
Что такое Process Mining и как его применять, мы рассказывали в первом посте. Во второй части мы представили краткое руководство пользования библиотекой для интеллектуального анализа процессов SberPM. В данной статье мы подробнее раскроем функционал библиотеки и расскажем о новом модуле оптимизации процессов и клиентских путей, использующем обучение с подкреплением для поиска оптимального пути.
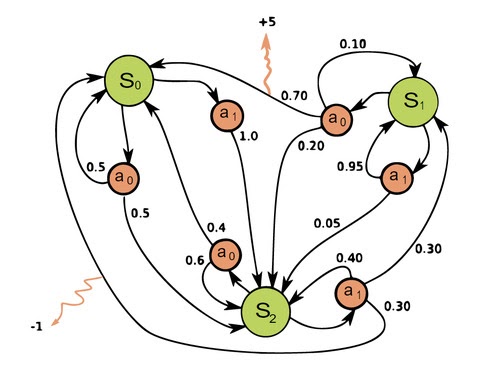
Оптимизация бизнес-процессов играет важнейшую роль в повышении операционной эффективности компании. В SberPM обучение с подкреплением используется для реконструкции процесса в соответствии с заданными критериями:
Отсутствие зацикленности.
Минимальное время выполнения этапов.
Минимальное число этапов.
Успешное завершение процесса.
Когда применять?
Анализ процесса, где слишком много этапов. Процессы с сотнями и тысячами этапов сложны для анализа и практически непригодны для наглядного отображения.
Есть редко используемые пути. Не все пути в процессе используются равномерно. С помощью RL можно определить и отсеять неоптимальные пути.
Нужен редизайн процесса. Еще один кейс – понять, как улучшить процесс для редизайна.
Необходимо сформировать клиентский путь. Узнать, как быстро и безболезненно «провести» клиента до успешного завершения процесса.
Таким образом, одной из ключевых областей применения данного модуля нам видится аналитика пути клиента. С помощью RL можно не только понять потребности клиента, но и оптимизировать его путь посредством увеличения скорости и конверсии.
Немного теории
Сперва поговорим о том, что такое обучение с подкреплением, или Reinforcement Learning, и чем оно отличается от других разделов Machine Learning.
Все алгоритмы машинного обучения упрощенно можно разделить на 3 большие группы:
Supervised Learning, или обучение с учителем. Модель обучается на заранее размеченных данных c правильными и неправильными ответами. К таким алгоритмам относятся различные классификаторы и регрессоры, на этом же принципе функционируют нейронные сети, решающие задачи сегментации, детекции и т.д.
Unsupervised Learning, или обучение без учителя. Здесь нет разметки, поэтому используются различные закономерности в структуре данных, их размещение в пространстве и другие характеристики. В эту группу входят всевозможные кластеризаторы, алгоритмы понижения размерности, эмбеддеры и так далее.
Reinforcement Learning. Его ключевое отличие состоит в том, что модель учится решать задачу методом проб и ошибок, то есть наиболее приближенно к тому, как мы с вами учимся чему-либо в реальной жизни.
Рассмотрим подробнее, каким образом это происходит. Обычно в обучении с подкреплением выделяют два абстрактных объекта – среда (environment) и агент (agent). Агент взаимодействует со средой, получая от нее фидбэк в виде наград. В процессе обучения агент стремится совершать действия, которые максимизируют получаемые им награды.
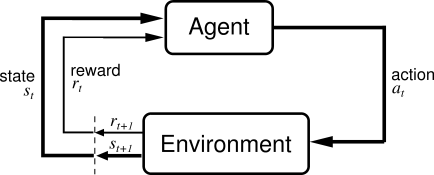
Для лучшего понимания того, что происходит в RL, также необходимо ознакомиться с Markov Decision Process (MDP). МDP позволяет математически корректно сформулировать любую проблему, возникающую в обучении с подкреплением.
Markov Decision Process – это набор пар(кортеж) (S, A, P, R, ????), где:
S – конечное множество состояний;
A – конечное множество действий;
P – матрица вероятностей перехода;
R – награда, которую аккумулирует агент;
???? – discount factor, определяющий, насколько важны для агента мгновенные награды по сравнению с удаленными по времени.
Как уже было сказано, «адекватный» агент при обучении стремится максимизировать математическое ожидание наград EttRst, где 0 ≤ ???? ≤ 1 – наш discount factor. Для того, чтобы агент действовал эффективно, нам необходимо найти функцию policy π, сопоставляющую каждому состоянию S наилучшее действие A, Ai:Si∀ i. Эту задачу можно решить с помощью уравнений Беллмана:
")

