
Нет, конечно же, не убивает.
То, что мертво, умереть не может: доля линукса на десктопах колеблется около 2% уже много лет, и не имеет тенденций ни к росту, ни к падению, изменяясь на уровне статистической погрешности.
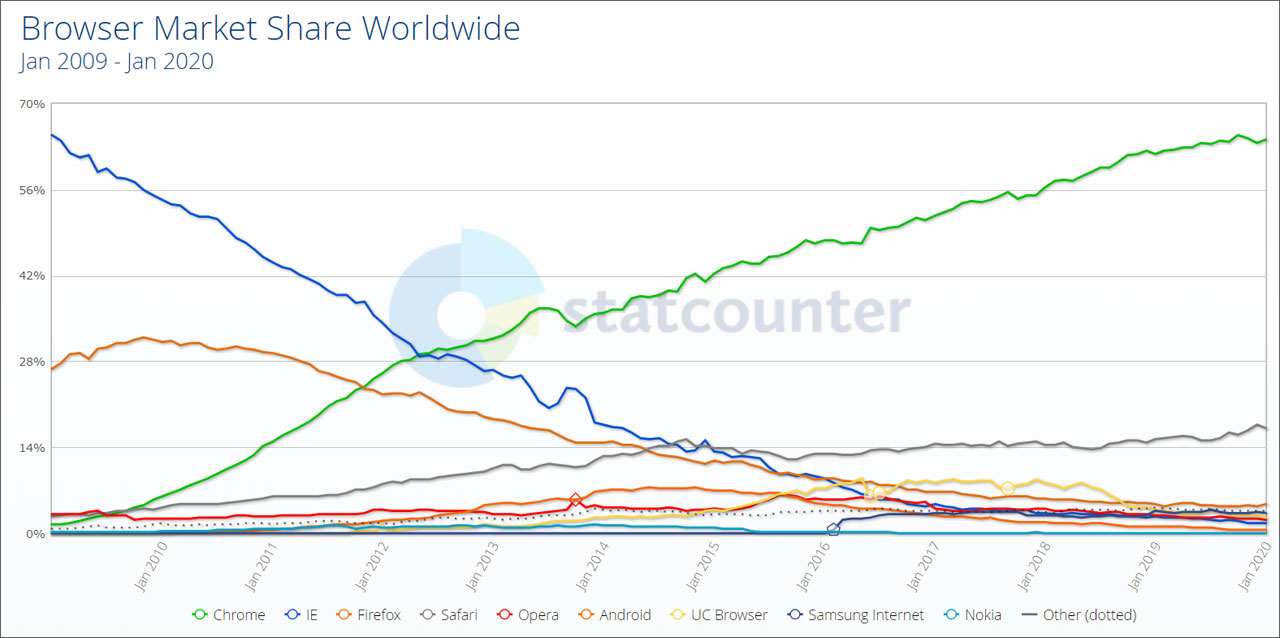
Как выглядит захват рынка конкурентоспособным продуктом, можно видеть на примере Chrome: за 10 лет рост на 70%. Или Android: за 5 лет рост на 75%. Отчасти за их успех ответственна поддержка своих продуктов гуглом, но поддержка и насаждение своей платформы это не основной двигатель: Windows Mobile (и второй, и первой) не помогла вся стоящая за спиной громада Microsoft.
А вот у Linux рост, от силы, пол-процента в год, несмотря на то, что он, например, лучший из существующих вариантов для использования в качестве национальных/государственных ОС.
{kind=link}
{kind=link}
Так что да, учитывая долю в 2%, которая не растет, но и не падает, все-таки "не дает вырасти", а не "убивает".
Дисклеймер
Автор не претендует на абсолютную правильность выводов и суждений, приведенная идея — скорее, затравка для дискуссии, а не всеобьясняющая концепция.
Автор предостерегает от спора с позиции "а у меня такая же нога и ничего не болит", и напоминает, что личный пример не служит доказательством. У вас нога не болит, у меня болит: мы тут в равных условиях. Но я потрудился подвести хоть сколько-нибудь логическую базу к моим тезисам, потрудитесь и вы спорить не с конкретными примерами (на каждый из них можно найти или придумать контрпример и рассказать, почему так), а с идеями. Примеры всего лишь иллюстрируют идеи.
Под "Десктопным Linux" автор имеет ввиду GNU/Linux-based дистрибутивы (Ubuntu, Debian, etc), установленные на обычном x86/x64 компьютере/ноутбуке, с GUI и используемые для бытовых или рабочих целей. Туда не входят такие системы как (даже если они используют ядро linux и его окружение):
1)Android и Chrome OS: несмотря на ядро, это не Linux в той мере, в какой мы его понимаем как продукт: там своя оболочка, свои настройки, свои интерфейсы, свои API для программных продуктов и так далее. Это не линукс, так же как и MacOS это не BSD.
2)Cпецифичные встраиваемые системы, тонкие клиенты, планшеты, умные телевизоры, умные приставки: хоть планшет и телевизор можно с натяжкой назвать десктопом, если подключить к нему клавиатуру, у всех этих систем, как правило, невозможно выбрать ОС по своему вкусу. Что производитель поставил, то и используется.
3)Специфичные рабочие станции для рендеринга, обсчета данных или проектирования микросхем, суперкомпьютеры и так далее. Часть из этого можно использовать как десктоп, но из-за требований к рабочему окружению, возможность выбора ОС на них так же ограничена.
Данные по процентному соотношению разных ОС взяты отсюда. Если у кого-то есть статистика по годам на протяжении десятка лет, покажите, будет интересно посмотреть на долговременные тенденции.
Так в чем же дело? Почему несмотря на все старания, Linux, который стал стандартом де-факто на встраиваемых устройствах, работает на подавляющем большинстве серверов, целиком захватил рынок суперкомпьютеров, Linux, над которым работают сотни компаний и десятки тысяч людей... практически не используется на обычных компьютерах и ноутбуках?
Причины этой ситуации, как ни странно, те же, что сыграли роль в популярности Linux на серверах: unix-way, "Философия Unix": "Пишите программы, которые делают что-то одно, и делают это хорошо, и имеют возможность получать и принимать данные через текстовый интерфейс (потому что он универсален)".
Это очень хорошее решение, когда у вас нет:
Быстрого постоянного интернета
Stackoverflow
Github
Высокоуровневых простых языков типа Python
Кучи фреймворков и библиотек для этих языков в легком доступе
Но есть желание делать свою работу, компьютер и ОС с базовыми инструментами (т.е. ситуация 90-х или 2000-х). Если вы специалист, который может понять некоторые абстрактные концепции, готов писать скрипты-связки, и не требует кнопочки "сделать все хорошо.
Базовое окружение хорошего качества, которое можно комбинировать как угодно, универсальное, бесплатное, переносимое и дописываемое (если уж совсем не хватает фичи или обнаружен баг) — это серьезный шаг по сравнению с поставкой первых ЭВМ, где зачастую-то компилятора нормального не было, или с другими ОС того времени, где приходилось пользоваться, чем дают, да еще и платить за это деньги.
В таких условиях проявляются все преимущества, так странно звучащие в наше время: "я могу просмотреть код любой программы, я могу исправить баг или дописать фичу и отправить в мейнстрим".
Звучат эти аргументы странно потому, что они наследие золотой эпохи опенсорса, когда отдельные утилиты были написаны на одном стандартном для всей кодовой базы языке, были маленькие, потому что делали одну функцию, и сопровождались одним человеком, которому можно было написать письмо. Весьма приятная ситуация, если вы тоже подобный специалист.
Сейчас, когда код программы — это десятки мегабайт текста (и далеко не все из него непосредственно код, там может быть 2мб XML-а) и огромное количество библиотек, когда сборка — отдельное приключение, когда кодовая база пишется десятком человек, ни один обычный пользователь не будет в здравом уме просматривать весь код или пытаться исправить ошибку в чем-нибудь, типа OpenOffice, GIMP-а, KDE или Chrome.
Все исходники прочитать очень сложно, а вероятность найти там ошибку или закладку, просто просматривая код, стремится к нулю: простые места проверили до вас, а в сложных способны разобраться только профессионалы и авторы статических анализаторов :).
Поиск места, в котором засел баг, который вам мешает (даже если вы можете его воспроизвести), если вы обычный пользователь — гиблое дело: отладка больших программ со зрелой кодовой базой (читай "легаси") это отдельное занятие, которому надо учиться, и даже в чем-то искусство.
Произошло это потому, что за 30-50 лет ситуация изменилась. Железо стало более доступным, возникло такое понятие как десктоп, он же "персональный компьютер", и за ними начали массово работать обычные люди, не являющиеся специалистами ни в IT, ни в программировании.
И в этой новой ситуации, достоинство Linux начинает превращаться в недостаток
Для того, чтобы понять, как именно оно становится недостатком, надо немного поговорить о том, как вообще происходит развитие продуктов на долговременном периоде.
В процессе развития IT-отрасли мы непрерывно размениваем ресурсы на пользовательский охват: именно этим объясняются страдания людей на тему "почему процессоры в 10 раз быстрее, а скорость работы текстового редактора такая же". Скорость работы такая же, потому что "выгоднее" увеличить покрытие людей инструментом, чем улучшать пользовательский опыт уже покрытых. Вы этого не видите, потому что для вас, как для уже существующего пользователя, долетают только отголоски этого процесса: новые фичи, переделанный интерфейс, и так далее. А при взгляде со стороны разработчиков — новый интерфейс это более удобная пользовательская навигация -> простое освоение инструмента -> меньший процент отказов -> бОльшая пользовательская база -> больше денег и ресурсов на разработку.
И это ситуация, от которой никуда не деться: если ваш сосед играет грязно, то без внешнего регуляционного механизма (которым может выступать государство, например), и вам придется играть грязно, иначе вы не сможете с ним конкурировать.
Если ваш конкурент меняет ресурсы на пользовательскую базу, то вам либо надо делать так же, либо смириться с тем, что ваш конкурент вырастет, а вы нет.
Но человеку, знакомому с современным десктопным линуксом ясно, что его разработчики, в принципе, не прочь поменять ресурсы на пользовательский охват: ни один из основных дистрибутивов не пытается остаться в состоянии голого терминала, все они предлагают графические оболочки, конфигураторы, инсталляторы, новые программы управления, и так далее.
Таким образом, не является проблемой ни отсутствие ресурсов (например, веб-приложения постоянно топчутся около самой этой черты, и их разработчики гарантируют нормальную работу своих приложений только на достаточно производительном железе и последних версиях браузеров), ни нежелание разработчиков идти по стандартному пути увеличения пользовательской базы. Как минимум, не основной проблемой.
Так в чем же дело?
Проблема лежит не в плоскости разработки, а в плоскости менеджмента
Процесс развития IT-отрасли не просто привлекает новых пользователей. Он привлекает неподготовленных пользователей. Те рассказы о том, как технарь слету разбирается в интерфейсе телевизора, и на вопрос "ой, у вас наверное дома такой же" отвечает "нет, я его впервые вижу" — это не демонстрация высокого интеллекта этого технаря, это демонстрация знания принципов, по которым строятся почти все интерфейсы. Когда за десяток последних лет вы используете интерфейсы iOS, Android, Symbian, Windows, Linux, двух фотоаппаратов, трех телевизоров, кассетного магнитофона с программируемой записью, факса, копировального аппарата, настенного пульта для кондиционера, MP3-плеера и vi, то у вас появляется насмотренность — вы знаете, как спроектированы большинство в мире интерфейсов, хоть и не можете формализовать это знание в виде четких инструкций, но можете использовать. Например, быстро найти нужный пункт в меню, которое видите впервые.
Но те пользователи, которые приходят в IT сейчас — у них всего этого нет.
У них нет необходимости придумывать пути решения задач — большая часть их работы превращается из творческой в алгоритмическую, когда специалиста учат цепочкам действий, необходимым для работы, а не умению создавать эти цепочки. Потому что дешевле, быстрее, и тоже вполне работает.
У них нет желания и необходимости сортировать файлы по папкам: для них уже сделано облако, отдельное для каждого приложения. И там зачастую не файлы, а абстрактные "проекты".
У них нет страха потери всего: их данные хранятся не на их жестком, и это не совсем их данные, будем честны.
У них нет необходимости разбираться с десятком интерфейсов, они могут вырасти до сознательного возраста, не видя интерфейса кроме айфона и десятка приложений на нем для настройки кондиционера, светильника и вибратора.
Именно для них создаются такие интерфейсы, как, например, Fluent (ribbon) в MS Office: он непривычный, и возможно, менее удобный для тех, кто привык к старому меню, и умеет им пользоваться, но он определенно снижает порог входа для тех, кто еще не умеет.
Время, когда отраслью безраздельно владели гики, закончилось
Это время было возможно потому, что только гики имели достаточную настойчивость, чтобы добраться до дефицитного железа и разобраться в текстовых интерфейсах, написанных такими же гиками. Сейчас борьба за пользователя происходит на другом уровне: компьютеры и телефоны доступны всем.
И если вы хотите, чтобы вашим приложением пользовалось максимальное количество людей, вам придется ориентироваться на всех: от ребенка во втором классе с андроидом за 5000, и 16-летней девушки с айфоном в розовом чехле, до 55-летней дамы, которой внук подарил ноутбук на юбилей. И общего у них будет только одно: они представляют собой просто квинтэссенцию не-гиковости.
Для того, чтобы они могли пользоваться вашим продуктом, вам необходимо понять, как мыслит ваш средний пользователь, придумать и протестировать интерфейс, функциональность, фичи и пользовательские пути так, чтобы пользователю было как можно более удобно (или, если переформулировать, чтобы покрыть максимальное количество пользователей: на достаточно больших числах это одно и то же).
Этот процесс начался не сейчас, и даже не десять лет назад: уже в 1992 году (почти 30 лет назад!) в Microsoft были специальные отделы, которые проектировали интерфейсы новой системы. И не просто проектировали, а проводили, как сейчас модно это называть, кастдев — интервью с живыми пользователями с проверкой гипотез на прототипах.
Сейчас фокус исследований сместился с того, как именно пользователь будет взаимодействовать с интерфейсом на то, каким путем он будет решать свои проблемы: базовые элементы интерфейса известны, нарисованы в дизайн-гайдах, SDK, фреймворках, и что гораздо более важно, уже запомнены пользователями, поэтому придумывать их не надо, а изменять следует только если у вас есть веская причина.
Сейчас исследования юзабилити концентрируются на другом: сложность логики и пользовательских путей, которые выводятся на уровень пользователя, увеличивается, и интерфейсы необходимо изменять так, чтобы эта сложность была доступной для пользователей.
Если десяток лет назад интерфейс выбора билетов представлял собой текстовые формы с сокращениями в окне терминала, для работы с которым существовали специальные люди в агентствах, к которым надо было прийти ногами, и они превращали ваши запросы в команды системе, то сейчас произошла серьезная трансформация — процесс подбора рейса не потерял в комбинаторной сложности (рейсов и параметров не стало меньше), но очень уменьшился в интерфейсной сложности: сайты вроде aviasales/tutu/skyscanner создали интерфейс настолько дружелюбный к пользователю, настолько заботливо обмазанный подсказками, предложениями, основанными на обычных запросах пользователей, что для их успешного использования гораздо важнее принципиальное знание "да, так можно купить билет, в этом нет ничего страшного" и согласие это так делать, чем умение пользоваться конкретным интерфейсом.
Именно поэтому главное достоинство Linux — комбинационность и расширяемость, столь любимая гиками, — становится главной проблемой. У нас есть миллионы комбинаций инструментов в системе, но это слишком сложно для обычного пользователя, он хочет десятки и сотни путей. Но для того, чтобы понять, какие именно из миллионов путей надо сделать доступными и простыми для пользователя, надо сфокусироваться на пользовательском опыте, надо работать с новыми пользователями и пытаться понять, как они будут использовать новый интерфейс. В этой части принципиально не могут участвовать разработчики и даже просто существующие пользователи — проклятье знания не дает им возможности непредвзято судить о качестве нового интерфейса: существующий всегда будет лучше и привычнее.
Из этого следует два вывода: во-первых, для ориентации на не-гиков нужны интервью с не-гиками, а не просто идеи разработчиков о том, как "сделать лучше", а во-вторых, интересы пользователей необходимо ставить выше интересов разработчиков: мало кому нравится выбрасывать существующие наработки и делать кучу скучной работы по упрощению пользовательского пути, который самому разработчику вовсе не кажется сложным, но это придется делать.
Именно интересы разработчиков, которые ставятся выше интересов пользователей — это и есть бич Linux
Происходит это потому, что линукс разрабатывается и поддерживается разработчиками, а прочие роли (продакты, аналитики, маркетологи, дизайнеры, UI/UX, редакторы) там присутствуют только по случайности, если они каким-то образом оказались в одном человеке с этим разработчиком (или партнером этого человека).
В традиционной разработке пользовательского ПО, где так или иначе присутствует бизнес, есть четкое понимание, что пользователь = деньги. Возможно не сейчас, возможно в будущем, возможно, он заплатит не напрямую через подписку или покупку, а через рекламу, или вообще деньги придут от инвестора (но будут рассчитаны из количества потенциально-платежных пользователей). В корпоративной (B2B, B2B2C, B2G) разработке может быть по-другому, и деньги могут формироваться даже из того, настолько хорошо ваш продажник дружит с ЛПР другой компании, но в коммерческой B2C разработке деньги приносит пользователь, и удовлетворенность ЦА пользователей это то, что конвертируется в размер аудитории, а значит и в деньги.
В OpenSource-разработке десктопного линукса не то, чтобы нет денег... Они есть: разнообразные гранты, пожертвования, платная поддержка, выделение свободного процента времени сотрудников компанией, оплата разработки кода через коммиты в опенсорс от компаний или просто выкладывание всего инструмента в опенсорс, программы господдержки национальных ОС, в конце-концов. Но там нет бизнеса: как правило, ни одна из этих форм оплаты не принимает в качестве метрики успеха количество удовлетворенных или даже просто пользующихся продуктом пользователей.
А без интересов бизнеса в отношении пользователей нет возможности продвигать решения, неинтересные для разработчиков: сама разработка (написание кода, тестирование, документация) и запиливание новых фич занимает едва ли 30-40% в разработке продукта. Остальное занимает: предварительная аналитика существующих продуктов и рынка, разработка унифицированных и документированных интерфейсов (в случае GUI это соглашения об одинаковых паттернах использования элементов, в случае API это единообразность и логичность методов и формата данных), высокоуровневая документация, которая описывает принципы, по которым строится работа с продуктом ("все есть файл" — это именно такой принцип, например), изучение пользовательских задач и путей (не доступная пользователю функциональность, а то, как и для чего он ее будет использовать: например, подход к tar с этой точки зрения заставил бы добавить ключи --archive и --unarchive), логика миграции между разными версиями, механики проброса низкоуровневых ошибок на уровень пользователя, и так далее.
Но для всего этого, как правило, необходимо подняться на уровень выше, начать рассматривать комбинацию инструментов как систему, которая представляет собой нечто большее, чем сумму входящих в нее частей.
Но это противоречит философии Unix: зона ответственности разработчика кончается на том, что он делает функциональную программу с унифицированным вводом-выводом.
О том, насколько интерфейсы этой программы совпадают с другими программами (насколько ключ -v одинаково работает у всех консольных утилит, например: --v/-vv/-v 1 и так далее), он уже не заботится: в данный момент ему удобнее принять решение о создании интерфейса по своему вкусу (никто не регламентирует создание нового интерфейса), а в дальнейшем не существует механизма вывода успешных решений на уровень составного продукта. Создав новое удачное интерфейсное решение в опенсорсе, вы оказываетесь меж двух зол: либо применить его у себя, и тем самым, нарушив хоть призрачный, но паттерн проектирования, либо забыть об этом удачном решении, и поддержать бездействием устаревшие концепции девяностых годов, созданные в других условиях и для другого поколения пользователей. Сделать так, что это удачное решение сможет попасть в другие продукты, которые разрабатываются рядом с вами, почти невозможно. Отчасти за это отвечает обратная совместимость, но это не единственный механизм: с болью и возмущениями python смог перейти на третью версию, значит, это вполне возможно.
Примеры? Да сколько угодно.
Проблема #1: отсутствие изоляции программ
Традиционный Windows-путь — это хранение данных в папке пользователя, а настроек программы в папке с программой. Нужные программе библиотеки, за исключением системных и всяких .Net Framework, хранятся в той же папке. То, что windows довольно долго была де-факто однопользовательской ОС, наложило свой отпечаток в виде того, что не было ничего страшного в том, чтобы хранить настройки вместе с кодом и библиотеками: все равно это настройки конкретного пользователя. А если ему очень нужны другие настройки, то он может сделать копию папки.
Был еще вариант хранить свои настройки в реестре, но это штука, которая убивает плюс миграции, не принося ничего взамен, кроме некоторого упрощения логики записи-чтения настроек.
Сейчас Windows приходит к модели разделения пользователей друг от друга и от системных данных, поэтому современные программы теряют права на запись в свою папку с исполняемыми файлами и библиотеками совсем, а настройки предлагается хранить в глубинах домашней директории пользователя (как в Linux, см. ниже).
Традиционный Linux-путь (ну, точнее, *nix-путь) — это хранение настроек и данных в домашней папке пользователя (отличный задел), а библиотек программы — размазанных тонким слоем по системе. Так сложилось исторически, потому что *nix системы представляли собой многопользовательские системы, запущенные на едином "сервере", к которым пользователи подключались с помощью "тонких клиентов" (очень тонких) — в минимальном варианте это был принтер и клавиатура, что и определило текстово-консольный интерфейс как основной, заложив основы того, что позволило Linux занять свое текущее положение на серверах. Со временем "очень тонкий клиент" превратился в монитор, к которому подключался либо знакогенератор, либо упрощенный компьютер. Это, в свою очередь, привело к тому, что графический интерфейс оказался разделен на серверную и клиентскую части, что доставило (и продолжает доставлять) немало проблем в условиях, когда в таком разделении нужда отпала. Из-за множества пользователей логичным решением было экономить место на жестком диске, жестко отделяя исполняемые файлы от данных, и как логичный следующий шаг — экономить место среди исполняемых файлов, разделяя выделенную логику конкретного приложения и библиотеки, которые могут использоваться не только этим приложением. Это почти не давало выигрыша в ранних однопользовательских системах (все равно приходилось хранить как минимум одну копию исполняемых файлов и библиотек к ним), но ощутимо экономило место для многопользовательских систем.
Но в современном мире ситуация изменилась.
Во-первых, резко возросло количество библиотек, пакетов, и их зависимостей, вырос темп разработки, а место на жестком диске очень сильно упало в цене.
Во-вторых, современные системы — однопользовательские. Ну, в худшем случае, двух- или трех-пользовательские: стоимость железа такова, что не проблема купить каждому пользователю по компьютеру или даже по высокопроизводительной рабочей станции (она все равно не будет стоить больше пары зарплат специалиста). А если ресурсов ее не хватит — с развитием интернета к вашим услугам огромное количество облачных серверов: стоимость и развитие аппаратных ресурсов, позволяет переносить многопользовательность в область виртуальных машин: накладные расходы на это небольшие, их с лихвой окупает изоляция и возможность кастомизации каждой виртуальной машины.
В тех применениях, где присутствует все-таки множество пользователей (например, в веб-сервисах), их количество настолько большое, а спектр запросов настолько мал (я имею ввиду функциональность одного сервиса по сравнению со всеми комбинациями инструментов в *nix), что нет никакого смысла отдавать им настоящую системную многопользовательность со всеми ее возможностями и недостатками, гораздо проще написать свою, маленькую и карманную, сделав это выше системного уровня, на пользовательском уровне ОС: когда база данных одна, логика приложения одна, веб-сервер один, все это работает от одного или от 2-3 пользователей ОС, но внутри они разделяют между собой тысячи аккаунтов клиентов.
Из всего этого можно сделать вывод, что современная многопользовательность на уровне ОС — это фишка на 50% для удобства разделения пользователей и их данных в рамках одного компьютера, и на 50% для безопасности. Разделение пользователей пригождается, если у вас все-таки один домашний компьютер, а для безопасности хорошо, когда процесс веб-сервера не может читать данные процесса базы данных, и оба они не могут переписать системные файлы.
По факту, современные системы — однопользовательские. Это не означает, что от многозадачности надо избавиться, но означает, что практически не встречается ситуации, когда у нас в одном пространстве ОС существуют множество пользователей, использующих одни и те же программы и библиотеки, чтобы их "схлопывание" серьезно экономило деньги, затрачиваемые на хранение их в памяти.
Однако, софт в Linux до сих пор использует концепцию разделяемых библиотек, отчасти "потому что так сложилось", отчасти по причине плюсов, связанных с безопасностью: ошибка, допущенная в ssl-библиотеке может создать уязвимость в десятке приложений, ее использующих. В случае разделяемых библиотек достаточно будет обновить пакет библиотеки, и при условии неизменности ABI библиотеки, все остальные приложения сразу же исправят уязвимость без каких-либо действий авторов и мейнтейнеров.
Альтернатива — это пакетирование программ в самодостаточные сборки, со всеми (или большинством) зависимостей. Вариантов много — Application Bundles / AppImage / Snappy (Ubuntu) / Flatpack (Gnome), но они тоже имеют недостатки и критику.
Однако и текущая реализация механизма разделяемых библиотек и установки пакетов с зависимостями — это далеко не совершенная конструкция, которая на задачах чуть сложнее стандартных легко скатывается в dependency hell, что тут же на порядок повышает сложность обслуживания системы: там где в Windows надо просто переустановить программу, в Linux приходится ковыряться в глубине пакетного менеджера. Причем получить ситуацию ада зависимостей можно достаточно легко — при попытке поставить новую версию ПО, которая требует новой версии библиотеки, которая несовместима с существующим ПО, погуглить, как установить вторую версию библиотеки, ввести пару команд с SO... Все, apt-get невнятно ругается, не предлагая никаких осмысленных действий. В связи с отсутствием механизма миграции (см. следующий пункт) альтернатива "снести все и поставить заново" превращается в долгий и нудный перенос данных и настроек — тоже плохой вариант.
У меня нет готовой идеи, как решить этот вопрос: у обоих подходов есть минусы, и есть плюсы, даже если не принимать во внимание призрачную экономию места. Однако проблема абсолютно точно есть, но без четкого понимания, кто будет за ее решение платить, двигаться ситуация никуда не будет. И кстати, мнения что динамическая линковка это не всегда хорошо, придерживаюсь не только я.
В качестве рабочего примера можно посмотреть на Docker. Так как он работает в сегменте серверного Linux, то там есть интересы бизнеса (в стоимости ресурсов, поддержки, обновлений, обслуживания, раскатки и т.д.), который видит решение проблемы и из-за этого голосуют за использование и разработку докера, даже несмотря на ощутимый оверхед по ресурсам.
Это происходит из-за того, что основной плюс докера вовсе не в быстрой раскатке и обновлении приложений — этого можно было бы добиться и с Ansible, например.
Сила докера — в самодостаточности образа (все нужное окружение он несет в себе, и при правильном проектировании образа есть хорошая гарантия, что он запустится где угодно) и принудительности хранения данных и настроек отдельно от кода (так как образы докера эфемерны и легко удаляются и создаются заново при обновлении или новом деплое, и для юзера, де-факто, неизменны, а значит, заставляют хранить данные в другом месте).
Всем этим докер сводит логический модуль к черному ящику: дай ему ресурсы (память, хранилище, процессор, сеть), укажи место хранения настроек и данных через унифицированный механизм ФС (хоть что-то у нас есть унифицированного), и дальше он будет работать сам. Сломался код? Надо мигрировать на новую версию? Образ убивается, собирается новый, запускается с теми же параметрами, и опа, все работает как и прежде.
Я говорю о логических модулях, потому что изолируются именно куски логики (бизнес-логики, если угодно), а не отдельные программы: контейнер может включать в себя, например, два сервиса на разных языках программирования (или на языках разных версий), сами языки программирования, их зависимости и библиотеки, логику обслуживания при падении, централизованный клиент сбора логов, мониторинг, локальную временную БД, и так далее. И у десяти разных контейнеров это не размазывается тонким слоем по системе, начиная интерферировать друг с другом, а работает изолированно и обособленно друг от друга, непринужденно убивается, сносится и ставится заново, никак не ломая хост-систему и друг друга.
И именно поэтому, несмотря на ситуацию, когда образ с единицей логики в 5мб весит 500мб, потому что тащит за собой копию потрохов системы, такая концепция настолько упрощает работу, что "на ура" принимается бизнесом.
И что интересно, этот подход вовсе не имеет таких глобальных проблем с безопасностью, как можно было бы ожидать от пакетирования программ: так как образы у нас состоят из слоев, их можно обновлять, по сути, независимо друг от друга (на самом деле, нет, они накатываются заново, но для конечного пользователя отличия только во времени обновления), поэтому исправление уязвимости в стандартной библиотеке в слое базовой системы автоматически применяется ко всем работающим приложениям, не требуя внимания создателей слоя конечного приложения. Нечто подобное можно было бы реализовать и для установки программ для десктопного линукса.
Проблема #2: сложность миграции с версии на версию
Во время многопользовательности линукса настройки были разделены на два места: настройки пользовательских программ и настройки общесистемных программ. Пользовательские настройки лежали в /home/user/.config, а системные, которые применяются к программам, запущенным не от пользователя или используемыми всеми пользователями — в /etc.
Но в процессе превращения в де-факто однопользовательскую систему эта стройная логика была разрушена.
Например, xorg/x11 — в текущей реальности это программа пользовательского уровня: настройки в ней настраивают конкретную видеокарту и конкретный монитор пользователя. Второй может пользоваться консолью, третий ходить исключительно по ssh. Но файл настроек лежит в /etc (и хорошо если не в /usr/share/X11), и он одинаков для всех.
apt-get — тоже программа пользовательского уровня. У каждого пользователя могут быть свои репозитории, и негоже пытаться установить python-4-alpha-dev всем пользователям только потому, что для одного из них это обычная среда. Но конфиги и репозитории лежат в /etc. apt-get, кстати, запускается тоже только от root.
Ладно, фиг с ними, с репозиториями. Но вот список установленного софта — уж точно пользовательская штука, правда? Я на каждый компьютер ставлю определенный список программ, и если уж у нас есть рабочая система с репозиториями, которая снимает необходимость качать и ставить софт вручную, давайте же упростим задачу установки любимых программ на новую систему. Как мне получить список установленных мной пакетов?.. Никак. Не существует нормального механизма, который бы показал, что именно вы устанавливали (есть вот такие неофициальные решения, которые могут сломаться в любой момент), и не предполагается никакого метода хранения этого списка вместе с пользовательскими настройками.
Ладно установленные программы, раз они шарятся между юзерами, то может и правда логичнее ставить их всем, не разбираясь. Но вот запускаемые программы-то — это собственность пользователя, правда же? Ну, я поставил мускуль, коллега постгри. Каждый из-под своего аккаунта. При старте запустятся оба, если не сделать сложных телодвижений по поводу запуска из скриптов оболочки. Какая там многопользовательность, о чем вы. Я понимаю, что на это есть причины, и даже знаю, какие. Но эти причины не отменяют то, что список программ, которые при запуске нужны мне, как конкретному юзеру, лежат в /etc.
Что у нас там еще из пользовательских программ? reboot. Пользователь же может перезагрузить компьютер, правда? Это же его компьютер? Нет, не может? Нужен root? Блин.
openvpn, ppp — тоже же пользовательские штуки. Зачем другому пользователю мой корпоративный vpn и зачем для его добавления себе нужен root? Но лежат в /etc.
Ладно. Как я уже говорил, я установил себе БД для работы. База запускается от своего пользователя, mysql:mysql какой-нибудь. Настройки лежат... Наверное в /home/mysql/.config/mysql? Нет не угадали. Тоже в /etc! Почему? А вот. Ладно. БД хранит данные где-то на диске. Где они хранятся, в /home/mysql/data? Нет. В /var/lib/mysql. Ну йооооханный.
Особенно весело, когда вам и вашему коллеге надо будет поставить две одинаковых БД с чуть разной версией. Опытный админ пошлет вас на х.. запускать виртуалку или ставить в докер, и будет прав.
В общем, тут надо или крестик снять, или трусы надеть: или перестать делать вид, что система многопользовательская и начать концентрировать конфиги в одном глобальном месте, либо сделать систему действительно разделяемой многопользовательской, в которой у каждого пользователя свое окружение и свои конфиги.
Ситуацию осложняет то, что программам предоставлена полная свобода: кто где хочет, тот там и хранит данные/бинарники/настройки, кто хочет, тот от такого юзера и запускается. Система, вместо того, чтобы ограничить программы и дать им выбранное системой место для хранения (она же тут главная, она организует место, она выделяет ресурсы, она изолирует программы, она следит за тем, чтобы все получили свою долю тиков), в этом месте расслабляется и "ну вы там как-нибудь разберитесь сами, сделайте как деды завещали". Пацифизм губит ухоженные сады, вот это все. Оно ведь не только про общение, а про любые разделяемые ресурсы в условиях множества независимых агентов.
Что в итоге? А в итоге, миграция на новую систему — адский геморрой: скопировать свою папку недостаточно, часть файлов надо вытащить из /etc, но все копировать нельзя, потому что это сломает новую инсталляцию, часть файлов собрать по системе, никогда не знаешь, на что наткнешься в следующий раз, список пакетов получаешь с трудом (о существовании возможности это сделать кроме как через history|grep install я узнал только при написании этой статьи, хотя опыта с линуксами с полтора десятка лет).
Несмотря на то, что официальный способ конфигурирования — через текстовые конфиги, никто не реализовал способ сравнения конфигов (неважно, через diff или через layers ФС), чтобы иметь хотя бы представление "а что я там в конфиге в прошлый раз правил", чтобы отделить свои правки от системного стока. Вот в гите такое есть, потому что это требование бизнеса в виде разработки, а в ОС.. И так норм, мы привыкли.
В винде таскается пользовательская папка, папка с инсталляторами программ. Системные настройки приходится настраивать заново (но можно выборочно экcпортировать в .reg, благо, от версии к версии их место не особо меняется). Не идеал, но жить можно.
В макоси творится магия: мало того, что программы пакетированы, и переносятся копированием файлов за некоторым исключением, так еще и все настройки таки хранятся в папке пользователя. Как будто этого недостаточно, еще и есть встроенный инструмент, который при переходе на новое железо с новой системой корректно все переносит по нажатию трех кнопок. Все файлы пользователя, все настройки, весь софт, и остается сделать пару мелочей: дать разрешение программам, установить console tools и тому подобное.
В серверном линуксе это решается с помощью ansible, который хранит все настройки и действия по приведению чистой системы в рабочее состояние, или с помощью докера, который хранит данные и конфиги в определенных на стадии запуска контейнеров местах, а процесс развертывания бинарников и сопутствующего — в докер-файлах. Но это требует некоторой культуры и необходимости разворачивать все заново при изменениях в конфиге.
Десктопный линукс... десктопный линукс сидит и ест клей.
Проблема #3: отсутствие единого конфигуратора
Эта проблема отчасти пересекается с прошлой, но она, тем не менее, отдельна: множество мест хранения настроек мешают не только миграции, но и настройке системы.
Например, настройка скринсейвера и вообще выключения экрана.
В макоси — один ползунок. В винде — два разных места, в одном ползунок, во втором, через интерфейс пятнадцатилетней давности можно настроить более точно.
В андроиде — не помню точно, везде ли можно отключить это совсем, но тоже обычная менюшка.
В iOS — в менюшке.
В линуксе... ну, в интерфейсе вы можете отключить скринсейвер. Но это не означает, что экран не будет выключаться. Функция "отключить скринсейвер" отключает скринсейвер, программу-делающую-красивые-картинки. Локскрин, отключение экрана для экономии энергии, и так далее, она не отключает.
Кроме того, настройки отключения экрана для консоли и иксов — в разных местах. В общем, если вы погуглите "как отключить скринсейвер и отключение экрана в линукс", то соберете вот такую библиотеку разных вариантов уже с первой страницы гугла:
"consoleblank=0" >> /sys/module/kernel/parameters/consoleblank
"setterm -blank 0" >> /etc/rc.local
"setterm -blank" >> /etc/init.d/boot.local
"sleep 10 && xset s 0 0 && xset s off && exit 0" > autostart.sh
"xset s off" >> .xsession
'setterm -blank 0 -powersave off -powerdown 0' >> ~/.xinitrc
DISPLAY=:0.0 xset s activate
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash consoleblank=0"
Option "DPMS" "false" > xorg.conf
TERM=linux setterm -blank 0 -powerdown 0 -powersave off >/dev/tty0 </dev/tty0
apt-get remove xscreensaver
echo -ne "\033[9;0]" >> /etc/issue
gconftool --type int -s /apps/gnome-power-manager/backlight/idle_dim_time ***time***
gconftool-2 --direct --config-source xml:readwrite:/etc/gconf/gconf.xml.defaults --set -t boolean /apps/gnome-screensaver/idle_activation_enabled false
gconftool-2 --set -t boolean /apps/gnome-screensaver/idle_activation_enabled false
gnome-screensaver-command -d
gsettings set org.gnome.desktop.lockdown disable-lock-screen 'true'
gsettings set org.gnome.desktop.session idle-delay 0
gsettings set org.gnome.settings-daemon.plugins.power active false
remove @xscreensaver -no-splash from ~/.config/lxsession/LXDE/autostart
setterm -blank 0 -powerdown 0
setterm -blank 0 -powersave off
systemd-inhibit sleep 2h
xset s 0 0 &
xset s noblank
xset s off && xset -dpmsГотовы сказать, какие из них будут работать, а какие нет? Какая-то команда меняет поведение сразу, другая команда записывает это в автозапуск, третья пытается что-то конфигурировать центрально...
Из-за отсутствия единого центра настроек, даже такой простой вопрос "а как мне выключить вообще любое отключение экрана" требует как минимум нескольких часов работы довольно дорогостоящего специалиста.
И такое — с почти всеми нетривиальными настройками системы. Разрешение монитора не определяется нормально? Добро пожаловать в волшебный мир конфигурационных файлов иксов (или wayland, если вам "повезло". Повезло в кавычках — потому что документов по конфигурированию wayland-а еще меньше). Хотите повернуть экран? Выбирайте:
gsettings set org.gnome.settings-daemon.plugins.orientation active false
xrandr -o normal
xrandr --output HDMI1 --rotate left
xrandr --output LVDS1 --rotate left
xrandr --output $(xrandr |grep eDP|cut -d" " -f1) --rotate left
xrandr --output LCD --auto
"[output] \n name=HDMI-A-1 \n transform=90" >> weston.ini
"display_rotate=1" >> /boot/config.txt
"video=DSI-1:800x480@60,rotate=0" >> /boot/cmdline.txt
snap set pi-config.display-rotate=2
snap set pi-config.lcd-rotate=2
"lcd_rotate=2" >> /boot/config.txt
"display_hdmi_rotate=2 " >> /boot/config.txt
"display_lcd_rotate=2" >> /boot/config.txtНу, вы поняли. В зависимости от того, хотите вы повернуть экран вообще, на уровне драйвера HDMI, или немножко, на уровне иксов, хотите вы его переворачивать в процессе работы или один раз, в зависимости от того, в какой из портов на видеокарте у вас подключен монитор, в зависимости от того, ноутбук у вас или десктоп, в зависимости от того, малина у вас или x86, в зависимости от того, NVIDIA/AMD/Intel у вас видеокарта, вам нужны разные команды.
Часть команд, которые вы найдете в интернете, безобразно устарела. Часть — от других операционных систем и других рабочих сред. Часть — настраивают не то.
И такая штука — со всеми нетривиальными настройкам. Я могу понять, когда мне надо искать тонкости настройки пересборки ядра для включения туда какого-то модуля: нет смысла выносить это в интерфейс, потому что эта функция нужна очень редко и не нужна обычным пользователям, нет смысла включать ее в юзерспейс.
Но уж команды отключения скринсейвера, настройка мониторов, разрешения, поворота — явно юзерспейс. И куча прочих таких штук, которые настраиваются в конфигах, и не просто в конфигах, а в непонятных местах, которые можно найти только методом перебора и тестов.
Когда вы берете консольный Debian, ставите туда хорг, потом ставите свое любимое окружение, это понятно. Вы собрали конструктор, это не поставляется вместе. Когда вы берете убунту, которая поставляется в виде продукта, там должен быть нормальный конфигуратор основных функций системы, или это какой-то так себе продукт. Как этот конфигуратор будет реализован — через переработку всех интерфейсов или через генерацию конфигов для разных программ из единого файла конфигурации, не суть важно.
Кстати, единый файл конфигурации в стабильном формате — это замечательная идея для решения предыдущего пункта про миграцию. Неважно, какие там конфиги лежат внизу, где они лежат, и как они изменились с прошлой версии системы. Важно то, что новая система способна распарсить файл конфигурации с прошлой системы и на базе него создать эти полтора десятка конфигов.
Проблема #4: рассинхронизация интерфейсов общения с пользователем
Вот например, довольно обычная ситуация для любой системы: запускаемая программа не запустилась, а упала, например, не найдя библиотеку или файл конфигурации. Для Windows базовым интерфейсом взаимодействия является графический, поэтому ошибка будет выдана в виде системного диалога.
Для Linux базовый интерфейс это текстово-терминальный, поэтому ошибка будет выдана текстом в терминале. ...если, конечно, вы запускаете программу из терминала. Если вы запускаете ее из GUI, то ошибку программы можно найти: а)в ее собственном логе, б)в системном логе в)нигде, потому что несохраненный в терминальной сессии вывод stdout/stderr нигде более не сохраняется. Для решения этой проблемы надо иметь договоренность о том, что при завершении программы с кодом ошибки надо показать пользователю сообщение об ошибке, и это сообщение не должно составлять собой содержимое stderr, а быть кратким, в одну строку, и действительно описывать место, где произошла ошибка.
У Windows это есть, хоть иногда и встречается невнятное "Память не может быть read" и "Error 0x000000F2DA563333".
У MacOS это реализовано хуже: ошибки в программе скорее всего выведутся, а вот некоторые программы могут падать при запуске, ничего не говоря
В Linux нормальна ситуация, когда ты нажимаешь кнопку в интерфейсе, она не нажимается, и ничего не говорит. И только в консольном выводе можно увидеть ошибку библиотеки фреймворка, которая говорит, что undefined какой-то аргумент объекта кнопки.
В итоге, даже просто желание погуглить ошибку при работе GUI программы зачастую превращается в увлекательный квест. С консольными программами тоже есть приколы — в целом, пользователь не знает, куда складывает лог конкретная программа: это может быть свой лог в соседнем файлике или текущей папке, это может быть /var/log/program_name, это может быть какой-то общесистемный журнал или журнал конкретного метода автозапуска программы.
Проблема #5: непроработанность функциональности ПО и неконсистентность инструментов
Это уже последствия отсутствия продуктового подхода: разработчики рассматривают программу как некий интерфейс, в котором есть объекты, которые вызывают функции. Нажимаем кнопочку — выполняется команда. Так же, как в консоли, набрали команду, нажали ввод, команда выполнилась, только вместо команды — кнопка в интерфейсе.
О том, как пользователь пользуется всей программой в целом — не задумываются. Условно, если мы сначала копируем один обьект, а потом в 99% его вставляем рядом, хорошо бы не закрывать меню с кнопками "копировать" и "вставить", это меньше движения курсора, меньше кликов. А еще хорошо бы сделать кнопку "дублировать". Это самый простой синтетический пример.
Реальные проблемы сложнее и включают в себя множество действий, которые часто выполнятся друг за другом в рамках одной пользовательской сессии, и которые хорошо бы сворачивать для упрощения работы. Или действия, которые выполняются наоборот, очень редко, и каждый раз вызывают недоумение у пользователя, потому что он успевает забыть, как именно это делается. Такие действия наоборот, можно разбивать на несколько более простых шагов, чтобы упростить пользовательский путь: логическую цепочку запомнить проще, чем магическую кнопку, спрятанную в недрах меню. А если она не спрятана в меню — все еще хуже, потому что ненужные и неиспользуемые функции загромождают меню, и не дают вынести в него то, что нужно на самом деле.
Но для этого надо понять, что именно делают пользователи, и как они это делают. У разработчика может не быть проблем — он, в конце-концов, сам проектировал этот интерфейс, и он точно сделан идеально под него. У опытных пользователей тоже может не быть проблем: они уже привыкли и ощущение "блин, ничерта непонятно" у них уже давно в прошлом (как пользователь Blender и Eagle заявляю, что привыкнуть можно к любому интерфейсу, если пользуешься им достаточно часто).
И вот тут опять же, провал: проблемами пользователя никто не занимается. Можно сравнить GIMP и Photoshop, Inkscape и Illustrator: базовый функционал у них действительно похож. Но покажите обе программы начинающему пользователю, и будет понятно, в чем разница.
И проблема не в ресурсах на разработку, они есть. Проблема в том, чтобы понять, куда разрабатывать.
Итоги
Все описанное выше — это не какие-то недоработки, которые можно взять и исправить, или страдания миллениалов, не могущих освоить не очень сложный интерфейс (а ваши деды в микрокодах писали!).
Это системные прое.. проблемы в архитектурной части, для исправления которых нужны значительные ресурсы не только в части времени и денег, но и запас проектной диктатуры, и смелости ломать уже существующие пользовательские привычки. Ведь, поправив все это — линукс уже не будет той системой, к которой привыкли эти миллионы людей, составляющие два процента. Лично для них миграция будет более болезненной и неприятной, чем освоение новой системы новичком.
К тому же проектной диктатуры в Opensource не хватает, потому что система построена на интересе. Уменьши интерес от запиливания новых фич, сказав "нам надо заниматься рефакторингом и слушать вот этого чувака-продакта безоговорочно" и разработчик пойдет коммитить в другой, более лояльный к интересам разработчика проект.
У меня нет плана, как это все исправить. Деньги — не настолько большая проблема, как кажется: они есть у государства, например. Правительство вполне понимает риски завязывания всей IT-структуры страны на чужое ПО и может выделить деньги в рамках программы импортозамещения, например. Гораздо важнее, как построить структуру так, чтобы эти деньги пошли именно на продуктовую разработку: как я уже говорил, для этого необходимо сделать метрикой успешности удовлетворенность пользователя.
Но, выделяя деньги на "российский линукс" абстрактно, это сделать невозможно: если государству нужен российский линукс, у него будет российский линукс, а про качество продукта там ничего не сказано.
Если выделить деньги госучреждениям с тезисом "закупайте сами", они закупят привычный Windows.
Если сказать "закупайте что угодно, кроме Windows", закупят ту систему, которая откатит больше бонусов: выбирать из десятка систем сложно, потому что они все одинаково кривые.
Если так и поставить задачу "сделайте линукс, которым удобно пользоваться", то сделают линукс, которым будет удобно пользоваться по мнению экспертной комиссии, а не по мнению пользователей: без свободного рынка оценить удобство можно только экспертно, а вот критерии экспертности уже формализуются настолько сложно, что никто этим заморачиваться не будет (или будет, что еще хуже).
Но если все пойдет, как идет сейчас, то Linux как Desktop-система продержится еще 5-10 лет, вряд ли больше: Microsoft осознает свою проблему в отсутствии POSIX-совместимости и невозможности работать со всеми теми наработками в OpenSource, созданными за 20 лет, и активно впиливает поддержку, используя ядро Linux внутри своей системы. Через некоторое время интеграция станет настолько хорошей, а инструменты вроде терминала разовьются достаточно, чтобы те, кто работал на Linux из-за удобства разработки, отладки и запуска серверных решений, перешли на винду: разницы нет, а интерфейс и удобство на порядок выше. И тогда десктопный линукс останется уделом полупроцента фриков и параноиков, из-за чего любая разработка заглохнет окончательно.
P.S. Что забавно, несмотря на многократное использование слова "Linux" в статье, к Linux-как-ядру описанные проблемы как раз имеют мало отношения: благодаря единому центру принятия решения о стратегии развития можно не опасаться проблемы абсолютной демократии, когда продвигаются решения, которые имеют меньше всего возражений. Там есть деньги, есть диктатор, который в любом случае фиксирует то или иное решение, и понимание того, что фиксировать решения необходимо. Ну и "пользователи" ядра Linux — это все еще категория разработчиков, а не конечных пользователей.


0mogol0
Помнится, в конце 90ых в Компьютерре была большая, и в принципе толковая, статья на тему «почему Линукс не заменит на десктопах Windows», где объяснялось, что линукс прекрасно реализует серверные фичи, но конечному пользователю они зачастую не нужны, а то, что ему нужно в линуксе отсутствует и никто не планирует разрабатывать.
В фидошных эхах типа RU.LINUX кто-то запостил эту статью и понеслось. Меня я помню впечатлил один из первых комментариев, в котором товарищ рассказывал как легко и просто он может на домашнем компе с линуксом развернуть БД и почтовый сервер, а для экономии ресурсов (напоминаю, это где-то 97-99 год) отключить GUI и что ничего подобного невозможно в винде. На робкие попытки ответить, что развёртывание БД и почтового сервера на персональной машине — не самые частые задачи «обычного пользователя ПК», а вот запуск игр, редактирование текстов или просмотр гифок — гораздо более часто встречающиеся, и на Линуксе они реализованы мягко говоря не очень — были всеми дружно проигнорированны.
И мне кажется в этом именно и есть проблема — Линукс разработчики делают «под себя», и just for fun, и думать о пользователях и заставлять себя работать на пользовательские хотелки — это превращает хобби в работу. Так что как по мне — вероятность развития линукса как десктопного окружения невелика, но зато он сможет служить инкубатором для будущих идей для десктопов.
В свое время ядро для новой макос взяли у FreeBSD (если ничего не путаю), чем очень любили хвастать её сторонники, когда система взлетела. И очень обижались, когда у них спрашивали, верят ли они, что система взлетела только потому, что там в ядре фря, или потому что Джобс заставил написать к ней отличный, продуманный GUI…
mistergrim
sparhawk
Нет, надо бы раз и навсегда разобраться и понять, кто чей сын)
Ой, оказывается, это уже разбирали на Хабре: habr.com/ru/post/198016
Если коротко, то BSD — это набор концепций и API системы. Реализация ядра может быть сделана на основе некоего эталона (FreeBSD), так и «с нуля». Причем совместима только на уровне исходников (и то теоретически), а не бинарно.
Грубо говоря, у macOS X+ свое микроядро, а некоторые подситемы взяты из FreeBSD, NetBSD и др.
lealxe
Вы BSD с Posix перепутали. BSD — это генеалогия от BSD Unix.
Dmsrg
Ядро не брали, но взяли так много кода из различных подсистем, что такая вот легенда родилась.
fedorez
не вполне так. Darwin, лежащий в основе макоси, такой же потомок BSD, как и фря.
kekoz
Казалось бы, немыслимой сложности задача, но на самом деле всё довольно просто: открыть (всем доступно) “Kernel Programming Guide” на сайте developer.apple.com (надеюсь, это считается авторитетным источником? :), там открыть главу “BSD Overview” и прочитать собственноглазно всего лишь половинку самого первого предложения.
icCE
а лучше все запостить
```The BSD portion of the OS X kernel is derived primarily from FreeBSD, a version of 4.4BSD that offers advanced networking, performance, security, and compatibility features. BSD variants in general are derived (sometimes indirectly) from 4.4BSD-Lite Release 2 from the Computer Systems Research Group (CSRG) at the University of California at Berkeley. BSD provides many advanced features, including the following```
icCE
ну и можно добавить, что например на 5 версию слоя bsd они переползли в 7 версии darwin или в пантере (BSD layer synchronized with FreeBSD 5)
WinPooh73
Программист из компании Эппл
В снах кошмарных исходники грепал.
Находил же везде
Код из Фри-Бэ-Эс-Де,
И чесал озадаченно репу...
viklequick
Однако же бредовости тезисов в статье это никак не отменяет.
Я как-то себе слабо представляю «неподготовленного пользователя» с фреймворками и стек оверфловом наперевес, которым нужен «единый конфигуратор», но при этом их почему-то бомбит от деталей размещения конфигов в системе. Для которых смайлик на BSOD и квадратики в квадратике — это ок, а прочесть в логе или терминале об ошибке — это ай ай :-)
0mogol0
ну тут есть несколько упрощений:
* помимо квалификаций условного админа и секретарши / бабушки, есть целый спектр пользователей с разным уровнем подготовки. И если для админа и продвинутого пользователя не проблема поискать информацию где-то ещё, то для среднего пользователя — это уже не очевидный вопрос.
Справедливости ради — за пять лет на домашней Win10 видел BSOD один раз по моему. И в принципе, всё работало именно в режиме «next-next-next-complete» и дальше я могу либо работать над своей задачей, либо играться. Это не значит, что у всех остальных винда работает так же, но в сравнении с 95/98ой прогресс на лицо.
В тоже время, линукс (кубунта последний lts) у меня бегает на старом ноуте, где постоянно приходится гуглить решение каких-то мелочей, типа почему не работает переключение между окнами в обратном порядке, почему не закрывается окно оповещения итп. Это мелочи, но они заставляют работать над ОС, а не над моими задачами. Возможно, если бы я сделал линукс своей основной системой — то удалось бы за полгода допилить его до работоспособного варианта, но в нём нет некоторых нужных мне приложений (схожие не канают), да и не вижу смысла тратить на это свое время, если всё работает в винде.
ИМХО, нынешний десктопный линукс по дружелюбности к пользователю (я не говорю про стабильность, безопасность и прочие безусловно важные характеристики) находится где-то на уровне Win98, когда система уже берет на себя немалую часть задач, но в случае проблем (которые всё равно регулярно всплывают) — тебя по прежнему ждёт много геморроя в процессе их решения.
viklequick
Вот натурально, в Редмонде занялись карго-культом — в линуксе два основных фреймворка для гуев? И у нас тоже будет! У них крутой терминал — и мы тоже…
… существует андроид. Под линуксом. И игр — завались, и офис от микрософта в комплекте, и даже креатив клауд от адоубей.
Так что мелкомягкие не с перепою занялись WSL. Просто время платформы IBM PC уходит, она перемещается в узкую нишу «рабочих станций», как это уже происходило с теми же Sun, DEC и SGI много лет назад. На место «ПеКа» уже пришли планшеты и хромабуки, уже мобильный мир неиллюзорно «поддавливает» на сжимающийся рыночек «десктопов».
И вопрос тут уже — как долго еще продержится платформа Windows.
А мы тут читаем про «нет экспансии линукса в десктопы»… Truly? А зачем? Что тут захватывать, вымирающих домохозяек, которые по недоразумению когда-то купили десктоп?
10 лет назад «мощА» мобильных чипов была на порядок ниже десктопных. Сегодня — они уже наравне. Темпы инноваций — в разы выше. Еще через 10 лет стандартом «десктопа» будет ARM — а у микрософта тут дела швах (даже в сюрфейсе у них собственный офис — в емуляторе). Срочно надо сделать поддержку линуксового софта, а то скоро на новых десктопах под окнами нечего будет запускать :-)
vvzvlad Автор
Она произвольно перезагружалась без обновлений :)
t13s
Ну нееее, приходилось руками. Или через Ctrl+Alt+Del, или резетом :)
Vaitek
Ctrl-Alt- а Del дважды) на первый раз появлялся бесполезный список задач, который мало что показывал и не всегда мог убить зависшее
zuek
Подтверждаю — дважды. И с ожиданием 30 секунд (если просто попытаться снять процесс).
Но, с другой стороны, иногда аптайм на моей Win95OSR2 домашней машинке с ZMH-MMH нодой доходил до полугода. И это я любил почитать книжки в букридере, пошататься по зачаткам интернета, поиграться в Warcraft II и прочие старкрафты с дьяблами… да и ребутать, чаще, приходилось ради очередного апгрейда, а не из-за зависаний/BSOD (хотя когда забыл вентилятор на кулере запитать, познакомился с знакомой всем оверклокерам ошибкой 3F0).
svsd_val
Аптайм на моей рабочей машинке с Debian GNU/Linux год с небольшим был, я тогда ставил все обновления но не перезагружал систему, всё это бы продолжалось и дальше если бы не отключение света и храбрая смерть акб, после этого я перестал гнаться за аптаймом.
0mogol0
Кажется я понял идею разработчиков Линукс, мы будем сидеть на берегу пока мимо не проплывёт труп виндоус. :-) Ну и «зелен виноград» конечно тоже.
Вот только не факт что место покойной займёт линукс в его linux way. Я скорее поверю, что на место винды придёт андроид или макось, которые конечно где-то в глубине могут иметь ядро на технологиях *nix, но любить и ценить их будут вовсе не за это…
Ogra
Нет, вы не поняли идею разработчиков линукс. Совсем. Винда для них не антагонист, а неуловимый джо.
viklequick
Тут другое интересно — именно линуксоиды активно шевелятся и разрабатывают шайтан-арбы разного вида (wayland, привет!), а вот потуги ребят из Редмонда — в положении догоняющего…
Все верно — не займет. Не его это задача.
Уже пришел. И это вдвойне интересно — линуксоиды с их жалкими 2% это давно поняли и активно работают в направлении интеграции с андроид — приложениями, обеспечивают ядро, платформу и тулчейн и себе и андроиду, пилят новые браузера и т д.
А микрософт — ничего подобного не делает. Хотя им-то это куда более актуально :-)
Alex_ME
Кстати, KDE Connect - очень крутая штука. Общий буфер обмена, управление громкостью и воспроизведением, уведомления с телефона на десктопе итп. Встроенный в винду "your phone" даже не близко.
mastan
В каком году появилась поддержка HDR-дисплеев в догоняющей винде и что там с этой поддержкой в шайтан-арбе?
vvzvlad Автор
Макось не придет, потому что у нее принципиально другая концепция — apple продают продукты в виде ноутбуков/компов с экосистемой, а ОС на них это только дополнение, важное, но она не отдельный продукт как windows.
А вот андроид может, особенно если наработки по десктопу в мейнстрим засунут.
PsyHaSTe
Причем линуксом оно будет только если мы говорим про долю рынка или число программ. Если зайдет речь об уязвимостях и т.п. то сразу же окажется что андроид совсем не линукс :)
0xd34df00d
Проблема в том, что вы обобщаете свой личный опыт и делаете из него выводы об объективных качествах систем. У вас убунта на старом ноуте и, видимо, винда на всем остальном, а у меня наоборот: гента (поставленная много лет назад) на рабочей машине, на всех моих ноутах, и так далее, и винда на игровой машине. И впечатления у меня ровно обратные: на линуксе я просто работаю и трачу околонулевое время на его поддержание в рабочем состоянии (несмотря на роллинг-релиз), а в винде все время что-то отваливается по мелочи, и надо гуглить, и некоторые проблемы у меня починились только с полной переустановкой ОС.
У отца вон винда вообще не так давно совсем накрылась, пришлось вызывать мастера ее переустанавливать (я бы и сам сделал, но я по другую сторону океана, это было бы больно).
BigBeaver
Есть смысл переходить с дебиана на генту? Насколько безболезненно это можно вообще сделать?
0xd34df00d
Смысл зависит от того, что вы за машиной делаете, насколько вам нужен роллинг-релиз, или возможность подкрутить фичи у пакетов (у меня вот вим собран без поддержки x11, чтобы он не лагал после перезапуска иксов и подключения к той же screen-сессии, или, например, у меня нет пульсаудио, потому что зачем она мне), насколько мейнтейнеры нужного вам софта в дебиане вас достали, и так далее.
Короче, если вас чем-то дебиан не устраивает, то имеет смысл посмотреть, чинит ли гента нужные вам проблемы или нет. Если плюс-минус норм, то и не нужно.
Безболезненность — ну, я школотроном ещё году в 2004-м попробовал генту, потратил с неделю на то, чтобы разобраться, с тех пор так и живу. Какие-то негативные вещи, конечно, есть, но это мелочи, и они не вызывают достаточного желания перейти (или даже посмотреть) на другие дистрибутивы. Возможность сидеть на тех же иксах, том же openrc, а не тратить время на изучение особенностей вяленда или systemd — это хорошо.
BigBeaver
0xd34df00d
А чего там с Qt?
BigBeaver
Любое Qt приложение кроме лежащих в appimage выдает
0xd34df00d
Это прям как-то совсем жёстко, не ожидал от дебиана.
BigBeaver
Это не совсем настоящий дебиан (avx) — я хотел сборку, заточенную под JACK, и оно правда работает из коробки. Но вот такая подстава вылезла.
Опера, вроде, тоже на Qt сделана, но работает.И кстати да, я соврал. QtCreator запускается. Но попытка запустить уже свой код ведет к
viklequick больше похоже на проблемы с xcb. не?
bogolt
Похоже на проблему разных версий Qt в системе. Посмотрите через ldd какие библиотеки использует программа, можно ей подложить другие через переменную LD_LIBRARY_PATH
У меня такое было что использовались какие-то локальные либы, шедшие с программой а при переходе на системные все заработало.
viklequick
Не факт… Могли конечно и сломать. Или какая-нибудь libQt5Gui покоррапталась. Но вряд ли.
Вероятно, Qt пересобиралась из исходников, и что-то полезное забыли включить в проект. Или по ошибке включили Qt статикой. А может там вообще банально забыли про deployqt, так по интернету сложно сказать.
Но если сам QtCreator и опера запускаются (и KDE поди тоже запустится?), а проблема с собранными в криейторе приложениями, то вряд ли виновата именно системная Qt.
BigBeaver
Antervis
BigBeaver
У меня нет такого пути в системе, и не понятно, должен ли быть.
А вообще, ваша ссылка у меня кликнутого цвета, так что либо я там что-то не понял, либо не посчитал релевантным. Не помню уже. Ну и навыки админства забылись уже с тех пор, как линукс стал дружелюбным)
viklequick
так Mesa обновить / доставить поди надо? И драйвер видео, видимо Intel, заодно :-)
Alex_ME
Arch/Manjaro как промежуточный вариант? Тоже роллинг и есть возможности сборки из исходников при желании.
0xd34df00d
Там, судя по всему (и по рассказам окружающих), нет такой же свободы и чувства владения системой. Опять же, я до сих пор сижу на openrc, потому что к
/etc/init.d/blah {start,stop}я привык, а в этом вашем системдэ ещё разбираться надо. Или, например, я на KDE 4 сидел сильно после выпуска KDE 5 — зачем переходить на новую версию, пока старая отлично работает и есть не просит? Тем более, KDE 4.0 ? KDE 4 я отлично помню, и что там в первых релизах KDE 5 сломали, выяснять на собственном опыте неохота. Или, например, ядро я обновляю раз в несколько лет — а зачем, если и так всё работает?anwender95
А в чем проблема с системд? Надо взаимодействовать с сервисами? Юзаешь systemctl. enable\disable\start\stop.
Недавно надо было превратить одну прогу в службу — даже переписывать ничего не надо было. Просто добавить саму службу с минимальным
Description=Example systemd service.
[Service]
Type=simple
ExecStart=
[Install]
WantedBy=multi-user.target
saege5b
Манжаро спокойно в библиотеках путается.
spider_xp52
если хочется rolling, но собирать по минимуму и если что легко превратить систему в обычную gentoo можно попробовать наш отечественный продукт Calculate Linux
DieselMachine
Я на генте уже больше 10 лет, и последние года четыре столкнулся с такой проблемой при обновлении: время сборки chromium растёт с каждым годом в геометрической прогрессии, а так как Qt его использует в качестве движка (qtwebkit), то и время сборки Qt также растёт. Если 10 лет назад обновления у меня собирались за три часа, то теперь нужно трое суток. Поэтому я стал обновляться раз в год, а при таких редких обновлениях обязательно что-нибудь разваливается, нужно потом руками чинить.
svsd_val
Увы это не только в GNU/Linux так, так везде. Увеличивается сложность программ, увеличивается их функционал.
Во многом тормоза потому что начали использовать монструозные фреймворки, и кучу зависимостей даже на самых элементарных приложениях… так что это всё закономерно
DieselMachine
Время сборки firefox например не так сильно выросло, да и других программ тоже. У меня сборка этих двух пакетов занимает примерно половину времени обновления
svsd_val
Всё зависит от того как у них устроен код, многие перешли на монструозные фреймворки и кучу зависимостей которые особо то и не нужны. Если проект не использует их тогда его время сборки не будет сильно меняться.
alsoijw
Разве бинарной сборки нет? Плюс ещё ccache должен помочь.
DieselMachine
Для chromium была, но уже вроде не поддерживается, для qtwebkit точно нет. Придётся купить комп помощнее :-)
Displacer
Есть бинарный www-client/google-chrome. Вместо chromium-а.
0mogol0
Вы невнимательно меня читали, я написал, что предполагаю, что если сделать кубунту основной системой — то за полгода её можно было бы довести до рабочего состояния и так же тратить мало времени на текущие проблемы.
ИМХО, проблема здешнего обсуждения, что среди участников — мало людей, которых можно назвать «неопытными пользователями» ПК. И потому аппроксимировать наш персональный опыт на объективные качества системы — это нерепрезентативно.
Я не противник линукса, а как серверная ОС он мне весьма нравится. Но повторюсь, что с моей точки зрения пока как универсальная десктопная система (т.е. подходящая для самых разных задач и пользователей разной квалификации), он пока проигрывает в удобстве использования Виндоус и Макос (про эту сужу по отзывам знакомых). И при текущем положении вещей я согласен с автором поста, у линукса нет шансов стать массовой «пользовательской» ОС.
При этом она вполне может сохранить ведущую роль как серверная ОС, а так же основа для новых проектов.
linux_art
Все подобные статьи исходят из порочного тезиса, что у линукса стоит цель стать массовой пользовательской ОС. Не припомню чтобы кто-то из более менее известных реальных контрибьюторов топил за эту идею. Хотя и не исключаю вариант, что пропустил озвучивания такого тезиса.
vorphalack
так и не надо «самой», надо — достаточно распространенной для того, чтоб с тобой начали считаться не потому что «этот клоп зело вонюч». но проблема в том, что до сих пор тут одни пытаются закенселить других, у третьих по жизни NIH, четвертые выпали в манию, пытаются рожать РешательВсехПроблем9001 и забили в очередной раз даже читать багрепорты, а пятые, наоборот, ушли в запой от осознания своей ничтожности, вот мы и имеем что имеем. и это я еще не говорю про борьбу
бобра с осломкоммерсов и фанатиков FOSS разных степенией поехавшести.linux_art
Для того чтобы начали считаться — уже достаточно распространена. А разброд и шатание — это нормальная ситуация. Каждый занимается тем, что ему интересно по тем или иным причинам.
vorphalack
мало. «достаточно» — это когда производители ноутов будут с тобой считаться.
разброд и шатание это хорошо до тех пор, пока это не выражается в полном игнорировании происходящего не в их уютном маняноуте.
linux_art
Не помню когда последний раз видел ноут, с которым были бы проблемы под linux'ом.
vorphalack
везение, без издевки.
linux_art
Вполне допускаю такой вариант.
martin_wanderer
Да вот хотя бы Acer Aspire e5-575g и вообще любой ноут с Wi-Fi на QCA9377 — скорость подлючения без объяснения причин просаживается до единиц мегабит. А запрос в гугл по этой проблеме открывает кроличью нору с десятками нерабочих решений.
linux_art
Asus K42Sj много лет работал без проблем под linux, подарил его приятелю т.к. для меня стал уже слабоват. Под win10 сеть завелась после двух дней плясок с бубнами. Asus x200ca покупался с предустановленной вендой 8. При первом включении обновился до 8.1 и wifi в принципе работать перестал. Сети видит но не подключается. Решить удалось только откатом до 8ки и запретом обновлений. И да, туда линукс вообще поставить нельзя ибо на нем uefi анально огорожен. Таких примеров можно про любую ось найти тонну.
alexeykuzmin0
Я 4-5 лет назад подумал поставить линукс на свежий (около года с момента покупки) на тот момент ASUS ROG (не помню точную модель) — единственным дистрибутивом, live cd которого запустился, был Arch. Все остальные ругались на видеокарту и падали. Арч тоже ругался, но запустился и поставить систему смог, а потом я уже и дрова подтянул правильные
linux_art
Я честно говоря давно не пробовал User-friendly дистры ставить. Как-то давно подсел на Gentoo и не вижу смысла что-то менять :)
alexeykuzmin0
Gentoo был первым же, который я попробовал. Live CD не запустился, а собирать установочный диск самому было бы сложнее, чем поставить Arch
linux_art
Я даже представить себе не могу что должно быть с ноутом чтобы gentoo minimal не запустился… За без малого 20 лет такого ни разу не видел…
alexeykuzmin0
Я тоже не мог себе представить, до этого случая
JerleShannara
Имею такую машину — двухголовая брендовая рабочая станция на базе второго пентиума. Умеет в IOAPIC/APIC, но не умеет в ACPI, плюс apic у неё сломаный и надо кормить любой линукс тонной ключей ядра, иначе не загрузится. Впрочем под виндами она зависает из-за перегрева (почему и как в винде два вторых пня перегреваются — я не знаю), под линуксом спокойно выносит все стресс тесты.
linux_art
«Кормить тонной ключей» и «не запускается» все таки сильно разные вещи.
