

На рисунке – граф, визуализирующий межкомандное взаимодействие в Дивизионе развития и сопровождения производственного процесса (SberWorks) Сбера
Мы решили разобраться, как выглядит общение участников команд в цифровых каналах Сбера, а точнее, в трех ключевых инструментах производственного процесса:
- Jira – тикет-системе для управления задачами
- Confluence – вики-системе для управления требованиями
- Bitbucket – системе управления кодом
И попробовать понять по цифровым следам, как на самом деле взаимодействуют команды и люди между собой, определить соответствующие зависимости. Иными словами, увидеть настоящую структуру работы, которая отражается в инструментах производственного процесса.
Мы изучили каждый источник, определили, какие связи он иллюстрирует, как люди работают совместно, как именно они общаются и решают поставленные задачи.
Изучив связи, мы присвоили веса самому источнику данных, конкретным видам связи и на базе данных построили граф взаимодействий. При формировании графа по источникам, которые были упомянуты выше, все-таки принимается во внимание, что сотрудники обсуждают именно рабочие вопросы, а не котиков.
В итоге, получили следующую визуализацию коммуникаций:
- Точка – это человек или команда.
- Линия между точками – свидетельствует о наличии связи, которая является агрегатом взаимодействий, найденных в источниках данных, которые мы определили у людей. У линии связи есть свой вес, начало и конец.
Поиск точки отсчёта
Основа командной работы – общение. Можно было бы подумать, что, как людей объединили, так они и будут взаимодействовать друг с другом, но есть нюансы.
- Как же люди на самом деле, работая, общаются, и общаются, работая?
- Есть ли какие-то паттерны?
- Зависят ли они от реальной структуры команды?
- Как структура общения влияет на метрики эффективности?
Ответы на эти вопросы мы можем найти с помощью нашего продукта.
Как «читать» ДНК?
ДНК рассказывает нам, как фактически работают люди, как они взаимодействуют друг с другом в рабочем процессе, в том числе и за пределами Sbergile-периметра.
Например, при создании нового трайба (группы взаимосвязанных команд, сформированных вокруг определенного продукта и бизнес-цели, отвечающих за общий бизнес-результат) мы сможем понять по цифровым следам уже сложившиеся связи и использовать эту информацию при создании оптимальной структуры.
С другой стороны, появилась новая задача – «нарезать» команды так, чтобы улучшить lead time (LT), то есть время от начала разработки до вывода продукта в ПРОМ. LT делится на два этапа: непосредственное время команды и время ожидания. Последнее, в свою очередь, зачастую свидетельствует о зависимостях между командами.
Когда же мы визуализируем взаимосвязи таким образом, то можно задаться вопросом: а как нам синхронизировать эти команды, как лучше объединять людей, чтобы сделать минимальным количество внешних (по отношению к команде) связей?
Можно увидеть, что участники команды не общаются друг с другом, при этом активно взаимодействуют с внешними контрагентами и экспертами, то есть выходят за рамки своего круга.
Встречаются «песочные часы» – так мы называем сотрудника, который в равной степени взаимодействует с двумя командами. И нет однозначного решения, в какую из них его нужно поместить. Он может быть владельцем продукта, который пилят обе команды, а может быть уникальным экспертом – «узким горлышком». Такую связь нужно как-то разрывать: «размножать эксперта», пересматривать подход, но это решается уже за пределами нашего продукта.
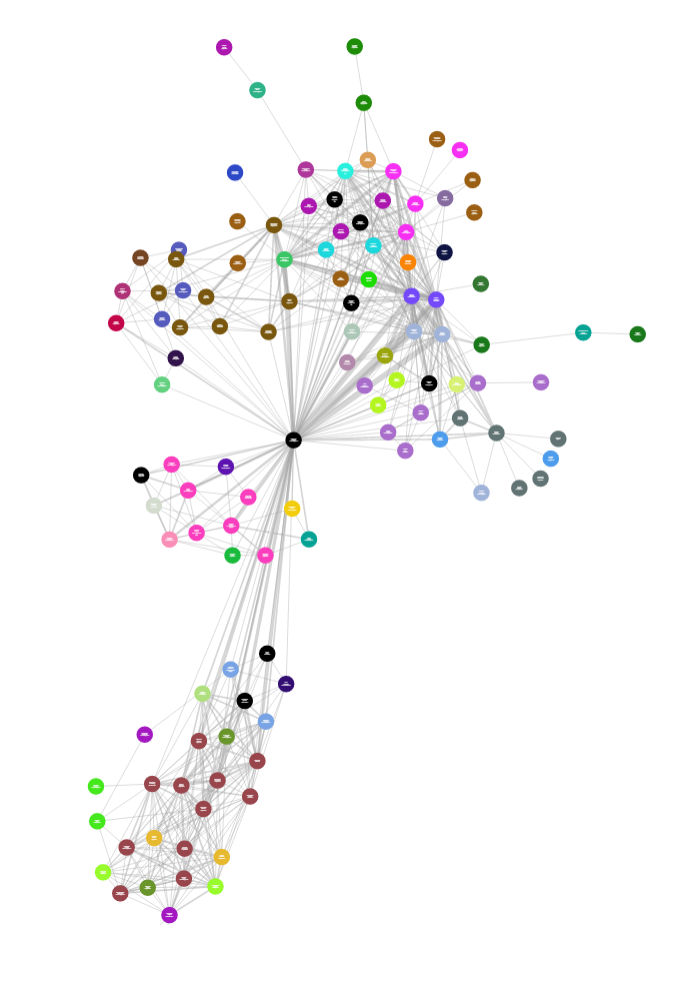
Есть еще «люди-снежинки». Это, когда группа людей, которая между собой никак не общается, объединена через центр – конкретного специалиста, с которым они взаимодействуют.

