

На собеседованиях стороны чаще всего хотят понять, подходят ли они друг другу и будет ли им комфортно работать вместе. Я руковожу командой разработки бэкенда, которая за последние два года выросла вдвое, поэтому собеседований было достаточно. Кандидаты чаще всего задают вопросы о процессах и правилах в компании, а я всегда хочу узнать, что им нравится или не нравится в текущей работе, а также — какой они видят идеальную команду для себя.
С этих собеседований вынес интересное наблюдение: в первую тройку «пожеланий» попадает такая трудно формулируемая вещь, как «хочется, чтобы в работе был смысл». Если начать раскручивать этот клубок, то часто приходим к более негативной формулировке «прошлый заказчик/бизнес не знает, чего хочет и постоянно меняет требования».
В такие моменты всегда вспоминаю, как познакомился с data-driven подходом. Для себя больше люблю называть это доказательной разработкой (по аналогии с доказательной медициной) и расскажу на примере. Сейчас этот подход кажется обычным и естественным, но когда-то стал для меня настоящим откровением. И, судя по вопросам кандидатов на собеседованиях, все еще может быть полезен, хотя обсуждается уже давно.
За свою карьеру также довелось работать в компании, где взаимоотношения между коммерческим и IT-департаментом не складывались, требования и задачи постоянно менялись без видимого смысла. Вспоминать этот опыт я не люблю, но зато есть с чем сравнить, когда говорю о применении data-driven подхода.
Суть метода очень простая: бизнес не оперирует понятиями «задача», «спринт» или им подобным — вместо этого у нас есть гипотезы, а бизнес проверяет влияние гипотез на понятные метрики.
Гипотеза всегда формулируется так, чтобы проверка её была чисто статистической операцией. То есть ответ на вопрос, сбылась ли гипотеза, можно получить математическими действиями, а не личным мнением менеджера «кажется, этот синий цвет недостаточно благороден».
Как мы проверяли ML-гипотезу
Рассмотрим методологию на примере свежего эксперимента с главной лентой (Featured), которая открывается при старте приложения iFunny — там пользователи видят лучший User Generated Content, который уже прошел фильтрацию сообществом в другой ленте.
До недавнего времени пользовательский контент попадал в главную ленту на основании алгоритма по типу «многорукий бандит» (подробнее про задачи этого класса). Но с тех пор, как стали персонализировано для каждого пользователя сортировать главную ленту при помощи алгоритмов машинного обучения (про это, кстати, была отдельная статья), стали думать о том, как использовать эту мощную рекомендательную систему шире.
Гипотеза для нового эксперимента звучала так: «Если выбирать контент для главной ленты с помощью ML-рекомендательной системы, то Engagement и Retention вырастут».
Здесь надо сделать отступление. Чтобы фиксировать изменение метрик, эти метрики надо сначала иметь в своём распоряжении. Именно поэтому так скрупулезно собирается обширная аналитика обо всех действиях пользователей в приложении — об этом можно почитать в статьях о переходе с Redshift на Clickhouse и оптимизации трафика аналитических событий.
На основе аналитики можно проверять любые гипотезы с нужной достоверностью. Например, Retention — это процент пользователей, которые были в приложении 1, 7, 30 и так далее дней назад и зашли сегодня (хотя на самом деле это разные метрики: R1, R7, R30, ...). Engagement — еще одно семейство метрик, отражающих активность пользователей в приложении. Самые показательные — это Smile Rate (количество лайков на 1000 просмотров контента) и Share Rate (количество событий «пользователь поделился контентом в Facebook/Twitter/Instagram и т.д. на 1000 просмотров).
Но чтобы делать выводы о том, как гипотеза повлияла на метрики, надо поставить чистый эксперимент. Чистый — значит с контрольной группой. Делим всю аудиторию на две части и показываем одной выдачу нового алгоритма, а во второй оставляем, как было.
Код пишется так, чтобы он, получив на вход группу, для которой выполняется, прошёл по одному или другому пути (звучит несложно, но это пока нет необходимости обрабатывать сочетания экспериментов, затрагивающих одни и те же модули и пути исполнения). Когда код готов, протестирован и выкачен в прод — запускаем эксперимент, записываем метрики для каждой группы и смотрим на то, как они различаются. Групп, кстати, может быть больше двух (если тестируем немного разные варианты или коэффициенты), но контрольная — всегда одна.
