.
Многие думают, что это единственный вид полиморфизма, ведь именного его изучают, когда проходят ООП. И это проблема. Наследование в ООП очень спорная фича из-за наследования кода. С ним легко написать код, который можно читать только под дебагером.
Допустим, есть класс ClassA, у него есть потомок ClassB, а у него потомок ClassC. И есть три метода foo, bar, baz у каждого класса. Причем метод foo вызывает метод bar, а тот вызывает baz. Тогда если ClassB переопределяет foo и baz, а ClassC только baz, то будет очень сложно понять какая цепочка вызовов образуется, если позвать ClassC.foo(). При чтении с вами случится вот что: вы нажмете перейти к декларации у ClassC.foo() попадете в ClassB.foo() там перейдете в ClassA.bar а оттуда в ClassA.baz, а надо было прийти в ClassC.baz. Реальная история, кстати, одного известного опенсорс проекта, все имена заменены.

Здесь можно немного позанудствовать, но в целом наследование кода с более, чем одним уровнем наследования, плохая практика. Например, оно плохо сочетается с сериализацией и сравнением.
А вот наследование интерфейсов — ключевая вещь, без которой остальные трюки не будут работать.
Интерфейсы в аргументах функции, это прямое использование полиморфизма включений. Но ещё можно возвращать интерфейсы: обязательный прием для библиотечного кода, чтобы иметь возможность возвращать разные реализации, оптимизированные под разные сценарии, не меняя API.
Хорошим примером является List.of — метод в стандартной библиотеке Java, который создает неизменяемый List. Если ему передать пустой массив, то новых объектов не будет создано и вернется единственный на всех пустой лист. Для одного и двух элементных массивов возвращается класс List12, который может хранить до 2х элементов, что экономит на аллокации массива и его заголовка, и только для бОльших массивов используется реализация, которая хранит склонированный массив. При этом ничто не помешает добавить ещё реализаций, если потребуется.
Параметрический полиморфизм
Дженерики — это реализация параметрического полиморфизма во многих языках, хотя, например, в С++ для этого используют темплейты. Это крутая, но сложная фича. Поначалу все выглядит тривиально, но это иллюзия. Вариантность, вложенные дженерики, вывод типов, да и просто особенности конкретной реализации, усложняют тему сверх всякой меры.
Кажется, нет двух одинаковых реализаций параметрического полиморфизма, поэтому что бы сохранить language agnostic стиль статьи, я опущу множество важных java-специфичных деталей, но даже и без них остается много трудностей. Давайте я расскажу в чем, собственно, проблема.
Вариантность
Допустим, у нас есть дженерик класс List<T>, и два обычных класса: X и его наследник Y. Мы написали метод, который принимает List<X>, хотим ли мы разрешать передавать в него ещё и List<Y>? С одной стороны, это было бы гибко, но с другой — это не всегда безопасно. Например, если у X есть ещё потомок Z, тогда, отправив List<Y>, мы начнем работать с ним как с List<X>: положим туда Z, и тогда пользоваться исходным листом как листом List<Y> будет уже нельзя. Случится то, что в java называется heap pollution. Добиться такого поведения для коллекций без кастов нельзя (а для массивов можно, но мы это здесь опустим)
Понятно, что в общем случае провалидировать подобное поведение сложно, поэтому разные языки выкручиваются как могут.
Правила вариантности в каждом языке говорят когда, куда и что можно передавать.
Есть всего три вида вариантности:
Инвариантность — можно передавать только в точности тот же тип: не гибко, зато никаких сюрпризов. По умолчанию в Java все дженерики инвариантны.
Ковариантность — в нашем примере это ситуация, когда передать
List<Y>можно. Обычно используется для чтения. В Java записывается какList<? extends X>.Контрвариантность — ситуация обратная, когда принимая
List<Y>разрешено за одно принять иList<X>. Обычно используется для записи. В Java записывается какList<? super Y>.
В Rust, например, тип вариантности выбирается автоматически из контекста. В Java и C# их нужно задать руками и принципы там немного разные. Свои минусы и плюсы есть у всех подходов.
Стоит отметить, что сегодня считается, что подход, который выбрала Java не самый лучший. Например, в Kotlin все немного переделали. Проблема в том, что использование вайлдкартов (знаки вопроса) в Java не редко порождает нежизнеспособные объявления.
Здесь я буду вынужден коснуться деталей реализации дженериков в Java. Когда принимаете List<? extends X> языку необходимо как-то запретить вам добавлять элементы в этот лист, чтобы избежать heap pollution. Java поступает очень просто: она запрещает передавать в аргументы методов, где фигурирует дженерик тип, что либо кроме null. Или строже: если ковариантный дженерик тип находится в аргументе метода, то единственное допустимое его значение это null, а если он указан как возвращаемое значение, тогда он равен указанным границам (т.е. для List<? extends X> это X).
