

Эта статья для новичков и не претендует на высокий технический уровень, а если вам интересны сложные современные решения, обратите внимание, например, на статью о GIRAFFE, который для генерации реалистичного движения объединяет самые современные подходы в ИИ.
В конце статьи вы найдёте ссылки на проект очень простой веб-страницы с распознаванием рукописного ввода при помощи ИИ, а прочитав это руководство, переводом которого мы делимся к старту курса о машинном и глубоком обучении, сможете самостоятельно написать такую страницу. Для этого вам понадобится свой блокнот Colab или блокнот автора статьи. Скачиваемые блокнотом файлы модели занимают меньше мегабайта.
Обучим простую модель распознавания цифр на наборе данных MNIST
Если вы решили завести блокнот и выполнить всё с нуля, чтобы загрузить данные, в первую ячейку Вашего блокнота введите этот код:
import tensorflow as tf
# import digit dataset
mnist = tf.keras.datasets.mnist
(tx, ty), (vx, vy) = mnist.load_data()
# preprocess input types
tx = tx[:,:,:,None].astype('float32')
vx = vx[:,:,:,None].astype('float32')
ty = ty.astype(int)
vy = vy.astype(int)
# display relevant info
print("""tx:%s, ty:%s
vx:%s, vy:%s""" % (tx.shape, ty.shape, vx.shape, vy.shape))Код отображает размерности данных tx и цели ty, а также данных валидации vx и целевых данных vy:
tx:(60000, 28, 28, 1), ty:(60000,)
vx:(10000, 28, 28, 1), vy:(10000,)Выведем 10 образцов изображений каждой цифры, чтобы понять, как выглядят данные:
import matplotlib.pyplot as plt
# create a grid of plots
f, axs = plt.subplots(10,10,figsize=(10,10))
# plot a sample number into each subplot
for i in range(10):
for j in range(10):
# get a sample image for the 'i' number
img = tx[ty==i,:,:,0][j,:,:]
# plot image in axes
axs[i,j].imshow(img, cmap='gray')
# remove x and y axis
axs[i,j].axis('off')
# remove unecessary white space
plt.tight_layout()
# display image
plt.show()Обратите внимание на чёрный фон и белые цифры. Это важно в смысле рисования чисел и кода canvas в HTML:

