

Мне довелось продолжительное время работать менеджером-админом (эдакий играющий тренер) на большом 1С-Битрикс веб проекте: более 40 сайтов для разных организаций холдинга из разных стран, Oracle БД, редакция «Веб-Кластер», более 100 Гб файлов, несколько лет истории, более 20 правок ядра переживших множество обновлений Ядра, параноидальный режим безопасности и… прямые изменения функционала «руками» на боевом сервере без каких либо намёков на версионный контроль…
Очень грустная картина, вызывающая множество «несчастных случаев на производстве», которую после очередного инцидента была приказано исправить.
В данной статье описывается мой опыт, однако полезна она будет в первую очередь владельцам небольших интернет-проектов, которые никогда не пользовались системой контроля версий и не знают с чего начать.
Собственно все наши беды были из-за 2 основных причин:
- Большой проект нёсся на полном ходу по своей узкоколейке в светлое будущее, и менять рельсы под ним в этот момент было немного затруднительно.
- Несмотря на огромное количество литературы, посвящённой системам контроля версий и GIT в частности, почти вся она страдает от отсутствия сценариев и чётких указаний. Например, великолепный Pro Git прекрасно описывает каждую отдельную функцию и операцию, но почти не даёт представления о том, с какого конца начать этим богатством пользоваться.
Вот просто возьмите и начните хоть с чего-то.
А потом усложняйте.
Лично мне очень помогло расставить по полочкам написание сценариев и инструкций.
Повествование будет разбито на части:
- Описание обстановки
- Инструменты
- Инструкции
- 3.1 Инициализация Репозитория
- 3.2 Накат обновления задачи
- 3.3 Фиксация ежедневных изменений (в конце дня)
- 3.4 Откат изменений
- Заключение
- FAQ
Часть 1 — Описание обстановки
Я нахожусь непосредственно на территории Заказчика и служу своеобразной перемычкой между ним и Разработчиком.
Добрые безопасники Заказчика ограничивают доступ ко всему, что может быть хоть чем-то заменено.
Вероятно, эта статья никогда бы не появилась (а скрывающиеся за ней проблемы были бы гораздо меньше), если бы у меня и у Разработчика были SSH/FTP доступ.
Однако, такого доступа не было, нет, и вероятно не будет, поскольку чисто формально внесение изменений возможно 2 путями:
- Удалённо через админку 1С-Битрикс
- Непосредственно на территории Заказчика (под чутким присмотром)
Поэтому при накате некоторых задач я периодически получал от менеджера Разработчика звонок:
Алексей, мы тут хотим накатить задачу ХХХ. Забекапьте пожалуйста init.php, а то мало ли...
Естественно «мало ли» порой наступало, и просьба восстановить указанный файл шла по всей цепочке, а сайт был в это время недоступен…
Аналогично доступ к Центральному Репозиторию (GitLab), когда он был создан, был ограничен полностью территорией Заказчика. Это приводит к важным ограничениям по внедрению GIT:
- Разработчик не может получить репо с серверов Заказчика (только если руками скопирует папку .git)
- Разработчик не может накатить обновление средствами GIT. Накат происходит вручную.
Системы контроля версий Заказчика и Разработчика фактически изолированы друг от друга (сообщение происходит исключительно в ручном режиме через админку 1С-Битрикс).
А ещё административный доступ (1 группа 1С-Битрикс) ограничен по времени. Есть специальный скрипт, который на уровне БД (Oracle) раздаёт права мне и Разработчику в 9.00 и отбирает в 17.50 по Москве.
Я знаю, что это кошмар. Не стоит напоминать мне об этом в комментариях. =)
Часть 2 — Инструменты
2.1 Сервера
Prod — основной боевой сервер.
По указанию Начальства были созданы помимо Боевого сервера 2 копии:
- Test — может быть пересоздан по запросу (процесс продолжительный, поскольку требует задействования людей из других управлений, ориентировочный срок реализации — сутки). Сервер доступен только из сети Заказчика и Разработчика.
- Prelive — автоматически пересоздаётся 1 раз в сутки (ночью), затирая все внесённые изменения, берёт актуальную на момент создания версию Боевого сервера. Сервер доступен только из сети Заказчика и Разработчика.
Доступ ко всем 3 серверам как у меня, так и у Разработчика только по https (при этом по сертификату происходит автоматическая авторизация в 1С-Битрикс).
Доступ по SSH/FTP только у моего непосредственного начальника. =(
GitLab — отдельный сервер для развёртывания GitLab, используется в качестве Центрального Репозитория. Сервер доступен только из сети Заказчика по прямому IP (предположим, что 172.***.***.61 для конкретики данной статьи, но на самом деле это может быть любой IP или домен, в вашем случае, например github.com).
Все 3 веб-сервера (Prod/Test/Prelive) имеют ssh доступ к GitLab.
Я имею доступ к GitLab только по http (фактически могу лишь создавать/удалять репозитории и смотреть красивую картинку с ветками).
DEV — Условное обозначение сегмента серверов и рабочих станций Разработчика. В рамках статьи не рассматривается. Все изменения из сегмента переносятся на сервера Заказчика руками через админку 1С-Битрикс мною, либо Разработчиком.
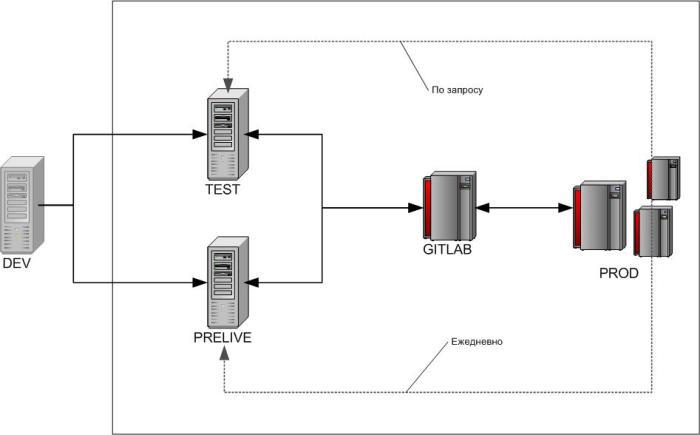
Первоначальная схема наката Задач предполагала прохождения всей цепочки:
DEV > TEST > PRELIVE > PROD
Предполагалась финальная проверка на «максимально актуальном» Прелайве перед накатом задачи на бой. Схема естественно оказалась очень муторной и малополезной.
