
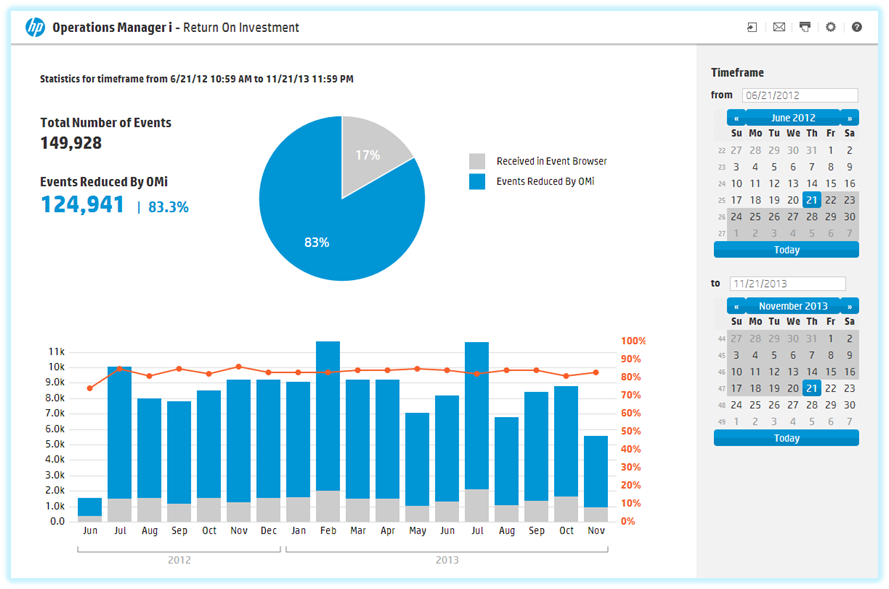
Управление и мониторинг ИТ-инфраструктуры – одна из главных задач ИТ-департамента любой компании. Решения HP Software позволят упростить задачу системных администраторов и организовать эффективный контроль сети организации
Современная ИТ-инфраструктура представляет собой сложную гетерогенную сеть, включающую в себя телекоммуникационные, серверные и программные решения разных производителей, работающие на базе различных стандартов. Ее сложность и масштабность определяют высокий уровень автоматизированных средств мониторинга и управления, которые должны использоваться для обеспечения надежной работы сети. Программные продукты HP Software помогут решить задачи мониторинга на всех уровнях, от инфраструктуры (сетевого оборудования, серверов и систем хранения) до контроля качества работы бизнес-сервисов и бизнес-процессов.
Системы мониторинга: какими они бывают?
В современных платформах для мониторинга ИТ существует 3 направления для развития и вывода мониторинга на новый уровень. Первую называют «Мост» («Зонтичная система», «Менеджер менеджеров). Ее концепция заключается в утилизации инвестиций в уже имеющиеся системы, которые выполняют задачи мониторинга отдельных частей инфраструктуры, и превращении самих систем в информационные агенты. Такой подход является логичным развитием обычного мониторинга ИТ инфраструктуры. В качестве предпосылок внедрения системы типа «Мост» может служить принятие ИТ-отделом решения консолидировать разрозненные системы мониторинга для перехода к мониторингу ИТ услуг/систем как чего то целого, разрозненные системы не способные показать всю картину, случай не диагностирования серьезного сбоя приложений, а также большое количество предупреждений и аварийных сигналов, отсутствие единого охвата, приоритезации и выявления причинно-следственной связи.
Результатом внедрения станет автоматизированный сбор всех доступных событий и метрик ИТ-инфраструктуры, сопоставление их состояния и влияния на «здоровье» сервиса. В случае сбоя оператор получит доступ к панели, отображающей корневую причину сбоя с рекомендациями по ее устранению. В случае типового сбоя есть возможность назначить скрипт, автоматизирующей необходимые действия оператора.
