

Какое-то время назад мы писали цикл статей про то, как правильно измерять качество систем распознавания речи, и собственно снимали метрики с доступных решений (цикл статей — 1, 2, 3) (на тот момент и коммерческих и некоммерческих решений). На Хабре была выжимка из этого цикла в рамках этой статьи, но до масштабного обновления исследования, достойного публикации на Хабре, руки никак не доходили (это требует как минимум большого количества усилий и подготовки).
Прошло некоторое время и пора обновить наше исследование, сделав его по-настоящему ультимативным. По сравнению с прошлыми исследованиями изменилось или добавилось следующее:
- Добавилось много валидационных сетов из разных реальных доменов;
- На рынок вышел Сбер, в первую очередь интересно протестировать именно его;
- Для чистоты эксперимента, мы не предупреждали разработчиков систем о доменах и факте проведения тестов;
- Мы также попробовали немного протестировать пропускную способность сервисов (понятно, что мы не знаем какое железо и ограничения стоят в облаке);
- Мы рассматриваем только коммерческие системы, к которым у нас получилось получить доступ и которые показали хоть какой-то намек на "всеядность", работу с холодного старта и "энтерпрайзность";
Методология
Мы старались следовать нашей стандартной методологии (см. ссылки выше) с небольшими изменениями:
- Тестируем одни и те же данные в формате
wav(или просто PCM); - Мы слали запросы во все системы в 8 параллельных потоков (если было очень много таймаутов или все было медленно, то снижали);
- Расчет скорости делался отдельным небольшим прогоном без всяческой пред- или пост-обработки, чтобы не "загрязнять" метрики, допустим, нормализацией или ресемплингом;
- Считаем основную метрику — WER. Не пугайтесь высоких показателей в районе 20% WER, нужно понимать что в самой разметке заложено порядка 5% WER и что иногда система получает штраф за неверную форму слова (но корень сохраняется, подробнее писал по ссылке в начале статьи);
- По причине большого количества доменов в этот раз на каждый домен случайно выбрали по 1 часу аудио. Стабильные результаты как правило получаются с 2-3 часов аудио (поэтому некоторые метрики могут визуально быть "хуже" прошлых тестов). За тесты в Гугле нам пришлось заплатить почти 500 долларов!;
- Метрики считаются на нормализованных текстах (то есть без цифр, "как слышится так и пишется"), так как системы нормализации могут быть разными и строго говоря к качеству распознавания имеют непрямое отношение и зачастую делаются под домен;
- Если у системы нет такого функционала, то мы нормализуем тексты самостоятельно. В любом случае это влияет в рамках 1 п.п. WER, мы проверяли;
- Сначала мы пробовали слать
ogg/opusв системы, которые его поддерживают, но потом отказались от такой идеи, потом что резко вырос процент "пустых" ответов; - Все данные по умолчанию отправляются с родной частотой дискретизации (8 или 16 kHz), но мы не записывали исходную частоту дискретизации всех оригинальных аудио до обработки;
Сухие метрики
Все модели, кроме Silero bleeding egde, это модели упакованные в production сервисы. Используемый показатель — WER (для простоты восприятия можно мысленно пририсовать знак процента или считать WER процентом ошибок в словах).
| Датасет | Ashmanov | Sber | Sber | Silero | Silero new | Tinkoff | Yandex | ||
|---|---|---|---|---|---|---|---|---|---|
| default | enhanced | IVR | prod | bleeding edge | |||||
| Чтение | 10 | 11 | 10 | 7 | 7 | 6 | 8 | 13 | |
| Умная колонка | 35 | 24 | 6 | 30 | 27 | 27 | 14 | ||
| Энергосбыт | 24 | 39 | 41 | 20 | 16 | 11 | 15 | 13 | |
| Звонки (такси) | 47 | 16 | 18 | 22 | 32 | 13 | 12 | 21 | 15 |
| Публичные выступления | 28 | 27 | 24 | 18 | 14 | 12 | 20 | 21 | |
| Финансы (оператор) | 31 | 37 | 37 | 24 | 33 | 25 | 24 | 23 | 22 |
| Аэропорт | 31 | 36 | 37 | 26 | 21 | 22 | 25 | 21 | |
| Аудио книги | 22 | 60 | 54 | 19 | 24 | 20 | 28 | 22 | |
| Радио | 24 | 61 | 40 | 26 | 18 | 15 | 27 | 23 | |
| Умная колонка (далеко) | 42 | 49 | 8 | 41 | 27 | 52 | 18 | ||
| Банк | 62 | 30 | 32 | 24 | 28 | 39 | 35 | 28 | 25 |
| Звонки (e-commerce) | 34 | 45 | 43 | 34 | 45 | 29 | 29 | 31 | 28 |
| Заседания суда | 34 | 29 | 29 | 31 | 20 | 20 | 31 | 29 | |
| Yellow pages | 45 | 43 | 49 | 41 | 32 | 29 | 31 | 30 | |
| Финансы (клиент) | 43 | 55 | 59 | 41 | 67 | 38 | 37 | 33 | 32 |
| YouTube | 32 | 50 | 41 | 34 | 28 | 25 | 38 | 32 | |
| Звонки (пранки) | 44 | 72 | 66 | 46 | 41 | 35 | 38 | 35 | |
| Медицинские термины | 50 | 37 | 40 | 50 | 35 | 33 | 42 | 38 | |
| Диспетчерская | 61 | 68 | 68 | 54 | 41 | 32 | 43 | 42 | |
| Стихи, песни и рэп | 54 | 70 | 60 | 61 | 43 | 41 | 56 | 54 | |
| Справочная | 39 | 50 | 53 | 32 | 25 | 20 | 27 |
Чем меньше WER, тем лучше.