Вот, например, график Smile Rate по часам сразу после включения нового алгоритма отбора контента для главной ленты:
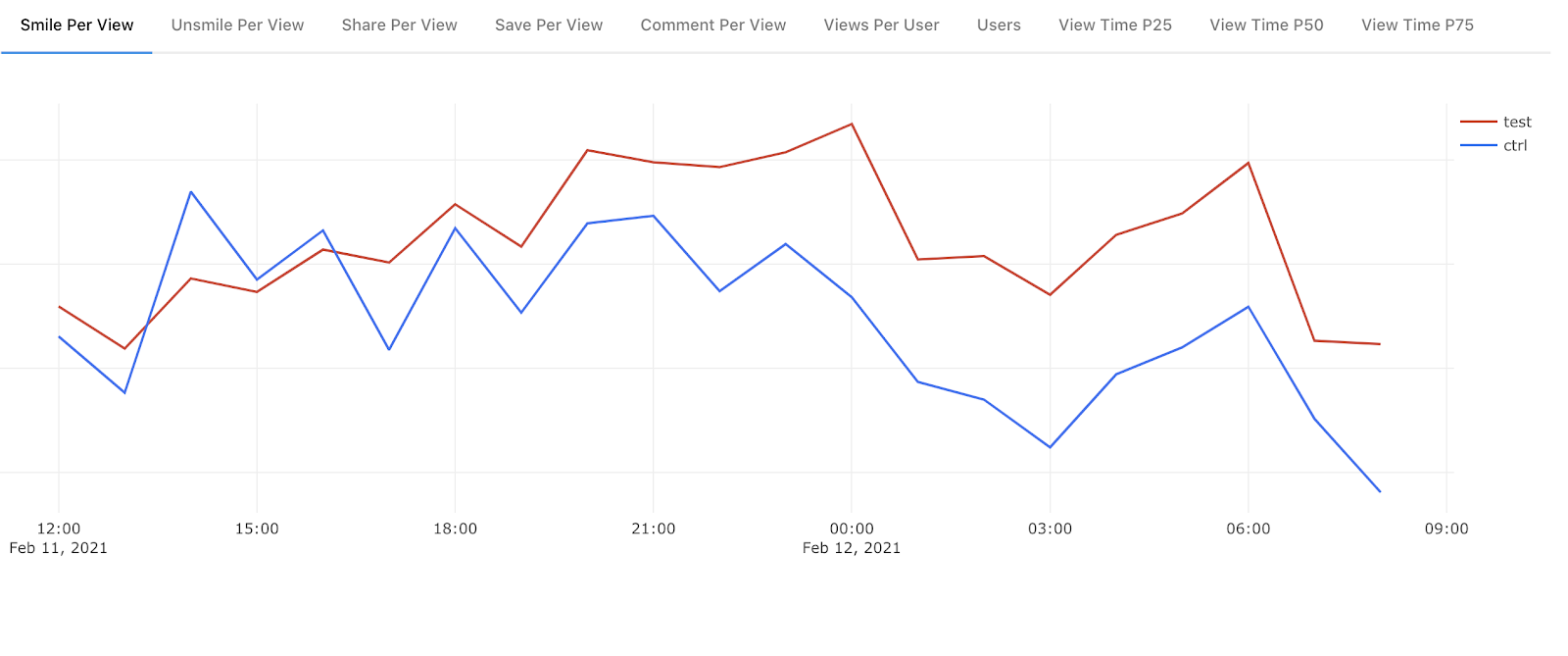
Как видно по списку наверху, мы собираем намного больше данных: там и Unsmile Rate (да, у нас, в отличие от трендов социальных сетей, есть дизлайки), и Share Rate, и Comment, и View Time. Разумеется, чтобы принять решение об удачном результате эксперимента, нужно проанализировать их все.
На этом графике победа тестовой группы кажется очевидной. Но есть ещё одно правило: разница в значениях метрик должна быть статистически значима, иначе мы можем принять желаемое за действительное и сделать поспешные ошибочные выводы.
То есть в идеале исходная гипотеза «Если выбирать контент для главной ленты с помощью ML-рекомендательной системы, то Engagement и Retention вырастут» должна звучать так: «Если выбирать контент для главной ленты с помощью ML-рекомендательной системы, то Engagement и Retention вырастут статистически значимо». Но мы эту формулировку часто опускаем, потому что она подразумевается по умолчанию.
Именно поэтому (отвечая на вопрос в комментариях к прошлому моему рассказу про сжатие входящего в дата-центр трафика на 70%) мы собираем 100% аналитики со всех пользователей приложения. Иначе для накопления нужной для принятия решения статистики ушло бы пропорционально больше времени, а мы и так проводим эксперименты по нескольку недель и иногда даже месяцев.
Как только эксперимент завершён, он или раскатывается на 100% аудитории, или выключается, а в бэклог ложится задача по выпиливанию из кода лишних (т.е. проигравших) путей.
Тем временем в очереди ждут новые готовые к А/Б-тестированию эксперименты, и цикл повторяется.
Итог
С точки зрения инженера, самое главное в этом подходе — это то, что мы начинаем постановку задач и написание кода только после формулирования гипотезы, которая не может быть истолкована двояко. Поэтому, когда работаем над задачей, все участники процесса знают, в чём состоит смысл их действий.
Да, тот самый «смысл в работе», которого так часто не хватает. Когда я это осознал сам в первый раз, то испытал шок: неужели вопрос «а зачем нам это надо?» теперь не просто имеет ответ, но и никакая деятельность не начинается без этого ответа? Сейчас это кажется очевидным и естественным, но в первый раз это произвело эффект просветления.
Но чтобы data-driven подход работал, нужны качественные и надежные метрики. А для этого нужно собирать много аналитики, что уже сложно и дорого. Хорошо, что многие компании уже идут по этому пути.
При этом сами метрики — это не просто отвлеченные цифры, от них напрямую зависит эффективность бизнеса. От Engagement, например, зависит субъективное ощущение пользователями качества контента, насколько он им нравится.
Как я вижу на примере коллег, это дополнительно воодушевляет и вдохновляет на поиск способов выполнять задачи оптимальнее и эффективнее, а со временем — и на генерацию собственных идей об улучшении продукта, которые очень приветствуется. Между прочим, вопрос «принимают ли все участие в развитии того, над чем работают» — еще один частый на собеседовании.
fedor7
Все логично и красиво. Настолько, что выглядит как «вести из элизиума».