
Введение
Этот туториал содержит материалы полезные для понимания работы глубоких нейронных сетей sequence-to-sequence seq2seq и реализации этих моделей с помощью PyTorch 1.8, torchtext 0.9 и spaCy 3.0, под Python 3.8. Материалы расположены в эволюционном порядке: от простой и неточной модели к сложной и обладающей наибольшей точностью.
В качестве платформы был выбран фреймвёрк PyTorch, т.к. он требует меньшего уровня смирения при отладке по сравнению с TensorFlow. Кроме того, последняя версия PyTorch демонстрирует производительность, сопоставимую с производительностью TensorFlow (см. недавний сравнительный пост).
Разделы
Название каждого раздела, за исключением 4-го, соответствует названию породившей его статьи. Если визуальный формат постов разделов вам не нравиться, то каждый раздел будет снабжён ссылками на английскую и русскую версии jupyter notebook.
-
1 - Sequence to Sequence Learning with Neural Networks
В этом разделе рассматривается процесс работы над моделью seq2seq с помощью PyTorch и torchtext. Мы начнём с основ сетей seq2seq с использованием модели кодировщик-декодеровщик кодер−декодер, реализуем эту модель в PyTorch с использованием torchtext для выполнения всей тяжелой работы, связанной с обработкой текста. Сама модель будет основана на реализации Sequence to Sequence Learning with Neural Networks, которая использует многослойные LSTM сети.
-
2 - Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Теперь, когда мы познакомились с базовым рабочим процессом модели seq2seq, в этом разделе сосредоточимся на улучшении полученных результатов. Основываясь на наших знаниях о PyTorch и torchtext, полученных из первой части, мы рассмотрим вторую модель, в которой решена проблема сжатия информации, возникающая в модели кодера-декодера. Эта модель будет основана на реализации Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, которая использует GRU сеть.
-
3 - Neural Machine Translation by Jointly Learning to Align and Translate
Далее мы познакомимся с таким понятием как внимание, реализовав модель из статьи Neural Machine Translation by Jointly Learning to Align and Translate. Эта особенность новой модели разрешает проблему сжатия информации, позволяя декодеру «оглядываться» на входное предложение, используя для этого векторы контекста, которые являются взвешенными суммами скрытых состояний кодера. Веса для этих взвешенных сумм вычисляются с помощью механизма внимания. Как итог, декодер учится обращать внимание на наиболее важные слова в конструкции входного предложения при построении выходного.
-
4 - Уплотнённые Последовательности, Маскировка, Использование модели и BLEU
В этой части мы улучшим предыдущую архитектуру модели, добавив уплотнённые последовательности и маскировку. Эти два метода обычно используются в обработке естественного языка NLP. Уплотнённые последовательности позволяют нам обрабатывать только элементы входного предложения нашей рекуррентной сетью. Маскировка используется для того, чтобы заставить модель игнорировать определенные элементы, на которые мы не хотим, чтобы она обращала внимание, например, на дополненные\вспомогательные слова. Вместе они дают некоторый прирост производительности. Кроме того, будет рассмотрен простой способ использования модели для вывода, позволяющий получать перевод любого предложения, которое пропускается через модель. В дополнение к этому, будет реализован способ просмотра значений элементов вектора внимания для этих переводов в исходной последовательности. Наконец, будет показано, как вычислить метрику BLEU по выданным переводам.
-
5 - Convolutional Sequence to Sequence Learning
Наконец, мы отойдём от моделей seq2seq на основе рекуррентных сетей и реализуем эту сеть полностью на основе свёрточной модели. Одним из недостатков рекуррентных сетей — это то, что они являются последовательными. То есть, прежде чем слово будет обработано рекуррентной сетью, все предыдущие слова должны быть пропущены через неё. Свёрточные модели можно полностью распараллелить, что позволяет обучать их намного быстрее. Мы будем реализовывать модель Convolutional Sequence to Sequence, которая использует несколько свёрточных слоев как в кодере, так и в декодере с включённым механизмом внимания.
