

Всем привет! Меня зовут Михаил Дьячков, и в Ситимобил я занимаюсь анализом данных и машинным обучением. Сегодня я хочу поговорить о Data Science: что же это вообще такое в глазах кандидатов, работодателей и экспертов; о несовпадении ожиданий, грейдах и собеседованиях, а также о том, какие задачи решают дата саентисты в Ситимобил.
Что такое Data Science?
Пожалуй, самое лаконичное определение, которое мне удалось найти в интернете:
Data science (Наука о данных) — это дисциплина, которая позволяет сделать данные полезными.

Я думаю, что если найти пересечение различных определений что же такое Data Science, то им будет лишь одно слово — данные. Всё это говорит о том, что широта применения Data Science огромна. Согласитесь, но ведь в этом нет ничего хорошего ни для кого: ни для вас, ни для бизнеса. Эта широта не дает никакой информации о вашей потенциальной деятельности. Ведь с данными можно делать всё, что угодно. Можно строить сложные отчеты или «шатать» таблички с помощью SQL. Можно предсказывать спрос на такси константой или строить сложные математические модели динамического ценообразования. А еще можно настроить поточную обработку данных для высоконагруженных сервисов, работающих в режиме реального времени.
А вообще, причем здесь слово «наука»? Безусловно, под капотом у Data Science серьезнейший математический аппарат: теория оптимизации, линейная алгебра, математическая статистика и другие области математики. Но настоящим академическим трудом занимаются единицы. Бизнесу нужны не научные труды, а решение проблем. Лишь гиганты могут позволить себе штат сотрудников, которые будут только и делать, что изучать и писать научные труды, придумывать новые и улучшать текущие алгоритмы и методы машинного обучения.
К сожалению, многие эксперты в этой области на разных мероприятиях зачастую связывают Data Science в первую очередь с построением моделей с помощью алгоритмов машинного обучения и довольно редко рассказывают самое важное, по-моему, — откуда возникла потребность в той или иной задаче, как она была сформулирована на «математическом языке», как это всё реализовано в эксплуатации, как провести честный эксперимент, чтобы правильно оценить бизнес-эффект.
Кто такой Data Scientist?
Когда мы поняли, что ничего не поняли, стоит поговорить о data scientist’ах — специалистах по анализу данных.

Одни считают, что эта должность подразумевает построение нейросетей в Jupyter Notebook’e. Другие ждут от таких специалистов, что те придут и будут закрывать все задачи «под ключ». А третьи просто хотят иметь в штате таких модных ребят. Такое разное понимание должности или непонимание вовсе может навредить при найме и вам, как кандидату, и компании.
Очень хорошую аналогию с Computer Science привел Валерий Бабушкин в своем докладе «Почему вы никогда не наймете дата саентиста». Постараюсь кратко ее передать.
Computer Science — некоторая область тесно связанных между собой дисциплин, но при этом почему-то никто не ищет на работу Computer Scientist’a. На работу ищут разработчика, тестировщика, DevOps’ов, архитекторов. Даже разработчика ищут frontend- и backend-разработчиков, вплоть до того, что ищут backend-разработчика на C++. Почему это хорошо? Потому что даже из названия вакансии на 90 % понятно, чем будет занят backend-разработчик на C++. Это дает довольно много информации и снижает энтропию. А если вы вдруг ищете Computer Scientist’a, то по-русски это что, компьютерщик? Это что-то из девяностых или нулевых. «У нас сломался принтер, позовите компьютерщика».
Из всего этого вырисовывается проблема. Если сходить на 10 собеседований, даже не обязательно в разные компании, в которых ищут Data Scientist’a, то вы поймете, что на каждом собеседовании от вас будут ожидать совершенно разного, и в конечном итоге у вас будут совершенно разные задачи. Где-то вам предложат в рамках ИИ-трансформации 200 Excel-файлов. В другом месте предложат поднять кластер на несколько петабайт. На третьем собеседовании вам расскажут, что ожидают от вас визуализацию метрик в Tableau. На четвёртом вас попросят построить real-time рекомендательную систему, которая будет работать под нагрузкой в несколько тысяч запросов в секунду. На пятом собеседовании будут задачи по компьютерному зрению, а на шестом придётся писать сложные SQL-скрипты. В седьмой компании вас заставят читать статьи, строить красивые Jupyter notebook’и и писать какие-то прогнозы. А где-то ещё и собрать эти расчеты в Docker-контейнер, и с помощью Kubernetes развернуть свой сервис на много машин.
Налицо проблема несовпадения ожиданий у кандидата и работодателя. Она в первую очередь касается неопытных ребят, которые думают, что они, наконец-то, попадут в мир Data Science, придут на работу и будут писать .fit() .predict() на уже готовеньком датасете.