JerleShannara
Ну так до того, какие ключи ему скормить, надо ещё додуматься, оно виснет в чёрный экран. Информации по железу — почти ноль, там даже южный мост заказной, соответственно гугл мало чем может помочь, зато помогает навык разработки этого самого железа.
NetBUG
Простите, вы серьёзно пишете про этот артефакт как рабочую машину, или всё же это пример нестандартной конфигурации времён ACPI 1.0?
JerleShannara
Естественно нет(кстати, ACPI там нет вообще, оно даже в буклетах заявлено как ACPI Ready, по факту там только APM), она у меня идёт как пример того, где сложно запустить gentoo minimal livecd.
PsyHaSTe
Я ставил несколько линуксов на то же железо где у меня стояла винда. И т.к. я буквально с разницей в несколько дней на одном и том же железе пробовал разные ОСи то впечатления достаточно релевантные. События около 2 лет назад, железо: 3800 рязань, 32гига памяти, 2070 GPU
а. слишком старое железо
б. слишком новое железо
в. слишком старая ось (нужно обновиться на альфа версию с доп. поддержкой рязани)
г. слишком новая ось (нужно немножко откатиться, мб че-то отломали).
Вот как-то так.
А в прошлый раз я ставил убунту и там у меня пакетник не работал. Вот так сразу — после установки и входа в систему. А без пакетника как можно догадаться ничего не работает. В итоге потратил полчаса+ пока понял что интернет-есть, просто днс отвалился. на другом устройстве почитал, как настроить днс, прописал 8.8.8.8 — заработало. Как будет это делать обычный пользовтаель — для меня загадка.
А до того я сидел и компилировал драйвера на вай-фай на ноутбук с репы в гитхабе с 5 звездами, потому что больше его нигде не было. Обычный пользователь тут с вероятность 99% просто смирится что интернет у него только по проводу.
При этом с виндой у меня худшее что происходило — система не может поставить обновления, но каждую неделю показывает напоминалку что мне надо перегрузиться их поставить. Жму "не напоминать" и оно начинает считать очередную неделю. А, ещё лет 7 назад был бсод.
В общем, может у меня карма такая или ещё что, но когда я спрашиваю про линук который "just works" мне крутят пальцем у виска и говорят что я ваще обнаглел. Похожим образом кстати со мной общаются любители вима — я не то что емаксер, у меня вообще IDEA. Но есть очень схожие фразы и манеры построения речи у этих двух (возможно, совпадающих)
hhba
Во-во-во, как это знакомо.
Я слышу байки про то, что «современный линукс может эксплуатировать даже домохозяйка» уже 19 лет. В будущем году будет 20…
FRiMN
Часто совсем наоборот.
Особенно это касается драйверов. Например, около года назад просто не обновлялись драйвера на Nvidia. В чём ошибка и как исправить -- не ясно, т.к. посмотреть скорее всего негде. Либо там тонны непонятных логов. Беглый гуглёж не дал вообще ничего, кроме идиотских советов в стиле "перезагрузите винду".
То же самое с некоторыми играми, которым не подходит то DirectX, то еще что-то по-экзотичней. Кроме того, если я не путаю, то DirectX общий на всю систему.
Или например, внезапно исчезнувший звук в системе. Естественно никакие телодвижения в меню, такие как тырканье переключателей или запуск визардов предназначенных для решения проблем, не дали никаких результатов.
Это я к тому, что для условной "домохозяйки" Windows совсем не "just works". Любые действия выходящие за рамки "запустить MicrosoftWord" вполне могут привести к неустранимым (или устранимым при помощи шаманства в виде переустановки случайных драйверов разных версий для случайных устройств в случайном порядке) проблемам. И чаще всего они решаются переустановкой Винды в стиле "начинаем жить заново".
Я не говорю, что с Убунтой было бы лучше. Я говорю, что и с Виндой так же.
"Домохозяйку" окно настроек современной Винды пугают не меньше, чем окно настроек Убунты.
AndreyHenneberg
Это называется «какая Вам разница, чем не уметь использовать». Потому что всё равно ничем пользоваться не умеют. Радостно поставив Windows (не сами, конечно, а пригласив кого-нибудь), эти горе-пользователи потом через раз дёргают меня, спрашивая, как что-то сделать в Windows, при том, что я эту ОС вижу исключительно эпизодически.
Кстати, лично знаю нескольких домохозяек, которые отлично сидели на Linux. Только одна сначала отказывалась делать обновления, а потом жаловалась, что что-то переставало работать в силу дикого устаревания, а другая вполне себе продолжает на нём же сидеть, хотя там уже давно пора железо менять.
FRiMN
Это я еще забыл упомянуть, как однажды случайно сделал так, что файлы в одной из директорий смог просмотривать только в стоящей рядом Убунте. Окна интерфейса, через который это можно было исправить просто не было в моей версии Винды.
ValeriyFilatov
> Как будет это делать обычный пользовтаель — для меня загадка.
Я конечно извиняюсь, но мне кажется, что _обычный_ пользователь не будет сам ставить/переставлять систему. Он скорее позовет кого-нибудь помочь, и не важно Винды это или Линукс…
У меня немного противоположный опыт, все мои домашние (и дети, и пенсионеры-родители) успешно пользуются Линуксом без нареканий.
Браузер, GIMP, LibreOffice, etc…
У самого были проблемы с Виндами, когда надо было включить что-то не совсем «стандартное», причем я знал _что_ надо сделать, но не мог найти _как_, чтение документации неизбежно приводило к «Обратитесь к вашему системному администратору», в то время как в Линуксе «man <что-то>» в большинстве случаев дает исчерпывающую информацию.
AndreyHenneberg
«Обратитесь к вашему системному администратору,» — прочитал на экране системный администратор и схватился за голову.
Вот интересно, а системный администратор-то как должен угадывать, что случилось? И из каких потаённых гребеней доставать нужную документацию, если ни Гугл, ни Яндекс, ни Утка не знаю ничего даже о существовании этой документации?
BigBeaver
Заплатить микрософту за поддержку, очевидно же)
AndreyHenneberg
Эм… Пробовал когда-то с Windows на рабочей машине. Там всё довольно печально: отвечают по скрипту.
JerleShannara
Лицензионная BOX версия Windows 7 Professional, система обновлений зависла в вечном цикле «перезагрузите для завершения обновлений», семёрка на то время ещё была на нормальной техподдержке. После кучи потраченного времени и выдачи доступа к компу какому-то индусу я получил совершенно стандартый(походу один из двух в мире их техподдержки без расширенного платного плана) — «Попробуйте переустановить систему».
COKPOWEHEU
А второй — «попробуйте перезагрузиться»?
JerleShannara
Именно.
Мне потом люди, которые имели всякие статусы Microsoft Gold Partner сказали, что вообще удивительно, что я дошёл до того, что надо было дать доступ к машине, т.к. обычно это уже требует всяких расширенных уровней техподдержки, которые денег стоят.
DMGarikk
я около 5 лет проработал админом, у меня была и винда и линукс, вот не могу сказать что 'man мне сильно помогал'… единственный плюс линукса в том что инструментов для всякого костылестроения и поиска концов в нем больше, а вот устраивать шаманство с поиском непойми чего 'kernel panic через два часа работы oracle client… вот иди и ищи чё там произошло'
p.s. пару раз раз у меня была реальная проблема с продуктами MS, это в ISA — совершенно мозговыносящий способ проковыривание дырки под FTP на нестандартных портах… еще в exchange тоже такое встречается (где чтото надо магическим способом в реестре искать и менять), а самой винде, только если в настройки dcom влезть (а туда вообще очень редко надо ходить)
не больше чем документация на винду
вот запускаете вы какуюто комманду, а она пишет 'library not found on '' program closed ' (вот именно так, пустые ковычки)
и топаете в гугл… начинаете всякие strace и прочие адовые шаманства… и никакой man вас не спасет
вот достаточно поковырятся в pam модулях, и… и блин тоже вам man не поможет на permission denied
AndreyHenneberg
Прямо-таки сисадмином я был только на Linux, с поиском решений всё-таки проще. Хотя бы в силу более внятной организации документации. И если советовать RTFM — вполне разумный совет для начала разбирательств, то посылать в MSDN — это как посылать в пешее эротическое. У всех свои недостатки, но в том, что касается документации, Linux однозначно выигрывает, потому что документация идёт в комплекте с программой, а не добывается где-то в другом месте.
DMGarikk
с виндой нет проблем с поиском документации, пусть она даже и в интернете… не 90е года всётаки
Причем виндовая документация в разы лучше линуксовой кстати, особенно если вопрос стоит о комплексных проблемах (не — тут мануал на fd, тут на iptabes, тут на sudo… а как сделать двухфакторную авторизацию в ftp например — это вы уж както сами давайте, гуглите учебник, пишите pam-ы)… я уже на хабре дискутировал в комментах по вопросу «как включить гибернацию в убунте», можете мне тыкнуть в «правильный man» где это описано от и до? на офиц-сайте убунты, мануал устаревший и ссылается (в качестве замены) на какойто маразм с подменой ядра (wtf?)
Я то конечно уже разобрался, но man и изумительная документация изкоробки мне тут не помогла
AndreyHenneberg
У меня с Ubuntu всегда были проблемы, поэтому никогда с ней не работал как администратор. А в Федоре никаких трудностей с гибернацией нет, потому что она, вроде как, работает из коробки.
DMGarikk
Стоп стоп. Мы сейчас про конкретные дистрибы или про линукс в целом?
Я в федоре сталкивался с проблемами переключения раскладок клавиатуры… а в убунту не сталкивался, предложите на русском писать в убунте, а гибернацию активировать в федоре?
vtb_k
И рядом не стояла с арчвики.
DMGarikk
которая применима в полной мере только к арчу? а к остальным линуксом «обратитесь к вашему линукс-гуру, он расшифрует и адаптирует под ваш дистриб»
vtb_k
А вы ожидаете что она будет применима к андроид/хромОс/МакОс?
DMGarikk
Мы начали говорить про «У Linux отличная документация, вон арч!»
А если у меня линукс — не Арч, то чё уже заявление «у линукса отличная документация» — ложно?
Вы вводные на ходу то не меняйте
vtb_k
У линукса целая куча дистров, в некоторых хорошая дока, в некоторых нет. Почему я должен отвечать за сборки васяна? Или вам кто-то запрещает пользоваться качественными дистрами?
DMGarikk
так пишите об этом отдельно.
А то я напишу что у меня есть офигенная дока для PupkinLinux где описано всё всё всё, вплоть до детального описания всех ф-ций ядра с примерами как установить это всё на космический корабли и как всё настроить, и я не понимаю в чем проблема если вы на федоре такой мануал найти не можете.
начинали мы просто с «Linux vs. Windows»… а теперь оказывается Linux (Arch/Fedora) vs. Windows
svsd_val
Как бы то ни было, но у арча действительно хорошая документация и она во многом будет актуальная и на других дистрибутивах
DMGarikk
но для этого надо в этом разбираться
А если человек разбирается в ОС, у него нет проблем с ошибкой «Обратитесь к системному администратору» в винде, с чего эта дискуссия и началась собственно
Я чёт не помню что плакал схватившись за голову когда настраивал винду в промышленных масштабах
alsoijw
Несколько раз пользовался арчвики на системе без FHS. ЧЯДНТ?
DMGarikk
> ЧЯДНТ?
Вы в этом разбираетесь
alsoijw
Адаптация множества советов довольно тривиальна, с ней не справится только тот, кто может следовать только полной инструкции, когда переход на следующую версию, например с xp на vista будет точно так же непосилен.
BigBeaver
Для администрирования любой системы надо в ней разбираться.
DMGarikk
гениально, но если у админа возникают трудности с окошком «Обратитесь к системному администратору» и он не знает что делать — то человек элементарно не разбирается
Oxyd
Нет. Арчвики и убунтоиды и пользователи прочих дистров пользуются.
svsd_val
Согласен, я с Дебы тоже захожу читаю периодически.
unsignedchar
Что-то мне подсказывает, что в документации по Windows такого тоже нет.
Jacen11
чтобы поставить винду сейчас нужно жать далее далее далее ок ок, ждем все готово. А в линуксе мне коллега рассказывал что другой сотрудник установил под свап весь терабайтный хдд диск. Хотя там стоял ссд и подразумевалось что хдд только для файлов. И это был как бы типа не просто «продвинутый» пользователь, а эникейщик которому деньги платят за это
svsd_val
У меня на работе эникейщик rm -rf / сделал ))) И отправил выездную группу на 500км покататься ))
qrKot
Вот, собственно, вы и нашли реальную «болячку» линукса. 10% десктопа нужны не для того, чтобы затащить в линуху бабушек. Единственная реальная цель — чтобы производятели железа стали считаться с операционкой/ядром. Т.к. действительно важная трабла — всего одна. Драйвера для железок.
Собственно, если вы хотите линукс, который «just works», начните с железяки 100-пудово совместимой, тогда и «just works» будет. Собственно, есть они, но очень мало. А вот чтобы «дискретный xonar» и прочая экзотика штатно и «искаропки» работала — это надо «сегмент рынка», чтобы производитель этих самых «xonar'ов» почесался если не драйвер написать, так хотя бы спеки дать, хоть показать, хоть одним глазком издалека почитать дал…
COKPOWEHEU
Ну, большая часть железа все-таки работает. Еще часть работает после патча драйвера и пользователя. Так что не так все плохо.
Вот такого точно не надо. Еще не хватало лицензионных проблем.AndreyHenneberg
А какие проблемы-то, если производитель спецификации сам отдал? Вот AMD спеки не зажимает и в итоге старая видюха, ещё от ATi, у меня работает бодрее, чем гораздо более новая и мощная от Nvidia.
COKPOWEHEU
Если отдал — никаких. Проблемы если «одним глазком, издалека», то есть под всякими странными лицензиями, запрещающими полноценное использование
AndreyHenneberg
Ну если «одним глазиком издалека» — это на таких условиях, тогда да.
COKPOWEHEU
«одним глазком издалека» намекает на какое-то подглядывание пока руководство не видит. То есть для личного пользования еще туда-сюда, но в публичный доступ уже не выложишь.
По крайней мере у меня примерно такие ассоциации возникли.
AndreyHenneberg
Если что, вроде как Lenovo скоро год как выпускает ноуты, гарантированно совместимые с Федорой. Ну и с другими линуксами тоже, но для них, теоретически, может понадобиться небольшой бубен. А Федора — из коробки. А то и просто предустановленная. А так — да, надо подбирать железку. Хотя на большинстве не сильно топовых всё заводится с полуклика. А с экзотикой можно и в Windows таких радостей огрести, что из прочитанных мануалов потом можно дом построить. За последние лет 10 проблемы видел только с видеокартами от Nvidia, да и то, со старыми: мне их хватает за глаза (в игры не играю, видео не монтирую и так далее), но производитель их поддерживать не хочет, а спеки зажимает, так что из дистрибутивов драйвера через какое-то время выкидывают.
BlackSCORPION
Ну это вопрос экспертизы. Вы опытный линукс пользователь, поэтому Линукс у Вас просто работает. У Опытного виндоус пользователя точно также Виндоус просто работает.
И наоборот, для человека без опыта самым очевидным способом починить Линукс будет переустановка с нуля, потому что сделал что то не так, гугл выдает тонну непонятных слов, давайте ка я просто начну с начала ок )
BigBeaver
Это практически невозможно, если не играть в админа. А при неудачной комбинации софта и железа проблемы будут в лбом случае у кого угодно.
BlackSCORPION
Так же как и на Линуксе.
Я сильно сомневаюсь, что если бы Вы в своей жизни только кликали мышкой в Убунте, Вы бы смогли собрать генту из исходников ) Вы накопили много опыта в линукс прежде чем поняли что Вам нужен генту, и стали способны его установить и настроить.
BigBeaver
Я про линукс и говорю. Винда-то сама умрёт — на ноуте я раз в год-два делаю фактори ресет (чтобы не разбираться, что случилось) при том, что пользуюсь им только изредка.
spqr_voldi
Как минимум редактирование текстов и просмотр гифок под линуксом всегда были реализованы гораздо лучше. С массой _современных_ игр тоже вроде как вопрос решается.
0mogol0
Знаете, тут я даже не знаю, что ответить на такое заявление… поэтому пусть для вас будет так как вы сказали.
Stecenko
Если считать MS Word — текстовым процессором, а представителем текстовых редакторов под Windows считать блокнот, то таки можно сказать, что редактирование текста в linux лучше :-)
saboteur_kiev
А почему хотя бы не notepad++ или встроенный редактор FAR или множество других текстовых редакторов?
Или нужно только смотреть только то, что из-коробки прямо идет?
werevolff
В целом, я готов согласиться и с вами, и с автором, но хочется сделать ряд критических замечаний.
1. Популярность десктопного Linux растёт в разные периоды времени. Например, вспомним нулевые. Это было время расцвета почившей Мандривы и победившей Убунты. Это время призового спринта Unity, которая, по сути, превратила Gnome в живой труп. Последствия десктопного развития Linux в нулевых мы видим и сейчас. Допустим, GIMP доказал, что фотошоп, по большей части, слишком сложный и не нужен во многих кейсах. VLC плеер занял свою долю на рынке. Open/Libre Office привели к тому, что стандарт открытого документа был принят, в том числе, в Microsoft Office. Сама Windows обзавелась в десятой версии встроенным менеджером буфера обмена, screenshot maker'ом и менеджером аудиопотоков приложений (когда ты можешь переключать вывод и ввод звука для отдельных приложений на отдельные устройства). Всё это последствия работы энтузиастов, которые пилили юзер-френдли решения для Linux. Энтузиазм гаснет, да, но сейчас нет никаких предпосылок к тому, что не будет такого периода, когда энтузиазм снова вспыхнет, и молодые люди вновь вовлекутся в гик-культуру. Да, сегодня истинных гиков мало. Ты умеешь настроить приложение на Андроид, и уже считаешь себя технарём. Но я уверен, что со временем появятся те, кто поймёт, что можно и нужно копать глубже, чтобы добиться большего результата.
2. В те же нулевые Linux активно использовался в качестве виртуальной песочницы. Вспомним тот же DrWeb Live CD. На винде часто ставили Virtualbox/WMWare с убунтой. Мой знакомый тогда работал компьютерным мастером (своё ООО). Он несколько раз ставил убунту в виртуалку нерусским клиентам. Они любили посмотреть порнушку, но не пользовались одним единственным аггрегатором, а искали её через поисковики, что приводило к заражению компа вирусами. Вот он им ставил всё и объяснял: «Хочешь смотреть свою порнуху — открываешь этот значок, загружаешь песочницу, через неё смотришь, иначе будешь мне постоянно платить». Сейчас есть такое решение, как Vagrant — по сути, обёртка над виртуалкой. То есть, есть тенденция развития юзер-френдли над виртуализацией. Опыт контейнеров типа Docker, а также, WSL ведёт к тому, что целой виртуалки с убунтой не нужно для запуска нескольких приложений в окружении Убунты из-под винды. Прогнозы делать здесь сложно, но можно предположить, что безопасная песочница с десктопными линукс-приложениями может вскоре стать более популярным и доступным решением. Во всяком случае, за развитием виртуализации интересно наблюдать. И если раньше мы пытались запустить windows приложения внутри wine, то сейчас всё может пойти в другом направлении, и мы будем запускать приложения в виртуальном окружении Linux на винде.
3. Десктопный линукс, побеждающий винду, в принципе не нужен. Просто оставьте мне, и подобным мне, эту визуальную среду для энтузиастов с популярностью 2%, и не надо пытаться превратить её в коммерчески успешную оболочку. Я и сам сейчас работаю на Windows с использованием WSL. Мне хватает текстового интерфейса для работы с Linux. Если в плане графических оболочек под Линукс случится очередной взрыв энтузиазма, я с радостью поставлю второй диск с каким-нибудь новым дистрибутивом, чтобы поиграться и снова вернуться в винду. Но этот опыт будет для меня отдушиной и радостью.
4. Вы забываете, что огромная доля пользователей Windows — это корпоративный сектор. Я знаю, какие там, зачастую, используются приложения для управления документооборотом, базами данных и т.д. В большинстве случаев, wsl может решить проблему с дерьмовым софтом корпоративного сектора, поскольку разработка серверного ПО для линукс-сервера развита лучше. У нас лучше окружение и инструментарий. У нас больше практики, и наша разработка стоит дешевле. Вопрос стоит только в том, что сервер требует клиента, а клиент — это десктопное приложение. То есть, по-хорошему, с развитием WSL разработка кроссплатформенного GUI может и выстрелить. Опять же, прогнозы делать рано, но я уверен, что компании, которые решатся переписать большую часть корпоративного shit-software в России под WSL, сорвут неплохой куш.
PsyHaSTe
Так это в новом WSL решено, можно не переключаться :)
https://devblogs.microsoft.com/commandline/the-initial-preview-of-gui-app-support-is-now-available-for-the-windows-subsystem-for-linux-2/
Merrynose
Вот я застал расцвет Линукс в начале нулевых и хорошо помню это время. Я был просто очарован тем, как быстро и легко ставится Убунта по сравнению с ХР, не задавая лишних вопросов, как подтягивает автоматом все необходмые драйвера и что при первом же запуске системы экран уже в родном разрешении. И все это все довольно шустро работало и не дергало жесткий диск каждые полсекунды в отличие от Винды. А еще был восхитительный ОпенОфис, который был круче и стабильнее Ворда просто на несколько пордяков.
Я был абсолютно уверен, что дивный новый мир победит!
Но шли годы, Винда становилась все стабильней, МС Офис становился все удобнее и мощнее, а Линукс с ОпенОфисом, кажется, просто застряли во времени. Я, как поользователь, реально не вижу, чего там поменялось за эти 15 лет. Новый мир не победил, увы.
major-general_Kusanagi
ardraeiss
Только победил не новый мир, а корпоративный порт/форк/подвариант/копипаста/whatever кусочков этого мира с усиленным допилом.
AndreyHenneberg
OpenOffice скончался давно, но, кажется, там наблюдаются какие-то шевеления. Не знаю, будет ли это возрождением или попыткой зомби выбраться из гроба, но отпочковавшийся от него LibreOffice работает отлично и развивается весьма шустро. А вот MSO как испортился в 2007, так и остался уродцем, распространяя метастазы по всей ОС.
Ubuntu никогда не ставил — не везёт мне с ней, а вот Fedora ставится на раз и работает вполне стабильно. Бывают закидоны на новых версиях, но они и в Windows бывают не реже. И я, как пользователь, могу сказать, что за последние 10 лет большая часть проблем исчезла. Почему ещё все не пересели на Linux? Могу ответить. По большей части, причина — софт. Сын вполне себе сидел в Linux, пока не увлёкся играми. Пришлось переезжать. Дочери тоже хватало, но она пошла учится на дизайнера. Да, есть программы и под Linux, даже нашли несколько, которые ей зашли и которыми она пользуется в сборках под Win, но всё-таки стандартом в этой профессии является продукция Adobe и Corel, а они под Linux не пишут.
svsd_val
Что в статье… что ваш коммент, смешали твёрдое с мягким… Основная причина успеха в том что могли позволить себе «агрессивную рекламу», доходившие парой до абсурда. GNU/Linux это не нужно, тут каждый решает что и как нужно. Если брать Мак, дошло до того что до сих пор Вы имеете право разрабатывать под Mac используя только Mac и только их софт и их железо. А успешность навязывания «Понтов» дошла до того что многие ведут себя как сектанты, готовые за новый мак и девственность свою продать и печень…
Мелкомягкие в своё время успешно организовывали атаки на скудные умы, показывая только + и зачастую выдуманные + своего продукта и — чужих продуктов…
А автор статьи связывает мягкое с газообразным… Он пытается положить вину на OpenSource, за то что он OpenSource и то что пользователи и разработчики тратят свои скромные ресурсы на развитие их любимого продукта… Отличная логика достойная похвалы от M$… Я знаю множество людей которые работают, используют десктопный Linux (дома) без всяких там дуалбутов и при этом не являющихся программистами. Я сам использую уже давно ~ Debian Etch GNU/Linux, особых проблем не наблюдаю, на десктопе играю во многие ААА игры, рисую, пишу музыку. Может у меня одного руки не из опы. Но нет, много людей знакомых которые сами юзают GNU/Linux и при этом я на них никак не влиял…
Ishi
Я не очень понял пару моментов.
1. В большинстве своем данные пользователя хранятся в папке с пользователем, а данные программы в папках с программой, это не есть плохо, а наоборот лишь улучшает работу с системой. Если взять винду, то данные могут храниться где угодно, от папок пользователя и папки с программой, до AppData, в которую путь обычному пользователю (условно) недоступен. Так и сами программы, например discord, частенько обитают в AppData/Local. К таким программам доступ у пользователя только через строку поиска. То есть рядовой пользователь просто не поймет, где что лежит и даже не станет пытаться в итоге, что приведет к переустановке системы за n сумму.
2. Не вижу особых проблем с миграцией. Требуется использовать какую-то версию программы, вперед, но зачем ставить 2 и более сразу, мне не очень понятно. Хочу уточнить, вы подняли тему с того, что линукс для разработчиков и это не есть хорошо, но сами приводите в пример разработку. Если так, то стоило привести в пример что-то кроме. Если это рядовой юзер, кроме пакета офиса, браузера и мессенджеров ему ничего не нужно. А соответственно: графический установщик с большей частью программ, которые ему только могут пригодиться, сюда включены, как удаление, так и обновление. Даже переход с ядра на ядро делается в 1 клик.
3. Не понимаю на основе какого конкретно дистрибутива вы судите, но однозначно могу сказать, что таких проблем нет. Они возможно имеются на узконаправленных дистрибутивах, которые или не нуждаются в подобных настройках, или просто больше не обновляются. Но уже давно имеется графический интерфейс почти для каждой задачи и настройки. Также хочу сразу уточнить, в отличие от мака и винды, линукс имеет достаточно много различных дистрибутивов, что дает пользователю возможность выбора уклона: разработчик, архитектор, дизайнер, специалист, если одним словом, то скорее всего fedora ваш друг, если подросток и любит поиграть, то скорее всего ubuntu или manjaro, если любитель экспериментов и нравиться разбираться в работе с компьютером, то ядро arch в помощь. Ну а если это просто студент, преподаватель или даже сотрудник какой-либо компании, то возможно mint вам понравится. В этом и есть один из плюсов линукс систем, если вы, к примеру, разрабатываете микроконтроллерную систему, то найдется облегченная версия, которая возьмет только нужное для вашей работы.
4. Ошибки программ нельзя списывать на работу системы, так как разработчик ОС не отвечает за разработчика ПО. Поэтому подобную проблему даже смысла рассматривать смотреть нет.
5. Не проработанность интерфейса точно также нельзя списывать на разработчика ОС, но все же здесь можно много что дополнительно проговорить. Чем плох интерфейс, который не ограничивает пользователя в свободе выбора? Это еще к вопросу о бизнесе внутри линукс, но об этом чуть позже. Ограничения со стороны винды и мака даже в настройке внешнего вида, не есть плюс. Кто захочет иметь компьютер на котором настроек нет вообще, если можно иметь такой же компьютер, но с возможностями полной настройки области под свои нужды. Из популярных окружений XFCE, KDE, GNOME. Я как разработчик и пользователь могу утверждать, что пользователю приятно, когда он чувствует свободу действий. Учитывая ваши сравнения с детьми и пожилыми людьми, можно привести пример: «Чему обрадуется ребенок больше коробке конфет или одной конфете?».
Теперь про интересное.
Областью все еще владеют гики.
Если вы считаете то, что линукс не использует людей ради денег, то это не есть минус. Они в отличие от других компаний видят в людях — пользователей, а не деньги. По-моему, линукс существует не ради прибыли, а ради совершенства, которое, думаю, совместными усилиями и постепенно они смогут завоевать. В любом случае бизнес идея никогда не должна стоять на первом месте в проекте. Иначе суть проекта пропадет. Я не вижу плюсов в проекте, суть которого кардинально сменилась из-за того, что какой-то пользователь, много платящий, попросил ее изменить под его нужды. А подобная свободная система, позволяет пользователю производить свои собственные действия со всей системой, что не есть минус. Пользователя это только разовьет, что в дальнейшем может послужить его развитию, как специалиста. Если майкрософт собрали систему для даже самого неумелого и глупого пользователя, что совсем не так, потому что логика работы не из понятных, то, пожалуйста, платите и вам все сделают, за вас все решат. Линукс сделан не для глупых пользователей, а для вполне сознательных, которые осознают как плюсы, так и минусы, они есть у всех, но они готовы взять ответственность за себя и свои действия. Но даже для самых неумелых найдется то, с чем они совладают. Огромное комьюнити постоянно развивает систему, последние несколько лет именно для рядового пользователя.
Я лично вижу одну проблему, которую действительно сложно решить и стоит осветить:
Из-за количества дистрибутивов комьюнити достаточно разобщенное. Каждый пытается сделать что-то свое, но не что-то общее. Если подобной проблемы не было, то линукс, как и его сообщество, давно мог бы выйти на первый план, а не отсиживаться на скамье запасных.
Я разработчик, но и обычный пользователь, работал на Windows 95, XP, 7, 8, 8.1, 10, Windows Server, MacOS, Debian, Kali, Ubuntu, Arch, Pop!_OS, Manjaro, Fedora, CentOS.
Пользуюсь, как виндой, так и линуксом, и маком, но из-за работы. Свое предпочтение всегда отдаю линуксу. На домашней машине он и стоит. Это все личное мнение и я не претендую на правоту во всем.
svsd_val
Полностью согласен с вашими словами
duplodel
Вот знаете, я ненастоящий админ, и пытаюсь пересесть на линукс уже не первый раз, даже наверно в 7 8 или 10. И каждый раз возвращаюсь обратно. И каждый раз это боль в попытках настроить систему под себя. Это либо квест, либо невозможно. Причем в винде я систему под себя настраиваю за 30-40 минут, не таща при этом для нее виджеты, темки, иконки, значки (да кстати значки в линуксах унылые дальше некуда.) Что кеды, что гном, выглядеть красиво я так и не смог заставить, сделать чтобы было удобно тоже, и ощущения от него такие же, как от богомерской десятки, которую анально окупировали в угоду домохозяйкам, меня честно тошнит от монотонного интерфейса с 2-3 переключателями на весь развернутый фхд экран. Вот и остается доживать дни на семерке, пока она еще шевелится и делать попытки переползти на линукс и страдать там.
svsd_val
10 попыток это не так уж и много, я писал выше про свою историю, так что могу только пожелать вам удачи =)
viklequick
Так вы неправильно готовите :-) вам просто не хватает мотивации.
Придумайте себе мотивацию (любую), возьмите себе что-нибудь по вкусу (KDE plasma или mate / cinnamon — неважно). И попробуйте поизучать систему.
И вы очень быстро обнаружите преимущества двух «карманов», практически тотальный drag and drop, и широчайшие возможности по настройке прямо мышкой (смело используйте правую кнопку мыши как саму по себе, так и в сочетаниях с Ctrl, Alt и Win).
И через пару месяцев — новые привычки окажутся на кончиках пальцев, и вы обнаружите — даже в окошках есть как минимум часть возможностей. И в маке. Ну и смелее используйте свой пакетный менеджер. Вы удивитесь, как много всего у вас есть из коробки и доступно прямо в yast/synaptic/launchpad.
И все получится, главное продержаться начальный период «набивания шишек». В окошках он ровно такой же, к слову :-)
qrKot
Вам там советуют «придумать мотивацию». Не слушайте их, выдуманная мотивация равна ее отсутствию. Просто либо оно вам не нужно, либо «время не пришло». Пока нет вещи, которая для вас а) важна, б) объективно удобнее реализована в линухе — никуда вы с винды не денетесь.
Сползание заради сползания — прохладная история. Что винда, что линукс, что макось, прастихоспади — это инструменты. Разные, по-разному работающие и для разного предназначенные, хоть и выглядят местами похоже. Вот представьте, есть у вас перфоратор, пусть будет Bosh (не реклама). Вы им пользуетесь и, в целом, он вас устраивает. Одна проблема — старенький уже, та же модель уже не продается, а у новой вам цвет вот прямо не нравится, не любите вы розовые, допустим, инструменты. И вы принимаете решение всенепременно переползти в своей работе на шуруповерт Makita. Ну согласитесь же, что на какую-то фантасмагорию похоже.
Вот как только появится задача в промышленных масштабах «шурупы вертеть», там как-то само получится на шуруповерт перейти, без высосанных из пальца «мотиваций». Да, на первых порах будет несколько непривычно, что он стены не долбит, но тут уже будет ролять, насколько важно для вас именно «вертеть шурупы». Если окажется, что шурупы таки для вас основная задача, а стену надо не долбить в арматуру, а ковырять, и ту из пеноблоков да и то раз-два в год — там вы и шуруповерт с ударником приобретете и спокойно положите свой перфоратор в шкапчик на балконе да будете расчехлять по суровой необходимости.
А остальные пути — бред. Если нет чего-то, что для вас лично объективно лучше решается в линуксе — не ходите туда. «Просто обновись», меньше боли будет. А уж консольку пощупать да докеры потыкать нынче и в винде можно.
daggert
Простите, но вот этот тезис противоречит вот этому:
Разделяйте тогда уж программы и систему.
Система виндоуз и система, например, elementary — меня устраивает. Использование программ на системе виндоуз меня устраивает, а вот в системе elementary — меня не устраивает ибо часть Гномовская, часть Qt, часть горячих клавиш не пашет на русской раскладке, а смесь gnome 2 и gnome 3 выбешивают по сотням причин. То что про на винде есть огромный слой легаси, который пишет вообще в корень диска или в папку программы, или программы игнорирующие правила — это МОЖНО и в линуксе делать, лично я сам видел программы которые гадят неведомо куда и берут конфиги чуть-ли не с log. Спасает только пакетный менеджер, однако вот магазин приложений на винде даже мне использовать лень.
Переустановка системы это сейчас все же редкий кейс, особенно с перетаскиванием данных. У меня уже самые типичные домохозяйки как поставили себе десятку во времена когда она сама прилетала, так и живут с ней, я им только диск свапнул на ССД, при условии детей и установки вареза. Если-же брать пользователя чуть выше рядового — он прекрасно знает где у него шаблоны/конфиги/модели.
alsoijw
daggert
Вот вам баг — долгое переключение раскладки в gnome. До двух секунд, при этом еще и система виснет. Я слово бываю напечатать, прежде чем смена языка пройдет. Баг регулярно всплывает на лаунчпаде. Поделать ничего не могут. Лично я этот баг знаю со времен гнома 3.
Я пользователь, а не бета-тестер. Я не знаю а) куда б) как и в) как правильно оформить баг-репорт. То что я репортил — всегда было закрыто со словами "не туда пишите". А уж про горячие клавиши в приложении для одного DE в другом — это вообще типичный волейбол на багтрекере — каждый кидает говном в другой DE.
LiquidSnake
Не угадали — пользователи и Винды и Линуха — бетатестеры.
Первые за свои деньги, вторые потому что бесплатно =)
unwrecker
О! Спасибо за способы отключения скринсейвера! Как раз вчер искал как его вырубить в mx-linux :) В Убунте с такой проблемой не сталкивался.
Catslinger
А я как раз ищу способ включения скринсейвера: чтобы выбранная мной программа запускалась через 10 минут бездействия, причём просмотр ютуба не считался бездействием. Не, нормально не работает.
smartov
Знающие люди говорят что надо просто поставить Андроид, потому что это тоже Линукс так что считается.
viklequick
Киньте в них тапок :-)
Андроид вещь прекрасная… для бабушек, их внучек, и прочих домохозяек. Покупаете планшет с нужным cover — и вот у вас мини-ноут, с клавиатурой.
Надо бабушке початиться в жадноклассниках или внучке поделать домашку в школе — клавиатуру пристегиваете. Не надо — мама-домохозяйка берет сам планшет и смотрит на нем сериальчик с ты-трубы.
А папа — айтишник берет планшет с собой в отпуск — и на нем же без проблем читает почту и редактирует эксели с вордами. Или через ремот десктоп заходит на «десктоп», заботливо оставленный включенным. Я так через ssh к иксовой сессии хожу, если вдруг припекает :-)
Отдельно доставляет, что этот самый планшет весит грамм 700, держит от батареи целый день, оборудован минимум двумя приличными камерами, а часто еще и умеет притворяться телефоном. Снабжен кучей чипов — от нейро-процессора до декодера видео. И все это за четверть цены от «взрослого» ноута.
Ну и зачем платить больше?
smartov
Как папа-айтишник слабо себе представляю редактирование кода с самого распрекрасного планшета, но у каждого свои приколы.
viklequick
Ха. У меня коллега лежал в больнице под капельницей и коммитил код. С телефона. Если надо — то можно :-)
svsd_val
Я лежал в больнице и с телефона работал, кодил и сопровождал. Проблем в этом нет, установлена хацкерная кб, все символы и клавиши есть, ssh,vnc,rdp работают.
alsoijw
Уже и больничный отобрали, со своими планшетами -_-"
svsd_val
Да как сказать, там время есть свободное и его ну просто ОЧЕНЬ много, так что я писал музыку, играл, смотрел хаутухи..., Да и если без тебя справится не могут, а так в больнице то совсем скуууучно, хоть что-то более менее интересное.
Конечно можно ещё заняться тем что я не делал и никому не советую, честное пионерское:
взломом/подменой фоток чужих акк, тоже весело, тем же aircrackом и вайршарком, с перехватом куков )))) но думаю это быстро надоедает…smartov
Если с этим нет проблем то чего перестали? :)
svsd_val
Дык я и не перестал, я вылечился, гайморит был, после неудачного удаления зуба… А так у меня на телефоне всегда есть чрутная деба, для «поиграться», а к работе и консоль и bvnc с openvpn и pptp, так что если что-то уж больно срочно нужно, можно быстро сделать )))
smartov
Если всё так удобно то надо использовать это каждый день. А если не используете — значит есть что-то более удобное. Что и следовало доказать.
svsd_val
Дык а кто бы спорил то? смартфон заменит клавиатуру с мышкой и двумя мониторами ?? Я где то утверждал это? Я лишь сказал что это очень неплохая вещь когда иного под руками нет. Хотя мой смартфон и планшет при подключении к монитору так же можно использовать как десктоп с GNU/Linux, но пока в этом необходимости нет, так как у меня есть стационарный комп.
smartov
(передразнивая) А где я утверждал что вы утверждали то????? (/передразнивая)
Пипец разговоры ниочем. Пока
svsd_val
Похоже что вы сами себя запутали.
viklequick
Так скринсейвер — это просто программа. Запускаете ее по событиям от электропитания и все :-)
Для любителей напильника — есть готовые примеры кода.
Вообще говоря, многие просто не помнят — зачем были нужны скринсейверы. Screen saver действительно save ваш screen. От выгорания люминофора на вашей ЭЛТ от статической картинки. Те, кто не пользовался подобными программками — могли потом монитор выключить из розетки, и полюбоваться на выжженную картинку на кинескопе.
Catslinger
Как раз ваши примеры реагируют только на ввод с устройств. Открыл видео с веба, откинулся на кресло, через 20 минут бац — скринсейвер. Я бы сказал, что это, мол, концептуально нерешаемая проблема, и надо броузер ковырять — но вот только штатный локер Cinnamon прекрасно справляется с этой задачей на любом сайте, с любым браузером. а как он это делает — я не могу найти.
Заодно сразу скажу: если ориентироваться на idle переменную в иксах, либо на power manager в KDE, будет то же самое. Видео в броузере игнорируется. Сейчас я использую костыль, когда наличие любого звука считается за активность. Но это костыль.
BigBeaver
Посмотрите в эту сторону.
viklequick
Так браузер (и вообще любой медиаплеер) при проигрывании чего-либо об этом сообщает через d-bus. Это MPRIS называется. Поэтому — вполне можно этим управлять.
Вешаетесь на нужный сигнал, и в onChanged учитываете — запускать или погодить. Точно так же — можно и все остальное отслеживать, вот пример.
alsoijw
red75prim
Угу. И поэтому использование её в качестве lock-screen'а (как делается в X Window System) — это примерно уровень защиты windows 98. Убивание процесса открывает доступ к рабочему столу. Например, при отключении второго монитора.
viklequick
Так именно для таких случаев и нужна красота на мониторе, не? Так-то стандартный автолокер сессий в комплекте, но вот некоторым хочется еще и чтобы поверх автолокера — еще и рыбки плавали :-)
red75prim
Это проблема X11: https://blog.martin-graesslin.com/blog/2015/01/why-screen-lockers-on-x11-cannot-be-secure/ Автолокер ничем кроме лучшей протестированности не отличается.
viklequick
If you don’t control the remote side it could? Так это еще постараться надо. Тут даже если надо — то с куками xauth запаришься :-)
А если зловред уже под вашим аккаунтом запущен и имеет доступ к вашему X server — то сессия X11 далеко не в списке приоритетов на защиту…
linuxoid
GNOME Desktop? KDE & Plasma? Линукс для домохозяек? Не, не слышал, нам надо руками и по самый пояс… \сарказм\
zanzack
И от меня спасибо! Зачем лепить принудительно скринсейвер, когда Линукс крутится в VirtualBox — этого я простите, не понимаю. Или там настолько крутая песочница, что определить наличие виртуализации нельзя?
soniq
Как ОС для рабочей станции десктопный линукс очень ок. Ещё в нем можно развлекаться и экспериментировать. Предлагается потратить кучу ресурсов и разломать экосистему, сделать очередную винду, чтобы затащить в неё бабушек и детей. Не понятно только, какой от этого профит?
t13s
Так вот самое интересное, что для бабушек и детей десктопный линукс очень даже годен: без рутовых прав сломать его сложно, а браузер с котиками там работает отлично.
soniq
Вопрос не в том, годен ли линукс для бабушек. Вопрос в том, зачем нужны бабушки линуксу?
t13s
С точки зрения исторического развития линукса вопрос «зачем?», обращенный наружу, смысла не имеет вообще :)
А адаптировать линукс для бабушек не стоит хотя бы потому, что он уже к этому вполне готов. Поэтому, да, любая адаптация тут будет, скорее, во вред.
soniq
Ну вот же, вот прям тут в посте автор написал километр текста, рассказывая почему линукс не готов для бытового пользователя. Ваше заявление «нет же, готов» без каких-либо аргументов выглядит, так сказать, слабовато на этом фоне.
t13s
Так в этом вопросе надо плясать от ТЗ. В моем представлении «компуктер для бабушки» должен позволять ходить в одноклассники, звонить внучкам по скайпу/телеграму/зуму, ну, может, еще пасьянс какой разложить. При этом всякие зловредные действия не позволять. Глубинные настройки при этом побоку, равно как и гадание по логам / окнам с ошибками.
И вот если брать ровно это ТЗ — то десктопный линукс тут очень даже ОК, ровно так же, как и недесктопный линукс в виде, допустим, андроидного планшета с клавиатурой и большим экраном.
vvzvlad Автор
У вас какой-то очень бинарный взгляд на мир: либо «станция для разработчика», либо «компьютер для бабушки». В первом случае все можно, во втором нужен только браузер, скайп и пасьянс.
В реальности 90% распределены где-то между этими точками: это вполне вменяемые люди, работающие там со своими инструментами, способные погуглить проблему в каком-то виде, но не желающие глубоко погружаться в системные тонкости. Но их не удовлетворяет набор «браузер, скайп и пасьянс», они хотят именно вот этот инструмент, возможность скачать с торрентов фильм
и посмотреть его, поработать со своими файлами, календарем, почтой, етс.
t13s
Да, он, скорее, бинарный. Причем «станция для разработчика» сейчас в этой шкале чуть ближе к «компьютеру для бабушки»: разрабатывать софт под линукс сейчас гораздо, гораздо приятнее, чем те же 10 лет назад: есть IDE, есть те же самые фреймворки — бери и паши.
А вот как дела с точки зрения продвинутого пользователя, которому нужен и фотошоп, и обычный офис, и все игрушки из стима — я не знаю. В последний раз, когда я трогал — было не очень.
Но вот кейс «скачать с торрентов фильм и посмотреть его, поработать со своими файлами, календарем, почтой, етс» — линуксом очень хорошо решается. Есть слабенький комп, который использую как «приставку к телевизору»: как раз торренты, фильмы, почта — вот это вот всё. Изначально развернул на линуксе, и, в общем, жаловаться не приходилось. Потом решил попробовать то же самое, но на винде. И вот она-то в таком юзкейсе бесит несказанно: почему-то она лучше меня знает, когда ей надо перезагружаться после обновлений, для настройки авто-логина нужно плясать с бубном, prefetch почему-то считает, что грузить Chrome нужно далеко не в первую очередь.
linux_art
С игрушками в стиме проблему радикально нивелировали разработкой photon'а.
AlexP11223
Да фотошоп большинству как раз на самом деле не нужен, и вообще пиратить — плохо )
Все игрушки тоже нужны скорее меньшинству. С играми, особенно из стима, сейчас вполне неплохо после появления Протона и активизации разработки вайна и т.д. Многие работают, проблемы в осноном с некоторыми античитами (над этим тоже идет работа, в ядро недавно добавили что-то нужное для этого) и некоторыми новинками (но например тот же киберпанк работал с первого дня). Мне хватает, и так скопилась очередь из игр. Нативные релизы тоже участились (правда часто с задержкой), из последнего: десперадос, метро, томб райдер + куча инди.
МС Офис может быть нужен для взаимодействия по работе, если работа подразумевает постоянный обмен сложными документами не в пдф. А пару раз в месяц дома что-нибудь открыть, написать пару страниц хватает и либрофиса, я и на винде МС Офис не использовал давно.
nsn00b
добавлю случай, когда пришлось дистанционно настраивать убунту отцу под новые нужды. и как же это было приятно сделать в пару телодвижений через терминал. да и стоит она у него года 3 не убиваемая, ибо залезть случайно глубоко чтобы сломать не получится. до этого были мучения с виндой и было тяжело — терпелась идиллия максимально полгода…
khajiit
Проблема этого километра текста в том, что это километр ниочемного текста.
Особенно забавны примеры из гугла, где смешаны в кучу разные дистрибуции, железки от одноплатников до DR'ок; причем половина найденных ответов в винде звучали бы как невозможно в принципе и не будет возможно никогда.
В этом километре попросту нечего обсуждать и нечему возражать: он как та речь политика в гостях у Основания, самоуничтожается при разборе.
poxvuibr
Мне много раз разные люди говорили, что нужно выделять для home отдельный раздел, потому что тогда при поломке можно просто поставить линукс заново и примонтировать к нему старый home. И тогда сохранятся все настройки. На самом деле не сохранятся. Как минимум вот этот момент автор отразил неплохо.
FRiMN
Потому, что они и не должны были быть перенесены. Так задумано.
В 99% случаев сохранение настроек программ и ДЕ через монтирование хомяка работает. Я так постоянно обновляю систему (лет 10 уже наверно), или даже меняю дистрибутив.
Собственно в винде это у меня никогда и не срабатывало. Каждый раз как с чистого листа начинать приходилось.
Сложные системы, что вы от них хотите? ))
poxvuibr
Если их не переносить, у меня система не будет работать. И я тут не один такой уникальный.
Ну да, так задумано. Это одна из проблем линукса на десктопе, что так задумано.
Наверное. Но вот мне нужно сохранить конфигурацию докера, systemd, postgresql, xorg и так далее. Никто из них не хранит конфигурацию в home. Я раньше думал, что standalone cборки это для windows актуально, но чем дальше, тем больше у меня впечатлени, что это актуально и для линуксов. Может быть за исключением NixOs или Guix
BigBeaver
vvzvlad Автор
Потому что для десктопа — это пользовательский софт. Вот PG — это база данных, не системная, не привязанная к железу, запускается от отдельного пользователя. Какого хрена ее настройки в /etc, а данные в /var? Почему не в /home/pguser?
BigBeaver
У вас какое-то странное представление о работе ОС и сервисов.
В целом, нет проблемы поставить что угодно в ~/
Но надо понимать, что оно будет недоступно, пока вы не залогинитесь в систему. Делать такое поведение сервера баз данных дефолтным, мягко говоря, тупо. С какого перепугу он вдруг пользовательское ПО? Он даже локальным быть не обязан.
vvzvlad Автор
Я не предлагал ставить его в папку пользователя. Я предлагал ставить его в папку юзера, от которого оно запускается. Запускаться оно будет так же, как и раньше, ничего не изменится.
А какое оно, простите? Системное?
FenestramDeveloper
Возможно, возникла путаница в понятиях. Что вы понимаете под системным софтом, какой критерий разделения?
vvzvlad Автор
Системный — тот, что обеспечивает функционирование ОС. Драйвера, менеджеры запуска, например. Хорг можно назвать системным с натяжкой. Но база данных не нужна системе, а нужна лишь пользователю. Он ее поставил на свой компьютер, не на сервер. Он ей пользуется самолично. Почему она системная?
qrKot
Вот тут подвох. Он не самолично, а параллельно с другими пользователями ей пользуется. Поэтому она сервис/демон, и вот ну никак не пользовательское приложение.
vvzvlad Автор
Нет, пользователь, который ее поставил, пользуется ей самолично — настраивает, определяет структуру бд, раздает права, останавливает/запускает/обслуживает. Остальные клиенты использует некий API в выданных им ролях, не более.
Но даже с учетом этого, я не очень понимаю, почему ее настройки в /etc?
unsignedchar
Мантейнеры дистрибутива так решили. У некоторых принято /usr/local/etc, например. Технически ничто не мешает хранить настройки где угодно. Хоть в папке с самой программой (MS DOS), хоть в базе данных (реестр Windows).
qrKot
Потому что идея поменять служебного пользователя, из-под которого запускается postgres, не должна влечь за собой необходимость перекладывания файликов по папочкам?
Если вам уж действительно хочется прямо персонального постгресу — вы, как пользователь, имеете полное право вкорячить его в свой хомяк, вместе со всеми конфигами, логами и данными. Это законно, это достаточно просто делается. За остальными же предлагаю оставить право считать вас извращенцем.
Физические сервера постгреса, ввиду специфики баз данных, чаще всего используются для ровно одной задачи — крутить эту самую базу. Зачем в этой задаче конфиги и данные, разложенные по папкам пользователей — вообще непонятно. А удовлетворять ваш внутренний перфекционизм десктопного пользователя в ущерб серверному применению постгри… Эй, мэн, оно не то не пользовательское приложение, его по умолчанию на твоем десктопе быть не должно в принципе, оно не для того писалось.
alsoijw
qrKot
То, что вы можете на своей домашней машинке постгрю поднять, еще не делает ее пользовательским приложением, ровно как и факт запуска «Сапера» на сервере не делает его сервисом.
svsd_val
на 2003 приводил к зависаниям ))
BigBeaver
Это демон. Можно ли называть его системным, я хз, но пользовательское это клиент к нему.
Ваш вопрос скорее про то, почему системные пользователи не имеют папки в /home в отличие от нормальных пользователей. Полагаю, это связано с тем, что нормальный пользователь не является обязательным и /home может вообще отсутствовать.
qrKot
Служебное, наверное. Пользовательским его уж точно не назовешь, т.к. оно, как минимум многопользовательское.
Пользовательское приложение — это такая штука, которая запускается определенным пользователем (заметьте, не от имени пользователя, а именно пользователем, хоть это можно, наверное оспорить) и (а вот это важно, тут уж не оспоришь) доступное конкретно запустившему пользователю (монопольно, т.е. единолично). Т.е. это штука, существующая внутри пользовательского сеанса и работающая в рамках этого сеанса.
Постгрес же висит на порту и обслуживает соединения из любого сеанса, ему по барабану, от имени кого запущено приложение, приславшее ему запрос. Более того, он в принципе не в курсе, у него этой информации просто нет. Он обработает запрос от самого пользователя, от любого пользователя той же машины, от пользователя за соседним компом, в Магадане и на Аляске.
У него своя авторизация и он предназначен для работы в многопользовательской среде. Так что пользовательским приложением его назвать можно… никогда.
unsignedchar
Однопользовательский режим у postgres есть между прочим ;)
Ничто не мешает запускать его как обычное пользовательское приложение.
FenestramDeveloper
чем не устроило разделение, описанное в википедии? если ПО взаимодействует с пользователем — значит пользовательское ПО, если является прослойкой между пользовательским ПО и железом — значит системное.
Согласно нему база данных попадает под определение системного ПО, тогда как консоль к ней вполне пользовательское ПО. Можно представить гипотетически базу данных как пользовательское приложение, в котором можно работать (и нельзя никак иначе) с базой данных интерактивно, как с вордовским файлом, но не слышал, чтобы кто-то такое реализовал.
BigBeaver
vvzvlad Автор
И? Его запустил пользователь, оно запускается от пользователя(от другого), оно не взаимодействует с ядром, оно не обеспечивает функционирование системы. Если пользователь запустил веб-сервер на пайтоне у себя, чтобы показать коллеге сверстанную страницу, он тоже превращается сразу в системное многопользовательское ПО? А что, из магадана он тоже может запрос обслужить.
Но и это даже не так важно. Пусть считается служебным многопользовательским, если вам проще. Вопрос был в другом: почему приложение, которое запускается от конкретного пользователя (pguser или как там), хранит свои настройки и данные не в папке этого юзера, а размазанными по системе?
unsignedchar
Ответ где-то внутри man hier, наверное. Иными словами, так повелось. Никого же не смущает, что в Windows что-то из настроек может храниться в реестре, а что-то в файлах?
qrKot
И факт наличия всего одного пассажира в вагоне метро не делает этот вагон персональным транспортом.
Собственно, систему в целом тоже запустил он. Где грань?
Собственно, запускается оно «от какого скажут», совершенно вот не обязательно, что от другого. Но таки да, вы, хоть и случайно, указали на самую суть. Постгрес запускается от обособленного системного пользователя. Почему? Потому что он предназначен для использования в многопользовательской среде, соответственно, ни один из реальных пользователей не должен быть «хозяином» процесса напрямую.
Собственно, одно из ключевых отличий пользовательского приложения от многопользовательского сервиса, например, то, что он «by design» запускается от имени другого служебного пользователя (у процесса должен быть владелец, сед дура, дура лекс).
В общем и целом то, что запущено, пусть и вами, но от имени другого пользователя — это по определению не пользовательское приложение, т.к. оно существует вне сеанса запустившего его пользователя.
А я и не говорю, что оно системное. Оно, скорее, инфраструктурное, сервисное. Если процесс приложения запущен от имени вашего пользователя — это ваше пользовательское приложение. Сеанс убили, оно сдохло вместе с сеансом. Если поведение отличается от написанного, это не пользовательское приложение.
В системное — не превращается, оно служебное.
В многопользовательское — тоже не превращается, оно по определению многопользовательское. Зачем превращать что-то в само себя?
Потому что это не однопльзовательское приложение? Более того, оно вообще не пользовательское. Оно для десктопа в принципе не предназначено, оно для серверного окружения писалось. Инстанс постгри монопольно владеет немасштабируемым ограниченным ресурсом системы — портом, по этому критерию его вполне к системным отнести можно. Пользовательское приложение, конфликтующее с аналогичным приложением, запущенным от имени другого пользователя — говно, а не пользовательское приложение.
Если несколько разных пользователей запустили разные инстансы постгресов, как минимум, им нужно согласовать номера портов, т.е. все конфиги постгресов лучше таки иметь в одной структуре, чтобы хотя бы достаточно просто можно было выяснить, какой инстанс каким портом владеет и какие порты свободны. Опять же требования оркестрации всего этого хозяйства — вас никто не похвалит за идею собирать статистику по используемым сервисам не в централизованном хранилище, а методом перебора файлов в папках пользователей. Постгрес — это вообще такая штука, к которой прямой файловый доступ пользователю ни к чему. Ему просто дали «базу данных», он ей пользуется, администрируют это другие люди.
Специфика серверных окружений, понимаете ли. Да и /var там очень обоснован, к слову. Под данные отдельное быстрое хранилище, тратить драгоценные быстрые байты места на конфиги — такое себе.
В общем, у вас вообще какой-то странный кейс. Завтра я решу запускать постгрю от имени другого системного пользователя — мне его копипастить в другой хомяк, или просто папку переименовывать?
Не путайте однопользовательские приложения, живущие внутри хомяка и в пределах сеанса пользователя с серверным софтом, ориентированным на многопользовательские окружения.
vvzvlad Автор
Сдается мне, что a)ситуаций, в которых так делается довольно мало б)на 10кб конфига всем насрать.
Но я вашу точку зрения понял. Не разделяю, но понял.
qrKot
Сплошь и рядом так делают, например. А уж про классику «кеш отдельно, данные отдельно, а это хранилище под лог» — можно и не говорить. Есть даже целая профессия DBA, и даже курсы с сертификациями, где учат, как это делать «правильно». Они (все эти курсы) прямо начинаются со слов «СУБД на десктопе — бред»
svsd_val
Ух сколько мне пришлось разргебать этот M$SQL, что бы добиться максимальной производительности. Там прям специфика работы БД, специфика работы ОС с файлами и ещё куча мелких тонкостей о которых мало кто говорит, потому что это ДЕНЬГИ… Найти ДБЩИКа хорошего очень сложно а если он ещё и с корочкой это так вообще писец дорогущий =)
Так что соглашусь там где есть БД и более менее нормальный оборот данными и кол-вом пользуюков без ДБА никуда.
Oxyd
Потому что надо читать FSHS, вот почему.
Oxyd
Буду краток. Да!
svsd_val
Начнём с того что:
PG как и Mysql и MarinaDB,MongoDB ставятся в VAR по умолчанию. Вы всегда можете инициализировать БД где угодно. Другое дело что оно нафиг никому не нужно, так как ставится обычно как системная для множества решений которые могут использовать их.
Если вам нужно отдельно БД вы можете использовать их отдельно поднимая бд на стороне пользователя, как это делают многие, к примеру через libmysq, который каждое приложение ставит себе нужной ей версии и хранит в ~.
Но если вы поднимаете сервер и ставите запуск от конкретного пользователя и его каталогов то это ничто иное что стрелять себе в ноги. Вы это поймёте когда начнёте разбираться в косяках которые пользюк устроил… А если его учётка залочилась из-за срока жизни и у вас упадёт использующийся сервер, то это будет такая попа боль разбираться что там и почему… что не завидую…
qrKot
Вот читал я вашу статью, простите уж за откровенность, и вот вроде мысль ценная есть, и начали за здравие, а потом…
Ну вот с какого перепугу, простите, PG вдруг стал пользовательским приложением? Постгрес — это СУБД (система управления базами данных), т.е. это сервис, обслуживающий соединения на системный порт или сокет (других, извините, не завезли, нумерация портов плоская общесистемная) и обрабатывающий запросы от некоторого множества разрешенных пользователей. Постгресс — многопользовательский сервис. By design.
Почему он должен лежать в «хомяке» пользователя? Почему он вообще должен от сеанса пользователя зависеть? Как делить один порт между постгресами разных пользователей? Кто вам мешает по надобности запустить отдельный постгрес на отдельном порту от отдельного пользователя со всеми настройками и var'ом внутри хомяка? Кто заставляет ставить общесистемный постгрес? Кто запретил положить его вместе со всеми потрохами в хомяк отдельного пользователя и запустить от имени этого пользователя? Кто запретил докер? Зачем вообще отдельный постгрес на пользователя нужен на домашней машинке за исключением случаев, когда понадобилось несколько версий держать в параллель (один фиг не понимаю, зачем это на домашней машине)?
Очень много странных заведомо риторических вопросов, порождаемых неверной классификацией постгреса в качестве пользовательского приложения. Он а) многопользовательский, б) сервис.
Ну и да, по дефолту у рядового пользователя все равно нет прав порт 5432 биндить, один фиг от рута делать.
Потому что /home — домашние каталоги пользователей. Из мяса которые.
ALexhha
Смотрим что порт слушается
Проверяем c другой машины
poxvuibr
Думаю нет большой разницы как это назвать. Постгрес это программа, которую пользователь может запустить или остановить.
А какие причины класть его куда-то ещё? Положить его в home имеет смысл хотя бы для того, чтобы можно было сразу использовать его после переустановки. Или снести просто удалив директорию.
Мне кажется это один из основных посылов статьи. Статья про линукс на десктопе, а на десктопе де факто не работает несколько пользователей одновременно. Поэтому этой проблемы совсем нет.
Ну как кто? Менеджер пакетов в линуксе. Хочешь держать постгрес в своей директории — делай всё руками.
Ещё один сервис, который не конфигурируется в home. Его никто не запрещал, даже наоборот, его сделали, чтобы решить проблему с постгресом, которую вы не считаете заслуживающей внимания.
Для разработки. Или штуки разные пробовать не засоряя систему. И так далее.
Какая разница, как его классифицировать? Сценарии использования какие были такие и остались. Хранить конфигурацию так, чтобы можно было править её не от рута, как было удобно, так и осталось.
alsoijw
Плюс можно войти в разные tty и быстро переключаться.
qrKot
Думаю, есть.
Постгрес — это программа, согласен. Которую рядовой пользователь не может ни запустить, ни остановить. У него прав недостаточно. Пользователь, способный внутри своего сеанса без прав администратора запустить и остановить постгрес, может претендовать на позицию сисадмина в не слишком большом бюджетном учреждении в легкую.
Например, на сервере создавать какой-то абстрактный хомяк для несуществующего пользователя только чтобы положить туда конфиг постгри — неудобно. Да и положить его можно хоть в хомяк, хоть напрямую в рут, если оно действительно надо. Но в 90% случаев /etc — оптимальное место для конфига, реально прямо вот нужно взять и поменять, чтобы его «удобнее было удалять с десктопа»? Да его на десктопе быть не должно!
Ну, раз уж мы по вопросам решили пройтись:
Что постгря на пользовательском десктопе вообще делает (реально интересно, какие пользовательские задачи она выполняет)?
Почему она это делает не в докере (реальный сценарий, когда вот прямо в хомяк надо и никуда больше — есть)?
Стоп, полегче. Нахождение конфигов в /etc, а данных — в /var чем в этом вопросе помешало? Тоже можно сразу использовать, прямо вот установил и пользуешься. Остановил — не пользуешься.
Кстати, маячок: пользовательское приложение — это такое приложение, которое админский пароль для запуска не требует. Иначе оно не пользовательское.
Постгря не для того, чтобы ее удаляли. Ее штатный сценарий использования предполагает, что удалена она будет сразу на свалку вместе с машиной, на которой крутится. Хотите «потыкать локально» и «чтобы сразу потом удалить» — докер есть. Вкорячил себе постгрю локальную на десктоп — ты что-то делаешь не так.
Вот я о том и говорю, что статья про линукс на десктопе. Каким боком постгря вообще относится к теме статьи-то? Откуда и зачем она на десктопе? Вот есть, например, такие штуки, как контроллер домена, днс-сервер, почтовый сервер, веб-сервер, сервер баз данных и еще миллион очень нужных и полезных серверных софтин. Они хорошие, правда. Одно только непонятно: что они, хотя бы предположительно, должны делать на пользовательском компьютере? Для чего они там? Вот постгря — СУБД, система управления базами данных. Зачем она у пользователя на компьютере??? Как она в фокус статьи, да еще и в качестве примера пользовательского приложения попала?
Чем он вам, простите, помешал-то? Не помогает — это да, но он и не обещал. Хотите странного — делайте ручками. Менеджер пакетов — это средство доставки софта в предназначенные для него места, с чего он должен вам помогать в странном?
Ну вот прочтите уже, наконец, свое собственное высказывание. Это сервис! Это не пользовательское приложение. Пользовательское приложение — это штука, запущенная от имени самого пользователя и во имя этого пользователя. Сервис — это штука, существующая в единственном экземпляре в системе. Поскольку пользователей бывает больше одного, в хомяке пользователя мы можем хранить только настройки пользовательских приложений (они потому и пользовательские, что на каждого пользователя — отдельный процесс). А общесистемную вещь в единственном экземпляре конфигурировать нужно за пределами хомяка, т.к. эта штука — общесистемная, т.е. общественная. Это примерно как предложить хранить денежные сбережения горожан дома у одного из них, а не в банке.
И уж если про докер. Постгрей хотя бы несколько поназапускать можно, а докер в системе один по определению, иначе работать не будет, он прям совсем-совсем системное приложение. С какого перепугу системный сервис должен следовать принципам конфигурирования пользовательского приложения — мне лично решительно непонятно.
Разработка. Такое слово… От него, наверное, произошло слово «разработчик»? Ну, намек понимаете? Разработка — задача разработчика. В тот момент, когда пользователь что-то разрабатывает — он перестает быть пользователем и становится разработчиком. И прекращает им быть по завершению процесса разработки.
Спросите, где же пользователь. Пользователь пользуется постгресом лишь опосредовано. Пользователь пользуется приложением, разработанным разработчиком приложения. Вот этим он пользуется, а постгресом пользуется уже приложение, и никогда — пользователь. Еще раз, постгрес не имеет никакого отношения к пользовательскому скоупу. Это инструмент, которым нереально пользоваться напрямую. Причем инструмент для разработчика, не для пользователя.
Штуки пробовать… Кхм, какие штуки пользователь должен пробовать с постгресом? Решительно непонятно. Это как автолюбителю выдать космодром байконур, чтобы он попробовал на нем чего-нибудь поделать…
И так далее… Ну т.е. «не пользовательская задача», «какие-то общие слова» и «так далее» — весь список пользовательских задач постгреса. Отлично, так и запишем.
Огромная. Классификация — очень важная и полезная штука. Например, вы же совершенно отчетливо понимаете, что шильдик «легковой автомобиль» совершенно точно означает, что осуществлять на нем тоннажные перевозки — плохая идея. Или классификация «грузовой самолет», видимо, говорит о том, что для перевозки пассажиров вышеописанное транспортное средство не приспособлено.
Вот так и тут. Системные утилиты устанавливаются и конфигурируются только системным администратором и стопудово не в хомяк пользователя. Само нахождение оной в хомяке пользователя делает утилиту таки пользовательской.
Пользовательские приложения предназначены для пользования пользователем и им же и настраиваются. Это его приложение — чо хочет, то и делает. А общесистемные инфраструктурны сервисы, как, например, СУБД — это такие штуки, которые живут в инфраструктурном слое, ну, т.е. тоже с пользователем ничего общего не имеют, нефиг лезть.
Ну да, сценарий использования «запустить на сервере, отдав все доступные мощности» — он как был, так и остался, вообще неизменный. Вот этот сценарий — именно ключевая «фича» СУБД (всех, не только постгреса), и без нее вся система теряет смысл. Городить что-то с папочками в угоду десктопным пользователям — такая себе идея.
Отберите у вас возможность запуска СУБД на десктопе вообще и… СУБД по-прежнему будут использоваться в своем спектре задач. Отберите у СУБД возможность работы в многопользовательской инфраструктуре — вы ее и на десктоп ставить не будете.
У вас почему-то слово «опасно» с 4-мя ошибками записано как «удобно»…
vvzvlad Автор
Это где написано?
COKPOWEHEU
в FHS наверное?
vvzvlad Автор
Наверное? Вот тут ничего не говорится о том, что эти каталоги могут иметь только мясные пользователи. Разве что "Non-login accounts created for administrative purposes often have their home directories elsewhere.", но это не совсем то.
COKPOWEHEU
Там говорится, что каталоги пользователей рекомендуется размещать в /home, но при этом уточняется, что на конкретных системах может быть иначе.
А уж логику размещать в /home виртуальных пользователей я не вижу вообще.
qrKot
Ну да, напрямую не сказано.
Сказано, что «стандарта нихрена нет и еще бывает, что и хомяка нет, если что — спрашивайте на месте».
В целом — тупо лишний вектор атаки.
Oxyd
У системных (UID<1000) аккаунтов нет отдельного домашнего каталога, в 99% случаев, а даже если есть, то вне пределов пользовательского
/homeв 100% случаев. И чёрт возьми это правильно. Как в смысле логичности (в/homeтолько хомяки реальных пользователей у которых UID ? 1000), так и в плане безопасности и надёжности системы (одна из причин почему хомяк root живёт в корне ФС)poxvuibr
Да, только люди вокруг зачем-то твердят, что для того, чтобы все настройки сохранились достаточно вынести home в отдельный раздел. А это, как быстро выясняется, не так.
Не должны. В статье собственно и написано, что на декстопе всё программное обеспечение принадлежит одному пользователю, и настройки логично было бы искать в директории пользователя, но линукс пользуется другой логикой.
Для того, чтобы совет выносить home в отдельный раздел действительно помогал сохранить конфигурацию.
BigBeaver
Ну так это говорят про настройки рабочего окружения а не про всю систему. Если тебя устраивают системные настройки, то зачем переустанавливать? А иначе представьте, вы убили сеть (просто пример) и решили, что переустановить проще, чем разбираться… а там раз и старые убитые настройки.
Так он и помогает — всё, что работает в моей сессии, переносится совершенно прозрачно. Ну кроме случаев конфликта версий (если накатил новую версию софта, не понимающую свои старые конфиги. но это не проблема линукса).С другой стороны, откуда у «обычного» пользователя сервер базы данных на «десктопе»?
vvzvlad Автор
С другой стороны, откуда у "обычного" пользователя ПО для разработки масок для микросхем?
BigBeaver
Ключевое слово было «сервер». Иначе говоря, нельзя приписывать логику работы серверного софта к минусам десктопа.