Ровно по этой причине ломаются методы в духе orElse(T default) из примера в начале статьи: если T объявлен как ? extends CharSequence передавать в такой метод можно только null, хотя метод T get() вернет объект типа CharSequence. Java не знает что делает метод — читает или пишет, но если ни одного объекта нельзя передать, то и сохранить его нельзя. А сохранение null не вызовет heap pollution.
Аналогично и с контрвариантностью: для List<? super Y> вызывать метод add(T) можно только с объектами типа Y, но вызвав T get(int) получится объект типа Object. Контрвариантность используется для записи и сделана, чтобы можно было сохранять объекты типа Y не только в List<Y>, но и в List<X> и List<Object>, поэтому нет никаких ограничений на то, что может вернуть метод get.
Сегодня, когда индустрия много лет черпает вдохновение из ФП, большинство наших классов стали иммутабельными. И хочется прежде всего хорошей поддержки иммутабельных объектов, а они всегда могут быть ковариантными без всяких ограничений, т.к. в них ничего нельзя записать и heap pollution невозможен в принципе.
Тем не менее полно случаев, когда вайлдкарты работают замечательно — например, с лямбдами.
Вложенные дженерики
Во время использования вложенных дженериков всплывает разница между наследником и подтипом. Скажем, List<Y> подтип List<? extends X>, хотя наследования там нет. Поэтому если вы хотите метод, который может принять как Map<K, List<X>>, так и Map<K, List<Y>>, то тип аргумента будет: Map<K, ? extends List<? extends X>>. Тип это вообще больше, чем просто конкретный класс. Если же написать Map<K, List<? extends X>>, то вы не сможете передать туда ни Map<K, List<Y>>, ни даже Map<K, List<X>>, т.к. ожидается конкретно тип List<? extends X> и ничего другого, потому что эта декларация сама является дженерик параметром, а они по умолчанию инвариантны.
Вывод типов
Когда вызывается дженерик метод, компилятор выводит конкретные типы. Это более мощная штука, чем то, что делает ключевое слово var (о нем ниже). На основе этого механизма можно делать произвольную валидацию кода, хотя и выглядит это довольно стрёмно.
Обычно мы не замечаем этого механизма и он просто работает.
Оптимизация виртуальных вызовов через параметрический полиморфизм
Поскольку в Rust и в C++ все дженерики/шаблоны раскрываются в конкретные типы на этапе компиляции, то можно таким образом заменить виртуальные вызовы на использование параметрического полиморфизма времени компиляции и получить оптимизацию. Поэтому в этих языках им пользуются очень часто.
Для Java это не имеет смысла. Но вообще, важно иметь ввиду, что трюки статической типизации не просто синтаксический сахар, они позволяют писать как и более надежный код, так и более быстрый.
Cадимся на шею системе типов
Теперь когда мы на одной волне и разобрались с разными видами полиморфизма, можно поговорить о том, как доказывать высокоуровневые свойства программы с помощью статической системы типов.
Доказываем производительность
Допустим, мы хотим написать дженерик функцию, которая считает сколько есть объектов типа T в коллекции source, не считая объектов из blacklist. Напишем её так:
<T> int filterCount(Collection<T> source, Set<T> blacklist) {
if (blacklist.isEmpty()) {
return source.size();
}
return (int) source.stream().filter(x->!blacklist.contains(x)).count();
}Обратите внимание на то, что у blacklist тип Set.
В Java, если упрощать, такая иерархия наследования коллекций: сперва идёт Collection, потом от него наследуется Set, List и некоторые другие. И у интерфейса Collection тоже есть метод contains, поэтому ничто нам не мешает использовать его вместо Set.
Однако подразумевается, что операция contains будет быстро работать у Set: за O(1) для HashSet или в крайнем случае за O(log n) для TreeSet. Здесь можно чуть-чуть порассуждать о кастомных Set-ах, но в целом, сознательное использование интерфейса Set ценой очень незначительной потери в гибкости позволяет увернуться от перформенсного бага в будущем. И всё благодаря системе типов.
Главная идея, которую я хочу донести: нужно заставлять статическую систему типов доказывать свойства программ. Причем даже такая, по современным меркам, простая система типов как у Java способна на много интересных трюков, которыми мало кто пользуется.
