
Эта статья – продолжение текста о мониторинге. Здесь предлагаю нам с вами поговорить о роли логов в оценке состояния наблюдаемой площадки, посмотреть, что они способны нам дать, а также затронуть вопрос – «можно ли отрывать логи от метрик?».
По ходу дела я буду возвращаться к некоторым тезисам, высказанным в предыдущей публикации, потому рекомендую предварительно с ней ознакомиться.
Итак, давайте поговорим о логировании.
Кстати, а как будет правильно: лоГирование или лоГГирование? Лично я склоняюсь ко второму варианту, просто потому, что loGGing, но замечаю, что большинство предпочитает первый. А вы?
Разбор полетов
Перед началом новой статьи хочу ненадолго вернуться к предыдущей. В комментариях было поднято несколько тем, которым, на мой взгляд, стоит уделить несколько предложений.
Собирать всё или только минимальный объем?
Здесь моя позиция такова – собирать надо все метрики, которые объект способен отдавать. Как заметил @BugM они лежат в БД, есть не просят, никому не мешают. А вот если у вас их нет, но они вдруг понадобились, особенно за, допустим, прошлый месяц – тут ничего сделать не получится.
Перефразируя знаменитую пословицу о бэкапах: «люди делятся на два типа – на тех, кто еще не собирает метрики, и тех, кто уже собирает».
Особенно актуально это в поиске аномалий на основе ML, для которых критично важно набрать объем данных с примером корректной работы наблюдаемой площадки. Тогда, чем больше у вас информации для обучения, тем точнее потом будет работать их (аномалий) выявление и прогнозирование. Человеку трудно найти закономерности в множестве, казалось бы, разрозненной информации (иначе не было бы необходимости изобретать ML), а машина может обнаружить их в неожиданных для вас местах.
При начале работ, исходить из метрик, или из инфраструктуры?
Соблюдайте баланс. Тезис, высказанный ранее, ответу на вопрос не противоречит:
… такие метрики относятся к самому низкому доступному вам уровню инфраструктуры, с которой вы работаете
Разумеется, вам нужно отталкиваться от возможностей вашей инфраструктуры, и только потом подбирать инструменты. Я намеренно не затрагивал тему выбора инструмента для сбора метрик, конкретные технологии упоминаются исключительно в следующих этапах. Берите такой агент и такую модель сбора, которая максимально удовлетворяет ваши потребности.
Продумать уровни тревоги
Абсолютно верная мысль @sizziff которую я недостаточно раскрыл.
Если вы заводите уровень «катастрофа» и отправляете нотификацию по СМС, это должно быть оправдано на 150%, иначе, рано или поздно, ваша команда поддержки будет выглядеть так:

Инженерный мониторинг не отражает реальное положение дел
Здесь @Dr_Wut приводит такой пример:
Простой пример из жизни — по всем метрикам почтовый сервер работает, а почта во вне не ходит — накосячили с spf. По итогу, пока разбирались, получили кучу претензий. А ведь достаточно было сделать простую проверку функции — отправлять письмо и проверять что оно дошло.
Если у вас возникла такая ситуация, значит, вам стоит добавить смок-тест функции, ведь результат такого теста – это тоже метрика, о чем я говорю в разделе о их разновидностях.
Бизнес-мониторинг и мониторинг бизнес-процессов
Давайте разделять эти понятия.
Мониторинг бизнес-процессов – зона ответственности «инженерного» мониторинга, о который мы с вами обсуждаем (наверное, стоило это сразу обозначить…). Задача здесь – обеспечить контроль за работоспособностью функций.
Бизнес-мониторинг и бизнес-метрики – это совершенно иная кухня, в ней шеф-повара это ваш СЕО и его окружение. Тут обеспечивается контроль за прибылью от функций вашей системы, а главный инструмент – BI-системы.
В своих статьях я не планирую затрагивать второй вид в силу отсутствия компетенций и релевантного опыта.
Теперь можем двигаться дальше.
О логах как источнике дополнительной информации
Если о мониторинге рядовой инженер имеет весьма смутное представление, то с логированием, как правило, ситуация обстоит чуть лучше, видимо, в силу того, что именно к логам обращаются в первую очередь, когда анализируют проблемы в работе софта.
Однако же, для многих становится откровением то, что логи бывают нескольких типов. Вот два самых распространенных:
Лог работы приложения – именно о нем думают в первую очередь; полагаю, вам знакома такая конструкция:
2019-04-23 00:39:10,092 INFO DatabaseConnector – Connection estabilishedВот это и есть запись из журнала работы. Характерные атрибуты такой записи – идентификатор уровня события и сообщение о событии. Часто также появляются имя класса/библиотеки, вызвавшей логгер, и идентификатор потока, в котором была сформирована эта запись.