В настоящий момент я отказался от неё в пользу использования 2 серверов для проверки Задач (на Test'е требующие длительной проверке, на Prelive'е быстро проверяемые):
DEV > TEST/PRELIVE > PROD
Передача кода с одного сервера на другой в сегменте Заказчика происходит ТОЛЬКО через Центральный Репозиторий (GitLab), так что схему наката можно представить в таком виде:
2.1.1 GIT на сервере
Устанавливается системным администратором. К сожалению, не могу ничего на эту тему действительно полезного рассказать (вопрос выходит за пределы моей компетенции).
Никаких особых манипуляций, кроме генерации SSH ключей (для связи между серверами и Центральным Репозиторием (GitLab)).
Инструкция легко гуглится, либо находится в разделе помощи GitLab.
2.1.2 Веб консоль на сервере (git_console.php)
Как уже было сказано выше, ни у меня, ни у Разработчика нет SSH доступа к серверам, поэтому для передачи команд GIT пришлось поставить отдельный скрипт, реализующий в браузере консоль.
Спасибо за него Elfet (статья про консоль на Хабре)
Мы внесли совсем незначительные изменения:
- Положили саму консоль в недоступную для Разработчика директорию в недрах сервера (чтобы ни Разработчик, ни я
, ни «потенциальный Злоумышленникне могли внести изменения в код консоли). При этом в ядре мы положили доступный администраторам файл git_console.php, который просто подключает скрипт из недр; - В настройках скрипта поставили ограничение на выполнение команд (только git, pwd и cd);
- Поменяли цвет фона консоли (Test — зелёный, Prelive — серый, Prod — чёрный). Это сделали после того как я пару рад запулил задачу „не туда“ =)
- Добавили ограничение доступа по сертификату (т.е. не каждый Админ имеет доступ к консоли. В тестовый период доступ был только у меня, после перевода в промышленную эксплуатацию доступ дали 1 программисту Разработчика).
Важное преимущество такого решения — автономность консоли! Т.е. даже если Разработчик неудачным
2.1.3 Структура Репозиториев
К сожалению, далеко не все сайты в системе находятся под системой контроля версий, а только „головы“ холдинга. Это вызывает определённые неудобства и проблемы (например, когда Разработчик вносит правку в Ядро для кого-то из Дочек), однако в основном это проблема владельцев самих этих сайтов „на местах“. Возможно, в будущем несмотря на накладные расходы и они будут добавлены в GIT.
Схема реальной структуры репозиториев (названия и адреса частично затёрты):
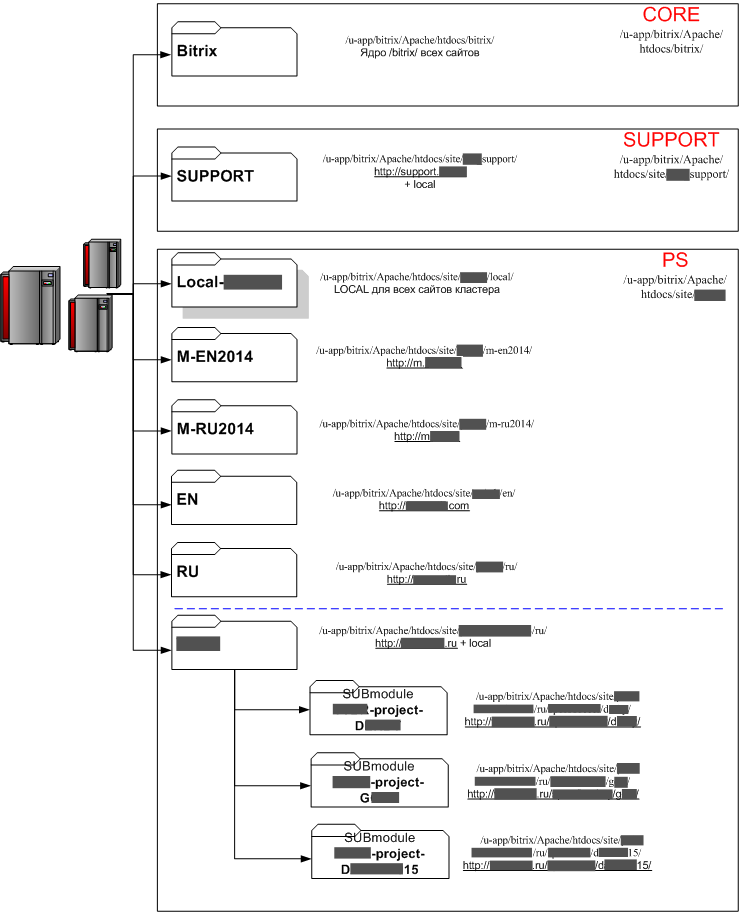
Как видим в нашей структуре:
- Ядро вынесено в отдельный каталог
- Папки некоторых сайтов сгруппированы в отдельных каталогах „по смыслу“
- Некоторые сайты имеют свой персональный каталог /local/
- Некоторые сайты имеют групповой каталог /local/
- Некоторые репозитории имеют субмодули (репозитории внутри репозитория) — это как правило спец-проекты, которые редко обновляются после завершения, однако имеют серьёзные отличия как по логике, так и по контенту (на них часто распространяются серьёзно отличающиеся правила для .gitignore). Поэтому они вынесены отдельно, чтобы не создавать кашу.
Ни один репозиторий (даже в худшие свои времена) не превышал 300Мб.
Это достигнуто политическим решением не включать определённые типы контента (бинарных файлов, вроде PDF, avi, jpg и т.п.) в такие репозитории без необходимости и соответствующим запретом в .gitignore.
2.1.4 Документация
Все картинки (кроме КдПВ конечно) для этой статьи взяты из Документации, которая находится на специальном ресурсе, доступном Заказчику, мне и Разработчику.
Изначально (на период тестовой эксплуатации) черновики документации хранились у меня на машине, однако сейчас вся документация опубликована для доступа всей команды.
Часть 3 — Инструкции
Вот мы и добрались до самого интересного.
Если всё, что написано в части 1 — сугубо для создания контекста (дабы снискать снисхождение опытных пользователей), а в части 2 больше для углубления в вопрос (как раз для тех, у кого так же как у нас большой проект, стремительно приближающийся к Горизонту Событий), то часть 3 — это как раз те элементарные примеры инструкций, которых лично мне так не хватало для начала.
Я надеюсь, что те, кто не пользовался GIT, но хотят начать (даже если у них небольшой интернет-магазин на shared-хостинге) смогут попросить о настройки GIT техподдержку, а в качестве Центрального репозитория использовать GitHub или BitBucket и с помощью описанных ниже сценариев начнут работу. А в процессе уже смогут начать изучать документацию Pro Git и адаптируют свои методы работы, сделают их более гибкими и совершенными.
Всё вышеописанное родилось не в один день. Но даже когда оно наконец появилось, то остался вопрос КАК использовать всё это богатство.