Следующая тенденция называется «Аналитика аномалий». Здесь, как и в первом случае, метрики и события собираются из ряда систем инфраструктурного мониторинга, а кроме того, настроен сбор логов ИТ и безопасности. Таким образом, ежеминутно накапливается огромное количество информации, и компания хочет получить преимущества от ее утилизации. Для внедрения «Аналитики аномалий» существует целый ряд причин: сложность своевременного сбора, хранения и анализа всех данных, потребность реактивно устранять неизвестные проблемы, невозможность быстрого определения важной для устранения сбоев информации, сложность выполнения вручную операций поиска отдельных журналов, а также необходимость определения отклонений и повторяющихся сбоев.
Внедрение системы позволит реализовать автоматизированный сбор событий, метрик и логов, хранение этой информации необходимый период времени, а также анализ любой информации, включая журналы, сведения о производительности и данные систем. Помимо этого, станет возможным прогнозирование и разрешение любых типов проблем и предотвращение известных сбоев.
И наконец – «Управление производительностью приложений», или выявление и устранение сбоев в транзакциях конечных пользователей. Такое решение может быть полезным дополнением, работающим в плотном контакте с предыдущими двумя. При этом такая система сама по себе тоже может давать быстрый результат от внедрения. В данном случае в компании есть приложения, важные для бизнеса. При этом важны доступность и качество услуги, одним из ключевых элементов которой является приложение (интернет-банкинг, CRM, биллинг и т. д.). При падении доступности или качества предоставления этого сервиса, как правило, заходит речь о проактивности и быстром восстановлении. Такая система обычно внедряется, когда необходимо повысить доступность сервисов приложений и производительность, а также сократить среднее время восстановления работоспособности. Кроме того, такой подход хорош для устранения лишних затрат и снижения рисков, связанных с соглашением об уровне обслуживания (SLA), и для предотвращения ухода заказчиков (защита бизнеса).
Результаты внедрения в зависимости от главной задачи могут отличаться. В общем случае это позволяет реализовать выполнение типичных действий пользователя «роботом» из разных регионов\сегментов сети, разбор «зеркалированного» трафика, проверку доступности и качества работы сервисов с выявлением узких мест, информирование оператора о необходимости восстановить работоспособность с указанием места деградации. При необходимости становится возможна глубокая диагностика работы приложения для поиска причин систематического ухудшения работы сервисов.
Указанные выше подходы могут быть реализованы с помощью продуктов HP Software, о которых и пойдет речь далее.
«Мост» от HP
HP Operations Bridge представляет новейшее поколение «зонтичных систем мониторинга». Решение объединяет данные мониторинга от собственных агентов, различных модулей мониторинга HP Software и средств мониторинга других разработчиков. Поток событий от всех источников информации накладывается на ресурсно-сервисную модель, к нему применяются корреляционные механизмы для определения того, какие события являются причинами, симптомами и следствиями.
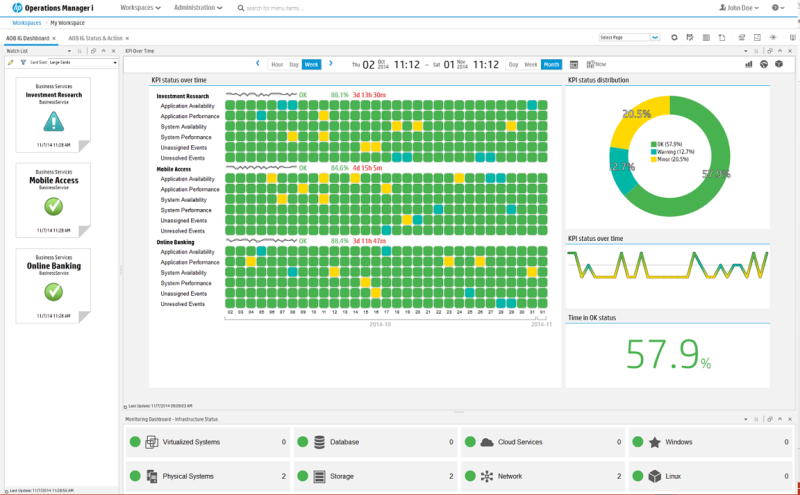
Отдельно следует остановиться на ресурсно-сервисной модели, а точенне моделях, так как таких моделей может не ограниченное количество для анализа информации в разных ракурсах. От ее полноты и актуальности зависит возможность решения выполнять корреляцию потока событий. Для поддержания актуальности моделей используются средства разведки на базе агентов и безагентных технологий, позволяющих получать детальную информацию о компонентах сервиса, взаимосвязях между ними и взаимном влиянии друг на друга. Также есть возможность импорта данных о топологии сервиса из внешних источников – систем мониторинга.