Парси, а не валидируй
Принцип парси, а не валидируй в сущности очень прост: если на каком-то этапе исполнения программы вы узнали о своих данных что-то новое, надо положить эту информацию в тип. Для этого не обязательно иметь какую-то мощную систему типов, для начала подойдет любая статическая.
Допустим, у нас есть таблица в БД и есть два варианта схемы для неё: старая и новая. Пусть схема это просто мапа String->String из имени колонки в её тип, а хотим мы вычислить изменение в схеме, чтобы дальше что-то с ним сделать: распечатать его скажем.
Наивный разработчик сделает так: заведёт класс SchemaDiff и у него будет поле String name и два Nullable поля с типом для первой и второй таблицы соответственно.
final class SchemaDiff {
final String name;
final @Nullable String oldType;
final @Nullable String newType;
SchemaDiff(
String name,
@Nullable String oldType,
@Nullable String newType
) {
this.name = name;
this.oldType = oldType;
this.newType = newType;
}
@Override
public String toString() {
if (oldType != null && newType != null) {
return String.format(
"Column %s changed the type: %s->%s",
name,
oldType,
newType
);
}
if (oldType == null) {
return String.format(
"Column %s with type %s has been added",
name,
newType
);
}
return String.format(
"Column %s with type %s has been removed",
name,
oldType
);
}
}Тогда null будет обозначать отсутствие в соответствующей таблице такого поля. Это не история про борьбу с NPE: даже если обернуть эти поля в Optional, логические ошибки все равно легко допустить т.к. физический смысл объекта зависит от содержимого его полей: если старый тип равен null, тогда в таблицу добавили колонку, если новый, тогда удалили, а если оба не null, то изменили тип.
Метод toString показывает сложность работы с таким объектом. Скажем, придется затратить некоторые усилия, чтобы понять почему в последней строчке oldType не может быть равен null.
Правильный же способ, минимизирующий логические ошибки, это создать три класса: RemovedColumn, AddedColumn и TypeChanged. Стоит унаследовать их от общего класса SchemaDiff, чтобы было удобнее обрабатывать их вместе.
abstract class SchemaDiff {
final String name;
protected SchemaDiff(String name) {
this.name = name;
}
}
final class RemovedColumn extends SchemaDiff {
final String type;
RemovedColumn(String name, String type) {
super(name);
this.type = type;
}
@Override
public String toString() {
return String.format(
"Column %s with type %s has been removed",
name,
type
);
}
}
final class AddedColumn extends SchemaDiff {
final String type;
AddedColumn(String name, String type) {
super(name);
this.type = type;
}
@Override
public String toString() {
return String.format(
"Column %s with type %s has been added",
name,
type
);
}
}
final class TypeChanged extends SchemaDiff {
final String oldType;
final String newType;
TypeChanged(String name, String oldType, String newType) {
super(name);
this.oldType = oldType;
this.newType = newType;
}
@Override
public String toString() {
return String.format(
"Column's %s type has been changed: %s->%s",
name,
oldType,
newType
);
}
}Таким образом мы переносим все смыслы на уровень типов, где им самое место, а данные остаются абстрактными без всяких смыслов. Поэтому из метода toString ушли все условные переходы.
Контринтуитивно тут то, что строк кода, вы написали больше, а надежность увеличилась. Обычно происходит наоборот. Секрет в том, что вы написали меньше кода с логикой и больше объявлений, а объявления проверяются статически — такой код более безопасный.
Для знатоков функционального программирования отмечу, что здесь я фактически руками реализую алгебраический тип данных.
Дедубликация кода с помощью параметрического полиморфизма

Как-то раз я подготавливал код к миграции, для этого мне надо было вбить небольшой временный костылек такого вида:
void process(List<Item> items) {
if (isLegacy) {
List<Legacy> docs = items.stream()
.map(x -> toLegacy(x))
.collect(toList);
legacyTable.store(docs);
logEvent(docs.stream().map(x->x.getId()).collect(toList()));
} else {
List<Modern> docs = items.stream()
.map(x->toModern(x, context))
.collect(toList);
modernTable.store(docs);
logEvent(docs.stream().map(x->x.getId()).collect(toList()));
}
}И проблема в том, что типы Legacy и Modern разные. Методы toLegacy и toModern тоже разные, и у них разное число аргументов. Так же legacyTable и modernTable не только физически разные таблицы, но и разного типа содержат объекты.
Но при этом высокоуровнево бизнес-логика одинаковая. Вообще ситуация: типы разные, а бизнес-логика одинаковая — это звоночек что пора обмазываться полиморфизмом.
Дублирование кода — не мне вам объяснять — это прежде всего источник багов.