Лог доступа к приложению – тут уже интереснее; это информация о том, какие функции приложения запрашивались. В подавляющем большинстве случаев это будут журналы обращения к API. Вот так, например, может выглядеть запись обращения к Nginx:
66.249.65.62 - - [06/Nov/2014:19:12:14 +0600] "GET /?q=%E0%A6%A6%E0%A7%8B%E0%A7%9F%E0%A6%BE HTTP/1.1" 200 4356 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"Здесь основные атрибуты уже другие – идентификатор запрошенного ресурса и информация о запросившем. Также, здесь может появляться информация о затраченных на обработку ресурсах приложения.
У обоих видов журналов также есть штамп времени – информация о том, когда событие произошло.
В этом месте я обращаюсь к разработчикам: коллеги, пожалуйста, когда настраиваете библиотеку журналирования вашего софта, сделайте так, чтобы штамп времени был полным – год, месяц, день, время с точностью до миллисекунды, таймзона операционной системы. Поверьте на слово, вам будут благодарны, ведь без полного штампа времени однозначно понять, когда произошло описанное событие, очень и очень трудно, если вообще не невозможно.
Подводя итог написанному выше, давайте ответим на вопрос «что логи могут нам дать?».
О логах приложения
В этом случае всё очень просто – если метрика сообщает нам о факте наличия ошибки, лог рассказывает, какая именно ошибка произошла.
Пример – пусть приложение работает с базой данных, тогда у неё есть счётчик ошибок database_error_count. Когда счётчик инкрементируется, мы видим, что что-то пошло не так, однако не знаем подробностей, ведь такую информацию не принято (и не стоит) выводить в метрики. Тут нам должен помочь журнал:
2019-04-27 00:39:10,092 ERROR DatabaseConnector – Error connecting to database MSSQLDB – connection refused on port 1433И сразу понятно – у нас порт недоступен.
Конечно, это идеальный вариант. На практике же, ситуация часто складывается так, что приложение «размазывает» информацию о своем состоянии по логам и метрикам, а информацию, например, о фатальной ошибке при старте, можно, по понятным причинам, понять только из журналов.
О логах доступа
Как я писал выше, с этим типом журналов всё интереснее. Во-первых, эти логи, при наличии информации о затраченных на обработку запросов ресурсах, внезапно, превращаются… в метрики!
Смотрите – в логах HTTP-запросов принято писать о запрошенном ресурсе, времени, затраченном на обработку запроса, и еще, как минимум, фиксировать код ответа, из чего уже можно получить информацию о производительности:


Более того, такие логи, если в них есть информация о авторе запроса, превращаются в инструмент аудита доступа. С ними у нас в руках появляется еще один элемент Observability – данные безопасности.
Кто и откуда запрашивал ваши ресурсы? Какие именно ресурсы? Как часто? Были ли такие запросы раньше? И еще много вопросов, на которые можно найти ответы.
На основе этих данных уже можно искать аномалии доступа:
Запросы из неизвестных источников (99% реквестов к такому-то API ранее выполнялись таким-то пользователем из такой-то локации, а теперь появился кто-то еще)
Запросы к скрытым ресурсам и функциям (кто-то ломится в непубличный API)
Множество неуспешных попыток авторизации (вас брутфорсят)
И так далее. Продолжите список в комментариях.
Уточню, что HTTP лог здесь является только примером – с тем же успехом вы можете собирать аудит лог вашей БД.
Трассировки
Еще на логах можно строить трассировки. Работает это примерно так:
Входная точка в вашей DMZ устанавливает идентификатор трассировки (trace ID) на запрос; должна быть предусмотрена возможность ручной установки!
По мере прохождения запроса по вашей инфраструктуре, приложения должны, во-первых, сохранять идентификатор неизменным, во-вторых, этим же идентификатором помечать соответствующие записи в журналах
Если такое предусмотрено вашим приложением, trace ID стоит записывать не только в лог доступа, но и в лог работы – так вам будет легче связывать ошибки с конкретными запросами.