Все приведённые ниже инструкции были написаны
3.1 Инициализация Репозитория
3.1.1 Инициализация Репозитория на Prod (и пересоздание Prod/Prelive)
Наиболее простой и правильный метод.
Заключается в том, что вы создаёте репозиторий на Бою, а потом копируете весь сайт (включая репозиторий) с Боя на Тест и Прелайв.
На примере каталога /local/ (общего для нескольких сайтов)
Web консоль (на PROD) – https://********.ru:1119/bitrix/admin/git_console.php
cd /u-app/bitrix/Apache/htdocs/site/******/local/(переходим в каталог /local/ общий для сайтов Пресс-Службы из любого другого места)
pwd– определяем текущий каталог (проверяем местонахождение)
git status– проверка статуса GIT (должен показать отсутствие репозитория)
Положить .gitignore (см. образец в приложении)
git init
git config user.name "Zadoiny Alexey"
git config user.email "aleksey.zadoiny@******.ru"
git add -A .
git commit -m 'initital'
Создаём, если не был создан репо в GitLab (с именем local-******)
git remote add origin git@172.***.***.61:Alexey.Zadoiny/local-******.git
git push -u origin master
*.log
*.tar
*.gz
*.sql
#*.flv
#*.mp4
#*.avi
#*.png
#*.jpg
#*.gif
#*.bmp
*.rar
*.zip
*.7z
*.webm
#*.mp3
#*.wav
#*.swf
/log.txt
*._log
/mail_log/
/_log.txt
*sitemap_*.xml
.htaccess
urlrewrite.php
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
deny from all
3.1.2 Инициализация Репозитория на Prod (и перенос на пустой TEST/PRELIVE)
Зачем это нужно? Например, тестовые и боевые сервера уже созданы и настроены, а синхронизация между ними в ближайшее время не возможна.
Важно, чтобы было лишь небольшое количество файлов, не подлежащих синхронизации, но необходимых (т.е. способ подойдёт для ядра, т.к. там не синхронизуются только файлы подключения к БД, но не подходит для публичной части, если там много контента в виде бинарных файлов, которые исключены из репозитория, иначе см. пункт 3.1.3)
Web консоль (на PROD) – https://*******.ru:1119/bitrix/admin/git_console.php
cd /u-app/bitrix/Apache/htdocs/bitrix/(переходим в каталог /bitrix/ общий для всех сайтов из любого другого места)
pwd– определяем текущий каталог (проверяем местонахождение)
git status– проверка статуса GIT (должен показать отсутствие репозитория)
Положить .gitignore (см. образец в приложении)
git init
git config user.name "Zadoiny Alexey"
git config user.email "aleksey.zadoiny@********.com"
git add -A .
git commit -m 'initital'
Создаём, если не был создан репо в GitLab (с именем bitrix)
git remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.git
git push -u origin master
Пример .gitignore:
*.log
*.tar
*.gz
*.sql
*.flv
*.mp4
*.avi
*.rar
*.zip
*.7z
*.webm
*.mp3
*.wav
*.swf
cache
stack_cache
managed_cache
tmp
php_interface/dbconn.php
.settings.php
на Тесте/Прелайве:
Делаем резервную копию файлов /bitrix/.settings.php и /bitrix/php_interface/dbconn.php (любых других жизненно необходимых файлов, которые не будут синхронизованы средствами GIT)
Удаляем содержимое папки /bitrix/
Web консоль не работает. Идём в обычную консоль!
cd /u-app/bitrix/Apache/htdocs/bitrix/(переходим в каталог /bitrix/ из любого другого места)
pwd— определяем текущий каталог (проверяем местонахождение)
git init
git remote add origin git@172.***.***.61:Alexey.Zadoiny/bitrix.git
git pull origin master
Восстанавливаем резервную копию файлов /bitrix/.settings.php и /bitrix/php_interface/dbconn.php
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
deny from all
3.1.3 Инициализация Репозитория на Prod (и перенос на НЕпустой TEST/PRELIVE)
Зачем это нужно? Например, тестовые и боевые сервера уже созданы и настроены, а синхронизация между ними в ближайшее время не возможна, а директория содержит большое количество контента, не синхронизуемого с помощью системы контроля версий (например, бинарных файлов контента: pdf, jpg, swf, avi и т.д.)
Web консоль (на PROD) – https://*******.ru:1119/bitrix/admin/git_console.php
cd /u-app/bitrix/Apache/htdocs/site/******/m-ru/(переходим в каталог Мобильной РУ из любого другого места)
pwd– определяем текущий каталог (проверяем местонахождение)
git status– проверка статуса GIT (должен показать отсутствие репозитория)
Положить .gitignore (см. образец в приложении)
git init
git config user.name "Zadoiny Alexey"
git config user.email "aleksey.zadoiny@******.ru"
git add -A .
git commit -m 'MOBILE RU 2014 initital'
Создаём, если не был создан репо в GitLab (с именем m-ru2014)
git remote add origin git@172.***.***.61:Alexey.Zadoiny/m-ru2014.git
git push -u origin master
git log
Последняя команда (
git log) выполняется для того чтобы узнать hash коммита:
Он потребуется нам, если на Тесте/Прелайве будут отличаться какие-то файлы, контролируемые GIT (тогда мы откатимся к этому коммиту, считая что на бою у нас наиболее актуальное состояние сервера и фактически выполним синхронизацию)
Пример .gitignore:
bitrix
local
upload
docs
/.htaccess
*.log
*.tar
*.gz
*.sql
*.flv
*.mp4
*.avi
*.png
*.jpg
*.gif
*.bmp
*.rar
*.zip
*.7z
*.webm
*.mp3
*.wav
*.swf
/log.txt
*._log
/mail_log/
/_log.txt
*sitemap_*.xml
.htaccess
urlrewrite.php
Теперь скопируем с боя целиком папку .git, появившуюся в коре каталога мобильной версии (предварительно лучше её заархивировать, поскольку внутри много мелких файлов) и перенесём на Тест/Прелайв.
Там распакуем и проверим состояние репозитория:
Web консоль (на TEST/PRELIVE) – https://*******.ru:1119/bitrix/admin/git_console.php
cd /u-app/bitrix/Apache/htdocs/site/******/m-ru/(переходим в каталог Мобильной РУ из любого другого места)
pwd– определяем текущий каталог (проверяем местонахождение)
git status– проверка статуса GIT (должен показать отсутствие изменений)
Если изменения всё же есть:
git reset --hard #HASH#где #HASH# — первые 4-5 символов из хеша коммита, который мы получили на бою (можно и больше, но обычно достаточно малого числа)
После создания репозитория в папку .git необходимо положить файл .htaccess со
следующим содержанием:
deny from all
3.1.4 Инициализация Репозитория Субмодуля на Prod (и перенос на НЕпустой TEST/PRELIVE)
Сложность с субмодулем заключается в том, что вам необходимо внести правку внутрь уже имеющейся экосистемы (Т.е. репозиторий уже существует, и вдруг вы хотите ему сказать „э, не, дорогой, вот тут будет забор, а за забором будет жить Вася!“)
В частности, если вы сперва развернёте какой-то функционал, закоммитите его, то чтобы создать на этом месте субмодуль все созданные файлы/каталоги придётся удалить (вопрос на TOSTER'е на эту тему).
