
Примечание переводчика: В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Мы уже рассказывали о дата-центре фотосервиса imgix, описывали детективную историю поиска проблем с SSD-дисками проекта Algolia, а сегодня представляем вашему вниманию адаптированный перевод заметки инженеров сервиса Netflix о том, как как они занимаются выявлением неисправных серверов.
На дворе два часа ночи, а половина нашей команды по методам обеспечения надежности уже на ногах и пытается понять, по какой причине сбоит потоковая трансляция на Netflix. Все наши системы работают в штатном режиме, но что-то явно не в порядке, и мы не можем понять, что. После часа поисков мы выясняем, что зачинщиком беспорядков стал один из серверов нашей фермы, характеристики которого отклонились от нормы. Мы не сразу заметили его среды тысяч других серверов, потому что искали очевидную проблему, а не скрытые аномалии.
В сериале Netflix «Сорвиголова», входящем в кинематографическую вселенную Marvel, Мэтт Мёрдок благодаря своим обостренным чувствам способен определять необычное поведение людей. Это позволяет ему замечать то, что не видят другие, например, он может «почувствовать», когда человек лжет. Мы решили создать подобную систему, которая бы искала неочевидные отклонения в работе серверов, способные вызывать проблемы с производительностью. В этом посте мы опишем наш автоматизированный способ выявления отклонений в работе серверов и их устранения, который спас нас от бессчетных часов ночного бдения.
На данный момент сервис Netflix работает на нескольких десятках тысяч серверов, и, обычно, менее одного процента из них работают неисправно. У экземпляров, попавших в этот процент, может быть снижена сетевая производительность, что ведет к увеличению задержек обработки запросов. Неисправный сервер отвечает на запросы во время проверок работоспособности, а его системные метрики остаются в пределах нормы, однако он функционирует не на оптимальном уровне.
Медленный или неисправный сервер гораздо хуже неработоспособного, так как его негативное влияние на работу системы может быть настолько малым, что оно остается в пределах толерантности систем мониторинга и может быть пропущено инженером при проверке графиков. Однако даже настолько малого воздействия может быть достаточно, чтобы вызывать дискомфорт у клиентов, заставляя их обращаться в службу поддержки. Где-то там, среди тысяч исправно работающих серверов, скрываются несколько неисправных.
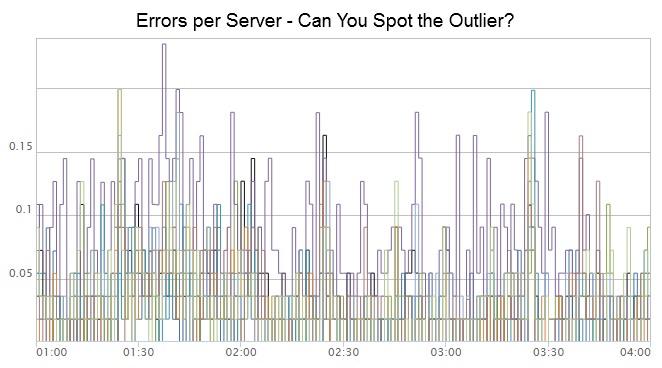
По фиолетовой линии на графике, приведенном выше, видно, что частота появления ошибок на этом сервере выше нормы. Все остальные сервера также имеют выбросы, но их характеристики «падают» обратно в ноль – а вот фиолетовая характеристика постоянно находится выше остальных. Расцените ли вы это как отклонение? Есть ли способ автоматически определять подобные отклонения на основании временных данных?
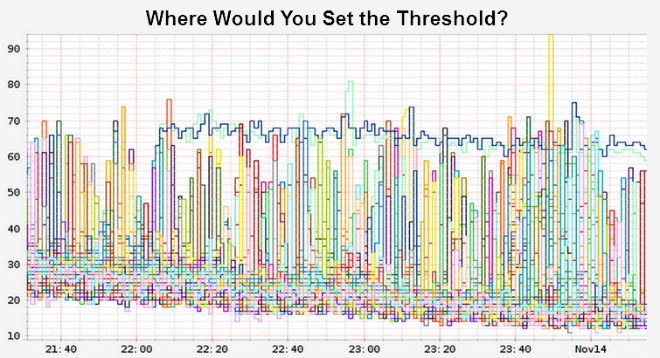
Сервер с серьезными проблемами работоспособности может быть легко обнаружен системами мониторинга, если значения задержек превышают некие пороговые значения. Однако такие системы требуют установки широких допусков, чтобы учитывать резкие скачки при обработке данных; также они требуют периодической настройки, в зависимости от объема данных и модели доступа. Ключевым шагом к достижению нашей цели – увеличению надежности – является автоматизация поиска неисправных серверов, которые не выявляются системами мониторинга.