-
6 - Attention Is All You Need
Продолжая реализовывать модели, не базирующиеся на рекуррентных сетях, создадим модель Transformer из Attention Is All You Need. Эта сеть основана исключительно на механизме внимания с особой реализацией "многонаправленного внимания". Кодер и декодер состоят из нескольких уровней, каждый из которых состоит из подслоев "многонаправленного внимания" и Positionwise Feedforward. Эта модель в настоящее время используется во многих современных задачах последовательного обучения и передачи знаний.
Список литературы и дополнительных источников
Ниже некоторые ссылки на работы, которые помогли при создании этих учебных материалов. Некоторые из них могут быть устаревшими.
https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://www.analyticsvidhya.com/blog/2019/06/understanding-transformers-nlp-state-of-the-art-models/
Николенко С.И., Кадурин А., Архангельская Е.В. Глубокое обучение. Погружение в мир нейронных сетей. Санкт-Петербург: Питер. 2020. 481 с.
Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое обучение. Москва: ДМК-Пресс. 2018. 652 с.
1 - Sequence to Sequence Learning with Neural Networks
Для запуска кода втомчислевGoogleColab:
Исходная версия jupyter notebook
Русская версия jupyter notebook
В этом разделе из серии мы построим модель машинного обучения для преобразования одной последовательности в другую, используя PyTorch и torchtext. Это будет продемонстрировано на примере переводов с немецкого на английский. Однако эта модель и все последующие могут быть применены к любой проблеме, которая предполагает преобразование одной последовательности в другую, например, для задачи обобщения, то есть преобразования длинной последовательности в более короткую на том же языке, или к задаче предсказания пространственной третичной структуры белков на основе последовательности нуклеотидной цепочки мРНК (AlphaFold).
В этом разделе для понимания общих концепций моделей seq2seq мы начнем с простого примера на основе модели из статьи Sequence to Sequence Learning with Neural Networks.
Введение
Наиболее распространенными моделями sequence-to-sequence seq2seq являются модели кодера-декодера, которые обычно используют рекуррентную нейронную сеть RNN для кодирования исходного входного предложения в один вектор. Здесь и далее в серии мы будем называть этот единственный вектор вектором контекста. Мы можем думать о векторе контекста как об абстрактном представлении всего входного предложения. С точки зрения когнитивистов, этот вектор контекста — набор образов сущностей с образами взаимоотношений между ними. Данный вектор декодируется второй RNN, которая учится выводить целевое выходное предложение, генерируя его слово за словом, по одной ликсеме за раз.
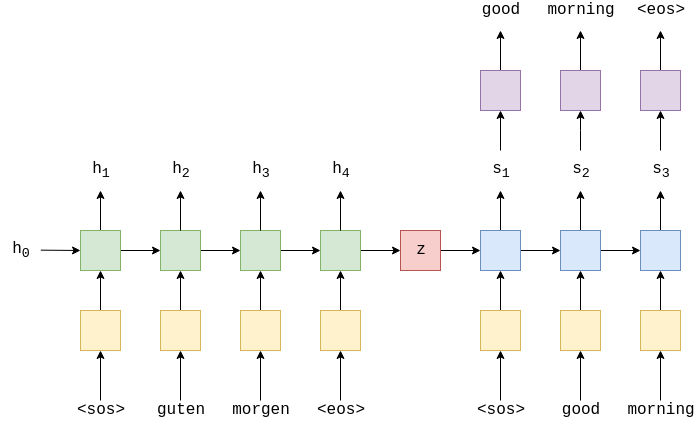
На изображении выше показан пример перевода. Предложение ввода/источника, «guten morgen», проходит через слой эмбеддинга желтый,служитдлясопоставленияэлементовречислова,предложения,...числовомувектору, а затем вводится в кодировщик зеленый. Всегда добавляются токены начало последовательности (<sos> — start of sequence) и конец последовательности (<eos> — end of sequence) в начало и конец предложения соответственно. На каждом временном шаге на вход в RNN кодировщика подаётся как эмбеддинг-версия текущего слова которая порождена слоем эмбеддинга e, так и скрытое состояние из предыдущего временного шага,
На выход RNN кодировщика подаёт новое скрытое состояние
Здесь мы можем думать о скрытом состоянии как о векторном представлении предложения. RNN кодировщика может быть представлена как функция EncoderRNN от переменных
и
Здесь и далее используя аббревиатуру RNN, подразумеваем под ней сеть любой рекуррентной архитектуры: например, LSTM LongShort−TermMemory или GRU GatedRecurrentUnit.