Кстати, не расскажете, как PG на винде устанавливается и работает? Это чисто для кругозора — у меня просто нет винды.
vvzvlad Автор
Так а в чем отличие сервера в данном кейсе? Это все еще не системное ПО. Оно все еще не ПО уровня ядра. Оно все еще запускается от своего пользователя.
Понятия не имею, не работаю в винде. Наверняка криво
BigBeaver
То, что вы поставили серверную часть на клиентскую машину, не делает это ПО пользовательским. Администрирование таких систем это совершенно точно не задача домохозяек и к сабжу нерелевантно.
qrKot
И эти люди
запрещают мне ковыряться в носу!пеняют нам на то, что мы пользователей делим на «домохозяек» и «продвинутых», упирая на то, что «спектр пользователей сильно шире».Есть системное ПО, служебное ПО уровня ядра. Есть пользовательское — ПО в юзерспейсе, предназначенное для того, чтобы с ним работал пользователь.
А есть, например, базы данных, которые работают НЕ в пространстве пользователя. Постгрес работает от имени ДРУГОГО пользователя. И делает он это строго по одной причине: от имени пользователя ему работать не положено, а права рута ему выдавать — глупо.
svsd_val
Самое интересное что не только по этой причине, разбивают специально на отдельных юзеров с иногда даже с сильным ограничением прав. И продиктовано это безопасностью. В случае взлома/получении не авторизованного доступа к БД, атакующие не смогут принести существенного вреда остальным системам и процессам. Только автор об этом не думает, показывая свою безграмотность и наивность.
unsignedchar
Тут бы я поспорил ;)
А так, конечно, с разграничением прав лучше чем без разграничения. Но этим сервисам понадобится как-то взаимодействовать друг с другом.
svsd_val
Если он будет настроен плохо и запущен от пользователя который ещё к тому же и имеет рутовские даже права через судо… Это будет нести больший вероятный вред чем, запущенная от своего пользюка у которого на уровне АППАрмор/Селинукс и т.п. порезаны права ко всей части системы, где сам процесс сможет иметь доступ только к файлам с которыми ему разрешено работать. Так же и по сокетам куда и что он имеет право отправлять. Тоже настраивается. И тогда шаг влево / шаг в право — расстрел…
Обычно они через сокеты и разделяемую память взаимодействуют.
Busla
… есть ещё такие странные данные, которые за данные никто не считает, пока они из системы не пропадут — «шрифты» называются
BigBeaver
И? Вы же не предлагаете каждому пользователю руками их ставить в свой юзерспейс? Ну и шрифты сами же ставятся.
Busla
Не очень представляю, как это должно быть в идеале. Но некоторая проблема есть, когда вместе с ПО автомагически прилетают какие-то библиотеки «данных» — шрифты, шаблоны, и прочие сэмплы; а потом документы или настройки используют ссылки на такие «данные».
BigBeaver
Не очень понимаю, как это относится к теме.
wigneddoom
>и настройки логично было бы искать в директории пользователя, но линукс пользуется другой логикой
Логично кому? В многопользовательской системе логично отделять общесистемные настройки от пользовательских. Точно так же это сделано и в Win.
alsoijw
Oxyd
Ну ситуация с нехваткой места с лёгкостью разруливается при помощи LVM и прочими похожими технологиями.
unsignedchar
Иногда разруливается. В ноутбуке, например, LVM пихать некуда.
В домашнем десктопе, когда приходит фантазия расширить дисковое пространство, за те же деньги обычно доступны диски обьёмом х1.5 (прогресс всё же есть); можно перенести информацию на новый диск, а старый отключить. Меньше шума, меньше энергопотребления. Но немного дольше по времени.
LiquidSnake
Да, с ноутбуком такие проблемы чаще, это не виртуалка чтобы туда горстями диски добрасывать, а потом перераспределять. После установки на домашний ПК разметка уже более-менее статична.
alsoijw
имхо, но это несколько сложный вариант для пользователя, не особо желающего вникать в разметку дисков.
linuxoid
А что будет с виндой, когда полетит диск? Подсказать? С большой долей вероятности на новой системе после установки того же набора софта, пользак не заметит, что один из его НЖМД умирал если хомяк и основная система были на разных физических дисках.
(А как уж я радовался в детстве, сделав sudo rm /usr -rf, что у меня сохранился мой хомяк с курсачами на месяцы работы...)
linuxoid
Если автор написал километр текста (он хороший копирайтер), это не значит, что его точка зрения или точка зрения, обозначаемая в тексте в общем верна.
Есть ощущение, что автор взял некий голый сферический
XXXX Server, поставил на негоtwmи пытается доказать, что домохозяйка в это не сможет.Разумные люди приходят, смотрят, улыбаются, идут дальше. Менее разумные (например я) сидят в комментах и аккуратно пытаются показать, что позиция в тексте спорная в мягких выражениях.
Мы не будем забывать про GNOME Desktop, KDE + Plasma и некоторые другие "full desktop experience" вполне успешно построившие вокруг себя мир десктопа "для домохозяйки". Их набор функциональности и удобства вполне достаточен для кажодневного использования. Покрутить громкость, поставить нескучные обои, почта посмотреть, кинцо, забросить файлик на телефон по блюпуп, с FAT32 флешки ворд-документ открыть, скачать торрент, пошариться по ВКонтактику\Фейсбучеку — всё это в очень красивой обёртке, плавно и вот ни разу не хуже, чем в винде.
COKPOWEHEU
unsignedchar
Что страшнее — Страшная Чорная Консоль или Жадный Билл Гейтс с Телеметрией? :D
COKPOWEHEU
Пока практика показывает, что Консоль все же страшнее. Сколько ПолтерГейтсом не пугали, а массового оттока с винды не заметно.
werevolff
Вопрос уже в том, зачем линуксу нужна молодёжь? Бабушки так-то в молодости могли и Дженту собирать, и на Слаке в качестве десктопной системы сидеть.
Bobovor
Абсолютно не годен для бабушек.
Бабушка будет работать, нажимая кнопки как ей показали, если что то потребуется свыше — бабушка позовёт соседа игната, который на работе «компьютерщик», а по факту менеджер по продажам. Игнат увидит линукс и ничерта не поймет.
Если же бабушка чутка продвинулась и попробует нагуглить какой-то новый, ей потребовавшийся функционал…
Короче это стокгольмский синдром и манямир. Линукс именно враждебен к новым и слабым пользователям. Ставить его не знакомым людям — клиника.
viklequick
Bobovor
Ага терминалы и десктоп для бабушки…
Я не буду с этим спорить, я совершенно не против этих 2% занимаемых. Такого не нужно в массы.
vvzvlad Автор
Не путайте использование/эксплуатацию и обслуживание. В вашей стиралке вообще внутри бинарник без способов отладки, но вам не мешает это ее использовать. Но вот обслуживать это невозможно — обычным вариантом при любых глюках является «купить новую плату».
Использовать Linux можно не-гиками. Но вот обслуживать, в отличии от винды, нельзя. А обслуживать приходится, в отличии, например, от андроида.
t13s
А вы, простите, как Windows у бабушек обслуживаете? И, главное, зачем?
Revertis
Но кто-то ведь должен это делать!
Или у бабушек и пароль рутовый есть?
t13s
Вот поскольку у бабушек рутового пароля быть не должно, я и недоумеваю, а что там обслуживать, кроме как раз в несколько лет поставить свежий LTS.
Revertis
Но тогда надо чтобы бабушка умела пользоваться sudo и обновлять софт. Иначе незакрытых уязвимостей в том же браузере через месяц-два будет уже слишком дофига. А вы видели это Discover в Убунте? От его вида у бабушки инфаркт случится.
BigBeaver
Зачем?
Как это связано?silent_jeronimo
Буквально сейчас накатываю обновления в OpenSUSE через GUI-уведомление от YaST. Процесс не требует даже пароля и состоит в нажатии двух кнопок тогда, когда мне удобно.
Sudo для обновлений уже некоторое время не нужно в большинстве дистрибутивов.
Revertis
В Убунте требуется.
Причём, Discover (магазин приложений) тупой до безобразия. Выглядит как будто школьник накидал контролов и пустил в релиз.
При проверке обновлений либо нажатии на «Update all» сначала прогоняет прогресс-бар до 100%, потом показывает диалог ввода пароля для sudo.
Вот пока софт в линуксе будет так себя вести ему не видать большей доли на десктопах.
BigBeaver
Автоапдейт по крону нельзя разве сделать?
alsoijw
В убунте он уже есть из коробки, по крайней мере для обновлений безопасности.
BigBeaver
Тогда о чем тред вообще?
Mingun
Ну вот, в Ubuntu 20.04, внезапно, некоторое время все обновления требовали вводить пароль. Потом также внезапно все обновление перестали это требовать, даже те, что ранее требовали (установка нового ядра традиционно требовала, сейчас уже нет). Вот где гарантия, что на очередном тихом обновлении такое опять не всплывет? Не надо было вводить, а тут хоп — и надо. И вот про такое обслуживание автор и говорит — нужно быть готовым, что что-то может случится. Это на любой системе такое может быть. Пока, к сожалению, в декстопных линуксах тонус готовности должен быть выше :)
BigBeaver
Ну не обновится — ничего страшного.
saege5b
Если долго не обнвляться, протухают ключи безопасности, схлопываются зоны доверенности и можно поймат взаимоблокировку пакетов/библиотек.
BigBeaver
Ну долго это сколько?
Metal_Messiah
то что он не требует пароля выглядит как-то стремно. Вон в маке дял повышения просят пароль текущего юзера.
На самом деле в десктопномлинуксе с безопасностью все мягко говоря не очень. Того-же secure screen как в винде нет, который по сути в другой сессии работает.
AlexP11223
Так вы навещайте бабушку хоть раз в пару месяцев и обновляйте )
Вообще обновления безопасности, браузера можно и автоматически настроить. Риск что они что-то сломают минимален, это в основном от обновлений драйверов (нвидии, ...) может происходить.
FRiMN
Вы так говорите, как будто винда сама умеет обновлять софт. И никогда такого не бывает, что она и саму себя обновить не может. А там потом у бабки 500 неустановленных критических исправлений.
Revertis
Нет, просто браузеры — самая большая поверхность атаки, обновляются сами. А в линуксе централизовано.
Это тот момент, когда централизация и «защита от изменений ОС» играет против пользователя.
khajiit
4pda, xda…
qrKot
справедливости ради, в фразе Использовать Linux можно не-гиками. Но вот обслуживать, в отличии от винды, нельзя часть «в отличии от винды» — лишняя. Любую систему обслуживать будет специалист, не-специалист обслуживать сможет ничего.
vvzvlad Автор
Опять бинарный мир. Когда вы обычный пользователь — вы и используете, и вы же обслуживаете (чуть-чуть), прям в тот момент, когда гуглите "как исправить ошибку Х" или "как отключить сон". Брать специалиста, чтобы обслуживать — ни времени, ни денег не хватит, если мы о домашнем применении. И вот в винде обслуживание заключается во многом в "давайте переустановим программы" и "в панели управления ткнуть в галочку", а в Linux в "давай поищем решение на SO и будем пробовать, пока одно не сработает или не сломает систему". Не всегда, да. Можно найти примеры того, что в Linux проще, а в винде сложнее. Но в целом картина такая.
alsoijw
BigBeaver
Когда вы обычный пользователь, у вас и postgre сервер не установлен.
vvzvlad Автор
Вы понимаете, что я имею ввиду, когда говорю про бинарный мир? У вас нет четкого разделения на "тупых домохозяек" и "продвинутых админов". У вас есть куча людей между ними, и все они — пользователи, которые вовсе не умеют администрировать систему.
Обычный пользователь = "не разработчик и не админ". Программист, который пишет на JS и ему вот нужна БД — обычный пользователь. Он знает свой язык, но вовсе не желает разбираться с системой. Если так хочется — замените вы PG на что-нибудь другое.
svsd_val
Так зачем же вы про PG завели речь? Обычная домохозяйка не знает что при установке браузера она в месте с ним ставит себе ещё и бд. Что в винде что в линухе и ставится всё в ХОМЕ как вы хотели ))))
vvzvlad Автор
Вы, простите, комментарий читали или ключевые слова распарсили и тут же пошли писать возражение? Попытайтесь осмыслить первый абзац.
qrKot
Не знаю, если честно, каким образом разработчик у вас в разряд «пользователей» попал. Пользователь — он потому и пользователь, что пользуется программами. Нет сценария, в котором пользователь пользуется постгресом. Ну не хранит он свою домашнюю бухгалтерию в постгресе — он ее «в программе МояЧудеснаяБухгалтерия1.0» ведет.
Просто есть пусть не домохозяйка, пусть будет «чистый и незамутненный пользователь». Он ведет свою бухгалтерию «в программе». Если он хоть немного понимает, что за ширмой творится, что за красивым интерфейсом еще какая-то база данных есть — он уже не совсем пользователь, он таки в деле познания «всей этой компьютерной магии» поднялся если не неизмеримо выше окружающих (без негативной окраски, только в деле познания, а так он, может, хороший человек и в целом ведет себя прилично), то уж на пару ступеней — это точно.
Вот между «ведущими в программе» и «заполняющими БД» такая пропасть, что не дифференцировать их — ошибка.
qrKot
«В любой непонятной ситуации перезагрузите компьютер» — это не обслуживание. Обслуживание — это достаточно сложный комплекс мероприятий, направленный на поиск, анализ, исправление и сокращение появления в будущем неисправностей. Все остальное — лечение гангрены подорожником.
И да, вы правильно упомянули стоимость специалистов. У пользователя тупо два пути: либо тратить деньги на обслуживающего специалиста, либо тратить время на приобретение какой-никакой экспертизы самому. Третьего путя, сорян, не завезли.
LiquidSnake
Для линукса ее нужно больше, вот и все
svsd_val
Угу, но есть и несомненные плюсы, более менее адекватный уровень владения GNU/Linux может помочь при поиске работы ) Чего нельзя сказать о Винде
LiquidSnake
Представляете Windows админы тоже есть и нужны. Хоть и меньше.
Потому что линукс — прекрасная ОС для серверов.
svsd_val
У нас она на работе дексктопах у участи народа стоит и гемора с ними меньше чем с теми на которых установлена внида. Может просто потому что она работает? а может потому что адекватно настроили?
LiquidSnake
А у нас винда. И тоже все ок. Дальше что?)
svsd_val
ИМХО:
Если вы используете лицензионную винду и которая обновляется, то должны были сталкиваться со странными проблемами после обновлений когда обновлённый менеджер печти выдавал бсод, когда после очередного обновления пользюк через некоторое время терял доступ к шарам и только ребут помогал. Очередное обновление открывало DCOM и RPC и вирусы заходили и антивирусы не видели их. После очередного обновления удалялись фалы у пользюков. После очередного обновления все компы на AMD уходили в бсод. После очередного обновления замедлялась работа ОС включая загрузку ОС.
Если хотите можно продолжать. Но как по мне это нельзя охарактеризовать «ВСЁ ОК».
Конечно в маленьких фирмах это не заметно особенно тем которые на пиратских ОС с выключенным обновлением сидят этого не заметно до пары до времени… Когда нужно ставить какой либо софт а его установка приводит к босду ))) Очень приятно )) Либо по фирме вирусы ходят горой и им пофигу. Да что то комп тормозит, а там у глав буха и его окружения стоят майнеры )))
Но это моё скромное мнение )
qrKot
та не, вот вообще одинаково. Просто способ «подачи материала» разный. Линуксоид книжку читает, а виндовс-пользователь фильм смотрит. Содержание примерно одно.
LiquidSnake
На английском языке, потом сталкивается с проблемой, идет на форум, ему говорят — ты «глупый» человек, это не бестпрактис и методы твои устарели — делай так.
Ладно тут я приму во внимание что это чисто мое когнитивное искажение, потому что а) Винду я не админил б) Линукс реально удобен на серверах
svsd_val
Если очень повезёт скажут sudo rm -rf / :D
qrKot
Ну тут уж издержки профессии. Собственно, на английском языке что «фильмы», что «книжки», как правило, и получше, и посвежее. Их просто очень много, переводить — долго, дорого и нудно. Тем более, что, пока вы переводите, авторы уже следующую редакцию пишут…
qrKot
Да не, столько же. «Найдите иконку подключения к сети справа внизу экрана правой кнопкой мыши, выберите пункт Управление сетями, в открывшемся меню ПКМ на Локальное подключение к сети, выключить, затем включите обратно» и «sudo dhclient -r eth0», фактически, делают одно и то же, просто выглядят по-разному
red75prim
Вообще-то, там ещё нужно "чтобы это работало и после перезагрузки посмотрите, какая система инициализации у вас используется. systemd? Пропишите то-то там-то. SysV? Пропишите то-то там-то. Админ настраивал инит-скрипты? Обратитесь к нему."
С последним вариантом мне пару раз пришлось довольно долго (ругаясь вполголоса) копаться в скриптах, чтобы разобраться что там наворочено, вместо использования описанных в документации способов. Оказывается не все линукс админы читают документацию.
khajiit
Меняем линукс на 10-ку, а Игнат знаком только с XP. Продолжать? )
Revertis
Не может быть такого. Уже и Семёрка не поддерживается. Любой менеджер по продажам работает в 10-ке.
khajiit
Знаете… вот когда вы из своей Москвы вернетесь в Россию, тогда и поговорим.
Бюджету плевать, кто там у кого чем не поддерживается. Если в нем нет средств на обновки — обновок не будет.
А вот теперь скажите, что обязательно надо брать "правильного" Игната, работающего в "нормальной" конторе ;)
saege5b
Не работает нужный софт/железо в 10-ке.
Легко. Я десятку использую раз-два за полгода.
OnelaW
Работать то мы работаем в десятке, но вот для кучи пездемушек держим допами по два три ПК или ноута и разбираться в зоопарке нет желания.
Даже многим нелюбимая тема с играми можно осветить с иной стороны, когда вдруг узнаёшь, что ни на маке ни на десятке не поиграть. Приложение не поддерживает 64 или некорректно работают на новом железе. И не только с играми такое есть и не только со старыми приложениями. Есть приложения которые продаются ещё, но вот в 64 не могут. И наоборот обновленные версии приложений не могут корректно работать на аппаратной начинке пятилетней давности или позднее.
mistergrim
Стандартный риторический вопрос: аппаратное ускорение видео в браузерах когда будет? На слабых ПК ютуб смотреть невозможно.
t13s
Так есть же! На «новом» атоме 4K в хроме идет, на старом 1080p без проблем.
mistergrim
Подружка купила пару лет назад ноутбук на каком-то АМДшном APU, на ютубе в 1080p треть кадров выпадает и загрузка процессора 100%.
qrKot
как и в любой другой ОС/да и в принципе задаче — оборудование, увы, приходится подбирать под задачу, а не наоборот.
mistergrim
Подбирать оборудование под задачу «посмотреть ютуб»?
Странно, почему же линукс не стал десктопной ОС.
JerleShannara
Эмм, вот у меня наоборот — под линуксом 4К на i7-2600k + RTX2080 играет прекрасно, а в винде вознкает проблема — слайдшоу.
alsoijw
linux_art
Лет 10 уже есть вроде…
mistergrim
Повторяю: В БРАУЗЕРЕ. Нужно проделать крайне замысловатые танцы с бубном и, может быть, оно заработает.
BigBeaver
Ни разу не видел проблем с ютубом.
alsoijw
Замысловатые действия — это изменить несколько параметров в about:config?
mistergrim
А чего это я должен лезть в about:config, чтобы заработало то, что должно работать по умолчанию? А потому, что заработает оно 50/50. И это в 2021 году. В то время, когда в винде ещё на унылой GF8600 запросто декодировалось H264 с ютуба.
BigBeaver
Так это к вашему браузеру вопросы, почему оно по-умолчанию не включено. Вам же не ядро линукса галочки в браузере расставляет.
alsoijw
Mingun
Думаю, тут имеется ввиду как в анекдоте: 1 рубль за удар и 999 за то, что знал, куда ударить.
dartraiden
Замысловатые действия — это, например, пересобрать Firefox, потому что Мартин Странски намертво заблокировал работу VAAPI патчем, до тех пор, пока VAAPI не сможет работать в песочнице.
alsoijw
Это где?
linux_art
Так и я про браузер. На древнем eeepc1215n (это такой недоноут на ion2 если не в курсе) все работало нормально с момента покупки то ли в 2010 то ли в 2011ом году. Даже не смотря на богомерзкий optimus который тогда в линуксах работал очень сильно через пень колоду.
mistergrim
Да оно прекрасно работает! Только декодирование идёт посредством процессора. Особенно рады владельцы ноутбуков.
linux_art
Ну да ну да. Декодирование на древнем атоме :) Через процессор :) Если 4 кадра в секунду в 1080p получится на процессоре — уже хорошо будет.
mistergrim
Ну вот запустите _сейчас_ ютуб на этом атоме.
linux_art
Рад бы :) Да он уже приказал долго жить…
duplodel
отвечу за вас. В разрешении монитора 1280х1024 ютуб прекрасно работает. При подключении телека и включении фхд атом говорит кря и показывает слайдшоу, а где-то на фоне потихоньку уползает звук
linux_art
Чего не пробовал того не пробовал. На его штатном 1366x768 работало нормально.
alsoijw
wiki.archlinux.org/title/Hardware_video_acceleration#Application_support
romashko_o
Есть, да не совсем. Свежая Федора 33, АМд проц (2700Х), 2060 — не работает vaapi в хроме. То есть во флагах включаешь, все зависимости ставишь — в логах GPU VAAPI модуль инициализировать не удалось. Проблема в том, что с проприетарными дровами нвидии это дело не работает — нет нормального драйвера/модуля vaapi, свободные дрова не работают нормально с 2060 (куча артефактов, я пробовал что вейленд, что иксы), а ютуб в 1080p или твич в фоне во время сборки джава проект в идее тормозит.
Еще из интересного — проблема с блютузом. Мои блютузные наушники в федоре просто отваливаются — и ничего я сделать не могу. Думал, может с модулем проблемы — взял USB свисток отдельный, через терминал сделал активнм второй устройство, запейрил наушники — все равно отваливается.
А еще мониторы разного разрешение с проприетарными дровами нвидии и вейлендом — это просто сделать нельзя, не работает, пришлось возвращаться на иксы и там уже можно кое как настроить скейлинг.
Вернулся на винду в итоге.
Edit: дрова винды это интересно, но я имел в виду дрова nvidia.
linux_art
У федоры своя атмосфера, «спасибо» Поттерингу… Когда его поделки притаскивают в другие дистрибутивы там тоже начинает всякое отваливаться…
datafile4
Если учитывать, что аппаратного ускорения видео в браузере в Линукс дистрах нет, то не отлично. Дёргается проц и становится слишком шумно при просмотре видео.
vtb_k
Давно уже есть и в лисе и в хроме. Все отлично работает даже на интегрированной видео.
JerleShannara
Gentoo это дистрибутив Линукса?
IvUs
Я пишу библиотеки и конечные приложения для обработки видео. Так вот, как ОС для рабочей станции линукс не очень ОК. К примеру, если мне нужен кодек для моего транскодера под windows я просто беру библиотеку и линкую. Если транскодер пишется под linux, я должен сначала спросить у клиента, а какой именно у него линукс. Потому что часто бывает, что SDK собран под новой модной убунтой, а у клиента какой-нибудь centos 6.x и нужно все пересобирать под старой glibc. Просто приложить старый рантайм, как в windows, невозможно. При этом может оказаться что «кодека под старый линукс» у нас просто нет.
В итоге оказывается, что нужно держать у себя несколько десктопов — для этого клиента — древний centos, а для этого, наоборот, новый ubuntu, потому что, в древнем центосе нет свежего gstreamer в репозиториях.
При этом возникает проблема с GUI-программами для разработки, только привык к чему-то на одной платформе, как оказывается, что в новой версии эта тулза отстутствует и собрать руками её толком нельзя, потому что там куча зависимостей. Из того, что реально выбесило — потеря RapidSVN и GnomeCommander.
Одни и теже тулзы на разных сборках могут работать по-разному — я сталкивался с тем, что для сборки gstreamer на ubuntu и на centos нужно использовать разные скрипты, хотя исходники одни и теже — просто autotools по разному работают.
Или вот прикол — как раз из разряда «поэксперементировать». Захотел себе VisualStudioCode под CentOs 6.x Ну официально не ставится, но можно как-то там пропатчить. Пропатчил. В итоге там поменялись системные библиотеке и у клиента перестал запускаться транскодер. Пришлось откатывать (что само по себ ещё тот квест). Иногда подобные «эксперименты» заканчивались перестановкой системы, поэтому я стараюсь на своих линуксовых машинах ничего не трогать и даже код редактирую в gedit.
Вобщем, я согласен с авторами статьи — как десктоп линукс очень плох.
soul_survivor
У вас было бы ровно столько же проблем, если бы вас просили тоже самое делать для Windows XP, написание софта для морально и дефакто устаревших систем дорого и неудобно, надо проводить просветительские беседы с заказчиками, что сидеть на системах 10 летней давности очень дорого, лучше переходить хотя бы на lts 2-4х летней давности.
IvUs
В том-то и дело, что нет. У меня на личном сайте висят shareware программки, разработку которых я забросил в 2008 году. Прекрасно запускаются на 10ке. И наоборот я могу сделать проект для XP, просто поставлю на 10ку старую студию и всё.
Что до задушевных бесед с заказчиками — беседы были, но закончились ничем. Это серьезные люди, которые не бросаются апгрейдить сотню своих станций молотящих в продакшне 24/7 только чтобы сделать мне удобнее. Там много чего приходится поддерживать, например, приходится поставлять компоненты собранные в двух вариантах — под AVX2 и под SSE4 only, потому что часть станций это старые сервера без AVX.
dartraiden
DrPass
Надо ещё постараться написать такой код, по крайней мере, если вы не разработчик системных утилит.
qrKot
Родоначальник треда, вроде, упирал на «Я пишу библиотеки и конечные приложения для обработки видео.»
Вполне наступит, имхо.
FRiMN
Некоторые разработчики игр (не ААА) вполне себе наступают, при чем иногда в обратную сторону.
ALexhha
разрабатываешь под EOL ОС — готовься к проблемам
IvUs
ПО писанное для windows XP спокойно работает на Windows 10.
K-Lite Codec pack это просто сборка кривых поделок написаных кое-как. Сама ОС тут не причём.
Вобще-то у centos 6 поддержка закончилась недавно — в ноябре 2020.
ALexhha
Ну и да, никто не мешает под Linux собрать программу статически, и избавиться от множества проблем. Я специально собирал тот же curl, который будучи собранным на Ubuntu18, отлично запускается на Ubuntu 14-20/Debian 8-10, CentOS/RHEL 6-8 и даже alpine, хотя там вообще нет glibc. Так что вопрос совместимости очень не однозначный
А еще для решения таких задач — придумали docker, который так же избавляет от подобного рода проблем
смотря какое ПО и как написано, помню куча СКАД программ, а так же бухгалтерского софта, которое либо не работало на 7/10, либо работало, но с танцами и бубном. Так что не все так радужно
Osnovjansky
ALexhha
У СentOS и Windows разные жизненные циклы. Ок, при переходе с 95/98 на XP очень много софта превращалось в тыкву, и только с выходом SP1 ситуация немного стабилизировалась. Так будет «честнее»?
IvUs
Ну так это вы сами собирали. Если мне достался коммерческий компонент, собраный кем-то, мне его никто собрать не даст. И обеспечить совместимость крайне затруднительно, потому что никто этой совместимостью особо не озабочен.
ALexhha
IvUs
Под windows закрытость исходников компиляции никак не мешает.
unsignedchar
Это как?
IvUs
Я имею ввиду, что под windows я могу компилировать свой проект и линковать чужие dll не вникая в их зависимости — мой проект скомпилируется и слинкуется.
unsignedchar
То есть эти зависимости решатся немного позже с помощью магии?
IvUs
Мы приходим к тому, что я изначально написал выше. При возникновении проблем с зависимостями в Windows они решаются простым копированим потребных dll. При возникновении проблем с зависимостями в linux возникает необходимость перекомпиляций.
unsignedchar
dll hell это красиво ;)
IvUs
dll hell возникает, когда зависимости копируются в системную папку. Если зависимости приватны никакого hell нету.
alsoijw
PsyHaSTe
для .net есть точно так же self-contained сборки. 50 мегабайт оверхеда и ваш апп полностью портабелен.
unsignedchar
А всякие snap не так работают?
LiquidSnake
Это особый кайф линукса =)
Что-то поставлено из репозитория, что-то через snap, что-то через pip
Организованно управлять этой оравой тоже неудобно.
PsyHaSTe
А в винде: что-то из chocolatey, что-то из ms store, что-то разбросано в виде msi/exe/… по всему интернету.
Организованно управлять этой оравой тоже неудобно.
LiquidSnake
chocolatey — вообще впервые слышу
ms store — возможно, мне не приходилось.
msi/exe — прописывается в реестр, и прекрасно удаляется через «Установку и удаление программ»
unsignedchar
А всякие чистильщики реестра, модные когда-то, это для красоты. Или сейчас уже не актуально?
Насколько я помню, при нажатии на «Uninstall» запускается притащенный той же программой деинсталлятор. Он, конечно же, написан пряморукими программистами, и вернёт систему в именно то состояние, которое было до него, и ни в коем случае ничего не сломает.
LiquidSnake
Я конечно понимаю что «а у меня таких проблем не было» не аргумент, но все именно так.
Линукс притаскивает лютую кучу зависимостей почти к любому софту. Линукс не подскажет тебе что софт не работает потому что пакет поставили из пакетного менеджера, а не из pip. Криворуких программистов хватает везде.
sergey-b
Вот как раз в линуксе с этим попроще, чем в виндах. Видно, какой пакет для чего нужен, и снести нужный пакет просто так не получится. А то, что вы упомянули, это, на мой взляд, питонячая проблема, которая и в винде так же проявится. Python нужно уметь готовить, у него своя экосистема.
LiquidSnake
Покажите пример где это видно плиз.
sergey-b
Запустите rpm -e filesystem и увидите. Он вам покажет, что от этого пакета зависят другие пакеты, поэтому его удалять можно только вместе с ними или с бубном.
svsd_val
К примеру синоптика поставьте.
JerleShannara
Живу в Gentoo, даю пример.
Хочу я снести qtcore — ну не нравится мне его имя.
emerge --depclean qtcore
в ответ ругается, что не снесёт, поскольку у него reverse dependencies, какие — он не пишет, но следом говорит: to see reverse dependencies, use --verbose
Окей, сделаем как оно сказало:
emerge --verbose --depclean qtcore
И вот оно вывалило кучу строк вида «x11-misc/sddm requires dev-qt/qtcore»
FRiMN
А разве когда вы ставили генту, вас не предупреждали, что будет больно? ;)
JerleShannara
Ну я её ставил после того, как понял, что Alt Linux Junior 1.0 и Mandrake Linux (забыл версию) не очень шустро работали на Pentium MMX, а далее мне этот кактус очень даже зашел =)
Да и попытка снести QT сидя под KDE сделана сугубо ради вывода в консоль 100+ зависимостей, которые этого не дают сделать без получения медали ССЗБ =)
BigBeaver
svsd_val
Это обычное дело. Просто пакетный менеджер решил что вы этим не пользуетесь, либо после очередного обновления поменялись зависимости, а пакет то остался и может быть кем то использован, потому он и пишет посмотри типа что есть… можете исправить это либо удалив либо повторно установив их, тогда пакетный менеджер пометит их как используемые и установленные в ручную.
BigBeaver
Ну да. Это ответ на вопрос, как узнать, что в системе потенциально лишнего. Кем используется, проверить тоже не сложно.
qrKot
Не, вы что-то путаете…
Давайте по пунктам:
1. Есть дистрибутив, и у него есть пакетный менеджер. Тчк.
2. Разработчики дистрибутива (как минимум, предположительно) протестили работоспособность того, что есть в пакетном менеджере в различных комбинациях.
3. То, что (и, главное, зачем) вы вкорячили в систему pip'ом, и почему для своих разработок не пользуетесь инструментами вендоринга (.pyenv, например, или что конкретно сейчас в python модно) — это отдельный и, главное, исключительно ваш головняк.
4. Линукс никаких зависимостей не притаскивает вообще. Таскать зависимости — задача пакетного менеджера. И вот эта штука а) подтягивает те зависимости, которые нужны, б) строит граф этих самых зависимостей, чтобы не тянуть одно и то же дважды, в) пересчитывает этот граф при удалении пакета, т.е. умеет удалять зависимости рекурсивно, чем похвастаться не может больше вообще никто.
Ну, т.е. не в криворуких программистах дело (как минимум, не всегда в них).
qrKot
Тут скорее вопрос о том, как оно устанавливается.
MTyrz
А через pip, конечно, в винде никакие питоновские модули не ставятся.
LiquidSnake
Пару раз всего ставил. Для винды их сильно меньше
MTyrz
Я тот еще питонист, конечно — но мне казалось, что большой разницы нет. На винду я ставил не меньше, чем на пингвина…
Но вообще я скорее к тому, что в его лице вы помянули не системно-специфичную систему обновлений. Можно еще npm вспомнить и прочие php composer'ы: это другие, извиняюсь за выражение, экосистемы со своими игрушками в своих избушках.
qrKot
Там вся разница в том, что сама винда не юзает python в качестве системного инструмента. Поэтому нет риска сломать что-то в системе от установки/удаления/чего-попалы pip'ом, т.к. эта штука — строго параллельна.
Вот поэтому виндовс-кодеры на python'е очень поздно узнают, что такое вендоринг, и почему складывать все-все-все прямо в системные библиотеки — плохо. Плачут, жуют кактус, но им, видимо, нравится.
qrKot
Казалось бы, при чем тут снап и как он связан с репой и pip'ом?
Или вы нашли способ из софтинки, которую вы пишете, импортировать либу, лежащую в snap'е?
qrKot
Один вопрос (вдруг я чего не знаю):
чем, с точки зрения сакрального смысла, подкладывание .dll отличается от подкладывания .so? И при чем тут компиляция?
nilford
Хватит сравнивать с виндой. Хоть там не все так без облачно, но облаков всяко меньше чем в линуксе. Нам как гос учреждению поставили "наш" linux и какого же было узнать что установить принтер это квест на полчаса! И это hplib. Про Canon я вообще молчу, так как те что у нас имеются вообще под этой системой не работают, драйверов тупо нет. Настройка системы... о это та ещё песня. Конфигурации размазанны ровным слоем по гуи и при этом о зависемостях узнаешь лишь в процессе "какого х.. это настройка не работает?" А есть ещё конфигурации которые в гуи не представлены. А отваливающися интерфейс из за кривых дров на видео это тоже прикольно, когда кнопки у тебя полосами идут и нечего не понятно. Для разработчикика линукс может и хорошо. А для обычного пользователя нет. Хотя-бы потому что рут часто просят в юзерспейсе причём безосновательно(например назначить принтер по умолчанию). Зачем это сделано я хз.
svsd_val
А подскажите что вы имеете под словом «НАШ» linux. Я сталкивался и с альтом и с росой и астрой. Скажу что наши дистрибутивы зачастую собираются как то странно, у Астры, встречал глюки описанные вами… так как там своя специфика и многого нет, многое разбито по своему и даже права на файлы раздаются не только через chown/chmod да и часть народа ставит стандартные репозитории от основного дистрибутива что бы добиться относительно нормальной работоспособности… Но это не есть все дистрибутивы. Это раз. Во вторых. А чего вы хотели с дровами ???? когда большая их часть пишутся только под M$? Да при работе с GNU/Linux нужно учитывать специфику и выбирать совместимое оборудование а не китайское борохло которое даже под виндой косячно работает. Интерфейс можно получить полностью работоспособным даже без дров, но для этого нужно знать 1. что это можно, и знать как это включить. Да… опыта у вас мало и отсюда настолько сильно подгорает… Я встречал много «Вумных» людей которые даже простой вопрос не могут решить сами и горит от всего, хотя вопрос гуглится за минуту, находится в первых 2х кликах и решается за пару минут… Так что от человека тоже зависит многое.
LiquidSnake
Не хочется по всякому взаимодействию с компом лезть в гугл. Особенно дома.
svsd_val
Хотите сказать что в работая с иными ОС ниразу не обращались к поисковикам?
Даже простые вещи в разных ОС включая Мелкомягких и парой находятся в такой *опе мира что сам никогда не додумаешься а для иных вещей нужен специфичный платный софт. А если Вы вдруг займётесь администрированием и попробуйте поглубже настроить ОС то столкнётесь с ещё большими отклонениями и не явным поведением… Хотя это справедливо и для Яблочников, у них там многое требует денюжку…
LiquidSnake
Давайте так: я не админил Винду.
Да, я гуглю, но значительно реже чем с виндой. Про яблочников тоже не знаю, только iOS вживую щупал.
Специфичный бесплатный софт — в этом весь линукс. Он слишком не юзер френдли. Если я админ — пофиг, переживем, если пользователь — я не хочу тратить свое личное время на решение этой проблемы.
svsd_val
Имхо:
Дык, а что Вам мешает оставаться на Винде? или вас силком заставляют переходить да ещё на домашнем частном ПК на GNU/Linux под страхом смерти?
Да, GNU/Linux она не для всех, она разборчива в выборе друзей… У неё есть свои + и свои -. Но только лишь из-за того что она имеет более высокий порог вхождения — не говорит о том что эта плохая ОС.
А для тех кто не хочет думать для них есть ОС в которых всё решили за них, за их же деньги ограничили в правах, ограничили в возможности действовать и навязывали и навязывают лишь однобокое понимание мира, где определённая последовательность действий являются правильными и только они являются и «истиной»…
Но это всего лишь моё скромное мнение как простого человека.
LiquidSnake
Вы будете смеяться — я линукс админ. И на работе он меня устраивает.
Дома стоит как раз Убунта, по многим причинам Винда меня просто не устраивает(в т.ч по причинам озвученным вами выше), но вот домашним она не нравится. и я их понимаю.
И вообще, я нигде не говорил что Линукс плохая ось. Просто она для другого. И не юзер френдли. Поэтому никогда не понимал почему все кричат что она для всех. Нет, всем она не подойдет.
svsd_val
Вы тоже будете смеяться, но я не только админ GNU/Linux но и M$ Windows и что на работе и что дома сижу на Debian SID(unstable) GNU/Linux… Я разово настроил дома домашним (из за проблем с вирями и кучей овнософта который ставился с тулбарами итп), они в начале были недовольны что интерфейс изменился, я попросил посидеть не долго и сказал что верну им винду через 2-3 месяца… Через это время вернул винду, но им это не понравилось, так как они уже «распробовали» что такое нормальная работа в сети и открывай что хочешь без тормозов и вирей… Так что теперь у домашних везде GNU/Linux они сами что хотят ставят и сами умеют в ней работать… Но это лишь моя история, возможно потому что мне удалось настроить всё так что бы всё работало нормально и при этом их интересы и потребности были удовлетворены.
Знакомые тоже много переходят на GNU/Linux но это их решения, при мне один знакомый рассказывал (ставил Ubuntu ещё до стима с протоном) и после через некоторое время возвращался на винду лишь ради одной игры, но не смог выдержить и удалил винду, по его словам: так как на каждый пук нужно было искать софт, ставить антивири и т.п. что бы можно было более менее побыть в винде и при том бсоды от игр и дров… всё это хорошее развлечение о которых он забыл )) потому вернулся на Ubuntu.
По поводу того что юзер френдли, не юзер флендли, всё зависит от человека, лично для меня она очень даже юзер френдли, мне удобно что я могу к примеру пересжать кучу фотографий с применением кокретных фильтров написав небольшой скриптец. Или что я могу очень просто сдёрнуть с сайтов ту инфу которая мне нужна без применения специфичного софта… либо захотел проверить какие из мелодий в разных форматах у меня в дублях, через ффмег снимок всех сделал сравнил и очистил пару десятков гигов музыки. Так что понятие юзер френдли полностью зависит от человека…
Она для всех кто не только хочет в этом разбираться но и прикладывает к этому усилия. К примеру захочу стать «стройным качком» этого одного желания ведь мало будет? Конечно мало, нужно будет заниматься и тратить время… А это скучно. И многие кто сталкиваются с GNU/Linux просто хотят, но ничего для этого не делают.
Вот по этому и говорю что она разборчива в выборе друзей… А взаимность она и в дружбе нужна.
LiquidSnake
Вот это улыбает. Скриптец. Вы уже как минимум, продвинутый пользователь, если это можете.
А если ваши домашние научились пользоваться браузером, играми и запускать мультимедиа, не факт что они без вас смогут что-то еще.
Юзер чаще всего не хочет разбираться и прилагать усилия.
Повторюсь, я хочу сесть в машину и поехать, а не собирать ее на коленках. Да, собрать будет лучше, можно под себя, гибче, много настроек. Но мне нужно «сейчас» не разбираясь и не тратя времени.
svsd_val
Я же сказал, что это именно для меня. Я являюсь инженеГром. Мои знакомые которые не умеют ни программировать ни писать скрипты спокойно используют GNU/Linux, пишут музыку, рисуют в 2D и 3D. Им это не мешает, да они перебрали множество дистрибутивов но сами выбрали для себя то что им больше нравится.
Сами могут управлять своими ОС, сами ставят софт/удляют, пользуются вином, обновляют ОС и в общем особых проблем не испытывают. Так что и без меня справляются без проблем.Что бы сеть в машину вам нужно сначала её купить, потратить немалые деньги и оформить документы, вы понимаете к чему я?.. А вас же не устраивает готовые и свободные и бесплатные жигули и нивы, вам нужно иномарки класса люкс. Но это другие категории, со временем… со временем GNU/Linux общими усилиями дойдёт до такого уровня… Но на это нужно время. Ваше мнение тоже ценно, так как оно поможет разработчикам видеть недостатки в своих продуктах и позволит улучшать их. Так что если будет возможность если вы действительно желаете лучшего подкидывайте и багрепорты и хотелки и данаты разработчикам, что бы позволит им развиваться.
LiquidSnake
Простите мне мой скепсис, ждем и ждем долго.
Так как я активный пользователь Убунты — попробую с багрепортами, может правда станет лучше.
PsyHaSTe
Я не представляю про какие вирусы вы говорите. Последние что я помню были у меня на семерке с флешкой притащенной из универа.
Вот уже лет 10 ничего подобного не происходит.
Хотя конечно, лишняя защита никогда не повердит. Просто удивлен, что оно ещё живо сколько-нибудь массово. Хотя если UAC отключать, обновы зверскими тулзами насильно отрубать и подобным заниматься то мб и происходит.
svsd_val
Поверьте, на работе сталкивались и не с таким… Что говорить, если даже прилетают шикарные обновления от мелкомягких которые ломали обработчик печати так что бсод получали кучу машин и не только )))
А так как винда даже не ломается а сразу ложится готовая ко всему… Я не знаю сколько там ещё бэкдоров и открытых невидимых портов оставленных в наследство…
У нас письма счастья доверчивым бухгалтерам прилетали что выводили бухгалтерию из строя на полдня… Да и года 2 назад все помнят о нашумевшем вире/вымогателе который подкосил множество предприятий и зашировал всё и вся… При этом хвалёные антивири не особо то и спасли положение так как сигнатуры этой гадости у них то и не было )))… Только линуксовые системы включая десктопы и сервера тогда живые и остались ))). А все 10 тки и 2016 и 2019 серверные посдыхали…
Причём и обучения вроде бы проходили по безопасности, но юзеры умудряются делать такое что мама не горюй…
В общем с тех пор усилили защиту по многим направлениям и ещё больше порезали права… особо опасным по самое не балуйся, поставили контролирующие шлюзы и т.п…
PsyHaSTe
Не, на предприятии где есть админ линукс может быть прекрасным выбором. И безопасность от всяких троянов никогда не лишняя, конечно. Мне просто казалось, что под десктопом имеется в виду обычно домашний комп, где из админа только ты сам и яндекс (ибо гугл страшный и на английском тексты обычно показывает)
svsd_val
У нас на предприятии всячески приветствуют переход на свободные ОС и свободное ПО, потому часть из разработчиков и поддержки перешли на GNU/Linux часть на Хакентоше(но их мало) и были далже фряхи. Из плюсов это усиливает защиту и экономит немалые деньги на лицензиях…
А так десктопных линух дома многие юзают. Некоторые потому что нравится, некоторые потому что винда свежая не особо то рада работать на столь древнем железе, в общем у всех свои причины.
PsyHaSTe
Ну я говорю за себя. У меня лично были три попытки — каждая длиной примерно в день. Под конец суток когда я задалбывался а список проблем оставался непустым я плевал на это дело и сносил всё. Может будет четвертая — пока не знаю. Либо карма, либо руки действительно кривые.
svsd_val
Возможно вам нужен просто друг к которому вы сможете обратиться, спросить света или помощи?
Я когда только с линухой познакомился я матерился много, громко и зарекался что это гомно полное… Это были года 2003-2005… тогда интернета не было особо и всё что я имел это покупной набор из 5 и 8 дисков для разных дистрибутивов от редхата, федоры коры до мандривы и дебиана. Я много раз ломал линуху, к примеру удалял ядро и писал известную фразу «Сделать так как я хочу» )))) даже а потом не понимал что же я такого наделал что она перестала запускаться… ломал иксы и тп. Удалял и ставил винду, но всё же после возвращался и ковырял дальше. В итоге Debian с его кучей дисков со всем и вся стали для меня тем самым что помогло, ну и я тогда купил матаролку с попорезом, который на сверх скорости в 8кб мог позволить мне гуглить инфу. В общем история становления линуксойдом у меня та ещё длинная и весёлая. Зато после этого знакомые тоже захотели фишки которые были только в линухе и многие с хорошим тырьнетом ставили себе арч и до сих пор на нём =)
PsyHaSTe
Ну вот а что делать, если такого друга нет? Я может айтишник, но друзья-то в основном всякие менеджеры, продажники и прочие полезные, но далекие от компов личности. И как раз я для них "хакер"-линуксоид, я ведь знаю что такое ssh, dhcp, dns и могу реббит на удаленной вдске поднять. Правда, эти навыки не помогают от зависающего гуя, неработающего звука или пробелм с видео. Ну, просто потому, что на серверных машинах таких проблем нет за неимением подобной периферии.
Я верю что после прохождения пути в тысячу ли все проблемы решаются на раз-два. Уверен, что какие-то виндопроблемы я не замечаю просто потому, что на автомате по привычке их решаю. Но если знакомого нет, а из источников только интернет да чятик который быстро теряет мотивацию помогать если проблема не была решена в первые же сообщения — то использование системы превращается в ад.
svsd_val
Нет проблем можете писать мне, помогу чем смогу. А вообще есть у нас же специализированные форумы (https://linux.org.ru/ debianforum.ru unixforum.org), на них можно вопросы задавать и многие постараются помочь.
PsyHaSTe
Мне кажется что ЛОР это притча во языцех, воспринимать его как форум где могут неиронично помочь даже как-то в голову не приходило.
Спасибо за предложение, если пойду на четвертый заход — не примену воспользоваться :)
hhba
А зачем вам четвертый заход?
PsyHaSTe
Ну раз все говорят какая расчудесная ось — то может что-то в этом есть?
В раст я вот с третьего захода зашел, все время что-то отваливалось. Сейчас не нарадуюсь с ним
nilford
Сейчас гос сектор насильно переводят на Linux. И нас не спрашивают а какие у вас там принтеры или другое переферийное оборудование. Что меня всбесило в линуксе так это постоянно отваливающиеся принтеры, в основном HP. Че им надо понять не могу. Да принтеры старые но что поделать, на новые денег не дают, да и качество нынешних не очень. И да, нам закупили base alt Рабочая станция 8. Так то вроде все работает, не без глюков. Но принтеры бесят.
BigBeaver
Сейчас? Вроде, лет 10 назад что-то было такое.
alsoijw
linux_art
Вероятно в незнании о существовании всяких snap'ов и appimage…
IvUs
Ну вот есть некий codec.so собраный в убунту 16.04. Он требует GLIBC_2.23. В системе есть только GLIBC_2.13. Ваши действия?
ardraeiss
Справедливости ради, под Windows тоже можно получить замечательнейшие dll-hell'ы когда приложение установлено не через установщик, а через какой-нибудь Windows Store. С соответствующе весёлым раскручиванием "что и как пересобрать", а тио и "может ещё и какие версии промужточных библиотек припаковать к нашей?".
Что из этого хуже — леший его знает.
alsoijw
Я не пишу на си/плюсах, плюс данных недостаточно, чтобы понять всю картину. Исходный код кодека недоступен? Что мешает слинковаться статически/собрать контейнер/переопределить местоположение библиотек через LD_PRELOAD?
nick758
Я так понимаю, codec.so подгружается в какую-то клиентскую софтину. Слинковаться с glibc не позволяет GPL (кодек не свободный?), софтина клиента использует системную glibc, наличие нужной версии для codec.so положение не спасёт. Как я понимаю ситуацию.
alsoijw
IvUs
Еще как может.
IvUs
Нету вообще никаких проблем c GPL
Пробемы чисто техническая. Даже на LTS системах поддержа продолжается годами, но новые glibc не поставляются. В итоге мой компилер в centos линкует к моей проге системную glibc2.13. А где-то «продвинутые» разработчики юзают 2.23. И мне её взять негде.
IvUs
Код недоступен, кодек куплен у стороннего поставщика.
Статически линковать glibc — а где его взять? Линковать glibc плохая идея, по нескольким причинам — во-первых glibc зависит от ядра, во-вторых даже при статической линковке загрузчик загружает динамическую версию (непомню для чего). Вобщем -моветон и опасный.
Отсутстствие этой самой библиотеки. Ну вот нет под центос 6.x готовой glibc 2.23.
alsoijw
Если идти через чрут, то и линковать статически будет ненужно.
IvUs
Нельзя взять из убунты. glibc из убунты на centos не будет работать, потому как ядра разные. Добро пожаловать в суровый мир linux.
Я собирал свою glibc из исходников и прикладывал в локальной папке.
Но это 1. потребовало много усилий. 2. это тоже небезопасный способ, т.к. glibc завязано на ядро, а процесс смены ядра я никак не контролирую. При первой же возможности я от этого зоопарка избавился посредством смены кодека. Но с костылем пришлось жить несколько лет.
alsoijw
IvUs
свежая glibc из системы с более свежим ядром будет пытаться использовать фичи, которых нет в старом ядре.
COKPOWEHEU
Так может собирать свою программу со старым glibc и в зависимости прописывать >=glibc-2.01 или что-то в этом роде?
IvUs
Так я и собираю свою программу со старым glibc 2.13. Но у меня есть third-party либа собранная под убунтой и glibc 2.23 и вот оно-то и источник головняка.
qrKot
Ну это, например, как приложение, написанное под Windows 10, вероятно, может попросить «умелок», которых в Windows 3.11 нет, да? Я все верно понял?
Alex_ME
LD_LIBRARY_PATH=<app directory>?IvUs
И как это поможет загрузить библиотеку, которой физически нет на «устаревшей» ОС?
BigBeaver
Так положить рядом и загружать. Как все-то делают?
IvUs
ЧТО? ЧТО положить рядом? glibc из убунты 16 в центос 6? Она не заработает, ядра разные.
BigBeaver
Новую glibc нельзя собрать под старое ядро и положить, куда надо?
IvUs
Можно. Только это и есть неудобство и потенциальный источник проблем. Я в конечном итоге так и делал, т.к. деваться было некуда.
А теперь смотрите. Кастомер почитал хабр и понял, что нужно мигрировать с centos 6 на centos 7 или даже на 8. Обновляется, копирует прогу — она падает, т.к. наша приватная glibc была собрана для другого ядра. И хорошо, если просто падает. А если начинает тихонько глючить это вообще беда.
BigBeaver
Я, может, не достаточно глубоко знаком с темой, но бывали времена (лет 10 назад), когда я держал чуть ли не по 5 разных ядер, часть из которых — самосборные. И, вроде, проблем не было.
IvUs
Если посмотреть в sourceware.org/glibc/wiki/FAQ#What_version_of_the_Linux_kernel_headers_should_be_used.3F
То там пишут
The other way round (compiling the GNU C library with old kernel headers and running on a recent kernel) does not necessarily work as expected.
То есть может, оно будет работать, может нет — никто ничего не обещает.
ALexhha
vvzvlad Автор
Процедуру обновления для чего?
ALexhha
И по шагам расписывается, что надо делать и в каком порядке, чтобы софт после CentOS6 заработал на СentOS8.
У нас например была версия 1.x, которая работала с PostgreSQL 9 на RHEL6. Сейчас версия 2.x, которая работает с PostgreSQL 12/13 на RHEL 7/8. Естественно прямой и бесшовной миграции нет, но есть четкая процедура, в которой описано, что надо делать при переходе на новую ОС
qrKot
Не, мне кажется, вы не совсем верно транслируете суть проблемы. Т.к. это не проблема. Проблема — это «DirectX12 нельзя использовать под WindowsXP». Вот это проблема, нерешаемая в принципе. А то, что вы описываете — это возможность хоть как-то решить проблему свежих зависимостей на устаревшей системе.
Вот если бы вы говорили про софтину, которая всенепременно glibc2.13 просит при наличии в системе glibc2.23 — я бы понял суть претензии про «отсутствие обратной совместимости». Но когда система штатно умеет только более старую версию, а новую не умеет — ну это ни одна ось не умеет. Вообще ни одна. На линуксе вы, хотя бы, костыль подобрали. Какая альтернатива у вас в Windows/MacOS/WhateverЛюбаяДругаяПроприетарнаяОсь?
IvUs
Это вы не верно транслируете суть. DirectX12 — это неотъемлемая часть системы. А сишный рантайм — это всего лишь сишный рантайм. И проблема линукса как раз в том, что сишный рантайм вшит в систему довольно прочно и глубоко. Это создает массу неудобств не только разработчикам но и конечным пользователям
unsignedchar
Смайлик_с_разведенными_руками.
Программисты, которые делают teamviewer, как-то справляются, например. Во всяком случае, версию glibc при скачивании ихнего продукта не спрашивают.
IvUs
community.teamviewer.com/English/kb/articles/6318-how-to-install-teamviewer-for-linux
TeamViewer for Linux requires a Linux 2.6.27 kernel and GLIBC 2.17
unsignedchar
Это приблизительный аналог требований ихнего же клиента под Windows. Teamviewer 15 — требует Windows 7 +.
Linux 2.6.27 kernel существует с 2008 года, GLIBC 2.17 — с 2012. Или вы намекаете, что на современных линуксах, с более новыми kernel и glibc, этот самый TeamViewer не работает? ;)
IvUs
Я намекаю на то, что никакой магии нет — просто разработчики используют рантайм 9-летней давности.
Это, значит, что среда разработки под linux должна жить в бородатой системе с kernel 2.6.27 и GLIBC 2.17.
А под windows их разработчик вполне может сидеть на свежей Win10, никаких проблем с запуском приложения под Win7 у него не будет.
unsignedchar
Можно и так, только скорее всего нет. Не обязательно сидеть на Ubuntu 10 (протухшей 6 лет назад), чтобы собирать с ней совместимые программы.
IvUs
В том-то и дело, что приходится делать именно так.
Есть всякого рода хаки типа
stackoverflow.com/questions/2856438/how-can-i-link-to-a-specific-glibc-version
но это все очень сильно снижает надежность разработки и просто еще более неудобно, чем просто компилять в старом linux.
JerleShannara
Я правильно тогда понимаю, что разработчик под aarch64 в мире линукса должен сидеть на этой самой aarch64 или всё же такая штука как crosscompile в природе существует наравне со всякими build server?
IvUs
crosscompile-среду каждый разработчик сам себе собирает или берет готовую, собранную людьми, которые в теме?
JerleShannara
Как хочет. Я могу собрать её себе сам, могу взять готовую, которую уже собрали люди, которые в теме.
IvUs
А windows для решения проблемы в VS есть комбобокс, в котором можно выбрать рантайм совместимый с WinXP. и больше ничего не нужно. А для всех версий новее, чем XP вообще ничего делать не нужно, разве что указать константу препроцессора с минимальной версией windows.
Это — удобно и понятно. Извращаться с кросскомпиляцией только для того, чтобы подлинковать старый glibc — это неудобно.
alsoijw
У вас проблема из-за ваших зависимостей, а там это одним флажком не решить.
IvUs
В linux — не решить, а в windows проблема не возникает, т.к. самый новый рантайм официально доступен для системы выпущенной 15 лет назад.
alsoijw
IvUs
Vista SP2 - поддерживается.
alsoijw
На данной странице я не вижу упоминания висты. Нужно какое-то другое ключевое слово? Самая свежая студия тоже на висту встанет?
IvUs
Разговор был про рантайм, а не про студию
https://www.microsoft.com/en-us/download/details.aspx?id=48234
alsoijw
IvUs
Зависимости, на которые конкретно я жаловался и которые осложняют жизнь конкретно мне - от сишного рантайма. Я не могу обсуждать проблемы зависимостей от других библиотек, поскольку я с ними не работаю. Зато поучаствовавшим в дискуссии оппонентам, похоже, всё равно, к чему оппонировать, главное сам процесс.
alsoijw
IvUs
Конечно, без кодека было бы проще, но без него транскодер не будет транскодировать.
alsoijw
IvUs
Ну в конце концов пришлось перейти на собственный, но на это потребовалось время.
А с коммерческим поставщиком кодеков дела обстоят примерно так: У поставщика в описании пакета кодеков сказано "glibc 2.17 and GNU libstdc++ GLIBCXX_3.4.19". И получить положительный ответ на просьбу собрать кодек для более старой glibc у "обычного" покупателя нет никаких шансов. Даже старую версию кодека не дадут. Если покупатель кодеков имеет статус VIP, т.е платит licensing fees с большим количеством нолей, тогда, конечно, ему и кастомный билд соберут и исходники дадут и выделят персонального инженера техподержки. Но небольшой конторе это всё не светит.
unsignedchar
Не знаю как в linux, а в qtcreator это решается: ь
unsignedchar
Спасибо Visual Studio за наше счастливое детство :)
И отдельное спасибо БГ, который выпустил только Windows XP/7/8/10 (и несколько серверов по мелочам), а не весь этот вот зоопарк, через каждые полгода обновляющийся ;)
unsignedchar
IDE каждый разработчик себе сам собирает, или берёт готовое? ;)
Приблизительно так. Можно взять chroot с Ubuntu 10, разработку делать хоть и под debian 10, а сборку релиза — в нужном окружении. А может, достаточно компилятору указать --sysroot где старые либы лежат.
alsoijw
Только при условии, что весь рантайм совместим с семёркой. DX 12 вполне может выступать аналогом в данной ситуации.
IvUs
Дык. Он не только с семеркой совместим, но и с более старой вистой.
www.microsoft.com/en-us/download/details.aspx?id=48234
vtb_k
Минимальные требования к системе не исключают новых версий. Дальше обсуждать ваш бред смысла не вижу. Любые доказательства можно вывернуть наизнанку
basilisk
Это те ребята, что сломали 2 года назад поддержку митингов под linux и до сих пор их не починили?
Так себе пример :)
svsd_val
Никогда не слышал о митингах в TeamViewer и никогда не видел такого, зачем оно нужно софту который предоставляет доступ к рабочему столу по типу РДП ???
basilisk
Хе. У них много разных свистоперделок для разных случаев. Это уже давно не просто удалённый доступ типа RDP :)
И, кстати, весьма удобные митинги у них. В отличие от появившихся позже всяких zoom'ов есть весьма удобный шаринг экрана с возможностью управления компом (настраивается модератором). Мы активно использовали TeamViewer для обсуждения и тыканья мышой в нашей распределённой команде. Зачастую весьма удобно получив управление тупо показать на том компе, чем пытаться словами описать, что владелец должен сделать. Такой себе коллективный RDP :)
Но, начиная с версии 12 (если мне не отшибает память) в linux сломали работу митингов. А в 13-й вообще такой пункт меню убрали в линуксовой версии. Пользователи винды могут и сейчас, а вот линуксоидов лишили этой возможности. Просто патамушта.
wigneddoom
Сишный рантайм - это неотъемлемая часть unix-like системы, впрочем как и windows.
unsignedchar
Я слышал что-то про ppa в убунтах. А автор софтины не слышал. Жаль.
Ну, допустим, chroot с убунту 16.04. Если не хочется танцев с бубном.
IvUs
Вот вы смешные. Думаете, что дело в том, что я не умею загрузить либу из кастомной директории. Проблема в другом. Либы нет. НЕТ. Да её можно собрать руками, что само по себе квест. И положить куда надо. И загрузить. И даже будет работать. Я даже так делал. Куда деваться-то. НО. Кто даст гарантию, что ядро кастомера совпадет с тем, что у меня? Особенно если кастомер через полгода обновится? А glibc завязана на ядро. Да, там есть гарантии, что новая glibc будет работать на более старом ядре. А наоборот — нет гарантий.
А в винде я просто копирую 2-3 дллки в папку с прогой. Всё.
ALexhha
А то получается из серии — вы написали крутую игру на dx12, и тут к вам приходит возмущенный клиент и заявляет, что он не может запустить ее на своем лицензионном Windows XP и DX9
что мешает собирать статически? Особенно в том же golang это cделано просто и удобно, а так же хорошая мультиплатформа из коробки.
Яркий пример — github.com/mikefarah/yq/releases/tag/v4.9.1
IvUs
Я немогу указать glibc X. Потому что заказчик скажет — её нет в стандартных репозиториях, мы не будем поддерживать кастомные сборки.
Во-первых stackoverflow.com/questions/57476533/why-is-statically-linking-glibc-discouraged
А во-втрорых статическая линковка не решает проблему совместимости. Линкуя glibc статически вы фактически статически линкуетесь к к конкретной версии ядра. Со всеми вытекающими.
ALexhha
Я себе могу представить только один вариант — заказчик в ТЗ озвучил примерно так — «Хочу чтобы работало на Linux»
В нормальных продуктах эти требования всегда определяются очень четко и никаких — «нет в стандартных репозиториях» уже не прокатывают. Мы например не поддерживаем Gentoo/Archlinux
И соответственно, если клиент обращается с вопросом из серии — «Не могу установить/запустить ваш продукт на Gentoo» ему support объясняет, что это не возможно и данный дистрибутив не будет поддерживаться. Если прям очень сильно хочется — на свой страх и риск, без каких либо гарантий и поддержки.
IvUs
Это заказное ПО - разрабатывается под конкретного заказчика. У заказчика конкретная версия линукс, что оговорено в ТЗ.
unsignedchar
… И для разработчика вызывает затруднение собрать программу, совместимую ровно с одним окружением… О-о…
ALexhha
IvUs
Я и пытаюсь донести, что разработка коммерческого софта под linux — это почти всё время какая-то «другая история». Вместо решения задач предметной области приходится тратить много ресурсов на преодоление побочек от unix way.
BigBeaver
Unix way тут не при чем. Да и нет проблемы собрать скриптом хоть под все версии сразу.
ALexhha
IvUs
Фактически вы перекладываете проблему совместимости на конечного пользователя. Но это не значит, что она пропадает.
Я так сделать не могу, т.к. софт штучный и пишется под ТЗ конкретного заказчика. Т.е. первое, что я спрашиваю, это под какую платформу нужен продукт.
BigBeaver
Ну Мелкософт всю жизнь так делает с самой первой версии дос и по ныне. Вроде, нет жалоб.
qrKot
Это не он, это все так делают…
qrKot
Погодите, вы сейчас на полном серьезе утверждаете, что я вот сейчас возьму папку, например, «The Witcher 3», скопирую на WindowsXP, подложу dll-ки DirectX'а 12-го, и оно прямо вот возьмет и заработает?
UPD: Попробовал, не заработало( Чувствую себя обманутым.
Sequoza
Musl осел.jpg
qrKot
— chroot?
— /path/to/newglibc/ld-linux.so.2 --library-path /path/tonewglibc/lib64:/path/to/newglibc/usr/lib64 /path/to/myapp?
— snap/flatpak?
— собрать glibc нужной версии?
ну, из того, что быстро пришло в голову/нагуглилось.
В целом, более старую glibc вполне занести можно. Более новую, чем системная… Ну, если честно, такое себе… Возможно, будет работать, но а) не гарантировано, б) вообще не факт. От Windows XP вы же не требуете умения UWP-приложения запускать, и поддержки DirectX12 от Windows 95.
andi123
Почему вас так волнует, что линукс не занял больше 2% десктопов?
Лично мне плевать (да, моя нога не болит. Я им просто пользуюсь и вся моя семья и даже некоторые родственники).
Может «проблема» не в том, что вы перечислили, а в том что линукс для десктопа это не продукт и никто не собирается его им делать (нет никакой проблемы). И за что мы его все так любим.
vvzvlad Автор
Он не продукт, и его никто не собирается делать, это так. Но раз за разом появляются статьи (вот недавно про телефон на линуксе была) в которых начинается срач на тему «подходит или не подходит линукс для декстопа». Запрос есть. Я бы сам хотел третью ОС.
soniq
Так есть же третья ОС, вот же она! Да, десктопный линукс кривоват в некоторых аспектах, но мы его за это и любим. И давайте смотреть правде в глаза, времена когда для настройки линукса нужно было PhD уже прошли (достаточно магистерской степени, кек)
Зачем ещё одна прилизанная винда в которой нельзя ковыряться в конфигах, а надо ставить галочки в гуе?
vvzvlad Автор
Потому что я не могу им пользоваться. Потому что надо постоянно что-то подкручивать, доделывать и донастраивать, из-за того, что сборщики системы-как-продукта не осилили подумать за пользователя и постоянно меняют интерфейсы. В итоге, не знаешь, что сломается при миграции на новую версию и как это починить: система не работает сама, а требует смазки и обслуживания. Винда не требует, андроид не требует (разве что на мажорных обновлениях), макось и ios не требуют. Линукс требует.
Пусть не галочки в GUI, я согласен ковыряться в конфигах, я люблю ковыряться к конфигах, но пусть это будет один(или 3-4) нормальный документированный и с устойчивым интерфейсом конфиг, а не 100500 штук, размазанных по системе, с неясным версионированием и без актуальной документации.
solver
Ну вот к чему эти грязные инсинуации?
Вы же сами говорите в своей статье про такую же ногу которая не болит. Если лично у вас не было проблем с обновлениями винды, андроида и и макоси, это вовсе не значит, что там нет проблем. В идеальных ситуациях никто не требует "смазки". Но вообще проблемы есть абсолютно у всех перечисленных вами продуктов. Да, они могут быть в разных аспектах, но абсолютно все доставляют головняк пользователям. Погуглите, походите по тематическим форумам. В винде вообще регулярно минорные обновления всё ломают) Куча новостных сайтов постоянно постит об этом. И лично у меня с виндой регулярные проблемы возникают. Она постоянно требует каких-то телодвижений. И даже в захваленной по самые помидоры макоси проблем хватает. У нас, в корпоративном чатике, постоянно вопли о том, что обновили макось и все отвалилось и рекомендации админов не спешить с обновлениями)
Как пример моей ноги, у родителей убунта обновляется уже лет 8 наверное, без каких либо проблем.
Так что не надо передёргивать, раз вы тут зашли типа с аргументами.
Ogra
Винда не требует смазки? Вон свежая новость, при обновлении сломали 5.1. На фоне описываемых в этом посте проблем со звуком в Линуксе очень эпично звучит, если честно.
dartraiden
Тем не менее, смазать проще: обновление можно откатить через графический интерфейс, вход в который логично расположен в разделе настроек «История обновлений». Чтобы откатить его в Linux, придётся гуглить даже мне, потому что для этого добро пожаловать в консоль.
zmc
Да да да, слышали, знаем. К примеру KB5000808/KB5000802, ну ни как не хочет откатываться через графический интерфейс, они видите ли являются обязательным по мнению MS. Ну ни чего, мы же через консоль его можем откатить wusa /uninstall ...., блин блин блин — это же как в Linux получается, а нет, оно и так не удаляется. Бедные бабушки и не опытные пользователи, так и сидят с синим экраном.
PsyHaSTe
Это хреново. Но это куда лучше, чем скажем постоянно зависисающая ось.
Ещё момент такой, что винда чаще работает после установки, но ломается во время использования. Тогда её можно переустановить и она опять заработает. С линуксом (ИМХО) чаще наоборот: после установки ничего не работает, и нужно подкручивать чтобы заработало. Если что-то не работает то пеереустановка сделает только хуже, т.к. теперь нужно не забыть, что там крутили в прошлый раз чтобы делалось, что нужно.
MTyrz
По несколько устаревшему эникейскому опыту скажу, что у винды среднее время настройки после установки больше, но предсказуемее. Драйвера, софт и вот это вот все.
Ставить какую-нибудь убунту для интернета, кинца и вордокнопа в среднем сильно быстрее и безгеморройнее. Некст-некст-некст-готово. Пользуйтесь.
Но если что-то идет не так, или если у пользователя есть дополнительные задачи… Вот тут можно потратить и несколько суток.
khajiit
Покажите такой не-в-линуксе, пожалуйста.
Наглядно разницу между конфигами корпов и OSS демонстрируют конфиги Skyrim и skse-uncapper, например. Или виндошаринг и самба.
Приведите пример неустойчивого конфига в пределах минорных версий.