Чтобы решить стоящую перед нами проблему, мы используем кластерный анализ, который является методом машинного «обучения без учителя». Целью кластерного анализа является объединение наиболее схожих объектов в группы. Достоинство техники «обучения без учителя» в том, что ей не нужна размеченная выборка, то есть нам не надо создавать тренировочный набор данных с примерами статистических выбросов. Существует достаточно большое количество различных кластерных алгоритмов, каждый из которых обладает своими достоинствами и недостатками. Для наших целей подойдет алгоритм кластеризации пространственных данных с присутствием шума DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
DBSCAN – это кластерный алгоритм, который придумали Мартин Эстер (Martin Ester), Ганс-Питер Кригел (Hans-Peter Kriegel), Йорг Сандер (Jorg Sander) и Сяо Вей Ху (Xiaowei Xu) в 1996 году. Метод принимает на входе набор точек и маркирует как точки кластера те из них, которые имеют большое количество соседей. Точки, которые находятся в областях с меньшей плотностью, считаются статистическими выбросами. Если определенная точка принадлежит кластеру, то она должна находиться на определённом расстоянии от других точек этого кластера, которое определяется по специальной функции. Нафтали Харрис (Naftali Harris) в своем блоге привел отличную визуализацию метода DBSCAN.
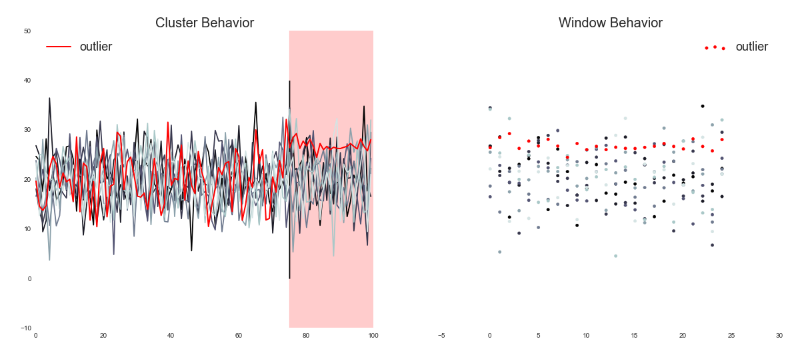
Чтобы наш метод выявления неисправных серверов заработал, владельцу сервиса необходимо определить метрику, которая будет использоваться в DBSCAN. Atlas – наша основная платформа динамической телеметрии – отслеживает эту метрику и формирует окно данных. Затем эти данные передаются алгоритму DBSCAN, который возвращает набор серверов с подозрением на неисправность. На изображении ниже показаны данные, которые поступают на вход алгоритма DBSCAN; область, выделенная красным – это текущее окно данных.
Кроме специальной метрики владелец сервиса определяет минимальный промежуток времени, который должен пройти, перед тем как сервер будет расценен как неисправный. Когда серверы определены, управление передается нашей системе оповещения, которая предпринимает одно (или несколько) из нижеследующих решений:
Для настройки DBSCAN требуется два входных параметра: расстояние и минимальный размер кластера. Вот только владельцы сервисов не хотят утруждать себя подбором их верной комбинации, способствующей эффективному определению неисправных серверов. Мы упростили этот процесс: теперь им нужно просто указать текущее количество выбросов в момент конфигурирования (если такие есть). На основании этих данных мы можем сами определить расстояние и минимальный размер кластера с помощью алгоритма имитации отжига. Такой подход эффективно снижает сложность методологии, поэтому другим командам проще начать её использовать, а владельцам сервисов больше не надо забивать голову тонкостями работы алгоритма.