Еще один важный аспект – удобство управления. В сложных и динамично меняющихся средах важно обеспечить подстройку системы мониторинга при изменении структуры систем и добавлении новых сервисов. В Operations Bridge входит компонент Monitoring Automation, который позволяет в автоматическом режиме настраивать системы, вводимые в периметр мониторинга, для чего используются данные о сервисно-ресурсных моделях. Одновременно поддерживается конфигурирование и изменение уже выполненных ранее настроек мониторинга.
Если раньше администраторы могли выполнять одинаковые настройки однотипных компонентов инфраструктуры (например, метрик на Windows, Linux или UNIX-серверах), что требовало немалого времени и усилий, то теперь можно динамично и централизованно настраивать пороговые значения для метрики в разрезе услуги или сервиса.
Аналитика приложений
Использование традиционного подхода к мониторингу подразумевает, что изначально известно, какие параметры контролировать и какие события отслеживать. Растущая сложность и динамика развития ИТ-инфраструктур заставляет искать другие подходы, так как становится все сложнее контролировать все аспекты работы системы.
HP Operations Analytics позволяет собрать и сохранить все данные о работе приложения: лог-файлы, телеметрию, бизнес-метрики и метрики производительности, системные события и т.д., и использовать аналитические механизмы для выявления тенденций и прогнозирования. Решение приводит собранные данные к единому формату и затем, осуществляя контекстный выбор, на основании данных лог-файлов отображает на временной шкале, что, в какой момент и на какой системе происходило. Продукт предоставляет несколько форм визуализации данных (например, интерактивная «тепловая карта» и топология взаимосвязей лог-файлов) и использует функцию помощника для того, чтобы в контексте события или по введенному в строке поиска запросу найти всю совокупность данных, собранных за конкретный период. Это помогает оператору понять, что привело к сбою (или, при использовании данных HP SHA вместе с данными HP OA, сделать соответствующий прогноз), а также выявить как виновника, так и корневую причину случившегося сбоя. HP Operations Analytics дает возможность воспроизвести картину работы сервиса и окружения в момент возникновения сбоя и изолировать его в контексте и времени.