Мажорные сами по себе предназначены для breaking changes.
vvzvlad Автор
Панель управления в винде. Настройки макоси. Не?
Это же не обязательно должен быть текстовый конфиг.
BigBeaver
COKPOWEHEU
оригинальное у вас представление о конфиг файлах…
… и об устойчивом интерфейсе
vvzvlad Автор
Эм. Исходный тезис был «дайте мне стабильный интерфейс, пусть даже это будет текстовый конфиг». О наличии где-то стабильного текстового конфига для всей системы я и не говорил.
А панель управления в винде — она очень устойчивая. Если до нее докопаться в десятке, то она почти не изменилась с 98 винды, только добавились новые функции. Принципы остались теми же.
BigBeaver
vvzvlad Автор
Я имею ввиду вот эту панель управления:
Электропитание, система, звук, администрирование, дата и время, клавиатура, диспетчер устройств, учетные записи, телефон и модем(!), региональные стандарты, программы и компоненты — это все мало изменялось.
unsignedchar
Почему «Диспетчер устройств», «Телефон и модем (устройства же?)», «Мышь (тоже вроде как устройство)», «Клавиатура», «Устройства и принтеры» — интуитивно понятно (нет). Где настройки дисплея (в диспетчере устройств? в устройствах и принтерах? В управлении цветом (или это про цветной принтер?). Или у дисплея нет настроек совсем? ) — интуитивно не понятно.
Инфракрасная связь, телефон и модем… Живую инфракрасную связь я видел последний раз лет 15 назад…
vvzvlad Автор
Это уже вопросы к проектированию панели управления. Мне она этим тоже не нравится: чуть лезешь глубже, там торчат уши систем 15-летней давности и иконки с флоппи-диском.
Но факт-то в том, что панель управления меняется слабо.
DaemonGloom
Панель управления тоже отмирает. Того же пункта «Система» там уже нет, остался ярлык с этим названием, открывающий новые «Параметры».
Big-Bag
Это в какой системе так? Только что посмотрел, открывает, как и раньше, обычные «свойства системы».
DaemonGloom
Это так с версии 2004, насколько помню.
qrKot
Обновись, man!)))
khajiit
Слабо — это с перетасовкой пунктов как попало, выдергиванием их в новые виджеты, не являющиеся частью показанной как образец панели?
Вы бы сразу уточнили, что у вас двойные стандарты: под линуксами обязательно интерфейс не должен 20 лет измениться ни на йоту, а под виндой как образец возьмем то, что deprecated уже 8 лет (и по этой причине на роль образца не годится совершенно).
vvzvlad Автор
У меня просили пример, я привел пример. ПУ нифига не deprecated, потому что 80% не реализованы в красивом новом интерфейсе.
qrKot
Мы тут, вроде, про стабильность же?
Ну вот такая статья от MS: support.microsoft.com/ru-ru/windows/%D0%B3%D0%B4%D0%B5-%D0%BD%D0%B0%D1%85%D0%BE%D0%B4%D0%B8%D1%82%D1%81%D1%8F-%D0%BF%D0%B0%D0%BD%D0%B5%D0%BB%D1%8C-%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F-aef7065f-a9ec-1ba9-8cab-79b2b83bdda5
Прямо от саппорта, статья по часто-задаваемым-вопросам: "Где находится панель управления?"
Т.е. вы на полном серьезе позиционируете как показатель стабильности «Панель управления» при том, что у пользователей возникают вопросы как туда в принципе попасть? Ну, как бы, да, я с ними согласен, в «Пуске» ее нет… А в 8-ке еще и пуска не было… Красота… Стабильность…
Mingun
Полагаю потому, что в «Диспетчере устройств» спрятано все то что находится внутри системного блока, а все, что снаружи, имеет собственные пункты. По-моему, вполне логично, если вылезти из консоли и посмотреть на хардварный рабочий стол :)
Впрочем, если его открыть, то понятно, что это просто общий реестр вообще всех устройств, и физических, и виртуальных, более технический. Вынос отдельных часто используемых его пунктов в отдельные ярлыки настроек — вполне здравое решение
Так это же вроде и говорит о стабильности интерфейса. 15 лет не менялся (по крайней мере не исчез из места, где все собрано)
BigBeaver
Если настолкьо абстрагироваться, то в линуксе так же то же самое всё.
Это не правда. Я вот вижу винду вживую раза 2 в год. Не помню чтобы удавалось с первого раза найти что-то в настройках. Вам, видимо попроще, если регулярно пользуетесь.О, мемный случай. Недавно папа коллеги (мужчина пенсионного возраста) спрашивал что-то про линукс. Очень, говорит, трудно без знаний английского разбираться… но попроще, конечно, чем в десятке, ей-то совсем пользоваться невозможно стало.
Вот и делайте выводы=)
vvzvlad Автор
Да нет, каждый раз сам мучаюсь, хоть вижу и чаще двух раз в год. Вот выше unsignedchar правильно написал, те же претензии.
qrKot
Ну, значит, со стабильностью там все тоже не очень хорошо?
Тут вопрос в чем. С точки зрения того, что это все та же панель с группировкой пунктов по какому-то одному микрософту известному принципу — ну да, стабильно, давно уже так. Ну, собственно, и в линухе как были текстовые файлы — они до сих пор текстовые, тоже давно. В чем разница — непонятно.
А вот если посмотреть на удобство пользования этим — как ни зайдешь, они опять значки перетасовали. В линухе хотя бы строки местами в конфигах не меняются — и на том спасибо.
0x9d8e
Тоже недавно открыл ноут с семёркой, кое-как нашел панель управления, а там вот вообще ни разу не то, что в XP было (и которое я знаю наизусть спустя годы). С горем пополам нашел где блютус настраивается, но так и не смог колонку подключить. При том, что в убунте это примерно как в андроиде: тык в правый верхний угол, настройки, Bluetooth, тык в переключалку, тык в устройство, окай, готово".
ALexhha
А это разве не ее ms чуть ли не в каждом обновлении меняла вместе с многострадальным Пуск? Я вот точно помню из новостей, возмущение людей из серии - ну сколько можно что-то менять и что теперь нет единого места управления и настройки. А все размазали по нескольким местам
vvzvlad Автор
Сама панель управления осталась на месте.
khajiit
Из нее пропал с концами, например, bluetooth. Или "настройки" обновлений — на картинке вашей его не видно.
Так-то, небось, и
write.exeиfileman.exeвсе еще "на месте".FRiMN
Так вроде подобное есть и в Линуксах и там оно то же годами почти не меняется.
vvzvlad Автор
...только вот все равно для настройки приходится лезть в конфиги
alsoijw
www.reg.ru/support/dns/DNS-servery/gde-nahoditsa-fail-hosts-i-kak-ego-izmenit а где же тут панель управления и графический интерфейс?
FibYar
В пуске вводишь интересующую настройку (прямо словом/словами) -> винда предлагает соответствующее меню для настройки. Ещё со времён Windows Vista (или семёрки).
BigBeaver
А если чуть ошибся запросом, то получаешь кучу непонятного мусора в поисковой вадыче.
Mingun
Справедливости ради, в семерке мусора почти нет никогда. Вот в 10-ке часто можно найти только по более-менее точной фразе
BigBeaver
Видимо, семерка не зря считается лучшей версией винды. Но ведь версию винды не выбирают, верно? Вот купил я ноут с 8.1 (разумеется не в 2021), и что я должен делать? Пиратскую семерку накатывать?
PsyHaSTe
Ну не знаю, такая же нога и не болит :)

COKPOWEHEU
MTyrz
Процитирую-ка я свой же коммент из каких-то предыдущих срачиков на эту же тему.
qrKot
Вы либо одно, либо другое не видели…
khajiit
У макоси, говорят, настроек — кот наплакал.
Панель управления в винде — это которая из них? )
Ну и, на засыпку, где по им документация? Ваше же условие:
0xd34df00d
Я ничего там не мог найти в 8.1, и снова ничего не могу найти в 10.
qrKot
Стабильность же, чо не так?)
linux_art
Панель управления в винде мало того что имеет 2-3 разных вида (в зависимости от версии десятки), так еще и в рамках десятки по мере накатки обновлений там исчезают или появляются опции.
qrKot
Не, буквально вот же переделали к хренам. И в каждом релизе продолжают переделывать кусками. На годик с винды отлучился — и на тебе. Рыдал в поисках привычных кнопок.
t13s
Вот пока я читал это предложение, выхваченное из контекста, мне казалось, что это вы про винду, вот чесслово :)
linux_art
Подпишусь под каждым словом :) Именно такие эмоции были когда пытался завести навигацию на купленном по случаю Panasonic'e под 10кой…
mrbald
Посмотрите на systemd. По-моему круто. Все мои любимые животные (RH, Debian, Arch) и их производные уже пересели довольно давно. Я сам сисадминю зоопарк разношерстный зоопарк на работе и дома — вполне терпимо, надо просто всё промышленно делать — читать релизнотес, трэкать всё что меняем, записывать и подучиваться немного каждый раз (например про systemd книжку почитать а не трахаться методом trial and error).
С виндой же просто кошмар, всё через одно место, хорошо хоть SSH портировали к себе наконец.
mikhailian
systemd на разных дистрибутивах работает по-разному хотя бы потому, что и версии разные, и костыли. Попробуйте сделать что-то чуть-чуть неочевидное, например настроить mdns в Debian и Arch средствами systemd-resolved. Потеть придётся два раза.
Rohan66
А давайте обсудим процесс миграции (с сохранением всех настроек) по пути: WinXP — Vista — Win 7 — Win 8 — Win 10!
На любом этапе, скорее всего, проще будет всё снести и поставить заново. ИМХО.
viklequick
… в отличие от Linux, который только у меня пережил переезд от S.u.S.E. (он тогда назывался с точками), далее до OpenSUSE с остановками, и с 15.2 я ушел на роллинг — Tumbleweed. С 1997 года — только апгрейдами. Причем — не подряд.
Апгрейд с 7.1 на опенсусь 10 помню жесткий был, из-за моих шаловливых ручек (я тогда в целях экономии — пораскидал по разным дискам части системы, а при апгрейде забыл часть из них смонтировать. Ссылки стали показывать вникуда, инсталлятор их убрал и пососздавал каталогов обратно, хорошо хоть в логе все перечислил. Потом я долго матерился и склеивал).
С 12.2 на 42.2 тоже весело было, опять же из-за моего перфекционизма (устроил зачистку древнего хлама еще с 90х, попакетно, потом выбрал файлы без пакетов и их тоже снес, не без ошибок конечно).
А так — живо и работает до сих пор. Я даже из списка модулей ядра до сих пор piix3 не выбросил, нету и нету, ворнинг dracut недостаточно парит чтобы я в этот список полез.
Последние лет 10 — обновляюсь через zypper dup --allow-vendor-change, даже не отключая 3rd party репозитории. Просто в /etc/zypp.d/ ручками меняю на нужное — и вперед.
Из вот относительно свежего — в новых кедах на кнопку пуск мой любимый лончер стал меньше чем я люблю. Нашел этот самый kickoff, прописал больше размер в .qml, лепота…
Ign0r
Если из списка исключить Vista, то я, пожалуй, скажу что прошел указанный Вами путь на одном из своих ПК. Естественно, железо для новой ОС уже не достаточное, но тем не менее все настройки программ и документы двух пользователей переносились. Несколько программ уже нет, а настройки для них - остались.
symbix
Вот у меня ровно такое ощущение от винды. Сталкиваюсь с ней нечасто, но когда приходится — все время с очередным апдейтом что-то ломается, сидишь и гуглишь как чинить. С линуксом у меня такое было лет десять назад, сейчас и не вспомню, чтобы что ломалось в последние годы, просто все работает, как и на маке. Manjaro причём, роллинг вроде как.
beeruser
Не мы, а вы(с)
ultraElephant
В действительности для меня это то что нужно. Тот самый 1% как конечное число пользователей — достаточно большой, что позволяет ОС динамично развиваться, но не настолько обширный, что бы привычные мне инструменты управления ОС прятали под грустными смайликами и толстыми GUI приложениями.
DrPass
Вот могу буквально позавчерашний пример привести. Я как раз решал самую что ни на есть гиковскую задачу - подключал sdr-трансивер. На убунте - стянуть из репы sdk самого трансивера, стянуть сурцы пары библиотек, собрать их, увидеть, что не собирается, залезть в исходники, поправить, снова собрать, скачать собственно софтину, собрать, увидеть, что молча не работает, потыкать палочкой в разные места, наугад обновить прошивку трансивера, начать работать.
На винде: скачать софтину, выбрать тип трансивера, начать работать.
И вот скажите, на кой ляд даже мне, ит-шнику, это надо?
DaemonGloom
Увы, это проблема везения с конкретным трансивером. Бывает и наоборот ситуация — и тогда отладить железяку становится значительно сложнее.
DrPass
Это в первую очередь проблема юникс-стайл. И виндовая, и линуксовая софтины опенсурс. Но виндовая - монолит, у которой одна команда разработчиков, и подход "запустил-работай". А линуксовая зависит от пачки сторонних пакетов, каждый из которых живёт и развивается своей жизнью. И собирать всё это в одно целое и работоспособное - тупая бесполезная трата времени пользователя, ничего более.
dlinyj
Да, но проблем с дровами в винде я имел несоизмеримо больше, чем в Linux. Банальный пример, с которым бегаю по хабре, дрова на старые принтеры. Устройства есть, а дров в Windows 10 нету, и если попытаться заставить их работать, там такой unix-way будет, что уууу. В Linux подключил и работай.
Та же история была, заменил видяху, винда тупо не стартанула (так и снял жёсткий с ней, и больше не включал), а линукс загрузился и работает. Да, знаю, что с видяхами пьёт много крови, но я не сталкивался. И тем не менее, я считаю, что есть задачи где винда незаменима, как линукс.
Revertis
Так ведь всё правильно — Линукс для работы со старым железом, Виндовс для работы с новым.
dlinyj
История с видеокартой - это было новое железо
mistergrim
Ага-ага, запустите линукс на старой видеокарте.
JerleShannara
GeForce FX5200 это достаточно старая, или поискать второго жырафа?
mistergrim
А вы Radeon попробуйте, 9600 какой-нибудь. И да, чтобы не просто VESA, а все функции работали.
khajiit
Это из разряда заведите ESS Solo в x64
mistergrim
Ок, давайте X600 какой-нибудь. Они, между прочим, как затычка в слот вполне годятся по сей день.
Да что там говорить. В линуксе и намного более новые не поддерживаются уже.
slonopotamus
Пойдите и пожалуйтесь вендору видеокарты. При чём здесь линукс? Линукс должен открывать спецификации на видеокарту или драйвер писать?
vorphalack
а вы заведите Radeon Xpress чипсетный на десятке.
(hint: у него последние дрова под висту были)
mistergrim
Вот с этими дровами и заведу (что уже и проделывалось, когда дискретка приказала долго жить).
OpenMind4423
radeon free драйвер тянет эту видуху на ура. На х300 по крайней мерее проблем не обнаружено точно. Кроме того что там всего 64 мб памяти.
mistergrim
И что он умеет?
Ладно, а если у меня, допустим, какой-нибудь HD7750 или 4870?
Oxyd
Radeon HD 6320 13-летней давности, для вас достаточно старый?
Если что, все функции работают.
OpenMind4423
Нормально работает на Linux Mint Cinnamon x64.
COKPOWEHEU
В копилку:
1. Давным-давно (~2010 год) устанавливал на ноут win7 и какой-то линукс (debian наверное). В настройках BIOS можно было выставить режим жесткого диска ACPI или IDE. Установил обе ОС, проверил, все хорошо. Потом ради интереса поменял этот флажок харда. Винда ругалась и вываливалась в BSOD, линуксу пофиг.
2. Примерно в те же времена захотел установить драйвер на дискретную видеокарту. В репозитории не нашел (потому что не знал как оно называется), скачал *.run с сайта производителя, установил все по инструкции, перезагрузился и получил… черную печальку с мигающим курсором. Впрочем, из нее удалось удалить «фирменный» драйвер и откатиться на дефолтный. А там и разобрался как установить фирменный по-человечески.
3. Совсем недавно устанавливал debian-netinst, во время установки графики решил сразу же установить и драйвер тачпада, в той же команде что иксы. После загрузки графики оказалось, что тачпад-то работает, но и только: ни клавы, ни мыши. Хорошо хоть SysRq + R сработало и позволило выйти в консоль, откуда и разобраться, что иксам нужен _хотя_бы_один_ интерфейс ввода, а раз я указал тачпад, они спорить не стали. Соответственно и решилось установкой остальных xserver-xorg-input-*
4. Разбирался с USB в контроллерах — как какими устройствами прикидываться. Основной полигон, понятное дело, линуксовая машина. Потом, когда железка начинает приемлемо работать, подключаю к виртуалкам с разными виндами. В зависимости от той кривизны железки, что осталась неисправленной, винды либо ее просто не определяли, либо пугались до BSOD'а. Справедливости ради, только старые: win10 не падала. Впрочем, она не видела и десятой части издевательств, которые перенес линукс. Который, естественно, и не думал ломаться.
Junecat
> Винда ругалась и вываливалась в BSOD — просто для информации, в винде это лечится тремя правками реестра: recovery-software.ru/blog/enable-ahci-mode-for-sata.html
COKPOWEHEU
Ах да, забыл совсем
5. В ~1018 году устанавливал линукс на MSI GL62M-7RD. Дискретная видеокарта запускаться отказалась, в после обновления до testing система начала зависать даже на чтении конфигурации вроде lspci / glxinfo, а потом и просто при загрузке. Как именно разработчикам MSI умудрились настолько накосячить, я боюсь предположить. В общем, будьте бдительны и обходите MSI стороной
TheKnight
Мужик, дай машину времени погонять, очень надо!
COKPOWEHEU
Не могу, уже вернул телепатам с ЛОРа, они с ее помощью новости пишут и вендокапец предрекают :)
zmc
Согласен на все 100%. Пример из жизни, usb сканер Be@rPaw 1200CU, на коробке написано Windows 7 Ready, типа воткнул, подождал чутка и сканируй в свое удовольствие, и так оно и есть.
Но вот под Win 10 почему то уже нет. Не, конечно можно подсунуть и из 7-ки и пошаманить можно, но это уже ни чем не лучше того же юникс-стайл'а.
balamutang
Ну так это заморочки мастека, они не написали драйверов для него под десятку (EOL) и не сертифицировали в мс — поэтому автоматом и не подтягивается.
zmc
Я полагаю могу ваше сообщение переадресовать DrPass, типа все то же самое, по поводу sdr-трансивера и того что производитель не удосужился создать бинарный пакет под него?
А че, заморочки производителя и т.д и т.п.
qrKot
Это другое (тм)
ne555
Доводить до ума и мотоблок после покупки, новый телефон для прошивки на свободную+рут и даже паяльник…
Бездарные, безграмотные и ленивые останутся за бортом в 21 веке.
dlinyj
Хочется так думать, но на деле это не так.
DrPass
Именно так. Только эта палка обоюдоострая, и одинаково действует и на пользователей, и на разработчиков, которые не уделяют внимание юзабилити своего софта или железа.
PsyHaSTe
Надо полагать, вы не видите в этой ситуации ничего плохого? Уверяю, что все люди бездарные и ленивые в большинстве областей, не связанных с полем деятельности. Например, я вот ленив в области занятия физкультурой, слежением за здоровьем в целом, соблюдением work-life balance и т.п. (сижу, кожу допозна постоянно). И я рад, что для меня придуманы системы доставки еды "заплати и мы тебе привезем здоровую и вкусную еду", такси где я могу по одной кнопке доехать до другого города (и мне не нужно разбираться, что такое карбюратор, как используется в двигателе масло и под какое число тактов расчитан микрокомпьютер в движке) и так далее.
Все вот эти неленивые айтишники в областях, не связанных с компьютерами сами и оказываются теми же "безграмотными бездарностями", которыми называют других. Которые не знают юриспруденции, которые не чистят зубы,…
Когда вы к врачу приходите, вы спрашиваете какое лекарство взять? И он такой "ну, милок, очевидно же что димихрил травторида перорально 5/25мг. Что ж вы непонятливый такой?!?!".
Слава богу, мне не надо быть юристом, экономистом, врачом, электриком и т.п. чтобы жить. И рекомендую вам не быть ханжой — вы сами пользователь, и вам в первую очередь не понравится если ваше отношение развернут прекрасной половиной которой вы рекомендуете — к вам, и отправят в биореактор на славо прогрессивного общества грамодных трудолюбивых небездарностей
hjornson
>На винде: скачать софтину, выбрать тип трансивера, начать работать.
… а потом внезапно обнаружить что работать оно перестало, потому что заблокировано проверкой подписи драйверов, и начать перебирать разной степени хацкерности рецепты отключения проверки подписи…
0x131315
Если ситуацию взять как у дрпасс, то скорее так: скачать программу, обнаружить что трансивер не работает, обновить прошивку, обнаружить что… трансивер не работает. Финита ля комедия: исходников нет, ничего не поправить, выбрасывай трансивер покупай новый, с шильдиком win10 pass.
DrPass
Как я выше написал, опенсурсные они обе. Только виндовая поставляется в виде готового к употреблению приложения, а никсовая в виде процесса инсталляции и сборки на полчаса не считая подводных камней.
unsignedchar
Разработчикам софтины лично Столман запретил делать удобно? ;)
vvzvlad Автор
Им никто не запретил делать неудобно
masterbo
Так причем здесь линукс? Претензии конкретно к разработчикам. Ну или к себе - желающему пользоваться непромышленной железкой и при этом наивно полагая, что её софт делался по стандартам массового потребления. Не нравится, что для HackRF софт не достаточно коммерческий - переплатите пару десятков тысяч долларов за промышленный SDR. (Не факт, что тамошний интерфейс вам понравится больше, но техподдержка будет)
smartov
Спустя 20 лет аргументы всё те же. Прямо слеза умиления скатилась по моей шершавой щеке Штирлица.
khajiit
А если ваш трансивер не заработал бы под виндой, то молча отправился бы на полку/авито? )
DrPass
Речь была не про трансивер, а про то, что программы, для использования которых конечному пользователю надо не инсталлятор запустить, а выполнить кучу действий по подбору пакетов и сборке — саксъ и маздай по меркам 21 верка.
BigBeaver
Зато, если на винде сразу не заработает, то скорее всего, ни каким сексом уже не заставишь.
FibYar
Если что-то не заработает на винде, товар можно смело вернуть в магазин.
BigBeaver
А пользоваться-то чем?
FibYar
По крайней мере, перед покупкой можно сразу узнать, работает ли устройство на конкретной винде (благо их сейчас всего одна). То есть изначально покупать совместимое устройство. Сразу же в магазине заменить на другое, но с шильдиком «for Windows 10».
qrKot
Потом прийти домой с этим шильдиком и выяснить, что он тоже не работает? Была такая эпопея с принтерами Canon года с полтора назад, например. Просто разом все отвалились, а шильдик — нет… Но мне не шильдик, мне попечатать…
khajiit
Тем не менее, в случае с виндой вы остаетесь вообще без вариантов.
И вот напоминают эти двойные стандарты (винда не смогла то, что и не должна была по причине отсутствия поддержки производителя — молчать в тряпочку, линукс "не смог" то, что и не должен был по причине отсутствия поддержки производителя, но удалось завести с помощью комьюнити и приложения мозгов — аааа, ваш линук плахой!) одну часто встречающуюся ситуацию, когда с раздолбайки Даши нет никакого спроса, потому что она раздолбайка, а отличницу Машу шпыняют и в хвост и в гриву…
DrPass
Почему без вариантов? Программа опенсурсная, и что я на линуксе с ней могу сделать такого, чего не смогу сделать на винде?
khajiit
Программа поставляется-то хоть пакетом или бинарем?
FRiMN
Если ничего не путаю, много лет назад приходилось руками копировать файлики из одной версии DirectX в папку с другой версией. Ну а из недавнего: пришлось перебрать несколько сборок XP и запускать ее в виртуалке, чтобы запустить довольно свежую игру.
По поводу инсталляторов: расскажите нам, как там с обновлением драйверов на видеокарту и сопутствующего софта через Nvidia Experience? Откатов по неведомым причинам через пол часа установки не бывает?
F0iL
Как-то раз здесь эту историю уже рассказывал.
smartov
[linux sratch mode on] Проблема не в Линуксе, а в лени юзеров!!!
MTyrz
Алаверды недельной давности.
Соседскому сыну купили смартфон сяоми. Он им что-то там наснимал, надо перекинуть на комп. На компе семерка, которой пользуется сын, и дебиан, которым пользуется его отец.
Но смартфон-то сына?..
— Не могу, — говорит винда, — открыть ваше устройство, драйвера нетути. Ищем драйвер у сяоми. Лазаем по сайту, скачиваем какую-то охрененных размеров тулзу для взаимодействия с виндой. Не работает. Находим что-то еще — не работает. Гуглинг подсказывает ADB драйвера, скачиваем — не работает. Другая версия — не работает. Третья… А вот еще можно в реестре поковыряться, советует нам безымянный гуру с безымянного форума. А вот еще можно через вайфай, и похрен, что у нас десктоп на проводе: смотрите, у нас целая статья про двадцать пять приложений, которыми можно… А вот…
… На этом месте я перегрузился в дебиан, подключил телефон, слил фотки и положил на общий для обеих систем диск (NTFS, в линуксе монтируется).
— Извини, Велько: будешь перекидывать фотки через линукс. Ты сейчас видел, как это делается — все понятно?..
DrPass
Разница в том, что такие проблемы на винде возникают у одного из многих тысяч, а такие как у меня с линуксовым софтом — этак у каждого третьего.
Ну и опять же таки, дебиан у вас был ведь свежий, не одиннадцатилетней давности как та винда, верно?
MTyrz
Девятый, если мне память не изменяет. Как я его четыре года назад поставил, так он и стоит.
Вы хотите сказать, что каждый третий пользователь компьютера имеет проблемы с линуксовым софтом?Только вот сколько я эту задачу помню, линукс все эти внешние носители просто цеплял и просто работал, а винда постоянно кобенилась.
Или вы хотите сказать, что задача подключения телефона встречается настолько реже задачи запуска трансивера?
DrPass
Как по мне, вы странное говорите. Если смартфон реализует mass storage, он в любой более-менее современной винде будет работать нормально. Если не реализует, но реализует медиа-девайс, то в семёрке и старше тоже должен работать без дополнительных драйверов. Я не то, что сам не встречал, но вообще впервые слышу про такую проблему, как у вас. Может, у вас там какой-то дистрибутив «с особенностями» или твики. Не знаю. Но это никак не общая проблема винды.
«Третий» — это условно, но да, жить на линуксе без подобных проблем можно только если у вас компьютер — печатная машинка «офис/интернет». И то, у вас когда-никогда будут проблемы совместимости форматов офиса :)
MTyrz
Для себя я всегда решал эту проблему с помощью внешней SD-карточки, и не морочился. Для не-себя: чаще заставить работать получалось, но именно что поплясав с бубном.
Видимо, это у меня карма такая неудобоваримая.
P.S. Дистрибутив MSDN, других не держу.
ptica_filin
Какие девайсы были с такими проблемами?
Через мои руки прошли 1 сониэриксон, 3 соньки, штук 5 самсунгов и парочка хуавеев. Ещё были несколько планшетов (асус и нонейм) и читалок с андроидом. Винда - 7 и 10. Андроид от 3-какогототам до 11. Драйвер именно для передачи файлов ни разу не понадобился. Ну иногда приходилось потыкать в настройках смартфона, чтобы он включился в правильном режиме USB.
Отдельный драйвер ставил только для перепрошивки сонек.
MTyrz
Из своих — Samsung P3100, потом две леновы. С леновами, кстати, проще всего, под них хоть драйвера нормально находятся. У одной, правда, для этого пришлось включать режим разработчика: восемь, что-ли, тапов подряд по полю «About», чувствуешь себя редкостным идиотом…
Из чужих — да как-то довольно дофига их было, я всю эту мобильность не люблю, но эникеить-то приходилось. Винда, правда, в основном седьмая, с десяткой я общался немного, когда она пошла в массы, эникеить я как раз перестал.
Я для себя предположил когда-то, что каждому именитому производителю нафиг не упал простой обмен между телефоном и компом, ему лучше, чтобы скачали его фирменную утилиту — поэтому прямой обмен всячески затруднен. Но не проверял.
Косвенно это подтверждается тем, что у всяких нонеймов за три копейки с AOSP с подключением к винде проблем меньше на два порядка (так что да, насчет «ни одного устройства» я пожалуй душой-то покривил).
ptica_filin
Да вроде никаких утилит именно для подключения и передачи файлов нет.
Самсунг, Асус и Сони — вроде бы достаточно именитые производители :)
Есть фирменные утилиты для бэкапа, вроде Smart Switch, ну и всё.
MTyrz
Самсунг у меня был старый — возможно, сейчас что-то изменилось.
Тогда однозначно требовалась здоровенная (и чертовски глючная) самсунговская утилита, которая предлагала на выбор USB, wired (в смысле, утилита тыкалась либо в проводной интерфейс компа, либо в беспроводной) или wifi соединение, из которых получилось установить только вайфай, и то настолько глючно, что SD-карточка была наилучшим вариантом.
ptica_filin
KIES, наверное? Оно уже сто лет не нужно и не поддерживается.
MTyrz
Точно, так и называлось. Спасибо за напоминание.
Что же: когда настанет время менять планшет, буду знать, что теперь этого геморроя нет.
linux_art
Не припомню смартов с mass storage со времен 4го андрооида…
vvzvlad Автор
Китайцы до сих пор предлагают на выбор
JerleShannara
Мои китайцы тоже предлагают «передача файлов и данных» при подключении выбрать, вот только за этим пунктом кроется MTP, а не MSD.
qrKot
Вообще, стандартной болячкой Samsung'ов и HTC было, емнип. Массово, подтверждаю, например.
LiquidSnake
Я бы сказал даже «каждый второй»:
— Если банальная замена нативных драйверов на проприетарные выливается в черный экран.
— Если апдейт системы тоже часто кажет черный экран.
Софт еще пойди найди, в определенных случаях очень много возни с репами. Ок, я айтишник, я найду, но родственникам это нафиг надо?
Нужно поставить хром на свежую систему, открываем диспетчер приложений (или как он там?) инсталлим. Прога говорит — done, а хрома — нема. Плюем, идем в консоль, ставим хром.
Пример с телефоном — странный. Винда всегда определяла телефон как файлохранилку при подключении, даже китайские ноунеймы.
Я не против линукса, я с ним работаю и люблю. Но исключительно в виде консоли с курсором, там это быстро и удобно. Как серверная ОС он шикарен, десктопный линукс — боль.
unsignedchar
Это если в прошивальщики телефонов не играться.
LiquidSnake
Угу, но выше речь шла о скинуть данные с телефона на декстоп.
unsignedchar
Кто-то (что-то) притащило в систему драйвер, срабатывающий вместо ожидаемого mass storage.
FRiMN
Так хрома нету в системных репозиториях -- он проприетарный.
COKPOWEHEU
А Хромиум? В Дебиане точно есть.
0xd34df00d
И у вас, конечно, есть подтверждающая это статистика?
FRiMN
Ваше заявление как минимум не соответствует цифрам из статьи. Я не удивлюсь, если соотношение окажется равным.
duplodel
проблема притянута за уши. при втыкании смарта в комп — сяоми (да и любой другой) спрашивает как подключить с передачей или без? и дальше семерка прекрасно вам без всяких дров открывает как флешку. проверено на 3 семерках и десятке смартов, в том числе этого года выпуска
MTyrz
Вот дебиан открывает именно так.
А семерка… приезжайте, посмотрите сами.
duplodel
рискну предположить, что таки сборка от «васяна» ибо с чистыми образами со всеми правильными апдейтами такого нет. На сборке я в сове время погорел — даже в ТП бразера звонил, ну не работает долбаный принтер. а сборщик просто вырезал службу печати… я тогда молодой зеленый был, только в конце дня нашел причину
MTyrz
(Разводя руками)
Мне остается выбирать между вашими предположениями и собственными воспоминаниями (я ее и ставил). Ммм…
Может такое быть из-за отсутствия медиаплеера? Мне такое вероятным не кажется, но это ж винда…
OpenMind4423
Может проще кидать через FTP?
COKPOWEHEU
Через ftp медленнее и иногда приходится спец софт ставить.
MTyrz
Я уже не помню, почему я отказался от этой идеи: помню, что подумал, и быстро отмел.
Дома, на предпоследней инкарнации домашней винды у меня были расшаренные папки на компе и X-plore с настроенным логином на планшете, но то дома. Громоздить на чужой телефон дополнительный софт…
А дебиан с планшетом работает, как с флешкой — это просто удобнее.
0xd34df00d
На эту вашу историю у меня есть своя история, когда USB-свисток для вайфая под линуксом просто работает, а винду вываливает в бсод. Но это не гиковская задача, согласен.
dartraiden
На это у меня есть история, когда разгон по шине официально неразгоняемых процессоров Skylake (но на практике это было реализовано в каждой уважающей себя материнке на Z170) валит Linux в панику (что-то там not synced). И надо догадаться отключить турбо-буст (при разгоне уже бесполезный), чтобы ядро не пугалось. А винда просто работает.
VADemon
Это ли не BlueSoleil? Windows 7 x64
Пол дня угробил, прежде чем понял, что из-за него не работал логин в систему (экран входа, а никаких кнопок и пользователя нет) и сопуствующее выяснение отношений с ним и BSoD-ом.
Причем втыкая нагорячую и устанавливая драйвера в онлайне всё работало.
osipov_dv
вы сравниваете несравнимое, линукс это только ядро. Каждый дистрибутив, это отдельная экосистема. Андроид в какой-то мере это тоже дистрибутив линукса.
vvzvlad Автор
Специально написал, что имею ввиду Desktop-linux. Каждый дистрибутив это не отдельная экосистема, потому что они используют одни и те же программы внутри, просто меняются способы развертывания, дефолтные оболочки и настройки.
Android это не дистрибутив Linux, потому что в нем от линукса только ядро, да bisybox. Все, что накручено сверху — свое. Вы не можете запустить на андроиде программы от десктопного линукса.
osipov_dv
Вас послушать, так FreeBSD станет тоже линуксом, так как там те же программы внутри… условно те же :)
почитайте вот эту книжку, там многое из unix way становится понятным: Время UNIX. A History and a Memoir Керниган Б.
vvzvlad Автор
Ну почему? Linux — это программы+ядро и системные механизмы. Вот это и составляет экосистему. Впрочем, есть проект Debian GNU/kFreeBSD, и это очень близкая к линуксу экосистема.
ne555
Фанаты могут обидеться.
Linux — ядро (пример, шумихи с ядром).
GNU — софт (пример шумихи с ПО).
Все вместе образует дистрибутивы OS GNU/Linux.
vvzvlad Автор
Если так подходить, то придется везде в статье писать Desktop GNU/Linux-based. Поэтому я в дисклеймере описал, что я имею ввиду, предполагаю, что это избавит от неопределенности.
qrKot
Чтобы GNU/Linux написать — это еще заслужить надо, например. Там набор критериев есть. Может, ваш — недостаточно ГНУтый, потому и не пишут.
FRiMN
Мне показалось, что тут именно это и обсуждают.
BlackSCORPION
Linux это и есть ядро.
t13s
Позиция автора интересная, но такое ощущение, что он смешал в одну кучу мух и котлеты: как, например, unix-way влияет на сложности конфигурации системы или удобство пользования каким-то GUI продуктом как GIMP? То есть вынесенная в заголовок тема не очень, я бы сказал, раскрыта.
При этом немножко за уши к линуксу притянуты претензии, которые так же можно адресовать и Windows: тот же DLL hell он потому и DLL. Или, например, когда автор в последний раз пытался что-нибудь отконфирурировать в Windows — там же черт ногу сломит, в каком интерфейсе (старом или новом) находится нужная настройка (а иногда что-нибудь можно сделать только через cmd / powershell). Или, например, что, неужели не бывает проблем при обновлении Windows?
Еще нельзя забывать, что линукс — это не какой-то один продукт, который можно загнать в рамки при помощи «эффективных менеджеров» какой-то конкретной компании — это результат работы множества совершенно разных людей. Поэтому это привносит такие вот неудобства и недостатки, которые описаны, но так же дает и разнообразие, необходимое для устойчивого развития, что бы это ни значило.
Плюс к этому, немножко забавно выглядит утверждение, что раз Microsoft добавила поддержку консольного линукса (того, плохого, сделанного в unix-way) в Windows, то всё, линуксу хана. Это как-то аргумент из серии того, что виндекапец, как только заработал Wine. А ведь обе ситуации можно рассматривать и по-другому: как признание заслуг конкурента.
Еще один вопрос: а так ли нужен полноценный десктопный линукс? Тот, который со скринсейверами, GIMP и прочим? Сильная сторона линукса — сервера, встроенные системы и прочая и прочая. Desktop — ну, потому что можем. Причем не стоит забывать, что можем бесплатно. В отличие от.
vvzvlad Автор
Он не плохой, а сделанный для других условий. В консоли он как раз проявляет себя довольно хорошо: гибкость и повторяемость настройки.
Линуксу не хана, всегда будут некоторое количество людей, которые готовы с ним работать, из интереса или по необходимости. Я так же некоторое время работал с FreeBSD на ноутбуке(!). Но о росте можно будет забыть.
Я бы хотел иметь еще одну систему, конкуренция лучше, чем монополия. Макось хороша, но заточено под свое железо. Я даже не хочу бесплатно, я хочу хорошо. А мне говорят «ну, зато бесплатно».
t13s
Чтобы был рост, нужно, чтобы это кому-то было надо. А надо оно, видимо, не очень много кому. При этом если говорить о росте в целом, то количество устройств, работающих на ядре линукс, ни с одной другой осью сравнится не может. А десктоп — ну да, он просто не в фокусе.
Так а нельзя разве найти контору, которая за денюжку «отключит скринсейвер» и «сделает хорошо» на линуксе? :)
vvzvlad Автор
Которая будет делать платную поддержку? Это обойдется сильно дороже, чем стоимость лицензии windows, например. И ладно скринсейвер. А кто будет мне интерфейс программ перерабатывать? И за какие деньги? На поддержку я наскребу, а вот на переработку всего, чем я могу пользоваться — точно нет.
t13s
Эмм… а как вообще линукс и его way связаны с прикладными программами?
Adobe не делает Photoshop для линукса, ну да. А Jetbrains, например, Rider и прочие IDE делает. И выглядят и работают они ровно так же, как в винде. Так что если есть спрос — будет и предложение.
А еще бывают и обратные ситуации. Я, например, пользуюсь GIMP под виндой, т.к. нужно оно мне раз в пятилетку, поэтому платить за Photoshop смысла нет.
Pilat
Как и все нормальные пользователи Линукса я не стал читать эту статью дальше заголовка, так как и так понятно о чём она :)
Линукс на десктопе для обычных пользователей бесперспективен по нескольким причинам.
Во-первых, пользователям всё равно и они выбирают то что им поставят, а ставить Линукс (для тек кто профессионально окучивает лохов) менее доходно чем Windows — по разным причинам, то есть те кто вообще далеки от компьютерных наук выбирают всегда Windiws (объективность такого выбора отдельный предмет обсуждения).
Во-вторых, Линукс ставят дети из протестных соображений. Это понятно.
И в третьих, Линукс ставят профессионалы, которые понимают что делают, у которых есть понимание где Линукс (десктопный) силён и где нет, и у которых так же есть и Windows для каких-то задач ( может и в виртуалках, но есть).
Отдельная категория — те кто ставит Windows по простой причине — профессиональный софт пишется для Windows и почти никогда для Linux. Это почти третья категория.
По опыту моего сына (12 лет) на Линукс вполне можно установить всё что надо для игр.
По моему опыту — всё что надо кроме узкопрофессионального софта которого для Linux не бывает.
Отвечать на пост я не буду — скажите спасибо свои собратьям, сбившим карму :)
0xd34df00d
Хоть вы отвечать и не будете, но скажу, что куча другого профессионального софта (вроде сред разработки или компиляторов некоторых специфичных языков) пишутся именно под линукс (и иногда под мак), а под виндой у них поддержка не сильно лучше условного solidworks, завернутого в wine.
PsyHaSTe
Не припоминаю ничего из распространенного. Про редкость вроде идриса написал ниже — но это очередные доли поцентов от тех долей процентов кто в целом составляет категорию пользователей профессионального софта :)
PsyHaSTe
Фишка в том, что например вот я — программист, но для ОС я пользователь. Да, я выбираю, что ставить, как оно будет работать, но у меня нет ни малейшего желания заниматься этим. То есть если у меня есть желание что-то покрутить — окей, я готов смириться с тем, что у меня что-то не будет работать или я даже насмерть запорю. Но когда я ничего не трогаю а оно "само" — то тут получается в худших традициях той десятки, которые решила обновиться во время презентации на конференции.
Я хотел бы ОСь которая работает после установки, где мне не надо знать что там под капотом, где настройка любой задачи не выглядит длиннее чем 3-4 команды в терминале, а ошибки происходят только в нетривиальных случаях — и по всем им можно нагуглить единственное, при этом рабочее, решение. И что если решение не гуглится, то проблема хотя бы не критичная, и не блокирует основные задачи.
Это все верно для винды по моему опыту, но не все гладко.
Экспериментировать с языками программирования на винде не очень просто. У крупных япов есть взрослые пакеты, установщики и остальное, у маленьких — баш-скрипт или make которые на винде запускаться не хотят (а разбираться с ними — см. п.1, я действую как пользователь)
Докер хочется запускать нативно — виртуалка все же дает некий оверхед
Частный случай предыдущего пункта — некоторые рабочие задачи на компе трудно решать. Например — на сервере тормозит чтение докер демоном из стдаута приложения. Почему, как? Неясно. Надо бы локально воспроизвести — а нельзя, у винды другой стек совсем, и докер тоже другой.
...
Думал про мак — но там свои заморочки, и не все он решает. Да и дорогой собака. Мб если по работе выделят — потыкаю.
Не знаю что там с кармой — дам плюсик чтоб скомпенсировать. Хотя на общем фоне думаю не сильно скажется, но хоть что-то.
Ogra
И ничего вы с этим не сделаете, потому что система закрытая. Да, в линуксе гораздо больше неровностей и шероховатостей, но кувалда и напильник идут в комплекте. Поэтому если вам нужна система, где "не надо знать, что там под капотом" - берите винду, а если вам нужна система, которая гарантированно не будет обновляться на презентации, берите линукс и настраивайте, настраивайте, настраивайте.
А промежуточного варианта нет и не будет, ведь нельзя быть "немножко беременной", знаете ли.
red75prim
Хех. Почему-то вспоминаются несколько видео (кажется два или три, ссылки уже не вспомню) с линукс-конференций, где докладчик подходит со своим ноутбуком, подключается, изображения на экране нет, и начинается перешёптывание "бу-бу-бу hdmi бла-бла-бла nouvaeu ду-ду-ду xorg.conf".
COKPOWEHEU
У меня была обратная ситуация. На полугодовых докладах в аспирантуре откуда-то выделили проектор и непонятный ноут, который к нему никогда не подключался с первого раза. В результате все полугодовые доклады проходили с моего линуксового ноута, который просто подключался и просто работал. Ну разве что некоторые презентации в ppt открывались криво, но тут уж ничего не поделаешь, нормальные форматы использовать надо.
DaemonGloom
/me смотрит на Steam и Thunderbird, запущенные на Chrome OS и думает, что что-то здесь не так. Равно как и фраза «своя оболочка, свои настройки, свои интерфейсы» будет относиться к любому дистрибутиву в частности.
qark
"Знаю, что заголовок желтушный, но исправлять, конечно, не буду".
soul_survivor
Купил я как-то компьютер родителям, живущим в другом городе, с Windows 7 было довольно неплохо, в среднем переустанавливать систему нужно было 1 раз в год, хотя за компьютером только игрались в казуалки и сидели в интернете, но время 7 прошло, купил лицензию на 10ку home, и после чистой установки теперь приходилось переустанавливать систему с каждым квартальным обновлением да и заставить работать периферию — принтер, сканер, веб камеру стало очень непросто. 2 года назад я не выдержал, поставил Ubuntu, вся периферия работает отлично, система стабильна и спокойно обновляется между LTS версиями, о таком удобстве работы на виндоус можно только помечтать. И вечно друзья не айтишники жалуются, что у них из-за обновлений все сломалось, просят помочь, я уже отказываюсь, потому что такой антипользовательской системы как Window 10 я не видел и при возможности стараюсь не прикасаться к сему поделию
tommyangelo27
Субъективщина, же.
У вас так, а у меня на одной машине Win7 стоит 7 лет без переустановок и починок, на второй был 5, два месяца как на десятку переехал. А на рабочем ноуте 10 работала с 2016 по 2021 без проблем, просто уволился и надо было ноут отдать.
Принтеры, вебки, всё спокойно себе работает и не жужжит.
А когда пробовал с Убунту экспериментировать (примерно 2012-2014 годы) — постоянно то звук отвалится, то тачпад не так работает, то ещё какая-то фигня непонятная.
И что из этого следует?
FRiMN
Из этого следует, что сложные системы чувствительны к "положению Юпитера на небе".
neonkainside
Я сейчас не про "а у меня такая же нога не болит" и не собираюсь давать свои особо ценные советы, но мне реально интересно, что у людей случается с виндой. Со времен XP SP2 не переустанавливал винду кроме как ради перехода на следующую.
oWeRQ
Я тоже в это не верил, пока не пользовался виндой, потом купил ноут с десяткой(или восьмеркой которая сразу обновилсь), по началу было хорошо, работало достаточно шустро для hdd, пока не прилетело несколько обновлений, через 2-3 года, без левого софта, система стала тупить после старта настолько, что стало невозможно пользоваться браузером(конфиг: 2.5' hdd 5400rpm, 6G ram, intel i5 2core@2.6ghz), переустановка как ни странно в таких случаях помогает, возможно, если ресурсов с запасом, то можно это и не заметить.
Revertis
А ведь просто надо установить новые драйвера :)
oWeRQ
После каждого накопительного обновления системы надо вручную ходить по сайтам производителей и скачивать новые драйвера? О_о
DaemonGloom
А после накопительного обновления старого железа — устанавливать заново старые драйвера, ибо винда команду «не трогай драйвера этого устройства» понимает… не всегда.
khajiit
И никаких танцев с бубном, все документировано =)
neonkainside
Вообще не было таких проблем. Ни с виндой ни с линуксом. Не понимаю, чем другие юзеры их засоряют.
saidelman
Порой с ней случаются удивительные вещи.
У меня на ноуте после очередного обновления вин10 перестал выводиться звук через HDMI. В мониторе есть миниджек, но звук туда вывести нельзя, его просто нет в списках существующих устройств.
Поиск решений в гугле напоминает попытки прорваться к живому человеку через автоответчик какой-нибудь службы поддержки: первые N страниц выдачи заполнены одинаковыми инструкциями со скриншотами: "откройте настройки, нажмите сюда, в списке выберите нужное устройство. Готово, вы восхитительны!".
buldo
Это удивительно, но иногда такие советы помогают. Сидишь, думаешь "эта утилита исправления проблем никогда ничего не исправляла и вообще, я что не смогу без неё?"
Но последнее время виндовые автоисправлялки начали работать. Как минимум апдейты и звук мне починили.
saidelman
У меня как сломался звук через HDMI год назад, так и не работает. И автоисправлялки как не находили проблем, так и не находят.
На том же ноуте в дуалбуте линукс стоит, в котором всё в порядке.
PsyHaSTe
Такие же ощущения от поиска проблемы в линуксе. Там правда ещё добавляются ребята из чатика, которые первые минут 15 ещё мб подсказывают, но если проблема чуть-чуть менее тривиальна чем "забыл ldconfig/chmod/chown/..." то советуют покурить маны, выпрямить руки или перестать заниматься ерундой
Ogra
Если вам нужна ОС, где все легко и просто для пользователя, то у вас есть два отличных варианта. Берите и пользуйтесь, сколько влезет. Есть еще два варианта похуже, но тоже жить можно.
Линукс - он про другое. Линукс не для пользователей, линукс для разработчиков. Нет простого способа отключить скринсейвер и экран блокировки? Наплевать. Зато мы можем выбрать (и даже написать!) любое окружение, любой скринсейвер, любой экран блокировки. Пользователи Винды - не могут.
Тяжело настраивать? Этот продукт не для вас, не настраивайте, возьмите Мак, и пользуйтесь настроенной системой. Миллионы людей пользуются Маком и радуются. Я возьму Линукс и буду его настраивать под себя, так, как это нужно только мне. Тайловый оконный менеджер (что там с тайловостью у Винды?). Клавиатурные комбинации (попробуйте поменять Win+E, попробуйте повесить переключение раскладки на CapsLock). Скрипты.
Revertis
Так ведь Линукс может в простых вещах подвести. Например не выходить из режима Sleep или гибернации. Разработчику это ведь тоже может понадобиться, но нет.
COKPOWEHEU
Значит вы запомните, что на данной машине на данной ОС режим сна «не работает» и отключите его. После чего можно либо пассивно ждать обновлений, которые это починял, либо писать разработчикам, либо тестировать другие дистрибутивы / драйверы / DE.
Можно подумать, на других ОС это решается как-то иначе.
Revertis
Вот у меня была такая проблема, и в нескольких дистрибутивах она была одинаковая. А в винде ни разу о таком не слышал. Может ноги не такие, уж не знаю.
Vaitek
У меня из сна ноут не выходит в 20% случаев. Пришлось перейти на гибернацию. Windows 10 с обновлениями, свежий BIOS, вот как такое дебажить?
Osnovjansky
В недавней статье Выживание Windows XP x32 на современных ПК c процессором Intel
Возможно, натолкнёт на какую-нибудь идею. Кстати, проблема может быть и аппаратной. Например, а нет ли с подключенной периферией петель по земле?winwood
Ровно наоборот. Уход на линукс решил проблемы «непросыпания» ноута. Правда давно это было, в 2010. Ушел с ХР на дебиан 5. Ни разу не пожалел.
0xd34df00d
Согласен, этой проблемы в винде у меня не было: она, начиная с некоторого времени, стала просто отказываться уходить в гибернацию. Как чинить, непонятно, и в итоге починилось с переустановкой.
qrKot
Как и любая другая ОСь, не?
Bellerogrim
> что там с тайловостью у Винды
Ну есть варианты — github.com/fuhsjr00/bug.n
saidelman
Сразу скажу, что сам не пользовался и не знаю, что там под капотом, как хорошо работает и т.д. Но с месяц назад внезапно обнаружил несколько репозиториев, которые себя называют TWM для Windows. Чтобы не быть голословным:
https://github.com/fuhsjr00/bug.n
https://github.com/rickbutton/workspacer
https://github.com/TimUntersberger/nog
https://github.com/McYoloSwagHam/win3wm
Junecat
> Зато мы можем выбрать (и даже написать!) любое окружение, любой скринсейвер, любой экран блокировки. Пользователи Винды — не могут. — ой, да ладно Вам. Программист может напсать программу под разные системы, которыми пользуется. А вот Вам пример: когда ПунтоСвитчер был куплен Яндексом, он (Пунто, не Яндекс!) разжирел и обнаглел. посидев вечер-другой я написал свой аналог. Под Винду. Под Линукс — уже года два периодически пытаюсь, но так и не понял, куда там коней запрягать. Я бы Вашу сентенцию закончило словами «Не работает скринсейвер? — да плевать...»
Tujh
уже всё
украденонаписано до нас, даже тут, на хабре, с примерами кода и репозиториями (только я не проверил живы они или нет)habr.com/ru/post/495748
DrPass
Давайте по-честному. Вот конкретно это — не для разработчиков, это для любителей поковыряться в своём компьютере. Разработчику компьютер нужен для работы, а писать скринсейверы, экраны блокировки и тому подобные свистоперделки обычно надоедает где-то на втором-третьем курсе института. На той же винде была куча альтернативных десктопов. И где они все сейчас? Пользователи наигрались, выросли и благополучно забыли.
Ogra
Как где? Убиты Майкрософтом, который регулярно меняет системные API, делая кастомизацию невозможной. Можете почитать про разработку "простейшего" Classic Shell для винды.
oWeRQ
Несколько раз целенаправленно пытался найти хоть один которым можно заменить Explorer и пользоваться, не нашлось, забыли не потому что не нужны, а потому что этим просто нереально было пользоваться. Сейчас заметил, что ожил https://cairoshell.com/, так что дело живет. К тому же линуксовые DE — это больше чем замена таскбара и иконок на рабочем столе, это и оконный менеджер/композитор, и набор стандартных приложений, и конфигураторы, сервисы итд.
BigBeaver
Aston shell был норм в начале нулевых. С выходом ХР потерял актуальность.
d_ilyich
По поводу клавиатурных комбинаций. Подозреваю, что буду
поснаправлен в сторону гугла/форумов, но всё же спрошу. Сразу уточню, что не являюсь знатоком Linux/*nix (или как там идеологически правильно называть)Имеется Manjaro/xfce Live USB, заметил пару особенностей поведения сочетаний клавиш:
— [некоторые] срабатывают на нажатие;
— [иногда] учитывается символ, а не клавиша (сканкод?).
Скобки поставил, потому что не уверен, что это общесистемное поведение. Всеобъемлющих экспериментов не проводил.
Поясню. Я привык переключать раскладку сочетанием Ctrl+Shift. В Windows раскладка переключится после отжатия одной из клавиш, а если нажать сочетание, например, Ctrl+Shift+P, то оно сработает, но раскладка не переключится. При этом сочетание сработает независимо от текущей раскладки. В Manjaro же при нажатии данного сочетания сначала произойдёт переключение раскладки, а затем сработает сочетание, но выполнится другое действие (можно проверить, например, в Firefox).
Собственно вопросы:
— можно ли в принципе настроить работу сочетаний как в Windows (т.е. на отжатие и чтобы учитывались не символы, а клавиши)?
— можно ли это сделать быстро в рамках Live-сессии (например, несколько действий в консоли/GUI или скрипт разок написать)?
alsoijw
Скорее всего это баг.
stryaponoff
Я с этой проблемой сражаюсь уже не первый год — находил кучу упоминаний в разных багтрекерах. Везде суть одна — проблема есть, решения — нет.
Очевидно, что дело не в манжаро и не xfce, у меня дебиан с гномом.
alamer
Решается с помощью PowerToys как это было бы не странно.
Зато навесить дополнительную комбинацию Alt+Shift в гноме я через Gnome Tweaks все же не смог. Опция есть, все прекрасно отмечается и сохраняется. Но не работает.
ImagineTables
Что за сказки? «Первая» WM (а их было несколько?) безраздельно владела рынком (по крайней мере, в отдельных странах, например, России), начиная с WM2003, пик пришёлся на WM5. Найти смартфон под управлением чего-то иного было очень трудно. Под отщепенцев (продвинутый Symbian у Нокий) в магазинах выделялся скромный уголок. Блакберри свою вотчину не покидал, сюда его ввозили отдельные личности в частном порядке.
Потом появился iPhone. И вскоре, ещё не успев утратить своей чудовищной доли рынка, MS объявила WM мёртвой. После чего ей ничего и не осталось, как начать умирать. Процесс занял много лет.
«Вторая» (речь, видимо, идёт о Windows Phone?) стала абсолютно новой, никому не нужной ОС, ни с чем не совместимой, лишившей привычных удобств (.cab'ов — аналогов .apk — в частности и файлов вообще), со спорным дизайном. Вот ей уже ничто не смогло помочь.
vvzvlad Автор
Она умерла не потому, что MS объявили ее мертвой, а потому, что в ней все было насмерть приколочено гвоздями к резистивному тачу и стилусам, и никакие 6.5 не могли этого изменить, что в условиях, когда iphone «зашел» было не очень. Поэтому быстро, за 3 года (в 2007 вышел, в 2010 представили Windows Phone 7) подняли старые наработки и написали новую. Windows Phone и далее Windows 10 Mobile помочь было можно более активной работой с разработчиками по перетаскиванию их на платформу и работой с фичами. Но это хорошо сейчас говорить, с позиции послезнания.
Я к тому, что если рынок хочет чего-то другого («хотим мобильные телефоны с красивым экраном и тачем»), то большая, огромная компания ничего не может сделать, кроме как выбросить наработки и начать писать с нуля, и то не факт, что получится. Поэтому нельзя говорить, что успех андроид/хром — целиком следствие продвижение его гуглом.
t13s
На HTC Diamond в свое время я стилус вынимал не то, чтобы очень часто. По крайней мере, точно не чаще, чем сейчас приходится использовать обе руки: одной держать аппарат, а второй тыкать пальцем в гиганские кнопки на гигантском же экране. То есть, по факту, один неудобный костыль сменили на другой.
ImagineTables
На эту тему можно долго спорить, знаете ли. Например, посмотрите на Galaxy Note — вполне себе можно было купить не Nokia, а Wacom и сделать аналогичный премиальный девайс с чувствительным к нажатию пером вдобавок к капаситивному экрану. Я бы посмотрел, как это Яблокам понравилось.
Можно, но я не буду (история есть история). Я ограничусь, собственно, тем, что уже написал: WM была в своё время лидером рынка и ни в какой помощи не нуждалась. На обратном утверждении нельзя строить дальнейшие рассуждения.
vvzvlad Автор
Только вот тач-экран в этом случае был бы бесполезен, потому что 90% интерфейса было заточено под этот стилус.
ImagineTables
Возьмите любой нетбук с тач-скрином и Windows 8. Он позволяет при необходимости использовать высокоточный ввод (мышью), имеет новые метро-приложения, заточенные под палец, и отличную поддержку пальца в старых приложениях (пинч, скролл и т.п.)
Мысленно замените мышь пером, нетбук — смартфоном, Windows 8 — Windows Mobile X, а Билла Флору — нормальным дизайнером... И вот уже невозможное возможно!
lll000lll
Познакомился с Андроидом только начиная с пятой версии потому что много лет пользовался HTC HD2. Стилуса там нет, емкостной экран, винда. В последние годы существования мобильной винды появилась мода на интерфейсы удобные для управления пальцами. Версии всех нужных мне программ с такими интерфейсами были в наличии.
soul_survivor
Windows Phone умер потому что гугл саботировала любые попытки создания приложений для своих сервисов, и сама не делала, и другим запрещала, а телефоны без гугл поиска, карт и ютуба были не конкурентноспособны изначально
KinshoMokuroku
На самом деле, всё было несколько сложнее (и во многом обусловило провал). Сначала, стало быть, в трубу отправилась старая система (6.5 и предыдущие) на ядре «WinCE» со всей базой пользователей, устройств и приложений. Людей кинули, но, допустим, это было неизбежно. Далее последовала совершенно несовместимая со старыми приложениями «Windows Phone 7» на базе всё того же ядра. И тут людей кинули второй раз, потому через два года вышла «Windows Phone 8», которую написали уже на «WinNT», что снова сделало все старые устройства несовместимыми (параллельная поддержка седьмой версии ещё была какое-то время, но разработчики приложений, естественно, забили на неё сразу же). Но и этого оказалось мало: несмотря на первоначальные обещания, «Windows 10» получили далеко не все устройства под 8.1, включая популярные флагманские модели навроде «Люмии-920». Т.е. многих людишек (включая меня, лол) кинули уже в третий раз. Я бы очень удивился, если бы оно взлетело с такими плясками по граблям. Для кого приложения писать (хотя у меня не было особенных проблем с ними на пике платформы времён выхода 8.1), если сами держатели пользовательскую базу не накапливают, а наоборот распугивают каждые пару лет?
776166
Думаю, ни один из приведённых доводов не является определяющим даже близко, а их совокупность — тем более.
1) Производители желефза не ставят линуксы. Это сразу минус 99% потребителей.
2) Игры, которые не все на MacOS работают, что уж про линуксы из коробки говорить.
3) PR, которого нет. История, которой нет.
4) Домохозяйки вертели Линукс на миксере.
Нет сегмента в доме, куда линукс мог бы встать, не конкурируя с Win/Mac.
Положение решил бы дистрибутив Линукса с предустановленным Майнкрафтом для переманивания молодого поколения, но этим никто не занимается.
djv57
1) нормальные производители выкладывают среди прочего драйвера в форматах .deb и .rpm
2) спорный вопрос, см. Steam
3) история есть и она увлекательна, см. Youtube
4) и Виндовс вертели в том числе, зачем нужен комп если есть телефон
776166
1) Я имел в виду тех производителей, которые делают готовые компьютеры, которые в магазине купить можно. На самом деле, конечно, они продаются.
2) Не спорный. У хороших игр проблемы с оптимизацией под Винду, что говорить, у большинства нет версий под MacOS, о каком линуксе вообще речь?
3) Тут спорить не буду. До меня эта инфа не доходила, и процент потребителей всё равно сепусечный. По вполне понятным (для меня) причинам.
4) Ну да. Давайте, расскажите, как ребёнку писать реферат на телефоне и как с таблицами работать, если в таблице больше одного столбца и трёх строк в таблице. Вы даже Хабр скорее всего нормально и продуктивно не сможете читать на телефоне. Не то, что отвечать на что-то. Потому что телефон не про лонгриды и не про структуризацию данных.
5) Профессиональный софт, про который тут уже говорили. Запустить его, конечно, понятно как, но кто будет этим морочиться?
JerleShannara
1) Насколько помню Lenovo и Dell таки предоставляли опцию «Linux» на борту своих железок.
2) В Steam под линуксом уже некоторое время как включен Proton, который вполне себе тянет. Более того, сейчас чтобы поиграть мне наоборот надо быть в линуксе, ибо под семёркой новых игорей не завозят.
3) Хз
4) Новое поколение, которое с детства тупит в планшет и т.д. в гробу видало все эти ноутбуки и десктопы — контент прекрасно кушается с экрана телефона/планшета, всякие тиктоки и схожий мусор с него тоже прекрасно делается/раздается, да и игрушкек хватает, см. недавний срач Эпика с Яблоком. И с такими привычками оно скоро там и таблицы начнёт делать.
5) Некоторый проф. софт наоборот только под линукс изначально был, правда это не фотошоп и прочие.
linux_art
Valve пытались пилить SteamOS как раз для такой цели. Ничего это не изменило по сути кроме того, что линуксах стало можно нормально играть в виндовые игры.
major-general_Kusanagi
LiquidSnake
Мало одинаковых картинок в теме, мало!
Тут обсуждают десктоп а не планшеты. Увидите андроид на ноутбуке — ПК, пишите.
major-general_Kusanagi
Чем планшет на Андроиде с внешней клавиатурой принципиально отличается от ноутбука?
LiquidSnake
тем что это планшет на андройде с внешней клавиатурой)
И используется для других целей. Тем не менее процент таких девайсов все еще мал.
major-general_Kusanagi
Нет принципиальной невозможности использовать планшет на андройде с внешней клавиатурой в тех же самых целях, что используют ноутбук.
qrKot
Кхм, хотите на спор найду пару-тройку-сотню применений, где «не взлетит»?
Тут вопрос, что вещей, которые принципиально нельзя делать на ноутбуке, на планшете нет и быть не может. Это да. И если вы используете ноут только в тех задачах, где планшет вполне справится — тут да, тут вы не заметите разницы. В обратную сторону не работает. Ноутбук > планшет.
BigBeaver
Втыкаешь в USB любую понравившуюся, или в чем проблема у вас?
COKPOWEHEU
>Тут обсуждают десктоп а не планшеты. Увидите андроид на ноутбуке — ПК, пишите.
Видел. Не понравилось.
AlexP11223
1) появляются некоторые ноуты от Делл/Асуса/Леново/… с линуксом, и менее известные производители типа System76 (ну это конечно для тех, кто уже знают, что хотят линукс, а не просто пришли в магазин).
2) как раз лучше, чем на макос. см. habr.com/en/company/ruvds/blog/556124/#comment_23047314
glebiuskv
Только вот с протоном их в никсах стало много больше чем в маке ()
Им не важно, что вертеть.
776166
На Мак тоже можно поставить Параллелз, и будет всё хорошо с виндоиграми. Но домохозяйки будут вертеть эти действия на миксере. Это слишком сложно. Там сложно абсолютно всё, что не из коробки. Впрочем, что в коробке тоже бывает сложно. Начиная от масштаба в текстовом редакторе и заканчивая отдельными учётками без рута для детей.
ertaquo
А мне очень «нравится», что когда отваливается X-сервер, отваливаются также все запущенные приложения и сеанс полностью начинается сначала.
В той же винде при аналогичной ситуации (критическая ошибка композитора либо explorer) перезапускается лишь отвалившийся процесс, все остальные приложения этого практически не замечают. Ах, да, а еще в винде можно поменять драйвер видеокарты на лету, без перезапуска всего и вся.
namikiri
«Видеодрайвер перестал отвечать и был восстановлен» — вот оно самое. Однажды такое поведение и спасло от потери несохранённого вовремя документа. Так что, пожалуй, соглашусь, Windows в плане драйверов постабильнее будет.
13_beta2
Как-то в этой цепочке сарказм рассогласовался
namikiri
Его тут и не было.
soul_survivor
но вот обновления применить на лету так за 25 лет и не научилась
khajiit
KDE neon, кстати, тоже отличились в эту сторону: у них теперь установка обновок происходит отдельно от всего остального, между перезагрузками.
firefox85
Да, Neon со своими offline-апдейтами доставил неимоверно. Благо, их можно отключить.
PsyHaSTe
Если выбирать из этих двух фичей то я отдам предпочтение существующему трейдофу
0xd34df00d
Ошибка композитора — это не аналогичная ситуация. При ошибке в kwin или plasmashell никакие приложения не отваливаются. Отвал иксов — это ближе к бсоду в винде. Я слышал, она при этом и сегодня перезагружается целиком.
И даже запущенную при этом игру не придется перезапускать?
К слову — до сих пор перевтыкание наушников (например, если они выпали из разъема) приводит к отсутствующему звуку до перезапуска игры. Воспроизводится как минимум на двух играх из двух, в которые я последнее время играю.
Alex_ME
У меня отключение гарнитуры вешает Terraria под виндой наглухо =)
PsyHaSTe
Завсисит от игры. Пятую циву, например, мне перезапускать не нужно было :)
Alex_ME
И беда, и сила линукса на десктопе в том, что никакого единого линукса на десктопе нет.
Одних только сколько-то популярных дистрибутивов более десятка на любой вкус: от Ubuntu до Gentoo. Особые извращения для тех, кто хочет попробовать что-то другое (напр.: NixOS, Guix, которые, кстати, решают некоторые проблемы с конфигами, переносимостью и зависимостми, описанные в этой статье). И еще несколько сотен (!) малопопулярных.
Два крупных малосовместимых друг с другом графических тулкита (Qt, GTK) и два основных мейнстримных DE (KDE и Gnome), куча видов гнома (Gnome 2, 3, flashback, mate, cinnamon) и куча менее популярных от OpenBox до DWM.
Куча DE обросли кучей похожих программ (nautilus, thunar, nemo etc… в чем разница?).
Даже несовместимые друг с другом пакетные менеджеры и репозитории.
Ужас? Ужас.
С другой, это позволяет пользователю использовать то, что ему хочется, а не загоняет в рамки*. Стабильные релизы? ОК. Роллинг? Пожалуйста. Хотите apt? Будет apt. Хотите pacman с целым AUR в придачу? Будет pacman. Полноценное навороченное окружение рабочего стола, такое, как KDE (которое мне удобнее, чем даже винда, в винде нет много того, что есть в KDE) или тайловый WM?
Теоретически, можно сделать "десктопный линукс" продуктом. Влить денег, применить диктатуру, вести в нужном направлении. Какой-то один десктопный линукс, например, Ubuntu. Может быть, можно получить удобный дистрибутив, которым смогут пользоваться домохозяйки и дети из коробки. Получим Windows на ядре Linux. Но зачем? Windows и так есть, и, как бы очевидно это не звучало, из линукса не сделать настолько же хорошую винду, какой является Windows. Получим крепко сбитый user-firendly дистрибутив, где все интегрировано прибито гвоздями, как в винде, а извращенцы, вроде меня, так и продолжат бултыхаться где-то за бортом со своими тайлингами и роллингами.
Можно ли сделать "линукс с человеческим лицом" не потеряв в возможностях извращений? Не знаю, вряд ли. Разве что путем улучшения прикладных приложений, которые примерно одни и те же на любом дистрибутиве, но это не то, о чем Вы говорите, не системный и не продуктный подход.
mrbald
Не могу плюсануть из-за кармы, но вот да! Нету у Линукса GUI, и "главного" GUI IDE нету. У макосников есть классный CLion, у масдаев — офигенный VisualStudio, а у красноглазых что? Хреначьте в VIM? Я в итоге на Tk делаю в текстовом редакторе (там сразу результат видно), когда прямо надо GUI, в 21 веке, и стараюсь избегать ситуаций, когда надо вникнуть в какой-нибудь специфический WM.
COKPOWEHEU
«у линукса нет графического интерфейса»? Что?
Почему нет? Я в KWrite + make программирую от контроллеров до гуёвых программ.