Чтобы определить эффективность нашего метода, мы проверили его в боевых условиях на нашем рабочем сервисе. На основании недельных данных мы вручную определили, какие сервера должны попасть в категорию подозрительных и каким следует уделить внимание. Затем мы сопоставили наши результаты с результатами, предоставленными системой определения выбросов и получили возможность вычислить набор параметров, в том числе точность, полноту и F-меру.
Глядя на эти результаты, мы видим, что идеально точно выбрать из огромного количества серверов все неисправные невозможно, но можно сделать это с довольно высокой вероятностью. Неидеальное решение вполне допустимо в нашей «облачной» среде, так как стоимость ошибки здесь достаточно мала. Поскольку отключаемые серверы сразу же заменяются «свежими», то ошибочная остановка сервера или его отключение оказывает незначительное воздействие на систему, если оказывает вообще. Статистических решений для автоматического восстановления должно быть достаточно; неидеальное решение лучше, чем никакого.
Наша текущая версия системы использует mini-batch подход, когда мы формируем окно данных и используем его для принятия решения. По сравнению с обработкой в реальном времени наш алгоритм имеет недостаток: точность определения выброса связана с размером окна. Если выбрать слишком маленькое окно, то система начинает реагировать на шум, слишком большое – катастрофически падает скорость вычислений. Улучшенные подходы могут использовать достоинства фреймворков для потоковой обработки в реальном времени, таких как Mantis (система для потоковой обработки событий Netflix) и Apache Spark Streaming. Более того, в сферах поточных методов data-mining и динамического машинного обучения также была проделана огромная работа. Мы советуем любому, кто хочет внедрить подобную систему, обратить внимание на динамические техники, которые минимизируют время определения выбросов.
Можно усовершенствовать процесс выбора параметра, если внедрить еще два дополнительных сервиса: маркировщик данных для построения тренировочных наборов данных и сервер модели, который будет заниматься вычислением показателей производительности и переобучать модели с помощью приемлемого набора данных, собранных маркировщиком. Мы хотим позволить владельцам сервисов проводить начальную настройку перед определением неисправных серверов, путем маркировки данных (область, с которой они знакомы), передаваемых DBSCAN для вычисления параметров (область, которая лежит за пределами их компетенции) байесовским методом. Такой подход оптимизирует значения необходимых параметров на основании тренировочных данных.
«Облачная» инфраструктура Netflix постоянно расширяется, а автоматизирование операционных решений открывает новые возможности, улучшая доступность сервиса и снижая количество ситуаций, когда требуется вмешательство человека. Сорвиголова использует свой костюм, чтобы усилить свои боевые качества, мы же можем использовать машинное обучение и автоматику, чтобы увеличить эффективность наших инженеров и on-call-разработчиков. Определение неисправных серверов – это всего лишь один из примеров подобной автоматизации. Другими хорошими примерами могут служить Scryer и Hystrix, а еще мы исследуем дополнительные области автоматизации, как то автоматизация:
Тем не менее, это – всего лишь некоторые из шагов на пути к построению самовосстанавливающихся систем огромных масштабов.
На дворе два часа ночи, а половина нашей команды по методам обеспечения надежности уже на ногах и пытается понять, по какой причине сбоит потоковая трансляция на Netflix. Все наши системы работают в штатном режиме, но что-то явно не в порядке, и мы не можем понять, что. После часа поисков мы выясняем, что зачинщиком беспорядков стал один из серверов нашей фермы, характеристики которого отклонились от нормы. Мы не сразу заметили его среды тысяч других серверов, потому что искали очевидную проблему, а не скрытые аномалии.
В сериале Netflix «Сорвиголова», входящем в кинематографическую вселенную Marvel, Мэтт Мёрдок благодаря своим обостренным чувствам способен определять необычное поведение людей. Это позволяет ему замечать то, что не видят другие, например, он может «почувствовать», когда человек лжет. Мы решили создать подобную систему, которая бы искала неочевидные отклонения в работе серверов, способные вызывать проблемы с производительностью. В этом посте мы опишем наш автоматизированный способ выявления отклонений в работе серверов и их устранения, который спас нас от бессчетных часов ночного бдения.