Но проходит какое-то время и наступает суровая реальность: оказывается, что прежде чем обучать модели и подбирать гиперпараметры, нужно сделать очень много чего. Например, пообщаться с бизнесом и понять, какая же у них на самом деле головная боль, затем сформулировать эту боль на математическом языке, найти данные для задачи, очистить их, подумать над признаками, собрать модели, обернуть всё это в MLflow, положить в Docker-контейнер, оценить потенциальные нагрузки и отправить в эксплуатацию. Это можно сравнить с ситуацией, когда у вас спрашивают: «Ягоду будете?», вы отвечаете: «Да» и получаете арбуз — это ведь тоже ягода.
Как решать проблему несовпадения ожиданий?
Алексей Натекин в своем докладе «Чем отличаются data analyst, data engineer и data scientist» нарисовал картинку с распределением Дирихле, то есть с вероятностью вероятностей.

Предположим, что в Data Science существуют три основные компетенции:
Математика. Теоретические знания алгоритмов машинного обучения, и математическая статистика для проверки разных статистических гипотез и обработки результатов, а также любые другие фундаментальные знания, которые будут важны в вашей предметной области.
Разработка. Всё, что связано с разработкой, инженерными составляющими проекта, DevOps, SysOps, SRE, и прочее.
Предметная область. Навыки коммуникации с коллегами и бизнесом, чтобы понимать, какую проблему они хотят решить, на какие вопросы ответить.
И Data Scientist в этой парадигме — это некоторое наблюдение из нашего распределения Дирихле. Но с помощью этого распределения можно ввести несколько новых должностей, которые будут давать более ясное представление о вашей потенциальной деятельности. Рассмотрим несколько из них.
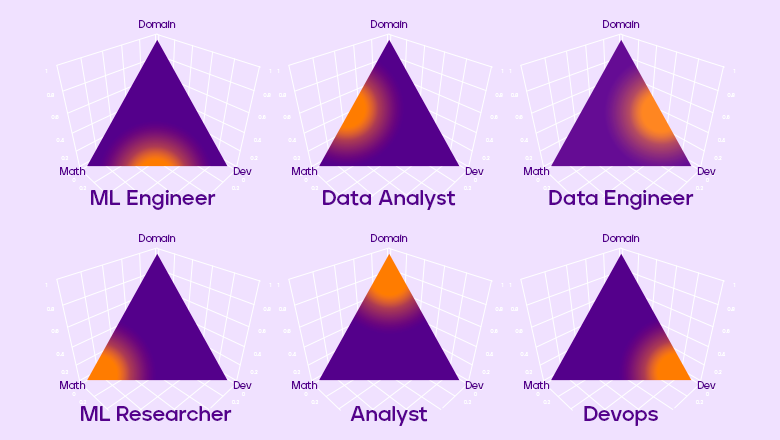
Если вы ищете работу на позицию Machine Learning Engineer, то, скорее всего, будете заниматься введением в эксплуатацию моделей машинного обучения и поддерживать их в актуальном состоянии. Для этого вам потребуются навыки и знания в области алгоритмов машинного обучения, ну и, конечно, разработки.
Если вы аналитик данных, то, вероятно, вы будете заниматься проверкой статистических гипотез, проектировать и проводить эксперименты. Для этого вам требуются фундаментальные знания математической статистики, а также необходимо держать руку на пульсе бизнеса.
Дата-инженер — это человек, который занимается ETL-процессами, архитектурой хранилища, составляет витрины и поддерживает их, организовывает потоковую обработку данных.
Machine Learning Researcher занимается исследовательской работой. Пишет и изучает статьи, придумывает новые математические методы. Таких позиций в России довольно мало, да и встречаются они, как правило, в крупных компаниях, которые могут себе это позволить.
Аналитик — это человек, который отвечает на вопросы бизнеса, и его плотность вероятности приходится на предметную область.
Наконец, DevOps максимально сосредоточен на разработке и развёртывании вашего кода в продакшене.
Junior/Middle/Senior/Team Lead/...
Попробуем коротко сформулировать профиль человека, который будет находиться на каждом из грейдов в мире Data Science. Не стоит забывать, что от компании к компании уровень компетенций для каждого из грейдов может довольно сильно отличаться.
Junior Data Scientist

Умеет реализовать полный DS-пайплайн: «приготовить» данные, обучить модель, измерить ее качество.
Делает только то, что ему сказали.
Нуждается в постоянной опеке и контроле.
Middle Data Scientist

Имеет подтвержденный на практике результат, например, построил и внедрил модель оттока клиентов, которая экономит компании N млн. руб в год.
Может обсуждать бизнес-постановку задачи.
В меру самостоятельный.
Редко ошибается.
Senior Data Scientist