Из контекста можно предположить, что вас не устраивает что в линуксе нет одного стандартного набора графических виджетов. А в чем проблема, если есть минимум два, причем кроссплатформенных, gtk и Qt? То есть можно сразу писать, например, Linux + Windows программу. В принципе, я так сейчас и делаю. Жаль, gtk не умеет в статическую линковку, приходится еще и все виндовые библиотеки для него таскать. Ну да все лучше, чем через winapi делать.
shellenberg
Что простите? Если вы о IDE от JetBrains — то она написана на Java и проекрасно идет под Linux. Более того в Ubuntu она зашита в Snap и устанавливается в 2 клика мышкой
mrbald
Опечатался, Xcode конечно. На CLion я редактирую большие проекты (вот и сейчас, простите за неровный почерк) чтобы не сойти с ума от переключений с раскладки IntelliJ и PyCharm.
shellenberg
Ну вообще там все горячие клавиши настраиваются, так что можно поберечь психику и сделать как удобно. Возвращаясь к вопросу под Linux из IDE есть вся линейка JetBrains, Eclipse, Netbeans. Из легковестных есть VSCode, Sublime и еще дофига всего
General_Failure
Xcode — это который с рейтингом 2.5 и с интересными отзывами, но зато №1 среди девтулзов?
mrbald
А есть несколько Xcode?
General_Failure
Я думал что один, но
Покажите мне классный пожалуйста, многие вам спасибо скажут!
mrbald
У меня везде стоит полный набор JetBrains уже очень давно, так как надо писать на нескольких языках и с разных компов (99.9% не GUI).
Когда учился делать GUI на Mac OS X — скачал и использовал Xcode кроме маковских шорткатов ничего не раздражало вроде.
И когда на 11 плюсах надо было много писать и читать и Xcode был единственным нормально синтегрированным с Clang и CMake без костылей.
Что не так-то с ним?
General_Failure
Я не занимался разработкой на плюсах, а вы похоже не занимались разработкой на свифте под айос, поэтому мы и видим икскод по-разному. Видимо, все баги икскода собраны в айос-разработке.
Например, отваливается либо ломается автокомплит. Или дебажный просмотр дерева UI-элементов. Крашится при переключении гит-веток. Короче, много весёлых и увлекательных приключений с его использованием.
mrbald
Я в шоке. Да, GUI на aйос только игрушечные для расширения кругозора и не на Свифте (по-моему на Obj C но уже не помню даже).
0xd34df00d
xcode не осиливал и не осиливает прожевать темплейты в моем опенсорс-проекте, падает на индексации. Не знаю, что в этом классного.
mrbald
Странно. Он же clang-ом это делает вроде. У CLion тоже тогда должны быть проблемы с ним по логике?
0xd34df00d
CLion есть и под линуксом, а кроме него есть и kdevelop, например. Последний не работает ни под маком, ни под виндой, а под линуксом — молниеносно, не жрет по 10-20 гигабайт памяти, как CLion, и был там и 10 лет назад, когда MSVS
пешком под столпугался буста и при встрече#include <boost/отключал интеллисенс.А, и да, в агде или идрисе именно что фигачу в виме. Ну и в хаскеле иногда там же. Не подскажете альтернативу под винду?
mrbald
Boost "сам виноват", если честно. MPL — полный трындец для компилятора (был), а они (авторы некоторых хороших библиотек) его пихали в самых неожиданных местах, абсолютно без надобности.
linux_art
А кто запрещает запустить CLion на Linux?
mrbald
А никто не запрещает. JetBrains — очень хорошие кроссплатформенные продукты, у меня лицензия на всю пачку уже много лет, но это не “Linux GUI IDE”. Это Java Swing и Vendor product. Нету у Линукса GUI IDE.
linux_art
Вероятно тогда я не понимаю вводную задачу. GUI IDE это про натаскать кнопочек на форму? Тогда есть Qt DesignStudio для Qt и Glade для GTK+
mrbald
Вводная задача — обсудить убивает-ли Unix-way GUI на Linux. Ну и пофлеймить.
Разработать подсистему GUI в стиле Unix-way вполне себе можно, просто тогда каждая кнопка и каждый ярлык — это юниты, которым надо протокол и контекст исполнения, и man page. И работать должно как "если эта кнопка в чужом GUI делает то, что мне надо, то я могу ее забрать в свой GUI за минуту, что практически означает что компоненты будут native, а клей будет весь на скриптах, прямо как Tk, WxPython, PyQt. Я почти так и пишу, когда мне надо, в принципе.
В Linux многим, если не большинству, пофигу на GUI если не глючит терминал и может быть еще любимый текстовый редактор если с VIM не срослось в детстве. В Linux X/Wayland и графика вообще это просто another symmetric extension point, как bash vs zsh. Это очень круто и не в коем случае не надо менять, но это никогда не сравнится по качеству с GUI на Mac, которые там служат парадным входом, за разработкой GUI стоит тот же вендор, что и за самой OS, всё органично выглядит и для разработчика GUI существует хороший default choice.
vkni
Поскольку эти споры идут уже лет 25, то всё это, реально, экономическое. Главный вопрос — кто будет платить за превращение системы из конструктора в десктоп? Пользователь не будет — он купит Windows, которая уже есть сейчас. Нам — разработчикам это обернётся только потерями: неудобство, какие-то ненужные телодвижения.
PsyHaSTe
Затем чтобы пользоваться линукс экосистемой и при этом не есть кактус. Вот хочется — пользоваться линуксов, но ничего про него не знать. Ну как андроид, только для ПК.
Хочется верить, что можно
FRiMN
Ну так вроде Убунта под этим лозунгом и запускалась.
EddyEm
Да, к сожалению, всякие мартышки, пришедшие в линукс из игровых прошивок, вынуждают некоторых недальновидных мейнтейнеров отходить от главных китов СПО: UNIX-way и принципа KISS! В итоге дистрибутивы обрастают всякой ненужной дрянью вроде pulseaudio, systemd и т.п. И линукс превращается в очередную мастдайку.
Жаль, конечно, что так происходит. Похоже, еще несколько лет, и в линуксе вообще невозможно будет работать. Придется либо на BSD переходить, либо отказываться от использования компьютера в работе.
PsyHaSTe
kkslider
На Windows конфиг может храниться в где-нибудь в папке с приложением (или в одной из подпапок, тысячи их), может быть скрыть где-то в дебрях реестра, может лежать где-нибудь в произвольной user-папке, а может прилететь в %appdata%, коих там три штуки и все разные.
У Mac OS X это в меньшей степени проявляется, но тоже есть, несмотря на рекомендации хранить все конфиги в самом .app или Libraries. Android тоже весьма часто мусорит папками вместо того, чтобы хранить конфиги в com.vendor.application или Android/Data.
Ну, и так далее, примеров тысячи.
Mac OS X и iOS шлют пламенный привет, особенно когда Apple решает выпилить фичу необходимую для поддержки тысяч приложений, обновлять которые для новых версий MacOS/iOS никто не собирается. Android тоже таким грешит, кстати, но куда меньше. Windows, да, там проблем с миграцией особо нет — но это киллер-фича Windows, сложно ожидать чего-то другого.
О да, а вот Windows с тремя разными панелями управления, которые друг другу не равноценны — это, конечно, зашибись. А ведь есть еще групповые политики и реестр.
К Mac OS, Android и иже с ними претензий в этом плане, в принципе, мало.
Единственное, что напрягает у них, так это то, что люди с рут-доступом — граждане второго сорта в уютном мирке Google с Apple, а соответственно, провести какие-то более-менее нестандартные действия не представляется возможным из-за SafetyNet (добавить поддержку какого-нибудь нестандартного устройства ввода, например — вон на днях геймпад с Android успешно подружил, без рута было бы все намного сложнее).
C этим полностью согласен, консистентность пользовательского опыта в десктопном Linux примерно нулевая, если не пользоваться стандартными дистрибутивами и оконными менеджерами. Можно сделать красиво, можно сделать удобно, можно сделать полезно — выбери два из трех.
Впрочем, у Windows и Android та же проблема из-за того, что от стороннего софта не требуется соответствие стандартам, просто у Linux это куда сильнее выражено.
Ну да, ну да, а вот когда (например) Mac OS X Lion решил убрать функцию Save As… и заменить с помощью Duplicate (причем, что характерно, не везде) — так это непризнанный гений Джобса. И это, на секундочку, корпорация с многомиллиардным бюджетом, которая гордится своим непревзойденным handcrafted UI/UX.
Ну, и конечно, сложно ожидать, что несколько программистов на коленке сделают то же самое, что и компании с огромными бюджетами. Вот эти все дистрибутивы, форки и респины типа pop_OS, Zorin, elementary и иже с ними — не от хорошей жизни, люди все таки задумываются об унификации UX.
____
А в целом по сабжу — у десктопного Linux есть замечательный use-case, которого никогда не будет у конкурентов — а именно переиспользование старого оборудования для новых систем.
Какой-нибудь Zorin Lite летает на оборудовании 15-летней давности, а выглядит не хуже современных систем, и имеет все актуальные пакеты. Lubuntu или puppyLinux ставится на оборудование 20-летней давности и поддерживает весь современный i386 софт (единственное, правда, с чем приходится мириться — практически полное отсутствие аппаратного ускорения).
Короче, от лукавого всё это.
GloooM
Про 20 летнее оборудование, какой в этом толк если на том оборудовании уже и современный вэб тормозит, и видео в норм качестве не посмотреть и продвинутую IDE не запустить.
kkslider
Потому что иногда приходится жрать кактус.
А если серьезно, то если компьютер выполняет свои основные задачи (офис, медиацентр, или просто какой-нибудь софт/сервер крутить) — почему бы и нет?
Кстати, видео в нормальном качестве и IDE — это да, но вот по поводу современного веба — есть uMatrix/NoScript, есть генераторы статических страниц, есть dedicated приложения для особо тяжелых сайтов (привет YouTube), вот это вот все. Вариантов масса.
Revertis
Не стоит забывать, что те же CPU 20-летней давности намного прожорливее, хоть и тормознее. То есть эффективность выполнения задач там в разы уступает новому оборудованию.
kkslider
Согласен, но иногда вопрос целесообразности перевешивает фактор производительности.
Ну вот, в качестве примера use-case, реальный случай буквально пару недель назад — есть iMac 5,1 с Core2Duo и 4GB RAM (из них Mac OS 10.6.8 доступно только 3GB, но это мелочи).
Отличный 24-дюймовый монитор, качественные динамики, стильный моноблок, все дела — есть даже родной Apple Remote.
С задачами торрентокачалки, медиасмотрелки в 720p и синхронизации с таким же допотопным iPod вполне справляется.
Выбрасывать — жалко, продолжать использовать Snow Leopard — стремно (то, что security-поддержку прекратили 8 лет назад и приложения не обновляются можно еще простить, но вот то, что uBlock Origin Legacy перестал адекватно работать где-то месяц назад — уже ставит вопрос краем).
А вот накатить условный Lubuntu/Xubuntu/Zorin Lite и продолжать использовать — вполне рабочий вариант.
Revertis
Странно сознательно зажимать себя в рамки 720p.
kkslider
Это вопрос к качеству интернет-провайдера, а не к железу.
Cekory
В целом статью сложно оспорить, но исходная предпосылка про постоянные 2% неверна. Смотрим на statcounter: https://gs.statcounter.com/os-market-share/desktop/worldwide/#yearly-2009-2021
В 2010 доля Линукса на десктопах 0.78, в 2021 — 2.04 — более чем двукратный рост за 10 лет. Не головокружительно, конечно, но он есть.
Про инсталляцию программ и их настройки — это везде сделано фигово. Хотелось бы, чтобы была папка с программой и всеми её настройками, которую можно таскать куда угодно и перетаскивать на новый комп простым копирование. Но такого нет ни на одной платформе. Разве что специально приготовленные portable-версии.
vvzvlad Автор
Можно назвать это двухкратным ростом за 10 лет, а можно сказать, что он рос на (2.04-0.78)/10=0,126%/год. В первом случае он достигнет 64% через 50 лет, во втором через 500. Оба варианта все равно неутешительны.
Cekory
Да я с вами по сути скорее согласен: большую долю он не займет никогда. Но на самом деле это не так важно. В начале 2000, если вы пишете софт — то это почти безальтернативно винда. Сейчас надо думать о вебе, андроиде, iOS, винде, MacOS. Из-за этой фрагментации, мне кажется, тренд идет к тому, что все будет достаточно кроссплатформенно. И скорее всего за счет деградации пользовательского опыта. Электрон — это только первая ласточка. В условиях, когда труд программиста стоит очень дорого и все хотят зарабатывать на рекламе, а не продажей софта, интерфейсом и скоростью будут
немногожертвовать...То есть Линукс не станет лучше, но другие станут хуже. Я сам на него пробовал перейти с Windows 7 в 2010 и был ужас-ужас. А в 2018 перешел и вроде хорошо, но это скорее по контрасту с десяткой....
oWeRQ
Если было 0.78%, а через 10 лет — 2.04%, то это рост примерно на 10% в год, еще через 10 лет будет 5.2%, через 20 — 13.6%, через 30 — 35.3%, а через 40 лет будет примерно 92%.
Но все это просто цифры, на мой взгляд может быть всего 2 варианта: наберется критическая масса(8-15%) и будет резкий рост, либо не наберется и линукс вытеснит какая-нибудь фуксия.
Revertis
Так ведь Фуксию потому и разрабатывают, похоже, что поняли, что текущая экосистема Gnu-desktop так и будет гнить.
jakushev
Статья, все таки написана со стороны администратора и продвинутого пользователя. По этому вопрос надо ставить чуть иначе — «Что получит (обычный, далекий от IT) пользователь при переходе на GNU/Linux, и что получит сообщество, захватив большой процент десктопов?» Ответ, ИХМО, очевиден. Ничего. Пользователь не работает с ОС, он работает с софтом. По этому ему все равно, что «под капотом», будь то FreeBSD или Win. Если компьютер рабочий — решает работодатель, что использовать, домашний — браузеры и текстовые редакторы есть в любой ОС. Производители ПК почти на все устройства предустанавливают Windows (снова же, простой пользователь купит или готовый ноут или системник, не будет замарачиваться со сборкой из компонентов), по этому смысл все сносить и ставить GNU/Linux нет, да и пользователь это не умеет. Сообщество же, получив диктатуру пользователя / менеджера, как и упоминалось в статье, потеряет интерес к проектам или форканет, как было с несколькими проектами, где появилась приставка «Libre». Ну а среди ITшников, спор, что лучше, так это моветон…
Да, что касается Линукса и домохозяйки — вполне рабочий кейс, проверенный на жене и дочке. Сломать что либо сложно, работает надежно.
dlinyj
Да вообще проблемы уходят сразу
jakushev
К сожалению, не все. Мелкая умудрилась поскакать на ноуте, сломав тач, правда, тогда ей и 2х не было, а жена недавно весь свой архив наработок удалила, и вот в 3 часа ночи спрашиваю у Гугла, «а как восстановить удаленные данные на ext4fs?» Хорошо что обычный винт, trim не поддерживает… А так — да, проблем много меньше стало.
vvzvlad Автор
Нет! Ему пофиг, что под капотом, но ему не пофиг, как с этим работать. Если ядро линукса прикрутить к винде так, что для пользователя ничего не поменяется, то пользователь, конечно, будет работать с линуксом. Но пока ядро и все накрученное вокруг него требуют внимания пользователя — ему не пофиг, на какой системе он работает.
jakushev
vvzvlad Автор
Когда вам для результата приходит лезть в конфиг, тут-то и поднимается на поверхность проблема.
jakushev
Ну для меня это не проблема, так как я — не админ, а поддерживать 4 компьютера не отнимает много времени. Да, со многими вещами из Вашей статьи согласен, но… Допустим, кто то сделал такую систему, где есть унификация, подобна той, что в MacOS. Вот прям идеальную, все конфигурируется в едином приложении, забыли про поддержку >1 пользователя, только одно окружение рабочего стола, только один магазин приложений (привет Андроид). Вопрос, а каким пользователям она будет нужна? Она не даст нового положительного опыта, по сравнению с той же Виндой, а для тех 2% не будет интересной, так как убьет самое главное — гибкость. Тут главный вопрос, а зачем обычному пользователю Линукс на десктопе? Что он даст? Учитывая, что цену Винды уже закладывают в оборудование.
FRiMN
С каких пор в Убунте надо лезть в конфиг, чтобы отредактировать тестовый документ?
На прошлом месте работы сменилось несколько наборов программистов, а у менеджеров как стояла Убунта, так и стоит. Никто ее не обслуживал никогда. Она даже не обновлялась годами. И не было ни одного дня простоя по причине проблем с ОС.
Rohan66
— Какой у вас браузер?
— Яндекс!
(Ещё до появления Я-браузера!)
vkni
В точку! Его можно переформулировать в «что получит сообщество от пользователя?»
Поскольку у нас не коммунизм, то от пользователя можно получить что-то только через деньги, а Linux на Desktop'е рассматривается в том смысле, что денег пользователь платить не будет (по ряду причин, в том числе и не нужны пользовательские копеечки разработчикам того же st или Window Maker'а).
Поэтому тут кто платит (в основном временем и работой), тот и заказывает музыку. А это — разработчики, сисадмины, «продвинутые пользователи».
А человек, который не может даже заметку на Stack Overflow тиснуть с описанием решения определённой проблемы, не нужен — он не включён в сообщество и не хочет быть в него включён.
dlinyj
Мне лениво читать, потому что сама постановка вопроса несколько глупая…
Мне само понятние десктопный линукс не очень понятно, автор, а ты понимаешь чем отличается серверный linux от десктопного? Можно ли их заменить друг другом?
Я поставил всей своей семье «десктопный линукс» и забыл о тысячах проблем. Игры, редакторы документов, отсутствие вирусов и титаническая надёжность, а так же отсутствие обновлений в самый неподходящий момент.
Касательно целевой аудитории — линукс с одной стороны для всех, с другой совершенно не для всех. Те кто используют его как инструмент, как я, прекрасно понимают его сильные и слабые стороны. Те кто не понимают, либо используют его по воле случае, как моя родня, либо из любопытных побуждений.
vvzvlad Автор
Я очень рад за вашу ногу, но хотя бы дисклеймер стоило прочитать.
dlinyj
Здесь нет предмета спора вообще. Есть инструмент, он хорош для своих задач. Если инструмент прекрасно решает 2% задач, где другие инструменты не могут решить, то глупо считать что этот инструмент хуже других 98%. Даже если доля инструмента составляет доли процента.
У меня есть инструменты, обычные, которые я достаю раз в несколько лет (например, зарядное устройство для свинцовых аккумуляторов), но это не означает, что оно хуже болгарки.
vvzvlad Автор
Ну, тут речь о том, что инструмент спроектирован так, что им можно решить только 2% задач, а для остальных 98% надо брать другие инструменты. Можно было бы небольшими (относительно остальных усилий по разработке) усилиями сделать так, что им станет можно решать 40% задач, но нет, несмотря на попытки, не получается. В статье мой взгляд на то, почему не получается.
Если вам не надо решать ничего более этих 2%, рад за вас. Но сам факт того, что это всего 2% задач, намекает на то, что не у всех так.
dlinyj
Всё банально, вопрос финансирования. Причина почему положение вещей, как вы описываете именно такое, кроется в том, что финансово это никому не интересно. Если бы в «десктопный линукс» влилось столько бы денег, как в Andoid, MacOS или Windows, а так же в его рекламу (достаточно было бы только рекламы, честно), уверяю, доля его на рынке сразу взлетела бы до небес.
vvzvlad Автор
dlinyj
Прочитал, ощущение, что человек, ни разу не разработчик экстраполирует личные проблемы на всю операционную систему. Не понимая как она работает.
vvzvlad Автор
?\_(?)_/?
Если аргументация не убедила, более ничего не смогу сделать.
dlinyj
Ребята, давайте не будем в этой ветке сыпать минусов vvzvlad, я в действительности могу заблуждаться в своей позиции.
dlinyj
У меня завелся персональный хейтер, которой прошел и поставил минус у всех моих комментариев. Это успех!
alsoijw
Похоже тут минусы идут всем гну/линуксоидам.
PsyHaSTe
Ну вот я виндой в основном пользуюсь (хотя конечно прод сервера, CI и прочее — исключительно линукс по ссш, т.е. я и то и то предпочитаю в зависимости от задачи) — за ночь карма уменьшилась ан 3пп. Мелочь, но на определенные мысли наводит)
vtb_k
Это вы сейчас про виндовс или линукс?
vvzvlad Автор
Это риторический вопрос? (не пойму, надо на него серьезно отвечать, или нет)
vtb_k
Нет, совсем не риторический. Потому что в винде ну никак не сделать целую кучу задач, которые просто тривиальные в линуксе. Управление без костыльной мыши? 100500 вариантов интерфейса? Я когда года 3 назад сел работать на винде(корпоративный стандарт) то даже месяца не выдержал. Теперь на есть пункт на собеседовании — возможность работать в линуксе. Это как жить в ракушке, когда кругом море возможностей. Нет, я очень доволен, что есть системы, где можно настроить абсолютно все.
DrPass
Справедливости ради, вы не назвали ни одной задачи :)
Причём с одной стороны, эти «недостатки» вообще не являются недостатками, т.к. это просто индивидуальная вкусовщина, и для эффективной работы на компьютере не нужно ни управлять без удобной мыши, ни тем более менять привычный интерфейс на какие-то кастомные поделия. А с другой стороны, даже сами они надуманы, т.к. в современной винде можно при желании полностью жить в командной строке, и даже оконный интерфейс вполне себе управляется с клавиатуры. А также винда испокон веков позволяла ставить кастомные десктопные менеджеры, и сейчас позволяет. Правда, они почти все (если не все) сдохли давно от отсутствия популярности среди пользователей.
BigBeaver
Ок, Как сделать в винде чтобы при выделении текст копировался в буфер?
DrPass
В смысле, автоматически? А как тогда отличать, вы текст выделили для копирования в буфер, или для переноса, или для удаления/замены?
alsoijw
У вас есть два буфера для мыши и для клавиатуры.
khajiit
Вы сейчас человеку всю лодку раскачаете )
0xd34df00d
Зачем? Я просто выделяю текст, и он просто копируется в selection buffer.
BigBeaver
В прямом. Выделил текст, ткнул в нужном месте среднюю кнопку — текст вставился. Не понимаю, как люди живут без этого на винде — абсолютно нереально работать с текстами. Ладно бы они полностью от мыши отказывались, так нет же — все наоборот заточено максимально под неё.
alsoijw
Я часто использую vim, так что порой у меня появляется ещё и третий буфер.
BigBeaver
Повезло. Я вот часто использую SES, а он перехватывает буфер. И если внутри него еще можно настроить поведение нормально, то вот с системными буферами стыкуется только клавиатурный.
khajiit
То же касается и
nano:Ctrl+k|uvtb_k
НЕТ. Мышь просто бесполезная трата времени впустую. Она не удобная ни разу, вот вообще меня просто бесит. Для меня тайловый интерфейс привычен, а вот виндовое поделие нафиг не нужно, когда все удалят винду и поставят тайлинг? Ведь если мне удобно, значит всем удобно. Позиция автора кстати.
0xd34df00d
Ну, например, одна задача — писать на агде и хаскеле. В линуксе я просто, одной командой ставлю вим, ноду (для вимовского CoC), соответствующие компиляторы и гит, гитом клонирую свой dotfiles, и все, привычная среда разработки готова на новом месте. В винде, чтобы этот зоопарк собрать вне WSL (а иначе какой смысл?), я даже не представляю, сколько усилий нужно будет приложить.
DrPass
В винде я одной командой ставлю Visual Studio. Гитом в ней клонирую свой солюшен, она автоматически подтягивает недостающие пакеты из репы, и всё, привычная среда разработки готова на новом месте.
0xd34df00d
Не уверен, что VS умеет в агду или хаскель. VS Code я пробовал — это не то, там чуть меньше фич, чем в vim + CoC для хаскеля и vim + vim-agda для агды. По сравнению с последним — вообще в бесконечное количество раз меньше.
Это, опять же, как если бы человек привык, не знаю, к SolidWorks, а вы бы ему рассказывали про FreeCAD.
0xd34df00d
А, и да, забыл: как вы управляете настройками VS и всего прочего?
У меня в упомянутом выше dotfiles весь конфиг вима, zsh, tmux/screen, git и ряда других вещей. Я его просто клонирую (ну и делаю
git submodule init/git submodule update, чтобы плагины к виму подтащить), и у меня под рукой среда с привычными мне настройками, хоткеями, плагинами, цветовой темой и задержкой автокомплита. При этом в том же виме для условного хаскеля настройки одни, для плюсов — немножко другие, для агды — третьи, для латеха — четвёртые.DrPass
А она их сама синхронизирует, через учётку.
0xd34df00d
Включая шелл, гит и прочее?
Окей, шаг на уровень выше: у меня есть ноутбук, с которого я пишу код вечером в кровати, и есть десктоп, стоящий недалеко от окна (вернее, стоявший, но неважно). На первом у меня тёмная тема, на втором — светлая (иначе от контраста с окном становится больно). Мои dotfiles это учитывают — достаточно создать (пустой) файлик
~/light, чтобы всё переключилось на светлую тему (можно даже сделать переключение по времени суток, но это уже лень). Заняло три строки вимскрипта и три минуты на гуглёж «vimscript check file exists». В VS так можно, и какой кровью?DrPass
Настройки гитовского плагина синхронизирует. А что такое «синхронизация шелла» применимо к винде?
Установить из репы плагин «theme switcher», и сразу можно.
0xd34df00d
А где вы там команды всякие вводите, если вдруг надо сделать какой-нибудь
git grep -iw?А его настройки тоже синхронизируются?
alsoijw
Какие языки она поддерживает?
jtraub
> Я очень рад за вашу ногу, но хотя бы дисклеймер стоило прочитать.
При этом вы в статье сами пишете
Это и многие другие ваши утверждения относительно Windows — как раз из разряда «у меня такая же нога и ничего не болит». Не далее как вчера помогал матушке переехать на новый ноутбук и познал детали поиска настроек програм в тысяче папок и дебрях реестра.
duplodel
и все это идет лесом, когда кейсы чутка выходит за рамки браузера и косынки. И тут же начинается а как? и ты такой лезешь в гугл, чтобы узнать а как и охреневаешь от кучи манов, 90% из которых не работает
svsd_val
не согласен, вы считали сами то ?? 90% — откуда эта цифра?
duplodel
«По статистике 90% статистики в интернете взяты с потолка»
А мы тут с вами вроде в интернете
sborisov
Да, я помню ещё проблемы с воспроизведением звука с разных источников, в Win2k — всё было отлично, в Linux не играло… Сервер KDE arts (так кажется назывался), не всегда справлялся -много программ не умели с ним работать.
А как настраивали flash в Mozilla в 2004м в Fedora… вот это был квест…
Сейчас же всё работает «из коробки», и весь тот багаж знаний стал не нужен…
Для «рядового» юзера, как мне кажется — не хватает пакета типа iLife, чтобы было просто и удобно работать со звуком и видео. Именно просто, так как сложные редакторы для профессионалов есть…
BigBeaver
TL;DR — никак.
GarretThief
Те кто сидит на линуксе (99% девелоперы), привыкли к проблемам и ошибкам, вознкающим в линуксе, а обычные юзеры оказываются в неизвестном для них мире, где сколько ни копай в любую сторону — понятной информации не найдёшь. И наоборот — на винде миллион ограничений, но она понятна и знакома. Вот и получаем, что девелоперам важнее свобода с необходимостью разбираться, а обычным людям из реального мира не до этого/незачем, и важнее удобство, чем кастомизация.
А ещё как-то слышал такую фразу
Разработчикам особого профита от дополнительного миллиона юзеров не будет, им важнее фича, которая сделает что-то удобнее для других разработчиков, поэтому они и не делают вторую винду, а для пользователей линукс слишком сложен и непонятен, поэтому они и сидят на винде.
dlinyj
Ошибка делать статистические выводы на основании своего окружения. Выборка ни разу нерепрезентативная. В моём окружении, большинство кто сидит на линуксе: моя мама, жена, сын, и я. Среди них разработчик только я, означает ли что 75% кто сидит на линуксе — обычные пользователи?
GarretThief
99% — это обобщение. Да, пусть не 99%, есть военные с их Астрой, есть госпредприятия, есть просто любители
всё свободное время просто проеизучить что-то новое. Но даже если и девелоперов не большинство, то одна суть, что они являются основной аудиторией, на которую расчитывают разработчики не-специализированных дистров типа той же астры, а обычных федор-дебианов-арчей.dlinyj
Я согласен с тем тезисом, что linux ОС от разработчиков для разработчиков. Но утверждать в процентном соотношении — некорректно.
oWeRQ
Верно, но так же верно и в обратную сторону, мне как пользователю линукса сложно чинить проблемы и ошибки винды, "инструкция" по решению которых обычно сводится к перезагрузке, установке подозрительного софта или переустановке системы. Последний раз винда заставила меня попотеть при переносе на ssd, в процессе поломалась и исходная копия, а установить с нуля на уже размеченный диск оказалось крайне не тривиальной задачей, потребовавшей пользоваться консольными утилитами винды, которые мягко говоря не дружелюбные.
GarretThief
Ну да, я и сказал, что порог вхождения во много раз меньше, но сделать что-то нетривиальное — боль :)
oWeRQ
По моим ощущениям порог примерно одинаковый, только пользователям винды его помогают преодолеть все вокруг, родственники, друзья, преподы и коллеги. Хочу сказать винда не проще, просто другая, а понятна не потому, что сделано лучше, а потому, что привыкли.
LiquidSnake
Что проще: поставить галочки в GUI или идти в консоль и вбивать непонятные символы? =)
unsignedchar
Проще позвать мальчика который сделает чтобы работало.
А если делать самому… Что проще: скопировать нагугленное заклинание или просмотреть несколько видеоинструкций по 15 мин?
PsyHaSTe
Вам объективно или с точки зрения испуганной девочки бухгалтерши? Я вот до 1 курса универа не знал куда эти буквы все набивать нужно. Даже в самом раннем детстве на 386 компе я пользовался гуем

BigBeaver
Вон у вас командная строка внизу на скриншоте.
PsyHaSTe
Ну, для меня в 5 лет это было скорее элементом декора. Пользовался я стрелочками, табом и энтером. Ну и мышкой когда какую-нибудь дюну запускал, где она есть
unsignedchar
С точки зрения бухгалтерши: не коннектится VPN к удалённому рабочему столу. Какую кнопку на каком GUI нажать, чтобы всё починилось?
LiquidSnake
Окей, в линуксе какую кнопку нажать/какую команду в консоль написать? Не от рута.
BigBeaver
Позвонить админу.
LiquidSnake
Окей, с виндой путь будет тем же. Так зачем переходить на линукс?)
unsignedchar
Давайте сначала ответим на этот вопрос:
Какую галку в каком GUI нужно поставить, чтобы хотя бы продиагностировать проблему?
LiquidSnake
Ох, как вы меня половили (нет).
В случае конкретно с впн, в зависимости от клиента, есть вкладка с логами которую можно отправить админу.
В случае с консольным вариантом, надо пойти в /var/log/vpnclientname/ найти тот лог который отвечает за коннекты и отправить его админу.
Только будет ли условный пользователь писать это руками? Или запоминать путь?
BigBeaver
У админа есть SSH. А если упала сеть, то как вы что отправите админу?
unsignedchar
Когда есть админ — он найдет способ. Когда админа нет (я сам себе админ, например) — буквы гуглятся лучше чем картинки.
LiquidSnake
SSH куда? На сервер где крутится впн? А у условной девушки не работает сеть?
Я не стебусь, правда не понял что вы имеете в виду
BigBeaver
Что он сам посмотрит логи, и нет необходимости что-то ему отправлять. А если у админа нет возможности посмотреть самому, то и отправить пользователь ничего не может тоже.
LiquidSnake
Стоп. Если нет сети у клиента, то разницы нет винда у него или нет. Что на сервере где крутится впн, что на удаленном раб.столе клиента есть будут логи.
BigBeaver
Я так и сказал. Поднимать интернет, очевидно, не задача девочки бухгалтера.
LiquidSnake
Тогда вам не мне надо было отвечать, а комментатору выше.
Я же ответил на вопрос:
«Какую галку в каком GUI нужно поставить, чтобы хотя бы продиагностировать проблему?»
В гуях винды приложения впн есть вкладки с логами. В линуксе — идем /var/log/ четотам.
Нет сети у клиента — идем ногами.
Вопрос в том что проще запросить, натыкать мышкой лог, или идти в консоль.
BigBeaver
FRiMN
Проблема еще в том, чтобы можно было в гуе выделить и скопировать текст. А то иногда эта миссия невыполнима. Мне в таких случаях приходилось делать скриншоты текста ошибки (здесь должна быть картинка с фейспалмом).
svsd_val
Ок, Вы сейчас только балтологией занимаетесь. Вы с реальными пользователями то работали? Мне по работе приходится и нашим сетевым администраторам тоже. И тот случай с девочкой о которой вы сказали так же имеет место быть. Так что скажу как это происходит у нас, несколько примеров из жизни:
1.
Звонит девочка, не знама по чему не подключается мой компуктор. Не фидятся мои файлы.
Сетевой админ: вы подключили VPN. (на рабочем столе у вас ярлычок).
Она: жму не помогает.
Сетевой админ открывает микротик, смотрит логи, и говорит обатитесь к продавайдеру, у вас залочены нужные пакеты.
Она: Ок.
Проходит несколько минут, часов, звонок. Мне сказали что так и так они не лочят. всё хокей, но не работает.
Сетевой админ: угу, сказали, дайте их контакты. Звонит говорит какого художника потеряла страна, и всё сразу начинает работать.
2.Звонит девочка, моя с дома связь рвоётся…
Сетевой админ заходит на микротик, смотрит логи, там всё ок. Заходит на VPN сервер смотрит логи, по логам находит в чём дело и устраняется всё по телефону на стороне девочки…
3. Был случай когда девочка лочила учётку из-за не правильных паролей. Тоже в логи зашли посмотрели почему и как.
4. У нас у всех учёток есть срок жизни паролей, после чего они лочатся. Так вот нерадивые пользователи забывают про это И через несколько недель отпуска, не могут войти. Тоже всё логами смотрится и лечится по телефону.
5. Пользователь в сети, не поднимается, цепляются через анидеск, смотрят что и как.
6. Пользователь не может подключиться в логах даже попыток нет, поднимает панику, не может работать с данными, а как обычно это срочно нужно, выясняется что тупо деньги на тырьнете кончились…
Вот такая вот она правда жизни.
oWeRQ
Возможно Вы хотели сказать: зачем пользоваться открытой, бесплатной, универсальной и безопасной системой, когда можно купить Windows 10 Home за 10к или Pro за 16к, оправлять кучу телеметрии за бугор, быть ограниченным только десктопными устройствами на x86-64 и развлекаться с небезопасным софтом? Да и правда, надо поддержать корпорацию, они же так бережно наносят добро =)
LiquidSnake
Я скорее о том что винда обычно уже есть и установлена, а на линукс надо еще перейти
oWeRQ
Тут возникает дилемма курица и яйца, на линукс не переходят потому, что им не пользуются, а не пользуются потому, что он не предустановлен, а не предустановлен потому, что не пользуются… Тогда любые рассуждения о готовности линукса и любой сферической идеальной системы для дектопа бессмысленны, пока есть армия фанатов винды, считающих, что это венец творения и готовых прощать любые издевательства, мы все останемся ее заложниками.
З.Ы. Я не говорю, что линукс идеален, везде есть свои проблемы, но при прочих равных мне кажется выбор очевиден.
PsyHaSTe
При прочих равных — да.
Но прочих равных у нас нет.
red75prim
Армия фанатов-заложников, издевательства… Вот это пафос. Ну не взлетают десктопные дистрибутивы. Потому что никаких особых преимуществ перед windows у них нет. Apple тут выезжает за счёт того, что они предоставляют полное решение: железо, ОС, часть программ, сервисы.
Что может предложить Линукс кроме "вы можете настроить всё, и вам придётся всё настраивать, и возможно патчить"?
oWeRQ
Откуда взялось, что в линуксе все нужно настраивать и патчить? Уже даже арч с гномом ставится просто установкой нескольких пакетов, а дальше все необходимое настраивается в гуе. Никто же не заставляет, да, это возможно, некоторые и винду патчат(привет простая замена иконок) и хакинтошники патчат, но это не значит, что всем это нужно.
svsd_val
Я со времён 2.6.32 забыл что такое патчить (к слову для тех кто не в курсе сейчас самое свежее стабильное ядрышко 5.12.x ). Я ядрышко уже столько лет не собирал что даже не знаю смогу ли сейчас )) так как в этих операциях надобности особой нет, стандартное всё идёт достаточно адекватно настроенное. О чём говорить если у меня в sysctl тупо одна строчка: kernel.dmesg_restrict=0…
А может просто я обленился? О_о
PsyHaSTe
Обычно там есть кнопочка "расширенные настройки", где можно попереставлять галочки разные.
Если и тут не работает то это уже не компетенция пользователя. Но часто помогает.
LiquidSnake
О, вот уже и мальчики понадобились.
Нагугленную последовательность из заклинаний, обычно. Которую пользователь не понимает, вследствие чего не может воспроизвести потом — нужна инструкция, опять.
Почему по 15 минут? почему видео? Последовательность картинок запоминается лучше.
unsignedchar
Ну, давайте нагуглим инструкцию по запуску ssh туннеля ;)
habr.com/ru/post/81607
И putty.org.ru/articles/putty-ssh-tunnels.html
Всё то же самое, но эти непонятные цифры нужно вписать в несколько разных вкладок. И нажать ещё несколько кнопок, скриншотов с которых в инструкции нет — но это же интуитивно понятно, что после этих манипуляций нужно вернуться во вкладку sessions, и там нажать кнопку save.
Инструкция для командной строки короче и проще. Как в изготовлении, так и в использовании.
Да чорт его знает. Модно сейчас записывать видеоинструкции, всё чаще попадаются.
Если у человека фотографическая память. Я очень часто видел людей, которые записывают в тетрадку свои действия. Но никогда не видел, чтобы они их зарисовывали.
major-general_Kusanagi
Нет, дело не в «фотографической памяти», а в том, что математики по образу мысли делятся на алгебраистов и геометров. Алгебраистам легче думать формулами, а геометрам легче думается графиками и прочими визуализациями.
red75prim
Фотографическая память нужна, чтобы воспроизвести картинку по памяти. Чтобы узнать окно и найти кнопочку на нём достаточно обычной средней памяти. Поэтому и не зарисовывают — не требуется.
PsyHaSTe
Внезапно понятно, да. Например, в случае команды нужно помнить какие у неё аргументы (или вызвать help и смотреть что там она умеет), тогда как в интерфейсе сразу написано что куда вводить.
Короче не значит лучше. Например словесное определенеи предела 99% людей поймет намного лучше, чем куда более точное и короткое

unsignedchar
Как человек, привыкший к тому, что кнопка Save находится на той же форме, где все остальные поля — на эту милую особенность конкретно этой программы я наступал раз 100 ;) Но это такое.
Я про инструкцию-текст vs инстркуция-набор картинок.
Текст: всё видно сразу. Если это инструкция, разработанная местным фиксиком — можно просто копировать и запускать. Накосячить — сложно.
Если есть сомнения — можно открыть man и проверить, нет ли тут патча Бармина.Картинки. Открываем настройки по очереди, внимательно просматриваем, где там красные стрелки. Накосячить — возможно. Даже если фиксик вписал во все места картинок правильные цифры — их нужно перепечатывать вручную.
PsyHaSTe
Во-первых, как я уже сказал — то что объективно скопипастить текст проще не означает, что людям это проще субъектинвно. У них другой UX совершенно. Для них это чуждо, непонятно и страшно. Лучше уж с картиночками и ютубом
Во-вторых всегда есть риск, что человек берет и выполняет rm -rf / или ещё что-то подобное.
Чтобы набирать текст нужно быть уверенным, что будет нужный результат а не как выше нужно ещё и понимать — что набираемые буковки означают. А это уже совсем другой уровень использования и понимания Оси.
P.S. за время обсуждений мне карму на десятку слили, хотя я вроде старался говорить вежливо и аргументировано. Забавно, однако.
Ещё десяток таких статей и комментить я смогу раз в час)
red75prim
Хех. Есть вариант патча Бармина, для тех, кто любит проверять подозрительные скрипты.
"вроде_бы_строка_uuencode" | uudecode | sh
Payload спрятан в строке и работает даже если убрать
| shи| uudecode. *nix shell — это те ещё грабли.oWeRQ
Дурное дело не хитрое, в половине инструкций написано скачать какой-то неведомый софт(аля Super Mega Tweaker/Cleaner) и пользователи это делают, хорошо если попутно ставится только рекламный софт. Скажете это только начинающие, окей, задачка для продвинутого пользователя: "Как перенести windows на ssd", много инструкций показывающих как это сделать известными инструментами, а не с помощью "MiniTool Partition Wizard", "Renee Becca", "HDClone" и прочими утилитами которые лично я вижу первый раз?
oWeRQ
Не припомню когда последний раз приходилось пользовательские настройки в линуксе править через консоль, так что разговор только об администрировании системы.
Проще то, с чем чаще всего работаешь, непосредственно сложность зависит от задачи, что-то проще и быстрее через гуй, что-то через консоль, но частенько если попытаться в паре абзацев описать что нужно сделать гуе — проще застрелиться, если это решается парой команд — передать их мессенджере, форуме, инструкции проще чем сделать десяток скриншотов.
FRiMN
Вы что, в линуксе настраиваете из консоли? Зачем? Почему не пользуетесь GUI с галочками предоставленными вашим ДЕ?
LiquidSnake
Софт ставлю например.
Правлю конфиги после того как драйверы видеокарты не ожили.
Запускаю bash скрипты.
Ищу причины снижения производительности системы.
oWeRQ
Есть масса графических приложений для управления пакетами, в том числе в составах DE идут gnome-software и plasma-discover, есть пакетоспецифичные synaptic и pamac, в конце концов есть packagekit который может использвать видеоплеер чтобы установить кодеки, в общем на любой вкус.
Это пожалуй единственный пункт из-за чего может быть необходимо воспользоваться консолью, но это не то что нужно конфигурировать каждый день, не припомню чтобы графика из коробки хоть с каким-то драйвером не работала вообще, кажется еще в ubuntu 8.04(т.е. 13 лет назад) добавили графический инструмент для установки и переключения видео драйверов.
Довольно разумно запускать их в терминале, хотя в общем это можно делать и из гуя.
На пользовательском уровне можно открыть графический системный монитор(аля таскменеджер), а для подробного анализа, да фиг его знает где это вообще можно сделать через гуй, в винде я не смог найти и исправить узкие места, чтобы не тормозило на hdd, на маке тоже не припомню подобных инструментов.
COKPOWEHEU
Да много чего. Не запускать же графические конфигурялки если можно просто поправить текстовый файлик. Собственно, я даже не знаю как эти конфигурялки называются, потому как без надобности.
FRiMN
На винде сидят не из-за того что она удобней, а из-за того, что часто уже есть бэкграунд с ней. Напомню, что до недавнего времени в тех же школах небыло никакого линукса. Была винда. На уроках по информатике изучали винду. С 99% вероятностью везде в офисах стояла винда. Винда была везде. Увидеть линукс -- всё равно что встретить единорога. И это заслуга менеджмента майкрософта.
LiquidSnake
Изучали это громко сказано. Винда и будет везде.
Какой вы видите сценарий перехода на Линукс? из коробки он мало где. Возможно Админ своей семье поставит линь — только тогда.
Сам пользователь даже если подумает в сторону линукса, может столкнуться с дилеммой «а какой дистриб взять?», если вообще будет знать что они разные.
major-general_Kusanagi
В смартфонах и в планшетах повсеместно встречается Линукс в форме Андроида.
LiquidSnake
Пожалуй в дальнейшем я буду вас игнорировать. Подобные комментарии мне уже надоели, вы прекрасно понимаете о чем вопрос, но повторяете одно и то же
vtb_k
Я не понимаю вашей логики. Вы спрашиваете какой сценарий перехода с винды на линукс? Так почему это не может быть андроид? Моя жена ноут открывала последний раз 2 года назад. Моя мама включала десктоп тоже где-то в тоже время. Просто потому что телефон/планшет покрывают все юзкейсы. В андроиде ядро линукс, так же как в любом дистрибутиве. Сейчас спор идет только исключительно про использование компа для работы. Все остальные юзкейсы забрал себе андроид/іос
LiquidSnake
Потому что это не переход. Там оно «изкаропки», плюс вылизанно гуглом и обычно производителем hardware. Продукт платный, потому и стараются. Планшеты и телефоны это отдельная ниша и винда там не прижилась.
Давайте я задам вопрос точнее «Каков сценарий перехода с Windows на Linux на ПК/Ноутбуках?»
Я все-таки за то что Линукс — серверная ОС. На рабочем ПК он мне неудоен.
vtb_k
Что значит не переход. Я вам говорю, что обычная домохозяйка раньше включала десктоп, чтобы посмотреть фотки/видео, а теперь не включает, потому что планшет покрывает все. У вас проблемы с пониманием слова переход?
Андроид свободный и никогда не был платный. Вендоры платили лицензию только за плей сервисы гугла. Хуавей сейчас не платит например.
Для меня работать удобней. И если будут заставлять работать на винде, я просто поменяю работу. Я вообще никогда не слыщал, чтобы линукс кому-то навязывали, в отличии от винды. Вообще не понимаю плача автора
LiquidSnake
У меня нет проблем. Я в своем предыдущем посте конкретно поставил вопрос. Если вы пишите комментарий, не дочитав до конца, это не моя беда.
Я о технике. Телефон / планшет — платная штука, поэтому производитель будет стараться чтобы софт на нем работал лучше, т.е допливать, т.к конкуренция.
Вам да, пользователям винды какой резон переходить?
Да, согласен не навязывали, мне тоже непонятно зачем что-то менять. Профессионалы пользуют линь и радуются, остальные — по удобству и хотелкам.
vtb_k
Полностью согласен
Я все прекрасно дочитал. Вот только не понимаю, почему переход должен ограничиваться ПК? Завтра придумают обруч на голову с виртуальной реальностью и все перейдут с телефонов на обручи. ПК сам по себе не важен, важны задачи, которые он позволяет делать.
svsd_val
Busla
с произвольной кодировкой несколько сложнее:
Конечно, всё это можно записать компактнее, но я столько кнопок и не нажимал — оно по табу само дописывает. Можно всё это ещё больше упростить, если файл умещается в память.
FenestramDeveloper
А в обратную сторону он умеет? И чтобы в нормальный uft8, из которого потом не надо первые два байта вырезать.
Busla
Можно и в обратную без BOM (он три байта):
в UTF8 BOM хоть и избыточен, но вполне валиден — 23.8 Specials:требование «нормального» utf8 — косвенный показатель, что инструмент на самом деле unicode не умеет, а довольствуется той частичной обратной совместимостью с ASCII, что заложена в сам стандарт utf-8FenestramDeveloper
Спасибо. Это удивительно, что у вас хватило терпения разобраться в этом синтаксисе. Ещё был какой-то хак, как сделать переводы строк \n, а не \r\n. Стандарт — это хорошо, а по факту множество программ, включая apache или php, считают недопустимым, если файл содержит BOM или \r или другие виндувсовые сюрпризы, и будут выдавать ошибки.
svsd_val
Вы это проверили на каком объёме данных ?? до 4гб?
Busla
Здесь построчная обработка текста. Она не эффективна в плане операций чтения/записи; но если ваш документ разбит на строки, то общий размер файла не имеет значения.
svsd_val
Многие XML идут как однострочный файл.
unsignedchar
И ещё спасибо пиратам за наше счастливое детство ;)
General_Failure
Мелким как бы пофиг на пиратство, борьба с домашними юзерами чисто символическая. Потому что если привык к винде ещё с детства (пока гонял игорей и делал школьные рефераты в ворде), то и работать будешь скорей всего с виндой.
LiquidSnake
Да, так и есть. Я бы даже добавил что борьбы вообще нет. Вспомните легализацию при переходе на 10.
ALexhha
Ну и последние лет 7-8 использую linux (дом/работа) и частично macos. Возвращаться на windows нет никакого желания.
При смене работы, я кстати, тоже учитываю этот фактор — и если работодатель говорит, что windows у них корпоративный стандарт и ничего другого использовать нельзя — я просто отказываю таким.
General_Failure
Не думаю, что ваш вариант наиболее вероятный :) Хотя и единичный тоже вряд ли.
Мой варик — работаю в макоси, винда нужна только для игр (отдельный комп для этого). Да и то многие идут из-под лини. Можно было бы и на маке рубаться, но мой мак мини имеет очень слабую видюху.
LiquidSnake
Какая у вас была боль? С хрюши пользовался виндой.
vtb_k
В винде никогда не будет такой свободы как в линуксе. Лично мне не нравится, когда меня ограничивают. Я этого не понимал, пока не попробовал. Теперь я не могу этого "распробовать". Когда есть дополнительные возможности и нету ограничений, то зачем возвращаться?
LiquidSnake
Аргументов против нет. Сам пользую Убунту на личном устройстве. Именно по той причине что вы сказали плюс еще несколько.
Не ищите противоречий почему я в комментах топлю за винду, а сам пользую Линь. Мне не нравится что Линукс тут считают решением всех проблем.
Плюс и минусы есть у каждой ОС.
speakingfish
Скринсейвер? Вроде давно уже после того как скринсейверы объявили малварей имеющей доступ к паролям на вход в систему его стали выпиливать из дистрибутивов. Не везде выпилили? Впилили обратно? Кто в курсе нынешних скринсейверных тенденций?
eyudkin
А мне кажется, что в первую очередь линукс — это не конкретный набор пакетов, а экосистема, примерно как npm. Миллион версий гуёв, миллион версий менджмента сервисов от initd до systemd, миллион оболочек — это чистый хаос, который постоянно развивается во множестве направлений и логично не имеет никакого единого «стандарта» или конфигуратора, а любая попытка всё это загнать под один стандарт заранее обречена на провал, потому что сразу как в меме появится несколько конкурирующих стандартов.
Целая экосистема, из которой можно выстроить что угодно, это действительно плюс для серверов и программистов, потому что из такого конструктора можно собрать всё что угодно, но минус для «пользователей», потому что требует знания даже не конкретной программы, а целой экосистемы — и никто из пользователей не захочет тратить несколько лет жизни просто ради того, чтобы уметь подключить к ноутбуку блютус наушники.
Хотя лично я бы очень хотел и был бы готов заплатить за это разумные деньги (ну скажем до 200$ раз и навсегда при уверенности, что эта система проживет у меня лет 10 и не загнется от недостатка времени у автора к примеру), чтобы нашелся дистрибутив, который максимально жестко стандартизирует всё, от конфигурации до оболочек и при этом будет чуть больше для людей, чем для гиков. В идеале будет единая специальная бд (ну или фс со строгими правилами) для конфигов, вообще всё будет запускаться в докере и тд и тп, что-то среднее между андроидом в плане управления программами и вообще строгости API и линуксом в плане экосистемы утилит для разработки, баш, питон, все дела. Даже и не знаю, может, windows или макось когда-то до этого эволюционируют.
oWeRQ
Snap(на основе AppArmor) и flatpak(Bubblewrap) и есть контейнеры аля docker для дектопа, с изоляцией и отдельным runtime.
GospodinKolhoznik
То, что Линуксом пользуется 2% это не беда, а наоборот хорошо. Буда случится, когда им будут пользоваться от 20% и выше. Вот тогда наверное на фряху придётся переходить. Ибо тогда вскроются бэкдоры, расплодятся всяческие трояны, и т.д. и т.п.
oWeRQ
"С большой силой должна прийти и большая ответственность", будет больше вредоносов — будет лучше и защита, бекдоры и сейчас делают, просто нацелены они больше на сервера и IoT, рано или поздно будут массовые атаки которые зацепят и декстопных пользователей.
SergeiMinaev
Надо же понимать, что убрав все эти, как ТС выразился, "проблемы", линукс потеряет гибкость и прозрачность. Лично мне по кайфу, что я и ядро могу конфигурить сам, и выбрать один из кучи оконных менеджеров, и всё в таком духе.
Проблемы отключить скринсейвер у меня никогда не было — я его тупо не устанавливал. Сейчас ради интереса решил погуглить, как изменить время выключения монитора при неактивности. Ранее этой с такой задачей не сталкивался. Всё заняло несколько минут. Если кому интересно, в /etc/X11/xorg.conf:
Да, неопытный юзер может и час на такое потратить, но пусть линукс остаётся системой для опытных пользователей, пожалуйста. Когда разработчики начинают затачивать продукт под чайников, продукт частенько становится ужасен.
inferrna
В убунте такое доступно из GUI, не пугайте людей.
SergeiMinaev
Приехали — три строчки конфиг файла уже могут напугать :)
PsyHaSTe
Никто не потеряет в гибкости если унифицировать конфиги или сделать фасад, где для всех тех же настроек есть рабочие пресеты (но можно на свой страх и риск руками править как угодно где угодно)
SergeiMinaev
Согласен, когда конфиги удобный и есть пресеты, то это удобно. Но это уже не к unix-way, а к разработчикам.
PsyHaSTe
А в чем это не юникс вей? Приложение-конфигуратор, единственная его задача: взять на вход конфиги и показывать им красивый интерфейс. И при изменении в интерфейсе отражать изменения обратно на ФС. Чем не юникс? 1 задача, делать надо её хорошо.
FRiMN
Уже давно сделано в apm. При установке или обновлении некоторых программ конфиг можно править галочками в гуе (на самом деле я помню только ncurses вариант, но думаю для варианта обновления через гуй, там будет обычное окно).
oWeRQ
Встретились как-то деньги, диктатура и смелось, и получился у них Gnome 3, ушли от unix-way(даже панелька не отдельное приложение), "система" получилось не похожей ни на что существующие, получилось просто для новичков, а бывалые мигрировали болезненно, настолько, что образовалось несколько форков.
З.Ы. Считаю Gnome 3 одной из лучших сред, но ущерб из-за резкой смены направления просто колоссальный, возможно, будь Gnome Shell более дружелюбен к пользователям привыкшим к винде и маку — популярность десктопного линукса могла бы быть и выше, проще переход, меньше фрагментация. Майки наступили на те же грабли с интерфейсом Win8, но гораздо быстрее одумались.
MTyrz
Ежеквартальная статья про Linux для чайников — done.
4p4
Я за check)
MTyrz
Я думал над этим вариантом… )
Fen1kz
Вижу косяк в логике:
1) Линукс всегда занимал и занимает занимает 2%
2) Времена поменялись и теперь ОС для разработчиков не нужна
Согласно п. 2, мы бы видели рассвет Линукса в (199х-200х) и потом его сокрушительное падение. Но он всегда занимал определенную нишу.
---
Ну и от себя лично - а можно мне оставить одну ОС для разработчиков? Ну пожалуйста, ну хоть одна пусть будет для нас, остальные не жалко - делайте для пользователей.
dlinyj
Крепко жму руку
hhba
Обычно в человеческом обществе число лиц с отклонениями (в хорошем смысле этого слова) более-менее стабильно десятилетиями. Уверен, что число косплееров-лесбиянок и рыцарей добра и света в мундирах тоже плюс-минус одинаково год от года. В процентом отношении я имею в виду.
djv57
На комп десятилетней давности можно спокойно поставить современный дистрибутив Линукс. А вот Win10 — вряд ли.
dlinyj
Да не, десятилетней давности достаточно мощные компы уже были.
dlinyj
Те кто минус ставят, давайте аргументы. На компах десятилетней давности не будет нормально работать Windows 10,а? Я хочу понять, где я не прав!
djv57
Работа со старым железом (пусть и мощным) в Win10 — это своеобразная лотерея. См. мой недавний пример из жизни. Я не минусовал, если что.
dlinyj
Ну вот, теперь справедливо
duplodel
комп десятилетней давности это сэнди бридж вплоть до ай7 или фикус вплоть до 8100, ддр3 до 32гб и сата2\3 и даже м2, если не нативно, то через адаптер в пси-е. В каком месте десятка там не будет работать?
d_ilyich
Поставить-то можно, а вот пользоваться…
SergeiMinaev
Ну, у меня материнка, проц и видюха примерно 2009-2012г выпуска. Если не нужно играть в современные игры и кодировать видео, внезапно 10-летние ПК становятся не так уж плохи.
d_ilyich
Да, зависит от железа. У меня вот ноут 2009г, официально он не поддерживает больше 2 Гб оперативы (согласно найденным мной спецификациям, сам чипсет поддерживает и больше, но он не поддерживает планки по 2Гб, а поскольку слотов всего 2...). Установлено 1,5. Смысла ставить 2 не вижу — не думаю, что это сильно повлияет. Уж правильнее, наверное, было бы новый комп купить.
Ставил 10-ку. Загружалась, что удивительно, быстрее 7-ки, но пользоваться тяжко было.
JerleShannara
Gentoo, которая раз в месяц обновляется (и крутится на Core 2 Extreme) сойдет за современный дистрибутив? i7-2600k сойдёт за 10летний комп (ради теста готов даже туда воткнуть видяху тех лет)?
SergeiMinaev
О, у меня почти так же :) Кстати, спустя несколько лет использования, заметил, что "красноглазая" Gentoo, поставленная и настроенная ещё году в 2013-м, внимания почти не требует. Пережила безболезненно перенос на SSD пару лет назад. Работает себе и не шуршит.
achekalin
У меня "под руками", внезапно понял, как раз ваш пример, и Вы в нём не правы: 10-летний породистый бук (в котором заменен диск на SSD и добита ОЗУ) хорошо тянет Win 10 (с которой, правда, порой очень хочется уйти на Win 7, если говорить про UI) с софтом.
Всего хватает. Грузится быстро, гудит тихо. IPS, опять же. Алюминиевая рама бука, тонкий корпус, в котором, однако, есть и полноценный RJ-45, и даже BR-привод (слотовый, тонкий) — красота! "Раньше деревья были зеленее" — так вот тот самый случай.
Правда, и задачи у меня больше в консоли.
Характерно, что хороший бук из современных на замену подобрать — тот еще гемор оказалось!
djv57
Sony Vaio, 10-летний. Драйверов под Win10 нет на сайте производителя. ОС сама что-то нашла поставила из своих закромов. Операционка работает, часть устройств (включая вебкамеру и bluetooth) вообще не определились. Получаем условно рабочий ноутбук. Для эксперимента ставлю live-версию Ubuntu 20.04. Всё железо корректно определилось. Какую ОС предпочесть?
buldo
Ту, которая дольше батарею держит при прочих равных
linux_art
Мои последние 3 ноута под linux живут автономно примерно вдвое — втрое дольше чем с штатными виндами, с которыми покупались.
djv57
Это такое завуалированное недовольство нынешними ценами? [/sarcasm]
COKPOWEHEU
Да если бы ценами! Я в прошлом году подбирал в основном по удобной клавиатуре, нашел единственный вариант, которым сейчас и пользуюсь. Важными были полноразмерные стрелки (а не убожество половинной ширины, которую не нажмешь, не задев вторую), естественно цифровой блок, раздельная кнопка включения, кнопки home, end, pgup, pgdn рядом друг с другом и прочие особенности, которые современные производители всячески стремятся испортить.
Забавный побочный эффект: этот ноут оказался последним в магазине и шел без предустановленной винды (вкрутили туда какую-то endless os) и оптического дисковода. Зато заботливо вложили в коробку диск с драйверами для винды. В ноут без оптического привода диск с дровами на систему, которой там никогда не было. Честно скажу, долго с этого ржал.
Для информации по ноутам: ASUSPRO P2540FB_P2540FB, линукс Debian установился почти без проблем. Только вайфайная карта там удивительно кривая, с ней могут быть проблемы. Еще там по идее есть bluetooth и сенсор отпечатка пальца, но их я даже не пытался настроить или проверить за ненадобностью.
mistergrim
У меня ПК девятилетней давности, FX-4300 и 8 ГБ оперативки. Хотите сказать, на нём Win 10 не работает? Странно, а я на нём Doom (который 2016) запросто запускаю.
dlinyj
У меня рабочий комп. Летает всё
djv57
Проблема не в мощности железа, а в драйверах для этого самого железа. В ноутбуках, например, это очень больная тема.
dlinyj
Ну в линуксе всё хорошо, хотя бывает без бубна не обходиться.
red75prim
Перевожу: к ноутбуку должен быть приложен сисадмин.
Xaliuss
У меня есть комп 13 летней давности (Athlon XP 4800, 2 GB ram), на котором установлены последние версии Win10, Office 365, браузер, несколько разных программ для офиса и меди и пара старых игр. Единственно что SSD был добавлен.
И всё работает, единственное что подтормаживает — браузер на тяжелых страницах. Для современного интернета уже ресурсов не хватает для комфортного серфинга.
Tujh
Поворчу что ли.
У меня дополнительный монитор подключен через переходник DVI-HDMI и имеет не особо распространённое разрешение 1650x1050 и что-то случилось с переходником, разрешение монитора перестало определяться автоматически…Fedora 33 + Gnome — без проблем дали выставить практически любое разрешение без правки конфигов, и более того, разрешение применилось корректно.
MacOS X 10.15.7 — окно настроек тоскливо показало три разрешения 640х480, 1024х768 (третье не помню) всё, других вариантов просто нет. Погуглил, нажал Option — одна кнопка сменила метку, а в списке разрешений появилось ещё с десяток позиций, но все строго с соотношением 4:3 или 16:9, варианта 16:10 не было ни одного, вообще. Очень зотелось бы залезть в конфиги, а их нет…
Уж лучше Gnome в этом случае, он просто работает.
Помнится в «сугубо однопользовательской» Windows 98 для каждого пользователя можно было выставить индивидуально разрешение экрана, а в «многопользовательской» NT/2000/XP и так далее этот параметр был глобальным и применялся для всех пользователей разом. Я не про тюнинг сейчас, а именно про настройки стандартными средствами.
По сути статьи
Вот на этом и стоило бы остановиться. Потому что все изложенные претензии легко решаемы в рамках грамотного менеджмента :)
vvzvlad Автор
Да, я про это и говорю. Это не проблемы разработки или чего-то такого, это штука про проектное управление.
dakuan
Проектное управление каким именно проектом? Одна часть ваших претензий адресована разработчикам ядра, другая часть разработчикам графического окружения, третья разработчикам дистрибутива, четвертая вообще разработчикам сторонних приложений типа GIMP или MySQL. Совершенно разных людей из разных проектов вы почему-то собрали в одну группу под довольно размытым названием Desktop Linux. Вот например, единый конфигуратор кто из них должен сделать?
vvzvlad Автор
Ну, я про этого и говорю: нет единой точки, которая говорит «делаем конфигуратор, вася, задача на тебе».
DigitalBerd
Никогда не установлю себе на домашний комп Linux потому, что:
P.S. Linux через ssh гораздо более user friendly, чем desktop версия
unsignedchar
Бесспорно. Но половина софта под Windows тоже совсем не шоколад :)
PsyHaSTe
И вместе они формируют 100% — все верно :)
dlinyj
Играю в кучу игр из стима, что я делаю не так?
mint — мало отличается от винды, что я делаю не так снова?
Воткнул и работаю, как и любое устройство. В винде приходится плясать, а если принтер старый, то не работает (подключите в Windows 10 laserjet 1010). Что опять я делаю не так?
Эм… Не замечал. Скажем, не надо сравнивать gimp и фотошоп (вы же фотошоп не сравниваете с пеинтом). А для своих задач очень даже.
yadowit
А у меня стима вообще нет, но также играю в кучу игр на windows. На стиме свет клином не сошёлся.
А если погуглить? Ссыль.
А с чем можно сравнить фотошоп, в линуксе? Если не с чем, тогда так и скажите — приличного графического редактора в линуксе нет.
viklequick
Krita, GIMP, Photoshop — это то что у меня «вотпрямщас» установлено и используется (прицеплен Wacom-овский планшет и все три редактора — с ним отлично работают, включая силу нажатий).
«Отлично» означает в том числе и поддержку сразу двух цветных МФУ, HP лазерный и Epson с СНПЧ и фотобумагой.
Ну и Inkscape рядом для вектора, тоже работает.
yadowit
Только не смейтесь, но всё названное и в windows имеется. А если не видно разницы, зачем тогда Линукс? В Windows программ и побольше, и сами они дружелюбнее.
dlinyj
Так мы не заставляем, это вы пришли нам доказывать почему вам линукс не подходит. Непонятно только зачем. Нравится винда, пожалуйста.
Но пожалуйста, заведите старые принтеры в Windows 10. Вот прям из коробки, без бубнов.
yadowit
Я там выше уже советовал:
Умение гуглить, кажется, не является запретным? А «без бубнов», это точно не к линуксу, у вас без них вообще ничего не обходится, а в windows — лишь иногда.
P.S. И кстати, где я пообещал, что обойдётся без бубна? Вы, безапелляционно заявили, что вообще не работает:
dlinyj
Ну то есть мне в линуксе достаточно просто его воткнуть? Значение, мне с виндой гуглить призодится сильно чаще, в лине все интуитивно через гуи можно настроить
unsignedchar
Интуитивно это хорошо. Только интуиция сильно зависит от опыта
Если нет опыта в ковырянии реестра Windows (или с линуксовыми конфигами) - интуиция не сильно поможет.
dlinyj
Эм, если мы говорим не про серверный линукс, а как выразились, десктопный, то лично мне хватает графического интерфейса, чтобы настроить абсолютно всё.
BigBeaver
BigBeaver
Если не видно разницы, то зачем windows?
viklequick
Так в Windows есть даже KDE — но вопрос-то был — какие приличные в линуксе :-) Оказалось — ровно те же. Но если они ровно те же — зачем платить больше?
Why is Krita not free on Windows Store?
Publishing Krita on the Store takes time, and the Krita project really needs funding at the moment. (Note, though, that buying Krita in the Windows Store means part of your money goes to Microsoft: it's still more effective to donate).
А так-то да, опенсорцу пофиг на подложку, в большинстве своем.
oWeRQ
Встречаются два "новых русских". Один другому:
З.Ы. В данном случае дело не столько в цене в вечно зеленых, сколько в том что за ваши деньги вас же и используют как товар.
dlinyj
krita
Tujh
Если утилита от HP висит в фоне то всё норм. На той же «дизайнерской» MacOSX принтер HP отказывается печатать из любого приложения кроме HP Smart, а оно умеет печатать только pdf и картинки. Не зная про программу — танцев больше, результата меньше.
А куда подевались все поделки из серии «сервер на tv-box», кластер Кубернетиса на «малинке» и прочее?
COKPOWEHEU
Так установите, вам что, кто-то мешает?
Так настройте, вам что, кто-то мешает? У меня вон вообще три панели — снизу «виндоподобная», сбоку кнопки для быстрого запуска и сверху индикаторы. Как мне такое сделать в винде?
Угу. Запустить какой-нибудь synaptic, вбить туда название принтера и установить пакет — все в графическом режиме. Непосильная задача, понимаю.
Ну так пользуйтесь остальными 20000 программами (или сколько там сейчас пакетов?). Да и wine никто не отменял.
unsignedchar
Бывает по разному. У меня опыта с граблепринтерами немного, но МФУ от HP, это что-то. Оно печатает по сети, да. А со сканером через сеть беда. Драйвер all-in-one от HP — это ПЦ. Во первых, обещанного GUI нет :D, есть монструозный установщик на python. Во вторых, при установке он что-то ищет по всему жесткому диску (обещает, что более старые версии себя же), и через полчаса падает (то ли не нашел, то ли нашел не то что искал, то ли файлов у меня много а ОЗУ мало..)…
Tujh
fedora + hplip + DeskJet 3630 = полёт нормальный
из затыков, не работает автопоиск по сети при установке принтера, но если указать IP прямо — всё устанавливается без проблем. И саму графическую утилиту hp нужно держать запущенной в фоне (просто поставил в автозапуск).
Но это проблема именно HP, я уже написал, что тот же 3630 под макосбю в принципе работает только с HP Smart и отказывается печатать из других программ, то же и с телефона на андроиде.
khajiit
Но, тем не менее, это проблема производителя принтера, а не линукса, так ведь? )
Oxyd
МФУ HP LaserJet 3052, подключенный по сети + HPLiP + CUPS + SANE на Manjaro. Принтер и сканер завелись сами, сразу из коробки, при помощи стандартного
hp-setup, в отличие от 64-х битных виндей, где драйвер сканера отсутсвует как класс, а сами драйвера весят безумные сотни мегабайт.JerleShannara
1) У меня только одна претензия: в киберпанке под линуксом не получается включить лучи, а я ради них его скачивал, беда. Proton — рулет.
2) Не знаю, у меня она снизу
3) HP Laserjet 4M+ и Mustek SP-12000 говорят «дрова не найдены» под десяткой
4) Вообще половина софта — говно
5) Смотря что.
geher
Их есть. Просто они не те, которые вам нужны.
И вообще: "Лучшая игра на свете - это Тетрис. Играйте лучше в нее. А лучше и в нее не играйте".
У меня изначально была снизу. Вбок пришлось задвигать (как и в винде).
А убунта с их Юнити (или как его там правильно) - это отдельная история. В большинстве дистрибутивов панель по умолчанию снизу.