Начнём со строительного блока свёртки, который кроме самой свёртки будет содержать пакетную нормализацию, функцию активации RELU, максимальное объединение и отсеивающие слои:
# defines a standard 2d convolution block with batch normalisation,
# relu activation, max pooling and dropout
def normConvBlock(filters, return_model=True, name=None):
lays = [
tf.keras.layers.Conv2D(filters, 3, padding='valid', name=name+'_conv'),
tf.keras.layers.BatchNormalization(name=name+'_bn'),
tf.keras.layers.Activation('relu', name=name+'_act'),
tf.keras.layers.MaxPooling2D(2, strides=2, name=name+'_mpool'),
tf.keras.layers.Dropout(0.1, name=name+'_drop'),
]
if return_model:
return tf.keras.models.Sequential(lays, name=name)
else:
return laysНаша полная сеть будет состоять из двух normConvBlock, затем плоского и последнего плотного слоя с активацией softmax. Оптимизировать модель мы можем при помощи Adam . В целевых данных есть маркировка порядка, поэтому также воспользуемся категориальной потерей перекрёстной энтропии:
# create NN model
model = tf.keras.models.Sequential()
model.add(normConvBlock(64, name='b1'))
model.add(normConvBlock(128, name='b2'))
model.add(tf.keras.layers.Flatten(name='flat'))
model.add(tf.keras.layers.Dense(10, activation='softmax', name='logit'))
# compile model with adam optimizer and crossentropy loss
# note that 'sparse_categorical_crossentropy' loss should be used as our target
# is encoded as ordinal. if using one hot change this to 'categorical_crossentropy'
model.compile('adam', 'sparse_categorical_crossentropy', metrics=['acc'])
# test model with a sample image
_ = model(tx[:1,:,:,:])
# summary of model structure
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
show_dtype=True,
expand_nested=True,
dpi = 50
)Код выше отобразит структуру модели:
, за ними следуют плоский и плотный слои")
Чтобы обучить модель, вызовем model.fit с обработанными выше данными, а также определим обратный вызов ранней остановки, чтобы избежать переобучения:
# define an early stopping callback. This callback will load the iteration with
# the best val loss at the end of training
es_call = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0, patience=2, verbose=0,
mode='auto', baseline=None, restore_best_weights=True
)
# fit the model with the mnist dataset
history = model.fit(tx, ty, validation_data=(vx, vy), epochs=20, batch_size=1024, callbacks=[es_call])Точности модели достаточно для примера (~99 % в наборе валидации). Если нужна модель точнее, измените её структуру или дополните набор данными:
Epoch 11/20 59/59 [==============================] - 3s 50ms/step - loss: 0.0317 - acc: 0.9906 - val_loss: 0.0338 - val_acc: 0.9899 Epoch 12/20 59/59 [==============================] - 3s 50ms/step - loss: 0.0292 - acc: 0.9913 - val_loss: 0.0496 - val_acc: 0.9823 Epoch 13/20 59/59 [==============================] - 3s 50ms/step - loss: 0.0275 - acc: 0.9918 - val_loss: 0.0422 - val_acc: 0.9866Весь код
TensorFlow.js
Для взаимодействия с моделью TensorFlow.js разработаем набор компонентов HTML и JavaScript. TensorFlow.js — это библиотека с открытым исходным кодом для обучения и запуска моделей ML полностью в браузере при помощи JavaScript и высокоуровневого API.
Преобразуем TensorFlow в TensorFlow.js
Первый шаг размещения модели TensorFlow в браузере — её преобразование в модель TensorFlow.js, для которого можно вызвать метод tensorflowjs.converters.save_keras_model библиотеки tensorflowjs.
# install / update the tensorflowjs package
!pip install tensorflowjs > /dev/null 2>&1
import tensorflowjs
print(tensorflowjs.__version__)
# convert keras model to tensorflow js
tensorflowjs.converters.save_keras_model(model, './mnist_tf_keras_js_model/')При работе в Colab загрузите файлы на локальную машину, они нам понадобятся.
# download generated files from colab to local
from google.colab import files
files.download("mnist_tf_keras_js_model/group1-shard1of1.bin")
files.download("mnist_tf_keras_js_model/model.json")Пишем веб-интерфейс
Начнём со структуры приложения. В папке digit_recognition создайте два файла с именами index.html и script.js. Внутри digit_recognition создайте папку tensorflow. Скопируйте два файла из блокнота Colab, group1-shard1of1.bin и model.json , в новую папку, вот так:
- digit_recognition/
- index.html
- script.js
- tensorflow/
- group1-shard1of1.bin
- model.jsonОткройте index.html любым редактором кода и скопируйте в него код ниже. Этот сценарий определяет основные компоненты для рисования и распознавания цифры:
<html>
<head>
<!-- Imports TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.7.0"> </script>
<!-- Imports tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.5.1/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Defines the container with the predictand erase buttons, and the canvas to draw a digit -->
<div id="container">
<h1>Draw a number</h1>
<p id="result">Prediction </p>
<div>
<!-- This button tells the model to return a prediction for the current canvas -->
<button type="button" onclick="predictModel()">Predict</button>
<!-- This button clears the canvas so that we can draw a new digit -->
<button type="button" onclick="erase()">Clear</button>
</div>
<!-- This defines the canvas on which we can draw a digit.
If the canvas is too small increase the width and height -->
<canvas id="canvas" width="386px" height="386px" style="border:1px solid #b9bfc9;margin-top:25px;"></canvas>