На Бою проверяем и если есть – удаляем папку /u-app/bitrix/Apache/htdocs/site/**********/ru/*****/******/d****/
Заходим в веб-консоль — https://********.ru:1119/bitrix/admin/git_console.php
cd /u-app/bitrix/Apache/htdocs/site/*********/ru/(переходим в каталог Репозитория из любого другого места)
pwd– определяем текущий каталог (проверяем местонахождение)
git status– проверка статуса GIT (должен показать наличие корневого репозитория)
git submodule add git@172.***.251.61:Alexey.Zadoiny/****-project-d****.git *****/****/d****/
Если сейчас сделать git status, то мы увидим:
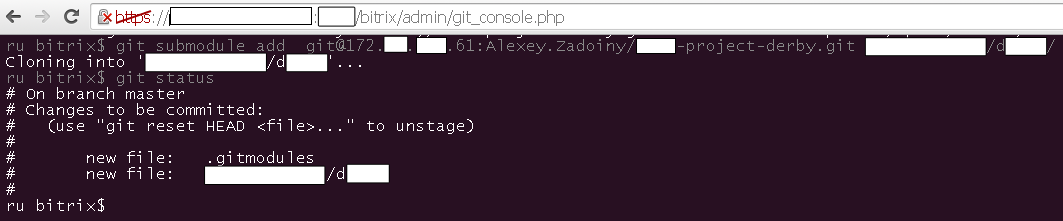
git add -A .
git commit -m 'INIT SUBmodule D****
- Теперь мы можем работать с субмодулем как с самостоятельным репозиторием (коммитить его состояние, меняться им через GitLab с Prod/Test/Prelive сервером и т.п.)
- При актуализации состояния основного репозитория на Test/Prelive, туда автоматом будет установлен и новый субмодуль!
3.2 Накат обновления задачи
Напомню, изначально данный процесс должен был идти по схеме:
DEV > TEST > PRELIVE > PROD
Поэтому схема обновления содержала 11 основных и 4 дополнительных шага и имело несколько разветвлений:

Горизонтальный вариант этого кошмара до сих пор висит у меня на рабочем месте (надо бы наверное убрать, но уж больно смешно смотреть на задумчивое качание головой людей, впервые работающих со мной, например представителей нового Подрядчика, приехавших накатить спец-проект)

Сейчас схема упрощена до
DEV > TEST/PRELIVE > PROD
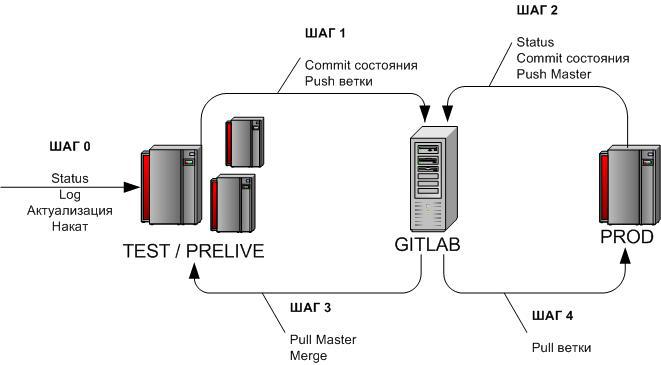
Примечание. На самом деле во всех инструкциях у меня не 1 адрес (cd ХХХХХ), а табличка со списком всех адресов. Т.е. при выполнении действия можно выбрать 1 любое и скопировать целиком (а не вспоминать пусть к дирректории того или иного репо)
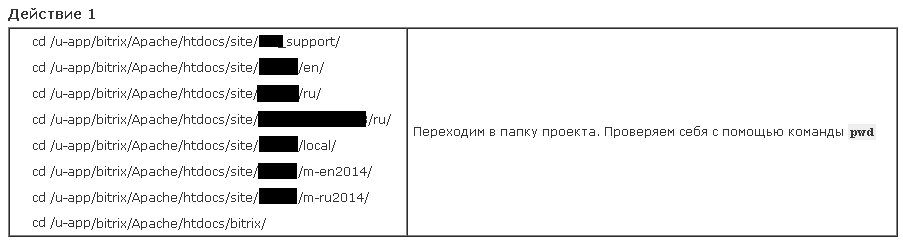
В рамках этой статьи для краткости я буду везде использовать 1 адрес (т.к. полагаю, что большинству начинающих пользователей GIT далеко не сразу потребуется работать сразу с множеством репозиториев.
Каждый шаг рассматривается как самостоятельный и автономный, поэтому начинается с перехода в дирреторию репозитория. Если процесс не прерывается, то этот пункт инструкции просто можно игнорировать.
3.2.0 Накат обновления задачи — Шаг 0
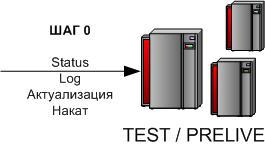
cd /u-app/bitrix/Apache/htdocs/bitrix/ — переходим в папку проекта. Проверяем себя с помощью команды pwdgit status — не должно быть незакоммиченных изменений.git log — последний коммит должен соответствовать последнему коммиту Master ветки центрального репозитория GitLabЕсли
git log показал не последний коммит — переходим к шагам 3,4 и после наката актуального состояния с боя на тест/прелайв начинаем процедуру с начала.Накат — переносим на тест/прелайв функционал задачи любыми средствами (FTP, админка).
3.2.1 Накат обновления задачи — Шаг 1
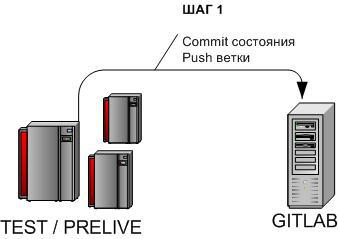
cd /u-app/bitrix/Apache/htdocs/bitrix/git add -A .git commit -m 'TIKET ######'git push origin master:TIKET_######Коммитим изменения, отправляем из ветки разработки (мастер на тестовом/прелайв сервере) в ветку задачи в центральном репозитории.
git add -A /puth/либо
git add -A /puth/file.phpДля всех директорий и файлов, которые необходимо внести в систему контроля версий. Точка вместо пути индексирует Все изменившиеся (а так же созданные и удалённые) файлы.