Вот как раз недавно столкнулся. Нужно было прикрутить МФУ от HP. МФУ свеженькая, в прошлом году только начали выпускать.
У человека дуалбут линукса (Альт) с виндой-десяткой.
Под линуксом завелось само сразу после подключения. Вообще ничего делать не пришлось.
Под виндой быстро промелькнуло уведомление и пропало. Неопытный пользователь просто не обратил бы внимания. Для него "принтер не видится, драйвера не ставятся, все пропало!"
Если ткнуть таки уведомление, то начинает ставиться какой-то невменяемый HP Smart с обязательной регистрацией на hp.
Пришлось качать драйвер с hp. Причем по умолчанию там предлагали все тот же hp smart, а нормальный драйвер почему-то спрятан в разделе "Утилиты".
Я, конечно, понимаю, что hp smart - это круто: печать по WiFi, печать со смартфона. Но если это не нужно, то зачем обязательная регистрация на hp?
Вы оптимист, однако. Говно - это значительно больше, чем половина софта. Причем под виндовс то же самое.
А я под ним дома дескопствую. И ничего, полет нормальный.
За последние пять лет только один раз пришлось помучиться с USB хабом. Так оказалось, что это хаб неисправный, под виндой он тоже не завелся.
wolfreid
У меня так с Quadro k4000 на минте было. Уже думал что все, придется слезать с минта… А потом воткнул в комп с виндой(стоит ради того, чтобы на нем афанасий рендер сервер крутился, тк я со своей криворукостью так и не смог запустить его на лине) и узнал что это видяха умирает.
AlexP11223
1. habr.com/en/company/ruvds/blog/556124/#comment_23047314
2. ну у кого-то и на винде сбоку. В Минте например по умолчанию снизу.
3. у меня и на винде были проблемы. Большинство производителей принтеров выпускают драйверы и для линукса.
4. какой именно софт нужен? Половина (а то и больше) софта говно независимо от платформы )
tommyangelo27
Ошибочка, должно быть
1. «Игорь тонет»
achekalin
"Как Linux не осилил быть дестопной ОСью 'для всех'", наверное так было бы правильнее назвать.
debagger
Я вот много лет был убежденным сторонником windows. Дело в том, что в те времена, когда я только учился пользоваться компьютером, альтернативы по большому счету не было. Да, мне попадали в руки дистрибутивы линукс, и я их даже устанавливал себе на компьютер дома. Но что с ним делать дальше? Под виндовс были доступны тонны софта с варезных дисков, фотошоп, саундфордж, брайс3д (классная штука для рендеринга красивых «фотореалистичных» ландшафтов) в которых я зависал часами. Я не был тогда ИТшником или программистом (если что — речь про старшие классы школы и первые курсы института), скорее ИТ-энтузиастом, и винда мне давала все, что мне было надо для удовлетворения любопытства.
А линукс пугал, реально, командная строка вызывала фрустрацию и чувство паники. Если винду можно было исследовать кликая мышкой в рандомные настройки и смотреть, что выйдет, то консоль просто не давала никакой мысли для размышления, никак не раскрывала своих возможностей. Учтите, что в те времена интернет был по карточками, а книга по линуксу, которую мне дали почитать никак не помогла. Короче я остался на винде, и когда закончил институт и на работе понадобилось писать программы, я не особо думая выбрал .net (о чем не жалею кстати) — опять же просто потому что вижуалстудия была просто шикарна и был полностью офлайновый msdn.
Линукс в моей жизни появился значительно позже — когда мне понадобилось поднять vps и оказалось, что vps с виндой стоят значительно дороже, чем с линуксом. Переборов свои страхи я начал изучать — спасибо гуглу и особая благодарность стэковерфоу. Было тяжело, но постепенно запомнились основные команды и стало легче. И я понял за что любят линукс.
И я тоже его полюбил. Но я никогда не поставлю его себе в качестве десктопа. Потому что винда шикарна в этом качестве. Потому что я чувствую здесь себя как рыба в воде. И идея поменять ее на линукс снова вызывает у меня давно забытые чувства беспомощности и фрустрацию.
dlinyj
Это старость и дело привычки :). На самом деле сегодня линукс в качестве десктопа более удобен и дружелюбен чем винда. Все настройки графические в одном месте, а не размазаны по трём местам, всё логично, просто. Куча софта из коробки.
debagger
Давайте не будем о грустном ))
Охотно верю, но все равно нет ))
alsoijw
У гну/линукс нет корпорации, которая всеми правдами и неправдами будет навязывать его пользователям, подобно мелкомяхким или огрызку. Как следствие, даже если пользователю сто процентов хватит гну/линукса, то в первую очередь этого пользователя нужно обмануть, так как он от одного только названия он придёт в неописуемый ужас.
И именно по этой причине, у винды постоянно перекраивается интерфейс: и умение выключать 7 никак не поможет в 8. С каждым разом становится всё больше всяких уникальных элементов, характерных только для малого количества программ. И в то время, как в гну/линукс можно бес проблем вернуть старый рабочий стол, в винде каждое изменение необратимо.Интересно, в винде обычные пользователи через командную строку файлы архивируют? Если нет, то что им запрещает так же через гуи архивировать в гну/линукс?
Даже в таких случаях всё ещё нужно постараться, чтобы одной командой повредить базу установленных пакетов. Проблема ада зависимостей уже давным давно решена, но автор о ней почему-то не знает. В nix/guix можно мало того, что ставить разные версии одной и той же библиотеки, так ещё и персонально для каждого пользователя столько раз, сколько потребуется.
Автор опять осознанно вводит в заблуждение, так как что перезагрузка, что работа с сетью возможно без прав суперпользователей.
И как вы в собственнических осях конфиги сравниваете? А если по теме, то в Nix/Guix проще простого добавить конфиг в гит, так как все системные настройки реализуются через него.
Вы в винде тоже через реестр настройки внешнего вида делаете?
Вобще-то, это есть даже на дебиане, так как входит в состав DE.
Огромное спасибо нужно сказать подобным статьям, в которых незнание автора смешивается с клеветой, которое потом будет раз за разом повторяться, обрастая новыми искажениями.
Boozlachu
лучше не скажешь. только «спасибо» в кавычках
anwender95
«спасибо». Что бы это ни значило.
ilmarin77
Если у линукса на ПК стабильно 2% рынка — значит он растёт с той-же скоростью что и рынок ПК.
Дальше, в увеличении доли Андроида на рынка мобильных устройств заинтересована крупная корпорация, которая нанимает уйму людей чтобы это делать. А в увеличении доли абстрактного Линуха не заинтересован никто, а энтузиастам это только дополнительная головная боль.
bouncycastle
По поводу единого формата конфигураций и проблемы с миграциями - советую автору посмотреть в сторону NixOS
0decca
Я просто оставлю это тут.
en.wikipedia.org/wiki/The_UNIX-HATERS_Handbook
Над этой книжкой я много смеялся когда она еще не была копролитом, но автор поста думаю найдет в ней много знакомого.
daniilk
Это философия того, что считать Linux. Linux — это ядро. А дистрибутивов куча разная, которых объединяет одна общая боль — это отсутсвие пользовательских приложений. Для Линукс полно приложений для программирования, по-этому для программистов совсем нет проблем использовать Линукс. А вот для повседневных вещей это бесконечная тоска. Причем речь не об альтернативе, а именно нужен фотошоп, нужен ворд, нужен какая-нибудь приблуда Intune, игры без допила напильником и прочее, прочее.
Как пример Андроид, Linux дистрибутив — куча приложений, работает, возьмите другие мобильные платформы на Linux, нет и в помине.
Возьмите Windows и Windows Mobile, казалось бы не Unix Way, но опять же, последнее не смогли набрать базу приложений и пришлось закрыть.
Пользователю все равно на философию — ему нужны приложения, для него что Unix, что Windows.
unsignedchar
Где в андроиде фотошоп, и зачем он нужен, например?
JerleShannara
play.google.com/store/apps/details?id=com.adobe.psmobile&hl=ru&gl=US
Ну вот например, а зачем оно нужно — я не знаю, но пользователям нравится.
oWeRQ
От того что в названии есть слово "Photoshop" — фотошопом оно не становится, в данном случае это редактор уровня instagram, даже фотошоп для iOS хоть и ближе, но все равно другое приложение(хотя для iOS это норма выпускать совершенно другие приложения под известными названиями, например все популярные браузеры).
daniilk
Полноценного фотошопа нет (я условно сказал фотошоп), но есть Lightroom например. Фотошоп есть на ipad.
Мне лично фотошоп не нужен нигде, но есть куча студий, куча дизайнеров, которые тоже пользователи, это огромный рынок.
Опенсорс сообщество вместо того что бы пилить, никому не нужные десктоп менеджеры, лучше бы потратили силы на разработку нормальных приложений, и пытались привлечь в нее уже популярные приложения.
Возьмите Windows — очень убогая система с точки зрения програмистов, это боль. Что сделало Microsoft, запилила WSL. Вот тебе норм десктоп, и норм тулзы для программирования. ( В принципе, Windows превращается в гибридный Линукс дистрибутив)
COKPOWEHEU
daniilk
Как раз я об этом и говорю, опенсорс сообщество не занимается полезными вещами с точки зрения обычного пользователя. Оно занимается полезным для программистов, по-этому Линукс любят программисты, по-этому Линукс это сервера, встроенные системы и прочее. А для простых пользователей не создано толком ничего, даже ваш оконный менеджер — это не полезная штука и вы им не пользуетесь, вы пользуетесь приложениями, барузером (возможно только им, ибо все остальное в Линукс — это катастрофа) почтовым клиентом, файловым менеджером и так далее. Оконный менеджер — это не инструмент. По-этому большинство линукс дистрибутивов как инструмент, кроме как для программистов, абсолютно бесполезная вещь.
Я перешел на МакОС потому что это то, каким должен быть Линукс дистрибутив.
COKPOWEHEU
«Люди тратят свое свободное время на то, что им нравится или необходимо, а не на непонятных хомячков, которые потом даже спасибо не скажут»? Возмутительно!
Ошибаетесь. Когда активно используется хотя бы пяток окон (а это совершенно типичная ситуация), работа по их переключению должна помогать, а не отвлекать. Этой же задаче способствуют рабочие столы. Или всякие панельки с индикаторами и кнопками быстрого запуска. То есть когда идет работа не с одной программой и одним окном, а со многими.
daniilk
Ключевое - когда идёт работа с программой. А если программ нет?
svsd_val
Тогда поможет чистый дос =)
daniilk
Я помню как в своё время было куча сравнений винды и Линукс, а вся демонстрация преимущества Линукс на виндой заключалась в том, как круто переключались столы в виде 3D куба.
На вопрос во что можно поиграть, ответ был: ни во что, но можешь столы попереключать.
svsd_val
Игры там были и даже в то время было вино. Не да всё работало. Меня отсутствие игр не остановило ))
daniilk
Вино? Мы же говорим про запуск без высшего технического образования и привлечения духов и шаманов и прочего колдунства.
AlexP11223
Ну сейчас всё проще, есть протон в стиме или Lutris.
habr.com/en/company/ruvds/blog/556124/#comment_23047314
daniilk
Даже фанат Линукс поймёт что проще в винду перегрузиться, если хочется просто поиграть, а не быть бета-тестером. Все эти системы - скорее существуют ради спортивного интереса нежели как продукт.
AlexP11223
Куча людей пользуется этим. Для почти всех игр, что пробовал, всё было норм. Для 1 надо было установить Proton GE вместо стандартного (распаковать архив в папку стима и выбрать в свойствах игры). Еще для 2-3 прочитать отзывы ProtonDB и применить несложное исправление.
FenestramDeveloper
Перезагружаться не проще, но ставить всякую дрянь (виндувсовые приложения) в рабочую систему тоже неприятно. Насколько такие приложения изолированы от остальной системы?
daniilk
Вы этим словами сами подтверждаете, что это все для энтузиастов, а не для широкого круга пользователей.
Надо что-то где-то читать, искать исправления. В большинстве своем люди думают так — я купил игру, заплатил за нее кучу денег, пришел и хочу поиграть сейчас. Одна из причин почему игровые консоли стали популярны, что даже не надо думать о том потянет твоя игра или нет, герцы, рамы, и прочее это все непонятно, не говоря уже о том, что надо где-то что-то гуглить.
AlexP11223
Так десктоп в целом для энтузиастов. Не энтузиасты сидят на телефонах и консолях.
Но энтузиастов не так уж мало, миллионы.
Например, даже относительно скучные видео про десктопное железо от GamersNexus набирают сотни тысяч просмотров. У всяких более веселых LinusTechTips — миллионы.
daniilk
Энтузиастов много согласен, иначе бы вообще этого ничего не было, но 0.81% веб клиентов с Линукс. Говорить о массовом рынке не приходится. Капля в море.
В мире — 21 млн программистов, при 4 миллиардах пользователей.
svsd_val
А что не смогли ассоциацию победить вина и ехе? из любого ФМ запускает
daniilk
Профессиональный снобизм - это называется. Я же своё уже открасноглазил.
COKPOWEHEU
Или имеется в виду что под линуксом нет привычной для него программы? Тут четыре варианта: либо искать и осваивать непривычную, либо искать как запустить привычную (если речь о виндовых, то это скорее всего возможно), либо уходить туда, где привычная работает, либо платить за разработку нужной программы.
Но как это связано с исходной темой про то, что сообщество пилит то, что ему нужно, а не то, что ему не нужно?
daniilk
Имеется ввиду что-бы платформа была привлекательной для пользователя, на ней должны быть привычные для него приложения, либо эксклюзивы. Ни того ни другого на Линуксе нет.
Я наверное не сообществе говорю, а о том почему Линукс провалился как десктоп система, а занял нишу как платформа для IT профессионалов.
Смотрите Аппле переходя на новый чип акцент делает на том, что все приложения будут работать, а не на том, как здорово и быстро открывается файловый менеджер.
COKPOWEHEU
Это если бы стояла задача сделать платформу более привлекательной для пользователя. Но такой задачи обычно не стоит.
Стоит задача «улучшить то, что помогает лично мне работать».
Зачем вы выдаете заведомо ложное утверждение за аксиому? Раз на линуксе возможно нормально работать без перезагрузки в винду, он по определению не провалился как десктоп.
daniilk
Как раз цель такая стояла, так появилась Ubuntu, которая заняла нишу пользователей профессионалов. Но явно не достигла желаемого и переквалифицировалась в нишу RedHat и так далее.
А вы на мой взгляд подменяете понятие, успех и работоспособность.
COKPOWEHEU
Ну это у вас может такая цель и была. У линуксоидов — нет. Они просто пользуются своей ОС и снисходительно поглядывают на проблемы виндузятников
daniilk
Вы может просто не застали тех времен когда не было Убунты и даже графического установщика для Линукс, и драйверов от Nvidia и так далее?
По-этому я Линукса перешел на Мак и снисходительно смотрю на виндузятников и линуксоидов.
BigBeaver
А когда эт было? Убунте уже больше 15 лет. В середине нулевых у дебианского установщика уже был графический установщик, хоть и в текстовом режиме работы монитора. А в 90х у меня был msDOS. Так что гэп совсем небольшой.
COKPOWEHEU
А под «графическими установщиками» вы имеете в виду и псевдографические тоже? Просто если есть выбор, псевдографика как-то проще.
surVrus
По моему почти весь текст уже был на Хабре, в потом на его основе вырос очередной линукс-срач?
Не? Может я чего-то путаю?
vkni
Эти тексты появляются с известной периодичностью. Буквально с появления KDE 1.0.
kozar
В винде все хорошо, пока все работает. Если что-то сломалось — все, приехали. Логи хз где, если даже и есть. Либо там запись вида «ошибка 0xFC_U в модуле notyourbusiness.dll», настройки хз где — то ли в папке с программой (кстати, где она, в program files? program files (x86)? Users? ProgramData?), то ли в user data (local или roaming? или documents?) то ли в реестре (удачи в поисках нужного ключа) в хз каком формате, нередко бинарном. Документация? Хаха. Комьюнити? Ну да, можно конечно попробовать все эти 250 противоречащих друг другу советов с форумов…
LiquidSnake
А в декстопном линуксе часто банальные вещи не работают. Софт вываливает питонячую ошибку в таком-то модуле на такой то строке. Что делать? Идти ковырять код конечно.
Я совсем не одобряю под ход винды «Ой, что-то пошло не так :(» но в Линуксе не сильно лучше.
Меняем оконный менеджер на LightDM — перестает принимать пароль. Ох…
По поводу конфигов — в линуксовом софте порой кучи настроек, разбросанных по разным директориям. Зачастую документации либо нет, либо ее не хватает.
FRiMN
Ну в линуксе хотя бы есть мейнтейнеры, которые проверяют совместимость с конкретной версией дистрибутива
Daddy_Cool
Ох… никогда не участвовал в этой специальной олимпиаде но видимо время пришло.
В чем и плюс и минус свободного софта? За каждым творцом не стоит менеджер с палкой. В результате мы имеем массу линуксов всех расцветок и размеров на любой вкус.
А окон всего… 3.1-3.11-95-98-ME-2000-XP-Vista-7-8-10. Актуальных — ну четыре. И всё плавненько перетекает из одного в другое.
Если человек хочет что-то изучить — это есть у всех и по сути в одном варианте. Соответственно и разработчикам проще.
С тем же андроидом и маком — всё также под контролем одной корпорации.
ardraeiss
Вовсе не факт. То, что какой-то софт с открытым кодом, ещё не означает что там не было работы на корпоративной зарплате и задачи работать именно над открытым кодом.
Dee3
Проблема звучит так — есть инструменты, которые помогают решать регулярные задачи а, есть которые не помогают.
Если ты вместо решения высокоуровневых задач лезешь опять в терминал и на форумы потому что опять что то зависло\не работает как задумано, значит где то люди не решили какую то инженерную задачу и нужно решать её самому.
Оно конечно интересно пару раз там скомпилировать чего-нибудь или пересобрать. Потом понимаешь что в жизни можно заняться еще чем нибудь кроме 100500-того решения проблемы которую сообщество не смогло решить сразу для всех, в продукте.
Поэтому и ставят люди винды и покупают айфоны. Потому что уже кто-то нашел лучшее решение твоей задачи, ты попробовал и тебе подошло и даже готов купить.
hellamps
15 лет у меня десктоп - debian и я не считаю его сколько нибудь ущербным, наоборот.
Но порог входа действительно высок, и, вероятно, для непрограммистов это все такое...
Но для них есть мак.
Не вижу проблем в том, что профессиональные тулзы не являются распостраненными среди любителей. Много ли фотолюбителей снимают не айфоном(винда), а зеркалкой(мак), а много ли - большим форматом(читай линукс)?
axp
Заголовок не соответствует содержанию статьи.
Вообще, никогда не понимал, что такого плохого в том, что linux на десктопах — это доля в 2-3%?
Да, сиситема для гиков. Да, высок порог входа. И что?
В чем плюс массовости? Он (линукс на десктопе) что, умрет без массовости что ли? Да вряд ли…
В общем, меня устраивает как маленький процент так и статус «системы для своих».
AN3333
Именно. Только это не время пришло что-то менять, а время ушло. Давно.
Вот я не работаю пол Линуксом. Почему? Потому что с любой проблемой надо идти к админу, а проблемы очень часты. (О том чтобы самому разбираться в устройстве ОС речь не идет. Мое время дорого и не предназначено для разборок с чужими ошибками.)
soniq
Давайте смотреть правде в глаза, ничто из окружающего меня в жизни не требует настроек. В том числе и компьютеры.
Настройки ушли вместе с детством.
MTyrz
А, нет же, их в магазин привозят.
LiquidSnake
Ирония понятна, но дело в том что профессионал и пользователь хотят разного.
Пользователь хочет чтобы было легко, понятно и красиво.
Профессионал хочет полный контроль над системой и возможность максимально кастомизировать ее под себя.
MTyrz
Просто не стоит выдавать желаемое за действительное.
И компьютер, и айфончик, и стиральная машина с хлебопечкой, или что еще там окружает цитируемого юзера в его жизни — даже молоток, если уж на то пошло — настроек требуют. То, что этими настройками занимается не цитируемый юзер; то, что для него булки растут прямо на прилавке, говорит больше о юзере, чем об окружающей его действительности.
LiquidSnake
Ну так в количестве и сложности настроек.
Линукс часто прихдится допиливать. Винду — реже.
Другое дело что линукс более «ремонтоприоден», правда если знаешь что делаешь.
MTyrz
BigBeaver
Очевидно, зависит от юзкейсов.
LiquidSnake
Логично, все это опять же из своего опыта, что не аргумент, согласен.
Вопрос: минуса фигачить в карму тут модно? Или тяжело переносить мнение другого человека?
BigBeaver
LiquidSnake
Учту. Я не конкретно вас, просто писать в пустоту коммент с таким вопросом было бы не менее странно. А так вы были со мной в диалоге, я и предположил что это ваших рук дело
BigBeaver
Колебания кармы туда-сюда на пару единиц это шум, как вам верно заметили ниже. Не обращайте внимания)
MTyrz
Я вам поправил в меру своих способностей — но вообще не обращайте внимания, это стохастика.
JerleShannara
Окей, компьютерное кресло не требует настроек, микроволновка тоже не требует как и газовая/электроплита. Кресло в автомобиле тоже без единой настройки будет удобно как карлику с ростом 1.30м, так и баскетболисту с 2+ метрами. Что там ещё, душ тоже вообще никаких настроек не требует, нажал кнопу и он моет всё как надо.
Не, ну нафиг, я лучше газлифт на своём кресле настрою, а то неудобно коленками в столешницу втыкаться, потом настрою время и мощность на микроволновке, а то задолбало есть замороженную хавку. Температуру/уровень пламени на плите тоже пожалуй настрою, а то сосиски системы «уголёк» моему желудку не нравятся. Кресло в ведре тоже пожалуй настрою, а то тов. инспектор не очень оценил то, что я до тормоза не могу дотянуться. Кстати, надо не забыть настроить температуру душа, в прошлое использование мне не очень понравилось получить 60*С воду в лицо. Может у вас конечно всё идеально везде и ничего не надо настраивать, но что-то мне подсказывает, что это не так.
LiquidSnake
Приведу аналогию. «Linux» кресло будет регулироваться по всем осям, газлифт будет работать не через нажатие рычажка, а через текстовую команду с клавиатуры, плюс десять разных конфигов с нетривиальными именами будут отвечать за каждый параметр :)
А, и обивку придется сделать самому.
JerleShannara
Поскольку я давний (с 2004 года) пользователь Gentoo, то за такое кресло я буду только благодарен, ибо хорошее сейчас фиг найдешь, либо китай, либо кожа/дерьмантин который летом к пятой точке липнет, либо алькантара, которую чистить задолбаешься, того, чего я хочу нету в продаже.
unsignedchar
Неправильная аналогия подобна котенку с дверцей ;)
Это зависит только от креативности программиста. Это сам Торвальдс заставляет программистов креативить и делать неудобные вещи, а БГ, наоборот, запрещает? :D
BigBeaver
И это при том, что кресло, где можно настроить все параметры без использования ключа и отвертки стоит как весь мой «офис» в сумме. Это если вам вообще удастся найти приятное вам по дизайну кресло, где можно одновременно настроить и высоту и глубину спинки (например).
inemiten
Линукс неудобен прежде всего разработчикам программ. В нем нет приятных IDE, уровня MVS (с VSC стало немного полегче). В нем нет нормальной отладки по дампам, полученным с других машин, на которых слегка различаются системные библиотеки (винда в этом случае скачает отладочные символы со своих символсерверов). В нем нет нормального способа распространения программ, типа магазина приложений. В нем нет нормально выглядящих шрифтов, хотя бы под все основные графические оболочки. В нем нет совместимости между различными графическими подсистемами, что делает неинтересным написание графических программ, т.к. их придется либо сложным образом полдерживать под все TLS всех популярных дистрибутивов, либо поставлять в исходниках. Все это отталкивает большинство программистов от разработки прикладного графического ПО (да даже вирусописателей отталкивает, ибо заколебешься отлаживать свою малварь под все основные дистрибутивы). А отсутствие широкого набора конкурирующих друг с другом прикладных программ, автоматически влечет отсутствие пользователей системы.
spqr_voldi
Только вот всё ровно наоборот.
COKPOWEHEU
На самом деле в windows программировать гораздо тяжелее. В основном из-за отсутствия нормальной консоли, нормальной системы распространения программ, отладочных утилит и т.п.
Буквально текущая моя задача: разбираюсь с USB на контроллере. Естественно, возникают косяки (от которых винды до 7 падают в BSOD), нужны образцы дескрипторов и отладка потока данных. Ладно, косячные прошивки опустим (win10 все же не падает). Но чтобы посмотреть дескриптор «эталонной» железяки я могу запустить lsusb -v и видеть вообще все. Для просмотра обмена могу запустить wireshark (вроде, под винду он тоже есть), но для фильтрации нужно в том же lsusb посмотреть адреса устройств, которые меня НЕ интересуют, вроде мышки или программатора.
Допустим, устройство я собрал, оно выглядит как COM-порт и передает данные с какого-то датчика, мне их нужно оценить на правдоподобность. Можно запустить screen или просто cat /dev/ttyACM0 | awk | feedgnuplot (с флагами, естественно) и видеть красивый график, без единой строчки кода.
Понадобилось написать драйвер для научного вольтметра е24. Не будем упоминать очередные проблемы winapi на ровном месте… как представить измеренные данные? Сейчас реализация использует tmpfs, в которой создает файлы adc1, adc2, adc3, adc4, в которые текстом пишет значения. Прочитать их оттуда может кто угодно без малейших проблем. Хорошо бы, конечно, fuse прикрутить, но пока не очень понимаю как. Суть в том, что в винде не получается сделать даже этого.
Про отсутствие в винде нормального менеджера пакетов и говорить не стоит. Вместо простого apt install приходится лазить по инету, качать толстенные инсталляторы, выискивать в них галочки яндекс мусора и угадывать папочку для установки. Ах да, после удаления они почти гарантировано не приберутся за собой.
Не знаю о какой несовместимости вы говорите.Можно взять gtk или Qt и получить на халяву совместимость не то что внутри линуксов, но даже с виндой. Отметьте, без всякого геморроя с кошмарным winapi!
Так это же замечательно! Годный софт собирают мантейнеры каждого дистрибутива. Уж они-то знают как это делается, куда софту лезть можно, а куда нельзя, какие права выставить и с какими библиотеками линковать. А то, что жулики да бракоделы страдают, так их не жалко.
LiquidSnake
Но в UX/UI эти меинтейнеры не могут, поэтому остаются только ценители сего подхода.
В итоге пишется софтина либо с ужасным дизайном (не умеем да и кому это надо) и с монструозными возможностями (Без иронии) но который весьма нетривиально управляется.
К каждой команде более десятка ключей и флагов, а потом из материшься и пытаешься понять, как правильно ее прописать то.
MTyrz
LiquidSnake
Так и не нужно сажать. В Win порог вхождения ниже.
А в лини и без постороннего софта сложностей хватает.
А если продолжить вашу аналогию, то я скорее поеду поездом, там крутилок поменьше)
BigBeaver
Для меня вот самый высокий порог — iOS. Бывает, подруга дает свой айфон типа «на посмотри сам» и вне зависимости от контекста любые мои три дейстия приводят к «я не знаю, что сделал и как вернуть обратно». А вот линукс я в детстве настраивал без проблем.
MTyrz
Компьютер у него завелся с моим приездом. Там стоит семерка сыну для игр, и дебиан (МАТЕ) отцу для интернетов с фейсбуками, кина и музыки. Никакой разницы в освоении ими винды или линукса я не заметил. Пользуют что то, что это. Винду, правда, еще сыну в школе преподают, а вот линукс отцу не преподает никто.
Короче говоря: пресловутый «порог вхождения» ниже оказывается для того, кто уже имел опыт с виндой, но никакого с линуксом. Как только мы убираем этот нюанс, порог становится примерно равным.
unsignedchar
LiquidSnake
Ну я не спорю что такой софт есть везде. Просто в лине его больше. По умолчанию.
unsignedchar
Зря вы так резко ;) Это из статьи «8 best file rename software for Windows 10», между прочим.
СлабО найти подборку из N (N>8) best file rename software for Linux? :)
COKPOWEHEU
Вот в UI мейнтейнеры обычно не лезут, не их это задача. Им надо чтобы работало и не лезло куда не надо. Претензии с UI к апстриму.
hhba
Вот не надо про кошмарное винапи. Тем более не надо его лечить кошмарным gtk. Возьмите наконец дотнет и забудьте про все остальное.
COKPOWEHEU
Можете сами сравнить скажем открытие файлов в winapi и posix.
Мне казалось, он на C# рассчитан, а не на Си. Да и под линуксом говорят не все с ним хорошо.
hhba
Вы думаете я не сравнивал? Да, любые posix-ОС удобнее в этом смысле. Но еще лучше — дотнет.
Не так плохо же?
Да и Бог с ним (с линуксом). Используйте виндовс)))
COKPOWEHEU
Не так плохо что?
Нет уж, спасибо! Я не мазохист.
alsoijw
hhba
Не то что бы ограничивать, просто ИМХО плюсы+винапи это хуже, чем дотнет.
alsoijw
Если я не ошибаюсь, то qt имеет кучу своих обвёрток, что позволяет создавать нативные приложения без необходимости работы с винапи.
BigBeaver
Ну так обертки-то зависят от винапи)
hhba
Куда хуже то, что кутэшные обертки в сравнении с… Ну, такое…
И, да, это оценочное суждение, не воспринимайте лично.
sergey-b
Главная проблема линуксового десктопа - отсутствие единого буфера обмена. Именно он является основным рабочим инструментом на десктопе.
AN3333
Это даже не основная проблема, но демонстрация пользователям — нам на вас плевать.
lealxe
Вообще-то их минимум два. Вы, наверное, огорчаетесь наоборот, что есть помимо привычного еще обычный иксовый буфер обмена и некоторые программы только его поддерживают? Пичальбида.
sergey-b
Два единых буфера? Оригинально. Какие программы какой из них поддерживают? Или все программы из коробки работают с обоими буферами? Ctrl-C и Ctrl-V с каким из двух работает? Во всех ли программах поведение Ctrl-C и Ctrl-V одинаковое? Кроме текста что-нибудь еще можно скопировать?
BigBeaver
Так это от софта зависит. Вы же не жалуетесь, что нельзя вставить скриншот прямо в комментарий на хабре? А во вконтактик — можно. Это буфер обмена какой-то неправильный? Очевидно, нет.
Но вообще, есть программы, которые перехватывают работу с буфером, реализуя свою логику, какую хотят.
Ctrl-C и Ctrl-V в винде тоже не везде одинаково работает. Откройте консоль, например.
sergey-b
Только что вставил. Пользуюсь этим постоянно. Поэтому на линуксовом десктопе мне работать неудобно. Это проблема прежде всего линуксовых десктопов. В винде, если где-то не работает Ctrl-C, то эта программа сей момент отправляется в трэш.
COKPOWEHEU
sergey-b
У меня к линуксу вообще никаких претензий нет. Я активно ползуюсь им больше чем виндой.
BigBeaver
Ну он работает. Вопрос только в том, как вставлять картинки в комментарии не по ссылке.
COKPOWEHEU
Нет. Тот, который по средней кнопке, работает в пределах одного окна. Собственно, поэтому я не уверен, что это именно буфер. Не похоже чтобы он хранил выделенный кусок где-то в памяти. Хотя утверждать не буду.
Буфер ^C / ^V работает в стандартных компонентах, а поскольку почти весь интерфейс линукса построен на них, найти где это не работает, достаточно сложно.
BigBeaver
COKPOWEHEU
Да, вы правы. Только что проверил. Значит, когда я с этим сталкивался, была какая-то экзотическая комбинация, которую я тогда принял за норму. Спасибо за исправление.
BigBeaver
Есть подозрение, что когда-тодавно это было только в GTK окружении. Но я не уверен.
UPD: я даже больше скажу — это оснойной инструмент работы с текстом, тк позваляет абстрагироваться от хоткеев, принятых в конкретных приложениях (привет, консоль).
sergey-b
Чего угодно. Вот, например, вставка куска таблицы.
COKPOWEHEU
«копировать ссылку на изображение» — «вставить картинку». Сам редактор Хабра принимает только адреса, поэтому все еще непонятно чего вы хотите
Osnovjansky
Судя по паре комментариев что я встречал, хабр на десктопе умеет автоматом загружать картинку из буфера обмена на hsto.org и вставлять ссылку (но у кого и как это работает, я пока не разобрался)
sergey-b
Проверил только что на CentOS. PrintScreen по-тихому создает файлы, Ctrl-V не работает.
alsoijw
Тут важен не дистрибутив, а рабочее окружение.
sergey-b
Именно так. Проблема десктопного линукса в том, что на десктопе все зависит не от линукса, а от гнома, KDE, lightdm, xfce и прочих плазм.
COKPOWEHEU
Вы хотели сказать — преимущество. Если где-то что-то сделано криво, можно попробовать другой компонент. Ядро работает себе и никак разработчика или пользователя не ограничивает.
В той же винде мне как сделать панельки снизу, сбоку и сверху? Как настроить горячие клавиши на запуск терминала, калькулятора или, скажем, на отключение микрофона?
FenestramDeveloper
Сам не думал, что это возможно, пока не увидел, но:
1) правая кнопка по панели задач -> открепить -> можно перетащить панель на любую сторону экрана
2) закрепить нужные приложения на панели задач -> сочетание win + цифра будет запускать соответствущее приложение.
Ещё правая кнопка по любому ярлыку -> свойства -> быстрый вызов. Если сможете написать скрипт на PowerShell, который отключает звук, то создав ярлык на него и назначив комбинацию клавиш вы можете добиться чего-то похожего.
Не так гибко, как в линукс, но вдруг тоже пригодится…
BigBeaver
Ок, как отделить таскбар от панели быстрого запуска? Как сделать панель наверху экрана а таскбар внизу?
COKPOWEHEU
В тему настройки виндовой панели
1. Ее можно сделать двустрочной, поместится больше окон до того как они станут скукоживаться. Естественно, группировку окон в одну иконку отключить, уж очень она сильно мешает.
2. Можно создать где-нибудь в профиле пользователя папочку с ярлыками программ и прикрепить на панель в качестве кнопок быстрого доступа. Хорошо там смотрятся «компьютер», «калькулятор», «блокнот» и «консоль».
Впрочем, этим я развлекался в win7, возможно в win10 уже так просто не будет.
MTyrz
Есть даже специальный совет от мелкософта, как вернуть панель быстрого запуска в семерке.
(плюясь йадом: к вопросу о том, чего в настройке винды гуглить не надо, ага-ага)
sergey-b
Мы, линуксоиды, в винде делаем просто:
MTyrz
Тоже вариант, но я
без трубки уже не могупривык к такому способу.COKPOWEHEU
Ну, для редкого запуска одного приложения без параметров кнопка все же удобнее.
d_ilyich
В этом плане мне нравится 10-ка. Можно не только закрепить значок панели управления на таскбаре, но и «внутри» него с помощью ПКМ закрепить элементы самой панели управления. Получается этакое меню бытрого доступа. Это не только к ПУ относится. Можно таким образом подобие закладок для браузера организовать, например.
P.S. Прошу прощения за оффтопно-ностальгические сопли :)
MTyrz
Я к этому привык еще с 98-х. Поэтому отсутствие этого в семерке из коробки вызвало нефиговый такой WTF.
sergey-b
Если где-то в линуксовом десктопе что-то сделано криво, то можно потратить некоторое количество часов и поработать на еще более кривом десктопе.
Таково мое, сугубо личное впечатление.
COKPOWEHEU
А можно пару минут на настройку. Увы, в виндовсе парой минут дело не обойдется.
sergey-b
К сожалению, все линуксовые десктопы жутко кривые. Нормальных среди них нет. Опять же, на мое сугубо личное имхо. Самый продвинутый, на мой взгляд, был 2-й KDE. Там можно было выбрать какие элементы управления окнами и где должны быть, выбрать их оформление, настроить любые хоткеи, вызвать любую кнопку из командной строки, накрутить всякие панельки со своими приблудами и т. п. Однако все эти красивые идеи благополучно похоронили.
BigBeaver
Добро пожаловать в XFCE.
LiquidSnake
Панельки делаются насколько помню.
Если что-то сделано криво, пробуйти другой компонент/дистрибутив пока они не закончатся. А красивого, удобного и главное доделанного до конца софта — нет. И бесконечные апдейты да, чуть ли не каждую неделю. Да, это можно не делать, хоть какой-то плюс.
alsoijw
Кто вам посоветовал центось для десктопа?
LiquidSnake
Федора не лучше, хотя это одно и то же посути.
Какие альтернативы для rpm based?
viklequick
Вот например — https://opensuse.org
alsoijw
LiquidSnake
Я и в убунте на нее наткнулся. Как и на проблему с драйверами Nvidia.
Я не сказать чтобы новичок. Просто дома реально держать центос — боль. А работать с ним приятно. OpenSUSE еще не трогал даже.
alsoijw
COKPOWEHEU
Debian / xfce, местная утилита сохраняет в буфер обмена, потом без проблем можно вставить в Офис
0x9d8e
Постоянно копирую скриншоты и картинки (в т.ч. прямо из браузера) в почту и слак. То есть можно кроме текста копировать «что-нибудь». Файлы ещё.
А «второй» буффер это тот замечательный буфер, в котором лежит выделенный текст. И вставляется он средней кнопкой мыши. Очень удобно и не затирает тот что «Ctrl+C, Ctrl+V».
alsoijw
О чём речь? Если я правильно понял, то вам нужно поставить менеджер буфера обмена, в некоторых случаях(kde) он идёт из коробки.
COKPOWEHEU
Что вы имеете в виду под «единым буфером обмена»? А то может и правда полезная штука, о которой мы тут не знаем. А то про иксовый буфер, который по ^C/^V знаем, про буфер по средней кнопке (кажется, он не совсем буфер) знаем. Может, в Майкрософт еще какой изобрели?
sergey-b
Да, это такой буфер обмена, в который можно вставить что-то из одной программы, а потом перенести в другую программу. Например, можно сделать скриншот и вставить его в джиру или в документ, в ватсапп, телегу и т. п. В линуксе такого отродясь не было, хотя, возможно, что-то подобное уже изобрели.
BigBeaver
Вы, наверное, шутите.
COKPOWEHEU
То есть вы просто фиг знает сколько лет не знали о существовании буфера обмена? Так может, стоило ознакомиться с вопросом или выбрать менее категоричный тон сообщения?
Просто я познакомился с линуксом в 2008 году, тогда он уже был обыденностью. Когда именно он появился не знаю, не интересовался.
sergey-b
COKPOWEHEU
«так» это как?
Хранение в буфере не одного значения, а нескольких? Да.
Написать программу, которая эту историю сможет видеть? Да.
Умеет ли это какой-нибудь из калькуляторов? Не знаю.
sergey-b
Вставьте скриншот из линукса в комментарий, пожалуйста. Сравним результаты.
COKPOWEHEU
Вы сначала определитесь что именно вам надо. Скриншот чего вам показать?
AlexP11223
sergey-b
Значит, линуксовый десктоп не безнадежен.
linuxoid
О, прям инцепшон. Видео в комментарии о снятии скриншота для комментария :)
BigBeaver
Всегда было можно. Вопрос только в том, как вставлять картинки на хабр без промежуточных действий (возможно, я тупой и что-то не знаю).
sergey-b
Через habrastorage.
BigBeaver
Так надо сначала в habrastorage загрузить как-то, не?
sergey-b
В хабрасторадж заливается через Ctrl-V на винде. Приходится делать 3 лишних клика. Но это явная особенность хабра. Никто не мешает вставить скрипт с habrastorage на habr.com.
В линуксе это не работает — только файлы загружать.
BigBeaver
sergey-b
На CentOS это не работает. При копировании картинок в браузере программа, показывающая содержимое буфера вообще показывает предыдущий текст.
BigBeaver
Ну буфер-то работает. Просто программа снятия скриншотов его не использует в вашей сборке системы. Почему не использует — не ко мне вопрос. Может, так настроена, может, еще почему.
PsyHaSTe
А, я думал там какая-то магия. А это просто прокидывание линка со стораджа.
Если через стороннюю приблудную сайтину, то я имгуром для того же пользуюсь — ctrl+V там точно так же работает. Как и в большинстве сайтов в интернете.
JerleShannara
Gentoo Linux ~amd64, KDE Plasma, xorg. Нажал PrintScreen, вылезла Spectacle с предожением, чего с этим принтскрином делать, нажал «Копировать в буфер обмена», открыл hsto.org в огнелисе, оно авторизовалось, нажал Ctrl-V — оно спокойно загрузило скриншот из буфера.
alsoijw
Примерно так это выглядит. В DE это можно сделать по хоткею.
sergey-b
Там написано, что скриншоты сохраняются в файлы. Это именно потому что отсутствует буфер обмена, куда его можно было положить. Скриншоты это малая часть того, для чего нужен буфер.
BigBeaver
Конечно же присутствует этот буфер и всегда был. И для скриншотов и для текста.
sergey-b
Почему им никто не пользуется? Почему все скриншоты сохраняются в файлах?
BigBeaver
Все пользуются.
Все сохраняют, куда хотят. Нет ни какой проблемы вставить скриншот в браузер или в редактор. Но хранить картинки таки удобнее в файлах.Вы лучше ответьте, как вы вставляете картинку в хаброредактор, который принимает только ссылки. Или у вас в винде PrintScreen сразу в habrastorage сам загружает?
sergey-b
Через habrastorage, а там через Ctrl-V. Хз, почему хабр так сделал.
BigBeaver
Ну так вставка скриншотов в браузер в линуксе нормально работает.
sergey-b
На CentOS не работает.
BigBeaver
Ну это конкретно к вашей машине/системе вопросы. Я не видел ни одного дистрибутива без буфера обмена. А за почти 15 лет я их повидал.
Oxyd
В 95% случаев я пользюсь именно буфером обмена. Всё прекрасно вставляется, как в телегу-матрикс так и во всякие социалочки vk, mastdon etc.
AN3333
Это какой-то секретно-тайный буфер? Когда спрашивал о нем линуксоидов:
— Это тебе не Виндоус.
BigBeaver
Вы это о чем? Хотите сказать, в линуксе нельзя копировать текст/картинки между программами?
sergey-b
Только что проверил на CentoOS. Не работает. Яндекс.Браузер так вообще упал после Ctrl-V.
BigBeaver
Что не работает?
sergey-b
PrinstScreen, Ctrl-V -> core dump. вернее PrintScreen не копирует ничего. PrintScreen, Double Click, Right Click, Copy, Ctrl-V -> core dump.
BigBeaver
У вас может приложение скриншотилки быть не установлено/выключено/битое или хз. У меня всё работает и всегда работало.
И хотя я готов признать, что в некоторых сборках ситуация со скриншотами странная, к буферу обмена это отношения не имеет.
sergey-b
Я, прям, заинтригован. Сейчас подниму десктоп на одном из севреров и пойду посмотрю, как это там устроено.
alsoijw
sergey-b
У меня на линуксе такой нет.
alsoijw
echo $DESKTOP_SESSIONРискну предположить, что у вас GNOME 3, они затеяли кардинальную переделку рабочего окружения, вызвав бурю негодования. В этом случае нужно либо запустить средство создания скриншота вручную, либо задав ключgnome-screenshot -csergey-b
Запустил типовую установку со стандартного исошника.
Лучшее, что я видел в плане десктопа на линуксе — 2-й KDE.
MTyrz
sergey-b
Как я и говорил, линукс-десктопы не безнадежны, хотя у меня в гноме такой нет. Однако, специально для вас я поставил в линукс идею. На винде я в идее делаю Copy на файле и Paste на десктопе. На линуксе делаю Copy на файле, Paste на десктопе сделать не могу, как и в любом другом каталоге.
MTyrz
Эм…
На слово поверите, или вам видео записать? Debian/MATE, УМВР.
sergey-b
Охотно верю. Только на винде это все работает в любой версии в любой программе, а в линухе как повезет. Вот я скачал десктоп-образ одного из самых популярных дистрибутивов, и там это через пень колоду работает.
MTyrz
Фигня, короче, эти ваши автомобили (велосипеды, компьютеры, наручные часы и самовары).
Я купил Жигули, и они у меня сломались (у велосипеда спустило колесо, компьютер глючит, часы отстают, самовар прохудился). Нормальный человек автомобилем, велосипедом, компьютером, наручными часами и самоварами пользоваться — не будет!..
sergey-b
Запишите, если не трудно, ибо на MATE УМННР.
MTyrz
sergey-b
десктоп и окно файлового менеджера — это фактически одна программа. Буфер необходим для взаимодействия между разными программами. Я проверил на примере десктопа с IDEA. В винде работает, в линуксе нет.
MTyrz
Ах, вот что имелось в виду под идеей! Извиняюсь, не понял.
Но тогда я еще и не понял выполняемого вами действия. Вы пытаетесь скопировать файл из просмотра файлов IDEA?
MTyrz
В общем, IDEA у меня нет, есть ПХПшторм. Оттуда файл действительно нельзя скопировать и вставить: по крайней мере, с ходу у меня не вышло.
Если вас утешит, мышкой таскается (именно копируется) без проблем (ненавижу драгэнддроп, но иногда помогает).
unsignedchar
В windows да, в линуксах скорее всего нет. А вы в Windows тоже можете скопировать файл в проводнике и вставить в Word?
sergey-b
Да. И не только в проводнике.
BigBeaver
И какой должен быть результат такого действия?
FenestramDeveloper
да можно. в виндовс в документ будет вставлен объект OLE (если правильно называю), содержащий в себе весь файл.
в линукс это не сработало, зато Drug and Drop сработал — вставилось URL вида file:///
полагаю, программа может обработать данное событие как ей заблогарассудится.
BigBeaver
Ну в линуксе и Ворда нет и OLE, вроде, тоже.
unsignedchar
То есть можно скопировать в проводнике файл с прошивкой для ардуины, и вставить в Word… Скопировать в проводнике каталог и вставить в Word… Скопировать текст из Word и вставить в проводник… Скопировать резистор из какого-нибудь FreeCad и вставить на рабочий стол…
alsoijw
sergey-b
По итогам холивара я пришел к выводу, что если в линуксе есть нужные мне фишки, то скорее всего в MATE. На первый взгляд выглядит гораздо приятнее и удобнее, чем гноме.
MTyrz
МАТЕ приятная оболочка.
Супруга говорит, Cinnamon красивее — а мне нравится. Относительно третьего гнома мы вдвоем сходимся, что ужос-ужос.
sergey-b
Ну так вот и ответ, что убивает десктопный линукс — выбор убожества в качестве основы для стандартной поставки.
MTyrz
Тут есть один малозаметный плюс.
Если MS решает сделать убожество основой стандартной поставки (по моим представлениям, винды после семерки — именно оно) — мне остается только оставаться на устаревающей системе.
Если разработчики конкретного дистрибутива решают сделать убожество основой стандартной поставки — я его даже не увижу, ибо предпочитаю кастомизированную установку с самого начала.
И установка нового DE в одну команду тоже приятна. Да хоть десяток их себе поставьте, и переключайтесь на экране логина в тот DE, который вам приятнее в это время суток. Я так держу тайловые оконные менеджеры: выглядит завлекательно, но привыкнуть так, чтобы перейти совсем, не могу. Заглядываю под настроение.
sergey-b
У MS еще и обновления неожиданные прилетают, после которых может что-то привычное и удобное пропасть.
MTyrz
В общем, куда ни пойди, грабли ждут. Лежат и ждут.
JerleShannara
Нет никакой стандартной поставки десктопного линукса. Есть установка по умолчанию у AnotherName GNU/Linux, Whattheheck GNU/Linux и т.д. У того, который я использую, даже этого не существует.
alsoijw
У Linux Mint нет сборки под гном, у остальных дистрибутивов оболочки по умолчанию нет, и можно качать любую понравившуюся.
alsoijw
Ещё можете на KDE посмотреть, остальные оболочки будут либо легковесными, либо малопопулярными.
PsyHaSTe
А можно поподробнее как вы это делаете? А то я как дурак постоянно на imgur заливаю картинки чтобы вставить.
Вот наживаю ctrl+v/win+v — ничего не происходит. чяднт?
major-general_Kusanagi
Ваша картинка залита и хранится по адресу hsto.org/getpro/habr/comment_images/bd1/905/71a/bd190571a332710212e298d95e37e85a.png
PsyHaSTe
Ну то что хабр перезаливает картинки из сторонних источников мне известно. Но Я все ещё не понял как оно у вас автомагически само из буфера в ставляется
MTyrz
Открыв хабрастораж, вы можете просто нажать Ctrl+V, и он зальет себе содержимое вашего буфера обмена. Даст ссылки, как при загрузке файлов.
0x9d8e
Именно то что вы описываете я в убунте делаю 100500 раз на дню. Делаю скриншот куска экрана (кстати, штатными средствами) и вставляю в почту, джиру или слак. Сразу картинкой, а не ссылкой какой-нибудь.
surVrus
Стесняюсь спросить, а это как?
27 лет работал в Виндовс, сейчас 3 года в Линуксе, все время делал кучу документов (много гигабайт уже), причем сложных, технических. И ни в виндовс, ни в Линуксе никаких проблем с буфером обмена не встречал.
Мне кажется все зависит от методологии работы с документами.
Я использую в работе инфраструктуру Google Workspace, там со всеми видами документов нет никаких проблем с использованием буфера обмена.
Все картинки, рисунки и диаграммы лучше всего хранить отдельно от документа, в отдельных папках. Пихать все в один документ — ну тоже можно, но это так себе вариант. Для презентации или для какой-то научной статьи худо-бедно прокатит, но не для технической документации. При использовании стандартов ISO для документации обычно картинки и схемы идут отдельно.
nivorbud
Ага, «магия»… Захотел я в macos удалить джаву…
Очень просто для обывателя, да… Очень сильно пожалел, что купил imac, наслушавшись фанатиков. Элементарные вещи вызывают головную боль… Установить нормальную механическую pc-клаву — головная боль (пришлось вручную раскладку рисовать). Установить нормальную эргономичную мышь — головная боль (чтоб плавную прокрутку колесом сделать). Масштабировать размер шрифтов сразу везде нельзя, надо индивидуально по прогам лазить менять. Как буду прочищать от пыли, пока даже не знаю… Корпус склеен, надо будет с помощью фена горячим воздухом расклеивать, потом с помощью специального двухстороннего скотча назад склеивать… Замечательно!
Что касается винды, то всё познается в сравнении. Я с конца 90-х работаю с линуксами, на винду приходится смотреть редко, но если смотрю… Раньше во времена xp и семерки всё было ок, винда была очень приятной системой. Но сейчас… сразу испытываю сильнейшее раздражение. Даже не буду подробно расписывать. Время от времени покупал ноутбуки и всегда одно и то же: тормоза, диск вечно шуршит, какие-то процессы постоянно грузят систему на 50-90%. Сначала вычищал, потом надоедало и в итоге всё сносил и ставил тот или иной линукс, после чего всегда испытывал сильнейшее облегчение.
Теперь вернемся к обывателям. Всем из своих родных и знакомых, которым я поставил mint/ubuntu, абсолютно по барабану, в чем они работают, ибо пользуются стандартным набором программ: браузером/почтой/офисом (для простых документов)/просмоторщиком фоток. И линукс для них (и меня!) предпочтительней: меньше вероятность повредить систему, всё обновляется одной кнопкой, риск подхватить вирусы значительно ниже, вопросов ко мне почти не возникает — всё работает, как часы. В итоге у всех намного меньше головной боли.
BigBeaver
nivorbud
В инете я глянул конструкцию системы охлаждения и пришел к выводу, что вряд ли продувка извне поможет. Так что через какое то время придется разбирать. Заодно может быть и i5 на i7 поменяю.
unsignedchar
Если внутре вентилятор - компрессор выдует пыль вместе с лопастями.
BigBeaver
Не сталкивался. Просто раскрутится и всё. Ну и можно же атмосфер до 2-4 скрутить редуктором.
grub-itler
А зачем нужен второй виндовс, если первый никуда не делся?
black_knight
Раз в 5-7 лет пробую разные дистрибутивы на предмет возможности пользоваться этим на домашнем ПК. На мой поверхностный взгляд, user experience со времен 2007 года не поменялся в лучшую сторону, а времени и желания разбираться у меня становится все меньше.
estatic
Я бы сказал, что вы не разобрались в том что и для чего нужно. На самом деле что это гумно, что то. Каждая ОСь имеет кучу недостатков и взгляд на вещи может зависить именно от задач.
К примеру на моем десктопе дома и на работе я сидел с линуксом около 7 лет. Не менял дистрибутив, ничего не переустанавливал, апдейты только по необходимости. Так сказать проблем не знал. До этого 5 лет с Макосью. По сути тоже проблем не знал. Сейчас уже 4 года с виндой 10.
Что в макоси у меня переодически были проблемы с библиотеками, лагами, убиванием SSD, перегревами из-за непонятной активности.
Что с линуксом были переодические проблемы на лэптопе из-за кривых дров производителей (дрова на трэкпад и видеокарту конфликтовали), а также кривой работе с памятью приводящей к зависанию всей машины.
Что с виндой появились проблемы на ровном месте: эта зараза сначала ставила мне дополнительный язык в раскладки сама, а теперь переключает языки через раз (хотя индикатор показывает переключение), или произвольно добавляет в раскладку еще один язык. Или сейчас мельком появляется сообщение на синем фоне «блокировка» и комп уходит в сон.
Все зависит от текущих задач. Играть в игрушки лучше на винде. Работать с Unix-like софтов лучше под линукс и писать такой же софт проще под Unix. Если надо окружение MS + Unix, То макось.
Так или иначе, каждому нужно, чтобы его девайс работал стабильно и вот в данную минуту выполнял заложенную задачу.
Но в любом случае, если вам нужно хоть чуть-чуть больше заложенного стандарта вам придется извращаться, читать мануалы, логи, тратить свое (или чужое) время и делать многие вещи руками (пусть даже чужими).
— Хотите под маком заняться ML? придется почитать о том, как заставить ваши библиотеки с этим работать (бубны, танцы, время). Сюда же все зависимости для скачивания, сборка пакетов из исходников (особенно если brew/ports уже не помогает), да много чего.
— Хотите работающее железо лэптопа в Linux? Велкам на сотни статей в инете. Часть сложного софта пишется для «здесь и сейчас» и по большей части жутко сырое, не адаптированное, медленное и забагованное. Несовместимость библиотек, неизолированность этих библиотек порождает иногда сильную головную боль, просто потому что вам надо запустить какое-то приложение.
— Даже по винде, половина решений от самого MS это пустышка, потому что оно работает только здесь и сейчас и не будет работать при повторной проблеме или вообще не будет лечить проблему, потому что «Стив» не понял что вы от него хотите, а по инструкции у него написано «ребут 3 раза, выключить и включить 3 раза». Слетающие настройки, крайне кривой интерфейс, невозможность кнопкой(ну или удалением файла конфига) сбросить настройки без головной боли.
Постоянно вылезающие нотификации или уведомления, которые блокируют окно, в котором вы работаете — это вообще бич всех операционок.
RockindDemon
Плохому танцору всегда unix way мешает.
Тут всё-таки нужно понимать несколько вещей. Линукс не стремиться агрессивно занять место десктопных ОС. Потому:
1. Архитектурно многие решения заточены под максимальный контроль со стороны пользователя, а для того, чтобы его обеспечить, нужно рисовать много красивых админок и т.п. — а это никому не нужно и никто не готов вкладывать в это деньги. Потому мы имеем правильное решение — набор тулзов, где каждый тул умеет решать свою задачу и делает это круто.
2. Весь зоопарк настроек, как правило, доступен к редактированию в виде текстовых файлов. Ох сколько раз я пытался что-то нестандартное сделать в Windows… Вот там как раз всё по схеме «если дяди из Microsoft решили, что вам этого не нужно, то хрен вы это сделаете».
3. Я очень рад, что эта ОС не старается привлечь к себе массового пользователя. Все подобные попытки приводят не к росту уровня Пользователя, а к деградированию системы. Кто долго пользуется линуксом, застали эпичный провал с появлением Unity-оболочки в Ubuntu. Это убожество стало как раз следствием стремления быть «стильной-модной-молодёжной».
4. Приведу забавный пример. Вот есть у меня несколько звуковых интерфейсов: встроенный HDA, USB звуковая карточка и HDMI — на телевизор. Под линуксом (спасибо pulseaudio) я могу в любой момент любой приложение перекинуть на любой интерфейс. Сидели у меня дети смотрели мультики (из браузера) за монитором — без проблем, перекидываю на телевизор, а сам забираю монитор и HDA выходы себе. Без каких-то специальных приложений, которые должны сами выбирать себе устройство вывода. Винда так не умеет. Грёбаный стыд.
Ну и напоследок. Дома все мои компы и ноутбуки работают под линуксом. Это либо Ubuntu, либо Manjaro — для ноутбуков со свежим железом (Ryzen 7 4500U/4700U). Также линукс установлен у родителей как моих, так и жены. Все замечательно пользуются системой и никакого дискомфорта не испытывают. Да, бывают проблемы. Да, производители железа практически не стремятся что-либо оптимизировать под Линукс. Отсюда и проблемы. Но в Линуксе ЕСТЬ способы решения, вплоть до настроек через sysfs. А вот в винде, если добрый дядя не предусмотрел, то и всё.
А в остальном, если вы пишете интегрированный комбайн, то разницы, под винду или линукс — вообще нет (это с точки зрения разработки). Выделяете платформенный слой — он будет разный. А остальное — без разницы.
LiquidSnake
Все правильно, Linux не нужен GUI просто-напросто.
Система отлично управляется через консоль, и профессиональные задачи решает на отлично.
Для домашнего пользования все это обилие настроек и крутилок не нужно и мешает.
Авторы зачем-то пытаются скрестить ежа с ужом.
major-general_Kusanagi
LiquidSnake
Как вы, однако, любите картиночки.
В андроиде от линукса только ядро. Он уже давно уехал в другом направлении.
Там как раз консоль не очень то и нужна.
major-general_Kusanagi
То, что имеет ядро Линукса, Ликусом и является. Андроид — это GUI для Линукса.
LiquidSnake
Ок, но удобнее GUI в условной Убунте или Федоре не стал.
PsyHaSTe
То есть любое юзер-френдли решение это деградация система? Надо полагать, что автомобиль, где каждым колесом по-отдельности нужно управлять и лекарство где десяток компонент нужно в пробирке смешать (вдруг вам чуть больше или меньше какого-нибудь компонента нужно) тоже благо.
Неужели вам самим не хочется, чтобы Ось стала стабильнее на дефолтных настройках, интерфейс унифицировался (а не то что на одном экране контролы 3 разных стилей), чтобы поддержка сколько-нибудь необычных требований (175% увеличения во всех аппах, кроме A,B,C) и прочего не вызывали дикой головной боли и т.п.? Я понимаю подростков, у которых есть потребность в преодолении, но для взрослых людей обычно важна кратчайшая прямая между проблемой и решением — не у всех есть часы на то, чтобы сидеть и настраивать под себя систему.
Про себя лично скажу, что мне по работе нужен домашний комп на линуксе, для приближения к продакшн окружению. Но при этом я не готов потратить больше 1 дня на настройку системы в состояние, когда все работает и ничего не надо дополнительно делать. Какие у меня ауты? А вот получается, что никаких. Надо будет мак попробовать, не линукс но мб поближе будет к тому, что требуется. Но и там все не слава богу.
Вопросы, вопросы...
chnav
Спасибо автору за статью, чувствуется что заняло много времени структурировать мысли и вспомнить личный опыт.
Тем не менее многие комментаторы не удержались и скатились до уровня «вы ничего не понимаете в линуксе, есть вот такая команда и такая» (читать как: вы все тупые), даже не пытаясь понять, что огромная часть пользователей пришла в IT или стала пользоваться компьютерами во времена, когда линуксом ещё не пахло, а был DOS, 3D Studio, AutoCAD 12 DOS и т.д.
Это были полноценные CAD, написанные профессионалами для профессионалов. Был замечательный дизассемблер Sourcer, был Turbo C++, dBase, Foxpro, Wolfshtein…
а линукс был на уровне обсуждений в FIDO или небольших заметок в журналах. Напомню, что общедоступного интернета тоже не было и широкого обсуждения тоже.
Вполне логично, что когда появился съедобный линукс — львиная часть профессионального софта уже была написана под DOS/Windows, портировать его под сырую ОС никто не планировал. Так и живём. Будь линукс и софт под него в то время, когда было огромное желание учиться всему новому и копаться в деталях — кто знает, в чьём лагере бы я был сейчас.
PS: да я знаю, что был софт, работавший на рабочих станциях под Солярисом и пр. (3D-анимация, геофизика, сейсморазведка и др.), его со временем, когда производительность PC стала достаточной, портировали под Линукс, но это капля в море.
chnav
Порог вхождения в программирование тогда был значительно ниже: небольшой выбор языков, не было каши фреймворков, не было монструозных библиотек типа boost — всё писали сами. Возможно отсюда растут вырвиглазные интерфейсы, но многие программы писались инженерами, работающими в отрасли и понимающими её изнутри, а не по изолированным задачам, поставленным заказчиком. А альтернативы DOS и Windows на PC тогда не существовало.
AN3333
Всё так. Начинал с DOS. Когда появился Линукс я раз в пятилетку сувал в него нос.
— Ну что, дорос до моих нужд?
Не-а, всё что у меня есть под виндами, под виндами и лучше. При этом сложность аховая. Зачем такая сложность если ничего не лучше? Так оно и идёт. Линукс так и остался игрушкой для Линукс разработчиков. Внешнего мира для них нет. Секта.
А во внешнем мире то солнышко светит, и столько всего… Не, люди живут даже не в виртуальном мире, а в крошечном кусочке виртуального. Все удовольствие в жизни, тем или иным способом драйвер подключить. Мне этого не понять.
eldog
Мне кажется, что изначальное ограничение, при котором рассматривается только «классический» десктопный линукс не совсем уместно и поэтому приводит к неверным выводам.
Общий смысл статьи: десктопный линукс (классический)- система для гиков, обычным пользователям неудобен (правда), поэтому надо бы сделать то-то и то-то, после чего гикам он, конечно, будет нравиться меньше, зато обычный народ придёт. Всё верно, только вот это уже сделано :-)
Вот вам Андроид, вот хромбуки, вот умные тв с клавиатурами. Тот самый десктопный линукс, на который народ уже давно пришёл и с радостью пользуется.
Cvaroge88
У меня о линуксе сложилось схожее мнение. Разработчики не особо стремятся сделать систему дружелюбной для пользователя.
Постоянные проблемы при обновлении ( если систему не трогать — то можно один раз настроить и радоваться, в принципе ), то несоответствие версий Qt для программ его использующих, то не соответствие старых конфигурационных файлов новым стандартом ( сейчас такого уже, вроде, нет, но во время активного внедрения systemd и довольное продолжительное время после этого — было ). Это, кстати, следствие разрозненности самих разработчиков между собой ( что странно ).
К тому же системы зависимостей зачастую требуют обновления множества компонентов и если на машине ведётся какая-то разработка и используются приложения которые сильно завися от версии библиотек ( у меня было с Qt 5.7, чтоли, и во время установки какого-то приложения требовалось обновить часть системы — поставилась 5.14 и обновлённое приложение выдавало segfault на конечном оборудовании, что не говорило о проблемах именно с Qt ), то лучше от них отказаться, чтобы не словить неожиданную, возможно, трудноразрешимую и неочевидную проблему. Было бы куда проще организовать свободное применение библиотек и приложений различных версий централизовано ( а не отдельной установкой программ из внешних источников ) — без вреда для старых компонентов.
Вообще, сам процесс настройки многих вещей в системе посредством редактирования разрозненных файлов — очень неудобен. Причём меня больше всего удивляет, что эти файлы зачастую находятся вперемешку с исполняемыми файлами и файлами библиотек. Либо присутствует плохое разделение основных конфигов от редко используемых ( которых большинство, например в Asterisk'е приходится прыгать по списку файлов в mc если надо нового абонента внести и немного подправить правила набора ). Хотя это всё серверные компоненты иерархия которых должна быть продуманна до мелочей.
Если что-то не работает у обычного пользователя ( а такое часто бывает ) — он не в состоянии это исправить и, на самом деле — это действительно нелепо иметь проблемы с абсолютно обычными вещами, для которых ПК обычно и используется ( лет 5 назад часто ловил проблемы со звуком на ровном месте из-за неправильных стандартных конфигов в Ubuntu, Archlinux и Gentoo, то есть практически в любом дистрибутиве ). Мало кому захочется иметь десктоп с проблемами со звуком или графикой ( что бывает не реже — то тормоза даже в системном GUI из-за отсутствия драйвера, то ещё какая напасть в виде артефактов ). Сложно представить выбор системы с подобными проблемами если есть другие, в которых они встречаются значительно реже.
Ну и красивый/приятный внешний вид тоже надо настраивать. Много несуразного и неудобного в использовании ( например мне огромный размер элементов управления окна в GNOME кажется нелепым и неудобным. Мало тем для Qt и GTK с одинаковым отображением элементов. ). Хотя — если будет больше именно пользователей, то, скорее всего, это быстро поправят.
А вот качество низкоуровневых утилит и серверных приложений действительно очень высокое, стабильность и скорость работы системы, малое требование к ресурсам, масштабируемость — это огромные возможности для бизнеса которых нет в больших системах типа Windows и достойна всяких похвал. Именно за это любят весь *nix (BSD, QNX, Linux, Solaris ).
Мне видится толко такое применение, достойное и единственно возможное до тех пор пока не будет организована единая система конфигураций с удобным API ( чтобы не было разрозненности в спорах и стилях настройки разных частей системы ). Это приведёт к достаточной строгости, лаконичности и удобству использования системой как разработчиками, так и для пользователями, что создаст толчок к разработке дружелюбной каждому экосистемы.
Надеюсь когда-то мы всё это увидим и даже сами разработчики убедятся в целесообразности дружелюбного подхода.
KarmicDude
Если бы я за каждое упоминание, что линуксу на десктопах осталось еще 5 лет получал по 5$, то сейчас бы скопил на 1 биткоин.
Это смешно. Ну серьезно, такое утверждать может человек, не особо погруженный в происходящее с UI/UX линуксов. И на самом деле плевать на статистику, для этих 2%+ все с каждым годом становится лучше. Есть множество дистрибутивов, дающих высокоуровневые инструменты управления. Для обычной домохозяйки и не нужно лезть никуда глубоко. Осуждать за возможность кастомизации, выбора путей решения проблемы и пр. вещей — это совершенно не правильно. Смешали все в кучу. Причем вообще unix way к неконсистентности среды и оболочек софта которые там.
В целом рассуждения понятны, но все вывернуто наизнанку. Мне, как человеку работающему в linux среде в качестве десктопа уже много лет, совершенно невозможно находится в windows или macos. Возможности настройки окружения под себя ужасны. Расположение окон, переключение, тайлинг и много всего такого, скорость и эффективность работы в таком окружение очень высокая. Понятное дело, что это нужно не всем. Но, вроде как, линукс и не претендует на то чтобы отнять рынки у интерфейсов macos или windows. Это альтернатива для тех, кто понимает множество преимуществ этой среды и готов идти на определенные компромиссы, без них никак.
LiquidSnake
Возможно это «проф» деформация?
Я может кривой пример приведу, но есть товарищи которые играют в стрелялки на консоли и говорят что джойстик удобнее мыши. Чем вызывают мое недоумение.
Вы привыкли, поэтому вам лучше.
major-general_Kusanagi
LiquidSnake
Обязательно было включать режим зануды? =)
Я прекрасно знаю разницу между геймпадом и джойстиком, но вы же не придираетесь к комментаторам выше, которые лаптоп ноутбуком называют, правда?
Не уверен что в онлайн шутерах autoaim работает.
KarmicDude
Ну есть же объективные вещи. Например, слепой набор. Говорить, мол, что слепой набор это дело привычки, потому что это только вам лучше — не правильно. Это объективная вещь, что слепой набор помогает быть эффективным, меньше уставать и т.д. Можно без него обходиться — конечно. Нужен ли этот навык всем? Нет.
Если мне для того чтобы переместить окно, изменить его размер, сделать удобный лайаут консолей, вызвать нужную программу, запустить что-то в нужном рабочем столе/на нужном мониторе мне приходится либо браться за мышь, тысячу раз нажимать Alt-Tab или же выбирать окно из десятка превью (опять же мышью) — ну увы, это не эффективная работа.
Возможно, кто-то довольствуется меньшим. Кому-то просто не нужны такие кейсы, не все работают с консолями, не у всех запущено 5+ экземпляров vscode, несколько мессенджеров и пр. набор нужных в работе инструментов, между которыми нужно быстро перемещаться, создавать вокруг этого удобное окружение, чтобы не путаться и чтобы навигация происходила быстро.
Когда попробовал что-то хорошее, уже сложно откатываться назад. Именно это я чувствую, когда попадаю в среду Windows, например. Я остаюсь как без рук, без удобной среды. Я не говорю о красивости окошек и элементов интерфейса. Я говорю о удобстве работы, где эти элементы, зачастую, вообще не нужны.