</div>
<!-- Imports the main script file -->
<script src="script.js"></script>
</body>
</html>Разберём код:
В разделе
<head>загружаются TensorFlow.js и её зависимости.Строка 23 создаёт кнопку вызова функции вывода модели
predictModel, которая запустится после нажатия, результат предсказания вы увидите в теге<p id="result">.На строке 26 создаётся кнопка очистки холста
erase.Строка 31 определяет объект
canvas, где мы будем рисовать цифру для распознавания.В строке 35 содержится файл script.js с логикой JavaScript, которая переносит цифру с холста в тензор и применяет модель.
Откройте файл script.js и добавьте показанные ниже фрагменты кода.
Основные переменные скрипта:
// define relevant variables
var canvas = document.getElementById("canvas");
var ctx = canvas.getContext('2d');
var dragging = false;
var pos = { x: 0, y: 0 };Триггеры холста:
По событию
mousedown(нажатию и удержанию кнопки) запускается сценарий, который инициирует рисование и записывает текущее положение мыши/прикосновения.По событию
mousemoveскрипт начинает рисовать на холсте. Поmouseup(когда отпускаем кнопки мыши) срабатывает останавливающий рисование скрипт:
// define event listeners for both desktop and mobile
// nontouch
canvas.addEventListener('mousedown', engage);
canvas.addEventListener('mousedown', setPosition);
canvas.addEventListener('mousemove', draw);
canvas.addEventListener('mouseup', disengage);
// touch
canvas.addEventListener('touchstart', engage);
canvas.addEventListener('touchmove', setPosition);
canvas.addEventListener('touchmove', draw);
canvas.addEventListener('touchend', disengage);Чтобы правильно выбрать событие в setPosition, напишем функцию проверки того, поддерживается ли устройством сенсорное управление:
// detect if it is a touch device
function isTouchDevice() {
return (
('ontouchstart' in window) ||
(navigator.maxTouchPoints > 0) ||
(navigator.msMaxTouchPoints > 0)
);
}Определим флаги начала и прекращения рисования:
// define basic functions to detect click / release
function engage() {
dragging = true;
};
function disengage() {
dragging = false;
};Запишем положение мыши/прикосновения. Обратите внимание, что нам нужно знать, поддерживается ли сенсорное управление:
// get the new position given a mouse / touch event
function setPosition(e) {
if (isTouchDevice()) {
var touch = e.touches[0];
pos.x = touch.clientX - ctx.canvas.offsetLeft;
pos.y = touch.clientY - ctx.canvas.offsetTop;
} else {
pos.x = e.clientX - ctx.canvas.offsetLeft;
pos.y = e.clientY - ctx.canvas.offsetTop;
}
}Перейдём к функции рисования.
Флаг draging определяет, рисует ли пользователь прямо сейчас (строка 8). Если это так, между прошлой позицией из setPosition и текущей позицией возникает линия, это строки с 18 по 21:
// draws a line in a canvas if mouse is pressed
function draw(e) {
e.preventDefault();
e.stopPropagation();
// to draw the user needs to be engaged (dragging = True)
if (dragging) {
// begin drawing
ctx.beginPath();
// attributes of the line
ctx.lineWidth = 40;
ctx.lineCap = 'round';
ctx.strokeStyle = 'red';
// get current position, move to new position, create line from current to new
ctx.moveTo(pos.x, pos.y);
setPosition(e);
ctx.lineTo(pos.x, pos.y);
// draw
ctx.stroke();
}
}Очистка canvas:
// clear canvas
function erase() {
ctx.clearRect(0, 0, canvas.width, canvas.height);
}Загрузим модель. Метод tf.loadLayersModel загружает модель по URL или из локального каталога (строка 5). При первом предсказании она инициализирует веса, поэтому, чтобы во время первого предсказания избежать задержки, рекомендуется разогреть её (строка 8):
// defines a TF model load function
async function loadModel(){
// loads the model
model = await tf.loadLayersModel('tensorflow/model.json');
// warm start the model. speeds up the first inference
model.predict(tf.zeros([1, 28, 28, 1]))
// return model
return model
}Получим текущие данные о цифре с холста:
// gets an image tensor from a canvas
function getData(){
return ctx.getImageData(0, 0, canvas.width, canvas.height);
}Теперь о функции выводов модели:
getDataзагружает данные холста (строка 5).tf.browser.fromPixelsпреобразует их в тензор (строка 8).tf.image.resizeBilinearизменяет размер изображения до размера для модели (строка 11).model.predictполучает предсказание на строке 14, а строка 17 устанавливает цифру из прогнозаy.argMax(1)в тег<p id="result">.
// defines the model inference functino
async function predictModel(){
// gets image data
imageData = getData();
// converts from a canvas data object to a tensor
image = tf.browser.fromPixels(imageData)
// pre-process image
image = tf.image.resizeBilinear(image, [28,28]).sum(2).expandDims(0).expandDims(-1)
// gets model prediction
y = model.predict(image);
// replaces the text in the result tag by the model prediction
document.getElementById('result').innerHTML = "Prediction: " + y.argMax(1).dataSync();
}Тестируем модель
Ради безопасности браузеры ограничивают HTTP-запросы от скриптов. Это означает, что веб-приложение может запрашивать ресурсы только из того источника, откуда оно загрузилось, если ответ от других источников не содержит правильных заголовков Cross-Origin Resource Sharing (CORS). Здесь воспользуемся Firefox.
Чтобы разрешить CORS в Firefox, введите about:config в поиске внутри Firefox, в строке открывшейся страницы введите privacy.file_unique_origin и измените значение по умолчанию на false.