Мы имеем последовательность где
и т.д. Начальное скрытое состояние,
обычно либо инициализируется нулями, либо является параметром обучения.
После того как последнее слово было передано в RNN через слой эмбеддинга, мы используем конечное скрытое состояние
как вектор контекста, то есть
. Это векторное представление всего исходного предложения.
Теперь у нас есть вектор контекста z, который мы можем начать декодировать, чтобы получить выходное/целевое предложение «good morning». Как и в предыдущем случае, мы добавляем токены начала и конца последовательности к целевому предложению. На каждом временном шаге входом в RNN декодера синий является эмбеддинг текущего слова , а также скрытое состояние из предыдущего временного шага
, где начальное скрытое состояние декодера
, является вектором контекста,
. Т.е. начальное скрытое состояние декодера является окончательным скрытым состоянием кодера. Таким образом, аналогично кодеру, мы можем представить декодер как функцию от переменных
и
:
Хотя слой эмбеддинга входа/источника e и слой эмбеддинга выхода d оба показаны жёлтым цветом на приведённом рисунке, они представляют собой два разных слоя эмбеддинга со своими собственными параметрами.
В декодере нам нужно перейти от скрытого состояния к фактическому слову, поэтому на каждом временном шаге мы используем для распознавания (передавая эту величину через слой
Linear, показанный фиолетовым цветом) того, что мы считаем следующим словом в последовательности .
Слова в декодере всегда генерируются одно за другим, по одному за один временной шаг. Мы всегда используем <sos> в качестве первого слова для ввода в декодер, но для последующих слов для ввода yt> 1, мы иногда будем использовать фактическое, истинное/целевое следующее слово в последовательности
, и иногда будем брать слово, предложенное нашим декодером
. Такой метод обучения называется обучением с принуждением, подробнее об этом здесь.
При обучении/тестировании нашей модели мы всегда знаем, сколько слов в нашем целевом предложении, поэтому мы перестаем генерировать слова, как только набираем это количество. Во время рабочего вывода обычно генерируют слова до тех пор, пока модель не выдаст токен окончания последовательности или после того, как будет сгенерировано определенное количество слов.
Когда у нас есть предсказанное предложение , мы сравниваем его с нашим фактическим целевым предложение,
, для расчета потерь/ошибок. Затем используем эти потери для обновления всех параметров обучаемой модели.
Подготовка данных
Мы будем описывать модель в PyTorch и использовать torchtext для выполнения всей необходимой предварительной обработки. Кроме того, мы будем использовать spaCy для помощи в токенизации данных.
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import timeМы установим случайные начальные числа для получения детерминированных результатов.
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = TrueДалее мы создадим токенизаторы. Токенизатор используется для превращения строки, содержащей предложение, в список отдельных токенов, составляющих эту строку, например "доброе утро!" становится "доброе", "утро", "!". С этого момента мы начнем говорить о предложениях, представляющих собой последовательность токенов, вместо того, чтобы говорить, что они являются последовательностью слов. Какая разница? Что ж, «добро» и «утро» - это и слова, и знаки, но «!» это знак, а не слово.
В spaCy есть модель для каждого языка de_core_news_sm для немецкого и en_core_web_sm для английского, которую необходимо загрузить, чтобы мы могли получить доступ к токенизатору каждой модели.