AN3333
Так действительно много лишнего в Виндах. Вот только в Линуксе лишнего в сто раз больше. Вы просто много про Линукс знаете. Линукс надо изучать.
А я про Винды знаю мало. Через 30 лет. И не буду знать больше. Незачем. Вот и вся разница. ОС это такая штука для запуска программ. К ней правда зачем-то файловая система приделана, не знаю зачем, но привык. :)
Я с программами работаю, зачем нужна ОС не знаю. Тут говорят всякие магические вещи про поднятие серверов, установку драйверов. Не знаю что это и зачем. Я пользуюсь программами, иногда их пишу. Для ОС в моей жизни места нет.
novemix
Хрупкий и ошибочный тезис. Linux, в отличии от, не конечный продукт, а база для некоего продукта. Очень уместно упомянуты продукты и системы построенные на нем. Соперничать с MS и прочими никому не приходит в голову именно потому, что никто не стремиться продавать Linux как таковой. Несмотря на это и десктопные версии очень даже развиваются и вполне сносны для тех же госструктур (о чем тоже было уместно упомянуто) и непритязательных юзеров типа разработчиков. Так что Unix-way тут совершенно не при чем. А вот универсальность и гибкость обеспечили Linux будущее надолго. Учитывая тенденцию переноса данных и служб в облака, развитие кросплатформенных вэбприложений сильно беспокоюсь за будущее неповоротливых десктопных ОСей раздутых фичами и фоновыми службами (в том числе сомнительными) на все случаи жизни. Если бы это хотя бы не пожирало беззастенчиво ресурсы.
LiquidSnake
И никогда не будет законченным продуктом.
Поэтому и позиционируется как ОС для разрабов. Хочешь чего-то допили сам. Безусловно, возможность «конструирования» это плюс, вот только усложняет систему для пользователя в разы.
novemix
Конечно, недостатков с точки зрения рядового пользователя у десктопного Linux хватает. Однако, по моему мнению, это главным образом необходимость послеинсталяционной настройки, особенно возня с некоторыми драйверами. Пресловутые танцы с бубном. Юзабилити для условной домохозяйки (интернет, почта, соцсети, фото) мало чем отличается от монстров десктопа. Здесь предпочтение просто в силу вещей отдается «общепринятому стандарту» с вылизанным дизайном, так проще во всех отношениях.
В целом я хотел сказать, что unix архитектура никак не причина непопулярности десктопного линукс. Причина в отсутствии стимулов. Тем не менее ползучее развитие графических оболочек делает по капле свое дело. Стоит государству и крупным корпорациям начать всерьез внедрять линукс, как его десктопное окружение начнет стремительно прогрессировать.
LiquidSnake
Да, дело не в архитектуре. Дело в том что профессионалам десктоп не нужен, они живут в консоли, а на пользователей им побоку, написали что-то, а дальше — лень.
Линукс есть конструктор, но мало кто захочет собирать себе машину из запчастей чтобы на ней ездить. Все берут готовое.
unsignedchar
Смотрю на коллегу, лабающего код в qtcreator… Сказать ему, чтобы не позорился и запустил vim? :D
LiquidSnake
Улыбнуло =)
Помню как меня по рукам били чтобы я vim использовал, а не nano с tui :)
Так вот, я не в курсе а можно ли из консоли, условный qt запустить в окне?
Сам VSC цепляю по ssh к хостам.
AN3333
А Qt не надо запускать. Это библиотека.
Там конечно есть какие-то прибамбасы. Только зачем они… У микрософта среды хороши.
LiquidSnake
qtcreator вроде же ide?
alsoijw
Oxyd
Всё это безобразие ни разу не консольное и используется каждый день. И далеко не под голыми иксами. Тайловый оконный менеджер, да. Но обычным пользователям я-б советовал KDE.
FenestramDeveloper
Попробовал qutebrowser из этого списка:
# qutebrowser
Running as root without --no-sandbox is not supported.
# qutebrowser --no-sandbox,
qutebrowser: error: unrecognized arguments: --no-sandbox
Весит более 200МБ. Ссылается на хром. Профессионалы точно таким пользуются? Почему не surf тот же к примеру?
Oxyd
Начнём с того, что профессионалы не работают под рутом (Вообще! Никогда!). А surf оставил очень гнетущее впечатление, в плане совместимости с современными сайтами. qutebrowser может использовать один из двух, на выбор, движков. qtwebkit и webengine (по умолчанию)
ddddroid1195
Кажется я знаю кто выиграет макбук
bkstan
Да нет никакой проблемы, с 2012-2014 года всю работу веду на Linux Desktop. Всё хорошо. Семь лет, полёт нормальный. И на десктопе, и на ноуте.
smx_ha
Я думаю все таки главная причина того что десктопный linux не взлетает это повсеместное использование людьми принципа «Не трожь работающее» :)
Guul
Ладно экран повернуть, я одно время перешёл на xfce только потому что это была единственная нормальная среда где из коробки на разные мониторы можно было ставить разные обои. Особо гномоголовые без доли иронии советовали клеить обои гимпом.
Johan_Palych
Библиотека Мошкова
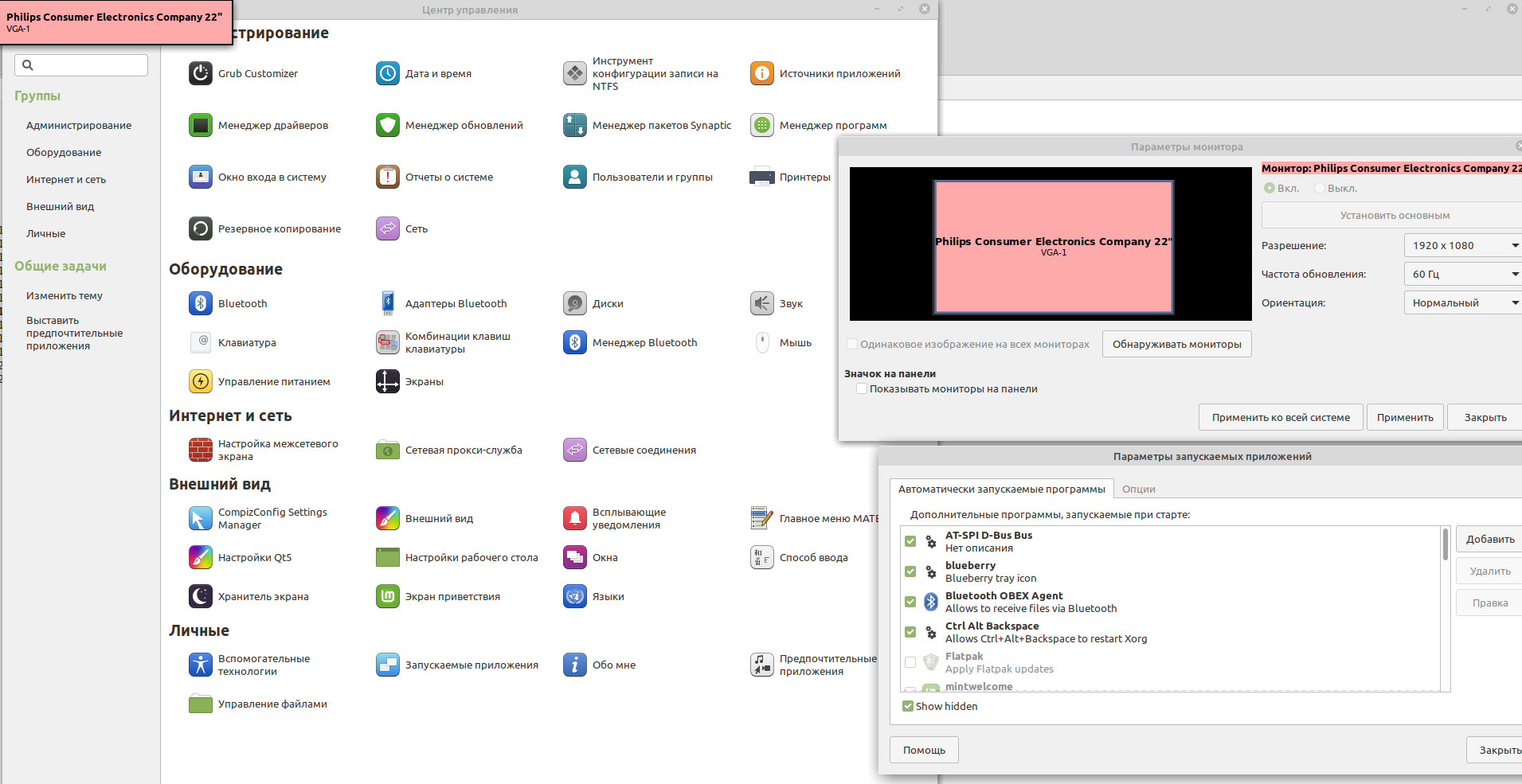

Клуб Настоящих Unixоидов
Я плакал.
«Про apt-get и (есть вот такие неофициальные решения, которые могут сломаться в любой момент)»
Автор внимательно читал ответы? Никогда не использовал Synaptic Package Manager?
I would like to give a GUI solution.
Open Synaptic Package Manager
Go to Status
Click Installed (manual)
Ну и в Synaptic можно всегда посмотреть куда установлены все файлы любой программы.
«Традиционный Windows-путь — это хранение данных в папке пользователя, а настроек программы в папке с программой.»
Забавно. Автор пробовал когда-нибудь деинсталировать например MS Office и вычистить все остатки в системных директориях и реестре?
«отсутствие единого конфигуратора»
Центр Управления например в MATE.
Microsoft, Red Hat, Canonical активно сотрудничают. Linux-сборки Microsoft Edge, ms-teams, mssql-server-2019, vscode, dotnet, PowerShell.
«активно впиливает поддержку, используя ядро линукса внутри своей системы...»
Запуска Linux-приложений с графическим интерфейсом.WSL2
Просто виртуалка
13werwolf13
с трудом дочитал… сходу видно что автор не разобравшись ругает непривычные вещи надумывая им оправдание…
и это ещё умудрилось собрать плюсов.
автор выдаёт плюсы за минусы а минусы за плюсы
статья похоже создана для "майнинга" коментариев если это зачем-то нужно, щас любители холиваров тут разойдутся
uz3rname
Я и не стал пытаться после первых абзацев. Время жалко.
У меня из коробки работает манжарыч и проблем фатальных не замечаю. Работаю, играю в игры иногда.
Johan_Palych
Согласен. Похоже куски надерганы из переводных книжек по Linux-Unix начала 2000-х. Стилистика очень напомнила издания из Библиотеки Мошкова.
engine9
У меня иной бэкграунд, я перешел на линукс лет 10 т.н. но не пользовался смартфоном, а стал активно его использовать с этой зимы. Так в нём сделано довольно запутано (я про андроид) и не очевидно, много рекламы и есть постоянное ощущение дезориентации, т.к. не понятно где именно находишься, на веб-странице или в приложении, всё словно перемешивается. Так что я «хомячок наоборот». Пришедший в мобильные ОС с чистого листа.
К слову сказать «Виндовс мобайл» был эталоном лаконизма и упорядоченности и целостности UI/UX.
FenestramDeveloper
Непонятно, каким образом автор «код программы — это десятки мегабайт текста», «когда сборка — отдельное приключение», «типа OpenOffice, GIMP-а, KDE или Chrome» соотнёс с Unix-way. Эти приложения сделаны чтобы заменить аналогичные в windows, ни о какой Unix-way в них речи и близко не шло. Соберите систему только из unix-way приложений и попробуйте к нему выдвинуть те же самые претензии. Вдруг проблема как раз в том, что в linux слишком много не unix-way ПО?
unsignedchar
Может, этот самый unix-way не все задачи решает изящно и просто?
lisnake
NixOS + home manager решает большинство из описанных проблем. С другой стороны, посоветовать обычному пользователю использовать NixOS на десктопе может только очень недобрый человек…
ittakir
Удивлен теми, кто ставит всем своим бабушкам Linux и гордится, что у них все нормально, больше с проблемами не обращались.
Поймите, если человек, мало знакомый с компьютерами, будет сидеть под Windows, то он со временем научится файлы копировать, лазить по папкам, менять обои, устанавливать программы. И этот навык он сможет использовать в любом другом месте — на работе, в гостях.
А тот, кого продвинутый внучек заставил сидеть под Linux, да еще не Ubuntu, а какой-нибудь более «крутой» с его точки зрения системой, тот никакого полезного навыка не приобретет.
Другая притензия. Один пишет: «Я могу потоки вывода быстро туда-сюда перенаправить, HDMI туда, клавиатуру сюда, мышку в /dev/null» и всей семьей потом сидеть одновременно за компом. Мышку коту, клавиатуру мне, а HDMI детям.
Другой пишет: «Я USB тут отлаживаю, и быстро накидываю пайплайн из кучи команд, фигак-фигак и готов вывод графика через временные файлы и awk».
Ребята, это конечно здорово, но это вообще не показатель нормального использования системы. Нормальное использование — это когда ты парой кликов мышки отключаешь скринсейвер и блокировку, и он не появляется снова. Или когда хочешь установить программу, скачиваешь её с сайта, устанавливаешь, и она работает под любой версией, хоть под 20 летней XP, хоть под 10кой. При этом не нужно вспоминать что там нужно написать после sudo apt когда хочешь поставить себе фотошоп.
Хочешь включить детям мультики — дай им отдельный ноутбук. Хочешь сделать USB интерфейс к прибору — сделай отдельную DLL для этого, а не временные файлы.
AlexP11223
Скорее научится ловить вирусы с баннеров в интернете )
Менять обои и лазить по папкам примерно одинаково везде.
Программы тоже вполне можно установить через какой-нибудь Software manager из меню Минта. Как на телефоне, да и в винде тоже есть.
Ну а то, что сложнее зайти на первый попавшийся сайт и поставить оттуда — скорее плюс для безопасности. Вряд ли бабушка обрадуется украденным почте и аккаунту скайпа )
LiquidSnake
Ну или не найдет нужные репозитории для инсталляции в линуксе, зато безопасненько :)
Software Manager убунты ужасен.
Возможно дело в том что я терпеть не могу apt и мне куда ближе rpm-based
AlexP11223
Да почти все не будут ничего искать ни в какой ОС, а просто позовут внука и т.д. )
Репозитории обычно искать надо для чего-то непопулярного. Большинство бабушек не выходят никуда дальше браузера, скайпа, может иногда офисный документ открыть, фото/видео (и то сейчас чаще через браузер).
LiquidSnake
Ну вот у меня условный родственник играет в wot:
Зайти в браузере на сайт танков, нажать «скачать» и запустить exe, или пытаться запустить это дело под вайном? С кучей зависимостей.
Сейчас да, они в стиме появились, стало проще.
Но вопрос, что делать той прослойке пользователей которой нужно чуть больше чем пользоваться уже установленным, но чуть меньше чем шариться по консоли?
Если ваш ответ — учиться, то в этом и есть недружелюбие ОС =)
Даже поставить линь — иногда боль. Стандартная разметка не годится под требования Home User.
Помню знакомый поставил какой-то из дистрибов, не назначил хоткей на смену раскладки, поставил пароль и поставил дефолт на rus. И не смог потом залогиниться =)
BigBeaver
Вайн же прозрачно работает, не? Последний раз, когда я что-то виндовое запускал, он (вайн) сам установил какие-то свои модули (или что там ему надо было) и всё.
LiquidSnake
Ну у меня на тот момент создался кривой виртуальный диск, не хватало места под апдейты и что-то еще. Сложности были в общем, возможно из-за моей криворукости.
В итоге я нашел какую-то статью по установке и таки поставил. Потом начал PlayOnLinux юзать, там все автоматизировано. А щас вот вижу что протон подвезли, но я еще не пользовался.
svsd_val
Попробуйте протон, он никаких дополнительных телодвижений не требует, включите в стиме в настройках (Steam Play) -> галки поставьте и выберите свежий протон. После перезапуска стима сможете играть, просто нажав на Play…
PsyHaSTe
Человек что с виндой, что с линуксом когда-нибудь научится жрать кактус и пользоваться этим. Вопрос только в затраченном времени и силах
COKPOWEHEU
А зачем вы смешиваете задачи разработчика и домохозяйки?
То, что вы описали — задачи разработчика, для которого ОС — конструктор. При этом подветка — про домохозяек, для которых она — черный ящик.
То есть мне еще полдня потратить на написание утилиты вместо пары минут на стыковку существующих? А что я при этом выиграю?
LiquidSnake
Смешивает скорее всего потому что глобально речь идет о том что десктопный линукс — штука нишевая, и нужная только профессионалам.
COKPOWEHEU
Ну так и не надо его тянуть хомячкам. Если линуксоид готов установить, настроить и поддерживать систему, флаг в руки.
Но вот требовать от инструмента наличия стразов и свистелок не надо. Пользы от них ноль, а вот мешают порядочно.
FenestramDeveloper
В связи с коронавирусом сотрудники массово вышли на удалённую работу. Разумеется, их старенькие ноутбуки видовс с трудом переваривают, она у них то виснет, то уходит в перезагрузку по полтора часа, пользователи звонят нам, но мы ничего не можем сделать! Ставим чистый образ — он изначально не работает, драйвера не ставятся, ошибки сыпятся. Так и говорим, что либо вы покупаете новое оборудование, мы его настраиваем, и будет вам счастье, либо терпите. Недавно добавил новую опцию: готовая рабочая станция линукс с предустановленным VPN, RDP, браузером, проводником, плеером ещё всякой мелочи. Для сложных задач вынес на рабочий стол скрипты. Всё делается двойным кликом по соответствующей иконке. Пользователей пока единицы, зато все счастливы. В первую очередь оттого, что им не пришлось угрохать месячную зарплату только из-за того, что микрософт сломали совместимость со старым оборудованием. Пусть решение делалось в очень большой спешке, оно всё-таки работает, причём очень стабильно — ни одной жалобы, и отклик у Х11 несравненно быстрее, чем у винды. У них нет возможности ни включить, ни выключить скринсейвера, и обои на рабочем столе не поменять, но это правда болшая потеря?
svsd_val
Мы нечто подобное стали делать, проводим исследования и где можно ставим линуху с крысой, при этом для удобства пользователей стилизованную под 7ку, многие даже не замечают что они не на винде, другие говорят что работает лучше чем прежние ОС =)
FenestramDeveloper
Если не секрет, какой дистибутив/прикладные приложения ставите?
svsd_val
Взяли xubuntu, в неё zoom, remmina, google-chrome, firefox, audacious, libreoffice, thunderbird, gimp, krita, inkscape, simple-scan, wine, mpv, vnc, cpufreq-utils, zabbix. Это основные приложения которые пришли на память, остальное доставляется по хотелкам/потребностям (включая специфичные для нас).
freecoder_xx
А есть статистика, сколько продается ноутбуков и PC c предустановленными Linux-дистрибутивами? А сколько с Windows?
PsyHaSTe
Непонятно, что она покажет. Мало ли кто покупает ноут с виндой и ставит туда линукс (без траханья мозга с возвратом 5000р за лицензию). И уж тем более делается наоборот — покупается линух (дос) комп и туда впиливается крякнутая винда.
freecoder_xx
Много чего покажет. Особенно если есть возможность прикинуть, какой процент покупателей вообще заморачивается с переустановкой (теряя при этом софт от производителя и некоторые гарантии).
COKPOWEHEU
Вы видели качество этого «софта от производителей»? Если бы его можно было просто выкорчевать из системы, переустановок было бы раза в два меньше.
PsyHaSTe
И все же. Вот покупается миллион ноутбуков с линуксом. Из них на 990 тысяч ставят потом пиратскую винду (или не ставят — статистики нет).
И что миллион проданных с линуксом ноутбуков вам покажет? То что пользователь не заморачивается с переустановкой блоатвари которая идет с виндовым ноутом совсем не означает, что человек покупающий ноут с freeDOS так на нем сидит.
LiquidSnake
Вряд ли найдете Windows вижу все же больше, но чаще и чаще идет DOS :)
Хотите — ставьте линь)
freecoder_xx
Я, когда покупал себе ноутбук, не смог найти подходящую мне модель без предустановленной винды. Но это частный пример, как и ваше субъективное мнение, что DOS стали ставить чаще. Потому я и спрашиваю, владеет ли кто-нибудь статистикой?
LiquidSnake
Может мнение субъективно, но мне правда лень самому проводить исследование на эту тему. Просто видеть стал чаще.
Видимо связано с тем что техника стала дороже
Praktik
В общем и целом согласен с автором. У экосистемы Линукс достаточно проблем, которые никто не спешит решать.
Интересно было бы перевести статью и запистить на реддит. Что скажут товарищи из Дебиана, Убунты ...?
emusic
Если что, это произошло двадцать лет назад. И авиабилеты продавались с вебсайтов десять лет назад. Как-то многовато устаревшей информации.
anonymous
«а место на жестком диске очень сильно упало в цене»
Автор вообще вкурсе о майниге на жестских дисках? И взлете цен на них в РФ?
Автор вообще вкурсе насколько много увеличивается код программ скомпилированных под e2k?
Теперь место на жестком диске не такое уж и дешевое.
FenestramDeveloper
А ведь отлично замечено. Для линукс намного проще купить какой-нибудь nvme на 16,32,64 ГБ, куда целиком встанет система и ещё хватит на всякое, чем для виндовс это превратится в 64-256-1024 ГБ.
svsd_val
Я одно время игрался, запускал всю ОС в ОЗУ, тогда было 16гб и 10 занято линухой со всем софтом… Вот это скорость была, даже на слабом ЦП грузилось махом… Сейчас у меня озу больше я туда игры закидываю ))) что бы открывались за пару секунд…
И да свободное озу на видюхе как свапик юзать очень удобно =)
FenestramDeveloper
Насколько такая процедура оправдана? Система может и загрузится быстро, но при работе у неё останется меньше памяти для кеширования, что может вызвать больше тормозов при обработке больших файлов… в том числе игр. Если в системе нет фоновой активности записи на диск, то будет ли давать tmpfs преимущество перед встроенным кешированием?
svsd_val
Саму систему как выяснилось особой необходимости хранить в памяти нет. Так как современные SSD и тем более nvME предоставляют достаточную производительность где всё упирается в производительность ЦП. Однако игры имеет смысл пихать в ОЗУ, многие из них работают шустрее и при этом полностью мелкие пропадают лаги в особенно играх запущенных через вино. К примеру когда только вышла ori and the will of the wisps и под вином она очень и очень сильно тормозила и лагала (нужных патчей в тогдашнем вине не было, и ждать не хотелось) а увеличение количества открываемых одновременно файлов не спасало положение и одним из решений было просто засунуть всю игру в ОЗУ, это позволило играть без каких либо проблем, хотя моя видюха не сказал бы что прям новая, Radeon R9 285, но игра просто залетала =)
PsyHaSTe
То, что оно не бесплатное — не означает, что оно дорогое. Потребительское место стоит 16 центов за гигабайт — не сказал бы, что дорого
Adrianus
Ну такое.
Половина проблем — субъективные/невнятные/надуманные.
Касаемо отсутствия информации — ой ли, ищущий да обрящет. Arch Linux и его Wiki — прекрасный пример «как надо».
Перешел на линукс два года назад. По порядку были Linux Mint Cinnamon, Ubuntu/Kubuntu 20.04/20.14, Kali Linux. Сейчас стоит EndaevourOS, тот же Arch, по сути. Системе год, проблем ноль. Win10 сносил за это время четырежды, уткнувшись четыре раза в проблему с grub и dualboot — и в очередной раз из-за «мелкософта».
Для меня в роли «продвинутого пользователя» чёткость и стабильность работы операционной системы в приоритете. Всё под контролем, никакая программа без разрешения никуда не лезет, всегда ясно, что, где и как, в отличие от «форточек» с сотней невнятных дублирующихся служб и процессов, неясной сетевой активностью на корпоративные сервера, собирающие кучу инфы и прочее… причем лучше вообще ничего не трогать, а то на пятую переустановку уйду.)
Не то, чтобы я очень уж параноик, но с установкой 10ки у меня постоянное и стойкое чувство проходного двора на компьютере.
Да, м.б., и для гиков… таких всегда будет немало. Как немало будет примитивистов, не желающих погружаться глубже в тему и копаться ручками. Это — нормально, естественно и привычно. Ничего нового, собственно. Люди и пользователи — разные.
LiquidSnake
Соглашусь с бесконтрольной виндой.
В дуалбуте Убунту — десятка проблем не встречал, заинтересован узнать в чем там проблема?
Ну вот искать инфу для использования дома — мне лень. Хочу все и сразу. :)
Adrianus
Проблема перезаписи загрузчика при переустановке винды рядом с линем.)
Обычно ставим винду, а потом линь с грабом, чтобы последний свой загрузчик записал. Оно работает, пока вдруг не приходится переустановить винду. После переустановки оная переписывает загрузчик — и дальше начинаются танцы и камлание. Но опять же, случаи разные бывают… смотря какое железо и как ставить. С другой стороны, я не изгалялся особо и загрузчик родной использую.
saidelman
О, проблемы бывают самые неожиданные :)
Вот у меня есть линукс, в нём работает вайфай. Поставил десятку, в ней тоже работает. А в линуксе больше не работает! Причём не работает ни в установленной манджаро, ни в live usb с манджаро и с никсом (что-то ещё пробовал, уже не вспомню).
Сначала я выяснил, что линукс вообще не видит адаптера, как будто этой железки вообще нет в системе. Оказалось, что винда при установке по умолчанию включила себе опцию быстрой загрузки, которая (как я понял) подразумевает, что не все ресурсы система "отпускает" при выключении, чтобы быстрее их "подобрать" при включении. И с конкретно моим модулем вайфай эта палка стреляет.
Причём описание этого механизма и рецепт "отключите быструю загрузку в винде" я нашёл на багтрекере ядра!
Больше всего меня печалит то, что винда вела себя как собака на сене ("эта железка общая, но я к ней получила доступ и вам не отдам"), но в глазах менее настойчивого пользователя именно линукс выглядел бы хреново ("ну а чего, в винде же работает, почему тут не может").
COKPOWEHEU
По идее, помогло бы выключить линукс, чуть подождать и включить обратно. Иногда кривые вафли и без багов винды могут заглючить подобным образом.
saidelman
В какой-то момент (я долго разбирался и много чего бытался менять в настройках по всей системе, поэтому уже не помню, что за чем следовало) был один способ получить работающий вайфай в линуксе: винду не выключать, а перезагружать. Тогда почему-то ресурсы освобождались, устройство появлялось, всё работало, единороги и бабочки повсюду.
Intel AX200 Wi-Fi adapter. Не знаю, насколько он кривой-косой.
alsoijw
Аналогично, винда не размонтирует диски. Интересно, с учётом того, что в 10 обещают возможность монтировать файловые системы линукса, не приведёт ли это к проблемам?
svsd_val
Их можно монтировать и раньше было, через отдельный драйвер, правда до недавнего времени он мог писать только на ext2, да уступал по производительности ntfs… но сейчас это вроде исправили.
alsoijw
Раньше не было быстрой загрузки, и возможности монтировать диски «из коробки». Если хотя бы одного условия не будет, значит проблем не будет.
saidelman
Вспомнил ещё одну историю, которая в тот же момент времени случилась :) Тоже с вайфаем и операционками, поэтому пусть будет в этой ветке (давно хотел где-нибудь поделиться).
Ноутбук, тоже дуалбут, такие же десятка и манджаро. Тогда же, когда на десктопе пропал вайфай в линуксе, я купил новый роутер. И винда в ноутбуке не видит моей сети. Линукс видит, работает, всё его устраивает, а винда в упор говорит, что нет такой сетки.
Но должен покаяться, я не проявил такого же упорства, как с проблемами в линуксе, а просто прокинул провод к ноуту.
red75prim
WiFi, случайно, был не 5GHz? Я недавно столкнулся, что телефон не хотел подключаться, хотя ноут работал без проблем.
Оказывается есть такая штука DFS: https://en.wikipedia.org/wiki/Dynamic_frequency_selection.
WiFi модуль должен проверять присутствие радаров на некоторых частотах и снижать мощность передачи/переходить на другую частоту, если радар обнаружен. Но некоторые модули просто не работают на этих частотах. В телефоне был такой.
В качестве бредовой идеи: может быть винда обнаружила присутствие радара. Или более вероятно обнаружила что wifi модуль старый, не реализует поддержку DFS, и отключила эти частоты.
saidelman
Роутер вещает две сети на двух частотах. Меня бы устроило, если бы винда видела только 2.4, но она вообще ничего не находит. Модуль в ноутбуке точно совместим, раз в линуксе тот же модуль видит нужные сети.
Вполне может быть, что можно как-то поковыряться в настройках роутера, я даже пытался, но не смог починить: моих компетенций в этой области явно недостаточно, поэтому я смирился с тем костылём, который воткнул вместо решения (а также потому что тем ноутом пользуюсь недостаточно активно, чтобы это было критично).
JordanoBruno
Статья оставляет двоякое чувство, сначала я подумал, что автор действительно с большим опытом и хорошо разбирается в теме, но вот такие косяки напрочь доверие убивают:
Библиотеки использовали не только для того, чтобы на диске место сэкономить, а еще и сэкономить на ОЗУ, которой всегда не хватало. Выигрыш существенный даже для однопользовательского использования, так как все равно в системе запущены десятки процессов.
Если админ действительно опытный, то ему не составит большого труда установить сколько надо разных версий, благо возможность с указанием prefix заложена в configure очень давно.
Linux кто только не хоронил, но он живет и развивается, у него есть свой
красноглазыйпользователь.Лично я считал, что Canonical вполне удастся сделать Ubuntu Desktop полноценной альтернативой Windows, но после того, как они перешли с Gnome 2 на тормозной и глючный Gnome 3, похерив проверенный UI второго гнома, я начал сильно сомневаться. Дальнейший их переход на Unity мне показал, что в Canonical вообще не понимают, что нужно юзерам от десктопа и пришлось перейти на мак.
Что нужно сделать Canonical, чтобы Ubuntu стал опять лидером:
silent_jeronimo
1. Есть же MATE и Cinnamone
3-5. Требования к пространству на диске же вырастут при той реализации, которую может позволить себе Каноникал
JordanoBruno
MATE и Cinnamone я пробовал, но так как это все же не Canonical, то были и баги и куча нюансов в использовании.
Место на диске сейчас не является такой проблемой. Даже если статично скомпилировать или включить нужные библиотеки для приложения, то это добавит всего несколько мегабайт. Даже если +10 мегабайт — это будет практически не заметно, на телефоне гораздо больше приложения занимают.
svsd_val
У меня сложилось мнение что автор выдаёт все + за -, а существенные — за +. Да и понимания как работает ОС тоже не шибко то наблюдается. Ставит в вину то что OpenSource является OpenSourc'ом, что народ тратит своё время и ресурсы на создание какого либо продукта и не требуют в замен ничего… Что не пытаются нагнуть народ и заработать денег…
vvzvlad Автор
У меня нет претензий ни к кому, включая разработчиков. У меня есть рассуждения, почему сложилось так. Возможно, кому-то будет интересно посмотреть на все это с точки зрения продуктовой разработки.
svsd_val
ИМХО:
Сложилось так благодаря нескольким факторам:
1. Очень сильным рекламным и антирекламным акциям со стороны мелкомягких яблочники(на моей памяти особо ничего существенного не делали, хотя я могу и ошибаться), начиная с момента когда линуха только стала распространяться и набирать обороты года 1998-2000 стали проводить компании по дискредитации в глазах общественности, дошло до того что они подняли компанию «Get the Facts» против Linux, когда более менее опытный народ стал доказывать обратное они заменили её на Compare и насколько мне известно продолжают по сей день но уже против всех Unix систем.
2. Благодаря большим финансовым вливаниям со стороны мелкомягких и яблочников, их продукт известен многим.
3. Производители оборудования ориентировались на то топ рынка, а у кого деньги тот как говорится и танцует девушку… Следовательно большая часть оборудования выпускалось и выпускается с оглядкой на M$. А то что у Яблочников бывают те же проблемы что и у юниксойдов кода не заводится оборудование… все предпочитают умалчивать.
4. Преемственность и привычка — многие впервые сев за ПК увидели там что? правильно Винду, меньше Мак. Они мало что слышали о каких либо иных ОС… Они научились только определённым патернам поведения, знают как скачать пиратский софт, переставить пиратскую винду и всё.
5. Развитое пираство, у нас многие пиратят софт, как ни странно купить комп это пол беды, потому что если брать софт лицензионный то большую часть бюджета будут съедать именно лицензии софта, так что там это на самом то деле дорогое удовольствие.
6. В следствии пукнтов 4 и 5 — узкомыслие (делится на 2 стороны медали):
Первая: многие мыслят с точки зрения: «Я такой хороший, я пуп земли всё вертится вокруг меня и моих и только хотелок, а почему она(* GNU/Linux), не даёт мне то и то и то и это… да и вообще они заботятся о других а не обо мне великом».
Вторая: А зачем мне вообще шевелить мозгами, я привык к одном, я не хочу ничего нового это же нужно учиться, это нужно напрягать последние извилины… и на первых же проблемах мылят так: Лучше пойду поставлю то что я знаю, это проще ))).
7. Нехватка времени и лень — на изучение чего-то нового, многие сейчас погрязли в работе что они выжаты как лимон. Им просто лень что либо делать, у них дети, семья, машина, выпивон и игры. Зачем им тратить его, можно пойти по пункту 4 и 5.
В общем можно это продолжать бесконечно…
Но вот теперь перейдём к вопросам, если «реальная» доля пользователей всего «2%» то:
1. Как вы думаете зачем всё больше фирм выпускают версии софта под GNU/Linux?
2. Как по вашем зачем мелкомягким WSL и WSL2, вроде и софт *омно и народу мало? или всё же не так всё плохо у unix систем?
3. Почему подавляющее большинство одноплатников работают под управлением GNU/Linux и BSD.
4. Raspbery Pi и ему подобные весьма популярны и как десктопные компы, особенно с выходом 4й версии.
в общем можно тоже продолжать…
таким образом это моё очень скромное мнение как инжеНегра.
alsoijw
svsd_val
Потому что в винде они встают перед фактом что никак обойти от этого нельзя и придётся что-то делать.
LiquidSnake
Ой да, в одном из дистрибов настройка сети уехала со стандартных нетворк скриптов в netplan. Сходите посмотрите как это конфижится по-новому.
В винде хотя бы критически важные вещи не меняли так.
unsignedchar
:D
В системе, которая развивается, постоянно что-то меняется.
LiquidSnake
В поиске оно ищется без проблем.
Я бы не возмущался так Линуксом, будь там один готовый и вылизанный дистрибутив для пользователей. (Пожалуйста не надо сейчас про Убунту).
Ну и в принципе, выбор это конечно хорошо, но зачастую не хочется учиться «новому» в другом дистрибе, когда он попадается под руку.
alsoijw
Простой пользователь каждый день настраивает сеть, да. Через блокнот, как в видне.
vvzvlad Автор
Зачем вы спрашиваете меня о чем-то, что не касается десктопного линукса? И к тому же, приписываете мне то, что я не говорил ("или всё же не так всё плохо у unix систем?").
svsd_val
Запомните, само по себе ядрышко LINUX никому не нужно, Десктоп и Сервер используют набор свободных приложений, в начале от проекта GNU а постом и от других. Это и есть ОС. Если вы не понимаете понятия ОС, зачем было писать и рассуждать об этом. Винда Серверная тоже самое что Десктопная и отключить гуи там просто так не получится. Настройки же серверной системы почти такие же как и в Десктопной, потому что это ОДНО И ТОЖЕ, они лишь убрали за денюжку установленные ограничения на количество пользюков, количество соединений и т.п. Без набора программ — ОС сама по себе не имеет смысла. Вы же не будете сидеть под DOS, это тоже ОС, но в ней нет софта.
В общем Я как и Вы даю вам повод подумать о том что вы писали выше и той точке зрения с которой вы смотрели на проблематику.
LiquidSnake
В смысле не получится? minimal install и не ставим никаких GUI
svsd_val
Скажем так minimal install это к GNU/linux, у M$ есть Windows Server Core которая появилась, которая имеет графический буфер и не имеет консоли, вы всё так же сможете запустить explorer( потому что большая часть гуи осталась вшита включая вшита в ЯДРО), а по уровню работы вы получите только головную боль. Если хотите попробовать… пробуйте но кроме попа боли не получите ничего.
vvzvlad Автор
Вы пишите какую-то чушь.
svsd_val
Это говорит человек который ни разу ничего не адмниил ) Который даже в простых вещах путается. Спасибо ваше мнение имеет вес )
vvzvlad Автор
Это говорит человек, который не имеет отношения к продуктовой разработке. Спасибо, ваше мнение имеет вес.
svsd_val
Вы точно не знаете о чём говорите, я разрабатываю проприетарный софт в одной из торговых сетей, сопровождаю сторонний проприетарный софт и в свободное время разрабатываю открытые решения. За частую мне приходится патчить проприетарщину (и бинарики и то что на скриптовых языках) потому что их разрабы настолько не поворотливые что мне проще накидать им багрепорты, исправить всё что фирма может работать без остановок а не ждать неделями когда они поставят исправления. Бывали случаи что я им уже готовый код исправлений скидывал который бы позволил исправить их косяк. Они его мутузили несколько дней а после принимали. Но это потеря нескольких дней. Зачастую даже дописываю тот фукнционал которого нет в проприетарных сторонних поставках. Так что если вы хотя бы что то подобное умеете и знаете как работают системные вызовы (в чём я сильно сомневаюсь) ваше мнение будет иметь вес. А пока что я вижу что о многом вы даже понятия не имеете, но берётесь рассуждать.
vvzvlad Автор
Ну я о чем и говорю: вы разработчик, возможно хороший, возможно с крутыми компетенциями, но ваш уровень — "разработка софта, сопровождение софта, патчинг софта". Продуктовой разработкой и не пахнет.
svsd_val
Поясните что такое продуктивная разработка по вашему мнению? Может мы не правильно друг друга понимаем?
У нас.ренова гора пользователей, которые используют наш софт, при том что у нас юзабилити уже в горле сидит потому что есть отдел который следит за этим и говорит а вот тут можно ещё упростить и сделать ещё лучше, ведь пользователю лень нажимать 3 кнопки. А так будут 2. Пользователю лень читать всплывающие подсказки и предупреждения, давайте сократим по минимуму. В итоге такое ощущение что ты разрабатываешь софт не для взрослого человека а для детей младше 7. В общем прошу поясните своё понимание продуктивной разработки, потому что я понимаю под этим разработку софта в определённый срок с адекватными поставленными задачами с запланированным и согласованным интерфейсом который выдаёт прогнозируемые результаты с максимально понятной логикой.
COKPOWEHEU
Тут немножко подмена понятий: WSL скорее для серверных и консольных приложений, чем для десктопных. Собственно, с десктопными особых проблем и нет, причем именно благодаря опенсорсной природе.
Снова огромное преимущество Линукса как ядра и опенсорса. И сама архитектура оказалась достаточно гибкой, и доступ к исходникам позволяет портировать на что угодно.
Майкрософты вон свои винды на ARM уже раза три портировать пытались, постоянно что-то ущербное получается. Особенно, если сравнить с тем же Дебианом, который без шума портирован на полдюжины архитектур — со всеми пакетами.
А они популярны? Я про то, что мощность как ни крути ниже, чем у x86, плюс установить ту же винду или тамошние программы не получится вот никак, а это минус целый ряд софта.
svsd_val
Не согласен, сам лично запускал и вину на OrangePi и CounterStrike 1.6 на RaspberyPi, работают нормально. Но некоторые вещи всё же работают намного меньше потому что большая часть X86 вызовов эмулируется. Так что можно на Arm запускать и i386/i686 и amd64 и aarch64 без проблем., К примеру запускал Insurgency 2 Dedicated Server, на Orange Pi с 1гб озу, оно работает но больше 4х человек в игра уже заметны просадки в откликах. Даже приобретал себе ExaGear, что бы повыше производительность была и транслировались вызовы графики.
Если сравнивать по производительности пересобранный софт то вы увидите что нативный работает и даёт столько же попугаев сколько и средние Intel Atom (проверял лично).А так эмуляция иной архитектуры всегда тяжкое дело даже ля X86 и X86_64.
COKPOWEHEU
Вот видите, вы сами признали, что эмуляция другой архитектуры, тем более х86, задача сложная, скорость такого решения будет ниже, чем нативного даже при прочих равных. Да и профит на настоящий момент не очевиден.
Другое дело если начнется наконец переход на открытые стандарты, тогда хотя бы с офисными пакетами проблем поменьше будет.
Но пока, повторюсь, массового использования одноплатников в качестве основного рабочего места я не видел. В качестве «мозгов» для всякой служебной мелочи — сколько угодно. Но не десктопа. Хотя технически возможно, конечно.
svsd_val
Я нигде и не говорил обратное. Сказал что даже на X86 архитектуре эмуляция других архитектур это тот ещё трудоёмкий процесс. Все эмуляторы ПиЭСок и других приставок тому подтверждение. Но сама концепция весьма неплохая, отсюда всякие JAVA и т.п. со своей VM что бы добиться максимальной производительности )
кстати на одноплатниках неплохие вещи получаются, отличный адблок к примеру и системы умного дома =) Сам использую их в качестве умного Монитора, ком выключен, а новости почитать, код и музыку на lmms пописать, ютуб посмотреть хватает.
LiquidSnake
Ух как, еще и узкомыслие. А от вас видимо снобизм.
А действительно, зачем пользователю лишний раз думать и разбираться, если есть готовое и довольно хорошо работающее?
Linux думает обо всех? Удобно. Больше выглядит так, что раз это бесплатно то какие претензии?
А не узкомыслие ли думать что человеку хочется и нужно изучать что-то на компе? А не просто его использовать? Может человек вообще кройкой и шитьем увлекается а вы к нему со своим Линуксом.
COKPOWEHEU
В линуксе хотя бы все само настраивается, варез искать не надо.
LiquidSnake
Виндовс у него из коробки скорее всего стоит. Или зверьсиди от соседа Васи.
Что блин там само настраивается, может там еще и кнопка «сделать хорошо» завалялась?
Попробуй еще нужный репозиторий найди. и выбери из этого зверинца что тебе вообще нужно.
COKPOWEHEU
Да в общем-то все. У себя на Debian я привык сразу устанавливать firmware-linux-nonfree, firmware-iwlwifi чтобы вафельный адаптер включился, но вот интереса ради попробовал Mint — оборудование подключилось самостоятельно, разве что на дискретную видеокарту вывалило табличку «тут у вас драйвер скачать надо, разрешаете?», после жмяка на «ОК» установился и он. И базовый софт весь установила сама — браузер, офис, текстовый редактор, какие-то игрушки, какие-то утилитки. Но поскольку ставил «на поиграться», глубже не копал. Лично мне все же проще устанавливать нужное, чем вычищать ненужное.
— После ваших слов аж захотелось провести эксперимент: дать кому-нибудь флешку с тем же Минтом и комп. Потом флешку с виндой. Что окажется настроенным быстрее.
oWeRQ
Это еще быстро, у меня на ноуте с hdd накопительное обновление качалось(на полгигабитном канале) и ставилось до первой перезагрузки 3 часа, работать в это время было практически невозможно и еще 3 часа ушло на установки с перезагрузками, итог, будь это рабочий день, можно было бы собираться домой, но как назло под виндой я не работаю, так что пока ставятся обновления — даже кофе не попить.
COKPOWEHEU
Ну, это от тяжести
веществобновления зависит. Я про то, что комп достаточно новый, а уже тормоза на ровном месте пошли. Причем там еще достаточно аккуратный человек им пользовался, а если будем говорить про домохозяйку, которой «посоветовали» чистильщики реестра, отключалки обновлений и телеметрии, антивирусы и прочую чушь?LiquidSnake
Не, окей, обновления винды это «притча во языцех», речь правда не об этом.
Вы не отвечаете по теме, а идете дальше.
Убунта 16 «искаробки»:
— Проблема с разметкой, в дефолтной она раскатываться не желает.
— Стоит какой-то пакетный менеджер, ставим хром. Пишет Success — да фиг там, хрома нет, идем в консоль. ставим.
— Ставим игрушку — черный экран. Плююемся, ищем проприетарный драйвер, ставим его, ребутаемся — черный экран. Плююемся, курим форумы, правим.
— Хотим LighDM ставим, ребутаемся — не подходит пароль, плюем и откатываемся.
— LibreOffice не имеет нормальной совместимости с MS Office.
— Система запрашивает апдейт, делаем, система не поднимается.
— Запускаем видео, нужен кодек, ставим типовые, не хватает, роем интернет
— Закрываем ноут, уходим на 10 минут, открываем — экран не включается.
Я могу еще с десяток примеров привести, дружелюбности системе не занимать.
alsoijw
Запрос рядового пользователя
Персональная проблема гну/линукса, а не жадного мелкософта, да.
В инсталяторе одну галочку забыли поставить. В минте и галочки нет, из коробки идёт. В видне до недавнего времени была аналогичная ситуация.
LiquidSnake
Драйвера NVDIA? Он не заработал. Или «должно быть» уже считается что проблемы нет?
Да, мелкософту запрещено зарабатывать на своих разработках.
Маленькая проблема, пользователей линукса меньше чем винды, поэтому если у виндовода не откроется файл, придется править его — мне.
Да, тут ругают винду, что она из коробки уродлива и неудобна, мол и поменять не на что. Когда то же самое сказали про линукс — дали ответ: Посмотрите как много альтернатив. Вот пользователь и пытается ее применить. Это вполне рядовой вопрос кастомизации системы.
Хорошо, удалю убунту, поставлю минт, пока кто-то не посоветует opensuse /sarcasm
Не было там галочки, я сдался воевать и жахнул установку через консоль.
Остальные проблемы тоже не проблемы? Мне всегда нравилось, что косяки мелкософта это «ууууу, корпорация, вы во всем виноваты», а в линуксе, «Ну мейнтейнер так написал, идите к нему».
Основные советы — сменить дистриб, что-то решается в %appname%, который у каждого свой, а зачем вы используете это решение, ведь есть лучше ( по субъективному мнению комментатора). Плюс чтобы в этом зоопарке разобраться надо гуглить, много гуглить.
Блин, да банальный сброс данных на флешку «искаропки» проблема — надо идти в sysctl, иначе прогресс в конце зависает.
unsignedchar
О_о
Никогда не замечал, правда.
LiquidSnake
Это сообщение от пользователя тут, в комментах.
Я тоже с этим столкнулся. Гуглится кстати нетривиально.
Не уверен что рядовой пользователь должен лезть в параметры sysctl
unsignedchar
Вроде такая же нога есть и у меня, но никогда таким образом не болела.
LiquidSnake
Вы был бы хорошим врачом. Если у вас не было, значит проблемы нет. Следующий!
unsignedchar
— Покажите вашу ногу
— Вы наверное плохой врач, и диплом у вас купленный (хлопает дверью, уходит)
:D
Проблема есть, если она решается гуглением. Но, похоже, она проявляется не в любом окружении. Так лучше? ;)
svsd_val
Сейчас даже разработчики новые не умеют пользоваться гуглом, то что гуглится за 5 минут и решается за другие 5, они не могут решить…
LiquidSnake
Нет, вашу «шутку» я не понял.
Проблему я описал, чего вы еще хотите?
Проблемы с виндой тоже не в любом окружении, что не мешает вам ее хейтить. Двойные стандарты?
svsd_val
Плохо что на хабре нормально не отображается к чему коммент ))) ХАБР ТЫ ПЛОХОЙ, ДИЗАЙН ОЦТОЙ )) Измените точки на линии со стрелками )) уехало всё )))
unsignedchar
Ничего ;)
У меня этой проблемы нет, а решение вы и так знаете.
Вы меня с кем-то путаете ;)
svsd_val
у меня в sysctl только kernel.dmesg_restrict=0, что я делаю не так?
LiquidSnake
А ну раз у вас все работает, то такой проблемы нет. В таком случае винда — беспроблемная ОС, ЧЯДНТ?
svsd_val
Я не говорю что её нет, я говорю что:
1. Для понимания: У вас не зависает процесс копирования, он продолжается просто система позволяет себе хранить эти файлы в кэше и выгружает их по мере того как освобождается носитель.
2. Настройки от дистрибутива к дистрибутиву меняются порой очень сильно, даже сборка ядер происходит по разному, отсюда то чего нет в одном дистрибутиве то вполне может быть в другом. В этих случаях я сравнивал различия в конфигах и параметрах сборки и находил тот самый камень об который спотыкался.
Но это мой подход, я люблю всякие «извращения», запускать к примеру дебиан на копирастном арчевом ядрышке ))) или ещё чего по хуже…
LiquidSnake
Да, так понятней.
К сожалению, без этого параметра запись зависает на 100% и не отдает флешку. Если ее выдернуть, данные покрашатся.
2. Да, вы делаете Just for fun, я тоже иногда люблю копаться в коде, мне интересно. Но бывают моменты когда я просто хочу запустить игрушку или посмотреть фильм и натыкаюсь на проблемы. Неимоверно бесит. Но, это все еще лучше некоторых особенностей винды.
svsd_val
Но это я как инжеНегра говорю, мне удобно так =) Хотя я согласен с вами, что по умолчанию нужны средние настройки которые будут адекватны на большинстве ПК. Но тут уже либо ждать когда ваш дистрибутив созреет, либо настроить самому, либо сделать флешку/сд с нужными вам пред настройками и ставить с неё, либо сменить дистрибутив на более адекватный =)
JerleShannara
Дёргать флешку без размонтирования это плохо, постарайтесь избегать этого.
П.С. Просьба не упоминать, что в винде и без этого можно, я успешно несколько раз таким образом убивал ФС на флешках и хардах под XP/7.
П.П.С. Кеширование записи на флешки в винде было по дефолту, т.е. отключено, но MFT почему-то отправилась в мир иной, при этом состояние флешек и хардов было исправное.
svsd_val
Я не знаю откуда у многих такая уверенность что это можно и нужно они даже внешние винты в сон не отправляют перед отключением а на горячую дёргуют с…
LiquidSnake
Спасибо, я это знаю =)
Просто с этими вещами я столкнулся пару лет назад. Вот и рассказываю о своем опыте перехода.
alsoijw
При чём тут заработок? Я не прошу запретить им продавать офисы или винду. Мелкомягкие, пользуясь своим монопольным положением навязывают свои собственнические форматы, спецификации которых либо закрыты, либо не полны
Тем не менее, в их офисе есть поддержка ODT(возможно не из коробки)
Если пользователь может копаться в реестре, значит сможет и в консоли, иначе пусть возьмёт готовую сборку, или пригласит того, кто это настроит за него. К тому же всё равно остаётся открытым вопрос, из-за чего это произошло, так как это может быть либо баг, либо неверные действия пользователя.
Если вы не хотите гуглить каждый элемент, то скачиваете готовое решение. Если у вас уже установленная система, то в ней нужно разбираться. Я не знаю как сейчас, но раньше, во времена висты или семёрки винда из коробки не умела ничего, ни pdf открыть. ни офисный документ поправить, ни видео открыть. И никого не смущало, что после установки винды им нужно кучу софта руками ставить.
Так работает дисковый кеш, и прогресс не зависает, а просто замедляется. В винде при прочих равных по времени это должны быть сопоставимые цифры.
LiquidSnake
Так ладно.
Не верите, вот вам
COKPOWEHEU
Не знаю, что вы с бедной системой настолько противоестественного делали, что сумели найти все это. Я описал типичную ситуацию. Вот оно просто ставится и работает.
А современная?Между прочим, с виндой так просто не получится, как минимум надо будет довольно долго искать и устанавливать драйвера и отключать всякий мусор.
Что такое «дефолтная разметка»? Не знаю как вы, а у меня никогда не возникало желания потерять на винте все файлы при установке системы. Лучше уж я сам ей укажу куда ставиться.
Ну так напишите в Microsoft об этом, пусть исправляют. Хотя я догадываюсь куда они вас пошлют «мы тут ночей не спим, думаем как бы и стандарт открытым назвать, и чтобы у всех конкурентов дизайн ломался, а вы тут что предлагаете? Удобно пользователям делать?!»
Вот такое один раз видел. Там заглючил скринсейвер, но можно было ввести пароль вслепую, тогда входило без проблем.
LiquidSnake
В то время когда я ее ставил, только выходила 18. Извините, других не было.
Установил. У меня те же вопросы к вам про винду.
Та которую, система предлагает если скормить ей весь диск. Что вы боитесь потерять на пустом диске? Или у вас таки дуалбут?
Почему бы при разметке /boot/efi или /biosboot не сделать по дефолту. Человек впервые видящий линукс либо поставит дефолтную разметку, либо знатно офигеет с этих опций.
Для новичка в линухе будет неочевидно назначение папки /home. А когда он поймет что туда встанут все его приложения, начнет переразмечать всю систему.
В винде же надо десять раз нажать «далее».
Проблема ли это мелкософта? Пользователей винды в 10 раз больше.
Да и вообще это то с чем сталкиваешься только поставив систему. Винда после установки требует только драйвера.
COKPOWEHEU
Я про проблемы с виндой пока ничего не говорил — только про то, что там на чистой системе ничего толком нет.
Все последние разы даже не дуал, а скорее мультибут. Система, которая поставлена производителем, хоть как-то но работает, не хочется ее терять просто так.
Вы можете сформулировать предложение от начала до конца, чтобы не пришлось додумывать? Что вы хотите в /boot/efi сделать по дефолту? Сколько я устанавливал системы, все сразу подхватывали существующий /boot/efi.
Где вы видели человека, ставящего линукс первой системой? Типичная устанока это именно дуалбут.
Для новичка будет неочевидно назначение вообще любой папки. Непонятно почему вы за /home зацепились. При установке его никак не выделяют, при использовании тоже.
Что??? Приложения в /home не устанавливаются. Какой-то особой разметки он не требует, можно даже на отдельный раздел не выносить.
Нет, это проблема пользователей, которую создал майкрософт.
… и ничего не умеет. Для полноценного использования надо ведь еще браузер поставить, офис, текстовый редактор, плейер, просмотровщик всяких картинок и pdf'ов. Да и прочие настройки вроде отключения звуков на каждый чих.
LiquidSnake
Могу. Сорри. Зачем система просит указать его вручную? этот раздел обязателен, и занимает оооочень мало места, зачем его нужно добавлять вручную при manual разметке?
Я до того как поставить Линух домой, только на серверах его пользовал. Там папка /home практически не пригождалась, я иногда туда скрипты приносил.
При разметке дома и опростоволосился выделил пару гигов всего, естественно все забилось, я первое время делал ссылки на внешний диск, потом переустановил и разметил нормально. Да, сказалась неопытность на тот момент, да, сам себе злобный буратино, но это лишь показывает недружелюбие системы.
И да, винда тоже съест место обновками, если ей выделить меньше ста гигов, не спорю. Но для меня все-таки это было сюрпризом.
Кстати за /home я не цеплялся, это первое упоминание мной.
А должен? pdf в хроме откроется, его вы и в линуксе поставите. Текстовый редактор и плеер есть в винде, плюс приедет MPC с кодеками, а кодеки тоже нужны в линуксе. И картинки в винде тоже внезапно можно смотреть.
Про настройки звука — не знаю какие проблемы у вас возникли.
alsoijw
LiquidSnake
Ну вы же даже его размер выбрать не можете, ЕМНИП. Просто кликаете biosboot и он размером один мегабайт уже сконфижен. Забудете — система напомнит что вы его не добавили. Но конфигурить там просто нечего)
BigBeaver
Ну место расположения-то вы можете выбрать? Носитель же не обязан быть одним в системе.
LiquidSnake
Ладно, я не буду спорить)
FenestramDeveloper
Видимо, он настолько обязательный, что у меня даже каталога такого в системе нет. Но даже если бы и был, можно предположить, что в каких-то случаях 1 МБ может быть мало, или нужно указать дополнительное смещение для раздела или на рейд его поставить. Ручная настройка на то и ручная, что осуществляется руками.
LiquidSnake
/boot/efi или /biosboot должен быть в системе.
alsoijw
Только при загрузке в uefi режиме. При загрузке через bios он не нужен. Некоторые дистрибутивы позволяют грузить bios режим даже с разметки gpt.
FenestramDeveloper
Начать с того, что это актуально только для загрузки с UEFI, иначе раздел он в принуипе не нужен. Да и в этом случае достаточно иметь раздел на диске: монтирование происходит после того, как он своё отработал, поэтому особого смысла не имеет. При обновлении или каких-то других административных задачах может пригодиться смонтированный раздел, но это всё прикладные задачи. Ничего такого, чтобы говорить, что /boot/efi «обязательно» должен быть.
PS. Нашёл записи, что опытным путём получилось 35МБ минимальный размер раздела.
JerleShannara
Открою секрет, как не заводить кучу лишних разделов. Вот карта разделов с девайса, который только в UEFI (х86_64) умеет нормально грузиться:
/dev/sda1 -> /boot
/dev/sda2 -> swap
/dev/sda3 -> /
/dev/sda4 -> /home
Решение очень простое: /dev/sda1 отформатирован в fat32
alsoijw
sda2 и sda4 в данной разметке тоже не обязательны.
JerleShannara
Совершенно верно, надо чтобы EFI загрузчик был просто доступен для UEFI, а уж fat32 все UEFI системы обязаны уметь по стандарту.
COKPOWEHEU
Я ее и сейчас на отдельный раздел не выношу. Но, правда, с дуалбута привычка основные данные на отдельном разделе хранить, раньше его из винды было видно.
Сложно мне это обсуждать, поскольку винду устанавливаю редко и почти не пользуюсь потом.
Были там какие-то косяки и с картинками (то ли просто долго открывалось, то ли не было пролистывания, то ли просто интерфейс противный) и со всем остальным.
Толко то, что включена бесячая озвучка всего подряд. Отключить ее — тоже действие, которое надо не забыть.
LiquidSnake
Ну готов сказать что стандартное приложение Video в убунте тоже такое себе, да и Rhytmbox был ужасен.
Приму к сведению, но честно, не сталкивался.
major-general_Kusanagi
Вы про Андроид? :)
COKPOWEHEU
Вы пробовали пользоваться Андроидом на ПК? Вот попробуйте и только после этого пихайте его во все щели.
major-general_Kusanagi
С чего это речь только о ПК, исключая всё остальное, включая сервера?!
Если же речь об обычном пользователе, то полно таких, которым хватает планшета/смартфона.
COKPOWEHEU
major-general_Kusanagi
Чем планшет с подключаемой клавиатурой принципиально отличается от десктопа?
COKPOWEHEU
Еще раз повторяю: попробуйте полноценно поработать под Андроидом — с клавиатурой и планшетом. Редактировать документы, программировать, рисовать, читать документацию, чертить.
svsd_val
В последних редакциях кстати весьма удобный он, у него появилось многооконность, а судя по отзывам нескольких людей чьи нотуты подверглись аднройдотизации им это нравится ))
LiquidSnake
Я пытался с этим товарищем «Бодаться» но он упоро не видит тему статьи и сует андроид куда не нужно.
svsd_val
Андроид это всё же дистрибутив GNU/Linux если посмотрите он будет держать все те же утилиты внутри. Да он специфичен, у него пересмотрели корневую архитектуру. Но он как был дистрибутивом GNU/Linux так и остался.
LiquidSnake
Его прежде чем юзеру отдать, «вылизывает» гугл и производитель оборудования. Чтобы юзер не видел консоли и знал как можно меньше проблем. И отбирает рута.
Это не похоже на систему «искаропки»
svsd_val
Дык, же съели и даже причмокивали ))) А более менее умный народ и рутит и чрутит…
LiquidSnake
Снобизм чистой воды.
svsd_val
А чем вам факты не угодили? Хотите сказать что я наврал? Они сделали народ своими рабами, вы покупате телфон думаю что он принадлежит вам, хотя это не так, вы его арендуете за эти деньги, они хотят обновления кидают не хотят не кидают, хотят следят за вами, не хотят следят )) Или что то я сказал не то? где то солгал?
Если вы считается что быть открытым и выражать и отстаивать свою точку зрения снобизм, ну что же, пусть будет так )))) Двойные стандарты они такие )))
LiquidSnake
Давайте расшифрую, мне не понравилось «те кто поумнее». Многим это просто не нужно.
Специфика андроида в том что самые популярные вещи они допилили, остальное скрыли в кишках и их не видно.
Десктопный линукс сделали GUI так «шобы було» но до блеска не дополировали.
Я вас не обвинял в обмане.
svsd_val
Андройд как дистрибутив линухи стал популярным из-за больших вливаний и гугла и организации возможности вытягивать деньги, они добились того пользователь на андройде выступает в роли источника денег а сам андройд стал самым успешным источником телеметрии. И всё это подаётся под вкусным соусом и люди которые не привыкли критически мыслить на это ведутся. В общем как и на обычную рыбалку и вам звонят с банка дайте нам ключи от сэйфа где деньги лежат ))…
Сейчас подобная тенденция наблюдается и у мелкомягких. Они следят за пользюками и предлагают контекстную рекламу по словам прочитанным с переписки в каком либо мессейнджере… Что мягко говоря не говорит в пользу этой системы.
Возможно я человек старый просто и мне нравится простой дизайн минималистичность. Мне не нравятся всякие свистелки перделки которые никак на работу не влияют а только отвлекают.
А развитие гуи как это сталу у гнома 3 и 4 мне кажется извращением. Гном 2.32, Кде 3.4, Крыса — по мне это лучшее есть и было, Да есть иные jwm, энлаймн, бохди, дипин тоже неплохой, но не КДЕ 5 и Гном 3 и и 4… Это сугубо моё скромное мнение, потому я выбрал из всех то что мне по душе и маленькая крыска стала тем ДЕ на котором я сижу после перехода с Gnome 2.32.
Думаю последствии гуи допилят и для вашего вкуса, но я бы порекомендовал поиграться и посмотреть ещё может уже есть то ч то вам придётся по душе.
major-general_Kusanagi
Абсолютно всё тоже самое делается и с Apple, и всё сразу готовое к работе сразу после покупки!
Это и есть «из коробки» для пользователя.
LiquidSnake
Да, но мы же об этом и говорим.
2% десктопа линуксячего это спецы и члены их семей.
Остальных устраивает MacOS, Win, Android
svsd_val
У меня друг который купил мак бук про, не шибко то он рад макоси…
DMGarikk
это дело привычки (переход с винды на макос по началу несколько обескураживает) и сценариев использования.
COKPOWEHEU
На счет GNU не уверен, уж больно много там сверху не-гнутого накручено.
В любом случае речь не про линукс, а про десктоп. Получится на андроиде полноценно работать? Сомневаюсь.
svsd_val
Десктоп ставится ведройд неплохо даже работает. У нас у парочки саппортов стоит.Им нравится.
svsd_val
Вы 6 и 7 пункт читали? Похоже что нет.
vvzvlad Автор
Это пока у нас чистая установка. Как только разные версии бд начнут требовать разные версии библиотек — все, все плохо.
JordanoBruno
Это не зависит от чистой или нет установки. Версии библиотек в системе вообще не имеют значения. Ключевая фраза тут «Если админ действительно опытный».
vvzvlad Автор
А, ну ок, я и не претендую, я пользователь, я пользуюсь десктопной осью, и иметь специального админа, чтобы просто поставить корректно две версии — ну, странно.
JordanoBruno
Так юзайте докер, он как раз для обычных пользователей и сделан, чтобы по-быстрому развернуть что-то.
vvzvlad Автор
Во-о-от. Классический ответ на вопрос "а почему у меня нога сломана и плохо работает?", это "ну вот вам же сделали замечательные удобные костыли". Костыли замечательные. Ногу чинить планируем?
svsd_val
Он вам предложил решение альтернативное, которое базируется на его точке зрения. Вы же всё судите по своему мировосприятию и отсюда выходит всё остальное. В место того что бы просто сотрясать воздух, создайте баг репорт, опишите хотелки, помогите денюжкой. А вы Доктор гомно у меня нога болит, а он не лечит… хотя доктор может быть даже не в курсе ваших потребностей, или у него столько больных что он делает то что лучше для большинства. Ах да, это же большинство это не я, а значит он гомно.
Пока такое рассуждение будет, сложно будет что-то поменять, потому повторюсь, если есть проблемы создавайте баг репорты, пишите о них разработчикам, данаты кидайте что-бы было ресурсы которые позволяли бы решать проблемы.
LiquidSnake
Окей, когда там коммьюнити отреагирует на такой багрепорт? Скорее всего «когда захочет».
Большинство из них махнет рукой: «Мы тут важные проблемы решаем, а ваши хотелки подождут»
svsd_val
Если вы будете дельные советы давать то думаю что нормально. А если вы будете вести себя как подишах, моя главный и все мне обязаны — тогда вы знаете ответ и сами =). Я всячески за описание хотелок и багрепортов, если не не сложно и есть свободное время я дорабатываю софт…
vvzvlad Автор
— У вас криво реализовано
— Вот вам костыль
— Я хочу правильную реализацию
— Почини сам
— Я не умею/нет ресурсов
— Задонать и напиши багрепорт
— А это гарантирует, что так будет?
— Нет, конечно
Т.е. пути к правильной реализации нет.
silent_jeronimo
Извините, но под виндой разве иначе?
— У вас криво реализовано
… молчание и игнор…
— У вас криво реализовано (замечание 2006 года)
— Поправим в ближайшем обновлении (ответ 2009 года)
проблема унаследована в следующей версии ОС
— У вас криво реализовано
— Ну и что?
— Мне хотелось бы исправления этой ошибки в продукте, который стоил мне довольно много.
— Нет. Это не проблема и исправлено не будет.
То есть пути к правильной реализации нет.
vvzvlad Автор
О, еще один аргумент.
— У вас криво реализовано!
— А что, в винде по-вашему, лучше? Там тоже криво!
COKPOWEHEU
Скорее, это «у вас криво реализовано» — «покажите где реализовано прямо» — молчание и ступор
vvzvlad Автор
Я описал принципы, по которым это будет реализовано менее криво. Но упорно спор идет не с ними, а с какими-то другими вещами.
Oxyd
Ну послушайте, это уже не смешно. Вот я ни разу не кодер, хотя в потрохах системы ± ориентируюсь, но дело не в этом. Даже с моим, не кодерским, а более админским бэкграундом, в меру сил стараюсь сделать лучше для различных опенсурс проектов. Например так. Попробуйте так же, вам может быть понравится. А плакаться в жилетку, в комментах, каждый может. Для этого много ума не надо.
BigBeaver
А, то есть всё сводится к недовольству тем, что мир не идеален?
Ну… С подключением)
svsd_val
Может вы не правильно формулируюете мысль? Вы хотя бы пробовали думать перед описанием проблем и хотелок. Предложите варианты решения. Чем больше информации укажите в решении тем больше вероятность что оно будут приняты исправления…
vvzvlad Автор
— А как можно гарантировать?
— Правильно опиши, подумай над проблемами и хотелками, предложите варианты
— И это гарантирует?
— Нет, конечно
— Т.е. способа починить не существует?
— В винде тоже баги!! Их тоже не чинят!!
Мое время, как специалиста, стоит дорого. К тому же, когнитивный ресурс конечен, и я не смогу активно думать сверх определенного времени. Я готов потратить время на опенсорс-проекты, которыми я пользуюсь, потому что они мне нравятся, и хотелось бы, чтобы они жили хорошо, и мне хотелось, бы, чтобы ими было удобно пользоваться. Но нет смысла тратить это время, если тебе (и любому другому специалисту) в ответ скажут "сорян, нам это не интересно реализовывать, мы лучше новую фичу запилим".
BigBeaver
Ммм… Вы говорите, что у Х маленькая доля рынка потому, что в нём всё криво. Но, когда вас спрашивают, где прямо — оказывается, что нигде. Из этого очевидным образом следует, что связи с кривизной нет.
Если линукс плох в роли десктопа, но на винде всё то же самое, то она хороша в роли десктопа или тоже плоха? А кто тогда хорош на десктопе? Хороший десктоп вообще существует?
LiquidSnake
Если линукс хорош в виде десктопа, то почему его 2%?
И почему так много в серверном сегменте?
unsignedchar
Так вы слона не продадите ;)
Бесплатный софт продавать сложно.
LiquidSnake
Хотите сказать что предустанавливать Линукс и продавать так ноутбуки и пк нельзя? Почему Андройду смог?
unsignedchar
За Андройдом стоит Google. Они сделали ОС для телефонов, значительно отличающуюся от аналогов.
Десктопный linux — он практически как Windows. В чем-то лучше, в чем-то хуже, но для задач домохозяйки — особой разницы нет. Только на бесплатном linux сложно заработать, а платная ОС уже есть.
DMGarikk
проблема линукса отнюдь не в бесплатности, учитывая что были преценденты с платными версиями (для декстопов) и все они провалились.
unsignedchar
Ещё бы. Платный линукс должен быть значительно лучше бесплатного, иначе он не нужен.
Собственно, у бесплатного Windows тоже есть фатальное преимущество перед платным.
LiquidSnake
Бесплатный виндоуc это ReactOS. Кому он нужен то?
svsd_val
Предприятиям которые ставят винду лишь ради пары приложений которые не портированы на другие ОС. А платить лицензию предприятиям кстати дороже и проверяют их чаще, чем домохозяек.