Имеет более обширный опыт по сравнению с мидлом.
Может самостоятельно формулировать и решать задачи.
Имеет опыт наставничества или готов быть ментором.
Обладает высоким уровнем эмоционального интеллекта.
Уровень технических компетенций выше мидла.
Если у middle ребят возникают проблемы с ростом и развитием, то зачастую это связано с
отсутствием проактивности
не готовностью брать ответственность и инициативу на себя и доводить дело до конца
неумением находить общий язык с бизнес заказчиками и смежниками
синдромом самозванца
недостаточным уровнем эмоционального интеллекта и/или отсутствия понимания его важности в рабочей деятельности
А дальше уже сложнее, потому что тимлид может руководить как командой из 2-3 человек, так и несколькими отделами. Вот примеры «уровней» тимлида:
Эксперт, который отвечает за конкретные участки DS-пайплайна. Работает в соответствие с поставленными перед ним задачами. Координирует работу нескольких младших коллег.
Ставит задачи экспертам в соответствии с заданным планом и координирует их работу. Несет ответственность за конкретное направление DS в компании.
Отвечает за продукт/проект/направление, имеющие большое значение для крупной компании. Определяет требования к команде и составляет планы в соответствии с заданным направлением действий.
Отвечает за стратегически важный продукт/проект/направление в крупной компании. Руководит большой командой data scientist’ов и аналитиков. Задает команде направление действий, оценивает сроки и затраты, отвечает за результаты проектов.
Чем выше ваш уровень, тем больше ответственности и тем сложнее направление R&D. А значит, и больше ваша зарплата.
Но всё же можно выделить характерные отличия тимлида. Безусловно, этот человек должен обладать техническими навыками (hard skills): он знает, как сделать так, чтобы «всё заработало», может ответить на специфичные для продукта вопросы, знает, как работает продукт. А еще тимлид планирует и формулирует задачи (впоследствии «продаёт»), раскладывает их на составляющие, напрямую общается с бизнесом, работает с командой, занимается развитием и ростом своих ребят. Для тимлида важно думать и жить в терминах продукта и бизнеса, быть проактивным и доводить дело до конца.
Подготовка к собеседованию
Я за свою карьеру провел немало собеседований и могу дать несколько советов начинающим специалистам, что нужно обязательно сделать перед отправкой резюме в компанию и собеседованием.
Прежде чем откликаться на вакансию, внимательно прочитайте её описание до конца. Казалось бы, что за дурацкий совет. Но, как показывает практика, очень многие не делают даже этого. И на собеседовании порой возникают неловкие моменты.
Попробуйте поискать информацию о вашей потенциальной компании. Было бы здорово иметь представление о ней и о продукте.
Ознакомьтесь со списком ожидаемых знаний и навыков. Ответьте себе на вопрос, пересекаетесь ли вы с этим списком, и если да, то насколько глубоко.
Определите для себя, на какую зарплату вы претендуете. Если не можете ответить, то можно посмотреть актуальные вакансии с вилками в сообществе OpenDataScience в канале #_jobs, и таким образом оценить текущее состояние рынка.
Займитесь своим резюме. Его структура и выделение ваших ключевых особенностей, навыков и результатов очень важны при просмотре работодателем.
Не нервничайте. Проходить собеседования тоже нужно уметь, и тут без опыта никуда.
Что будет на собеседовании
Беседа будет строится вокруг:
Вашего опыта, подтвержденного результатом. Важно понимать, как ваш проект повлиял на бизнес, а не как вы повысили auc roc на 2 %.
Ваших знаний о моделях и алгоритмах машинного обучения. Причем вряд ли на собеседовании на позицию, где предстоит заниматься задачами динамического ценообразования, вас будут спрашивать о глубоких нейронных сетях, которые решают задачи сегментации изображений.
Метрик оценки качества моделей (как оффлайн, так и онлайн).
Статистических критериев и всего, что каким-то образом связано с проведением экспериментов.
Программирования, например, на Python (задача для разминки: реверсировать список).
Возможно, алгоритмов и структур данных, если ваша работа как-то связана с высоконагруженными сервисами.
Технологий, с которыми вы работали и/или с которыми вам предстоит работать.
Culture fit и поведенческой составляющей.
Примеры популярных технических вопросов на собеседовании с начинающим специалистом, ответы на которые, увы, могут дать далеко не все:
Что такое логистическая регрессия и как она работает?
Чем фундаментально отличается градиентный бустинг на деревьях от алгоритма случайного леса?
Как проверить статистическую значимость в АБ-эксперименте?
Какие вы знаете метрики оценки качества в задачах бинарной классификации?
Какие встроенные структуры данных в Python неизменяемы?
На самом собеседовании не стесняйтесь задавать вопросы. Это не экзамен, здесь должен быть диалог. Поинтересуйтесь, какая у вас будет команда, задачи, какие технологии вы будете использовать в работе, какие от вас ожидают результаты, какие глобальные цели у компании.
Как дела обстоят у нас
Мы создаем систему городской мобильности с человеческим отношением к пассажирам и водителям. И хотим сделать это отраслевым стандартом. Хотим встречать и провожать пассажиров в аэропорты и на вокзалы; доставлять важные документы по указанным адресам быстрее курьеров; сделать так, чтобы на такси было не страшно отправить ребёнка в школу или девушку домой после свидания, даем возможность выбрать транспорт — каршеринг, такси или самокат. И даже если нашим пассажиром является котик, то ему должно быть максимально комфортно.
У нас есть большой отдел эффективности платформы (или Marketplace), где в каждом из направлений работают специалисты по обработке и анализу данных.
Ценообразование: правильный и правдоподобный предрасчет цены для клиента на предстоящую поездку. Мы разрабатываем алгоритмы, которые тонко настраивают наши цены под специфические региональные и временные условия, а также помогают нам держать вектор оптимального ценового роста и развития
Клиентские мотивации: помогают нам привлекать новых клиентов, удерживать старых и делать нашу цену самой привлекательной на рынке. Основное направление — это разработка алгоритма оптимального распределения бюджета на скидки клиентам для достижения максимального количества поездок. Мы стремимся создать выгодное предложение для каждого клиента, поддержать и ускорить наш рост
Водительские мотивации: одна из главных задач Ситимобил — забота о водителях. Наши алгоритмы создают для них среду, в которой каждый работает эффективно и зарабатывает много. Мы стремимся разработать подход, позволяющий стимулировать водителей к выполнению поездок там, где другие алгоритмы не справляются: возмещаем простой на линии, если нет заказов, и гарантируем стабильность завтрашнего дня для привлечения всё новых и новых водителей.
Динамическое ценообразование: главная задача направления — гарантировать возможность уехать на такси в любое время и в любом месте. Достигается это за счет кратковременного изменения цен, когда желающих уехать больше, чем водителей в определенной гео-зоне.
Распределение заказов: эффективные алгоритмы назначения водителей на заказ уменьшают длительность ожидания и повышают заработок водителей. Задача этого направления — создать масштабируемые механизмы назначения, превосходно работающие как в целом по городам, так и в разрезе каждого тарифа.
Исследование эффективности маркетплейсов: центральное аналитическое направление, задачей которого является анализ эффективного баланса между количеством водителей на линии и пассажирами.
ГЕО сервисы: эффективное использование геоданных помогает различным командам эффективно настраивать свои алгоритмы, которые напрямую зависят от качества этих данных. Мы стремимся создавать такие модели, сервисы и алгоритмы, которые не только повышают качество маршрутизации и гео-поиска, но и напрямую воздействуют на бизнес, а также клиентский опыт.
Итог
Специалист по анализу данных (data scientist) может иметь очень широкий спектр обязанностей. Это сложная и увлекательная профессия, требующая самых разных навыков и позволяющая решать очень интересные задачи. Если вас заинтересовали наши направления, то обязательно заходите на нашу публичную страницу с вакансиями и откликайтесь на них.