Очень обобщенно, это можно представить следующим образом:
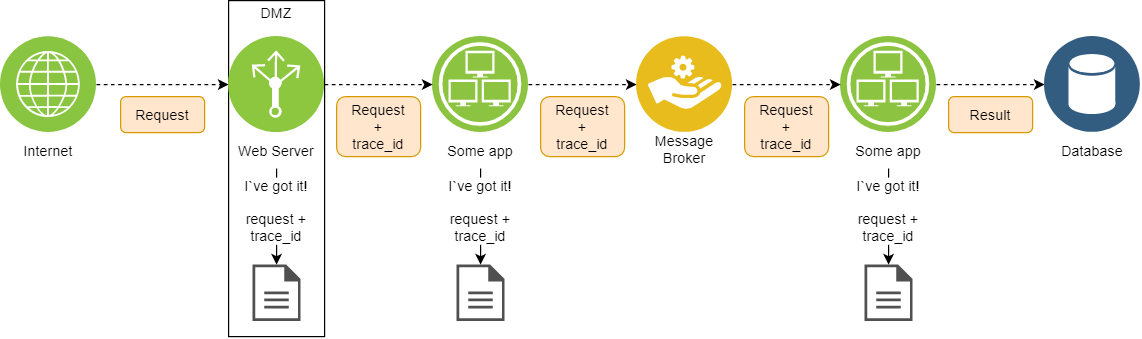
Преимущества трассировок сложно переоценить – на их основе можно, как минимум:
Строить маршруты выполнения операций и выявлять недостатки инфраструктуры
Оценивать общую их длительность; особенно это полезно в асинхронных процессах
Оценивать длительность выполнения операций на конкретных этапах и выявлять узкие места
О сборе логов
Видов взаимодействий тут снова два, прямо как с метриками – Pull и Push.
Pull – это когда приложение ведет свой журнал (в файле, в табличке в БД, в журнале операционной системы), а агент журналирования этот журнал читает, обогащает метаданными о приложении/хосте/чем-то ещё и отправляет на дальнейший парсинг и индексацию. Минус – нужно деплоить и конфигурировать агенты; плюс – приложению не нужно знать о системе централизованной обработки и хранения логов, от него требуется только вовремя писать свои журналы.
Push – приложение активно отправляет свой журнал в систему парсинга/брокер сообщений/напрямую в базу. В таком случае агент не нужен, но приложение должно знать, где находится точка для сброса логов.
На этом этапе важно добиться того, чтобы на записи из журналов ставились те же метки, что и на метрики этих приложений (как я писал в предыдущей статье, в самом примитивном виде это теги с идентификатором хоста и именем приложения), дабы сохранить возможность связать их между собой и выполнять комплексный анализ.
О структуризации
Приложение может вести логи в разных форматах – plain text, jsonl, logsft, тысячи их. Здесь ключевая задача – привести их к единому виду, и тут рекомендую начинать с определения контрактов событий.
Контракт – соглашение о том, какой минимальный набор полей должны иметь те или иные типы логов после парсинга.
Можно выделить сначала общий контракт:
@timestamp<time>: Штамп времени события
application<string>: Имя приложения, к которому относится событие; должно соотноситься с таковым в мониторинге
host<string>: Имя хоста, на котором расположено приложение
log_type<string>: Тип события; application|access|.... (если приложение пишет не только application логи)
trace_id<string>: Идентификатор трассировки (при наличии)А затем определять контракты для других типов.
Например, для журналов приложений:
message<string>: Значимая часть события
generic_message<string>: Обезличенная значимая часть события
level<string>: Текстовая репрезентация уровня события
level_value<int>: Численная репрезентация уровня события
logger_name<string>: Имя класса, сгенерировавшего событие (при наличии)
thread_name<string>: Идентификатор потока, сгенерировавшего событие (при наличии)
stack_trace<string>: Трассировка стека; в более общем виде - вторая и последующие строки сообщения (при наличии)И для журналов доступа:
status_code<int>: Код ответа по запросу
elapsed_time<int>: Время, затраченное на обработку запроса в миллисекундах
requested_resource<string>: Запрошенный ресурс
method<string>: Метод запросаЗдесь очень важно соблюдать установленные контракты при передаче логов на дальнейшие индексацию и хранение.
При этом, текстовое и численное обозначения уровня события необходимо определить заранее и для каждой записи её собственный уровень приводить к одному из них.
Следование контракту приносит пользу сразу с нескольких сторон:
Упрощается индексация – многие NoSQL базы не любят, когда в рамках одного сегмента данных происходит попытка сохранить поле сначала одного типа, а затем другого. В лучшем случае, в такой ситуации вы получите неадекватно разрастающийся индекс, в худшем – ошибку при сохранении
Процесс поиска становится единообразным – когда у вас есть контракт в рамках одного типа журналов, вы можете подготовить один-два дашборда для работы с ними, просто соблюдая контракт и на этапе визуализации. С единым дашбордом можно, например, одновременно анализировать логи сразу нескольких приложений в одном интерфейсе
Только не пользуйтесь, пожалуйста, уровнем «EMERGENCY», если не уверены, что абсолютно каждый, кому предстоит работать с структурированными журналами, точно знает, что он обозначает. Я встречал очень мало таких людей, поэтому вместо него использую «FATAL» - достаточно говорящее обозначение для всех.