Откройте index.html в Firefox:

А теперь нарисуем цифру и нажмём Predict:
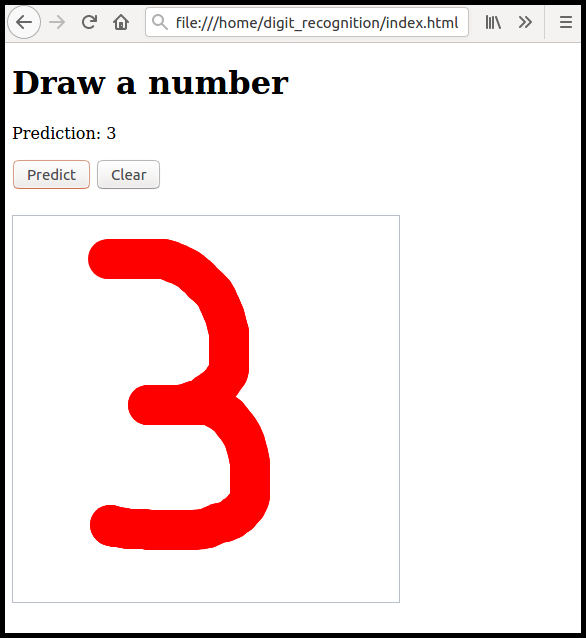
Для размещения модели в сети автор оригинала использует хранилище Amazon S3, а для очень простых экспериментов подойдёт, например, Github Pages, отдельно отключать защиту CORS уже будет не нужно, поскольку всё будет выполняться на одном ресурсе.
Модель в действии
Эта статья напоминает, что модели машинного обучения могут работать не только в очень сложных, непривычных непосвящённому человеку системах, но и в самом простом окружении, а со временем искусственный интеллект, который называют новым электричеством, будет занимать всё больше места в быту. Если хочется изменить карьеру или прокачать свои навыки в ML, вы можете присмотреться к нашему курсу «Machine Learning и Deep Learning», а если интереснее веб-разработка, обратите внимание на курс по фронтенду или по Fullstack-разработке на Python. Также вы можете узнать, как начать развиваться или выйти на новый уровень в других направлениях:

Machine Learning, Data Science и Python
Веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
Комментарии (8)

spam312sn
29.07.2021 01:12Мне правда не хотелось бы обесценить ваш труд этим комментарием, но я думаю, что нейросеть нуждается в дополнительной тренировке:
Screenshot