И если вы пойдёте к какому бы то левому человеку подхалтурить и переставить винду, можете схлопотать штраф либо строк, а если вы ещё и какой то софт ломаный поставите… считайте вы попали надолго…
LiquidSnake
Вы реально видели чтобы его использовали?
Он ведь только с виду винда, работспособность под большим вопросом.
svsd_val
Да видел.
unsignedchar
А что пиратов ущемляют - это уже фатальный недостаток платного софта ;)
Короче, все равно дело в деньгах. На бесплатном софте для домохозяек сложнее заработать. На платном - легко и просто. Казалось бы, ноутбук с предустановленным линуксом должен быть дешевле аналогичного с Windows на цену лицензии. Но почему то на ноуте "без ОС" оказывается совершенно бесполезная китайская поделка, которую все равно нужно сносить. Наверное, у продавца нет цели продаж подешевле.
unsignedchar
Разница между платным Windows и бесплатным ReactOS значительная ;) В чём будет разница между бесплатным Linux и платным, и чего это будет стоить домохозяйке? Мне приходит в голову только support. Но оно же и без поддержки работает — зачем платить?
LiquidSnake
Вам приходилось общаться с саппортом?
Мне да. Полезность зачастую сомнительная.
Разница между платным и бесплатным значительная, да.
Только скажите мне какая)
BigBeaver
Вы на поставленный вопрос прямо ответьте пожалуйста. Мой комментарий никак не зависит от того, хорош линукс или нет. Давайте примем, что линукс на десктопе — говно для извращенцев — нет проблем. Вопрос второго абзаца остается в силе.
LiquidSnake
Если вы спрашиваете меня сейчас — отвечу:
Винда тоже плоха, чем-то лучше, чем-то хуже, каждый сам выбирает какие плюсы для него важнее. Скорее всего идеальной системы нет. Я не могу отвечать за мак, т.к его не трогал.
BigBeaver
Ок, согласен. Я сам, в целом, считаю, что все системы становятся только хуже где-то начиная с 2012. Но это лирика. Теперь главный вопрос — если все системы ± плохие, то наеврное, процент рынка связан с чем-то другим?
alsoijw
BigBeaver
Вас не смущает, что я на стороне линукса? Конструкция выше — чисто гипотетическая, и к реальности и/или моему мнению отношения не имеет. Она прямо говорит «даже если мы примем Х, Y всё равно ни каким следствием не выводится, тк Z».
svsd_val
А где доказательство что десктопного линукса всего 2%? У меня в браузере установлен идентификатор какой я хочу, телеметрию я не отправляю никуда. Откуда взялись эти цифры?
LiquidSnake
Вам понравится больше если будет «Значительно меньше чем пользователей Windows»?
Что будет правдой, хотя вы опять можете задать вопрос «Что значит значительно?» и я замолчу, потому что статистики нет, мне лень ее искать, хотя все и так очевидно.
svsd_val
В данном аспекте даже смысла нет рассматривать, потому что это дело вкуса =) Мне безразлично что она имеет меньше долю чем винда, мне безразлично на то что и кто о ней думает. Мне нравится она своим удобством, быстротой, тем что мне никто и ничего не навязывает, я с ней могу позволить себе обойти роскомпозр и иные ограничения включая наглую обдираловку от билайна которое не даёт расшаривать тырьнет семье. в общем у всех свои плюсы )
svsd_val
Я не видел такого, в большинстве случаев я видел что предлагали откровенно бесполезный, мало востребованный, либо очень сложный в реализации функционал, на что разработчик вполне правильно говорил что: есть более приоритетные вещи, нет средств или нет народа кто этим бы занимался. Всё вполне понятно и адекватно. Были конечно индивиды которые клали на всех но и тут же форки получали…
Oxyd
Я-б не делал таких поспешных, смелых заявлений. За то время, что вы потратили на написание 60+ немаленьких комментов, в этом треде, не один линукс можно было вылизать под себя. Или это другое ©?
LiquidSnake
Как по мне, все же другое.
Пишу комменты сюда в свободное время, и я явно сам выставляю приоритеты того что хочу и делаю. Если общение на хабре форма отдыха, то ковыряние в настройках линуха не всеми оценивается как отдых.
alsoijw
svsd_val
В текущих реалиях развивается новый дистрибутив ключевой особенностью которого стал пакетный менеджер который рассчитан установку множественных версий п.о. почитайте про GuixSD GNU/Linux. Так что в последствии вы сможете поставить хоть все версии одного и того же п.о. В общем было бы только желание.
Mausglov
Хочу поделиться примером пользовательского опыта:
Лет 10 назад моей сестре, преподавателю социологии в ВУЗе, срочно потребовался ноутбук для работы, а с деньгами было туго. Она купила супербюджетный eMachines с DOS, а я туда поставил Федору ( поскольку было очевидно, что семёрка там будут тормозить).
И знаете, сестра была вполне довольна: он шустро просыпался, там был браузер, архиватор, понятный файловый менеджер, аудио- и видеоплеер, можно было просматривать картинки и читать PDF. Обслуживания система фактически не требовала: раз в несколько месяцев я запускал yum update, оно что-то обновляло, но внешне ничего не менялось. Интерфейс Gnome Shell оказался сильно удобнее семёрки: уже запущенные приложения было видно в доке, а остальное можно было быстро найти через "нажать Esc и начать набирать название".
Камнем преткновения стал офисный пакет: созданные в Libre Office документы на вузовских компьютерах отображались криво ( у меня попасть в вуз и увидеть это собственными глазами не получилось ), заставить работать MS Office через Wine я не смог из-за недостатка опыта, а суррогат в виде VirtualBox с XP и Офисом работал медленно.
В статье есть хорошая фраза:
Вот глядя на ту систему и моих знакомых среднего и старшего поколения, я видел, что их потребности как пользователей она закрывает полностью. Таких людей, думаю, сильно больше 2% ( хотя, наверное, меньше 50%). Но:
Тот ноутбук продержался 2 года, пока сестре не надоела медленная работа с офисом. Следующий уже был с Win 8 ( вроде, она потом даже обновилась до десятки) — спустя какое-то время он стал адово тормозить после перезагрузки и в произвольные моменты времени ( что было очень-очень плохо для вебинаров ). Причины не удалось выявить ни мне, ни мастерам из сервиса, а старая добрая переустановка с новой виндой помогать перестала.
В итоге был куплен ещё один ноутбук ( уже с предустановленной Win 10) — схожей конфигурации, но другой фирмы. Он не тормозит ( пока?).
red75prim
Начальное обслуживание не считается? Или твикать vm.background_bytes, vm.background_dirty_bytes не пришлось, чтобы запись на usb флешки не подвисала в конце?
svsd_val
Мы в институте использовали нетбуки с атомом n270, мне вполне хватало Debian Sid (на тот момент самый свежий унстайбл был Jessie). При этом тогда хватало OpenOffice после он распался на LibreOffice. Все лекции я вёл в электронном виде, успевал и сложные формулы записывать, а что не успевал по записывал от руки в тетрадь и после переносил в OpenOffice. Даже диплом сдавал написанным в OpenOffice и odt формате. Правда вначале не хотели принимать типа шрифт не таймс нью руман… после чего показал что в методичке написано: Таймс нью руман либо аналогичный. В итоге приняли всё и я успешно защитился.
А многим не верится, что такое возможно…
develop7
правильный ответ (если вы, конечно же, не из неолуддитов, которые избегают systemd всеми силами) будет "б) в системном логе", а именно в (пользовательском) journal. Всё.
k_skov
Частично, я согласен с мыслью, озвученной в статье. Хотя, мне показалось, что материал какой-то устаревший. Я уже год, с переменным успехом пытаюсь пересесть на linux на домашнем компьютере. И не так чтобы там всё(!) было сложно. И экран повернуть можно, и программы не падают, без видимых на то причин. Однако!
Такое дело: у меня макбук 11го года. Для него Mojave уже не вариант (легальным путём), а 13 ОСь перестала поддерживаться рядом программ (первая, пришедшая на ум, Homebrew). WTF? Мне не круто, когда меня подталкивают к походу в магазин за новой железкой. При том, что моей мне хватает. Не велик список требований, но они исполнимы на этой связке камня/памяти/SSD. Если на лептоп накатить тот же Manjaro, всё збс. Забываешь о существовании вентиляторов внутри корпуса. Всё более менее норм. Но ...
… теперь за linux скажу. Случаются такие стечения обстоятельств, когда "вот, очень срочно надо!", а ни-че-го не работает. Это из мира нематериального примеры. Когда всё в одну точку сошлось, а ты документ на принтер отправить не в состоянии. В смысле, лептоп, тебя отсылает по известному направлению. В другой ситуации — расслабился, и нашел бы решение с гугл, а тут — времени ну вообще минусноль! И вот об такие моменты (которые раз в 100 лет случаются), я и спотыкаюсь при переходе. Мне кажется, что основное слово, которое отсутствует в лексиконе десктоп систем из мира nix — предсказуемость*.
Из легенды: руки у меня норм, не в разные стороны направлены. И ломать, и чинить — умею. Инженер, и всё такое...
bigov
2% рынка — это то число предустановленных систем на компьютерах в продаже. Когда в продаже появится 20%, тогда и пользователей станет больше. А влияние тех, кто купил десктоп с предустановленной MS или Apple операционкой и переустановил себе Linux — ничтожно. Большинство вобще не может ответить на вопрос: «какая операционная система у вас на компьютере»? Мне некоторые отвечали: «Ворд»!!!
major-general_Kusanagi
На смартфонах и планшетах, Линкус в форме Андроида — доминирует, и занимает большую часть рынка.
LiquidSnake
Вам важнее быть правым я так вижу? В жертву приносится здравый смысл
major-general_Kusanagi
Что не так? Андроид внутри себя содержит Линукс, и следовательно Линуксом является.
LiquidSnake
Окей, живите теперь с этим.
LiquidSnake
И поэтому линукс им не подходит. Потому что при первой проблеме придется лезть в консоль.
mpakep
Ну очень спорное утверждение.
LiquidSnake
Пользователь — не будет. Пользователь зачастую даже программировать не умеет.
oWeRQ
За 15 лет пользования линуксом не пришлось лезть в исходники, хотя это не отменяет пользы от открытых исходников, необходимые приложения можно поставить практически на любое устройство. Тут вспоминается провал Windows RT, в основном из-за отсутствия приложений собранных под arm.
red75prim
Обычное правило одного процента или 90-9-1.
90% луркают, 9% иногда что-то пишут, 1% активно участвует. Подозреваю что для поддержки ПО это правило будет 99-0.99-0.01: 0.01% пишет код, 1% — багрепорты, 99% как-то живут с этим.
MTyrz
Позор на мою седую лысину. Встречайте:(с) Алекс Кантровиц. «Always Day One»; вольный перевод отрывка мой.
Как выглядит захват рынка успешным продуктом?
Просто сделайте успешный продукт, а затем влейте в его рекламу бюджет Google.
LiquidSnake
Ну вы правда думаете что я сижу с хрома потому что мне его рекламировали?
BigBeaver
Ну не лично вам. Но, в целом — да.
Прорекламировали/навязали => выросла доля юзеров => сайтостроители больше ориентируются на него => большинство сайтов работает в нём лучше => вы начинаете думать, что выбрали его сами по объективным причинам.
При этом все знают, что самый лучший браузер — Опера 8. Лишь за тем исключением, что 90% интернета в ней не работет.
MTyrz
Я вправду думаю, что хром на компах пользователей «заводится сам по себе» больше, чем в половине случаев. А когда его продавливали из каждого утюга, включая адоб флеш и драйвера к материнкам — он заводился сам по себе много больше, чем в половине случаев.
К вопросу: в той самой винде того самого соседя хром завелся «сам». Сын не понимает, как — вроде бы он ничего даже не качал…
LiquidSnake
Ну, они всегда не понимают :)
У меня после установки винды стандартный пункт — скачать хром.
MTyrz
Я тоже его скачал, когда он только вышел.
Впрочем, скорее ради интереса, чем использования. Но речь тут не про нас с вами, мы попадаем в те «десятки миллионов энтузиастов», о которых говорил Апсон. А реальные сотни миллионов установок — это агрессивнейший маркетинг с использованием рекламного бюджета (в то время) четвертой корпорации мира — плюс совковая лопата темных паттернов.
alsoijw
Есть, конечно, вероятность, что вы веб-разработчик, и вам больше нравятся инструменты разработчика хрома(почему не хромиума?), но всё же есть не меньшая вероятность, что на ваш выбор повлияло чьё-то мнение. Сейчас веб-разработчиков не волнуют альтернативные движки, и они всем навязывают хромые браузеры, так как они не хотят поддерживать другие, вплоть до того, что они прямым текстом говорят поставить хром.
qrKot
Буду краток: да
Xaliuss
Потом дополнительно постоянные предложения установить хром при заходе на страницы гугла (как минимум с ИЕ и первого Edge), и оптимизация их по максимуму под хромиум. В итоге и набралась критическая масса.
MTyrz
Сейчас, по моему скромному, мы наблюдаем вариант стратегии EEE в исполнении Гугла. Давайте вводить сорок восемь проектов стандартов в год, и не дожидаясь утверждения, поддерживать их своим хромым браузером. А остальные пусть догоняют, как могут (демонический хохот).
BigBeaver
Так это с самого начала так было, не?
MTyrz
«С самого начала» так быть просто не могло, гугл не Афина Паллада, чтобы родиться из головы Зевса во всеоружии и с капитализацией из топ-3. Но уже к моменту разработки хромого — да, было так, хотя многие (в том числе я — грешен, каюсь) находились под скромным обаянием.
BigBeaver
Ну я про внедрение хрома и говорю. Они очень быстро внедряли фичи для своих сервисов, которые плохо работали за пределами хрома.
MTyrz
С начала доминирования — да, конечно. Вы правы.
Xaliuss
При этом видны двойные стандарты, когда майкрософт пытается продвигать свои продукты в своей ОС большинство говорит как это плохо и вспоминают ту же браузерную войну 90-х, хотя то что делает гугл такой же реакции не вызывает «так как хром лучший браузер и сервисы гугла топ». Та же мобильная винда очень сильно страдала из-за того, что гугл просто не делал под неё свои приложения.
Нужно, чтобы больше людей рассказывало о некорректных практиках гугл, поскольку сейчас им слишком многое сходит с рук.
MTyrz
Не знаю, по-моему гугл сейчас успешно борется с ФБ за звание Палпатина десятилетия. И Амазон возбужденно сопит им через плечо.
Так-то они все хороши… пауки в банке.
oWeRQ
Не в защиту хрома, просто навеяло воспомянаниями об IE. Когда майкрософт продвигал IE, этот самый ишак работал только под виндой, да был еще порт под Mac OS и какой-то Unix, но это были еще более кривые поделия, которые забросили, это был полностью закрытый движок, в котором годами не исправляли баги и не развивали его(между релизами IE6 и IE7 прошло больше 5 лет, возможно ли такое с хромом?), сколько интернет баков и прочих систем нельзя было использовать нигде кроме Windows, так что да, это другое, это две совершенно разные ситуации.
BigBeaver
Там больше в ActiveX проблемы были. В офисе они до сих пор сохранились.
alsoijw
VladC
Сижу на Ubuntu около двух лет и считаю, что для простых пользователей (не айтишников) Linux нафиг не нужен и даже неудобен.
BigBeaver
Вконтактик-то не всё равно, на какой системе использовтаь?
LiquidSnake
Я не понимаю почему вы упорно делите пользователей на «совсем домохозяек» и «спецов». Между этими категориями есть еще куча типов людей. Мне представьте, кроме условного «вконтактика» нужно еще много чего делать. И оказалось что мне удобнее это в винде.
Обычный пользователь может столкнуться с LVM, fstab, selinux, iptables/firewalld, etc. И все это будет нетривиально.
unsignedchar
Обычный пользователь может столкнуться с
LVM, fstabdiskmgmt.msc,selinuxgpedit.msc,iptables/firewalldWindows Firewall, etc. И все это будет нетривиально.:D
LiquidSnake
И вправду смешно, диск я размечал через «администрирование системы» просто назначив букву. Насколько я помню фс разлилась автоматом. Все, проблема решена.
Что надо сделать в линуксе если вы притащили новый диск? сделаем fdiskom разделы, или прям там бахнем новую. Сделаем ручками новую фс и пойдем в фстаб. Где ошибившись в буковке вы угрохаете систему. Ну с точки зрения пользователя. Нам то очевидно как это исправить.
Идем дальше. gpedit? А нафига пользователю править групповые политики? серьезно?
Windows Firewall? вы о брендмауэере? Ну, на каждый запуск софта он спрашивает «А можно ли пустить этот софт в интернет?»
unsignedchar
Меню — параметры — disks, наверное. Но можно и через консоль, как предки делали :D
Нафига пользователю selinux?
И что именно нужно настраивать на пользовательской машине через iptables?
LiquidSnake
Ну как минимум потому что селинукс мешает запускать софт. И нигде об этом инфы нет. Оно конечно полезно, но вот непрозрачно.
Если вы за натом — ничего конечно.
unsignedchar
Судя по www.linode.com/docs/guides/how-to-install-selinux-on-ubuntu-18-04 — чтобы он начал чего-то мешать, его нужно сначала установить. А то что ставится по умолчанию — никогда не слышал, чтобы оно мешало что-то запускать.
LiquidSnake
Принято, я плаваю между дистрибами. в centos он из коробки.
Можем этот аргумент не засчитывать.
BigBeaver
LiquidSnake
Возможно в 16 убунте было по-другому. Признаю неправоту.
BigBeaver
Тут я должен честно добавить, что не помню, когда это сделали. Но достаточно давно чтобы я не помнил, как fstab вообще работает, хотя в нулевых действительно периодически его правил (правда, тоже не помню, для каких целей).
COKPOWEHEU
Не исключено что для монтирования всяких fat'ов и ntfs'ов чтобы юзер туда писать мог
BigBeaver
Он и так может. Возможно, я просто хотел более удобно расположить их на дереве.
COKPOWEHEU
Он может если монтирует раздел от пользователя. А если automount, то нужно прописывать права (виндовые ФС ведь не умеют в права доступа) и кодовую страницу.
BigBeaver
Разве? На флэшках же как-то работает.
COKPOWEHEU
То есть если вы в интерфейсе нажали иконку флешки, она смонтируется нормально. Но если хотите чтобы она монтировалась при старте системы командой mount -a, то fstab поправить придется, включая права доступа.
BigBeaver
А, вот вы о чем. Ну да, наверное, так и было.
DMGarikk
ntfs?
COKPOWEHEU
Какие-то есть, но не обычные rwxrwxrwx. Насколько я понял, в линуксовой реализации ntfs вообще заводится один пользователь на всю файловую систему. Хотя, наверное, можно и похитрее настроить.
DMGarikk
правильней сказать что это линукс изкоробки не умеет в права доступа на виндовых ФС, а не «виндовые ФС не умеют в права доступа»
==
Но вообще установка прав доступа, для любых ФС, на флешке, это такая себе затея если флешка будет использоваться на разных не связанных друг с другом компах
COKPOWEHEU
Давайте уж еще расширим определение: «файловые системы, доступные для нескольких независимых ОС». Сюда в числе прочего будут входить и разделы, доступные разным ОС при дуалбуте. Там тоже могут быть проблемы с правами.
DMGarikk
само собой. Я вообще отвечал на фразу 'виндовые ФС ведь не умеют в права доступа"… это мы уже потом съехали в обсуждение прав доступа на флешке как таковых
резюмируя — 'виндовые ФС" (точнее одна — ntfs) умеет в права доступа не хуже (а может и лучше) линуксовых, а то что в линуксе оно не поддерживается это другой вопрос
oWeRQ
Сейчас в том же gnome-disks есть галочка монтировать при загрузке, раньше, после того как диски начали определяться и показываться в FM, приходилось лезть в fstab чтобы это включить, например, для диска с музыкой и загрузками, а еще раньше без этого пришлось бы каждый раз после перезапуска запускать mount чтобы просто открыть диск.
alsoijw
JerleShannara
А теперь вам кидаю задачку, очень смешная вышла. Купил пользователь диск, чтобы кино на телике смотреть. Воткнул в комп с виндами, кинул кино на диск, а телик говорит: ты в меня воткнул что-то но оно пустое. И что дальше делать?
LiquidSnake
Пользюк — хз.
Я либо пойду форматну диск в то что понимает телек, либо просто настрою DLNA и буду смотреть так.
JerleShannara
Направление движения правильное. Телик умеет в NTFS, диск в NTFS, но телик ругается.
LiquidSnake
Что дальше не подскажу. Скорее всего буду гуглить особенности диска и телека. Потому как дело явно не в формате файла.
COKPOWEHEU
косяк с таблицей разделов? Скажем, в ntfs отформатирован /dev/sda, а не /dev/sda1. Или GPT / MBR.
[пытаюсь угадать ход мысли]
JerleShannara
habr.com/ru/company/ruvds/blog/556124/#comment_23063506
red75prim
Звоним в поддержку. И там скорее всего начнут с "Вставьте диск в компьютер, нажмите кнопку пуск..."
LiquidSnake
Спасибо, поржал. Вы наверное первый кто звонил в поддержку.
red75prim
Первый, кто звонил в поддержку производителя телевизора? Это врядли.
Кстати, вот ещё задачка. Прямо из жизни. Сегодня провайдер апгрейдит оборудование до гигабитного и интернет периодически отваливается. Что я делаю на винде? Цепляю телефон по usb, ставлю на телефоне галочку "Шарить интернет по USB", ставлю в windows галочку "Metered connection" для нового соединения (или он спрашивает при первом подключении? не помню). Всё. Роутинг меняется автоматически при недоступности интернета по ethernet.
Что я делаю в линуксе?
LiquidSnake
У вас в телеке есть «вставьте диск в компьютер, нажмите пуск»?
red75prim
Э? Если поддержка будет советовать форматировать внешние HDD на телевизоре, без упоминания того, что сначала нужно скопировать все файлы куда-то ещё, то очень многие будут недовольны пропавшими данными.
LiquidSnake
Вы сказали что позвоните в поддержку и услышите от нее «вставьте диск в компьютер, нажмите пуск»
С каких пор поддержка телевизора говорит с вами о винде? Они вообще таких советов даже давать не могут.
red75prim
Кто им запретил? Например вот: http://kr.eguide.lgappstv.com/manual/w16_mr/dvb/Apps/w16_mr_e01_e/e_rus/share.html
"Используйте только USB накопители, отформатированные в файловую систему FAT32 или NTFS с помощью ОС Windows."
unsignedchar
Кроме LG, есть и других телевизоров. И некоторые из них могут уметь в NTFS, но не уметь в GPT.
red75prim
И? У них в техподдежке запрещено упоминать windows?
unsignedchar
Не знаю, правда. Если у вас проблема с телевизором — при чем тут Windows?
red75prim
Спор ради спора. Если техподдержке потребуется решить проблему с тем, что телевизор не видит файлов на диске, записанном на компьютере, то они они в первую очередь будут ориентироваться на пользователей windows и mac OS. Просто по экономическим причинам.
unsignedchar
Они будут работать по скрипту в любом случае. Кандидат компьютерных наук, специализирующийся на Windows, не будет сидеть на телефоне. Если в скрипте есть решение — вы его получите. Если нет — значит нет.
red75prim
Шанс пятьдесят на пятьдесят? Как с динозавром?
ЗоопаркМногообразие десктопных дистрибутивов линукса не особо способствует наличию решения в скрипте.BigBeaver
Зато, разнообразие рабочего окружения не сильно отличается от числа версий винды)
red75prim
Давно вам наверно не приходилось диктовать консольные команды по буквам. "С как доллар". Хех.
BigBeaver
Естественно. А зачем это нужно вообще? Всё в гуях давно. Хотя сам я предпочитаю консоль, конечно, тк стандартные команды всегда одинаковые, а гуи меняются с годами, какой бы консервативный дистр ты не выбрал.
unsignedchar
Давно вам не приходилось рассказывать, на что похожа иконка, похожая на флоппи-диск :D
red75prim
Это реальный случай или продолжение спора ради спора?
BigBeaver
Звучит реально. Хорошо, что я не сапорт.
red75prim
Да, не завидую саппорту. Кстати, что там в линуксе вместо флоппи-диска?
BigBeaver
Где? Подозреваю. что много где так же флопи диск и есть.
unsignedchar
Это шутка, конечно же. Но где-то в комментах есть похожий сценарий поиска панели управления ;)
JerleShannara
Воо, проблема решена на первой стадии. Телик не умеет в GPT, но умеет в NTFS. А теперь продолжение: после перевода диска в MBR(пользователь сделал это под Windows 7) телик увидел диск и то, что на него закинули сразу после этого, но вот при повторном подключении к компьютеру диск пропал, телик его продолжает видеть, но в «Мой компьютер» диска больше нет.
red75prim
Открыть "Менеджер дисков", правой кнопкой на раздел без буквы, назначить букву.
JerleShannara
Это помогало ровно на один раз. Подключили диск, нет в «Мой Компьютер», зашли в эти дебри, назначили букву, диск появился, что-то поделали(файлы там позаписывали), безопасно извлекли, подключили — и опять диск не появился в «Мой Компьютер».
Диск при этом полностью исправен.
red75prim
Попробовать сделать при отключенном диске
diskpart
automount scrub
и заново назначить букву
JerleShannara
И началась магия виндовой консоли.
Естественно не делали, сказал, чтобы притащили мне диск, занулил до начала раздела и накатил новый MBR. Что там винда записала и почему только она сама не могла увидеть свою работу без танцев с бубном — знает только тот индус, который драйвера писал.
unsignedchar
Вот в этом и есть разница между 2 магиями ;)
Линуксовая магия постижима. Можно найти причину странного поведения. Посмотреть исходники. В крайнем случае, если хватает квалификации, даже починить.
red75prim
Или тот, который писал работу с диском в прошивке ТВ. Теперь уже не разберёшься.
unsignedchar
Делаете то же самое, но по линуксовому ;) Вы же откуда-то узнали, какие кнопки где нажимать? Или знание пришло во время медитации над рабочим столом? :D
red75prim
Какое, блин, знание? Тыкнуть "Metered connection" нужно не для того, чтобы винда начала автоматически роутить траффик через линк с работающим интернет соединением, а для того, чтобы она через телефон обновления не качала (и, по-моему, эта галочка устанавливается автоматически, но написал на всякий случай, чтобы у кого-нибудь лишний трафик не съело). А тыкнуть "Расшарить интернет-соединение через USB" — это знания про андроид.
Так что в линуксе нужно сделать для настройки автоматического роутинга через интерфейс с работающим интернет-соединением? Один ответ я знаю, но может быть что-то изменилось с тех пор.
Ответ: находим имена сетевых интерфейсов для ethernet и телефона, находим скрипт для детектирования работы интернет подключения на конкретном интерфейсе (или пишем свой), пишем скрипт для смены default gateway при пропадании интернета на основном интерфейсе (используем имя телефонного интерфейса для получения его gateway), прописываем его в cron. Возможно ещё придётся подшаманить что-то с настройками сети, так как теперь у нас multihomed конфигурация.
Ну или отключаем ethernet и гоним всё через телефон, периодически проверяя, не включил-ли провайдер интернет.
red75prim
Сейчас проверил ещё один вариант: воткнуть телефон в роутер в качестве backup connection, там линукс, USB-модемы он поддерживает, автоматическая смена роутинга должна быть настроена из коробки. И… нет. Шаринг интернета с андроидофона через usb он не поддерживает.
Лезть через ssh разбираться в чём дело, не буду, извините.
oWeRQ
Не понятно к чему это, линукс для роутеров и для десктопа отличается в конфигурации, например, на роутерах наверняка нигде не используется Network Manager, который на десктопах отвечает за дружелюбность при работе с сетевыми соединениями. Это не значит что на десктопе оно работает, я понятия не имею, никогда не было нужно, но сравнивать поведение десктопной винды и встраиваемой системы некорректно.
red75prim
Никаких претензий к дружелюбности интерфейса командной строки роутера у меня нет. Я просто констатировал, что этот вариант тоже не работает из коробки. И что разбираться в чём там дело мне лень и, к моему удовольствию, ненужно.
unsignedchar
Вот видите. А я вот этим знанием не обладаю.
А то, что у этой галки есть замечательный побочный эффект, приводящий к автоматическому выбору роутинга — это прекрасно же.
JerleShannara
У меня нет кнопки пуск, она была на старом компуктере а на новом её нет.
unsignedchar
Смешная задача получилась ;)
Воткнул в DVD плеер, смотрит. В чём задача он так и не понял. DVD проигрыватели сейчас на барахолках за шоколадку отдают.
Или имеется в виду флешка, а телевизор с USB, а флешка ему попалась в формате ext4?
JerleShannara
Внешний жесткий диск. Куплен потому что другой пользователь сказал «я купил его и у меня телик с ним работает».
unsignedchar
Покупки надо с кем-то из взрослых согласовывать. Есть такое слово совместимость.
Но если уж поставил себя в такую ситуацию — тут нужен администратор телевизора ;) Может в нем прошивку нужно обновить, или откатить, или эта модель никогда этого не умела…
svsd_val
Обычный пользователь не пойдёт лесть настройки безопасности и тем более настройки файрвола… Ему это совершенно не надо. Те кто не понимает в компьютерах они с лёгкостью могут убить винду, стереть винт, в общем всё то за что хаят линуху, но в упор не признают в винде, а при столкновении с более менее не тривиальной задачей он встанет перед выбором нарастить компетенции или расстаться с деньгами, тут уже будет выбор от него.
И вот тут повторно, уже возникнет вопрос к линухе, А ПОЧЕМУ МНЕ ЭТО что-то учить, почему я должен за что-то платить, но в случае с виндой у них таких вопросов нет… Двойные стандарты в действии ))
LiquidSnake
Ну а пользователь Линукса не может rm -rf /* сделать, ага.
Отвечаю, потому что в винде мне узнавать что-то новое для повседневного использования не приходилось так часто как в линухе. Это было постепенно. Выше я оставлял коммент с чем я столкнулся только поставив Убунту. У меня нет никакого желания постоянно тратить свое время, на исправление ошибок и багов.
Ваши же двойные стандарты в том, что вы не признаете что проблемы чаще встречаются именно при настройке линукса.
unsignedchar
Сможет, почему нет? А зачем ему это делать? Что помешает ему сломать Windows с помощью diskmgmt.msc или diskpart.exe?
Наличие генетически приспособленных к Windows человеков наукой не доказано ;) Вы просто увидели комп с Windows раньше. А вот синдром утёнка наукой доказан ;)
LiquidSnake
Я вам еще раз повторяю, я с виндой не ловил столько проблем, сколько с линуксом на домашнем компе. Притом что я администрирую линукс по работе, правда другой дистриб.
Единственное что вы не учитываете, это вероятность возникновения сложностей, которых в линуксе больше, за счет усложнения системы.
Я думаю дальше говорить не о чем, каждый останется при своем мнении.
svsd_val
Как бывший пользователь M$ Windows говорю что в ней я сталкивался и с куда более сложными проблемами. Которые даже с переходом на Линуху древних версий 2.6.x я не видел. Если человек извиняюсь за термин «чайник» то он сможет с лёгкостью застрять в любой ОС и сломать любую ОС.
А теперь по поводу вероятности возникновения проблем, если всё адекватно настроено, то она стремится к нулю. А винда даже настроенная, которую никто не трогает часто может выдавать глюки даже в неожиданных местах.
В линухе, да, были раньше проблемы… Но по своему опыту говорю их всё меньше и меньше, в отличии от винды.
LiquidSnake
Может но почему-то я проблем не вижу.
Вопрос, это я везучий или настолько «мазохист» что зная что есть альтернатива (и даже пользуясь ей дома) все таки не говорю что винда хуже лини?
svsd_val
Проблем многие не видят в виду, привычки, своих низких потребностей, лени либо настолько редкого использования, что с большей долей вероятности решали её путём переустановки винды при встрече с проблемами.
С тем же самым успехом многие даже самые неопытные «чайники», которые с лёгкостью убивают всё и вся… при использовании уже настроенной GNU/Linux не встретят никаких проблем и даже будут рады её функционалу и производительности.
Да из коробки каждый дистрибутив имеет свои уникальные настройки, свои параметры компиляции пакетов, свои собственные уникальные особенности, функции и ошибки… Всё точно так же как и в винде. Только в случае с виндой они пробуют зверь едишин, кролик едишин и любые другие версии от Васянов… Довольно таки хорошо работают у «Чайников» и чуть более менее продвинутых пользюков с уже установленными этими самими Васянами троянами, шпионами и рекламщиками… И при этом горя пользюки не знают, так как не могут определить что есть качественная работа, а что нет. И каждый из подобных пользюков выбирает их (ОС) замечу на свой вкус ориентируясь на свои хотелки и свои умения… Только в случае с виндой такие люди не говорят о том что вся винда гмно так как они встретили проблемы которые были на Зверь Едишн, Гэйм эдишн, Мелкомягких 3.1,95/95se,98,98se,me,xp,2k,2k3,7,10,16,19 и т.п. эдиш ))))
Так что проблемы есть, они специфичны, они зависят от потребностей, от манеры работы с ОС, от знаний, от устремлённости и от интеллекта.
Теперь, вы говорите об альтернативе, но вот только общении сетуете на то какая плохая жизнь, как много пришлось делать, как много пришлось думать что бы чего-то достичь. Но правда жизни в том что: если вы хотите жить, вам придётся учиться и развиваться всю жизнь, хотите вы того или нет…
LiquidSnake
Я повторюсь, опять. Для работы — несомненно, какие-то еще жизненные вещи — тоже. Вы ошибаетесь, если думаете что мое мнение касается линукса в целом. Я говорю только о десктопе.
Не помню, вам ли отвечал, но мое мнение такое:
Линукс хорош на серверах, быстр, удобен и минималистичен, но на десктопе просто не нужен. Как минимум обычному пользователю. Что и говорит рынок и распространненость ОС.
Меня не напрягает необходимость учебы. Но лишь в отведенное для этого время. Для развлечения дома, при желании поиграть и прочем, я не хочу разбираться с лишними на мой взгляд проблемами.
BigBeaver
LiquidSnake
Ну так а я о чем? А вы мне «Винда» отстой)
BigBeaver
Я такого не говорил. Я наоборот утверждаю, что простому пользователю без разницы. Компуктер включается? В интернет заходит? Берём.
Эти люди даже как-то живут без selection buffer, о чем тут можно говорить?
unsignedchar
В том то и дело, что готовых компов с предустановленным актуальным линуксом нет. Есть то, что называют «Без ОС» — это либо FreeDos, либо демо-огрызок, пригодный только показать, что эта штука включается.
BigBeaver
Ну вот потому и доля рынка маленькая. А не потому что он неудобный юзерам. Как бы в 2021 не особо важно, какую прошивку для запуска браузера использовать.
svsd_val
С андройдом получилась иная история Гугул делает его условно бесплатным для вас. Но с вас собирает кучу телеметрии с производителей железа и программ свои взносы и отчисления. Так что можно поставить под больной вопрос о свободном и бесплатном андройте…
Ни о каком честном рынке речи не идёт. И о 2х % тоже.
Да, людям впихивают гамбурегы за их же деньги по 2й цене и говорят ваше право быть линивым, да и весить под 150-200кг… Защищайте его. Это легче чем заняться спортом, вести здоровый образ жизни, а всё кто пытается вам сказать что займитесь спортом — еритеки!!,
Так что вроде бы всё и можно, но не всё полезно )))
LiquidSnake
А давайте доведем ваш аргумент до абсурда.
Защищайте право сходить в магазин и купить там еды, идите на поле и вырастите себе рис, пшеницу, приготовьте хлеб. Сшейте себе одежду. Не пользуйтесь готовым. или «вы не понимаете, это другое»?
И пожалуйста, не надо сравнивать Линь со здоровым образом жизни. Вообще ничего общего. Котенок с дверцей.
Убунта насколько помню тоже собирает «Репорты об использовании», ой телеметрии там нет, конечно.
Можно было бы сделать условно платный линукс, если его стандартизировать. Но спроса нет. Надо влить деньги для допиливания, а что взлетит, гарантий нет.
Андроид популярен в отсутствие альтернативы, и в том что там в консоль вот вообще лезть не надо. А еще и допиленный производителем телефона / планшета он зачастую быстр и красив.
unsignedchar
Лицензия GPL требует предоставлять исходники. Если есть исходники — зачем покупать, если можно собрать бесплатно?
Если исходники не показывать — будет ещё одна платная ОС. Зачем платить, если есть годный бесплатный аналог? И почему не купить Windows? этому бренду хоть годиков побольше.
LiquidSnake
Вопрос цены. Винда нынче очень дорогая.
svsd_val
Да, вы же пиратскую ОС используете с пиратским софтом, о какой дороговизне вы говорите?
LiquidSnake
Ничего себе вы заявление сделали.
А вы из магазина наверное продукты воруете?
svsd_val
Вот )) Хоть какая то нормальная реакция. А теперь по фатку, какая часть народа использует лицензионную винду а какая часть использует лицензионный софт? Все считают что купить железки это самое дорогое, а вот на счёт софта и ос все забывают ))
DMGarikk
чтобы собрать бесплатно — надо или самому суметь это сделать или заплатить тому кто сможет это сделать. И далеко не факт что это получится дешевле чемть купить готовое
unsignedchar
Профессиональный сборщик ПО Васян, цены Х/4 от официальных.
DMGarikk
это тот который еще антивирус установит, браузеры, настроит почту и ютубчик за отдельную плату?
unsignedchar
Он самый. Только он теперь не пират, а честный капер ;)
Нужны условному RedHat такие
партнерыконкуренты? ;)alsoijw
То-то же, когда поменяли поддержку Centos, все резко начали искать куда переходить — они просто не понимают, как легко пересобрать всё самому.
Возможно вы сами ничего не пересобирали, так как в сумме всё собирается довольно долго, и это несколько утомляет.
unsignedchar
Долго — да. Но пересобирать всё подряд на своей собственной машине — это какой-то gentoo way. Профессиональный сборщик софта Васян может под это дело даже VPS арендовать. Особенно если клиентов у него >1. Это же машинное время, следить за процессом не обязательно.
Но раз подобная услуга не распространена — платить за неё никто не готов. Парадокс ;)
FenestramDeveloper
после 2016 года не видел ни одного быстрого телефона. купил недавно android one — получше, но зная расположение кнопок интерфейса как правило успеваю нажимать их быстрее, чем они успевают появляться. А браузер там… переключился на соседнюю вкладку и занимаешься своими делами секунд 5, пока она прорисуется — это при монопольном использовании вайфая под 150мбит.
BigBeaver
LiquidSnake
Возможность есть. Даже в гуглосторе есть приложения — консоли.
BigBeaver
И что они умеют?
LiquidSnake
Предположу что если рутануть условно «все».
Исходя из комментариев тут, я так понимаю что местная аудитория этим повсеместно занимается
svsd_val
Ога ))))) упал под стул. Они ОЕМ ограничения ставят что без отключения защиты и взлома некоторых компонентов позволяют сделать они ровным счётом НИЧЕГО. даже убить приложение уже не получится. Так как стандартный PS уже обрезали до нельзя. Повторяю ваш мобильный девайс вам не принадлежит. В обычных условиях вы в общем как и любой иной простой пользователь не более чем источник их телеметрии, денег и временный пользователь их продукта. Чьи интересы им не важны. Они спокойна отправляют вам обновления которые ухудшают работу устройства, каждое последующее обновление с покупки девайса приводит к заметным проблемам и вас ненавязчиво вынуждают покупать новое. Вы думаете ой он же тормозит… Он же лагает… куплю ка я новый ))
Вводят всякие «исключительные» сири, которые «не работают на старом девайсе» и делают новый девайс дороже… Хотя по факту железо одно и тоже, п.о. тоже и грёбанная сири тоже портируется и работает с аналогичной производительностью )) Но вам без критического мышления этого не понять, вы пойдёте покупать новый девайс )))
LiquidSnake
Когда кончаются аргументы, начинаются домыслы и смайлики.
За сим общение с вами заканчиваю, адекватностью тут и не пахнет.
svsd_val
Ага, «отличная» попытка дискредитации КЭП, нет возможности возразить и понимаете что я прав, давайте дискредитировать оппонента. Вы хотите сказать что я наврал? Что это не аргументы? Поясните с аргументами мне и народу пожалуйста где я что наврал, мне просто любопытно. Где я что домыслил.
Можете даже разобрать на примере современные девайсы, покажите что вы можете сделать и как. Я на полном серьёзе.
svsd_val
Вы похоже сами не понимаете о чём пишите, от слова совсем.
1. Я ничего абсурдного не сказал, я вам указал на факты которые имеют место быть, Вы же из-за того что вам не приятно это решили дискредитировать факты, зачем же вам тогда глаза если очевидное вы отрицаете и в упор не хотите замечать.
2. Ваше казалось бы абсурдное, сравнение про магазинную еду и еду выращенную самим… Скажем так химии в магазинной еде, в разы больше и под сомнения это никто не никто не ставит. То что выращено же самим обычно в разы более здоровое и в разы вкуснее. Вы сравнивали кур и уток которые растут сами на нормальной пище с тем что в магазинах? Не говоря о том что в последних куча воды, так и куча антибиотиков и другой гадости которой пичкают всё и вся ради прибыли что не делает еду лучше. Даже хлеб магазинный отличается от испечённого дома, магазинный вкусный пока он свежеиспечён, но стоит остыть теряет свои вкусовые свойства, а домашний нет он вкусный на протяжении длительного времени.
Так что я не вижу ничего тут абсурдного, Да вы можете есть жирные гамбургеры с тучей усилителей вкуса и консервантами, есть нашпигованные всякой гадостью продукты и терять своё здоровье. Это ваше право, вам говорят что это хорошо и правильно, потому что это делают все )) Будьте покорны и используйте то что вам дают, думайте так как вас заставляют думать…
То что собирает убунта — это крохи и это можно отключить. Я тоже в Дебе участвую в программе популярности приложений, потому что я так решил. Я хочу что бы Debian GNU/Linux знал какие приложения чаще используют и дорабатывал их либо передавал разработчикам эту инфу для доработки. Я могу всегда отказаться. А в винде нет. Свас собирают столько инфы что могут построить ваш цифровой портрет, предсказывать поведение и не заметно для вас влиять на вас. Вы же будете думать что это не так. Только в нужный момент вам покажут инфу невзначай которая подорвёт вам пукан и заставит вас делать то что нужно им. Уже проходили и смотрели…
Телеметрию в Огнелисе так же отключаю, хром хоть и использую но редко и тоже по максимоу пытаюсь обрезать как на стороне хрома так и на стороне Pihole. Основной у меня огнелиса.
Такие есть и редхат и ему подобные живут неплохо ) Только народу не в корпоративном секторе этого не нужно, им хватает то что есть, они могут читать, учиться и принимать взвешенные решения сами. У них нет KPI и небольшой простой не губителен.
Дану? Вы даже понятия не имеете о чем говорите.
1. Мобильных ОС фигова гора: iOS, BlackBarry, KaiOS, SailFish Os, Windows Mobile и как ни странно обычная x86 Windows, не говоря уже о том что китайци сейчас делают свои собственные ОС которые на внутренним рынке показали свою состоятельность и в последствии будут портированы на внешний рынок.
2. Вы внутренности андройда видели? А то что с ним делают производители когда там костыль на костыле что приводит к тому что Даже сам производитель теряет возможность обновлять свои же продукты это вам о чём то говорит? Хотя нет, у массы людей сейчас нет критического мышления, им проще потратить деньги, иногда зп нескольких месяцев и купить новый смартфон, планшет который будет чуточку лучше предыдущего… Отличное решения для корпораций )) Но не для человека.
В общем я могу писать много и подробно, но это нужно писать тогда когда человек хочет думать, хочет взглянуть на мир с иной точки зрения, но не тогда когда он управляем и размышляет навязанными стереотипами и уверен что корпорации всегда делают ему только добро и совершенно бескорыстно…
LiquidSnake
Сравнили винду с фастфудом и назваил это фактом. Ржу.
Ну так растите, вы же не делаете этого. И зачем-то доказываете мне что я фастфуд ем. Кривые нелогичные выводы.
Маленькая телеметрия — не телеметрия, я понял.
Удачи вам с установкой iOS не на apple.
Опенсорс — образец надежности, ага.
То что вы сказали верно и в обратную сторону.
Разговаривать с вами более не намерен
svsd_val
А в чём это сравнение не корректно? Конкретизируйте пожалуйста.
Я участвовал в OpenSource когда ещё на видне был и с переходом на GNU/Linux так и участвую.
1. Любой человек может её отключить.
2. К тому же обезличенный сбор данных о популярности пакетов не несёт в себе ничего плохого.
3. То что винда и ведройд собирает нельзя ни отключить, ни повлиять.
Удачи вас с установкой иной ОС на свой телефон. Покажите и расскажите на как Вы сделали это. Без взлома ОЕМ, без потери гарантии на девайс.
очередной суперский диванный аналитик — пустобрёх, даже близко ничего не видели, не щупали, а уже с видом эксперта говорите. Спасибо ваше мнение ценно и находится на уровне плинтуса для нас =)
alsoijw
svsd_val
Согласен, только GNU/Linux в данном случае не базар, а скорее открытая ферма где много народу выращивают в еду для всех, каждый может взять сорт и сделать форк и начать выращивать новый сорт/вид. В общем: Бери не хочу… Да некоторым часть продукции может не подойти в ввиду индивидуальных особенностей, к примеру не переносимость лактозы… Да многие не используют усилители вкуса и подкрасители…
В любом случае данное упрощённое представления процесса GNU/Liniux/Unix думаю весьма соответствует текущему состоянию дел =)
qrKot
Не-не-не, именно базар, официально юридически закреплено: ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B1%D0%BE%D1%80_%D0%B8_%D0%91%D0%B0%D0%B7%D0%B0%D1%80
svsd_val
Да, но вы употребили Базар в своём сообщении немного в иной формулировке. в Там написано на виду
Вы описали Базар как закрытое производство к которому нет доступа и где только итоговый продукт разрешено брать за отдельную плату всем. Так что это не совсем то…
BigBeaver
LiquidSnake
Да вы что. Удивительный комментарий.
Я простой пользователь, уж винды точно. И ставил и ее и линукс.
Я стал от этого админом винды?
BigBeaver
Вы давно видели в продаже компы без предустановленной системы? Или вы сами из раздельно купленного железа собрали (тогда плохие новости — вы не просто пользователь)?
На пол шишечки. Суть просто в том, что в оптимальных условиях любая система ставится и рабоатет одинаково хорошо, и тогда действительно можно установить, не имея специальных навыков. Но если это типовая пользовательская задача, то скажите пожалуйста, как это (установка винды) стало платной услугой разного рода «компьютерных мастеров»?Лично я, напрмиер, с 2012 года ни разу не админил свой линукс кроме случаев, когда мне нужно повыпендриваться (поднять вебсервер с ddns, или, когда хотел дать именные порты программатору, 3д принтеру и другим железкам своим). Но это все относится к профессиональным задачам. А так я даже драйвера на видео ни разу не трогал — оно просто само работает и всё. Интернет работает сам, принтеры работают сами, программатор/тладчик и то сам цепляется.
А вам просто не повезло с комбинацией железка/дистрибутив — такое бывает и с виндой.
LiquidSnake
Вижу сейчас, с DOS. Подешевле чем с современной ОС. И да, собирал комп сам, жизнь заставила. Нет альтернативы. А с ковырянием линукса — альтернатива есть.
С тех пор что нет черного и белого, сисадмина и совсем нуба. Между ними есть большой промежуток людей которые чуть-чуть разбираются.
Уж очень странно мне слышать про комбинацию, ибо это ПК с довольно мейнстримными компонентами
BigBeaver
LiquidSnake
На мейнстримном железе? Я удивлен, но пусть будет так.
Больше чем уверен что готовые системники тоже на совместимость никто не тестировал. Да и документации такой для любой из ОС нет.
svsd_val
qrKot
Рядовой пользователь не-рут — не сможет…
Да и рут, емнип, нынче на такую вещь явно переспрашивает «ты дурак?», емнип. Вроде в убунте такую штуку пилили.
COKPOWEHEU
это если ввести дословно. А если cd /; rm -rf * то не спросит. Проверять, впрочем, я это не буду…
BigBeaver
Что «простой пользователь» вообще забыл в этой вашей консоли?
BigBeaver
Потомучто вы упорно пишете о каких-то «простых пользователях» в вакууме. Я вот не знаю абсолютно ни каких кейсов, которые бы не являлись профессиональной деятельностью, но при этом выбор ОС играл бы для них какую-то важную роль.
Зачем ему это? Если не выпендриваться с кастомизацией, то всегда всё само работает. iptables я настраивал один раз, когда хотел сэкономить на роутере для раздачи интернета на второй комп. Ну то есть, да, в нулевых были трудности с настройкой разного рода провайдерских pptp/ppoe и тд, но они и в винде были — постоянно приходилось править маршрутизацию руками (да, в виндовой консоли, которая полный ад), и были даже специальные утилиты, которые то ли чистят сетевой кэш то ли что — был полный ад. В линуксе всё, разумеется, работало само без этого сасописного хакерства (хотя поднять туннель было не легко иногда, но опять же не потому, что линукс такой трудный а потомучто суппорт провайдера сам не знает настроек своей сети [а для винды их админ уже сколхозил утилитку/батник]).Ну ок, еще игры, но это вкусовщина — я, напрмиер, не играю в игры младше 2000 года — а это на любой системе будет dosbox либо режим совместимости.
qrKot
Поясню: принцип Паретто применительно к распределению пользователей. «Спецы» — 1%, «совсем домохозяйки» — 80%. «Куча типов людей» и весь вот этот спектр утрамбован в оставшиеся 19%. Так уж это работает.
Поэтому почему не выделять «подавляющую массу пользователей (80%), которым нужен только вконтактик» в отдельную категорию, не понимаю уже лично я. Очевидно же, что если ваша ОСь непригодна для использования именно домохозяйками, ваш потолок в идеальных условиях — 20%, ни о каком доминировании на рынке и говорить нельзя.
LiquidSnake
Окей те же 80% пользуют винду. Если верить статистике выше, даже больше.
Не помогло это линуксу, никак.
BigBeaver
ну так логично же — 80% используют то, что дали.
qrKot
Хм, а почему это должно помогать линуксу?
Давайте попробую объяснить позицию. ЕстьWindows, есть Linux, есть еще, к слову, MacOS, BSD и некоторое количество откровенно маргинальных осей. На десктопе правит бал Windows и MacOS, т.к. «третий в списке» — это 2%, остальные — не более аналогичного показателя в сумме (2% на всех — оптимистичная оценка).
Цифры эти обусловлены вполне объективными причинами. Не тем, что «виндоуз лучше линукса» или наоборот, не тем, что есть настолько объективные преимущества какой-то одной системы над другой. Вся «вишенка» в том, что реально весомых «фич», заради которых среднестатистическому пользователю будет смысл «слезть» с предустановленной/массовой винды на линукс — их нет.
Линукс не лучше винды, и не хуже «в среднем по палате». Способен ли он заменить «окошки» в 90% задач рядовых пользователей (коих, как мы помним, 80%)? Да сможет, чо нет-то -Google Chrome на всех один. Вопрос в том, какой смысл этому самому рядовому пользователю в этой замене?
Вот реально, у вас есть ось, которая вас удовлетворяет. Какой смысл вам менять ее на что-то другое? На что-то принципиально лучшее — не вопрос, переползаем. На что-то примерно такое же, в чем-то сильно лучше, где-то похуже… А зачем?
Вот и получается — при паритете «умелок» такое разное разное распределение доли рынка. А почему? А потому что «доля рынка». У Microsoft и Apple есть рекламный бюдет, стратегия маркетингового развития и план прибылей — поэтому у них на двоих 96%. У Linux нету, поэтому 2%
VladC
если б всё ограничивалось одним только вконтактиком, то да, без разницы
BigBeaver
А чем ещё? Ютубчиком, офисом, торрентами? Да тоже инвариантно.
JPEGEC
Отлично, пусть так и дальше будет. С ростом популярности начнется та же дичь что и в виндовсах, макосах — внедрение ненужного для неадекватов. А также нашествие многочисленных паразитов типа вирусописателей и прочих подобных.
Спасибо, не хочется.
svsd_val
Как ни странно, соглашусь с вами, к тому же вирусы пишут и сейчас под линуху, и обычно распространяют их методами социальной инженерии и умных админов локал хостов с паролями 123, 12345678,qwerty итп.
BigBeaver
Ну процентов до 5 было бы неплохо поднять долю.
MTyrz
Уже и сейчас топ выдачи по банальным вопросам плотно забит копирайтерами в стиле «как открыть текстовый файл в Linux — десять лучших утилит от лайфхакеров». Еще несколько лет назад по тем же запросам в топе были профильные форумы.
Так что не надо поднимать долю, совсем не надо.
BigBeaver
Ну копирайтеры засрут любую тему — это неизбежно. Зато, с поддержкой железа получше будет и со специфическим софтом.
MTyrz
Копирайтеры — это мухи, которые летят на запах.
Это симптом. Если в теме появились копирайтеры, тема обретает популярность. И если бы на запах популярности слетались только копирайтеры — это еще можно было бы пережить: но в первом комменте треда кратко перечислены и некоторые другие побочки.
BigBeaver
Ну вы сами утверждаете, что процент заинтересованных копирайтеров вырос сам без роста доли рынка. Возможно, дело в чем-то другом? Точно так же нет оснований полагать, что небольшой медленный (без хайпа) рост как-то ощутимо усугубит ситуацию.
COKPOWEHEU
Не процент, а количество. Шлака стало много и по другим темам.
BigBeaver
Ну да, вы правы. Но сути не особо меняет.
MTyrz
Нет, это утверждал все-таки не я.
А если погуглить «доля Linux на десктопах», то можно нагуглить довольно противоречивые данные, но в том числе и свидетельства роста.
qdb
yadowit
В принципе проще. Например, что сделает новый пользователь программы, впервые поставивший GIMP, если захочет сохранить свою картинку в другом формате? Он воспользуется командой «сохранить как», работа которой ему знакома по другим программам. Вот только в GIMP`е его ждёт жёсткий облом — «сохранить как» в нём хоть и имеется, но делает совершенно другое, она сохраняет файл в архив. И пользователю, чтобы узнать, как найти давно известную ему функцию, волей-неволей придётся воспользоваться поиском в интернете. Само-собой, что гугл никто не отменял и он найдёт, как сохранить файл в GIMP`е в другом формате, но осадочек останется.
И останется справедливо. Заставлять лезть в интернет, чтобы найти то, что в других программах работает «по умолчанию» — не самая лучшая идея. Или разработчики GIMP об этом не знают? Можно ведь не заморачиваться и просто переименовать «сохранить как» в «архивирование», а «экспорт» в «сохранить как». Юзабельность от этого, хуже точно не станет. Скорее даже наоборот. Но GIMP продолжает идти «своим путём». Вот только непонятно — ради чего?
И это только один пример. Подобное, свойственно многим линукс программам, когда на удобство использования и взаимодействие с пользователем относятся наплевательски.
BigBeaver
ом числе от adobe) это как раз редко так работает, тк есть четкая разница между проектом и «всякими внешними форматами». Эта часть меню как раз достаточно короткая и интуитивная чтобы ничего не искать — там «export as» двумя строчками ниже. Если вы хотите пример неинтуитивной логики гимпа, то лучше бы рисование кругов привели.
Ну и ваш кейс в принципе надуманный. Пользователь, который впервые поставил гимп, не рисует ничего с нуля. 90% всех кейсов это кропом пройтись и цветокоррекцией, перезаписав исходник, что делается тривиально. А так-то на синтетических примерах можно любых выводов понаделать.GIMP это не линукс программа. Да и альтернатив особо нет.
p.s. подменять «проще» на «привычнее» нехорошо, тк второе полностью субъективно.
FenestramDeveloper
В применённом контексте альтернатива для gimp — это imagemagick. Для других контекстов есть другие программы. Только глубокая ручная ретушь — задача, с которой у GIMP не нашёл альтернатив, но тут и ГИМП хорошо (не плохо) справляется.
yadowit
unsignedchar
В старых версиях GIMP пункт меню Save As работал точно как в этом вашем Adobe Photoshop. Export as появилось в версии 2.8, если я правильно понял. Ок, gimp 2.7 был так же дружелюбен к пользователю, как и фотошоп? ;)
svsd_val
Есть крита, он круче гимпа и фотошопа )
BigBeaver
Ну вот только в фотошопе да в офисе то так и работает.
Vilgelm
С чем-то я конечно согласен, но некоторые вещи вызывают вопросы. Например, отключение экрана вполне себе настраивается прямо в GUI в меню Настройки. В KDE, возможно в каких-то экзотических DE и не так. И тот миллион команд, которые там приведены не нужны. И поворот экрана на соседней вкладке:
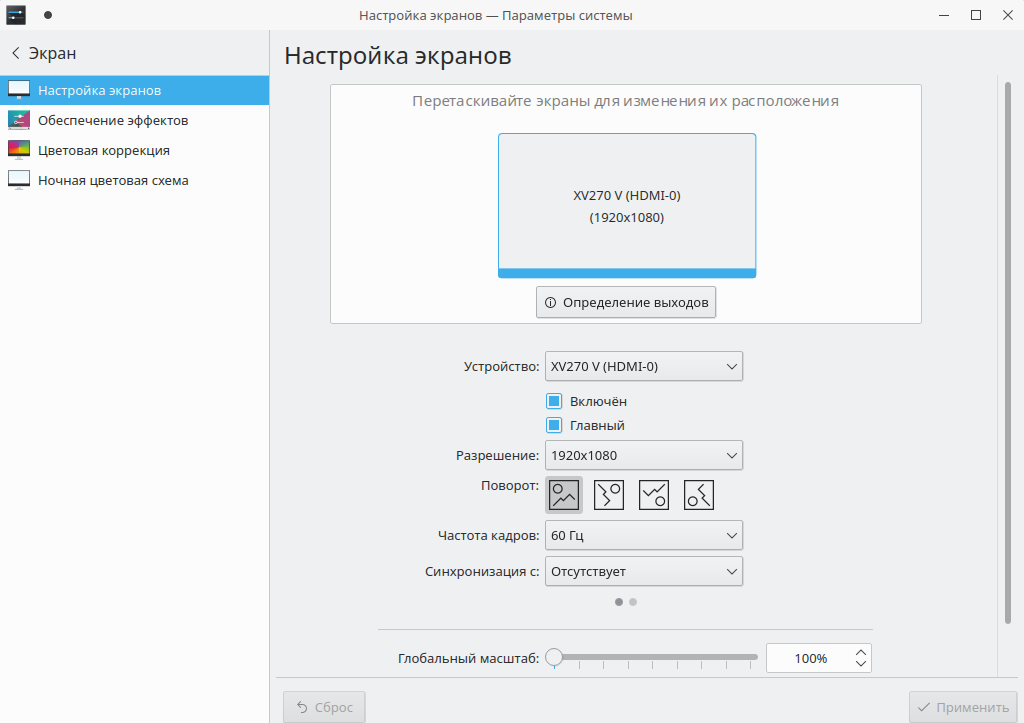
Что касается ошибок — по консольному выводу можно понять намного намного больше, чем по какому-нибудь краткому графическому «ошибка стоп ноль ноль ноль ноль», которая хоть и нагуглится, но к решению проблемы приблизит слабо и придется смотреть логи (если они конечно есть, в Windows с этим не очень хорошо).
Чего действительно не хватает в Linux по сравнению с Windows — это возможности откатиться. Да, в Windows это тоже работает так себе, но по крайней мере после кривого обновления можно загрузиться в режиме восстановления и откатиться до предыдущей точки восстановления. В Linux если тебе прилетело какое-нибудь кривое обновление драйвера и при следующей загрузке вместо системы ты наблюдаешь kernel panic гребля на следующие несколько часов обеспечена. Благо это происходит крайне редко.
alsoijw
BigBeaver
Вроде, есть менеджеры бэкапов для линукса. Некоторые дистрибутивы даже используют их вместо программы инсталлера.
svsd_val
Есть такие вещи, вы можете пользоваться к примеру TimeShift, можете настроить как хотите. Но учтите место нужно под это дело выделять…
Если вы поймали его это что-то из разряда выигрыша на трилиард )) и обычно в 99% случаев связано с аппаратным косяком. Если вы это действительно о Kernel Panic (когда все светодиоды на клавиатуре мигают).
Vilgelm
У меня ноутбук, там нечему мигать. Там вообще интересно — ноутбук с Ryzen (со встроенной видеокартой) и дискреткой Nvidia. Если поставить какие-нибудь не такие драйвера на Nvidia (другую версию проприетарного или Nouveau), то при загрузке будет kernel panic (так и будет написано) со ссылкой на отсутствующий модуль amdgpu (но зависит именно от дров Nvidia, все работает нормально только с определенной версией проприетарного драйвера и только на (k)ubuntu (а на KDE Neon, например, никак уже)).
Я не стал сильно заморачиваться и просто поставил версию драйвера и дистрибутив, в котором это работает, но насколько я понимаю оно работает только с дискретки, а если с ней что-то не то, то при попытке запустить райзеновскую встройку все падает потому что на нее нет драйверов или что-то в этом роде.
Еще про amdgpu можно увидеть при обновлении initramfs:
W: Possible missing firmware /lib/firmware/amdgpu/navi12_gpu_info.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_gpu_info.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_ta.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_asd.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_sos.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_ta.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_asd.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_sos.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_rlc.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_mec2.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_mec.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_rlc.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_mec2.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_mec.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_me.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_pfp.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_ce.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/arcturus_sdma.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_sdma1.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_sdma.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi10_mes.bin for module amdgpu
W: Possible missing firmware /lib/firmware/amdgpu/navi12_dmcu.bin for module amdgpu
I: The initramfs will attempt to resume from /dev/dm-2
I: (/dev/mapper/vgkubuntu-swap_1)
I: Set the RESUME variable to override this.
svsd_val
Скорее всего у вас по какой то причине Nouveau не попал / был убран из blocklist и получилась ситуация что Nvidia драйвер и Nouveau не смогли поделить видео карту. Обычно даже при установке дров нвидиа с оффсайта она всегда в блоклист кидает его.
По поводу сообщения, это обычное дело, так как скрипты одни на amdgpu, он смотрит что блопы от амд не стоят. Если не планируете подключать к ноуту дискретную AMD, то не обращайте внимание.
Dr_Sigmund
СЕЙЧАС приходит?! Да она этим занималась больше 20 лет назад, когда я запускал доменные сети под NT 4.0.
DooDLeZz
Я искренне считаю, что процент UNIX на десктопах способно увеличить всего «пара вещей»: 1. Драйверы для видеокарт от производителей; 2. Поддержка DirectX; Дайте геймерам возможность запускать игры на той же убунте — статистика заметно изменится.
saboteur_kiev
Поддержка DirectX — это пока что путь вникуда. Проприетарная технология, которую MS точно не будет контрибьютить в Линукс на постоянной основе.
*никсу нужен свой стандарт для графики, но производители многих дистрибутивов в него вкладываться неготовы (ну кроме Андроида).
Была надежда на SteamOS
FenestramDeveloper
OpenGL, Vulkan — не годится?
RAslM
Добавлю свое менее авторитетное ИМХО.
На мой взгляд проблема gnu/linux в том, что нет единого дистрибутива или так сказать эталонного ПО, который вылизали до какого-то лучшего результата. Каждая творческая личность считает, что лучше сможет и отпочковывается и начинает клепать свой мегакрутой дистрибутив потом люди делятся на несколько лагерей и начинают кидаться непристойностями кто-то адепт RHEL кто-то возносит Debian и так можно перечислять с 10ок интересных дистрибутивов отсюда и проблемы, если кинуть всех энтузиастов на один дистрибутив с единым мозговым центром, то скорее всего получили бы что-то намного лучше чем сейчас, но это пока несбыточные мечты пока 10500 дистрибутивов и такая сильная конфронтацией между лагерями. Автор кстати об этом упоминал тонко, что нужен диктатор, кем собственно и является Торвальдс, который и следит за разработкой ядра. Ваш КЭП ))
ALexhha
ну есть у людей время и желания, вам ли не все равно? Вот лично мне нет никакого дела до Slackware, я не слежу за его развитием от слова совсем. Ну делают там что то для узкой группы людей — на здоровье, это их выбор. Я даже слышал, правда не уверен что это правда, что ее используют в проде на серверах
для каждой задачи свой инструмент
Лично для меня есть две группы — Ubuntu/Debian и CentOS/RHEL. Все остальное от лукавого, имхо
RAslM
Вот даже тут любимый дистрибутив появился. Если посмотреть Ubuntu, начали продвигать unity, что-то пошло не так вернулись к gnome и так по мелочи.
Насчет чужого времени, мне нет никакого дела, помечтал о том, что этот энтузиазм можно было направить на 1 классный дистрибутив и сделать конфетку, не ищи агрессию или упрека. Рассуждение, а что если.
COKPOWEHEU
Энтузиазм на то и энтузиазм что человек занимается тем велосипедом, который интересен лично ему. В крайнем случае — нужен.
Допиливать свистелки для хомячков не нужно и не интересно.
Допиливать дрова бывает нужно и интересно, но документацию не дают.
Допиливать совместимость с проприетарным софтом — аналогично.
JTG
Похоже на мою дипломную работу: намешано всего подряд, а что в итоге получили — непонятно. В заголовках обозначена одна проблема, под заголовком куча других. Чтобы разобрать все нестыковки, понадобится статья в 2 раза больше этой. Пока вот небольшой комментарий :)
… и потом чтобы «не пугать пользователя запросом прав суперпользователя» хром устанавливается со всеми своими потрохами в AppData. Угу, збс, 10 изоляций из 10, удобненько.… и спустя неделю после того, как «просто переустановил программу», внезапно выясняешь, что уже в другой программе «точка входа в процедуру X не найдена в библиотеке Y». Пакетный менежер же неспроста указывает на конфликт зависимостей, да и происходит это дай бог раз в полгода при попытке установить сторонний deb-файл, чего при нормальной работе происходить в общем-то не должно.
Нет смысла комментировать: в этом разделе автор свалил в кучу вообще всё — почему древние иксы работают так, а не этак; почему мускуль так; почему нет способа получить список установленных программ — мол под виндой-то удобно, там я "просто складываю все инсталляторы в папочку [а через 5 лет снова устанавливаю уже устаревшие версии софта оттуда]". Нет, так-то и у меня самого есть папка с дровами и инсталляторами, но это же не от хорошей жизни.
Если речь идёт о реестре, то в том виде, в котором он существует — не нужен. А реестр, который пережил переезд с 7 на 10, не нужен совсем. Если бы это работало как следует, не существовало бы советов «почисти реестр» и всяких твикеров-ccleaner'ов. GSettings, кстати, тоже не нужен. dot-файлы, конечно, не идеал, но они так-сяк решают поставленные задачи не хуже реестра, а работать с ними куда проще и это, блин, как раз unix-way.
Такого диалога? :)
Для сравнения, в таком же бесполезном диалоге в убунте можно хотя бы тыкнуть на «show details» (где никогда ничего полезного не бывает)
Можно запустить приложение в консоли и посмотреть на вывод. Можно в конце-концов дописать спереди strace и получить хоть какое-то представление о том, что же пережила программа непосредственно перед смертью. Обработанные исключения остаются на совести разработчиков ПО, но, согласитесь, если уж мы ориентируемся на пользователя «тук-тук, я сам открою», то толку от окна с подробнейшей ошибкой «при обращении к функции такой-то произошла ошибка такая-то потому что файл такой-то недоступен для записи» и трейсом будет ровно столько же, сколько от окна «foo.exe has stopped working» — «У меня вылезла табличка я нажал ОК помогите как починить?».
Щито? Покажите начинающему пользователю Photoshop и Sai и будет понятно в чём разница. А разница в том, что это разное ПО, созданное разными людьми (что, однако, не отменяет долбанутости интерфейса GIMP и вообще плохого GUI в куче софта под линукс). А по поводу «неконсистентности» — вы десятку-то давно видели? Там диалоги местами аж из 3.1 остались, а видов менюшек поди штук 5 разных, и всё это сдобрено сверху новым модным софтом на электроне, который весь разный и которого всё больше и больше. Более менее остатки адекватности в плане интерфейса сохраняет только макос, да и то зачастую ценой «сделаем всем неудобно, зато одинаково».
В xfce я могу нажатием кнопки сохранить текущий рабочий профиль в пятницу вечером — все запущенные приложения, открытые окна, их размеры и положение etc. В субботу утром открыть другой профиль, где меня с прошлых выходных дожидается открытое окно с брауезром, где в интернете кто-то неправ, а в понедельник опять вернуться к пятничной работе. Но я не могу сделать то же самое в Windows. Что же это получается, в винде «непроработанность функциональности ПО»?
Господи, вот влез же в этот проклятый пост, потерял час жизни :)
svsd_val
Приветствую собрат по разуму )) Ты смотри осторожней а то ещё затянет тебя…
Тут всё больше как в анекдоте: Нас было 10 учёных и один дурак, силы были почты равны ))