Также интерес представляет процент пустых ответов сервисов (не совсем ясно, это баг или фича, артефакт нагрузки или самих моделей, но где-то снижение нагрузки помогает снизить этот процент). Традиционно этот процент высокий у Гугла. И как ни странно он довольно высокий у Сбера (и там скорее всего это фича, так как их пропускная способность явно не узкое место).
| Ashmanov | Sber | Sber | Silero | Tinkoff | Yandex | |||
|---|---|---|---|---|---|---|---|---|
| default | enhanced | IVR | ||||||
| Чтение | 0% | 0% | 0% | 0% | 0% | 5% | 4% | |
| Умная колонка | 0% | 2% | 0% | 0% | 4% | 0% | ||
| Энергосбыт | 1% | 12% | 13% | 6% | 0% | 2% | 1% | |
| Звонки (такси) | 0% | 0% | 0% | 1% | 0% | 0% | 7% | 0% |
| Публичные выступления | 0% | 1% | 0% | 0% | 0% | 2% | 0% | |
| Финансы (оператор) | 0% | 0% | 0% | 2% | 0% | 0% | 6% | 0% |
| Аэропорт | 0% | 8% | 10% | 4% | 0% | 4% | 0% | |
| Аудио книги | 0% | 22% | 6% | 2% | 0% | 1% | 0% | |
| Радио | 0% | 19% | 2% | 3% | 1% | 4% | 0% | |
| Умная колонка (далеко) | 0% | 12% | 0% | 0% | 1% | 0% | ||
| Банк | 0% | 2% | 3% | 1% | 1% | 0% | 5% | 1% |
| Звонки (e-commerce) | 0% | 0% | 0% | 7% | 1% | 0% | 7% | 0% |
| Заседания суда | 0% | 0% | 0% | 1% | 0% | 4% | 0% | |
| Yellow pages | 1% | 13% | 9% | 14% | 0% | 2% | 2% | |
| Финансы (клиент) | 0% | 0% | 7% | 35% | 9% | 0% | 5% | 0% |
| YouTube | 0% | 13% | 1% | 6% | 0% | 1% | 0% | |
| Звонки (пранки) | 1% | 33% | 12% | 17% | 5% | 1% | 1% | |
| Медицинские термины | 0% | 1% | 0% | 7% | 0% | 6% | 1% | |
| Диспетчерская | 3% | 26% | 28% | 25% | 0% | 2% | 4% | |
| Стихи, песни и рэп | 2% | 19% | 3% | 25% | 0% | 1% | 1% | |
| Справочная | 1% | 12% | 14% | 9% | 0% | 3% | 0% |
Чем меньше ближе к нулю этот процент, тем лучше.
Качественный анализ и интерпретация метрик
Неудивительно, что каждый силен в том домене, на котором фокусируется. Tinkoff — на звонках в банк, справочную, финансовые сервисы. Сбер имеет ультимативно лучшие результаты на своей "умной колонке" (спекулирую, что они поделились в лучшем случае 1/10 своих данных) и в среднем неплохие показатели. IVR модель Сбера на доменах, где оригинальные данные лежат у нас в 8 kHz, показывает себя достойно, но она не ультимативно лучшая. Приятно удивил Яндекс — в прошлых рейтингах их модели были не в списке лидеров, а сейчас точно лучше, чем в среднем по больнице. Другой сюрприз — Google, который является аутсайдером данного исследования вместе с Ашмановым.