Примечание: сначала необходимо загрузить модели на диск, используя следующую команду в командной строке:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_smДля загрузки в Google Colab используем следующие команды (После загрузки обязательно перезапустите colab runtime! Наибыстрейший способ через короткую комаду: Ctrl + M + .):
!pip install -U spacy==3.0
!python -m spacy download en_core_web_sm
!python -m spacy download de_core_news_smМы загружаем модели в память следующим образом:
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')Далее мы создаем токенизирующие функции. Они могут быть переданы в torchtext и будут принимать предложение в виде строки, а возвращать предложение в виде списка токенов.
В статье, на основе которой мы реализуем данную модель, авторы считают полезным изменить порядок ввода токенов, который, по их мнению, «вводит множество краткосрочных зависимостей в данные, значительно упрощая задачу оптимизации». Мы копируем результат, переворачивая немецкое предложение после того, как оно было преобразовано в список токенов.
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings (tokens) and reverses it
"""
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
"""
return [tok.text for tok in spacy_en.tokenizer(text)]Класс Field в torchtext указывает как данные должны быть обработаны. Все возможные аргументы детально описаны здесь.
Мы устанавливаем правильную функцию токенизации в качестве аргумента tokenize для каждого языка, причем немецкий является полем SRC источник, а английский — полем TRG цель. Экземпляры класса Field содержат токены «начало последовательности» и «конец последовательности» как аргументы «init_token» и «eos_token». Все слова преобразуются к нижнему регистру.
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)Далее скачиваем и загружаем данные для обучения, валидации во время обучения и тестирования.
Набор данных, который мы будем использовать, - это корпус Multi30k. Это набор данных из ~ 30 000 параллельных предложений на английском, немецком и французском языках, каждое из которых содержит порядка 12-ти слов в предложении.
exts указывает, какие языки использовать в качестве источника и цели источник идет первым, а fields указывает, какое поле использовать для источника и цели.
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))Мы можем проверить, что загрузили нужное количество примеров:
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")Мы также можем распечатать пример, убедившись, что исходное предложение перевернуто:
print(vars(train_data.examples[0]))Точка стоит в начале предложения на немецком языке src, поэтому похоже, что предложение было правильно перевернуто.
Затем мы создадим словарь для исходного и целевого языков. Словарь используется для связывания каждого уникального токена с индексом целым числом. Словари исходного и целевого языков различаются.
Используя аргумент min_freq, мы разрешаем только токенам, которые появляются как минимум 2 раза, появляться в нашем словаре. Токены, которые появляются только один раз, конвертируются в токен <unk> неизвестно.
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")Последний шаг подготовки данных — создание итераторов. С их помощью можно итерационно возвращать пакеты данных, которые будут иметь атрибут src тензоры PyTorch, содержащие набор оцифрованных исходных предложений и атрибут trg тензоры PyTorch, содержащие набор оцифрованных целевых предложений. Оцифрованные предложения — это просто причудливый способ сказать, что они были преобразованы из последовательности читаемых токенов в последовательность соответствующих индексов с использованием словаря.
Нам также нужно определить torch.device. Эта величина используется, чтобы указать torchText, куда помещать тензоры для вычислений: на GPU или нет? Мы используем функцию torch.cuda.is_available(), которая вернет True, если на нашем компьютере обнаружен графический процессор. Мы передаем это поле итератору.
Когда мы получаем батч примеров с использованием итератора, нам нужно убедиться, что все исходные предложения дополнены до одинаковой длины, как и целевые предложения. К счастью, итераторы torchText справятся с этим за нас!
Мы используем BucketIterator вместо стандартного Iterator, поскольку он создает пакеты таким образом, чтобы минимизировать количество отступов как в исходном, так и в целевом предложении.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)Построение модели Seq2Seq
Мы будем строить нашу модель из трех частей. Кодер, декодер и модель seq2seq, которая инкапсулирует кодер и декодер, и обеспечивает способ взаимодействия с каждым из них.