3.2.2 Накат обновления задачи — Шаг 2
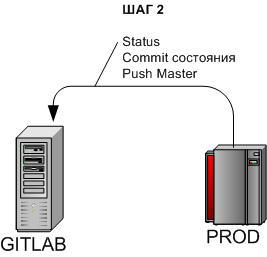
cd /u-app/bitrix/Apache/htdocs/bitrix/git status git add -A . git commit -m 'Prod changes #дата#'git push origin masterПроверяем состояние боя.
Если Состояние боя изменилось (и тест/прелайв находятся в более неактуальном состоянии), то коммитим изменения и отправляем в центральный репозиторий для синхронизации.
Если изменений нет > перейти на Шаг 4.
3.2.3 Накат обновления задачи — Шаг 3
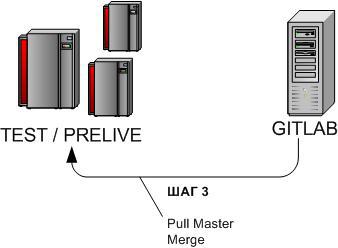
cd /u-app/bitrix/Apache/htdocs/bitrix/git pull origin masterЕсли за время наката задачи на Тест/Прелайв Бой успел измениться (см. Шаг 2), следует накатить изменения с боя (через центральный репозиторий) на Тест/Прелайв и смерджить изменения.
Если GIT не удастся произвести мердж веток самостоятельно (возникнут конфликты, например в силу изменения в одних и тех же файлах), следует вручную разрешить конфликты.
В завершение шага > вернуться на Шаг 1.
3.2.4 Накат обновления задачи — Шаг 4
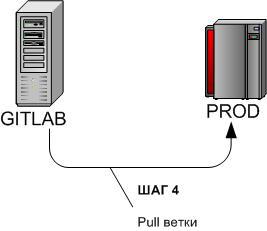
cd /u-app/bitrix/Apache/htdocs/bitrix/git pull origin TIKET_######Накатываем обновление задачи на Бой из центрального репозитория
3.3 Фиксация ежедневных изменений (в конце дня)
К сожалению, несмотря на описанный выше процесс у нас постоянно возникают изменения прямо на бою из-за 2 основных причин:
- Есть множество контент-редакторов, имеющих доступ к изменению файлов в публичной части боевого сервера (естественно с ограниченными правами, без доступа к редактированию php кода, но с возможностью изменения html разметки)
- Есть задачи Дочек, которые зачастую затрагивают ядро /bitrix/ (как правило появляются или изменяются шаблоны и компоненты)
Поэтому ежедневно в конце рабочего дня (а как вы помните из начала статьи после 17.50 по Москве Разработчик и я теряем возможность к редактированию php на Бою) я подвожу итог и коммичу все накопившиеся правки, произведённые вне моих задач.
Однако, это добавляет сложностей, поскольку Prelive и Prod синхронизуются именно ночью! Т.е. незафиксированные изменения утром будут не только на бою, но и на прелайве!
Это означает, что либо придётся отказаться от деплоя задач на прелайв в течение суток, либо синхронизовать файлы с помощью GIT:
- Откатить состояние Прелайва к последнему коммиту (см 3.4.1)
- Накатить актуальное состояние на Прелайв из GitLab (git pull, см 3.1.3)
Процесс полностью идентичен фиксации изменений на бою (см 3.1.2):
cd /u-app/bitrix/Apache/htdocs/bitrix/git status git add -A . git commit -m 'Prod changes #дата#'git push origin master3.4 Откат изменений
- Есть 3 типа ситуаций, когда необходимо произвести откат изменений (по мере ухудшения ситуации):
- Откат на Тесте/Прелайве (не важно внесена ошибка или задача успешно проверена — нужно „освободить площадку“, никаких правок на Тесте/Прелайве не предвидится)
- Откат на Бою незначительной ошибки, пришедшей через GIT (ключевое слово — незначительной. История версий представляет ценность например для анализа в GitLab, но на бой необходимо вернуть стабильную версию. Практикуется только для СВЕЖИХ правок)
- Откат на Бою критической ошибки (ситуации из серии „Шеф, всё пропало!!!!1111одинодин“, когда работоспособность проекта критичнее чем красивая история в GitLab)
3.4.1 Тест — Откат к последнему стабильному состоянию
Никакой работы на тестовых серверах с задачами по „доведению до ума“ не проводится. Для этого у разработчиков есть Dev среды, сюда приходим только тестировать перед сдачей Заказчику, поэтому стерильной условий критичнее истории (именно поэтому флаг hard, и именно reset, а не checkout или что-то иное).
git reset --hard HEADЕсли надо откатить не на 1 коммит, то берём хеш конкретного коммита из GitLab и откатываемся к нему:
git reset --hard #HASH#
3.4.2 Бой — Накаченная задача вносит ошибку (пришла через GIT)
Если правка не положила сервер и 100% пришла с последним коммитом, а не была внесена 2 месяца назад и уже ассимилировалась, создав зависимость с какой-нибудь другой задачей, вот тогда можно сделать встречный коммит, отменяющий правку.
Преимущество в том, что вы сохраняете в GitLab историю этой правки и Разработчик (при наличии доступа) может ещё раз осмотреть коммит, пошевелить мозгами. Да и если коммит уже попал в master ветку GitLab нет никаких заморочек.
Если правка была сделана сразу на бою (кому руки оторвать?), то для этой стратегии придётся сперва сделать коммит, что явно не рационально.
git revert HEAD
Создаёт встречный коммит, отменяющий изменения из последнего.
3.4.3 Бой — Правка сломала бой (полностью)
Если всё очень плохо (сервер лежит, либо вдруг выяснилось что „очень важный функционал“ был сломал давным-давно, то особо деваться некуда:
git reset --hard HEADЕсли надо откатить не на 1 коммит, то берём хеш конкретного коммита из GitLab и откатываемся к нему:
git reset --hard #HASH#Если в результате такого отката выясняется, что уничтоженный коммит уже попал в master ветку на GitLab, то для восстановления порядка проще зачастую удалить весь репо на GitLab и создать заново. =)
Заключение
Описанные мною сценарии очень просты. В этом их преимущество и недостаток одновременно.
- Преимущество — они позволяют даже начинающему пользователю GIT осуществлять работу с системой контроля версий (проверено на моём начальнике за 2 недели моего отпуска)
- Недостаток — опытный пользователь видит некоторые более гибкие и интересные сценарии, которые сложно формализовать под набор простых правил применения. Именно поэтому я рекомендую после их успешного освоения и внедрения прочитать книгу Pro Git.