P.S.: Новая форма для комментариев довольно непривычна

quwarm
29.07.2021 07:55Точности модели достаточно для примера (~99 % в наборе валидации).
Конечно, можно добиться гораздо лучшего результата.
Здесь можно посмотреть примеры архитектур и их результат на MNIST.
Кроме того, можно ради интереса попробовать сеть попроще: Dropout(0.4), Dense(250, linear), Relu(), Dense(250, linear), Relu(), Dense(10, linear) с оптимизатором Adadelta(lr=5), инициализацией параметров xavier normal normalized и batch_size=500 (у меня получается после 500 эпох лучший результат со 100% точностью на обучающей и от 99.10 до 99.19% точностью на тестовой выборках; обучение не более 15 минут).
quwarm
10.08.2021 20:15Здесь я не прав по поводу сети «попроще».
Точность от 99.10 до 99.19% на ней достигается при использовании extra training data.
Если говорить о стандартном MNIST, то для точности 99% и выше на тестовой выборке следует использовать сверточную нейронную сеть. Например, следующую:Описание нейронной сети
=== Settings: batch_size=500 optimizer=tf.keras.optimizers.Adadelta(learning_rate=5) loss='categorical_crossentropy' === Layers: 1. Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1), padding='same'), 2. MaxPooling2D(pool_size=2, strides=2), 3. Conv2D(filters=48, kernel_size=(3, 3), activation='relu', padding='same'), 4. MaxPooling2D(pool_size=2, strides=2), 5. Dropout(0.5), 6. Flatten(), 7. Dense(500, activation='relu'), 8. Dropout(0.25), 9. Dense(10, activation='softmax') === Code: model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1), padding='same'), tf.keras.layers.MaxPooling2D(pool_size=2, strides=2), tf.keras.layers.Conv2D(filters=48, kernel_size=(3, 3), activation='relu', padding='same'), tf.keras.layers.MaxPooling2D(pool_size=2, strides=2), tf.keras.layers.Dropout(0.5), tf.keras.layers.Flatten(), tf.keras.layers.Dense(500, activation='relu'), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer=tf.keras.optimizers.Adadelta(learning_rate=5), loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(train_data, train_labels, validation_data=(test_data, test_labels), batch_size=500, epochs=30)15 эпох, около 5 минут, точность на обучающей 99.08%, точность на тестовой 99.41%.
Если подождать ещё 15 эпох (5 минут), то результаты ещё лучше — точность на обучающей 99.57%, точность на тестовой 99.52%.
Результаты нейронной сети, предложенной автором, немного хуже (в плане обобщения) — точность на обучающей 99.69% и точность на тестовой ~99.21% (30 эпох).

apelsyn
29.07.2021 18:50+1Там есть один ньюанс, который автор может пофиксить, необходимо провести нормализацию нарисованного изображения: цетрировать и маштабировать нанесенный рисунок. Для того чтоб понять как проявляется проблема, напишите цифру в углу (даже если цифра будет очень правильная) будет ошибка.
quwarm
29.07.2021 20:50Это правда. Однако есть более очевидные ошибки, например, в почти идеальных случаях с цифрами 5 и 6:
Screenshot

Думаю, можно опустить этот вопрос, т.к. статья носит больше демонстративный характер.


apelsyn
Много лет назад писал статью "Нейронные сети на Javascript", тогда еще небыло TensorFlow.js и реализаций сверточных серей для JS. Функционал разпознавания цифр был реализован с помощью простого персептрона на brain.js
belav
В Вашем варианте идет поиск границ введенного символа, поэтому более корректно распознает. В варианте автора такого нет, поэтому результат зависит от места, где нарисован символ, например, рисую ноль по середине, определяет как 0, рисую ближе к правому верхнему углу, определяет, как - 1, к левому -7.
belav
впредь буду сначала читать все комментарии...