Первое уравнение позволяет оценить, к какой именно policy сойдется агент, совершая действие at в состоянии st .Полученные Q-values Q(s, a) говорят о том, насколько хороша в смысле оптимальности конкретная пара состояние-действие.
Благодаря второму уравнению (Bellman Optimality Equation) становится возможным найти наилучшую policy * среди всех π в пространстве заданного MDP.Оно также говорит о том, что в любом MDP есть как минимум одна оптимальная policy *.
Интуитивно видно, что типичный процесс в Process Mining и MDP очень похожи: состояниями s являются активности (или узлы на графе процесса), а действиями a являются переходы между активностями (или ребра на графе процесса). Для удобства вероятностями переходов P можно пренебречь или считать их равновероятными, так как для задачи поиска оптимального пути они несущественны. Осталось понять, как решать приведенные выше уравнения.
Алгоритмы RL можно разделить на 2 группы:
Model-free. Данные алгоритмы при обучении полагаются только на реальные объекты из среды, в зависимости от структуры которой агент меняет свое поведение. К ним относятся Monte-Carlo, Q-Learning, SARSA, Actor-Actor, Actor-Critic, REINFORCE и т. д.
Model-based. Алгоритмы, использующие принципы динамического программирования для поиска оптимальной policy *, напрямую вычисляя ее из заданных вероятностей переходов, состояний и действий. Их использование трудозатратно, поэтому на данный момент они применяются довольно редко. К ним относятся Policy iteration, Value iteration.
Еще одна проблема, встречающаяся в RL, называется Exploration-Exploitation trade-off. Ее суть заключается в том, что при обучении агента можно пойти двумя путями:
Exploit. Здесь агента обучают исключительно на известных действиях и примерах, которые, по мнению разработчика, являются наилучшими. В ряде случаев этот подход действительно надежен, но обычно при его применении есть большой риск оказаться в «глобальном минимуме» наград.
Explore. В данном случае при обучении агент будет сам пытаться найти лучшие действия для всех состояний, жертвуя временем и силами.
Мы подошли к решению этой проблемы основательно – в SberPM у пользователя есть выбор между двумя подходами. В случае эксплуатации известных примеров используется Monte-Carlo, а для исследования среды предназначен уже популярный и известный Q-Learning. Остановимся на нем подробнее.

Как показано выше, Q-Learning основан на уравнениях Беллмана и позволяет быстро и эффективно найти оптимальные Q-values для каждой пары состояние-действие. Изначально все Q-values инициализируются нулями, после каждого действия агента они обновляются в соответствии с заданным Learning Rate. Таким образом, Q-Learning напрямую аппроксимирует оптимальную policy *. Фактически алгоритм строит таблицу S-A-Q(S, A), которую еще называют Q-table, а затем выбирает из них комбинации с максимальными Q-Values.
Перейдем к реализации указанных алгоритмов в SberPM.
Использование SberPM для поиска оптимального пути в процессе
Как применять?
Шаг 1. Создание среды и выбор метода.

data_holder содержит лог-файл по процессу;
RLOptimizer создает среду по процессу, в которой состояния это этапы процесса, а действия – переходы между этапами. Каждый переход награждается в зависимости от того, насколько он оптимален по заданным критериям.
Рассмотрим для примера следующий процесс:
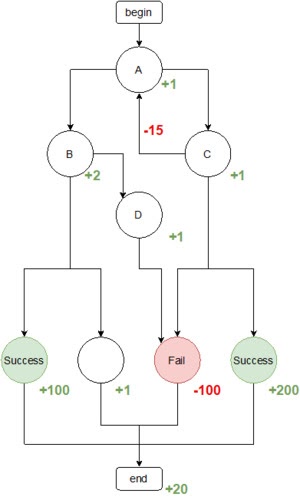
Агент помещается в состояние begin и выбирает следующее состояние процесса таким образом, чтобы максимизировать ожидаемую суммарную награду за завершение цепочки.
При создании среды необходимо выбрать тип обучения:
Exploitation: агент следует только по цепочкам, которые присутствуют в лог-файле, обучая свою политику выбора действий. После обучения агенту разрешается выбирать действия самостоятельно для реконструкции процесса.
Exploration: агент волен выбирать действия самостоятельно с самого начала. Таким образом при обучении могут появляться цепочки, отсутствующие в данных. Однако в этом случае больше вероятность обнаружить оптимальные цепочки, например, с отложенной наградой.
Например, с методом Exploitation более вероятно обнаружить оптимальную цепочку begin->A->C->success->end. В случае Exploration такой путь можно не найти, если в данных были только пути begin->A->B->…
Шаг 2. Задание наград.

Дизайн наград – ключ к построению успешной реконструкции. Необходимо оценить, какая из метрик наиболее важна для процесса, задать успешные исходы и определиться с штрафом за циклы. Если некоторые зацикливания для процесса являются нормой, штраф может быть уменьшен.
Шаг 3. Обучение и реконструкция.