Однако даже такой ограниченный инструментальный набор позволяет наблюдать в GitLab вот такие замечательные картины:
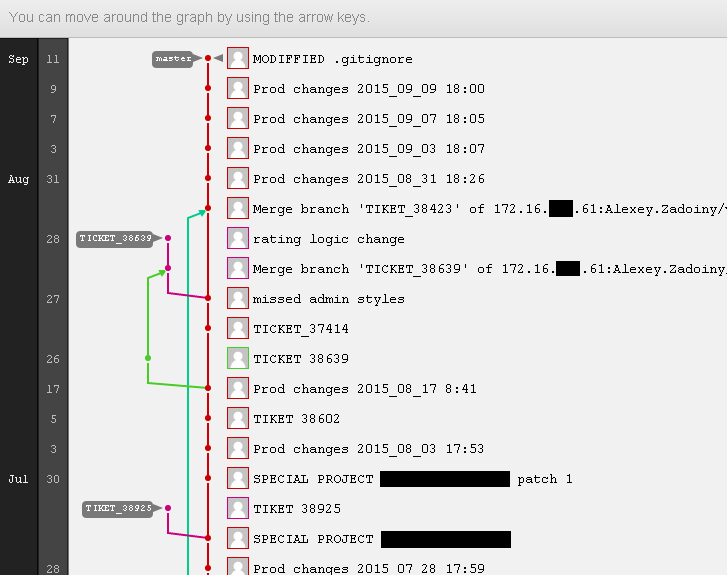
Несколько коммитов названы не по моим правилам правилам — это результат быстрой настройки Разработчиком функционала на Test/Prelive сервере при накате задачи. Я в таких случаях писал TIKET_###### Patch_## (номер Тикет и порядковый номер патча), чтобы проще опознавать к какой задаче в трекере относится та или иная правка.
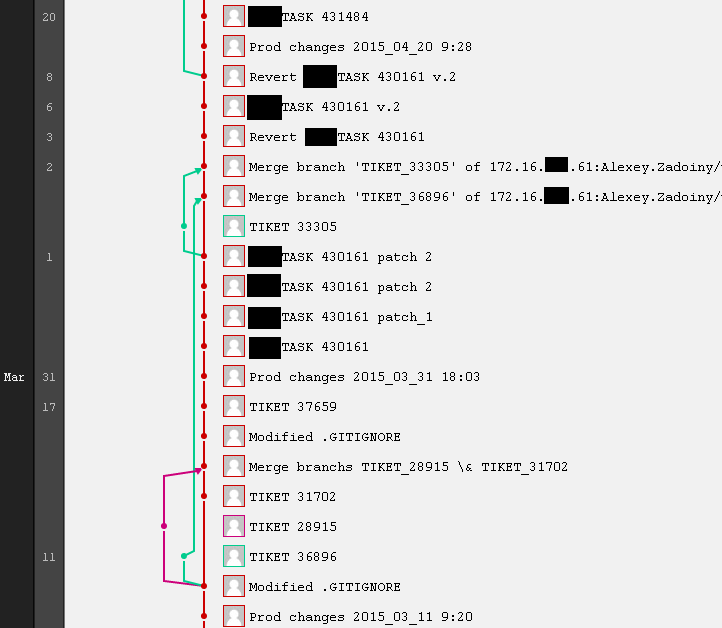
Часть задач реализуется непосредственно мною, а не Разработчиком. В этом случае я называю из Task, а не Tiket и указываю ID связанной задачи в другой учётной системе.
На самом деле такие ветвления и пересечения — это совсем не здорово. Выглядит прикольно, но в действительности каждая отложенная на неделю-месяц для проверки задача создаёт геморрой тому, кто потом всё это будет мерджить.
Не то чтобы у нас что-то ломалось (хотя пару раз возникали конфликты, которые не мог исправить GIT и их приходилось разрешать мне). Но нервничать заставляет.
A: на каждом из сервером как правило есть только 1 ветка — master. Много веток существует только в Центральном Репозитории (GitLab). Очень редко требуется скачать оттуда отдельную ветку (этот сценарий не описан, т.к. не является типовым в силу своей редкости). Естественно ненужные ветки (чьи коммиты влились в master) приходится периодически чистить. Понимаю, что очень похоже на SVN, но у нас это работает и очень помогает.
Q: Не описан merge. Как это делать?
A: Как правило merge выполняется GIT'ом автоматически. В редких случаях требуется разрешение конфликтов. В этом случае вы получаете уведомление о том, что автоматический мердж провалился.
Если в этот момент сделать git status, то будет получен список файлов с конфликтами. По ним необходимо пройти и разрешить все конфликты (специальный маркер выделил куски кода из разных коммитов).
Однако нам проще избежать конфликтов слияния организационными методами, чем разрешать их. В любом случае, зачастую это может сделать только опытный программист.
Ну и глава про merge в Pro Git очень полезна, если что.
Q: Нельзя ли убрать звёздочки из примеров кода и закрашенные места на картинках?
A: Я прошу прощения у читателя за это чудовищное порождение конспирологии.
Это минимальное искажение наших реальных инструкций на которое по соображениям безопасности согласился представитель Заказчика, согласовывавший черновик статьи.
Комментарии (29)

voidnugget
29.09.2015 09:45+3Странно, но когда читаю про очередные поделки в РНР мире, кажется что люди застряли в нулевых.

lafayette
29.09.2015 10:02+6Почитайте лучше про Symfony или Laravel, Битрикс — мягко говоря, не самое удачное, что есть в мире PHP.
voidnugget
29.09.2015 10:35-2Я это прекрасно понимаю, но хотел глянуть что за пафосная муть скрывается под катом.
ИМХО php 7 (уже RC3) на подходе, так что почти все существующие решения устаревают не по дням, а по минутам.
lexnekr
29.09.2015 10:41+2пафосная муть
Вот это уже обидно, если честно.
Стараешься поделиться с людьми опытом, а в ответ подобное отношение.
Вы же согласитесь, что далеко не все выбирают технологию? И кто-то вынужден работать с php 5.3, а не 7. А кто-то с 1С-Битрикс, а не Symfony/Laravel. Причём я сейчас не о себе, мне-то в общем всё равно.
P.S. если вдруг возникло ощущение, что пост рекламный, увы мне и ах. Не ставил целью и собственно интереса такового не имею (не продаю и не внедряю, сотрудником компании не являюсь).
pewpew
30.09.2015 09:11Очень жаль вас, что приходится работать с этими неповоротливыми технологиями. Но кто-то же должен это всё разгребать.