Также интересно посчитать количество доменов, где production модели поставщика лучшие / худшие (допустим с неким "послаблением" в 10% от лучшего или худшего результата):
| Сервис | Лучше всех | Хуже всех |
|---|---|---|
| Ashmanov | 0 | 7 |
| 1 | 13 (9 у enhanced) | |
| Sber | 2 | 0 |
| Sber IVR | 4 | 4 |
| Silero | 13 | 0 |
| Tinkoff | 6 | 2 |
| Yandex | 10 | 1 |
Как и ожидалось — наша модель показывает в среднем неплохие показатели на всех доменах, заметно отставая на банках и финансах. Также если смотреть по формальной метрике "на каком числе доменов модель лучшая или почти лучшая" — то наша модель как минимум лучше всех генерализуется. Если включить в забег нашу bleeding edge модель (мы пока не выкатили ее еще), то она отстает только на "умной колонке" и банковских датасетах, лидируя уже на 17 доменах из 21. Это логично, так как у нас нет своей колонки и банки очень неохотно делятся своими данными даже приватно.
Удобство использования
У Сбера на момент тестирования было только gRPC API. Это не самое удачное решение для SMB клиентов с точки зрения удобства, имеющее более высокий порог на вход. Также в их реализации вообще не прокидываются важные ошибки (или отсутствуют в принципе, чем часто грешат корпоративные сервисы). Документация запрятана внутри портала их экосистемы, но в целом кроме лишней "сложности" проблем особо там нет, читать приятно. 40 страниц на два метода это конечно сильно (мы читали сначала в PDF), но документация хотя бы подробная и с примерами и пояснениями.
У Яндекса и Гугла стандартная корпоративная документация. Она несложная, но иногда длиннее, чем хотелось бы. Есть и обычные и потоковые интерфейсы. У Яндекса кстати она стала сильно приятнее и человечнее с момента, когда я в последний раз ее видел.
У Tinkoff само распознавание работает по умолчанию также через gRPC, а поверх написаны клиенты (в тех, которые мы разбирали было много лишнего). С учетом фокуса на enterprise (оставим за скобками этические, правовые и финансовые последствия монетизации банком ваших данных без явного согласия и возможности отказаться) это имеет больше смысла, чем то, что сделал Сбер. Это уже мои спекуляции, но скорее всего это в первую очередь артефакт разработки решения под свои нужды.
У сервиса Ашманова… вообще нет документации, примеры не работают из коробки, пришлось немного позаниматься перебором для запуска. Отдельно отмечу, что обычно b2b сервисы не славятся читаемыми ошибками и читаемой документацией, но тут вообще не было ни ошибок, ни документации. Или 500-я ошибка или 200 с пустым ответом. Это создает легкий когнитивный диссонанс с учетом проработки анимации девушки-маскота, количества маркетинговых материалов и "успешных" кейсов.
У нашего сервиса само публичное АПИ весьма минималистичное и состоит из 2 методов (синтеза и gRPC нет еще в публичной документации) с примерами. Есть также gRPC АПИ, которое сейчас проходит обкатку. Наверное я тут не лучший судья, но основная ценность как мне кажется состоит в радикальной простоте для публичного АПИ и детальных инструкциях / сайзингах / опциях конфигурирования для более крупных клиентов.
Пропускная способность
Все АПИ, которые мы протестировали (кроме Ашманова) показали себя довольно бодро по скорости (это баг или фича — решать вам). Для измерения пропускной способности мы считаем показатель секунд аудио в секунду на 1 поток распознавания (RTS = 1 / RTF):
| Сервис | RTS per Thread | Threads | Комментарий |
|---|---|---|---|
| Ashmanov | 0.2 | 8 | |
| Ashmanov | 1.7 | 1 | |
| 4.3 | 8 | ||
| Google enhanced | 2.9 | 8 | |
| Sber | 13.6 | 8 | |
| Sber | 14.1 | 1 | |
| Silero | 2.5 | 8 | 4-core, 1080 |
| Silero | 3.8 | 4 | 4-core, 1080 |
| Silero | 6.0 | 8 | 12 cores, |
| Silero | 9.7 | 1 | 12 cores, |
| Tinkoff | 1.4 | 8 | |
| Tinkoff | 2.2 | 1 | |
| Yandex | 5.5 | 2 | 8 — много пустых ответов |
Чем выше RTS, тем лучше.