И этот код можно дедублицировать, введя такой метод:
<T extends WithId> List<T> store(
List<Item> items,
Function<Item, T> mapper,
Table<T> table
) {
result = items.map(mapper).collect(toList());
table.store(result);
return result;
}и переписать основной так:
void process(List<Item> items) {
List<? extends WithId> docs = isLegacy ?
store(items, x -> toLegacy(x), legacyTable) :
store(items, x -> toModern(x, context), modernTable);
logEvent(docs);
}Сигнатуру logEvent тоже надо подправить, чтобы она принимала любые списки, у которых есть id.
Хочу заметить, что дедублицирование бизнес-логики это важно, т.к. она меняется и должна быть консистентна по всему проекту, плюс изменения в ней должны проходить легко.
Вывод типов
Вообще, то, что делает ключевое слово var в Kotlin, C# или в Java, не совсем правильно называть выводом типов, т.к. никакого "вывода" там не происходит: настоящий вывод типов способен определять тип объекта по его использованию.
На Java:
var list = new ArrayList<>(); // К сожалению list будет иметь тип ArrayList<Object>.
list.add(1);На Rust:
let mut vec = Vec::new(); // vec будет иметь тип Vec<i32>
vec.push(1);Взгрустнув немного, вы можете решить, что фича слишком слабая и большого смысла в ней нет. Но это не так.
Сперва немного отвлечемся. Думаю, вы слышали, что некоторые кодстайлы рекомендуют вместо такого кода:
HashMap<String, String> map = new HashMap<>();Писать такой код:
Map<String, String> map = new HashMap<>();Мотивация такова: если вы захотите поменять HashMap на TreeMap или какой-то другой Map, то вы внесёте меньше изменений в файл. Очень удобно, но работает только, если между объектами есть наследование.
На моем старом проекте на Java 11 пересели не так давно, а на новом проекте уже я не так давно, поэтому истории успеха с var у меня нет и здесь будет умозрительный, но правдоподобный пример.
Допустим, у вас был метод какой-то такой:
Long2LongOpenHashMap createMap(long[] keys, long[] values);Он возвращал конкретный тип какой-то вашей мапы long->long с какой-то вашей очень хорошей хеш-функцией. Никакого интерфейса нет, т.к. вы решили тогда, что это оверинженеринг. Плюс не было тогда до конца понятно какие методы стоит класть в общий интерфейс, а какие могут быть реализованы только для частного случая.
Но потом метод стал популярным, обнаружились проблемы производительности, и вы захотели возвращать все же интерфейс с разными реализациями под разный размер данных, например.
Long2LongMap createMap(long[] keys, long[] values);Если при этом использование было каким-то таким:
var map = createMap(keys, values);
for(long x: xs) {
f(map.get(x));
}то такие файлы не будут затронуты рефакторингом! Код программы не изменится, а типы поменяются, т.к. никаких противоречий по API нет. Если же тип писался явно, то потребуется в ручную рефакторить возможно сотни файлов — можно случайно и лишнее что-то задеть (у меня такое было).
Вычисления над типами и лифтинг
Итак, реальная задача. У нас есть сервис, который считает ML-ные фичи для потока документов, и мы делаем API доступа к ним. Сервис кладет данные в БД, а пользователи из БД читают. Так что балансировка нагрузки и прочее — уже решенная задача. Важно то, что у фичей есть версии — при обновлении конфигурации появляется новая версия, она тестируется и потом применяется вместо старой. Есть возможность откатить и прочая бизнес-логика.
Разные виды фичей, допустим, лежат в enum-е:
enum FeatureType {
ELMO,
SLANG,
LIFETIME_7D,
}и каждая фича имеет свою таблицу со своей схемой. Скажем, для ELMO это EmbeddingEntry — массив float, для LIFETIME_7D — это FloatEntry, один float — вероятность, что через 7 дней новость устареет, а для SLANG вообще BlacklistEntry — список найденных матных слов в тексте. Все они наследуются от FeatureEntry, в котором ещё лежит id документа, к которому эта фича относится.
И вот мы делаем, допустим, такое простое API:
<TEntry extends FeatureEntry> Collection<TEntry> find(Collection<Id> ids, FeatureType type);По id документа и типу фичи возвращаем значения фичей. Внутри в этом методе есть логика по выбору нужной версии.