Недавно мне в работу попал допил проекта на 1С-Битрикс (редизайн и небольшое изменение структуры). Честно сказать — грустно всё. Сразу захотелось всё переписать заново, например на YII. Разгребать эту кучу граблей было куда менее интересно. Деплой через FTP и 8 гигабайт кэша, который на самом деле не нужен (сайт занимает около 16 гигабайт места).
Вообщем, я конечно понимаю, что решения на 1с-битрикс продаются и весьма неплохо. Но не хотелось бы, чтобы не петрящие в технологиях менеджеры одерживали верх. Им важно продать. А реализация — дело десятое…lexnekr
30.09.2015 09:228гб кеша это ещё немного. Я работал в интернет-магазине размером меньше 500Мб, который генерил больше 5Гб кеша ещё в 2010 (за счёт большого количества фильтров).
Тот проект, о котором речь в статье генеровал совершенно сумасшебшее количество кеша, пока мы не перешли на мемкеш.
Вообще файловый кеш — это конечно не очень хорошо.
P.S. не знаю как принималось решение о покупке в данном случае, но уверен, что если бы пришлось писать свой велосипед, то проблема деплоя была бы точно такая же. Параноидальный режим безопасности + потребность в срочных правках представителями Заказчика контента прямо на бою + удалённый Разработчик.
Хотя желание снести всё ударом тактического ядерного заряда не оставляет меня уже более 2 лет…

VolCh
29.09.2015 11:02+1Почти все существующие решения будут тянуть совместимость с, минимум, 5.3 ещё очень долго. Многие решения даже на php 5.5 сыпят depricated предупреждениями, но пока у бизнеса нет понятных ему причин переводить то, что приносит деньги сейчас на новую платформу, с трудно оцениваемыми им рисками, ресурсы на борьбу с ними выделяться не будут.


farcaller
29.09.2015 10:05+10позволяет наблюдать в GitLab вот такие замечательные картины:

я бы не пустил вас в prod с такими коммитами.lexnekr
29.09.2015 10:10-4Надеюсь на ваше снисхождение в связи с тем, что именно мне и пришлось всё это безобразие поднимать. Никого умнее не нашлось.
ИМХО такие коммиты лучше, чем отсутствие контроля версий за состоянием боевого сервера, хаотично изменяющегося под воздействием внешних сил (редакторов контента в том числе).
VolCh
29.09.2015 10:57+1Я правильно понимаю, что большинство сложностей из-за того, что:
а) правки кода на боевом сервере, минуя репозиторий, норма рабочего процесса (то ли из-за битрикса, то ли «так исторически сложилось»)
б) отсутствие нормального доступа к серверам (хотя через веб-морду можно делать практически всё, включая правки кода из пункта а)
в) у разработчиков не должно быть даже ro доступа к центральному репозиторию или его клону
Просто совсем недавно тоже переводил legacy проект под git с gitlab и почти автоматический деплой коммитов, но обошлось куда меньшей кровью и почти безугроз «руки оторву»административного вмешательства.
lexnekr
29.09.2015 11:02а) правки кода на боевом сервере, минуя репозиторий, норма рабочего процесса (то ли из-за битрикса, то ли «так исторически сложилось»)
Увы, да.
Все проекты, где я работаю постарался перевести на данную схему. Изредка разработчик вносит правку на бою, не закоммитив. Это отклонение от нормы уже.
б) отсутствие нормального доступа к серверам (хотя через веб-морду можно делать практически всё, включая правки кода из пункта а)
о да!
в) у разработчиков не должно быть даже ro доступа к центральному репозиторию или его клону
И вновь да.
Был бы рад познакомиться с вашим опытом.
К сожалению, в таких ситуациях очень заметны проблемы, но не так просто их решать, поскольку всё переплетается в один адский клубок.VolCh
29.09.2015 12:05Ну у нас ситуация попроще была. Хоть как-то процесс был выстроен, SVN использовался (пускай без веток и хотя по результатам ревизии на боевом сервере нашлось не менее сотни незначительных отклонений от репозитория). После вливания всех изменений в свн репозиторий и импорта его в git, было объявлено, что с этих пор никаких ручных правок или деплоя с дев-машин путем копирования изменений, лишь потому что деплой будет осуществляться через rsync без подтверждений перезаписи и с удалением файлов в десте, которых нет в сорсе и игнорлисте. Потом написаны скрипты для деплоя на тестовый сервер (использовался и как приемочный, и как обучающий для новых сотрудников или при введении глобальных фич) произвольной ветки любым разработчиком, а на боевой только главной, с правом мержить в главную и деплоить на боевой строго ограниченным кругом лиц (де-факто мною, плюс в теории могут главный админ и директор ИТ-департамента). Чуть позже разделили функции обучающего и приемочного серверов, обучающий теперь деплоится время от времени с главной ветки (по сути синхронится с боевым), а приемочный (у нас препрод называется, аналог вашего прелайва), а приемочный с любой. В ближайших планах то ли создать каждому разработчику отдельный виртуальный хост на препроде, то ли использовать что-то типа докера для поднятия виртуальных хостов под каждую фичу/баг/ветку, чтобы мог «полуофициально» давать заказчику конкретной фичи возможность предварительного тестирования, чтобы в идеале было минимум замечаний с препрода, чтобы он отличался от боевого лишь на один коммит и деплоился со специально отведенной ветки, в которую разработчики будут мержить изменения с тикет-веток и откатывать свой мерж, если возвращено на доработку.
Из технических проблем, общего решения которых не найдено пока, сейчас по сути только необходимость ручного управления миграциями при переключении препрода с одной ветки на другую, если в них есть изменения схемы и(или) справочников БД. Используемый инструментарий миграций совсем к работе с ветками не приспособлен, учитывает их, грубо говоря, по номерам, присваиваемым каждый раз заново на момент на момент запуска миграции по, грубо говоря, дате создания. То есть, если в одной ветке сейчас создать миграцию, во второй через 5 минут, запустить вторую миграцию, потом переключиться на первую ветку, то система будет уверена, что все миграции применены, потому что у первой тот же номер, что у второй, пока они не слиты вместе, а когда сольются, то система будет уверена, что применена первая, а вторую только нужно применить, хотя дело обстоит ровно наоборот. И такая дребедень даже если миграции никак не пересекаются.
Из организационных проблем — заставить разработчиков (себя в том числе) следить за миграциями (особенно за добавлением записей в справочники) и делать атомарные коммиты, а не аккумулирующие несколько этапов типа начали писать новую фичу, написав с треть предполагаемого кода узнали про готовое решение второй трети, заинтегрировали его, дописали последнюю треть и закоммитили одним коммитом и интеграцию, и готовое решение, вместо того, чтобы или коммитить сначала интеграцию (можно стэшем воспользоваться например), потом полное решение, или наоборот, или хотя бы три коммита сделать.