Кодер
Во-первых, кодер — это двухслойная LSTM сеть. В статье, на которую мы опираемся при реализации, используется 4-слойная LSTM сеть, но в целях экономии времени мы сократили количество слоёв до 2-х. Многослойную RNN легко расширить с 2 до 4 уровней.
Во многослойной RNN входное предложение после эмбеддинга передаётся в первый нижний слой RNN и порождает скрытые состояния
. Выходные данные этого слоя используются в качестве входных данных для RNN на уровне выше. Таким образом, представляя каждый слой надстрочным индексом, скрытые состояния в первом слое задаются следующим образом:
Скрытые состояния во втором слое задаются следующим образом:
Использование многослойной RNN предполагает, что нам понадобится исходное скрытое состояние в качестве входных данных для каждого слоя , а сеть будет предоставлять вектор контекста для каждого слоя
.
Не вдаваясь в подробности о LSTM сети (см. здесь, чтобы узнать о них больше), все, что нам нужно знать, это то, что эти сети являются RNN, которые вместо того, чтобы просто принимать скрытое состояние и возвращать новое скрытое состояние для каждого временного шага, принимают и возвращают состояние ячейки , на каждом временном шаге.
Мы можем принять как другой тип скрытого состояния. Подобно
, величина
будет инициализирована тензором, заполненным нулями. Кроме того, наш вектор контекста теперь будет образован конечным скрытым состоянием и конечным состоянием ячейки, то есть
.
Распространяя наши многослойные уравнения на LSTM, мы получаем:
Обратите внимание на то, что наше скрытое состояние из первого слоя передается в качестве входных данных во второй слой, а не в состояние ячейки.
Итак, наш кодировщик выглядит примерно так:

Мы реализуем это в коде, создав модуль Encoder, который требует, чтобы мы унаследовали это класс от torch.nn.Module и использовали super () .__ init __ () как некоторый шаблонный код. Кодировщик принимает следующие аргументы:
input_dim- размер / размерность one-hot векторов, которые будут вводиться в кодировщик. Они равны размеру входного исходного размера словаря.emb_dim- размерность слоя эмбеддинга. Этот слой преобразует one-hot векторы в плотные векторы с размерамиemb_dim.hid_dim- размерность скрытого состояния и состояния ячейки.n_layers- количество слоев в RNN.dropout- количественная характеристика дропаута. Это параметр регуляризации для предотвращения переобучения. Ознакомьтесь с этим здесь для получения дополнительных сведений о прекращении обучения.
Мы не собираемся подробно обсуждать слой эмбеддинга в этих заметках. Все, что нам нужно знать, это то, что есть шаг до того, как слова - индексы слов - передаются в RNN, где слова преобразуются в векторы. Чтобы узнать больше об эмбеддинге слов, посмотрите эти статьи: 1, 2, 3, 4.
Слой эмбеддинга создаётся с помощью nn.Embedding, LSTM с nn.LSTM и слой дропаута с nn.Dropout. Дополнительные сведения об этом см. в документации.
Следует отметить, что аргумент dropout для LSTM заключается в том, сколько связей необходимо отключить между уровнями многослойной RNN, то есть между скрытыми состояниями, выводимыми из уровня , и теми же скрытыми состояниями, используемыми для ввод слоя
.
В методе forward мы передаем исходное предложение X, которое преобразуется в плотные векторы с помощью слоя embedding, а затем применяется дропаут. Эти величины через эмбеддинг затем передаются в RNN. Когда мы загружаем всю последовательность в RNN, она автоматически выполняет для нас рекуррентные расчёт скрытых состояний по всей последовательности! Обратите внимание, что мы не передаем в RNN начальное скрытое состояние или состояние ячейки. Это связано с тем, что, как указано в документации (https://pytorch.org/docs/stable/nn.html#torch.nn.LSTM), если в RNN не передается скрытое состояние / состояние ячейки, оно автоматически создает начальное скрытое состояние / состояние ячейки как тензор с нулями.