demidovd98
Всегда было интересно почему принято считать что ML это как бы подкатегория DS. Обычно казалось что проблемы решаются путём как раз таки конвергенции ML & DS.
То есть как-то странно относить тех же ML Engineer и ML Researcher к «Дата сайнтистам», когда они по сути с работают только с готовыми данными в формате обработанных датасетов и ничего кроме нормализации с Данными оыбчно не делают.
Возможно проблема в том что обычно в проф. кругах термин Data используют в качестве «данные=прямая работа с данными», в то время как для общей публики термин преподносят как в качестве вообще любых данных (что не совсем верно и автоматически относит к DS даже тот же CS).
Что думаете по этому поводу, коллеги?
dim2r
Надо с помощью data-science построить модель того, что такое data-science ))
sunsexsurf
Парсим статьи, вытаскиваем из них смысл, строим граф знаний...
miwgan Автор
Думаю, что так исторически сложилось, что Data Science само собой подразумевает использование алгоритмов и методов машинного обучения.
Смотря что вы называете DS
miwgan Автор
ML Engineer — думаю соглашусь с вами, однако, этому человеку безусловно на каком-то уровне необходимо понимать что происходит в моделях под капотом, а также развитие некоторых DS компетенций может стать потенциальной точкой роста и развития
ML Researcher — всегда думал, что эти ребята не только читают статьи, но и воспроизводят их результаты на реальных данных компании