Внимание вопрос: как узнать какой именно TEntry соответствует какому FeatureType? Сейчас никак нельзя, чтобы работала сериализация придется сделать так:
enum FeatureType() {
ELMO(EmbeddingEntry.class),
SLANG(BlacklistEntry.class),
LIFETIME_7D(FloatEntry.class),
;
private final Class<? extends FeatureEntry> entryClass;
public FeatureType(Class<? extends FeatureEntry> entryClass) {
this.entryClass = entryClass;
}
public Class<? extends FeatureEntry> getEntryClass() {
return entryClass;
}
}В вашем языке, возможно, нельзя добавить произвольных полей в enum-ы. Далее вы увидите, что это не повлияет на повествование.
Теперь сериализатор в рантайме получит класс, в который надо сериализовывать. Однако в методе find тип TEntry не может быть выведен на этапе компиляции, и пользователям придется кастить. Причем в реальном проекте фичей не 3, а 56, так что если вы там думали три метода завести, не стоит.
Но можно сделать вот что:
final class FeatureType<TEntry extends FeatureEntry> {
public static final FeatureType<EmbeddingEntry> ELMO =
new FeatureType("elmo", EmbeddingEntry.class);
public static final FeatureType<BlacklistEntry> SLANG =
new FeatureType("slang", BlacklistEntry.class);
public static final FeatureType<FloatEntry> LIFETIME_7D =
new FeatureType("lifetime_7d", FloatEntry.class);
private final Class<TEntry> entryClass;
private final String name;
private FeatureType(String name, Class<TEntry> entryClass) {
this.name = name;
this.entryClass = entryClass;
}
public String getName() {
return name;
}
public Class<TEntry> getEntryClass() {
return entryClass;
}
}Пользовательский код не изменится: будет выглядеть, как будто это старый добрый enum. Однако тип ентри станет виден — мы добавили его в дженерик параметр — и API станет типобезопасным:
<TEntry extends FeatureEntry> Collection<TEntry> find(
Collection<Id> ids,
FeatureType<TEntry> type
);Причем теперь можно делать типобезопасные API, которые работают только с фичами, которые выплевывают какой-то конкретный тип данных. И новые фичи, которые генерируют выход такого же типа, сразу будут применимы к этому API.
Обратите внимание, что дженерики здесь не для того, чтобы что-то куда-то класть или доставать, это просто дополнительная информация в типе, живущая исключительно во время компиляции (но это скорее особенность Java). С помощью этой информации мы валидируем логику кода.
Когда я это придумывал, я вдохновлялся идеей "зависимых типов", однако, как позже мне подсказали знатоки ФП, на самом деле здесь я сделал лифтинг на уровне типов.
Обычно лифтинг превращает функцию над одними объектами в функцию над другими. Например так:
static <TLeft, TRight, TResult>
BiFunction<Optional<TLeft>, Optional<TRight>, Optional<TResult>>
lift(BiFunction<TLeft, TRight, TResult> function) {
return (left, right) -> left.flatMap(
leftVal -> right.map(rightVal -> function.apply(leftVal, rightVal))
);
}Этот метод превращает любую функцию с двумя аргументами в аналогичную, но работающую с запакованными в Optional значениями.
Я же, снабдив каждый инстанс FeatureType дженерик параметром, фактически создал "функцию" из инстансов FeatureType в типы FeatureEntry. В результате мне стало доступным, записывая рантаймовые вычисления над объектами типа FeatureType, делать компайлтаймовые "вычисления" над типами наследниками FeatureEntry.
Допустим, теперь, что наши фичи бывают разных видов. Есть те, что считаются отдельно для каждой страны, а есть те, что считаются отдельно для каждого языка. Скажем, отношение к мату в США и Англии разное, хотя язык один и тот же. Таким образом получается, что один и тот же документ может иметь разные значения каких-то фичей в разных странах, а значит её надо указывать в запросе. А MLным фичам важен язык безотносительно страны.
Здесь мы воспользуемся перегрузкой:
<TEntry extends FeatureEntry> Collection<TEntry> find(
Collection<Id> ids,
FeatureType<TEntry> type,
Language language
);
<TEntry extends FeatureEntry> Collection<TEntry> find(
Collection<Id> ids,
FeatureType<TEntry> type,
Country country
);Но снова та же проблема: даже если мы добавим информацию о виде фичи в экземпляры, это позволит нам делать runtime проверки, а хочется статическую.