nryzhonin
29.09.2015 11:50Очень интересно. Всегда тяжело наводить порядок, когда много исторических наслоений и политических ограничений.

LighteR
29.09.2015 12:59+3Да это же сюр какой-то. Люди в 2015 году открывают для себя систему контроля версий, деплой осуществляется с комментриями «Забекапьте пожалуйста init.php, а то мало ли...», при неудачном коммите практикуется «для восстановления порядка проще зачастую удалить весь репо на GitLab и создать заново».
P.S. Автор, у вас и ваших разработчиков руки растут из жопы. Я уж было хотел написать про development workflow, continuous integration, zero downtime deployment и т.д., но посмотрел на ваш год рождения и понял, что это уже не исправить.
evnuh
29.09.2015 13:40Мир битрикс разработки — это вообще сюр полнейший, как и весь 1С. И вполне достоверно замечено, что средний возраст битрикс программистов заметно выше чем в мире PHP. У них даже проблемы какие-то свои, ламповые (http://habrahabr.ru/company/1c/blog/267321/#comment_8582213):
«Ну вот когда появятся нормальные гайды по доступному функционалу, СКД и УФ?! Книги авторства Радченко в топку! Когда будут объёмные конференция масштаба InfostartEvent? Когда разработчики пишущие на 1C получат нормальный подстрочник не только на русском? Когда можно будет обратиться к документации, а не искать примеры в типовых коробках? Когда?..»
mvs
29.09.2015 13:58Ладно вам набрасывать Битрикс на вентилятор. руки, мозги, Битрикс, PHP и 1С никак не связаны и одно другому не мешает/не помогает.

Scogun
29.09.2015 15:19+2Я уж было хотел написать про development workflow, continuous integration, zero downtime deployment и т.д.
А почему бы и нет?! Я думаю всем будет интересно узнать, на сколько их знания соответствуют современным веяниям. Ждем от Вас статью!LighteR
29.09.2015 17:12-3А вас что, гугл забанил? В инете куча статей на эти темы. Ключевые слова я написал.
Scogun
29.09.2015 17:27+1В инете куча статей на эти темы.
Так всегда ведь удобнее читать, когда все собрано в одном месте. Плюс, наверняка ведь есть какие-то нюансы, узнанные из собственного опыта. Какие-то подводные камни, новые красивые решения. Делиться знаниями — это ведь замечательно!

Diden05
29.09.2015 23:00Последние версии Битрикс можно достаточно просто заворачивать в систему контроля версий, если бы не одно глобальное «но», база данных, эта проблема либо решается большими костылями, либо кучей оверхеда на написание скриптов обновления базы. Ну и еще один увлекательный квест который называется обнови ядро на на трех серверах. Да и по лиц. соглашению нельзя иметь три копии продукта.
PS: Алексей спасибо за статью.lexnekr
30.09.2015 09:26Вопрос 3 сервером решается через партнёрский отдел.
Нам необходимо обновлять 4:
- Prod
- Prelive
- Test
- Dev (1 из всех поднятых песочниц)
Тут главное обновление запускать с не большим интервалом, чтобы 1С-Битрикс не успели выпустить минорное обновление (ибо выбрать версию до которой обновляемся они нам до сих пор не дали).
Поскольку у нас более дюжины правок ядра кочуют из версии в версию, то GIT очень здорово помогает оперативно отследить какую правку забыли накатить.
а вот с БД беда…


kesn
30.09.2015 00:16Мне кажется, у вас описан слишком частный случай. Из заголовка ожидаешь какую-нибудь инструкцию по настройке .gitignore для битрикса. Надо было назвать «Работа в git при неадекватном заказчике» или что-то типа того.
lexnekr
30.09.2015 09:14Примеры .gitignore есть в части про инициацию репозитория. Там примеры для ядра, /local/ и публички (для субмодуля по понятным причинам отдельный .gitignore не нужен был).
В защиту Заказчика хочется сказать, что не все решается волевым решением «перейдём на новый стек технологий Х» — у больших компаний с сотнями тысяч человек персонала есть определённые политики безопасности для внутренних IT решений в которые очень сложно уложить внешний веб проект с внешним же подрядчиком (всё было бы гораздо проще, если бы Разработчик был в штате, ведь тогда была бы машина во внутренней сети и возможно даже SSH/FTP)
Так же хочется напомнить, что есть сегмент малых (начинающих) интернет-проектов. Такие сайты могут жить на виртуальном хостинге, зачастую без SSH, но с возможностью установки GIT (через техподдержку). Владельцы таких сайтов тоже могут пользоваться преимуществами системы контроля версий, хотя до полноценных процессов (вроде git workflow) ещё не скоро дорастут. Им пригодятся такие простые сценарии, я считаю. Мне бы пригодились, когда я начинал. Потому и написал статью.
Но спасибо за ваше мнение! Это действительно очень частный случай. И он от этого лишь выигрывает, мне кажется.
Ualde
Что-то не так.
Зачем каждый раз после команды cd выполнять команду pwd? она же вернет тоже что было написано в cd, особенно учитывая, что тут всегда показан абсолютный путь
lexnekr
Безусловно. На самом деле так же, как и сам cd в общем-то избыточен в каждом коротеньком сценарии.
pwd оставлен «для страховки» если процессом придётсяз аниматься неопытному пользователю. Так сказать «2 раза проверь, 1 раз запулль».
Ualde
Тогда вообще непонятна причина отсутствия готовых скриптов, принимающих параметры, на выполнение одних и тех же операций.
lexnekr
1) Постепенная модификация процесса.
если вы посмотрите под кат «Порождение ада», то увидите, что ещё совсем недавно процесс выглядел очень отлично от того, что описывается в статье. Возможно в будущем появятся дополнительные изменения (хотя пока особого смысла нет)
2) Потребность в гибкости. Иногда нужны незначительные отклонения от стандартных команд: закоммитить только некоторые файлы/папки, запушить не в ветку с номером тикета, а ветку «TIKET ##### Patch $$» и т.п.
3) к сожалению скрипты мы бы написали для себя, жёстко зашив настройки, и поделиться ими уже не смогли бы ни при каких обстоятельствах (мне и так пришлось немало побороться за эту публикацию). Да и пользы от них было бы мало кому.
Цель данной публикации — набор готовых практических сценариев с максимально простой структурой, каждый шаг которых начинающий пользователь GIT мог бы отладить и осмыслить.
Лично мне этого очень не хватало, когда мы начинали внедрять систему контроля версий.
Это сильно не то же самое, что использовать связку GIT-клиента VisualStudio или GIT GUI и GitHub/Bitbicket в соло-разработке.