В погоне за тенью
На данный момент сервис Netflix работает на нескольких десятках тысяч серверов, и, обычно, менее одного процента из них работают неисправно. У экземпляров, попавших в этот процент, может быть снижена сетевая производительность, что ведет к увеличению задержек обработки запросов. Неисправный сервер отвечает на запросы во время проверок работоспособности, а его системные метрики остаются в пределах нормы, однако он функционирует не на оптимальном уровне.
Медленный или неисправный сервер гораздо хуже неработоспособного, так как его негативное влияние на работу системы может быть настолько малым, что оно остается в пределах толерантности систем мониторинга и может быть пропущено инженером при проверке графиков. Однако даже настолько малого воздействия может быть достаточно, чтобы вызывать дискомфорт у клиентов, заставляя их обращаться в службу поддержки. Где-то там, среди тысяч исправно работающих серверов, скрываются несколько неисправных.
По фиолетовой линии на графике, приведенном выше, видно, что частота появления ошибок на этом сервере выше нормы. Все остальные сервера также имеют выбросы, но их характеристики «падают» обратно в ноль – а вот фиолетовая характеристика постоянно находится выше остальных. Расцените ли вы это как отклонение? Есть ли способ автоматически определять подобные отклонения на основании временных данных?
Сервер с серьезными проблемами работоспособности может быть легко обнаружен системами мониторинга, если значения задержек превышают некие пороговые значения. Однако такие системы требуют установки широких допусков, чтобы учитывать резкие скачки при обработке данных; также они требуют периодической настройки, в зависимости от объема данных и модели доступа. Ключевым шагом к достижению нашей цели – увеличению надежности – является автоматизация поиска неисправных серверов, которые не выявляются системами мониторинга.

Ищем иголку в стоге сена
Чтобы решить стоящую перед нами проблему, мы используем кластерный анализ, который является методом машинного «обучения без учителя». Целью кластерного анализа является объединение наиболее схожих объектов в группы. Достоинство техники «обучения без учителя» в том, что ей не нужна размеченная выборка, то есть нам не надо создавать тренировочный набор данных с примерами статистических выбросов. Существует достаточно большое количество различных кластерных алгоритмов, каждый из которых обладает своими достоинствами и недостатками. Для наших целей подойдет алгоритм кластеризации пространственных данных с присутствием шума DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Основная идея DBSCAN
DBSCAN – это кластерный алгоритм, который придумали Мартин Эстер (Martin Ester), Ганс-Питер Кригел (Hans-Peter Kriegel), Йорг Сандер (Jorg Sander) и Сяо Вей Ху (Xiaowei Xu) в 1996 году. Метод принимает на входе набор точек и маркирует как точки кластера те из них, которые имеют большое количество соседей. Точки, которые находятся в областях с меньшей плотностью, считаются статистическими выбросами. Если определенная точка принадлежит кластеру, то она должна находиться на определённом расстоянии от других точек этого кластера, которое определяется по специальной функции. Нафтали Харрис (Naftali Harris) в своем блоге привел отличную визуализацию метода DBSCAN.
Как мы используем DBSCAN
Чтобы наш метод выявления неисправных серверов заработал, владельцу сервиса необходимо определить метрику, которая будет использоваться в DBSCAN. Atlas – наша основная платформа динамической телеметрии – отслеживает эту метрику и формирует окно данных. Затем эти данные передаются алгоритму DBSCAN, который возвращает набор серверов с подозрением на неисправность. На изображении ниже показаны данные, которые поступают на вход алгоритма DBSCAN; область, выделенная красным – это текущее окно данных.

Кроме специальной метрики владелец сервиса определяет минимальный промежуток времени, который должен пройти, перед тем как сервер будет расценен как неисправный. Когда серверы определены, управление передается нашей системе оповещения, которая предпринимает одно (или несколько) из нижеследующих решений:
- Связаться с владельцем сервиса по email;
- Отключить сервер от сервиса, не останавливая его;
- Собрать экспертные данные для дальнейшего расследования;
- Остановить сервер, позволяя Auto Scaling Group заменить его.