Можно это сделать так:
class FeatureType<TEntry extends FeatureEntry> {
public static final ByLanguage<EmbeddingEntry> ELMO =
new ByLanguage<>("elmo", EmbeddingEntry.class);
public static final ByCountry<BlacklistEntry> SLANG =
new ByCountry<>("slang", BlacklistEntry.class);
public static final ByCountry<FloatEntry> LIFETIME_7D =
new ByCountry<>("lifetime_7d", FloatEntry.class);
private final Class<TEntry> entryClass;
private final String name;
private FeatureType(String name, Class<TEntry> entryClass) {
this.name = name;
this.entryClass = entryClass;
}
public String getName() {
return name;
}
static final class ByLanguage<TEntry extends FeatureEntry>
extends FeatureType<TEntry> {...}
static final class ByCountry<TEntry extends FeatureEntry>
extends FeatureType<TEntry> {...}
}И тогда API будет:
<TEntry extends FeatureEntry> Collection<TEntry> find(
Collection<Id> ids,
FeatureType.ByLanguage<TEntry> type,
Language language
);
<TEntry extends FeatureEntry> Collection<TEntry> find(
Collection<Id> ids,
FeatureType.ByCountry<TEntry> type,
Country country
);При этом код использования останется прежним.
Теперь мы добавили информацию в тип с помощью наследования. Кода, конечно, пришлось писать больше, чем с дженериками, но зато разная информация разделена по разным видам полиморфизма, что позволяет легко нам писать разные комбинации, валидируя любую логику.

Вам может показаться, что это оверинженеринг. И конечно, нет нужды каждый enum превращать в такую страхолюдину. Однако, если это какая-то важная сущность с множеством использований, тогда это оправдано. Более того, когда я сделал подобное преобразование в рабочем проекте, я немедленно нашел спящий баг. Глазами эту ошибку было не увидеть. А через некоторое время типизация уберегла нового разработчика от того, чтобы сломать сервис, который в тот момент умел обрабатывать только пострановые фичи.
Опять-таки, мы написали больше кода объявлений, но повысили надежность. Конечно, если бы в Java можно было делать хотя бы generic enum-ы с наследованием, то код существенно бы сократился — его большой размер следствие вербозности языка, а не заумности концепции. Как раз чтобы разделять эти две ситуации, и стоит изучать концепции из академических языков.
Развязывание
Ещё один важный методологический прием — это уменьшение связанности путем введения промежуточных сущностей. Будем называть это развязыванием. Избыточная связанность возникает от того, что каким бы гибким и выразительным ваш язык не был, написанный вами код все равно будет более специфичным, чем абстрактные бизнес-задачи, которые вы им выражаете.
Наш код — это выражение на формальном языке, но бизнес-задачи — это скорее философские концепции. Например, что такое поиск вообще? Поиск по ключевым словам? А поиск заданной фразы в аудиосообщениях? А если человек не знает, что спросить, а просто хочет позалипать в актуальные новости? Поиск оптимального маршрута ведь тоже поиск.
Поэтому во время дизайна системы, когда вы начинаете подбираться к высокоуровневым бизнес-задачам, имеет смысл заранее заложить дополнительную гибкость, введя пока ненужную промежуточную абстрактную сущность.
Поясню это примером. Недавно я делал тестовое задание, где мне надо было написать анализатор джавовых heap dump-ов, а так же сделать несколько инспекций. Инспекция ищет автоматически в heap dump-е какие-то проблемы: например, много одинаковых строк или большие массивы заполненные нулями и тому подобные странности. Важно, что heap dump-ы были слишком большими, чтобы хранить их целиком в памяти, так что я перекладывал их в LevelDB, чтобы потом можно было быстро делать лукапы и сканирующие операции.
И в рамках задания все инспекции, что я сделал, умещались в один последовательный запрос, который перебирает все объекты нужного типа. Но, разумеется, в общем случае инспекция может быть сложнее и делать несколько запросов, поэтому я создал проксирующую сущность Inspection, которая была интерфейсом с несколькими реализациями вокруг скан запросов, но само API сущности Inspection не делало никаких предположений о том, как именно результат будет получен: инспекция имеет имя, а также может запуститься на базе с хипдампом и вернуть некоторый объект для последующего отображения в UI.
Таким образом я развязал конкретную внутреннюю сущность — последовательный запрос, и абстрактную бизнес сущность — инспекцию. И теперь добавление нового вида инспекций, которые будут делать много разных запросов, не требует рефакторинга уже существующих.
Контринтуитивно здесь то, что обычно введение лишних сущностей мешает разработке: из-за нагромождения абстракций подчас трудно добраться до сути вещей. Это справедливо для почти всего кода, который мы пишем, за исключением этой тонкой прослойки между конкретными вычислительными задачами и абстрактной бизнес-задачей.

DSL vs composability
Как и у любого подхода, здесь тоже можно увлечься и сломать какие-то важные свойства вашей программы. Например, если слишком часто перекладывать данные из одних классов в другие, только чтобы сделать маркировку типа, в языке вроде Java это может привести к проблемам с производительностью. Но я бы обратил внимание на ситуацию, когда нагромождение классов создает что-то вроде DSL и ломает composability (наверное можно перевести как комбинируемость, компануемость или сочетаемость).