RNN возвращает: outputs скрытые состояния верхнего уровня для каждого временного шага, hidden (окончательное скрытое состояние для каждого слоя, , наложенное друг на друга) и
cell (конечное состояние ячейки для каждого слоя, , наложенных друг на друга).
Поскольку нам нужны только окончательные скрытой состояния и состояние ячейки для создания нашего вектора контекста, forward только возвращает hidden и cell.
Размеры каждого из тензоров оставлены в виде комментариев в коде. В этой реализации n_directions всегда будет 1, однако обратите внимание, что двунаправленные RNN описанные в разделе 3 будут иметь n_directions равное 2.
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cellДекодер
Далее мы построим наш декодер, который, как и кодер, будет двухслойной LSTM сетью 4-х слойной в статье.

Объект класса Decoder выполняет один шаг декодирования, то есть выводит один токен за каждую временную итерацию. Первый слой получает скрытое состояние и состояние ячейки из предыдущего временного шага и передаёт его через LSTM вместе с текущим встроенным токеном
, для создания нового скрытого состояния и состояния ячейки
. Последующие слои будут использовать скрытое состояние из слоя ниже,
, и предыдущие скрытые состояния и состояния ячеек из своего слоя,
. Это приводит к выражениям, очень похожими на те, что используются для кодировщика.
Помните, что начальные скрытые состояния и состояния ячеек для нашего декодера — это наши векторы контекста, которые являются конечными скрытыми состояниями и состояниями ячеек нашего кодировщика с того же уровня, т.е. .
Затем мы передаём скрытое состояние из верхнего уровня RNN , через линейный слой f, для предложения следующего токена в целевой выходной последовательности
.
Аргументы и инициализация аналогичны классу Encoder, за исключением того, что теперь у нас есть output_dim, который является размером словаря для выходной/целевой последовательности. Кроме того, добавлен слой Linear, используемый для прогнозирования токена на основе скрытого состояния верхнего уровня.
Метод forward принимает пакет входных токенов, предыдущие скрытые состояния и предыдущие состояния ячеек. Поскольку мы декодируем только один токен за раз, входные токены всегда будут иметь единичную длину последовательности. Мы «разжимаем» входные токены для получения предложения длины 1. Затем, как и в кодировщике, мы проходим через слой эмбеддинга и применяем дропаут. Этот пакет встроенных токенов затем передается в RNN с предыдущими скрытыми состояниями и состояниями ячеек. Таким образом создаётся «вывод» скрытое состояние из верхнего уровня RNN, новое «скрытое» состояние по одному для каждого слоя, накладываемое друг на друга и новое состояние «ячейки» также по одному на слой, уложеные друг на друга. Затем мы передаем «вывод» после того, как избавляемся от измерения длины предложения через линейный слой, чтобы получить «предложенное» слово. Далее мы возвращаем «предложенное» слово, новое «скрытое» состояние и новое состояние «ячейки».
Примечание: т.к. у нас всегда длина последовательности равна 1, мы могли бы использовать nn.LSTMCell вместо nn.LSTM, поскольку он предназначен для обработки пакета входных данных, которые необязательно входят в последовательность. nn.LSTMCell - это просто одна ячейка, а nn.LSTM - потенциально оболочка вокруг нескольких ячеек. Использование nn.LSTMCell в этом случае означало бы, что нам не нужно «разжимать» предложение, чтобы добавить измерение длины промежуточной последовательности, но нам понадобится один nn.LSTMCell на каждый слой в декодере и, чтобы гарантировать, что каждый nn .LSTMCell получает правильное начальное скрытое состояние от кодировщика. Все это делает код менее лаконичным — отсюда и решение придерживаться обычного nn.LSTM.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cellSeq2Seq
В заключительной части мы реализуем модель seq2seq. Она будет:
получать входные предложения предложения из источника
использовать кодировщик для создания векторов контекста
использовать декодер для создания выходного/целевого предложения
Наша полная модель будет выглядеть следующим образом:

Модель Seq2Seq принимает кодировщик, декодер и ссылку на девайс используется для размещения тензоров на GPU, если он существует.