Поскольку никто не публикует сайзинги облачных и даже иногда коробочных (тут поправьте меня, если пропустил) версий своих систем публично (кстати прошлая версия нашего сайзинга например доступна по ссылке), то довольно сложно оценить адекватность работы систем по ресурсам. Ведь за АПИ может скрываться как одна VDS, так и сотни карт Nvidia Tesla, которыми любят хвастаться корпорации в своих пресс-релизах (что кстати частично подтверждается результатами Сбера — пропускная способность там не падает от роста нагрузки совсем). Расчеты выше не являются заменой полноценным сайзингам.
В защиту нашей системы могу сказать, что за этим бенчмарком стоит довольно слабый сервер конфигурации EX51-SSD-GPU, у которого сейчас есть некоторая фоновая нагрузка и который скорее сейчас оптимизирован на скорость ответа а не на пропускную способность. Еще небольшой тонкий момент состоит в том, что мы считали время каждого запроса и суммировали и поэтому никак не нормализовывали результаты на пинг, но оставим это для следующих исследований.
Вообще меня очень приятно удивили результаты Сбера. На текущих версиях моделей у нас например сайзинг на 12 ядерном процессоре + GPU рассчитан на ~150 RTS. По идее это означает, что если мы поднимем тестовый и сервис на 12+ ядрах процессора на чуть более новой карточке, мы должны получить результаты более близкие к Сберу. У нас все равно не получается получить такие же высокие показатели без просадки от нагрузки, но какие-то выводы уже можно строить и получается все равно весьма достойно. Снимаем шляпу перед инженерами Сбера и ставим aspirational цель сделать наш сервис еще в 2-3 раза быстрее.
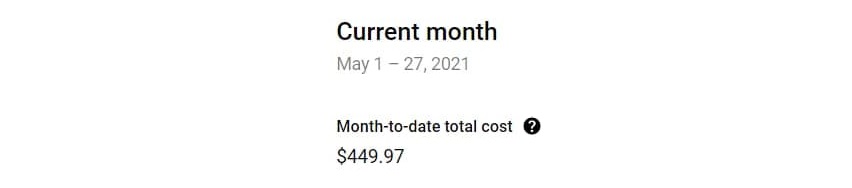
На цене мы останавливаться особо не будем (большая часть серьезных клиентов все равно не использует облако), но в очередной раз неприятный сюрприз преподнес Гугл выставив круглый счет за смешной (как нам кажется) объем. А ответ прост — зачастую облачные корпоративные сервисы распознавания имеют не только крутой ценник (и в случае Гугла еще и в долларах), но и неочевидные системы округления вверх. В начале своего пути мы тестировали какой-то сервис из Великобритании… который округлял до 60 секунд!
Небольшая ложка дегтя
Довольно приятно, что наш публичный некоммерческий датасет Open STT, неоднократно обсуждавшийся на Хабре, был предвестником релизов публичных данных, например от Сбера. Но долгосрочно все равно хотелось бы видеть хотя бы какую-то соразмерность вклада госкорпораций количеству вложенных в них публичных денег. В сравнении с похожими релизами на западе, мы пока сильно отстаем. Да и Яндекс традиционно не публикует ничего полезного в сфере распознавания речи, интересно почему.
Обновления / ошибки
Я перепутал, второй раз мы тестировали пропускную способность нашего сервиса на 1080 Ti, а не 2080 Ti. Это важно, так как между поколениями сильнее меняется скорость карточек.
Именно в Яндекс мы слали данные в формате opus. Мы потестили немного, вроде именно у Яндекса особой разницы между wav и opus нет.



sxdxfan
Как разработчик сервиса «Ашманова» хочу заметить, что доступ к веб интерфейсу закрытый, сам сайт исключительно демонстрационный, крутится на CPU, не предполагает нагрузки. Документация есть, клиентам мы её направляем, на сайт не успели её выложить, поддержаны протоколы wss, gRPC, MRCP обеих версий.
snakers4 Вы сравнивали в бенчмарке обе демонстрационные модели, 8000 и 16000?
snakers4 Автор
Мы использовали модель по-умолчанию
sxdxfan
На звонках гораздо лучше работает модель 8000, некорректно тестировать модель одного домена на другом
sxdxfan
Также просто для информации: этот демо сервис работает на AWS инстансе типа t3a.2xlarge, и к нему подключен t.me/voicybot, который тоже генерирует какую-то постоянную нагрузку, пусть и не очень высокую
snakers4 Автор
Ну на примере того же Сбера и нашего сервиса я бы с этим поспорил, но значит в следующий раз протестируем две модели