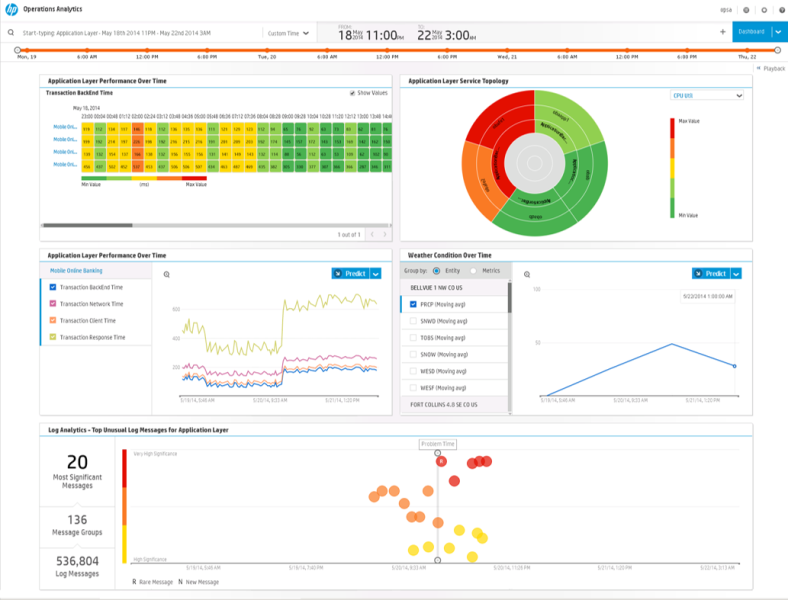
Еще один аналитический инструмент – HP Service Health Analyzer. HP SHA выявляет аномальное поведение контролируемых элементов инфраструктуры с целью предупреждения возможного отказа в предоставлении сервисов или нарушения заданных параметров их предоставления. В продукте применяются специальные алгоритмы статистического анализа данных на основе топологической сервисно-ресурсной модели HP BSM. С их помощью обеспечивается возможность построения профиля нормальных значений параметров производительности, собираемых как с программно-аппаратных платформ, так и с других модулей BSM (например, HP RUM, HP BPM), характеризующих состояние сервисов. В подобные профили вводятся типовые значения параметров с учетом дней недели и времени суток. SHA выполняет исторический и статистический анализ накопленных данных (для понимания сути выявленных данных), а также осуществляет сопоставление с имеющимся динамическим профилем (baselining).
Контроль производительности приложений
Когда речь заходит контроле производительности приложений, следует выделить следующие компоненты решения HP:
- HP Real User Monitoring (HP RUM) – контроль прохождения транзакций реальных пользователей;
- HP Business Process Monitoring (HP BPM) – контроль доступности приложения методом эмуляции действий пользователей;
- HP Diagnostics – контроль прохождения запросов внутри приложения.
HP RUM и HP BPM позволяют оценить доступность приложения с точки зрения конечного пользователя.
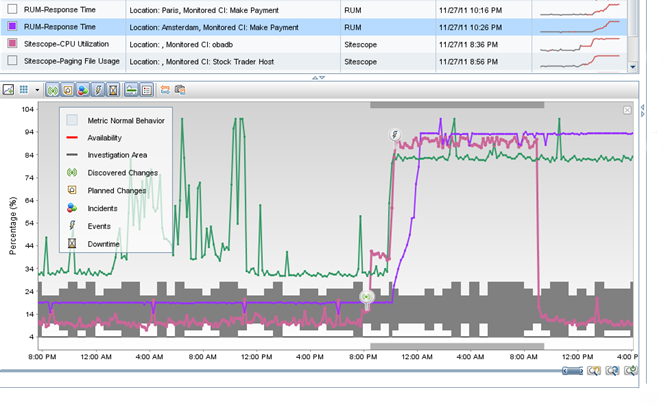
HP RUM разбирает сетевой трафик, выявляя в нем транзакции реальных пользователей. При этом можно контролировать обмен данными между компонентами приложения: клиентской частью, сервером приложений и базой данных. Это дает возможность отследить активность пользователей, время обработки различных транзакций, а также определить взаимосвязи между действиями пользователей и бизнес-метриками. Используя HP RUM, операторы службы мониторинга смогут мгновенно получать оперативные уведомления о проблемах в доступности сервисов и информацию об ошибках, с которыми столкнулись пользователи.
HP BPM представляет собой средство активного мониторинга, которое выполняет синтетические пользовательские транзакции, для контролируемых систем неотличимые от реальных. Данные мониторинга HP BPM удобно использовать для расчета реального SLA, так как «робот» выполняет идентичные проверки в одинаковые промежутки времени, обеспечивая постоянный контроль качества обработки типовых (или наиболее критичных) запросов. Настроив пробы для выполнения синтетических транзакций из нескольких точек (например, из разных офисов компании), можно также оценить доступность сервиса для различных пользователей с учетом их расположения и каналов связи. Для эмуляции активности HP BPM использует инструмент Virtual User Generator (VuGen), который также применяется в популярном продукте нагрузочного тестирования HP LoadRunner. VuGen поддерживает огромный спектр различных протоколов и технологий, благодаря чему можно контролировать доступность практически любых сервисов, а также использовать единый набор скриптов для тестирования и мониторинга.