Для этой реализации мы должны убедиться, что количество слоев и скрытые и ячейки размеры равны в Encoder и Decoder. Это не всегда так, и нам необязательно нужно соблюдать равенство количества слоев или равенство размера скрытых измерений в модели sequence-to-sequence. Однако, если бы мы сделали количество слоёв отличными, нам нужно было бы принять решение о том, как обрабатывать результаты. Например, если у нашего кодировщика 2 слоя, а у нашего декодера только 1, как это обрабатывать? Усреднять ли два вектора контекста, выводимых декодером? Пропускать ли оба через линейный слой? Использовать ли только вектор контекста с самого верхнего уровня? И т.п.
Наш метод forward берет исходное предложение, целевое предложение и коэффициент, показывающий вероятность включения метода обучения с принуждением. При декодировании на каждом временном шаге мы будем предсказывать, какой следующий токен в целевой последовательности будет взят из предыдущих декодированных токенов, . С вероятностью, равной указанноуму выше коэффициенту (
teacher_forcing_ratio), мы будем использовать фактический следующий токен истинной/целеовй последовательности в качестве входных данных для декодера в течение следующего временного шага. Однако с вероятностью 1 - teacher_forcing_ratio мы будем использовать токен, предсказанный моделью, в качестве следующего входа в модель, даже если он не соответствует фактическому следующему токену в истинной последовательности.
Первое, что мы делаем в методе forward, - это создаём тензор output, который будет хранить все предложенные моделью прогнозы .
Затем мы загружаем входное предложение, src, в кодировщик и получаем окончательные скрытые состояния и состояния ячеек.
Первым входом в декодер является токен начала последовательности (<sos>). Поскольку к нашему тензору trg уже добавлен токен <sos> (определяли init_token в нашем поле TRG), мы получаем , разрезая его. Мы знаем, какой длины должны быть наши целевые предложения (
max_len), поэтому мы повторяем этот цикл необходимое количество раз. Последний токен, введенный в декодер, - это токен перед токеном <eos> - токен <eos> никогда не вводится в декодер.
Во время каждой итерации цикла мы:
передаём входное предложение, предыдущее скрытое и предыдущее состояния ячейки
в декодер
получаем предсказание, следующее скрытое состояние и следующее состояние ячейки
из декодера
размещаем наше предсказание,
/
outputв нашем тензоре предсказаний,/
outputs-
решаем использовать ли обучение с принуждением
если мы решаем использовать, то следующий
ввод- это следующий токен в последовательности,/
trg[t]если мы решаем не использовать, то
ввод- это следующий токен в последовательности,/
top1, который мы получаем, пропуская выходной тензор черезargmax
После того как мы сделали все действия, мы возвращаем наш тензор, полный предсказаний /
outputs.
Примечание: наш цикл декодера начинается с 1, не с 0. Это означает, что в нулевом элементе нашего тензора "выходов" остаются все нули. Так что наши trg и output выглядят следующим образом:
Позже, когда мы вычисляем потери, мы отсекаем первый элемент каждого тензора, чтобы получить:
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputsОбучение модели Seq2Seq
Теперь, когда наша модель готова, мы можем приступить к ее обучению.
Сначала мы инициализируем нашу модель. Как упоминалось ранее, размеры ввода и вывода определяются размером словаря. Размеры эмбеддинга и дропаута для кодера и декодера могут быть разными, но количество слоёв и размерность скрытых состояний должны быть одинаковыми.
Затем определяем кодер, декодер и нашу модель Seq2Seq, которую мы загружаем в device.
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)Затем инициализируем веса нашей модели. В статье утверждается, что инициализируют все веса из равномерного распределения между -0.08 и +0.08, т.е. .