DSL не всегда пишется осознанно: иногда вы пишете код или даже рефакторите старый, выделяете общие сущности, пытаетесь сделать безопасный и минималистичный API, а в какой-то момент у вас получается DSL. Поначалу всё прекрасно, многие вещи очень быстро встраиваются, но в какой-то момент оказывается, что новые бизнес-задачи требуют другого DSL. На практике это приводит к костылям, т.к. времени, что бы переписать DSL и всё мигрировать, никогда не бывает.
Если вы когда-нибудь ловили себя на мысле, что надо переписать половину сервиса заново, чтобы нормально внедрить эту маленькую фичу — это оно. Проблема возникает потому, что разные средства языка имеют разную степень composability.
Допустим, вы заметили, что у вас часто возникает такой тип: CompletableFuture<Optional<T>> и вы можете написать много полезных методов для работы с ним. Конкретно в Java вы можете поступить только двумя способами:
Сделать обертку
OptionalFutureи добавить методы туда.Добавить статические методы в какой-нибудь
FutureUtils.
Первый способ считается более ООП-правильным. Но на практике второй способ намного более composable. Дело в том, что ваш OptionalFuture несовместим ни с какими другими библиотеками и методами для работы как с CompletableFuture, так и с Optional — помимо ваших прекрасных методов вам придется проксировать методы CompletableFuture, а их там будь здоров сколько. Причем методы, которые как-то работают с классом CompletableFuture, например, thenCompose (какая ирония), придется дублировать для двух типов и в одну сторону комбинировать будет проще, чем в другую.
Если говорить о Java, то набор максимально composable конструкций у него совпадает с точностью до нейминга с ядром языка С: вы легко можете комбинировать операторы и вызовы функций, а со всем остальным возникают накладки. Согласитесь, добавить поле в класс куда проще, чем реализовать интерфейс. Да-да, пресловутая композиция vs наследование. Даже лямбды, которые казалось бы созданы для комбинирования, плохо дружат с чекед эксепшенами.
Это довольно контринтуитивная мысль, но в действительности, по крайней мере в мейнстримных языках, composability находится в некоторой противофазе с теми концепциями, которые я тут описываю. И недавно мне попался потрясающе наглядный пример, который это иллюстрирует в коде Apache Lucene.
Apache Lucene — это движок для полнотекстового поиска: им пользуется Twitter, и на его основе написан Elasticsearch. У него очень интересный исходный код, в котором чувствуется дух времени: он написан очень умными людьми, но очень давно — сейчас так писать не принято. В частности сайдэффекты там — это часть API.
Представьте, что вам надо написать сортировку, но так, чтобы один код работал вообще в любых ситуациях, где что-то как-то сортируется: коллекции и массивы (между ними нет наследования в Java), объекты и примитивы (к сожалению, дженерики в джаве не работают с примитивами, и код принимающий T[] отвергнет int[]) и даже в ситуациях, которые не опишешь в двух словах (необъяснимый пример ждет вас впереди).
Как вы понимаете, условия, которые я поставил выше, ставят разработчика в трудное положение. Если воспринимать сортировку как функцию то, что у неё на входе? Загвоздка в том, что в Java невозможно выразить "это либо массив типа T, либо коллекция типа T, либо массив примитивов", поэтому вход описать невозможно.
Однако в Apache Lucene есть класс InPlaceMergeSorter, который это умеет, а работают с ним так:
// Код немного упрощен:
private BlendedTermQuery(Term[] terms, float[] boosts, TermStates[] contexts) {
assert terms.length == boosts.length;
assert terms.length == contexts.length;
this.terms = terms;
this.boosts = boosts;
this.contexts = contexts;
// Поля terms, boosts и contexts массивы с одинаковой длиной
// Обратите внимание на пустой конструктор: все нужные нам аргументы мы захватываем.
new InPlaceMergeSorter() {
// Сортируем казалось бы массив terms, по крайней мере сравниваем его.
@Override
protected int compare(int i, int j) {
return terms[i].compareTo(terms[j]);
}
// Но на самом деле мы сортируем все три массива, но по значениям из массива terms
@Override
protected void swap(int i, int j) {
Term tmpTerm = terms[i];
terms[i] = terms[j];
terms[j] = tmpTerm;
TermStates tmpContext = contexts[i];
contexts[i] = contexts[j];
contexts[j] = tmpContext;
float tmpBoost = boosts[i];
boosts[i] = boosts[j];
boosts[j] = tmpBoost;
}
// Нет возвращаемого значения, т.к. результат функции: сайд-эффект.