Интересно наблюдать, как участники команд разбиваются на несколько групп, при этом не взаимодействуя друг с другом. Хороший повод пообщаться с командой и понять, что им мешает работать сплочённо.

Можно увидеть и «одиночек», которые пока не обзавелись связями. Ничего страшного, скорее всего, это всего лишь новички, и у них всё впереди.

Выявляя подобные исключения, мы получаем возможность изменить ситуацию, подключить административный ресурс, чтобы помочь командам эффективно решать свои задачи.
Что под капотом?
В бэке стандартно – ELK-Stack (Elasticsearch, Logstash и Kibana).
На React мы написали приложение, которое умеет забирать из индекса в Elastic через самописное API данные, к которым был применен алгоритм кластеризации, тем самым отсекая слабые (незначимые) связи и визуализировать эти данные в виде плотных сообществ.
Вы спросите, как мы отсекаем незначимые связи? По результатам предварительного исследования мы определили два самых сильных алгоритма.
1. Алгоритм ACY
ACY – алгоритм от Яндекса. Агломеративная кластеризация. Подробнее в статье тут.
2. Алгоритм MCL
MCL – марковский процесс, случайные блуждания по Маркову.
Весь алгоритм описан на следующих страницах Марковский алгоритм кластеризации и MCL — a cluster algorithm for graphs. В итоге применяем именно его.
Алгоритм кластерного анализа основан на потоке (случайном блуждании) в графе. Изначально разработан для выделения кластеров в простом графе, однако может быть применен к любым объектам, для которых задана матрица сходства/различия. MCL является быстрым и масштабируемым алгоритмом кластеризации. В нашем случае мы доуточнили его пятью модификациями.
Мы запускаем его для того, чтобы выделить части плотно связанных между собой членов мини сообществ. Например, у нас есть граф на 100 человек. Мы хотим выделить группы не более 12 человек, состоящие из тех, кто наиболее плотно друг с другом взаимодействует при решении рабочих задач.
Алгоритм продукта даёт возможность минимизировать количество внешних зависимостей между группами, найти узкие места и предложить варианты для дальнейшей оптимизации структуры команд и трайбов.
Какие планы по развитию?
Мы в стадии пилотирования продукта: вовлекаем команды в изучение ДНК и собираем обратную связь, чтобы понять, куда двигаться дальше, какие фичи реализовать в первую очередь.
Но даже сейчас это работающий инструмент, который можно использовать, когда требуется подготовить и спланировать оптимальную организационную структуру. Он позволяет снизить административную нагрузку на Agile-коучей и всех тех, кто задействован в процессе «нарезки» команд, за счет полуавтоматического получения данных о коммуникациях или существующих зависимостях по тому или иному продукту или процессу.
В перспективе мы постараемся еще глубже погрузиться в наши источники, чтобы обогатить данные о связях. Хотя и сегодня открываются интересные вещи, которые могут быть полезны как существующим командам, так и их руководителям.
Спасибо Сергею Артюхову, исполнительному директору, лидеру кластера «Аналитика и визуализация данных производственного процесса» в Сбере и его коллегам за то, что поделились рассказом о новом продукте для кластеризации команд.
netricks
Таки аббревиатуру надо менять. ДНК — это дезоксирибонуклеиновая кислота.