Запустим обучение RL-агента. Результатом метода fit будет pandas.DataFrame со сгенерированными агентом цепочками активностей и наградами за них. Совокупность лучших цепочек и будет реконструированным процессом.
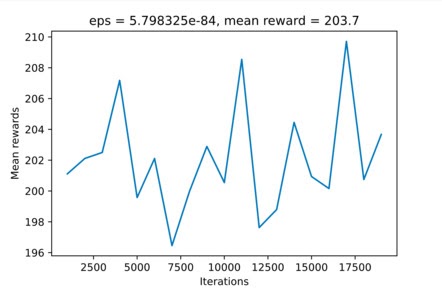
Продемонстрируем работу алгоритма на примере открытого лог-файла процесса по возмещению расходов на командировки с BPI Challenge 2020.
Исходный процесс выглядит так:
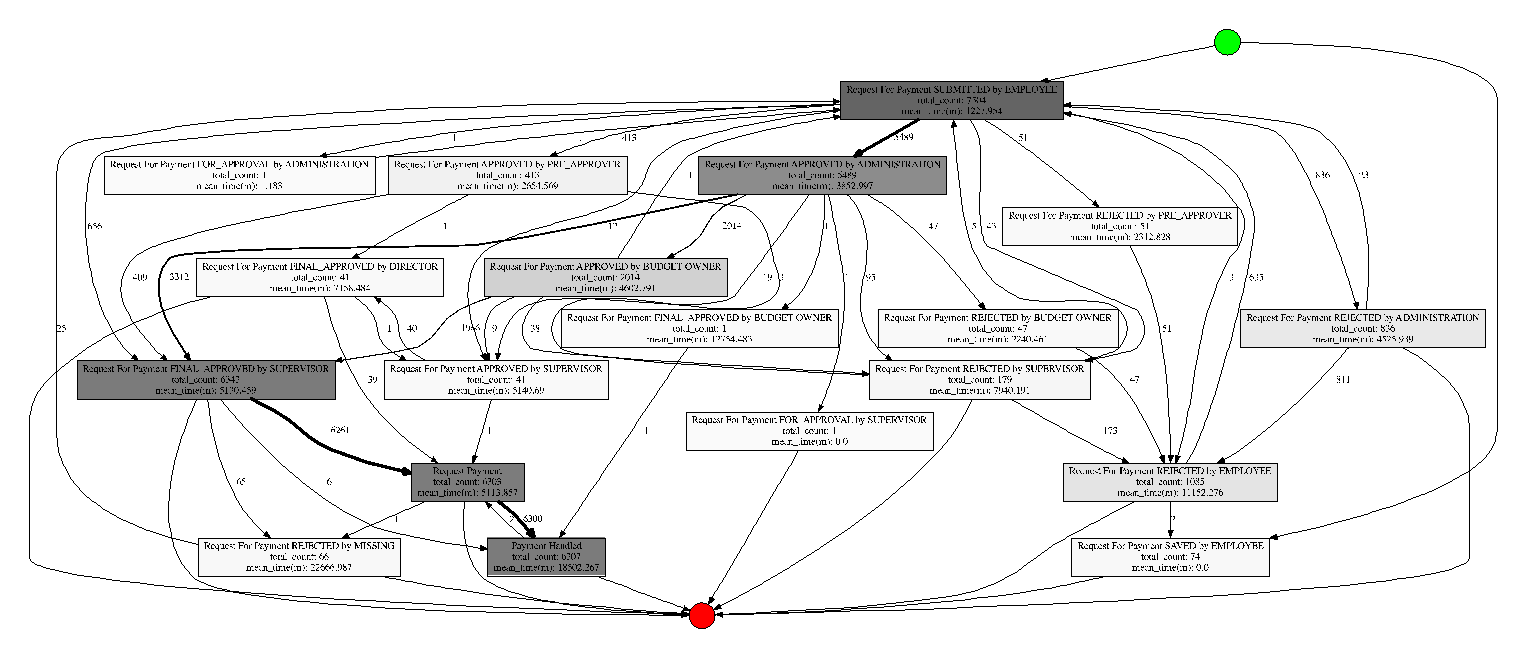
Граф имеет заметную структуру, видны разнообразные отклонения от основного течения процесса.
2.36% – средняя зацикленность этапа процесса;
8 этапов – средняя длина пути;
74% – вероятность успешного завершения.
Это хорошие показатели для такого процесса. Обучим реконструкцию с помощью модуля RL SberPM и сравним результаты.
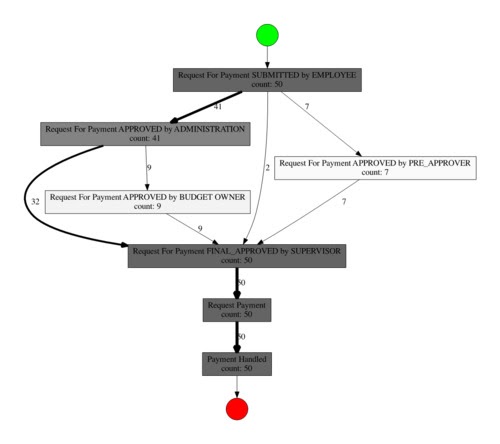
Dream-процесс имеет отчетливую структуру, которая совпадает с бизнес-смыслом оригинала, виден основной путь и его вариации. Вычислим метрики в реконструированном процессе:
0% – средняя зацикленность;
4.7 этапа – средняя длина пути (на 40% меньше);
100% – вероятность успешного завершения.
Модуль RL уже успешно применяется в анализе бизнес-процессов и клиентских путей и теперь он находится в открытом доступе репозитория библиотеки SberPM на GitHub.
Нам важна обратная связь по разработкам, ваши коммиты и отзывы очень помогут нам в развитии удобного и функционального продукта.