Обезличенные сообщения
Внимательные читатели могли заметить, что в контракте журналов приложений есть поле «generic_message». Рассказываю.
Для логов работы приложения я еще применяю такой ход – из некоторых событий вывожу дженерики (так их называли коллеги из разработки, мне понравилось обозначение).
Дженерик – это значимая часть события, приведенная к обезличенному шаблону. Вот пример:
Пусть исходное сообщение у нас такое:
Error on AMQP connection <0.12956.79> (127.0.0.1:52879 -> 127.0.0.1:5672, state: starting):Из него часть информации можно заменить на маркеры, тогда получается дженерик:
Error on AMQP connection <{connection_id}> ({remote_host} -> {destination_host}, state: {connection_state}):Извлекаемые значения при этом записываются в соответствующие поля события с становятся доступны для поиска.
Но что это дает? А вот что:
По дженерикам можно настраивать алерты; ошибка ошибке рознь, некоторые могут более критичными, некоторые менее. Если для критичных событий заранее подготовить паттерны, можно с помощью простых запросов ловить их появление и уведомлять об этом
Извлеченные ключи помогают в поиске; когда у вас идентификатор сессии везде называется «session_id» вы получаете возможность просто и быстро выполнять сквозной поиск
Поиск по ключам сильно проще поиска по регулярному выражению, как с точки зрения базы данных (обращаемся к индексу, а не выполняем анализ текста), так и с точки зрения пользователя (пачку регулярок еще надо заранее подготовить и хранить всегда под рукой)
Здесь важно не перегнуть палку и покрывать дженериками действительно важные записи. Злоупотребление дополнительными полями вредит здоровью ваших индексов.
О хранении
Как и в предыдущей статье, тут буду немногословен. Я предпочитаю Elasticsearch, и еще, говорят, Loki набирает популярность. На хабре можно найти несколько статей с их сравнением, вот одна из них - https://habr.com/ru/company/badoo/blog/507718/.
Ознакомьтесь, изучайте, выбирайте.
О связности с метриками
В предыдущей статье я условно разделял визуализацию так:
Уровень площадки
Уровень группы
Уровень объекта
Уровень фрагмента объекта
Уровень инфраструктуры
Выводить информацию о логах рекомендую на все уровни, кроме последнего (а может и на него, если вы собираете журналы операционной системы).
Принцип тот же самый:
На первом уровне к логике панели-индикатора добавляется блок, связанный с подсчетом количества событий уровня ERROR и выше
На втором уровне расширяется список панелей – появляется индикатор наличия ошибок в журналах, плюс обеспечивается возможность перехода к дашборду с логами с сохранением контекста и фильтра по уровню событий (если подсвечиваем именно количество ошибок, их и нужно показывать)
На следующих уровнях пользователю предоставляется возможность перехода к дашборду с логами с сохранением контекста, но уже без фильтра по уровню – предполагается, что если пользователь совершает такой переход, то ему интересны логи всех уровней, а не только определенных
Тогда диаграмма из предыдущей статьи приобретает такой вид:

О алертинге
Основные тезисы были высказаны в предыдущей статье, тут ограничусь парой предложений:
Выделите критичные события и настройте по ним алертинг; это станет хорошим дополнением к уже имеющимся нотификациям и повысит наблюдаемость за площадкой
Обогащайте алерты по логам теми же метаданными, что и алерты по метрикам; для пользователя они должны быть прозрачны, ему не надо задумываться, откуда взялась та или иная нотификация
Заключение
Итак, допустимо ли отрывать логи от метрик?
Я считаю, что нет – как видите, журналы отлично дополняют картину мира и раскрывают подробности, которые метрики не всегда способны предоставить. Применяйте оба инструмента для наблюдения за вашими площадками и будет вам счастье.
Огромное спасибо всем, кто ознакомился с этой и предыдущей статьей, кто писал комментарии, ставил под сомнение высказанное и делился практиками – действительно приятно видеть отклик со стороны сообщества.
Возможно, позже появится еще одна статья, уже с примерами использования конкретных технологий и практик, в которой попробуем реализовать описанное ранее и посмотреть, как это работает.