Выбор параметров
Для настройки DBSCAN требуется два входных параметра: расстояние и минимальный размер кластера. Вот только владельцы сервисов не хотят утруждать себя подбором их верной комбинации, способствующей эффективному определению неисправных серверов. Мы упростили этот процесс: теперь им нужно просто указать текущее количество выбросов в момент конфигурирования (если такие есть). На основании этих данных мы можем сами определить расстояние и минимальный размер кластера с помощью алгоритма имитации отжига. Такой подход эффективно снижает сложность методологии, поэтому другим командам проще начать её использовать, а владельцам сервисов больше не надо забивать голову тонкостями работы алгоритма.
Проверка боем
Чтобы определить эффективность нашего метода, мы проверили его в боевых условиях на нашем рабочем сервисе. На основании недельных данных мы вручную определили, какие сервера должны попасть в категорию подозрительных и каким следует уделить внимание. Затем мы сопоставили наши результаты с результатами, предоставленными системой определения выбросов и получили возможность вычислить набор параметров, в том числе точность, полноту и F-меру.
| Число серверов | Точность | Полнота | F-мера |
|---|---|---|---|
| 1960 | 93% | 87% | 90% |
Глядя на эти результаты, мы видим, что идеально точно выбрать из огромного количества серверов все неисправные невозможно, но можно сделать это с довольно высокой вероятностью. Неидеальное решение вполне допустимо в нашей «облачной» среде, так как стоимость ошибки здесь достаточно мала. Поскольку отключаемые серверы сразу же заменяются «свежими», то ошибочная остановка сервера или его отключение оказывает незначительное воздействие на систему, если оказывает вообще. Статистических решений для автоматического восстановления должно быть достаточно; неидеальное решение лучше, чем никакого.
Дополнительно
Наша текущая версия системы использует mini-batch подход, когда мы формируем окно данных и используем его для принятия решения. По сравнению с обработкой в реальном времени наш алгоритм имеет недостаток: точность определения выброса связана с размером окна. Если выбрать слишком маленькое окно, то система начинает реагировать на шум, слишком большое – катастрофически падает скорость вычислений. Улучшенные подходы могут использовать достоинства фреймворков для потоковой обработки в реальном времени, таких как Mantis (система для потоковой обработки событий Netflix) и Apache Spark Streaming. Более того, в сферах поточных методов data-mining и динамического машинного обучения также была проделана огромная работа. Мы советуем любому, кто хочет внедрить подобную систему, обратить внимание на динамические техники, которые минимизируют время определения выбросов.
Можно усовершенствовать процесс выбора параметра, если внедрить еще два дополнительных сервиса: маркировщик данных для построения тренировочных наборов данных и сервер модели, который будет заниматься вычислением показателей производительности и переобучать модели с помощью приемлемого набора данных, собранных маркировщиком. Мы хотим позволить владельцам сервисов проводить начальную настройку перед определением неисправных серверов, путем маркировки данных (область, с которой они знакомы), передаваемых DBSCAN для вычисления параметров (область, которая лежит за пределами их компетенции) байесовским методом. Такой подход оптимизирует значения необходимых параметров на основании тренировочных данных.
Что дальше?
«Облачная» инфраструктура Netflix постоянно расширяется, а автоматизирование операционных решений открывает новые возможности, улучшая доступность сервиса и снижая количество ситуаций, когда требуется вмешательство человека. Сорвиголова использует свой костюм, чтобы усилить свои боевые качества, мы же можем использовать машинное обучение и автоматику, чтобы увеличить эффективность наших инженеров и on-call-разработчиков. Определение неисправных серверов – это всего лишь один из примеров подобной автоматизации. Другими хорошими примерами могут служить Scryer и Hystrix, а еще мы исследуем дополнительные области автоматизации, как то автоматизация:
- Анализа и настройки таймаутов и порогов сервиса;
- Canary Testing;
- Переключения трафика во время плановых отключений электричества;
- Тестов производительности, настраивающих правила для автоматического масштабирования.
Тем не менее, это – всего лишь некоторые из шагов на пути к построению самовосстанавливающихся систем огромных масштабов.