Если же причина сбоев или замедления работы сервиса находится внутри таких технологий, как Java, .NET и т. д., поможет HP Diagnostics.
Решение обеспечивает глубокий контроль Java, .NET, Python на платформах Windows, Linux и Unix. Продукт поддерживает разнообразные сервера приложений (Tomcat, Jboss, WebLogic, Oracle и др.), MiddleWare и базы данных. Специализированные агенты HP Diagnostics устанавливаются на серверах приложений и собирают данные, специфичные для конкретной технологии. Например, для Java-приложения можно увидеть, какие запросы выполняются, какие методы используются и сколько времени тратится на их отработку. Автоматически отрисовывается структура приложения, становится понятно, как задействованы его компоненты. HP Diagnostics позволяет отследить прохождение бизнес-транзакций внутри комплексных приложений, определить узкие места и обеспечить экспертов необходимой информацией для принятия решений.
Дистрибуция решений НР в Украине, Грузии, Таджикистане, странах СНГ.
Учебные курсы по технологиям НР в Киеве (УЦ МУК)
МУК-Сервис — все виды ИТ ремонта: гарантийный, не гарантийный ремонт, продажа запасных частей, контрактное обслуживание
Комментарии (6)

YuriSerpinsky
28.09.2015 23:45Можно бесконечно разжевывать функциональность продуктов, но реализация мониторинга, как всегда, раскрывается только в конкретных кейсах. А графики, конечно, красивые.
amarao
Вы так рассказываете, как будто вы решили все проблемы мониторинга. Вот один из примеров, отвоёванный кровью и болью: Старшие 16 бит поля Seek_Error_Rate SMART'а для жёстких дисков Seagate не должны расти быстрее 10 на каждую минуту.
Или:
сообщение в логах ядра «CMCI storm detected: switching to poll mode» свидетельствует о выходе сервера за разумные пороги стабильности и требует пристального внимания (как минимум, вывода из эксплуатации).
Вы показываете фантики и ублажение глаза для ИТ-директора, котрый внутри не знает, зато снаружи гладенько и графички.
А как насчёт реального мониторинга реальных проблем?
Botkin
Что-то тоже вот смотрю — картинки вроде красивые. На сайт HP даже сходил, видосы посмотрел.
Но не верится мне, что это реально заработает на нетривиальных примерах. «Кончилось место — упала база — упало приложение» как-то и без модных машин лининг и биг дата аналэйзис на глаз определяется.
Muk
Этот набор программных продуктов действительно для мониторинга реальных проблем. Его уже используют в Vodafone.
См. http://www8.hp.com/ru/ru/software-solutions/operations-bridge-event-correlation/index.html
amarao
Знаете, мне эти энтерпрайзные сказочки «а ещё компании из fortune 500 юзают наши решения» надоели уже давно.
Какую часть инфраструктуры Vodafone оно мониторит? Сколько чеков для водафона было написано специально под них? Сколько у них стандартных чеков? Сколько чеков писал сам водафон? Главный вопрос: что именно мониторит эта штука? Active Directory для бэкофиса из бухгалтеров и сейлзов?
Muk
Речь не о «сказочках», а конкретном разговоре —
Вы интересуетесь с конкретным проектом? У вас есть такая проблема в компании? Мы можем сконтактировать вас с специалистом из Hewlett-Packard и он вам в подробностях объяснит функционал этого (и других) продуктов HP Software.
Если вы интересуетесь с чисто академическим интересом см. ссылку которую вам прислали. Там все описано в документах на русском языке.