}.sort(0, terms.length);
}Когда я смотрю на этот код, то чувствую себя персонажем Лавкрафта, который взирает на древнее могущественное зло, испытывая смесь страха и восхищения. Если вы никогда такого раньше не видели, потратьте несколько минут на осознание этого гимна сайдэффектам.
API этого класса максимально сочетаемо, наверное, нет ни одной в целом свете ситуации, где что-то как-то сортируется, а его нельзя было бы применить. Здесь по сути нет никакого API: конструктор пустой, переменные захватываются, а на выходе — сайдэффекты.
Одновременно с этим это API максимально опасное, ведь легко написать такое:
Foo(float[] boosts) {
this.boosts = boosts.clone();
new InPlaceMergeSorter() {
@Override
protected int compare(int i, int j) {
return Float.compare(boosts[i], boosts[j]);
}
@Override
protected void swap(int i, int j) {
float tmpBoost = this.boosts[i];
this.boosts[i] = this.boosts[j];
this.boosts[j] = tmpBoost;
}
}.sort(0, terms.length);
}Это еле заметно, но сравниваем мы тут один массив, а свопаем другой т.к. boosts указывает на аргумент а this.boosts на поле класса, и тут это разные объекты.
Писать такой код я ни в коем случае не советую никому. Он лишь служит мрачным напоминанием, что в этом мире ничего не дается бесплатно, и важно понимать, сколько вы платите, чем и за что.
Нет какой-то универсальной метрики кода, максимизировав которую, вы достигните нирваны. Увеличивая надежность, вы в какой-то момент начнете непростительно терять в composability, а безрассудно увеличивая composability, вы растеряете всякую осмысленность.
При проектировании API надо взвешивать каждый шаг и иметь широкий кругозор. На расширение кругозора и направлена статья.
Рассуждение о локальности
Вообще, все эти практики, как и многие другие, приходят из идеи похожей на принцип локальности из физики. Грубо говоря, код должен быть таким, чтобы изменения в одном месте не затрагивали код во всём проекте, а только в некоторой области вокруг места изменения. И хочется, чтобы эта область была поменьше. Критика этих практик стоит на не хитрой мысли: можно получить бенефиты, если анализировать программу глобально. С этой точки зрения сторонники динамической типизации и любители писать близко к железу с минимумом выразительных средств, в действительности, рассуждают одинаково, просто ставят перед собой разные цели.
Если представить, что внимания и памяти разработчика хватает на скоуп только одной функции, тогда без того, чтобы класть побольше информации в тип, не обойтись. В следующей функции вы просто не вспомните проверял ли вы массив на пустоту или нет, null твои аргументы или не null. Передать эту информацию можно только с типом. А если представить, что внимания и памяти разработчика хватает на всю программу целиком, тогда все это наоборот оказывается не нужным, и даже вредным. Зачем мне проверять, пусть даже статически, что я кладу совместимый объект? Я и так держу в голове всю программу и помню что можно класть в какие методы, а что нельзя. Аналогично рассуждают некоторые плюсовики: мне UB не мешает, я точно помню какие мои переменные могут быть null, а какие нет, в уме просчитываю лайфтаймы всех аллоцированных объектов, а код с гонками не пишу в принципе.
Разумеется, если бы мы могли умещать миллионы строк кода в голове единовременно, из этого можно было бы извлечь пользу. Наверное, и на скоуп больше, чем 1 функция, памяти нам тоже хватает. Поэтому на практике выбирается некоторая золотая середина, но эта середина все-таки, чем дальше, тем ближе к локальности, т.к. когнитивные способности людей фиксированны в то время, как кодовые базы растут каждый день. Это косвенно прослеживается по изменению дефолтного значение для кеша скомпилированного кода в Java.
P.S.
Я не ругаю C. Мне просто нужен был пример очень простой статической системы типов для противовеса.
Благодарности
Большое спасибо этим людям за ревью статьи до публикации:
Дмитрий Петров
Николай Мишук
Анастасия Павловская
Светлана Есенькова
Ян Корнев







amakhrov
Отличный слог. Автор, пиши еще!
По существу: поймал себя на мысли, что внутренее киваю, преодолевая раздел за разделом в статье. Да, согласен, так и есть, я тоже так думаю, звучит разумно. В целом, скорее увидел подтвержение своим соображениям на эту тему, нежели нашел что-то новое. Что тоже полезно времня от времени :).
Отдельное спасибо за ссылки на другие отличные статьи, многие из которых я в свое время пропустил.