Мы инициализируем веса в PyTorch, создавая функцию apply, которую мы применяем к нашей модели. При использовании функции apply функция весов init_weights будет вызываться для каждого модуля и подмодуля в нашей модели. Для каждого модуля мы перебираем все параметры и выбираем их из равномерного распределения с помощью nn.init.uniform_.
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)Мы определяем функцию, которая будет вычислять количество обучаемых параметров в модели.
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')Мы определяем наш оптимизатор, который используем для обновления наших параметров в цикле обучения. Посмотрите здесь информацию о различных оптимизаторах. Здесь мы будем использовать оптимизатор Adam.
optimizer = optim.Adam(model.parameters())Затем мы определяем нашу функцию потерь. Функция CrossEntropyLoss вычисляет как log softmax, так и отрицательную логарифмическую вероятность наших прогнозов.
Наша функция потерь вычисляет средние потери на токен, однако, передав индекс токена <pad> в качестве аргумента ignore_index, мы игнорируем потерю всякий раз, когда целевой токен является маркером заполнения <pad>.
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)Далее мы определим наш цикл обучения.
Сначала мы установим модель в «режим обучения» с помощью model.train (). Это включит дропаут и пакетную нормализацию, которую мы не используем, а затем итерацию через наш итератор данных.
Как указывалось ранее, наш цикл декодера начинается с 1, а не с 0. Это означает, что в нулевом элементе нашего тензора output остаются все нули. Итак, наши trg и output выглядят примерно так:
Здесь, когда мы вычисляем потери, мы отсекаем первый элемент каждого тензора, чтобы получить:
На каждой итерации:
получаем исходное и целевое предложения из пакета,
X и
обнуляем градиенты, вычисленные из последнего пакета
передаём исходное и целевое предложения в модель, чтобы получить результат,
-
так как функция потерь работает только с двумерынм входом с одномерным целевым выходом, нам нужно
спрямитькаждую из них с помощью.viewмы отрезаем первый столбец выходных и целевых тензоров, как упомянуто выше
вычисляем градиенты с помощью
loss.backward ()обрезаем градиенты, чтобы предотвратить их взрыв обычная проблема в RNN
обновляем параметры нашей модели, выполнив шаг оптимизатора
суммируем значения потерь в промежуточную сумму
Наконец, мы возвращаем потери, усредненные по всем батчам.
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)Наш цикл оценки аналогичен нашему циклу обучения, однако, поскольку мы не обновляем какие-либо параметры, нам не нужно передавать оптимизатор или значение отсечки.
Мы должны не забыть установить модель в режим оценки с помощью model.eval(). Это отключит дропаути и нормализацию партии, если она используется.
Мы используем блок with torch.no_grad(), чтобы гарантировать, что градиенты не вычисляются внутри блока. Это снижает потребление памяти и ускоряет работу.
Цикл итерации аналогичен без обновлений параметров, однако мы должны убедиться, что мы отключили обучение с принуждением. Это приведет к тому, что модель будет использовать только свои собственные предположения, чтобы делать дальнейшие предположения для предложения, что отражает то, как она будет использоваться при развертывании.
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)Затем мы создадим функцию, которую мы будем использовать, чтобы сообщить нам, сколько времени занимает эпоха.
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsНаконец-то мы можем приступить к обучению нашей модели!
В каждую эпоху мы будем проверять, достигла ли наша модель лучших потерь на валидации на данный момент. Если это так, мы обновим величину, отражающую лучшие потери при валидации, и сохраним параметры нашей модели (называемой state_dict в PyTorch). Затем, когда мы приступим к тестированию нашей модели, мы будем использовать сохраненные параметры, используемые для достижения наилучших потерь при проверке.
Мы будем печатать и потери, и сложность perplexity на каждой эпохе. Легче увидеть изменение в сложности, чем изменение потерь, поскольку цифры намного больше.
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')Мы загрузим параметры (state_dict), которые были сохранены для лучшей модели при проверке, и запустим их на тестовом наборе.
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')В следующем разделе мы реализуем модель, которая позволяет повысить сложность тестирования, но использует только один уровень в кодировщике и декодере.